
Abstract
Mining web usage data of e-business organizations is essential to provide knowledge about clients’ web utilization patterns, which can help these businesses in landing at vital business choices. Because of non-deterministic web access behavior of web clients, web user session data is usually noisy and imperfect. Such imperfection has a negative impact on pattern discovery process. One of the real issues associated with the prevalently used Fuzzy c-Means (FCM) and Fuzzy c-Medoids (FCMdd) methods is that they are not robust against the noise, because a single outlier object could lead to a very different clustering result. In this research we propose a robust Fuzzy c-Least Medians (FCLMdn) clustering framework to deal with the user session data contaminated with noise and outlier user session objects, with the objective of improving the quality of the extracted patterns. To deal with the high dimensionality of user session data which may contain noise and outliers, a fuzzy set theoretic approach for assigning fuzzy weights to user sessions and associated URLs has been proposed. Our results clearly indicate that quality of user session clusters formed using FCLMdn algorithm is much better than those using FCM and FCMdd algorithms in terms of various cluster validity indices.
Introduction
The “Web User Session Clustering” is articulated as the automatic discovery and analysis of usage clusters from web user session data as a result of user interactions with web resources on one or more web sites [1]. The discovered patterns are usually represented as collections of web resources that are frequently accessed by groups of users having common interests [2].
There are several challenges associated with user session clustering from unlabeled, semi-structured and noise contaminated web user session data [3]. Due to the human interactions and non-deterministic browsing patterns of various web users, user session data may be incomplete or may involve noise and outliers [4]. Such data which suffers from ambiguity and vagueness do not have the crisp boundaries and often have overlapping clusters [5]. Fuzzy clustering is more suitable techniques than the traditional hard or crisp clustering techniques for the discovery of web usage models from the web usage data [6].
One of the most well know fuzzy clustering technique is Fuzzy c-Means (FCM) clustering [7] was first proposed by Dunn and later modified by many authors [8, 9]. FCM algorithm uses an objective function that is minimized while trying to partition the data objects. The algorithm computes the cluster centers and assigns a membership value to each user session corresponding to every cluster within a range of 0 to 1. Another category of fuzzy clustering algorithm know as Fuzzy c-Medods algorithm [10] extends Hard c-medoids algorithm by incorporating fuzzy set concept to produces fuzzy clusters [11].
One of the major problems associated with FCM and FCMed based user session clustering algorithms, which try to minimize sum of the squared errors type objective function is that, they are not robust against the noise contaminated user session data. A single outlier or noise user session object could lead to a very different clustering result [12]. In this research work we propose a Fuzzy c-Least Medians (FCLMdn) based user session clustering algorithms to deal with the session data contaminated with noise and outlier user session objects.Unlike FCM and FCMed algorithms which minimize sum of the squared errors, FCLMdn algorithm tries to minimize the median of the squared error i.e. median of the euclidean distances of the
Figure 1 depicts an overview of the FCLMdn based framework for the discovery of web user session clusters. Various steps involved in the proposed framework include i) Fuzzy weight assignment to user sessions, ii) discovery of user session clusters using the proposed FCLMdn clustering technique and iii) evaluation of the discover clusters using various fuzzy validity indexes.
Fuzzy c-Least Medians based discovery of user session clusters.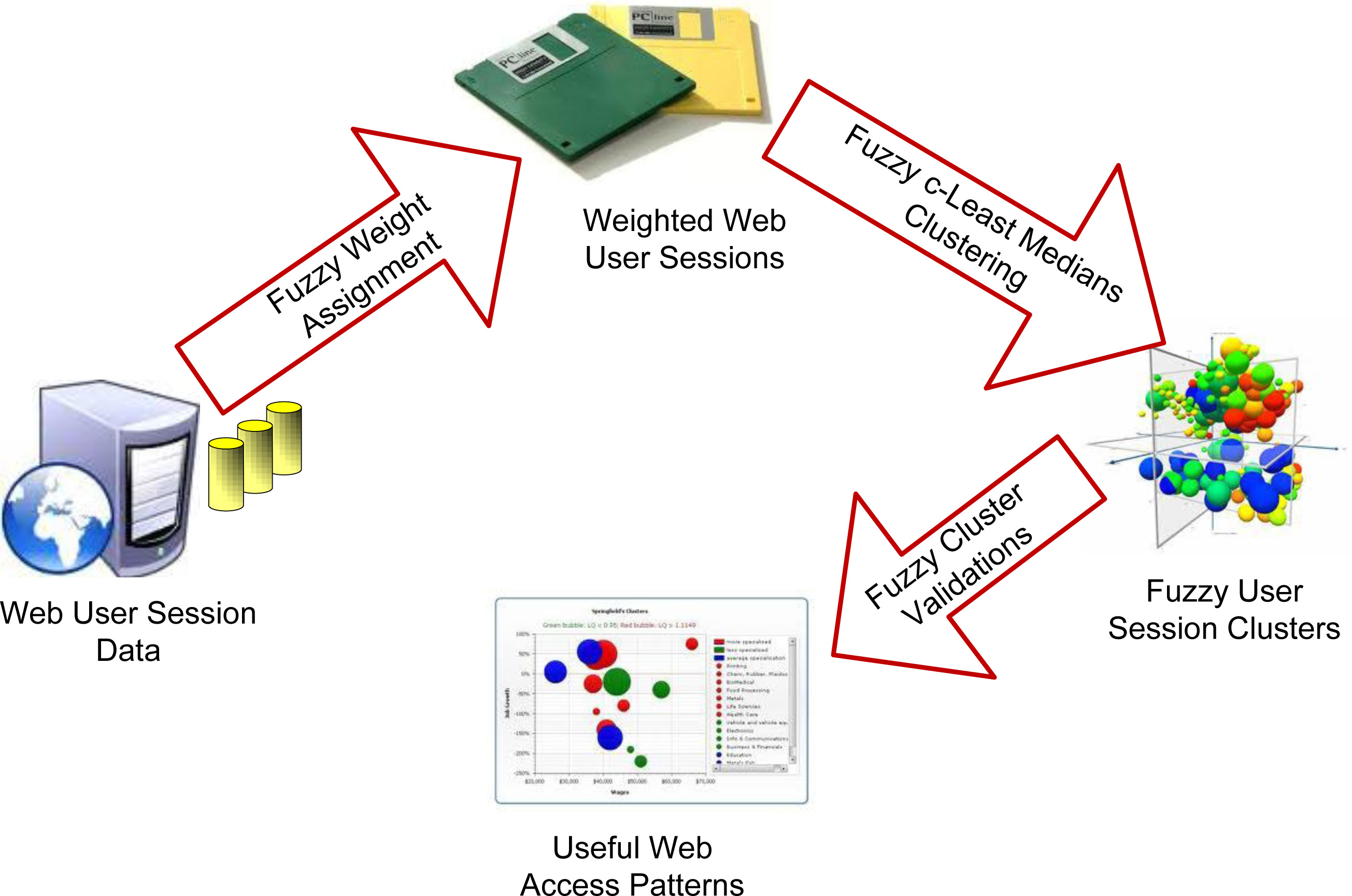
Organisation of the rest of the paper is as follows: In Section 2 we provide a brief overview of the related work in the field of web usage mining. Section 3 provides a brief discussion of the methodology to assign fuzzy weights to web user sessions. In Section 4 mathematical formulation and algorithmic details of the FCM, FCMed and the proposed FCLMdn based user session clustering is presented. Section 5 discusses various validity indexes utilized for the quantitative measurement of the quality of the discovered fuzzy clusters. Section 6 deals with the experimental results and the related discussions. Finally, conclusions are presented in Section 7.
