
Abstract
Mathematical Morphology (MM) is a set-theoretic technique for the analysis of geometrical structures. It provides a powerful tool for image processing, but is hampered by significant computational requirements. These requirements can be substantially reduced by decomposing complex operators into sequences of simpler operators, at the cost of degradation of the quality of the results. This decomposition also directly translates to streaming task graphs, a programming model that maps well to the kind of systolic architectures typically associated with many-core systems. There is however a trade-off between mappings that implement high-quality filters and mappings that offer high performance in many-core systems. The approach presented in this paper exploits a multi-objective evolutionary algorithm as a design-time tool to investigate trade-offs between the quality of the MM decomposition and computational performance. The evolutionary process performs an analysis of filter quality vs computational performance and generates a set of task graphs and mappings that represent different trade-offs between the two objectives. It then outputs a Pareto front of mapping solutions, allowing the designer to select an implementation that matches application-specific requirements. The performance of the tool is benchmarked on a morphological filter for the detection of features in a high-resolution PCB image.
Introduction
Mathematical Morphology (MM) is a non-linear branch of image processing and computer vision, based on geometry and on the mathematical Theory of Order [1, 2, 3, 4]. It was originally developed by Matheron and Serra in the 1960s, and its initial applications were in biomedical and geological image analysis problems [5]. Later, it proved to be a powerful tool for computer vision tasks involving binary and grey-level images for noise suppression, skeletonization, segmentation, pattern recognition, and for the design of morphological filters, just to name a few examples [6, 7]. Finally, in the 1980s, its theory was generalized for Complete Lattices, allowing it to be applied to colour images [8, 9].
The basic operators of Mathematical Morphology are dilation and erosion, which can be combined algorithmically to form more complex operators. The decomposition of complex operators into simpler instructions provides significant advantages in terms of computational performance (usually at the cost of some loss in quality), but the process is not trivial, even for a specialist, as the selection of operators and operands to be used in this scenario is known to be NP-complete [10]. This complexity has led to the development of approaches that exploit metaheuristic algorithms for this task [11, 12, 10, 13, 14].
To handle the computational complexity, several dedicated hardware architectures have been proposed in the literature to accelerate morphological operations through instruction decomposition, generally implemented by pipelined hardware accelerators on FPGAs [15, 16, 17]. However, while many of these archit- ectures are high-performance and energy efficient [18], they exploit fine-grained parallelism at the pixel or tile level, often with limitations to MM operators [19, 20, 21] and image resolution. In addition, most do not exploit the inherent parallelism of windowed operations [22], and introduce high latencies [23]. GPUs have also proved to be highly effective tools for accelerating MM applications [24, 25], but architectural constraints again limit the exploitation of parallelism to a relatively fine grain. As a result, many of these architectures are unable to take advantage of the image-level parallelism typical of more complex algorithms involving real-world image/video processing.
To exploit coarse-grained parallelism in software, some research has addressed MM implementations on multi-core systems [26, 27], placing the emphasis on the optimisation of accesses to shared memory.
The many-core paradigm is centred on large (generally 2D) arrays of computational nodes, each containing a complete processing unit (for a general discussion of many-core systems and their programming, see for example [28], and for examples of application parallelisation, see [29, 30, 31, 32]). These architectures thus represent an attractive choice for developing complex MM applications, as they allow the implementation of pipelined (streaming) applications [33, 34] at the image level without the restrictions of hardware pipelines or GPUs and in a distributed memory scenario that mitigates shared memory contentions.
This approach, however, introduces a different set of optimisation challenges, related to the clustering and mapping of MM operators to the processing nodes, where the optimality of the solutions in terms of MM conflicts with the performance parameters of the system [33, 34]. This article is meant to investigate this trade-off and describe how multi-objective optimisation can be exploited in this scenario.
The remainder of the article is organised as follows. Section 2 presents the theoretical foundations of Mathematical Morphology and a brief overview of many-core architectures, focusing on the basic assumptions that underlie the proposed approach and outlining the multi-objective search algorithm. In Section 3, the system is detailed, while tests and results are described in Section 4. Finally, Section 5 concludes the article.
Fundamentals
Mathematical morphology
As mentioned, the primitive operators of Mathematical Morphology are erosion and dilation. In the context of image processing, the (binary or grayscale) images are represented as a set of coordinates of active pixels (plus, in the case of grayscale, their intensities). Sub-images (called structuring elements) act as probes, iteratively compared to the original image to provide a quantitative measure of how the sub-image fits (or does not fit) within the original image.
