
Abstract
In the last few decades we have witnessed a significant development in Artificial Intelligence (AI) thanks to the availability of a variety of testbeds, mostly based on simulated environments and video games. Among those, roguelike games offer a very good trade-off in terms of complexity of the environment and computational costs, which makes them perfectly suited to test AI agents generalization capabilities. In this work, we present LuckyMera, a flexible, modular, extensible and configurable AI framework built around NetHack, a popular terminal-based, single-player roguelike video game. This library is aimed at simplifying and speeding up the development of AI agents capable of successfully playing the game and offering a high-level interface for designing game strategies. LuckyMera comes with a set of off-the-shelf symbolic and neural modules (called "skills"): these modules can be either hard-coded behaviors, or neural Reinforcement Learning approaches, with the possibility of creating compositional hybrid solutions. Additionally, LuckyMera comes with a set of utility features to save its experiences in the form of trajectories for further analysis and to use them as datasets to train neural modules, with a direct interface to the NetHack Learning Environment and MiniHack. Through an empirical evaluation we validate our skills implementation and propose a strong baseline agent that can reach state-of-the-art performances in the complete NetHack game. LuckyMera is open-source and available at https://github.com/Pervasive-AI-Lab/LuckyMera.
Introduction
In the last few years, Artificial Intelligence algorithms achieved astonishing results in a wide range of tasks, exploiting both classical, symbolic approaches and data-driven methodologies from the field of Machine Learning [23]. Research in this area was sustained and encouraged by the availability of several benchmarks, needed to experiment with new architectures and technologies. Video games in particular, gained a great popularity since they offer challenging experiences, similar to real-world problems, at a much smaller cost; therefore, they are excellent playgrounds to study and test different approaches. AI was applied to different environments with surprising success, e.g. winning against the world chess champion [9] and, especially with the introduction of deep architectures in the field of Reinforcement Learning (RL), beating professional players in Go [29] and Dota 2 [3].
Among the wide variety of games available, roguelikes are of particular interest due to their unique features. Roguelikes 1 are turn-based, role-playing games, with a deep focus on cautious exploration, fighting enemies and wise resource management. This kind of game also features random generation of the levels structure, together with the type of enemies and objects the player will find, and permadeath, meaning that there is no checkpoint during the game, and players have to start from the first level each time they die. Because of these features, roguelike video games are extremely challenging, since players are required to deal with a variety of situations, each time having to overcome many levels, where a single mistake could ruin an entire run. Given these characteristics, roguelike video games are perfectly suited to test AI agents ability to generalize in increasingly complex environments.
NetHack, published in 1987, is one of the earliest and most popular roguelikes; here, the player controls the hero, selected among different races, roles and alignments, with the objective to retrieve the Amulet of Yendor by exploring over 50 random generated floors, and offer it to a deity to became a demigod. Each level is made of rooms connected by corridors, filled with monsters, objects and other peculiar features, such as shops or altars. NetHack, in its original version, provides a simple terminal interface (Fig. 1), depicting the map of the current level. In addition, it shows a message on top of the screen offering additional information, and a bottom line with character statistics.
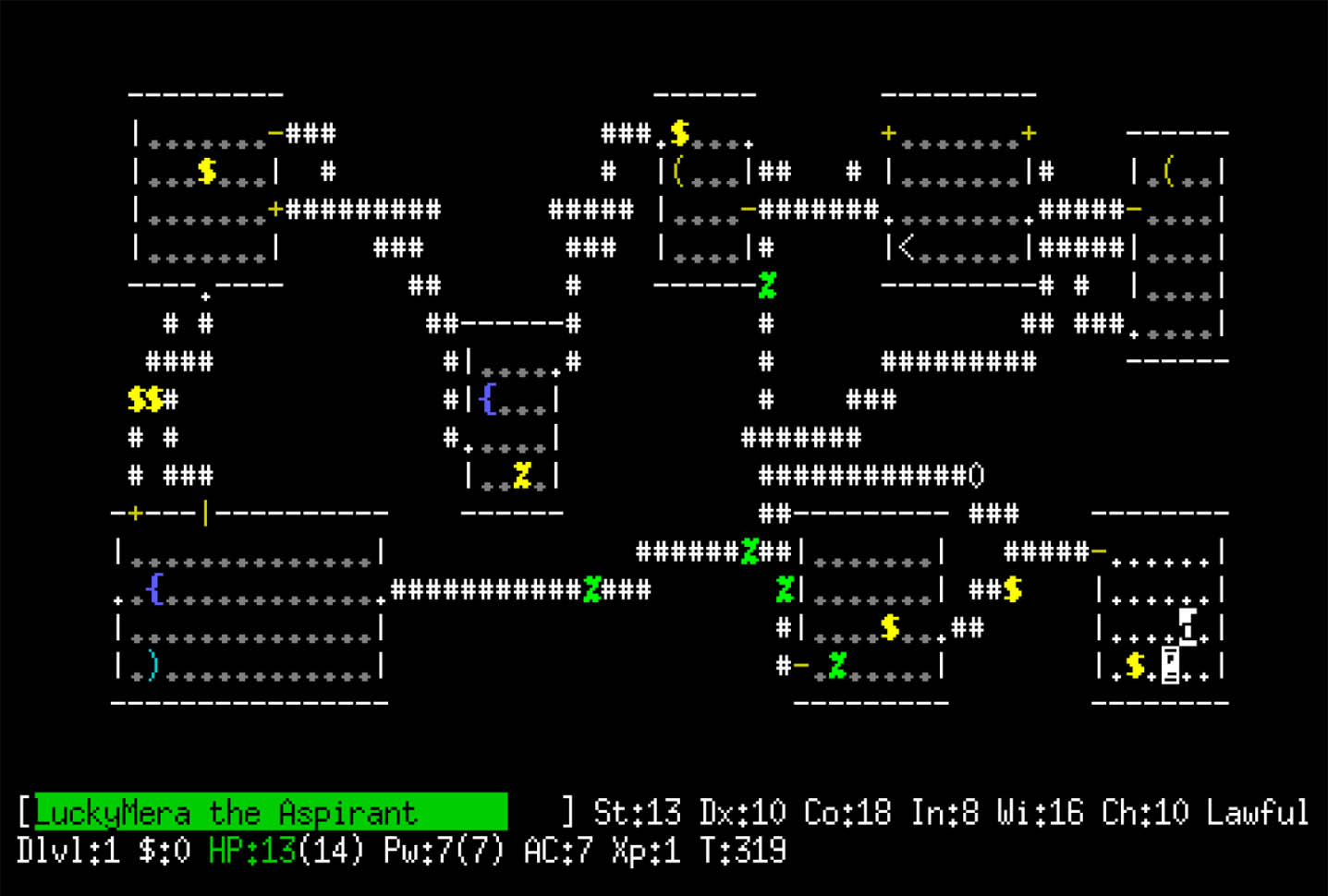
An example of the NetHack ASCII interface.
