
Abstract
As the availability of computational power and communication technologies increases, Humans and systems are able to tackle increasingly challenging decision problems. Taking decisions over incomplete visions of a situation is particularly challenging and calls for a set of intertwined skills that must be put into place under a clear rationale. This work addresses how to deliver autonomous decisions for the management of a public street lighting network, to optimize energy consumption without compromising light quality patterns. Our approach is grounded in an holistic methodology, combining semantic and Artificial Intelligence principles to define methods and artefacts for supporting decisions to be taken in the context of an incomplete domain. That is, a domain with absence of data and of explicit domain assertions.
Keywords
Introduction
Urban areas, given their increasing size and population density, are expected to be at the forefront of the current environmental revolution. However, cities are also facing their own challenges, such as environmental stressors, overpopulation, traffic problems, air pollution or the growing complexity of managing the city’s infrastructure. In the search for technology-mediated solutions for the current challenges, the so-called Smart Cities emerged [1].
By definition, the concept of Smart City depends on the use of Information and Communication Technologies (ICT) to connect its different services and/or resources. This communication layer allows data to be collected, analyzed and acted upon in real time [2]. However, the simple interconnection of these elements is not enough. Thus, Smart Cities also consider the notion of digital agents performing autonomous actions to provide a new level of support to the management of resources or services [3, 4]. This is paramount in the current scenario of information overload, as Human deciders cannot possibly be expected to deal with the increasing volume and complexity of the data [5].
Smart Cities also have a general goal, towards which all autonomous agents converge in their actions: to improve the citizens’ quality of life [6]. This rather broad and abstract goal can be broken down into more specific and well-defined ones, such as to improve the efficiency of the city management [7], the management of resources and energy [8, 9], the management of infrastructures and assets [10, 3, 4], the response to disasters [11], or the city’s sustainable growth [12] including smart mobility [13]. Hence, the challenges posed by smart city projects are socio-technical in nature [14].
In this context, energy management is one of the most complex [8]. This paper focuses on the specific issue of public lighting. Public lighting is, currently, one the the most important subjects on the cities’ management agenda, not only for economic and environmental issues, but also because it has a direct impact on citizen’s comfort, safety and perceived security [15, 16]. In Portugal, the latest available data, pertaining to 2017, show that 1.46 TWh (Terawatt-hours) were spent with public lighting in that year. This amounts to 3.1% of the country’s energy consumption [17]. At a global level, the total energy consumption for all types of lighting was estimated to amount to 3,418 TWh. This figure represents 19% of the world’s total electricity consumption. Public lighting alone amounts to 281 TWh, which represents around 1.6% of all the electricity consumed worldwide [18].
In this paper we describe a solution to improve the efficiency of energy consumption in public lighting networks taking into account internal, external and social factors related to public light fixtures, following a knowledge-based approach. The goal is twofold: 1) to devise a methodology to manage lighting level dynamically to minimize energy consumption, taking into account the individual characteristics of each fixture in the network (e.g. location, orientation, operating conditions) and current guidelines and legislation; 2) to formalize and produce knowledge about the system, thus contributing to a real understanding of the problem by Human experts. The developed approach was validated in a real public lighting network of more than 300 fixtures.
Thus, the key distinguishing factor in this work is that it addresses the problem by combining two approaches: a data-based and a semantic one. Data-based [19, 20, 21] and semantic approaches [22, 23] are often used in the domain of Smart Cities, albeit separately. The holistic nature of this work, on the other hand, emerges to address a twofold perspective of the problem, wherein data analysis and AI is only a part of the solution: identified data patterns should be contextualized by means of semantic artefacts, adding value to the information to be provided in the scope the the decision support process.
As the literature shows (Section 4), most of existing approaches rely on data and use Machine Learning (ML) or other AI techniques to address the problem. One limitation of these approaches is that they all treat fixtures equally, while we take into consideration their individual differences. These differences may stem from various factors, including the location or orientation of the fixture, or physical features (e.g. a poorly placed heat sink that increases heat and diminishes light quality and lifetime). Nonetheless, they all impact the operation of the luminary in some way, and make each luminary unique in the network. We take into account these differences [24] to implement an individualized management of each fixture in the network, thus maximizing gains.
Moreover, data-based approaches often have limitations concerning the interpretability of the results. That is, purely data-based approaches tend to work and effectively improve energy efficiency, but they lack in contributing to a real understanding of the system by Human experts. This is especially true in the cases in which so-called “Black Box” models are used [25].
The key innovative aspects of the proposed system can thus be enumerated:
We take into consideration the individual characteristics of each fixture, that stem from their location, orientation or physical properties, when modelling their behavior; We use an outdoors laboratory in which additional luminosity sensors are used, and model the relationship between fixture dimming, weather, ambient luminosity, and the luminosity experienced by the user; We create a model that can be used to predict the luminosity at the pedestrian level, given these factors, and use this model to set the ideal dimming of each individual fixture; We simulate the use of this model during four months of operation of a real public lighting network with 305 fixtures, to assess the potential energy savings.
The results show that, when compared to the scheme that is currently used by the municipality to manage this lighting network, the use of the proposed system leads to a decrease in energy consumption of 28% while still maintaining the levels of luminosity defined in National and European standards (e.g. EN 13201:2015) [26]. These results were obtained by comparing the energy spent in a public lighting network during 4 months of regular operation, to the energy that would have been spent if the proposed system was in operation. Energy savings are obtained through a dynamic dimming of each individual fixture, implemented through a Machine Learning model, that embodies multiple dimensions of the problem including individual characteristics of each fixture, placement/orientation, or ambient light.
Knowledge-based research methodology.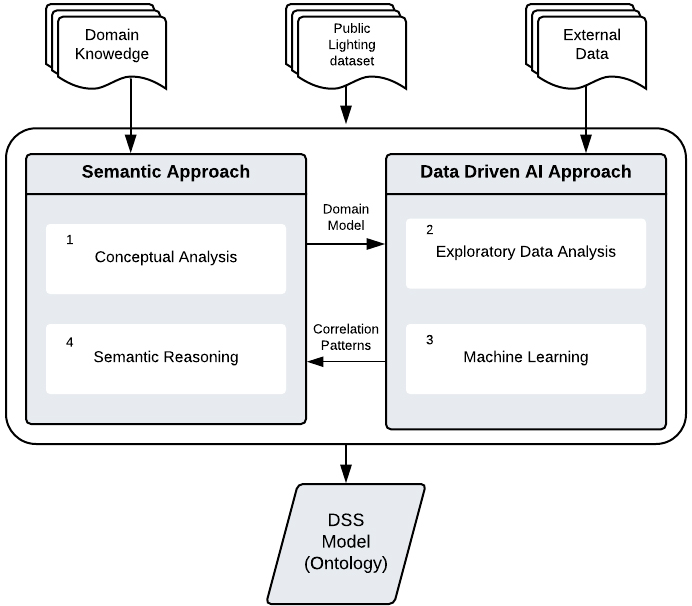
The rest of the paper is structured as follows. Section 2 describes the Research Methodology followed, namely how the two complementary approaches were combined to achieve the intended goal. Section 3 provides some fundamental context on the domain of public lighting. Next, Section 4 provides an overview of recent literature, framing it in different levels of increasing specialization and complexity. Section 5 details the knowledge model for the proposed Decision Support System (DSS). The following two Sections detail the Case Study in which the proposed approach was validated, as well as the results, in terms of both the accuracy and the energy savings obtained. The document closes with the concluding remarks in Section 8.
Moving to intelligent LED based public light fixtures allowed to adopt a data flow model with upstream and downstream communication channels, providing both the information flow and control flow. New challenges emerge from this data driven technological shift, where decisions are no longer based just on people experience and on one-size-fits-all policies or procedures defined by manufactures and energy providers. Real-time computed data, plays a key role on identifying usage patterns and/or thresholds from historical datasets. Based on this, the following research question emerged:
How to accommodate domain specific knowledge, internal data from fixtures and information obtained from data driven analysis processes, in a model capable of classifying each public light fixture, according to its consumption behavior and dimming adjustment interval?
To answer the aforementioned research question, a knowledge-based methodology (see Fig. 1) was designed combining semantic modelling and data-driven AI methods.
