
Abstract
The worldwide generation of waste electrical and electronic equipment is continuously growing, with electric vehicle batteries reaching their end-of-life having become a key concern for both the environment and human health in recent years. In this context, the proliferation of Internet of Things standards and data ecosystems is advancing the feasibility of data-driven condition monitoring and remanufacturing. This is particularly desirable for the end-of-life recovery of high-value equipment towards sustainable closed-loop production systems. Low-Power Wide-Area Networks, despite being relatively recent, are starting to be conceived as key-enabling technologies built upon the principles of long-range communication and negligible energy consumption. While LoRaWAN is considered the open standard with the highest level of acceptance from both industry and academia, it is its random access protocol (Aloha) that limits its capacity in large-scale deployments to some extent. Although time-slotted scheduling has proved to alleviate certain scalability limitations, the constrained nature of end nodes and their application-oriented requirements significantly increase the complexity of time-slotted network management tasks. To shed light on this matter, a multi-agent network management system for the on-demand allocation of resources in end-of-life monitoring applications for remanufacturing is introduced in this work. It leverages LoRa’s spreading factor orthogonality and network-wide knowledge to increase the number of nodes served in time-slotted monitoring setups. The proposed system is validated and evaluated for end-of-life monitoring where two representative end-node distributions were emulated, with the achieved network capacity improvements ranging from 75.27% to 249.46% with respect to LoRaWAN’s legacy operation. As a result, the suitability of different agent-based strategies has been evaluated and a number of lessons have been drawnaccording to different application and hardware constraints. While the presented findings can be used to further improve the explainability of the proposed models (in line with the concept of eXplainable AI), the overall framework represents a step forward in lightweight end-of-life condition monitoring for remanufacturing.
Introduction
Waste Electric and Electronic Equipment (WEEE) has become a worldwide concern, not only because of its hazardous impact on the environment and human health but also because of representing one of the fastest-growing waste streams to date. In 2019, 53.6 million metric tonnes of WEEE were generated, that is, 7.3 kilograms per capita, of which less than 18% was officially documented and managed in an environmentally-sound manner [1]. The Directive 2012/19/EU of the European Parliament and of the Council [2] provides a regulatory framework for the collection, storage and transportation of related materials, which is intended to prevent the generation of WEEE and to contribute to the efficient use of natural resources and also minimize the human health and environmental risks associated with WEEE disposal.
From all kinds of WEEE, Electric Vehicle Batteries (EVBs) are raising special interest in both industry and academia due to the exponentially-growing demand for Electric Vehicles (EVs), which is expected to result in an enormous number of battery packs reaching their End-of-Life (EoL) in the coming years [3]. While these will need to be handled accordingly to reduce their impact on the environment, life-cycle engineering strategies such as remanufacturing are gaining momentum these days in order to bring them to like-new condition and give them a second life [4].
EoL decision-making can benefit to a great extent from the availability of traceable information about the EVB’s health condition, which can also facilitate predictive maintenance, lifetime prognostics, and fault detection [5, 6]. Following an Internet-of-Things (IoT) architectural approach, the monitoring of EoL battery packs through embedded sensors prior to disassembly and inspection stages can result in time savings of up to 34% [7]. This, in turn, enables the individual virtual representation of each EVB –its so-called Digital Twin [3]–, which leverages fine-grained real-time sensor data for building and training highly-accurate predictive models [8]. While making little economic sense for low-value products, this has proved to be especially viable for complex high-value equipment [9].
The integration of accurate sensors in EVB packs is key to protecting them from damage caused by adverse operation, transportation or storage conditions. Cell-based data generated are used to estimate the state of health (SoH) and state of charge (SoC) of the battery. These indicators are useful to determine the aging and charge level of battery packs, which in turn provide valuable information to adapt EoL operational strategies for product recovery [10].
The wireless transmission of the EVB’s SoH and SoC is raising interest among reverse logistics providers as a means to expedite testing and grading operations [11, 6]. However, despite these being typically computed onboard, the complexity of estimation methods is negatively influenced by high quantities of battery cells to be monitored. Hence, there is also growing interest in the transmission of raw sensor data for remote server-side fault detection and preventive maintenance in order to improve decision-making [3, 12].
However, there are various barriers to the recovery of EoL EVBs that need to be overcome to guarantee their viability in remanufacturing. First, the presence of rare metals such as cobalt or lithium can release toxic gasses increasing the risk of fire, which requires strict compliance with local regulations during transportation that significantly increases the costs associated with their recovery [13]. Second, with local storage regulations limiting the minimum distance between battery packs and their stacking conditions, most industrial warehouses for EVBs are typically spread over large distances, which increases the infrastructure cost of real-time sensor-based monitoring.
The deployment of Low-Power Wide-Area Networks (LPWANs [14]) can bring multiple benefits while bridging IoT sensor data to the Internet over long distances, including low deployment costs (a single base station is due to serve thousands of nodes), low maintenance costs (expected lifespans of a few years under periodic data transmissions), and IoT-based interoperability with Industry 4.0 manufacturing systems [15]. Among LPWAN, the LoRaWAN standard has already become one of the most extended LPWAN solutions, whose open specification is provided by the LoRa Alliance for long-range and low-power communications [16]. However, to date, there is limited evidence on the suitability of LoRaWAN for high-traffic applications such as EVBs monitoring across industrial consolidation points for EoL recovery.
In this sense, several limitations exist associated with an inefficient use of the available spectrum caused by an Aloha-type random-access protocol [17, 18]. While time-slotted channel access represents a suitable collision-avoidance strategy to guarantee robust communication networks with delivery rates of nearly 100% [19], the lack of flexible resource-allocation mechanisms severely limits its applicability for reliable large-scale applications. In this context, the integration of knowledge-based decision-making can bring potential benefits [20].
Considering the aforementioned, this work presents a multi-agent system (MAS) framework for time-slotted LoRaWAN communications to optimize the allocation of resources in compliance with specific reliability requirements considering as well end application constraints [21]. To validate the end-to-end system in practice, a use case for the recovery and storage of EoL EVBs is addressed, where their major transportation and storage conditions are studied. These are then translated into a LoRaWAN-specific data payload design and implementation which, in turn, is used as a basis to assess scalability improvements achieved for different scenarios experimentally. As a result, this work focuses on capacity-oriented improvements by individualizing synchronization periods at the device level to take advantage of already defined guard times in the network. This is one of the first works to address the definition of variable guard times and individual synchronization periods per end node, which prevents transmission overlap due to clock skew while still ensuring large LoRaWAN cell capacities. Although a recent approach [22] has proposed the use of variable guard times in the network, its impact on the overall network scalability has not been evaluated.