The game offers a complex, procedurally generated open world with sparse rewards, forcing the agent to explore, reason and acquire knowledge about hundreds of entities. NetHack is considered one of the most difficult games for humans, and a hard challenge for modern RL models as well; in fact, current best models are only comparable to human beginners 2 , a beginner score is less than 2,000 score points.
In this work, our objective is to present a complete and integrated framework, that can facilitate the research in AI exploiting the environment offered by NetHack. We argue that our framework is an effective tool to design a number of agents playing the game, using both classical symbolic AI solutions and Machine Learning ones. To the best of our knowledge, this is the first open-source framework aimed at the definition of AI agents built around the game of NetHack and the NetHack LearningEnvironment.
Our main contributions can be summarized as follows: We introduce LuckyMera
3
, a modular and extensible framework for building intelligent agents for NetHack. It integrates different AI paradigms, i.e. symbolic and neural approaches, and offers the possibility to easily define custom modules to solve specific tasks; We discuss different approaches to the game, in particular Imitation Learning, Reinforcement Learning and Neuro-Symbolic methods. We perform ablation studies concerning these components, to analyze their performance; We show how a bot build with LuckyMera is able to reach state-of-the-art performances within the top 6 bots of the NeurIPS NetHack Challenge 2021 among over 600 submissions [15].
In this section, we review some studies related to our work, starting from the virtual environments defined around the game of NetHack for AI agents, and relevant AI approaches, namely Rule-Based, Imitation Learning and Reinforcement Learning methodologies.
NetHack as AI testbed
As we will see more in depth in Section 2.2, the environment offered by NetHack was widely used to develop and test intelligent agent capable of playing the game. An interesting approach is the one proposed in [7], in which the authors present a solution to explore the levels of the game exploiting the concept of occupancy maps, especially popular in robotics. In RL research, the first example of usage of NetHack is gym_nethack [8, 6], which offers an interface to the game through a Gym [5] environment. However, in this case, the dynamics were heavily modified by removing several obstacles, resulting in a much simpler version of the game.
In this work, instead, we make deep use of the NetHack Learning Environment (NLE) [21]: a Gym environment that leaves the game mechanisms unchanged. It is designed to wrap the entire game, returning all the observation available from the game, i.e. the map of the level, the current agent’s statistics, the textual message showed to the user and information about the inventory. The environment has 93 available actions, divided in 16 movement actions and 77 command actions. NLE is of particularly interesting because it is able to combine a complex environment with a fast simulator, being extremely efficient and computationally lightweight. Since current architectures cannot win the game, MiniHack [27] was released: a framework defined on top of NLE, which proposes a set of simpler environments, together with the possibility to easily design new tasks. The tasks proposed can be mainly divided into navigation tasks, in which the agent has to reach a goal position, and skill tasks, which involve more complex abilities, such as using potions, selecting the appropriate armor and fighting more powerful monsters.
We were deeply inspired by the results obtained in the NeurIPS 2021 NetHack Challenge [15]. Our framework was developed using mainly the
First AI Bots for NetHack
From its initial release, there have been several bots addressing the problem of NetHack. One of the first able to achieve significant results is TAEB 4 , a modular framework for designing automatic and semi-automatic players. It uses the publish/subscribe paradigm to perform the communication among the different components; for the pathfinding task, it employs Dijkstra’s algorithm [11]. The first symbolic bot able to "ascend", i.e. win the game, was BotHack 5 . Its architecture is particularly noticeable for the accurate recognition of the kind of floor the agent is exploring, and the use of the A* algorithm [17] for the navigation tasks. Nonetheless, it was able to achieve these results mostly using an exploit present in older NetHack version, which is no longer applicable in the current game. The current best open-source NetHack bot is AutoAscend 6 , winner of the NeurIPS 2021 NetHack Challenge. It implements a set of high-level strategies, each handling a specific behavior and wrapping multiple actions, and selects one based on its priority.
