
Abstract
Video sequence analysis systems must be able to operate for long periods of time and they must attempt that the different events that can affect the quality of the input data do not diminish the performance of the system to an excessive extent. In this work a method called Probabilistic Mixture of Deeply Autoencoded Patch Features (PMDAPF) is proposed. A Deep Autoencoder is the cornerstone of the methodology for robust background modeling and foreground detection that is presented in this document. Its purpose is to obtain a reduced set of significant features from each patch belonging to one of the several shifted tilings of the video frames. Then, a probabilistic model is responsible for determining whether the whole patch belongs to the background or not. Foreground pixel detection takes into account the information of all patches in which the pixel is included. The robustness of the proposal, as well as its suitability to the uninterrupted analysis and processing of visual information, is reflected in the experiments, in which the performance of the proposed system is affected slightly whereas those of the classic methods are degraded drastically.
Keywords
Introduction
The number of software applications that need to extract some kind of information from images or video sequences has grown steadily in the last decades. Among the fields in the area of artificial vision, video surveillance is still one of the most active because it involves several complex video analysis and processing tasks that must be resolved efficiently and reliably. That is the case of background subtraction, which consists in deciding which elements of the image are part of the background of the scene and which ones are moving objects, i.e, they belong to the foreground.
Background modeling algorithms must work continuously, thus a difficult goal that they should achieve is to perform adequately when processing each frame of the video sequence and not only the initial ones. Therefore, they should be robust enough to maintain their level of performance when events that may compromise the quality of input data occur and when the characteristics of the background itself vary. For instance, it is not uncommon for sudden lighting changes to happen in indoor scenes, while atmospheric conditions can affect object detection in outdoor environments.
Foreground detection algorithms can be considered as binary classification methods that compute the probability of each frame pixel or region to belong to one of the two possible classes: foreground or background. For that purpose, the most referenced proposals attempt to learn an underlying model that describes the changes of that pixel or region features over time.
In this work a background subtraction algorithm that works at the region level is presented. Each pixel is not analyzed independently but as a component of a square patch that is part of a particular tiling of the video frame. Since several distinct shifted tilings are employed for each frame, each single pixel is classified after taking into consideration the information about all those patches to which it belongs. The existent noise in the patches will be removed by a previously trained deep autoencoder [1], which is an unsupervised deep learning neural network well suited to information representation due to its ability to provide relevant data features [2]. Single layer autoencoders are proved to span the same subspace as a Principal Components Analysis technique [3]. Although deep autoencoders composed of several linear layers have been successfully used in background modeling in noisy environments [4, 5] it may be difficult for them to capture the visual patterns present in the pixel neighborhood. Deep autoencoders such as the one proposed in [6], try to capture relevant visual features by means of several initial convolutional layers, while the last layers are dense and devoted to compute several significant features of the input that can be expressed as linear combinations of the visual characteristics.
In the present work, we extend our previous methodology described in [4] (published in conference proceedings [7, 8]) by using tilings and proposing a new probabilistic model. Although the proposed methodology is conceptually based on [5, 4] the use of tilings causes it to provide a higher resolution and more stable segmentation than [5]. Besides, the proposed probabilistic method does not depend on parameters, improving the model in [4].
The paper is divided into the following sections: Section 3 explains the foreground detection methodology, which is based on a deep autoencoder which comprises convolutional and linear layers, and a probabilistic model that works with the reduced patch representation provided by the autoencoder; Section 4 reports the experimental results over several public surveillance sequences and finally in Section 5 the conclusions are presented.
