
Abstract
Ensemble learning has demonstrated its efficiency in many computer vision tasks. In this paper, we address this paradigm within content based image retrieval (CBIR). We propose to build an ensemble of convolutional neural networks (CNNs), either by training the CNNs on different bags of images, or by using CNNs trained on the same dataset, but having different architectures. Each network is used to extract the class probability vectors from images to use them as representations. The final image representation is then generated by combining the extracted class probability vectors from the built ensemble. We show that the use of CNN ensembles is very efficient in generating a powerful image representation compared to individual CNNs. Moreover, we propose an Averarge Query Expansion technique for our proposal to enhance the retrieval results. Several experiments were conducted to extensively evaluate the application of ensemble learning in CBIR. Results in terms of precision, recall, and mean average precision show the outperformance of our proposal compared to the state of the art.
Introduction
Content Based Image Retrieval (CBIR) is the procedure of automatically identifying images by the extraction of their low-level visual features like color, texture, shape properties or any other features being derived from the image itself [1]. The well-known ’semantic-gap’ issue that exists between low-level features of images and high-level semantic concepts perceived by humans has been addressed through a variety of techniques [2, 3, 4, 5, 6].
However, the huge diversity of semantical concepts contained in images suggest that many robust discrimination and learning techniques are needed. In that respect, deep learning has become a significant step forward in the already developing fields of computer vision. It is a technique which includes a family of machine learning algorithms that attempt to model high-level abstraction in data by employing deep architectures composed of multiple non-linear transformations [7, 8]. These models are originated from computational models inspired by the structure and functions of the brain called artificial neural networks. The main reasons behind its success are the availability of large annotated datasets and the computational power and affordability of GPUs. A typical example of deep architectures are feed-forward neural networks with many hidden layers, and backpropagation [9] as a learning algorithm. Recent successes of deep learning techniques, especially Convolutional Neural Networks (CNNs) [10] in solving computer vision and image understanding tasks [11, 12, 13, 14, 15] have inspired us to explore this approach with aim to end up with more robust and better performing CBIR systems.
In recent years, the study of CNN architectures for classification problems is mainly divided into two directions. One is to design a deep network structure to study the effect of depth on classification. Another direction is to optimize the network structure and integrate the outputs of different network structures or different training methods as the final result. This paper is based on the second idea because it is known that ensembles of neural networks are much more robust and accurate than individual networks [16, 17]. Ensemble learning is a machine learning paradigm where multiple learners are trained to solve the same problem. In this work the ensemble is composed of CNNs as base learners. The employment of different base learners generation processes and/or different combination schemes leads to different ensemble methods. Unlike our previous work [18] which is based on the use of individual CNNs, in this paper we propose to build an ensemble of Convolutional Neural Networks to identify the most relevant images in the database for a query image. To describe in detail the proposed model as well as the experimental results, the article is organised as follows. Section 2 introduces some previous related works. The methodological aspects associated with the development of the mentioned neural network system are detailed in Section 3. Experimental setup and results are presented and discussed in Section 4. Finally, conclusions are given in Section 5.
Related work
After the success of deep convolutional neural networks in large scale image classification [10], CNNs have been applied successfully to many computer vision tasks [19, 20, 21, 22, 23, 24, 25] including image retrieval by content.
Early applications of CNNs in image retrieval consisted in extracting features from fully connected layers [26, 27]. However, due to the lack of spatial information in deeper layers, later works used convolutional layers instead [28, 29, 30].
Features can be extracted from either a pretrained or a fine-tuned network. VGG [31] and RESNET [32] are examples of pretrained networks, which are widely used in the literature [33, 34, 35]. The experiments in [36] do not only show the improvements that can be achieved through deep learning in multimedia and computer vision, but also show how to apply and adapt an existing deep learning model trained in one domain to a new CBIR task in another domain. Fine-tuning allows adapting the network to a desired task such as landmark retrieval [37, 38]. In [37] Babenko et al. introduced “The Landmarks dataset” to evaluate fine-tuned CNNs and obtained good results. In [38], another large-scale challenging dataset was introduced, labeled “Google-Landmarks”. This dataset was utilized to retrain Resnet50 for effective feature extraction.
