
Abstract
In the last decades, individual urban traffic flows have increased all over the world with a consequent growth of road congestion and environmental pollution. In this context, car-pooling is an interesting car-based alternative to satisfy the individual mobility demand by optimizing the car loading factor with respect to the number of passengers, provided that all the participants share trip origin and destination in the same time slot. To make the system more appealing, this paper proposes an on-demand car-pooling service adopting variable fares, on the basis of trip length and number of participants. Multi-agent, reputation and recommender system technologies in synergy with a routing algorithm have been used to this aim. Experiments on simulated data proved the potentiality of the proposed approach.
Introduction
In the last decades, urban traffic flows have increased worldwide and afflicted heavily citizens’ life, particularly in densely populated urban areas, by increasing environmental and social costs for congestion, fuel consumption, travel time and health diseases among the others [2–4]. Most part of traffic flows is due to private cars that often move only their drivers, in an inefficient and disruptive way.
However, awareness on these issues have increased too and local, national and supranational authorities (e.g., the European Union) have adopted a wide range of strategies to reduce private car use. Inside urban areas, policies to tackle this phenomenon usually rely on (i) discouraging the use of private cars by introducing restrictions as well as increasing their operational costs [5–7] and (ii) improving and promoting different transit services [8, 9].
Despite such efforts, private cars continue to be perceived as more comfortable and flexible than transit for the absence of constraints in time and space (i.e., fixed stops and timetables) [10] that characterize transit although, from an economic viewpoint, this latter is more advantageous [11].
In this context, alternative forms of mobility have been developed based on the shared use of cars, such as car-sharing (CS) and car-pooling (CP). In particular, CS is mainly adopted for autonomous short trips (generally inside urban areas), while CP is based on sharing a private car and its traveling costs among several users. Looking to the future, these forms of shared mobility are expected to grow in popularity with the advent of autonomous vehicles (AV), as showed by the growing number of researches in this field. It is also conceivable that mobility services based on AVs and human-driven vehicles will have to co-exist in traffic systems [12]. For example, a recent study on this matter has been proposed in [13], where interesting results have been obtained by simulating on an on-demand service in Manhattan by using real traffic data and shared autonomous vehicles.
From an economic viewpoint, the business models of these forms of mobility belong to the “Sharing Economy” (SE) [14], which promotes the temporary acquisition and shared usage of goods, services or knowledge as an economically advantageous, effective alternative with respect to their ownership. SE is not a new phenomenon but in recent years it gained a new relevance thanks to (i) advancements in technological areas (e.g., computer science, communication, electronics and so on), which allows demand and offer to be matched in real time [15] and (ii) cultural changes in people’s habits [16] included increasing ecological awareness.
In this respect there is a general consensus on CP as an efficient car-based solution for private mobility, able to optimize the car use with respect to the number of passengers [17].
Unfortunately, some main issues about CP systems are still open [18, 19]. More specifically, conventional CP systems are mostly used for trips made regularly but lack flexibility. In other words, the participants to a CP trip have to share the same time and the same origin and destination for the outward journey and (usually) for the return journey; for such a reason, participants generally share also other characteristics like belonging to the same community, working in the same place, living in the same area and so on.
On the other hand, dynamic CP systems adopting on-demand pick-up and drop-off locations, need reliable tracking devices, simple user interfaces for passengers and drivers, good opportunities for matching the right time window for the planned trip and appropriate reputation systems to rate passenger and driver before the ride. In addition, among the reasons justifying the poor development of CP systems, for example in Europe, there is also an important behavioral aspect, i.e. the self-confidence and freedom feelings related to drive the own car [20].
To overcome these limitations, currently some CP services benefit from Web-platforms to provide sophisticated services developed to find quick and reliable matching between users with similar route and time trip needs. Web platforms mediate among demand and offer and are able to reach a larger audience at low costs [14]. They have enlarged significantly the basis of potential CP users and have reached a fair popularity (also thanks to additional services like reputation systems, insurance, clear fares and so on) [21, 22] but are characterized by a low adaptability with respect to the trip origin and/or destination of the potential passengers. Indeed, their main aim is to facilitate an agreement among unknown participants for a CP journey with a fixed route.
Recently, technological progress allows CPs to become more flexible in time and space to meet demand for mobility on the fly and serve multiple users, having different pick-up and drop-off locations, with the same vehicle. [23, 24]. The main constraint is that the change of route to add a new destination has to be compatible, within prefixed time thresholds, with those of the other on-board passengers. Obviously, it is required that the other passengers will accept a priori to adapt their trip route in exchange of a lower trip fare. In other words, if a ridesharing request is compatible with those of all the on-board passengers, then the route is modified to pick-up and drop-off the new passenger, like a shared taxi. Demand and offer must be processed in an automatic way as quickly as possible to provide an effective real-time service. However, similarly to other SE initiatives, a strong attitude to trust strangers is required to CP participants. This attitude can be reinforced by the adoption of specific tools like reputation systems [25] for allowing all users, regardless of their role (i.e., driver or passenger), to express their appreciation for each of their travel partners, and not only to the drivers. In this way, future potential users can choose in advance road mates to share the service by exploiting reputation scores.
To support dynamic CP, the contribution of this study consists of proposing an agent-based framework that relies on (i) a reputation system, (ii) a routing algorithm and (iii) a light content-based recommender system. In particular, it is required that each CP actor is associated with a simple personal agent, running on his/her smartphone (provided with suitable computation, storage, communication and GPS capabilities), which identifies, localizes and assists its user on the CP scenario. By exploiting the data provided by the personal agents, the framework agency, which manages the routing algorithm, matches demands and offers for CP rides by taking into account vehicle positions, seats availability, pick-up and drop-off places and departure and arrival time windows of all the participants. Then, each personal agent cooperating with the agency, will suggest to its owner the best opportunities with respect to his/her preferences, time, cost and reputation of the potential partner (i.e, driver or passenger). Personal agents will improve, over time, the level of customization of their suggestions by the preferences of their owners.
