
Abstract
In technical systems the analysis of similar situations is a promising technique to gain information about the system’s state, its health or wearing. Very often, situations cannot be defined but need to be discovered as recurrent patterns within time series data of the system under consideration. This paper addresses the assessment of different approaches to discover frequent variable-length patterns in time series. Because of the success of artificial neural networks (NN) in various research fields, a special issue of this work is the applicability of NNs to the problem of pattern discovery in time series. Therefore we applied and adapted a Convolutional Autoencoder and compared it to classical nonlearning approaches based on Dynamic Time Warping, based on time series discretization as well as based on the Matrix Profile. These nonlearning approaches have also been adapted, to fulfill our requirements like the discovery of potentially time scaled patterns from noisy time series. We showed the performance (quality, computing time, effort of parametrization) of those approaches in an extensive test with synthetic data sets. Additionally the transferability to other data sets is tested by using real life vehicle data. We demonstrated the ability of Convolutional Autoencoders to discover patterns in an unsupervised way. Furthermore the tests showed, that the Autoencoder is able to discover patterns with a similar quality like classical nonlearning approaches.
Introduction
A pattern is informally defined as recurring similar subsequences within a time series. As the focus of this work is unsupervised pattern discovery, the patterns are unknown in advance. Depending on the background of the user the intuition of a pattern can vary a lot and therefore lead to misunderstandings. One of the most used names in the wide field of pattern discovery in time series is motif discovery. Unfortunately definitions of motifs are not consistent in the literature. For example within the Matrix Profile approach it is defined as “the most similar subsequence pair of a time series” [1]. while Lin et al. described it as “a pattern that consists of two or more similar subsequences based on some distance threshold” [2]. To solve this inconsistency this work assumes a motif to be defined as a query subsequence and the subsequence that is most similar to the query, while the task of motif discovery is to find the best (most similar) motifs. Hence, a motif always only consists of two subsequences. In contrast to this a pattern is a group of
In general, we need reliable methods to detect recurring patterns with variable and previously unknown length in noisy time series. A pattern and its members should be similar in shape and invariant regarding offset and amplitude. Beyond this, we allow members of a pattern to be scaled in time to a certain amount. Suitable approaches need to be able to process data sets with far more than one million data samples at a reasonable runtime. Furthermore we also need to detect patterns in multivariate time series. However, in this paper we limit our analysis for simplicity to the univariate case. Following these requirements we will compare four different approaches from different research areas. First of all, the focus of this work is the investigation and development of an approach for pattern discovery based on artificial neural networks (NN). As a reference three nonlearning2 approaches will be implemented, that have already been proposed in previous work of [3].
Motivation
The analysis of time series data recorded from the operation of complex mechatronic systems provides information on usage, condition or even misbehavior of systems or components. In order to obtain long-term information on these objectives an analysis of the entire data record is required. In the context of wear-off or aging of systems having recurring load patterns it is advantageous to compare only such patterns. In our use case, we cannot expect experts to specify suitable patterns and therefore we need unsupervised methods for automatic definition of such recurring stress patterns without input of expert knowledge. The previously listed requirements for an unsupervised pattern discovery method are derived from these use cases.
In recent years the research in NNs succeeded in many disciplines. Rodríguez Lera et al. [4] for example, proposed a feedforward NN to recognize human activities in “at home” scenarios. In [5] Lara-Benítez et al. developed a deep learning framework for streaming data classification. A convolutional NN was applied by Molina-Cabello et al. in [6] in order to detect differenent kinds of vehicles based on video data. Macias-Garcia et al. [7] even applied two NNs in parallel to seperately detect obstacles and targets for mobile robots. Due to the great variety of applications it is evident to evaluate the possibility to apply NNs to the problem of unsupervised pattern discovery, too. While there are existing nonlearning approaches for our requirements, the amount of approaches based on NNs is nearly not existing. In this work we want to investigate the possibility to discover interpretable patterns based on NNs and rank them regarding nonlearning approaches.
Related work
In general NNs can be applied as supervised or unsupervised learning techniques. In the case of supervised use cases, like classification tasks, a great variety of NNs has already been developed to enhance classical feedforward NNs. In [8] for example, the authors proposed a more robust and dynamic approach for the optimization of their NN-based classifier and compared it to an enhanced probabilistic NN, which contains Bayesian rules and is said to be simpler and more efficient [9]. In [10] the authors even used an ensemble of NNs and proposed a technique to automatically design the ensemble. For the sake of completeness, there are also modern learning techniques that are not based on NNs. For example in [11] the authors proposed a finite element machine classifier for supervised learning problems. Even though these learning techniques are very interesting for the supervised case, they are not explicitly made for the unsupervised case of finding patterns without their prior knowledge.
The basic idea of the NN-based approach relies on the unsupervised feature-learning in time series data, while these features should represent or correlate with the patterns that need to be identified. In general [12] gives a good overview of techniques concerning the unsupervised feature learning in time series, but it does not focus on the extraction of sequential patterns, like it is necessary for our use cases. Instead, the interpretability of these features is mostly difficult, which is not a problem for e.g. classification tasks. In [13, 14] the authors proposed unsupervised feature learning techniques to identify shapelets, which are maximally discriminative features of time series. In [15] shapelets are defined as “subsequences which are in some sense maximally representative of a class”. Unfortunately this definition does not totally match with the definition of a pattern. A technique that is closely related to our pattern discovery problem is Convolutional Autoencoding. By the use of fully convolutional layers in NNs it is possible to extract e.g important and recurring parts of images. In [16] Benamara et al. for example applied convolutional NNs to extract human emotions based on facial images. Autoencoders like in [17, 18, 19] are able to learn important features of the input data by first encoding the input data to a lower dimensional space and then decoding it to reconstruct the input. While the unsupervised extraction of patterns from image or video data is a common task for Convolutional Autoencoders (CAE), the pattern discovery in time series is an underrepresented problem. In the following sections we take up some ideas regarding the architecture of CAEs from [17] and complement them by multiple additional methods to detect recurring patterns in time series data.
The first nonlearning reference approach is based on the principle of dynamic time warping (DTW). DTW is a distance or similarity measurement for time series with different lengths with the possibility to stretch or compress one of the time series to fit the other one [20]. Beyond that, DTW can be adjusted and extended to the problem of discovering patterns. The authors of [21] proposed a DTW-based algorithm called CrossMatch to identify similar subsequences in different sequences without the need of a query sequences. A similar technique is described in [22] where the approach is extended by a hierarchical clustering algorithm to find patterns.
The second type of approach is based on the symbolic representation of the time series, which is interesting in terms of reduction of complexity and therefore also for the reduction of runtime. However, these approaches can be more sensitive against noise than those based on DTW. To get a symbolic representation, there are many methods for time series discretization. The Symbolic Aggregate Approximation algorithm (SAX) [23] and other symbolic time series methods use intervals with equal probability. Besides, there is the possibility to use intervals of equal size. The relevance of symbolic approaches is evidenced by the variety of existing pattern discovery algorithms from various research fields like bioinformatics or text mining. For example in bioinformatics the Smith Waterman algorithm is used for sequence alignment, meaning the pattern discovery in DNA sequences [24]. As DTW, Smith Waterman is based on dynamical programming and is able to find time scaled patterns. The Sequitur algorithm, proposed in [25], extracts the hierarchical structure of a symbolic sequence by replacing recurring phrases with grammatical rules while forming a dictionary of these rules, which is formally known as grammar induction. Sequitur identifies only identical patterns and ignores possible similarities in rules/patterns. Furthermore it is not guaranteed to find all the patterns in the sequence, because of its replacing procedure. Pattern enumeration is often referenced to cope with this problem. To perform time scaled pattern discovery with those algorithms numerosity reduction techniques have been proposed, as e.g. employed in [2]. Especially for long sequences the number of enumerated patterns can increase exponentially. That is why there is also research in constraint programming techniques like in [26] or [27]. Beyond these methods, there is a huge amount of algorithms regarding pattern mining in symbolic sequential data summarized in [28].
The third approach is the Matrix Profile introduced by Keogh, Mueen, Yeh and Zhu [29]. Basically, it is a brute force approach to find motifs or patterns of a fixed length by calculating the distances between every possible query sequences and every other sequence of the chosen length. Nevertheless, since the Matrix Profile I was published in 2016 it grew to an open source framework for many time series analysis task. Until today the authors published more than 20 papers regarding the optimization, extension and application of Matrix Profile, which are consecutively named as Matrix Profile I to XX [29, 30]. Unfortunately all these publications focus on using the z-normalized Euclidean distance as a distance measure. Hence, it only allows e.g. patterns to be similar just in shape and ignoring the offset or amplitudinal scaling. Beside that, longitudinal scaling is not supported. A possibility to solve these issues is to replace the z-normalized Euclidean distance by DTW. However, all those optimizations proposed in the Matrix Profile framework [31, 32, 33] are based on z-normalized Euclidean distance, which is why the computational intensity would be to high to be competitive. Beyond that, this theoretical solution still does not solve the problem of fixed length pattern discovery. In Matrix Profile X [34] and XX [30] the authors additionally proposed solutions to this problem, but again focused on z-normalized Euclidean distance. Due to the fact, that Matrix Profile is still a relevant approach, we implemented an optimized version of the standard Euclidean distance as a reference to other approaches.
Purpose and structure
First of all, this work will demonstrate the ability of NNs to discover unknown patterns. The architecture and techniques that are crutial in order to guarantee the functionality will be proposed and critically evaluated. Furthermore, this paper deals with the comparison of the NN-based approach regarding aforementioned nonlearning approaches. Our target is an evaluation concerning runtime, parameterization effort and pattern quality. Therefore we apply different quality measures, which gives us the opportunity to evaluate and compare different approaches.
The remainder of this work is organized as followed: In Section 2 an NN-based approach using CAE is proposed for the unsupervised discovery of patterns. Section 3 deals with nonlearning approaches, which were already been proposed in previous work [3] and are now considered as relevant references for the NN-based approach. Section 4 explains the approach for the comparison of pattern discovery algorithms equivalent to previous work [3]. Section 5 evaluates the results and gives statements concerning the assessment of different approaches. After discussing the developments and findings of this work in Section 6, Section 7 finally gives a conclusion and an outlook to future research regarding pattern discovery with unsupervised feature learning techniques.