According to [7, 35], the characterization of fitting depends on translation (basic Euclidean-space operation). So, the translation of a set
Using this notation, the erosion of a set
where
The dilation operation is the opposite of erosion and can thus be defined from erosion through set complementation. The dilation of
where
Example of cost calculation for a hypothetical filter, according to Eqs (4) and (5). The original filter is decomposed into a graph of 8 tasks (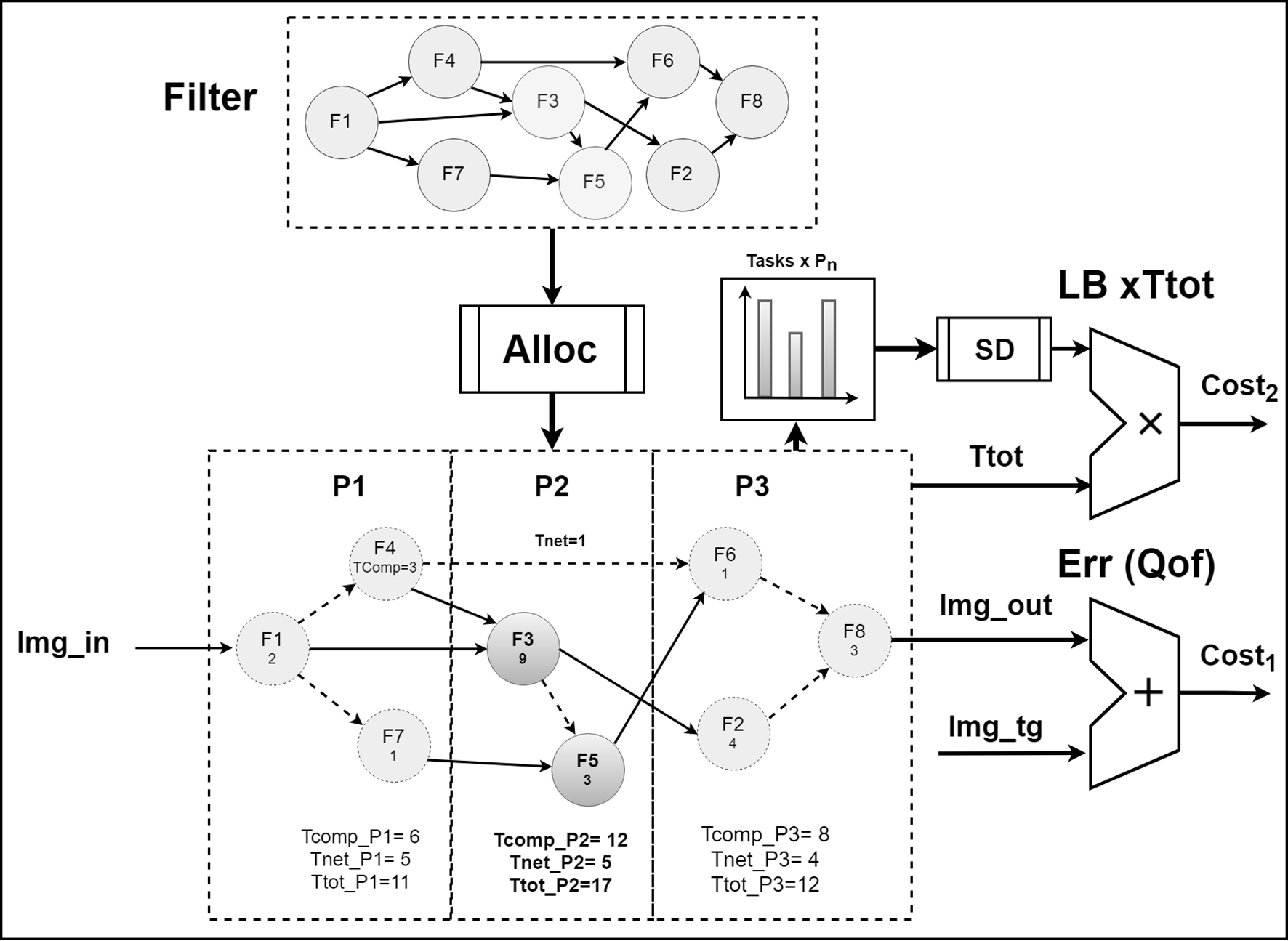
More complex operators, like opening and closing, among others, can be obtained by combining dilations and erosions algorithmically [35, 7]. These ideas can be extended to grey-level and colour image processing as well, using the maximum and minimum operators.
From these definitions, it can be evinced that the complexity (defined in terms of computational effort) of a MM filter has a strong dependence on the size of the structuring element
The first objective of the multi-objective algorithm presented in this paper (Fig. 1) will then be to decompose complex filters into simpler tasks (basic instructions) in such a way that the error introduced by the decomposition is minimised.
While numerous architectural variants have been proposed in the context of many-core systems research, the work presented in this article tries to preserve generality by limiting the assumptions made on the architecture:
The many-core system will consist of an arbitrary large number of processing nodes (experiments were run for 8, 16, and 32-node systems). Each node has access to a “significant” amount of local memory (this, however, only impacts the size of the images that can be processed). The nodes are connected by a deadlock-free Network-on-Chip (NoC) with a bandwidth sufficient to avoid congestion (again, largely a limit on image size).
Within this scenario, MM graphs (Fig. 1), can be considered as streaming applications [33, 34], where each node will receive images from upstream nodes, apply one or more MM operators, and then propagate the processed image to one or more downstream nodes, repeating this sequence operation for all images in the required set. It should be highlighted that this coarse-grained decomposition represents a departure from the vast majority of the literature that addresses MM implementations and is in fact complementary to, for example, FPGA- or GPU-based accelerators (in the sense that it does not preclude the presence of such accelerators within the many-core processing nodes).
In order for a graph of
One component of the overall time required by each node to process each image is obviously the time (Tcomp) necessary for the computation of the MM tasks allocated to it. By removing backward dependencies, the use of streaming graphs reduces this to a linear sum of the time required for each task (which can be pre-computed, given the platform specifications).
In a realistic scenario, however, the time required for each node to receive and send data (particularly for large image sizes) cannot be ignored. Given a specific platform and a constant image size, a node’s Tnet is then a function of how many input and output images are sent or received by all the tasks mapped to it (as derived from the task graph).
