
Abstract
Online misinformation is posing a serious threat for the modern society. Assessing the veracity of online information is a complex problem which nowadays is addressed by heavily relying on trained fact-checking experts. This solution is not scalable, and due to the importance of the problem the issue gained the attention of the scientific community, which proposed many based on Artificial Intelligence and Machine Learning methods. Despite the efforts made, the effectiveness of such approaches is not yet enough to allow them to be used without supervision. In this position paper, we propose a hybrid human-in-the-loop framework for fact-checking: we address the misinformation issue by relying on a combination of automatic Artificial Intelligence methods, crowdsourcing ones, and experts. We study the single components of the framework as well as their interactions, and we propose an interleaving of the different components which we believe will serve as a useful starting point for the future research towards effective and scalable fact-checking.
Introduction
Modern times have highlighted the centrality of the threat for the modern society of fake news and misinformation. Traditionally, misinformation detection is a slow and costly process that is made solely by expert trained fact-checkers, that can not cope with the ever-increasing amount of information shared online everyday. To address this issue, researchers are developing automatic techniques to identify misinformation at scale, and significant efforts have been made to develop fast and scalable state-of-the-art Artificial Intelligence (AI) and Machine Learning algorithms [21, 62]. Another less traditional approach to tackle such issue is to take advantage of the wisdom of the crowd [54] and leverage crowdsourcing workers [2, 51]. Both approaches have advantages and disadvantages: while AI is usually cheaper and more scalable, crowd-workers can perform more reliable and explainable classifications. To take the best from both worlds, researchers proposed hybrid Human-In-The-Loop (HITL) approaches that integrate AI, crowd, and experts, even though only a few implementations exist [15, 60]. Differently from previous work [15], in this paper we propose a concrete architecture for fact-checking, and we inspect the responsibilities of each component as well as their interactions. In particular, we first detail a pragmatical workflow which should be implemented to effectively classify the veracity of a set of statements at scale. Subsequently, we inspect the roles of each component and its interaction with the others. Finally, we analyze the possible different framework interactions between humans and AI tools. Specifically, we examine the diverse possibilities that humans have to provide feedback to an AI tool, and we discuss both post-training feedback (i.e., classical human in the loop systems) and feedback that occurs during training.
Related work
There are numerous examples of both AI-based proposals for misinformation detection [1, 21] as well as of academic interest in their development and evaluation [23, 41]. Many different AI approaches exist: Ozbay and Alatas [42] tested 23 supervised AI algorithms on public datasets, Zhao et al. [62] integrated linguistic, topic, sentiment, and behavioral features to develop a model for health misinformation, Stammbach and Neumann [52] used evidence retrieval techniques and fine-tune a BERT-based model for the FEVER challenge, Konstantinovskiy et al. [29] developed a pipeline to identify misinformation using a multi-task learning approach. Related to that, many approaches addressed the issue of credibility in social media [56].
Focusing on misinformation detection using crowdsourcing, La Barbera et al. [32] found an effect of judgment scales and evidence of worker assessors’ bias on political statements, Soprano et al. [51] used the dataset from Roitero et al. [45] to leverage a multidimensional scale to measure different aspects of a statement, Draws et al. [18] found that workers generally overestimate the truthfulness and that different type of workers show different biases when evaluating a given statement, Pennycook and Rand [43] used the crowd to study effects of reducing social media users’ exposure to low-quality news, and Allen et al. [2] compared the accuracy ratings between fact-checkers and crowd-workers. Godel et al. [19] found that the use of crowd-based systems can provide additional information on news quality, but that these approaches have significant variation in their ability to identify false information correctly.
Finally, some work investigated the combination of AI and humans: Demartini et al. [15] introduced a theoretical hybrid HITL framework for misinformation, Qu et al. [44] used self-reported scores from both AI and crowd to develop a hybrid system, Shabani et al. [48] collect humans judgments to provide feedback on news stories about statement contextual information and integrated those features into an AI pipeline, and Yang et al. [60] showed the potential speed up to the fact-checking process by organizing and selecting representative statements. Ximenes and Ramalho [57] analyzed some recent COVID-19 related initiatives that can be seen as preliminary interdisciplinary solutions of Human-Centered Artificial Intelligence.
