
Abstract
Measuring machine creativity is one of the most fascinating challenges in Artificial Intelligence. This paper explores the possibility of using generative learning techniques for automatic assessment of creativity. The proposed solution does not involve human judgement, it is modular and of general applicability. We introduce a new measure, namely DeepCreativity, based on Margaret Boden’s definition of creativity as composed by value, novelty and surprise. We evaluate our methodology (and related measure) considering a case study, i.e., the generation of 19th century American poetry, showing its effectiveness and expressiveness.
Introduction
Evaluation is a crucial concern in Artificial Intelligence and, more in general, in science. Measures and metrics are fundamental not only to check the validity of a hypothesis, but also to understand if some given results can be used with confidence as a starting point for future research. An example is Shannon’s entropy, which plays a central role as a measure of information, choice and uncertainty [20] and underpins many results in Information Theory [30]. The role of measures is even more crucial in machine learning, where models need to be evaluated during and after training. For example, most of the machine learning algorithms are evaluated using metrics like accuracy.
Excellent progress has been made in benchmark tasks coupled with metrics used to estimate the performance of algorithms [34]: examples include [32] for machine translation or [36] for image generation. At the same time, there is also a need to derive new metrics for examining the behavior of algorithms in different environments and in relation with society [34]. Among the spectrum of behaviors that could be exhibited by a machine, creativity is certainly one of the most interesting [30]. In fact, we have witnessed the emergence of an entire new field of research, namely Computational Creativity, with a focus on the study of the behaviors exhibited by artificial systems that would be deemed as creative [7, 48]. Indeed, one of the key goals of this field is the definition of computational techniques for measuring creativity.
In this paper, we present a novel methodology (and related measure) as a way to assess the creativity of an artifact. In particular, DeepCreativity is based on the very famous definition of creativity provided by Margaret Boden: “creativity is the ability to come up with ideas or artifacts that are new, surprising and valuable” [5]. Although it is not the only definition of creativity available (over one hundred of definitions have been proposed over the years [1, 42]), it is central in the field of computational creativity. The three aspects that are at the basis of this metric have played a prominent role in the scholarly discourse around the definition of machine creativity. Our proposed measure uses deep learning techniques, avoiding the need of a human in the process, to measure how much an artifact is valuable, novel and surprising with respect to a given context, and, therefore, to quantify the ability of an agent to come up with creative results. To the best of our knowledge, this is one of the first attempts to define an evaluation method for assessing the overall creativity of an artifact that is automatic and of general applicability.
This work is structured as follows: a review of the literature about automatic methods to assess creativity is presented in Section 2; then, in Section 3 we discuss the proposed creativity measure. An evaluation of DeepCreativity is presented in Section 4, considering a case study of text generation in the context of 19th century American poetry; finally, we discuss limitations of the proposed approach and potential future work in Section 5.
Related work
Over the years, several computational approaches have been proposed to automatically assess the creativity in products made by (human or artificial) agents, differing in the scope of evaluation or in the method. A complete survey can be found in [14]. All of them consider value and novelty as aspects of creativity, while only some of them also include surprise. In the following, we will consider the three factors separately.
Value
Value, sometimes referred as quality, expresses how an artifact compares to others in its class in terms of utility, performance or attractiveness. It is typically defined as a weighted sum of performance attributes or as a reflection of the acceptance of the artifact by society [25]. The authors of [11] follow the latter definition, which suggests to compute creativity by using an art graph where each vertex represents an artwork and each arc connecting an older to a newer work is labeled with the similarity between the two calculated by means of an appropriate similarity function. The higher the similarity with subsequent works, the higher the value (and the higher the creativity). However, this method does not allow to compute value for the most recent works, but only for the older ones. The former definition is more common in the literature. For instance, in [25] the authors suggest to derive value as the weighted sum of pre-defined performance variables. In [26], value is defined using clusters of artifacts built on a performance space – with artifacts expressed as sets of attribute-value pairs. The authors of [15] define it as the synergy [8] between artifacts, expressed following the regent-dependent model. Also several domain-specific methods follow the definition of value as the sum of performance attributes or performance measures: for example, for poetry generation, the authors of [50] consider topic distribution (through LDA), fluency (through a neural language model) and coherence (through mutual information and TF-IDF) as components of value. In [52] coherence is used (through BLEU, originally proposed for machine translation in [32]) with quality (through perplexity), while the authors of [51] uses BLEU only. However, the definition of value as the weighted sum of sub-components has the limitation of requiring the correct identification of all the relevant factors and their relative weights, which is a complex and time-consuming task.
