
Abstract
In this paper, a new data-driven method for short-range forecasting of spatio-temporal systems is proposed. It uses NCEP data as raw data to construct forecasting model. The global model consists of several local models. Each local model is constructed in three steps. In the first step, a local dataset is constructed based on NCEP raw data. This dataset is a very high-dimensional data with huge number of redundant and irrelevant features. In the second step, a feature selection method named GRASP is applied on the local dataset and produces a new local dataset whose features are reduced significantly. In the third step, a regression ensemble method called Bagging is used to construct a local model. Both GRASP and Bagging methods are scalable modules with respect to the computational power needed. The proposed method makes it possible to control the trade-off between speed and precision. In addition to the scalability, the proposed method, in some points produces forecasts more precise than the GFS system.
Keywords
Introduction
Weather and climate forecasting are two applications of spatio-temporal modeling that have been the focus of much research in recent decades. Meteorological models have proved sufficiently accurate to be used in saving lives from disasters, as well as in strategic planning and management in agriculture. Nowadays, numerical models are the centerpiece of weather forecasting. However, in some aspects they have limitations that make it imperative to devise and examine alternative approaches. The two main limitations of numerical models are the dependency on domain knowledge of real system and low extendibility. Numerical models are completely dependent on the knowledge that describes the target system usually by differential equations. Extension of the numerical models is a difficult task since it requires a deep knowledge of the system. In this paper, a flexible and scalable method is proposed that can be used to model a wide range of spatio-temporal systems. Further, experiments are designed to prove the efficiency of the method in application to weather data, though there is no assertion on its generalization. This paper is focused on modeling of a spatio-temporal, complex and very high dimensional nonlinear system, i.e., the weather system. In weather forecasting, it is necessary to model the physics of the atmosphere. Constructing a perfect model for the complex system is too idealistic, so the main objective of all research in the field of weather forecasting is to construct useful and applicable models. Currently, irrespective of their deficiencies, the numerical models are certainly useful for the real-world applications.
Many real-world applications involve parameters that vary over space and time. In recent years, much research has been carried out on the study, analysis and forecast of spatio-temporal systems. Nowadays, spatio-temporal data are available in many areas, e.g. wind speeds and directions [42], rainfall [16, 49, 52], flood [29, 47], cloud-aerosol interaction [8], risk of agricultural crop disease [4], house prices [14, 28, 38], air pollution [19, 40, 46], brain imaging [1, 3, 13], wildlife population monitoring and tracking [33, 37], and machine vision [11, 24]. Spatio-temporal data analysis is aimed at predicting the system state in different locations at a time in the future. For spatio-temporal systems, the observed data consist of a large number of variables that vary over time and space. Recording the observed data may lead to a very large dataset. In spatio-temporal modeling, machine learning is used for the following three purposes:
Pre-processing of the data, e.g., dimension reduction, data interpolation and noise reduction; Extraction of the spatio-temporal system dynamics and its modeling; Estimation of the spatio-temporal system parameter values.
There are two main approaches in modeling spatio-temporal environmental phenomena such as those involved in hydrology and meteorology: 1-data-driven modeling, and 2-knowledge-driven modeling or physically-based modeling. In physically-based modeling, the real system or process is described by mathematical equations [7, 32, 35, 36, 41]. In fact, these equations are derived from the domain knowledge acquired from the natural phenomena. Physically-based modeling can also be divided into two categories: mathematical and numerical modeling. In case of mathematical modeling, mathematical equations are used to directly forecast the next state. Mathematical description occasionally consists of some partial differential equations that are analytically intractable. In this case, numerical techniques are used to approximate the future state.