In general, works in CBIR that adopt deep learning focus on enhancing the discrimination power of extracted convolutional features. A variety of techniques for improving the final image representation was proposed. As examples, the work presented in [39] proposed a CBIR system based on a CNN and a SVM, where the CNN is used to extract the feature representations and the SVM is used to learn the similarity measures. In the training of the SVM, the generation of a validation set helps to tune the parameters. Another case can be found in [40], where a Triplet-CNN model is employed. The latter contains three identical CNNs sharing all the weights and biases. Additionally, it is trained considering intra-class and inter-class distances. Furthermore, features were regarded as heat sources and weighted with the heat equation in [41]. So that the “hot” features were assigned larger weights to have an important impact in the retrieval. An unsupervised strategy was proposed in [42] to select the discriminative regions from which features were extracted. These regional features were weighted according to their corresponding regions and aggregated into a single feature vector. Authors in [38] proposed to extract feature maps from an image pyramid, and then they fine tuned RESNET50 to improve these features. Moreover, features were filtered using an attention based keypoint selection mechanism so that only the most powerful ones participated in the retrieval. In [43] three masks were presented for features filtering: SIFT-mask, SUM-mask, and MAX-mask. In addition, the authors used recent embedding and aggregation methods for better performance.
Most of CNN CBIR methods extract features from a single CNN. Alternatively, features can be extracted from several CNNs and then combined, which is the idea of “ensemble learning”. The motivation behind using an ensemble of CNNs is that the collaboration of several CNNs helps reducing the bias and the variance [44] and improving the accuracy.
Ensemble learning has been successfully applied to many problems [45, 46, 47, 48, 49, 50, 51]. An example of this is the model called “Hydra” for land use classification in satellite images [52]. It uses two state-of-the-art CNN architectures, which are ResNet and DenseNet to create ensembles of CNNs, varying the training set. During testing, each classifier output is the probability of each class being the correct one. A majority voting is then used to determine the final label. Very recently, some works were interested in applying ensemble learning in image retrieval by content [53, 54]. In [53] images were represented by combined hash codes, which were generated from multiple views. The hash codes were learned using an ensemble of classifiers, where each classifier was assigned a different image view. In [54] the authors proposed to learn images features using two different CNN architectures (NIN and Alexnet). Features vectors of each image were then combined using the weighted average of the outputs of each CNN.
Despite its demonstrated efficiency, ensemble learning is still poorly addressed in the area of image retrieval by content. However, it must be considered that the most recent works focused on the search of criteria to form a good ensemble: Dynamic ensemble learning algorithms [55]. This paper deals with the problem of automatically detecting NN ensemble architectures (number of NNs in the ensemble and number of hidden neurons in individual NNs) with the variation of training examples for each individual NN. This idea draws a promising future in the use of ensemble learning.
Methodology
We aim to design a Content Based Image Retrieval (CBIR) system based on deep learning neural networks. We propose to build an ensemble of Convolutional Neural Networks (CNNs), so that they collaborate to identify the most relevant images in the database for a query image. To this end, the CNNs to be combined must have an output layer with one output neuron for each object class in the training image database. They may have the same or different network architectures and parameter settings. Let us denote
where X is the input image, and
After all the CNN s are trained under the above specifications, an ensemble can be built from them. Let us denote
where
where
After the ensemble has been built, it can be employed to retrieve the most similar images in the database, given a user query. Let us denote
where
If we are interested in the
Such a ranking process can be used to evaluate the performance of our CBIR system or when a parameter must be tuned.
If the number of results is not specified, then a similarity threshold
It is possible to add a simple way to refine the search of the closest images to a given query image using Average Query Expansion on the model proposed above. The proposed method is inspired by KNORA-UNION algorithm for dynamic ensemble selection [56]. The basic idea is described below.
