
Abstract
Short-term residential load forecasting plays a crucial role in smart grids, ensuring an optimal match between energy demands and generation. With the inherent volatility of residential load patterns, deep learning has gained attention due to its ability to capture complex nonlinear relationships within hidden layers. However, most existing studies have relied on default loss functions such as mean squared error (MSE) or mean absolute error (MAE) for neural networks. These loss functions, while effective in overall prediction accuracy, lack specialized focus on accurately predicting load peaks. This article presents a comparative analysis of soft-DTW loss function, a smoothed formulation of Dynamic Time Wrapping (DTW), compared to other commonly used loss functions, in order to assess its effectiveness in improving peak prediction accuracy. To evaluate peak performance, we introduce a novel evaluation methodology using confusion matrix and propose new errors for peak position and peak load, tailored specifically for assessing peak performance in short-term load forecasting. Our results demonstrate the superiority of soft-DTW in capturing and predicting load peaks, surpassing other commonly used loss functions. Furthermore, the combination of soft-DTW with other loss functions, such as soft-DTW
Keywords
Introduction
Load forecasting can be a valuable contribution to power system operation and the decision-making process of unit commitment. The transition from traditional centralized power stations to the decentralized energy system becomes more and more popular, as it allows for more optimal use of renewable energy and provides the possibilities for small energy producers to better connect with end-users. Microgrids, as one of the most effective forms of decentralized energy systems, gather facilities to generate, supply, and store electricity with or without the support of the centralized macrogrid [1]. Despite many advantages of microgrids, a smart control system is highly demanding due to the technical challenges associated with the control system. Smart grid is an intelligent electricity network with the integration of the users’ behaviors and actions to manage the volatility from multiple types of small power producers and small-scale electrical transmission and distribution networks [2]. One of the essential tasks of smart grid is short-term load forecasting with high granularity and precision to match demands and generations. Unlike the national aggregated load forecast, the disaggregated load, especially at the individual level, is hard to predict with rapid fluctuations and different user behaviors, making short-term residential load forecasting at the individual level challenging.
Before the success of artificial intelligence, load forecasting was carried out with physically explicit methods [3]. These models are based on heat and transfer equations to calculate energy consumption with detailed thermo-physical information. This physically explicit method can be described as a white box composed of explicit equations describing measurable variables. The advantage of the physically explicit method is that it does not rely on any historical data to perform load prediction. However, it requires the knowledge of many thermo-physical parameters which are not always easy to access. Therefore, it is challenging and time-consuming when addressing large and complex use cases with the physically explicit method. Another important limitation of such approaches is the complexity of the resulting models when taking into account all involved phenomena. Hence, simplifying assumptions are often chosen in order to obtain a less computationally expensive model, such as simplified user behaviors.
The development of smart electricity meters enables the collection of large datasets, making the data-driven model feasible for load forecasting. Deep neural network as one of the prominent techniques in artificial intelligence, has been proposed for short-term load forecasting within the last two decades [4]. As a data-driven approach, it does not require either thermo-physical information or occupant behaviors, but only historical data compared to the previous physically explicit model. Numerous studies have demonstrated the effectiveness of deep neural networks in short-term load forecasting [5, 6, 7, 8]. And there are different approaches to improve its performance by modifying the architecture of the neural network [9, 10] or adding preprocessing techniques [11, 12]. But only very few studies focus on the analysis of loss functions.
Mean squared error (MSE) has been primarily employed as a loss function for regression to train neural networks for short-term load prediction [13, 14, 15, 16]. Li et al. [17] compared mean absolute percentage error, cross-entropy, and mean absolute error (MAE) for the aggregated load. Dudek [18] added weights into MSE for different training samples. A critical constraint of training with these loss functions is that they measured the cumulative errors along the target time series without specific consideration of load shape. As a result, they may exhibit less capability to accurately predict peak loads, which is crucial for short-term load forecasting. Dynamic time wrapping (DTW) [19] may be a possible solution. It aims to find an optimal alignment between two time series. As it concentrates on the time series similarities, it may add more importance to the load shape of the prediction task in order to strengthen peak load forecasting. Because of its ability to measure the similarities between curves, DTW has been mainly used for clustering algorithms [20], but less for regression because of its non-differentiability for gradient descent optimization. In 2007, soft-DTW [21], a differentiable formulation of DTW, has been proposed to fit better the backpropagation of neural networks. It has demonstrated considerable success in clustering applications [22, 23, 24, 25, 26], while its application and analysis in the field of load prediction have been relatively limited [27]. Besides, the drawback of soft-DTW has been discussed in the literature, Le Guen and Thome [28] demonstrated its incapacity of capturing temporal distortion and proposed incorporating an extra term to the soft-DTW loss function: time distortion index (TDI). This combined loss function has gained attention in the task such as time series imputation task [29] and PM2.5 concentration prediction [30]. However, it is relatively rare discussed in load prediction.
Therefore, the main objective of this article is to conduct a thorough comparative analysis of the soft-DTW loss function in relation to other loss functions, with a specific focus on its peak prediction performance. Many existing studies used peak loads as the inputs and outputs for training [31, 32, 33], it is rare to find evaluations on peak prediction performance when forecasting the entire time series. Thus, we introduce in this article a novel evaluation methodology using confusion matrix and propose new errors for peak position and peak load, tailored specifically for assessing peak performance in short-term load forecasting.
The article is organized into three main parts:
Analysis of soft-DTW loss function: In this part, we provide an introduction to soft-DTW and the proposed neural network architecture, followed by a comparison to the result presented in the literature on a benchmark dataset to validate our model. Then three loss functions: soft-DTW, MAE, and MSE were compared on a real dataset from Irish residential buildings to give insights into the improvement of soft-DTW and the limitations of common error metrics. Peak evaluation: In this part, we give the definition of our new error metrics, namely peak position error and peak load error. We then evaluate the previous results using these error metrics and the confusion matrix to demonstrate how the utilization of soft-DTW loss function can enhance the accuracy of peak load forecasting. Combined soft-DTW loss functions: In this part, our focus is on comparing three different combined loss functions, namely soft-DTW
soft-DTW
Dynamic Time Wraping was first introduced in 60s [34] and developed for speech recognition [19] and pattern discovery [35] later. It measures the similarity between series considering the deformation of the curves, which is defined as the sum of the values from the cost matrix along this shortest path:
where
However, DTW is not differentiable everywhere. Cuturi and Blondel [21] proposed soft-DTW, a differentiable formulation of DTW by smoothing min operator from Eqs (1) and (2.1) with non-negative smoothing parameter
If
Residual block with skip connections
Skip connections shown as additional paths between layers reduce the length of gradient flow from output layers to the lower layers, thus easing neural network training [36]. One of the most successful applications of skip connections is ResNet [37], with multiple small residual blocks to train deeper neural networks. Li et al. [38] presented a visualization of the loss surfaces of ResNet with the comparison of skip connections. It indicated that the skip connection smooths the loss landscape of neural networks to make it easier to converge. Because of its effectiveness, many different neural network architectures with skip connections have been designed for load forecasting: Kiprijanovska et al. [39] chose fully-connected layer as the inner structure of residual block while Gong et al. preferred long short-term memory (LSTM) as internal layer [40]. Besides, temporal convolutional networks which have gained attention recently for load forecasting [14, 41] also adopt skip connections to ease the training.
