
Abstract
The average reward problem in the traditional Monte-Carlo tree search algorithms troubles the sudden death games for a long time, because of the average reward criterion will reduce the probability of a deterministic result. But this does not bother the non-sudden death games, such as Go, which can focus only on higher win rates rather than higher scores. In this work, we propose the miniMax-Monte-Carlo tree search with depth rewards to Outer-Open Gomoku (a variant of Gomoku) to discover a forced win/lose without any human knowledge, evaluation function, or pre-training. And it can solve not only the average reward problem but also the inaccurate win-rate problem in deep playout simulation in sudden death games. Finally, we propose a new integrated framework named BBQ (Big, Best, Quick win) MCTS for improving the performance of traditional MCTS.
Keywords
Introduction
The miniMax algorithm is a traditional search strategy for two-player zero-sum games. A full search miniMax solution is optimal in the combinatorial game theory. Due to the limitations of time and space, a fixed-depth miniMax algorithm is usually used for game tree search. Instead of searching enormous space, Monte-Carlo Tree Search (Coulom, 2007; Kocsis & Szepesvári, 2006) samples the search space to approximate the optimal solution. Moreover, UCT leads MCTS to converge to the game-theoretical optimum if enough time and space are given (Browne et al., 2012). So it is hard to choose between MCTS and miniMax approach when encountering a problem.
In the past decade, MCTS has been applied to many applications and got great success. But MCTS could not work very well on sudden death games (like connection games). As far as we observed, the MCTS accumulates the results of random playouts in the Backpropagation stage. It means that the win rate of a parent node is the average of all its children’s rewards. For example, assume a game state has two moves, one will lead to winning this game and get 1 point, the other will lose and get 0 point. In this case, the win rate of the game state will be averaged by MCTS algorithm. But a deterministic result should be recorded exactly or the win rate will confuse the result, as shown in Fig. 1.
Although MCTS has been studied extensively, the average reward problem still troubles the sudden death games. Herein the sudden death games, such as Outer-Open Gomoku, are games in which a single move can determine a win/lose. However, AlphaGo and AlphaGo Zero (Silver et al., 2016; 2017) did not need to deal with the average reward problem because their policy networks take over the tasks of random playouts and can suggest many good moves for MCTS. A single move of Go usually does not determine a win/lose result, so the average reward of those good moves is also excellent. And this is why MCTS can work well on computer Go.
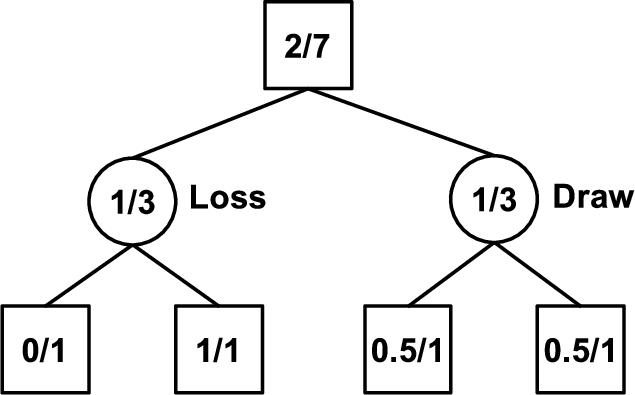
Two different moves with the same win rate but different results.