The use of MAS has attracted particular interest in recent years in the fields of civil engineering [23, 24], smart home [25], and connected mobility [26]. However, to the best of our knowledge, only two works in the literature have proposed the use of MAS on top of the LoRaWAN standard. One paper [27] presented an intra-slicing resource allocation technique, while another [28] focused on implementing a deep reinforcement learning technique for improved resource allocation. However, the evaluation of these works was based on a reduced set of LoRaWAN nodes: 4 real nodes in the former and 30 simulated nodes in the latter.
The major contributions of this work are: (i) the design and deployment of a multi-agent network management system for optimal resource allocation in application-oriented time-slotted LoRaWAN networks; and (ii) the experimental validation of scalability improvements achieved through the application-oriented allocation of resources in time-slotted LoRaWAN networks.
This work is an extension of a previous paper [29], where the first preliminary results of multi-agent-enabled allocation of resources in large-scale LoRaWAN networks were provided. To the best of our knowledge, this is the first work demonstrating scalability improvements on top of LoRaWAN communications in the reverse supply chain domain, an area where the number of studies involving the use of LoRaWAN technology has increased significantly in recent years [30, 31]. In the current extended work, nevertheless, the following new contributions are provided:
EoL monitoring of EVBs. By exploring the storage and transportation requirements for EoL recovery of EVBs, which is then considered as a baseline for the design of a realistic LoRaWAN frame payload to be reused in domain-specific industrial warehouses.
Decision-making logic. A new decision-making logic is proposed and validated on top of resource-allocation agents based on the lessons learned from our previous work.
Resource-allocation optimization. An optimization mechanism is presented to balance uplink and downlink resources efficiently in different application-specific network status scenarios, with the achieved network capacity improvements ranging from 75.27% to 249.46%.
This work is structured as follows: Section 2 reviews the condition monitoring of EoL EVBs and presents the LoRaWAN-based MAS including network fundamentals and metrics; Section 3 addresses the network design and setup conditions based on identified application-related constraints requirements; Section 4 presents the evaluation results and discussion based on experimental validation of the MAS in terms of achieved LoRaWAN network capacity improvements; finally, Section 5 highlights the major conclusions, learned lessons for the community, and future works.
This section addresses the multi-agent network management system logic design and architecture enabling on-demand resource allocation for EoL condition monitoring of EVBs. To do so, first, the conditions for EoL transportation and storage of EVBs – two of the most critical stages in their reverse supply chain [32] – are reviewed in Section 2.1. Second, LoRaWAN fundamentals and the selection of network metrics are described in Section 2.2 to introduce the proposed system logic. Finally, each of the agents being part of the MAS and the defined information flows in the end-to-end system architecture integrating LoRaWAN nodes, gateways, and the network server are briefly described in Section 2.3.
Condition monitoring of EoL EVBs
Case study on LoRaWAN-enabled monitoring of EoL EVBs in large-scale consolidation points to support remanufacturing.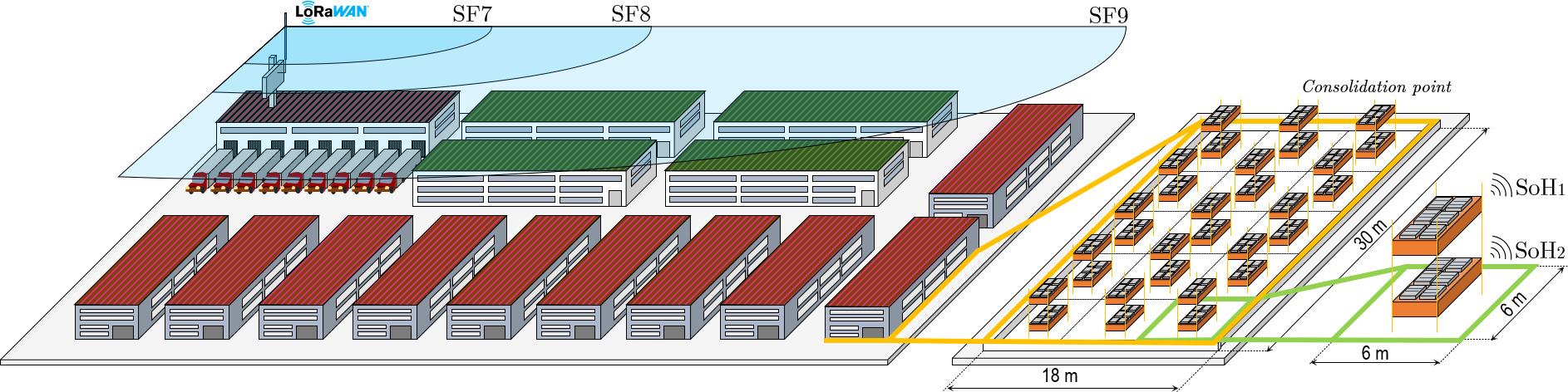
The battery management system (BMS) is the core component of the EVB, which is responsible for balancing the performance of individual modules and cells and providing relevant information about their health condition. It is in turn able to identify abnormal operating conditions through the on-board computation of different metrics such as their SoH, State-of-Charge (SoC), or State of Power (SoP) [33]. The SoH is defined as the ratio between an actual and initial battery indicator, such as its capacity, impedance or resistance [10].
The large number of operations involved in each stage of a reverse supply chain greatly increases uncertainty and, therefore, the resulting operational efficiency. The availability of real-time information about the condition of EoL EVBs is vital to support data-driven remanufacturing, which is expected to improve the economic and operational performance of reverse supply chains by enabling the re-use of modular components on demand [6].
While there have been numerous efforts to reach a consensus technique for accurate SoH estimation, two widely-extended strategies are [10]:
Experimental measurements. These require in-situ diagnosis, such as impedance measurements or capacity measurements, or more complex laboratory equipment like spectroscopy.
Model-based methods. These involve equation tuning, curve-fitting, or machine learning (ML) models trained to estimate the battery degradation over time.