Another reason to choose residual block, which has not been shown in the other references is the explanation of prior knowledge for load forecasting. Because the load profile of day
Residual LSTM neural network.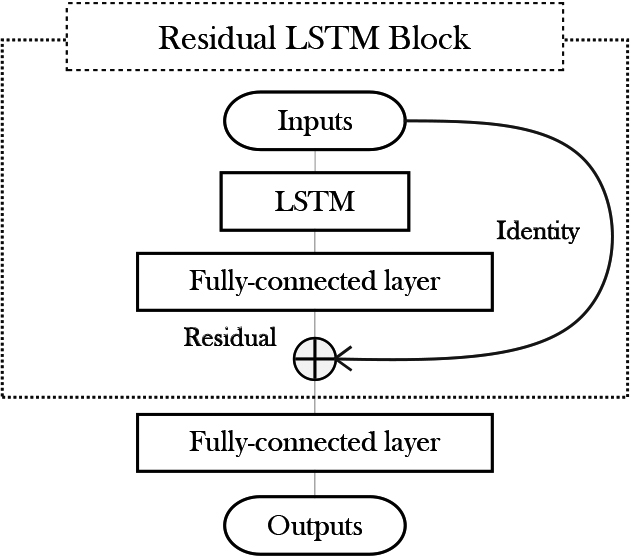
DBA K-means clustering of first two weeks loads for 929 residential users.
Flowchart of proposed methodology.
Residential load predictions with MSE, MAE, soft-DTW loss functions from 2010-11-10 to 2010-11-16.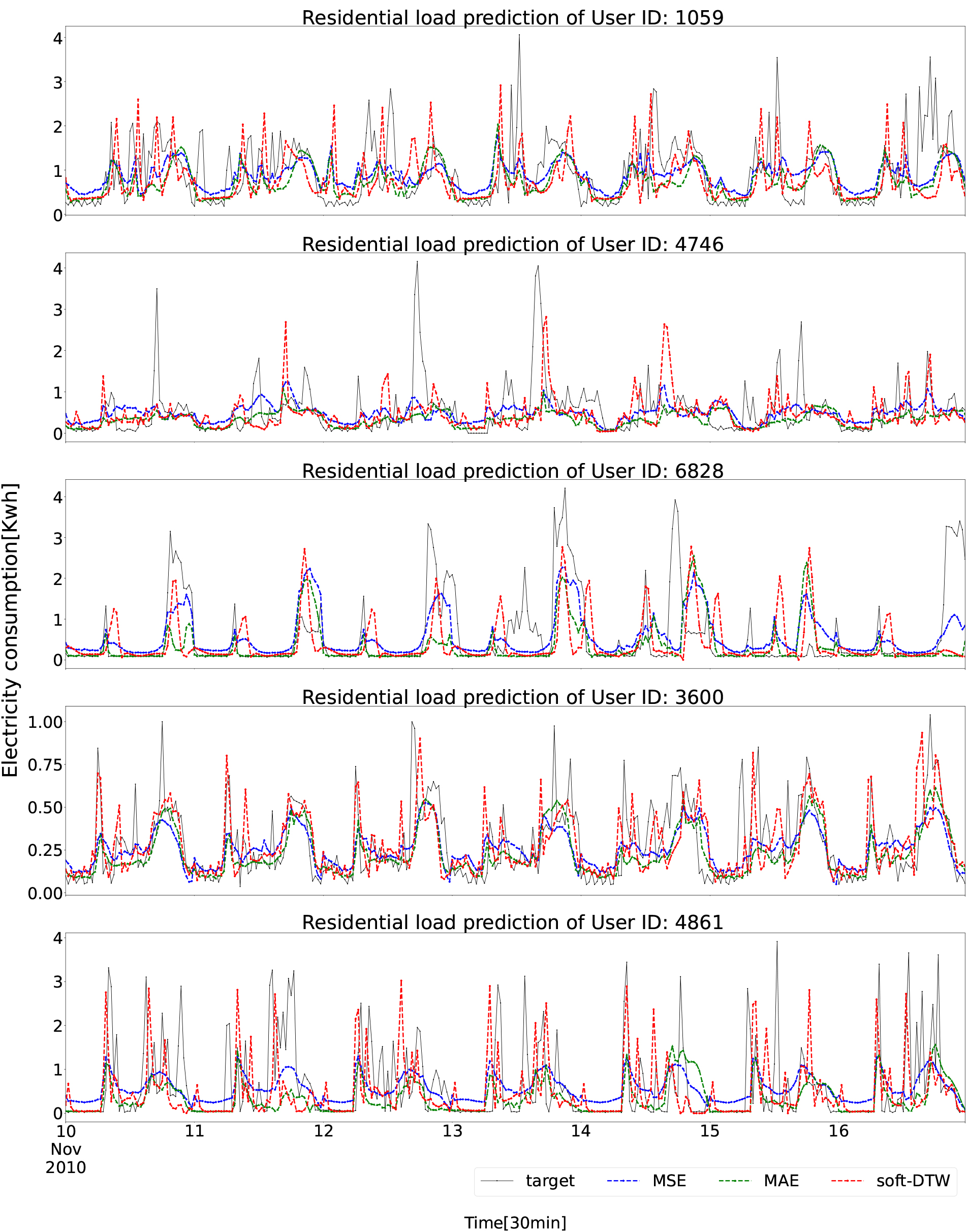
Daily dynamic time warping error with MSE, MAE, soft-DTW loss functions.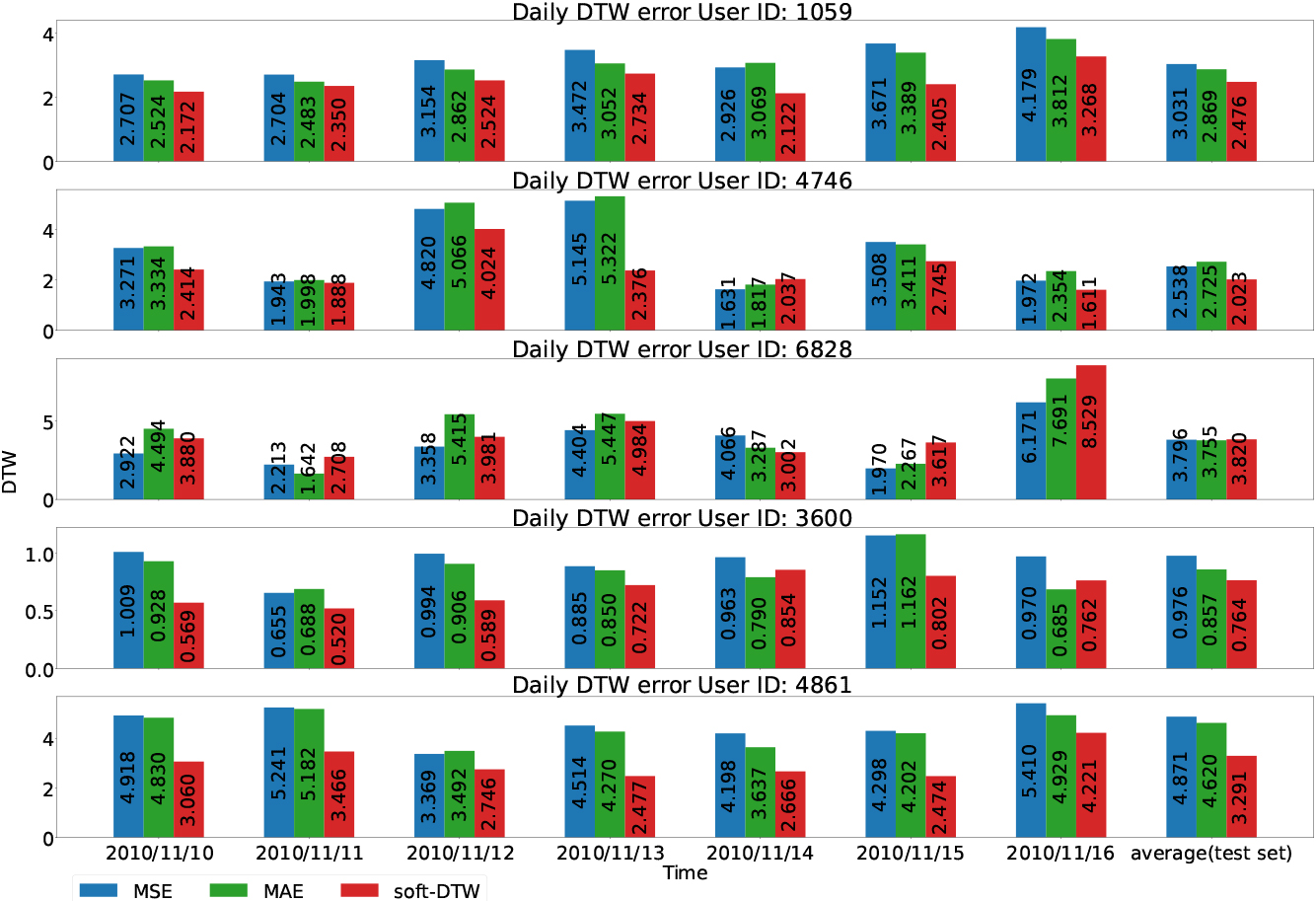
Recurrent neural networks (RNN) is one of the most common neural networks for sequence modeling thanks to the feedback connections to share parameters over time. However, due to the vanishing and exploding gradient problem, the variant named gated RNN is more commonly used for long sequences. Short-term load forecasting is not only influenced by the variables at the current time but also the past pattern, for instance, the profile of the last 24 hours, which explains the popularity of two gated RNNs for short-term load forecasting: LSTM and gated recurrent unit (GRU) [12, 42, 43, 44]. Therefore, in this paper, one of the most popular gated RNNs, namely LSTM with residual connection is selected (shown in Fig. 1) for the following comparison. The logic of this residual LSTM block design is to learn the characteristics of residual load with LSTM before addition operation and then add the identity shortcut to form the real load for the next fully-connected layers.
Validation on benchmark dataset
To validate our proposed neural network, we followed the same procedure as Mocanu et al. [45]: Dividing the benchmark dataset, which consists of three years of electricity consumption data from a residential building in France [46], into a training set covering the period from 2007-12-16 to 2009-12-16, and a test set spanning from 2009-12-17 to 2010-11-26; Filling the missing values with the mean values of the corresponding minutes from the other years.