The semantic approach is underpinned by a conceptual analysis [27] followed by a ontology engineering process, whose aim is to provide a shareable and reusable knowledge representation of public lighting energy performance factors. The result of this framework of understanding is articulated in an ontology, capable of processing and reasoning over public light fixture data.
The role of each scientific perspective, towards answering to the research question
The role of each scientific perspective, towards answering to the research question
As to the AI approach, it has a twofold role a well: i) to perform an initial investigation on data to discover patterns and identify anomalies, and; ii) to quantitatively determine the extend to which internal and external variables might influence public lighting operation patterns. This was accomplished using ML techniques, wherein it was considered the following artefacts: i) the original dataset; ii) the domain model resulting from the conceptual analysis, and; iii) external factors, such as weather data and illuminance, obtained trough a lab experiment (see Section 5), whose setup was based on the data understanding provided by EAD and the domain conceptualisation (see Fig. 3). The results obtained at this stage (i.e., patterns and thresholds that could be associated to an optimal operation behaviour of public light fixtures) are to be accommodated by the ontology as semantic rules (see Table 3), providing a knowledge-based decision-support artefact. The ontology is capable of automatic classify each fixture, according to its operation pattern and context, as well as the range of actions that might be taken in order to improve its efficiency. In practical terms, a specific fixture might be classified (or tagged) as operating in a “base efficiency pattern” and simultaneously be associated to a “decrease of dimming” action type through the reasoning engine. Due to physical devices constraints, the available actions for the control flow are limited to dimming adjustments and switch ON/OFF operations.
Table 1 summarizes the role of each scientific perspective towards answering the research question.
Energy issues continue on the agenda, in particular concerning efficiency aspects. In fact, we are witnessing a transitional period, wherein existing renewable and clean energy sources are not economically viable or are not sufficiently mature to answer current global demands. Meanwhile, new solutions focused on redesigning energy distribution and consumption patterns emerge, in order to overcome the sustainability unbalance. This is part of what Smart cities stand for: they are on pursuit of new resource management through digital sustainability approaches. Within this context, cities’ street lighting networks have been shifting towards a new technology paradigm that allows it to benefit from significant energy savings. However, despite the economic return, energy consumption efficiency is not guaranteed. Energy efficiency in the context of street lighting is a broader concept and socio-technical in nature. Measuring energy consumption efficiency in a decision-support perspective implies understanding energy efficiency at its basis and in a socio-economic perspective.
The European Union has been making efforts to increase energy efficiency within its member states. The 2030 climate and energy framework, revised in 2018 for the period of 2021 to 2030, aims at the reduction of 32.5% in energy consumption replacing 32% of the energy production with renewable sources and keeping the value of 40% in greenhouse gas emissions. Portugal has also defined its own energy strategy in accordance do the European Union commitment and developed the PNAEE (National Action Plan for Energy Efficiency), containing measures and guidelines to be followed in Portugal.
In the energy efficiency panorama, “lighting represents approximately 50% of the electricity consumption of European cities” [28], endows street lighting a crucial role on cities energy efficiency road map, whose guidelines were expressed in a set o documents/standards for road lighting (EN 13201:2015) [26].
Related work
So-called Knowledge-based or Expert Systems have been widely used to address the challenges of managing infrastructure, services or even the design of buildings or entire areas in cities. Early foundational examples include the use of Expert Systems to design large structures [29], to design floors in highrise buildings [30], to assess earthquake damage [31], among others [32].
Knowledge-based systems applied to energy management and distribution have increased in the last years, motivated especially by various factors including those related with the environment, sustainability, industrial competitiveness and energy security [33]. This Section focuses on this domain. More specifically, we look at systems dedicated to the management of public lighting networks.
The methodology followed to carry out the snapshot of the current state of public lighting detailed in this Section was to search for indexed papers in relevant journals and conference proceedings in the last 5 years. Specifically, we searched for the term “public lighting”, in combination with related terms such as “intelligent systems”, “knowledge-based systems”, “energy efficiency” or “IoT”.
The wide range of works found in the literature can be organized in a layered fashion, according to their level of sophistication and the degree to which they make use of the data (Fig. 2).
From a bottom-up approach, we have considered, at the first level, related works describing relative simple actions such as the replacement of obsolete fixtures, generally based on High-pressure Sodium (HPS) Lamps, by more modern Light Emitting Diode (LED) ones. At the opposite end, we classify articles with more advanced technical-scientific approaches, such as knowledge-based systems that support rich Human decision-making, through the provision of interpretable and actionable insights.
Depending on the level of sophistication of the system, literature shows that savings can go up to 50%, mainly due to fixture replacement, but also due to intelligent management solutions [34, 35]. Moving to LED-based fixtures, allows to significantly decrease energy consumption [36]. Infrastructure modernization has been the cities’ main focus in their public lighting management policies [37, 38]. This fairly straightforward action not only reduces energy and operational costs [39], but it is also the fundamental step for achieving the so-called smart public lighting, without which the higher levels depicted in Fig. 2 are not attainable.
Levels of sophistication of the papers analyzed in this literature review.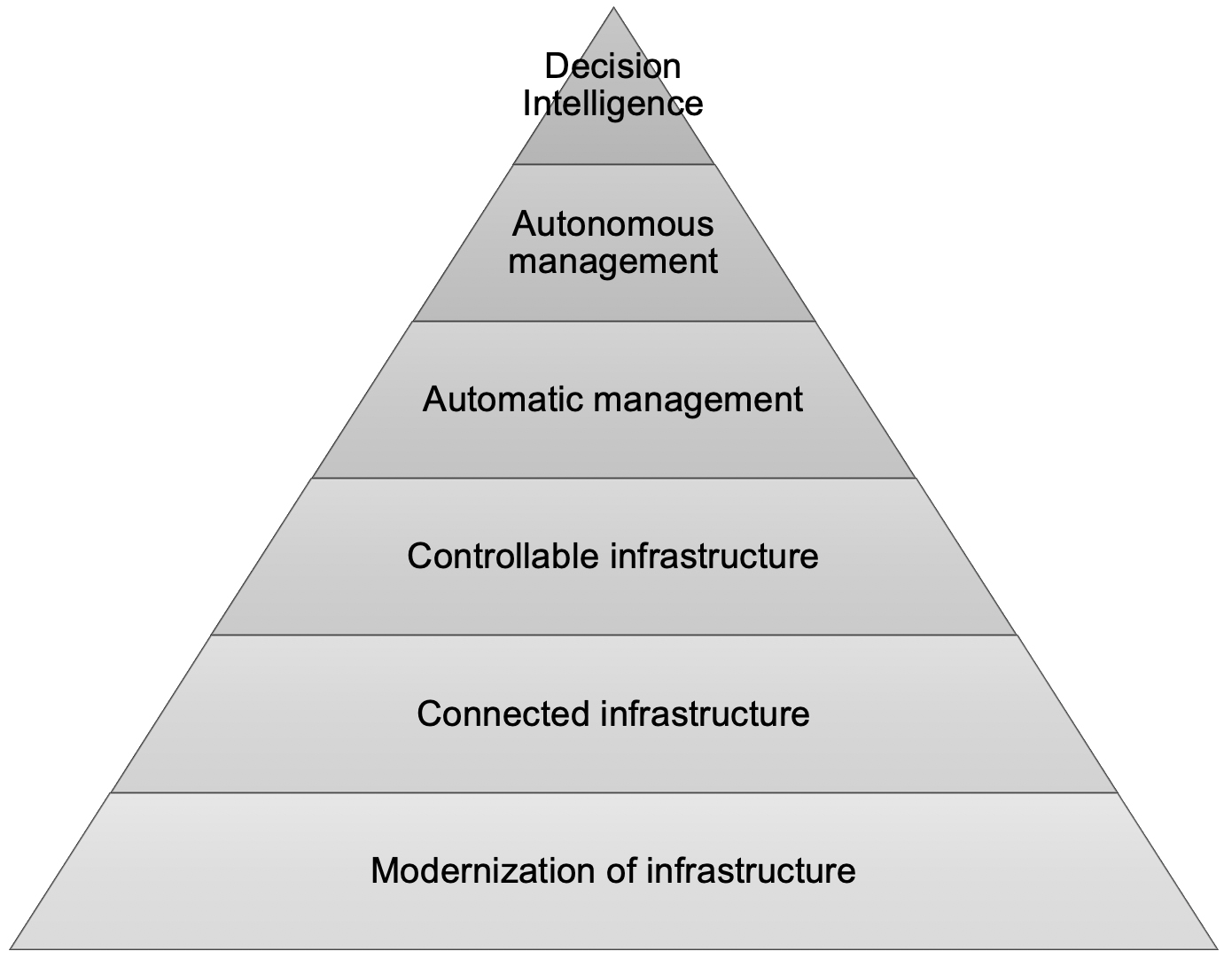
The next level requires these lamps to be connected through a data communication network. Indeed, new LED lamps which are now being used in public lighting, generally have a wide range of hard and soft sensors that collect data on the state of the fixture in real-time. These variables include driver temperature, instantaneous voltage, instantaneous current, and lifetime, among others. The collected data can be transferred to be stored by the managing entity. The stored data can later be analyzed to elaborate dashboards and reports, and allow decision-makers to better know the network and how to manage it.