Limitations of current approaches
As highlighted by Figure 2 of Demartini et al. [15] each of the three state-of-the-art approaches for misinformation detection, i.e., experts, AI tools, and crowd, has its own advantages and disadvantages in terms of accuracy, scale, cost, explainability, and bias control. We detail these aspects in this section, focusing on the limitations of each approach.
Certainly AI tools outperform both crowd and experts when considering costs 1 and evaluation speed, but despite recent works [4, 30], they provide less or no explainability. More importantly, such models achieve lower accuracy than crowd or experts. To provide some examples, classical machine learning models achieved 74% accuracy on a two-level scale [20], and the best model of this year CLEF CheckThat! Lab reached 54.7% accuracy on a four-level scale [41]. Other examples are available in Table 6 of Hu et al. [23], where the authors compare the performance of many automatic AI models over multiple widely used datasets. Considering the accuracy from the crowd, some experimental results [2] show a high correlation with the experts in terms of agreement, whereas other works [18, 51] report accuracy values that are lower and comparable to those obtained by AI methods. Thus, fact-checking performed using crowdsourcing shows a high variability in terms of accuracy, which is comparable to the variability in the accuracies reported by Hu et al. [23] when considering the AI methods. The crowd accuracy variability may be due to the low quality of the data collected [12, 26], or influenced by the crowd task design. Similarly, AI models achieve higher accuracies on easier datasets [23]. Although further studies are needed to draw definitive conclusions it seems reasonable to assume that crowd accuracy can be higher than automatic AI solutions.
The highest accuracy is achieved by the experts, which is usually set to the value of 1 for practical reasons. Nevertheless, even domain experts need confrontation and discussion phases to reach a final consensus (see for example the process used by PolitiFact 2 ). However, the practice of setting expert accuracy to 1 is disputed by some authors. Citing The Perspectivist Data Manifesto, 3 the use of aggregated data as gold standards for datasets leads to the assumption that “there is exactly one truth, one true value for each variable defined in the annotation scheme for each instance to annotate”. Thus, the use of aggregated data could reduce the available information in a dataset, and also hide some disagreement otherwise evident in the data. Interestingly, some of the better results for a crowd task for misinformation detection are achieved by Allen et al. [2], who compare the crowd with the experts using as comparison not only a ground truth, but also the raw judgments from both the experts and the crowd who evaluated a given piece of information.
The use of aggregated data has direct implications not only when considering the experts, that indeed represent the most reliable source of truth, but also when considering crowd [3] and automatic AI methods [27]. Nevertheless, aggregated data allows to mitigate bias, which is a crucial limitation of current approaches. Experts and crowd-workers being humans are subject to cognitive biases [18, 32], which can be mitigated by the discussion phase in the case of experts, but are difficult to remove for crowd-workers [17]. Moreover, all the aforementioned biases can be propagated from humans to AI models, e.g., when training or fine-tuning a model. Finally, to properly train AI and, in general, to correctly assess misinformation, it should be possible to distinguish bias and noise on the data, collecting judgments that represent the diversity of the crowd assessors, as well as the decisional process made by the experts.
Another limitation of current approaches is given by the specific truthfulness scales used; different scales exist and are used, and such heterogeneity, apart from making a fair comparison difficult, has an impact on the quality of the collected data [32].
We believe that a HITL framework for misinformation detection should address and overcome all of the limitations detailed above by fruitfully combining the capabilities of AI, crowd, and experts.
