
Abstract
We study equilibrium approximation in extensive-form adversarial team games, in which two teams of rational players compete in a zero-sum interaction. The suitable solution concept in these settings is the Team-Maxmin Equilibrium with Correlation (TMECor), which naturally arises when the team players play ex-ante correlated strategies. While computing such an equilibrium is
Introduction
In the last decade, game-theoretic approaches to deal with strategic environments with imperfect information allowed the scientific community to achieve outstanding milestones. Some of the most brilliant examples are games like Texas Hold’em Poker [1, 18] and Starcraft II [21] for which the researchers were able to develop algorithms achieving superhuman and high-human performances, respectively. Most of the efforts have been spent to tackle games with two competing players (i.e., two-player zero-sum games), while no satisfactory results have been proposed for games with multiple players. One of the reasons for this asymmetry lies in the different complexity of the equilibrium computation problem of the two settings. Indeed, while it is possible to develop scalable and efficient algorithms to approximate optimal strategies (i.e., equilibria) in the case of two-player zero-sum games, under standard complexity conjectures, the computation of equilibria in multi-player scenarios is a much more challenging task that can become intractable in the worst case.
In this work, we study the problem of approximating equilibria for adversarial team games (ATGs), a generalization of two-player zero-sum games in which each player is replaced by a team of agents. We focus on the case in which the team members can coordinate their strategies ex ante, i.e. they can freely communicate before the start of the game, in order to coordinate the choice of actions to be played. This model of coordination, together with the corresponding solution concept – the Team-Maxmin Equilibrium with a Correlation device (TMECor) – was introduced by Celli and Gatti [4]. In the same work, the authors show that approximating a TMECor is
Related Works. The seminal approaches to computing a TMECor are based on mathematical programming techniques and, more precisely, column generation algorithms. In particular, Celli and Gatti [4] propose an algorithm called Hybrid Column Generation (HCG) which works iteratively. At every iteration, first, it computes the equilibrium of a game in a reduced space of the correlated strategies. Then, it verifies whether that strategy profile is an equilibrium for the whole game, and if it is not, HCG enlarges the strategy space by adding joint plans until the equilibrium is obtained. Its bottleneck is the algorithm generating the new plan to enrich the strategy space, which is based on an Integer Linear Program (ILP). Farina et al. [7, 11] improve upon the column generation procedure of HCG and rely on more compact definitions of the correlated strategy space that allow the formulation of more efficient ILP oracles. Despite the successes in enhancing the efficiency of the oracle, such approaches fail to scale up to large games. This has been imputed to the difficulty of column generation approaches to approximate more complex strategies from a finite set. More recently, Zhang and Sandholm [22] propose a junction tree decomposition of the correlated strategy polytope. Such a technique induces a concise description of the strategy space that can be employed in a linear program to directly find a TMECor. Furthermore, Carminati et al. [3] presents a technique for converting an ATG into an equivalent two-player formulation called Team Public Information (TPI) game. The main idea behind the TPI conversion is to explicitly represent one coordinator per team who observes only the information commonly known to the team members. The idea of exploiting common information was similarly pursued by Zhang et al. [24], where the authors show that the underlying decision process faced by the team can be encoded without loss of generality with a Direct Acyclic Graph (DAG) called Team-Belief DAG (TB-DAG), in which the team decision points’ are differentiated based on what information the team has. Both the TPI game and the TB-DAG representation open a wide spectrum of opportunities for solving ATGs that range from the adoption of popular no-regret learning dynamics to the possibility of combining successful techniques previously developed for two-player games, e.g., abstractions and subgame solving [1, 18]. The DAG yields a strategy encoding that is significantly more compact than that provided by TPI and other previous representations. However, its dimension scales exponentially with the information complexity of the game (i.e., the maximum number of private states in a public state of the game), thus making the traversal, or in some cases even the memory representation, of the entire DAG unaffordable. This issue is particularly crucial as it prevents the adoption of tabular regret minimization algorithms in large instances of team games. More recently, several hybrid approaches have been proposed to overcome the challenges faced by algorithms based on pure column-generation and TB-DAG approaches. Zhang et al. [23] is a column-generation algorithm that employs a TB-DAG-based representation of the decision space to compute the coordinated strategy to add to the set of available strategies. Another direction has been taken by McAleer et al. [17], which combines the traditional column-generation pipeline with an algorithm based on deep reinforcement learning to expand the strategy set available to each team. However, both of the cited approaches face the same scalability limitation brought by the column-generation approach whenever the game to be solved has a relevant depth, as is the case of Leduc Poker testbeds. On the other hand, Zhang et al. [25] propose a mixed approach where a column-generation process is used to dynamically extend a TB-DAG representation of the coordinated strategy space, which is then solved for an approximated equilibrium using the no-regret techniques proposed by Zhang et al. [24].
