
Abstract
This paper introduces a novel spatial method for human action recognition that is discriminative without needing temporal information or action key poses. First, skeletal data is acquired with the Microsoft Kinect v2 sensor and undergoes a Pose Invariant Normalization (PIN) process. The PIN process translates, rotates and scales the various observed poses to eliminate body differences and positional differences between subjects. Second, the method uses a Body Related Occupancy Map (BROM), that describes in a 3D grid how the area around specific body parts is used, as a strong indicator of the particular action that is being performed. The BROM and its 2D projections are used as feature inputs for Random Forest classifiers. These classifiers are then combined in a hierarchic structure to boost the classification performance. The approach is tested on a self-captured database of 23 human actions for game-play. On this database a classification with an accuracy score of 91% is achieved for the hierarchic BROM (HiBROM) classification. On the public CAD60 dataset, the HiBROM classifier attains 87.2% accuracy which is comparable to other state-of-the-art methods.
Introduction
Due to recent development of low-cost and dependable sensor technologies, significant research effort has been made into human action recognition. The strong interest into this research field is further enhanced by the development of efficient optimization techniques [1, 2] and by the many possible application areas such as intelligent visual surveillance [3, 4], Human-Computer Interaction [5, 6], automatic annotation [7] and behavioral biometrics [8, 9]. In particular, marker-less vision-based systems have great potential to deliver inexpensive, non-obtrusive solutions for human action recognition.
Problem description
It is not always easy for children in physical rehabilitation or a fitness program to sustain their efforts and keep up with their exercises. Therefore, an application to motivate these children was designed as a platform for exergaming that combines exercising with gaming. Not only does the platform present an enjoyable way to exercise, it also offers the possibility of remote monitoring and coaching the subject in an e-environment. The therapist or coach can remotely monitor the child’s progress and select the appropriate difficulty levels and games. This way, the development can be followed continuously from home without the need for the presence of the therapist or coach. The application framework consists of a gross motoric exergame where the child controls the game by performing the required exercises in front of a Kinect sensor. Automatic human action recognition is therefore a key part of the application.
Related work
Since the release of the Microsoft Kinect sensor, it has been extensively used for vision based human posture, gesture and action recognition as the user’s skeletal information is accurately generated by the sensor from its depth images. The skeletal data is usually transformed to extract important features such as locations, angles and velocities of skeleton joints. The features are then used to classify the human posture or action. General classifiers, such as Support Vector Machines (SVM), or template-matchers are commonly used for recognition of static gestures (i.e. postures, sitting, lying, standing, …). Dynamic gestures however (i.e. running, walking, jumping, …), include a temporal dimension and are typically handled by Hidden Markov Models (HMM) or motion based models. Some existing methods for human posture and action recognition are here summarily explained.
The method by Zhang et al. [10] utilizes Kinect skeletal information to generate 9 normalized vectors representing different body parts. With an optimized SVM they identify 22 pre-defined postures. Through principle component analysis they found that, in the reduced feature space of the three main orthogonal principle components, most body postures were well separated from each other. An accuracy of 99.14% was achieved.
Gahlot et al. used spherical angles and angular velocities for action recognition [11]. The pose of the subject is first estimated by three joints near the torso. The angles and velocities are then computed in reference to the torso joint. Horizontal symmetry is incorporated through a motion energy based method to account for actions performed by either the left or right side of the body. The classification is finally obtained with an individual HMM for every supported action. Standing, sitting and bending were classified with an accuracy of 90%.
Hussein et al. [12] use covariance matrices from 3D joint locations to classify human actions. To account for the temporal dimension, multiple covariance matrices over sub-sequences of the action are employed in a hierarchical manner. Normalization of the joint locations is used to make the method scale invariant. An off-the-shelf SVM classifier was used to validate the descriptor on three different datasets with accuracy ranging from 90.5% to 95.4%.
Cippitelli et al. [13] developed an action recognition algorithm for Active and Assisted Living applications. Posture features are computed from skeletal data and used by a clustering method to select key poses without the need of a learning algorithm. A multiclass SVM is applied to classify the different activities with an accuracy ranging from 81.2% to 99.9% on five different public datasets.
Faria et al. [14] use a Bayesian Mixture Model to combine multiple learning classifiers into a single form. 3D skeleton features, such as distances between joints and motion features, are extracted as input for the single classifiers. Analysis of previous behavior of the classifiers provides confidence weights to the model to improve current-frame classification. This method achieves a classification performance of 96.9% on the CAD60 dataset.
Shan and Akella [15] proposed a classification method from 3D skeleton coordinates that address the spatial and temporal challenges inherent in human action recognition. Segmentation is performed on the normalized skeleton data to extract key poses of the action. Atomic action templates are then created from the key poses to eliminate the influence of nonlinear stretching and random pauses in the temporal domain. An SVM classification model classifies the action with an accuracy of 84.0% and 91.9% on two public datasets.
Lastly, an earlier method created for the exergaming project is discussed [16]. Normalized skeleton joint locations were used to classify every body pose with a Random Forest (RF) classifier. The idea was that different actions show sufficient different body poses to be distinguishable from each other. A sliding window over the classification results of the last several consecutive frames decides on the final classification by majority voting. The strategy obtained an accuracy of 96.7% on the exergame dataset and an accuracy of 98.3% on the Microsoft Research Cambridge-12 Kinect dataset.
The classification methods all show promising results, but there are a few issues that are not always handled by the existing solutions. The features that are extracted from the skeletal data should ideally be insensitive to small variations in a person’s appearance, action execution and camera viewpoint. At the same time, the features must be sufficiently distinctive to allow for robust classification. Some methods are sensitive to the general location of the subject in relation to the sensor. A related problem is that generally the subject has to be facing the Kinect sensor, making it view-dependent. A last issue is the scale-invariance. The features have to be independent from the person’s dimensions.
The classification method itself can also introduce some issues. By nature, posture recognition methods can only classify static actions. Dynamic actions however contain a temporal dimension that cannot be handled by the posture recognition systems. A much used solution for this problem is the HMM. However, the construction of a HMM is a complex and time consuming task.
Proposed solution
This paper introduces a novel way to recognize human actions. The proposed approach observes how the subject uses the space around him during the performed action. The philosophy behind this idea is that different actions require the use of different zones in the personal space around the human body. For example, waving your arms takes primarily place next to the torso. In contrast, pushing something away with both arms happens in front of the torso. The method therefore detects the areas that are occupied by the person while the action is being performed. The occupied areas are indicated by an occupancy map which forms a 3D grid around the subject. Furthermore, the temporal duration of the action is eliminated such that identical actions performed at different speeds are recognized as the same action. The experiments will prove that actions can be recognized by only registering how a person uses the space around him.
Moreover, the approach not only looks at the body as a whole, but also divides the body into different body parts. The idea behind this is that complex actions can be decomposed into simple actions performed by different body parts. Also, some actions are mainly performed by one part of the body and can be better observed when only the relevant body part is considered.
Additionally, the proposed method places the body (part) in reference to a specific point and transforms it to the model of a standard body. This way, the algorithm can recognize the same action regardless of the position, orientation and size of the individual performing the action. This property, called the Pose Invariant Normalization or PIN, will be proven crucial to the method in the experiments.
The major contribution of this paper is a novel feature that is able to recognize human actions by describing how a person uses his or her surrounding area, without the need to analyze any temporal information or key poses. This strongly differs from how other action recognition methods look at a human action.
This paper is the extended version of [17] where the Body Related Occupancy Map (BROM) method was first introduced in its most basic form. The BROM design is here further developed and optimized to reach a higher classification score. Based on the results from these new experiments, the hierarchic BROM (HiBROM) classification is developed and analyzed. Moreover, the importance of the PIN phase in the proposed solution is here demonstrated and confirmed. Additionally, both methods are tested against other state-of-the-art algorithms on a public dataset.
The remainder of this paper is structured as follows. Section 2 reveals the fundamentals of the PIN process and the construction of the BROM. In Section 3, the BROM and HiBROM are experimentally optimized on a self-captured dataset. Section 4 completes this paper with a critical evaluation of the PIN process on a dataset with children and adults, a critical evaluation of the BROM on a public dataset and a conclusion.
