
Abstract
Energy efficiency is at a critical point now with rising energy prices and decarbonisation of the residential sector to meet the global NetZero agenda. Non-Intrusive Load Monitoring is a software-based technique to monitor individual appliances inside a building from a single aggregate meter reading and recent approaches are based on supervised deep learning. Such approaches are affected by practical constraints related to labelled data collection, particularly when a pre-trained model is deployed in an unknown target environment and needs to be adapted to the new data domain. In this case, transfer learning is usually adopted and the end-user is directly involved in the labelling process. Unlike previous literature, we propose a combined weakly supervised and active learning approach to reduce the quantity of data to be labelled and the end user effort in providing the labels. We demonstrate the efficacy of our method comparing it to a transfer learning approach based on weak supervision. Our method reduces the quantity of weakly annotated data required by up to 82.6–98.5% in four target domains while improving the appliance classification performance.
Introduction
Energy efficiency has gained great traction in recent years [1, 2, 3], to facilitate the transition to NET-zero economy. Energy awareness plays a key role in improving energy efficiency [4, 5, 6, 7, 8, 9], and active user participation can potentially increase a household’s energy flexibility, leading to energy savings of up to 30% [8]. Evidence in [6] suggests that energy awareness encourages end-users to purchase energy-efficient products. This perspective may motivate users to actively participate in energy conservation and invest in devices that provide future energy and monetary savings. In fact, a study [5] conducted on two groups of low-income consumers revealed that 46.5% are interested in saving energy both for environmental and financial reasons, compared to the rest who are interested only for financial benefit or only for environmental reasons. A recent review [9] emphasised that providing effective feedback about consumption is another way to engage users actively in the long term. Moreover, the findings of the study highlight the need to develop strategies and technologies that are more user-centred. Energy awareness can be improved by monitoring energy [3] and particularly via Load Monitoring that provides detailed information about consumption. Specifically, Non-Intrusive Load Monitoring (NILM) is a purely algorithmic approach to estimate individual appliance power consumption that contribute to the measured aggregate signal, via smart metering for example. Over the past 40 years, NILM has been demonstrated as an effective software-based method for obtaining detailed energy consumption information, avoiding the installation of several meters to monitor individual appliances. NILM algorithms can be unsupervised and supervised, with the latter being more popular due to their excellent performance. Signal processing [10] and Machine Learning (ML) [11, 12, 13] methods have been initially proposed for NILM. Deep neural networks gained wide attention in the community in many fields [14, 15, 16, 17, 18, 19]. Following the work of Kelly et al. [11] that proposed three deep learning-based approaches, deep neural networks (DNNs) have been widely applied in NILM achieving the state-of-the-art performance [20, 21, 22, 23, 24, 25, 26, 27]. Many of these techniques have not demonstrated their performance in unseen environments [28] due to significant differences between source and target signal domains and the related feature spaces [29]. In NILM, differences in appliance load signatures and unknown loads inside the aggregate signal [30, 31] mainly affect the performance when a pre-trained model is deployed in a target environment.
To overcome domain differences, transfer learning [32, 33] has been demonstrated to be an effective strategy in increasing generalisation capability: recent methods operate by pre-training a neural network on a large dataset and then fine-tuning it on data acquired from the target environment [28, 34, 35, 36]. However, these approaches need an additional acquisition and labelling phase to be applied. Generally, data acquisition and annotation are costly and time-consuming procedures, also requiring expertise in the specific application field. In fact, for NILM, acquiring new signals in the target domain requires the installation of electrical sensors for each monitored appliance or the users’ involvement in manually annotating appliances’ states by recording and reporting the on-time and off-time related to the usage of one or more appliances. This type of label is used in supervised learning approaches. In the authors’ opinion, these annotations can be most effectively gathered via a mobile app on the users’ smartphone, which allows them to provide feedback about their appliance usage. If the focus is on monitoring the state of appliances, as in this work, there is no need for any hardware installation.