Related works
Background modeling has been of paramount importance in video surveillance systems [9]. In recent decades, a large number of published techniques model the background by analyzing the intensity of each pixel over time. Initially, the methods with better performance modeled this signal through parametric distributions. Thus, Wren et al. [10] assume only one type of moving objects in a not very dynamic environment and pixel classification is based on its color, location and information about a set of
Other proposals, such as SOBS[15], and FSOM [16], take into account not only color intensity but also pixel vicinity information. Pixel models are based on unsupervised artificial neural networks known as self-organizing maps [17], in which topological neighborhood relations of the input patterns are preserved. The combination of each pixel output with those of their neighbors allows for a more robust detection of foreground objects. Furthermore, SC-SOBS[18] and SOBS-CF[19] are revisions of SOBS that try to enforce spatial consistency to reduce false positives in detection. More recent techniques like LOBSTER[20], SUBSENSE[21] or PAWCS[22] increase noise resilience by including several local binary similarity patterns for each pixel representation, which describe texture patterns of the region to which the pixel belongs.
Dimensionality reduction techniques such as Robust Principal Component Analysis (RPCA) [23] have also been used successfully in the foreground detection field. Although delivering a good performance, conventional RPCA-based methods are not suitable for real-time applications due to their high computational complexity. More efficient RPCA-based algorithms are based on specific assumptions about subspaces and outlier distribution which prevent them from being used in some cases.
The use of deep learning techniques has been a true revolution in the field of intelligent information processing, especially when images or video sequences are the input data that have to be processed. Thus, it is possible to highlight proposals which evaluate infrared images for face detection [24], explore multi-channel EEG signals for seizure detection [25, 26, 27] or for interaction analysis between cortical regions of the brain [28]. In a context related to video surveillance, object tracking tasks [29] or object classification in road scenes [30] have been carried out. In addition, deep learning networks have also been applied in subjects as diverse as pupil identification [31], the detection of evidences of Parkinson’s disease by means of 3D images [32] or the evaluation of physical structures in engineering [33].
Background subtraction techniques which are based on deep learning neural networks have become very popular popular and effective in recent years [34]. Some of them focus on exploiting spatial and temporal information in order to learn a background model as precise as possible that is then used to classify the image pixels. In [35], a method composed of two stacked autoencoders which try to find the latent space features of the input video frames is employed to model the underlying structure of dynamic backgrounds. A convolutional long-short term memory is used in [36] in an attempt to learn not only spatial information but also the temporal associativity among the frames where sequential movements of foreground objects occur. Two different deep convolutional architectures that aggregate multi-scale information in order to improve foreground segmentation accuracy and robustness are proposed in [37]. Finally, a background estimation and foreground detection model that is able to reconstruct missing parts of the input image is presented in [38]. Generative adversarial networks are used for predicting new contexts in missing image regions while a semantic convolutional network is responsible for inpainting missing regions. On the other hand, in [39] the background is modeled with a simple grayscale image and a convolutional neural network is trained so that it can be able to subtract the single background image from the video frame image, and classify each frame pixel accordingly. A similar approach is followed in [40], where the subtraction operation is made by combining Bayesian generative adversarial networks and parallel vision theory.
Methodology
The standard strategy to model the background in video sequences for video surveillance purposes implies the representation of each pixel of the frame individually. As opposed to this strategy, we propose to model the video frames by dividing them into patches of
The process of classifying a patch as background or foreground consists of two steps. First, a compressed representation of the patch is learned by means of the extraction of its significant features as computed by a previously trained Deep Autoencoder (DA from now on) [2]. After that, in a second step, the reduced representation of the patch is inputted to a probabilistic mixture model which estimates the probability of the patch to belong to the foreground. Such mixture model is updated as the video sequence progresses.
Patch feature extraction
Since DA might fail to model too small patches, we propose to use
A pixel belongs to only one patch in each tiling. As there are
Shifted tilings example with 
Let
where
As the video sequence progresses, we use the coding layers from DA to discover relevant features so, for any patch
The goal of the training of the autoencoder is to minimize the mean squared reconstruction error
where
Although autoencoders are aimed to obtain a reliable representation consisting of general features, the influence of spurious factors such as illumination and local variation should be reduced. The invariance of the autoencoder to various scene conditions can be enhanced as proposed by several authors [42, 43, 5], that have used a training set that comprises a large volume of general image patches from natural video sequences with manually inserted noise, rather than employing patches extracted from the frames corresponding to the video to be processed. We follow this approach in our proposal. The training set for our unique autoencoder is extracted from the Microsoft Common Objects in Context (COCO) dataset [44].