The latter are receiving special interest in industry, since their deployment in BMSs for onboard fault detection and diagnosis is becoming ever more feasible.
According to a series of interviews with third-party logistics providers and recyclers [34], collection and storage are key phases in the reverse supply chain of EVBs. While the stockpiling of EVBs is a potentially unsafe practice [5]. The low volumes of battery packs reaching their EoL these days result in non-critical ones – also referred to as green or yellow – being transported and stockpiled in consolidation points, where they remain stored for long periods of time until a certain quantity is reached and their transportation for reuse or remanufacturing becomes economically viable. However, in the case of lithium-ion batteries, most accidents take place during their storage at warehouses, with short-circuit, self-heating and ageing being three of the most common causes [32]. The large size of the facilities used for the storage of these battery packs adds complexity in terms of covering wide areas under low infrastructure and energy costs [34].
Let us consider a consolidation point, as shown in Fig. 1, where yellow and green lithium-ion battery packs are stored once their EoL is reached. Through the deployment of a single-gateway LoRaWAN network, individual condition-monitoring of EVBs is proposed to enhance the remanufacturing information infrastructure. The goal is to improve decision granularity throughout the reverse supply chain based on real-time information availability prior to remanufacturing operations. The following metrics are monitored: SoH (provided by the on-board BMS), smoke, temperature and humidity, which have a significant impact on the aging of EVBs. Monitoring periods are considered constant for every LoRaWAN node attached to an EVB (equal to 5 minutes), while on-board BMSs are responsible for providing module-level fault reports which will be appended to periodic LoRaWAN frames when required.
Although the legal conditions for EoL storage of EVBs are highly dependent on the local authorities and municipalities, some general restrictions apply: standard distances between rows of pallets typically range from 6 to 2 meters, a maximum of 2 stacked EVBs are allowed, and the space left between layers should be, at least, of 1 meter [34]. Considering four EVBs from the marketplace, whose sizing and modular specifications are provided in Table 1, the reference dimensions of a baseline industrial warehouse are provided in Fig. 1.
LoRaWAN is an open specification for Long-Range communications [16], which is built on top of LoRa physical layer [36]. LoRaWAN defines the Medium Access Control layer (MAC) for LoRa end devices that communicate, following a star-of-stars topology, with one or more co-located gateways. These gateways forward uplink traffic to a network server via a backhaul such as Ethernet, 4G or 5G using TCP/IP, which is there de-duplicated and processed by an application server so as to decrypt data payloads. Most available multi-channel LoRaWAN gateway modems are half-duplex and, hence, not able to listen for upcoming traffic during ongoing downlink transmissions.
LoRaWAN technology operates in the unlicensed frequency bands of 433, 868 and 915 MHz in Europe, being the European Telecommunications Standards Institute (ETSI) responsible for regulating air-time usages in the different frequency bands [37]. While the ones destined for LoRaWAN end devices are, in most cases, restricted to 1-% duty cycles (DCs) –setting a maximum channel occupation of 36 seconds per hour and device–, the band used by gateways has a limit of 10% so as to support fair use of downlink capabilities. The time window for which LoRaWAN devices cannot access the channel is known as blackout period [38], which should be carefully considered in order to schedule downlink traffic in the network in compliance with the existing regulations.
LoRa is based on Chirp Spread Spectrum (CSS), where the achieved data rate depends on the selected spreading factor (SF), bandwidth, and coding rate. The SF ranges from SF7 to SF12 increasing the sensitivity of LoRa nodes at the expense of longer transmission air times; that is, lower data rates. As a result, LoRa transmissions using higher SFs are able to reach longer distances –in the order of kilometers– but also increase significantly the chances of wireless collisions, since each transmission occupies the channel for a longer amount of time. Transmissions at different SFs are quasi-orthogonal, which enables collision-free scheduling of simultaneous traffic over different SFs so as to increase the network capacity.
LoRaWAN regional parameters in Europe for a 125-kHz bandwidth
LoRaWAN regional parameters in Europe for a 125-kHz bandwidth
The duration of a LoRa frame is computed using Eqs (1) and (2) – by Semtech [36] for SX1276 and SX1278 LoRa modems – as a function of the physical-layer transceiver (PHY) configuration and payload length. The number of chirps per symbol, in turn, is determined by
where
where PL is the number of payload bytes, SF the spreading factor,
The proposed system logic is built on top of time-slotted LoRaWAN communications Class A communications [39], where gateways follow a Time-Division Multiple-Access (TDMA) schema [40] while being responsible for assigning fixed-length time slots to joining end devices on demand. The allocation is based on individual application-oriented requirements (such as payload length or periodicity) and real-world constraints (such as DC limitations or clock accuracy constraints). For this, upon joining, end devices get synchronized with a global time reference at the gateway level, whose feasibility was experimentally validated in the literature achieving ten-millisecond synchronization accuracies [19].
In this work, an orthogonal allocation of LoRaWAN end-node transmission slots over different SFs is proposed, which results in six simultaneous SF-specific schedules sharing a single downlink channel.
The slot length (see Eq. (3)) is defined as the sum of a guard time (required to compensate for device resynchronization over time due to positive and negative clock drifts), the time on air (computed according to Eqs (1) and (2)), and the synchronization offset (measured as the actual time offset with the global time reference upon synchronization).
where
We would like to textitasize that while most of the work in the literature is based on the existence of homogeneous clock skew (e.g. [41, 42]), this can significantly affect the reliability performance of communication in practice due to overlapping transmission slots (see an experimental study [19]).
The role of the MAS is to balance the available resources across SF schedules so as to ensure reliable time-slotted communications while delaying network congestion as much as possible. This occurs when the MAS is no longer able to accept new joining devices because one of the existing channels has exceeded its maximum capacity, either due to a transmission in progress or a slot reservation caused by an orthogonal transmission in progress. For this, the two network metrics monitored for decision-making are: (i) uplink occupancy and (ii) downlink usage.
Let us define the uplink occupancy, according to Eq. (4), as the time percentage to be reserved in all the orthogonal SF schedules (one per SF at every gateway) to guarantee both uplink and downlink communication of every node in the network.
where
Similarly, the downlink usage is defined according to Eq. (5) as the time during which the downlink channel will not be accessible due to either an ongoing uplink or downlink transmission or black-out period compliance.
where
The MAS is designed to comply with the following constraints:
Application-based constraints. These include payload size, transmission period, and end-node distance to a gateway (specified in Section 3).