Our Contribution. The aim of this work is to propose an alternative approach to surpass the scalability issues from previous algorithms and to unlock the adoption of regret-minimization techniques in huge ATGs. More precisely, we rely on the TB-DAG representation and propose to overcome the computational limitations arising from the need for traversing the whole DAG by combining no-regret algorithms with Monte-Carlo sampling techniques, starting from the Monte-Carlo CFR (MCCFR) algorithm originally proposed by Lanctot et al. [15]. In order to do so, we must face two different challenges. The first challenge is that both the trivial outcome sampling algorithm as introduced for two-player zero-sum games [15], as well as the computation of the average strategies of the players (i.e., the approximated TMECor) would require, in the worst case, a complete DAG traversal at each iteration. In the first part of this paper, we show how to define a suitable outcome sampling algorithm that, instead of visiting the whole TB-DAG, passes through a number of nodes that is linear in the depth d of the DAG. The second part of this paper is devoted to the problem of computing average strategies in this setting. We show how to efficiently track the average strategies by means of local updates at the nodes traversed during outcome sampling. Overall, our proposed solution can progressively optimize a correlated strategy by using light iterations based on sampling a single trajectory of play at a time while needing memory storage only for the nodes that have been effectively traversed during past play. Additionally, we provide high probability bounds for the regret and show that our method converges to a TMECor with
Preliminaries
Adversarial Team Games. ATGs are imperfect information sequential games in which the players are partitioned in two teams. We denote the two teams as ▲ and ▼, respectively. The extensive form of an ATG is commonly represented through a rooted game tree. Nodes in the game tree are used to model decision points in which players (or chance) must take an action, while edges model the available actions that the players can perform. Leaves represent, instead, terminal states in the game, i.e., all those situations in which the game ends. The set of tree decision nodes is denoted as
For any pair of nodes
Celli and Gatti [4] show that the problem of finding a TMECor is
Team Belief DAG. The TB-DAG [24] is a compact representation of the team’s correlated strategy space that exploits the notion of public information. Formally, two nodes The root ∅ is a belief that contains only the root node of the ATG. For each belief At any observation point
For completeness of exposition, we report an example of TB-DAG from [24] in Fig. 1.
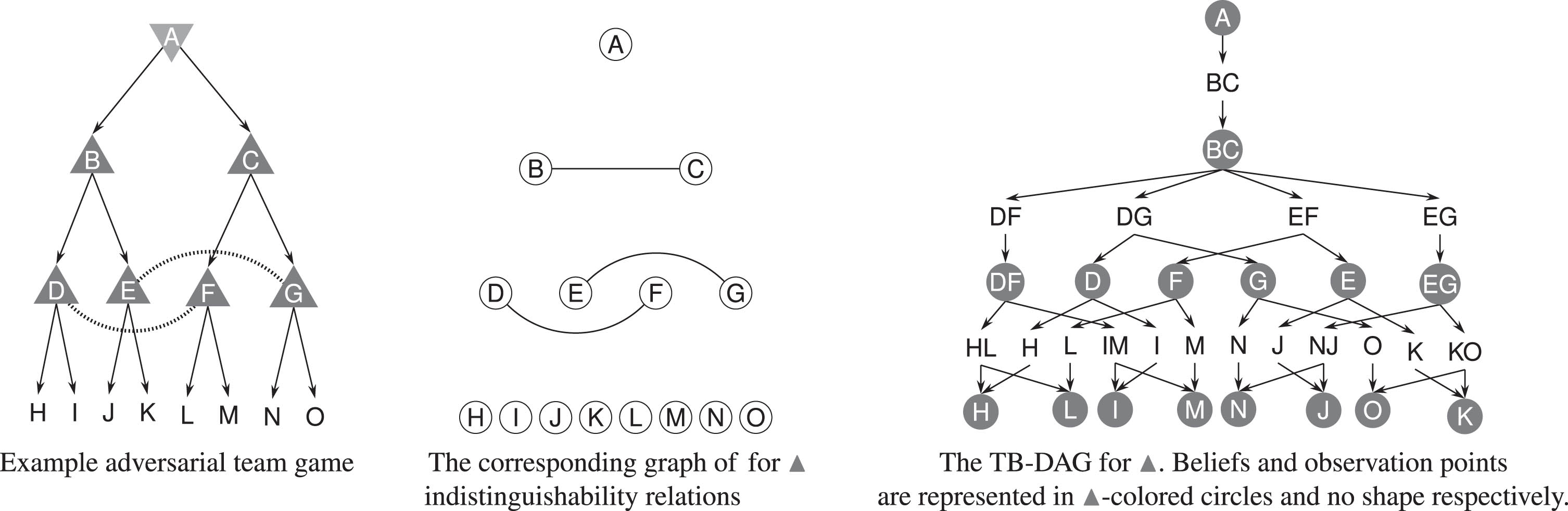
Simple example of adversarial team game from [24] (nodes named for ease of reference), its indistinguishability relation graph, and its TB-DAG.