Clustering techniques have been applied to the user session data in order to discover user session clusters representing similar URL access patterns. “Clustering aims at dividing the data set into clusters where inter-cluster similarities are minimized while the intra cluster similarities are maximized”. Detailed description about various clustering methodologies are provided in [13]. The most widely used clustering methods are partitioning based, which partition the given data objects into
Web personalization: The goal of personalization is to provide users with what they need without them asking for it explicitly [17]. Web personalization implies the delivery of dynamic contents, such as text, advertisement or product recommendations etc., as per the needs or interest of users [18]. Making dynamic recommendations to a web user based on the user’s profile is very useful for many e-commerce sites [19, 20]. web site design: In order to design a complex web site, the designer must anticipate the users’ needs and structure the site accordingly. Also users’ needs may change over time, and their usage patterns may violate the designer’s initial expectations [21]. Understanding user needs requires understanding how users view the data available and how they actually use the site [22, 23]. system improvements: Web usage mining provides the key to understand the web traffic behavior which can be utilized to decide strategies for web caching, load balancing and data distribution [24, 25]. business intelligence: Due to intense competition, the business community has realized the necessity of intelligent marketing strategies and relationship management [26]. Web usage mining attempts to discover useful knowledge from the data obtained from the interactions of the users with the Web [27] etc.
Due to the human interactions and non-deterministic browsing patterns of various Web users, user session data may be incomplete or may involve noise and suffers from ambiguity and vagueness [5]. Fuzzy clustering is more suitable techniques than the traditional hard or crisp clustering techniques for the discovery of web usage models from the web usage data [28]. Fuzzy sets are suitable for handling the issues related to understandability of patterns, incomplete or noisy data, mixed media information and human interaction [29]. Fuzzy set based clustering of user session data partitions a set of user sessions into clusters, where each user session may belong to several clusters with different degrees of membership. This enables the clusters to grow into their natural shapes [30]. A membership value of zero indicates that the user session is not a member of that cluster. A non-zero membership value shows the degree to which the user session represents a cluster [31].
For the discovery of user sessions clusters the most popularly used Fuzzy clustering methods include i) Fuzzy c-Means and Fuzzy c-Medoids Clustering algorithms. Fuzzy c-means algorithm [32] performs the fuzzy clustering in such a way that a given user session may belong to several clusters with the degree of belongingness specified by membership grades between 0 and 1. It uses an objective function that is minimized while partitioning the user sessions. The objective function of Fuzzy c-Means represents the weighted sum of distances between the user sessions and their cluster centers. Fuzzy c-Medoids (FCMdd) algorithm [11] provide the concept of medoid for each cluster which is the most centralized user session object representing that cluster [33]. The objective function of FCMdd method is similar to that of FCM with the only difference that it utilizes cluster medoids instead of cluster means.
FCM has been used for the discovery of usage patterns from the web log data [34, 35]. Some of the variants of of fuzzy c-Means that have been applied in the domain of web usage clustering include [36, 37, 38, 39, 40, 41]. FCMdd method have been used for user session clustering in [42]. The major problem associated with these algorithms is that, they are not robust against the noise contaminated user session data. A single outlier or noise user session object could lead to a very different clustering result [43]. In order to provide the robustness against against noise, a Fuzzy c-Least Medians (FCLMdn) based user session clustering algorithms has been proposed that deals with the user session data contaminated with noise and outlier objects. Fuzzy c-Least Median of squares algorithm tries to minimize the median of the squared error i.e. median of the euclidean dissimilarities of user sessions from their cluster centers.
Web user session data is extracted by preprocessing and transforming the the unlabeled, semi-structured textual raw web log data into a set of numeric user session vectors [44]. Preproessing utilizes a variety of algorithms and heuristic techniques to perform various preprocessing tasks such as data cleaning, user identification and session identification etc. Data cleaning eliminates the irrelevant, extraneous URL references and those generated due to the spider navigations [45]. User identification is performed to identify the users corresponding to the web log requests [46]. User session identification segments the rquests corresponding to individual users into sessions, each representing a single visit to the site [47]. In [48, 49, 50], authors have provided the details of various techniques utilized for preprocessing the web log data.
Let
where each
The number of URL items appearing in the access logs could number in the thousands. Filtering the logs by removing references to low session support URLs (i.e. that are not supported by a specified number of user sessions) can provide an effective dimensionality reduction method while improving clustering results. For this purpose fuzzy weights are assigned to all the URLs using membership function based on their user session support count. All URLs with session support count lower than the lower threshold
The fuzzy weight
Since very small sized sessions may represent the noise present in the data, weights are assigned to all the sessions using a fuzzy membership function based on the number of URLs accessed by those sessions. Let
Let
Table 1 provides brief descriptions of various mathematical symbols and terms used in this article.