In this streaming approach, the time Ttot required to process each image on
The performance of a mapping in terms of processing time is not the only measure of the quality of a mapping, since it provides no information as to how optimally the resources of the system are used. In terms of energy or in a multi-application scenario, for example, it becomes important to minimise the number of processors used to implement a filter and to equalise the computation across all nodes. In practice, this can be achieved by load balancing (LB) the computation across the processors or, in other words, by minimising the standard deviation of Ttot across all nodes.
Block diagram for the iMMf-Ma architecture, and its 3 basic modules: training, testing, and mapping. The training module is used to evolve individuals (filters) according to two conflicting objectives. The Testing module is used to verify the performance of the solutions. The filter(s) selected by the user are mapped onto the many-core architecture in the mapping module.
The second objective of the multi-objective optimisation algorithm proposed in this article is to group and allocate (i.e. map) the filter tasks to processing nodes in such a way that the performance (in terms of computation time) and the use of resources (in terms of load balancing) are minimised.
The quality of a filter implementation will thus depend on two metrics (Fig. 1), which correspond to the two objectives to be optimised. The
In general, filters with high complexity (larger structuring elements and/or more instructions) will have the best visual quality, but will require more time for computation, implying a conflict between the two metrics.
Resolving this conflict implies defining the relative importance of the two objectives. This, however, depends on the requirements of the designer: an application that needs, for example, to meet real-time constraints would prioritise the QoM metric, whereas QoF might dominate in high-precision filters.
The algorithm described in this article targets the design-time optimisation of a given mathematical morphology application (using pattern detection as an example) on a many-core architecture with known architectural parameters (computation and communication speed, number of processing nodes, etc.). As in similar research (e.g. as in [39, 40]), a multi-objective evolutionary algorithm was used to find a Pareto front of mapping solutions, each representing a non-dominated trade-off between the two optimisation metrics, allowing the designer to select an implementation that matches application-specific requirements.
Mapping of morphological filters on many-core architectures (iMMf-Ma)
Figure 2 illustrates the general block diagram of the proposed iMMf-Ma system, which consists of three basic modules: training, testing and mapping.
Training module
The objective of the training module is to automatically generate, using a multi-objective algorithm [41, 42, 43, 44, 45] and training images, acyclic graphs (filters) constructed from a set of basic instructions.
The training module (Algorithm 3.1, Fig. 2) was implemented using the PlatEMO tool [46]. After initial tests with several MOEA algorithms (including NSGAII [47], NSGAIII [48], MOEAD [49], and SPEA2 [50]) revealed no statistically significant differences, NSGAII was selected. The standard algorithm was then modified to use a CGP-derived [51, 52] encoding that matched the problem with no crossover and with a point mutation that more accurately fits the encoding.
Parameters and variables used in the algorithms
Parameters and variables used in the algorithms
For this module, the following parameters and inputs (Table 1) must be specified:
A set (train_set) containing pairs of training images (original + target), where the original is a binary or grey-scale image of any resolution and the target contains binary objects of interest present in its corresponding input; A set (MM_INSTR) of morphological (dilation, erosion, etc.), arithmetic (addition, subtraction, etc.), and logic (and, or, not, etc.) basic instructions; Parameters of operation of the modified NSGAII algorithm: N: population size; M: number of objectives of the multi-objective problem; L: chromosome length (number of genes); D: number of alleles in the chromosome; EVALUATION: number of generations; N_PROC: number of processors of the many-core architecture; MT_RT: mutation rate for the evolutionary strategy.
