
Abstract
In future resource constrained systems such as Industry 4.0 and Cyber-Physical Systems, thousands of resource constrained embedded devices communicate in order to reach a common objective. Information, then, is processed and transformed several times since it is acquired at physical level until it is received by user applications. Moreover, usually, each component in an current engineered system has almost no information about the other deployed modules. In that way, any malicious component may severely affect systems through the modification of operation data, as high-level applications can check the validity of received information in a hard way. Therefore, future technological components should only communicate with other trustworthy modules. Typically, solutions to address this problem are based on heavy technologies (such as certificates) which do not fulfil the requirements of embedded devices making up future systems. Thus, in this paper, a light computational solution to calculate the graph representing the trustworthy routes through which an application may obtain information is provided. Systems are represented as directed graphs, and untrustworthy branches are identified based on probability offered by a biparametric stochastic process (which is estimated by means an agent-based solution, consisting of a static and a mobile agent). Untrustworthy paths are also pruned following a hierarchical and scalable process. The proposed solution is based on the execution of some “elemental requests” whose response is known. Using the NS3 simulator, virtualization technologies and TAP bridges, the proposed algorithm is validated in a simulation scenario representing a real deployment.
Introduction
Recently, several different paradigms to support future digital and computational systems have been proposed. Among them, one of most popular proposals nowadays is Cyber-Physical Systems (CPS). CPS are integrations of computation and physical processes [1]. Contrary to other previous works about embedded devices, CPS are focused on communications. Thus, they are primary designed to be networked (usually making up big networks), working all the connected members for a common objective [1]. Around CPS many other definitions and technological paradigms have been reported, as (for example) “Industry 4.0”. Industry 4.0 [2], as defined during the 2014 Hannover Fair, is understood as the new industrial period when CPS, the Internet of Things (IoT) [3] and Next-generation Internet Services [4] are massively employed as supporting technologies for production systems and solutions. Although, as said, different technologies may be employed to deploy Industry 4.0 systems, CPS paradigm is the most employed one [5]. In particular several architectures and reports about the future challenges in this field have appeared [6].
Example of architecture for an Industry 4.0 system [66].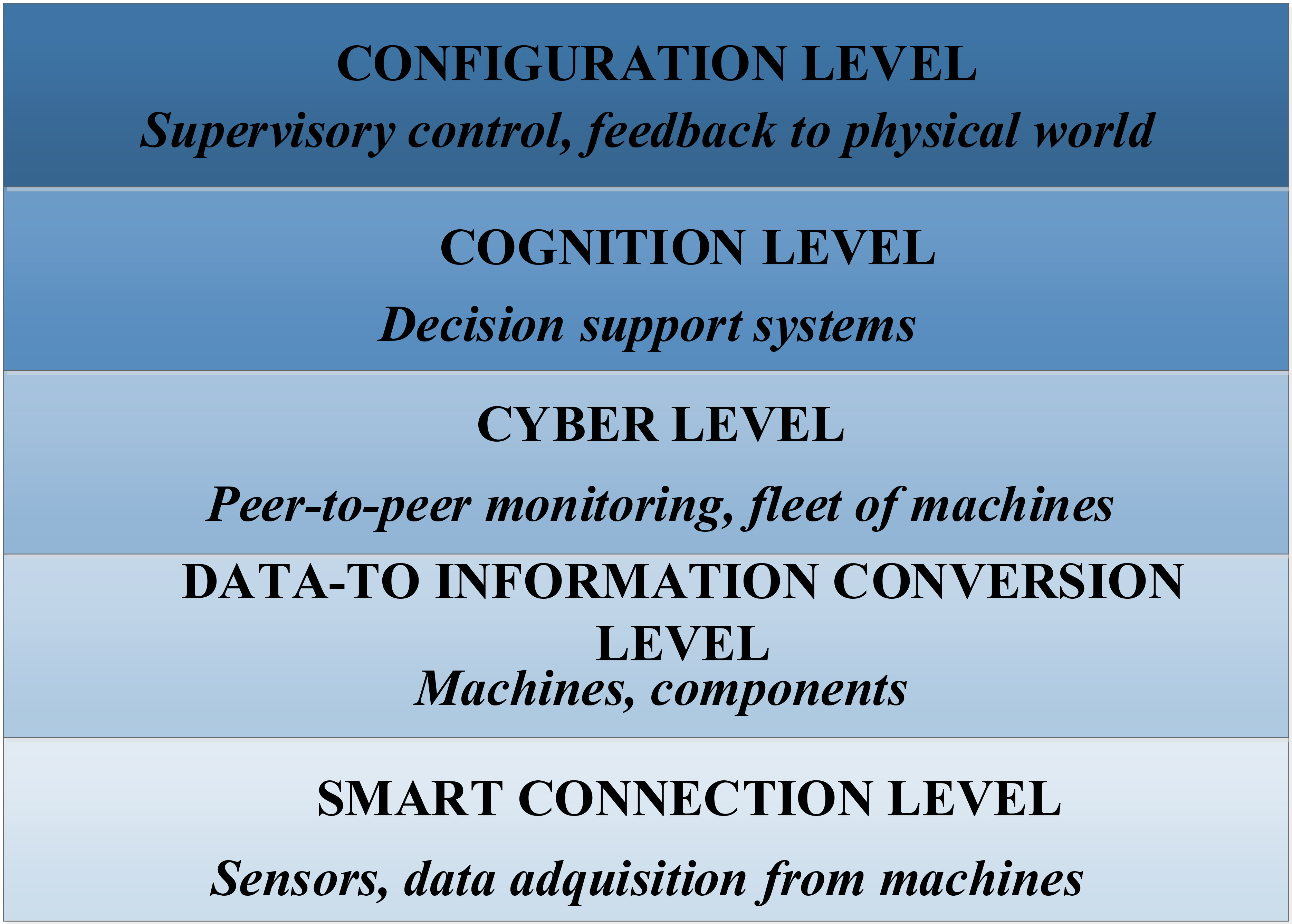
Any case, all these proposals present a very important and common characteristic. Both, CPS and Industry 4.0 systems are characterized by the complexity of the underlying networks, involving thousands of resource constrained devices and other components or modules (such as software applications, middleware, etc.). In a typical Industry 4.0 system (see Fig. 1) around five or six different abstraction layers are defined (following the proposed reference architecture for CPS by the National Institute of Standards and Technology [7]). These layers are isolated, and components belonging to each one of them have almost no information about the organization, modules and behavior of the other layers. Thus, important meta-information about the operation data and provided results is not accessible, especially, from the highest level, where user applications are hosted. Using this approach, different middleware may be deployed (such as those required to execute mobile agents) in an independent manner from heterogeneous hardware and embedded software components that usually made up platforms at low level.
In this context, systems are vulnerable to a new and more general type of attacks known as cyber-physical attacks [8].
These attacks are based on the strong dependencies among components in future technological systems, as well as on the great number of them composing the system, to perform malicious effects in a simple and “noiseless” way [9]. For example, as Industry 4.0 systems are usually employed to perform control policies [10], a secondary and/or small intermedium component in the system may be attacked to provide false information, so user applications operate and decide control actions based on false data. In that way, control loops may magnify the initial effect, and the entire system may fail starting from the infection of a non-relevant or critical module.