HITL framework for misinformation detection
In this section, we detail the proposed HITL Framework for misinformation detection. In Section 4.1 we list some of the possible architectural choices, in Section 4.2 we introduce the general framework proposed. Finally, we explore each of the framework’s components: in Section 4.3 we discuss the role of the AI in the framework, in Section 4.4 we describe the use of the crowd in the framework, and in Section 4.5 we outline the experts component.
Possible architectures
A natural solution to the task investigated in this paper is to employ a pipeline model where the components are sorted with an increasing accuracy (i.e., first the AI, then the crowd, and finally the experts). Thus, if a statement is not adequately classified by a component, the subsequent pipeline component will perform a more accurate classification. Also, such a pipeline concatenates each component according to their increasing cost and evaluation time. This allows to perform a pipeline of annotation tasks where the majority of the statements are quickly and automatically labeled by AI, only a subset of the statements is sent for a slower evaluation to the crowd, and the few remaining statements are sent to experts for an in-depth investigation. The key advantage of this configuration is that it takes the best from each component, and that it allows to minimize the overall costs. Particularly, this configuration lets the experts (i.e., the more costly component) evaluate a limited number of statements. Nevertheless, the pipeline model has important limitations as it does not provide feedback among the components: a statement is simply forwarded until it is eventually classified with not much cooperation among the components.
Another possible combination of the components is by means of a blackboard architecture, a common solution in distributed multi-agent settings [16]. Such an approach allows the components to select which statements to evaluate. Each component is an autonomous agent that can access a central repository that contains both the statements and the partial contributions provided by each component. This approach would require both a high synergy between the components and to split a classification task in atomic sub-tasks to take advantage from each specific component of the architecture.
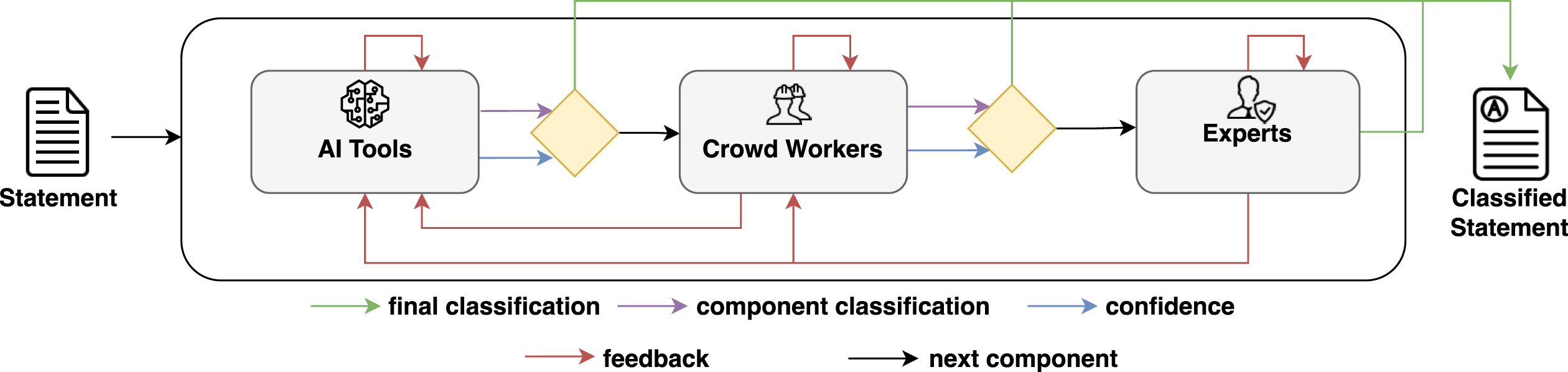
Overview of the proposed framework.
An ideal framework should maximize accuracy while minimizing the cost of each component and strengthening the cooperation between and within its modules. Therefore, we propose first a basic framework, where each component provides feedback to, and cooperates with, the others. We then discuss possible variants and extensions.