aux
iMMf-Ma Training
Chromosome format: each gene identifies the MM instruction used, the graph nodes (up to two) that provide inputs for the instruction, and the processor to which the instruction is allocated within the many-core array. The genotype is coded as integers, which by means of the Decode_Chrm function are transformed into a program listing, containing instructions from Table 2, representing the current chromosome. The fourth argument of each gene (processor id) is used by the mapping module.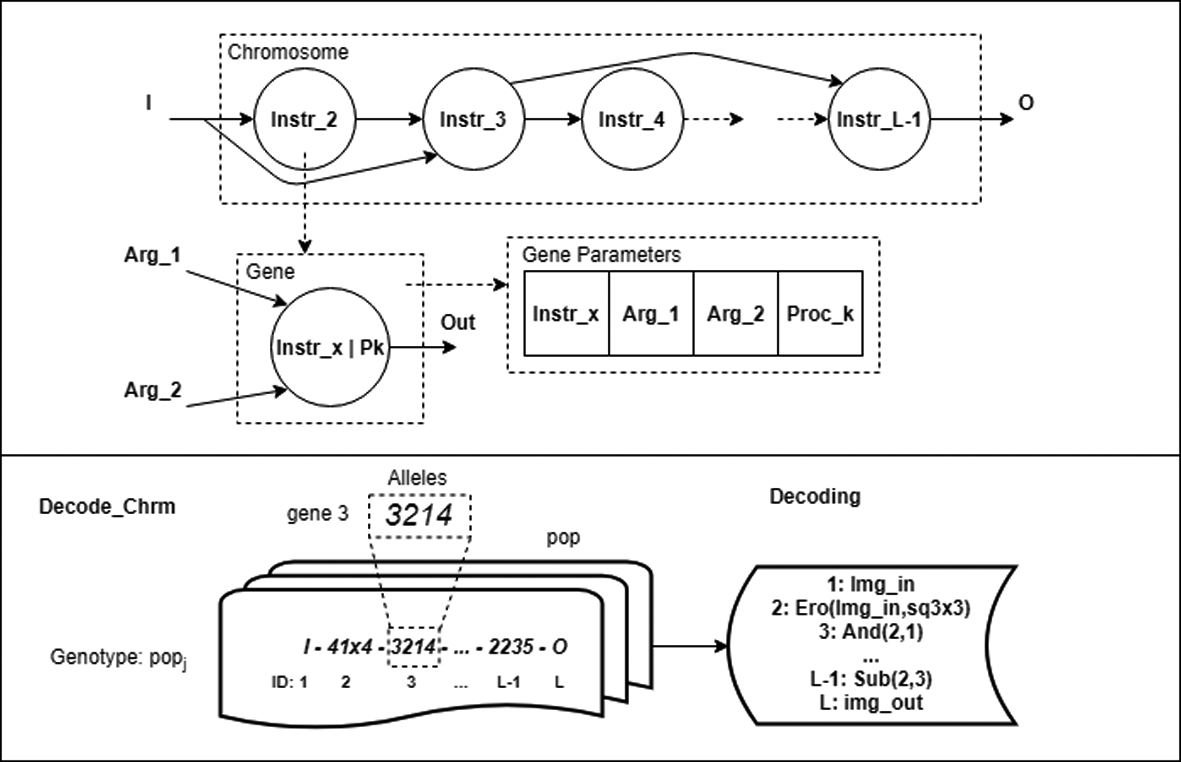
Given these, the algorithm outputs:
Pareto curves for the final population evolved, which can be used to select a filter satisfying user-specified requirements; Application task graphs representing each individual, together with the associated filter parameters and processor allocations; For visual verification purposes, the output images for the selected solution.
MM basic instructions currently implemented in the iMMf-Ma system
The training module relies on four main functions:
Initial_Pop: The initial population (pop) is generated randomly, based on the parameters N, MM_ INSTR, D and N_PROC. Each chromosome (Fig. 3) contains a set of genes that represent the nodes of the graph. Each gene consists of four alleles (although it is possible to use higher arity for its arguments if required): one instruction from an application specific set (Table 2), two input connections from previous nodes in the graph, and the id of the processor that will execute the instruction on the many-core architecture.
test
Cost_Eval: This function (Algorithm 3.1.1) computes the metrics (see Section 2) for the current population pop. The metric formulae are detailed below in Section 3.1.2.
NSGAII: This function implements the NSGAII algorithms. Its inputs are the EA parameters, the current population pop and the metrics for each individual in the current population (costs). As output, the function returns the set of non-dominated individuals (pareto_front) among the filters in the current population (Fig. 4), together with the next generation to be evaluated (pop).
GraphGen: This function receives as input parameter the pareto_front generated by NSGAII, as mentioned above, and returns as output the corresponding graphs, which can be used to select the desired
Metrics
The metric evaluation is carried out as in Algorithm 3.1.1 through the application of a sequence of 5 functions: Decode_Chrm, Eval, Std, Alloc, and Timing.
Decode_Chrm, as its name suggests, decodes the chromosomes of the individuals in
As an example, consider gene (graph_id: 3) of Fig. 3, with alleles “3-2-1-4”. From Table 2, the first allele 3 selects instruction AND, with the first input connected to the output of gene 2, and the second to img_in (gene 1). The instruction will be allocated to processor 4.
To evaluate the quality of the filters
Details of a point (Filter) of the Pareto curve generated by the NSGAII function. Costs has two columns, the first one referring to the filter error (Qof), and the second one to its complexity (total time through the pipeline (Tcomp 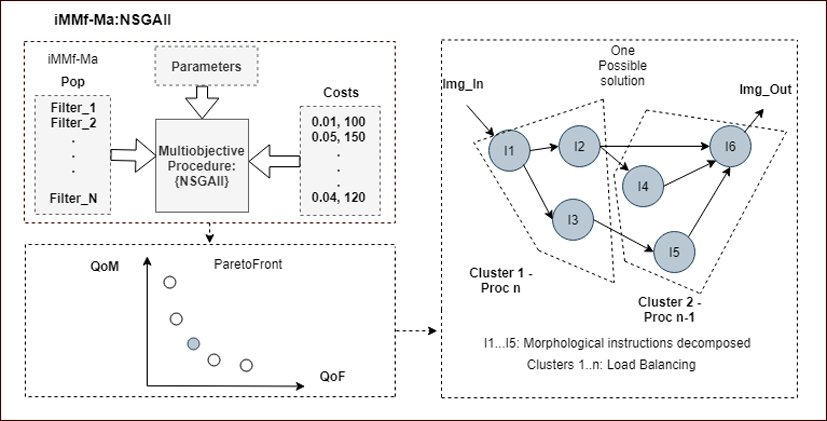
The images in the
where Iout is the filtered image for one evolved filter, Itg is the target image corresponding to its img_in, and
By contrast, the evaluation of the QoM metric is much simpler, as it does not require the application to the filter to the image. As described in Section 2.2, given a specific target platform the processing time Tcomp for each node can be estimated by the linear sum of the complexities of each basic instruction (Table 2). The communication time Tnet can be derived from the task graph, as it corresponds to the number of input and output arcs of the tasks mapped to a specific processor (Fig. 1). This allows the algorithm, in the Timing function, to compute the first component (Ttot) of the QoM metric using Eq. (4) (it also evaluates the sequential execution time of the graph, for comparison purposes, as detailed in the Results section).