We perform the background modeling by training a
where
The Gaussian and uniform mixture components are defined as:
Please note that
The mean vector and the vector of standard deviations of the Gaussian are defined as follows:
The covariance matrix of the Gaussian is assumed to be diagonal:
With this goal, Robbins-Monro stochastic approximation algorithm [45] is used to approximate the mean vector
Initially, in order to save memory, we use Welford’s online algorithm [46] to obtain first
The class probabilities given the encoded patch
So, given
Also, in order to update the a priori probabilities
Since all
For the sake of simplicity, we will set all prior pro-babilities
With
Since we use an uniform component to model the foreground, we need that the function
On Fig. 2 on page 7 the method scheme can be observed.
Method scheme. On the left we have the original image, which is divided into patches following shifted tilings. Each patch is encoded and segmented. Each pixel is segmented according to the segmentations of the patches that include it.
Autoencoder structure. On the left we have the original 16x16 patch (3 color channels). Blue figures are the outputs of convolutional layers with (5,5) filters where the number above them indicates the number of filters. Red figures and green ones are the outputs of (2,2) MaxPool and Upsampling layers respectively. Number above them indicates their data depth. Orange figures are the output of the two reshape layer: first one from data cube to vector, second one from vector to data cube. Black figures represent dense linear layers of the shown length. On the right we have the last 16x16x3 convolutional output. The type of convolutional layers in the decoding structure are the same as in the encoding one and padding is added to the data so that only depth dimension size is modified by convolutions.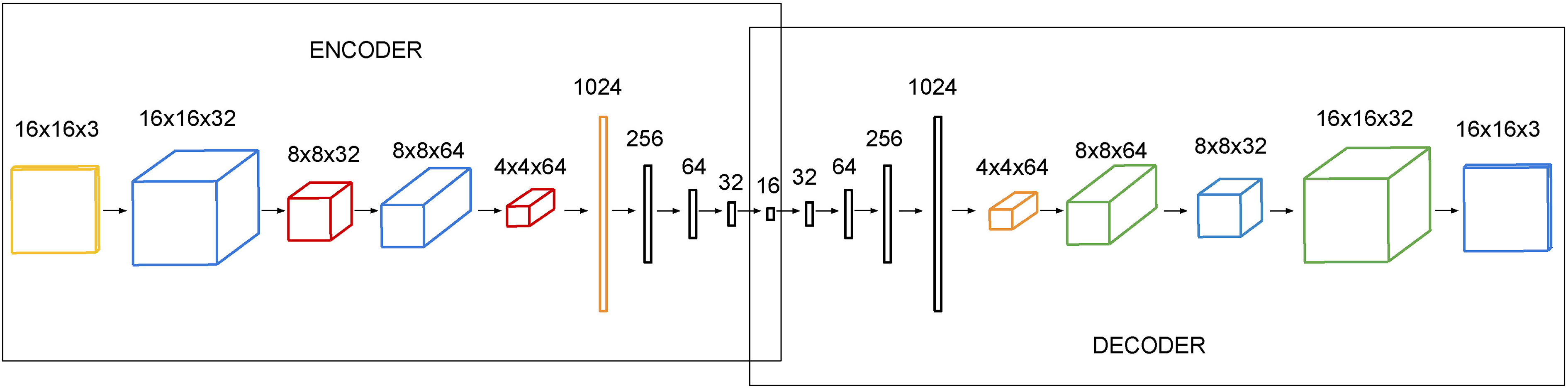
As the previous methodology section shows, our method needs the encoding layers from an auto-encoder to process each patch. The network architecture is shown in Fig. 3. Convolutional and max pooling layers have been used to get relevant visual features in the patch so that the last dense layers select the 16 most important features. The proposed auto-encoder has a 16
Based on our previous work [4], we have selected
The autoencoder has been trained using 400,000 16
In order to obtain the initial means and variances, the first video sequence frames are selected to train the probabilistic model prior to segmenting the following frames from that video sequence. The training frames are defined by the dataset used for the experiment and consists of all the frames that are not within the temporal Region of Interest that will be later employed to test the method.
