Abstract
Price comparison services are widely used by e-shopping customers. Such e-shopping sites receive product offers from thousands of online stores, and in order to provide price comparison, product categorization, and searching, it is necessary to match different offers referring to the same real-world product. This is a hard task, since they need to classify millions of product offers in thousands of classes, and distinct descriptions may exist for the same product, as well as very similar descriptions of distinct products. In this work, we propose a method that uses association rules to classify product offers from e-shopping web sites matching offers against offers without the need for a product catalog. This is a supervised learning method that trains a classifier, whose generated model comprises a set of association rules to identify product offer classes. Experimental evaluations show that our method is effective and efficient, and obtains better results than three baselines in several datasets with distinct characteristics. It is able to deal with large datasets containing thousands of classes and different types of products such as electronics and books. Moreover, we propose and evaluate strategies to reduce its execution time and we evaluate its weaknesses.
Keywords
Introduction
The comparison of product prices is a very important service, provided by e-shopping web sites, such as Google Shopping,1
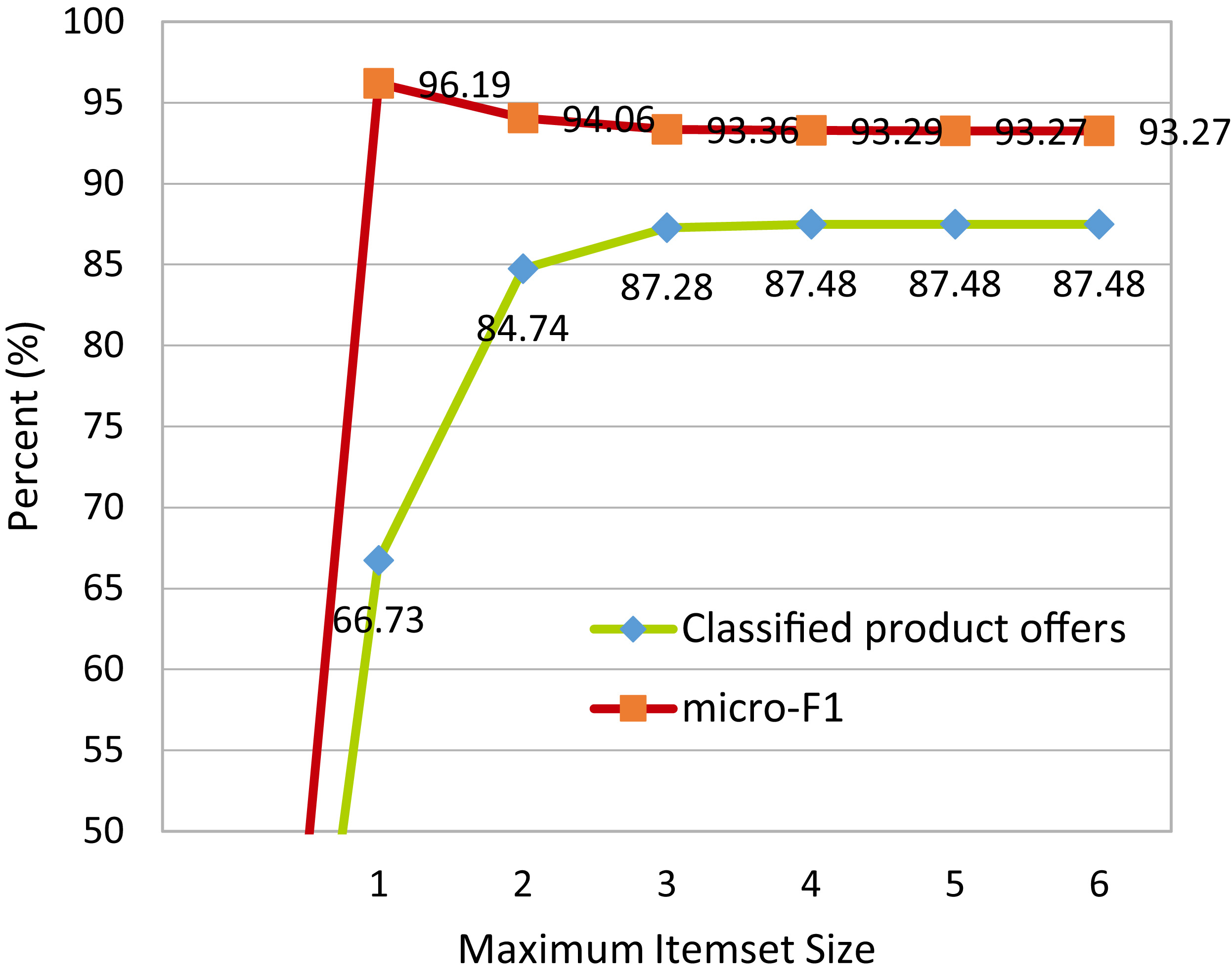
As an illustration, Fig. 1 shows some of the results of searching for the product HP Photosmart C4780 in Google Shopping. It is noticeable that Google performs product matching, since the first result refers to offers from 4 stores. However, it was not able to identify that the second result also refers to the same product.