To evaluate the second component (LB) of the metric, which corresponds to load balancing, the algorithm computes the standard deviation of the processing time across all processors (Section 2.2). The two components are then multiplied together to direct the search towards more balanced individuals.
The objective of the test module is to validate the graphs generated by the training module by applying a set of testing images.
For this, test_set, a new set of images, is used, containing different image pairs compared to the train_set training set. However, this new set contains the same image objects used in the training set, as it aims at validating the results generated from the training process. Thus, for the testing process, Algorithm 3.1.1 is also used to evaluate the metrics, and is applied to test_set rather than train_set. The graphs satisfying the requirements of the user are then passed to the mapping module to be allocated on the many-core architecture.
Mapping module
The objective of the mapping module is to cluster instructions (graph tasks) from the solution chosen by the user for implementation on the many-core architecture. This process would allow a platform-specific back-end to automatically generate the executables.
Printed circuit board (PCB) image used for the experiments. The highlighted area shows the three types of patterns (square island, circle island, and track) to be extracted by the filter.
According to Fig. 3 (Section 3.1), the fourth allele of each gene (Proc_k), represents the processor to which the task will be allocated. Thus, the final objective of this module is to cluster the nodes of a given graph, generating an application mapping (Fig. 4). This process (Algorithm 3.3) receives the input parameters pop and L and returns the
Mapping module – clustering
Experiment parameters
Mean and standard deviations of the filters evolved by the training module for each combination of pattern (circle island, square island and track), and numbers of processors (8, 16, and 32) over the 30 training samples. Three filters from each Pareto curve (the two extremes and one intermediate) were used in each case. Speedups are in bold in the table. As an example, the “Best Pareto” row represents, for each combination, the three points in the Pareto curve that contains the best QoF for an image pair
The lack of literature addressing the issue of mapping MM applications on many-core systems prevents a comparative evaluation of the tools. Performance comparisons with FPGA-based hardware accelerators (e.g. [19, 20, 21, 18]), besides being unrealistic as the images used for benchmarking in the literature are generally much smaller than the one used for the experiments in this paper, would also be largely irrelevant, since the two approaches are entirely compatible. In fact, should the many-core system nodes allow the implementation of hardware accelerators, this feature could be integrated in the proposed tool to improve Tcomp and thus shift the Pareto curve.
The results proposed in this article thus rely on implicit benchmarking: in order to evaluate the performance (
Example of an iMMf-Ma system result for square island detection in an 8-processor pipeline. Each point represents a chromosome (generated filter) in the final population. The green line connects non-dominated solutions on the Pareto curve.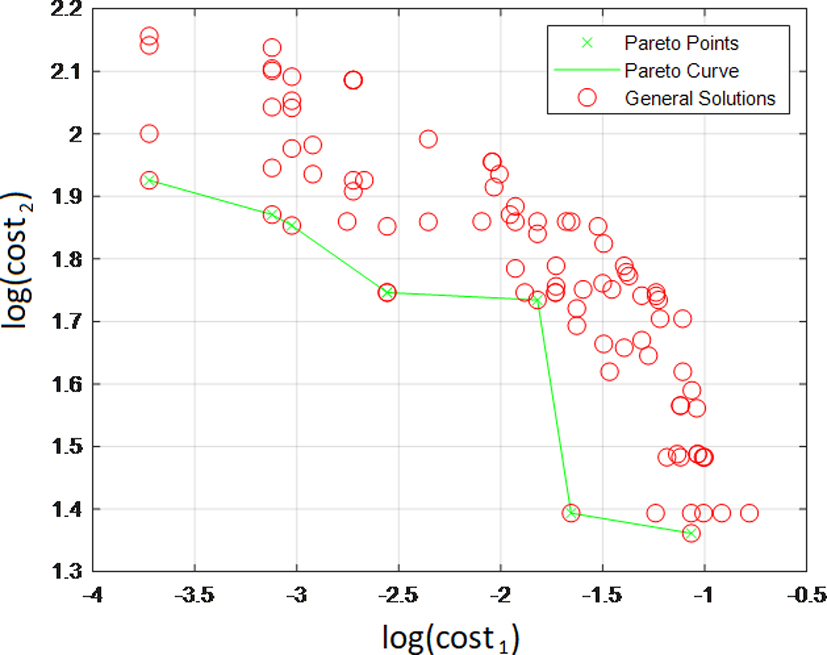
Mean, standard deviations and selected individual (bold) obtained from the testing process for the Best QoF filters
The train_set and test_set sets (Section 3.1) use binary sub-images from the original monochrome image of Fig. 5, with a spatial resolution of 3277
The EA parameters used in the experiments are described in Table 3 (the parameter values were derived through a set of calibration experiments). To evaluate the scalability of the algorithms, three different sizes of many-core architectures were used in the training and testing processes: 8, 16, and 32 processors. For the current application, only instructions 1 to 15 in Table 2 were necessary, due to the geometry of the objects to be detected. Because of the nature of the problem, a limit of two inputs per node was imposed on the graph, a restriction that can be relaxed by a tool parameter.
All time metrics were computed as a function of complexity, which is proportional to the number of active pixels in the structuring elements used by the morphological operations. Thus, for the morphological operations, the convention adopted was to consider the dimensions of the structuring elements to determine Tcomp for each base operation (Table 2). The complexities of the other operations were derived through comparison to the morphological operations.