NN-based approach for pattern discovery
There are many techniques for unsupervised feature learning in time series. Unfortunately most of these learned features lack in terms of interpretability. To solve this issue we chose a Convolutional Autoencoder (CAE) for further investigations. The idea is to reconstruct the input time series with convolutional encoding and decoding filters, while the filters contain interpretable features of the input time series. These features will represent the patterns that are contained in the input time series and which are necessary to reconstruct it. As we will show in the next sections by the use of 2D convolution, it is possible to interpret the extracted features as patterns in the common sense.
Convolutional autoencoder
We take up basic ideas of CAE architecture of [17]. It contains a convolutional and a sparsity layer, which are used for encoding the input images in a lower dimensional space. A deconvolutional layer then decodes the output of the sparsity layer to the input space. The convolutional and the deconvolutional layers consist of an equal number of filters, whereas one filter represents a pattern, which is necessary to reconstruct the input image. This network is trained by gradient descent method with the input being the desired output.
The approach of [17] offers the possibility to autoencode time series by 1D-convolution or images by 2D-convolution. We experienced that this architecture is rather optimized for autocoding of images instead of time series. In fact, we were not able to produce any kind of promising result with 1D-convolution. Due to more promising image autoencoding we decided to merge the advantages of 2D-convolution with time series analysis by creating a new 2D-representation of time series. In the end, this decision turned our to be the biggest enabler for NN-based unsupervised pattern discovery.
The time series is converted to a grey-scale image in two steps. First the time series is discretized with a given number of bins, as described in Section 3.2 of the discretization-based reference approach. Then the discretized time series is converted to an image by one-hot-encoding as shown for a small subsequence in Fig. 1. One major difference between a regular image and a time series image is its size. While a dataset of regular images always contains images of the same dimension, our time series dataset is just one very wide time series image. Hence, to fit this time series image in CAE we cut it in slices with an equal width.
Conversion of a discretized time series to an image; right: discretized time series; left: one-hot-encoded image.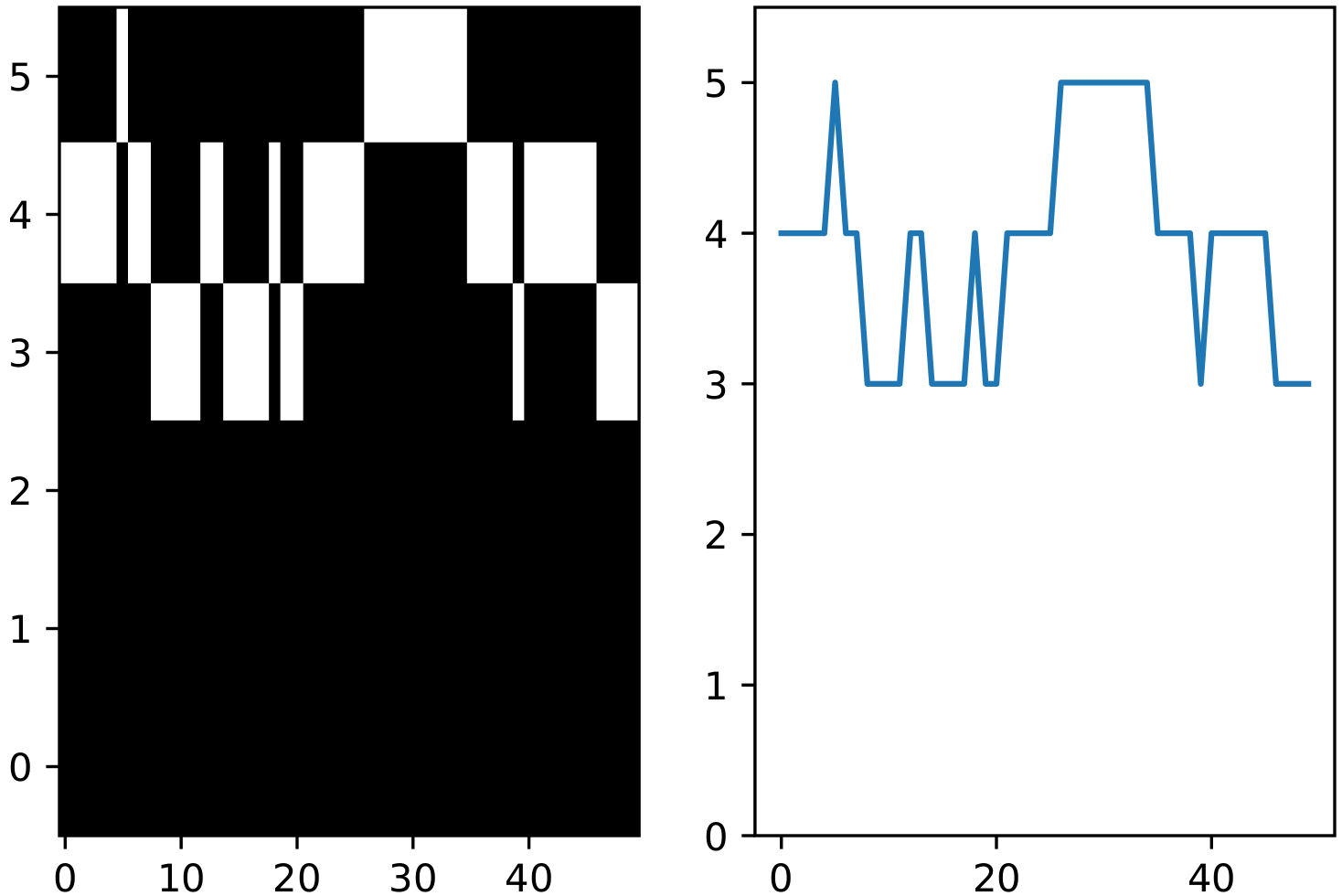
Exemplary input, filter, latent space and output of the Autoencoder for time series.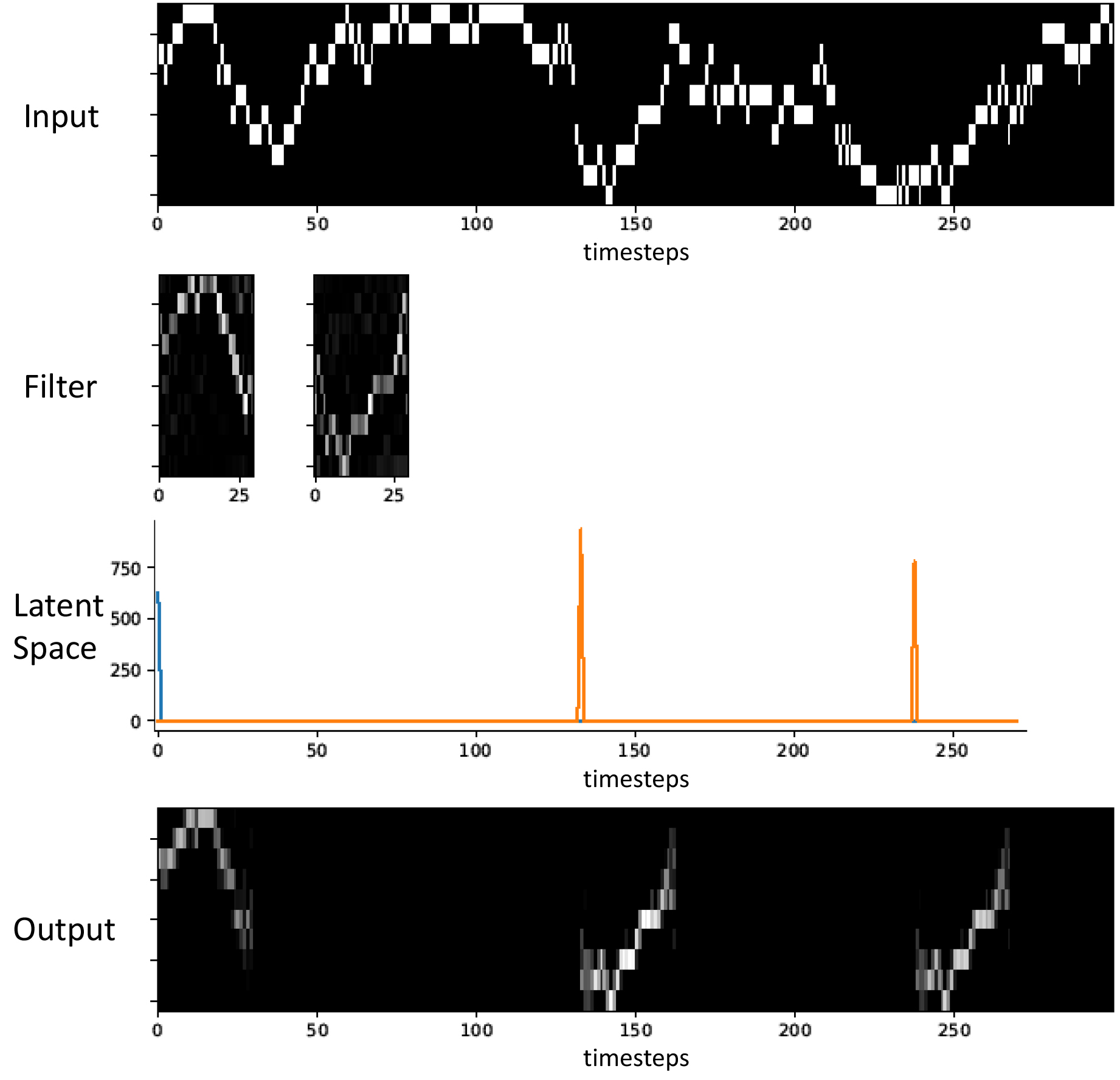
Left: good fit of a pattern; right: bad fit with noise.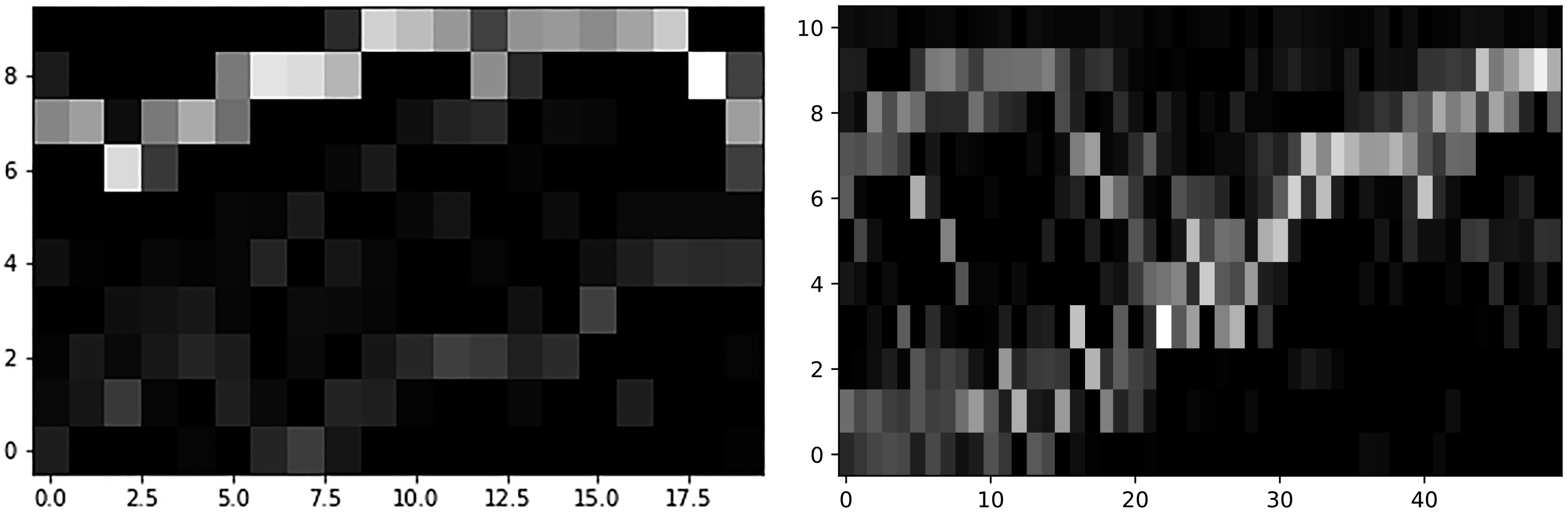
Assuming we already have a pretrained CAE, a convolutional filter contains an one-hot-encoded representative subsequence of a pattern, which is exemplarily shown for two patterns in the second row of Fig. 2. In the forward path through CAE, the convolutional layer at first produces one latent space vector per filter, which can be interpreted as a similarity vector of the convolutional filter and the corresponding subsequences of the input. Within the sparsity layer, the latent space vector is filtered, by setting every value to zero, except for the peaks. Therefore the parameter latent limit sets a relative threshold for these peaks. In the example of Fig. 2 the third row shows these filtered latent space vectors of both convolutional filters. The peaks are referring to the starting indices of similar sections in the input image. Hence, the deconvolutional layer can reconstruct at least parts of the input with these two filters and the latent space vectors.