Product offers related to search HP Photosmart C4780 in Google Shopping.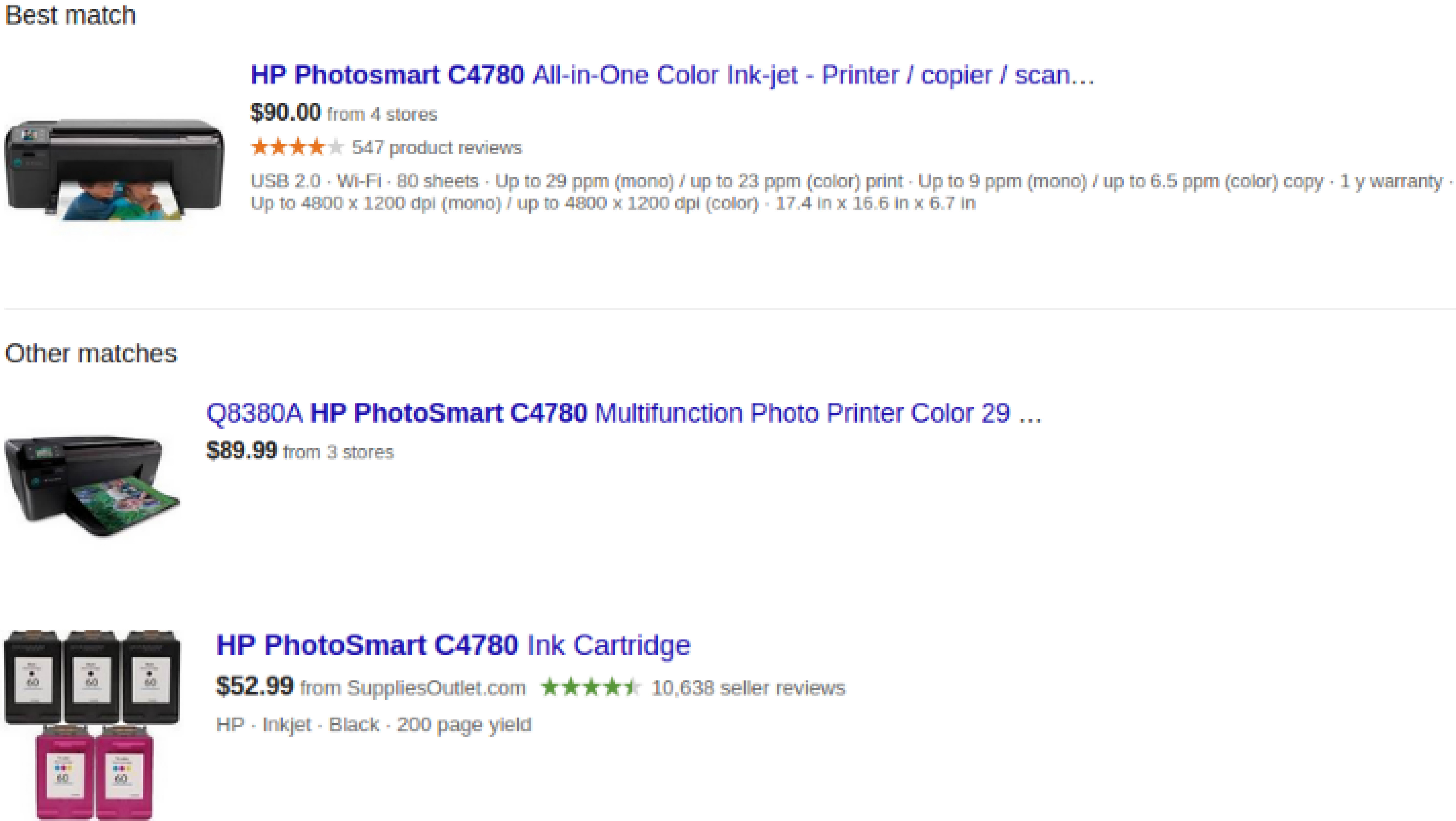
In addition to identifying when different descriptions refer to the same entity, as in the first two descriptions of Fig. 1, solutions for the problem of matching product offers also need to identify that very similar descriptions can refer to distinct products. For example, “HP OfficeJet Pro 8600 911a Wireless” and “HP OfficeJet Pro 8600 911n Wireless” refer to two distinct printers with different prices.