To reduce the requirement for labelled data, approaches based on semi-supervised learning have been proposed recently [37, 38, 36]. A different approach to reducing the labelling effort has been proposed in [39, 40], where a weakly supervised method is demonstrated to be more effective than the semi-supervised one [38]. Weak supervision allows a lightened data annotation since labels are required in a coarser form [25]. In terms of the aforementioned manual annotations, under this approach, users would only need to indicate whether an appliance was used or not within a certain time window. Also, for the transfer learning procedure, in [41] weak supervision was demonstrated to be effective compared to a supervised strategy, especially in the practical scenario of acquiring labels from the user feedback. Considering the multi-label appliance classification task, a weak label is provided for an entire temporal segment of the aggregate signal indicating whether an appliance is ON or OFF within that segment. Differently, strong labels used in supervised learning methods are annotations at the sample level, i.e., they indicate whether an appliance is ON or OFF for each sample, thus representing more fine-grained information. In Fig. 1, the concepts of weak and strong labels are graphically explained. The srong labelling approach is more prone to errors and requires intrusive sub-metering or expert knowledge about appliance load signatures for manual labelling. On the other hand, weak labels can be obtained more easily directly from the users in the target environment, by simply asking them if an appliance was active or not in a certain time period during the day as opposed to labels for each sample.
Although weak labels reduce the labelling effort, the number of time periods that need to be labelled for fine-tuning could be still large. Active Learning (AL) approaches [42, 43] are used in literature to optimise data selection for artificial intelligence algorithms by choosing the most informative data, and that way reduce the number of data segments needed to be labelled and added to the training dataset, but without compromising the algorithm performance [44]. AL approaches have been widely used for deep learning algorithms recently [45]. Specifically for NILM, a supervised AL-based framework was proposed [46] to find the trade-off between accuracy and number of queries to enlarge the training set in an unseen domain, and to improve the transferability of NILM models. Although improving the performance, this approach was based on a small original training set with strong labels, requiring sample-by-sample annotations.
We suggest that integrating a weakly supervised learning strategy into the AL framework with transfer learning avoids the need for expert labelling of target domain data, and annotation effort is reduced both in terms of the number of signal segments and the amount of information requested from users.
In this work, we propose a weak AL NILM approach to reduce the number of signals that need to be labelled by users. By asking users to assign only weak labels to the most uncertain segments of the aggregate signal and sampling the fine-tuning set, we further reduce the user annotation effort while obtaining improved performance compared to our previous work [41, 46] upon which we build. The proposed method is completely based on weak supervision, from the network pre-training to the adaptation in the target environment through to the AL procedure. We model the multi-label classification task as a Multiple-Instance Learning (MIL) [47] problem, and generate windows of aggregate samples as in [39] to which we refer as bags. We compare the proposed method with [41] and demonstrate that sampling the fine-tuning set via AL leads to better performance. Additionally, we compare our method with a NILM benchmark semi-supervised approach [38] demonstrating the effectiveness of weak labels over unlabelled data.
In the experiments, two widely used benchmark datasets, UK-DALE [48] and REFIT [49], were used to evaluate the performance of the proposed method. They were used respectively as the source and target domain datasets to pre-train, fine-tune, and test the neural network. The results show that the Weak AL approach improves the performance compared to an non-annotated fine-tuning set, demonstrating that significant benefits can be obtained with coarser information on a small number of signals.
The paper is organised as follows. Section 2 reviews recent approaches for multi-label classification and AL in NILM. Section 3 illustrates the contributions of this paper. Section 4 presents the problem formulation and the proposed method. Section 5 describes the experimental settings in detail. Section 6 presents and discusses the obtained results. Finally, Section 7 concludes the paper and discusses future work.
Background
NILM as multi-label appliance classification
The recent trend in low-frequency NILM literature, as illustrated by the methods discussed below, focuses on the disaggregation of more commonly available smart meter time-series measurements of low-frequency aggregate active power. Furthermore, most NILM research proposed for multi-label appliance classification is based on ML and approaches the problem using a supervised learning strategy.
Reference [13] proposed Random k-Label set (RAkEL) and Multi-Label K-Nearest Neighbours (ML-KNN) using both time- and wavelet-domain features to train the ML models. Multi-label Restricted Boltzmann Machine (ML-RBM) was proposed by Verma and colleagues [20] due to its effectiveness in learning high-level features and correlations. To achieve higher accuracy with continuously varying appliances and overcome low-frequency sampling-related problems, deep dictionary learning was adopted in [21]. A Sparse Representation Classification approach was proposed in [22], reducing the number of logging data collected for training. Temporal pooling was implemented in [23] to concatenate different time resolution information. A Gated Recurrent Units (GRUs) based approach was proposed in [24], where features from the aggregate signal and spikes are extracted using convolutional layers. A convolutional-recurrent and random-forest (RF) based architecture that addresses label correlation and class-unbalancing was proposed in [50].