In addition, variable travel fares are adopted depending on the length of the journey and the number of passengers sharing it. In fact, when a new passenger joins the trip then the unit cost per passenger decreases (as well as the passengers’ comfort). Consequently, when the number of passengers changes during the trip because a new participant is added, then the fares of the other participants automatically decrease due to loss of comfort and lower unit cost per passenger 1 .
The rest of the paper is organized as follows. Section 2 gives an overview on the related work, while Section 3 presents the proposed agent framework and Section 4 describes the main characteristics of the routing algorithm. The reputation model and the recommender system are described in Sections 5 and 6, while the results of a campaign of simulations are shown in Section 7. Finally, in Section 8 some conclusions are presented.
Related work
Intelligent Transportation Systems (ITSs) are receiving a great impulse by advancements developed in computer science, electronics and communication above all. Furthermore, an increasing attention is given to the adoption of the intelligent software agent technologies [26] thanks to their learning and adaptive capabilities [27], the attitude to cooperate (also by sharing their own knowledge [28]) and to deal with large, uncertain and/or dynamic systems [29] both in a centralized and distributed way.
In such a context, reputation systems are increasing in popularity due to the necessity, arising in larger and larger dynamics environments, of estimating the trustworthiness of potential counterparts. Moreover, such systems take benefit from cooperating with cryptographic techniques to warranty both data integrity and actors’ identity.
The main properties identifying a reputation system [25] can be summarized in: (i) dealing with long-living entities to obtain a suitable amount of information for foreseeing expected future behaviors with a reasonable reliability 2 ; (ii) taking decisions on the basis of past experiences; (iii) collecting feedback of new interactions and spreading reputation rates into a community 3 , also by adopting incentives (or symmetrically, disincentives). From our viewpoint, it means that in presence of frequent users it is possible to adopt a reputation system and exploit their smartphones for providing and/or obtaining detailed information.
In a CP scenario, reputation systems are worthy to be implemented [30] so that several reputation models have been proposed. For instance, in [31] a reputation system is used to refuse undesirable passengers. Similarly, the authors of [32] and [33] proposed two architectures for CP that consider, among their main components, a reputation system. These systems, respectively named Smart Rider Seeker and SmartShare, manage offers and requests for rides based on detailed information on both desired travels and preferences (e.g., timing, locations, capacity, prices, and so on) as well as to reject potential participants. The reputation services implemented in [32] and [33], once a ride has been fulfilled, gather, process and spread the feedback that drivers and commuters can leave to each other. However, any implementation detail is provided about these two reputation systems.
A new centralized reputation model, tested on a CP scenario with satisfactory results, has been provided in [34]. Its main peculiarity is to satisfy security requirements and warranty high levels of privacy by protecting users’ identities and preserving the anonimity of their feedback. A co-utility mechanism, is presented in [35]; it adopts a decentralized reputation protocol presented in [36] (inspired to [37]) exploiting a fully decentralized P2P ridesharing management network. The effectiveness of this reputation system was verified by using real mobility traces of cabs in the San Francisco Bay area. The obtained results have shown that rational peers have not any incentive to deviate from a desirable behavior.
Also business initiative like those realized by Uber [38] and Lyft [39] take advantage from the availability of reputation information, although these companies implement a business model closer to a taxi-ridesharing activity than to a CP. In particular, they match people searching for a ride with private drivers and monitor the involved actors, included cars, by taking into account information collected by a peer-reviewing system from both riders and drivers that can rate each other. In such a way, companies can verify that their behavioral codes are respected in order to monitor all the possible service barriers. Finally, also CS activities can benefit from the adoption of a reputation system and often such system can fit with a CP context directly or with a limited number of changes. For instance, in [40] agents assist users in improving their driving behavior by means of individual reputation measures, also adopted both for the access to the CS services and to obtain personalized fares. Some experiments on real and simulated data show the potentiality of this approach.
Our proposal also relies on the adoption of a Recommender System (RS), that is a very popular tool largely exploited to support users by generating potentially attractive recommendations [41–43]. To generate recommendations, RSs can adopt different approaches that are usually classified in [44]: (i) Content-based (CB), which exploits data exclusively derived from user’s past interests and preferences [45]; (ii) Collaborative Filtering, which realizes a knowledge space where items unknown to a specific user but popular among other users similar to him/her for preferences and interests are recognized [46, 47]; (iii) Demographic, which considers only users belonging to the same demographic niche [48]; (iv) Knowledge-based, aimed to infer user’s references and needs [49]. However, by joining two or more of these approaches it is usually possible to improve RSs performance; this particular family of RSs is usually identified as hybrid RSs [50, 51].
In our context, a CB approach is adopted, together with reputation information, to provide a user with some suggestions about CP opportunities potentially interesting for him/her. Such recommendations are generated by taking into account (i) his/her consolidated and emerging behaviors (stored in a local personal profile built by rates that he/she directly provided and/or automatically elicited by monitoring his/her activities) and (ii) reputation information needed to consider also the opinions of the other users.
To support smart mobility, included CP services, a significant number of authors exploited RSs as, for instance, GoTogether [52] that also exploits non-monetary and social aspects, intrinsic in user’s choices, to infer a personal ranking model adopted to generate an ordered list of rides potentially able to maximize his/her satisfaction degree. The RS adopted in [53] analyzes urban mobility traces, derived by telecommunication providers, to recognize riders for similar routes and suggest opportunistic ridesharing trips. In [54] a RS finds the best route and the best ride mates. To this aim, two similarity measures computed on the basis of the user’s mobility history (to discovery his/her interest for places) and social network information (to discovery friendships, assumed as a similarity measure) are taken into account. Some experiments validated this RS. Another RS is TaxiRec [55] that, by adopting a learning machine model, ranks and suggests to a user potential travel-mates belonging to the same road clusters. When taxi trajectory data are incomplete or unavailable, TaxiRec works by joining this model with a cluster selection algorithm. Feasibility and effectiveness of TaxiRec are witnessed by experimental results.