Most of new LED fixtures are also endowed with remotely-controlled actuators. This means that the data communication network might also act in a controlled network mode, allowing several of the operating parameters to be set remotely. The most frequent operations are to turn fixtures on or off or to adjust their dimming. Currently, most of the fixtures have on-board machine-to-machine communication modules that allow them to do so. However, there are also cases in which a control and communication network was installed in a public lighting setting using an external Wireless Sensor Network (WSN). A WSN is made of several modules: a computational unit for data processing, hard and soft sensors for acquiring physical quantities regarding the operation of the fixture or the environment around it, and a radio transceiver for sending and receiving data and/or commands [35].
The existence of sensors and actuators on the fixture is sometimes used to implement a first level of automated services, albeit relatively basic. At this level, services are generally not centralized and there is no centralized control. Services are rather reactive, generally implemented using simple rules, and tend to operate at the fixture level or encompassing a few nearby fixtures. In [34], the authors use motion detection sensors to automatically regulate the luminous flux of each individual street fixture. The system allows energy savings of up to 40% while respecting the lighting norms for all road users.
More recently, a new type of public lighting networks started to emerge, representing the next level of related works depicted in Fig. 2. This encloses approaches characterized by a full integration between three main elements: sensors, actuators, and a centralized governing entity. Systems that exist at this level are also often deemed smart public lighting, with the term smart referring both to the ability of sensing the state of the network and of autonomously managing it. Accordingly, many different architectures and approaches can be found in the literature, with varying degrees of sophistication, namely concerning the degree of autonomy.
At this point, it is important to distinguish between the concepts of automation and autonomy as a system may implement an automatic management of the network but have very low autonomy. Automatic management refers to the ability of the system to manage the public lighting network without the interference of Humans, following a pre-determined set of rules. These rules are, however, static, and the system does not have the ability to change them. Autonomy, on the other hand, implies the ability of the system to manage the network and to manage itself; that is, it has the ability to change the rules.
An example of an automatic system can be found in [35], in which the authors use a hierarchical WSN to control public lighting. It is hierarchical in the sense that there is a central control unit that controls special nodes of the network that act as a coordinators (gateways), and these gateways in turn are responsible for monitoring and controlling nearby fixtures. Gateways are also responsible for sending and receiving data to the central control unit. The control unit decides when to turn the fixtures on or off, as well as their dimming. The authors used a network of 737 fixtures, individually controlled through a network of 11 gateways. To reduce energy consumption the authors used a lower and time-varying power profile with adaptive dimming rules, achieving savings of around 30%.
In [40] the authors study the impact of retrofit actions in urban lighting systems and show that energy and economic savings can be obtained in different scenarios: time-based dimming strategy, changing of light bulbs by more efficient ones, or both. This is also an example of how an automatic system would result in energy savings by controlling the public lighting network according to pre-determined rules. When replacing light bulbs with more efficient ones while also automatically controlling dimming, the authors report energy savings and a reduction of CO
Automatic systems have also been used to control light intensity based on car traffic. In [41], the authors implemented a situation-based traffic adaptive control of public lighting. That is, rather than controlling public lighting based on time of day, the authors do so with information of traffic flow. Traffic level is discretized into categories and then a group of rules is used to remotely control the intensity of light based on the amount of traffic, in real-time. On the different test sites in which the authors validated their system, they reached energy savings between 35% and 50%. A similar approach can be found in [42].
There are also systems that, while automatic, are less deterministic in the way they take decisions, and are closer to autonomous ones. In [43], for instance, the authors present a hierarchical system in which fixtures are organized in a tree fashion. The authors implemented a voting scheme in which each parent node collects votes from the children nodes regarding “what to do” when ambient lighting changes. Decisions are thus taken, at different levels, according to a majority vote of each sub-tree. While not completely deterministic, the system is not yet deemed autonomous in the sense that it cannot change the voting rules.
At a higher level, one can find examples of true “intelligent systems” for PL management. In [25] the authors present an adaptive architecture that deals with control and intelligent management of public lighting to minimize energy consumption while maintaining visual comfort in illuminated areas. The authors combine elements from Artificial Intelligence and statistics, including Artificial Neural Networks and Multi-Agent Systems. Cost savings are twofold: in terms of energy consumption and by using a modular and easily scalable architecture.
Similarly, in [44] the authors present a decision making tool to support in selecting the optimal energy interventions on the public lighting network. In this specific case the authors approach the problem of energy efficiency through a quadratic integer programming formulation, with the goal to reduce the energy consumption and ensure an optimal allocation of the retrofit actions among the street lighting subsystems.
Economic savings can however be obtained by other means than dimming control. In [45] the authors investigate the use of solar energy and adapting lighting schemes based on motion sensor data, to improve the energy balance of PL networks. Not only that, but the authors also develop algorithms for forecasting the energy produced and consumed, and use these forecasts to optimize the energy management of the system by determining when to sell and when to buy electricity to/from the grid. The main goal of the optimization function is to minimize the cost of electricity in the context of a time-of-use variable energy tariff. Results show that adaptive lighting can decrease energy consumption by up to 55% in low traffic environments, and that the energy balance of the network can be positive throughout long periods.
An analysis of other smart lighting systems that share the characteristics of those addressed so far can be found in [46, 47, 48, 49, 50].
The topmost level of the Fig. 2 includes Knowledge-based systems. These are systems that are not only able to manage a public lighting infrastructure, but also to compile knowledge about the its operation. This knowledge is then shared with Human experts in a way that contributes to their understanding of the system and potentiates good decisions. An example is detailed in [51]. The main goal of the authors is to assess street lighting tenders based on energy performance indicators and environmental criteria. For this, they built a decision tool that ranks actions, and provides Human experts with recommendations regarding the most and least beneficial ones.
In [52], the authors detail an approach in which graph-based models and methods are used to manage adjustable fixtures through a dynamic sensor-based operation. Specifically, control is performed by means of rule-based systems and pattern matching and is applied to the system using graph transformations. The formal framework proposed by the authors includes information regarding the spatial characteristics of the area under consideration, illumination requirements, parameters of the fixtures, all inputs and outputs, and the methods for selecting appropriate configurations. The main advantage of the graph-based approach proposed by the authors is that of addressing the complexity of designing and controlling lighting systems given all the variables and requirements. A graph-based approach is also used in [53] to dynamically control street lighting. While the dynamic control of dimming has already been addressed before in this section and placed at a lower level, this system has the added advantage of having an increased expressive power, which makes it more easily interpretable for a Human expert. Namely, the graph represents features such as traffic intensity detector, ambient light intensity detector, road segments, fixtures and fixtures’ configurations. Aside from this, the authors also show that they are able to improve efficiency by reducing problem size at run-time. Specifically, experimental results show a reduction of computing time by a factor of 2.8. Other graph-based approaches to the problem of street lighting control can be found in [54, 55].
Regarding the approach proposed in this paper, it can be classified at the topmost layer of Fig. 2, distinguishing itself from the others by combining two usually independent approaches: a semantic one and a data-driven one.