Given a set of entity references, such as product offer descriptions, the process of identifying which of them correspond to a same real-world entity is known as entity resolution [20, 10, 5, 17, 12]. The matching of products is a specific case of entity resolution, where the entities are products. Traditional entity resolution approaches deal with structured data, applying similarity functions to each attribute of the records and combining the result to find duplicated records. The product matching problem is hardest because product offers come from thousands of merchants, which use different descriptions of the products. Such descriptions may be short as “HP C4780” or contain several technical characteristics of the product in a free textual field.
In this work, we address the problem of aggregating product offers from e-shopping web sites by matching product offers against other offers. This problem is more challenging than matching product offers against a catalog of structured products [16] due to uncleaned and non-structured data. Matching of product offers is highly relevant in many scenarios where a catalog is not available. For example, applications that monitor product price from different web sites typically do not have a catalog. Furthermore, aggregated offers could be used as a starting point for construction of product catalogs.
Few studies addressed the problem of matching product offers against product offers. In [19], the authors preprocess product offers to extract product codes and use them for matching. However, the effectiveness of their approach depends on the product category since not all categories have product codes. Furthermore, their method needs to submit queries to a web search engine, which may make the method non-scalable. The approaches in [13, 21] also need to submit queries to a web search engine, and they did not provide experiments with a large number of distinct products. Evaluations of several traditional entity resolution approaches made by [18] report poor results for precision and recall metrics in the product offer matching task. They also concluded that learning-based approaches, which obtain better results than non-learning approaches, do not scale with large input sets. Therefore, there is space for more studies in this area.
Therefore, we have the questions: can we develop an effective and scalable method for matching product offers, knowing that we need to deal with a large number (tens of thousands) of distinct products? Can we develop a generic method that does not depend on characteristics of specific product categories?
Our hypothesis is that we can treat the problem of matching product offers as a classification problem, and train a classifier to identify sets of tokens (words) in the product offer descriptions that discriminate different products, i.e., sets of tokens that occur in the descriptions of only one class of product offer. For example, in Fig. 1, the set of tokens {C4780, Printer} occurs only in the two descriptions of the printer, and can distinguish it from its cartridge, which can be identified by the set of tokens {C4780, Cartridge}.
We propose a method to classify product offers from e-shopping web sites that uses association rules [3] to find sets of tokens that distinguish each product offer class. This is a supervised learning method that trains a classifier whose generated model comprises a set of association rules, used to identify product offer classes. The association rules are of the form
Our method uses only the textual description of product offers, which is usually present for all product types. Therefore, it does not depend on the specific attributes of some categories of products. We have evaluated it on datasets containing several categories of products, such as electronics, perfumeries, fashion accessories, and books. Some categories of product contain an implicit, built-in, product code in their offer descriptions (e.g., C4780 in the example of Fig. 1). Our method is able to identify implicit product codes in the product offer descriptions, when they exist, and it is also generic enough to classify product offers that do not have codes.
We evaluated the effectiveness and the efficiency of our method experimentally, on several datasets with distinct characteristics, which indicates that our method is better than three baselines in the most situations. It is able to classify a large dataset containing thousands of instances and classes, in a reasonable execution time.