The different steps in constructing the BROM and its views.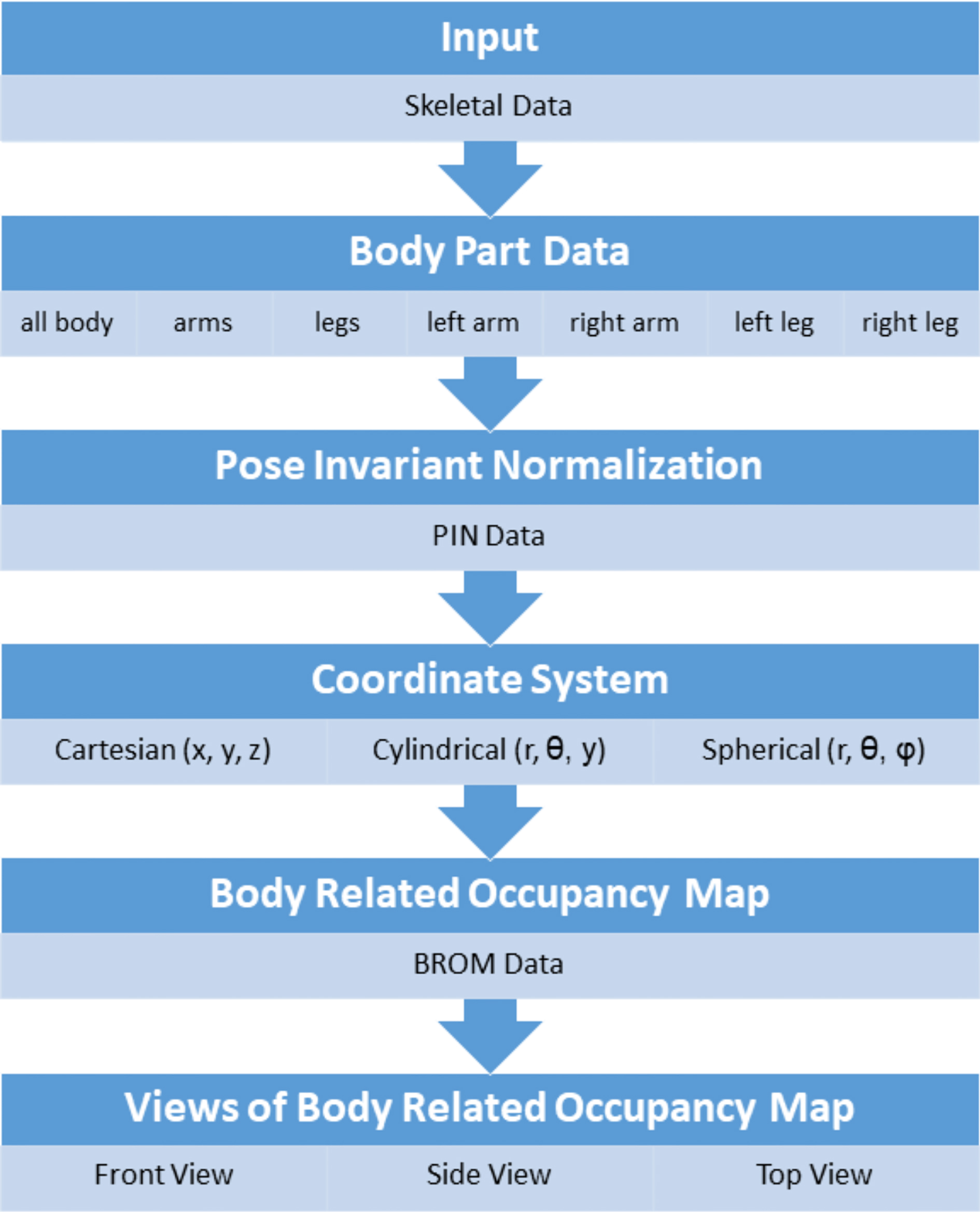
Figure 1 illustrates the different steps in the construction of the BROMs. In the first step, a body part is chosen from the Skeletal Data acquired by the Kinect sensor, and the joint data corresponding with the body part is selected. In the next step, body size differences and positional differences between individual subjects are eliminated from the body part data by the PIN process. This PIN data can then be transformed into a cylindrical or spherical coordinate system for different shaped BROMs. The BROM is finally constructed from the PIN data from each frame within the performed action. The three 2D projections represent the front, side and top view of the BROM and reduce the feature size of the BROM. Each step will be explained more in depth.
Kinect skeletal data
The Kinect v2 sensor from Microsoft is used for the human detection and tracking. It is a natural user interface device designed for the Xbox One gaming device and provides a system where the user controls the gameplay through his own movements in front of the sensor. It is equipped with a 1080p color camera, a 512p
The skeleton recognition algorithm involves 4 steps [19]. In the first step a rudimentary guess based on the depth data is made. Then, probabilities are calculated for the locations of the different body parts such as hand, head and shoulder, based on its experience from the pose database. In the third step, probable skeletons are fit to the probabilistic body parts based on formal kinematics models and experience. In the last step, the most probable skeleton is given as output.
The Kinect software can also distinguish humans and their movements even if they’re partially hidden. The Kinect extrapolates what the rest of the body is doing as long as it can detect some parts of it. This allows players to jump in front of each other or to stand behind pieces of furniture in the room.
The skeletal data that the Kinect acquires is used as input for the action recognition. The skeletal data is delivered at 30 fps and consists of 25 joint positions and orientations. These joints, as seen in Fig. 2, are connected to each other through bones with a parent joint and a child joint. The parent joint is the end joint of the bone that is closest to the reference joint, usually the spine base. For example, the upper arm bone has the shoulder joint as parent joint and the elbow joint as child joint. The elbow joint is in turn the parent joint of the lower arm bone. Note that in this work, not every joint is considered for every BROM. A BROM can be constructed for the whole body or for a body part, such as the arms, the legs, the left/right arm or the left /right leg.
The 25 joints of the Kinect skeleton.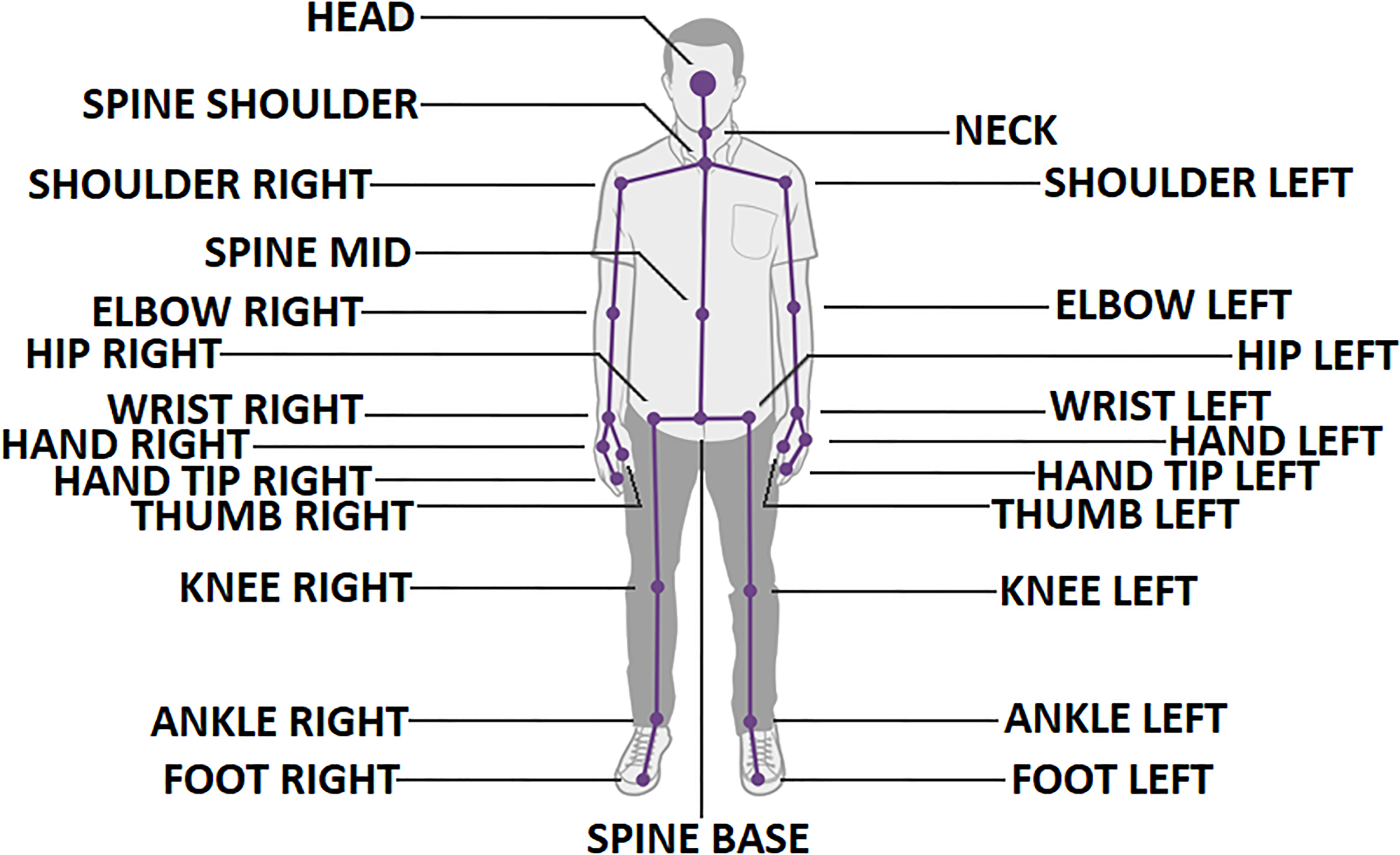
Before the BROM can be built, the skeletal data has to be normalized. The variability across subjects in height and other dimensions has to be eliminated to accurately classify the movements of the individual. Too much difference in body part sizes between different individuals will disturb the classifier performance. For this reason, every skeleton will be transformed to a skeleton model with standard dimensions.