Our proposal is summarized in Figure 1. Given a statement, each of the three components (AI, crowd, and experts) generates both a classification on a chosen scale and a confidence score for the performed classification. Whenever each of the AI or crowd components generates a prediction with a high confidence score, the statement is considered as correctly classified. Otherwise if the confidence is low, the statement is forwarded to the subsequent component. If this is the case, the output of the previous component (the confidence score and the classification) can be optionally forwarded along with the statement. This could allow the subsequent component to perform an informed assessment, if necessary. Also samples of statements considered as correctly classified by the component (i.e., with high confidence) should be propagated, to double check their classification score and deal with the problem of unknown-unknowns (i.e., statements for which AI is highly confident about its predictions but is wrong) using humans [5, 37] This allows each component to provide feedback to the previous ones, thereby improving their classifications.
In general, each component should aim not only to perform its own classification, but also to provide feedback to the other components with the aim of improving their own classifications.
In the following sections we detail for each component: its possible internal structure, its specific interactions with other components, and additional outputs that can be added to the general framework.
Assuming the use of a state-of-the-art model for misinformation detection [20, 62], the output provided by the AI component should be at least a classification score on a chosen truthfulness scale, and a confidence score. While the classification score is straightforward, the confidence can be reliably calibrated following the methodology by Guo et al. [22]. To provide an adequate classification, AI tools can rely on a Knowledge Base to perform evidence retrieval. Examples of such a system are the ones proposed by La Barbera et al. [33] and Stammbach and Neumann [52], who both use a transformer architecture who rely on retrieved evidence. The choice of the knowledge base to use to produce a classification and an explanation is not straightforward, since there is no evidence of a “universally best” knowledge base [53]. Thus, the choice of the specific knowledge base should be performed ad-hoc by leveraging statements and domain specific features, as for example the topic, speaker, year, etc. of the set of statements being processed. The retrieved evidence could be from different sources and composed by very long texts which would not be helpful if provided to humans as additional information for the classification. Thus, an additional AI model could be configured to meaningfully summarize the retrieved evidence. To evaluate the classification score given by the component, we can use optional output. For example, many AI models are able to provide reasons for their predictions [4, 30]. Some implementations are delivered by Kazemi et al. [25] and by Brand et al. [9] who develop models able to generate an explanation for their misinformation assessment. The generation of an explanation could improve the framework by providing additional and human-readable information useful for both the subsequent human-based components and the final classification.
Finally, the AI component could provide self-feedback by using counterfactual explanations [63]: generating instances that the model finds hard to classify or deceiving could improve the model performance, robustness, and generalization abilities.
The output of the AI component is thus made by classification and confidence, plus optional information (not shown in Figure 1), such as explanation and retrieved evidence. The decision whether the statement has been adequately classified or not can then be performed by relying on the confidence of the model [44] as detailed in Section 4.2. To help this decision, the optional explanation can be used, for example considering its readability or semantic scores. The decision for some statements might be more critical and not straightforward: a very recent statement made by an important public figure over a highly relevant topic with not much evidence available might be worth further investigation. Hence, it might be worth studying the effectiveness of an importance score using the statement’s metadata.
Finally, if the assessment for the statement has a low confidence, the explanation is not satisfactory, or the assessment needs to be refined for any other reason, the statement is sent to the subsequent component, the crowd.
As for the AI, the crowd component should perform two tasks: misinformation classification and provide feedback to itself and to the AI component. There are many examples of misinformation classification directly performed by the crowd [2, 51]. It could also be reasonable to perform an informed assessment relying on the output of the AI component [50], or to employ AI models to generate meaningful information to be used by the crowd workers when performing the misinformation assessment, as done by Xu et al. [59]. However, the use of this additional information could introduce biases into the assessment performed by the crowd, hence further studies in this direction are required. Moreover, to reduce the cognitive effort of the workers, it is possible to design a two-step task using disjoints sets of workers: similarly to to Xu et al. [58] a first set of workers will search for evidence for a given statement, while a disjoint second set of workers will classify the statement using the provided evidence (and eventual additional data). While all of the different mentioned tasks are indeed reasonable, it is necessary to perform more ad-hoc studies to find the best possible setting. Along this line, we can leverage work done in related fields [36] to identify the subset of best workers and exploit their features to be able to minimize the workforce needed and at the same time maximize its effectiveness.