The precedence relationship on the DAG is inherited from precedence ordering on ATGs, i.e., for two nodes
The appropriate strategy encoding in a TB-DAG is the TB-DAG form. The space of TB-DAG-form strategies is equivalent to the space of correlated strategies, hence, in the worst case, it is not possible to describe the former with a number of constraints polynomial in the game dimension
1
. However, the TB-DAG-form strategy representation is, in practice, significantly more compact than the typical correlated strategy representation. More formally, starting from any team i’s pure strategy, it is possible to derive the corresponding pure TB-DAG-form strategy
By definition of the TB-DAG-form polytope, the strategy
We introduce the following additional notations that we use in the paper. We denote with b the branching factor of the ATG, i.e.,
Stochastic Regret Minimization. We make extensive use of the Online Convex Optimization (OCO) tools introduced by Zinkevich [26]. The basic scenario faced in OCO problems encompasses a decision maker that repeatedly interacts with a possibly adversarial environment, choosing at each time t a strategy
The TMECor can be equivalently formulated as the solution of a bilinear saddle point problem in which ▲ and ▼ respectively maximize and minimize the expected value of u▲ over the game terminal nodes. Therefore, it is possible to use no-regret algorithms to approximate a TMECor.
Consider the setting in which at each iteration t ∈ [T] teams ▲ and ▼ select strategies
Proposition 3 constitutes a famous result in literature (see for example [8] for a proof). As a direct implication of Proposition 3, in order to compute an approximated TMECor, it would be sufficient to formulate a regret minimizing algorithm for the TB-DAG strategy polytopes
In the following, we first review how to apply Counterfactual Regret Minimization (CFR) [27] to the TB-DAG representation and discuss the main limitations of such an approach. Subsequently, we discuss a possible way of overcoming such limitations and lay the ground for the formulation of a sampling-based version of CFR on the DAG structure.
Counterfactual regret minimization on a DAG
In the following, we review the CFR algorithm proposed in [22] to operate on a TB-DAG. CFR is a self-play algorithm that performs regret minimization on a sequential decision problem by decomposing the regret into additive terms that are minimized locally at each decision point. For each iteration t ∈ [T], let
Counterfactual losses for ▼ are defined symmetrically. The counterfactual loss
The regret of the algorithm is upper bounded by a polynomial function of the DAG size:
As aforementioned, the representation of the TB-DAG strategy polytope is significantly more compact than the vanilla correlated strategy polytope’s encoding. This is due to the adoption of a correlation scheme that is local at each public state instead of being trivially defined over the set of pure strategies. However, since prescriptions are defined as tuples assigning an action to each information set with a nonempty intersection with the belief, the TB-DAG representation still requires a number of constraints that scales exponentially with the game’s information complexity. Considering this fact, Proposition 5 has two important implications: in the worst-case scenario (i.e., in games in which the amount of private information that the players have is high, e.g., Bridge) (i) the computational complexity of the single CFR iteration is exponential with respect to the ATG size and (ii) the regret bound has an exponential dependency on the ATG dimension. While (ii) is a drawback inherited from the TMECor’s APX-hardness, the exponential computational complexity of the single iteration is a much more undesirable property. Indeed, in practice, tabular algorithms like CFR and its deterministic variants can not scale past small games due to the necessity of traversing the whole DAG at each iteration (see experimental results reported in [24]). Another crucial point is related to the space complexity of the algorithm. Also, in this case, tabular procedures exhibit highly inefficient requirements, as they need to keep the whole DAG structure in memory.
Inspired by the literature on two-player zero-sum games [10, 19], we propose to overcome such limitations by combining the TB-DAG regret minimization framework with Monte-Carlo sampling techniques.