The conceptualisation phase
The process of managing the street lighting behaviour, towards its best balance between energy efficiency and light comfort patterns, implies an understanding of the underlying consumption factors and how they contribute to the performance of a fixture.
In this context, energy efficiency must be approached as an holistic concept [26] including several factors or parameters that might be classified as internal and external. Internal factors are related to current (I), tension (v), electric power (w), color, and temperature. External factors include ambient data [56] and the location of street lighting installation [26], as well as parameters describing quality of light [6]. To this end we followed a conceptual analysis, through which we proceed to concept identification by means of domain terms extraction, analysis of the knowledge they refer to, and representing their semantic relations between concepts in an network. This knowledge representation creates a framework for understanding in the scope of public street light consumption behaviour.
The conceptualisation process was triggered by defining a set of Competency Questions (CQs) [57] or focus questions, which aim at defining the scope of the conceptual analysis. Additionally, CQs might also act as a kind of stop criterion, to the extent that if all questions were answered, the process might finish.
CQ#1 – What kind of factors might contribute to the public lighting consumption behaviour? CQ#2 – What are the main types consumption behaviour of LED fixtures? CQ#3 – What “circumstances” determine public light consumption behaviour? CQ#4 – What kind of elements define light comfort? CQ#5 – What kind of light comfort constraints contribute to public lighting consumption behaviour? CQ#6 – What kind of “elements” determine the energy efficiency performance of a Public Street Lighting source? CQ#7 – What is the range of actions that might be performed in the scope of Public Lighting management?
Conceptual ontology for street lighting consumption behaviour.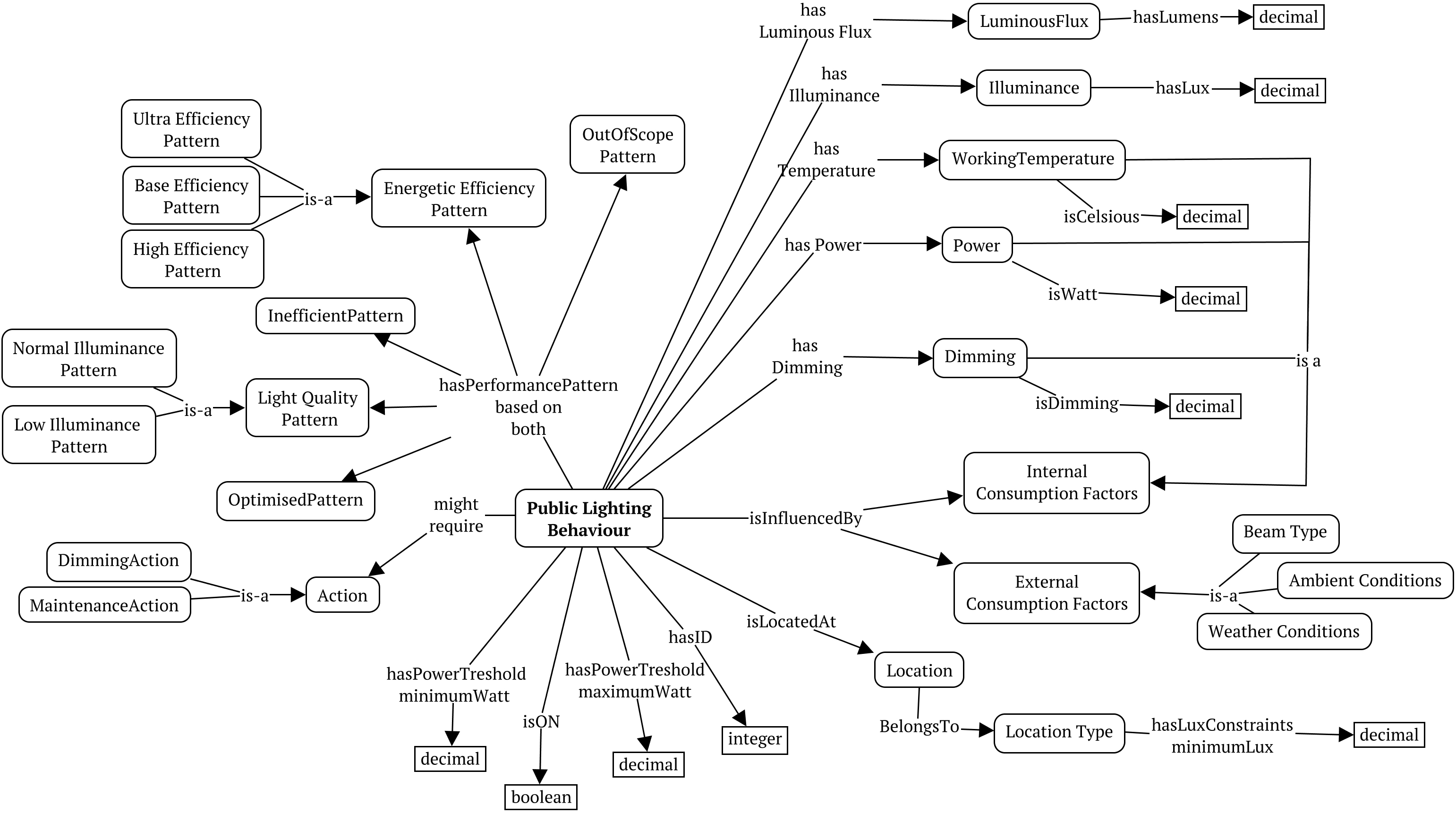
Figure 3 depicts a conceptual ontology for street lighting consumption performance, representing a common understanding upon the domain. It is grounded on the rationale that street LED fixtures have a consumption behaviour that may be classified in relation to its energetic performance and light quality performance. This classification is obtained according to the fixture’s energy consumption pattern defined according to several factors: i) savings, given by the fixture’s efficacy ratio; ii) internal factors such as dimming, temperature and power; iii) external factors (moonlight, weather, traffic, dust), and; iv) light quality factor, which depends on the location of the street light installation and the underlying illuminance pattern. The location is classified in EN 13201 according to the street utility and user needs, which in turn has an associated illuminance pattern. Additionally, it is also considered that the consumption behaviour might indicate that the street lighting source is operating in an inefficient or out of scope mode. For each pattern of street lighting behaviour, some action might be required, either a maintenance action or a dimming action, i.e., perform adjustments to the dimming value. According to the characteristics of the fixture, the available interfaces, and the technical setup, no other actions are feasible.
This conceptualisation work was implemented through an iterative and incremental process, supported by literature reviews, with interactions with domain experts. The conceptual ontology is to be further developed towards its formalisation. Meanwhile, it contributes for data interpretation and the classification of consumption patterns within an holistic perspective. The formulation of useful decisions, typically composed of a chain of actions, must be aligned to the intended outcomes. Actions and outcomes relations are better understood when there is a shared vision of the domain. In this sense, the conceptualisation eases the classification of the “system status”, promoting decisions’ utility.
Figure 3 depicts the conceptual ontology containing the key terms and concepts of the domain, semantically structured by means of conceptual relations. For this model to be used as a computational semantic artifact, its constructs must be defined through logical constraints.
Public street lighting relevant semantic restrictions
Public street lighting relevant semantic restrictions
PL sates and actions axioms and facts
The formal ontology was built using Protégé1 ontology editor, whereinto the following actions were performed:
Creation of the Class hierarchy; Creation of the ObjectProperties hierarchy; Modelling the class associations through ObjectProperties identifying the appropriate Domain and Range classes; Creation of the DataProperties identofying the appropriated Domain (Classes) and Range (literal, i.e., a value type); Identification of domain relevant semantic restrictions for the main “classification duties” of the ontology (Table 2); Definition of the Classes through logical constraints, using axioms and rules, as sated in Table 3. These descriptions allow the ontology to classify Public Street Lighting behaviour, regarding both the light comfort performance and energy efficiency performance, and determine simple actions in accordance to the status. The rules and axioms were developed in Semantic Web Rule Language and Description Logic, respectively.
Again, benefiting from this intertwined methodological approach, some of the created assertions were derived from the data-driven AI outcomes. The definition of thresholds and illuminance prediction are examples of aspects used on the definition of the inference rules.