Although these approaches are able to obtain good results at the game, none of them offers a valid research platform, as we do with LuckyMera. Their goal was to create performance-oriented agents to win the game, while our main objective is to provide a development-oriented framework, to train, integrate and test neuro-symbolic approaches.
Imitation learning approaches
Imitation Learning is a Machine Learning technique in which the agent, to learn an intelligent behavior, instead of relying on the interaction with the environment, is provided with a set of demonstrations from an expert [31]. The agent’s objective is to mimic the expert’s actions, hopefully achieving an optimal policy, following a form of Supervised Learning. The dataset contains trajectories of experiences, made of state-action pairs; in particular, the trajectories will be in the form of
One of the simplest Imitation Learning algorithms is Behavioral Cloning (BC): given a state-action pair
We will review in detail the implementation of the Behavioral Cloning algorithm we offer in LuckyMera in Section 3.2.4.
Reinforcement learning approaches
Reinforcement Learning algorithms are usually tested in simulated environments, like games. RL approaches have shown superhuman capabilities in classical games, such as Go [29] and Chess [28]; furthermore, there were also works on more complex, multiplayer games, like StarCraft II [30] and Dota 2 [3]. One of the most influential benchmark for Reinforcement Learning agents is the Arcade Learning Environment [2]. It offers an interface to hundreds of video games from the Atari 2600 game console, and it has been widely used in RL research as a testbed to experiment with different approaches [24]. However, the environments proposed are too simple and not adequate for current RL algorithms. Nowadays, AI research needs more challenging benchmarks, to test more elaborate capabilities in complex environments; in this sense, NetHack is perfect to drive the research in the next years. Furthermore, the Arcade Learning Environment simply provides an interface to the games, while LuckyMera builds on top of the game interface to offer a modular framework for designing AI agents.
A comparable framework to our work is OpenSpiel [22], which is a collection of game environments and algorithms, including both search/planning strategies and reinforcement learning, with the possibility to add new games and methods. Their objective is to provide a set of simple and traditional games, enabling researchers to assess the same algorithm across multiple environments. In contrast, we focus on a single yet complex environment, which requires different skills, releasing a framework mainly oriented towards the definition of modular architectures.
Several studies on Reinforcement Learning were conducted on the NetHack environment. The MiniHack suite was used to test the E3B algorithm [18], a method for defining intrinsic exploration bonuses based on learned embeddings of previous states. Chester et al. [10] proposed a hybrid approach, using symbolic planning for low-level actions, and Reinforcement Learning to train a meta-controller; they show that this method surpasses the baseline algorithms in a custom MiniHack environment. Powers et al. [25] presented CORA, a platform for Continual Reinforcement Learning, providing MiniHack as one of the benchmark environments. Using the MiniHack tasks from CORA, Kessler et al. [19] studied a task-agnostic, model-based method for Continual Reinforcement Learning, showing it to be a strong baseline compared to state-of-the-art approaches.
LuckyMera is instead an approach-agnostic research platform; it can be expanded to test any Artificial Intelligence method or paradigm, including Reinforcement Learning ones. It is particularly convenient because of the possibility to train targeted skills, tackling a more feasible problem, and then to integrate them with the other modules offered by the framework.