Since the action recognition must be independent of absolute positions, one joint is chosen as a reference point. The entire skeleton is re-positioned and rotated so the reference joint lies at the origin of the coordinate system and the orientation of the reference joint coincides with the axes.
This PIN process is done in three phases. Given a
First, the joints are translated so the reference joint lies in the origin. The translated skeletal data is:
The next step is the rotation of the translated skeletal data with the conjugate of the orientation of the reference joint:
The product of two quaternions, as in Eq. (2), is called the Hamilton product. The product of a vector and a quaternion is calculated by using the quaternion representation of the vector and then taking the Hamilton product of the two quaternions.
Overview of the skeleton PIN process for a child vs. an adult. The orientation of the reference joint, the spine base, is depicted by its x,y and z axes. (a) The original skeletons, (b) the skeletons in reference to the spine base joint, (c) the skeleton after the complete PIN process.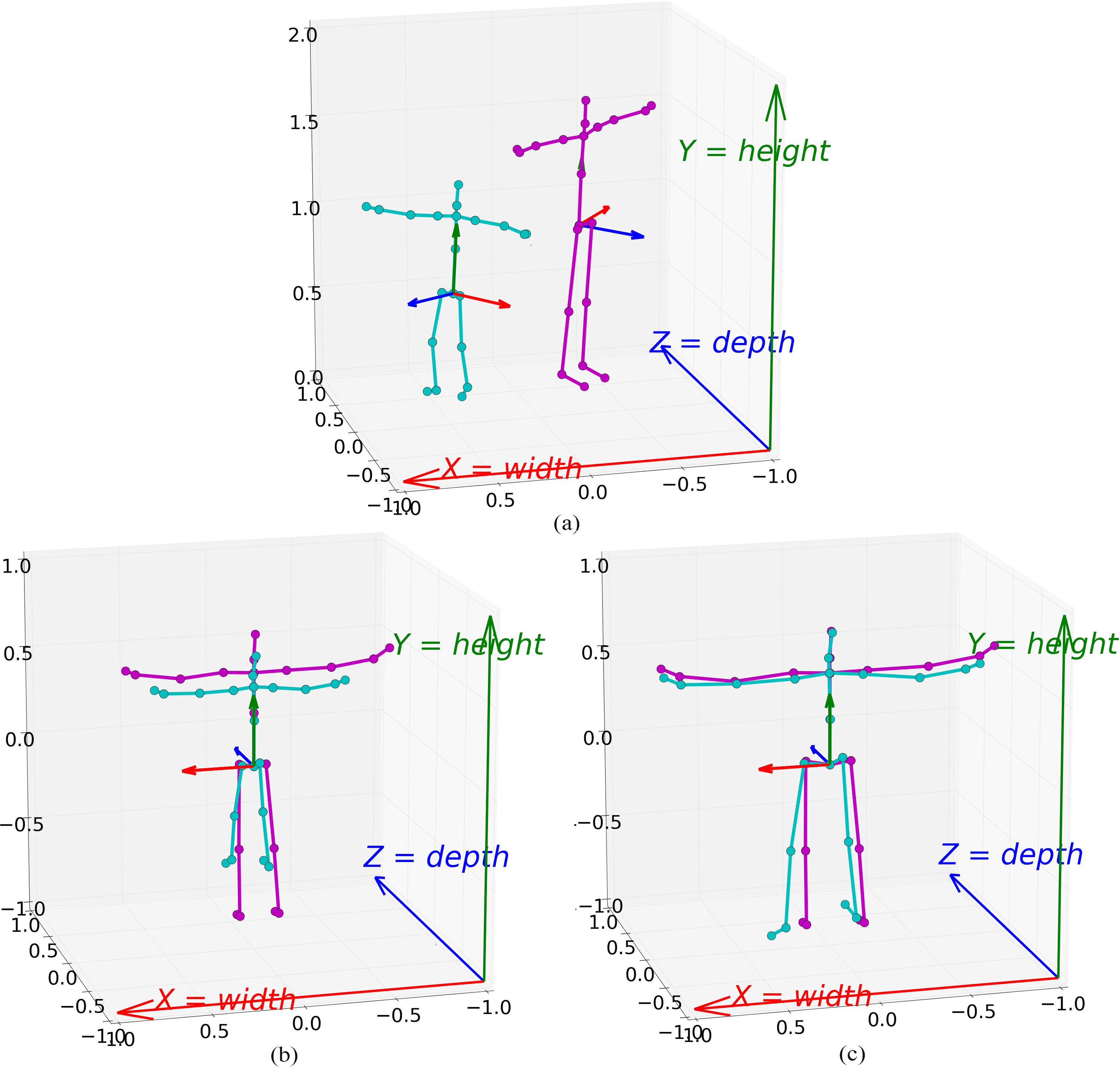
In the last phase, the dimensions of the skeleton are normalized to the dimensions of a standard skeleton model. The standard model is based on the mid-sized male aviator [20].
where
The skeleton is now normalized to a template that not only removes the individual body differences, but also the differences in the global positioning and orientation of the body. The normalization process therefore makes it possible to represent both adults and children with the same model despite the sizable differences in body shape. This is illustrated in Fig. 3 where the skeleton of a nine-year old child is compared to the skeleton of an adult before, during and after the PIN process. Both subjects are standing in the T-pose while looking in different directions (Fig. 3a). In Fig. 3b the skeletons were translated and rotated in reference to their own spine base joint. The orientation of the reference joint now coincides with the axes of the coordinate space. After remodeling the skeletons to the standard sized skeleton, the T-poses are clearly similar (Fig. 3c).
The purpose of the BROM, is to keep track of which areas in the space around the skeleton were occupied during the action performance and how much of the time they were occupied.
The BROM can be constructed relative to a room, a specific object in space, a specific joint of a skeleton, or even relative to a body part that belongs to another person present in the room. The proposed method is broad enough to handle each of these cases. The skeletal data is re-oriented in reference to the chosen point. The process is essentially the same as the first two steps of the normalization of the skeletal data. If the reference point is the same as the reference joint in the normalization phase, the re-orientation can be skipped. If the entire skeleton is analyzed, the optimal reference is the spine base joint.
To build the BROM, the space around the skeleton is first divided into adjoining cells according to a rectangular, a spherical or a cylindrical UxVxW grid depending on the application. For the first test cases in this paper, there was opted for dividing the space by means of a rectangular grid. If a cylindrical or spherical grid is selected to construct the BROM, the PIN skeletons are first transformed to their new coordinates. The reference point of the occupancy map always lies in the center cell of the grid, regardless of the shape of the BROM grid. The cells form the foundation of the occupancy map that is filled frame by frame.
For every frame, the occupation level of the 3D cells is considered. A cell is occupied if a joint from the skeletal data lies within its boundaries. Counters in the BROM for the current frame keep track of the number of joints that occupy every cell. The BROMs for every frame of the performed action are then added together and divided by the total number of frames for normalization:
where
It should be noted that the normalization doesn’t necessarily result in values between 0 and 1, but in fact results in values between 0 and the number of considered joints. Depending on the size of the 3D cells, multiple joints can occupy the same cell at the same time. Consider, for example, the special case where the 3D space is divided into 1 cell. All the joints will occupy the same cell in every frame. The occupancy map will therefore only contain one value that corresponds with the number of joints. It should also be noted that the center cell will always have minimum value 1 if the reference point of the map is a point of the mapped body due to the design of the cell grid.
