
Abstract
We propose a new approach for the radial basis function (RBF) interpolation of large scattered data sets. It uses the space subdivision technique into independent cells allowing processing of large data sets with low memory requirements and offering high computation speed, together with the possibility of parallel processing as each cell can be processed independently. The proposed RBF interpolation was tested on both synthetic and real data sets. It proved its simplicity, robustness and the ability to handle large data sets together with significant speed-up. In the case of parallel processing, speed-up was experimentally proved when 2 and 4 threads were used.
Introduction
Interpolation and approximation are probably the most frequent operations used in computational techniques [1]. Several techniques have been developed for data interpolation, but they require some kind of data “ordering”, e.g. structured mesh, rectangular mesh, unstructured mesh etc. A typical example is a solution of partial differential equations (PDE), where derivatives are replaced by differences and rectangular or hexagonal meshes are used in the vast majority of cases. However, in many engineering problems, data are not ordered and they are scattered in
There exist some techniques using space subdivision to compute a radial basis function (RBF) interpolation. Data point division into sub-domains using an adaptive octree subdivision method and then blending these local functions together with partition of unity is used in [3]. This work is an extension of well-known [4], which uses the multi-level partition of unity to construct surface models from very large sets of points. Spatial down sampling to construct a coarse-to-fine hierarchy of point sets is used in [5]. They interpolate the sets starting from the coarsest level and then they interpolate a point set of the hierarchy, as an offsetting of the interpolating function computed at the previous level. [6] proposed a highly parallel algorithm for RBF interpolation with the time complexity of
All these approaches use space subdivision to compute the RBF interpolation or approximation, but their joining phase is usually not easy to implement. One has many independent interpolations and needs to join them together. These interpolations usually have some overlapping parts and to join them together we need to solve additional systems of equations or iteratively update the resulting interpolation. Our aim is to improve this joining phase and speed-up the calculation of the RBF interpolation as well.
Another approach using virtual points for approximation is used in [15, 16]. Of course, there are other meshless techniques than RBF, such as discrete smooth interpolation (DSI) [17], which avoids explicitly computing a function defined everywhere and produces values only at the grid points instead. [18, 19] is based on statistical models that include autocorrelation. The scattered data interpolation method described in [20] exploits the topological structure and unsupervised learning algorithm of a
Our goal is to propose a new simple method for interpolation of scattered data points. In many applications, it is necessary to process and interpolate a large amount of data, thus our method has to be able to process such large datasets. There are other interpolation methods, but they are usually quite hard to implement.
Our method is to be easy to implement and it must achieve the same quality of interpolation like other methods. Furthermore, the condition of small memory requirements and low time requirements must be met as well.
Radial basis functions
Radial basis function (RBF) is a technique for scattered data interpolation [25] and approximation [26, 27]. The RBF interpolation and approximation is computationally more expensive compared to interpolation and approximation methods that use an information about mesh connectivity, because input data are not ordered and there is no known relation between them, i.e. tessellation is not made. Although RBF has a higher computational cost, it can be used for
The RBF is a function whose value depends only on the distance from its center point. Due to the use of distance functions, the RBFs can be easily implemented to reconstruct the surface using scattered data in 2D, 3D or higher dimensional spaces. It should be noted that the RBF interpolation is not separable by a dimension.
Radial function interpolants have a helpful property of being invariant under all Euclidean transformations, i.e. translations, rotations and reflections. It does not matter whether we first compute the RBF interpolation function and then apply a Euclidean transformation, or if we first transform all the data and then compute the radial function interpolants. This is a result of the fact that Euclidean transformations are characterized by orthonormal transformation matrices and are therefore two-norm invariant. Radial basis functions can be divided into two groups according to their influence. The first group are “global” RBFs [39], for example:
where
The “local” RBFs were introduced in [43] as compactly supported RBF (CSRBF) and satisfy the following condition:
where
Typical examples of CSRBF are
where
Examples of CSRBF from Eq. (2).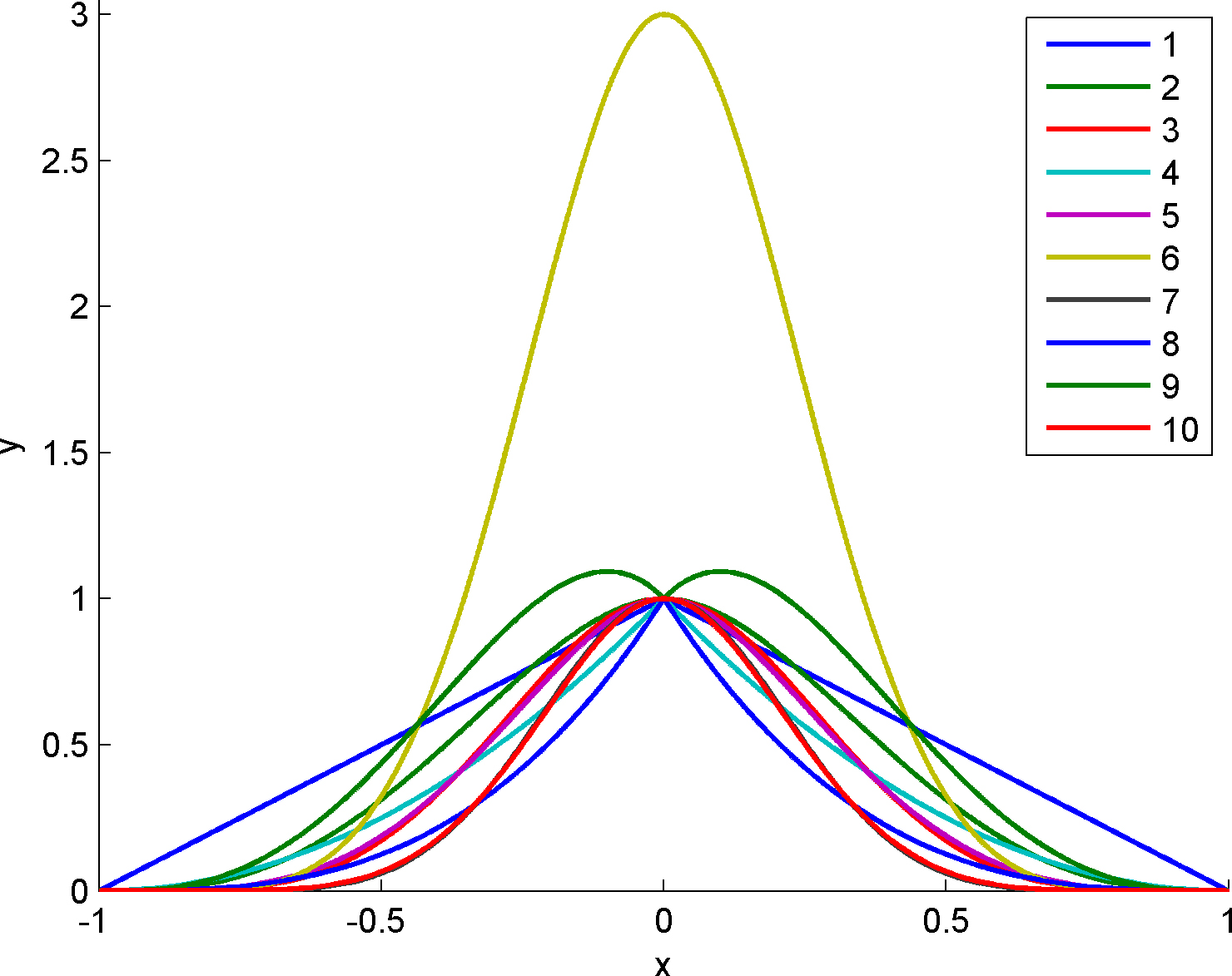
RBF interpolation was originally introduced by [44] and is based on computing of the distance of two points in any
where
where
Data values, the RBF collocation functions, the resulting interpolant.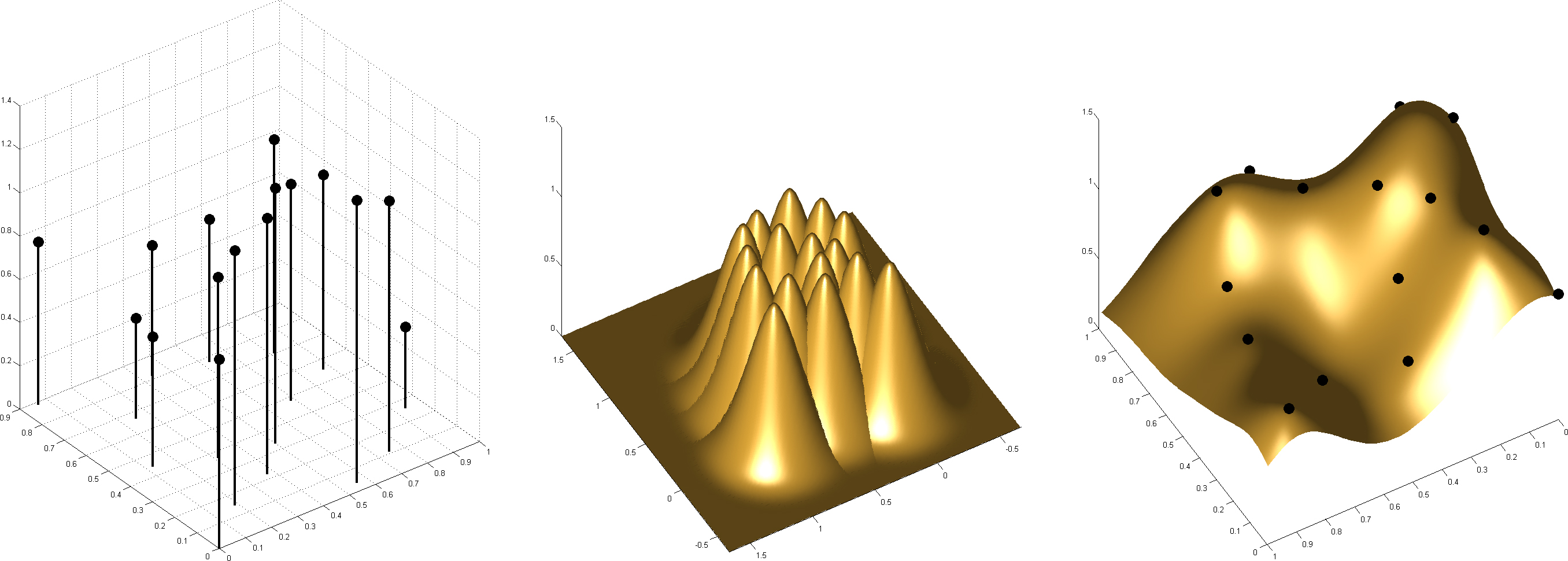
Equation (2.1) can be rewritten in a matrix form as
As
The RBF interpolation can use “global” or “local” functions. When using “global” radial basis functions, the matrix
In the case of the vector data, i.e.