Therefore, as most recent technological systems (such as pervasive computing environments) are not centralized, each component (and especially user applications with full system access) should evaluate which components are trustworthy and can be considered to provide trustworthy information. Components only providing false data must be pruned and isolated [11], and modules with a variable behavior have to be requested to evaluate the received information before submitting it to next component.
However, traditionally, trust in technological systems is managed through computationally heavy technologies (in terms or memory and processing time, especially for resource constrained devices) such as certificates, which do not fulfill the special requirements of resource constrained embedded devices making up future engineered systems such as Industry 4.0 solutions (they present a reduced computational power, a limited communication range, etc.).
In that way, this work is motivated by the need of new, fast and lightweight security solutions to evaluate the components’ trustworthiness in Industry 4.0 systems. These new solutions must be adequate for resource constrained devices, which cannot store in a permanent manner (due to memory limitations) trust evaluation algorithms and their related data. Besides, these devices cannot maintain a complete understanding or model about the system where they are integrated, so new algorithms must be based on simplified models which allow a broad security analysis although they only partially represent the system. Finally, complex statistical methods are not admissible as a large processing time would be required; on the contrary, trust evaluations should consist of simple key performance indicators. Thus, the objective of this paper is to propose a new lightweight computational solution to fulfill this gap.
As a novelty, in our solution Industry 4.0 systems are represented as graphs, where only communication links and cyber-physical components are considered (other elements, such as configuration mechanism are not represented, for example). In that way, complex and large systems may be modeled in a lightweight manner. Then, using simple statistics about exchanged traffic among the different components, trust is evaluated in a fast manner. Besides, trust evaluation algorithms are not permanently stored in embedded devices, but executed through mobile agents, which reduces the resource consumption of this solution. In particular, the proposed solution represents resource constraint environments as directed graphs, which are analyzed in a hierarchical and scalable way using agent-based techniques. In order to do that an epidemic protocol based on a sequence of “elemental requests” is proposed. Depending on the obtained results, branches in the system may be pruned or filters can be installed. When the configuration process ends, each component has calculated a “trust circle” including the components which provide it with correct data. In order to simplify the mathematical notation and the discussion, proposal is particularized to Industry 4.0 systems, although it is applicable in an identical way to any other resource constrained environment or system (such as CPS, IoT, pervasive sensing platforms, etc.).
As main advantages, the proposed solution presents a shorter convergence time, as simple traffic statistics are calculated much faster than previous complex statistical methods. Besides, the resource consumption in resource constrained embedded devices is also low, as models based on graphs and pruning techniques are lightweight technologies. Moreover, mobile agents guarantee computational resources are only employed for a short time in an opportunistic manner.
The rest of the paper is organized as follows. Section 2 presents the state of the art on Industry 4.0 solutions, trust management, graph pruning techniques and agent-based solutions for CPS. Although Industry 4.0 are integrations of hardware and embedded software for industrial applications, in this paper we are focusing on system modeling and transformation, using the graph theory and its applications and related technologies (trust calculation, pruning techniques, etc.).
Section 3 describes the main computational contribution, including the mathematical formalization and the epidemic protocol. In this case, as said, the proposal is mainly based on system modeling through graph theory as initial step to perform calculations and transformations over the system using agent-based techniques.
Section 4 describes the performed experimental validation (based on simulations), and Section 5 presents the obtained results. Section 6 concludes the paper.
This section presents an overview of the related research in the two main fields treated in this work: trust management and graph pruning algorithms.
Industry 4.0 solutions
Technically, and Industry 4.0 system is an industrial system based on CPS, but considering some special characteristics [12].
First, system heterogeneity, complexity and dynamism are pretty lower than in standard CPS [12]. Although some of the main problems to be addressed in CPS is self-configuration [13] and modeling [14], Industry 4.0 solutions usually consider static CPS, where architecture and components are stable with time. In fact, the use of CPS in Industry 4.0 refers a system where information related to the physical shop floor and the virtual computational space are highly synchronized [15], without considering other relevant characteristics (very relevant in other application scenarios). Industrial systems tend to be more homogenous and statistic than other technological solutions, a requirement that is usually considered in firstly reported Industry 4.0 real deployments [16].
Second, CPS are understood as a platform similar to other paradigms such as Internet of Things (IoT) or Smart Factories [17]. Actually, Industry 4.0 systems are characterized to integrate next-generation digital solutions such as smart networking, new digital business models or flexibly production schemes [12]. In this context, any system addressing these problems is considered an Industry 4.0 solution, although it does not fulfill traditional characteristic of CPS.
And, finally, Industry 4.0 are resource constrained environments [18]. Standard CPS may be composed of powerful components, but Industry 4.0 only considers pervasive sensing resource constrained platforms, where sensor nodes are employed to obtain real time information about critical infrastructures and processes (enabling new and advanced control techniques and solutions).
These characteristics increase the risk of Industry 4.0 of suffering a cyber-attacks in comparison to standard CPS. First because they are applied to critical systems, second because components are resource constrained and cannot implement complex protection policies [19], third because architecture is static, and attacker could take profit of bottlenecks and other similar problems; and finally because they implement advanced technological solutions which may present unknown security problems.
Nowadays, only initial proposals about Industry 4.0 have been reported; mainly architectures and reports about pending challenges [18]. However, some real deployments may be also found, including process execution systems [20] and security solutions [21].
The proposed agent-based solution is primary designed for CPS supporting Industry 4.0 systems. Thus, some additional assumptions may be done (see above) in order to develop our proposal and design the validation methodology (static architecture, low heterogeneity level, etc.). However, the proposed technology could be also applied to other resource constrained systems, including standard CPS (although performance may be different than showed in this work).
Trust management
Trust management refers all technologies focused on selecting the conditions on which a component is able to interact with other components in the system [2]. Questions about trust decisions such as when an interaction may take place, or with who a component should interact are traditionally addressed in works about trust and multi-agent systems [23]. However, most Industry 4.0 systems are not multi-agent solutions, but intelligent sensing platforms. Thus, although we are using agents as an enabling technology, we cannot consider Industry 4.0 systems as multi-agent scenarios, as it is not guaranteed all elements to be able to make decisions in a flexible and autonomous manner.
Trust management is an interdisciplinary idea, which has been investigated in different areas: from the Internet-of-Things and Peer-to-Peer systems (P2P), to social and autonomic networks.
There is little work on trust management for IoT [24]. Moreover, most of these works are related to the “social IoT”, a concept which refers the idea that common objects may interact with other daily living things and create a social network as people do [25]. In this context, contributions about protection, security and intrusion detection using trust models are divided into two groups.
In the first group, articles deal with trust evaluation. In these papers, researchers try to determine the cyber and physical parameters which should influence trust among IoT components. Typically, direct and indirect observations are employed to extract the required information through some data analytics procedures [26]. Observations may be related to networks parameters (such as the packet loss rate) [27] or may be based on the social network theory [28]. However, taxonomies about uncertainties and trust [20], enhanced processing algorithms [30] and uncertainty models [31] have been also reported. In all these proposals, trust is continuously evaluated and, employing a specific threshold, it is determined whether components communicating with a certain module in the system are trustworthy or not [32].
Sometimes, trust is evaluated through reputation models and frameworks, defining this concept as fuzzy information distributed around all the system [32]. Concepts such as local and global reputation are then proposed [11].
These previous proposals are useful but require a high computation capacity in Industry 4.0 nodes to be executed. Complex statistical frameworks or large databases have to be maintained. Moreover, these works usually try to “infer” the trust a component deserves, so protection actions are not necessary supported by clear evidences.