At the end of the formalisation phase a inference-ready and computable ontology artefact, represented in Web Ontology Language (OWL), was achieved.
Sources of data and process followed to train a model with the laboratory data and using it in the production setting.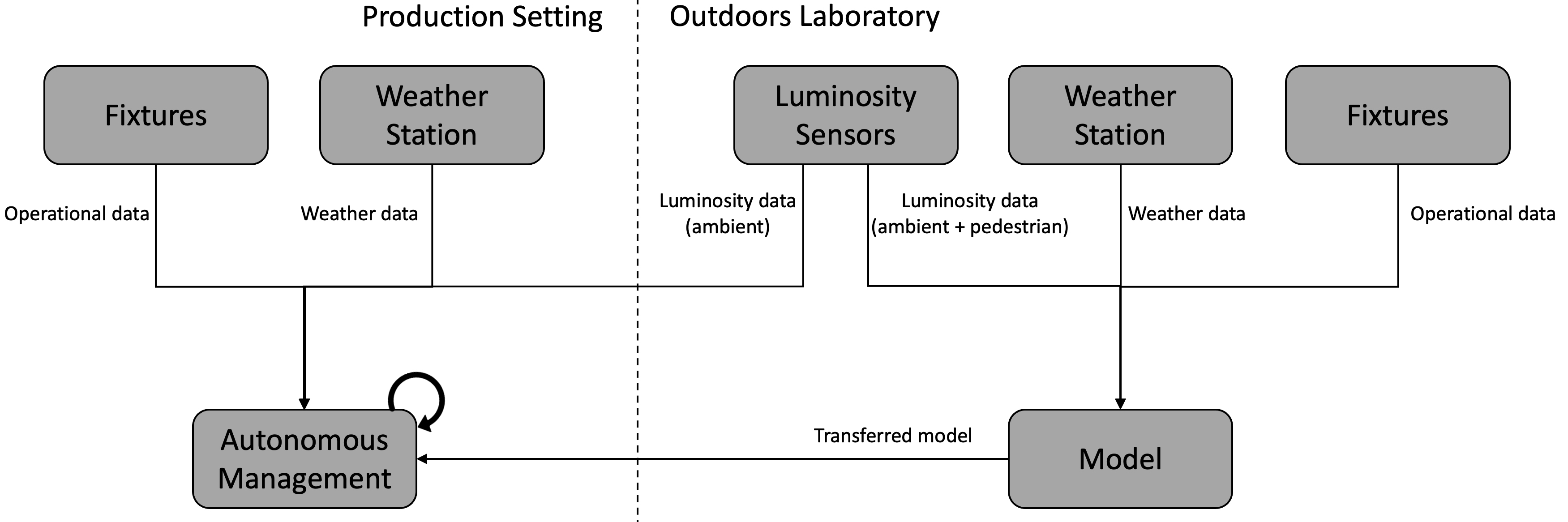
Providing smart decisions on how to minimize energy consumption requires contextualized data according to environmental factors (e.g., weather data, moonlight, traffic), normative factors, and the street lighting installation blueprint. Nonetheless, most existing data-based approaches lack this rich contextual information. Such is the case of the main source of data used in this work: a public lighting production setting in a Portuguese municipality with 305 ARQUILED’s ARQUICITY R1 fixtures. This specific model of fixture allows to collect data from its operation in real-time, and also allows the change of its operating parameters in real time. That is, we can for instance control the level of dimming of each individual luminary. In this model, a level of dimming of 100% means that the fixture is working at full power, while a dimming of 0% turns the fixture off.
According to EN13201 normative, the set of fixtures of the production setting are installed in a
The dataset collected from the production setting contains 3.963.730 instances of data. Each instance describes 5 minutes of operation of a specific fixture and includes, among others, features describing instant voltage, fixture temperature, instant power, accumulated energy (Wh), uptime or dimming. These data were collected over a period of four months, between September 5th 2017 and January 3rd 2018.
Before their use, data were cleaned. This included removing instances from warm up periods (first 1 to 4 minutes when a fixture is turned on) or shutting down periods. During the cleaning operation, 107.912 instances were removed. The resulting dataset thus contains 3.855.818 instances.
The resulting dataset is a very homogeneous one in the sense that it reflects the rigid management of the network by the municipality. For instance, 90% of the data were collected from fixtures set at a dimming between 80% and 90%. This prevents us to explore the whole search space.
Moreover, the data collected from this production setting is devoid of attributes other than those related to the fixtures’ internal factors.
We hypothesize that the ideal value of dimming is not static, i.e., it varies according to the conditions of the environment, and that it may be outside of the 80%–90% interval. Thus, there was a process of enriching the available data with other relevant attributes, taking into consideration the aforementioned domain model (Fig. 3).
Data enrichment
Data enrichment was achieved by a twofold approach (Fig. 4). First, data obtained from a weather station located near the production setting was integrated with the production dataset. The data from the fixtures was merged with weather data, also collected at 5-minute intervals from a local weather station. These data include air temperature (
Distribution of luminosity measured at pedestrian level at different levels of dimming, without ruling out the effect of ambient light. 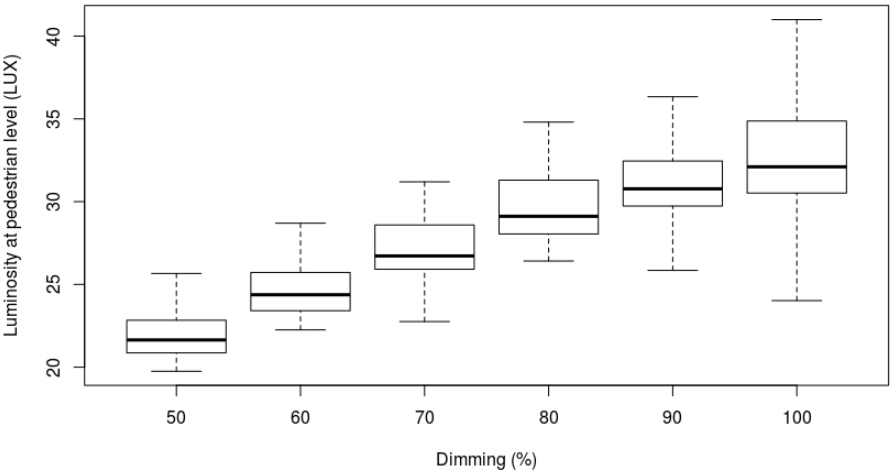
Second, an outdoors laboratory setting with the same fixtures of the production setting was set up, and equipped with additional sensors. The main difference between the production and laboratory settings, asides from the additional sensors, is that the operation of the laboratory setting can be changed at will, to generate and study specific scenarios, while the production setting cannot.
In the laboratory, data were also collected at 5-minute intervals between July 31st and October 4th, 2018. These data include, like in the production setting, data from the fixtures and weather data. However, additional sensors were also used to collect data regarding luminosity at two different levels: one at the pedestrian level and the other above the fixtures. This allows the studying of the effect of two key variables – dimming and ambient luminosity – in the level of luminosity experienced by the pedestrian.
Moreover, the fixtures were programmed to change dimming at every 20 minutes, continuously changing between 50% and 100% with steps of 10%. This provides a much more complete dataset in what concerns the fixtures’ behavior and operation under different conditions.
For instance, it is possible to analyze how the luminosity measured at pedestrian level under the fixture varies according to different settings of dimming (Fig. 5). As expected, luminosity tends to increase with dimming. Nonetheless, there are significant variations which may be related to variations in ambient luminosity (e.g. cloudy vs. clear night). It is thus important to model this relationship and quantify, at each level of dimming, the effect of ambient luminosity, so that this can be explored to minimize energy consumption (Section 5).
One major difference between both datasets is thus the lack of data describing ambient luminosity in the production dataset. Thus, it would be impossible to implement a context-aware and dynamic management mechanism, as the one proposed in this paper. To overcome this limitation, this dataset was further enriched as follows. For each night of data in the production dataset, a night was randomly selected in the laboratory dataset. Ambient luminosity data was transferred from the laboratory to the production dataset, according to the selected nights.