In this section we describe our new proposed approach for large data sets RBF interpolation. The proposed interpolation uses space subdivision to speed-up the computation and to significantly reduce high memory requirements [37, 15]. The algorithm consists of three main steps. The first one is the space subdivision, the second one is the RBF interpolation and the last one is the joining procedure of interpolated cells (“blending”) to create the final interpolation. The pseudo-code of the proposed approach is in Algorithms 3.1 and 3.1. We show the speed-up of the proposed algorithm compared to the standard one for RBF interpolation as well.
Space subdivision
The approach Pseudocode of the proposed RBF interpolation method.[1] RBF
The input points need to be divided into some cells according to the created grid for the space subdivision. Every domain of the grid needs to be enlarged to a cell and contains a few more points from the neighborhood, see Fig. 3. We will present the reason for this later in this paper.
The input points need to be divided into some number of cells. This number can be estimated according to the memory available. The RBF interpolation matrix for
Using this formula we can easily find out the maximal average number of points in cells, see Fig. 4, and set up easily the size of the grid needed for the subdivision.
Data points are generally scattered, so it might be further possible in the extreme case that nearly all points lie within one cell. In this case it would be necessary to split this cell again. Another possible case is when no point lie inside a cell. In this case, the shape parameter and grid size for RBF interpolation is inappropriately selected and must be changed in the sense that the influencing of the basis function is greater and sufficient for the data interpolation [41].

Now, we have all input points divided into overlapping cells and thus can do the RBF interpolation. Radial basis functions have one parameter, which is the shape parameter
Points inside a cell need to be interpolated using the RBF interpolation with CSRBF. This interpolation is done using the standard calculation of the linear system of Eq. (2.1). Each cell is interpolated as an independent cell and thus the calculation can be done totally in parallel. This parallel calculation will increase the performance and speed-up the RBF computation for each cell. The only problem that can arise is the memory consumption, as we need to store multiple interpolation matrices at once, so this should be kept in mind when computing the size of a grid for space subdivision.
For each cell we get one set of weighting values of the RBF interpolation
The size of the RBF interpolation matrix for different number of interpolated points. The matrix is stored in double precision and its size is in MB if full matrix structure is used. The memory requirements are 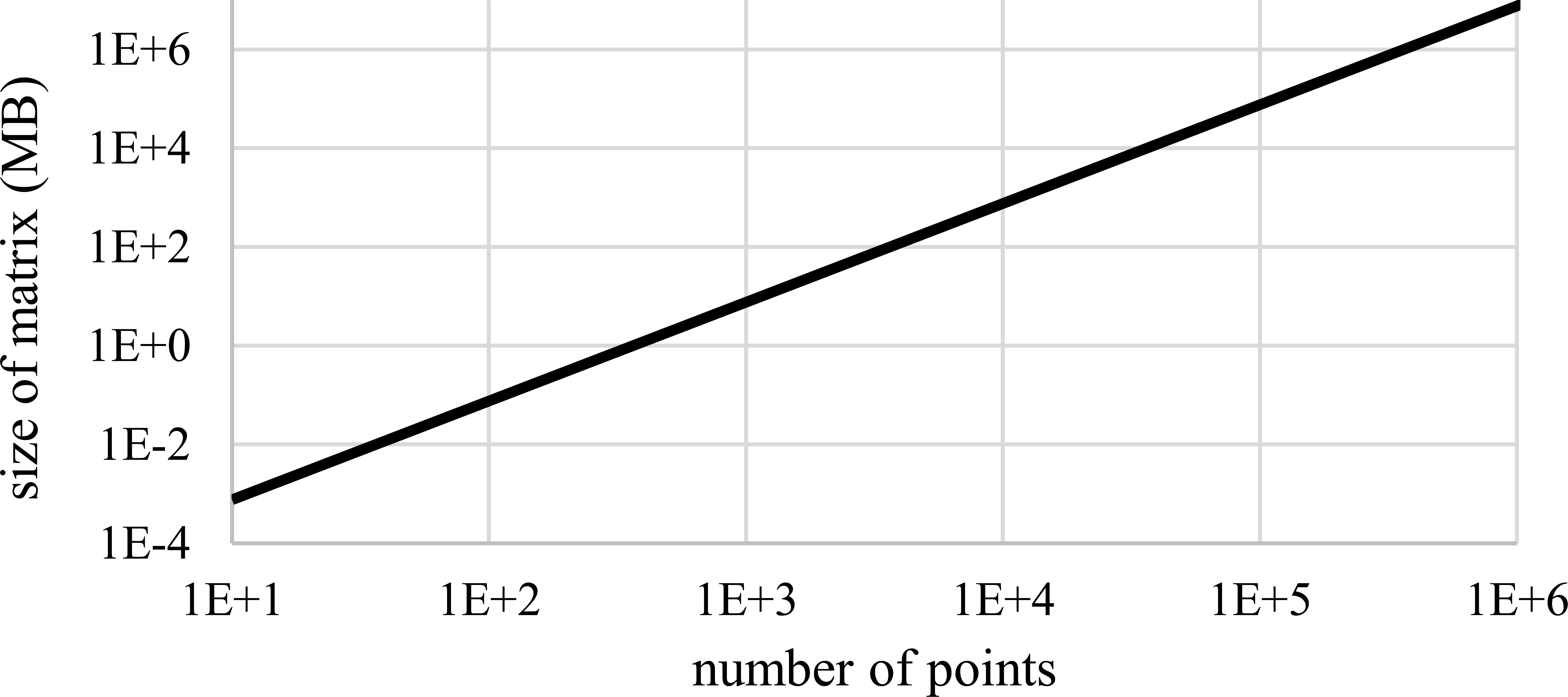
The interpolated cells computed in the previous step are overlapping each other. In this section, we show how to join, i.e. blend, them together to create a final continuous interpolation function that covers all the cells and thus all the input points for the interpolation as well.