From an operational viewpoint, taxi-ridesharing and CP are very close among them because their main difference is that the first one is carried out exclusively for profit. Like many RSs for CP, also the RSs developed for taxi-ridesharing are designed to optimize time and/or costs of a travel on a vehicle shared among several passengers [56]. Based on the taxi routes, in [57] a non-cooperative game approach is adopted to easily and quickly find taxis that are operative in a specific area. In [58] it is assumed that both taxi-drivers and riders’ positions are known at every time thanks to their mobile phones (equipped with GPS capabilities). A scheduling algorithm with time-window is applied to reduce the total distance traveled by the taxi. The framework described in [59] evaluates a “potential to rideshare” measure to predict and recommend whether and where a user could wait for a ride and, finally, a novel recommendation algorithm, trained by GPS traces data, suggests the taxis having destination close to those of potential passengers [60].
The multi-agent framework
A simple multi-agent framework (F), suitably conceived to support our proposed dynamic CP, is described in this section. The framework consists of two main components: Agency (Ag) - it is a trusted and safe centralized component, unique in F, that manages the routing algorithm (see Section 4), collaborates with the other agents and provides them with some basic services. The main tasks carried out by the Ag are: Personal Agent (PA) - each CP is associated with a user’s personal device (equipped with suitable computational, storing and communication capabilities) and supports his/her CP activities. Each PA is free of entering/leaving F at any time. The main tasks carried out by a PA are:
Note that although a distributed approach is generally more attractive than a centralized one, the latter allows (i) a more efficient match between demand and offer to be achieved and (ii) a lower communication overload (and lower power consumption of the users’ personal devices).
The routing algorithm
In this Section, the proposed routing algorithm, exploiting the computational and storage resources of the Agency where it runs, is synthetically described. More in detail, it is a variation of the well known Alpha-Beta Pruning algorithm (α-β P) [61], driven in the in-depth search by an heuristic that implements an efficient cut-off technique. Therefore, in the worst case its time complexity is b m where b is the branching factor and m is the maximum search depth that has been set. Note that if the optimal solution is not reached, because it is deeper than the chosen depth horizon, then the best solution found at the boundary nodes will be always provided. The main features of the proposed version of this algorithm are, synthetically, shown in Table 1 and summarized below:
Comparison with Brute Force (BF); Depth First Search Branch&Bound (DFS); Minimum (M); A+; αPruning (αP); Alpha-Beta Pruning (α-βP) - (b - branching factor, d - solution depth, m - maximum search depth).
Comparison with Brute Force (BF); Depth First Search Branch&Bound (DFS); Minimum (M); A+; αPruning (αP); Alpha-Beta Pruning (α-βP) - (b - branching factor, d - solution depth, m - maximum search depth).
the optimal solution is provided if it exists within the horizon set for the in-depth search, otherwise the more promising one is provided. At each visited node of the search-tree, the algorithm optimizes a function, defined positive, and depending on one or more parameters (e.g., cost, number of passengers); if the optimal solution search ends in advance (e.g., with respect to the depth search, search time or resource constraints, the temporary optimal solution found at the stop time is returned; if the solution’s depth is lower than set, then the search will end when the solution is reached; the optimal route is recalculated whenever there are changes in the boundary conditions; heuristic functions are adopted to estimate partial solutions, optimize the Branch & Bound and drive the in-depth search; any temporary list of expanded nodes is stored.
The flow-chart of the algorithm is depicted in Fig. 1. For sake of clarity, it is represented in an iterative form even if the algorithm is recursive. Note that the variables are appropriately initialized, the functions and the adopted heuristic are known and the term “root” refers to the node from which the search starts.
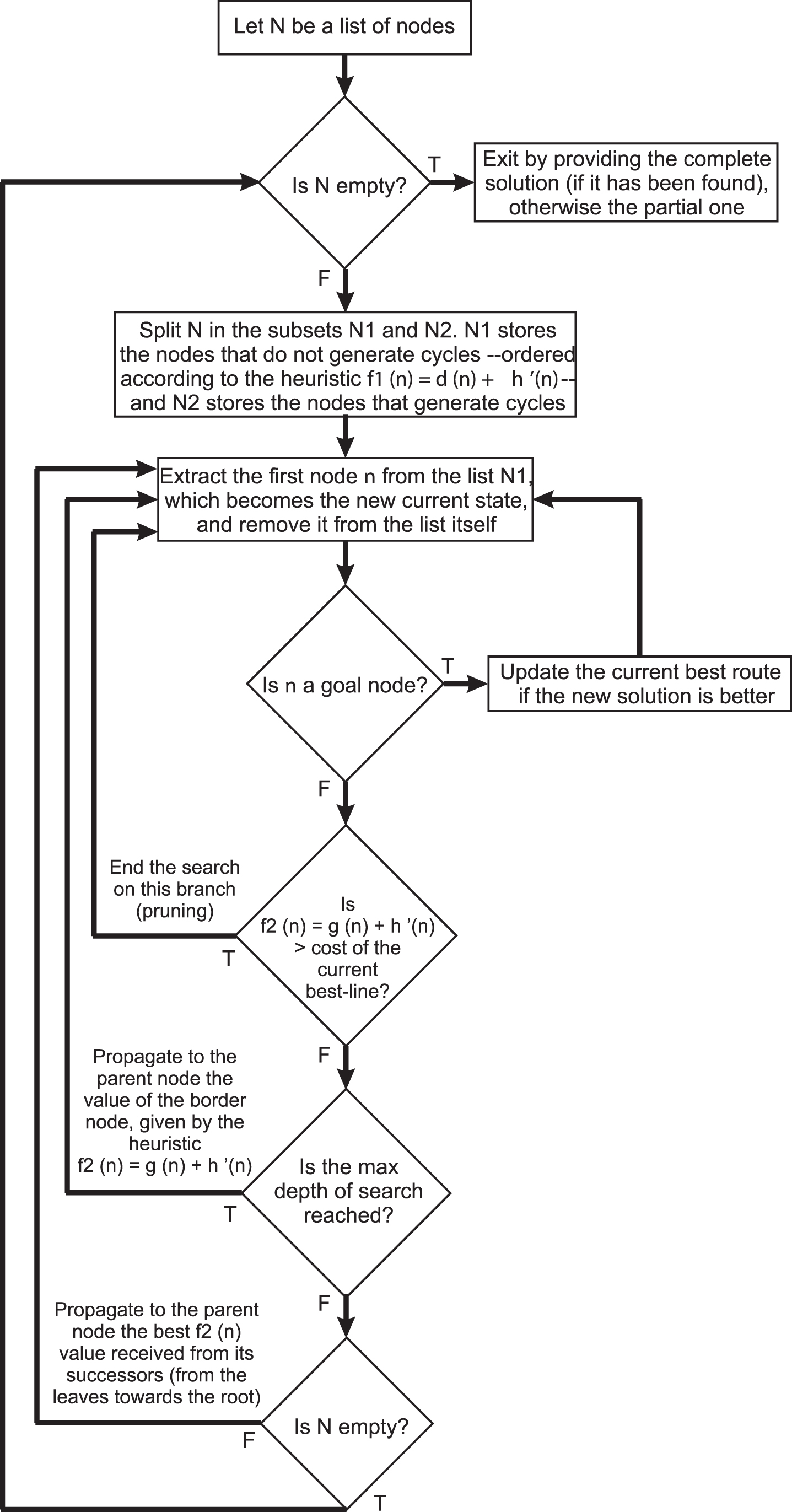
The flow-chart of the RA in an iterative version.