An encoder-decoder architecture based on a Long Short-Term Memory network (LSTM) was adopted in [26]. A CNN followed by three different fully connected sub-networks was implemented for multi-label state and event type classification in [27]. Deep Blind Compressed Sensing was proposed in [51], exploiting compressed information to reduce transmission rate to detect devices’ states.
To reduce the quantity of annotations required to train the ML algorithms, semi-supervised learning strategies have also been proposed. A semi-supervised approach is proposed in [37] with the Virtual Adversarial Learning strategy while [38] proposed a semi-supervised learning procedure based on teacher-student architecture and a Temporal Convolutional Network. Alternatively [39] proposed an approach based on a Convolutional Recurrent Neural Network (CRNN) trained with weakly labelled data, lightening the labelling effort by using a coarser type of labels to train the network.
It is worth highlighting that the approaches reviewed above still face domain adaptation issues when moving from one well-known data domain to another. Transfer learning methods are required to mitigate the domain shift. In [36], a semi-supervised Knowledge Distillation approach has been proposed to improve the domain adaptation to classify the activation states and recently in [41], a weakly supervised transfer learning approach has been proposed to reduce the labelling effort exploiting coarser labels, assigned to an entire window of the aggregate signal, modelled as a bag of aggregate samples. Although a better performance was obtained, the approach still relied on a large number of windows from the aggregate signal.
AL for NILM
AL [44] is a concept introduced to reduce the labelling effort needed to train ML algorithms, selecting only a subset of data to be labelled while keeping an acceptable level of performance. Unlabelled data samples belonging to the query pool are usually ranked according to informativeness or distance criteria, or a combination of both. Then, based on the ranking, labels are requested only for a small portion of data, i.e., for the data samples that will contribute to the model training the most. AL has been popular in many areas recently, such as natural language processing [52] and medical image processing [53]. A recent survey of [45] gives an overview of AL approaches applied to deep learning algorithms.
AL for NILM has not been extensively investigated yet – there have only been a few attempts for event-based methods using high-frequency load measurements, based on: k-Nearest Neighbours (k-NN) in [54], Support Vector Machines (SVM) in [55], Random Forest with semi-supervised and AL combined in [56], and a DNN, using high-frequency measurements and event detection in [57], and only one approach using low-frequency measurements and supervised model-based NILM in [46]. However, in [46], only strong labels are used, which can be hard to obtain from end users in a real-world scenario.
Representation of strong and weak labels for a segment of the aggregate power signal. Strong labels give information about the state of activation for each instance (thus each sample of the signal 
Weak supervision and AL-based strategies are effective in labelling effort reduction, but it is worth highlighting that:
as reported in [41], the weakly supervised approach for NILM requires a dataset annotated with weak labels to train the network. This learning strategy could have a concrete consequence in a real-world data collection scenario where the end-user is involved in the labelling process. the AL proposed for NILM [46] depends on a sample-by-sample labelling strategy that is challenging for a non-expert end-user.
We address the above two challenges and fill the gaps of the existing literature by introducing a weak AL framework for low-frequency, model-based NILM solutions. In this way, we exploit the advantages of both weak supervision and AL strategies, by querying the user to assign weak (bag-level) labels to specific aggregate windows selected by the AL loop. In summary, the contributions of this work are:
Algorithm 4.3, a multiple instance learning-based approach that embeds both weak supervision and AL to reduce the quantity of data to be weakly labelled, compared to the state of the art [39, 28], by selecting only the ones on which the network indicates poor confidence. Development of a feasible AL framework in a real-world scenario where the end-user does not need to annotate power profiles sample-by-sample, differently from [39, 28]. In this way, the effort is reduced, and annotations are less affected by errors. Adapted acquisition function to multi-label classification with weak labels (Algorithm 2) considering different behaviours and confidence levels for different appliances. Determining the optimal point, where additional samples will only negligibly, or not all improve performance via fine-tuning. Demonstration of the efficiency of the proposed method on two commonly used public datasets and four common household appliances (kettle, microwave, washing machine and dishwasher) to facilitate benchmarking.
Moreover, we demonstrate how the proposed approach of integrating the weakly supervised learning strategy into the AL framework improves network performance compared to our previous work [41] with reduced labelling effort.
CRNN architecture. FCL 
Each load inside a building contributes to the total power consumption