In [24], a preliminary proposal of our method was presented, applied to disambiguate publication venue titles in bibliographic citations. In this work, we changed some strategies of their basic algorithm, introducing the concept of support of a rule in the training phase and considering a new vote schema to choose the best rule in the test phase. We also proposed and evaluated new alternative strategies to the basic algorithm. And we evaluated several facets of the method, in terms of effectiveness and efficiency, in the application of classifying product offers. The main motivation to apply that method to classify product offers came from the fact that product offers usually contain implicit codes that uniquely identify each product, similar to bibliographic citations, which usually contain acronyms. Unlike bibliographic data whose methods get good results, product matching is a much harder problem to solve [18].
Our contributions can be summarized as follows:
We propose an association rules based method for classifying product offers from e-shopping web sites matching offers against offers without the need for a product catalog. Different from other associative classifiers, our method uses only the textual description of the entities, and we propose a new way of using support and confidence to find good rules; Our method is able to classify at product level, which enables customers to compare prices (currently and historically) and obtain other information about a product, such as customer reviews; It is able to classify large datasets, containing thousands of classes, which is the main challenge to manage e-shopping products. It works well for different types of products, such as electronics and books; We discuss the computational complexity of our method, propose and evaluate strategies to reduce its execution time; We evaluate experimentally our method, demonstrating its effectiveness and efficiency.
The remainder of this paper is organized as follows: In Section 2, we discuss related works on the classification of products and on association rules. In Section 3, we present our method, which uses association rules to classify product offers; and in Section 4, we discuss its computational complexity. In Section 5, we describe our experiments, evaluation metrics, and results. Finally, in Section 6, we present our conclusions and directions for future works.
E-shopping web sites usually organize their products hierarchically in categories, such as that in Fig. 2(a). They also keep a catalog of products, which contains detailed specifications for each product, organized in structures of attribute-value pairs, such as in the example of Fig. 2(b). Works in literature studied different tasks on classifying product offers in hierarchies and catalogs. Product offers can be matched to a catalog [16] or they can be classified in some level of the hierarchy, in classes such as “Clothing”, “Components” or “Printers” [32, 23, 8] or at product level (e.g., “HP PhotoSmart C4780”) [19, 13, 21]. In order to compare product prices, product offers need to be classified at product level, which is the focus of our work. This type of classification is much more challenging due to the large number of classes. It is also more challenging than matching product offers against a catalog due to the absence of structured and cleaned product data.
(a) Example of a hierarchy of products and (b) examples of attribute-value pairs of two products in a catalog of products.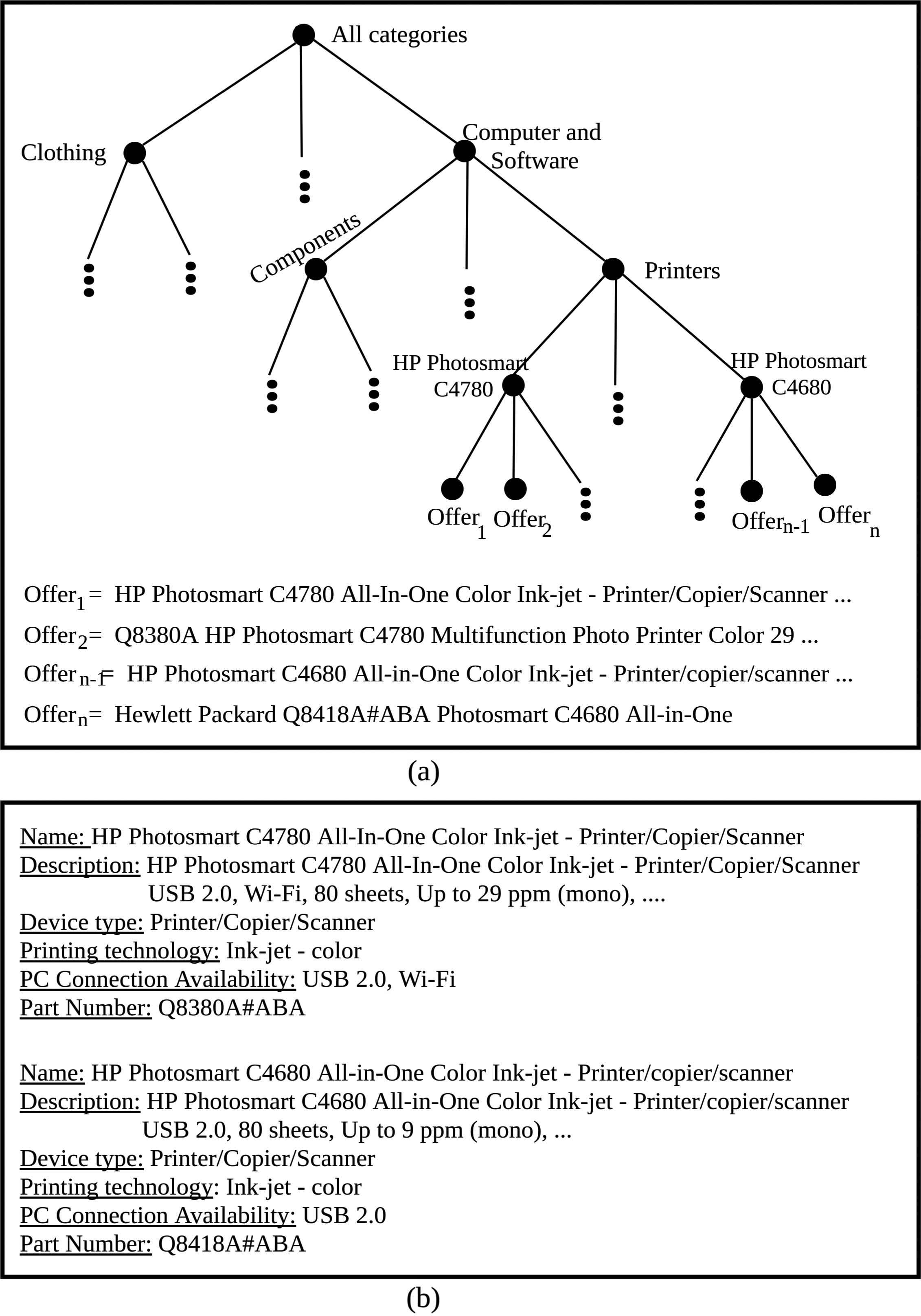