In the second group of works, papers are focused on recommendation algorithms. In this case, trust is calculated from opinions publicly shared by components in the system [33]. Phenomena, such as the trust reduction when receiving opinions from distant components, are evaluated [34]. In these papers, trust (and distrust) propagation in simple graphs is formalized, defining ideas like the iterative propagation of trust [35].
Social and automatic networks present an intrinsic social behavior [36]. In these scenarios, the concept of trust graphs (graphs representing the trust relationships in a system) is proposed, and (considering the particular proposed definition for trust) some algebraic properties of trust are obtained and validated [36]. As in social networks, usually, nodes publicly share their opinion; trust is typically based on voting in these papers. As in the first group, these contributions try to detect untrustworthy nodes in the network (although it is not specified how the network is protected or reacts once the malicious node is located).
Different contributions in the context of sematic technologies have appeared in relation with trust. Specific data formats for opinion and trust calculation algorithms (similar to weigh calculation techniques in neural networks [37]) have appeared [38]. Moreover, different formats to represent reputation have been also reported in other fields [39].
Finally, in the field of P2P systems (and ad hoc networks), different types of trust are defined [40], which are employed to propose new ideas such as “trust witnesses”. In these proposals, opinion is usually composed of various parameters (such as trust and confidence) which made up an “opinion space” [41] where algebraic structures [42] (e.g. semirings) are defined. In this field, besides, the idea of “trust graph” as protection or security policy is connected with other techniques as certificate distribution [43] (i.e. trust implies delegation) or reputation-based sharing platforms [44].
All the cited proposals, nevertheless, only aim to evaluate the trustworthiness of nodes (components in the Industry 4.0 system), keeping the same system architecture regardless of the obtained results. In that way, trust graphs are understood as graphs which include information about trust (but which preserves the original topology of the system and presents the same behavior). On the contrary, in our proposal, trust information is employed to dynamically modify the system topology, so during operation no more calculations are required (and resources may be used in a more efficient way). In order to reduce the global system graph to the trust graph, malicious components are pruned using the most appropriate technique. Pruned elements may be included another time in the system if their untrustworthy behavior changes.
Pruning techniques
Pruning techniques refers those algorithms and solutions focused on detecting and removing branches or nodes (components) in graphs, neural networks, workflows, etc. fulfilling certain conditions [45].
Different graph pruning techniques have been reported in the research literature.
A first type of proposals consists of removing a node without losing connectivity in the graph, by creating direct connections between the points previously connected through the removed node [46]. This approach is usually named as “creation of a dense graph”.
Other proposals consider different characteristics in the nodes (such as if they are dominant) to prune graphs following certain rules (for example, both created sub-graphs must include a dominant node) [47].
A particular case of pruning techniques is which are applied to decision graphs. In this case, when a node is removed, all its successors are also deleted. This technique is usually employed to simplify the decision-making process [48], as the resulting graph may be severely reduced compared to the original [49].
Other type of pruning techniques is focused on removing loops in graphs [50]. This technique, contrary to the previously cited ones, does not remove any node but connections among them.
With the same idea, other proposals have been reported, for example, calculating pruning actions by means of a forward-backward algorithm [51].
Pruning techniques based on graph simplifi- cation [40] are unhelpful in relation to Industry 4.0 systems, as with this approach large parts of the system may be get isolated and useless. Thus, with the proposed technique, vertices are not removed and only edges associated with the component under study may be affected. Solutions focused on removing loops are inapplicable, as it is not the focus of the article (in fact, in this work graphs with cycles are considered and admitted). Finally, in Industry 4.0 systems, components cannot be removed by a peer (another module), as this task is reserved to the system administrator. Then, the proposed technology should be focused on pruning graphs by removing edges instead of nodes. The proposed algorithm employed to select the edges to be pruned is explained in the next section.
Mobile agents and CPS
Agent-based solutions (especially when employing mobile agents) are a very well-known technology. For more than thirty years, different mechanisms and techniques have been reported [52]. This interest for mobile agents is still alive nowadays, and agent-based solutions for new paradigms such as Cyber-Physical Systems and Internet of Things (IoT) are constantly reported [32, 53].
Agent-based solutions for CPS cover a large catalogue of applications: from smart object implementation [54] to human-computer interaction models [55]. However, most common agent-based proposals for CPS are related to security issues [32, 56]. Actually, some important authors have evaluated how mobile agents break some traditional assumptions in computer sciences, opening new security issues which prevents the use of this technology in CPS and IoT [57].
On the other hand, CPS are very heterogeneous systems, a characteristic that may also prevent the integration of agents into CPS [58]. However, techniques to overcome the CPS heterogeneity and apply agents and other similar software technologies to CPS have been reported in the last years [59, 60]. In order to guarantee the feasibility of the proposed solution, the described technology in this paper should be combined with any of the existing mechanism to implement mobile agents on heterogeneous CPS.
Focused on the topic of this paper, different security solutions for CPS employing mobile agents may be found. Recent proposals addressing this topic include cyber-protection assurance through secure agent implementations (including, for example, a Public Key Infrastructure) [61]. However, most of these solutions employ agents to collect information about the system and make a decision about its operation in a previously defined bifurcation point [62]. Other solutions consider security point injection in workflows, which are managed by mobile agents, or intrusion detection mechanisms [5]. These proposals support the usability of mobile agents in the context of CPS for security applications; but proposed solutions are, nowadays, still very heavy and computationally costly. Moreover, they are focused on very particular scenarios, so more general and lightweight solutions are needed.
In the proposed solution, to create a lightweight mechanism, mobile agents do not collect raw data to be later processed but obtain simple traffic statistics which may be represented using small data structures. Thus, mobile agents are smaller and consume fewer communication and computational resources. Besides, generic parameters are studied, so the proposed technique is adequate for any CPS application scenario.
Trust graph calculation
In this Section a mathematical formalization of the proposed contribution is provided. Resource constrained environments (particularized into Industry 4.0 systems) are represented as directed graphs, which are pruned to obtain the trust graph of each component. Data structures and protocols employed to support the proposed algorithm are also described.
Previous works [11] described a simplified calculation process where only systems with one-to-one correspondences between hardware devices and user applications were allowed. In this paper we extend these previous proposals considering arbitrary systems.
Among all questions to be answered as part of the “trust” problem in technological systems, in this work we are dealing with the challenge: which components in the system should a certain element interact with?
Fundamentals of the mathematical modeling
An Industry 4.0 system
and
Both sets
Finally,
In that way, an Industry 4.0 system may be understood as a directed or oriented graph
The graph
In order to clarify this point, Fig. 2 shows a graphic representation of both functions. As can be seen, these functions allow transforming a technological system into a graph and vice versa, so (hereinafter) we are using indistinctly both notions.