For our Residual LSTM network, we employed 128 neurons with a many-to-many architecture, followed by a two-layer fully-connected neural network with 16 and 1 neurons, respectively. The configuration of the last fully-connected layer is identical to the setting of the fully-connected layer inside the residual LSTM block. We used the batch size of 1000 and the learning rate of 1e-05, with EarlyStopping and the Adam optimizer. The model was implemented and trained using PyTorch.
We evaluated the performance of one-day-ahead prediction for aggregated active power with 15 min resolution as this scenario is commonly encountered in practical applications. To ensure a fair comparison, we utilized the same loss function, mean squared error, as presented in Mocanu et al. [45]. The results are summarized in Table 1, which includes a comparison between our proposed model and other existing approaches, such as artificial neural networks with all fully-connected layers (ANN), support vector machines (SVM), recurrent neural networks (RNN), conditional restricted Boltzmann machines (CRBM), and factored conditional restricted Boltzmann machines (FCRBM), as reported in the reference. Notably, our model Residual LSTM achieves the lowest root mean squared error (RMSE), providing validation for its effectiveness.
One-day-ahead prediction with 15 min resolution
One-day-ahead prediction with 15 min resolution
Recognizing the limitations of the benchmark data-set, which included data from only one residential building, a richer dataset from the Republic of Ireland [47] was chosen to facilitate a more comprehensive comparison of the loss functions. Additionally, it is worth noting that the division of a dataset into train and test set without a validation set may impact the final result since the test set has been used for tuning the model’s hyperparameters. To address this concern, in this section, we divided the dataset into three subsets: train set for training, validation set for tuning, and test set for final evaluation.