Physically-based models can be constructed only if there is enough knowledge available about the natural phenomena. Here, modeling of the natural process or system is possible only if the history of main variables is available, and if the data can present the input-output relationships associated with the process or system. In such cases, the data-driven modeling (DDM) can be used to both model the process and forecast its future state [1, 2, 15, 22, 25, 27]. Recorded history of spatio-temporal systems may become a very large dataset describing several parameters that are extended in time and space. Appropriate modeling tools are needed to handle error, uncertainty, high volume of data, and achieve high degree of accuracy in spatio-temporal systems. Such tools are used for two main purposes: accurate forecast of the state of the system and interpolation of parameter values over the spatial region of interest. These tools should be able to work with large and complex datasets.
Big Data (BD) refers to high volume of data beyond the processing capabilities of usual computers. It is a term used to refer to a collection of large and complex data that is difficult to process using traditional methods and tools. Gartner Inc. [23] defines this term as:
“Big Data, is defined by three V’s as high volume, velocity, and variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making.”
Variety refers to combination of different types of simple or complex, structured or unstructured data, e.g., transaction-level, user interaction, video, audio and text data. Facebook’s data is a good example for BD with very high degree of variety. Velocity is an indication of how quickly data can be available for the analysis. In a dynamic system, model should be updated once a significant change occurs in the system. Ignoring parts of the data carelessly, may lead to unacceptable or poor solutions. Larger data provides better analysis and better analysis results in higher confidence in decision making, more profit and less cost and risk. According to these definitions, weather data can be assumed to be BD. Weather data is a kind of BD because of its huge volume, increasing growth and variety of its parameters and spatial scattering. Each day, a huge number of weather and climate parameters in numerous locations are recorded and stored [4, 45, 57]. Volume of these data is huge, and their variety and generation velocity are high.
Clouds, precipitation, atmospheric gasses such as water vapor and the earth and the ocean surfaces are considered meteorological objects. Using absorbed, scattered or emitted electromagnetic radiation, remote sensing techniques are used to collect information from the meteorological objects. The first civilian application of remote sensing satellite technology, a weather satellite named TIROS-1 (Television and Infrared Observation Satellite – 1), was used to monitor and forecast weather conditions. High spatial and temporal resolution of the remotely-sensed imageries makes them a better alternative to the data obtained from synoptic stations. They can provide information about the Earth’s surface, different layers of atmosphere, and oceans. This information includes atmospheric moisture, humidity, cloud cover, snow and ice cover, sea temperatures, surface radiation, fog intensity, precipitation quantity and other meteorological parameters. This information can be utilized in Numerical Weather Prediction (NWP) models for weather forecasting. NWP models are fed with assimilated version of the aforementioned information. NWP models use data assimilation to estimate initial conditions by (i) reducing observation error due to using related and redundant observations and (ii) interpolating parameters in uncovered areas to produce uniformly distributed observations.
According to the definitions provided by the World Meteorological Organization (WMO) [55], forecasting is performed within seven different time ranges. These time ranges are presented in Table 1.
WMO standard forecasting ranges [55]
WMO standard forecasting ranges [55]
The reported work is focused on design and development of a scalable framework for very short range weather forecasting. In this paper, scalability of a method means that it is capable of controlling the computational power required to execute the model. The proposed method can construct more accurate models at the expense of more computational power. This framework is not limited to a specific system and can be used to forecast a wide range of spatio-temporal systems. This feature is due to some novelties in the proposed framework. First, it constructs a local model for each data point. Therefore, the number of parameters, the density of parameters in local neighborhoods and the variety of dynamics in different parts of the system cannot hinder the framework from forecasting the overall state of the system. Second, using scalable modules make the proposed method computationally scalable.
Section 2 describes some related works in data-driven weather forecasting. Sections 3 and 4 are brief reviews on feature selection in high-dimensional data and regression ensemble. The proposed method is introduced in Section 5. Section 6 presents the implementation results of the proposed method and their analysis. Finally, Section 7 contains concluding remarks.
Recent advances in physically-based weather forecast models together with precise parameter measurements and higher resolutions in both temporal and spatial domains have led to ever-increasing improvements in weather forecasts. These advances make physically-based models applicable to real-world forecasting problems. In the past decade, European Centre for Medium-Range Weather Forecasts (ECMWF) [7, 41, 51, 54] and the National Centers for Environmental Predictions (NCEP) [12, 31, 48] have provided numerical weather forecasting systems which are used throughout the word.