In [17] the authors proposed additional regularization terms to enable CAE to identify patterns in images. Unfortunately not all of them are working for the case of a time series and the identification of recurring subsequences. We need the filters to represent a subsequence as clear as possible, which implies that in one column only very few pixels should be highlighted. While testing CAE of [17] we also discovered some artifacts, e.g. one filter containing two different patterns. An example for a good and a bad fit of a convolutional filter is shown in Fig. 3. To push CAE into optimizing the filters, we propose adaptions of the original CAE in the next subsection.
The
with
Hence, the variable
As described in Eq. (1), the size of
with NW: total number of weights;
The idea of using entropy for the optimization was already applied at [17]. The author’s goal was to minimize the entropy in the latent space vector to have only few and high peaks in the vector. Hence, it has a similar impact compared to the sparsity layer. We transformed the concept into an entropy at the level of convolutional filters and their pixels:
with
with
We aim for minimizing the entropy by adding it to the cost function with the quantifier
Change of distribution by TVD (dashed) in comparison to usage of entropy.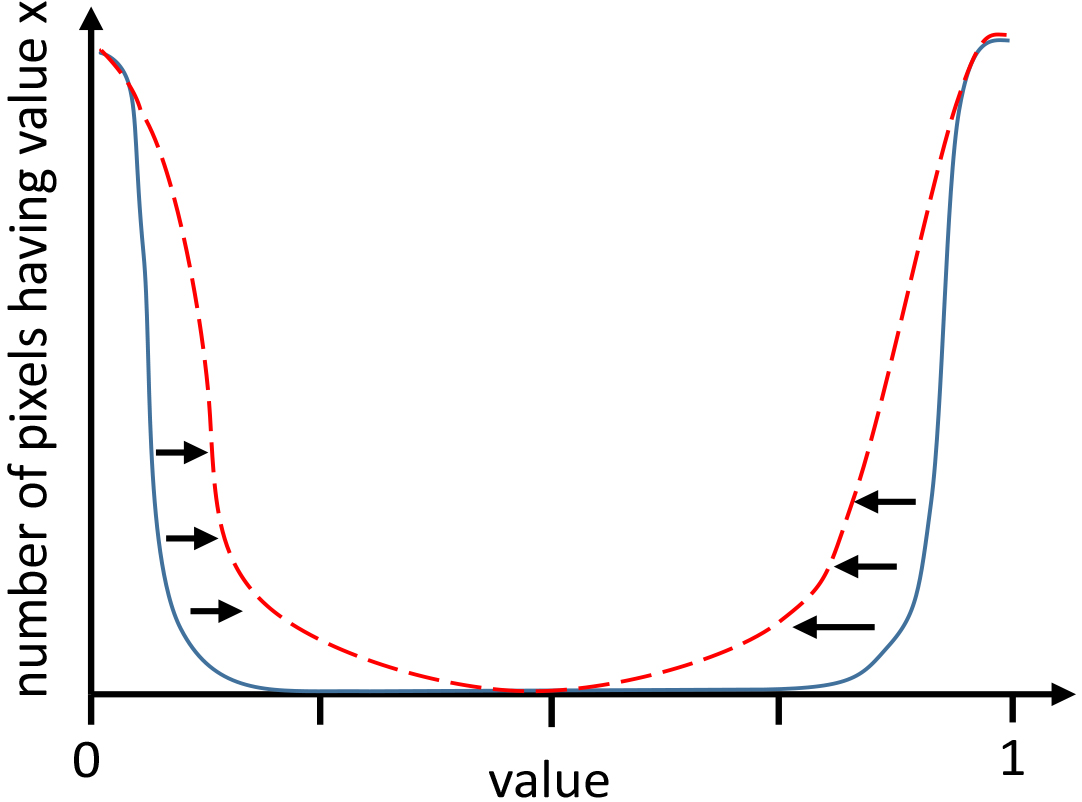
Beside the entropy and the
In theory this could help especially in time series images with a high number of bins. If there are too few bins, the smoothing by TVD may add too much dissimilarity. The use of entropy and TVD at once may also cause problems, because they are optimizing against each other. As shown in Fig. 4 the entropy pushes the frequency distribution of the pixel values to 1 and to 0. On the contrary the TVD smoothes the pixel-gradients and therefore also changes the distribution to the middle. The overall cost function with all regularizations now results to:
Furthermore we added a dropout layer to the CAE architecture between the sparsity and the deconvolutional layer. The dropout technique randomly sets a certain percentage (dropout rate) of weights to zero within every iteration of learning, which helps to find the global minimum of the cost function.
On top of these adaptions we enabled GPU computing for CAE by the use of TensorFlow-GPU. For the following evaluations in Section 4.2 we use a nVidia Quadro P6000.
The following nonlearning approaches for pattern discovery in time series were already proposed in previous work [3] and are now considered as relevant references for the NN-based approach proposed in Section 2. For better understanding Section 3.1 to 3.3 again describe those three nonlearning approaches.
DTW-based
The tested implementation is based on the approaches from [21, 22]. We are using the scoring function of the CrossMatch algorithm, which is necessary to compute the matrix equivalent to the DTW algorithm. In the case of CrossMatch the matrix contains values of similarity in contrast to the DTW which computes a distance matrix. The scoring function for every cell
In general, CrossMatch is made to find similar subsequences within long time series
Visualization of the similarity matrix 
A major difference between the scoring functions of the classic DTW and CrossMatch is the usage of weighting factors
For the tests, that we are going to perform, we limit the weighting factors to
In order to form patterns, additional to the CrossMatch, we extract and cluster the motifs like in [22]. To extract possible pattern candidates from the matrix, we use a minimum length and a minimum similarity. This process is exemplarily shown in Fig. 6. Both axis of the similarity matrix refer to one and the same time series
Visualization of the similarity matrix 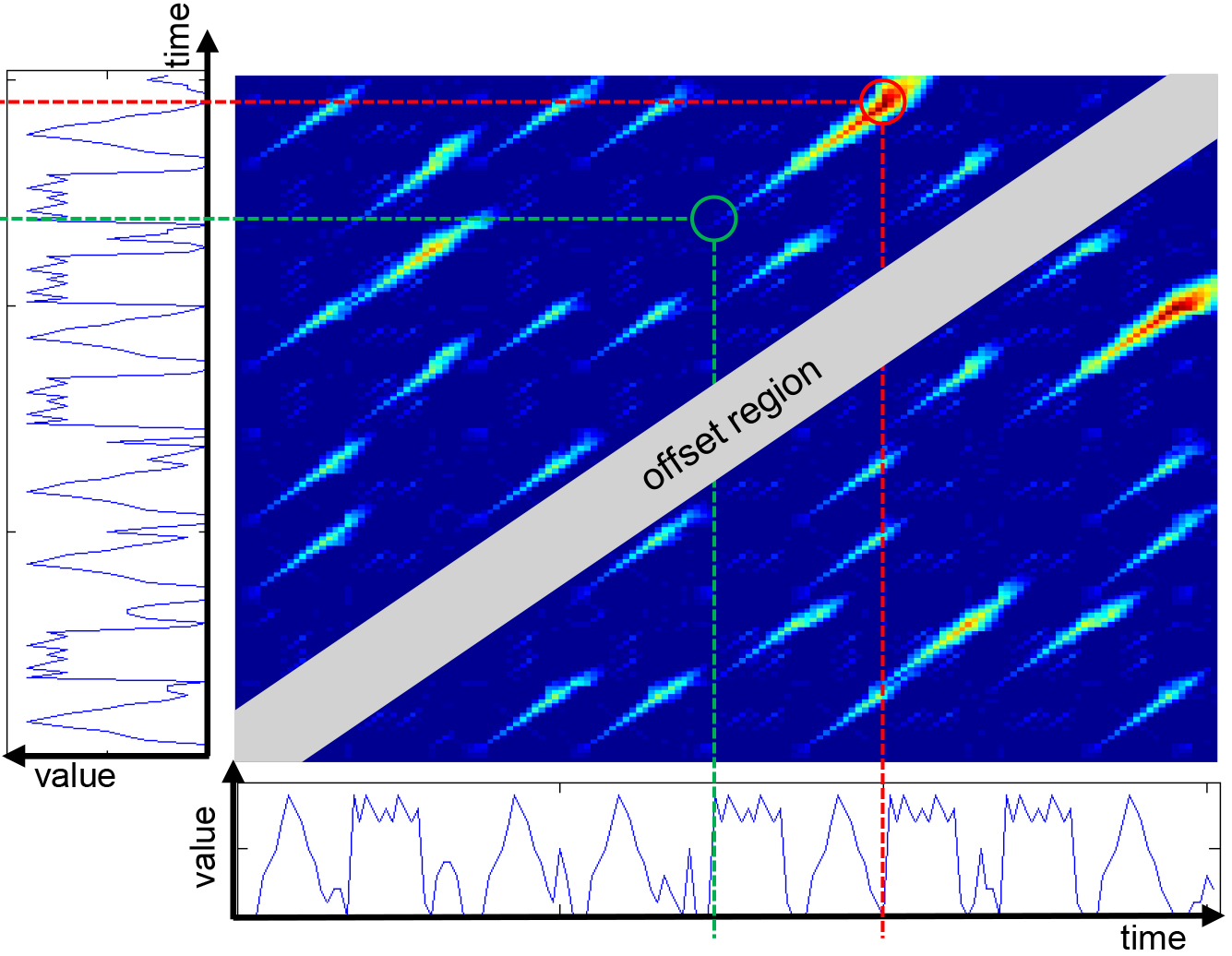
Concerning discretization-based approaches for pattern discovery we focus on an adapted Sequitur algorithm and an algorithm for pattern enumeration. Both are based on an equal probability discretization technique. However, in contrast to the technique described in [23], we do not assume a Gaussian distribution of the data values, which is necessary in terms of various signal types. We implemented a simple algorithm to form classes of equal count of data points with respect to the constraints uniqueness and allocation. Uniqueness means that there must not be multiple classes with the same data value. According to the allocation constraint, every data value has to be allocated to one class. The algorithms, which will be described shortly, are only dependent on one parameter, the number of discretization steps.