Correspondence between mathematical graph and Industry 4.0 system.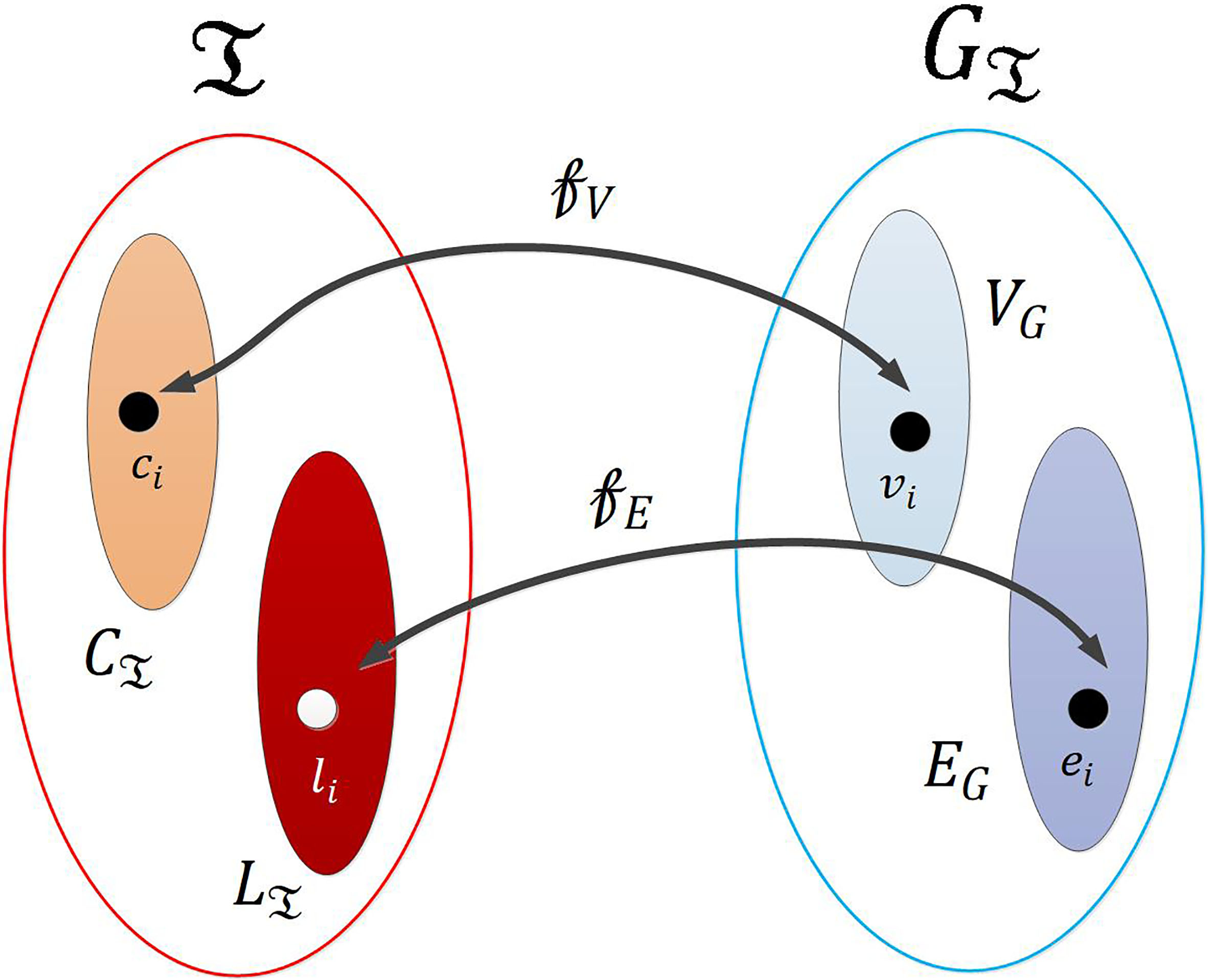
Moreover, vertices and edges in the
tier is an integer number indicating the abstraction layer to which the component (vertex) belongs. Usually, such as in the OSI reference model, layers closer to the physical layer (hardware devices) present lower numbers than layers closer to final applications (users).
On the other hand, edges are also characterized by two different parameters
trust represents a number indicating the trustworthiness of the messages being transmitted through the link. In general, this value is calculated by the source vertex. If desired, this value may be understood as a weight of the communication link. In that case
Figure 3 shows a graph representing a simple Industry 4.0 system.
In a generic case, thousands of components and communication links make up a resource constrained environment – or Industry 4.0 system – (and, thus, the same number of vertices and edges composes the equivalent graph). It is not strange if some of these components or links (due to different reasons such as interferences, cyber-attacks, etc.) behave in an untrustworthy way. The objective of every module in the system, then, should be to avoid as much as possible relating or employing these components or links.
Example of a graph representing an Industry 4.0 system.
In this context it is defined the absolute trust graph
The final objective for the component
The trust circle
Example of a graph with the proposed definitions for trust management.
With these ideas, each component should be able to calculate its own trust circle (as it has information about the adjacent nodes), and a mechanism by which this calculation also causes the obtaining of the trust graph must be defined (using, probable, a distributed procedure).
In all cases, however, the proposed “absolute definitions” are very restrictive; as components and communication links generally show different behaviors when different operations are performed. Thus, in order to maximize the use of the available resources in the system, components may employ a relative definition on the proposed concepts.
In that way, the relative trust graph
The relative trust circle is defined in a similar way.
From the computational point of view, the calculation algorithms, the obtained absolute trust graph and the relative trust graphs depend all in the same way on the number of elements (components and links) in the system. Thus, they present the same complexity order in respect to the system topology and size (and, then, the same scalability properties, bottlenecks, etc.). Later, these dependencies will be discussed. However, if relative definitions are employed, the calculation process depends also on the number of available operations. In fact, computationally, there is no difference between calculating the absolute trust graph or any of the possible relative trust graphs, only the employed protocols or data format may change. Thus, the manner of obtaining all the possible relative trust graphs is to repeat the calculation for every available operation. In that way, the corresponding algorithm depends linearly on the number of available operations. This situation should be considered when estimating the refreshing period or the required computational time to perform the calculations.
Hereinafter we are describing a trust graph calculation process, which may be applied to obtain the global graph or any relative graph.
Being
In its basic form, the adjacent matrix
Then, to calculate the number of paths between two vertexes
Equally, the number of paths that connect vertex
Thus, the number of paths
However, Industry 4.0 systems are characterized by presenting a lot of redundancies. Thus, a direct communication between particular low-level components and user applications is rather rare. Usually, connections are stablished with an entire platform containing several devices with similar functions. These platforms belong to a unique abstraction layer, so all devices (vertices) with similar functions present the same value for tier parameter. Considering that
Formally, the probability of a path
This approach, nevertheless, implies vertex
Let
Thus, in this work, it is said a vertex
In order to evaluate the trustworthiness of a path, whose elements (edges and vertices) are unknown, components are provided with the infrastructure that is shown in Fig. 5.
Each node maintains a Trust repository (TR) where trust information about the adjacent vertex and links is stored. In particular, the trust circle
Information in the TR is generated and updated by a Trust Agency (TA). The TA represents a multi-agent system, including two different types of agents. Among its functions, TA must control the generation, behavior, temporization, design, composition, etc. of agents (but is not an agent). Basically, it orchestrates the agents’ operation. This component is unique, contrary to agents that are diverse, and isolates the agent coordination from details about trust graph calculation encapsulated into agents (specifically, into MaA).