Description of the symbols used in this study
Fuzzy user session clustering data strctures and distance computations
Let
where
The
The partition matrix
Let
where
Following subsections describe the algorithms for the discovery of user session clusters using Fuzzy c-Means, Fuzzy c-Medoids and Fuzzy c-Least Medians Clustering techniques.
The objective function
where
Membership matrix
Algorithm 1 describes the steps involved in fuzzy c-Means clustering to discover the user session clusters.
Fuzzy
Fuzzy c-Medods algorithm extends Hard c-medoid algorithm by incorporating fuzzy set concept to produces fuzzy clusters. Each cluster is represented by a representative user session object as the medoid of that cluster. The fuzzy c-medoids algorithm tries to minimizes the objective function:
The membership martix
Once the membership matrix
Algorithm 2 describes the steps involved in fuzzy c-Medoids clustering to discover the user session clusters.
Fuzzy
Unlike Fuzzy c-Medoids algorithm that minimize sum of the absolute errors, Fuzzy c-Least Median of squares algorithm tries to minimize the median of the absolute errors i.e. median of the Manhattan distances of the
The membership
The new cluster centers that try to minimize the objective function
where
Proposed Fuzzy
Initialize the cluster centers matrix
Compute membership value
Compute dissimilarity term
Sort the dissimilarity terms
Compute new cluster center
The term cluster validity refers to the process of evaluating the results of a clustering method. The purpose of a fuzzy user sessions clustering methods is to identify the significant overlapping partitions present in the user session data set. Various quality measures to evaluate the quality of the discovered fuzzy clusters are given in articles [51, 52, 53]. In order to measure the quality of the fuzzy clusters, we used the Xie-Beni, Fukuyama Sugeno, Zahid separation compaction (SC), and error fuzzy cluster validity indices due to the following reasons.
The Xie-Beni Index has been used extensively for evaluating the quality of FCM cluster partitions in a wide range applications because it can validate fuzzy partitions by considering the geometrical features of the discovered clusters [54, 55, 9]. According to the Xie-Beni index, the cluster compactness and separateness are measured by intra-cluster deviations and inter-cluster distance, respectively [56, 57]. In the domain of web usage mining, the Xie-Beni index has been used to evaluate the quality of fuzzy web usage clusters [58, 1]. The Fukuyama Sugeno index captures the difference in intra-cluster compaction and inter-cluster separation, and it has been used widely for validating the quality of fuzzy clusters [59, 60, 61]. In the field of web data mining, it has been applied successfully to the validation of fuzzy clusters [62, 63]. The Zahid SC index measures the ratio of fuzzy separation relative to fuzzy compactness, where it computes the separation-compaction ratio based on the geometrical properties of the clustering data structure. It also computes the separation-compaction ratio using the fuzzy union and fuzzy intersection concepts of membership values [64]. The Zahid SC index has been used in various domains for validating the cluster quality [65, 66]. The error index measures the sum of the squared error, i.e., the objective function of FCM-based clustering [67]. We use the error index to measure the clustering error.
The following subsections provide further details of these validity measures. A clustering is considered as optimal if it provides good results for all the below mentioned validity measures:
The Xie-Beni validity index XB is the ratio of the intra-cluster cluster compactness relative to the inter-cluster separation [56]. This index is based on the objective function
where
If the clusters are highly separated, the value of
The Fukuyama Sugeno Index FS is defined as:
where
The first term of Eq. (25) measures the cluster compactness and the second term measures the separation. Smaller values of FS are expected for compact and well-separated clusters.
The Zahid SC index is defined as:
where
and
The term
The error index represents the objective function of the fuzzy user session clustering, which is defined as follows:
where
Input user session data is extracted from the web access logs taken from the Proxy Servers of a university campus. Total number of input user sessions are 319. Number of URLs of the resources accessed from these user sessions are 116. Perl scripts are used to assign the fuzzy weights to all the user sessions and URLs.
Results of assigning weights to user sessions
Reduction in the row dimensionality of the user session matrix
| Log | Session | No of | URL weight | |
| data | support | URLs | Linear | S |
| function | function | |||
| 1 | 46 | 0 | 0 | |
| 2 | 20 | 0.2 | 0.08 | |
| 3 | 16 | 0.4 | 0.32 | |
| 4 | 4 | 0.6 | 0.68 | |
| 5 | 4 | 0.8 | 0.92 | |
| 5 |
72 | 1 | 1 | |
Results of URL weight assignment
URLs are evaluated based on their session support count and their weights are calculated using linear fuzzy membership function as given in Eq. (3) and standard
The experimental code is implemented using Java language in Eclipse Integrated Development Environment and run in Windows 7 operating system environment on machine configuration AMD C-60 processor, 1.33 GHz, 4 GB RAM. Rest of this this section is organized as follows. Details of the experimental process is given below:
Multiple runs of Fuzzy c-Means, Fuzzy c-Medoids and the proposed Fuzzy c-Least Medians algorithms are conducted for the input user sessions i) without any weight assignment ii) with linear fuzzy weights and iii) with standard S fuzzy weights. The number of clusters parameter For all of the above cases following cluster validity measures are computed i) Xie Beni Index ii) Fukuyama Sugeno Index iii) Error Index and iv) Zahid SC Index. The details of these validity measures are described in Section 6. For all of the above Fuzzy clustering techniques, results for different types of input user session weights are compared using the specified validity measures. Performance of Fuzzy c-Means, Fuzzy c-Medoids and Fuzzy c-Least Medians algorithms are compared using the specified cluster validity measures.
Table 4 reports the values of Xie Beni Index, Fukuyama Sugeno (FS) Index, Zahid SC Index and Error Index for Fuzzy c-Means, c-Medoids and c-Least Medians clustering of Google user sessions with different types of weights assigned to them.