The LuckyMera Framework
LuckyMera is a framework for simplifying the development of Artificial Intelligent agents able to play the game of NetHack, designed following the principles of modularity, extensibility and configurability. The main objective of the architecture is to provide a high-level interface for defining game strategies, represented in the code through the
Design of the Agent
The LuckyMera framework is released together with the implementation of an AI agent, designed following the modular structure, that represents a useful baseline for further studies. At the highest level of abstraction, the agent’s strategy simply consists of the iterative execution of the highest-priority plannable skill in the current state; the user can easily set the priority of each skill via a configuration file. In Figure 2 there is a high-level representation of the system execution flow.
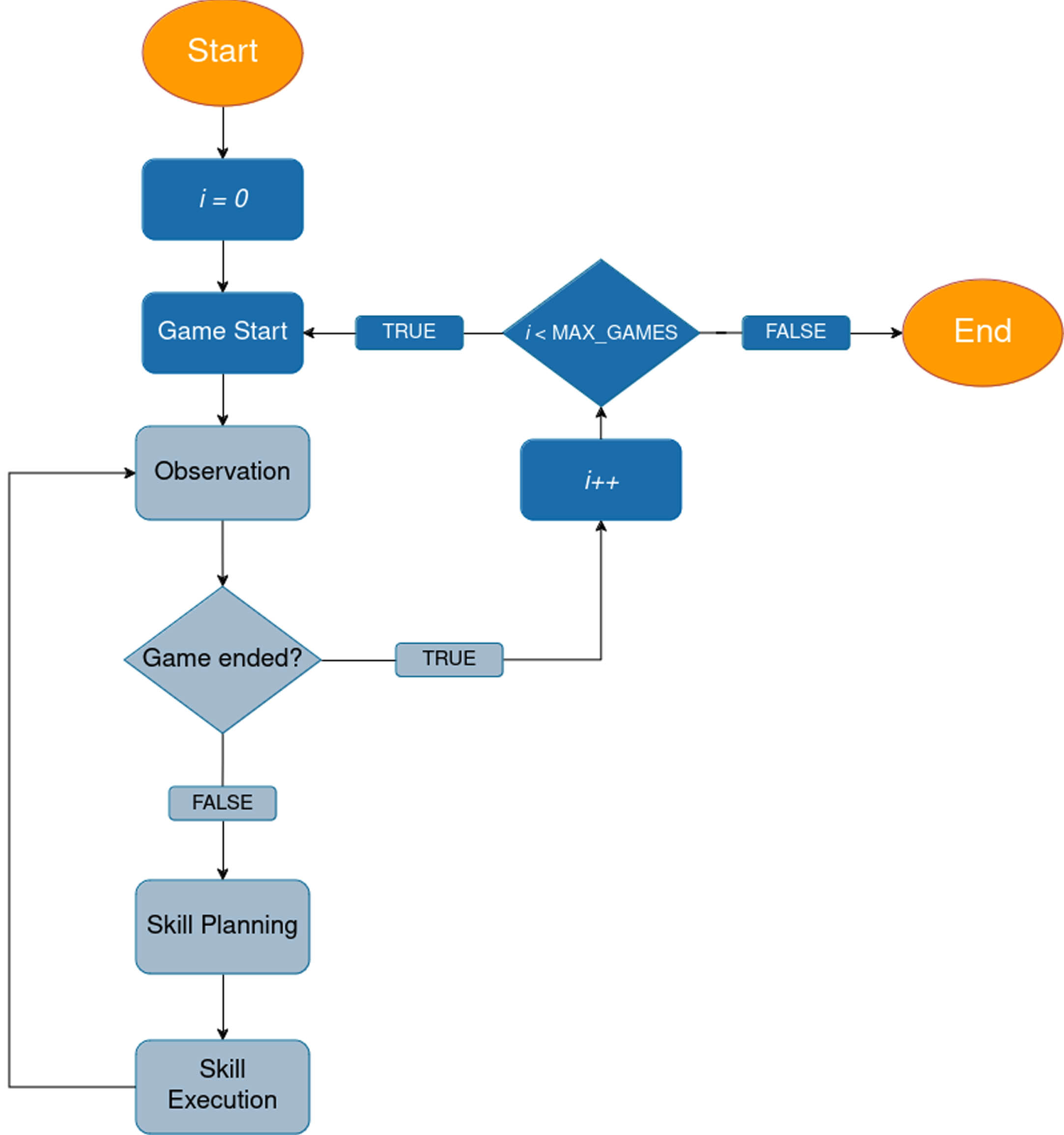
Flowchart of the behavior of the LuckyMera agent. Essentially, it iterates through planning and execution. During skill planning, it gets the highest priority skill that can be planned; then, this skill is actually executed.
The agent’s main execution flow is made by the iteration, throughout the duration of the game, of the two principal phases: skill-planning and skill-execution. The planning of a skill begins with the analysis of the game state, derived from the NLE observations. During this phase, the agent verifies if the skill can actually be executed, i.e. its preconditions are satisfied, and performs some preliminary steps, depending on the nature of the skill itself. The module implementing a skill should provide the planning method, in compliance with the framework’s main component interface. Thanks to this abstraction, the system is perfectly compatible out-of-the-box with any symbolic and neural skill implementation, and in general with any AI module; we will discuss this feature more in detail in Section 3.2.2. Once the planning of a skill succeeds, the agent performs the skill-execution phase. Each skill provides the implementation of a series of actions needed to perform its plan.
Our framework offers also the possibility to easily define custom modules. To leverage this extensibility property, we provide simple class templates, that enable the definition of any specific action. An in-depth discussion about the extensibility property of LuckyMera is present in Section 3.2.1 .
In addition to the high-level modules, the architecture also provides low-level solutions for interacting with the game. In particular, it is based on the
Here we will discuss some of the main features that LuckyMera offers, which make it an integrated framework for quick testing of new approaches, automatic creation of labeled trajectories and training of Machine Learning models. During the discussion, we will also present some possible applications of the framework, namely a neuro-symbolic approach and our baseline agent LuckyMera-v1.0.
Definition of New Skills
The main features of the framework are represented by its modularity and extensibility. In fact, each in-game action is defined as an independent module, and the LuckyMera main component is in charge of composing the various skills, without imposing constraints on their internal structure.
The interface it exposes has been designed to offer the possibility to define custom modules, by extending one of the classes that represent the concept of skill. The base class for defining new modules is
This interface simplifies the definition and integration of new skills, providing researchers with a convenient way to test any AI methodology on the challenging NetHack benchmark. Our framework reduces the need to write extensive boilerplate code to ensure functionality, as it manages all the low-level interactions with the game. This allows researchers to convey their efforts into the implementation of their approaches only.
