
Abstract
A strategy to find fair time controls for Armageddon chess games is presented and exemplified with 2750+ ELO players. The research was divided in two stages. The first one consisted in finding a time control for Stockfish 9 so that it played with an effective strength equal to the average 2750+ ELO players of the 2017 World Blitz Chess Championship. Analysis of this stage showed that a fair time control for an Armageddon game depends on the players’ rating. In the second stage, another instance of Stockfish 9 with a different time control was paired as the black player to the engine with the time control found in the first stage as the white player. The new engine’s time control was adjusted so that the expected result of Armageddon games between these two engines would be a draw. This game generation was done because there is a very small amount of Armageddon games in order to draw statistical conclusions out of them. The resulting time controls were found to be
Introduction
A chess match is a series of chess games played between two chess players. It is usually divided into stages, which can be thought of as a series mini-matches. If a mini-match is tied, the players move onto the next mini-match, which has a faster time control than the previous one. This could happen a lot because the most probable outcome of a chess game at the top level is a draw (Milener, 2018 (accessed December 1, 2018)). If after a number of those mini-matches the general match is still tied, the tie is resolved by an Armageddon game. Here, the piece colour is randomly assigned to the players. In the case of the World Chess Championship, the player with the white(black) pieces has 5(4) minutes on their clocks. In the case of the 2019 Altibox Norway Chess competition, the player with the white(black) pieces has 10(7) minutes. In both tournaments, after the 60th move, an increment of 3 seconds is added to the player’s clocks per move. In case of a draw the player with the black pieces is declared the winner.
So far, there is no scientific background on why the 5(4) or 10(7) minute settings are fair ways of breaking a tied match. In fact, many people think that these specific time controls in the Armageddon game favour black,1
This is probably the reason why the 2019 Altibox Norway Chess competition organizers decided to increase the time pressure on black with respect to the white pieces.
Therefore, this paper aims to answer, as formally as possible, the questions: how fair is the Armageddon chess game for different player strengths? For a given player strength, what is the fairest Armageddon time control? To answer these questions I propose a methodology explained in Section 2, where the main results of this study are provided. Then, in Section 3 the validity of the findings is discussed. Finally, in Section 4 a short summary is provided and the main conclusions of this work are drawn.
Let R be the outcome of an Armageddon chess game defined by
An Armageddon game is said to be fair if
The methodology exposed hereafter consists of two ideas. The first one is to experiment different time controls in order to find the ones that lead to the condition in Eq. (2). As it will be seen, this search is done using computer chess engines because the data on human Armageddon games is limited and negligible in size, so no statistics can be used to search a good estimate of a fair Armageddon time control. Therefore, computer engines games must be played in order to gather enough data for drawing conclusions. This introduces the second idea, which is to find a way to simulate the chess strength of human play.
World Chess Championship Armageddon time control
To check Eq. (2), the following method is proposed. Five matches between Stockfish 9 against itself (with the same parameters) are played, each consisting of 500 Armageddon chess games where the Perfect 2017 Polyglot opening book2
Winning probability for white, depth and nodes per second for each match labelled by the α value. From the 500 games of each match, 40 random samples of size 20 were taken from the results to estimate
On the other hand, one may argue that players’ approaches to an Armageddon chess game are not the same (Guntz et al., 2016). The white player will try to set the board on fire, whereas the black player will try to remain solid. To simulate this kind of behaviour, the Stockfish contempt parameter is helpful. In Stockfish 9, contempt goes from −100 to 100, where −100 favours draws and solid play, and 100 favours risky moves giving more chances for a decisive result. For instance, the Stockfish community decided to set the contempt to 20 in the Top Chess Engine Championship for 2018, aiming at more aggressive play from Stockfish and a greater number of wins. It is noteworthy that higher values of contempt are harmful for the results, as too many risky moves are played and hence punished by the opponent. As an example, results for the five matches with contempt set to −20(20) for black(white) player are shown in Table 2. It is observed that Armageddon is even less fair than in the case with 0 contempt for low values of α. Moreover, a monotonic decrease of fairness is present as playing strength increases.
Same as Table 1 but with contempt set to −20(20) for black(white) player
This same behaviour has been measured in human play in normal chess, when observing thousands of games of players grouped by rating ranges (Regan, 2018 (accessed August 19, 2019), 2016 (accessed August 19, 2019)). Stronger players tend to punish mistakes and convert advantages more easily, as well as defend fiercely, which is why the longer the time control, the more likely a draw is.