with
The appliances’ states are estimated using a CRNN, and the task is modelled as a MIL problem [47] to exploit weak labels. Based on the concept of instances and bags, MIL performs a weak supervision strategy in which the ground-truth is provided only at the bag level.
In our method, instances refer to the raw samples of the aggregate signal

The related weak label is encoded as a one-hot vector
With the above definitions, it is now possible to define formally the multi-label appliance classification task based on weak labels. Specifically, by exploiting only the aggregate power signal
The proposed method is based on a CRNN that was originally proposed in [58] and then adapted for the NILM problem in [39, 41], demonstrating good results that exceed benchmarks. It comprises a convolutional and a recurrent subpart, as shown in Fig. 2. The

As in [59] that applied MIL to the sound event detection task, we adopt the linear softmax pooling function defined as follows:

where
Consider a pre-training dataset

where

is a dataset composed of

is a dataset composed of
Based on the neural network architecture, two loss terms are defined

and:

where the bag index
Weakly Supervised AL Scheme. Each block corresponds to an element of the framework. The Convolutional Recurrent Neural Network (CRNN) model generates both strong and weak predictions. During the AL process, strong predictions are used to evaluate the current model, while weak predictions serve as input for the acquisition function. The acquisition function selects the windows to be labelled based on the uncertainty of the network predictions. The most uncertain windows are chosen, suggested to the user for annotation, and then incorporated into the fine-tuning set for the subsequent fine-tuning phase. A detailed description of the entire framework can be found in Section 4.3.
The proposed Weakly Supervised AL framework, schematically illustrated in Fig. 3, comprises the CRNN model pre-trained using
The AL process is iterative, and we indicate the iterations with

queried up to the
A pseudo-code of the weak AL procedure proposed in this paper is given in Algorithm 4.3.
At the end of the process, only the model that satisfies the desired requirements (i.e., a balance good performance and small number of data) is employed to classify the appliances, without considering the previous intermediate models’ predictions. In fact, the models generated after each fine-tuning phase are utilised to select the next batch of data for the subsequent fine-tuning phase. After this, the model can be discarded as it will not be used in the subsequent iterations.