Monte-Carlo tree search
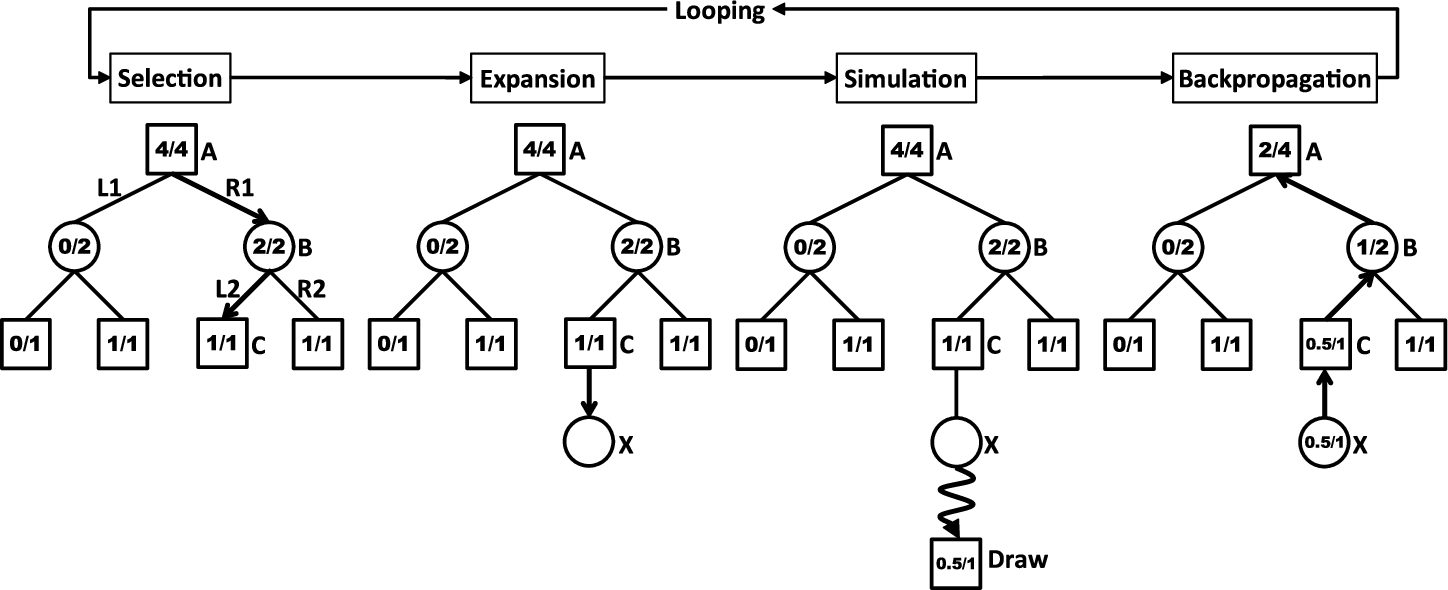
Monte-Carlo tree search (Coulom, 2007; Kocsis & Szepesvári, 2006; Browne et al., 2012) is a general-purpose search algorithm based on random sampling of the search space to approximate the optimal strategy. MCTS algorithm, illustrated in Fig. 2 (Chaslot, Bakkes, Szita & Spronck, 2008; Liu, 2017), consists of the following steps:
Selection: start from the root node R to descend through the tree until a leaf node D is reached. Expansion: expand one (or more) child node F. In this work, we only expand one child node for each simulated game. Simulation: play a random playout from node F until the end of the game. Backpropagation: update the final game result of each playout from the newly expanded node F to the root node R.
For the game tree in Fig. 2, the nodes represent states of the game and the edges represent legal moves. Each node statistics the number of wins and simulations for the node considered from itself. For example, the win rate of node B is

An iteration of the MCTS in practice.
MCTS-miniMax Hybrids was introduced by Baier & Winands (2013; 2015) that integrated miniMax within MCTS using three different ways: the playout (rollout), the selection and expansion, and the backpropagation phase. We make a brief introduction about MCTS-miniMax hybrids as follows.
In the playout phase, a fixed-depth miniMax search is used for choosing playout moves. The miniMax search can only find forced wins and avoid forced losses because of not using evaluation functions. A random move is returned when the miniMax search cannot find a win or lose path. Moreover, a miniMax search can also be embedded in the selection and expansion phases. A miniMax search can be triggered everywhere in selecting the most promising move from root to leaf. This strategy checks a shallow and wide game tree to guide MCTS tree growth by detecting shallow wins and avoiding shallow losses. So the miniMax search within the backpropagation phase allows MCTS to prove win/lose more quickly and excludes useless moves effectively.