Front view projections of the BROMs during the action “flying with big arm moves” for a child (top) and an adult (bottom). (a) FV for the entire skeleton, (b) for the arms, (c) for the legs.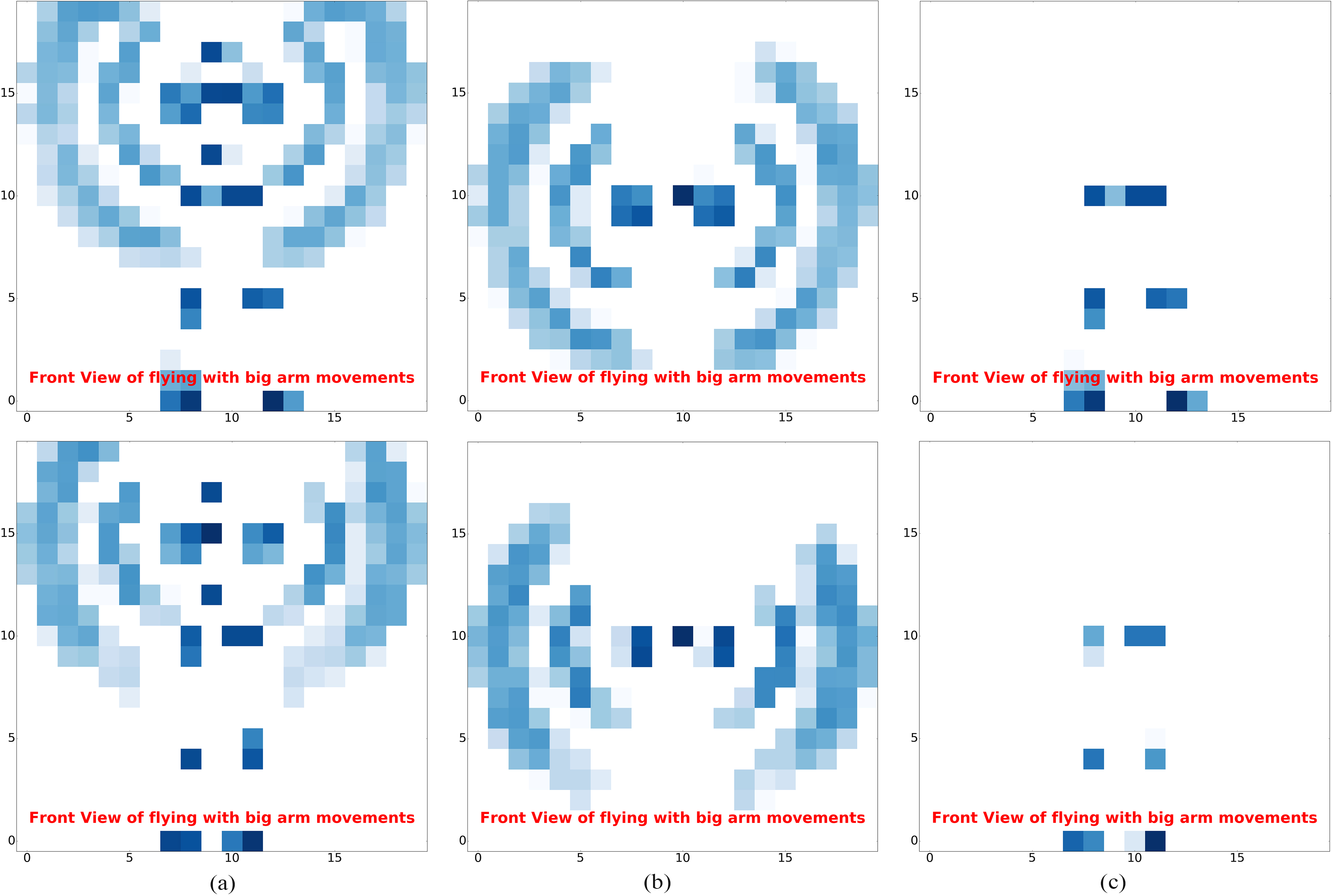
The BROM doesn’t only show what space was occupied during the action, it also indirectly indicates how much movement was performed. Consider the case where the subject stays completely still, all the cells in the occupancy map will have value zero except for a small number of cells that will have a value of at least 1. Values between 0 and 1 will not exist in the map. So if all the non-zero cells in the map have a high value (close to or greater than 1), it indicates that the subject didn’t move much during the action. In the opposite case, where the subject moves around a lot during the action, the non-zero cells in the map will be great in number and have low values.
The BROM can be partitioned into slices to make visualization as a 2D projection of the map possible. The frontal view (FV), side view (SV) and top view (TV) of the BROM are obtained by adding the 2D slices together and normalizing the resulting 2D grid. Only the formula for the FV is given as the SV and TV are similarly calculated.
Examples of the FV projection of a BROM are shown in Fig. 4 for the action “flying with big arm moves”. Due to the normalization of the skeletons, the FVs for a child and for an adult are indistinguishable from each other. It is also clear from the FVs that the action is primarily performed by the arms.
As mentioned before, the BROMs can be constructed from partial skeletons. The body is divided into different body parts such as an arm, a leg, a torso, etc., and BROMs are built for each body part. Complex actions are in this manner decomposed into sub-actions performed by different body parts. A hierarchic structure of the body part BROMs classifies the sub-actions and the performed complex action.
Similar actions are also classified with a hierarchic BROM structure. A general BROM, such as a full body BROM, is used to classify the action subset that contains similar actions. More detailed BROMs, such as a left arm BROM, classify the performed action from the predicted subset of actions. This hierarchic BROM classification method is further developed in the experiments.
Experiments
Evaluation method
The proposed strategy is evaluated on three different datasets. In this section, the algorithm is optimized on the self-captured dataset for the exergame application. In a later section, the proposed approach is tested on a self-captured dataset with children and is compared to state-of-the-art methods on a publicly available dataset.
The actions in the self-captured dataset are characterized by the sequence of frames from their start frame until their end frame. The BROMs for the actions are built from these frame sequences. Initially, the BROM discretizes the 3D Cartesian coordinate space into 20
The classifiers are trained on the leave-one-subject-out principle [21]. The data of all the subjects except one is used as training data for the classifier. The classifier is then evaluated on the data of the subject left out. This process is repeated for every subject in the database. Moreover, every experiment is repeated ten times to account for outliers that may result from possible randomness in the classifiers. The overall evaluation of the classification method is the average of the results. The balanced accuracy score is used to evaluate each classifier. In this score, each sample is associated with a weight that is inversely proportional to the action sample frequencies to counter the action imbalance in the dataset. The accuracy is defined as the weighted fraction of correct predictions:
with
The action dataset was recorded with the Microsoft Kinect v2 sensor at the Sport Science Laboratory of the department of Movement and Sport Sciences at Ghent University in Belgium. It consists of four male and one female subjects performing 22 specific actions three times each with the neutral action standing still with arms along the body in between (24256 samples). The performed actions are: “walking”, “running”, “step left”, “step right”, “bowing”, “bow left”, “bow right”, “little jump”, “big jump”, “little jump hands up”, “big jump hands up”, “climbing”, “hummingbird”, “flying small moves”, “flying big moves”, “punch left”, “punch right”, “pushing forward”, “high kick left”, “high kick right”, “low kick left” and “low kick right”.
Classification method
An important part in solving an action recognition problem is choosing the right classification model. In choosing a good model, the bias-variance trade-off is an important consideration. This dilemma concerns the diminishing of two sources of error that prevent supervised learning techniques from generalizing beyond their training dataset. The bias error of a classifier stems from underfitting the training data. Important relations between features and class labels are missed during the training phase of the classifier. Conversely, the variance stems from overfitting the training data. Random noise in the training data is erroneously considered important in the training phase. In general, a classifier that captures the consistency of the training data well and can generalize to unseen data is desired. This means a low-bias, low-variance classifier is needed. However, lowering the bias of a classifier, usually implicitly increases the variance and vice versa. Moreover, not every model is suited for every task as it depends on the type of data and the type of problem. Appropriate classifiers for a supervised multi-class classification problem like the one presented are SVMs, Nearest Neighbor classifiers and ensemble classifiers.
SVMs were originally created for binary classification. The classifier maps the feature vector to a high-dimension feature space where it divides the vectors into the 2 classes by constructing a linear decision surface. High generalization ability of the learning machine is ensured by the special properties of the decision surface [22]. By implementing the “one-against-one” approach or the “one-vs-the-rest” approach, binary support vector classification can be extended to multi-class classification. Experiments done by Hsu et al. indicate that the “one-against-one” strategy is more suitable for practical use [23].
Nearest Neighbor classifiers are based on the principle of finding the predefined number of training samples that are closest to the new sample and predict the classification label from these training samples [24, 25]. There are two types of Nearest Neighbor classifiers: in k-Nearest Neighbor classification the number of samples is a constant, in radius-based Neighbor classification however, the number of samples vary based on the local density of the samples. The Nearest Neighbor method is known as a non-generalizing machine learning method, since it simply remembers all of the training data. Nonetheless, despite its simplicity and being non-parametric, the method has been successful in a large number of classification problems, in particular where the decision boundary is very irregular.