[t] Pseudo-code for the Weakly Supervised AL procedure.
Acquisition function
The acquisition function used in this paper is uncertainty-based, which demonstrated in [46] to be the best performing among several compared acquisition functions. In iteration
Weak level prediction of the model for a given bag is a vector containing probabilities of each appliance being in an active state inside that bag, which can be used to estimate uncertainty levels of the model. If a probability for a particular appliance is higher than decision threshold
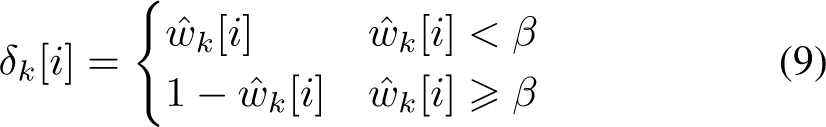
with
Since the problem considered in this paper is multi-label classification, with multiple appliances considered at the same time, two ways of estimating the overall model uncertainty
by taking maximum uncertainty level across appliances present in the house:
by averaging uncertainty level over all appliances present in the house:

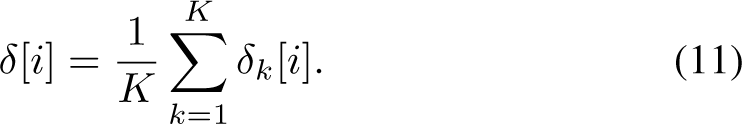

Then, the set of bags
[t] Acquisition function
A toy example of how the acquisition function described above works, for both cases of maximising and averaging uncertainties of individual appliances is given in Table 1. Table 1 shows the selected bags (a batch of
The code used to implement the approach is available on Github.1
https://github.com/GiuTan/WeaklySupervisedActiveLearning-for-NILM.

Train and Validation sets characteristics of UK-DALE

The number of labels is reported in thousands. SL: Strong Labels. WL: Weak Labels.
Fine-Tuning and Test sets characteristics for REFIT

Number of labels is reported in thousands. WL: Weak Labels.
Dataset
UK-DALE [48] and REFIT [49] datasets are used to evaluate the performance of the proposed method with typical appliances present in most households – Kettle (KE), Microwave (MW), Washing Machine (WM), and Dishwasher (DW). We decided not to include the fridge among the monitored appliances. This decision was made since a fridge is typically always in operation, which would mean the user would consistently assign the ON label. Although we did not monitor the fridge, it is present in the aggregate dataset.
UK-DALE contains data from 5 houses, with the aggregate power sampled at 1 Hz and appliance power sampled at 1/6 Hz, while REFIT contains measurements from 20 houses sampled at 1/8 Hz. To be aligned with UK-DALE, aggregate and appliance signals were up-sampled uniformly to 1/6 Hz. Selecting the same periods of data and following the procedure detailed in [39], both datasets have been used to create two sets of bags, one with UK-DALE data from Houses 1, 3 and 5 and one with data from four REFIT Houses 2, 4, 5 and 19. This choice has been made to include 4 houses that have different aggregate consumption characteristics, and have at least two appliances present in each house for evaluation, as shown in Table 3. Note that we balanced the occurrence of appliance activations and the number of strong labels associated with each appliance in both sets of bags. Table 2 and Table 3 report the details about training, validation, and test sets for the two sets of bags created, respectively, from UK-DALE and REFIT. The set used to validate the performance during AL process is the test set. Data was standardised subtracting the mean and dividing by the standard deviation. We estimated these values on the pre-training set.
Experiments setup
The experimental setup has been designed to evaluate several possible real-world scenarios that differ in annotation availability, based on the formulation in Section 4.2. In this way, we can evaluate the benefits from the AL procedure in more pre-training conditions. The performance has always been evaluated on 70% of the REFIT “Test and Fine-tuning” set reported in Table 3.
Referring to Eq. (5), we defined two pre-training dataset compositions:
Scenario 1: only weakly labelled data is available: in this case, Scenario 2: both strongly and weakly labelled data from the same domain are available: in this case,
Regardless of the pre-training condition, the validation set is represented by UK-DALE as reported in Table 2.
The bags that populate the query pool
For each pre-training condition, the Hyperband algorithm [60] from Keras tuner has been used to select the hyperparameters values that achieve the highest performance on the validation set. During the AL process, we do not perform any optimisation of hyperparameters. This is because the structure of the fine-tuned network is the same as that of the pre-trained network. The pre-trained network has already been optimised during the pre-training phase, performed in our previous work [41]. Adam [61] is used as optimiser and the learning rate was fixed to 0.002 and
When the source dataset is only weakly labelled, fine-tuning the bidirectional and instance layers has proven the best performing method on the validation set. When strongly labelled data are also available, only the instance layer has been fine-tuned.
The threshold for the quantisation of instance level predictions has been determined by optimal thresholding strategy on the test set for each pre-training condition.
In [41] a weakly supervised transfer learning approach has been proposed. Both the pre-training and the fine-tuning exploits only weak labels, or both weak and strong labels. In the fine-tuning phase, a set of weakly annotated signals has been supplied to the network to adapt the pre-trained model on the target environment domain. The best models obtained from the proposed method have been compared to “No Fine-Tuning” model [41], thus prior to fine-tuning, and “Weak Transfer Learning” model [41] obtained using the complete set of query pool data weakly annotated.
Additionally, we benchmark our method against a semi-supervised method based on knowledge distillation, proposed in [38], that is pre-trained using only strong labels, but in the fine-tuning phase only unlabelled data is fed to the model, as we consider that labels from the target environment are not readily available. Because of absence of labels from the target environment, and the way that the model works, bags with the lowest uncertainty were chosen instead of the highest during the AL process for this benchmark.
Evaluation metrics
Defining True Positive (TP(k)) as the number of correctly classified active samples for appliance