The Irish residential dataset, namely CER, contains 4232 Irish residential consumers with three variables: meter ID, time, and load from 1st July 2009 to 31st December 2010 with a time interval of 30 min. Among 4232 residential users, there are 929 in the controlled group without changeable tariffs and demand side management informational stimuli. It is time-consuming to train all 929 residential users, thus we select 5 representative loads after clustering the first two weeks of 929 residential users into 5 groups with DBA K-means [48] to present the effect of different loss functions. All the loads are standardized before clustering, the result is shown in Fig. 2.
Each cluster group contains 176, 94, 370, 166, 123 users respectively. We randomly select one load as a representative of each cluster group. The user IDs selected are: 4861, 3600, 1059, 6828, 4746. Datasets are split into train sets of the first 70% datasets, validation sets of the next 20% and the last 10% as test datasets for the prediction model. The target datasets to predict are unseen, so the standardization is based on the training set with its mean and standard deviation. The load is standardized during training, but the errors for comparison are recomputed on the original scale. The goal is to predict the next-day profile with an input sequence length of 48. During the training phase, inputs and outputs are batched with a sliding window of 30 min to enlarge the dataset, while the evaluation phase is based on next-day prediction with a sliding window of 1 day. Details are shown in the flowchart (see Fig. 3).
The configuration of the neural network is the same as in the previous section. Batch size
The prediction results in the test set from 2010-11-10 to 2010-11-16 with MSE, MAE, and soft-DTW loss functions are presented in Fig. 4.
It clearly demonstrates that the soft-DTW loss function outperforms the MSE and MAE loss functions in capturing the majority of the dynamics and peaks for all five residential buildings. This effect is related to the emphasis on the similarity of the curves rather than the cumulated error from the theory of DTW. In other words, models are trained to focus on learning the pattern of the profile with more capability to predict peaks.
To quantitatively analyze this effect, daily DTW prediction error is first compared. Error metrics from 2010-11-10 to 2010-11-16 and average daily DTW error on the test set are shown in Fig. 5.
Based on the results presented in this figure, DTW error roughly presents the peak prediction performance as the soft-DTW loss function has the lowest DTW error in most cases. However, DTW error cannot fully depict this performance. For instance, the residential building with ID: 3600 on 2010-11-16 has a lower DTW error with the MAE loss function. But Fig. 4 shows that soft-DTW loss functions are able to predict the two major peaks while the MAE loss function fails. The reason that soft-DTW has higher DTW error may be due to the two prediction peaks around 18:00 with position error.