Also, the crowd can be asked to provide additional rationales to motivate their classification [31, 38]. The classifications can be used to improve the AI component by fine-tuning the models with additional data, or even both workers and AI rationales can be used to adjust the confidence of the final assessment; nevertheless, this should be implemented with caution, as workers rationales might contain bias that can be involuntary injected into AI models. Finally, a subset of crowd-workers should look for counterfactual examples that could highlight AI classification errors with high confidence, and should be used to improve the overall quality of the AI module, as will be discussed in the Section 5. While these methodologies still need to be tested in the field of misinformation detection, some work [35, 40] shows the promising results of this approach applied to different domains.
As for the AI component, the output of the crowd component is composed by the default classification and confidence, along with optional additional data such as evidence, explanation, and rationales (not shown in Figure 1). Therefore, to decide if a statement is correctly classified or not it is possible to rely not only on the data generated by the crowd, but also to check for agreement and inconsistencies between crowd and AI [44].
At this point of the evaluation, the majority of the statements should have been classified by the framework, and only a very small subset will reach the final step of the workflow: the experts.
Third component: Experts
The last step of the framework is made by the experts. It is possible to let them evaluate a statement using a pre-defined fact-checking methodology, and ideally to provide to them all the outputs from the previous components to perform an informed assessment. The effects of such a decision need to be studied since, as discussed for the crowd, the use of additional information could introduce bias in the final evaluation. We remark that we believe that critical, important, and difficult statements should always be evaluated or at least checked by the experts. Note that to identify those statements it would be necessary to find a metric to be able to automatically evaluate the importance of a statement in a given context. Also, to increase the robustness of the framework, the experts should be able to directly look at the statements classified by the previous components and to decide whether some of them need to be re-assessed or not.
Experts should be carefully employed to provide feedback to the AI component with the aim of improving its performance, as will be discussed in Section 5. The experts should also help to improve the crowd performance, by providing guidelines and tools to be employed during the truthfulness evaluation made by the crowd. Finally, each classification performed by the experts should be used to retrain the AI models, and used as an example to train the crowd before performing the task. This final aspect could also be performed interactively, following an active-learning scenario. This step could also be done by following the perspectivist guidelines, and thus collecting not only aggregated judgments, but raw judgments along with information used during all the performed fact-checking activity. This could allow to build more informative datasets and to train automatic AI methods that perform predictions using a higher amount of informative data.
Framework synergies: Human feedback
In this section, we detail some aspects of the proposed framework, discussing the feedback synergies between the AI and both human components, i.e., crowd and experts. Particularly, considering Figure 1, we discuss alternatives on the two red arrows (feedback) from the crowd component back to the AI component and the arrow from the experts to the AI component. Thus, in Section 5.1 we list the possible alternatives of using human feedback in the framework, in Section 5.2 we discuss the different types of feedback that the crowd and the experts should provide to the AI component, and in Section 5.3 we detail how to employ the crowd during the AI training process to improve the model’s performance.
Human feedback alternatives
As already discussed in Sections 4.4 and 4.5, both crowd workers and experts should be employed to improve the quality of the classifier models of the AI component. There are multiple ways to use human feedback to improve the performance of an AI classifier. Human feedback can be used for selecting training data by identifying relevant data containing examples of misinformation. This process can improve the classifier’s ability to recognize and classify misleading information. Also, human feedback should be used to perform data labeling, i.e., to label examples of misinformation in the training data. This process involves human annotators classifying examples as true or false (assuming a binary truthfulness scale), or identifying specific types of misinformation (such as conspiracy theories). Human assessors can also be used for classifier evaluation by having them review and assess the classifier’s predictions. This process can help to evaluate the classifier by identifying areas for improvement. Moreover, human feedback can be used to detect and mitigate biases in the classifier’s predictions. Human annotators can review examples of misinformation and identify any biases based on race, gender, religion, or other factors. Finally, the human can be actively used during the classifier training phase to improve the classifier’s performance. This can be done in an active learning scenario, where examples from the data set are selected based on their potential to improve the classifier’s performance, or on a reinforcement learning scenario, where the humans provide feedback to the classifier in the form of rewards or penalties to adjust the classifier’s predictions [35].