The total width of overlapping parts is
where distance from the border is the shortest distance from the location to the border and it is calculated using the Euclidean metric. However, for the axes-aligned grid, the distance can be calculated using Chebychev metric, which is defined as
where
Bilinear interpolation between cells for the overlapped areas. Red part of color represents the coefficient for the main cell value, green part of color represents the coefficient for the down cell value and blue part of color represents the coefficient for the right cell value. The value for the corner cell is calculated as 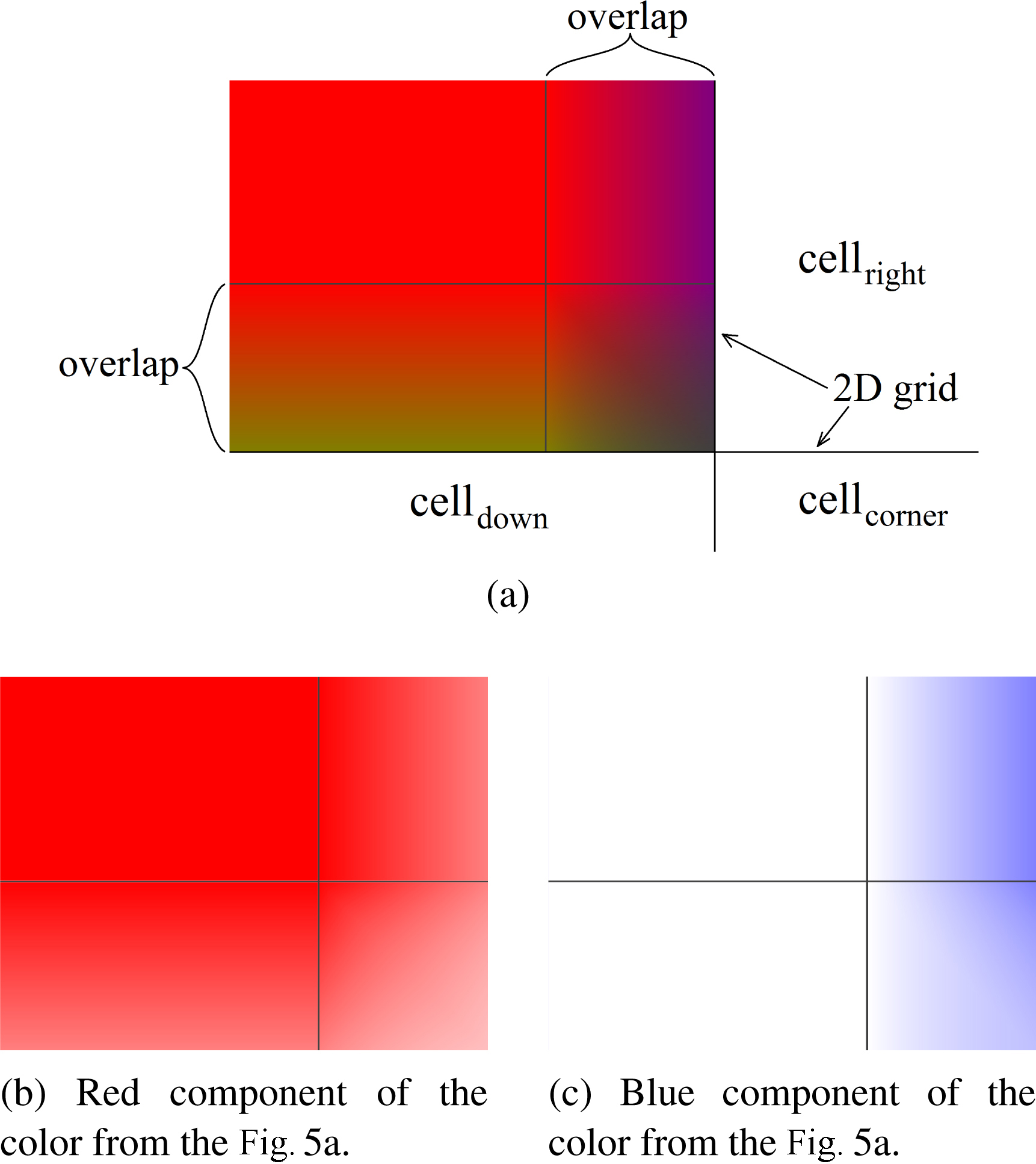
The final coefficients
where
Knowing all the coefficients
where
During the blending phase we perform the interpolation between the interpolations of cells. The result of the blending phase is thus again the interpolation of all input points, as the resulting function passes through all input points.
Visualization of a grid.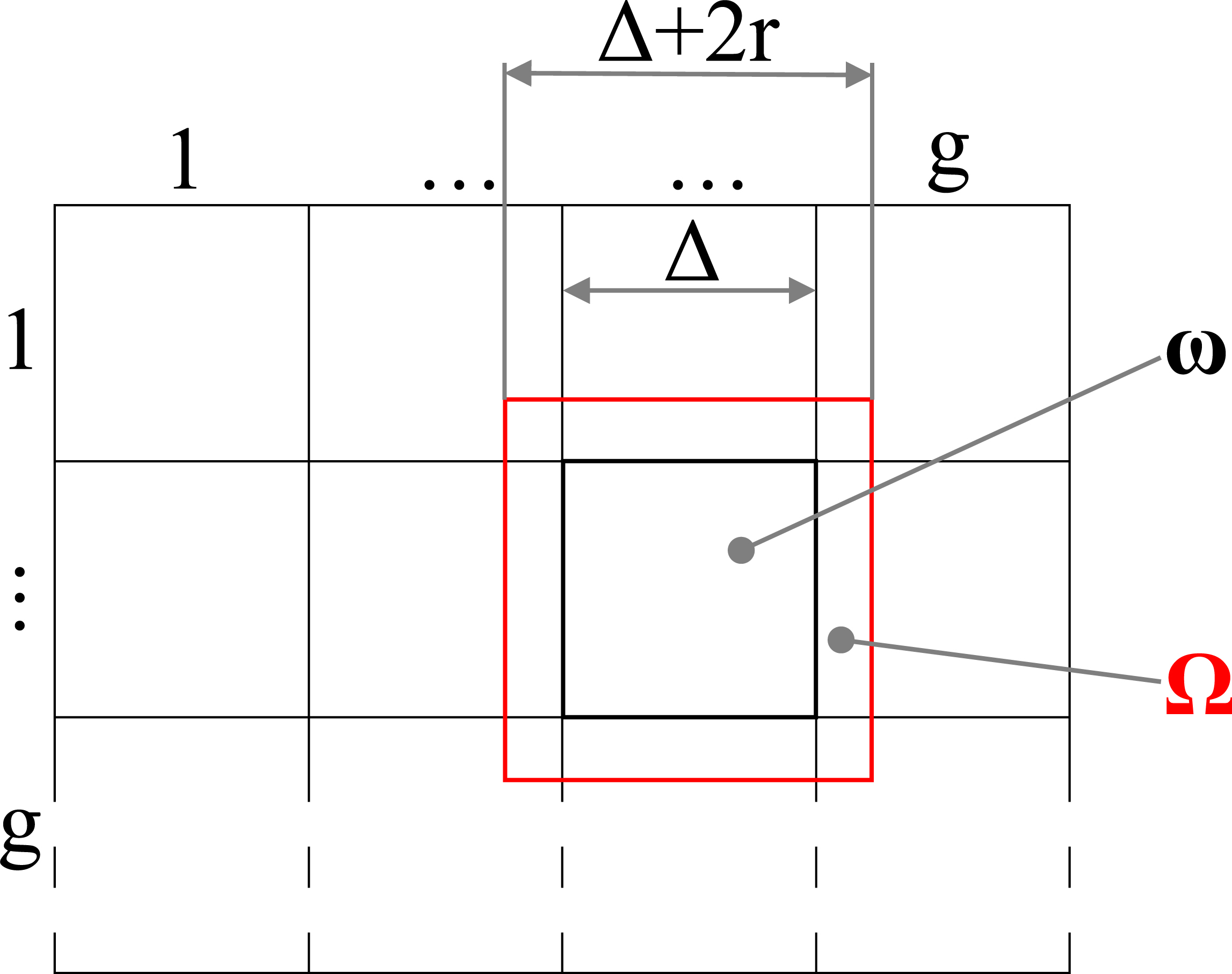
The proposed approach uses space subdivision to speed-up the calculation of radial basis function interpolation and to reduce the needed memory as well. In the following, we will use the notation shown in Fig. 6.