Given an ensemble of
We consider that a database image
Let
In that situation we generate a new query image vector by taking the average of the original
Thus, the suppression of misclassified samples allows the controlled construction of extended queries.
The designed CBIR system is described in Fig. 1, where a flowchart allows to follow the process from training the model to testing it. In the training phase, if the used CNNs share the same architecture, diversity is achieved through splitting the training images into
Schema of our proposal. The dashed frame corresponds to the bagging technique which is carried out only if the ensemble is composed of the same CNN architecture. The dashed arrows correspond to the Average Query Expansion process which can be applied on the query one time.
Methods
We have considered several recent well-known methods from the literature in order to compare our proposal with them. We took into consideration the best results of each competitor. The first method that we have selected is the approach that we denote as Wan[36]. In this work, images features are extracted from the last three fully connected layers and refined by similarity learning using the Online Algorithm for Scalable Image Similarity Learning (“OASIS”).
We also consider a method that we denote Cai[40]. In this algorithm, a triplet CNN-based architecture is used for feature extraction. First, the triplet CNN is retrained on the used dataset. After that, the features are extracted from the last two fully connected layers and then combined in order to obtain an efficient representation with different semantic levels.
The last competitor method is denoted as Fu[39]. It uses a CNN to extract images features. After that, an SVM is trained on the dataset to differentiate between similar images and dissimilar ones.
Regarding our proposal, it uses several CNNs having the same or different architecture. This way, well-known CNNs have been employed in the experiments:
VGG[57]: This architecture is characterized by the small size of convolutional filters receptive field (3 ResNet[32]: The main characteristic of this network is its depth which is up to 152 layers. Moreover, it has residual connections that decrease the complexity of the network and make its training easier. Similar to VGG, this architecture has 3 ResNetV2[58]: ResNetV2 is an improved version of ResNet. The main difference is in use of identity skip connections and identity after-addition activation to fasten the propagation of information. Similar to ResNet, this architecture is available with different depths, resulting in three variants: Resnet50V2 (50 layers), ResNet101V2 (101 layers), and ResNet152V2 (152 layers). Inception[59]: The variants that we use are InceptionV3[60] and InceptionResNet [61]. The latter are successors of InceptionV1 (GoogleNet) and they inherit the use of special layers called “Inception layers/modules”. Instead of doing a single operation on an input, an inception module allows several operations in parallel: 1 Xception[62]: It is worth mentioning that Xception is inspired by Inception architecture, i.e. it allows using several operations in the same layer. However, unlike Inception these operations are restricted to convolutions. Thus, Inception modules are replaced by special convolutions called “depthwise separable convolutions”, where, instead of having one convolution, several independent convolutions followed by a pointwise convolution are carried out. Note that a pointwise convolution has a filter size of 1 MobileNet[63]: We use the two versions of MobileNet architecture: MobileNet and MobileNetV2. This architecture is designed for mobiles and embedded vision applications. Similar to Xception, it uses depthwise separable convolutions to reduce the computational cost. However, the filter size is fixed to 3 Densenet[65]: The concept of Densenet architecture is based on residual connections introduced in ResNet. The idea is to connect each layer to all subsequent layers, in a manner that every layer has the outputs of all predecessor layers. This leads to a better propagation of information and speeds up the training. We use this architecture with different depths: DenseNet-121 (121 layers), DenseNet-169 (169 layers), and DensNet-201 (201 layers). NasNet[66]: The main novelty is that the architecture is learnt on a small dataset (Cifar [67]) using reinforcement learning, after that this architecture is used to train the network on a large scale dataset (ImageNet). Moreover, it uses “ScheduledDropPath” as a new regularization technique, which improves the model’s accuracy. The concept of the variants NasNetMobile and NasNetLarge is the same, with the difference that NasNetMobile is conceived for mobile devices.