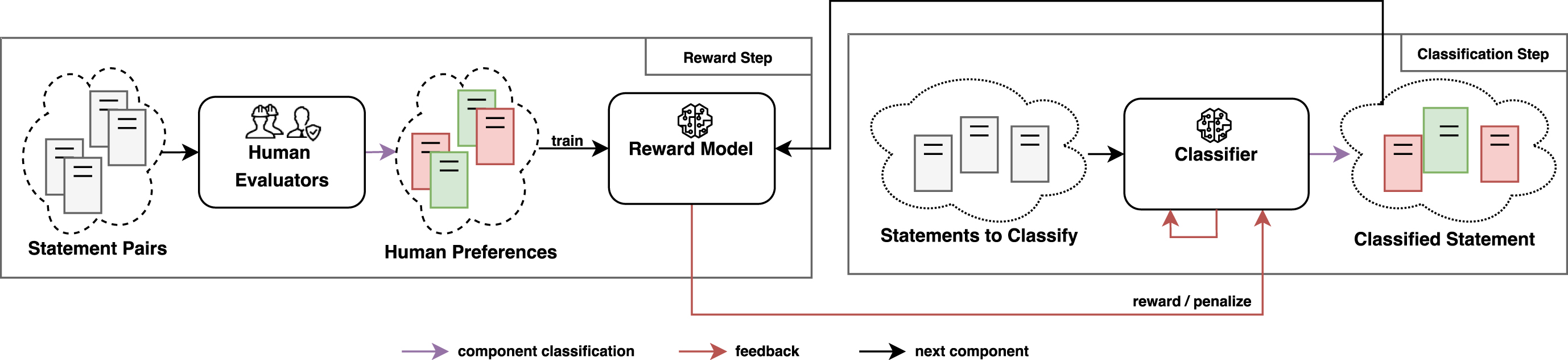
Preference Learning Framework overview.
In Section 5.1 we listed the main possibilities to include human feedback in the HITL framework to improve the AI component performance. Nevertheless, given the differences between the crowd and the experts, they should provide different types of feedback.
Particularly, data labeling and data selection tasks require a high amount of workforce and they are activities where the crowd is proven to perform adequately [11, 14]. Thus, the experts could be excluded. Considering the classifier evaluation task, the crowd should be employed to evaluate the outputs of the classifier that are difficult to measure, such as the quality of the explanation provided for a performed assessment, as done by Brand et al. [7, 8], while the classifier performance should be evaluated by relying on standard evaluation metrics.
Instead, considering the active learning scenario, experts are the most suitable choice, as the aim is to focus on a relatively small sample of statements that could have a high impact on the classifier performance. The classifier selects the most informative statements that once labeled by a human assessor could improve the most its accuracy. Therefore, it is reasonable to depend on the experts, since they are the most reliable component with the highest accuracy.
Finally, reinforcement learning could be meaningfully done by both the crowd and the experts. Nevertheless, the crowd is faster, more scalable, and more cost-effective (crowd workers are typically less expensive than hiring a few experts, making it more cost-effective to obtain a large amount of training data) when compared to the experts. Thus, the use of experts in the reinforcement learning scenario should be reduced to the most “critical instances” (e.g., those with lower confidence).