Visual results obtained for the circle island testing process for 8 processors and 2 different points of the Pareto curve.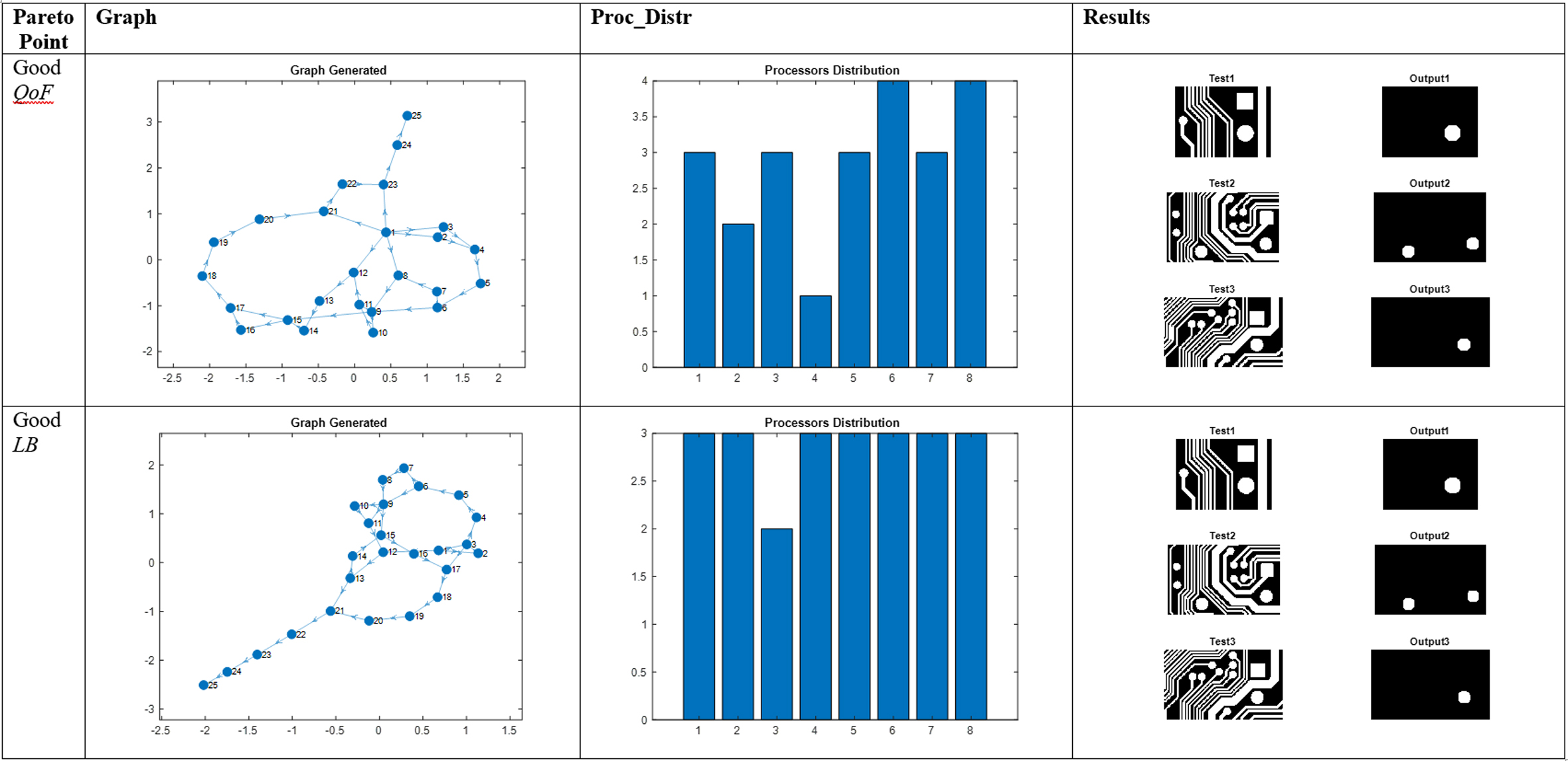
Visual results obtained for the square island testing process for 8 processors and 2 different points of the Pareto curve.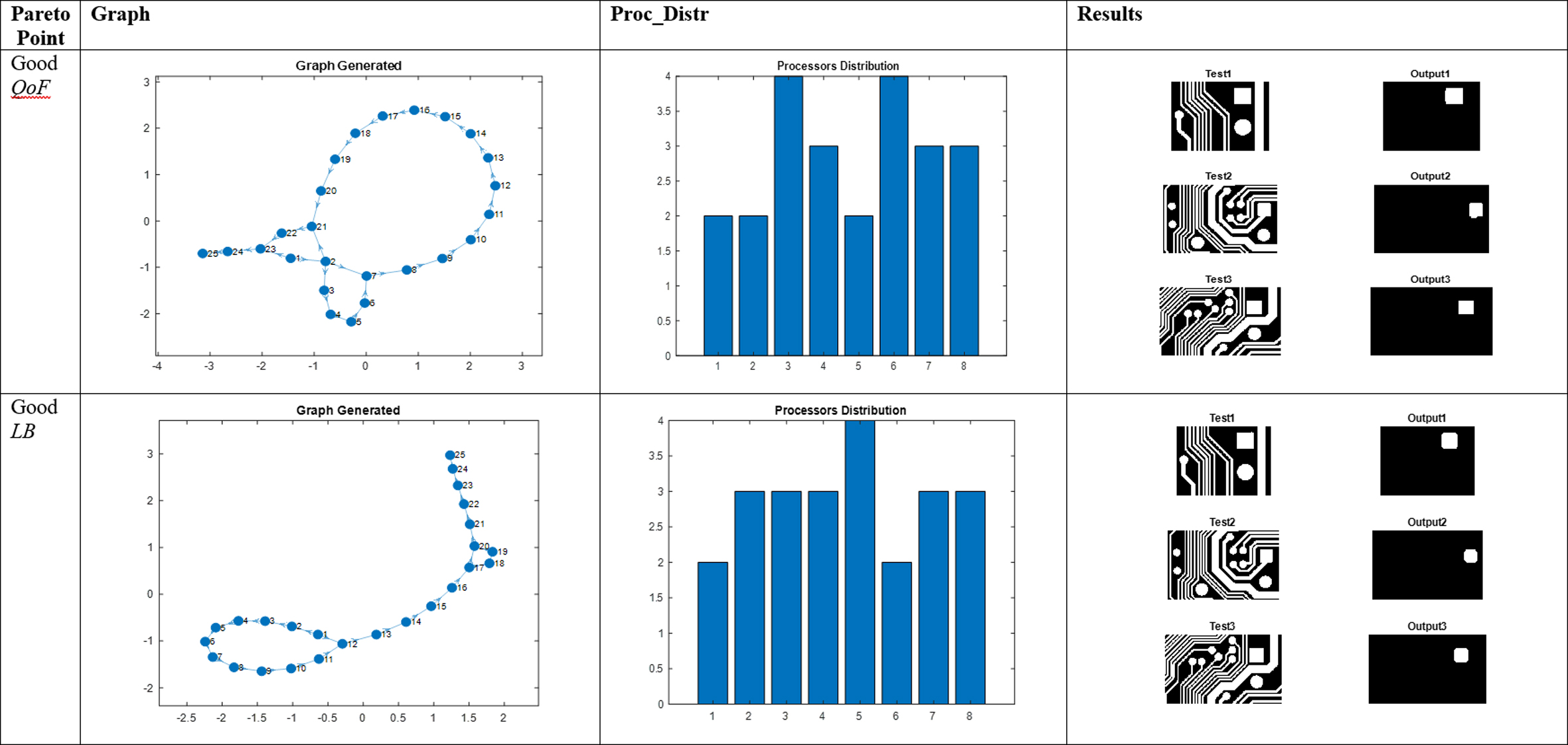
Visual results obtained for the Track Testing Process for 8 processors and 2 different points of the Pareto curve.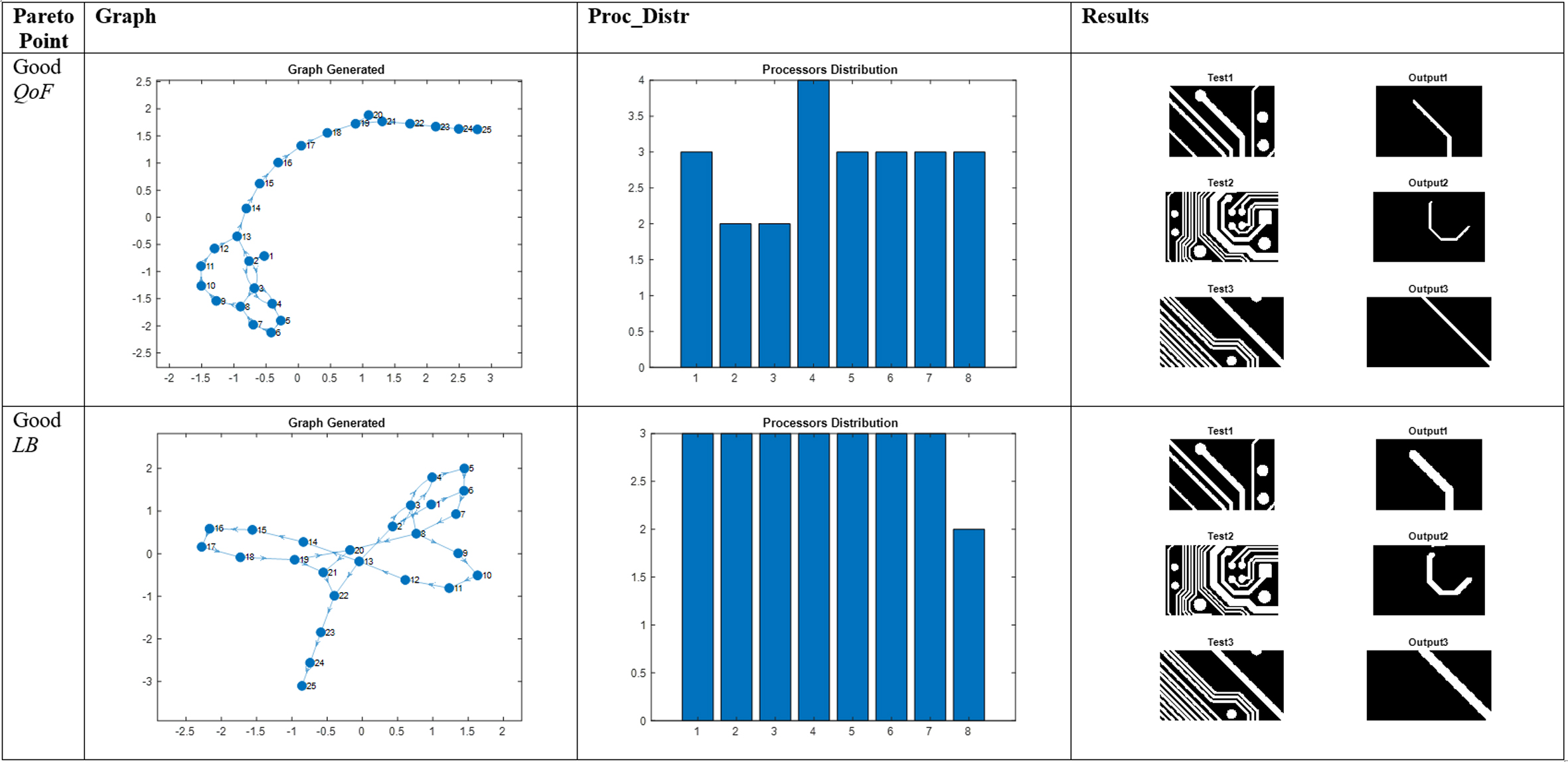
Given the assumptions on the NoC capabilities (Section 2.2) and the features of the application, Tnet was set to a constant value of 1 for each arc in the graph. It is important to note that, for the purposes of the EA, the units used in the estimation of the computational complexity are irrelevant, as long as the ratio between the component values matches their execution time in the target platform. Non-exhaustive empirical tests performed on a single-processor machine confirmed that the timing relationship between the instructions closely matches the complexity-based estimations.