Exemplary visualization of three similar subsequences, their unreduced symbolic representations as well as the symbolically reduced representation.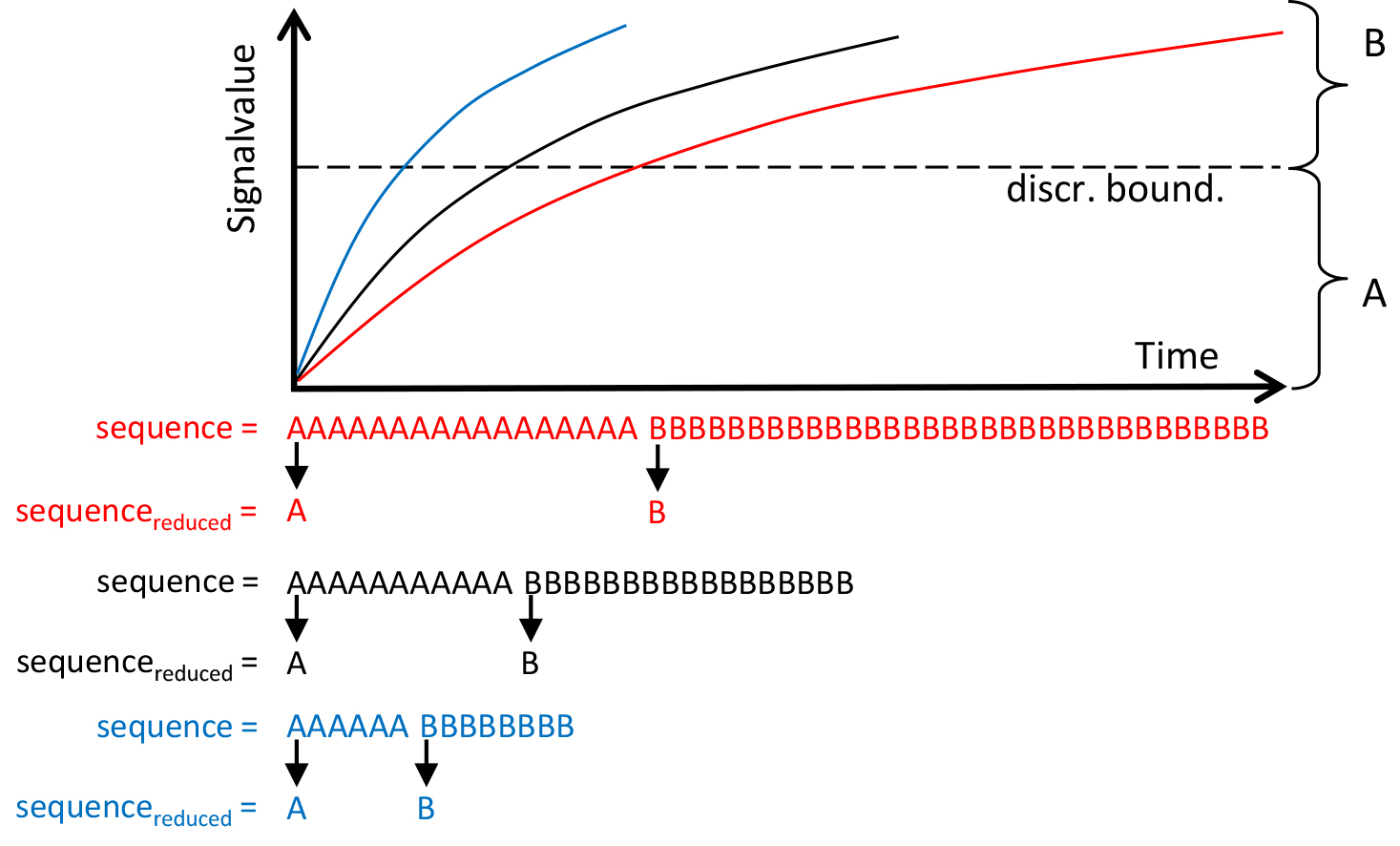
Because of the need of time scaling we apply an optional numerosity reduction technique like in [2], which we call symbolic reduction. Therefore every identical consecutive symbol in the time series is reduced to one unique symbol. Hence, in every step of the time series a change in the symbolic value can be observed. In Fig. 7 the discretization and symbolic reduction of three similar subsequences is shown. For simplicity the signal is discretized into two symbols
To evaluate the performance of our adapted Sequitur algorithm, we also want to apply a pattern enumeration algorithm. The algorithm repeatedly scans the whole time series with different query pattern lengths by using a matrix representation of the symbolic time series and a sorting algorithm. While scanning through all lengths, every pattern that occurs at least 2 times is stored in a dictionary. In text mining this kind of approach is often named as word count. In Algorithm 1 the approach of pattern enumeration is shown.
Pattern Enumeration[1] PatternEnumeration
get_symbolic_repr(ts_matrix_sorted)
Lines 6 to 8 are the core of the algorithm. In line 6 the time series array is transformed to a matrix of the size
Adapted Sequitur algorithm
The Sequitur algorithm proposed in [25] is based on two constraints. The first constraint is called digram uniqueness, which means that every digram (a pair of two adjacent symbols) is allowed to occur only once in the symbolic time series. If a digram appears more than once, then a rule is created that replaces the digram by a new symbol. All the rules are stored in a dictionary. Every rule has to fulfill the second constraint, the rule utility. It says that every rule has to occur at least twice. In Fig. 8 an exemplary execution of the algorithm is shown based on a symbolic sequence, that grows in every iteration by a new incoming symbol. In every iteration the extracted grammar, the dictionary, is updated under consideration of both constraints.
Execution of the original Sequitur algorithm on a sequence of symbols [25].
Our adaption of the algorithm is shown in Algorithm 2. Since the original Sequitur algorithm is a streaming algorithm, which is not the focus of this work, the adapted Sequitur implements the approach in an offline fashion. The first three steps within the WHILE loop are similar to the pattern enumeration algorithm, except for a fixed matrix column size of 2. To fulfill both, the diagram uniqueness and the rule utility, the algorithm adds the digram that occurs the most to the dictionary and replaces the diagram in the symbolic time series by a new symbol. While the original Sequitur replaces the rule that occurs first, due to the streaming approach, the adapted Sequitur opens up the opportunity to choose the next rule. In this implementation the digram that occurs the most is chosen to be replaced in line 8. The algorithm terminated when the diagram uniqueness is fulfilled.
Adapted Sequitur[1] AdaptedSequitur
get_symbolic_repr(ts_matrix_sorted)
Matrix Profile introduced in [29] is an approach able to be executed on raw time series without any preprocessing. Matrix Profile is based on the calculations of distance profiles, which is exemplarily shown in Fig. 9. A distance profile
Distance profile 
To extract motifs of a fixed length a maximum distance threshold is needed for two sequences being a motif. Because all the minimum distances are stored in the Matrix Profile, every entry and its corresponding subsequences that fulfill this constraint can be seen as motifs. The corresponding distance profile gives information about other sequences that are similar to the motif. Again every data point that falls below the maximum distance leads to a similar sequence. The motif with its similar sequences can then be called a pattern. To discover patterns without a fixed query length we have to apply the algorithm multiple times for a set of possible query lengths. [29]
Because of the naïve structure of the approach, the MASS algorithm was proposed in [29], which calculates the z-normalized Euclidian distance profile by convolution. In comparison to the naïve approach of calculating the Euclidian distance between the query and every other sequence, this technique reduces the time complexity for a distance profile from
In a second implementation we tested Matrix Profile with the Euclidean distance but reduced complexity. It is based on the fact that the distance profiles of the query at starting point
In this section we discuss a testing standard for the comparison of different approaches. One possibility is to use benchmark time series, for example from financial stock markets or from seismology, which are commonly used to test different time series exploration tools. However, generalized results regarding every possible kind of pattern can be obtained only by use of synthetically created time series. Our test data is composed of predefined patterns, which can be labeled automatically, as described later on in Section 4.1. The advantage of this approach is the independency of a certain test case. Furthermore we can create an infinite number of test sequences without the effort of labeling it.
The evaluation is divided in three steps. In the first step the test data is created automatically from patterns that are generated randomly. In the second step, the pattern discovery, the predefined patterns are rediscovered using different algorithms and parameter settings. By using the index information of every predefined and located pattern, in the third step quality scores for the results are calculated.
Time series test data creation
For a generalized evaluation for various use cases, the test patterns should cover every possible kind of shape. That is why we chose the random walk as the basis for every pattern. In our case we use a Gaussian random walk, which changes the distribution of the randomly chosen step size from equal to normal. For the creation of a primal pattern by a Gaussian random walk the following parameters are also chosen randomly once: Value of the first data point; number of steps; maximum step size.