Methods
Eight methods have been used to make a performance comparison with our proposal: WrenGA [10], ZivkovicGMM [12], ElgammalKDE [13], SOBS [15], SOBS_CF [19], SuBSENSE [21], LOBSTER [20] and PAWCS [22]. All of them are avaliable on the BGS library [47]1 that is which we have used in order to get the segmentation images.
The proposed method has been implemented using Python. Neural Network implementation uses Keras2 as high-level application programming interface working on Tensorflow.3
Sequences and noise
Average F-measure for all sequences and noises with different thresholds.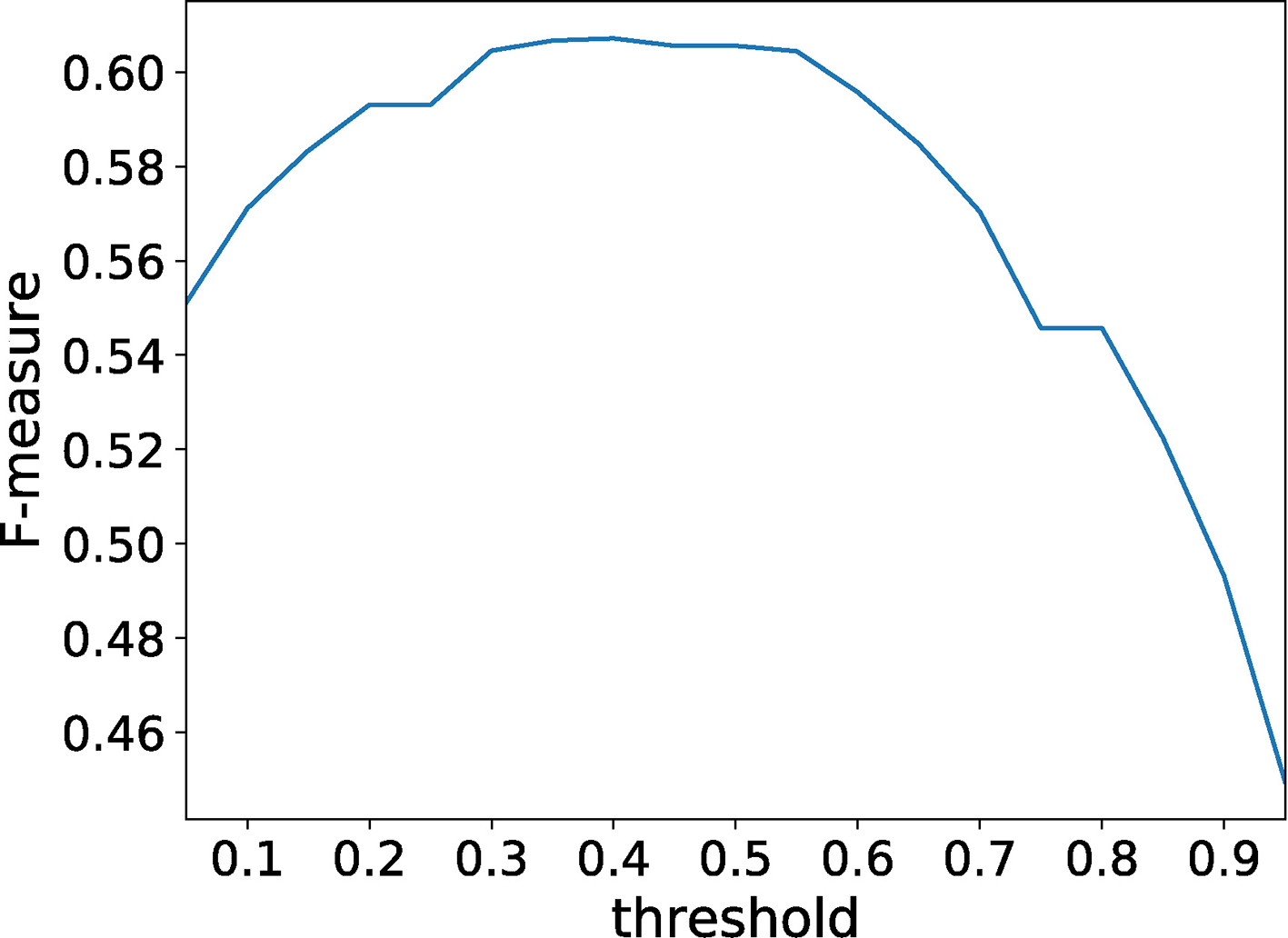
A total of 26 sequences have been selected from five categories from ChangeDetection.net website4 in order to test PMDAPF. The Baseline category presents a mixture of mild challenges that are common in computer vision, such as subtle background motion, isolated shadows, an abandoned object or pedestrians that stop for a short time to move away later (4 sequences). The Dynamic Background category includes scenes with strong background motion acting as intrinsic noise in the image, e.g. boats on shimmering water, roads next to fountain or trees shaken by the wind (6 sequences). The Shadows category contains video sequences with different strong shadows (6 sequences). The Night category includes videos recorded during night (6 sequences). Finally, the BadWeather category is composed of outdoor video sequences affected by winter weather conditions like snow or fog (4 sequences). These categories have been selected since they represent common video surveillance situations.
Noise
Original videos plus nine versions, which were obtained adding different type of noise to the original video sequence, have been used to test the proposed approach. As a result, 10
Raw videos with no noise added. Gaussian noise: four different versions were obtained by adding Gaussian noise with zero mean and standard deviations 0.1, 0.2, 0.3 and 0.4 respectively. Salt and pepper: Black and White pixels were randomly added to raw images. Uniform: two distinct uniform noises added to raw video. From 0 to 1 and from Compression: Raw images are saved changing the parameter cv2.IMWRITE_JPEG_QUALITY which defines the compression quality. The better quality is represented by the maximum value 100. The parameter was set to 10 and 1 respectively in order to obtain the corresponding noisy video sequences.