To address this problem, a more precise evaluation of errors should be conducted, specifically focusing on peak prediction performance, which includes both peak position errors and peak load errors.
It is important to note that soft-DTW increases its ability of peak prediction but meanwhile sacrifices its cumulated error MSE and MAE. Table 2 reveals that the soft-DTW function exhibits the highest MSE and MAE prediction error on the test set.
MSE and MAE on test set for different loss functions
MSE and MAE on test set for different loss functions
In the previous section, we observed an improvement in peak prediction performance through the utilization of soft-DTW. However, the common error metrics such as MSE, MAE, and DTW were unable to adequately capture this improvement. Thus, there is a need for a new measurement specifically designed to assess the peak load performance, which would provide a clearer representation of the observed enhancement.
Confusion matrix of peak performance on test set.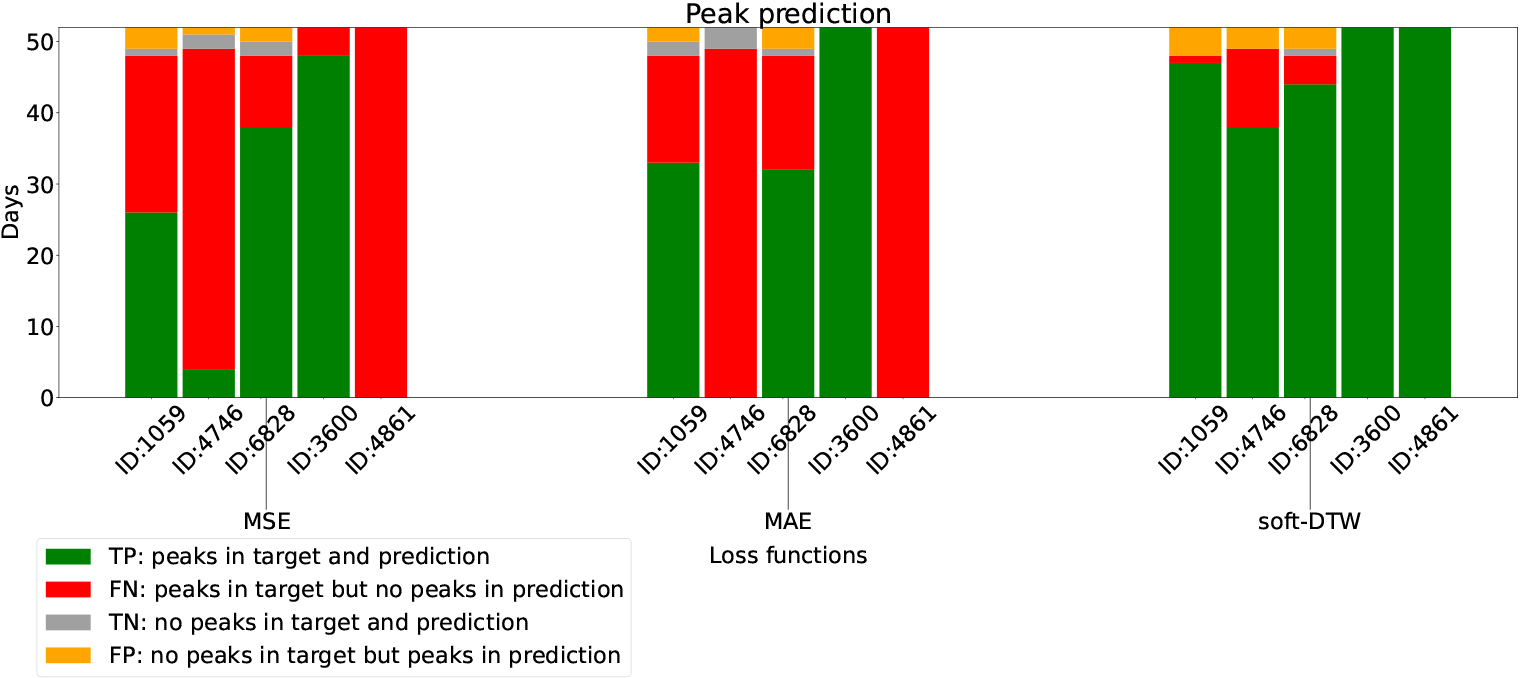
When evaluating peak load prediction, it is common to calculate error metrics such as MSE directly between the real peaks and the forecasted peaks. This approach is frequently applied when both the inputs and outputs are peak loads [31, 32, 33, 49, 50]. However, in our case, where we predict the entire time series, this evaluation method is not applicable as the number of peaks in the prediction may differ from those in the target. Therefore, directly accumulating these errors is not straightforward. In addition, since we predict the entire time series, we introduce another error measurement that is rarely analyzed in the literature: peak position error. Hence, when the number of peaks in the prediction does not match those in the target, two measurements need to be defined:
peak load error peak position error
To tackle this problem, the idea is to associate each peak in prediction with its nearest peak in the target, and then calculate the error respectively. Inspired by the DTW algorithm that was presented before, this association can be formulated as the match in the DTW path between the index of peaks, then the DTW path cumulates the distance between these pairs of peaks which represents the peak position error of two curves. We define this error as follows:
where
Once peaks are matched, similarly we define the peak load error:
where
In this article, peaks are defined as all local maxima that are higher than 1/3 of the global maximum. To analyze the model’s ability to predict peaks, four scenarios are defined based on the confusion matrix:
Confusion matrix of peak prediction
Confusion matrix of peak prediction
True Positive (TP): model successfully predicts peaks when peaks are presented in the target False Positive (FP): model predicts peaks however there are no peaks in the target (Type Error I) False Negative (FN): model failed to predict peaks when peaks are presented in the target (Type Error II) True Negative (TN): there are no peaks in target and prediction