After creating different primal patterns, each of them is multiplied and distorted to form a set of similar members for each of the primal pattern. The number of members within a pattern is randomly chosen. The distortion is done by adding white Gaussian noise to the members, given a fixed signal to noise ratio, and by randomly stretching or compressing the length of the members, given a maximum ratio between the length of the primal pattern and the distorted member.
To form a sequential time series based on the randomly created patterns and its members, the members are concatenated in a random order. Note that every member can only occur once in the time series. To overcome value jumps between the concatenated patterns, we insert a smooth crossing. Start and end indices of every member and every pattern are saved.
Pattern evaluation
Output of the pattern algorithms are indices of starting and ending points of the located pattern. To evaluate the rediscovered patterns we calculate different quality scores comparing these indices
with:
In Fig. 10 these index sets are exemplarily visualized for one member of a predefined and a discovered pattern. The dashed line shows the time series, while the blue line is the predefined pattern and the red line is the discovered pattern. In fact, the members of a pattern are not handled separately as shown in Fig. 10, but all simultaneously. Hence,
Exemplary visualization of index sets for the calculation of overlap, TPR and FDR.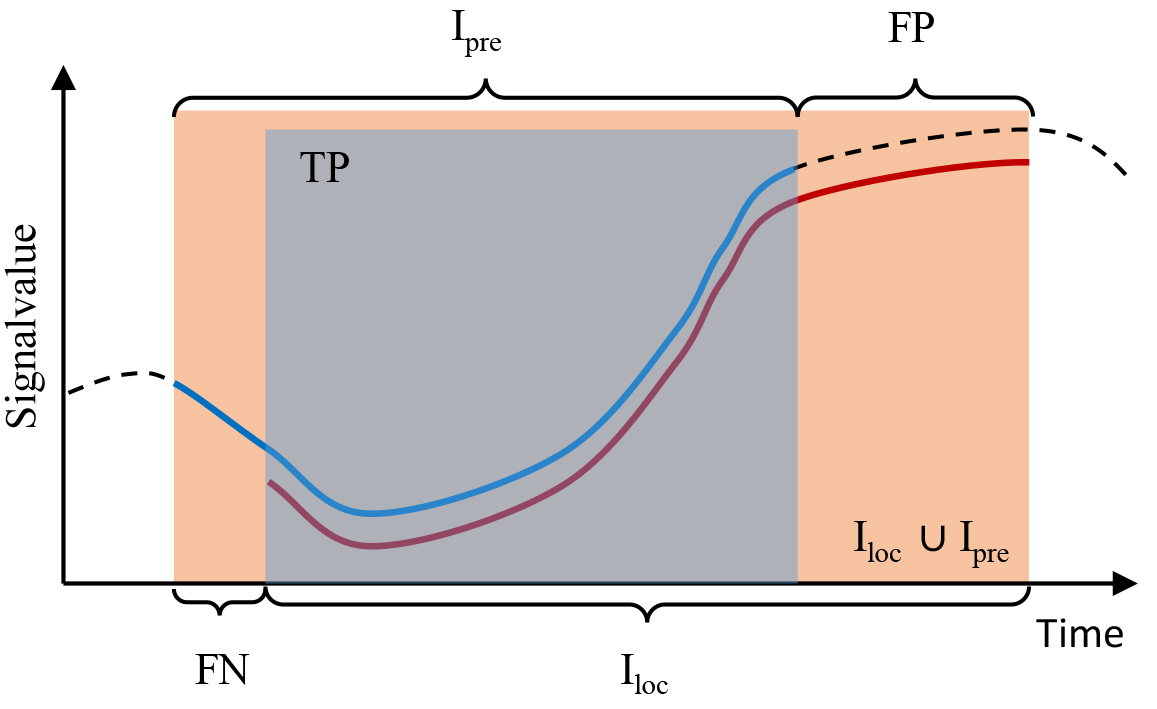
Overview of different approaches concerning overlap and runtime; length of datasets ca. 50.000 data points; average count of located patterns: DTW ca. 800; Pattern Enumeration 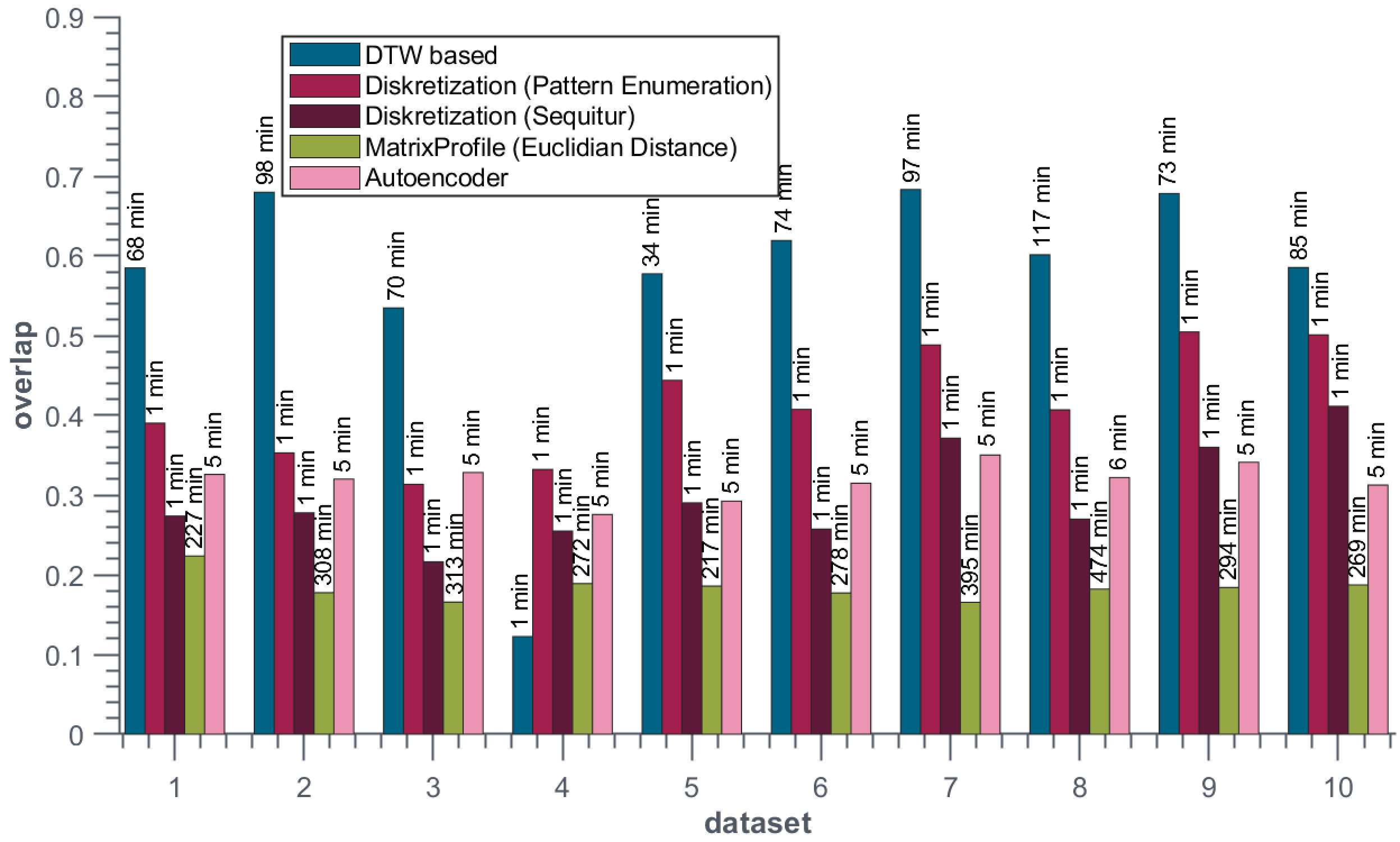
Furthermore we perform the whole routine 10 times, to get a reliable statement for the quality of the algorithms. This gives us also the possibility to make a statement concerning the variance of the quality. Beside this, in every iteration of the routine, the computing time of the different algorithms is recorded.
After explaining the different approaches for the pattern discovery and the methodology of calculating the quality scores, we now compare the different approaches. In Section 5.1 at first all the approaches are ranked based on synthetic data sets. In Section 5.2 follows a more detailed evaluation of the CAE. Sections 5.3 to 5.5 briefly deal with a separate evaluation of nonlearning approaches. Finally in Section 5.6 the approaches are exemplarily applied to a real life vehicle data set.
Comparison of best results
We created 10 random datasets each containing approximately 50k samples, ran every algorithm with different parameter settings and calculated the quality scores. For each algorithm we chose the parametrization leading to the best results, see Figures 11 and 12. In the upper plot of Fig. 12 these best results are visualized concerning the overlap and the runtime with different markers showing the corresponding approaches. Furthermore, the circled markers show the mean value of the approaches for all datasets. The standard deviation is highlightes as circle arround the mean value. Likewise, the lower plot shows the FDR and TPR.
Top: Vizualization of overlap and runtime for best parametersets including a marker for the mean value and a circle arround it showing the standard deviation for each approach; Bottom: Equivalent vizualization of TPR and FDR.
It is evident that the DTW-based approach outperforms every other tested approach concerning overlap and TPR. Discretization-based approaches, in turn, advance greatly concerning the runtime. The algorithm for pattern enumeration provides constantly better results than the Sequitur algorithm, except for the runtime. CAE produces a similar quality like the discretization-based approaches concerning overlap, TPR and FDR. But while CAE needs around 5 minutes for the datasets to process, the discretization-based approaches take only seconds. Here we need to point out, that the number of patterns identified by the pattern enumeration algorithm is extremely high. On the one hand this leads to a better quality in comparison to the Sequitur algorithm. But on the other hand this makes it hard to handle and implies the need for post processing methods.
As expected, the Matrix Profile with the use of the Euclidean distance is not able to compete with the other approaches because of its complexity and the inability of time scaling. We expect better results when using the Matrix Profile in combination with DTW instead of the Euclidean distance, though substantially increasing runtime. As the Matrix Profile is outperformed by every other approach, it is not suitable for our use cases. However, as we calculated an entire Matrix Profile for every possible query length, there is still optimization potential for reducing the runtime based on early abandoning. Nonetheless this reduces the runtime, but does not improve the overlap.