Without directly taking into account the underlying physical knowledge about the target system, data driven models rely solely on previous recorded history of the system. However, inaccuracy in data-driven modeling is inevitable. This inaccuracy is due to the simplification assumptions, insufficient training data, lack of model variables and model selection and configuration details. Most data-driven models are constructed using machine learning methods. In the reported works, data-driven modeling is used for two reasons.
The first reason is due to the fact that some existing spatio-temporal systems already have physically-based models but these models are not accurate or they are sometimes overly expensive. In these cases, data-driven models are used as an alternative for increasing accuracy or reducing cost. Fernando et al. [19] proposed a stochastic method for air quality prediction based on Neural Networks (NN) as an alternative for the commonly used deterministic photochemical air quality models. Their results show better performance for the NN in speed and cost without compromising the accuracy of predictions. Filippo et al. [21] used NN to predict sea level. One of the main challenges in their work was to handle gaps in the data where physically-based models are not capable of handling them. They used Fast Fourier Transform (FFT) to reconstruct the data. Their results are less accurate but comparable to results of an alternative method.
The second reason for using data-driven models is lack of enough knowledge about the dynamics of the system to construct such physically-based models. In these cases, a deep knowledge of the target system is lacking. However, there is sufficient data available to model the system by data-driven approach. Chang and Chien [9] used NN with multi-trend transfer function to forecast typhoon wave height near Taiwan. They used seven different variables in seven time lags, i.e.,
Feature selection in high dimensional data
Nowadays, many machine learning and pattern recognition problems deal with huge datasets. Hugeness of datasets implies using methods with lower time and space complexities. Dimension reduction is an option for reducing space complexity. Dimension reduction is the process of converting a dataset to a new one with lower dimensionality. Feature selection is a kind of dimension reduction that preserves the meaning of the features during the reduction process. Feature selection makes machine learning tasks faster, more understandable and sometimes even more accurate. In high-dimensional datasets, drawbacks of redundant and irrelevant features become even more critical. Judd [30] investigated modeling and forecasting of complex high dimensional nonlinear processes. The aim of Judd’s paper is to develop a scalable method that is capable of dealing with a very high-dimensional dataset of the kind encountered in weather forecasting. It uses a feature selection method that is based on an optimization method named Greedy Randomized Adaptive Search Procedure (GRASP). GRASP is a two-phase general optimization search algorithm introduced by Feo and Resende [17]. Extensions of this algorithm and its applications can be found in several subsequent works [18, 20, 39, 43]. Bermejo et al. [5] introduced a new algorithm for feature selection in high-dimensional data based on the GRASP meta-heuristic algorithm. This algorithm is depicted in Fig. 1.
Pseudo code for feature selection based on GRASP meta-heuristic search algorithm [5].
GRASP has two phases that execute iteratively: Phase 1-construction phase that starts with an empty set and enlarges set by randomly selecting items and, Phase 2-improvement phase that improves the output of construction phase using a local search algorithm. At the end of each iteration, both the constructed and the improved solutions are added to non-dominated solutions. A solution is called a dominated solution if there is at least one better solution with respect to accuracy and size of feature subsets.
Instead of a single learner, ensemble methods use multiple learners to produce a more accurate and complex learner [44]. The central idea behind the ensemble approach is to control the well-known trade-off between accuracy and complexity. Given a diverse set of learners, there is always a form of aggregation where an ensemble of learners may lead to a more accurate but more complex learner than each learner individually. Combining regressors, a more accurate ensemble is constructed at the expense of increased complexity. Ensemble methods are good options for using as an adjustable component to develop scalable frameworks. Using this component, Bagging is a simple but efficient solution to the problem of “how to build regressors for an ensemble” [6]. Bagging performs sampling with replacement to produce different subsets from the dataset. In Bagging, regressors are trained using the aforementioned subsets. There are a number of works reported on extension and improvement of this algorithm [10, 26, 34, 56].