Trust calculation platform.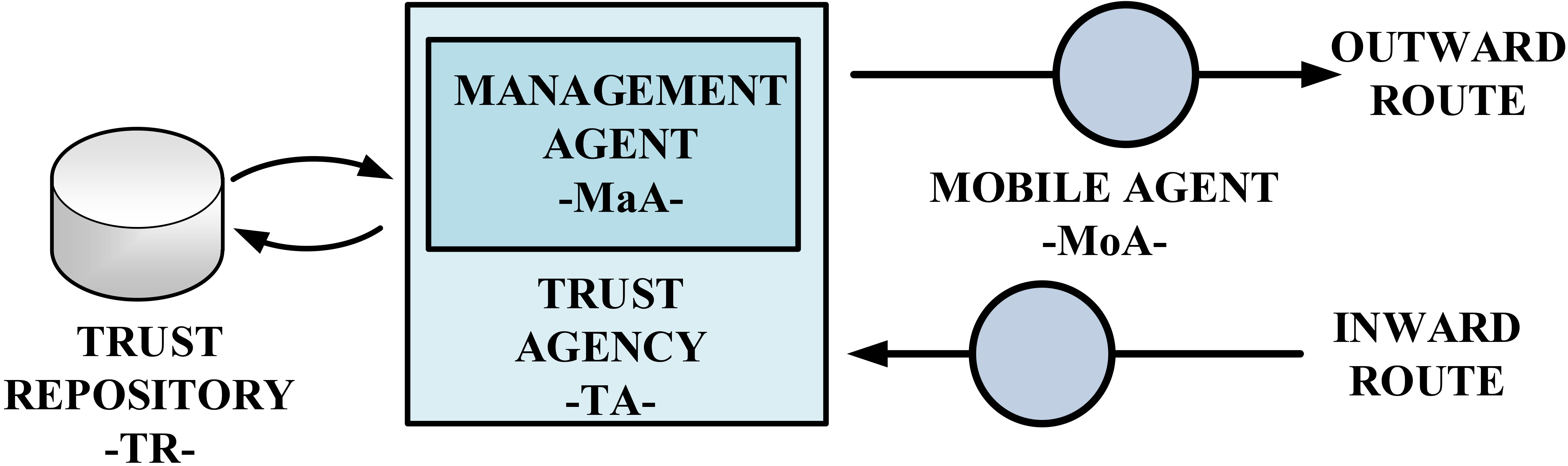
The management agent (MaA) is a static agent which controls the trust calculation process. It gets activated each time trust graphs have to be calculated or refreshed. Basically, it constructs the ephemeral data structures necessary to perform the calculation, activates the Mobile Agents (MoA) to visit the target vertices and computes the trust graph based on the behavior of the different paths when performing some simple operations named as “elemental requests”. These elemental requests are regular operation requests which have to be answered following a pre-programmed pattern. If received responses do not fit these patterns, the vertices through which messages are sent and/or received are suspected to be untrustworthy (see Section 3.3).
The use of mobile agents presents, in this context, three important advantages.
First, the use of mobile agents enables a fast a lightweight trust evaluation, as resource constrained nodes only must store and execute the proposed algorithm (which is also simple and computationally low cost) in an ephemeral and opportunistic manner. In that way, we are meeting the most important requirement and characteristic of Industry 4.0 systems (see Section 2).
Second, univocal vertex identification is enabled. In message passing solutions, nodes are usually identified by global communication identifiers which are location-dependent and ephemeral (such as IP addresses). Thus, any component moving around the system may appear with different identifiers at different moments which makes difficult to evaluate its trustworthiness in an efficient manner. Contrary to this approach, mobile agents may access to unique identifiers stored in components in a very easy manner. These identifiers do not change with the component location, and trustworthiness is then evaluated in a much more efficient way, even when components get in and get out the system dynamically.
Third, and finally, system scalability is enhanced. As trust evaluation is orchestrated by the TA, traffic engineering policies and other similar solutions to avoid network congestion synchronizing the operation of all components in the systems may be applied. On the contrary, traditional asynchronous message-passing solutions cause a traffic flood generating the system congestion when the number of interconnected components goes up.
Two additional considerations have to be taken into account.
First, in order to respond to the elemental requests (ERQ) with the previewed patterns, programming into components in the Industry 4.0 system should be modified. In order to avoid this problem, the TA also includes some MoA which visit the components of the system and respond to the ERQ with the pre-programmed patterns. These agents are triggered by the MaA, and also collect information about the transmission and execution process in order to improve the trust graph calculation. Agents are routed by the system following the standard routing rules, and get hosted in the vertices fulfilling a certain requirement (e.g. belonging a certain abstraction layer). If necessary, MoA can be replicated during routing to reach multiple destinations.
And, secondly, it has to be considered that absolute results are almost impossible to obtain. In that way, a trustworthy component will never return 100% of correct responses, random errors also occur and they do not have to affect the trustworthiness of nodes. In that way, two thresholds are defined
Although traditional expert-created weights could also be employed, some important differences with probabilities must be considered. First, probabilities represent a real, dynamic and measurement-supported estimation; while expert-created weights tend to be fixed and based on previous experiences whose applicability may be limited. Thus, efficiency of traffic engineering techniques is improved when probabilities are employed as weight. And, second, probabilities have a direct physical meaning, while weights may present different consequences. That makes easier the configuration of probability-based solutions than expert-created weights mechanism. Furthermore, as probabilities may be calculated in a systematic and automatic manner, human intervention may be totally removed (which is not possible when using expert-created weights).
On the other hand, a final risk must be discussed. While traveling through the graph, agents could be infected, duplicated or (in general) turned into malicious objects. In that way, cybercriminals could introduce confusion in the system. Then, a solution to protect agents would be required. However, different characteristics make this risk almost negligible, and no additional mechanism to protect agents is actually needed. Namely:
Contrary to cyber-physical components, that are persistent elements in the system architecture, proposed agents are ephemeral objects with a very short lifetime. Thus, infected or duplicated agents cannot operate indefinitely, and their temporal impact is very limited.
Besides, agents may be provided with a (light- weight) digital signature to guarantee the integrity and authenticity of ERQ and patterns. Moreover, as agents are ephemeral objects, this signature does not have to be very complex, and proposed solution may be still supported by resource constrained devices.
Considering all the previous descriptions, the trust graph calculation process is as follows.
First, the MaA of
The mobile agent is transmitted by means of an epidemic protocol through the system: each component receiving the agent transmits it to all its neighbors. Moreover, each mobile agent is marked with a unique sequence number (and, of course, the code to be executed). In order to avoid duplicated transmissions, a vertex only transmits agents with new sequence numbers (in other cases transmission is discarded).
Once the MoA arrives to a vertex fulfilling the requirements described in the dst filed, it gets installed.
At the same time, MaA triggers a timer. When time is over it generates a collection of elemental requests
Each elemental request describes the source vertex (the vertex through which the root vertex
Double entry table constructed by MaA
Double entry table constructed by MaA
When an ERQ is received by a MoA (hosted in a vertex belonging to the n-th tier) it responds following a pre-defined pattern. For example, if MoA is visiting a temperature sensor, it generates an answer (known as “elemental answer”, EA) containing a preset value instead of the real temperature which is unknown by upper components. The EA also includes the original ERQ.
The EA are sent to the root vertex
When the root vertex receives the EA, it completes the information with the target vertex information (the vertex through which the root vertex
When
The resulting double entry table, then, may be understood as a biparametric stochastic process
Then, each realization
As percentages in the same row or column are already calculated considering the same denominator (the number of performed ERQ), it is guaranteed the global probability add up to the unit. Thus, all incoming edges (on the one hand), and all outcoming edges (on the other hand) have associated probabilities meeting the basic probabilistic theory assumption (probabilities of all considered events add up to the unit). Edges in the global trust graph are not required to fulfill any requirement a priori, as they are (in the general case) independent components.