Novelty
Novelty is commonly defined as the measure of how much an artifact differs from known artifacts in its class [25]. For this reason, a classic technique to measure novelty consists in the calculation of the distance between a given artifact and the other artifacts on a descriptive space, as discussed in [25] and [26]. The descriptive space is usually identified by the attributes used to define the artifacts. Similarly, domain-specific methods consider novelty in terms of distance or dissimilarity: for instance, in case of text generation, the authors of [21] consider novelty as the average semantic distance between the dominant terms included in the textual representation of the story, compared to the average semantic distance of the dominant terms in all stories. In [50] diversity and innovation in poetry generation are measured by means of bigram-based average Jaccard similarity. As for value methods, the requirement of defining artifacts in terms of attributes appears to be as a rather strong limitation.
A different definition of novelty has been proposed in [3], namely as the degree an input differs from what an observer has experienced before. In [11] novelty is defined by considering the time dimension of personal experience: the lower the degree of similarity between an artifact and the previous works, the higher the novelty contribution of creativity. Even if not exactly used as an evaluation technique, in [10] a novelty score is proposed to guide the training of the generative part of the Creative Adversarial Network. This can be considered as a creative-oriented variant of Generative Adversarial Networks (GANs) [16]. In addition to the classic adversarial loss provided by the discriminative model, the generator is trained to maximize a novelty loss that represents how much the generated artifact differs from previous works in terms of style. Although considering novelty as the deviation from style norms is somehow simplistic, it only requires a style classifier, automatically capturing an important aspect of novelty at the same time.
Surprise
In [3], surprise is defined as the degree of disagreement between the real input and what it was expected in its place. This classic definition of surprise based on unexpectedness is typically also referred to as surprisal [43]. In [25], unexpectedness is calculated considering whether or not the artifact follows the expected next artifact in the pattern recognized on recent artifacts. In [17], surprise is measured as the unlikelihood of observing a particular artifact according to the predictions about relationships between its attributes. In the specific domain of text generation, in [21], surprise is defined as the average semantic distance between consecutive fragments of each story. For sequential artifacts like texts or sounds, the authors of [6] adopt the expected maximum surprise as measure (as one minus the probability of the most unexpected token of the artifact) and the expected count of ψ-surprise (as the count of all the tokens for which predictability is lower than a given threshold
A quite different approach is adopted in [26], where the authors consider a new artifact as surprising if it creates a new cluster in the conceptual space (instead of perfectly fitting into an existing one). The idea of surprise as related with the difference between prior and posterior models is at the basis of Bayesian surprise [2], used in [15] and [46]. It is a measure of surprise in terms of the impact of a data point that changes a prior distribution into a posterior distribution, calculated applying Bayes’ theorem (considering artifacts as a composition of attributes); here, surprise is the post-observation change rather than the prediction error.
Measuring creativity using deep learning
We now present DeepCreativity, a new Deep Learning creativity measure. The goal is to define a measure of more general applicability. Deep Learning is used for avoiding the need of identifying the required attributes to describe the artifacts or the components of creativity [14]. This leads to a measure that allows for automatic evaluation of artifacts. As discussed in Section 1, DeepCreativity is based on the definition of creativity proposed by [5]. Therefore, the measure is based on three main factors, which will be explored in the next subsections separately: value (Subsection 3.1), novelty (Subsection 3.2), and surprise (Subsection 3.3). Finally, in Subsection 3.4, we will put everything together by providing a unified definition of creativity.
Value
We measure value by means of the discriminative part of a Generative Adversarial Network [16]. The GAN is trained by considering the real artifacts as the true ones; in this way, the discriminative model should learn a representation of real (and valuable) data, and its evaluation of a new artifact provides insights of its value in that context. Therefore, the value of an artifact a over the value discriminator D
v
can be expressed as:
The choice of the real artifacts influence the value measure proposed above (acting as an Inspiring Set [35]). While it can be seen as a limitation of the approach, it is highly coherent with the nature of creativity itself. Creativity and, in particular, value are deeply context-dependent: the same work, proposed in two different moments of history or to two different social groups may be evaluated differently [5]. Under this lens, the need of real artifacts conceals the opportunity of representing, within the measure, a fundamental aspect of creativity. The real data used during GAN’s training will therefore represent a specific context, well-defined in temporal and cultural terms.