Fuzzy clustering of Google user sessions
Fuzzy clustering of Google user sessions
Fuzzy c-Means clustering of user sessions with and without fuzzy weights.
Figure 2 provides various validity index values for Google user session clusters discovered by applying Fuzzy c-Means algorithm as a function of number of clusters. Figure 2(a) shows the Xie Beni Index scores computed using Eq. (23) as a function of number of clusters. A smaller value of this index represents better quality of the clusters. From the figure this is very clear that the quality of the fuzzy clusters formed by using Fuzzy Weighted user sessions is much better than that of those with no user session weights. Also users sessions with linear fuzzy weights give better result than user sessions with standard fuzzy weights. Figure 2(b) describes the Fukuyama Sugeno (FS) index scores computed using Eq. (25) as a function of number of clusters. Since FS index represents the difference of the within cluster compaction and inter cluster separation, a lower value of this index represents better cluster quality. From the figure it is obvious that Fuzzy Weighted user sessions results in high quality clusters in terms of FS index. Sessions with linear fuzzy weight give slightly better performance than sessions with standard S weight. Figure 2(c) provides values of Zahid Separation Compaction (SC) Index computed using Eq. (27) as a function of number of clusters. A higher value this index represents better fuzzy cluster quality. Figure clearly indicates that Fuzzy Weighted user sessions results in high quality clusters in terms of SC index and sessions with linear fuzzy weight give better quality of clusters as compared with sessions with standard S weight. Figure 2(d) shows the Fuzzy Error Index scores computed using Eq. (30) as a function of number of clusters. A smaller value of this index represents less fuzzy clustering error and better quality of the clusters. Figure clearly indicates that the fuzzy clustering error by using Fuzzy Weighted user sessions is much less than that with non-weighted user session. Also the quality of the clusters using user sessions with linear fuzzy weights and standard fuzzy weights are comparable to each other.
Figure 3 provides various validity index values for Google user session clusters discovered by applying Fuzzy c-Medoids algorithm as a function of number of clusters. Figures 3(a)–(d) show clearly (for the same reasons discussed for Fig. 2) that the quality of the fuzzy clusters discovered using the LFMF- and SFMF-based fuzzy weighted user sessions was better than that of the clusters formed by user sessions without any weights in terms of the XB, FS, SC, and Error validity indices. This indicates that fuzzy weight assignment reduced the adverse effects of insignificant user sessions and URLs.
Fuzzy c-Medoids clustering of user sessions with and without fuzzy weights.
Figure 4 provides various validity index values for Google user session clusters discovered by applying Fuzzy c-Least Medians algorithm as a function of number of clusters. Figures 4(a)–(d) show clearly (for the same reasons discussed for Fig. 2) that the quality of the fuzzy clusters discovered using the LFMF- and SFMF-based fuzzy weighted user sessions was better than that of the clusters formed by user sessions without any weights in terms of the XB, FS, SC, and Error validity indices. This indicates that fuzzy weight assignment reduced the adverse effects of insignificant user sessions and URLs.
Fuzzy c-Least Medians clustering of user sessions with and without fuzzy weights.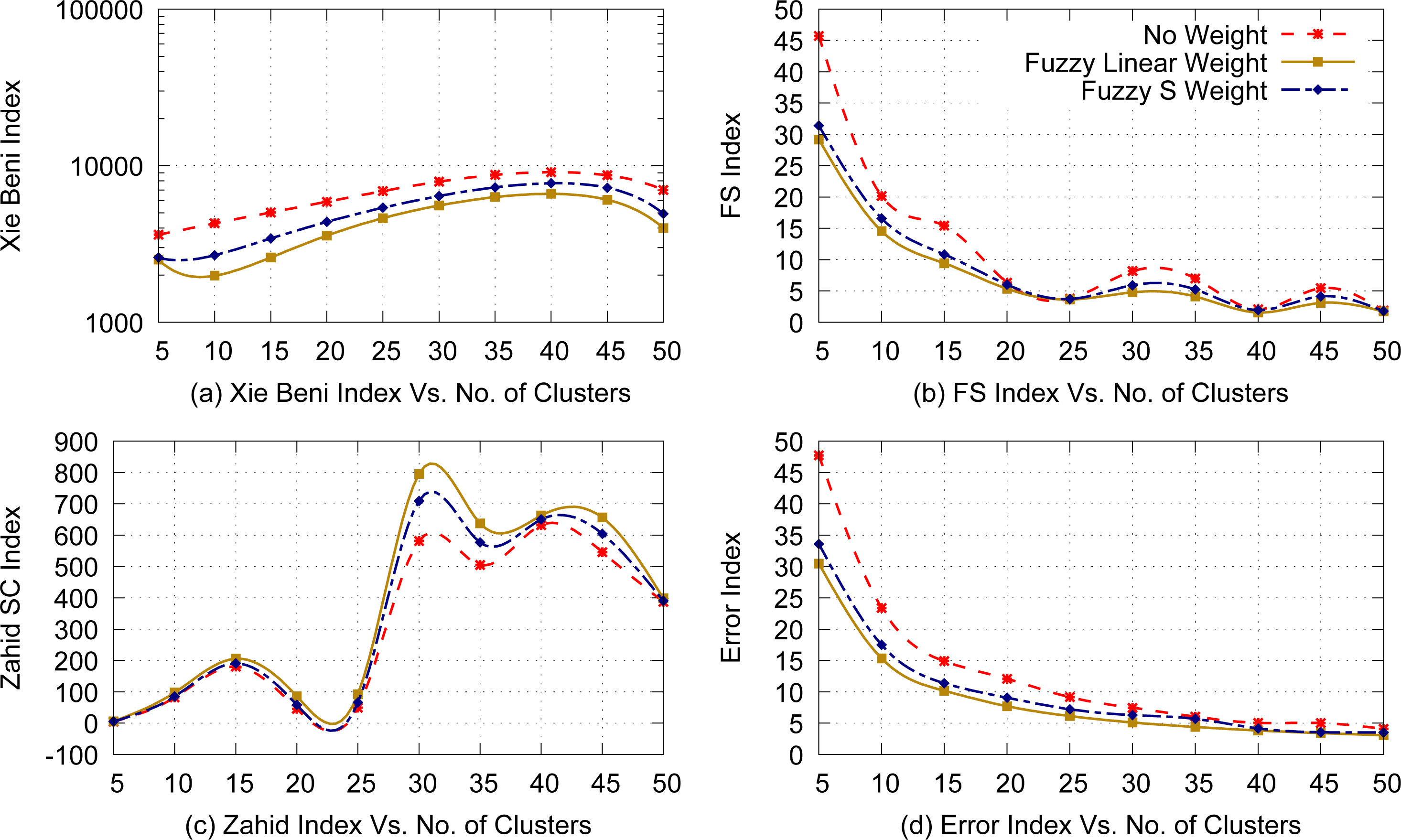
In this subsections experimental results of Fuzzy c-Means, Fuzzy c-Medoids and Fuzzy c-Least Median of Squares clustering of Google user sessions are compared. Comparison of these algorithms is performed by utilizing non-weighted as well as weighted user sessions having linear fuzzy weights. Comparisons are made using various fuzzy cluster validity measures provided in Section 6.