The proposed method
The proposed framework has several characteristics that, when considered together, make it different from other spatio-temporal modeling frameworks:
It is scalable. In the proposed method, forecasting time can be reduced by compromising precision. Alternatively, precision can be improved at the expense of losing speed in forecasting. Unlike NWP models, there is no need for a spatially homogeneous data. All NWP models need assimilated and gridded data. In the other words, NWP models have some spatial assumptions about the data but the proposed framework makes no such prior assumptions about the data. In the proposed method, data can be spatially heterogeneous. In the NWP models data should be homogenous in term of the number of parameters in each cell. In the proposed method, each data point may have different number of parameters from the other points. It can handle high dimensionality of some spatio-temporal systems that have large number of state parameters. The proposed framework can be used to model any spatio-temporal system that is logged within a sufficiently longtime range. In other words, the only prerequisite for constructing model in the proposed framework is existence of rich history of system states.
Constructing scalable frameworks, it is necessary to control the well-known trade-off between precision and speed. Scalability provides a controllable trade-off between accuracy and speed. The main idea of this research is to use modules with adjustable control variables, i.e. feature selection and regression ensemble, for controlling this trade-off. Adjusting the modules is carried-out using two main scalability parameters in the proposed model: the number of features and the number of estimators. These parameters directly affect speed and precision of the model. Generally, increasing the number of features may lead to more precision at the expense of consuming more time. GRASP-based feature selection is a good option for selecting features since it is a multi-solution algorithm. As mentioned in Section 3, the output of GRASP-based algorithm is a set of feature subsets called Non-Dominated Solutions (NDS). These subsets may be different with respect to the number of features and resulting precision. Some definitions used in the proposed method are given in Table 2.
Some definitions used in the proposed method
An example of local neighborhood with distance 2.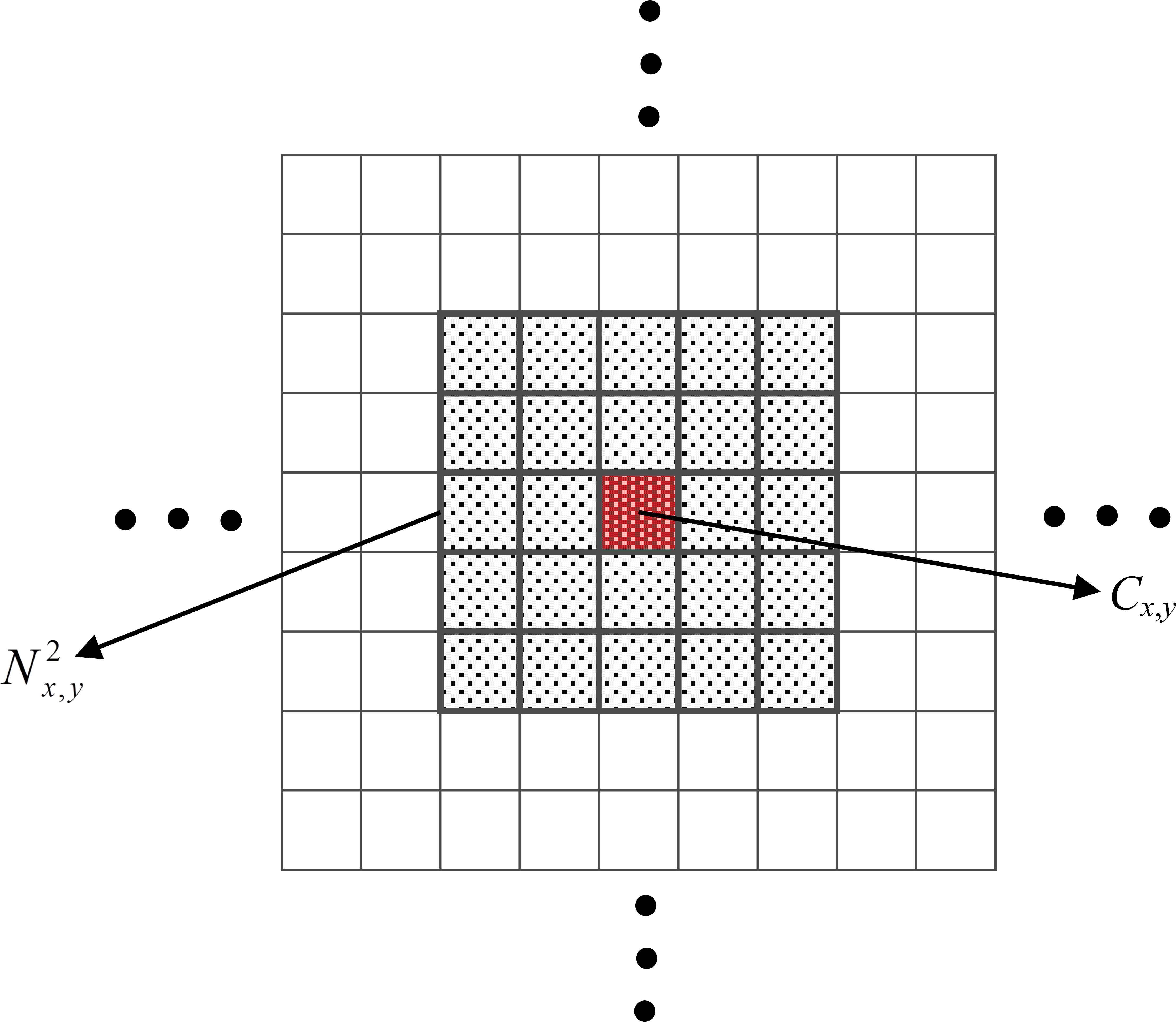
Weather forecasting is the same as predicting the next state of the atmosphere. Predicting the next state of the atmosphere requires determining the values of each parameter within each cell. To forecast the state of the whole atmosphere, a global model can be developed consisting of several local models. Each local model can be a black-box module predicting a target parameter for the next time step. This module maps values of all participating parameters in the neighborhood of the target cell to the value of the target parameter. The main focus of this paper is on developing a general framework for constructing these local models using machine learning and data mining techniques. More precisely, in the reported work each regressor represents a local model. Figure 3 shows the process of constructing the global model.
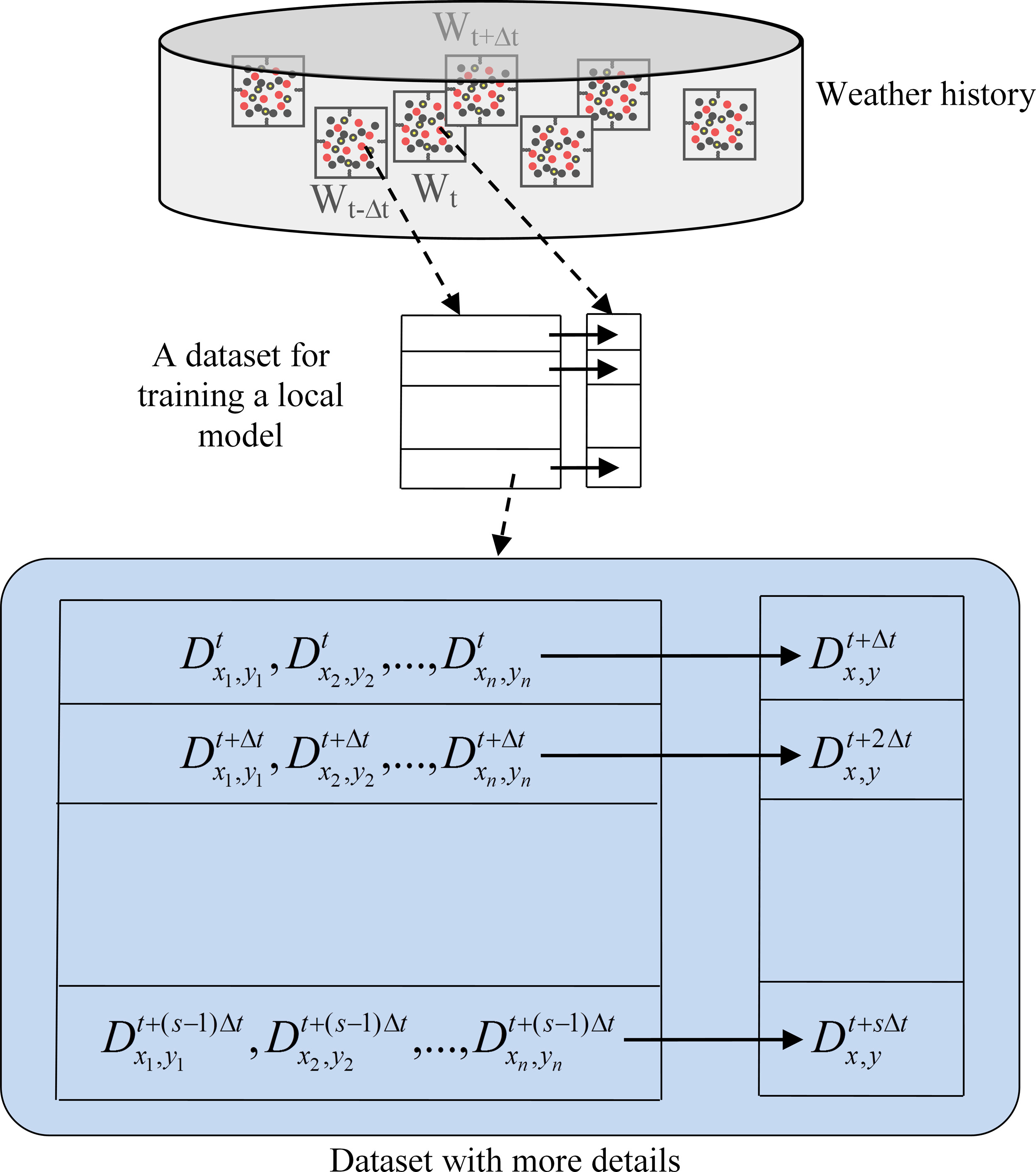
Once the region of interest is determined, a local model can be constructed for each parameter within the region. The role of each local model is to forecast its corresponding parameters for the next step. For each parameter in