Ensemble methods weigh several individual base classifiers and combine them in order to obtain a classifier that outperforms the single classifiers. The base estimators can either be independent or dependent from each other which leads to distinguishing two families of ensemble methods: the averaging methods and the boosting methods. In the averaging methods, the individual classifiers are built independently and their predictions are combined in some fashion. Alternatively, in the boosting methods, the prediction from a base classifier is used to construct the next base classifier [26].
The performance of several different classifiers will be compared to each other. For the SVMs, three subtypes will be tested: the linear SVM (linSVM), the Radial Basis Function SVM (rbfSVM) and the polynomial SVM (polySVM). Both the k-Nearest Neighbor classification and the radius-based Neighbor classification are assessed. Finally, Bagging and RF from the averaging ensemble methods and AdaBoost and Gradient Tree Boosting from the boosting ensemble methods are evaluated. For each classifier, the hyper-parameters were tuned for optimal performance by an exhaustive grid search.
Evaluation of different classification methods
Evaluation of different classification methods
Table 1 shows the results from the evaluation of the different classifiers. The Nearest Neighbor classifiers are the least suitable for this application as they achieve only 30–36% accuracy. SVMs score better with linSVM and rbfSVM reaching 60% accuracy. LinSVM performs slightly less than rbfSVM but is also slightly more stable. The best performing classifiers are the averaging ensemble methods. The selected classifier for the application is the RF classifier as it achieves the best accuracy with a score of 78%. It is also the most stable classifier with a standard deviation of 7% across the different test subjects.
The high performance of the RF classifier can be explained by its construction. The RF ensemble consists of several decision tree classifiers. A decision tree is easy to use and can be implemented extremely efficiently. The tree consists of different nodes that are connected by branches. Each decision-node (i.e. each non-leaf node), has exactly two child-nodes in a binary tree and represents a split in the feature data. The split is decided by a threshold value for a specific feature. The feature data is continuously split in the tree until leaf-nodes are reached who each represent a single class label.
During the construction of the tree, one feature has to be selected from the entire feature set for the split at each decision-node. Usually the feature with the highest local information gain is chosen for the split criterion in a greedy heuristic approach. The ID3 algorithm and its successor, C4.5 [27], are examples who utilize this method.
A decision tree is a low-bias high-variance classifier. To decrease the variance of the classifier, multiple decision trees are trained on different random subsets of the training data. The average probabilistic prediction of the different trees is then used to decide the resulting classification. This is the RF Classifier. It uses a divide-and-conquer approach to increase the classification performance and is based on the principle that multiple weak classifiers can be combined to create a strong classifier.
The trees in the forest are all trained on a different subset of the training data. However, often only a limited amount of training data is available. A well known method to overcome this problem is sampling with replacement, also called bootstrapping or bagging. This way, a sample can be selected multiple times to train a tree classifier from the forest. As a result, each classifier will have slightly different decision boundaries. By aggregating the resulting decisions of each of these possibly high-variance classifiers, by means of averaging, a low-variance classifier is obtained.
The use of bootstrapping to decrease the variance of the final ensemble classifier also has a downside. Because of the duplicates in training data, the bagged trees show a significant correlation between them. Highly correlated trees would therefore make the same errors in similar regions of the feature space. As a consequence, the bias of the resulting classifier increases. To counteract this and to insure diversity in the tree classifiers, randomness is introduced in the splitting criterion: only a randomly selected subset of all features is considered in the split for selecting the feature for the next decision-node.
In summary, a RF, is a low-bias, low-variance ensemble classifier, trained with bagging and random feature selection. It has been proven that RF’s are almost invariant to overfitting and are robust against noise. Finally, classification by means of RF has an extremely efficient implementation, since each decision tree can simply be represented by a set of conditional statements.
Different body parts with their reference joint and included joints
Accuracy score per label and in total for the classification of the BROMs of different body parts for the complete action set
Influence of the number of bins in the Cartesian BROMs on the accuracy of the classifier.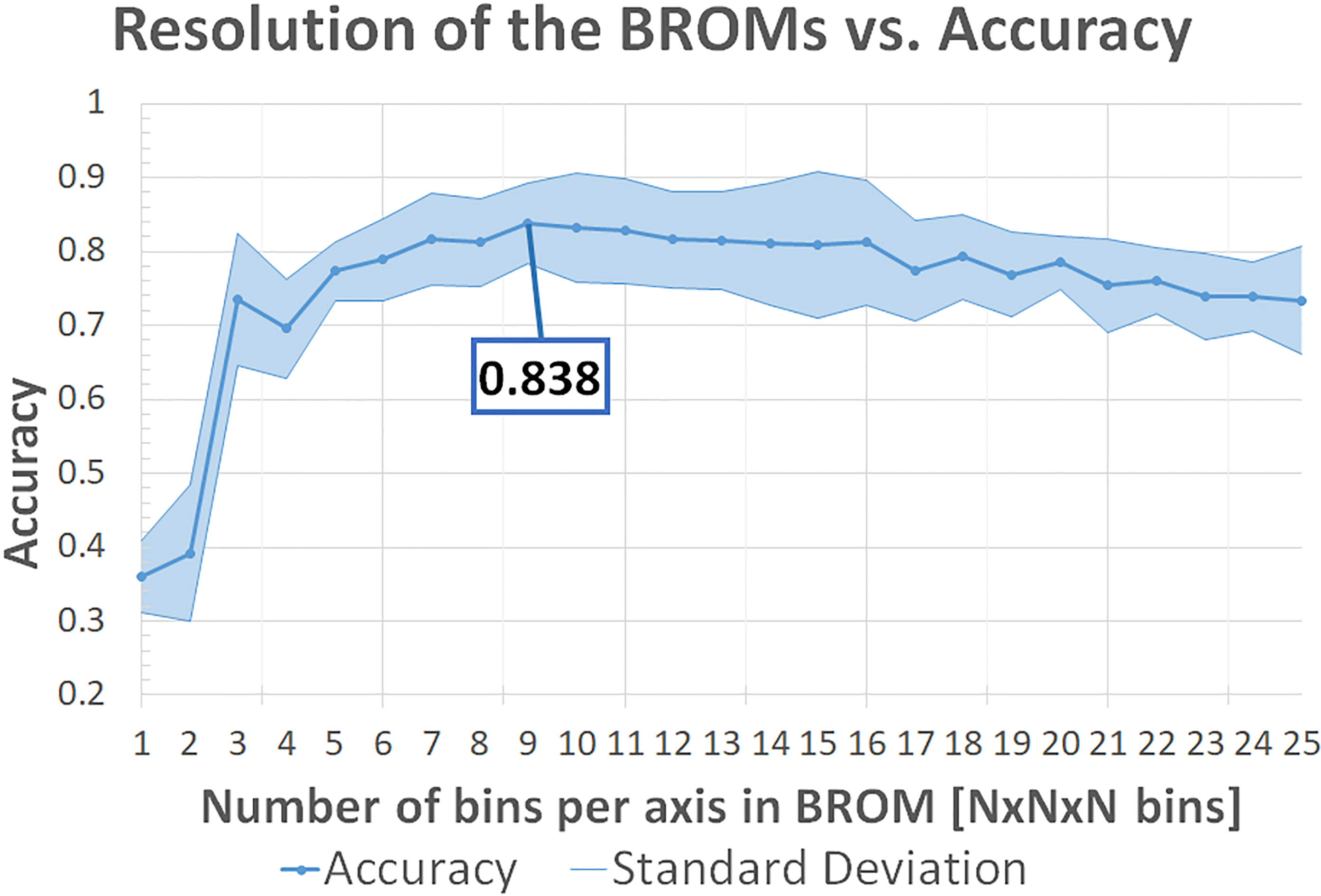
Normalized confusion matrix of the classification of the Cartesian BROM for the entire body.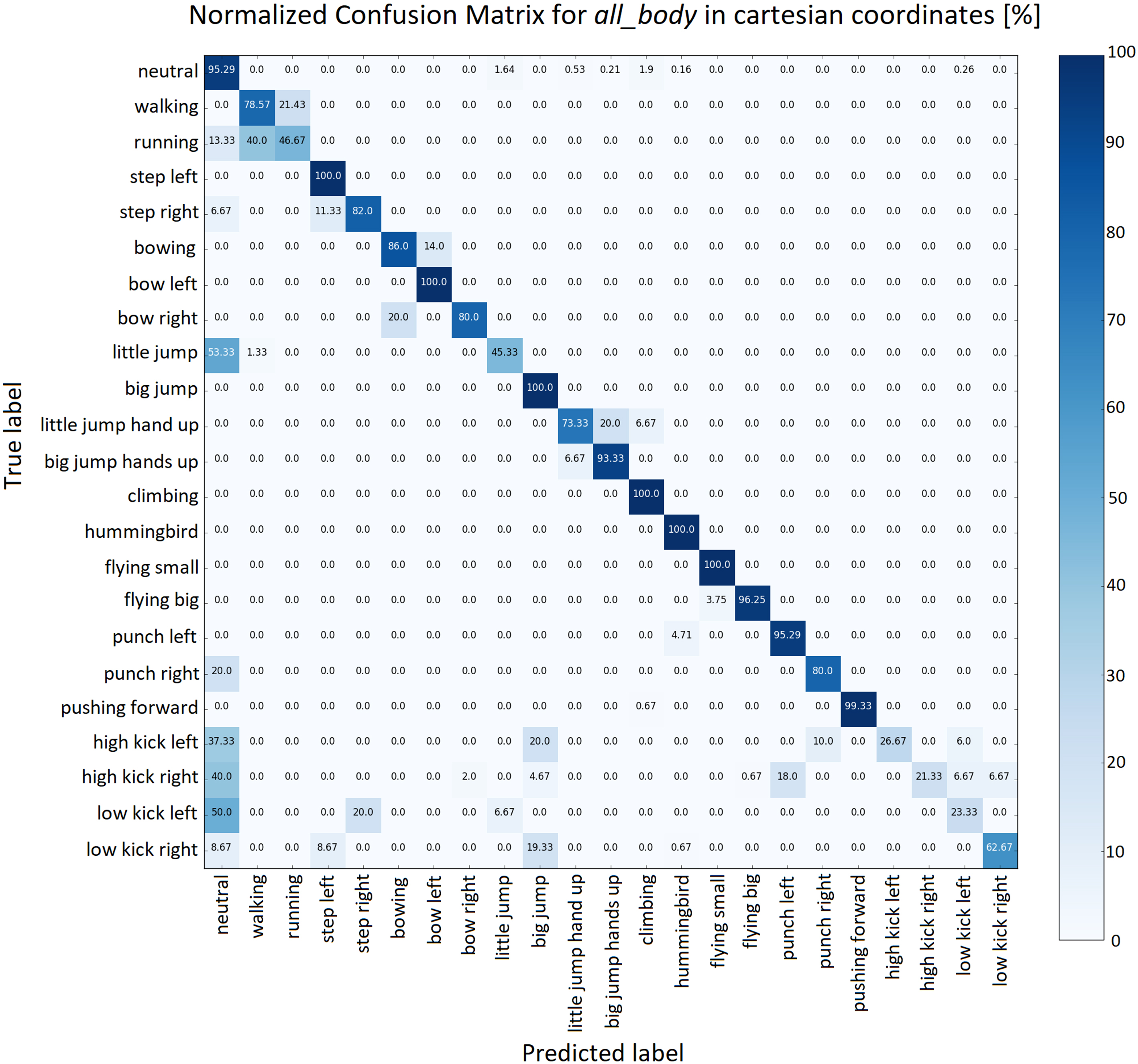
In the previous experiment, the BROMs discretized the space around the test subject in 20
The results in Fig. 5 show that the performance of the classifier is optimal between 7
Whole body classification versus body part classification