To train the GAN, it is important to distinguish between continuous tasks (like image generation) and sequential tasks (like text or sound generation). With respect to continuous applications, a GAN can be trained using the following loss function [16]:
As far as sequential applications are concerned, the impossibility of directly applying GAN to these tasks is a well-known problem [19]. A common way to solve it is by using SeqGAN [51]. SeqGAN considers the sequence generation process as a sequential decision making process, defining a reinforcement learning framework in which the generative model G
With respect to novelty, our definition is inspired by CAN [10] although the deviation from style norms cannot be used directly to measure the difference between artifacts. Therefore, as additionally done by the CAN discriminator, a neural network D
n
is trained to correctly recognize the style of real artifacts (from the given context). The neural network can just be a simple classifier (as in [31] for music or in [40] for paintings), outputting a probability vector of length N equal to the number of possible classes. Consequently, a novelty measure can be defined as:
With respect to surprise, we follow the conceptual framework presented in [2]. Starting from a sequential generative model G s trained to predict the next token given the previous ones on an appropriate training set (temporally and culturally defined, as stated for value), this allows for considering the impact of an artifact a over G s . Its influence is calculated using a weight correction applied over G s if G s is trained to correctly predict a. In analogy with the Bayesian surprise, surprise is measured as the distance between prior G s (before training) and posterior G s (after training on a). The difference is in how the posterior distribution is obtained, namely not by means of Bayes’ theorem, but through backpropagation and gradient descent. Notice that this idea is very close to the intrinsic reward presented in [37], where a measure of surprise is derived by maximizing a distance function between prior and posterior distribution of a predictive model.
At inference time, only measuring surprise is relevant, while the model update is not actually required. It is only used to compute the weight correction Δw
ji
, which expresses how much the posterior distribution will differ from the prior. Given an artifact a = {a1, a2, . . . , a
N
}, the mini-batch (of size N) gradient descent formula for Δw
ji
can be used:
We can now define the surprise measure more formally. Given a sequential generative model G
s
, an artifact a has a surprise over G
s
equal to:
We note that the correction is divided by the weight to represent the degree of correction, i.e., the influence of the artifact. Then, the learning rate in Equation (5) is not the learning rate used during training, but a parameter to adjust the magnitude of correction for the surprise measure. Even a value of 1 can be reasonable in certain problems. Finally, this approach requires G s in order to consider artifacts as sequential data, even if they are continuous. In case of image, G s may be, for instance, an autoregressive model [33, 45].
Given the definition of V (a, D
v
), N (a, D
n
), S (a, G
s
) in the previous subsections, the DeepCreativity measure (indicated with DC) is obtained by computing the creativity of a generative agent producing artifact a over a temporal and cultural context TCC as:
There is no common agreement about how to evaluate creativity measures. All the methodologies discussed in Section 2 have not been evaluated against a ground truth; on the contrary, they have just been tested over a generative system, in comparison with human judgements (always considering the products of a generative system) or they have not been tested at all. This can be attributed to the difficulty of finding a common definition of creativity, which is reflected in the lack of correct evaluation of creative productions.
However, a ground truth about this creativity process exists in this case: art history. The fact that in a certain moment of history, in a certain place, an artwork was appreciated or at least considered of sufficient quality to be “printable” may be used as useful information for evaluating a creative agent. Inspired by considerations done in [30] about CAN and its ability of intercepting the historical trajectory of art, a meta-evaluation test is defined, based on historical trajectories, to study if and how the proposed measure is able to correctly capture the changes of creativity over time in a fixed culture. In particular, the following experiment will concern the context of American Poetry. American poetry has been chosen because of the importance of this artistic production and its heterogeneity in terms of movements and styles, while still referring to a specific cultural context. Other cultures or artistic fields could have been selected as well; while the study presented in this work aims at demonstrating the effectiveness of DeepCreativity in principle, we are aware that further work is necessary to demonstrate its generality (see Section 5).