Quantitative results for all categories. Table shows average F-measure (and standard deviation) value for all videos for each method and noise. The higher, the better. Bold value indicates the best result within the row
Quantitative results for baseline category. Table shows average F-measure (and standard deviation) value for all videos for each method and noise. The higher, the better. Bold value indicates the best result within the row
For quantitative comparison purposes, the well-known F-measure, which is defined as a balanced harmonic mean of precision and recall, is chosen. This measure provides values in the interval [0,1], where values close to one mean better performance.
F-measure has been calculated for all sequences. True Positives (TP), True Negatives (TN), False Posi-tives (FP) and False Negatives (FN) from all frames in Region of Interest (frames to evaluate specified by ChangeDetection.net) are added to calculate sequence F-measure for each method segmentation.
with
Tables from 1 to 6 show quantitative results for videos with and without added noise. In accordance to them, the proposed method clearly outperforms WrenGA, ZivkovicGMM, ElGammalKDE, SOBS and SOBS_CF in nearly all of the test categories, specially when noise is added. Although PMDAPF performance in the case of raw video sequences is lower than those of robust methods such as PAWCS, SUBSENSE and LOBSTER, the performance of these methods is greatly affected and diminished when noise is present in the images. Due to its noise resilience, our proposal level of performance is reduced slightly and the method gets the best average F-measure values over almost all noisy videos (8 over 9) except compression 10 noise (Table 1).
It is also remarkable our method good performance with dynamicBackground and night categories when adding noise (Tables 3 and 6).