The value
The number of points
where
The average number of points in the enlarged cell
When computing the RBF interpolation, we need to solve a system of linear equations (LSE). Let us assume that solving an LSE of size
Therefore, the expected speed-up of the proposed algorithm compared to the standard one is
where
Expected speed-up of the proposed algorithm according to Eq. (3.4) for different numbers 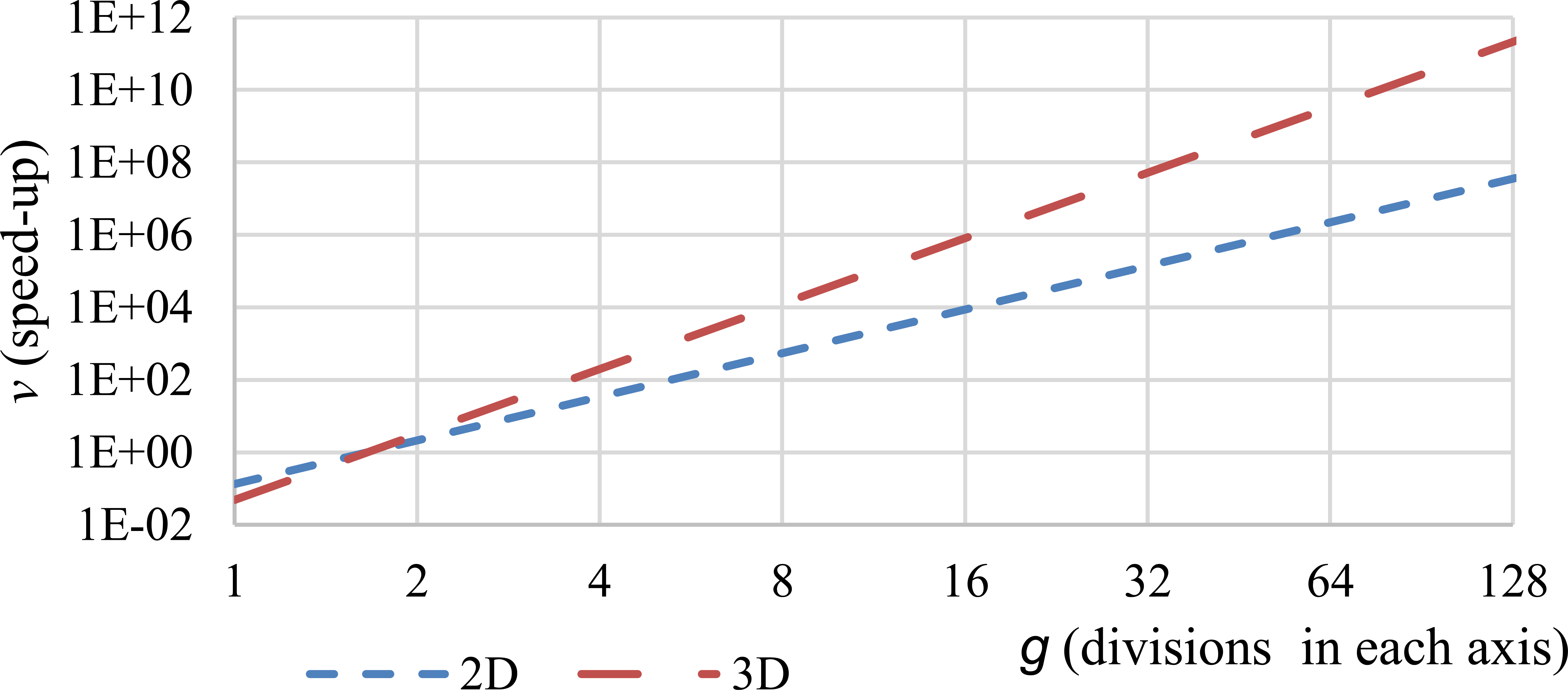
The time complexity of our proposed approach for the RBF interpolation is
where
The proposed approach does not speed-up only the RBF interpolation calculation, but it also speed-up the evaluation of the interpolation function as well. The time complexity of the function evaluation for the standard RBF is
The time complexity of the function evaluation for our proposed approach for the RBF interpolation is
Using Eqs (19) and (20), we can compute the speed-up of our proposed algorithm when computing one function value of the RBF interpolation:
For most grid resolutions the speed-up
Expected speed-up of function evaluation using the proposed algorithm according to Eq. (3.5) for different numbers 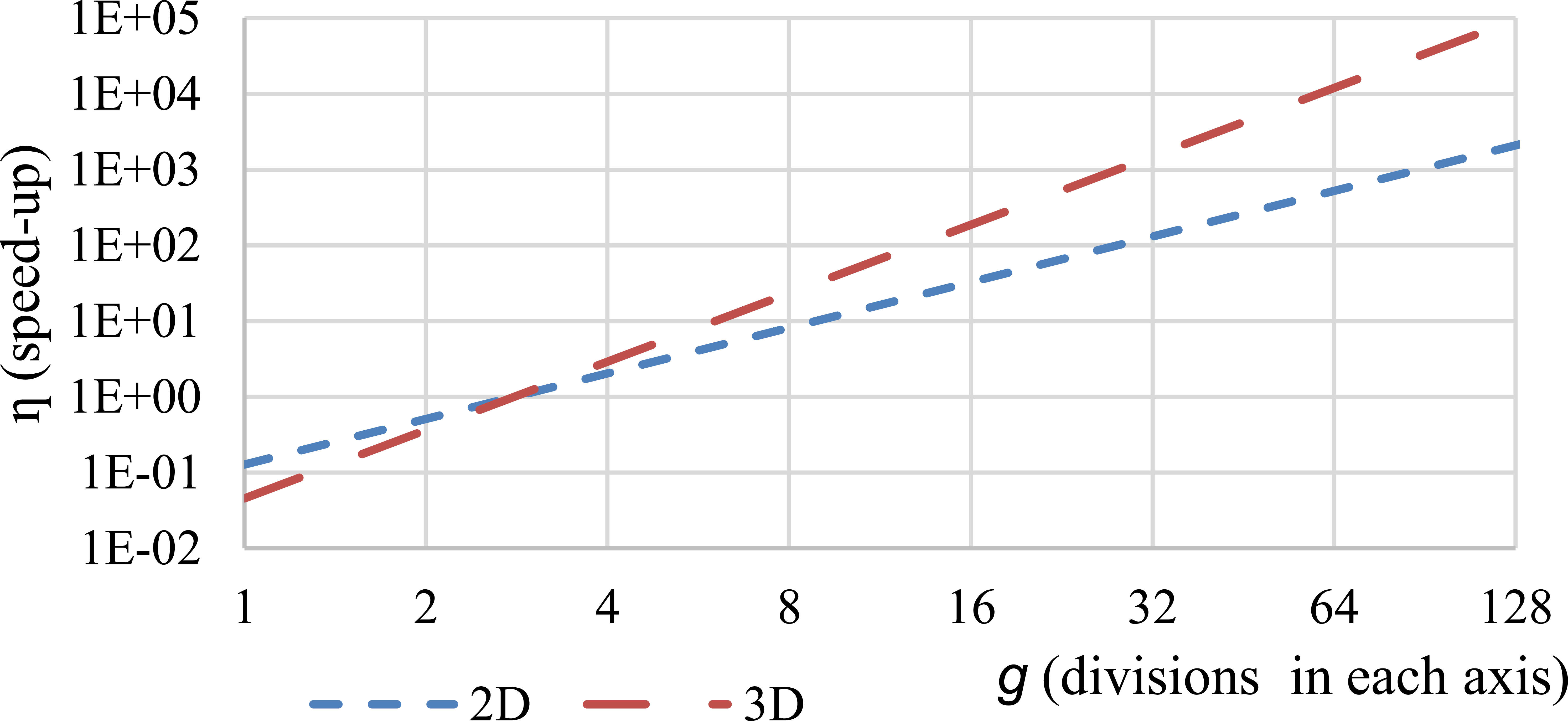
In this section we show the results of our proposed approach. This approach for RBF interpolation is especially convenient for large data set interpolation. However, in the first sub-section we test it for the case of its simplicity only with small synthetically generated data sets to show some basic results of the proposed method for RBF interpolation.
In the second sub-section we tested our approach with real data sets. The second example is a data set containing more than
Any of the CSRBFs in Eq. (2) can be used for the proposed RBF interpolation. However, in the tests we present results for one basis function, namely
We tested the proposed approach also with global radial basis functions, specifically with thin plate spline (TPS) and Gauss function. The results for global RBFs are very similar to those when using CSRBFs.
The implementation of the RBF interpolation was performed in MATLAB and tested on a PC with the following configuration:
CPU: Intel memory: 22 GB RAM, operation system: Microsoft Windows 8 64 bit.