The obtained information (as it only describes the beginning and end of every path), it is not enough to obtain directly the trust graph. Nevertheless, as said in Section 3.2, the first step in the trust graph calculation process is to obtain the trust circle of
Considering an epidemic protocol transmits in all directions with the same probability, every sample in the sample mean is weighted by the same coefficient.
Computation of these values is a very easy and fast procedure, so sources are much better used than in traditional statistical frameworks for trust management. It must be noted (besides) that, in all this calculation process, the trustworthiness of a link is considered together the trustworthiness of the target vertex of that link.
Once the probability of being trustworthy is calculated for every adjacent vertex to the component under study, various possibilities appear. First, if the probability to be trustworthy of a vertex is above the threshold
In order to remove untrustworthy paths, the initial and/or final vertices have to be pruned. In Industry 4.0 systems, components cannot remove any peer, as these privileges are reserved to the system administrator. In that way, pruning algorithm only removes the edge that connects the root vertex
For any other value
Once requested nodes have finished the calculation process (following the same described procedure), they notify the root vertex this event with an acknowledgement message (ACK). This ACK has to indicate also if some paths have been pruned or no changes have been performed. In the first case, the probability to be trustworthy of the affected vertices is refreshed following the same procedure described above. If obtained probabilities are unclear another time, these values are considered, anyway, as the final results of the calculation process. In the second case no more actions are performed.
In any case, probabilities and trust graph and trust circle are refreshed periodically, in a continuous actualization process. The first time this process is triggered is after all ACK are received, and all untrustworthy paths pruned. From this point, the procedure is repeated periodically.
With the obtained results, the intermediate values are employed as weights to perform traffic engineering in the system and/or to include annotations (using, for example, Semantic Annotations) about the trustworthiness of the received messages.
The use of epidemic protocols makes the proposed technology very scalable, as the system get “flooded” in a fast way. However, depending on the system topology (more than on the number of components in the system), if several paths start/end in the same vertex and an untrustworthy component is located very deeply in the system, the calculation process may imply several steps and require more processing time than expected.
In order to illustrate the behavior of the proposed algorithm, in this section we perform and provide some relevant simulations.
Simulations were performed using the (commercial) NS3 simulator, which implemented a platform based on TAP bridges and virtualization. The proposed platform turns independent the application layer and the network layer. The network layer is supported by NS3 simulator, where different libraries describing gossip protocols, mobile communications, wireless links, etc. are available. On the other hand, application layer is based on Linux paravirtualization, as native C programming is the most adequate to implement.
In particular, NS3 scenarios recreate very similar conditions to real networks, and using the described platform, nodes in these simulation scenarios may exchange data and implement applications as real hosts do.
The simulation scenarios are supported by TAP bridges, which connect virtual Linux machines generated using LXC technologies and the Libvirt library with the NS3 simulator, and ghost nodes, the virtual entity that represent the virtual machine in the network simulator. All parameters are provided using a configuration script, where nodes, network interfaces, connections and applications are described. Although this approach is more complex than the configuration of regular NS3 simulations, it is a more flexible design. TAP bridges are configured as “ConfigureLocal”. In that way, TAP bridges are generated in a row, inheriting the configuration properties one from the other. In order to orchestrate in the most efficient way the different parallel processes that require this type of simulations, a desktop application was created (see Fig. 6).
Graphic management application.
The employed simulation scenario consisted of an Industry 4.0 system composed of 250 components, distributed as follows:
Physical layer (175 devices). It includes 100 smart transducers (temperature sensors and buzzers) based on Atmel microprocessors. Moreover, 70 Programmable Logic Controller (PLC) supported by Samsumg Artik devices are simulated. Finally, 5 robotic arms are simulated. Control and data analytics (75 components). Twenty-five network devices among routers, bridges and hubs were considered. Besides 50 different middleware were also included (most of them focused on data translation). User applications [25]. Finally, 25 user applications obtaining information from physical platform and representing it on a graphic interface are simulated.
Although, in a real scenario, components would present heterogenous characteristics. This situation is a pending challenge which is not addressed in this paper. In order to evaluate the performance of the proposed solution, all components are provided with a mobile agent framework: Mobile-C [67]. Agents are described using XML documents containing the proposed algorithms in C code. In a real application, the described solution should be combined with other software engineering mechanisms to enable the implementation of mobile agents on heterogeneous CPS [60].
Two different scenarios were created with these devices, each one with a different system topology: (1) total connectivity and (2) branched graph.
In the described scenarios, the proposed algorithm for trust graph calculation was implemented and deployed. In particular, user applications were programmed to include this solution and perform calculations.
The total simulated time was two days (48 hours), for which a 15 hours simulation was required. Each simulation was repeated five times in order to compensate the possible random effects.
At
The numeric values assigned to the parameters described in the proposed technology are included in Table 2. Values are only illustrative, and they are not optimized or specifically designed for any particular situation. These two values may be modified in an independent manner, as they are two non-related variables. Although both parameters may be fixed as desired, in order to maximize the success rate, it is advisable to study the application scenario before selecting values. However, some important general remarks should be done.
In extremely secure or trustworthy scenarios,
However, when no information about the scenario is available, all possibilities should be considered to have the same probability, and
Numeric values of the solution parameters
Simulations are employed to perform four experiments.
In the first experiment, we evaluate the convergence time of the proposed solution and the correctness of the calculated trust graphs.
In the second experiment, obtained results from the proposed solution are compared to results obtained from state-of-the-art proposals. In particular, although no similar solution has been reported, other techniques with similar purposes may be found. In this case we have selected one of the most popular proposals: reputation and trust models [26, 27]. This approach employs direct and indirect observations to evaluate if cyber-physical components are malicious and, then, isolate them.
In the third experiment, the solution performance is evaluated in a dynamic Industry 4.0 system (where components get in and out of the system) and compared to an equivalent traditional message-passing solution. Basically, the mean convergence time is evaluated. Components may appear at any available location (logical or physical) randomly. Different behavioral patterns are considered. In particular, the probability for a component to leave or enter the system follows a gaussian distribution with time, whose mean value (or average stay time) is varied in each experiment realization.
Finally, in the fourth experiment, the global system overload caused by trust calculation and graph pruning is measured.
In respect to the first experiment, Fig. 7 shows the evolution in the use of the untrustworthy paths. As can be seen, the use rate of the untrustworthy paths follows, for both system topologies, a sigmoid-like evolution.