for

Optimal point of AL iteration process is determined as a point at iteration

This section presents the results obtained from the two experimental scenarios, as well as from the semi-supervised benchmark method.
Semi-supervised benchmark results
Benchmark – semi supervised method [38]. Model is pre-trained using strong labels, but fine-tuned using only unlabelled data from target environment. Results of the proposed approach are shown in the following format: metric (% of activation samples added to fine-tuning dataset).
Benchmark – semi supervised method [38]. Model is pre-trained using strong labels, but fine-tuned using only unlabelled data from target environment. Results of the proposed approach are shown in the following format: metric (% of activation samples added to fine-tuning dataset).

Experimental results for the semi-supervised benchmark approach [38] are presented in Table 4. In this case, strongly labelled data were used during the pre-training phase, and unlabelled data were utilised throughout the AL process. This scenario is challenging because with the semi-supervised strategy the model is fine-tuned with unseen data from the target environment without any labels provided. According to Table 4, the performance in House 2 does not improve after fine-tuning with all available data (100% of unlabelled bags used). There is a very limited improvement with AL for kettle only, but the performance level of the fine-tuning case with 100% of unlabelled bags used can be achieved using a smaller amount of data (6.7%–13.3%). In House 4, performance improves when all available bags from target environment are used, and the amount of data can be reduced to at least 38% of all data. In house 5, the situation is similar as in house 2 – no improvement after fine-tuning with all available unlabelled bags, and only small improvement for kettle with large portion of unlabelled bags used with AL. There is a similar situation in house 19 – no improvement after fine-tuning with all available unlabelled data, but small improvement for microwave with AL. The results from this benchmarking scenario suggest that while some improvement can be achieved using only unlabelled data to fine-tune the model to the new environment, it is not sufficient, and adding some labelled data is desirable. Therefore, results for weakly supervised AL scenarios are presented next.
Experimental results for the scenario where only weakly labelled data is available in the pre-training phase – pre-training scenario 1, and weak labels are used throughout the AL process, are presented in Table 5. This scenario is very challenging, because the model never sees strong labels, neither during pre-training nor during fine-tuning phase.
Results – pre-training Scenario 1. Results of the proposed approach are shown in the following format: metric (% of activation samples added to fine-tuning dataset)
Results – pre-training Scenario 1. Results of the proposed approach are shown in the following format: metric (% of activation samples added to fine-tuning dataset)