Sampling enters the picture: MCCFR-DAG
As stated above, we intend to exploit the advantages of sampling to pursue two objectives: (i) reducing the computational complexity of the single iteration and (ii) reducing the algorithm’s space complexity. In order to accomplish such a result, we propose to extend to the TB-DAG the Outcome Sampling (OS) approach that was previously proposed for two-player zero-sum games by Lanctot et al. [15]. In a nutshell, the main idea behind OS is to estimate the loss vector at each iteration based on a game rollout collected following the players’ strategies and perform sparse strategy updates starting from such an estimated loss. A high-level overview of the algorithm – that we call DAG Monte Carlo Counterfactual Regret Minimization (MCCFR-DAG) – is provided in Algorithm 3. A detailed analysis on how to use OS in order to estimate the loss vector and then how to perform strategy updates based on the loss observed is presented in Section 5.
Theorem 6 provides the formal guarantees for MCCFR-DAG.
Loss sampling and backpropagation
As widely mentioned before, the loss sampling algorithm that we adopt in this work is essentially an Outcome Sampling estimator. In the basic version already defined for two-players games, the definition of the OS estimator is obtained from the sampling of a terminal node through a game simulation. However, after sampling the terminal node, the trivial OS procedure would require to backpropagate the loss through all the DAG paths that connect the root ∅ to the terminal node sampled. Unfortunately, the number of such paths is, in the worst case, an exponential function of the ATG size, which would cause the required time to complete an iteration to explode. The solution that we propose in this work, instead, backpropagates the loss only through the path of nodes actually traversed when simulating the game, thus reducing the number of visited beliefs to a linear function of the TB-DAG’s depth.
A graphical representation of the two update schemes is given at Fig. 2, while the detailed algorithm for loss sampling and backpropagation is shown in Algorithm 4.
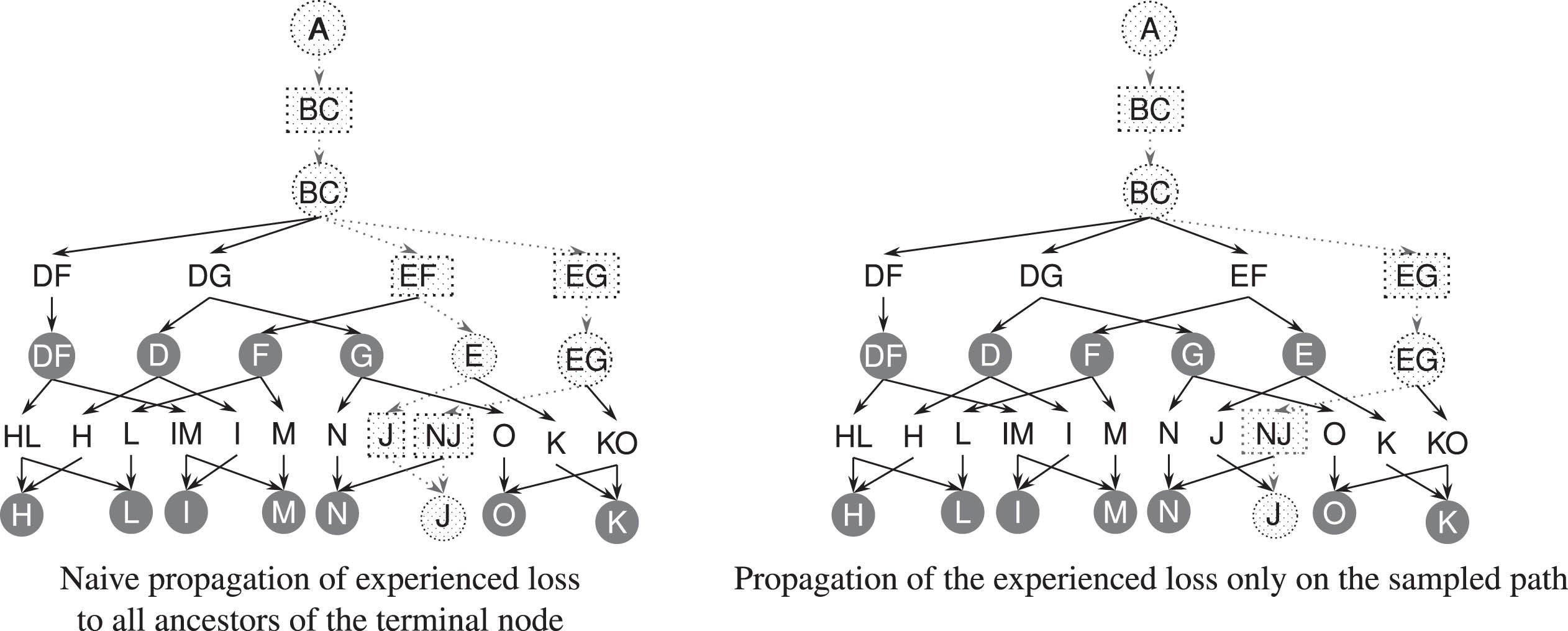
Example of different loss propagation algorithms on the example game from Fig. 1, where the nodes and edges traversed during the propagation are dotted. As an example, we assume to have reached terminal belief
For the sake of illustration, let us consider the problem of sampling the loss vector for team ▲. The loss sampling procedure for ▼ is defined equivalently. We assume to have as input a random sampling strategy
After sampling a joint path and the corresponding terminal node, at each belief
The following Lemma shows that
The second task that we address in this work concerns the computation of the average strategy. Such a procedure is indeed fundamental for the algorithm as the theoretical properties exhibited by MCCFR-DAG guarantee TMECor convergence on average (Proposition 3). In this section, we first discuss the challenges of tracking average strategies and present a simple algorithm that, at each iteration, runs linearly in time in the number of visited DAG nodes up to that iteration. Then, in order to reduce the computational burden of such a task, we introduce an unbiased estimator for average strategies and analyze its theoretical properties in terms of variance.