It is highly desirable to have a method that produces results with constant quality. As highlighted in Fig. 12 the DTW-based approach shows the highest standard deviation and, hence, the greatest variation in quality. This is mainly caused the bad performance regarding the dataset 4 (see Fig. 11). Excluding this run from the analysis would then result in a standard deviation similar to the value of discretization-based approaches. Furthermore, it is worth noting that CAE shows relatively low standard deviation in every dimension, even though its learning technique is nondeterministic.
The biggest challenge in applying CAE for pattern discovery is the choice a of good working parameter setting. In theory 14 parameters have to be chosen to parametrize CAE. After pretuning CAE we focused on varying 6 out of 14 parameters, which are listed in Table 1.
Overview of varied parameters for the experiments of CAE
Overview of varied parameters for the experiments of CAE
Results of CAE in overlap, runtime, TPR and FDR varying all 6 parameters. The difference in selecting the Entropy or the TVD is highlighted including a variation of the number of bins; Top: Vizualization of overlap and runtime; Bottom: Vizualization of TPR and FDR.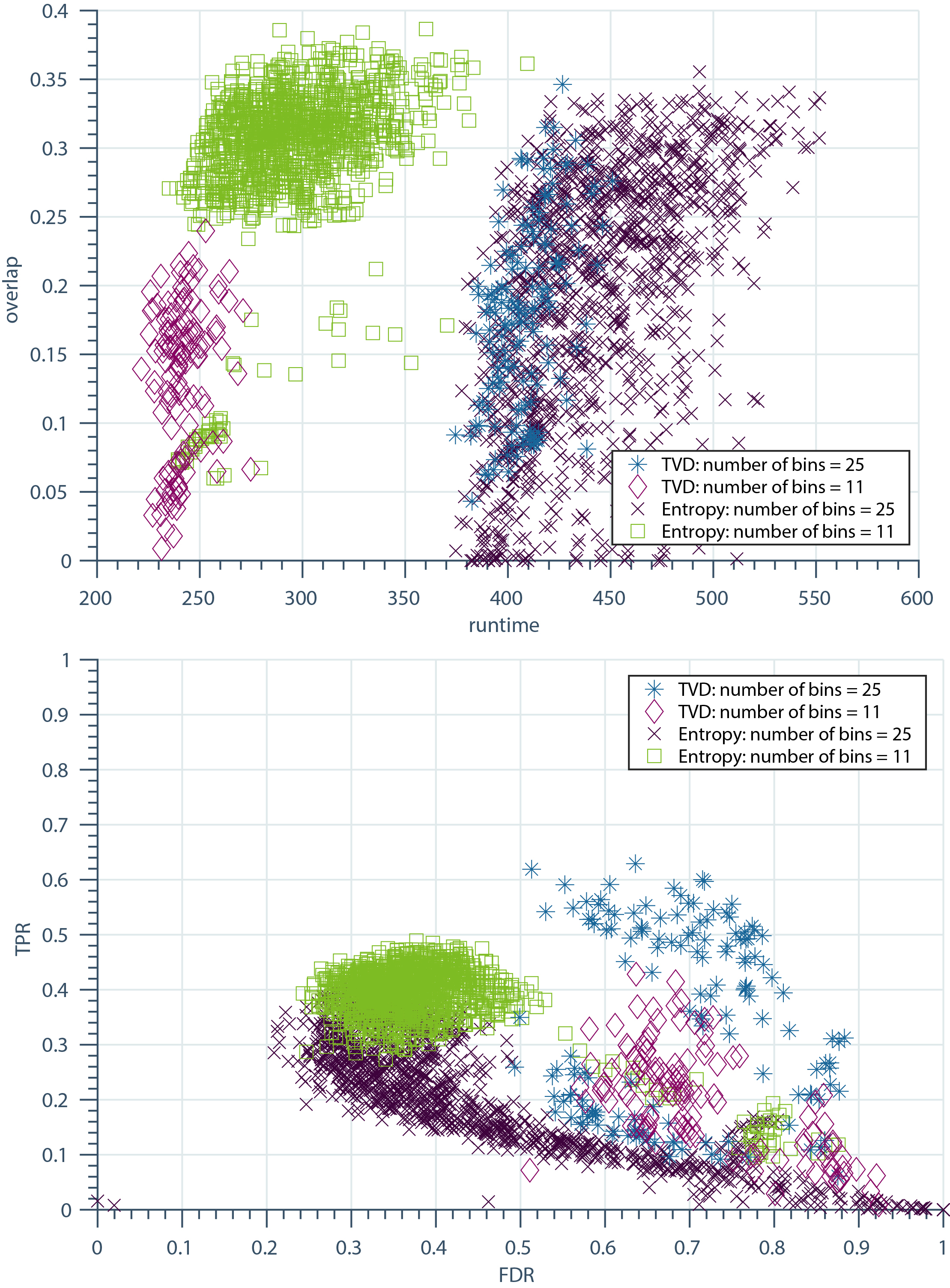
In general we experienced the dropout layer to be very effective in avoiding local minima and leading to good results of the pattern discovery. In most cases a dropout rate between 0.2 and 0.25 had the best impact. Furthermore, applying the
Visualization of 10 independend runs of the best parameterset (Autoencoder) for datasets 1-5 including a marker for the mean value and a circle arround it showing the standard deviation for each dataset; Top: Vizualization of overlap and runtime; Bottom: Vizualization of TPR and FDR.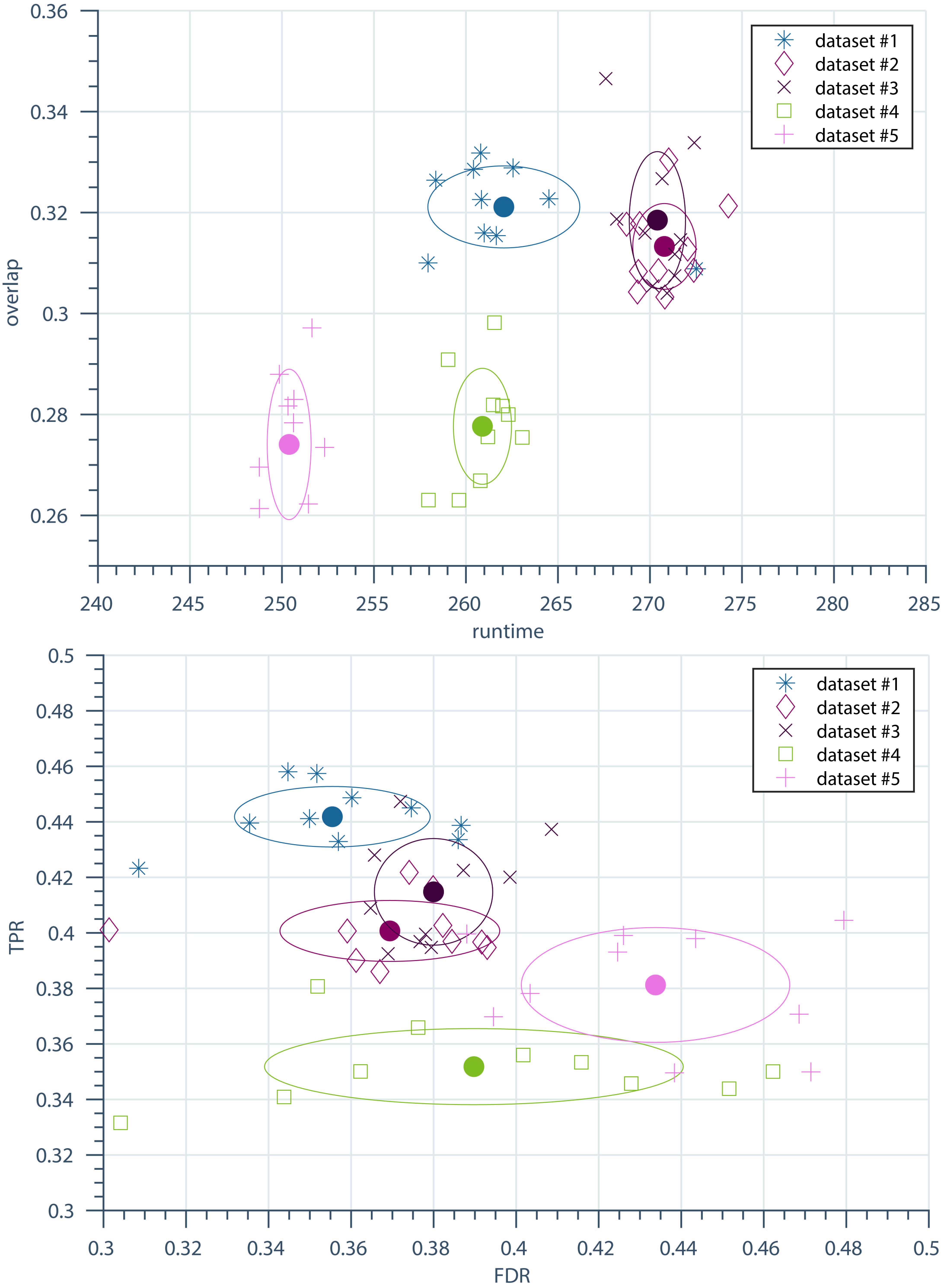
A major question was the functionality analysis of the entropy and the TVD regularization. Both methods can separately add value to the quality of patterns. As already described in Section 2.4 the use of entropy and TVD at once causes problems, due to their opposed objectives. We tested both alternatives with many different parameter settings to evaluate their effect in overlap, runtime, TPR and FDR. The result is shown in Fig. 13. Additionally the variation of number of bins is highlighted. Our previous assumption in Section 2.4 turned out to be correct: TVD works better when using a higher number of bins. CAE with the use of TVD is able to produce a higher overlap and TPR with 25 bins than with 11 bins. When analyzing the entropy the results are switched. Hence, the results are better when using a lower number of bins. In general CAE runs faster the lower the number of bins is. Comparing both approaches, it is shown that the TVD has a higher FDR in both cases (11 and 25 bins) than the entropy. Furthermore the results of entropy are in the best cases noticeably better in terms of overlap while also requiring less computing time. Regarding the overlap, even if both approaches run with 25 bins, the entropy is able to produce an equal or slightly better result.