Confusion matrix of peak performance on test set
Daily peak load prediction error with MSE, MAE, soft-DTW loss functions.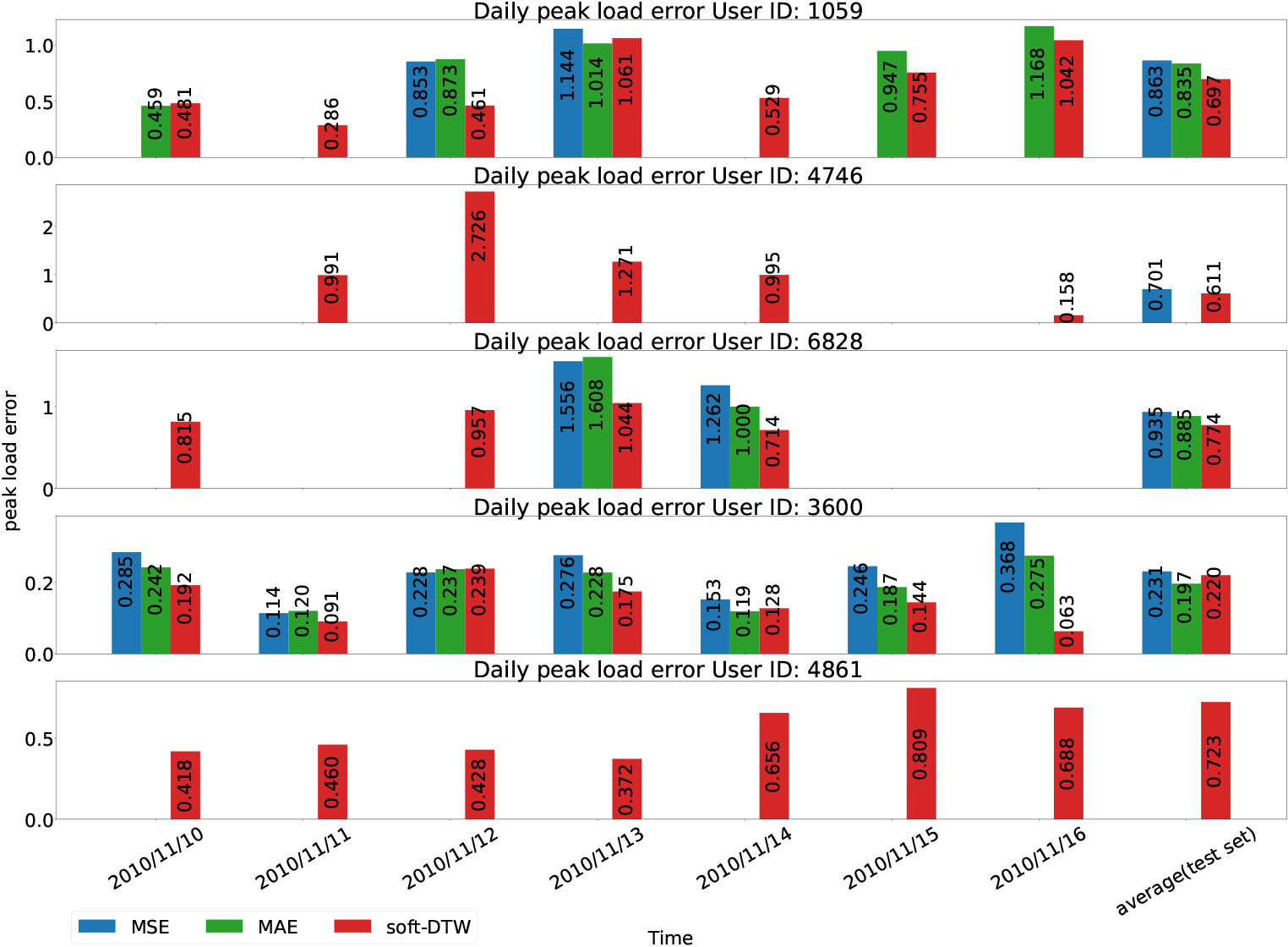
Daily peak position error with MSE, MAE, soft-DTW loss functions.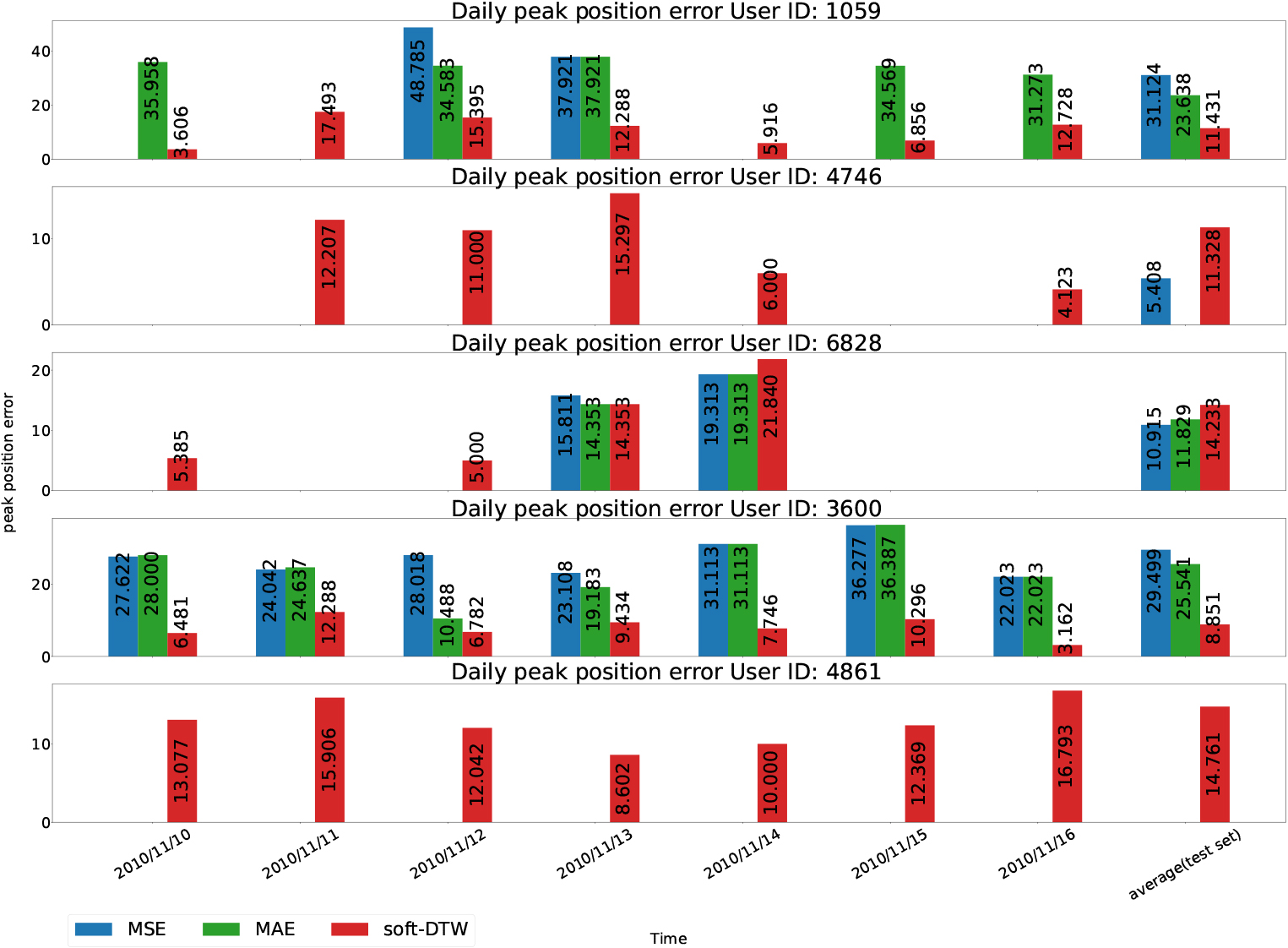
Figure 6 and Table 4 demonstrate these four scenarios on the test set, showcasing significant improvements in peak prediction for all these five residential buildings with the soft-DTW loss function: the number of successful peak predictions in the True Positive case (green in Fig. 6) is notably increased compared to the MAE and MSE loss functions; similarly, all five residential buildings experience a significant reduction of Type Error II (red in Fig. 1) with the soft-DTW loss function; the True Negative case (grey in Fig. 6) is slightly improved, with only one day missing. Nevertheless, for the False Positive (Type Error I), the soft-DTW loss function tends to overestimate compared to the other loss functions, which will be discussed in the next section for potential enhancement.
Deploying the Eqs (4) and (5) for the case TP, daily peak position error and daily peak load error are shown in Fig. 8 and Fig. 7 respectively.
In terms of peak load error, soft-DTW presents fairly good results for all these five buildings. Although the MAE loss function performs slightly better than soft-DTW for building ID: 3600, the difference is relatively small.
Three out of the five residential buildings (ID: 1059, ID: 3600, ID: 4861) achieve the lowest peak position error with the soft-DTW loss function. The remaining two buildings (ID: 4746 and ID: 6828) exhibit better performance in terms of peak position error with the MSE loss function. This could be attributed to two possible reasons. Firstly, the number of valid days for the True Positive case with the MSE loss function is lower than that of the soft-DTW loss function for these two buildings. Secondly, the soft-DTW loss function emphasizes the shape of the curves, which may focus less on time deformation and result in peak position errors. Thus, these results lead us to consider combining the advantages of the MSE loss function and the soft-DTW loss function. In the next part, different combined loss functions will be compared and analyzed on the same dataset.
Part III: Combined soft-DTW loss functions
In the previous section, we observed a significant improvement in peak prediction using the soft-DTW loss function. However, we also noticed that the model using soft-DTW may be overestimated with higher Type Error I, and some residential buildings exhibit higher peak position errors. Therefore, we would like to investigate whether combining the soft-DTW loss function with other loss functions can lead to further improvements in these areas.