Hardware-based constraints. These include the clock skew of end nodes and the half-duplex communication capability of LoRaWAN gateways.
Physical constraints. These include the gateway’s blackout period in compliance with ETSI regulations, that is,
Logic design constraints. Considering the proposed TDMA-based mechanism, six simultaneous schedules (one per SF) will run in parallel at the gateway level which, given their half-duplex constraints, need to be orchestrated to guarantee collision-free downlink channel sharing.
With reference to hardware constraints, as recently found in [19], not even end devices having the same reference model and manufacturer can be expected to have the same clock hardware specifications. This phenomenon is referred to as clock diversity in this work, which is used as starting point for the design of schedule-specific time slots by considering the coexistence of various clock skews in the network. To do so, a reference time-slot length is initially established for each schedule and, upon device join, its assigned guard time and time on air are dynamically tuned by the MAS according to individual hardware and application constraints. This represents a significant contribution in this work, since the previous TDMA approaches assumed fixed guard-time lengths for the sake of simplicity.
Three stages are proposed for agent-based resource allocation in the network, the transition between which depends on the number of active end nodes in the network and the amount of traffic being ingested at the gateway level. These are specified as follows:
Warm-up stage. The MAS collects metadata from the network while end nodes implement legacy Aloha-based channel access. This stage is activated under low network traffic conditions.
Launching stage. Based on the available information, once a specific network traffic threshold is reached, the agents are responsible for deploying the required instances for each SF-based schedule at the gateway level. Each of these instances is referred to as an SF-based Network Synchronization and Scheduling Entity (NSSE), which is responsible for guaranteeing end-device synchronization and time-slot transition for a specific SF schedule.
Joining stage. Based on application-specific and individual hardware constraints of the joining end node, the most convenient schedule and time-slot structure (including both guard time and transmission time) is assigned, which is notified to the concerned NSSE and end node via downlink so that it can request synchronization using a suitable SF. After joining, end devices follow a periodical data transmission schema until re-synchronization is required (negotiated directly with their already-assigned NSSE) or a more suitable configuration is received from the multi-agent network management system.
Based on the defined network metrics and stages, Algorithm 2.3 details the system logic implemented by the MAS in order to manage and allocate network resources on demand. According to Algorithm 2.3, during the initial warm-up stage, the MAS is responsible for collecting metadata from joining end devices as well as their clock skew (
MAS logic for end-node joining[1] Schedule Launching:
The proposed multi-agent architecture is shown in Fig. 2, which consists of seven software agents that are deployed, at gateway level, on top of the time-slotted logic described and interact with two ends: first, the LoRaWAN network (including its network server, gateway, and co-located end devices) and, second, the NSSE (responsible for launching the instances that handle synchronization and scheduling tasks).
Multi-agent network management system.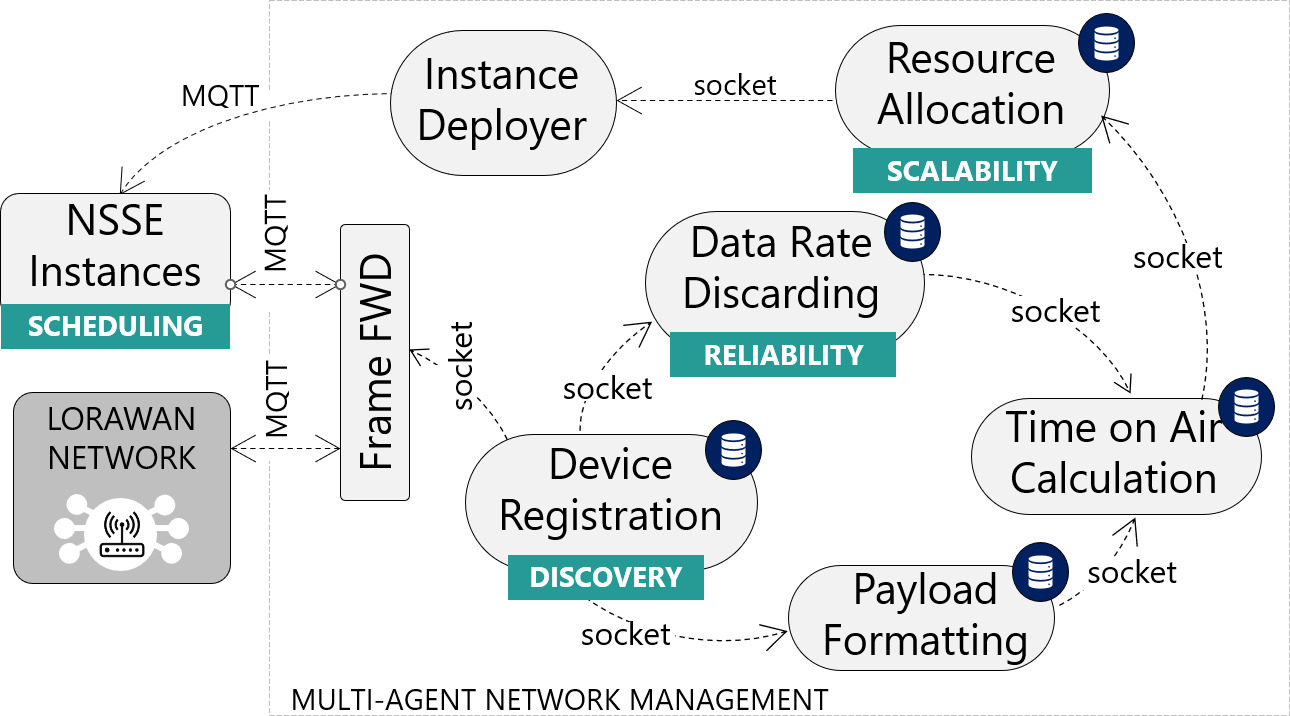
The proposed agents collaborate to balance the use of uplink and downlink resources in the network – e.g., uplink channel occupancies and downlink usages – by computing the required length of slots of each of the NSSE instances and assigning the most suitable SF and synchronization period to the joining nodes. These implement socket communication based on TCP (Transmission Control Protocol), which enables a distributed deployment.