For memory efficiency, we focus on the computation of average realizations over terminal nodes
Exact Computation. Previous works that combine Monte-Carlo sampling with model-free learning in sequential decision processes [6, 15] adopt an efficient procedure for average strategy computation based on a weighted behavioral averaging performed locally at each decision node, with weights equal to the reach probabilities of the decision node itself. While this technique is particularly efficient for tree-shaped decision problems, the DAG structure significantly limits its applicability in our scenario. The main issue is that we need to explore all the paths in the DAG reaching a specific node; hence, in the worst case, we could traverse the whole TB-DAG.
Stochastic Estimation. We propose an estimator that updates only along the sampled path
where, as before,
Thus, applying an Azuma-Hoeffding analysis similar to that of the proof of Proposition 2 yields the following result.
Therefore, if we use the estimated average strategies
This method of approximating the average strategy is not new: for example, it is implemented in the open-source library OpenSpiel [16] for two-player zero-sum games, that is, for tree-form decision problems. However, to our knowledge, its correctness has not been proven, even in the two-player zero-sum setting. In that setting, L and
Experimental evaluation
In this section we evaluate the performance of our proposed averaging scheme in the context of the MCCFR-DAG algorithm. To do so, we compare the MCCFR-DAG algorithm with exact averaging (only on the explored parts of the tree) against the stochastic averaging scheme. The performance is compared in terms of NashConv, i.e. a measure of exploitability of the current strategy against a best responding opponent. This metric is related to the distance from a Nash Equilibrium of the current strategy. In line with previous works in the field, the chosen benchmark is that of Kuhn poker [14] and Leduc poker [20] games, where we allow team collusion. In particular, we consider instances with three or four players (with the first two playing players in the same team and the remaining being their adversary) and vary the parameters governing the game size. Whenever considering game instances, we will use the pK-r acronym to indicate Kuhn poker instances where p is the number of players and r is the number of ranks of cards in the game. Similarly, the pLbrs acronym indicates Leduc poker instances where b is the maximum bet in each betting round, r is the number of card ranks, and s the number of suits. The experiments were run on a server running Ubuntu 22.04 LTS with a 32-core Intel Xeon E5-4610 v2 CPU and 128 GB of memory. The processes running the experiments have been limited to 5GB of memory.