The goal of this experiment is to measure the creativity of poems from different moments of history, while training the neural networks for the computation of DeepCreativity on a specific historical context. DeepCreativity can therefore be considered an appropriate creativity measure if the resulting creativity is higher for the artworks which really come after the context, because these are the ones been considered as highly creative in that moment. Consequently, it should also recognize the other works as less creative: later works should be judged more novel and surprising, but less valuable and understandable; while contemporary works should be judged more valuable but less novel and surprising.
Two separated experiments are conducted to verify if the measure is able to capture creativity for a certain period of time. Both of them involve poems from the 19th century (i.e., from American Renaissance (Brahmins and Romantics), Local Color, Naturalism, and Neogothic (or Protodecadentism)) as the context. The first experiment involves poems from the 20th century (i.e., a selection of poems from Imagism, Harlem Renaissance, Objectivism, Beat Generation, and Confessional Movement). The second one also considers poems from the 17th and the 18th century (i.e., a selection of poems from Puritanism, African-American Poetry, and American Revolution). A sample of poems from the training set is always considered for a complete comparison; full details are reported in Appendix C. As far as details about the implementation are concerned, two types of NNs have been used: a LSTM-based RNN for the generative models, and a CNN for the discriminative models. Full details about architectures and training processes can be found in Appendix B.
With respect to the first experiment, Fig. 1 shows the average of the creativity components during movements and the final creativity measure. It is interesting to note that the higher the novelty the further from the training set. This correctly captures the fact that a movement, which immediately follows a certain period has to be novel with respect to it. Moreover, the next movement has to be novel with respect to both the works produced in that period and the first one. The surprise curve generally also shows a similar behavior: temporally distant artifacts are the result of different contexts and different situations and they are more difficult to be predicted only considering a past version of the same culture. The last movement, the Confessional one, could be considered as an exception. This can be explained by considering how surprise is measured: it is calculated as the degree of change that the work causes over a 19th century American poems model, which is strictly related to a semantic view of the context, because it is based on the content. Indeed, temporally far movements might have a lower surprise measure if their themes (e.g., love) are semantically closer to those in the training set. The same consideration can be done to explain the value curve. For the first four movements, it tends to decrease with time, as expected. On the other side, Confessional Movement has a higher value; since its semantic content is closer to the one from the context, it results in a more similar and therefore comprehensible and admirable style, with a higher value.

The average of value, novelty, surprise and creativity computed on a sample from the training set and on 20th century American poems.
In general, it is possible to observe that creativity tends to decrease further in time from the period of reference of the training set, while it is higher for the central movement, which is able to conciliate a high degree of surprise without a consistent loss in value.
With respect to the second experiment, Fig. 2 shows the three components also considering previous movements. This should help study the appropriateness of the three measures over the time dimension. It is therefore interesting to note that two over three curves follow the same trends observed for the subsequent century. Novelty is the only one behaving differently, since the closest movement has more or less the same novelty than the furthest. On the contrary, value decreases further away from the period of reference of the training set, as desirable; in the same way, surprise increases. In addition, it is interesting to note that surprise is smaller than for the 20th century on average. This can be explained by observing that the 19th century poems include some knowledge about the previous poems, making them more predictable.