The classification performance of several BROM constructions are compared against each other. The entire action set is classified by BROMs constructed from the complete skeleton body vs. BROMs constructed from different body parts. Table 2 gives an overview of the different body parts with the reference joint and included joints that are used in the BROMs.
Table 3 shows the resulting accuracy scores per action. It is clear that the BROMs of the partial skeletons are not enough on their own for a reliable classification of the entire action set. However, it gives a first indication of which actions are best classified by which body part. To make it more clear, the accuracy scores that are greater than or equal to 0.9 were highlighted in bold green, the accuracy scores between 0.75 and 0.9 were highlighted in cursive orange and the accuracy scores between 0.5 and 0.75 were highlighted in pale yellow. The classification of the BROM with the complete skeleton, results in a accuracy score of an acceptable 83.4%.
Accuracy scores for the classification of the BROMs of different body parts for different action subsets
Accuracy scores for the classification of the BROMs of different body parts for different action subsets
Most of the mislabeled samples (42%) are classified as the “neutral” action, as can be seen in the normalized confusion matrix in Fig. 6. Especially the action “little jump” shows this behavior as more than half of the time it is misclassified as the “neutral” action. This is however not surprising as “little jump” consists of only a slight bending of the knees as seen from the spine_center joint. The kick actions are also regularly misclassified as the “neutral” action due to the very high speed in which the action is performed. Surprisingly, “low kick to the left” is an exception to this. 32% of the mislabeled samples are classified as an action with a highly similar use of the space around the subject. “Walking” and “running” are two such actions that are frequently switched. Unfortunately, the biggest difference between these two actions is the speed of execution which is lost in the construction of the BROM. This was an intentional choice in the design of the BROM because normalizing on the execution time, meant that, for example, slow flying and fast flying are both classified as flying. To classify similar actions with different speeds, the BROMs should be normalized on a fixed number of frames instead of on the execution time.
The computational time for creating the BROMs of the entire body took 52 s for the complete dataset (in Python on a Intel Core i7 processor). This averages to 2.20 ms/frame or 82.22 ms/BROM. A notable 94% of this time was spent on the PIN of the skeletons. The computational time was reduced to 0.42 ms/frame or 15.56 ms/BROM when the BROM was created for only the leg or the arm.
In the next experiment, each body part is assigned a subset of the actions to investigate if actions performed by the same body part can be classified by the body part BROM. The action subsets are derived from the main body part that is used to perform the action. For example, “flying” is mainly performed by the arms. The ac- tion is therefore only classified by the BROMs of the left/right arm and both arms.
Table 4 gives an overview of the actions that were classified by the BROMs of each body part and the resulting accuracy scores. A remarkable improvement in performance of the body part classifiers can be made if they are classified on their own action subset. The only actions that are still difficult to classify are “running”, “little jump”, “little jump hands up”, “climbing” and “high kick”. This experiment indicates that a combination of the body part BROMs can classify the full action set.
Accuracy scores for the combined classifiers of BROMs of different body parts on the whole action set
Accuracy scores for the combined classifiers of BROMs of different body parts on the whole action set
Some body parts, like the arm, have an almost circular range of motion. To better capture this range of motion, coordinate systems other than the Cartesian system are tested for the construction of the BROMs. For this, the Cartesian coordinates of the skeleton joints are transformed to their corresponding spherical and cylindrical coordinates conforming to Eqs (8) and (9) respectively. The BROMs are then constructed according to a cylindrical or spherical grid. The optimal resolution is for the cylindrical BROMs 11
The outcome of this experiment is shown in Fig. 7. Every body part with its own subset of actions was classified in Cartesian, cylindrical and spherical BROMs. The accuracy bar of the best coordinate system for every body part is bordered in the graph and is indicated with its value. From the experiment it is clear that some body parts are better classified in a different coordinate system. For example, all_body with the entire action set is best classified in a cylindrical BROM. This classifier performs on average 3.2% better than the Cartesian classifier. The left_arm classifier gains 2.4% in accuracy when its BROMs are constructed in the spherical coordinate system. The classifiers for the other body parts are closer in performance with a difference of 0.3–0.8% between the best and the second best coordinate system. In general, the arms and legs are best classified in Cartesian BROMS. However, the arms separately are better classified in a spherical system, while the classifiers for the separate legs perform better in a cylindrical system. As a result, the BROMs have gained their own coordinate system for every different body part.