In House 2, with weak transfer learning (100% bags labelled), performance increases compared to the one before fine-tuning (0% bags labelled) for dishwasher, but drops for kettle and washing machine due to over-fitting. However, for kettle, with AL when maximising uncertainty over appliances, performance increase is achieved at optimal AL point with 13.3% bags labelled, and when averaging uncertainty over appliances, performance increases with labelling 20% of bags, reducing labelling effort by 86.7% and 80% respectively. For washing machine, labelling 6.7% of bags retains performance whether uncertainty is maximised or averaged over appliances. For dishwasher, performance is increased at optimal point with only 13.3% of bags labelled with maximising, and with 6.7% when averaging uncertainty over appliances. Micro
This situation is a consequence of different appliance signature characteristics – a kettle activation, as a short duration appliance, is more likely to be present in bags with other activations from other devices, and hence needs more queries to augment its learning to see sufficient kettle activations with different aggregates. Washing machine is likely to be confused with dishwasher and, hence, in the absence of strong labels its performance cannot be improved, especially for the low-power state. For dishwasher, there are more high power samples in one activation and, therefore, with more training samples in the weak labels, it is possible to improve.
In House 4, weak transfer learning (100% bags labelled) increases performance for both kettle and microwave, as well as the micro
Considering best
Observed uncertainty levels in Scenario 1 (top) and Scenario 2 (bottom) for the whole query pool of house 4 bags.
In house 5, performance is poor before fine-tuning for washing machine and dishwasher. However, overall performance, as well as per-appliance performance, does improve (or remains the same for the dishwasher) with weak transfer learning (100% bags labelled), and also with weak AL with reduced amount of labelled data. With weak AL, the amount of data that needs labelling increases from 2.2 to 10.7% when maximising uncertainty across appliances, and from 2.2 to 26.1% when averaging, at optimal points. At best
In House 19, performance improves with AL exceeding the performance of weak fine-tuning (100% bags labelled), requiring only 1.5–3.2% of bags to be weakly labelled when maximising, and 2.7 to 8.1% when averaging uncertainty across appliances, at optimal points. NAR value of House 19 is the highest among all test houses – 0.93, but starting performance before any fine-tuning is good, which indicates that this domain has more similarities with training data than previous testing domains.
Results – pre-training Scenario 2. Results of the proposed approach are shown in the following format: metric (% of activation samples added to fine-tuning dataset)