Skills Integration
The main component of the framework offers a simple, straightforward interface, making it easy to integrate skill modules. Each module should inherit from one of the classes representing the
Besides these skills, it is possible to integrate any external module compliant with the interface, as presented in Section 3.2.1. In fact, the framework allows for the import of any given model, so that new actions — or new strategies for already defined operations — can be implemented, or trained neural models can be used to perform specific tasks. As an example, the framework was tested with the integration of a neural RL agent, trained using the IMPALA algorithm [12], with the implementation from TorchBeast [20]. Since the task of playing the entire game of NetHack is too difficult for current RL approaches, the training was executed on some MiniHack environments, which offers more controlled and feasible challenges. The environments selected are
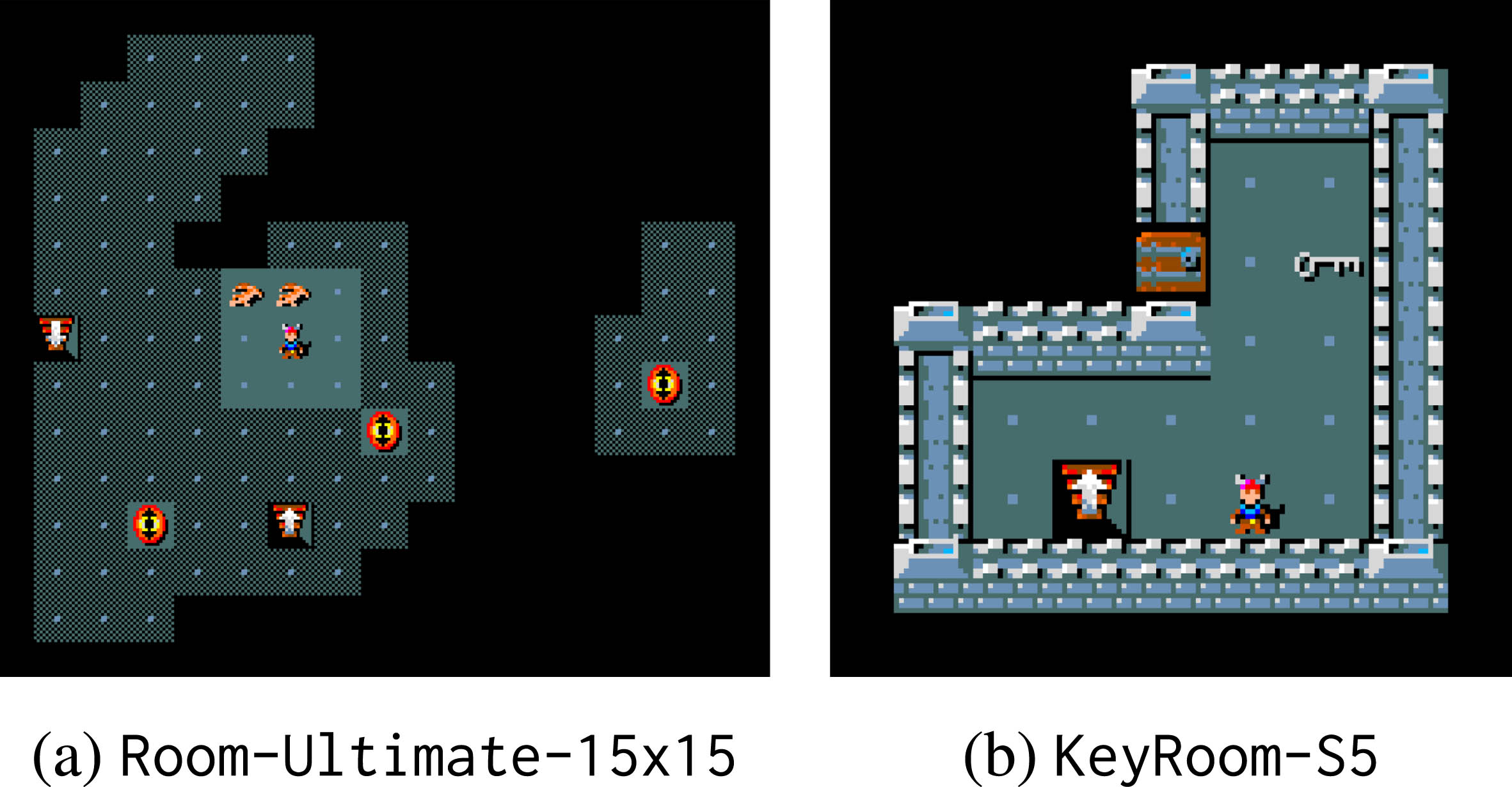
MiniHack environments used for the training of the RL agent.
The architecture we propose comes with the possibility to save the experiences of the bot with the environment, in the form of trajectories of state-action pairs. Given the performance of a LuckyMera bot, its behavior is meaningful and valid in the context of the game, and it could be used as an expert, e.g. in Imitation Learning applications. Within the framework, it is possible to exploit the capabilities of the bot to define a dataset of experiences, which is automatically labeled with the actual action performed by the agent. The trajectory saving mechanism is independent of the type of observation: it is possible to store any element present in the observation space defined by NLE, by defining them at runtime. The framework integrates also the NLE Language Wrapper [14], which translates the non-language observations from NetHack, e.g.