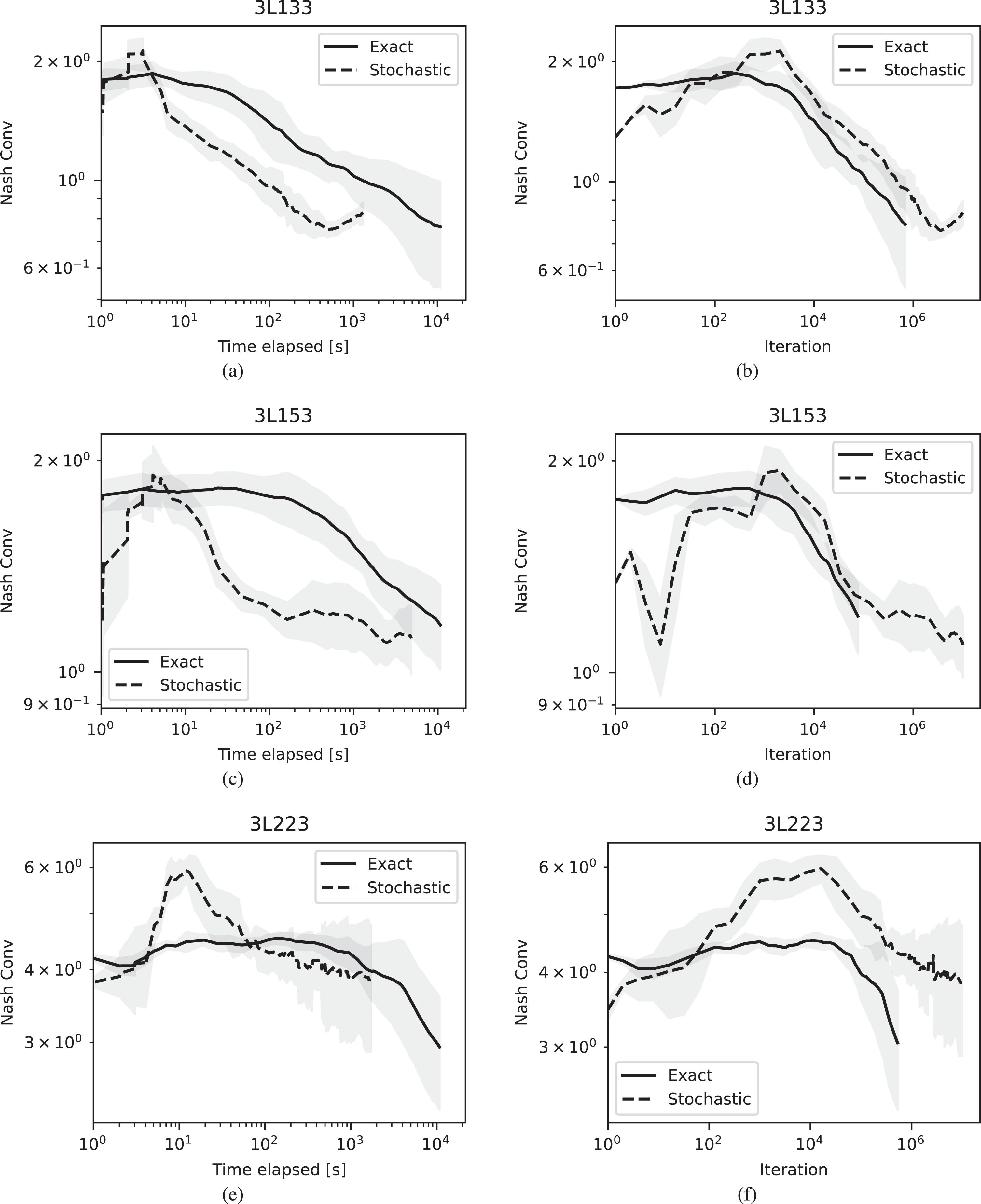
Figures 3 to 6 show the results of running the algorithms for either 106 iterations at most or with a time limit of 104 seconds and plot the NashConv performance both against time and iteration number. To reduce the effect of stochasticity due to the probabilistic nature of both MCCFR and the averaging algorithm used, we show the average performance across 5 runs. We remark the rank of the game is directly proportional to the information complexity of the team game, and that the theoretical convergence rate of MCCFR-DAG is

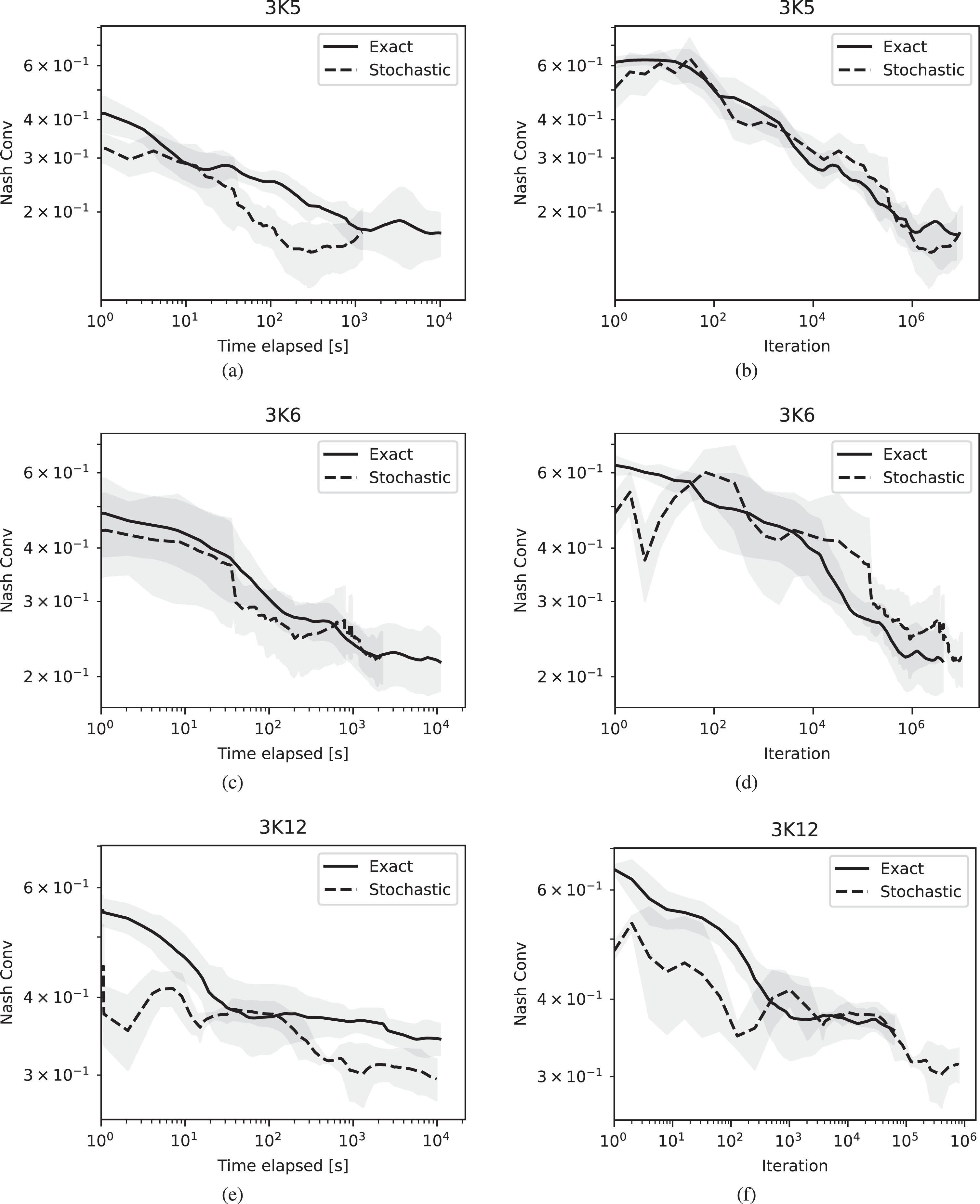
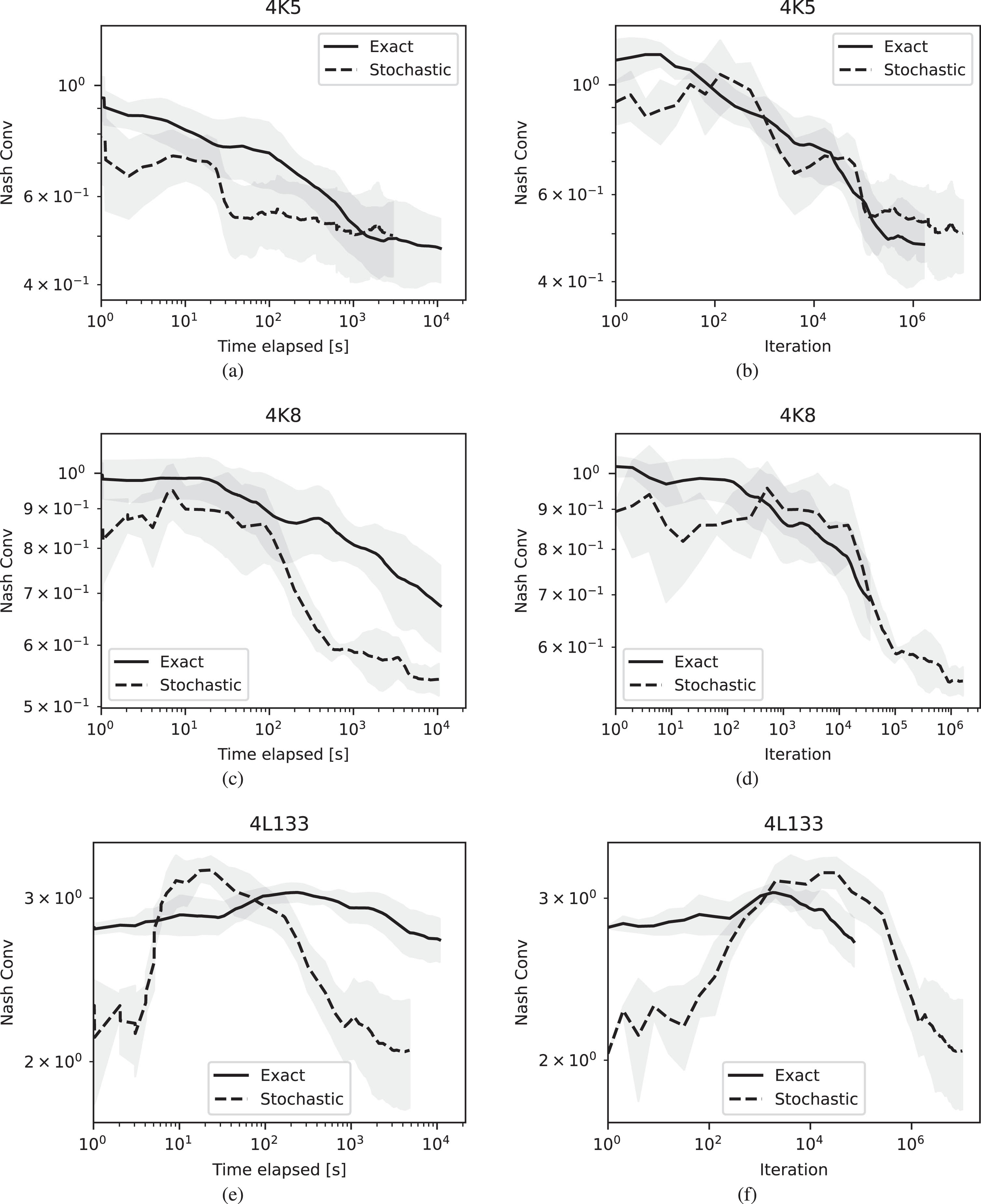
The experimental results confirm that stochastic averaging enables faster resolution times while the iteration performance remains comparable among the two averaging schemes. In particular, we highlight the results on large instances of games such as 3K12 Figs. 4e and 4f, where the proposed averaging scheme allows considerable time savings (≈106 vs ≈105 iterations in the same amount of time). This translates to comparable performance achieved in an order of magnitude of time in advance.