Use of the untrustworthy paths.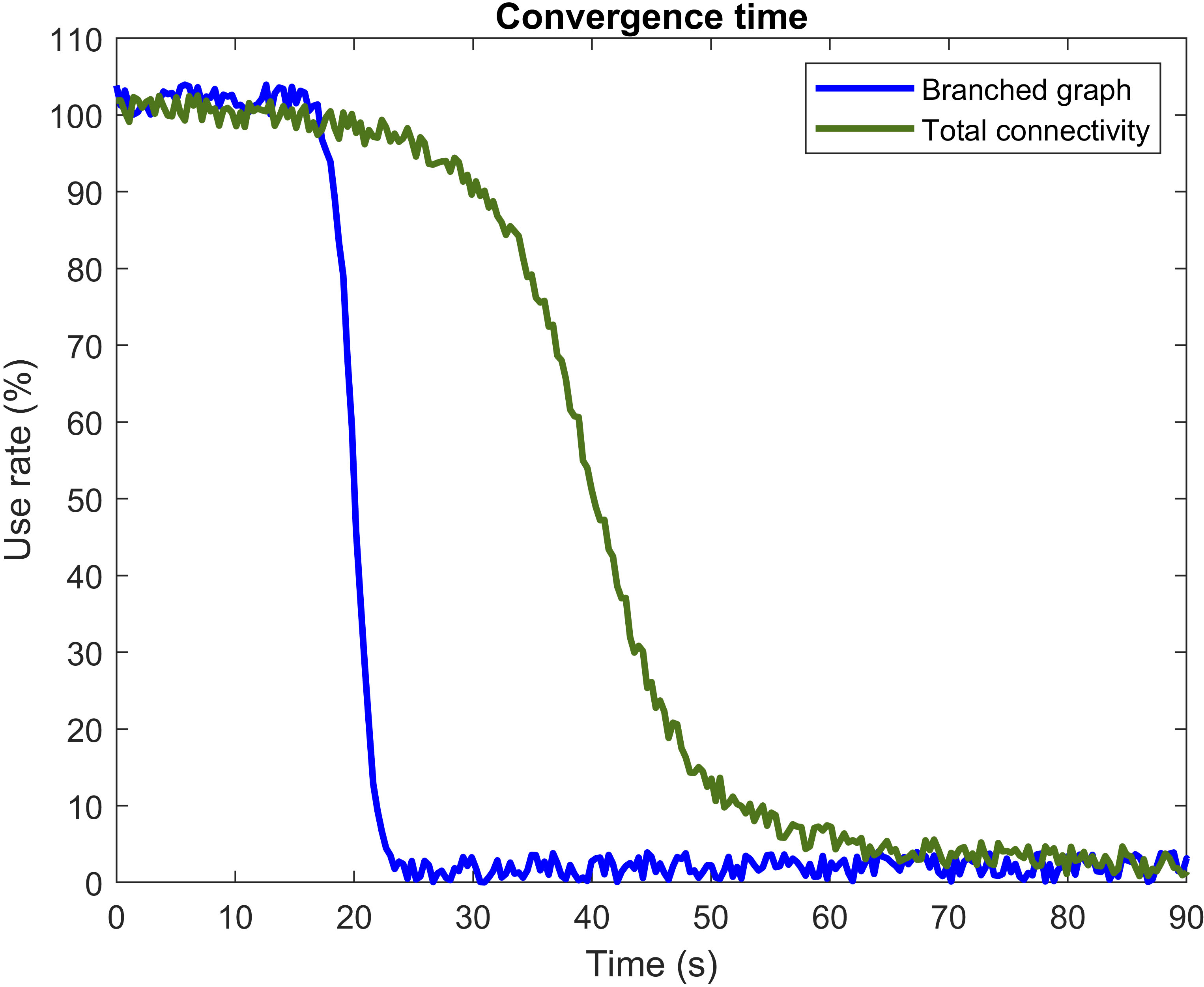
If a branched graph topology is considered, only twenty [20] seconds are required to isolate (almost totally) the untrustworthy paths. However, as the number of edges and links goes up, more time is required to traverse all possible paths, and more calculation time is needed to obtain the final trust graph. In that way, as can be seen, around sixty [60] seconds are necessary to locate all the untrustworthy paths in a system with total connectivity. Although this period may be too high for traditional Internet scenarios, Industry 4.0 applications inherit some special characteristics from current industrial systems. In particular, broadband communications are not usually deployed and components tend to exchange few messages (as production tasks usually take some time to finish). Thus, the potential impact of untrustworthy behaviors goes up much more slowly than in traditional Internet scenarios.
It must be noted that, once equilibrium is reached it is stable. Small variations of the curves are due to the statistical (stochastic) nature of the proposed technology.
Results in Fig. 8 shows the success rate in locating and pruning the untrustworthy paths depending on the system topology and the type of untrustworthiness considered.
Success rate.
As can be seen, in general systems with a branched topology allow a higher success rate. In these graphs, in fact, traversing all possible paths is easier, as it is possible to define an ordered way to analyze the topology. Any case, in all cases success rate is above 80%. As can be seen, this difference is obvious for initial and random trustworthiness, but smaller for cyber-attacks. Any case, all values are enough high to consider the proposed solution a successful technique.
Initial untrustworthiness is detected in a more successful way, and untrustworthiness appearing in a random way are the most difficult to locate. Cyber-attacks, as they are usually pretty “noisy”, they are detected and untrustworthy paths pruned in a more successful manner.
It is also important to remark that the proposed technique is applicable to both scenarios (branched graph and total connectivity graph), so Fig. 8 does not represent a comparison to show the obtained improvement. Below we are doing this analysis.
Once presented results from first experiment, we are discussing results from the second experiment. Figure 9 shows a comparison between results obtained from our proposal, and existing solutions’ performance [27, 63]. It is important to remark that both approaches are not equivalent, as application scenarios are not exactly the same, but this initial comparison may be employed to obtain first evidence about the obtained improvements.
Use of the untrustworthy paths (comparison to the state of the art).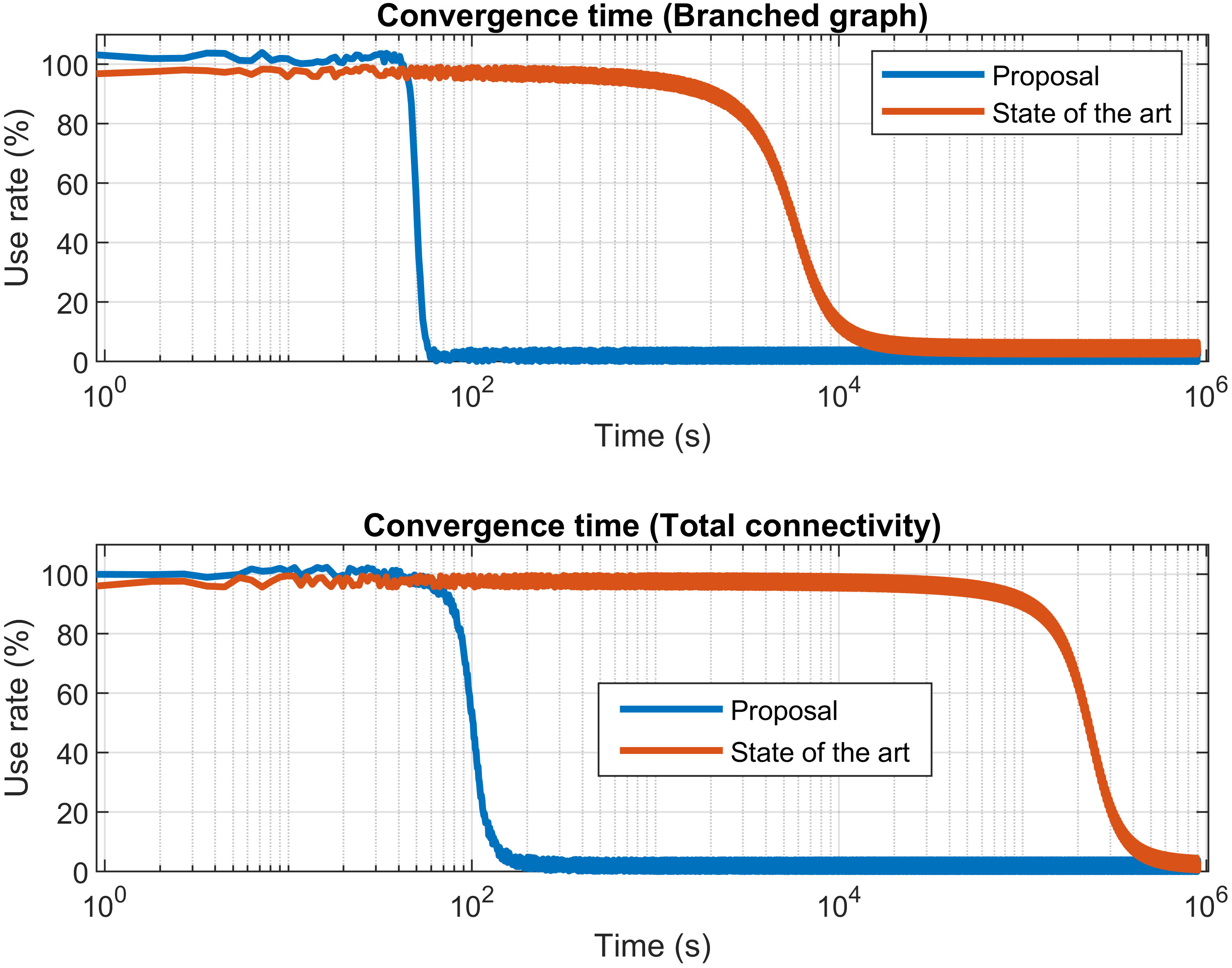
In order to show results in the most adequate manner, X-axis is represented in logarithmic form. Using this method, differences between the proposed solution and existing technologies are clearly shown, but comparisons between results for the different scenarios are hard to be analyzed. Considering this fact, some relevant initial conclusions may be done. First, the proposed solution is up to three magnitude orders faster than existing technologies [27] based on reputation and trust models. The main cause for this improvement is the different and new approach to evaluate the path trustworthiness. While in trust and reputation models [63] observations are passively collected during system operation, in the proposed mechanism a proactive evaluation procedure is considered. Thus, previous proposals [63] require a lot of time (up to fifty hours, depending on the number of carried out transactions among components per time unit) to collect enough information to make a decision and prune untrustworthy paths. On the contrary, proposed mechanism performs an exhaustive proactive evaluation procedure which detects malicious components and paths in few minutes.
And, second, the scalability of the proposed technique is much better than existing message-passing approaches. In fact, as can be seen in Fig. 9, when a branched graph increases its interconnections and turns into a total connectivity graph, previous mechanisms increment the required time to locale all malicious components and untrustworthy paths in two magnitude orders. Nevertheless, the proposed solution only duplicates that time. Therefore, using the proposed solution, the scalability curve has transformed from an exponential function to a linear law.
Previous experiment compares the proposed solution to existing trust evaluation technologies. On the contrary, third experiment compares the proposed agent-based solution to the equivalent message-passing algorithm. Besides, in this case, a more realistic scenario is considered, where components leave and enter the system dynamically. Figure 10 shows the obtained results for this experiment.
Convergence time (comparison to message-passing algorithm).
As can be seen, both solutions (agent-based and message-passing) have a pretty similar behavior when components remain in the same position for a long period (long enough to evaluate trust completely). In that case, both algorithms behave similar, and convergence time is around values showed in Fig. 7. However, this situation totally changes when components leave and enter dynamically the system. In that case, the use of agents is a key feature for a fast and efficient trust evaluation.