MiniMax-Monte-Carlo tree search
Monte-Carlo tree search has been a great success in many applications, computer Go especially, but not on sudden death games. The reason is that the average reward (win rate) problem will affect the accuracy of the result since the win rate of a game state is the average of all its sub-states’ rewards. So here we do not allow the average reward criterion to make a deterministic result become an uncertain outcome (see Fig. 1). In the practical situation, the first player would attempt to maximize their reward while the second player (his/her opponent) seeks to minimize the first player’s win rate when finding the most promising moves. To solve these problems, in this section, we propose to combine the miniMax idea into the MCTS. We divide the nodes of Monte-Carlo tree into min-nodes and max-nodes. The MCTS algorithm is modified as follows:
Selection: start from the root node to descend through the tree until a leaf node is reached. In this paper, we modify UCB1 policy to fit the sudden death games and to better balance between exploration and exploitation. The UCB1 policy is modified as:
Expansion: expand one (or more) child node. In order to simplify it, in this paper, we only expand one child node for each simulated game. Simulation: play a random playout until the end of the game. Backpropagation: update the final result of each playout from the newly expanded node to the root node according to the following formula:
We give an example in Fig. 3 to illustrate how miniMax-Monte-Carlo tree search (miniMax-MCTS) works. In the Selection stage, node A chooses R1 to reach node B which is the most promising move with the larger UCB value from the first-player’s viewpoint according to the following UCB comparisons. Since both children of node A are min-nodes, we have
After that, node B chooses L2 to reach node C which is the most promising move with the larger UCB value from the second-player’s viewpoint according to the following UCB comparisons. Since both children of node B are max-nodes, we have
Now the Selection stage goes down to the leaf node C and then the Expansion stage expands a child node X. When the first-player draws a game from the Simulation stage, the result of node X is labelled to
Since node B is a min-node, we have
Since node A is a max-node, we have
In addition, we should take care of the Backpropagation stage. Here we do not reduce the term
An iteration of the miniMax-MCTS in practice.
In the previous section, the proposed miniMax-Monte-Carlo tree search can solve the average reward problem on sudden death games and works well on Tic-Tac-Toe. However, previous MCTS approaches do not consider the depth reward of the random playout. In this section, we desire to discriminate the orders from moves that have different search depths but with the same playout results. Because the win/lose of Gomoku is well defined, a critical move is usually followed by a clear-cut result. It means that the win/lose result will come very soon if we miss a critical move. So the difference in search depths between moves is large. For instance, whatever a game is won by randomly playing 1-ply or 31-ply, the result (1 point) is always the same. But the fewer steps we play to win a game, the higher confidence we get. On the other hand, the longer path we defend for a losing game, the more chance we have to turn the tables. Therefore, we discount the rewards for each move based on the depth it has simulated. Then the win rate is close to 1 or 0 if a move wins/loses a game immediately. Thus, the win rate of miniMax-MCTS is no longer 1, 0.5, or 0 when the random playout results in a win, draw, or lose. It is tuned between 0 and 1 according to the playout lengths.