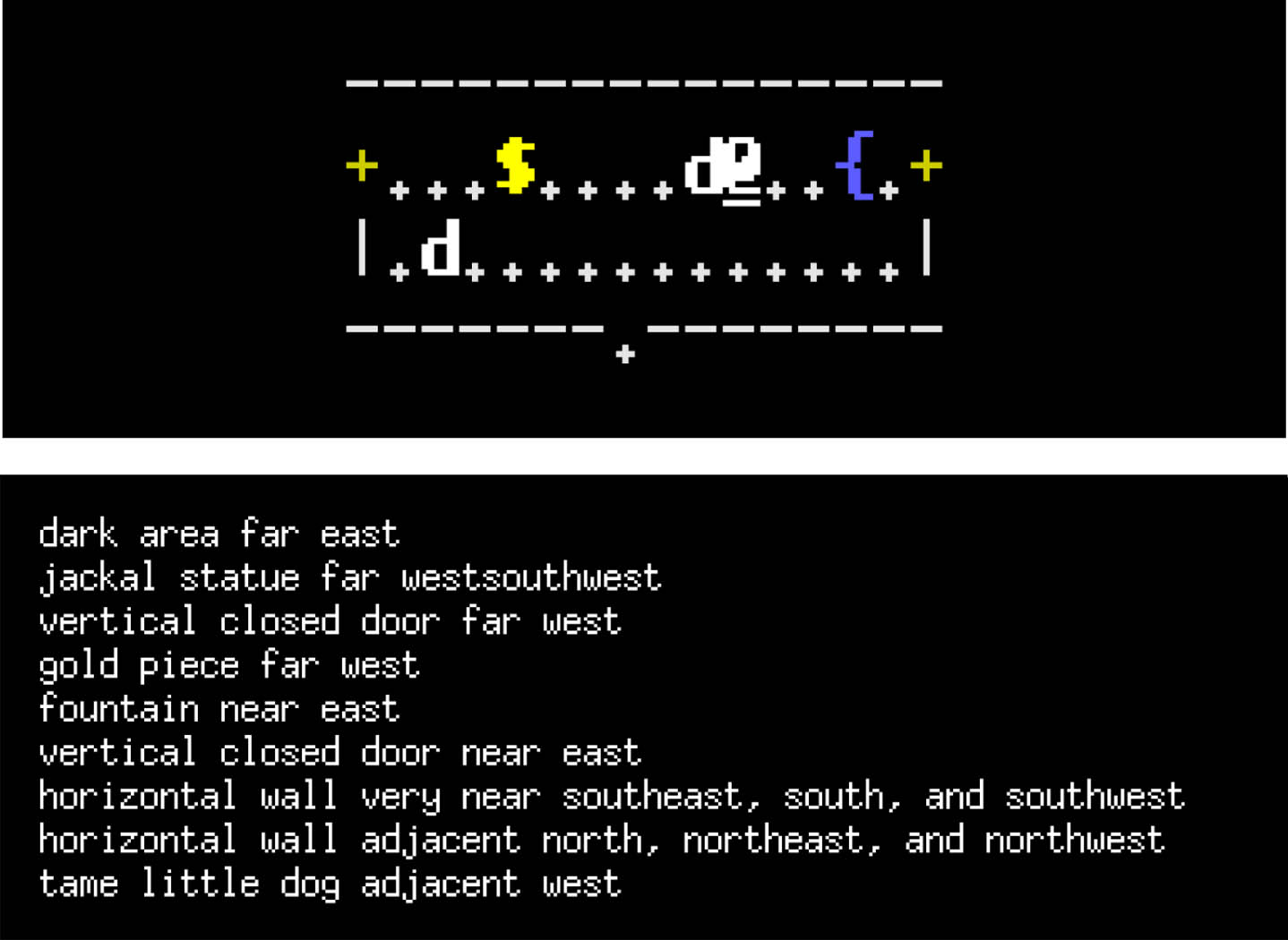
One level of NetHack viewed with different representations. The top image is the standard ASCII interface, while the bottom image shows the language representation provided by the NLE Language Wrapper.
The LuckyMera framework offers also the possibility to perform training processes on the NetHack environment, providing an interface that can handle any training algorithm. In fact, the architecture comes with an abstract class that represents a generic training procedure, that should be extended to define a specific algorithm. In this way, the training process is strictly incorporated in the system, so that it is easy to evaluate the model performance and integrate it with the other modules, giving the possibility to also define hybrid architectures. As an example, we provide the implementation of the Behavioral Cloning algorithm, one of the most intuitive approaches for Imitation Learning; it is briefly described in Algorithm 1.
Collect trajectories τ1, …, τ n from the expert.
Get all the
Learn policy π θ by minimizing L (a*, π (s)).
Example of Usage: LuckyMera-v1.0
LuckyMera comes with a set of pre-defined modules, to showcase one of the possible concrete use-cases of the framework. These modules implement some basic actions and the relative reasoning processes, that consider the facts known by the agent and its surroundings to select the best skill to perform. Such actions allow the agent to interact with the NetHack environment and to progress in the game. Indeed, there are modules designed to explore the dungeon, other ones to deal with the enemies present in the game, and other skills for actions such as eating or praying. The complete list of the skills released together with the LuckyMera framework is reported in Table 3.
These skills specify the behavior of a possible agent, referred to as LuckyMera-v1.0. This implementation mainly serves as a practical demonstration of the usage of the framework, emphasizing the intrinsic modularity of our architecture, rather than positioning itself as a fully-fledged AI agent. With the LuckyMera-v1.0 agent, our goal is to establish and release a solid baseline — a starting point for further developments — without the aspiration to surpass the state-of-the-art. Nonetheless, we assessed our approach against the current best-performing solutions, achieving comparable results. Further details regarding this evaluation can be found in Section 4.