Performance of the classification on the action subsets for BROMs in different coordinate systems.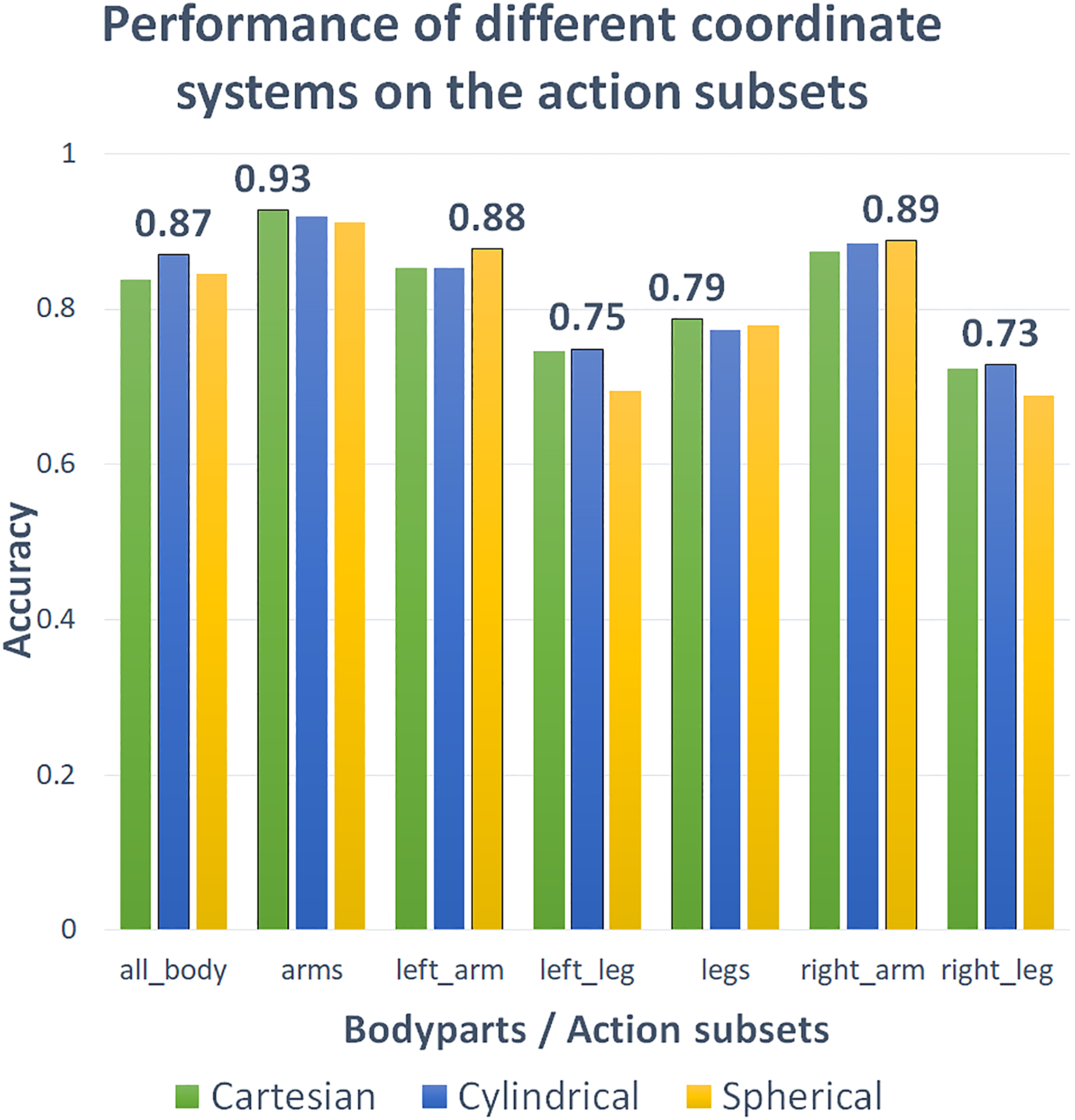
The next experiment consists of combining the predictions of the best body part BROM classifiers from the last experiment, into one general prediction. There are three ways to combine the classifiers. The first and simplest option is by taking the majority vote of the separate classifiers. The second method takes the probabilistic vote of the separate classifiers. The last method combines the classifiers in a Bayesian network where the prediction from each classifier is weighted corresponding to the tested accuracy of the classifier for that prediction.
An extra rule is implemented when the final prediction gives the neutral action. In the previous experiment, the body part classifiers were also tested on untrained actions. With very few exceptions, the untrained actions were classified as the neutral action. This means that generally, the classifiers give either the correct class or the neutral class. The extra rule is based on this finding. If the final classification is the neutral action, the second most probable class is returned instead, unless all classifiers are unanimous.
The experiment proves that the classification performance decreases when the body is divided into separate body parts as shown in Table 5. The smaller the different body parts, the more the performance of the general classifier suffers. Also, the method of majority voting gains only significance if the number of classifiers in the combination increases. The probability voting mechanism is the best option as long as the number of classifiers in the combination is small. Otherwise, the Bayesian network gives better results.
Action subsets for level 1 of the HiBROM and their corresponding level 2 classifier
Action subsets for level 1 of the HiBROM and their corresponding level 2 classifier
In addition, this experiment demonstrates that a hierarchic classification is necessary. The whole body BROM can be used to distinguish if the action is mainly performed by the arms, the legs or both. The second level in the hierarchy then uses the BROM of the main body parts. This way the BROM of the arms is only used if there is sufficient indication of arm action.
The BROM results in a large feature vector for the classifier. This experiment studies if this can be reduced through only taking the 2D views of the BROM. Classifiers for the views separately and the views together are trained for every body part and every coordinate system.
In some views, the best performing classifier for a body part is strongly dependent on the coordinate system. For example, the TV of the BROM is preferably classified in the Cartesian coordinate system, except when the body part is the left leg. For the SV however, the Cartesian coordinate system is only preferred in case of classification for the right leg. A poor choice of coordinate system for the classification can lead to an accuracy loss of up to 17%.
Performance of the views separately and together vs the BROM.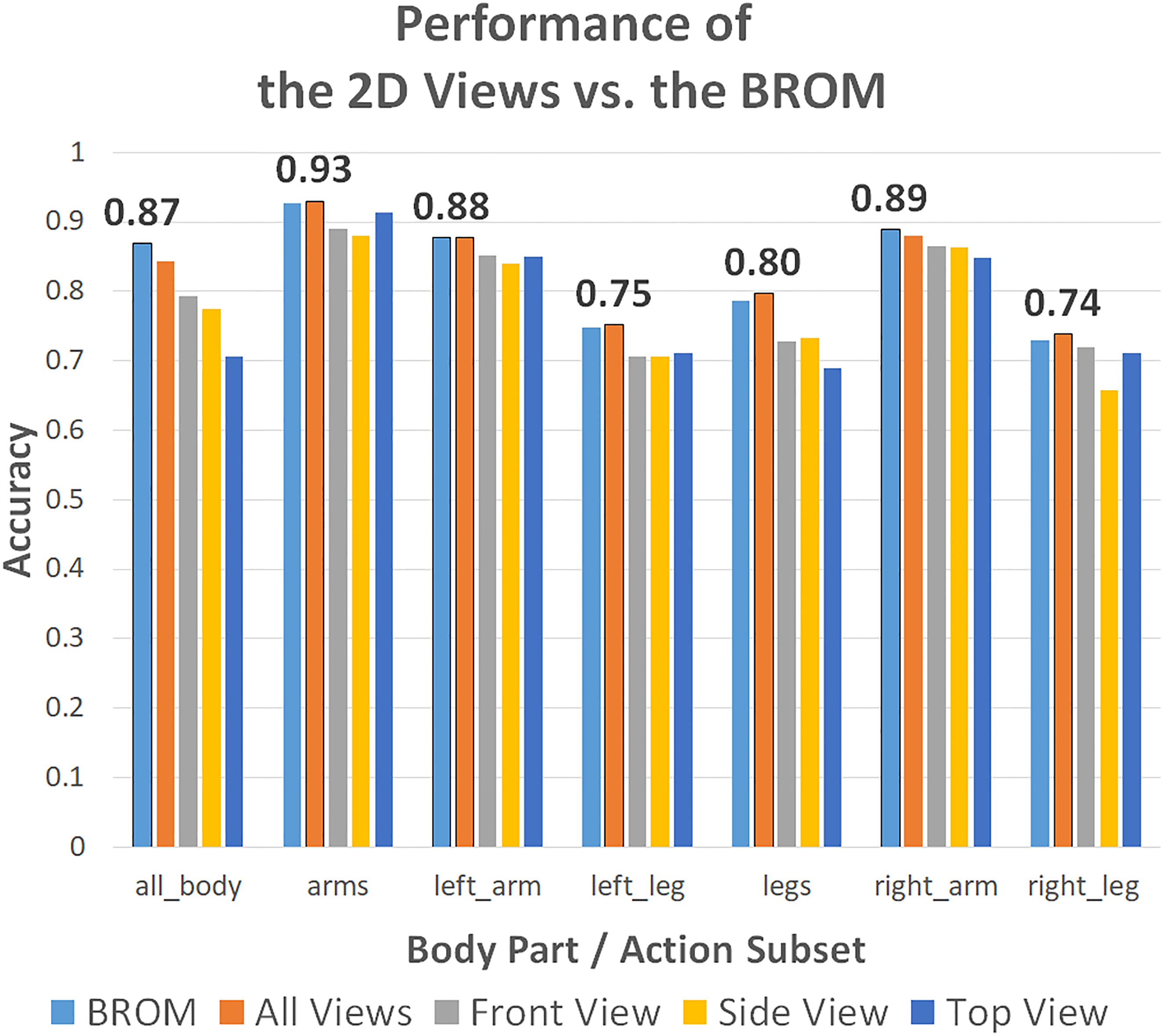
The accuracy score of the most optimal view and BROM classifiers are visualized in Fig. 8. Reducing the BROM to all its 2D views, slightly increases the performance of the classifier in most cases. The only exceptions are the classification for the whole body and for the right arm, where the accuracy is respectively 2.6% and 0.9% lower. Although the increase in accuracy is at most 1%, the great reduction in feature size means that the method is more efficient in training time as fewer estimators are necessary in the RF classifier. The training and classification time can be reduced to 11% of the original time. The necessary memory to store the feature vectors also reduces from
In this experiment, the HiBROM that was hinted at in previous experiments is explored. The hierarchy consists of two levels. In the first level, a classifier will predict an action subset. If this first level classifier works perfectly, then the performed action will be contained in the predicted action subset. Depending on the predicted action subset, the appropriate classifier for the next level is selected. The second level classifier will predict the correct action that is performed from the possible actions in the subset. In essence, a small cascade of two classifiers is used to boost the overall performance of the classification. The best performing classifiers from the previous experiments are used as building blocks for the HiBROM. The entire structure is presented in Fig. 9.