The role of each agent being part of the resource-allocation network is described in the following lines:
Frame FWD (FWD). Standing for frame forwarding, this agent is responsible for filtering join requests from periodic uplink traffic or synchronization requests sent to a specific NSSE. These are then forwarded from the LoRaWAN-specific network server to the MAS for device registration and metadata collection.
Device registration. This agent is responsible for gathering request information from joining end nodes (i.e., hardware and application constraints) as well as their metadata (i.e., received signal strength indicator (RSSI), signal-to-noise ratio (SNR), requesting SF, etc.), which is ingested into a database accessible by all agents.
Data rate discarding. This agent leverages the current system knowledge which, combined with the information included in the end-node’s join request, is used to discard unfeasible SFs due to either physical constraints (e.g., long distance to the gateway) or agent-based scalability constraints (e.g., congestion of a specific schedule). This agent of proactive nature is expected to implement reliability-oriented criteria.
Payload formatting. This agent is responsible for splitting the joining end-node’s data payload into standard-format magnitudes (e.g., temperature, humidity, clock skew, etc.)
Time-on-air calculation. This agent computes the required uplink transmission time on air according to Eqs (1) and (2) based on the magnitudes that will be periodically reported by the end node.
Resource allocation. This agent has a key role in the network management system, which is responsible for proactively implementing the scalability-oriented criteria based on the current network knowledge, joining end-node’s constraints, and available uplink and downlink time-slotted resources.
Instance deployment. This agent is responsible for launching new NSSE instances on demand based on the consensus reached by the previous agents or notifying existing ones about coming end nodes that will be requesting time synchronization. These, in turn, will receive a downlink frame including the required metrics to do so, that is, the assigned SF and time-offset to initiate synchronization with its assigned NSSE.
A practical approach to time-slotted LoRaWAN-based monitoring of EoL EVBs is addressed in this section. To do so, the required number of nodes and their relative distance to the gateway in the baseline condition-monitoring scenario are established. This is used to validate the scalability achieved when integrating the multi-agent proposal in the described scenario, for which LoRaWAN payload frames and encoding/decoding tasks carried out by agents are justified in this section.
To validate capacity improvements for large-scale network deployments supporting the remanufacturing of EVBs, a uniform distribution (
A previous real-world reliability validation of end-to-end synchronization and scheduling concerning end nodes and a single NSSE [19] encouraged us to use such a device emulator in this work in order to focus on application-oriented network capacity improvements through the addition of multi-agent components. The remaining system components (LoRaWAN network and application servers, MAS, and NSSE instances) were implemented and launched experimentally to validate network capacity improvements.
Payload frame design
Magnitude lookup table at payload formatting agent
Magnitude lookup table at payload formatting agent
Based on a set of related magnitudes to be transmitted periodically, bit-wise encoding was used to generate compact payload frames so as to reduce frame payload sizes and, hence, overall transmission time on airs in the network. Table 3 details the set of magnitudes defined, their header identifiers, sizes, and their achieved bit resolution. This information is retrieved by the payload formatting agent to compute data payload lengths after a device’s registration. For the sake of simplicity, the clock skew of joining end devices is considered to be known according to their manufacturer datasheet. Hence, a multi-selector for different thing IDs was defined, i.e. groups of devices that have the same clock specifications.
Header definitions are based on Cayenne’s Low Power Payload (LPP2) resource identifiers, which conform to the IPSO Alliance Smart Objects guidelines to enable interoperability, but considerably reduce payload lengths by starting to number object identifiers from 0. In order to further reduce payload lengths, bit packing is applied to LPP’s definitions to compress data. Furthermore, new object definitions such as clock skew or thing ID were included by assigning empty identifiers.
LoRaWAN payload frame design.
Two different models of data frame were defined in order to keep transmission times to a minimum, the field structure of which is detailed in Fig. 3.
On the one hand, the joining payload frame (see Fig. 3) consists of three fields:
Hardware constraints. It includes hardware constraints such as a device’s clock skew.
Application constraints. It includes application-based constraints, such as a node’s mobility condition (typically stationary) or uplink periodicity requirements based on the EVB status.
Data magnitudes. It serves as a declaration of the sensed magnitudes to be periodically reported by the node, such as the EVB’s SoH or its surrounding temperature.
Fault. It is reserved for the generation of module-level alerts.
Each magnitude, in turn, consists of three sub-fields: header identifier (16-bit header indicating the magnitude ID), availability bit (a single bit indicating whether the concerned magnitude is included in the next field) and, in case included, the magnitude itself. Generic-payload magnitudes are omitted during device registration by setting availability bits to 0, since headers suffice to compute payload sizes of future periodic data reports.
The periodical payload frame, on the other hand, omits the fields provided upon joining in order to reduce LoRaWAN transmission times and, instead, includes the content of the declared magnitudes following the same order. Additional space for module-level fault information is included in the packet, which requires the system to deal with variable payload sizes.
The geographic spread of EVBs determines the set of possible SFs to initiate communication with their associated gateway. For the sake of simplicity, a uniform distribution of 100 nodes per square kilometer within a round-shaped area with respect to the gateway is considered [43]). Specifically, two differently-spreading scenarios were considered to benchmark capacity improvements achieved by the MAS in rural- and urban-like deployments, namely Scenario 1 (
Percentage of joining nodes and cell radius per SF for end-node distributions in scenarios
and
Percentage of joining nodes and cell radius per SF for end-node distributions in scenarios
The methodology used to obtain the distance thresholds is detailed below. Cell radius distance thresholds (SF boundaries) were determined based on the experimental LoRa-based RSSI and SNR measurements from the coverage study conducted in [44], which considered both urban and rural deployment conditions. To do this, the following criterion was used to establish SF boundaries: 5 dB
Scenario 1 (
Scenario 2 (
It should be noted that these parameters are not intended to represent unique LoRaWAN network deployment conditions, but rather two case-specific examples inspired by recent literature to validate MAS scalability achievements under different physical constraints.
Two key differences between the two scenarios can be noticed in Table 4. First, there exists a higher proportion of end nodes that need to join using higher SFs in
Two decision-making stages were defined at the MAS level for the proposed distribution scenarios, which are based on the application of different strategies at Launching and Joining routines from Algorithm 2.3. They are specified in Table 5.