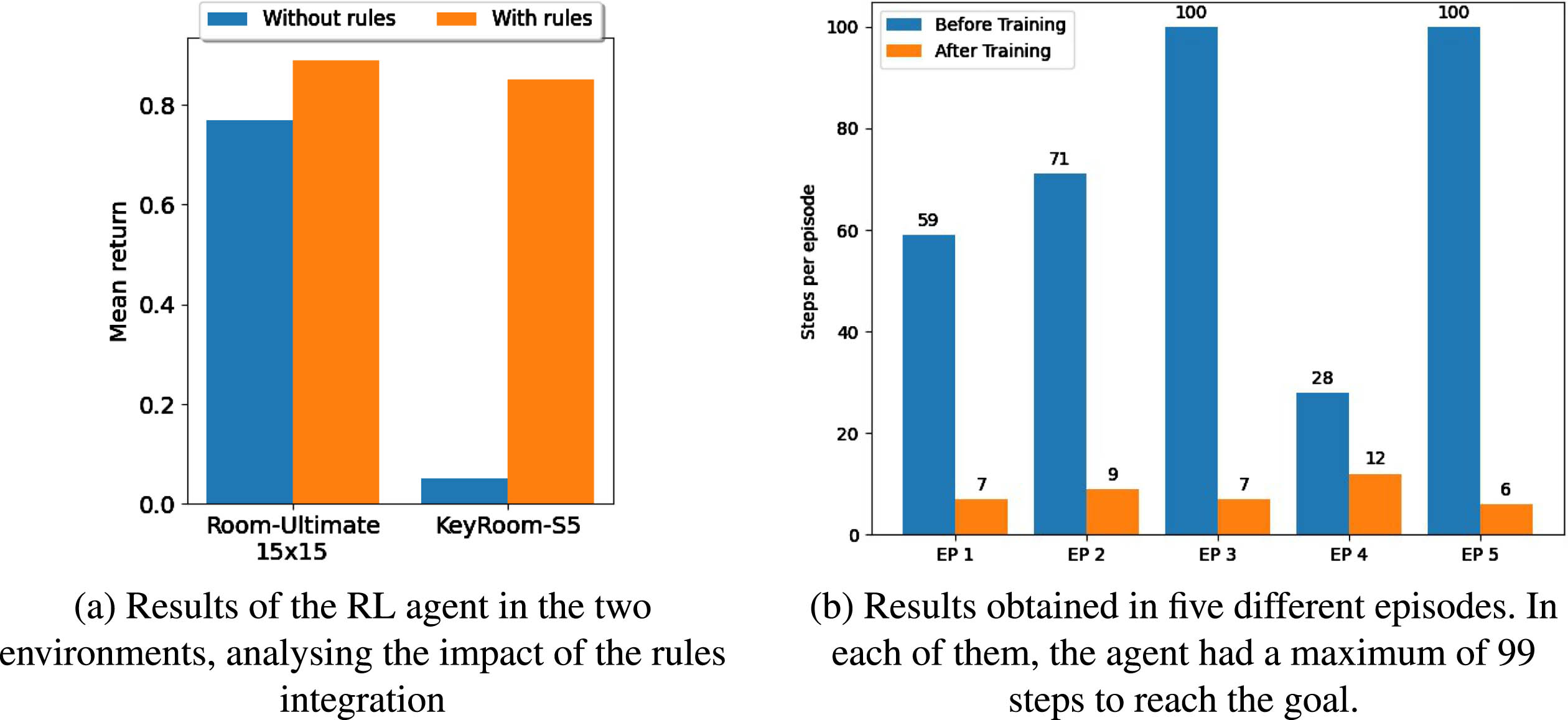
Results of the ablation studies performed on the framework.
In this section, we evaluate the results of the experiments we conducted with the LuckyMera framework. Firstly, we will analyse the ablation studies we performed on some modules of the architecture, namely the hybrid RL module and the Imitation Learning approach, to see their individual performance. We will then present the results obtained by the LuckyMera agent we release, comparing it with the participants in the NeurIPS 2021 NetHack Challenge.
Reinforcement learning approach results
We integrated a Reinforcement Learning approach, based on the IMPALA algorithm. As testing environments, we used the
Logic rules used in integration with the Reinforcement Learning
Logic rules used in integration with the Reinforcement Learning
In Figure 5a, results for the two environments considered are reported. It is clear that, in both cases, the integration of rules led to a increase in the agent’s performance.
The imitation learning approach implemented in LuckyMera is based on the Behavioral Cloning algorithm. This method was tested using the
LuckyMera-v1.0 Agent Baseline
As a final validation of our implementation, we designed a LuckyMera agent composed of multiple skills (more details in Appendix 5.1) and tested against the most challenging
Our agent was able to achieve an average score of 1046.96 and a median of 817. In Figure 6, the results of LuckyMera are put against the highest scoring teams from the challenge. The agent is able to virtually reach the 6th position, overcoming more than 80% of the competitors. The challenge ran for 144 days, with 46 participating teams and 631 overall submissions8.