Flowchart of the HiBROM classification.
In the first hierarchy level, the subset of actions is selected by the RF classifier with the cylindrical BROMS of the entire body as feature input. The subset of actions, listed in Table 6, is derived from the confusion matrix of this classifier. Similar actions are collected in a subset.
The second level of the HiBROM has three possible classifiers. The classifier that is used on this level is determined by the outcome of the first level. Each subset of the actions is associated with a classifier (see Table 6). The possible classifiers are the RF for the arms, the RF for the legs and the probability vote of the two as the classifier for the body action subsets. The input features for the second level are the three spherical views of the arms and the legs. The output of this level is the prediction of the performed action. The prediction of the second level can only be an action from the action subset that was predicted by the first level of the hierarchy.
The performance of the HiBROM is dependent from the performance of each block in the hierarchy. 100% performance of the first level can always be achieved if every action is in every subset, but this would be detrimental to the performance of the classifiers in the second level and would make the first level obsolete. The action subsets should make the classification for the second level classifiers easier. For the HiBROM to be useful, the performance of the second level classifiers should be better than when they stand alone. The level 1 classifier that estimates the action subset has an accuracy of 99.99%. This means that 99.99% of the performed actions are an element of the predicted action subset. This high performance rate is credited to the optimal division of the total action set into action subsets. The classifiers in the second level show an accuracy of 93.3%, 86.4% and 91.4% for the arms, legs and body respectively. This means that the first level of the hierarchy increased the performance of the arms classifier by 0.3%, the performance of the legs classifier by 6.4% and the probability vote between arms and legs with 10.8%. The collaboration of the different classifiers results in an accuracy score of 90.5% for the HiBROM classifier, making it the best estimator for the entire action set of the data set.
Accuracy scores of the individual actions for the best classifiers of the different classification methods: cylindrical BROMS, probability vote of Cartesian arms and legs, Cartesian views and HiBROM
Accuracy score for the BROM classification of the dataset with adults and children with and without PIN in the construction of the BROMs
Table 7 compares the accuracy score for each action label between the different classification methods for the entire action set. Only four actions are better classified by another method than the HiBROM. The action “running” is more accurately labeled by the BROM classifier by a margin of 3%. The action “punch right” loses 5% in accuracy compared to the probability vote method. “Pushing forward” was the only action that was misclassified by the first level of the hierarchy resulting in the 99.99% instead of 100% accuracy of the first level. The only action that shows a significant loss in accuracy is the action “high kick left”. This action gains 12.5% in accuracy when it is classified by the Cartesian views.
Evaluation of the PIN
The PIN is an important step in the construction of the BROMs. This step insures that the action recognition can handle subjects with different body shapes and heights with the same classifier. To confirm the importance of the PIN, a mixed dataset of children and adults is classified with and without the PIN step in the construction of the BROMs.
For the demo of the exergame application, an additional dataset was recorded with children as the test subjects. The performed actions were reduced to a subset of the original actions, namely: “neutral”, “walking”, “bowing”, “big jump”, “climbing” and “flying big”. The dataset of the children is combined with the dataset of the adults for the six selected actions to create one dataset performed by five adults and 14 children ranging from age 8 to age 13. The subjects contribute a variety of body shapes and body sizes to the combined dataset.
The accuracy score is calculated for the BROM classification in every coordinate system for the entire body, the arms and the legs. The results are presented in Table 8 for classification with and without the PIN step in the BROM creation. The accuracy of the classifier is proven to diminish drastically when the PIN phase is skipped. The spherical BROM classifier suffers the most with a loss of 27% accuracy in the recognition of the six actions. The minimum difference in accuracy for the entire body is 12% if the PIN step is foregone. Even the classification for the arms, which was near perfect with PIN, suffers in performance.
Evaluation on a public dataset
To further evaluate the BROMs for human action recognition, the proposed approach is also tested on a public dataset against published state-of-the-art methods. The Cornell Activity Dataset (CAD-60) consists of 60 videos with tracked skeletons of four subjects (two males, two females, one left-handed) performing 12 activities in five different environments [28]. The tracked skeletons contain 15 joints which are characterized by 3D coordinates and a rotation matrix. Fourteen state-of-the-art action recognition methods were evaluated on this dataset and compared to the proposed approach [13-15,28-38].
The measures used to evaluate the performance of each action classifier are the recall and precision of the classification. The precision is the aptitude to evade labeling a negative sample as a positive, and the recall is the aptitude to find all the positive samples. The precision and recall can be consolidated into one validation score, the f1-score. This score represents the harmonic mean between the precision and the recall. The f1-score reaches its best possible value at 1 and its worst score at 0 [39].
Comparison of state-of-the-arts methods with the proposed methods on the CAD60 dataset [13-15,28-36].
An important consideration in the evaluation of the BROM and HiBROM on the CAD60 dataset is the presence of the left-handed subject. The BROM method is designed to be able to differentiate between actions performed with the left side of the body and actions performed with the right side of the body. However, this differentiation is not present in the CAD60 dataset where the actions are defined regardless of the dominant hand. This complication can be handled by either detecting left-handed persons and artificially making them right-handed by mirroring the skeletons, or it can be handled by making symmetrical BROMs for left and right side of the body. Another solution is by doubling every action with a mirrored version like in [15], essentially creating a right-handed and left-handed sample for every subject in the database. For the BROM algorithms, the option of detecting left-handed actions with a BROM for the arms and making them right-handed results in the best performance of the classifiers.
The performance of the BROM method and the hierarchic BROM method against the state-of-the-art methods is shown in Fig. 10. The methods are ordered from high performance to low performance. The best performing method is the previously mentioned algorithm of Shan and Akella [15] with a f1-score of 94.1%. The proposed BROM method ranks on the 8th place with an f1-score of 84%. The other proposed method, the HiBROM, ranks on the 6th place with a 88.3% f1-score.
Two other state-of-the-art methods were only evaluated for the accuracy score on the CAD60 dataset. The Sparse Coding method by Ni et al. [37] reached an accuracy of 65.3%. Wang et al. [38] achieved an accuracy score of 74.7% with their Actionlet classification method. Both methods were outdone by the proposed BROM approach which accomplished an accuracy of 83.6% on the same dataset. The hierarchic BROM classifier obtained a higher score of 87.2% accuracy.
Although several state-of-the-art methods perform better on this dataset, the proposed method is not without its advantages. The solution is not reliant on any temporal information nor the extraction of action key poses. The algorithm can also be run at real time. Moreover, the principle on which the proposed action recognition approach is based is unique and can thus be used as a complementary method. Finally, the BROM and HiBROM are proven to work for both children and adults with the same classification model.
In this paper a new method of human action classification was presented that describes how the area around the body is used during the performance of the action. Skeletal data is used as the initial input data and undergoes a PIN process to account for individual body differences between people and to make the method view-independent. The BROM is then constructed by forming a 3D grid around the body or body part and observing the relative occupation level of the grid cells during the action. The BROM provides input for a RF classifier that recognizes the performed action. The HiBROM combines different BROM classifiers into a hierarchic structure for improved action recognition.
The results of the experiments show that the BROM and HiBROM are capable to recognize a diverse set of complex and partly similar actions in real time. The PIN process was proven to be a critical part of the method and makes it possible to recognize actions performed by adults and children with the same classification model.
The introduced method has a comparable performance with publicly published state-of-the-art methods while having a strongly different outlook on human actions and without having the need for temporal information or key pose extraction. The HiBROMs can therefore be used as an effective and complimentary feature for human action classification.