Fuzzy clustering results with no session weights.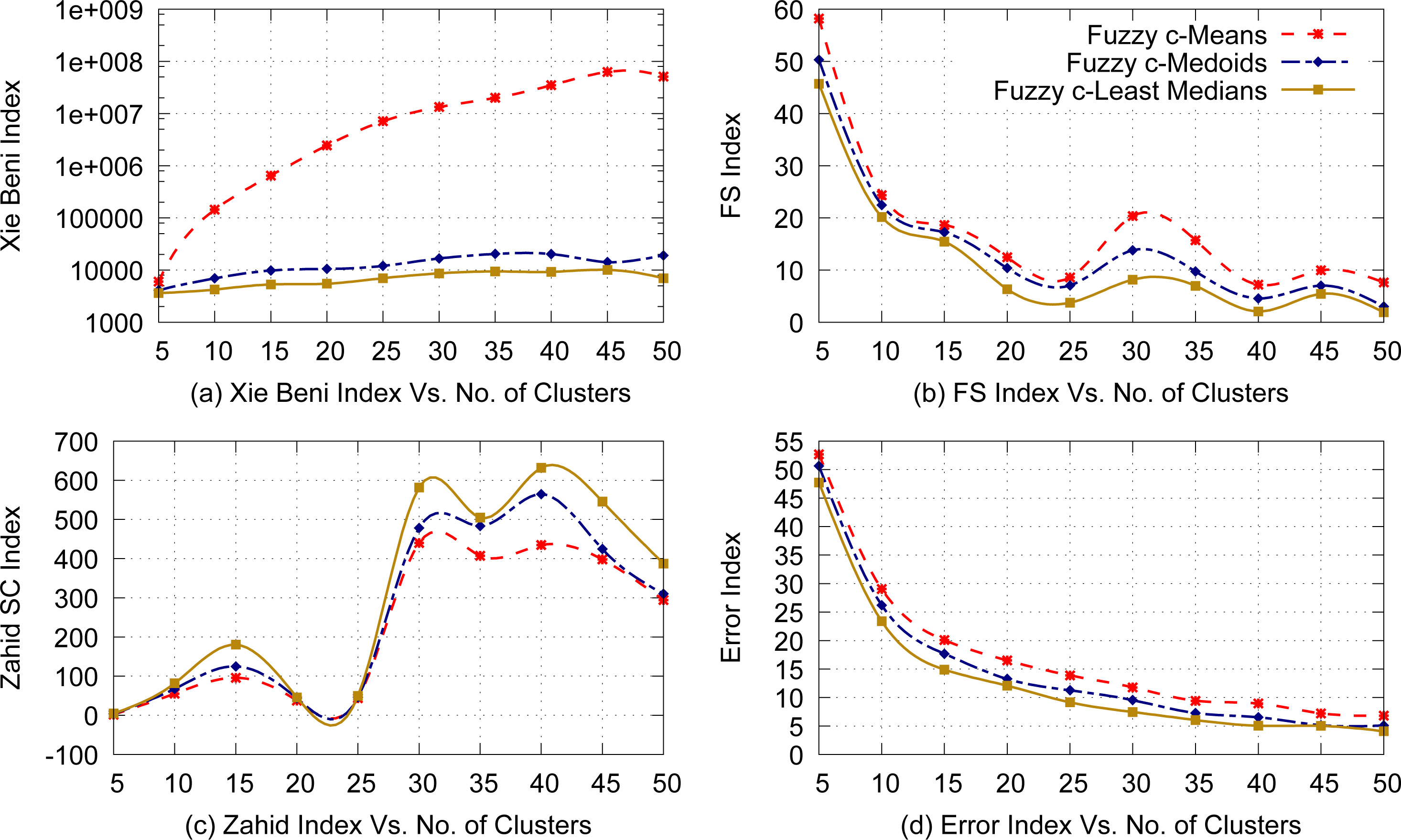
Fuzzy clustering results with linear fuzzy weights.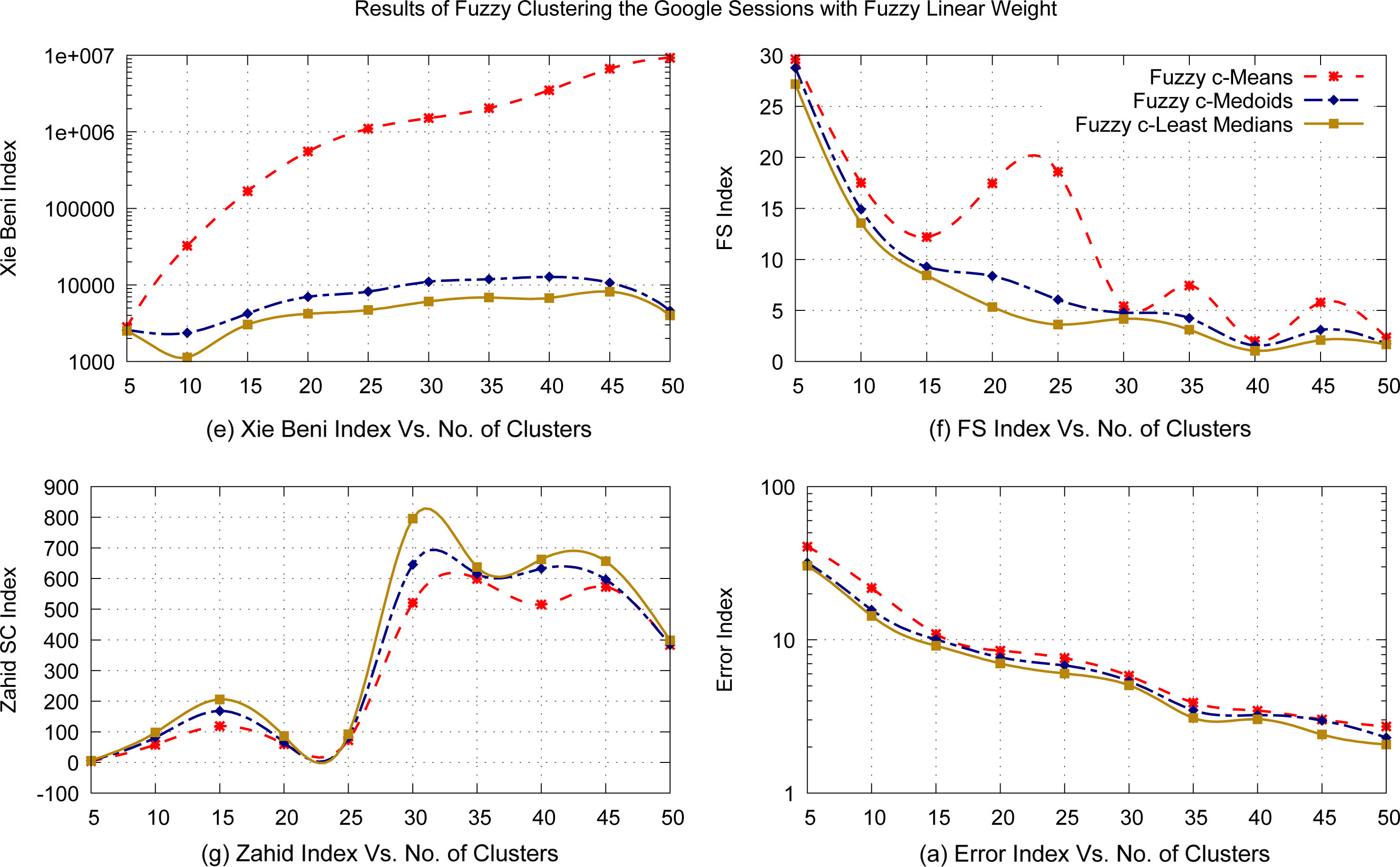
Figure 5 provides various validity index values for Google user session clusters discovered by applying Fuzzy c-Means, Fuzzy c-Medoids and Fuzzy c-Least Median of Squares with no weights assigned to the user sessions. Figure 5(a) shows the Xie Beni Index scores computed using Eq. (23) as a function of number of clusters. A smaller value of this index represents better quality of the clusters. From the figure this is clear that the quality of the fuzzy clusters discovered using Fuzzy c-Least Median of Squares algorithm is superior than those using Fuzzy c-Means and Fuzzy c-Medoids algorithms. Fuzzy c-Means algorithm produces clusters of worst quality as compared with the other two methods in terms of Xie Beni Index. Results of Fuzzy c-Medoids algorithms are better than Fuzzy c-Means but slightly inferior to that of Fuzzy c-Least Median of Squares methods. Figure 5(b) describes the Fukuyama Sugeno (FS) index scores computed using Eq. (25) as a function of number of clusters. Since FS index represents the difference of the within cluster compaction and inter cluster separation, a lower value of this index represents better cluster quality. From the figure this is clear that the quality of the fuzzy clusters discovered using Fuzzy c-Least Median of Squares algorithm is superior than those using Fuzzy c-Means and Fuzzy c-Medoids algorithms. Fuzzy c-Means algorithm produces clusters of worst quality as compared with the other two methods in terms of FS Index. Results of Fuzzy c-Medoids algorithms are better than Fuzzy c-Means but inferior to that of Fuzzy c-Least Median of Squares methods. Figure 5(c) provides values of Zahid Separation Compaction (SC) Index computed using Eq. (27) as a function of