In order to code our approach, the used programming language was Python with its machine learning library Keras1 running on top of Tensorflow.2
The experiments have been conducted on Google colab3 running on a NVIDIA Tesla k80 GPU.
Our proposal is evaluated on two benchmark datasets:
Caltech2564[57]: This dataset contains 30,608 images, grouped into 256 semantic categories. Moreover, it exhibits at least 80 images per category.
ImageNet5[68]: In order to evaluate our proposal on a large number of classes, we use the “ILSVRC-2010” dataset which is a subset from ImageNet. This dataset contains 1.2 million images for training, 50,000 images for validation, and 150,000 images for testing, all grouped into 1000 categories.
The great variety of categories included in both datasets can be observed in Fig. 2, where some samples are shown.
Samples of Caltech256 and ImageNet datasets.
In regards to Caltech256 dataset, for a fair comparison with methods Wan [36], Cai [40] and Fu [39], we follow the same experimental setting by using subsets of 20 and 50 classes from Caltech256 dataset, and images from each class were randomly split into training and testing sets of 40 and 25 images, respectively. Moreover, 15 images from each category were randomly selected for validation. In each subset, the classes were selected as suggested in [69]. The motivation behind this selection is to include diverse categories in terms of their semantics and their classification difficulty as measured by [57], where it is shown that the performance varies depending on the selected class.