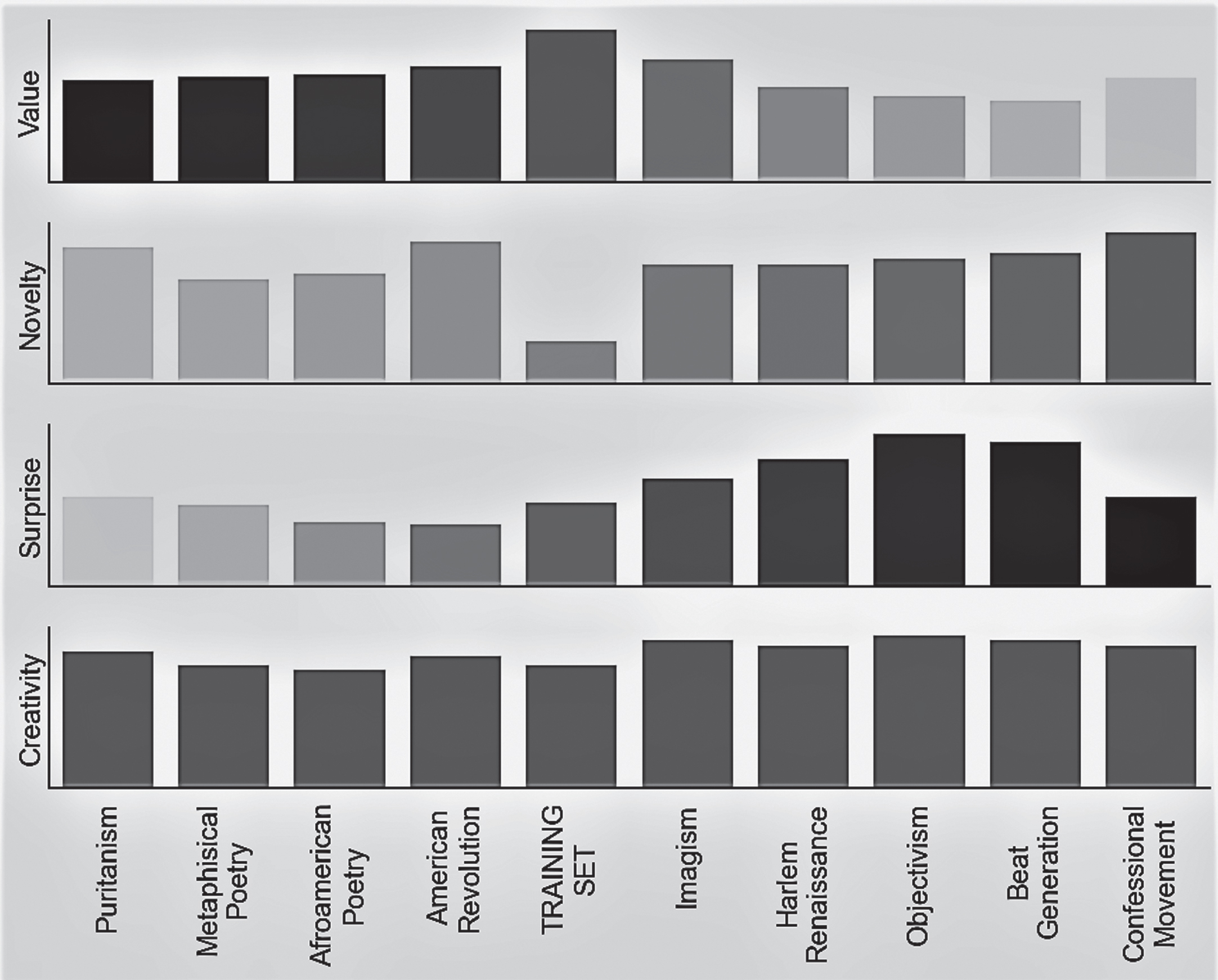
The average of value, novelty, surprise and creativity computed on a sample from the training set and on both 18th and 20th century American poems.
In this work, we have introduced DeepCreativity, a new creativity measure based on three components with the objective of measuring the value, novelty and surprise of a generative process or algorithm, in terms of their products. This general approach overcomes the limits of having measures applicable only to certain domains; in addition, the use of deep learning techniques overcomes the limits of having to manually define the attributes or the components which characterize creativity. Moreover, the automation of evaluation allows for embedding DeepCreativity in the creative generation itself; for instance, a generative model can be trained to learn to maximize such a measure [4] or it can be used inside a generate-and-test iterative process [41]. Finally, the need of a training set allows for the definition of a specific context of evaluation, which has been found to be a fundamental constraint of creativity. However, few limitations can also be found: novelty only considers the style or the genre, while it might lie in other traits of a work; surprise requires a sequential generator, which could be not optimal for (supposedly simpler) continuous tasks.
The experiments conducted in the context of generative learning of 19th century American poetry have demonstrated that the measure is able to capture the historic trajectory of creativity over time, either only considering future poems or also previous ones, showing its effectiveness. Additional tests should be carried out in order to confirm the correctness and the general applicability of the measure, ideally in different domains; contemporary contexts should be considered too, in order to have the evaluation of DeepCreativity validated against human judges (as in [10]). This is part of our future research agenda.