soft-DTW
MAE/MSE
The combined soft-DTW loss functions with MSE and MAE is defined as a linear combination with a hyperparameter
Residential loads predictions with soft-DTW, soft-DTW 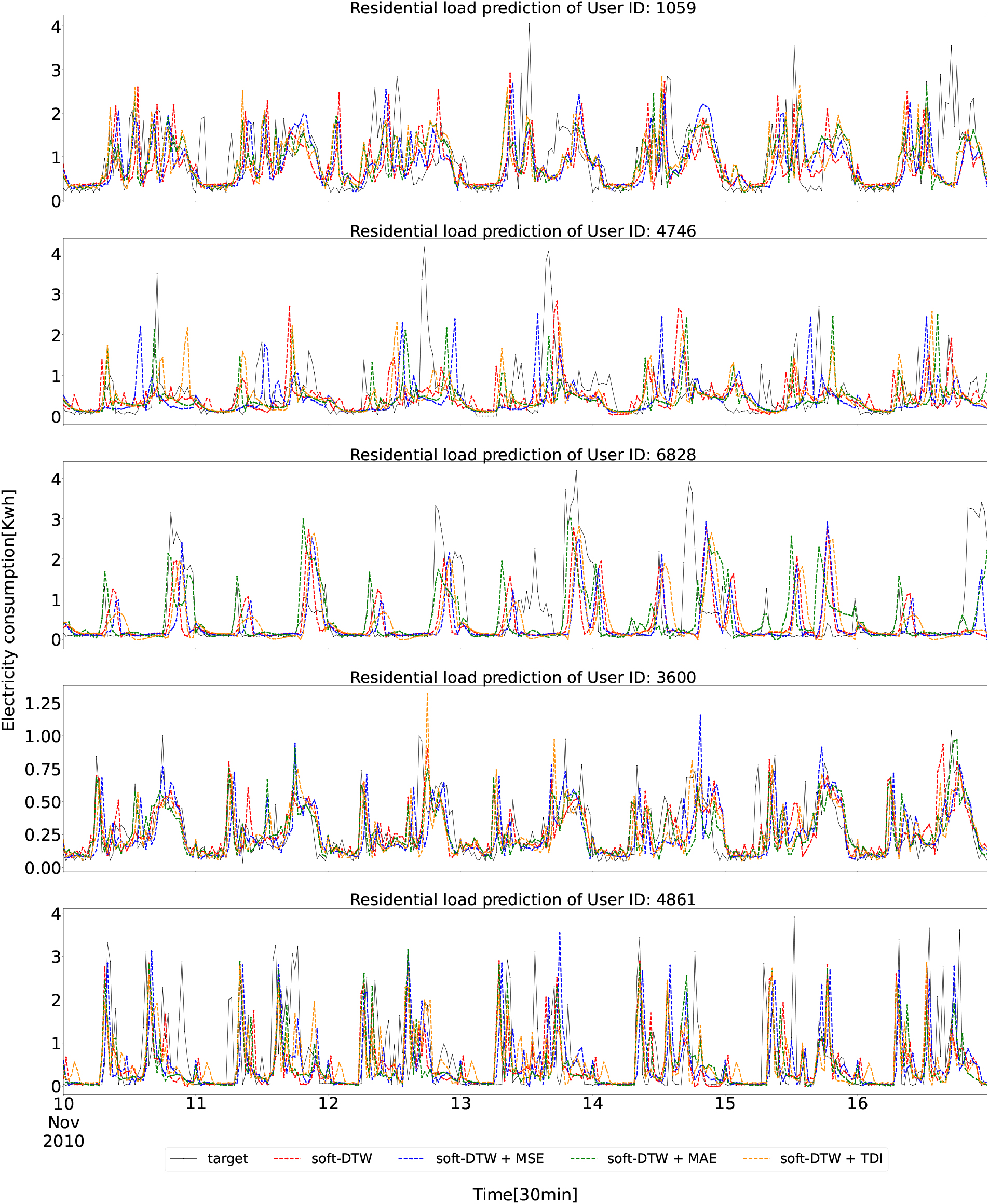
Confusion matrix of peak performance of combined loss functions on test set.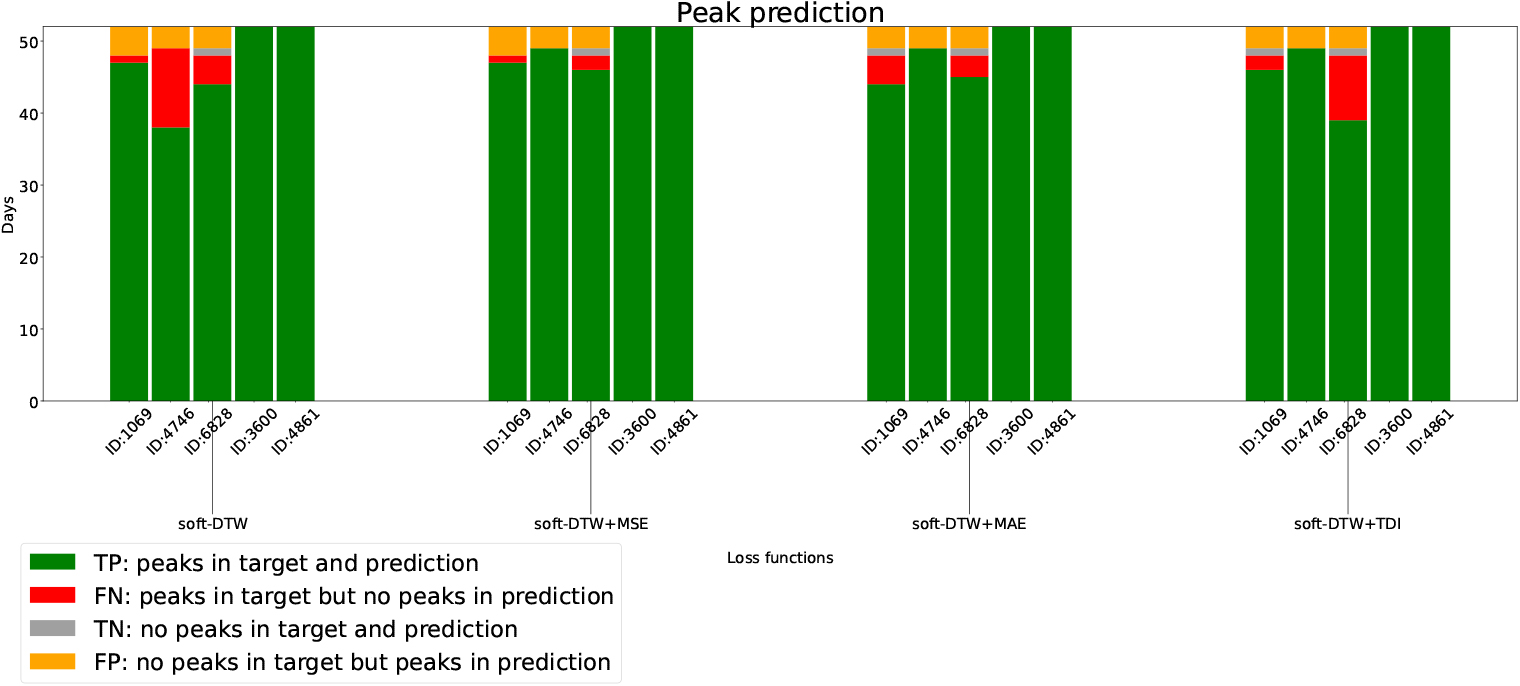
Average performance on the test set.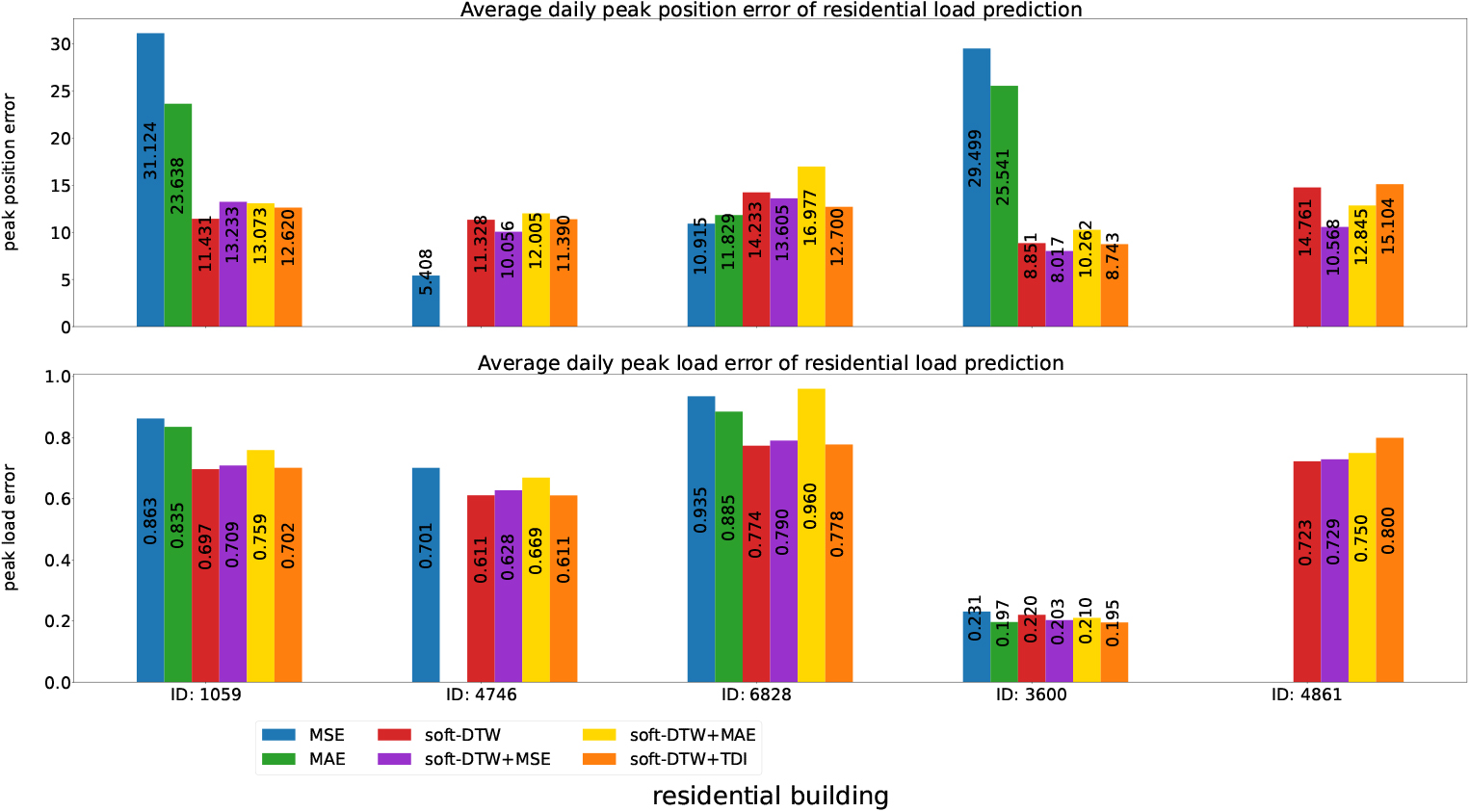
Another combined formula has been proposed in the literature by Le Guen and Thome [28], who introduced a time distortion index as a novel penalization term for the soft-DTW loss function. The time distortion index is defined as the inner product of the optimal alignment
where
The matrix
In order to make TDI differentiable everywhere, they replaced the optimal alignment
Then the combined soft-DTW with TDI, namely DILATE is defined:
To ensure a fair comparison, we followed the same procedure as in the previous section, with all combined loss functions set to
Confusion matrix of peak performance of combined loss functions on test set
Confusion matrix of peak performance of combined loss functions on test set
It can be observed that all of the combined loss functions are able to predict most of the peaks, surpassing the performance of the MSE and MAE loss functions. Despite the lower Type II error observed with the combined loss functions, the confusion matrix (Fig. 10) and Table 5 reveal that there is no substantial improvement in reducing Type I error, contrary to the initial expectations.
Regarding the peak position error, as shown in Fig. 11, our expectations are met with the MSE combined loss function, as four out of five residential buildings show a slight decrease in peak position errors. However, the MAE and TDI combined loss functions do not exhibit a consistent improvement across all buildings.
It is worth noting that all combined loss functions result in higher errors for peak load. This can be attributed to the hyperparameter
This paper presents a comprehensive comparison of different loss functions, including soft-DTW and its combined formulas, for short-term residential load forecasting with a specific focus on peak prediction evaluation. Additionally, a novel evaluation methodology is introduced, which involves the use of confusion matrix and new errors for peak position and peak load.
The comparison results indicate that using MSE or MAE as default loss functions for short-term load forecasting may not be optimal when dynamics and peak values are of greater importance. Soft-DTW loss function and its combined formula perform largely better than MSE and MAE loss functions in terms of peak prediction performance. However, the combined loss functions with MAE and TDI do not show a consistent improvement across all buildings. Even though the combined soft-DTW loss function with MSE shows a slight reduction in peak position error, the difference compared to soft-DTW alone is relatively small. To gain deeper insights into these issues, the utilization of landscape visualization for these loss functions holds great potential. We intend to pursue these investigations in our future studies.