For ImageNet dataset, the validation set is split into testing set and retrieval database. We select one query per category to evaluate our proposal, that is 1000 testing images. Moreover, we use 5000 images as a retrieval database, equally grouped into the 1000 categories. Images in both testing and validation sets were randomly selected.
In order to achieve diversity, we evaluated two ensemble techniques to generate the pool of classifiers. The first one is the bagging technique [70]. In the corresponding experiments,
The second ensemble technique is the use of classifiers having different architectures. All available pretrained CNNs in Keras library are used in this second technique, that is 18 different architectures. This second technique is evaluated on ImageNet dataset. Herein, no training phase is carried out, since the used CNNs are already trained on this dataset.
In the rest of the paper, we denote both techniques with the name of the used dataset in each experiment. That is, Caltech256 (or ensemble with networks with the same architecture) and ImageNet (or ensemble with networks with different architectures).
Results
In order to evaluate our proposal from a quantitative point of view, we have employed some well known performance evaluation measures. These measures are: Precision at
where
Additionally, the average precision is defined by:
Please note that the number of the required iterations in Eq. (14) is the number of the retrieved images
If the number of images to retrieve is defined, precision and recall are denoted as
We have studied the impact of several parameters on the performance of our proposal. The first parameter
A comparison between several
Impact of the ensemble size on the mAP for Caltech256 and ImageNet datasets where the considered methods are mean and median.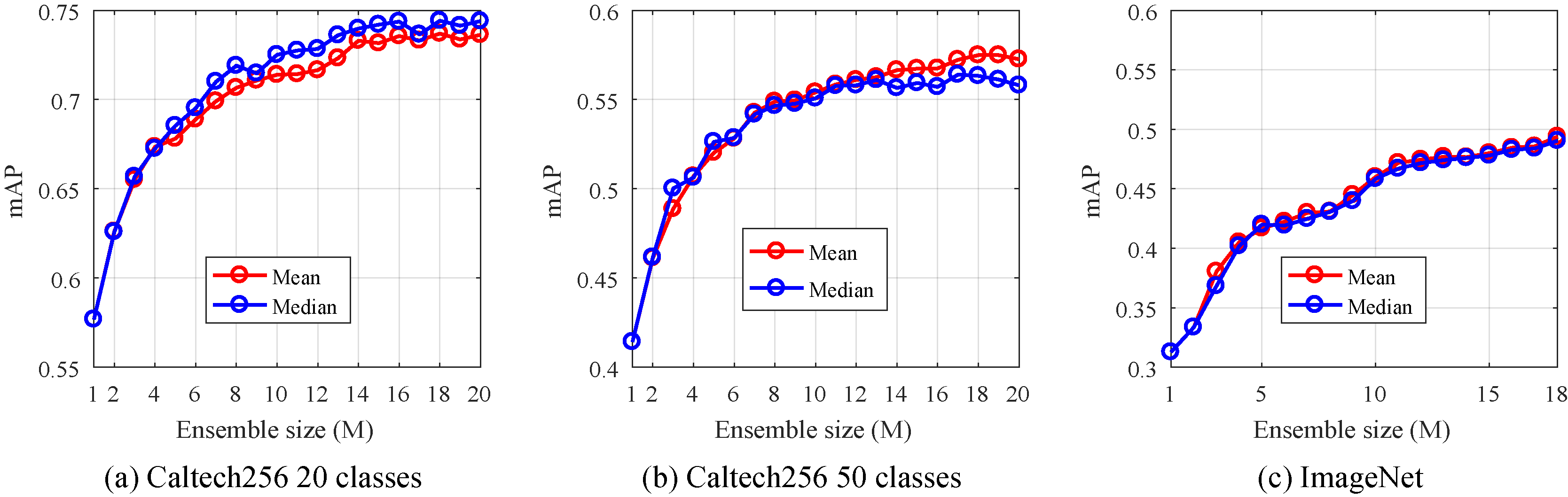