Related to product offers and catalog, [16] described their system, used by Bing Shopping, for matching unstructured offers to structured product descriptions in a catalog. They adopted a probabilistic approach to find the product in the catalog that has the largest probability of matching to the given offer. Their matching function takes into account matches and mismatches in attribute values between offer-product pairs, treats missing attribute values, and weights the importance of different attributes. In another work, [22] introduced the problem of product synthesis, which aims at identifying new products from a set of product offers and add them to a catalog, together with their structured attributes. Their solution addressed issues involved in data extraction from offers, schema reconciliation, and data fusion.
In order to classify product offers in categories above the product level, [8] presented a study about classification methods for large-scale categorization. They also proposed a probabilistic approach to model the classification problem, using a belief network. Their work differs from ours because we classify product offers in categories at product level. In our experiments, we used a dataset extracted from the same data source as their datasets, however, our dataset has much more classes than theirs’.
Other works also presented approaches to classify products in classes above the product level. In [23], they evaluated Naive Bayes classifiers for classifying product offers in Yahoo! Shopping. They studied the effects of data transformation on text classification with Naive Bayes classifier. Several heuristic feature transformations were experimented, such as IDF and normalization by the length of the text. In [32], the author presented a system for product categorization that uses a variation of the vector space model [26], modified to represent product attributes. The author considered textual and numeric attributes, such as product description, manufacturer name, and price. In our work, we used only the textual description of products. In a related study, [1] address the problem of matching of product categories from multiple web sites. They proposed an improved approach for the word sense disambiguation process.
The focus of our work is to classify product offers in categories at product level, matching offers against offers. The studies in [19, 13, 21, 18] addressed this problem. In [19], the authors used an entity resolution approach that preprocesses product offers to extract product codes and use them for matching. A product code is a manufacturer-specific identifier that typically appears in the product name and description. To extract product codes, they manually created list of regular expressions and used the web as an external knowledge source to verify the candidate codes. They employed a learning-based approach, combining several matchers on several attributes to derive a match decision for every pair of entities. The effectiveness of their approach depends on the product category since not all categories have product codes. Furthermore, their approach depends on submitting queries to a web search engine, and therefore is not scalable. Our method does not provide a specific strategy to extract product code like theirs’, however, if a code exists it is naturally extracted and embedded in the rules, and may contribute to improve the effectiveness of our method.