A PA request for ridesharing consists of few information about where and when to pick-up and drop-off the new passengers. Please note that the start and arrival times indicated by the PA are two mandatory time windows. Based on this information, when a new travel request is sent by a PA to the Ag, this latter will exclude from the following steps those drivers active on the network that could not surely satisfy the new request for ride because of their position and the seats availability. For the remaining drivers, the new destination will be added to their route and the algorithm will look for a new route able to serve the new potential user, depending on its pick-up and drop-off time windows, in compliance with the other commitments made with current passengers. If this new request cannot be satisfied because there are no ride available at the moment, this request must be refused and the user will have (i) the possibility to re-formulate it with different time windows or (ii) give it up definitively.
The approach adopted by the algorithm consists of considering (without loss of generality) any route problem as a sequence of best path search problems between two consecutive nodes (note that each one of these local searches can be optimized, for instance, with respect to the number of users served at each stop or the travel time). Each partial solution is assumed to be independent from all the other paths linking the other nodes belonging to the route.
For sake of simplicity, from hereafter the adopted Alpha-Beta Pruning routing algorithm will be named RA.
The reputation model presented in this section is managed by the agency and it is an improved version of the one presented in [1].
It considers the whole past history of each CP actor by means of feedback released to him/her by his/her travel mates [62]. In addition, it is resilient to malicious attacks due to alternate 4 , collusive 5 and compliant/noising behaviors 6 .
Each time a ride ends, each CP actor entrusts his/her appreciation about the ride participants with a feedback f. Let
The parameter W
y
depends on the feedback released by u
x
to u
y
and by three parameters (ranging in Px,y is computed as Px,y = Min (1, px,y/P
Max
), where px,y is the final price for the ride payed by u
x
to u
y
and P is the maximum cost threshold after which the relevance of the ride is assumed as saturated (i.e., maximum). rx,y depends on number and frequency of past rides occurred between u
x
and u
y
such that the higher the frequency the lower the value of rx,y. It is computed as:
a
x
is updated after each feedback f
x
released by u
x
, by considering in absolute value the difference between f
x
and the current reputation of the target user (i.e., R). The maximum accuracy of a
x
will be achieved when it is 1 and the minimum when it is 0. a
x
is computed as:
The recommender system
In this section the knowledge representation adopted to store the users’ preferences and the exploited recommender algorithm are described.
The knowledge representation
A PA supports its user in choosing the best available CP ride capable to satisfy his/her request and preferences. To this aim, the PA manages and updates a user’s profile UP adopting a compact knowledge representation (see Fig. 2), which is built on the basis of the past user’s CP rides. More in detail, the UP consists of: PSet, it is the Parameter Set storing: RD: a reputation threshold representing the lower driver’s reputation score considered as acceptable by u; w1, w2, w3, w4: they are weights, ranging in RSet: it is the Ride Set storing both timestamp and data (e.g., vehicle category, number of passenger and cost) of each CP ride chosen in the past by u; FSet: it is the Frequency Set storing information about the frequency of the u’s choices with respect to the vehicle category (VCat and number of the other passengers (NPass), e.g. from 2 to 4; The structure of the User Profile (UP).