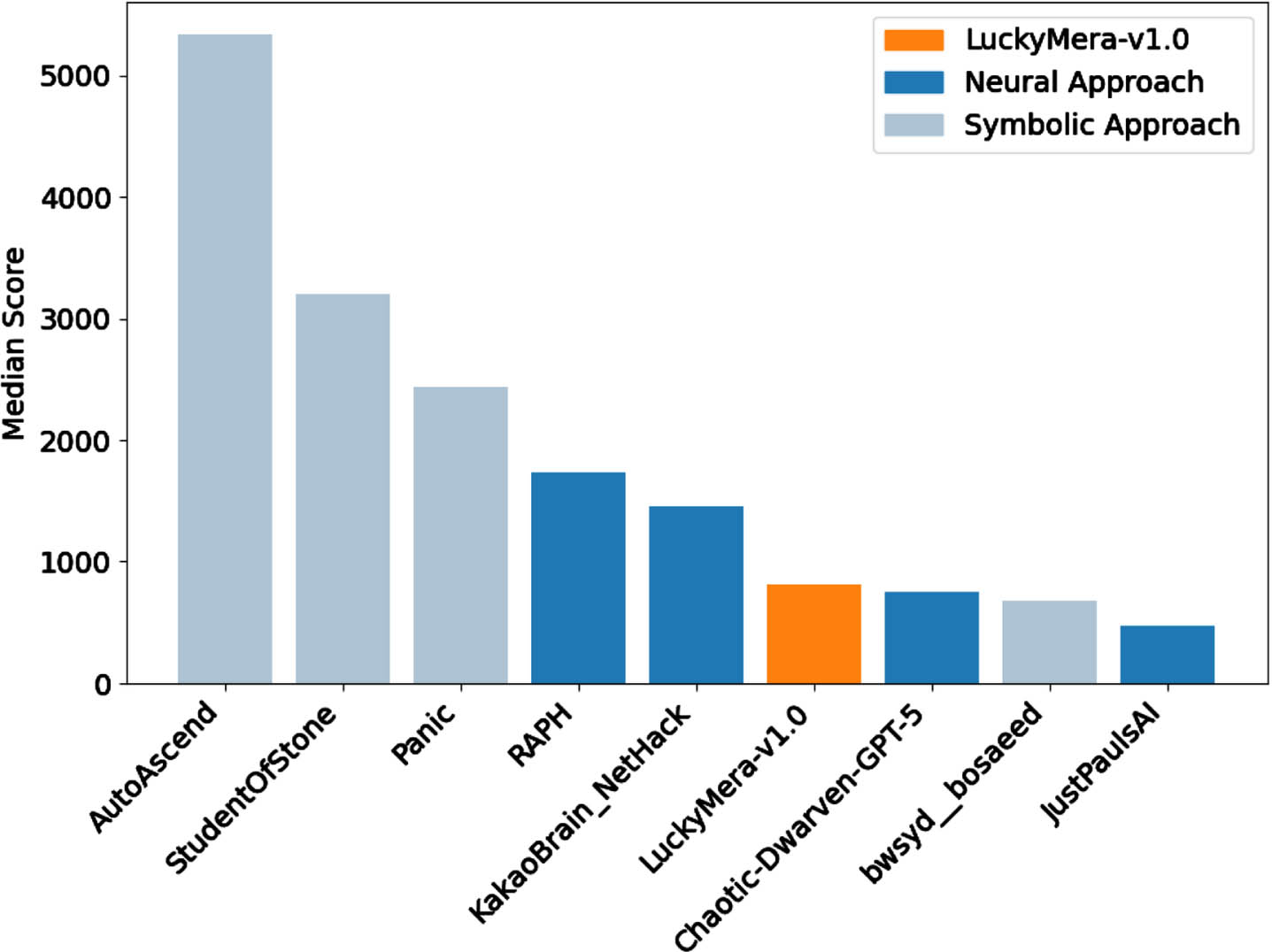
Results obtained by a LuckyMera agent, compared with the state-of-the-art bots from the NeurIPS NetHack Challenge 2021.
LuckyMera is a flexible, modular, extensible and configurable framework to speed up the development of smart AI agents tackling the NetHack game. The architecture is designed to assist AI researchers by offering them an integrated platform to seamlessly implement and test their solutions in a challenging environment, which represents an excellent test bed for evaluating AI approaches. That is provided through an intuitive code interface, that hides all the boilerplate code and implementation details needed to interact correctly with the game.
LuckyMera is also approach-agnostic, since it is capable of integrating any AI module. We tested it with symbolic skills, Reinforcement Learning policies and Imitation Learning approaches, and it natively supports any AI algorithm and implementation.
The framework also includes a strong baseline agent, called LuckyMera-v1.0, capable of achieving good results in the game, and offers the possibility to easily extend its behavior using external modules. Such modules can be symbolic rules performing a specific action, or neural models trained on a given task. The architecture also provides the possibility of creating automatically labeled datasets, by storing the experiences of the agent in the form of trajectories made by state-action pairs. It is possible to specify the elements of the observations to save, including the language representations from the NLE Language Wrapper. The trajectories can be used to train neural models via Imitation Learning, or to fine-tune language models to interact with the environment.
However, our approach has also some limitations. Firstly, the LuckyMera framework, being entirely developed in the Python language, currently supports only
Following that, we believe that our code base could be further optimized. We spent our efforts to make it clear and efficient, but additional improvements can be performed, to make it more accessible and open to external collaborations. Moreover, we plan to implement a new feature that exploit the parallelism of CPUs and GPUs architecture. This would allow researchers to simultaneously execute multiple runs of their LuckyMera agent.
Conflict of interest statement
All authors declare that they have no conflicts of interest.
Footnotes
Acknowledgments
Research partly funded by PNRR - M4C2 - Investimento 1.3, Partenariato Esteso PE00000013 - "FAIR - Future Artificial Intelligence Research" - Spoke 1 "Human-centered AI", funded by the European Commission under the NextGeneration EU programme.
Appendix
B. LuckyMera Skills
The LuckyMera framework is released with a set of implemented skills; those skills are the one used to obtain the results presented in Section 4. The complete list of LuckyMera skills is presented in ![]() . The list can be modified, by adding or removing skills, and each skill can be easily changed, implementing new approaches. Further details about the game mechanics can be found at the NetHack Wiki8.
. The list can be modified, by adding or removing skills, and each skill can be easily changed, implementing new approaches. Further details about the game mechanics can be found at the NetHack Wiki8.
Being a modular framework, it is similar to a chimera: a mythological hybrid creature composed of different animal parts. But NetHack is difficult, so it needs to be lucky "mera" (which stands for "a lot" in Sardinian)!.