Decision-making strategies assessed at the MAS level
Launching strategies depending on the distribution of guard time across SFs.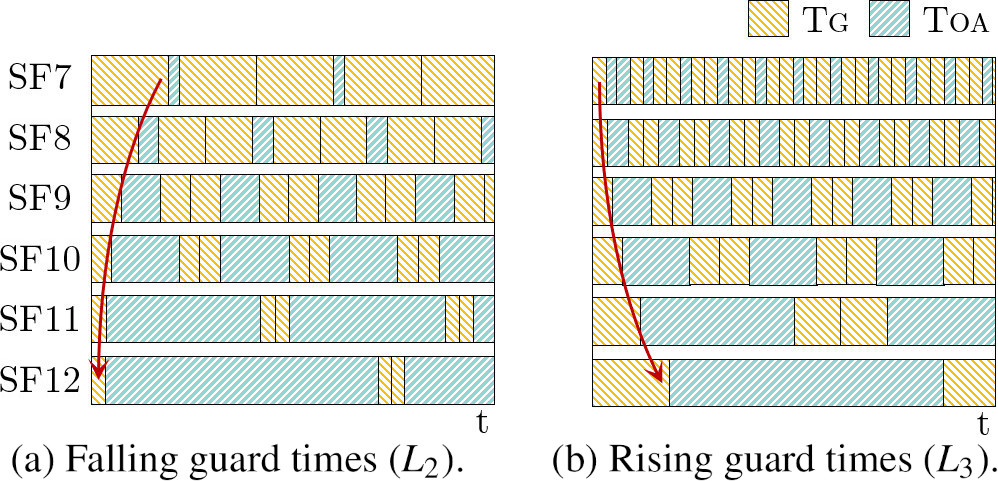
The results provided in this section are divided according to the two end-node distributions proposed (
Network capacity improvements in
Considering a uniform distribution of 100 nodes per squared kilometer and cell radius from Table 4, the maximum size of the network was set to 2500 devices.
Figure 5 shows downlink channel usages and uplink occupancies per SF over time for the MAS applying Launching strategies
Overall downlink usages (
Interestingly, the joining strategy
In view of the results, the decision-making criteria implemented by the MAS was extended with the computation of an optimal synchronization period in both launching and joining stages (
Optimal synchronization period pursuing applying strategies 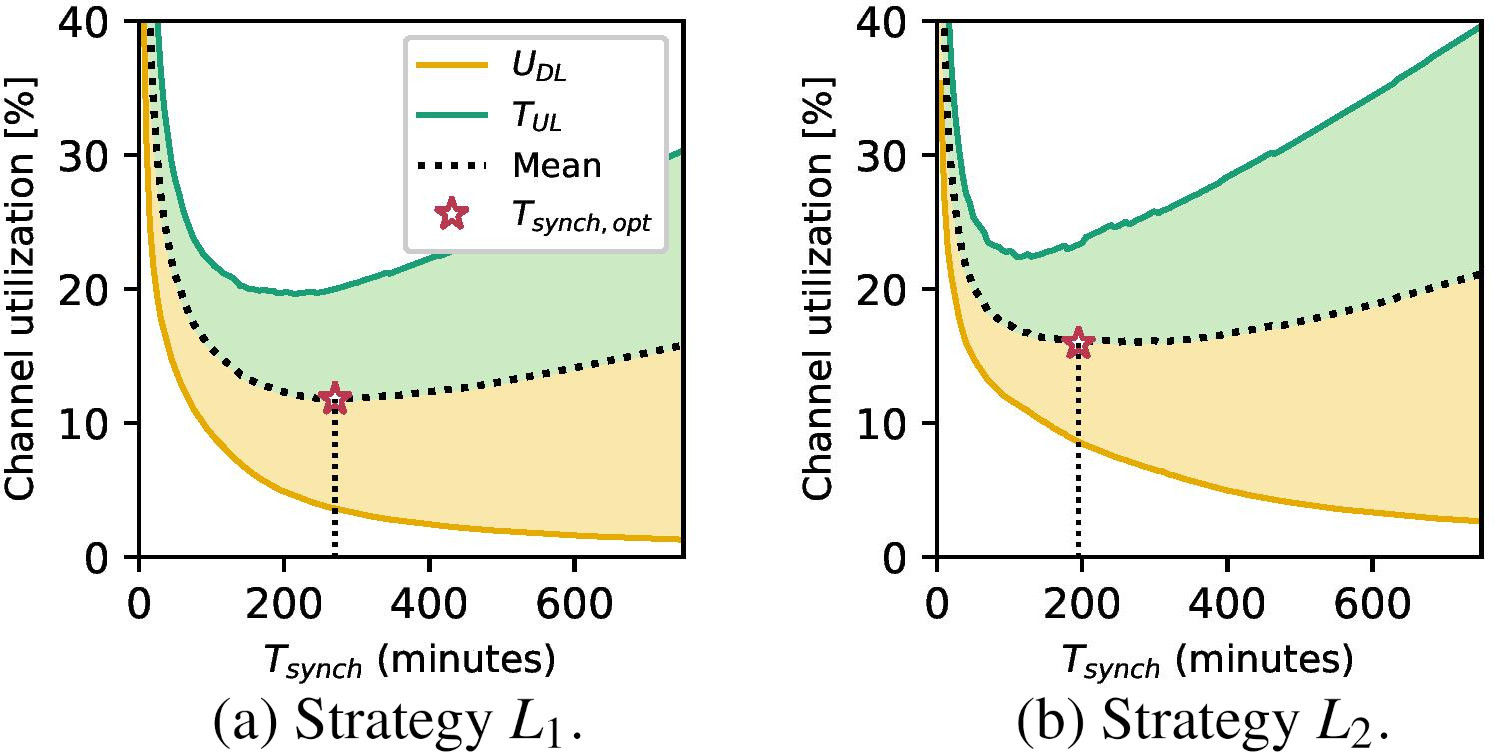
Figure 6 shows the uplink and downlink channel utilization as a function of the synchronization period for the same network configurations deployed in Fig. 5. The higher the synchronization period, the longer are the guard times at the expense of increasing downlink channel utilization. When an exponentially falling distribution of guard times is applied (strategy
Table 6 shows, for strategies
Metrics computed by agents for joining end devices when applying strategies