In this work, we apply miniMax-MCTS to Outer-Open Gomoku without any human knowledge, evaluation function, or pre-training. The win rate formed with Monte-Carlo random playout might not be trusted. Moreover, it may simulate very deep and the final result is also not suitable for utilization. Therefore, we set a maximum depth for each simulation. The result will be regarded as a draw if a simulation plays beyond the maximum depth. In addition, to accomplish the miniMax-MCTS with depth rewards for sudden death games, we scale up the values to retain the win rates and the total simulation numbers. By this way, the miniMax-MCTS with depth rewards can find out a defending move for avoiding the forced loss and an attacking move to run into the forced win, that is the situations traditional MCTS could not find. Now the formula for the Backpropagation stage is modified as follows:
Figure 4 shows an iteration to illustrate how miniMax-MCTS with depth rewards works. The steps of these four stages are the same as Section 3. The differences are that all the values are scaled up by a factor of
After that, node B chooses L2 to reach node C which is the most promising move with the larger UCB value from the second-player’s viewpoint according to the following UCB comparisons. Since both children of node B are max-nodes, we have
Now the Selection stage goes down to the leaf node C and then the Expansion stage expands a child node X. Then, the first-player wins the game by randomly playing a 5-ply simulation and gets
The Backpropagation stage uses the result of the simulation to update information in the nodes on the path from node C to node A. The calculation details are shown below:
Since node B is a min-node, we have
Since node A is a max-node, we have
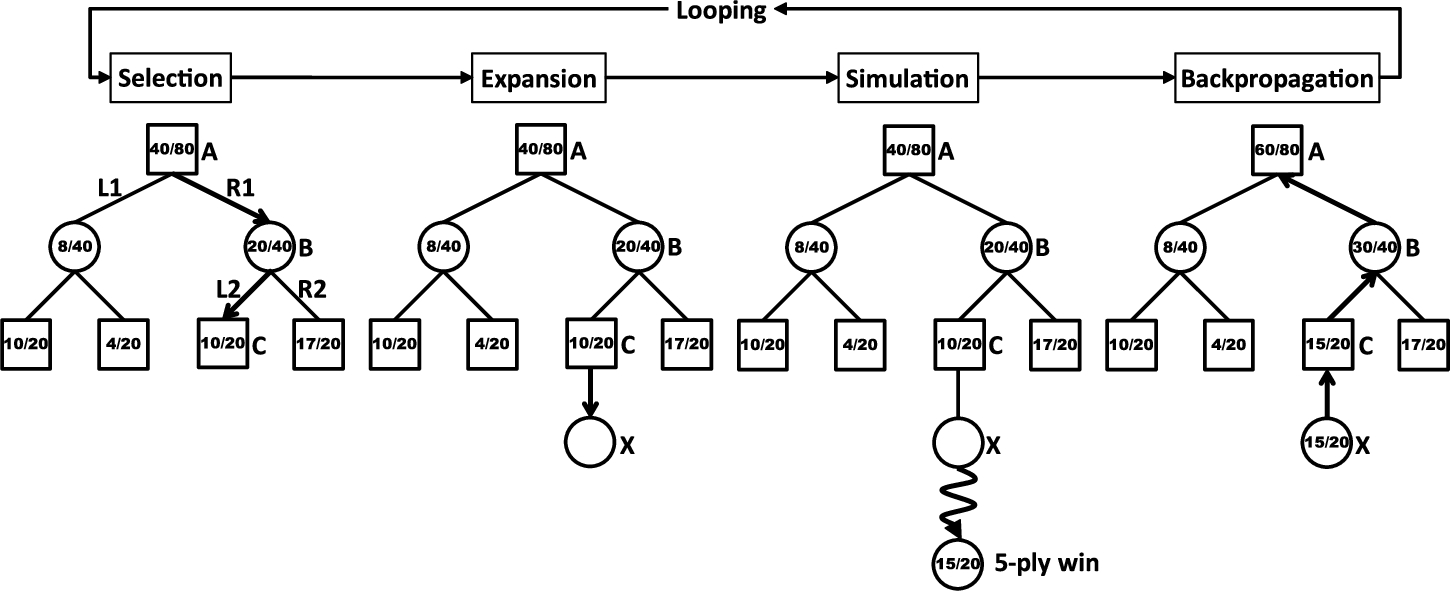
An iteration of the miniMax-MCTS with depth rewards in practice.
In this section, we pick two sudden-death games, Tic-Tac-Toe and Outer-Open Gomoku to test whether the traditional MCTS and our miniMax-MCTS work well.
Tic-Tac-Toe
For the Tic-tac-toe board shown in Fig. 5(a), the player “O” plays first and will be losing the game no matter where he/she plays. But only playing at C2, he/she can delay losing this game till 4-ply.
In this experiment, we repeat 100 iterations with 1 random playout per iteration. It means that the game tree will be expanded 100 nodes and will be played 1 random playout for each expanded node. Table 1 shows that the win rate for each “O” move evaluated by the traditional MCTS and our miniMax-MCTS with depth rewards. The traditional MCTS cannot distinguish between 2-ply (plays at B2 with win rate 0.2) and 4-ply (plays at C2 with win rate 0.2) losing, but our miniMax-MCTS with depth rewards can (plays at B2 with win rate 0 vs. plays at C2 with win rate 0.15). The results show that our miniMax-MCTS solves the average reward problem and our depth reward strategy distinguishes a contribution from the moves with different depths.
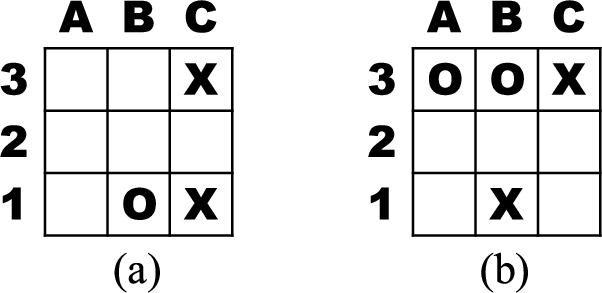
Two games with obvious results for testing traditional MCTS and miniMax-MCTS.
For the Tic-tac-toe board shown in Fig. 5(b), the player “X” plays first and will be winning the game unless he/she plays at B2 so that a draw is gotten.
The win rate for each “O” move in Fig. 5(a)
We use the traditional MCTS for the game shown in Fig. 5(b), repeat 20, 100, 200 iterations respectively and do 1 random playout per iteration. The first player “X” will win the game unless he/she plays at B2, but the results in rows 2 to 4 of Table 2 confused us because the traditional MCTS cannot distinguish between winning and drawing moves since all the five moves have a win rates around 0.5 to 1 in the 2nd to 4th rows of Table 2 and their order of win rates is not right. In addition, we increase the number of random playout to 5 times and run the example again. The results shown in the 5th to 7th rows also confused us because the average reward problem still troubles the traditional MCTS. If we increase the number of iterations for the traditional MCTS to be much more than 200, we may get more accurate results, but the average reward problem in MCTS still exists.