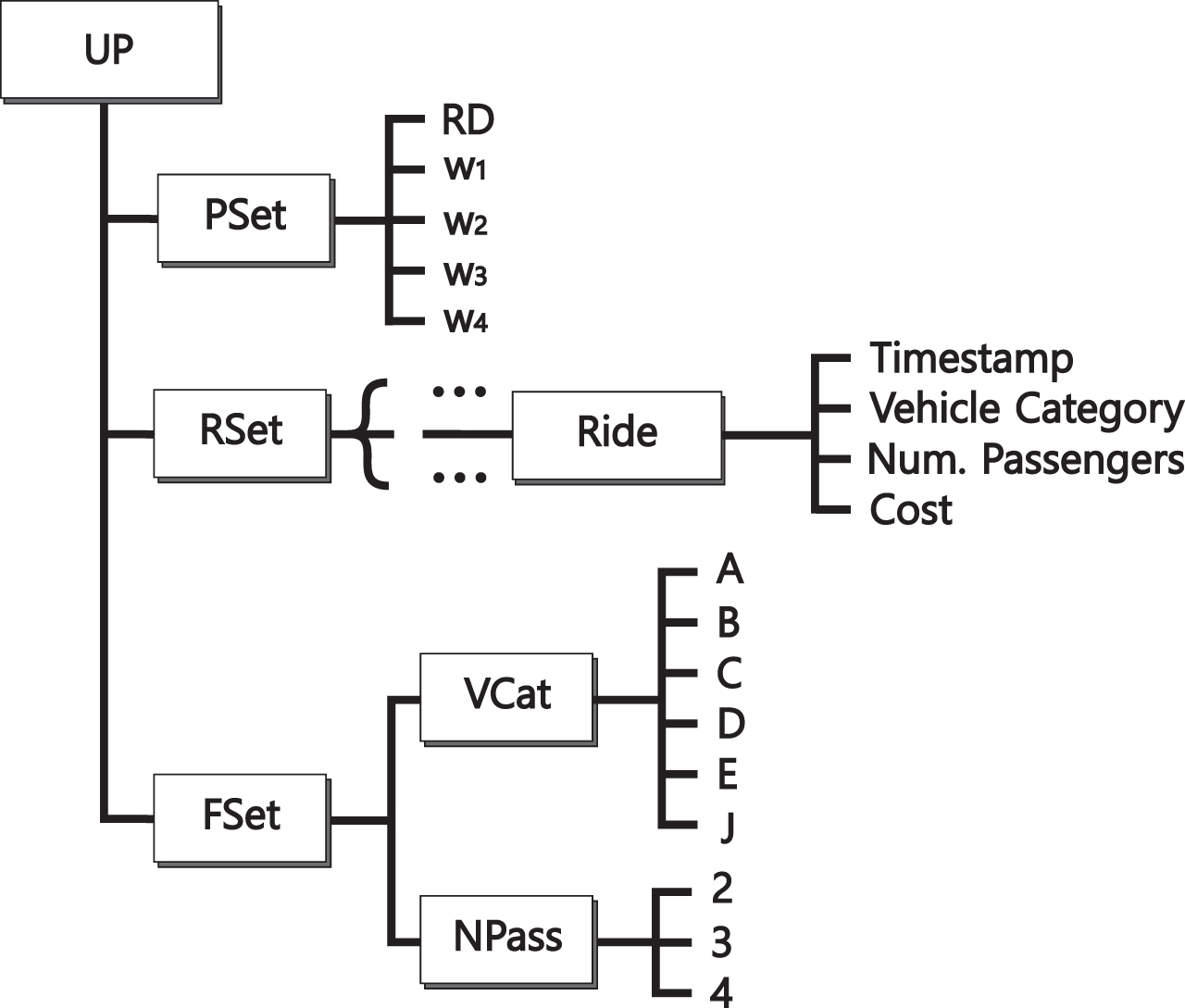
Each time that a ride choice is performed by u, then his/her profile is updated as specified below.
For each u’s request for a CP ride, the Recommender Algorithm (RA) generates some suggestions among those CP rides closer to both his/her ride request and preferences.
Figure 3 represents the recommender algorithm implemented by the the function where

The recommender algorithm.
Note that the selected suggestions generated by RS (returned by the function
This section presents the results of the experiments realized to test the performance of the reputation system, the routing algorithm and the recommender system described above.
The experiments have been carried out by using proprietary C++ code. In particular, trip demand for some pre-fixed origin/destination nodes has been generated to simulate link traffic flows during the reference period (vehicles/hour). For each minute of simulation (i) the traffic flow on each link of the transportation network has been computed, (ii) some requests for CP rides have been simulated and distributed within the reference period by identifying pick-up and drop-off nodes in a semi-random way (e.g., by rejecting those pairs of nodes too close to each other); for each CP request both the routing and recommender algorithm run and, finally, (iii) for each accepted CP request the updating reputation process starts at the arrival time of each passenger. In addition, requests are accepted based on time and distance criteria, i.e. a ride is possible if the additional time required by the modified path, which is computed to reach the new passenger, does not exceed a given threshold and the additional travelled distance does not move away from the final destination. Finally, the time threshold depends on passengers’ planned arrival time to their final destination. Note that the choice to simulate test networks has been made to avoid comparing real scenarios of different sizes, where the specificity of the network structures could produce distortion effects on results.
The results of the experiments carried out are presented in the next sections.
Reputation system
The performance of the reputation system described in Section 5, identified in the following as R1, has been tested and compared with three reputation systems: (i) the preliminary version of R1 described in [1], denoted by R2; (ii) a carpooling version of the EigenTrust [37] presented in [36] and denoted by R3; (iii) an eBay-like system [64] denoted by R4. Note that many reputation systems have been developed to support carpooling activities, but to the best of our knowledge almost all of them require significant changes or are not compatible with our scenario. Differently, R3 and R4 require any or only minor and not relevant adjustments.
The experiment has been arranged for epochs (each epoch corresponds to a day) and a population of 1000 users randomly distributed on 5 behaviors (e.g., very unpleasant, unpleasant, neutral, pleasant, very pleasant) has been simulated. Each user’s feedback has been randomly generated coherently with his/her behavior. Alternate
8
, collusive and compliant/noising malicious activities have been performed by 15% of population, i.e. 5% for each type of malicious activity
9
. For each epoch only a population share of 20% has been randomly selected and collusive activities happened only when at least one of the selected users was a malicious user. Moreover, for all the reputation competitors: The basic cost ( 1 € for trips ≤1 Km; linear variation from 1.00 to 7.50 € for trips from 1 to 7.5 Km; 7.5 € for trips >7.5 until to 10 Km, which is the maximum distance admitted in our CP scenarios. The cost of 25% of the rides has been set greater than 5 €. The number of ride mates n has been randomly generated in the range 2 ÷ 5 (including the driver).
For both the reputation systems R1 and R2: The parameters α and β have been set both equal to 0.2. The reputation parameters t
l
and t
p
have been set to the respective epochs and Δt has been set to 3 epochs. The coefficient P
max
has been set equal to 5 €. The value of the initial reputation score has been set equal to 0.5 for all the agents. Half of the ride cost of each passenger may vary depending on the number of passengers (x) him/her traveled together. More in detail, let L
k
be the trip length of a CP ride made by the user u
k
such that
In R3, drivers and passengers evaluate each other. The R3 reputation system generalizes the EigenTrust reputation model allowing non-binary opinions in input. More in detail, neutral trips are ranked 0, while positive and negative scores are assigned to satisfactory and unsatisfactory trips, respectively. R3 builds a matrix to represent local opinions expressed on the basis of the interactions carried out and where the generic component (i, j) is the opinion of agent i about agent j. Then local reputation values are normalized between 0 and 1 and all agents will contribute equally to the global reputation scores by making collusive activities ineffective. The normalization of negative values to 0 prevents compliant and whitewashing strategies, also if it makes impossible to distinguish between malicious and newcoming users, which receive (both drivers and passengers) an initial reputation score set equal to 0. To realize the experiment a centralized version of R3 has been simulated.