Results of DTW-based algorithm (10 random datasets), for every costwarp parameter value a separate plot; top: mean overlap of random datasets with different parameters; bottom: mean runtime in minutes.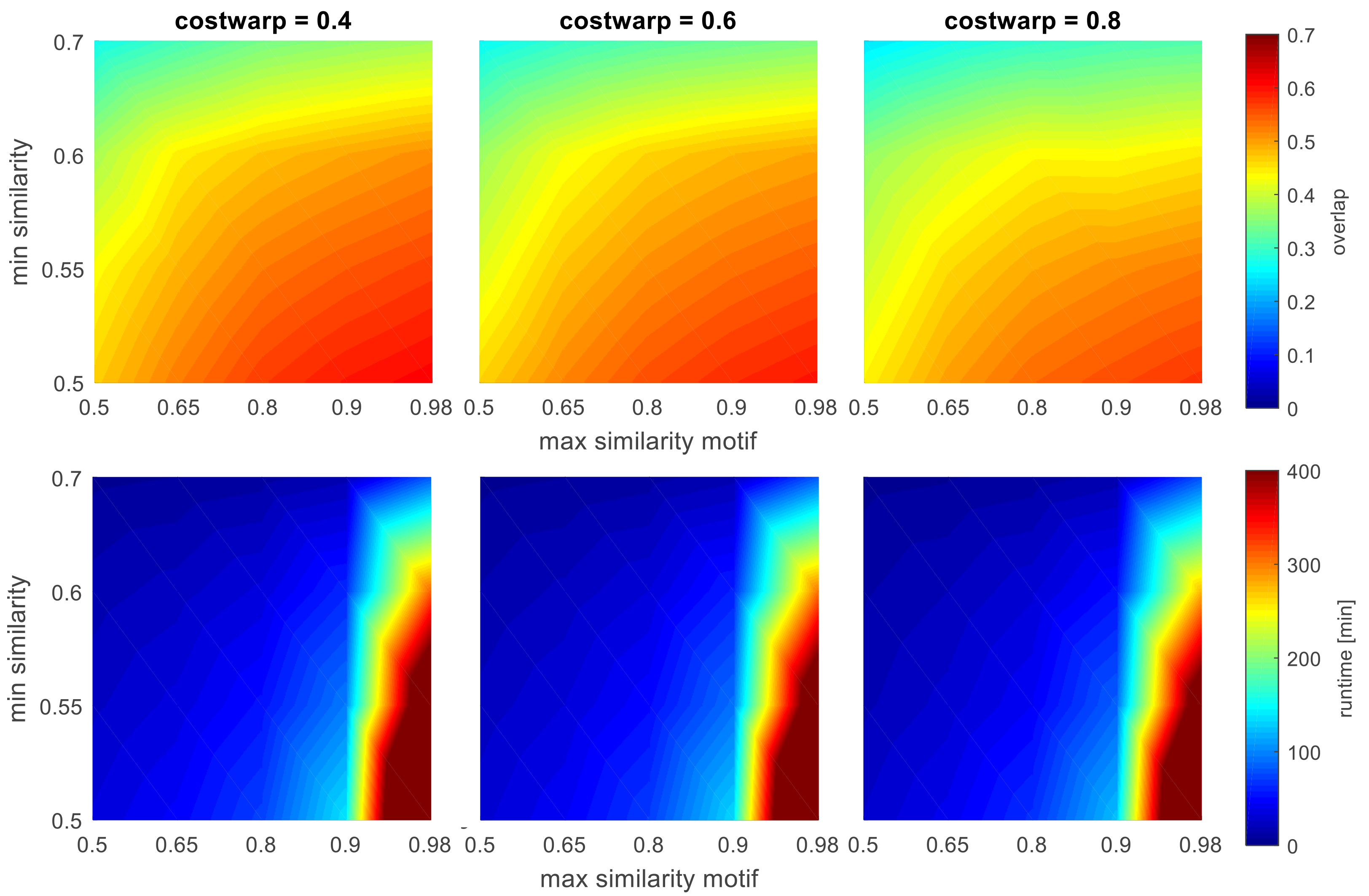
In contrast to nonlearning approaches for pattern discovery, CAE has the problem of nondeterminism, because of the randomly initialized weights of the convolutional and deconvolutional filters. We ran the best parameter setting for every dataset 10 times to estimate the influence of the randomly initialized weights. In Fig. 14 the results are shown for the first 5 datasets with different markers. Furthermore the mean value is visualized by the corresponding encircled marker. The maximum deviation for the overlap is 0.04, which could cause problems in use cases that require reproducibility. The ability to transfer a good working parameter setting to another dataset is given, if the datasets are from the same kind, e.g. time series of similar lengths containing information about the same sensor. Hence, in the case of a synthetic time series created by the method explained above, a good parameter setting tends to produce good results in every dataset.
Figure 11 shows the best case results of the approaches concerning the overlap. For the DTW-based approach, for acceptable runtime we chose a compromise between acceptable runtime and high overlap. This tradeoff is shown in Fig. 15. With growing values of max_similarity_motif, the runtime increases dramatically. This is caused by the clustering of motifs located by CrossMatch. In case of high values of max_similarity_motif there are only few motifs clustered together to form patterns. This leads to a high count of patterns, which are then again searched in the whole time series. For further research it has to be evaluated if this last step of the DTW-based approach can be reduced or replaced by a powerful clustering of the candidates. It is also noticeable that the effort of parametrization is high in comparison to the other nonlearning approaches. At least three parameters have to be chosen carefully to get the expected results. As shown in Fig. 15 the highest overlap values result at values of
Evaluation of discretization-based approaches
In Fig. 17 the performance of the discretization-based approaches are evaluated with respect to the variation of the number of discretization steps. Furthermore the benefit of the symbolic reduction is shown. It is visualized that the symbolic reduction has a higher impact on the results of the pattern enumeration algorithm than on the results of the Sequitur algorithm concerning overlap and runtime. However, in both cases the overlap as well as the runtime gets better with the use of the symbolic reduction, due to the time scaling. Nevertheless, compared to the DTW-based approach, it is a slight disadvantage because the time scaling is not controllable. I.e., after symbolic reduction, a symbol can represent two or considerably more identical consecutive symbols. A problem for both algorithms is the dependency of the discretization method, despite the dependency to only one parameter. Furthermore, we experienced a weakness in terms of multiple symbolic value toggling because of noise in value regions near the discretization boarders. This effect could be mitigated by applying a filter as a preprocessing step.
Results (overlap and runtime) of Matrix Profile with variation of the maximum distance.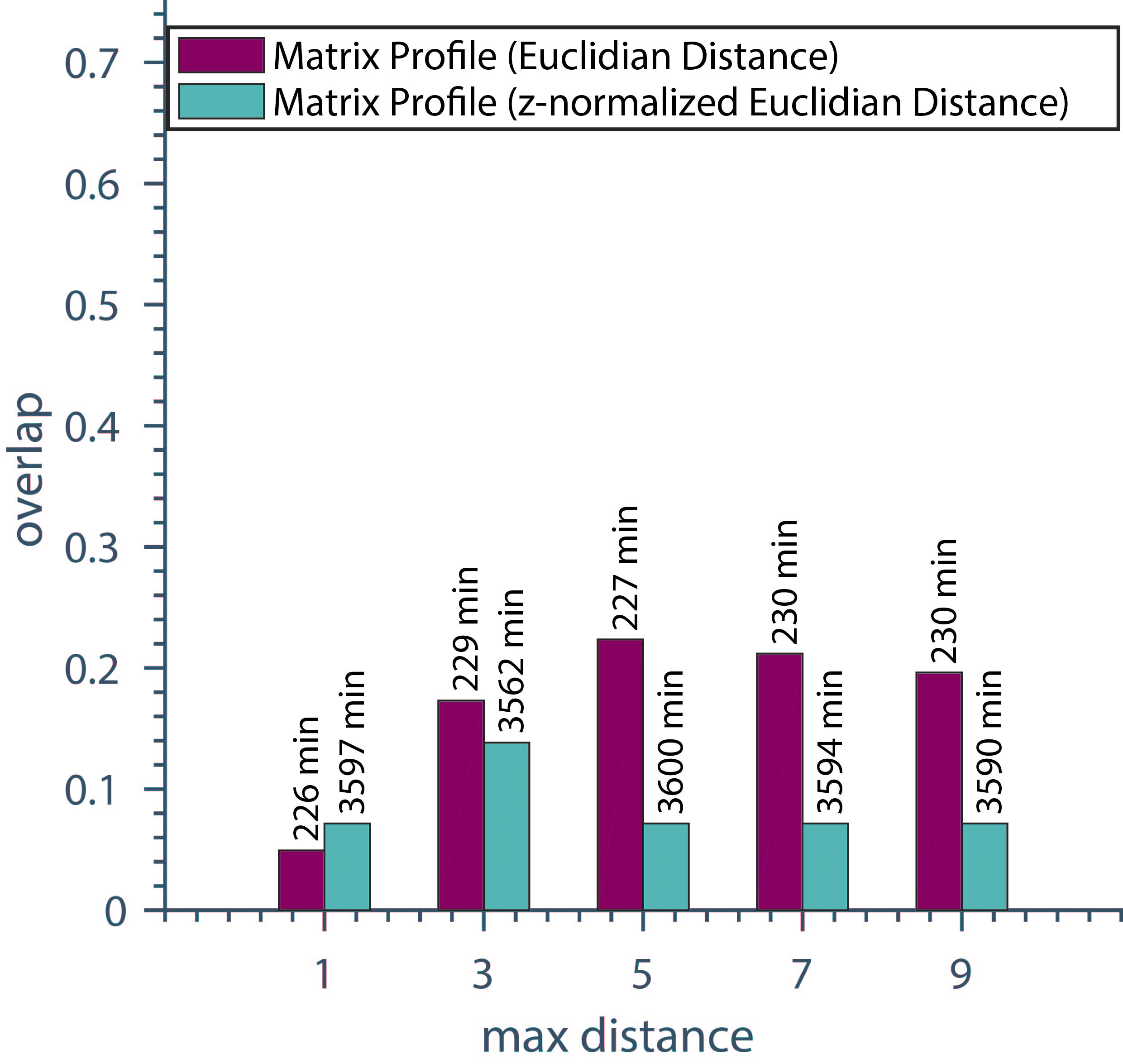
Results (mean overlap and mean runtime of all datasets) of the discretization approach (Sequitur, Pattern Enumeration) with and without symbolic reduction and with variation of the discretization steps.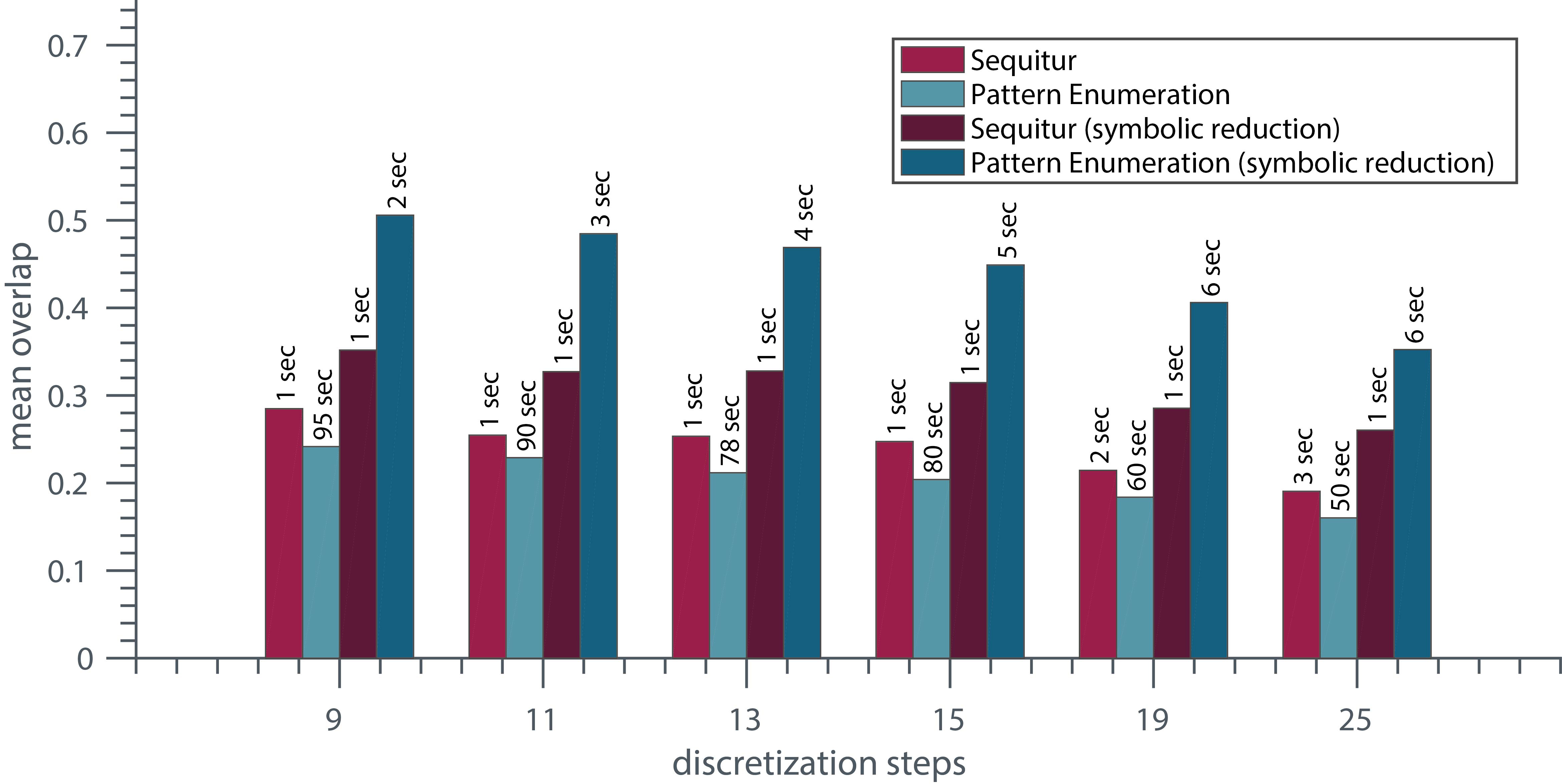
In Fig. 16 the performance of Matrix Profile with variation of the maximum allowable distance within a pattern and with use of Euclidean and z-normalized Euclidean distance is shown. The Euclidean Matrix Profile is calculated with the runtime reduction technique while the z-normalized Euclidean Matrix Profile is calculated by the MASS algorithm. As shown in Fig. 16 the Euclidean Matrix Profile leads to a better overlap for most of the parametrizations, while requiring less than 10 percent of the runtime.
Application to real Life data set
For a final validation, for each approach, we applied the best case parameter settings to a real life dataset from a typical use case in the automotive industry. It recorded the velocity of a vehicle that captured 28 hours of driving and 1 mio. samples. In general, this experiment has two major goals. First, it ought to show the applicability and transferability of all pattern discovery algorithms to data sets that are realistic in terms of size and origin. Secondly, it will show the magniture of runtime that has to be expected when applying these algorithms.
Exemplary results for real data set
Exemplary results for real data set
Table 2 and Fig. 18 show exemplary results for each algorithm, which were produced with the formally determined best case parameters. While the parameters of nonlearning approaches can be easily transferred from the synthetic case to a real life data set, the parameters for CAE need to be adapted. This is a major drawback when considering CAE for the task of pattern discovery and again shows the sensititivy of its performance regarding parameter variations. With identical parameters CAE does not identify patterns as required, because the time series is much longer and the diversity of patterns in a real life data set is much higher. Hence, patterns included in the data are rare. Due to the rarity CAE needs more data per training iteration to at least have a few similar subsequences in one batch. Therefore we slightly adapted the parameters by increasing the length of the input time series images (document size) and varying the learning rate.