The approaches in [13, 21] also match product offers against product offers, however, they are not scalable, since they need to submit queries to a web search engine to enrich the descriptions of products and other entities before matching them. They also did not evaluate them using a large amount of data containing a large number of classes.
The product matching problem was evaluated by [18] by using several entity resolution approaches, and concluded that it is not sufficiently solved with conventional approaches based on the similarity of attribute values. Furthermore, the learning-based approaches, which obtained the best results, are not scalable even for a small number of classes and instances. Entity resolution aims at identifying equivalent entities or duplicates within a data source or between data sources. Some surveys and tutorials on entity resolution can be found in [10, 17, 20, 12, 14]. A web-based entity resolution approach to treat product matching and bibliographic data was proposed by [25].
Our work uses association rules, a data mining technique that can find out relationships among item sets in a dataset [3]. It is based on associative classification, which combines association rules and classification to build a classification model. Several associative classification algorithms have been proposed in the last years. A recent survey can be found in [30]. The algorithms vary according to their different methodologies in rule learning, ranking, pruning, and prediction procedures. The main differences of our work to the others are in the generation of rules and in the way we use the support and confidence concepts. Support is measured only among the instances of the same class, rather than measure it in a global context. Confidence does not measure the accuracy of a rule, instead, we use rules with 100% of confidence only. As a result, we generate a small number of rules when compared to works that use confidence to rank rules, and we propose an efficient data structure to assist in generating rules by using an inverted index. Such form of using confidence may be applied to other contexts where implicit codes are important pieces of evidence for classification.
Association rules were also used in [28] to disambiguate author names in bibliographic citations. They proposed supervised learning methods where tokens in coauthor names, work title, and publication venue titles are used as features to train classifiers that exploit rules associating citation features to specific authors. Association rules were also used to classify documents in [29]. Their approach combines textual features of documents and links to form an associative classifier. Both works explore specific features of their applications, author name disambiguation and document classification. They also use the confidence to measure the accuracy of a rule. Our method uses only tokens in a text, it does not use other evidences such as links or prices, so it may be applied to disambiguate other types of entities described by text only.
Our work is an extension of the [24]’s work. They proposed a method that uses association rules to disambiguate publication venue titles originated from bibliographic citations. The disambiguator is a supervised learning method that uses a publication venue authority file [11] to train a classifier, whose generated model is a set of association rules to identify publication venues. In this work, we changed the strategies of their algorithm, and promoted a complete evaluation of its effectiveness and efficiency on the product matching problem. We added the support of a rule, which decreases the number of rare tokens that generate bad rules in the classification model. In the prediction phase, we do not need to generate all itemsets, the new vote schema prioritizes short rules and stops to generate itemsets as soon as it finds a decision. We also proposed an alternative strategy that decreases the number of tokens to be combined. All these changes were experimentally evaluated demonstrating improvement in effectiveness and efficiency of the new algorithm.
The product offer matching problem may be seen as follows. Given a set of product offer descriptions, originated from web stores, the objective is to map them into real classes of products known by the e-shopping, as illustrated in Fig. 3(a). Our solution to this problem uses a supervised machine learning technique, as illustrated in Fig. 3(b). It uses a set of manually classified product offers to train an associative classifier to predict the class of other unclassified product offers. In the training phase, the classified product offer descriptions are tokenized, cleaned, and indexed. Sets of tokens (itemsets) are generated from the tokens of each product offer description, and they are used to generate association rules that relate them to the correct product offer class. In the prediction (or test) phase, each unclassified product offer description is also tokenized, cleaned, and has its sets of tokens generated. The classification module uses the learning model created in the training phase to produce the product offer matching results. The following sections detail each one of these steps.