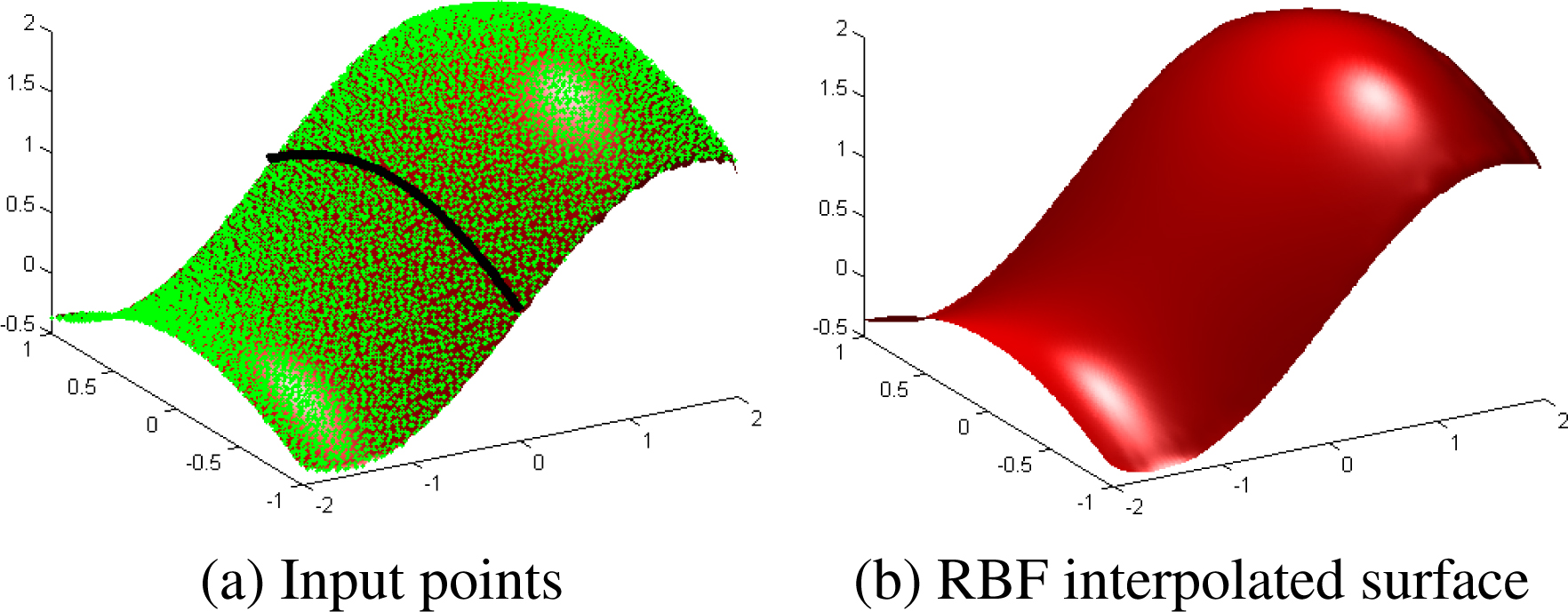
We first tested the proposed RBF interpolation on a synthetic data set of points using the function
We sampled the function at
We measured the difference of function values of the two RBF interpolations of two cells on their common border before the blending phase, see Fig. 9a. We should note that for this test, we did not blend these two RBF interpolations. The absolute difference between those two cells along the border is visualized in Fig. 10.
We measured the difference of function values between each cell RBF interpolation and the original function Eq. (23) on the common border before the blending phase. The difference between each cell and the original function is visualized in Fig. 11. We should note that for this test, we did not blend these two interpolations in any way.
Absolute difference in function values along the common border between the RBF interpolations of two cells without the blending phase, i.e. without the linear interpolation between cells.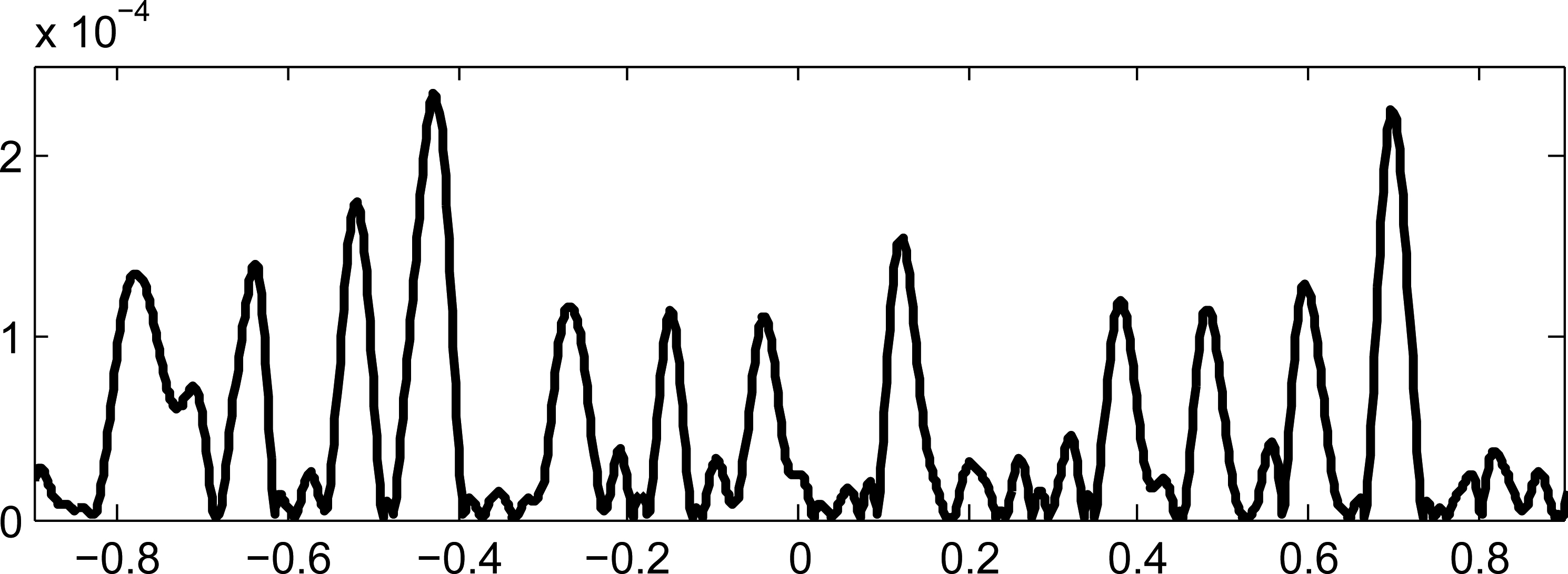
Difference of function values along the common border between the interpolation of each cell without the blending phase, i.e. without the linear interpolation between cells, and the original function Eq. (23).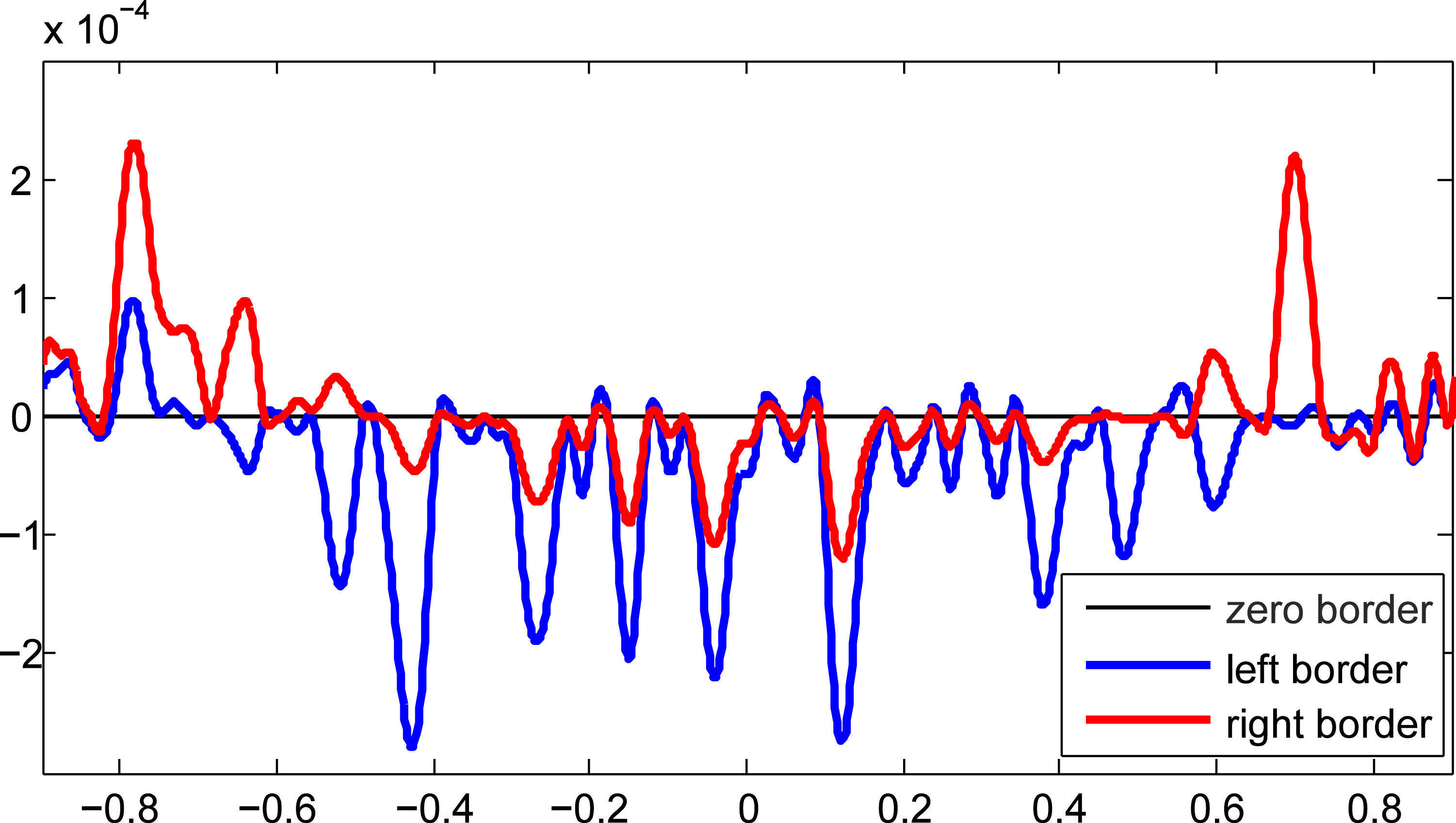
Difference in function values between the proposed RBF interpolation and the original function Eq. (23).