Comparison between PMDAPF and the method from [5] (denoted as PRL2019), both with 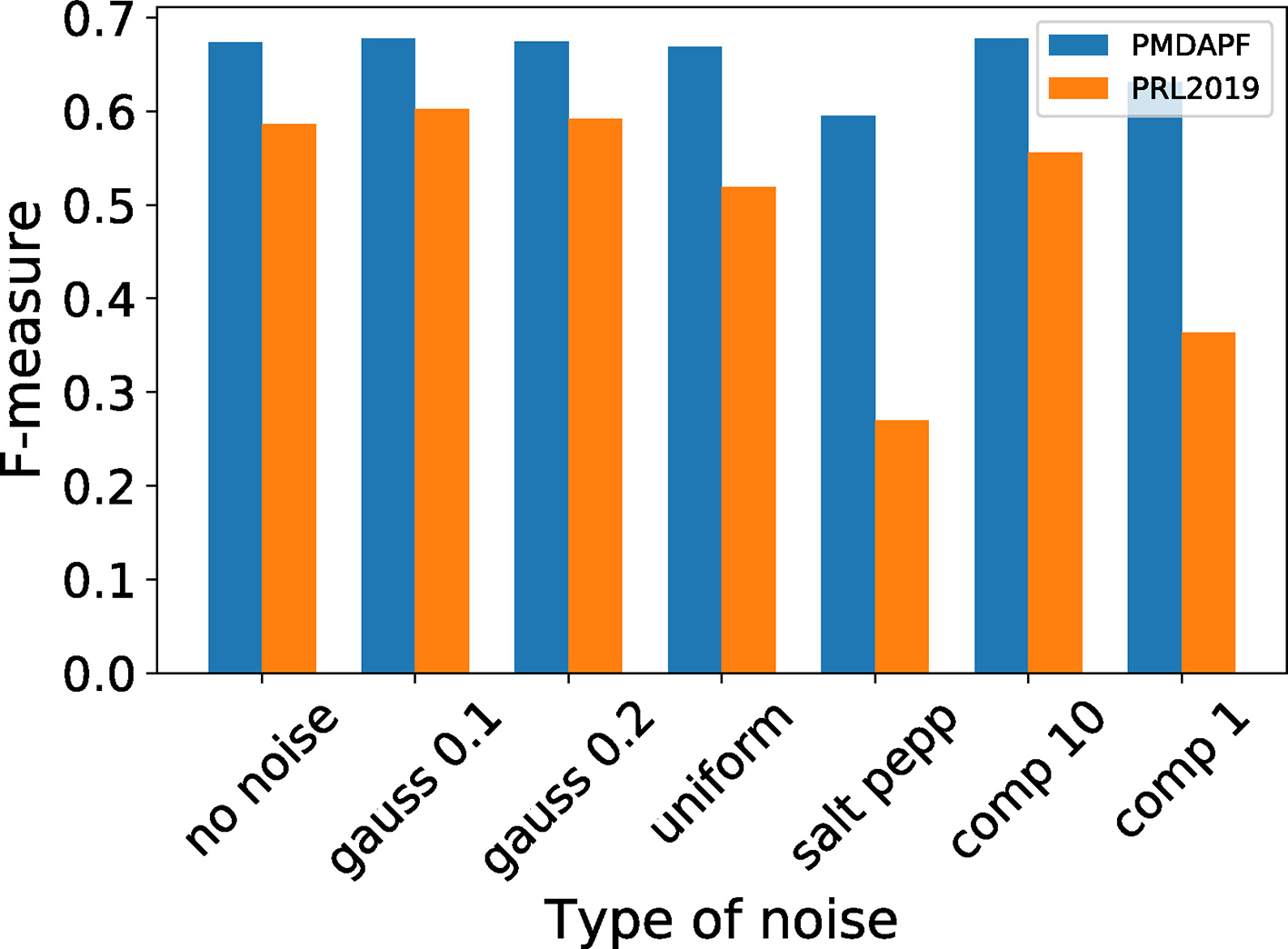
Quantitative results for dynamicBackground category. Table shows average F-measure (and standard deviation) value for all videos for each method and noise. The higher, the better. Bold value indicates the best result within the row
Quantitative results for badWeather category. Table shows average F-measure (and standard deviation) value for all videos for each method and noise. Bold value indicates the best result within the row
Quantitative results for shadow category. Table shows average F-measure (and standard deviation) value for all videos for each method and noise. The higher, the better. Bold value indicates the best result within the row
Quantitative results for night category. Table shows average F-measure (and standard deviation) value for all videos for each method and noise. The higher, the better. Bold value indicates the best result within the row
Qualitative results for the image 1275 from fountain02 from dynamicBackground category: First row shows original frames with different noises and ground truth GT. Following rows show the different segmentations created by our method, WREN, ZIVKOVIC, PAWCS, SUBSENSE, KDE, SOBS and SOBS_CF respectively.