Finally, Fig. 7 shows the resulting number of nodes (cell capacity) achieved when applying the MAS in the network for each of the defined launching and joining strategies. For the network distribution being deployed (scenario
Maximum number of co-existing devices achieved for different strategies being applied (Scenario 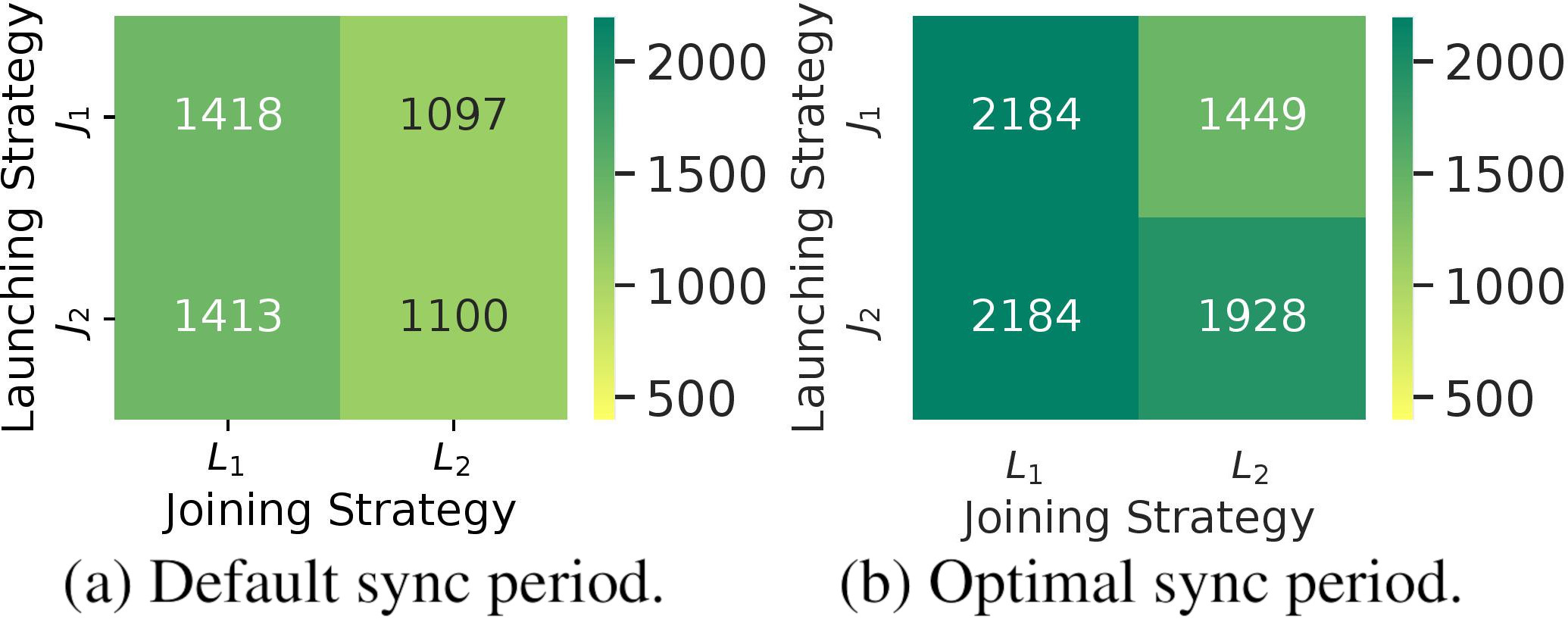
Channel utilization reduction applying an optimal synchronization period (
On the whole, nevertheless, balancing guard times across SFs (
Given a uniform distribution of 100 end nodes per square kilometer and the maximum cell radius from Table 4, the maximum size of the network served in the
Figure 8 shows the impact of implementing
By emulating a network with higher node densities but maintaining the same end-node distribution (Scenario
Maximum number of co-existing devices achieved for different strategies being applied (Scenario 
Some interesting conclusions are drawn from Fig. 9. First, exponentially-rising guard time distributions (
Impact of 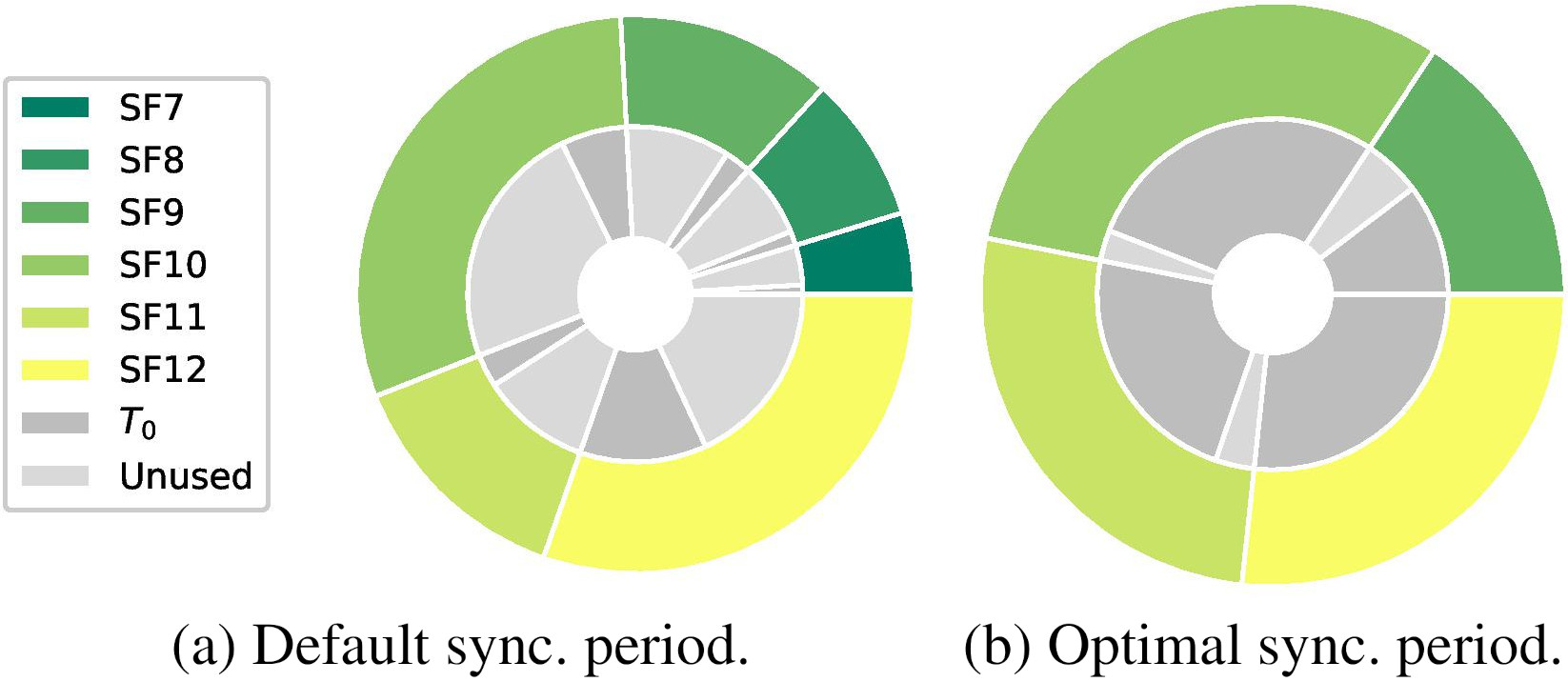
Number of nodes per SF over time for joining strategy 
Furthermore, the resulting SF distributions in the network while implementing
Finally, Fig. 11 shows the number of nodes over time for different launching strategies, and their impact on the overall network size. With SF9 resulting in the shortest slot lengths while applying
Finally, this section discusses various insights related to a real-world deployment in order to improve the replicability of this work through a detailed description of the hardware and software material resources required.