number of clusters. A higher value this index represents better fuzzy cluster quality. Figure clearly indicates that quality of the fuzzy clusters formed using Fuzzy c-Least Median of Squares algorithm is better than those using Fuzzy c-Means and Fuzzy c-Medoids algorithms. Fuzzy c-Means algorithm produces clusters of worst quality as compared with the other two methods in terms of SC Index. Results of Fuzzy c-Medoids algorithms are better than Fuzzy c-Means but inferior to that of Fuzzy c-Least Median of Squares methods. Figure 5(d) shows the Fuzzy Error Index scores computed using Eq. (30) as a function of number of clusters. A smaller value of this index represents less fuzzy clustering error and better quality of the clusters. Figure clearly indicates that quality of the fuzzy clusters formed using Fuzzy c-Least Median of Squares algorithm is better than those using Fuzzy c-Means and Fuzzy c-Medoids algorithms. Fuzzy c-Means algorithm produces clusters of worst quality as compared with the other two methods in terms of Error Index. Results of Fuzzy c-Medoids algorithms are better than Fuzzy c-Means but inferior to that of Fuzzy c-Least Median of Squares methods.
Figure 6 provides various validity index values for Google user session clusters discovered by applying Fuzzy c-Means, Fuzzy c-Medoids and Fuzzy c-Least Median of Squares with linear fuzzy weights assigned to the user sessions. Figures 6(a)–(d) show clearly (for the same reasons given for Fig. 5) that the quality of the fuzzy clusters formed using Fuzzy c-Least Median of Squares algorithm is better than those using Fuzzy c-Means and Fuzzy c-Medoids algorithms. Fuzzy c-Means algorithm produces clusters of worst quality as compared with the other two methods in terms of Error Index. Results of Fuzzy c-Medoids algorithms are better than Fuzzy c-Means but inferior to that of Fuzzy c-Least Median of Squares methods.