Finally, R4 is based on the well known centralized, feedback-based eBay reputation system which computes the simple percentage of positive feedback with respect to those received in a time window. A user cannot evaluate the same counterpart in a short time, while neutral feedback is not taken into account in the calculation. eBay contrasts multiple identities by assigning a null reputation at all the newcoming agents. The eBay system has been largely studied and if, on the one hand, its simplicity has favoured its acceptance, on the other hand it is particularly subject to attacks.
Figure 4 shows the results obtained by comparing the four reputation systems on the basis of the users’ behavior correctly recognized. First of all, the performance of R1 and R2 are quite similar and both show their ability in recognizing very quickly the users’ nature, in particular 90% of users is correctly classified in less than 17 and 19 epochs for R1 and R2 respectively. We highlight that R1 starts a little bit more slowly with respect to R2, but then it becomes a little bit more effective than this latter in identifying the users’ nature.
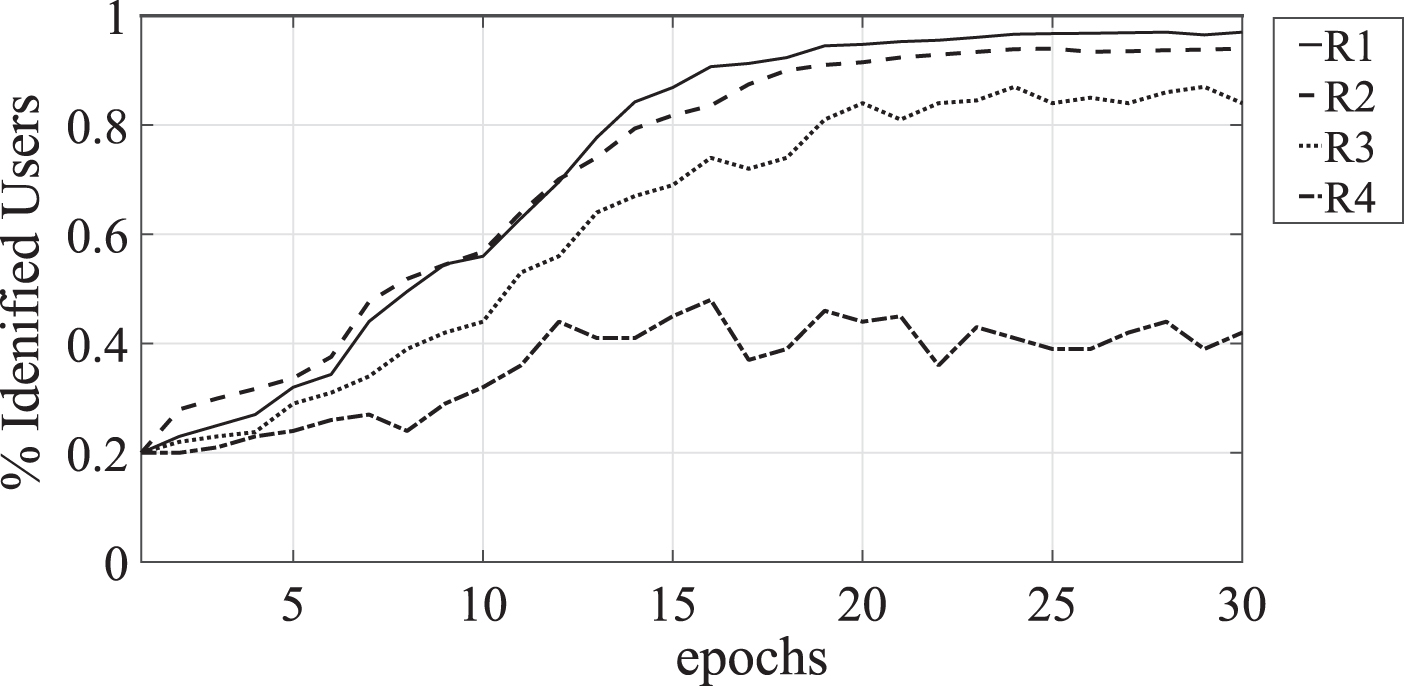
Percentage of users correctly identified.
R3 represents the best competitor of R1 although it performs less than 11% in average worse than R1 and R2. It shows a good resilience against some of the attacks carried out in the tests but it is not equipped against alternate behaviors. Finally, R4 is the worst among the competitors. From the analysis of experimental results it seems capable to identify all malicious users (but no honest ones). Really, it is defenseless against every malicious attacks and all the reputation scores are low for all the users. Therefore, R4 is not able to work in our context.
In the light of these results, we argue that R1 performs better than its competitors. Moreover, its high reactivity is mainly due to the fact that in our scenario each user can receive several feedback for the same ride, i.e. one feedback for each trip mate. Furthermore, “neutral” users’ behavior, which received an initial reputation set to 0.5, is correctly recognized from the first to the last epoch (note that also by setting a different value for the initial reputation, these users are quickly recognized like the other part of the population).
The second experiment verified the performance of the routing algorithm with different test transportation networks (even large ones) generated randomly by setting the parameters in a compatible way with the considered scenario.
In particular, RA performance was verified on 10 randomly generated test networks with 500 nodes (N) and a number of links equal to 3N. For each of these networks 100 pairs of nodes of the network have been randomly selected and a search depth of 50 has been set for RA. For each pair of nodes a CP service has been simulated and a new admissible (i.e., in terms of both time and reputation constraints and distance from the pair of nodes) request for that service has been randomly generated. For each admissible request the route was modified by verifying the three following criteria: (i) minimize the cost; (ii) maximize the number of served users; (iii) maximize the Users/Cost ratio.