(a) The product offer matching problem (b) Our solution to the problem.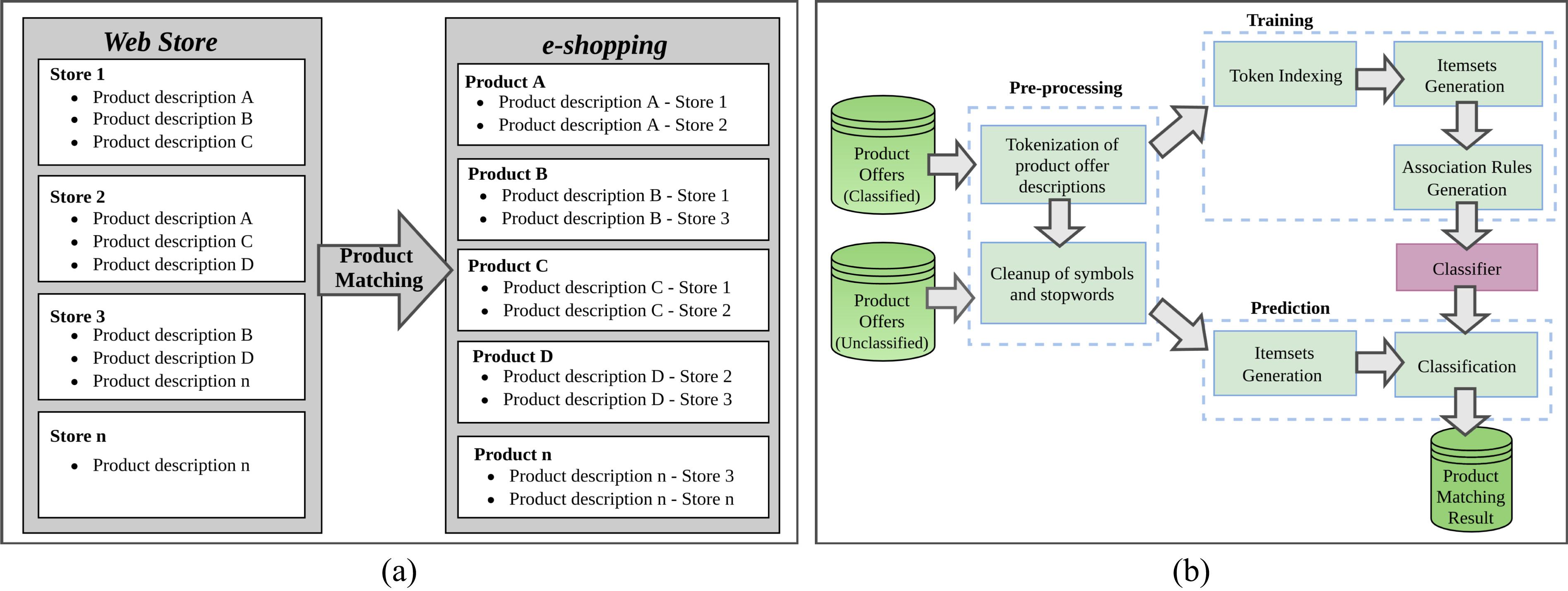
The task of classifying product offers may be formulated as follows. Let
Our proposal for solving the classification problem uses a supervised machine learning technique. In this case, we are given an input dataset, called the training data and denoted as
The learning function uses an associative classifier, which exploits associations among tokens in the product offers that uniquely identify each class. Such associations are uncovered using rules of the form
In order to produce association rules that uniquely identify each class, the associative classifier only learns rules that have a confidence of 100%. According to [3], a rule
The associative classifier also checks the support of a rule. The rule
Mathematical notations
Mathematical notations
The training data
Algorithm 1 shows the steps of the training phase. It receives as input a set of product offers, for which the classes are known, and a minimum support for generating rules, and returns a set of associative rules that have a confidence of 100% and minimum support to predict product offer classes. The algorithm’s first step (Lines 1–6) inserts distinct tokens from the instances into an inverted index structure [4]. This structure is composed of key-value pairs, where the key is a token and the value is an occurrence list of this token, containing, in each position, the class
Training Phase
Examples for training
Minimum support
The set of rules
for each instance
do
Tokenize(
)
for each token
do
InsertInvertedIndex(
,
,
)
end
for
end
for
for each instance
do
Tokenize(
)
Length(
)
for
do
GenItemSets(k,
)
for each k-itemset
do
if SizeOccurrenceList(
)
then
//100% confidence rule
if SupportRule(
)
then
InsertRule(
,
)
end
if
RemoveItemSet(
,
)
end
if
end
for
end
for
end
for
return
Training Phase
Examples for training
Minimum support
The set of rules
InsertInvertedIndex(
//100% confidence rule
InsertRule(
RemoveItemSet(
return
The second step of the algorithm (Lines 7–23) is an iterative process, to create associative rules. The GenItemSets function generates sets of items with
If a
An example of training data
Rules generated from the training data of Table 2