On the other hand, we use our miniMax-MCTS with depth rewards to run the example in Fig. 5(b) again. Table 3 shows that the results are more reliable. But we should note that the win rate of A1 with 20 iterations and 1 playout is 0.1-extremely low (the 2nd row of Table 3). This is because our miniMax-MCTS just do 1 random playout per iteration, and totally there are only 20 iterations-too small. So the result is not accurate. To solve this problem, we increase the number of random playouts to improve the accuracy of simulations, now the win rate is more stable and reliable by increasing the number of random playouts to 5 times. We can see that playing at B2 will have a win rate of about 0.5 and playing at C2 will have a win rate of about 1.
The win rate for each “X” move in Fig. 5(b) evaluated by traditional MCTS
The win rate for Fig. 5(b) evaluated by miniMax-MCTS with depth rewards
The search space of Outer-Open Gomoku is much large, but most of the legal moves are insignificant. In order to avoid searching those enormous and useless space, we aim to restrict the search space to grids near the occupied pieces on the board. We do self-play to compare unlimited (Dist(∞)), one-grid-apart (Dist(1)), two-grid-apart (Dist(2)) and three-grid-apart (Dist(3)) grids near the occupied pieces. Table 4 shows that Dist(1) wins more games than the others, so we restrict the search space in our Outer-Open Gomoku program to one-grid-apart grids near the occupied pieces.
Outer-Open Gomoku is a sudden death game in which a single move can determine a win/lose. It means that the win/lose result will come quickly if we miss a critical move. Furthermore, the result of a random playout is not accurate, so it is useless to simulate too deep on Outer-Open Gomoku. Therefore, we restrict the simulation depth of random playouts to 30-ply (Depth(30)), 40-ply (Depth(40)) and 50-ply (Depth(50)). Table 5 shows that the Depth(50) is the best and the difference between Depth(50) and Depth(40) is small. Due to time limit, we discard comparing 60-ply, 70-ply, etc.
Comparison between different versions
Comparison between different versions
Comparison between different simulation depths
In the traditional Monte-Carlo tree search algorithms, the win rate is the average reward for all random playouts. But the average reward problem will make a deterministic result become non-deterministic. So this work proposes the miniMax-Monte-Carlo Tree Search to solve those problems and can get the best winning strategy.
In addition, the conventional random playout approaches do not consider the accuracy of each playout. It means that the results formed with Monte-Carlo random playouts might not be reliable. So it is useless to simulate too deep on sudden death games. Therefore, we apply the miniMax-MCTS with depth rewards for solving the average reward problem and the problem of too deep simulating with useless results. We call the miniMax-MCTS with depth rewards as the quick win strategy.
The results of Tic-Tac-Toe in Section 5 show that the miniMax-MCTS can evaluate more accurately with less simulations because our miniMax-MCTS algorithm chooses the best move instead of the move with the highest averages of all its descendants. Unfortunately, at the present time, we don’t have an accurate neural network (evaluation function) to suggest where to put a good move and how good it is. Maybe our miniMax-MCTS could challenge the AlphaZero approach if we are able to train a good neural network like theirs.
Future work
Finally, we propose a new integrated framework named BBQ-MCTS (Big, Best and Quick win-Monte-Carlo Tree Search) for improving the performance of traditional MCTS. The Best win strategy is explained as the miniMax-MCTS where the best (not the averaged) value of the descendants is back-propagated at the Backpropagation stage of the MCTS. The Quick win strategy is to evaluate the rewards according to the winning depth.
The Big win strategy, is an on-going project in which we desire to win the game with the largest points/scores. In order to achieve the Big win strategy, we could keep a complete final points/scores in the process of training the neural network. The neural network will no longer only output win, draw or lose, but instead it will output how many points the player wins in the game. Therefore, the Big win neural network will suggest the BBQ-MCTS where to play in order to win the largest points/scores. On the other hand, when facing disadvantageous boards, it will suggest where to play in order to lose with the smallest points/scores.
Footnotes
Acknowledgements
This research was supported by the Ministry of Science and Technology (R.O.C.) under grants MOST 106-2221-E-003-027-MY2 and MOST 107-2634-F-259-001.