Two cells are interpolated using RBF interpolation independently and then blend together. We measured the interpolation error between blended cells and the original function Eq. (23). The results are visualized in Fig. 12. The proposed interpolation is continuous, without any disparity between domains.
We measured the interpolation error between the proposed RBF interpolation and the original function Eq. (23) on the common border. The error is visualized in Fig. 13. It can be seen that the error has a behavior similar to that represented in Fig. 12.
Difference in function value between the proposed RBF interpolation with blending phase and the original function Eq. (23).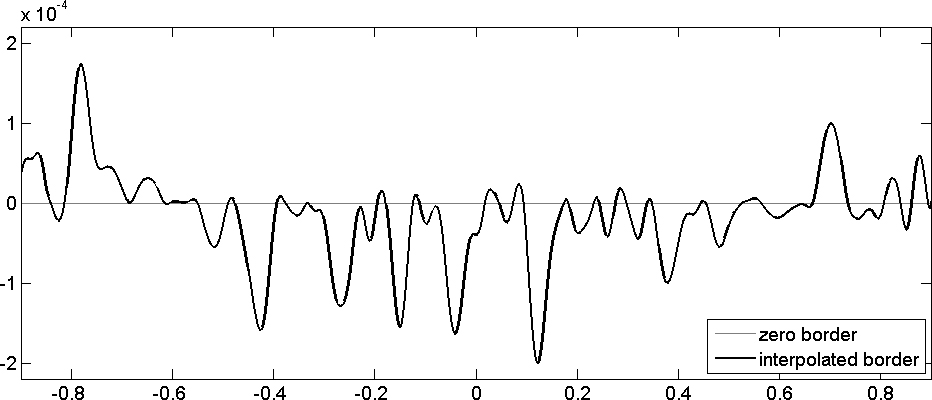
Absolute difference in function values along the common border between interpolations of the two cells for different sizes of overlapping parts (for 
The same measurement as in Fig. 10 was done for a different percentage of cells overlapping, see Fig. 14. It can be seen that the error decreases and for
However, we need also to measure the quality of this RBF interpolation. For this purpose we compare our proposed method using the space subdivision with the standard RBF interpolation method (2.2 in [26]) using
where
We used a grid of size
To evaluate the quality of the interpolation we generated
where
Average interpolation error of the proposed approach and the standard RBF interpolation. The interpolation error difference between both measured methods is only 0.03%
The result of RBF interpolation using the proposed method with space subdivision.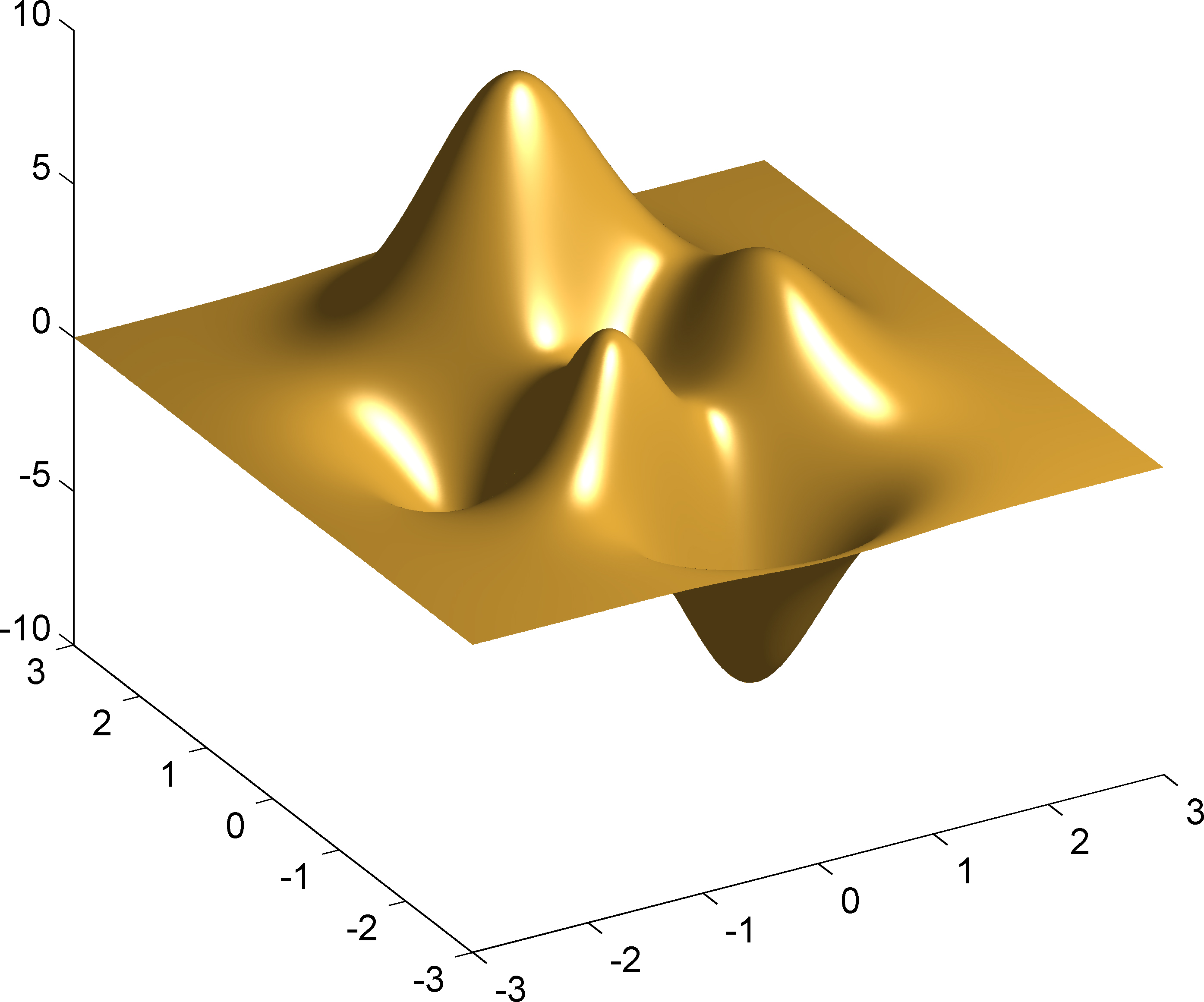
Histograms of interpolation errors.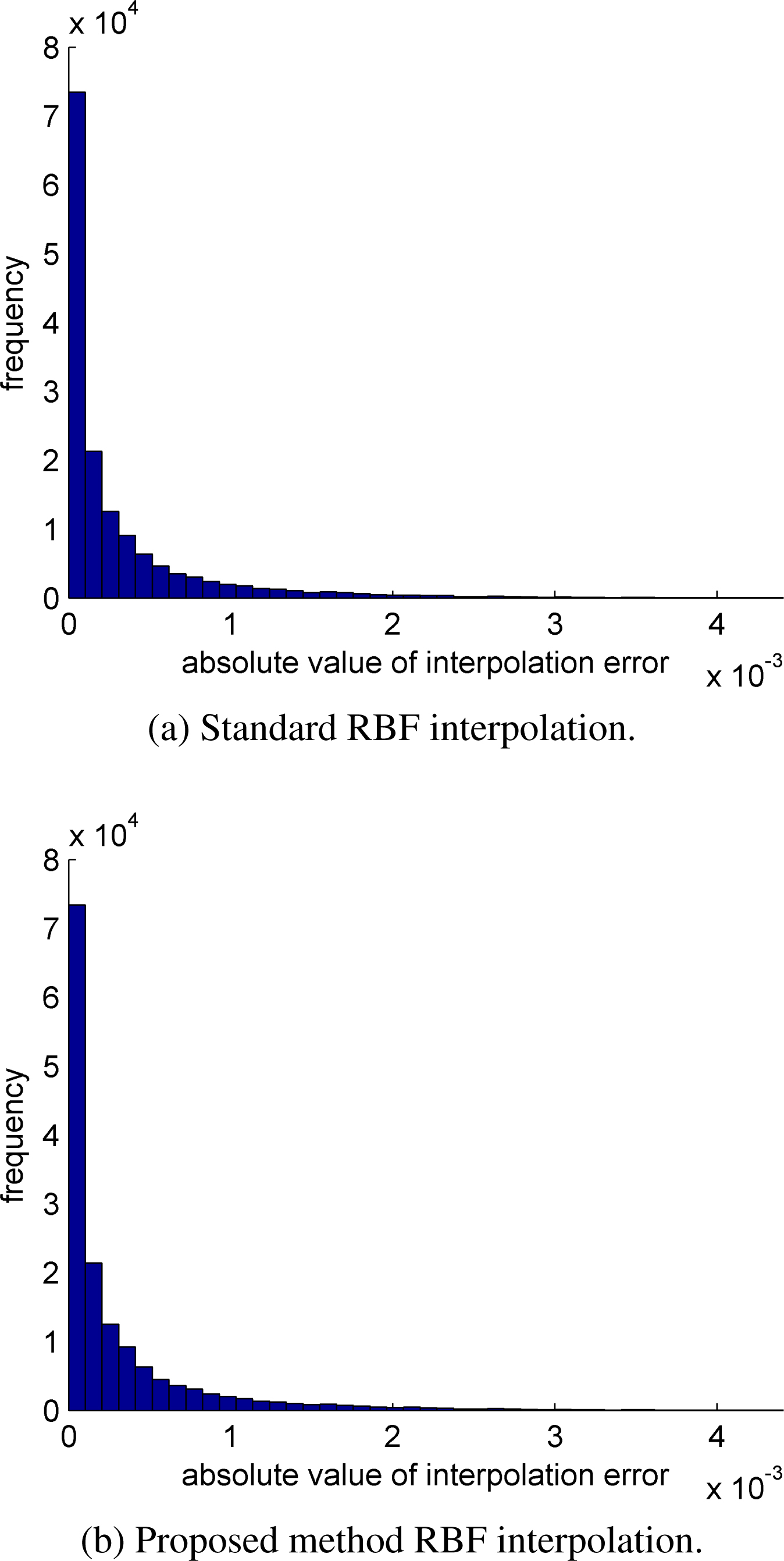
As both histograms in Fig. 16 are visually identical, we created a difference histogram between the two histograms. In Fig. 17 it can be seen that the interpolation errors distribution is almost identical. The difference in both histograms differs only slightly, see Fig. 17. Thus both interpolations have almost the same quality.