Table 6 shows results where strong and weak labels are used in the pre-training phase – pre-training scenario 2, and weak labels are used in the AL phase. This scenario is more favourable compared to the previous one, because even though only weak labels are available during fine-tuning phase, strong labels are available in the pre-training phase.
Observed ratio of uncertainty between kettle and microwave in Scenarios 1 (top) and 2 (bottom), when using mean (left) and maximum (right) uncertainty across present appliances.
AL curve obtained at REFIT house 4 in Scenario 2 when averaging uncertainty across present appliances. Original curve is smoothed using Savitsky-Golay filter of length 11 and order 3.
Compared to Scenario 1, as expected, performance for all appliances in all houses is improved over the baseline [41] with significantly less additional fine-tuning data. This behaviour can be attributed to the inclusion of strong labels during the pre-training phase, which increased the network’s knowledge, thereby necessitating a lesser quantity of data to achieve comparable or improved results.
Next we discuss levels of uncertainty observed at the start of the AL process. In Scenario 1, weak labels only are present in the pre-training phase, and the model tends to be either overconfident or very unconfident (as shown by the uncertainty histogram in Fig. 4 (top) – most of bags have low uncertainty values – and lower uncertainty means higher confidence), and the performance before fine-tuning is not as good as with strong labels present (Scenario 2). On the other hand, when strong labels are present in the pre-training phase (Scenario 2), performance before fine-tuning is better, but there are not as many low uncertainty (high confidence) bags as in Scenario 1 (as shown in Fig. 4). The model has been shown strong labels, hence better performance, but is also more uncertain (i.e., histogram is more flat) due to learning from strong labels with overlapping activations of multiple appliances contained in a bag. It is also worth noting that more high uncertainty bags are observed for kettle than for microwave. Uncertainty levels among bags that are queried for REFIT house 4 in each experimental scenario are shown in Fig. 5: Scenario 1 with mean uncertainty across appliances – upper left; Scenario 1 with maximum uncertainty across appliances – upper right; Scenario 2 with mean uncertainty across appliances – lower left; and Scenario 2 with maximum uncertainty across appliances – lower right. The figures show uncertainty level of microwave (orange) stacked to uncertainty level of kettle (blue) for each bag queried in the beginning of the AL process, before any fine tuning. In case of using maximum uncertainty across appliances as overall uncertainty measure, the model tends to pick bags in which uncertainty is high for kettle, but not necessarily for microwave – according to histograms in Fig. 4, kettle has more high uncertainty bags in general. On the other hand, if using mean uncertainty across appliances as overall uncertainty measure, bags are picked so that both appliances have high uncertainty. Therefore, as described in Section 4.3, querying based on mean uncertainty is more reliable and gives better overall improvement of the model.
From both Tables 5 and 6, we observe that with our proposed optimal point Eq. (12), performance improvement (House 2: 1.2%, House 4: 14%, House 5: 2.9%, House 19: 14%), for both acquisition functions, is almost the same as best F1 performance, with significantly less additional fine-tuning data.
AL curve with optimal points marked obtained in house 4 with mean uncertainty over appliances is shown in Fig. 6. In the beginning of the AL process, useful bags are chosen in the first couple of iterations, after which performance becomes steady for kettle, and improves further for microwave.
From the presented results, it is evident that sometimes adding less data is better than adding more, because not all data samples are useful, and not all data samples do improve the pre-trained model. Therefore, AL approaches can be used to select only high-uncertainty data and label and add only them to fine-tuning dataset. An important note is that weak labels only can be used throughout the AL process, and model performance can still improve. This is very encouraging, especially bearing in mind that weak labels are easily obtained, and that they could be obtained even from lay users, who do not have any knowledge of NILM and appliance signatures – weak labels could be inferred by only asking users when did they run specific device.
In this section, we provide a brief discussion on the complexity of the proposed approach. It is worth noting that this framework is primarily designed for data efficiency without compromising performance, but the method itself does not focus on reducing computational complexity.
In each AL iteration, there are two phases that require significant computational resources: acquisition and fine-tuning phase. In the acquisition phase, the model needs to examine all signal segments belonging to the query pool and rank them by uncertainty, which has the complexity of
Conclusions
Non-Intrusive Load Monitoring approaches need to be adapted to the new data domain, when deployed in a target unseen environment, to ensure acceptable performance. To this aim, data and labels collection phase is required. Usually this task is performed by the end users or service providers, where the labelling process is time-consuming. The works in literature that proposed approaches to help in reducing the user effort to provide labels, still face issues related to the feasibility of obtaining sample-by-sample annotations or to the large quantity of data to be annotated to obtain acceptable performance.
We proposed a weakly supervised AL framework in order to address the above gaps, exploiting weak labels and the AL loop to collect annotations for a reduced set of data. We also propose an approach whereby it is possible to determine the minimum number of samples needed to achieve optimal performance and prove experimentally that under multiple scenarios and appliances, across 4 test houses, including additional samples does not significantly improve performance. We also demonstrated that our approach exceeds the performance of a benchmark method while reducing the labelling effort by up to 82.6–98.5% in four target domains.
Future works will extend the method by considering criteria based on explainability [63, 64] to select the subset of data to be labelled by the users. Moreover, advanced neural network techniques [65, 66, 67] will be included to improve the effectiveness and efficiency of the method.
Footnotes
Acknowledgments
This project has partly received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 955422.