Impact of the ensemble size with respect to the classifiers accuracy on the mAP for Caltech256 and ImageNet datasets, where the considered methods are mean and median. 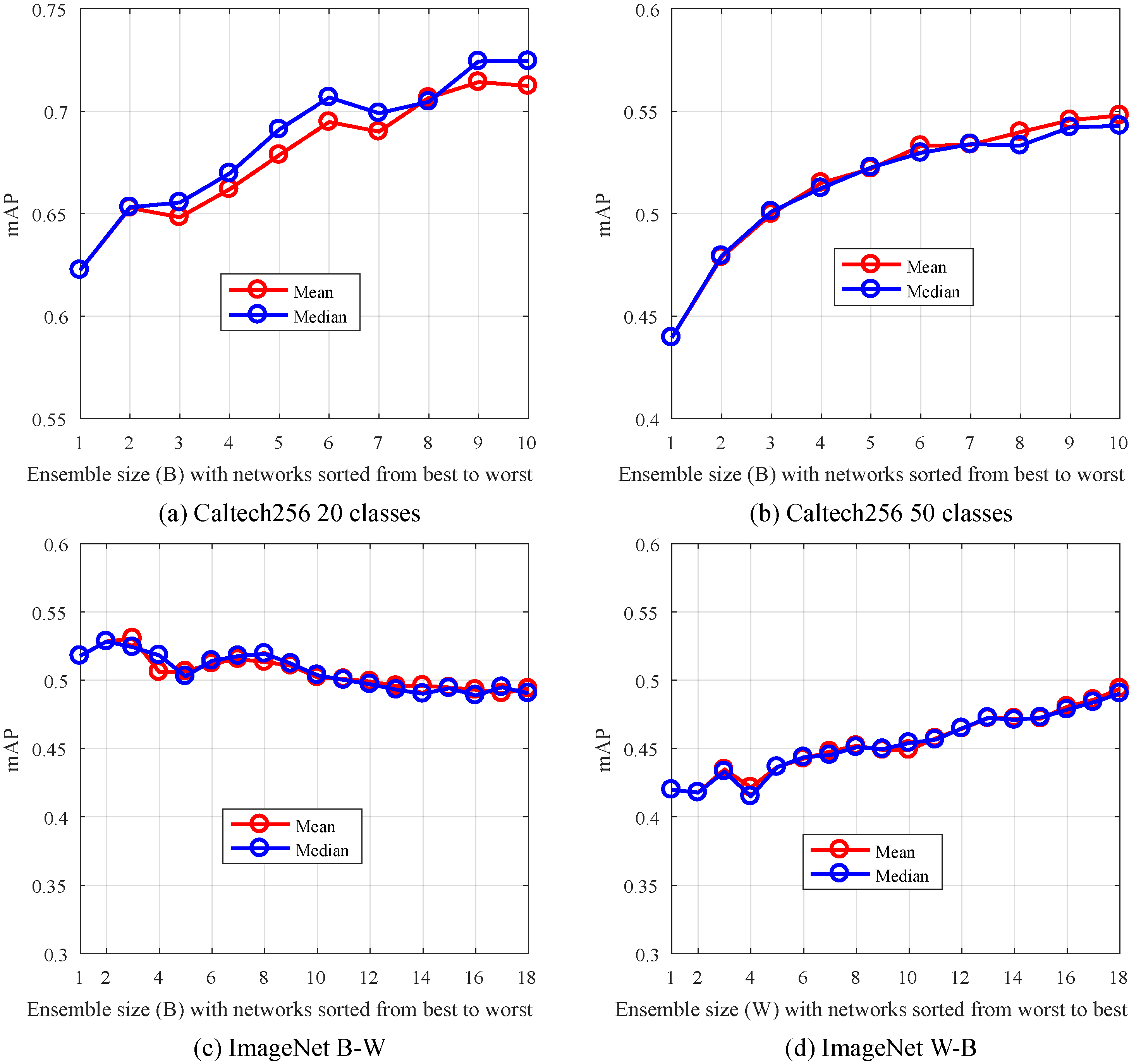
Moreover, we have studied the impact of the ensemble size
For 50 classes, The highest mAP is 0.5749 using the mean, where
For the same dataset, the most important margin in terms of mAP was recorded between ensemble sizes
Based on these results, the ensemble size
The general decrease in the classification performance when we pass from 20 classes to 50 classes is due to the greater difficulty in separating more classes. Our ensemble proposal is not related to this performance decrease, since it can be seen in Fig. 3 that the effect is present even for just a single CNN (ensemble size
Regarding ImageNet dataset, a significant improvement is observed for 1
In the same way, we ordered the CNNs from worst to best (W-B), and created ensembles of size
Image retrieval performance on the experimented datasets, best results are highlighted in
Precision and recall in terms of distance threshold on Caltech256 and ImageNet datasets. The considered methods are: Base, Mean, and Median, where results are shown in the left, middle, and the right of the figure, respectively. Images from the first row correspond to Caltech256 with 20 classes, images from the second row correspond to Caltech256 with 50 classes, and images from the third row correspond to ImageNet dataset.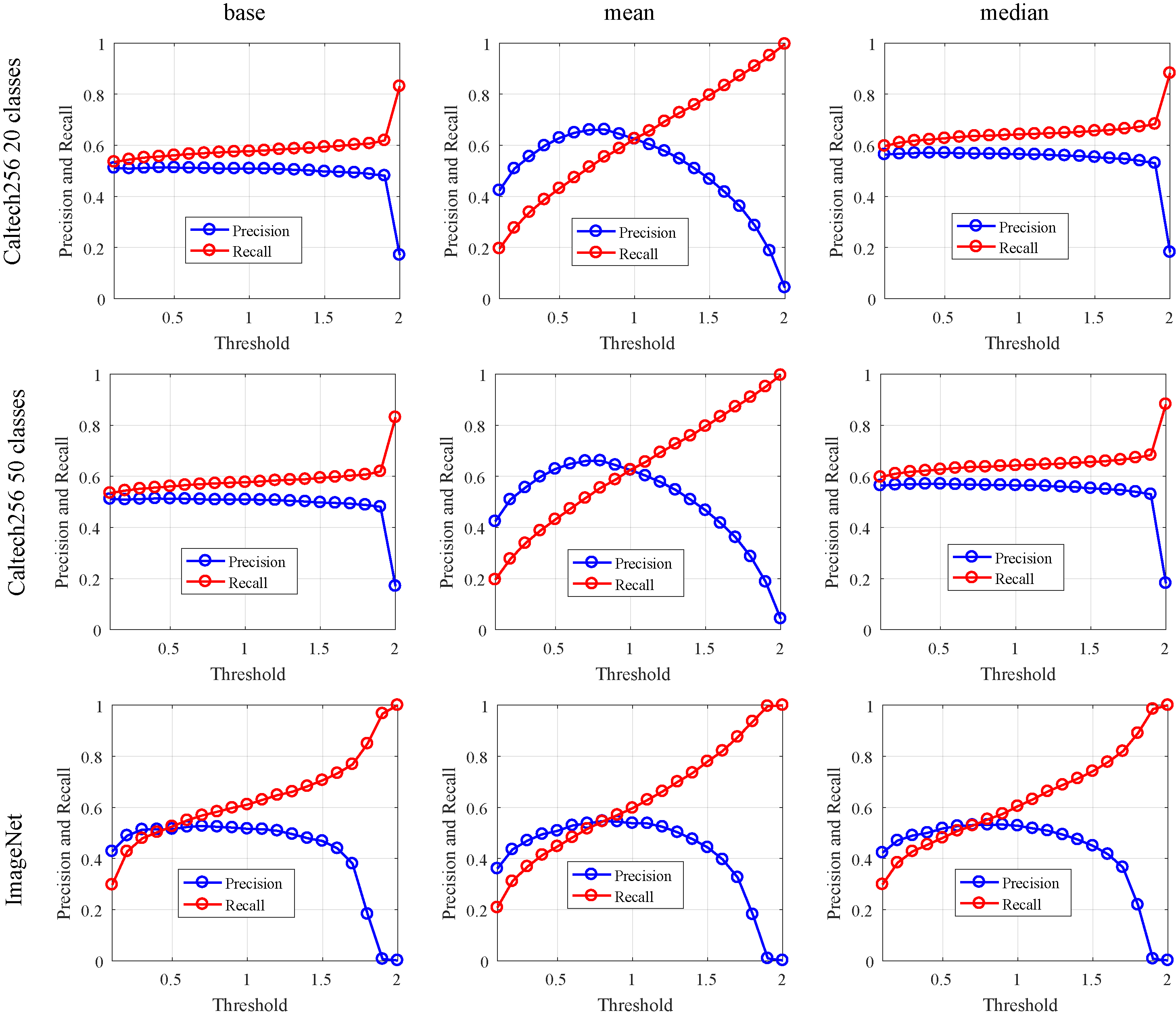
Based on these results, for ImageNet dataset
We repeated the experiment where classifiers are sorted from Best to worst on Caltech256 dataset. The classifiers are sorted based on their accuracy on the training and validation sets. We selected
The retrieval of similar images can be done either by defining the number of images to retrieve, or by considering a threshold for the distance between the query and the database images. After deciding the ensemble size
Taking into account these analyzed configurations, the performance of our CNN-based methods is shown in Table 2. We refer to the ensemble methods as Mean and Median, where the mean and the median were used to combine the extracted class probability vectors using each ensemble member, respectively. We refer to the base classifier as base. This classifier was trained on the whole training set and used individually to extract the class probability vectors from images. For the two datasets, the results show that both ensemble methods outperform significantly the base classifier in terms of all performance evaluation measures. The exception occurs in
mAP using the mean and the median with and without applying the Average Query Expansion to Caltech256 dataset, best results are highlighted in
Comparison between our proposal (mean and median) and related methods in terms of mAP, best results are highlighted in
The reason behind the outperformance of the ensemble architecture is that the latter takes advantage of the lack of correlation between the base learners. This lack of correlation is produced by training the CNNs on different bags of images. Thus, the CNNs are able to learn different patterns from images and make independent errors. For instance, if a CNN misclassifies a given input, then the collaboration of other CNNs may correct this error by combining their provided outputs for this image. Consequently, the ensemble is able to provide more powerful predictions, resulting in the improvement of the retrieval quality.