From Tables 1 and 2 it is seen that the expected result of an Armageddon game is highly dependent on the player strength; the lower the playing strength, the fairer the result. This dependence poses a big problem when trying to study fair Armageddon time controls for humans. If the dependence of
This paper shows how to overcome this issue and hence, tries to give an answer to what is the fairest Armageddon time control for players above 2750 ELO. The proposed strategy that I will follow to solve this question is the next one:
Play a 500 × double round-robin chess tournament between Stockfish 9 engines labelled by α with strength determined by a time control Select games where 2750+ ELO players played in the 2017 world blitz chess championship. For each 2750+ ELO player, concatenate their moves of all games into a file For each file Let For such an engine θ, find an engine ϕ with strength given by its time control To scale the engine time controls to human time controls, it suffices to see that engine θ is as strong as the average 2750+ ELO player’s strength when playing with a
Alternatives to the gain histogram method are the stochastic agent-based method proposed by Regan and Haworth (2011) or the more theoretically-robust Markov process approach to decision-making explained by Alliot (2017). However, it has been proven that the gain histogram method provides an excellent characterization of the players, as well as being faster to compute than the previous two studies mentioned earlier (Ferreira, 2013, 2012; Alliot, 2017). The results of the engine tournament are shown in the left panel of Fig. 1. It is seen that strong engines (long initial time) have almost 100% wins against weak engines (short initial time). When engines of equal strength play, the expected score is 50%. The gain cross-correlation defined by Ferreira (2013, 2012) to estimate the expected results for this tournament are shown in the right panel of Fig. 1. Interestingly, the cross-correlation expected results shrink in the expected score axis dramatically (This has been reported before in Table 6 of the paper by Alliot (2017)). This method states that strong engines have around 60% chance of beating weak engines, which is wrong, as evidenced in the actual tournament results from the left panel. Despite this important nuisance, there is a clear and logical behaviour of the strongest machine always having an expected score larger than 0.5. Moreover, the cross-correlation method shows that the expected score between two equally strong engines is 0.5.
For example if one wants to know the expected result between the
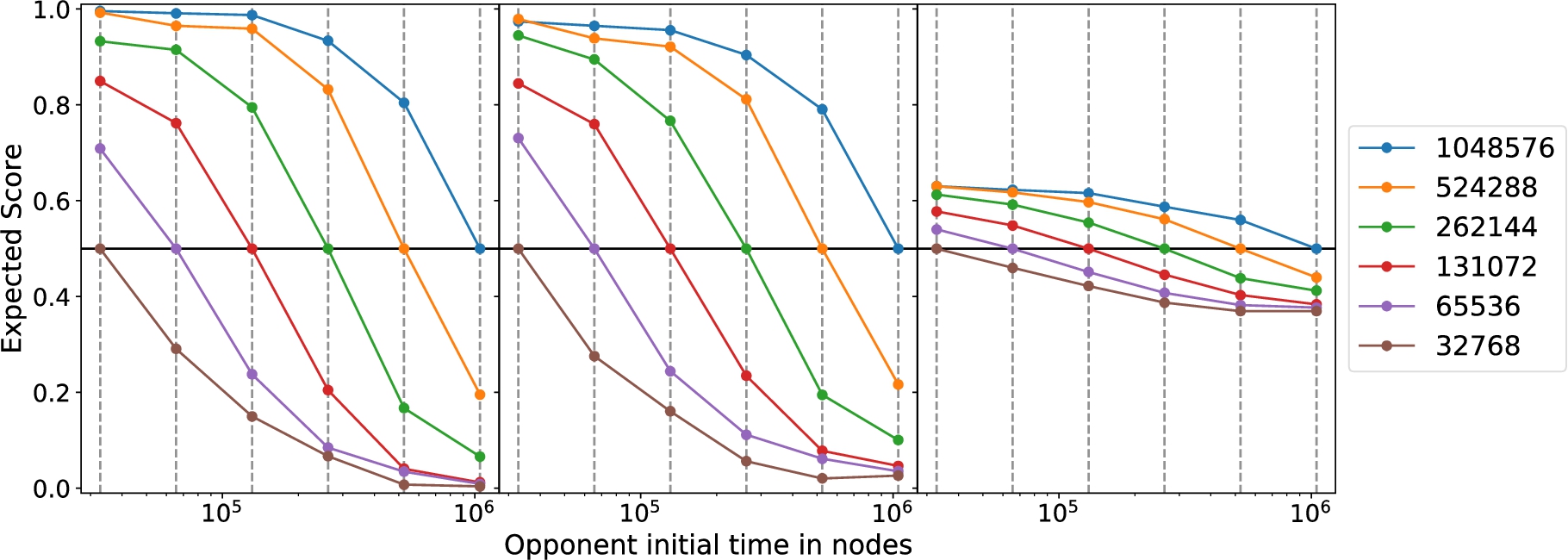
Tournament results, estimated results with neural network and estimated results with gain cross correlations in the left, centre and right panels, respectively, for each engine defined by the time controls
Unfortunately, the cross-correlation method cannot be used to estimate the expected score in general, even though it behaves well around 0.5. As pointed out by Alliot (2017), this problem can be overcome after a deeper interpretation of cross-correlations between gain histograms. In the case of this work, the shrinking problem of the cross-correlation method to calculate the expected score is dealt with through the use of a machine learning algorithm that can be trained to correctly calculate the expected score. For this, a neural network with just one hidden neuron was used to predict three classes (win for white, draw or loss for white). The neural network with one hidden neuron computes the quantity
With this enriched dataset, the neural network was trained. The engine tournament games were divided into two sets: one containing 7200 games, and the other one 10800. The one containing 7200 games was divided into a training set of 5040 games (70%) and a testing set of 2160 games (30%). The accuracy in predicting the result from the gain histograms was 92.9% in the test set, and 95.9% in the train set, showing that the neural network did not overfit. With this neural network, I proceeded to calculate the expected results for the tournament using the remaining 10800 games. These expected results are shown in the central panel of Fig. 1, which are more consistent with the left panel (that shows the empirical expected scores) than the right panel, as discussed before. In fact, Pearson’s correlation coefficient between the true expected results and the neural network calculated expected results is astoundingly 99.9%, which is even higher than the 95% achieved with a modified version of the cross-correlation method reported by Alliot (2017).