For the training process, 30 pairs of sample images (130
The output of the training process is a set of Pareto curves that present the non-dominated solutions obtained for each image pair. Figure 6 shows an example of a curve generated by the tool, for an architecture containing 8 processors with square island detection.
The results obtained in the training phase are summarized in Table 4. For each configuration (number of processors and pattern combination), three individuals (filters) were selected from the Pareto fronts of each image pair: best QoF, best QoM, and an intermediate solution. The table then displays the average and standard deviation of the MAE and Ttot across all individuals (note that the total execution time Ttot was selected over
To provide a comparison metric, the table also includes averages and SDs for Tseq, the execution time of each individual on a single processor (computed by setting Tnet to 0 and adding together the execution times of each instruction in the chromosome). This parameter then allows the calculation of the speedup (SeqT/Ttot) obtained through the parallelisation of the filter. The analysis of the values in Table 4 reveals that, as expected, the speedup in all cases is increasing with the number of processors.
Selected individuals among those found by the training process are then input to the testing process, where their performance is evaluated on the set of test images.
In a user scenario, the selection of individuals to be tested would be guided by the design priorities. For example, if the application requires a high-quality filter (low MAE) and performance (Ttot) is not a constraint, the “best QoF” column of Table 4 would be used to select individuals to be tested. In a real-time system that needs to minimise processing time, even if this implies lower visual quality for the filter (high MAE), tests would focus on individuals from the “best QoM” column. In cases where the two constraints have the same weight, the intermediate individuals provide a viable solution. Of course, the designer would be able to pick any of the Pareto points in the graph depending on requirements and not be limited to the three that were arbitrarily selected for Table 4.
For this article, in order to carry out a more thorough evaluation of the performance of the approach, three individuals (best QoF, best QoM, and an intermediate result) from each image pair (for a total of 270 chromosomes) were selected for testing.
Each filter was applied to three different test image pairs of 248
Table 5 shows an example of the results obtained for the set of best QoF individuals. For each combination of processors and patterns, the first two lines of the table refer to the MAE of all filters on each test image.
The third and fourth lines represent an individual selected from all the tested candidates as providing the best visual results. As other works in the literature have highlighted [12, 10], considering only the MAE in an image processing context is not the best option. The choice thus corresponds to solutions with the smallest SD, a more useful metric for visual quality.
The results were additionally verified through visual inspection (see examples in Figs 7–9). In every case, two individuals were selected for the tests: the first with low standard deviation (lower MAE) and the second with better speedup (lower Ttot and better load balancing (LB)). For example, in Fig. 9 (track detection), the tracks found by the second filter are marginally thicker than the first (higher MAE) but the mapping displays significantly better Ttot and load balancing (LB – visualised in the histograms).
Conclusions
Many-core architectures, while still at an embryonic stage of development, seem to represent ideal platforms for the implementation of mathematical morphology applications: as systolic, distributed-memory arrays of processing cores, they are well suited to handle the high computational demands of MM, particularly when the latter is decomposed into simpler operations, allowing the system to exploit instruction streaming.
In this paper, a typical MM application (a filter for pattern detection) was used to explore the use of multi-objective optimisation of many-core implementations. The MO algorithm is able to find a range of different non-dominated mappings that represent optimal trade-offs between the visual quality of the filter and computational performance on a many-core system. In this work, the assumptions made with respect to the many-core architecture are kept to a minimum to preserve the generality of the solutions. Within this scenario, the algorithm attempts to model realistic constraints by taking into account not only computation time, but also the time required for data transfers and the efficient use of resources by balancing the load across processors.
The approach was evaluated using a pattern recognition filter applied to a high-quality (3277
Footnotes
Acknowledgments
The first author is grateful to FAPESP (Grant 2017/ 26421-3) and CAPES. This work was partially supported through the EPSRC Graceful Project (Grant EP/ L000563/1).