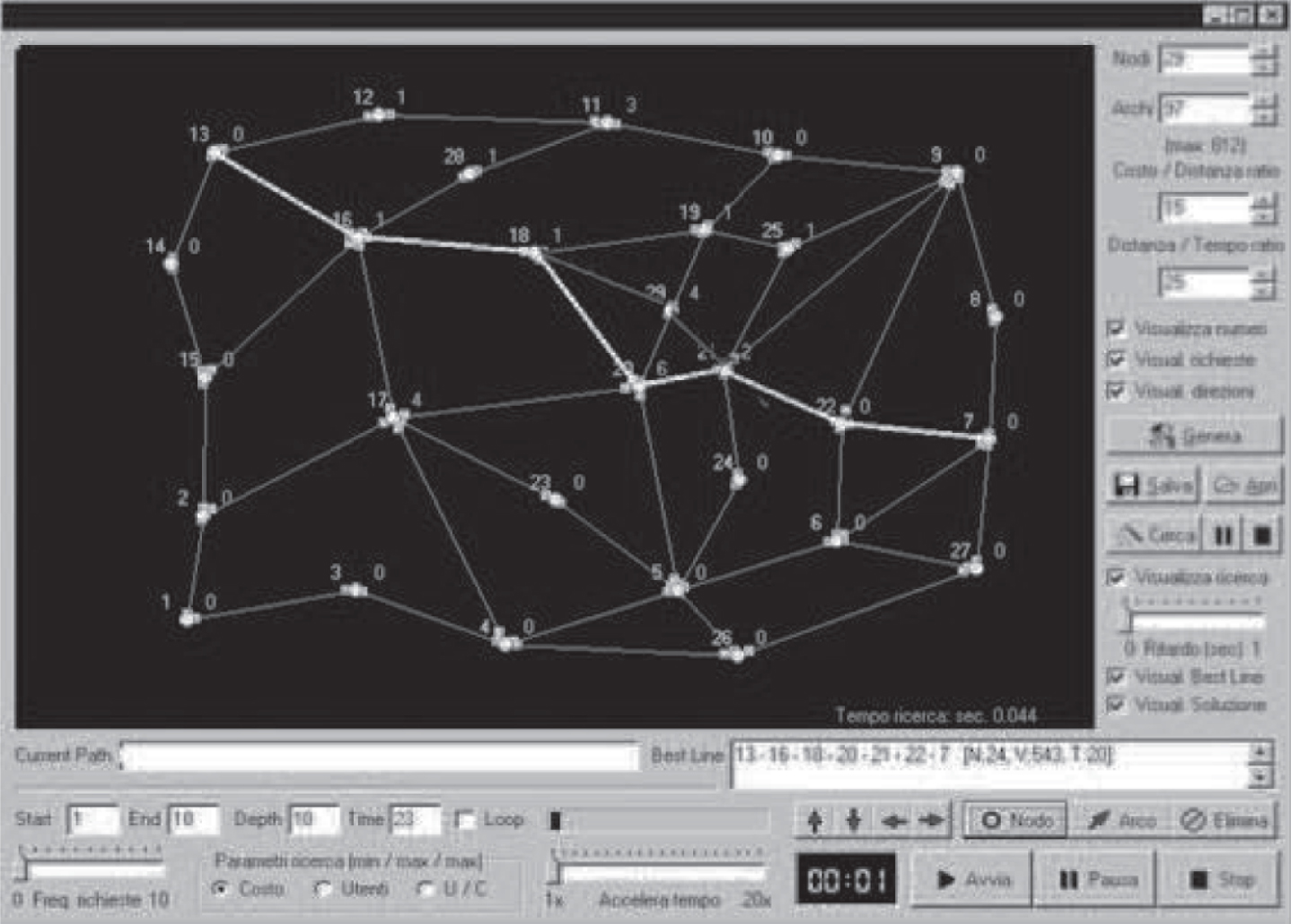
Random network 29 Nodes, 51 Links, path from 13 to 7, depth 6.
The results obtained, although at a starting level, showed a very limited number of nodes visited which, on average, is 31 nodes for paths formed on average by 23 nodes (i.e., a real branching factor of 1.148) and with a search time always less than 1 second 10 . From an operational point of view, note that cycles have not been admitted.
The third experiment tested the proposed RS by simulating 1, 000 users and 100 CP rides requests for user. For each simulated user (i) his/her reputation score, (ii) the PSet 11 and FSet of his/her personal profiles (see Section 6.1), (iii) the behavior (see Section 7.1) have been generated/assigned in a random way. In particular, for each of these users’ requests a list of m recommendations (with m = 10) has been generated in a random way. More in detail, first the characteristics of 2m CP rides have been randomly generated (with the constraint of having not more than five CP proposals for vehicle segment), then ordered on the basis of their Relevance scores (computed coherently with the profile of the involved user) and, finally, the first m of them were selected to compose the list of recommendations submitted to the user.
Random Network 500 Nodes, 1500 Links, path from 119 to 361, depth 10.