Impact of the number of neighbours considered in the Average Query Expansion technique on the mAP for Caltech256 dataset, where the considered methods are mean and median. 
A query image and the top 10 returned images from both Caltech256 and ImageNet datasets using the mean and the median.
Finally, we have applied the previously mentioned post processing technique called Average Query Expansion. We investigated the impact of the parameter
Results can be observed from a qualitative point of view. Figure 7 shows an example of a query and the top 10 retrieved images. In the given example, for Caltech256, both mean and median performed equally in terms of precision, where (
In order to further check the performance of our proposal, we compared it against relevant retrieval methods. The comparison is carried out on Caltech256 dataset in terms of mAP. In order to be comparable with the selected methods, the parameter
A novel architecture for image retrieval by content has been presented. This architecture is based on an ensemble of CNNs, which are trained on different bags of images, so that a variety of class probability vectors could be acquired from each image. The obtained image probability vectors are then combined into a single vector as a final image representation. Finally, we applied an Average Query Expansion technique to our proposal to improve the retrieval quality.
The averaging of the class probability vectors coming from an ensemble of CNNs has the beneficial effect that the expected error of the average probability vector with respect to the true probability vector is lower than the expected error of any individual probability vector coming from a single CNN and the true probability vector.
Results show that our method outperforms the state of the art in terms of mAP. However, ensemble based architectures are computationally expensive, i.e. our architecture takes more time in the output prediction depending on the ensemble size. The delay in the response time will be more significant for larger-sized ensembles. Thus, employing the proposed architecture depends on how critical the response time is in the desired CBIR system.
The key idea of our contribution is to build an accurate classifier by combining several weak learners. In this regard, it should be emphasized that it is possible to address this issue within CBIR, i.e. enhancing the class probability vector using other techniques. Away from ensemble methods, EPNN [71] and NDS [72] are individual classifiers that aim at enhancing the classification accuracy. In EPNN, the improvement in the classification is achieved through considering local information and heterogeneity in the training data. In addition, NDS aims at discovering feature spaces that maximize margins between clusters and minimize them between classmates. Thus, our contribution leaves open the possibility of exploring other classification models within the CBIR area.
Finally, it can be interesting to study possible improvements in this proposed architecture. One idea could be a dynamic selection of an ensemble of classifiers from the pool. Dynamic ensemble selection may empower the proposed architecture by selecting the most powerful classifiers for each image and reducing the computational cost.
Footnotes
Acknowledgments
This work is partially supported by the Ministry of Economy and Competitiveness of Spain under grants TIN2016-75097-P and PPIT.UMA.B1.2017. It is also partially supported by the Ministry of Science, Innovation and Universities of Spain [grant number RTI2018-094645-B-I00], project name Automated detection with low cost hardware of unusual activities in video sequences. It is also partially supported by the Autonomous Government of Andalusia (Spain) under project MA18-FEDERJA-084, project name Detection of anomalous behavior agents by deep learning in low cost video surveillance intelligent systems. All of them include funds from the European Regional Development Fund (ERDF). In addition, this work is partially supported by DGRSDT – Ministry of Higher Education and Scientific Research of the Algerian Government through a PRFU project [grant number A10N01UN2101201800001]. The authors thankfully acknowledge the computer resources, technical expertise and assistance provided by the SCBI (Supercomputing and Bioinformatics) center of the University of Málaga. They have also been supported by the Biomedic Research Institute of Málaga (IBIMA). They also gratefully acknowledge the support of NVIDIA Corporation with the donation of two Titan X GPUs used for this research. The authors also thankfully acknowledge the support of the Universidad de Málaga. Authors are also immensely grateful for ERASMUS+ program, CEI.MAR (Campus de Excelencia International del Mar), and University of Skikda 20 August 1955 for making this collaborative work possible.