A similar trend is verified in Leduc poker games (Fig. 5), which have a deeper game tree than the Kuhn poker instances, while the number of ranks is kept lower. In this case, we can also see the impacts from the extra variance due to stochastic averaging w.r.t. the exact averaging. This introduces an initial unstable phase where the exploitability increases instead of decreasing; this is then recovered after some iterations of the algorithm.
On the other hand, the fact of having two teams playing against each other instead of a team vs a single player does not impact the performance (Fig. 6). This is in line with the intuition that the information complexity and depth challenges impact the intra-team coordination capabilities rather than the adversarial aspect of the game.
Overall, the NashConv results obtained w.r.t. the time elapsed highlight the well-known difficulties that sampling-based methods have in computing low-exploitability equilibria, as already noted in [15]. While this makes algorithms such as the ones proposed by [23, 25] a better option for equilibrium computation in the games customarily used for benchmarks, the low resources required by the iterative sampling methods proposed in this paper can be useful to further scale the size of the games addressed. Again, this already happened in two-player zero-sum games, where sampling variants of the CFR algorithm have been the bulk of Libratus [1] and Pluribus [2] poker bots. Therefore, MCCFR-DAG is characterized as a low-resource equilibrium computation algorithm for computing TMECors in team games.
In this paper we propose Monte Carlo CFR techniques to compute TMECor strategies in large team games more efficiently. To do so, we formalized suitable techniques for loss sampling, backpropagation, and strategy averaging. After proving complexity guarantees on their convergence properties, we empirically showed how such techniques can benefit performance when solving team games.
Our contributions can open new paths for scaling solving techniques to larger instances of team games while maintaining a low computational cost per iteration. A particularly interesting research direction would be to further combine these techniques with the recent column-generation and TB-DAG hybrid approach from [25].