While the resulting production dataset is not real in the sense that the ambient luminosity data were transferred from a different location, it is still a realistic dataset. It allows to answer the following question: “How would energy-efficiency improve, if the proposed approach was implemented in the production network, assuming the transferred ambient luminosity?”.
As addressed previously, the level of light experienced by the pedestrian depends on two main factors: the level of dimming of the fixtures and level of ambient light. However, this relationship is not direct. For instance, the same level of ambient light will have a stronger effect at the pedestrian level if the dimming of the fixture is low, and vice-versa.
Moreover, this depends on additional factors, including environmental ones, as well as on the location of the fixtures: a fixture that is under a bridge or close to a tall building will have a different relationship with ambient light than one that is under the open sky. Hence the need for taking into consideration the individual factors of each fixture.
Best-of-class models, sorted by RMSE calculated on test data
Best-of-class models, sorted by RMSE calculated on test data
To model these relationships and obtain a model that can be used to predict the level of light at pedestrian level under a given fixture/conditions, the following methodology was implemented. A ML experiment was implemented with the data collected at the laboratory setting. The goal of this experiment is to obtain a model that infers the influence of each variable (among which dimming and ambient light) on the level of luminosity experienced by a pedestrian.
A hyper-parameter search was implemented over five different state of the art algorithms, that include boosting and bagging ensembles [58]. Specifically, the following algorithms were assessed: XGBoost, Gradient Boosting Machine, Distributed Random Forest, Deep Learning and Generalized Linear Model. The data was split, with 30% of it being held out for testing and 70% being used for training. For evaluating the models during the training phase, 5-fold cross validation was used with the training data. At the end, the best model of each class is selected and is evaluated on the test data. The performance on each of these best-of-class models on the test data will be the main criterion used for selecting the final model used in production. The results of this process are reported in Section 7.
The main limitation of this approach is that it was trained on the laboratory data and not on the production data. This is due to the previously mentioned fact that the production setting does not have the necessary sensors. Moreover, the model depends significantly on the fixtures that produced the data, as each one has unique operational conditions and placement characteristics.
To overcome this limitation and transfer the model to the production setting, the following approach was followed. For each fixture in the production setting, the most similar fixture in the laboratory was selected. Fixture similarity is calculated using the cosine similarity and takes into consideration a feature vector that includes orientation, position, context (e.g. open sky, covert, on the side of building), and statistical summaries of the main variables (e.g. operation temperature, energy consumption). Then, when the model is used in the production setting, the identifier of the fixtures (which are unknown to the model) are replaced by the most similar identifiers of the laboratory setting.
The resulting model can thus be used in real-time to manage the public lighting network, by finding the best configuration for each fixture, in order to minimize energy consumption while maintaining appropriate lighting levels. This process and the corresponding results are described in the following Section.
As described in Section 5, a hyper-parameter search with five models was implemented to find the best model to predict luminosity at the pedestrian level. Table 4 shows the best model of each class, together with the RMSE and
Observed luminosity (test data) vs. luminosity predicted by the best model.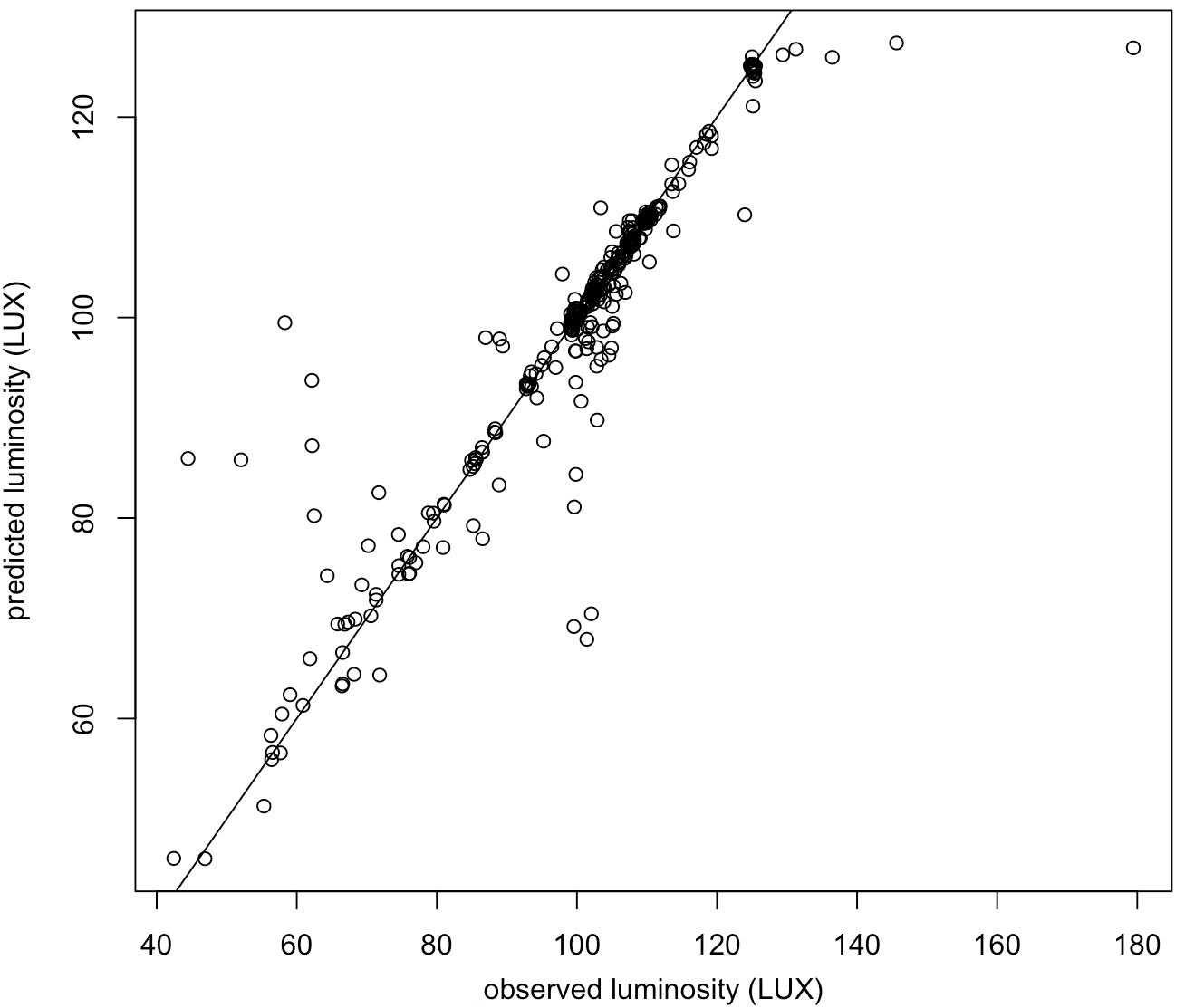
Figure 6 shows how the errors of the model are distributed when predicting luminosity for the test data. The solid line marks the diagonal, i.e., the region where predictions have no error. Given the train/test split methodology followed, these data points were extracted, at random, from different nights. Figure 7, on the other hand, shows the observed luminosity at the pedestrian level for a randomly selected fixture/night that was not used for the training of the models, against the luminosity predicted by the model for the same data. The correlation between observed and predicted values is 0.89.