In fact, as ERQ do not include any information about the node identity, in the equivalent message-passing algorithm, identifiers from the communication subsystem must be employed. These identifiers are ephemeral, and trust is not correctly evaluated until each component remains enough time in one specific location. This requirement is more costly as components change their location more frequently, as can be seen in Fig. 10. Convergence time for the message-passing algorithm is up to two magnitude orders higher. On the contrary, agents are hosted by the component (vertex) under study, so it may be univocally recognized using serial numbers or other similar information which is globally unique. In that way, even if components change their location, mobile agents recognize the components; and convergence time is independent from the location and only depends on the time the components remain connected to the system. Any case, when components are moving around the system, convergence time increases around 400% (although the specific amount depends on the behavior pattern of components).
Finally, results from the fourth experiment are analyzed to prove the proposed solution is lightweight. Two different indicators are measured to evaluate the overload in the system due to trust calculation: memory usage and consumed processing time. Table 3 shows the obtained measures.
Resource consumption
As can be seen, in all cases, the overload is higher during the initial calculation than during the (continuous) actualization processes. Any case, the mean aggregated overload is lower than 10% (around 9%). This value goes down to 5% (a reduction around 50%) during the continuous actualization process. In respect to memory usage, the overload is around 10%, although it may reach up to 12% for total connectivity graphs during the initial calculation. These values are a little bit higher for processing time, appearing an overload around 16% for total connectivity graphs during the initial calculation.
These values, for small resource constrained devices, show that the proposed technology is lightweight, as said before. In fact, previously reported lightweight security (encryption) techniques are proved to consume similar amounts of resources (an overload around 10%) [64]. Besides, other similar solutions (based on trust and reputation models) [63] are explicitly said to be implemented in powerful software components, as algorithms are complex and costly.
Actually, if common simple data gathering programs and algorithms are considered in sensor nodes, the generated overload by our solution is almost negligible in absolute vales. However, if complex algorithms and costly software is being already executed, this overload could be excessive; but this situation is inevitable for any proposed security solution.
In this work, a trust management technology to protect resource constrained systems against malicious components is proposed.
A mathematical formalization describing engineered resource constrained systems (particularized in Industry 4.0 systems) as directed graphs is described. Using the proposed notation and formalization, a model for trust in Industry 4.0 systems, defining important concepts such as the trust graph (absolute or relative) and the trust circle, is proposed. A probabilistic model based on a biparametric stochastic process is also described.
A platform based on two different types of agents support the calculation of the trustworthy paths in the graph describing an Industry 4.0 system. Untrustworthy paths are pruned and situations where a clear decision cannot be made, are solved using traffic engineering techniques.
Simulation results showed a success rate above 80% in all cases. Besides, a maximum calculation time of 600 seconds is required to locate all possible untrustworthy paths in total connectivity graphs. Comparisons to the state-of-the-art solutions show an improvement in the required calculation time and scalability. Besides, the generated system overload proves the proposed solution to be lightweight.
From the engineering point of view, different challenges must be faced when implementing the proposed solution. First, specific programming solutions for CPS must be employed, in order to solve problems such as timing (in our case the specific C-based language provided with microcontrollers was employed). Second, sometimes, mathematical expressions cannot be directly applied due to hardware characteristics (for example, no floating-point operation could be allowed). Then, adaptations are required. And, third, solutions to send mobile agents to all nodes under study must be coordinated with self-configuration technologies. That’s basic to share network addresses, communications ports, etc., but if built-in communication protocols are employed, it may require an additional effort.
Finally, the system topology is a basic variable in the proposed technology, so future works should consider this variable in the calculation process in order to optimize as much as possible the use of system resources (which, in Industry 4.0 systems, use to be scarce). In this sense, the proposed solution could be improved from a computational point of view if visibility graphs are employed [65]. Future works will also consider this technology.
Future works will also describe some specific solution for situations where the trustworthiness of paths is unclear.
Footnotes
Acknowledgments
Authors received funding from the Ministry of Economy and Competitiveness through SEMOLA project (TEC2015-68284-R).