The experiment tested the capability of the proposed RS to follow changes occurring in the users’ preferences. In fact, if for the user u the weights w
u
, stored in his/her personal profile, meet his/her preferences, then it is expected that u will choose always the CP ride that has the top Relevance score in the recommendation list. Therefore, in this case the set of weights w
u
must not be updated. Conversely, the set w
u
should be updated to take into account the u’s choices. To this aim, in the proposed experiment we assumed that u will choose always the CP ride, among those suggested by the RS, having the higher contribution for the parameter
The results of this experiment are shown in Fig. 7, where the average difference (i.e., Δ) between the Relevance measures of the CP rides having the top Relevance score (i.e., ρ
top
) in the recommendation list and those selected by the users (i.e., ρ
sel
) are represented for each of the 100 simulated CP rides. It is observed that the value of Δ decreases along the simulation from a value of 0.18716 to -0.00935. This means that during the simulation, the CP rides having the higher value of
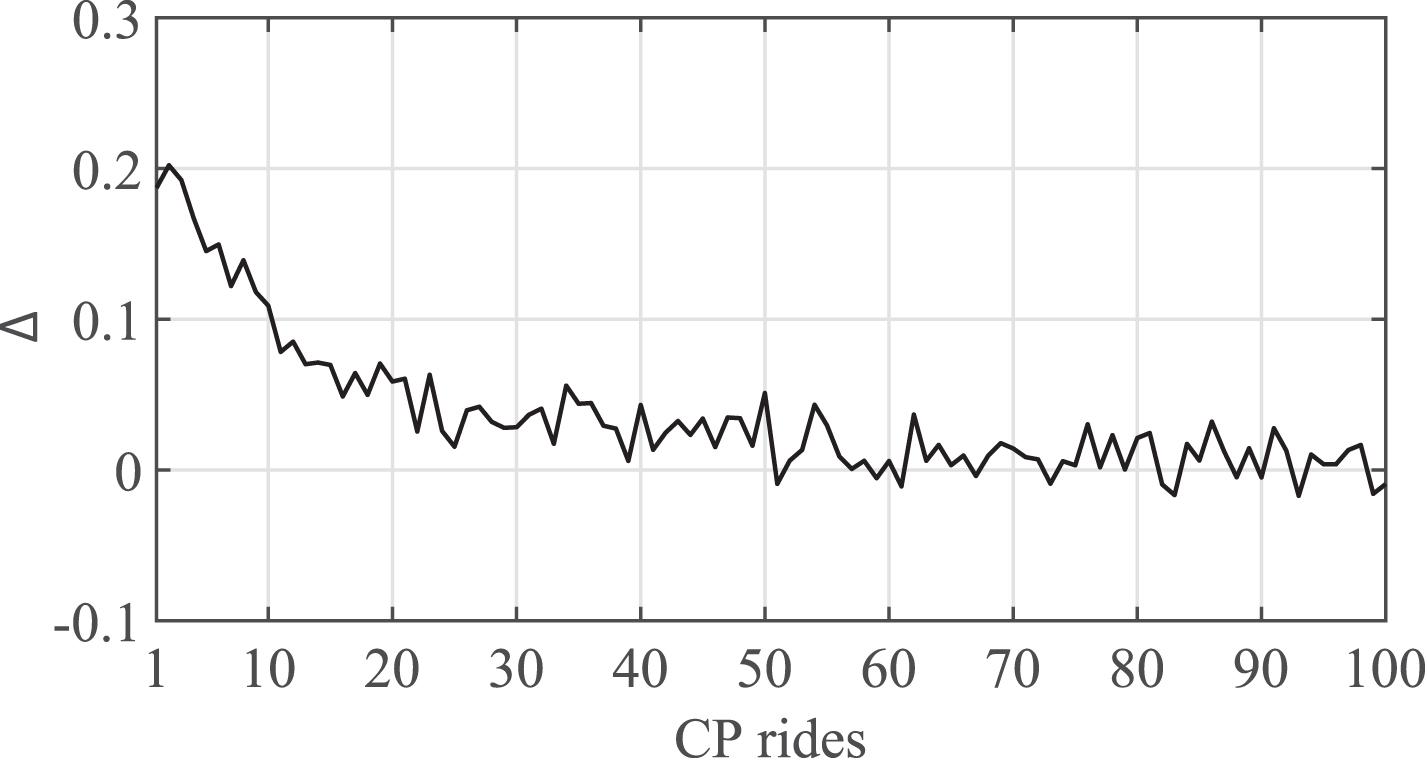
Average difference between the relevance measures of the top ranked and selected CP ride.
Car Pooling (CP) may provide a smart opportunity to support urban mobility and reduce urban traffic and the environmental problems it produces. To this aim, a framework implementing dynamic CP, potentially able to enlarge the number of CP users has been presented. It has been built on a routing algorithm and take advantage from the adoption of agent, reputation and recommender technologies.
To test the potential effectiveness of the proposed framework, some experiments carried out on simulated data have been realized and, in particular, with respect to (i) the capability of the reputation system to identify the behavioral nature of the users in presence of some malicious activities, (ii) the capability of the adopted routing algorithm of working correctly in real time and, finally, (iii) the quality of the suggestions generated by the recommender system.
As forthcoming researches we are planning to (i) carry out a test on a real urban network by using real traffic data and (ii) realize a distributed version of the framework able to run on mobile devices. This latter could lead to the opportunity of adopting other technologies, e.g. (permissioned) blockchains [65] replacing the agency in making irrevocable agreements for rides by using a smart-contract [66] and providing worthwhile services as safe payments, insurances or storing publicly and permanently car profiles, reputation scores and other data [67].
Footnotes
Note that all the issues referred to negotiation tasks and payment modalities are beyond our aims and, therefore, they will not be dealt with in this paper.
Obviously, whitewashing strategies aimed to clean bad reputations should be hindered as more as possible.
In presence of a distributed scenario, this task could be very complex.
Alternate attacks are possible when the same relevance is given to each feedback independently from the ride value; in such a way, it is possible to gain reputation for rides having a low value, in order to obtain positive feedback balancing negative one received when cheating in presence of high value rides.
Collusive attacks happen when two or more actors systematically provide each other positive feedback to gain an undue reputation.
Compliant/noising activities consist of frequently providing negative feedback or introducing unreliable feedback into the system to gain undue advantages.
Note that we consider the main six commercial vehicle categories for the cars, i.e. A (mini), B (small), C (medium), D (large), E (executive), F (luxury) and J (SUV).
With respect to the ride cost.
Note that alternate behaviors require also a cost of the CP services greater than 5 € (i.e., l ≥ 5Km).
Tests have been carried out on a computer equipped with an Intel i7-4700Q and 32 GByte of RAM.
For sake of simplicity, we generated the weights such that w1, w3 ⪢ w2, w4 and set DR = 0.
Acknowledgments
This work has been partially supported by the Networks and Complex Systems (NeCS) Laboratory - Department of Engineering Civil, Energy, Environment and Materials (DICEAM) – University Mediterranea of Reggio Calabria.