We also computed the average interpolation error for each RBF interpolation. The result is in Table 1. We can see that both average interpolation errors are almost the same, there is only a difference of
Difference of histograms in Fig. 16. Positive values mean that the standard RBF interpolation has more errors with the specific absolute value of interpolation error and the negative values mean the same for the proposed method for RBF interpolation.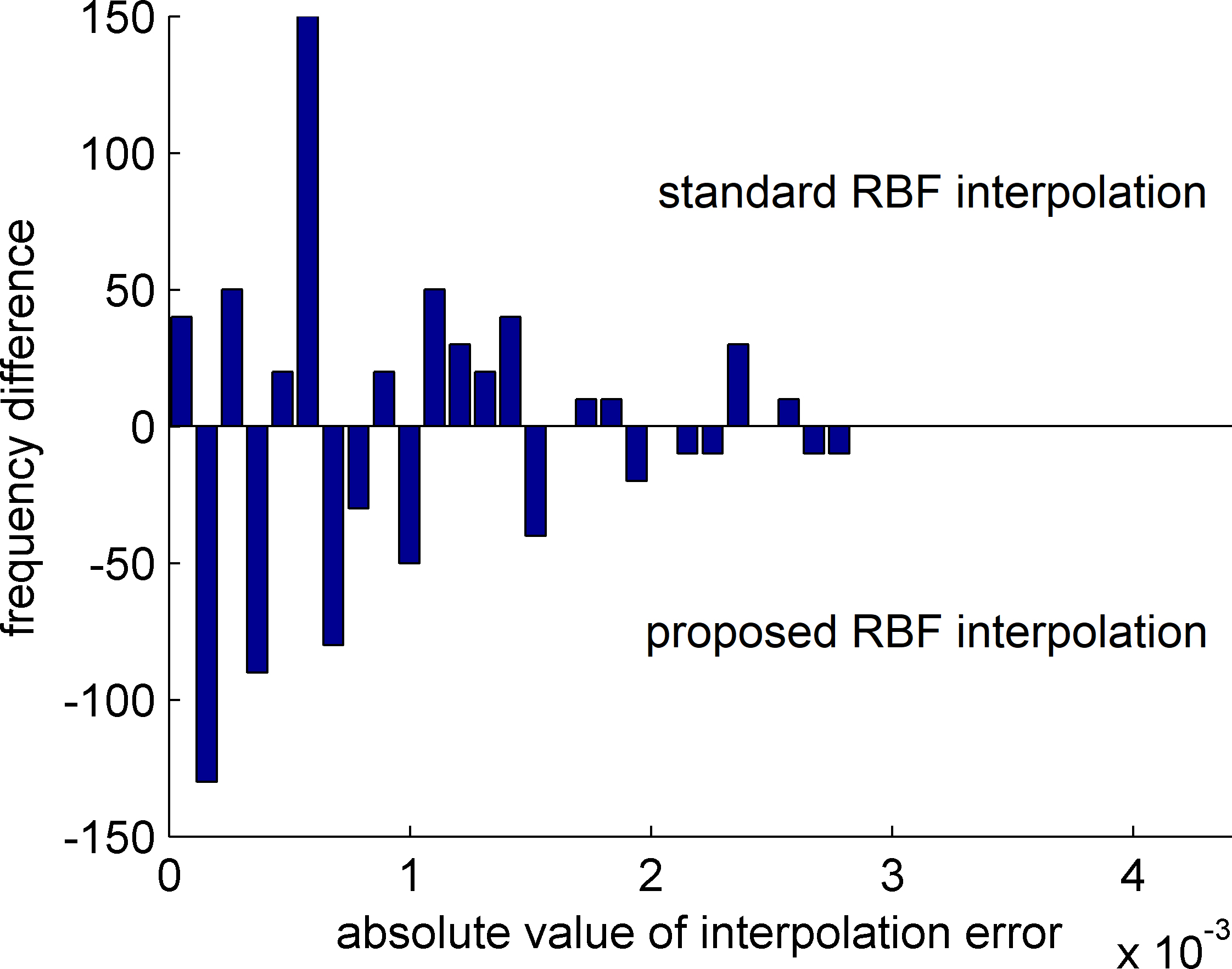
Visualization of the interpolated terrain produced only as a visualization of each domain separately. The orthogonal grid used for the space subdivision with resolution of 
The proposed approach is mainly suited for large data interpolation. For this reason we chose to use a real data set. The LiDAR data of Mount Saint Helens1 in Skamania County, Washington, contains scanned height data. The data set consists of 6,743,176
We chose to divide the input data set into a regular grid in a way such that the inside of a domain is going to be on average 5,000 points. To make square domains, we created a grid of the size
To perform the RBF interpolation, we needed to choose the shape parameter
points. The number of points inside the cell is almost double times more than number of points inside the domain, but the final speed-up will still be very high. For clarity we can estimate the speed-up of the proposed algorithm compared to the standard one as:
It can be seen that the speed-up is significant and we save a lot of calculations. The expected speed-up of the function evaluation is
This means that each RBF function computation for a given
Moreover, the standard algorithm for RBF interpolation would require around 330 TB to save the full interpolation matrix to the memory when double precision is used.