Observed luminosity at pedestrian level for a randomly selected night, and luminosity predicted by the model (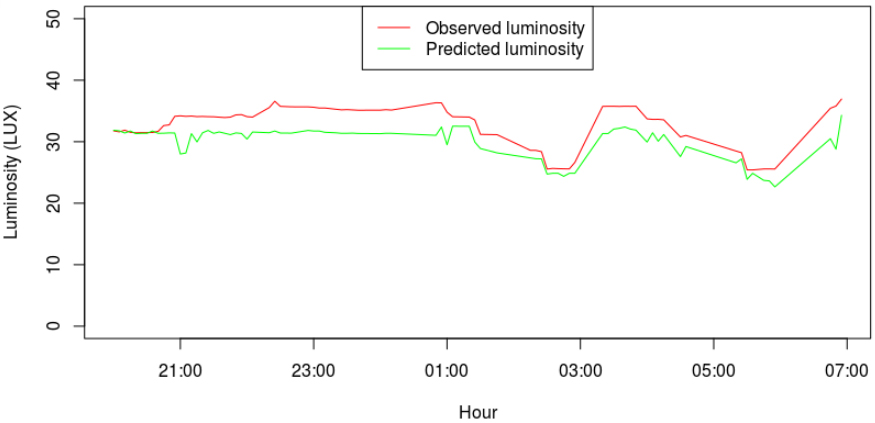
Observed ambient luminosity (bottom line) and predicted luminosity at pedestrian level with different dimmings.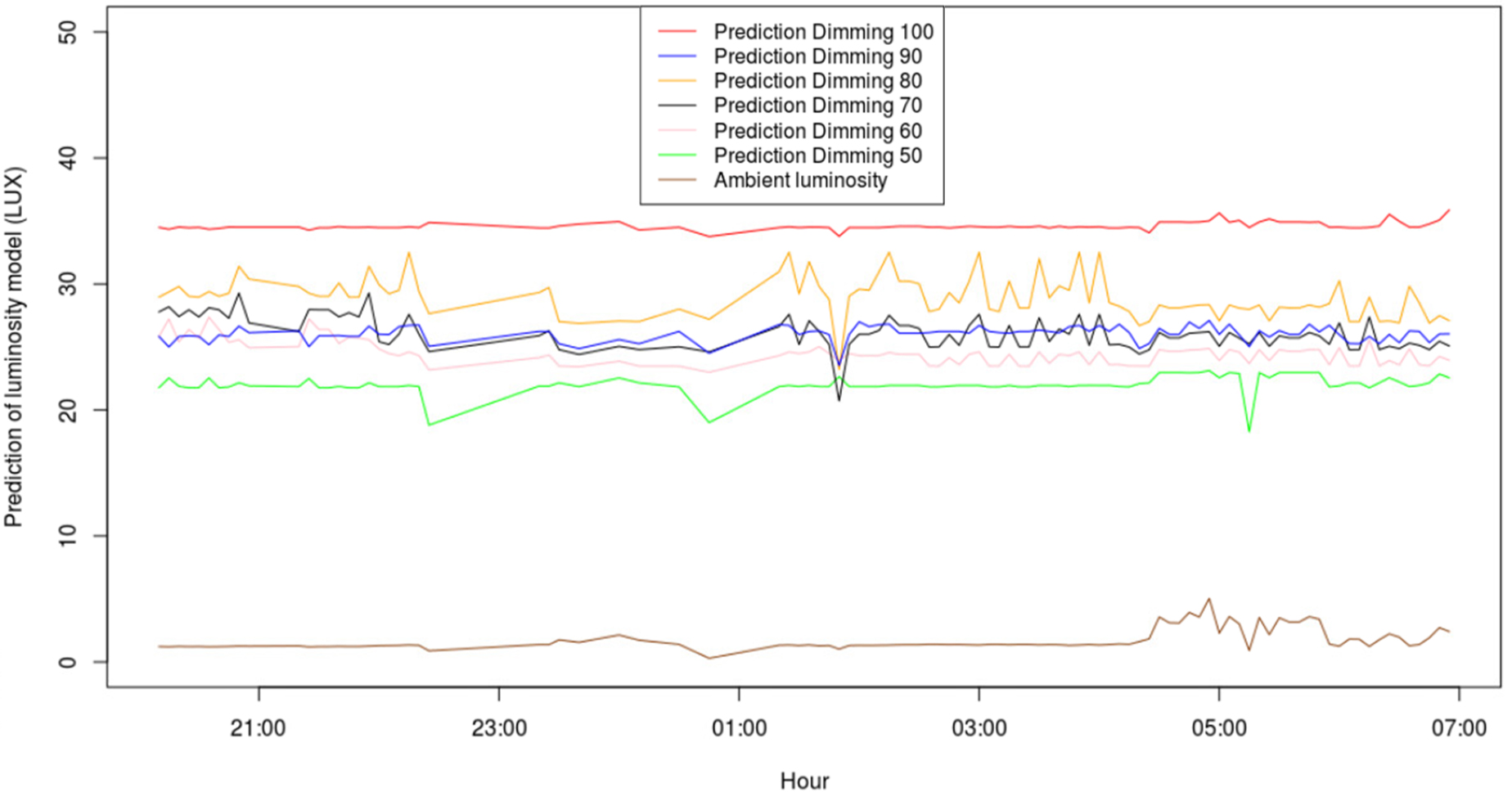
The variations in luminosity throughout the night are due to the ongoing changes in dimming in the operation of the fixtures of the laboratory setting, and to eventual natural changes in ambient light. The model thus satisfactorily predicts luminosity as a function of dimming, ambient light and the fixtures’ individual characteristics.
Figure 8 shows how the level of luminosity varies during one randomly selected night, and the prediction of the model for different levels of dimming. This Figure shows that, for this specific night, the optimum dimming would be around 60% as it provides the minimum desired level of luminosity according to the EN 13201 standard while minimizing energy consumption.
Once the model was trained and selected, the next step was to devise a method to implement the autonomous management of the public lighting network to optimize energy consumption while maintaining light quality. The current scheme used by the municipality to manage the production setting is rather rigid: in weekdays the fixtures are set to 80% of dimming and in weekends they work at 100%. This is hardly optimized for energy consumption. However, given that this is a production setting, we are not allowed to use this approach on site without prior validation.
To overcome this drawback, the following approach was implemented with the goal to estimate the energy savings of implementing an optimized management scheme in the production setting. First, we must note that the fixtures in the production setting do not have ambient luminosity sensors. This prevents us to directly apply the model. In that sense, for each day of data in the production dataset, we randomly selected one day of ambient luminosity data from the test dataset, and combined them. The goal is, in the absence of luminosity data, to simulate it in a realistic manner.
Relationship between dimming and power consumption (RMSE 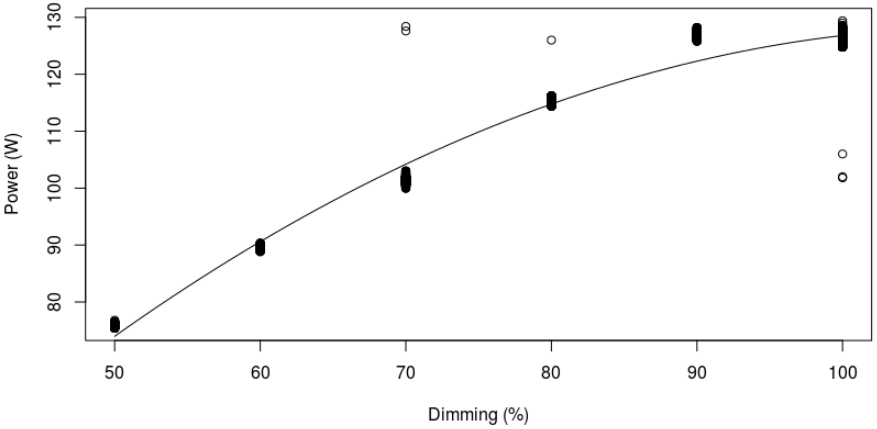
With this, we are able to predict the luminosity at the pedestrian level. The next step was to devise a method for selecting the optimum dimming for each fixture. To this end, it is first necessary to predict power consumption from dimming. Since the power consumption in a fixture grows with dimming, a quadratic fit was calculated to model the relationship between the two variables (Fig. 9). The resulting quadratic function can thus be used to predict the power consumption associated to a given dimming.
The following approach is implemented to select the optimum dimming for a specific fixture, at any given time. A binary search scheme is used for the interval 50%–100% dimming. Thus, it starts at a dimming of 75%. For this dimming, and given the ambient light, both the power consumption and luminosity level at pedestrian level are estimated: the former using the quadratic regression, the latter using the trained model.
If the predicted luminosity is below the 20 Lux threshold established in the EN 13201 standard, the search continues to the right, i.e., at a dimming of 87.5%. Otherwise, it continues to the left, at a dimming of 62.5%. At each step, the estimations of power consumption and luminosity are updated. The process goes on until a value lower than 20 Lux is reached and there is no possible search to the right. At this point, the previous value of dimming is selected.