Reinforcement learning using the crowd
In this section, we describe how it is possible to concretely include reinforcement learning using the crowd in the misinformation detection framework proposed. A simple approach is to incorporate human feedback into the training process by using a feedback loop at the end of each training iteration. The classifier is trained on an initial set of data. Later, the feedback provided by the human annotators at the end of each iteration (this could be done after each epoch or at the end of the pre-training and/or fine-tuning parts) is used to retrain the classifier. The advantage of using a feedback loop approach is that it allows the classifier to learn from the feedback provided by the human annotators possibly in real-time. This approach provides a direct way of incorporating human feedback into the training process, as the classifier is updated after each feedback iteration. However, this approach can be time-consuming and may require a large number of iterations before the classifier reaches an acceptable level of performance.
Another approach is to use a so-called Preference Learning Framework [6, 61]. In this approach, summarized in Figure 2, the classifier is trained to learn using the preferences from the human assessors. The Preference Learning Framework is composed by two separate steps: the reward step and the classification step, as shown in the figure. In the reward step (left box of Figure 2), the human assessors are presented with pairs of statements and asked to indicate which one they believe is more likely to be true between the possible options. A pair of statements can also be generated by a single starting statement turning a true statement into false by changing a few words or phrases, using the TextAttack framework [39].
The collected preferences are used to train a reward model, used to provide feedback to the classifier by rewarding its predictions. Given a different set of statements, if the classifier (Figure 2 right box) predicts that a false statement is more likely to be true than a true statement, the reward model will assign a low reward to that prediction. On the contrary, if the classifier predicts that a true statement is more likely to be true than a false statement, the reward model will assign a high reward to that prediction. These rewards can provide iterative feedback to update the classifier to make its predictions more likely to be rewarded by the reward model until a satisfactory level of performance is reached.
The advantage of using a Preference Learning Framework is that it allows the classification model to learn from the preferences of the human annotators efficiently. This approach requires fewer training iterations than the feedback loop approach, as the classifier can learn from a larger set of examples in a single training iteration. However, this approach may be less effective in capturing the nuances of the feedback provided by the human annotators, as it relies on their preferences rather than their direct feedback.
To ensure the effectiveness of the two approaches, it is important to carefully design the feedback loop and the preference learning framework. The feedback loop should be designed to ensure that the classifier model learns from the feedback provided by the human annotators in a way that is accurate and meaningful. Similarly, the preference learning framework should be designed to ensure that the classifier model learns from the preferences of the human annotators in a way that captures the nuances of their feedback. Ultimately, the choice of which approach to use will depend on the specific needs of the veracity assessment task and the availability of human annotators. Both approaches can be effective in incorporating human feedback into the training of a classifier model, and it is important to carefully consider the advantages and disadvantages of each approach when designing the training process. The advantage of using preferences on the output is that it allows the classifier model to learn from its mistakes and improve its predictions over time. However, this approach requires a large amount of training data and human annotators to provide preferences. Additionally, it can be difficult to ensure that the reward model is accurately capturing the preferences of the human annotators. Therefore, it is important to carefully design the reward model and ensure that it is consistent with the task of veracity assessment.
Conclusions
In this work we study the limitations of the current approaches for misinformation detection and propose a hybrid HITL framework that combines AI, crowd, and experts. Our main contributions are the following: we frame the problem and review the related work detailing frameworks for fact-checking; we study possible framework architectures detailing their respective advantages and disadvantages; we propose a solid architecture for performing fact-checking at scale, and we describe each component focusing on its role and outputs; we explore the possible interactions between each component, investigating how the human components could differently provide feedback to improve the performance of the AI component. The main advantages of our framework are given by an efficient combination of the components in terms of increasing accuracy and evaluation time, decreasing costs, and by the feedback between and within each component.
Future work aims at proving a full framework implementation. More in detail, further study will be done on the synergies between crowd and AI to investigate the effects of an informed assessment made by the crowd leveraging AI outputs, and to set thresholds to decide about statement forwarding among components. Finally, we aim to investigate the effectiveness to employ human assessors in a Reinforcement Learning scenario, also comparing the different approaches described in this work.