The data set divided into cells was interpolated one cell after another. We used one RBF interpolated cell to reconstruct the terrain inside one domain of the grid without blending step. The result can be seen together with the grid of domains in Fig. 18.
Parallel speed-up of the proposed method compared to the serial version of this method
Visualization of the final result of the proposed method for large scattered data interpolation with the RBF and space subdivision.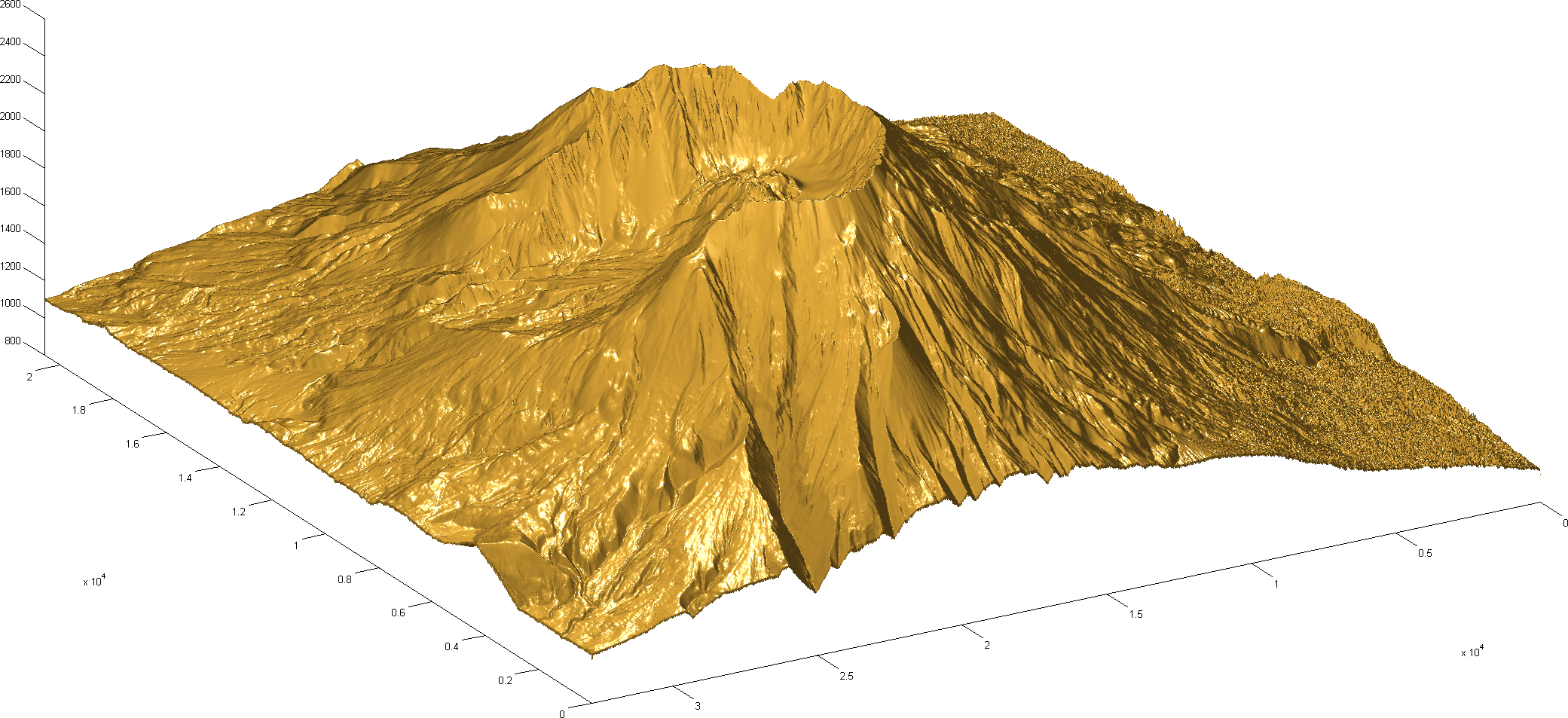
Figure 19 presents the result of the proposed RBF interpolation method. We used Eq. (12) to compute interpolation of the height values of the terrain for the visualization. This terrain does not have any discontinuity because of the proposed blending procedure.
The proposed algorithm can be easily parallelized as the RBF interpolation of each cell of the grid can be done separately and thus in parallel. We measured the running time of the interpolation when using
Visualization of the interpolated terrain produced only as a visualization of each domain separately. The orthogonal grid used for the space subdivision with resolution of 
We tested our proposed approach with another data set too. We chose a model of the terrain2 which contains 131,044 points with associated heights, i.e.
We divided the input data set to a regular grid so that a domain contains 3,000 points in average. We created a grid of the size
For the shape parameter, we used the size of
points. It is almost double times more, but the final speed-up will still be very high. We can estimate the speed-up of the proposed algorithm compared to the standard one:
It can be seen that the speed-up is significant and will save us a lot of calculations. The speed-up of interpolating function evaluation is
Moreover, the standard algorithm for the RBF interpolation needs around 128 GB to save the full interpolation matrix to the memory when double precision is used.
The data set divided into cells was interpolated one cell after another. We did a visualization of this RBF interpolation without doing any blending procedure. We used one RBF interpolated cell to reconstruct the terrain inside each domain of the grid. The result can be seen in Fig. 20, together with a visualization of the grid.
Figure 21 presents the result of the proposed RBF interpolation method. We used Eq. (12) to compute the height values of the terrain for the visualization. This terrain is continuous and does not have any discontinuity because of the proposed blending procedure.
Visualization of the final result of the proposed method for large scattered data interpolation with the RBF and space subdivision.
If CSRBF is used, many elements in the interpolation matrix are equal to zero, as the matrix is sparse in general. To decrease the memory requirements and be able to solve large interpolation matrices we can use a sparse matrix data structure. There are several existing sparse matrix representations. e.g. [45, 46, 37]. The main difference among existing storage formats is the sparsity pattern, or the structure of nonzero elements, for they are best suited. In our implementation, the coordinate format is used, which is briefly described in the following.
The coordinate (COO) format [47] is the simplest storage scheme. The sparse matrix is represented by three arrays:
Moreover, note that the elements in the interpolation matrix are zero for far away points, when CSRBFs are used. Therefore, we do not need to compute the elements for all pairs of points, so the kd-tree (A.2 in [26]) is used for computing the interpolation matrix.
As the proposed approach also needs to be compared with the standard one for RBF interpolation; we used the dataset in Fig. 21 which contains 131,044 points for interpolation. For the shape parameter for RBF interpolation we used the size of
Speed-up of the proposed approach for large scattered data interpoloation compared to the standard RBF interpolation. Both methods are using sparse matrix with COO format and kd-tree structure
According to the results in Table 3, the proposed algorithm is faster than the standard one and the speed-up is increasing with increasing of the grid resolution; both methods used the COO sparse matrix structure. We could not compute the speed-up when using the full matrix data structure as we were unable to fit such large data into the available memory for the standard algorithm.
Memory requirements for our proposed method and for the standard RBF interpolation method. The proposed method was tested with full matrix data structure and also using sparse matrix with COO format together with kd-tree structure. The standard algorithm for RBF interpolation uses sparse matrix with COO format together with kd-tree structure
According to the results in Table 4, the proposed approach has much lower memory requirements than the standard one. Therefore our approach enables to compute the RBF interpolation for very large datasets even on computers with standard memory size.
We presented a new approach for radial basis function interpolation of scattered data. It computes the interpolation on partly overlapping cells and then blends these interpolations together to create the final interpolation of the whole data set. This approach is especially efficient for large scattered data interpolation, as it reduces the memory required. It significantly speeds up computation of the interpolated value. The proposed approach is suitable for parallelization and it was tested on synthetic and large real data sets. It proved its robustness and high performance.
In future the proposed approach will be used for vector fields interpolation of large data sets based on [48, 49] and considering also vector field characteristics. We plan to modify the proposed method for
Footnotes
Acknowledgments
The authors would like to thank their colleagues at the University of West Bohemia, Plzen, for their discussions and suggestions, especially to Zuzana Majdisova, and anonymous reviewers for their valuable comments and hints provided. The research was supported by projects Czech Science Foundation (GACR) No. 17-05534S and SGS 2016-013.