Now that there is certainty that the neural network provides an acceptable prediction of the result of a game between two players given their gain histograms, I will compare the human gain histograms with the engine gain histograms. For that matter, Fig. 2 shows the performance of both the average 2750+ ELO player, as well as the performance of each of the 2750+ ELO players in the world blitz chess championship. For the first 5 engines, the expected result of the average 2750+ ELO player behaves logarithmically with respect to the time control, following the curve

Expected result of human players versus the different engines from the engine tournament. All 2750+ ELO players shown in left panel, and the average of the gain histogram of these players is used to compute the expected score vs the engines in the right panel. The orange line and the shadowed region indicate a 1–sigma confidence interval of the fit.
For the next step one must assume the following. Let
With this in mind, a grid of 9 different initial times in nodes was picked as the black time control playing against the

Normal expected score (purple) and Armageddon expected score (blue) for matches as black against the
The study so far presented is tied to some assumptions and approximations which must be highlighted. A witness engine was used to evaluate chess play and build gain histograms. Because of finite horizon search, the evaluation that the witness engine provides is thought to have some bias, and I assumed that this bias equally affects both players of a game being analyzed. However, this sometimes might be incorrect. Suppose that the witness engine analyzes at a fixed-node count white’s move. When the witness engine analyzes black’s move, white’s move is already on the board, which, in principle, makes black’s move analysis more accurate with respect to the previous white’s move evaluation. Of course, after black moves, another white’s move comes. This is why I argued that bias of the witness engine could equally affect both players. But there are scenarios when this may not happen (Ferreira, 2012).
Even though the neural network that was used to determine the winner of a game given the players’ gain histogram has a high prediction accuracy, it gives some room for error. Therefore, the uncertainty of the time control of the engine that plays at the same strength as the average 2750+ ELO player is prone to be underestimated. A more rigorous approach can be taken to take this neural network error into account, although it must be emphasized that this error is visually negligible around the value 0.5 of the expected result (see central panel of Fig. 1).
Additionally, throughout the work, I have used fixed-node count and not a fixed-depth for the witness engine because fixed-node count assigns the same computational power to every move. Although this condition is fair from my point of view, literature has mostly used fixed-depth (e.g. Guid and Bratko (2017)). In fact, when using fixed-node count, search depths can vary a lot since some positions are more complex than others. This can lead to unequal assessments of the different positions, yielding much better assessments on simple positions compared to those on complex positions. A systematic study of how fixed-node count influences position evaluation in several positions with respect to fixed-depth search is needed to clarify whether the seemingly fair fixed-node count strategy is valid.
Where there could be more improvement in this work is in understanding and quantifying how different humans and engines take decisions. Particularly, a set of questions of interest are the following. Suppose that a certain amount of time is given to an engine and to a human, and they have to decide what move to play. How much does this decision improve if they are given twice as much time as they had in the beginning? Who will improve the most? How much will they improve? How does this depend on the complexity of the position being analyzed? All these questions are important in order to be able to correctly simulate human play. During this research I have tried to modify the time control of the engine so that its effective strength comes close to the human strength. However, some elements of human play are lost and cannot be simulated (at least for now), such as how much time is assigned to make each move. Therefore, the assumption that a decrease in initial time affects in the same way both the human and the engine is a strong assumption and has to be checked in future work. Therefore, the validity of the results should only be considered solid at time controls similar to Eq. (8).
Conclusions and perspectives
I presented a method that combines 2750+ ELO human and engine chess play analysis to estimate the optimal time control so that the expected result of an Armageddon game is fair, i.e. is 0.5. Specifically, the method used gain histograms of both engine and human players in order to determine the time control at which the engine plays at the same strength as the top chess players in the world, as well as to determine the optimal estimate of the ratio between white and black time controls in an Armageddon game, so that it is fair. These optimal time controls were found to be
Hopefully, the present study will contribute as a first step from the scientific perspective towards implementing a fair time control in Armageddon chess games. However, the estimated time controls presented in this paper are just that: an estimation. Therefore I recommend the top chess tournaments that want to include Armageddon games to start testing whether the time control found here is really fair in human play.
For future work, I would like to perform the comparison between gain histograms of human white players and engine white players with different values of contempt, and to study if aggressiveness of a player can be simulated or approximated by contempt. Also, it seems that the agent-based method by Regan and Haworth (2011) can improve the simulation of human skills using an engine, since in this study I forced the engine to make mistakes by limiting its computing capabilities with short time thinks.