The presented end-to-end system architecture has been validated in practice using four B-L072Z-LRWAN1 STM32L03 end nodes (SX1272 transceivers) and an 868-MHz multi-channel LoRaWAN gateway based on Raspberry Pi and the iC880A concentrator4 (SX1301 transceiver). The approximate cost per end node is 45$ and per gateway is 200$, although depending on the size and cost requirements of the end application, the end nodes can be reduced to about 10$.
The gateway implemented the UDP packet forwarder,5 which was connected to a running instance of the ChirpStack open source network server, consisting of gateway bridge, network server, and application server services. The functionality of each agent was developed using the Python language, all of which were deployed on the same server (Intel i5-4590 CPU, 4 cores, 3.30 GHz, 16-GB RAM, Ubuntu 18.04 Bionic) as separate processes communicating internally via TCP sockets. The frame forwarder agent implemented both TCP and MQTT communication with the MAS and ChirpStack network servers, respectively. In addition, NSSE instances were built using the Click Router Framework [46] (for more details on the NSSE implementation, see our previous work [19]). Finally, the open source database PostgreSQL6 v10.23 was used to store end node metadata and network metrics.
While the previous end-to-end system was implemented to validate the proposal, the results shown in this work required the addition of the ChirpStack device emulator to increase the traffic load on the network. To do this, both the LoRaWAN gateway and the STM32 end nodes were replaced by a running instance of the ChirpStack device emulator, with payload frames designed to follow the format specified in Fig. 3 and Table 2, and SFs selected based on weighted probabilities from Table 4. This was done using the weightedrand7 implementation in the Go language.
Conclusions
In this work, an IoT approach to large-scale monitoring of EoL EVBs is proposed and designed on top of LoRaWAN communications. To do so, a time-slotted scheduling technique is followed for collision avoidance and the design of a multi-agent resource allocation component is introduced to optimize LoRaWAN channel access according to the available network resources, co-existing end nodes, and application-oriented constraints at the gateway level.
First, EoL storage and transportation conditions have been reviewed, which motivated the design of a single-gateway LoRaWAN communication network based on the number of monitoring nodes and the required payload magnitudes to be periodically transmitted. Second, the design and deployment of the multi-agent resource-allocation network manager are addressed following a modular design, on top of which different schedule launching and end-node joining decision-making strategies are defined at the MAS with a view to providing improvements in the maximum-achievable cell capacity for two different geographical end-node distribution scenarios: Scenario
An overview of the main scalability-oriented conclusions and lessons learned from our experimental setups is provided below, which support the role LoRaWAN communication networks for large-scale monitoring of EoL products as well as the suitability of MAS-enabled on-demand resource allocation:
The most relevant cell capacity improvements were achieved through the online computation and integration of optimal synchronization periods in the network, which guaranteed the balancing of uplink and downlink channel utilization according to individual end-node application and hardware constraints. Up to 75.27% improvements in the network capacity were achieved by the MAS for Scenario Once optimal synchronization periods are computed, the next decision-making stage achieving significant scalability improvements was launching. The allocation of guard times across different SF-based schedules prevented the network from early congestion at a single uplink schedule and resulted in 50.72% improvements in the maximum-achievable network size for Scenario Lastly, additional capacity improvements were achieved for different decision-making strategies being applied upon end-node joining. These guaranteed the balancing of uplink channel utilization across the different SF schedules on top of optimal synchronization periods and suitable launching strategies having been applied. Specifically, these improvements were up to 33.06% in the case of Scenario
As a take-home message, based on the results of this work, future contributions to LoRaWAN time-slotted resource-allocation systems should focus their efforts on optimizing the decision strategies involved in schedule initiation, which has been shown to be the stage where the most significant scalability improvements can be achieved based on contextual information collected during warm-up. That is, the design of guard times across multiple SFs in the network.
In the future, we plan to use of the selected network metrics in addition to their impact on uplink and downlink channel utilization to generate a dataset and improve the granularity of the conclusions drawn through a sensitivity study. To further improve the decision-making goals proposed in this work, the design and integration of a new context manager agent built upon ML techniques will be proposed, which will serve to automatically assess the scalability in time-slotted LoRaWAN networks through a semi-automated data ingestion pipeline from open sources of information following the open-source intelligence (OSINT) concept. Should this be the case, an end-to-end performance evaluation including agent-to-agent communication would be highly desirable.
To validate network scalability improvements under real deployment conditions, a preliminary network testbed will be deployed in an industrial setup with the aim to identify factors limiting the scalability of the proposal and design new agents to tackle them.
Footnotes
Acknowledgments
Grants 2019-PREDUCLM-10703 and 2022-GRIN-34056 funded by Universidad de Castilla-La Mancha and by “ESF Investing in your future”. Grant PID2021-123627OB-C52 funded by MCIN/AEI/10.13039/50110 0011033 and by “ERDF A way to make Europe”. Grant DIN2018-010177 funded by MCIN/AEI/10.13039/501 100011033.