This approach was used for every instance of data in the production dataset, in order to simulate the operation of an autonomous system carrying out a real-time management of each individual fixture, based on real-time data on ambient luminosity and fixture state. Results show a decrease in power consumption of around 28%. The observed energy consumption over the 4 months of data was approximately 95.728 kWh. In contrast, the estimated power consumption using the optimization scheme is of approximately 69.585 kWh.
In the context of the case study, the ontology was validated in relation to its utility, that means, the ontology must classify, properly, all the fixtures within the provided dataset. The process comprises five steps or stages (Fig. 10): i) Model configuration; ii) Parsing data; iii) Inference; iv) Store and Publish results, and; v) Visualisation.
Ontology service architecture.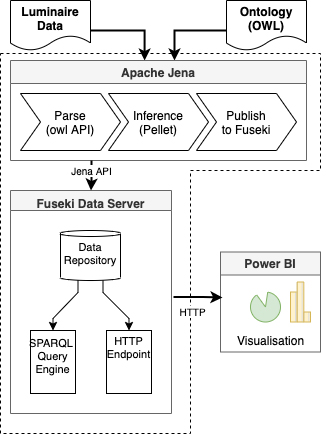
Excerpt results inferred from the ontology
The Model configuration consists of adding domain specific setup instances to the ontology, before it being populated with the luminaries dataset. This data is related to specific normative thresholds (e.g, EN13201 standard), locations’ type and fixtures beam types. This is done only one time at the beginning of the process. Afterwards, specific setup instances were uploaded to the ontology. This is performed only once, at the beginning of the process. Accordingly, instances have been added to each of the following classes: Dimming, Power, LuminousFlux, BeamType, LocationType, Actions and AmbientConditions.
Afterwards, specific setup instances were uploaded to the ontology. This is performed only once, at the beginning of the process. Accordingly, instances have been added to each of the following classes: Dimming, Power, LuminousFlux, BeamType, LocationType, Actions and AmbientConditions.
Finally, dimming increase and dimming decrease actions were also added to the model. For the time being this are the only operations remotely available. This is due to contractual constraints between market players, but it is also related to the fixtures’ technical constraints.
After the configuration stage, the parse phase starts, using Apache Jena,2 to load and validate the luminaire data to the ontology.
Once the ontology was populated, the next step was to perform some reasoning over the data. For this, we used the Pellet engine3 and SWRL plus Drools rules engine,4 both implemented using apache Jena Inference API.5
After the execution of the rules and synchronisation of the reasoner, ontology was enriched with the inferred data containing new statements and the results stored and publish to Apache Jena Fuseki,6 through which it is possible to access the classification being done by the model. Table 5 discusses, shortly, the behaviour of the model in classification process of specific entities. For the visualisation of the results, a front-end prototype was built using Microsoft Power BI,7 directly consuming data form FUSEKI SPARQL8 endpoint through HTTP/REST.
This ontology brings together domain knowledge and data science to offer a knowledge-based decision support model. Within the current case study the ontology was able to retrieve the necessary and sufficient data to answer the set of predefined competency questions (domain focus questions).
In general, every inferred assertion, fit the uploaded dataset and the results are considered suitable and desirable answers according to the knowledge model.
Most of the developed countries are currently committed with energy efficiency plans in which renewable energy sources and more efficient devices are used in order to decrease energy consumption and the associated carbon emissions. However, other technological developments such as those made possible by IoT and the Smart Cities umbrella, allow further improvements. In this paper we presented a twofold methodological approach combining a data-oriented and a semantic approach for the autonomous management of public lighting networks.
It is based on the acquisition of data from several sources, including fixtures, weather stations, and ambient sensors. The proposed management scheme treats each fixture individually and takes into consideration their surrounding conditions. When compared to the current management policy, the proposed approach leads to a decrease of 28% in energy consumption while still maintaining the lighting levels defined in the European norm for the corresponding zone.
Despite the diversity of works in the literature, which make direct comparisons difficult, our results can be critically analyzed in light of these existing approaches. Specifically, we can compare it with other approaches based on dimming control (either automatic or autonomous).
For instance, in [34] the authors achieve savings of up to 40%. However, their approach requires the use of motion sensors on every fixture, which is then used to regulate luminous flux. Our approach, on the other hand, assumes that there are no additional sensors and solves the issue by transferring the model learned in a laboratory setting to the production setting, by establishing the similarity between fixtures (e.g. operation conditions, location, orientation). Similar solutions that rely on additional sensors (e.g. traffic flow) can be found, namely in [41, 42]. These approaches report energy savings between 35% and 50%.
In [35], the authors use a hierarchical WSN to control public lighting, in which certain nodes (gateways) monitor and control nearby fixtures according to a central control unit. One major difference between both works is topology of the network, which is more complex in [35], namely when the network needs to be changed or re-organized. In our case, each luminary communicates directly with the central control unit. Moreover, the authors used a lower and time-varying power profile with adaptive dimming rules, while we use a Machine Learning model. The authors achieved savings of around 30%, which are similar to ours.
So, the proposed approach results in energy savings that are generally in line with the most similar approaches found in the literature. However, the main distinguishing factor is that most of these dimming-based approaches rely on additional sensors, while the approach proposed in this paper avoids their use in production settings by transferring the model learning from the outdoor laboratory setting.
Another major difference is related with the combined semantic and Data-driven efforts, which resulted in outcomes accommodated in an ontology, which represents the domain knowledge enriched with a set of axioms and semantic rules derived from the data-driven approach. As a result, a knowledge-based model was developed that overcomes (to a certain extent) the tacit knowledge gap during the conceptualisation process. On the other hand, the semantic approach provides means for data intelligibility within a context. The achieved ontology and its reasoning capabilities are to be implemented as-a-service or as a part of a DSS engine, performing a new paradigm for decision support in IoT environments.
Thus, future work will be steered by several goals. The major goal is to integrate the developed system with the system currently in use to manage the public lighting network. This integration will improve the existing system by transforming it into an actual Decision Support System rather than just an autonomous management system, in the sense that it will contribute with knowledge that can be used by experts to better understand the network.
Several steps will also be taken to address the limitations of current work. Namely, there is the need to study the behavior of other fixtures as the results presented on this paper apply only to a specific model (ARQUILED’s ARQUICITY R1) and, as there are changes between fixtures of the same model, there are bound to be even more changes when comparing different models. Doing so will significantly increase the reach and applicability of the proposed system and approach.
Another limitation of the present work is that the results were obtained by extrapolating from a laboratory setting, namely by transferring the model to the production setting. While this might give an estimate of the system’s behavior in the production setting, it is not as valid as a result obtained from the production setting. In future work we will either install the necessary sensors in part of the production setting to validate and assess the operation of the system in a real environment, or expand the laboratory setting so that we have a more representative group of fixtures to report on.
Finally, we will also investigate how the whole approach and developed system scales up to thousands of fixtures. Indeed, one of the main advantages of this work is that it considers the individual characteristics of each fixture, as previously described. However, as larger lighting networks are considered, the problem will become computationally more complex, with increasing training times and potentially more complex models. To address the issue of model complexity we will, on the one hand, use grid-search and/or meta-learning techniques to find model configurations that avoid overfitting. This will prevent the model from growing excessively while still maintaining accuracy. Concerning space and time complexity, we will use unsupervised learning techniques combined with dimensionality reduction and feature selection techniques [59] to determine which and how many types of fixture exist in a given network, according to their characteristics. Then, we will use their type instead of their unique identifier to identify them. This, we expect, will decrease the complexity of the problem, with a minimum negative impact in the performance of the model. To this effect, we will also look into state of the art algorithms, especially those that have faster learning rates or that are better at adapting to changes in the data, such as Neural Dynamic Classification, Dynamic Ensemble Learning or Finite Element Machine for fast learning [60, 61, 58, 62].
Footnotes
Acknowledgments
This work is co-funded by Fundos Europeus Estruturais e de Investimento (FEEI) through Programa Operacional Regional Norte, in the scope of project NORTE-01-0145-FEDER-023577 and by national funds through FCT – Fundação para a Ciência e Tecnologia through projects UIDB/00319/2020 and UIDB/04728/2020.