On Fig. 6 some examples of the behavior of our method compared to others can be observed. In accordance with quantitative tables, methods WrenGA, SOBS, ZivkovicGMM, ElGammalKDE and SOBS_CF generate images full of False Positives in cases where the input images are noisy. In addition, more complex methods such as PAWCS and LOBSTER show this behaviour when Gaussian and uniform noise is added. PMDAPF seems to be less accurate than the other methods when segmenting foreground objects in frames without noise, though it is able to maintain a similar level of foreground segmentation performance even in noisy images. It is also able to avoid the massive generation of False Positives shown by most methods in those tests where noise was added. Moreover, it does not suffer from the increase of False Negatives that affects SUBSENSE when Gaussian and uniform noise is present.
The average performance value as threshold
Since PMDAPF is conceptually based on the previous work [5], a comparison using five sequences with 7 variations (raw and with 6 different types of noise) has been included and its results can be seen on Fig. 5.
A foreground detection method for video sequences which represents the background as a probabilistic mixture model has been proposed. In order to provide estimations of the background probability for each image pixel, the method considers the
The chosen probability mixture model comprises a multivariate Gaussian mixture component with diagonal covariance matrix for the background of the scene, and a uniform mixture component for the foreground. This way, the foreground component is able to model equally well any incoming foreground object, while the background component specializes in the particular characteristics of the background region at hand. Stochastic approximation theory is employed to derive the learning algorithm for the probabilistic mixture. Finally, a Bayesian classification is carried out in order to obtain the background and foreground probabilities, according to suitably learned a priori probabilities.
The experimental design includes several heterogeneous scenes, with and without noise. These scenes have been processed by our method and other eight competing background modeling methods. According to the obtained results, the robustness of our method is outstanding. Not only it is able to keep a good performance even in the presence of moderate noise, but it also stands as the method that works best with very noisy sequences, which make the performance of the other methods fall drastically whereas the proposed method is just slightly affected. These experimental results confirm the validity of the proposed feature extraction architecture, the chosen probabilistic model and its associated learning algorithm.
As future work, a study about the influence of the autoencoder architecture in the performance of the probabilistic model could be developed. Different number and type (convolutional or dense) of layers and distinct number of neurons would be tested for that purpose. On the other hand, it is planned to analyze the influence of variational autoencoders (VAE) in the field of background modeling, since they try to represent the encoding latent space in a more organized way. Finally, from a supervised point of view, it is possible to consider the use of recurrent neural networks, since the significant information in video sequences is both spatial and temporal. This would permit the definition of end-to-end deep neural models, which would integrate both the representation of the codified information and the background modeling.
Footnotes
Acknowledgments
This work is partially supported by the Ministry of Economy and Competitiveness of Spain under grants TIN2016-75097-P and PPIT.UMA.B1.2017. It is also partially supported by the Ministry of Science, Innovation and Universities of Spain under grant RTI2018-094645-B-I00, project name Automated detection with low-cost hardware of unusual activities in video sequences. It is also partially supported by the Auto-nomous Government of Andalusia (Spain) under project UMA18-FEDERJA-084, project name Detection of anomalous behavior agents by deep learning in low-cost video surveillance intelligent systems. All of them include funds from the European Regional Development Fund (ERDF). The authors thankfully acknowledge the computer resources, technical expertise and assistance provided by the SCBI (Super-computing and Bioinformatics) center of the University of Málaga. They also gratefully acknowledge the support of NVIDIA Corporation with the donation of two Titan X GPUs used for this research. The authors acknowledge the funding from the Universidad de Málaga.