Exemplary patterns discovered in real life data set by different approaches.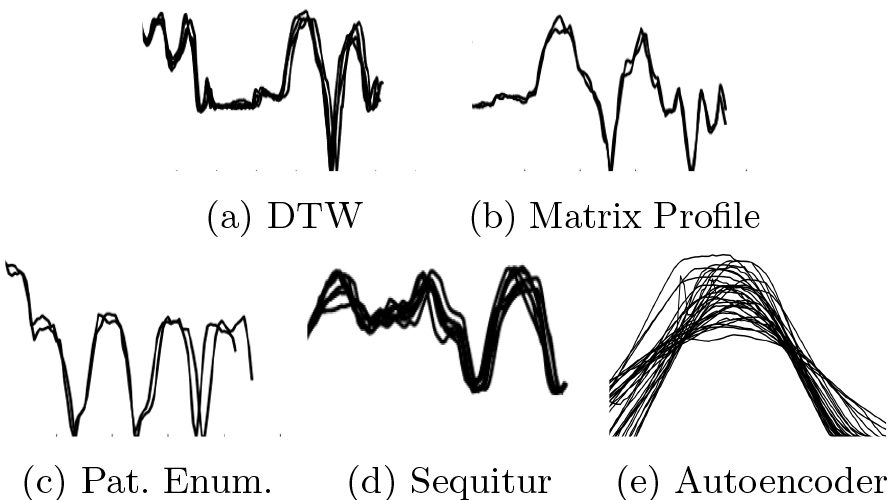
As mentioned in the introduction it is mandatory to have a pattern discovery algorithm that leads to results in an acceptable runtime. In Table 2 the runtime is given for the 1 mio. samples real life data set. Due to the fact, that data sets of vehicles are likely to be much longer than this, approaches like Matrix Profile or DTW are definitely not suitable to be applied to large datasets on a daily basis. CAE does need less than an hour, which may be acceptable with some more optimizations. Both discretization-based approaches run extremely fast, but especially the pattern enumeration subsequently requires some post processing to select relevant patterns.
For the NN-based approach we utilized a Convolutional Autoencoder. We proposed adaptions concerning regularization terms and the architecture itself in order to enable it to find patterns in time series. We merged the advantages of 2D convolution with time series analysis by creating a new 2D time series representation. The time series is transformed into a 2D time series image by discretizing, slicing and one-hot-encoding to enable 2D convolution. In the end, using 2D instead of 1D convolution turned out to be essential for NN-based unsupervised pattern discovery. Beyond that, we developed a dynamic
In an extensive test we identified advantages and weaknesses of all approaches to especially rank the NN-based approach regarding nonlearning approaches. In general, discretization-based approaches have a high performance concerning runtime while the DTW-based approaches perform best regarding the quality of the results. The Matrix Profile can be classified as not suitable for our use cases due to the inability of time scaling and the unacceptable runtime. The Convolutional Autoencoder, including our adaptions, identifies patterns with a similar quality like the discretization-based approaches, but needs much more time. Nevertheless, the Convolutional Autoencoder can be considered as a valuable alternative because it automatically discovers the patterns that in total best cover the time series. Hence, it contains a functionality that needs to be additionally implemented when using one of the other approaches.
A major weakness of the Convolutional Autoencoder is the effort of parametrization and the parameter settings being far from universal. As we showed in this study, 14 parameters are need to be set carefully in order to get good results. We were able to reduce the effort of parametrization to just 6 parameters. The remaining 8 can be kept constant within one kind of data sets. Unfortunately, if it is applied to a completely new kind of pattern discovery use case all parameters need to be reconsidered. Hence, if the use case does not change fundamentally, the Convolutional Autoencode is a valuable alternative.
Conclusion and outlook
In this work we developed a new NN-based approach for unsupervised pattern discovery in time series, compared it to three nonlearning techniques and evaluated them concerning special requirements, that derive from automotive use cases. Even though NN-based approaches currently have major weaknesses regarding the task of pattern discovery, they are still interesting because of their ability to capture highly complex relations. Thus, it was shown that the Convolutional Autoencoder is able to discover patterns with a similar quality like discretization based approaches. Due to the highly dynamic developements regarding NNs we encourage everyone to also consider NN-based approaches. In future work the Convolutional Autoencoder will be extended to the multivariate discovery of patterns. Additionally it would be interesting to include varying filter lengths into one and the same Autoencoder to eliminate the necessity to run it multiple times. Furthermore, the usage of sparse Convolutional Autoencoders like in [37] offers the potential of runtime reduction. One major task is the robustness of parameter settings, when switching between time series of different origin, especially in case of real life data. Beyond that, the layer-wise increase of depth and the implementation of other unsupervised learning techniques (e.g. based on LSTMs) has to be evaluated.
Footnotes
These reference approaches are classified as nonlearning, because they do not apply neural-learning. We are aware that the reference approaches do also have some kind of learning procedure. For simplicity these approaches will be named as nonlearning.
Acknowledgments
We thank the anonymous reviewers for their valuable comments that led to a significant improvement of the manuscript. We thank Thomas Lehmann3
thomas.lehmann@ivi.fraunhofer.de, Fraunhofer IVI, Dresden, Germany.
ralf.bartholomäus@ivi.fraunhofer.de, Fraunhofer IVI, Dresden, Germany.
jan.piewek@volkswagen.de, Volkswagen AG, Wolfsburg, Germany.