Execution time for fuzzy clustering of google user sessions
Execution time of fuzzy clustering the google user sessions with no weights.
Execution time of fuzzy clustering the Google user sessions with fuzzy linear weights.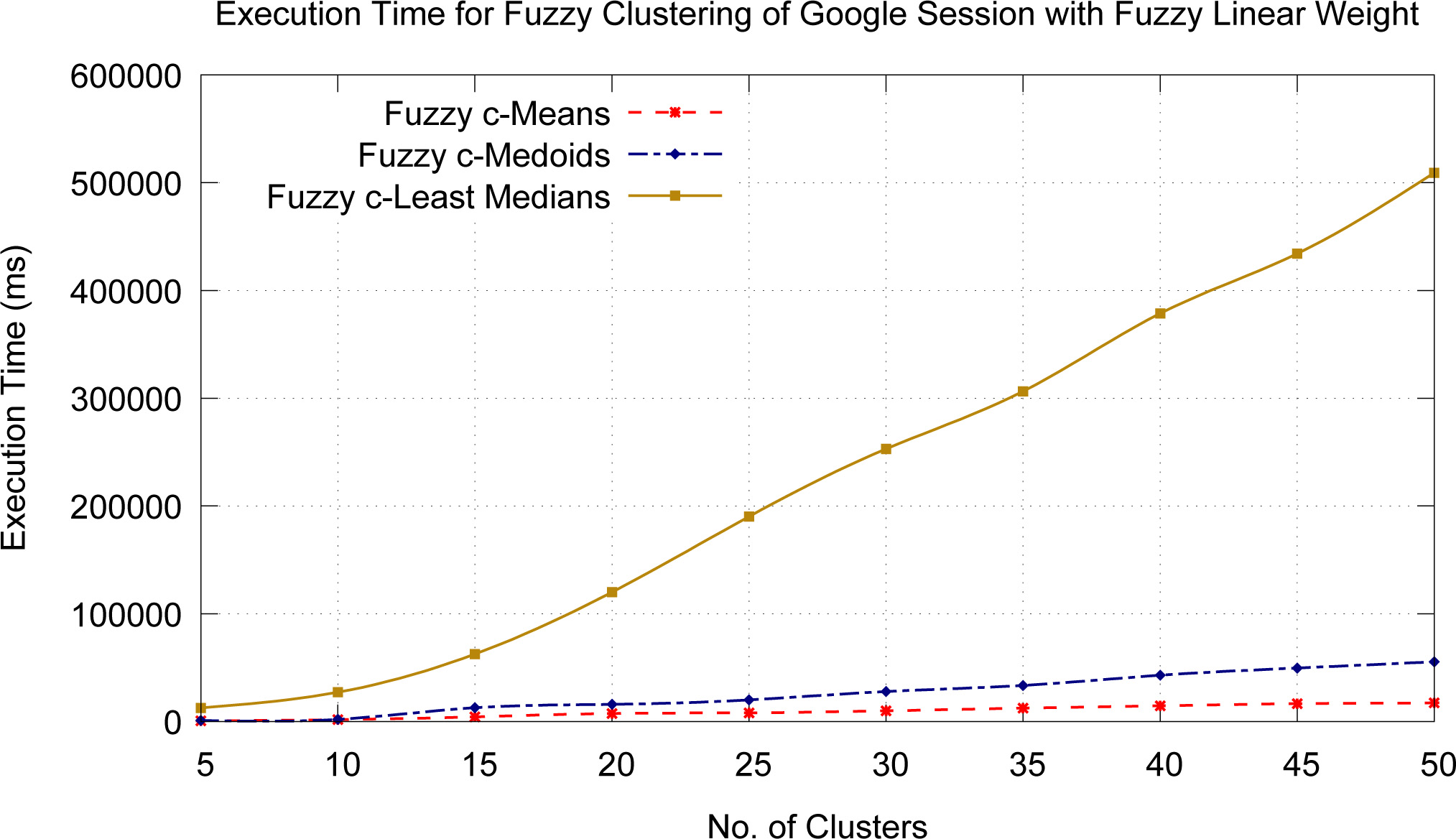
Execution time of fuzzy clustering the Google user sessions with and without fuzzy weights.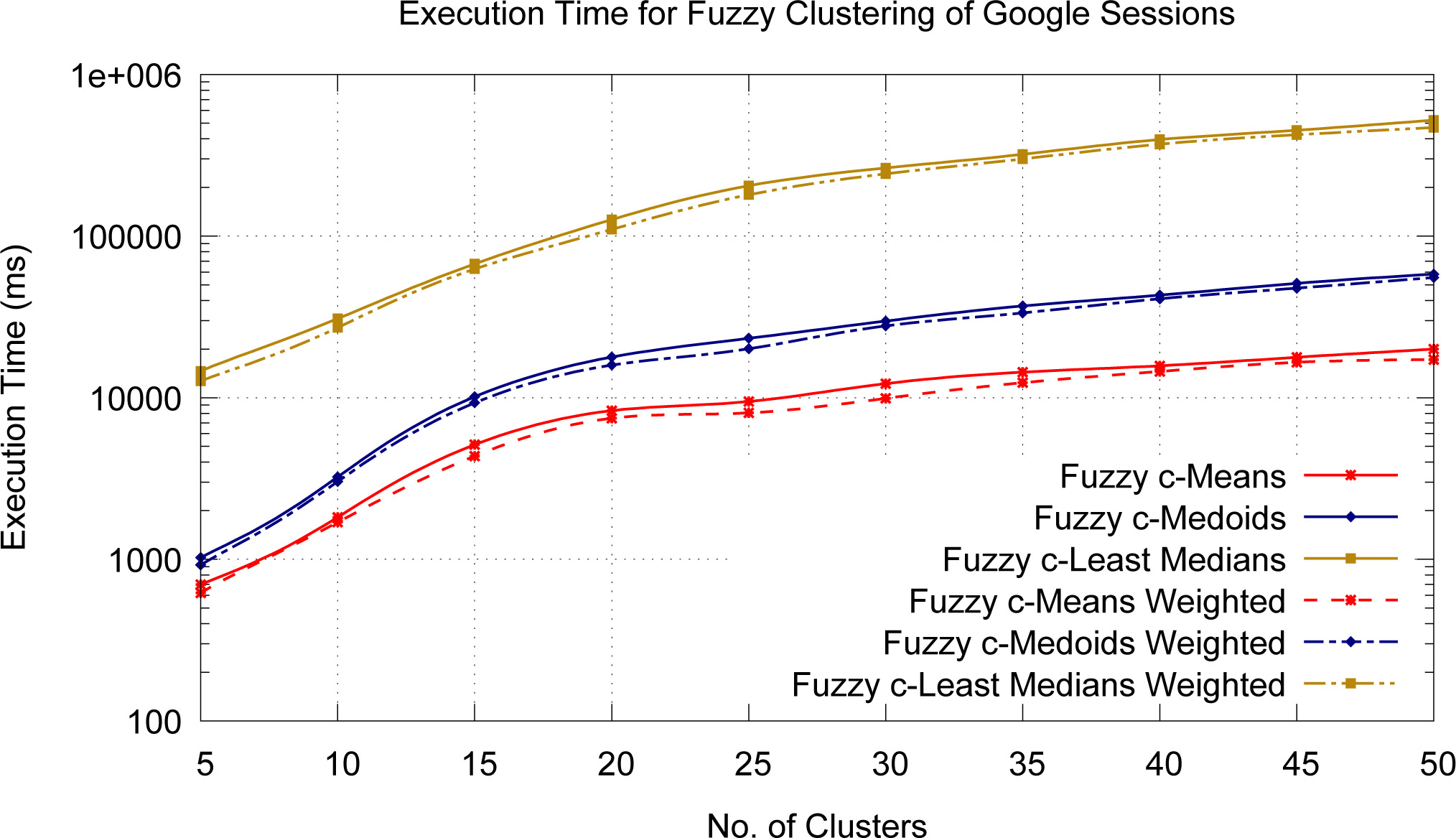
Table 5 provides execution timings in milliseconds for Fuzzy c-Means, Fuzzy c-Medoids and Fuzzy c-Least Median of Squares clustering of Google user sessions without and with linear fuzzy weights.
Figures 7 and 8 depict the graphs of execution time versus the number of clusters for Fuzzy c-Means, Fuzzy c-Medoids and Fuzzy c-Least Median of Squares clustering of Google user sessions without any weights and with fuzzy weights respectively. From these figures it is very clear that execution time required for Fuzzy c-Least Medians of squares clustering is much higher than the other two algorithms. Fuzzy c-Means algorithm show least execution time and Fuzzy c-Medoids algorithm requires higher than Fuzzy c-Means.
Figure 9 depicts the graph of Execution Time versus the number of clusters for Fuzzy c-Means, Fuzzy c-Medoids and Fuzzy c-Least Median of Squares clustering of Google user sessions with and without linear Fuzzy weights. From the figure it is very clear that execution time required for Fuzzy clustering of Google user sessions with linear Fuzzy weights is less than that of non-weighted user sessions for all the three fuzzy algorithms is much higher than the other two algorithms. Fuzzy c-Means algorithm show least execution time and Fuzzy c-Medoids clustering algorithms.
In this study to discover overlapping user session clusters from the noise contaminated user session data, Fuzzy set based clustering algorithms including Fuzzy c-Means, Fuzzy c-Medoids adapted and Fuzzy c-Least Median of Squares algorithm is proposed, implemented and tested. All these algorithms make use of fuzzy membership function to efficiently handle the overlapping clusters. The contribution of this work in the discovery of web usage clusters is multifold, namely:
A fuzzy set theoretic approach for assigning fuzzy weights to the user sessions and associated URLs is proposed to deal with the high dimensional user session data mixed with noise and outliers in the form of insignificant sessions and URLs. Fuzzy weight assignment is performed using linear fuzzy and standard S membership functions. This approach is tested extensively using various Crisp, Fuzzy, Neural, Rough and Genetic clustering techniques. For web usage pattern discovery, FCM and FCMdd based clustering techniques are explored. In order to rectify the problems due to noise sensitivity of FCM and FCMdd methods, we propose a robust Fuzzy c-Least Medians (FCLMdn) clustering framework to deal with the user session data contaminated with noise and outlier user session objects, with the objective of improving the quality of the extracted patterns.
Following conclusions can be drawn from the experimental results presented above.
The fuzzy weight assignments to user sessions and URL items have been found to improve the fuzzy clustering performance and quality in terms of Xie Beni Index, Fukuyama Sugeno Index, Zahid SC Index and Error Index. It is also observed that linear fuzzy weight assignment results in better fuzzy cluster formation as compared with standard S weight assignment. Weight assignment also resulted in dimensionality reduction of the user session data and trimmed down the execution time requirements of various Fuzzy Clustering algorithms. From the experimental results it is observed that user session clustering using Fuzzy c-Least Median of Squares algorithms provide better fuzzy clustering performance as compared with Fuzzy c-Means and Fuzzy c-Medoids algorithms in terms of Xie Beni Index, Fukuyama Sugeno Index, Zahid SC Index and Error Index, for user sessions with or without weight assignments. Fuzzy cluster quality of Fuzzy c-Medoids algorithm is better than that of Fuzzy c-Means algorithm. However execution timing requirement of Fuzzy c-Least Median of Squares algorithms is much higher than the other two algorithms. Fuzzy c-Medoids algorithm requires longer execution time as compared with Fuzzy c-Means algorithm and lesser than Fuzzy c-Least Medians algorithm. Thus Fuzzy c-Least Medians algorithm provides high quality fuzzy clusters at the cost of execution time.