Constructing a local dataset: A dataset should be constructed for each parameter. If the target parameter is within Applying the GRASP: Output from the previous step is a dataset with a very large number of features where the majority of them are redundant or irrelevant. Applying a feature selection algorithm to the dataset is necessary. GRASP is the proposed method for this process that converts the original the local dataset to a reduced local dataset. Constructing local model: In this step, using the reduced local dataset, a local model is constructed. A regression ensemble module that implements Bagging algorithm is used to construct the local model.
The process of constructing global model.
From a more practical point of view, there is large number of parameters that should be estimated. To estimate each parameter, all the aforementioned steps that are executed as demonstrated in the large rectangle depicted in Fig. 3. Initially, a local dataset is constructed from FNL files that includes two tables named
Executing the model, each local model is loaded and used to forecast a single parameter. All the forecasted parameters are used to form the next state of the atmosphere.
National Centers for Environmental Prediction (NCEP) continuously produces several gridded datasets describing state of the atmosphere [50]. In this section, two types of NCEP files are described that are used in the reported work as the raw input data. These types are (FiNal Analysis) FNL files and Global Forecast System (GFS) forecasts.
FNL data description
NCEP FNL files are generated every 6 hours on both 0.5
More precisely, each 1
Common parameters within all FNL files
Common parameters within all FNL files
In this research, the 1
Overall structure of a FNL files.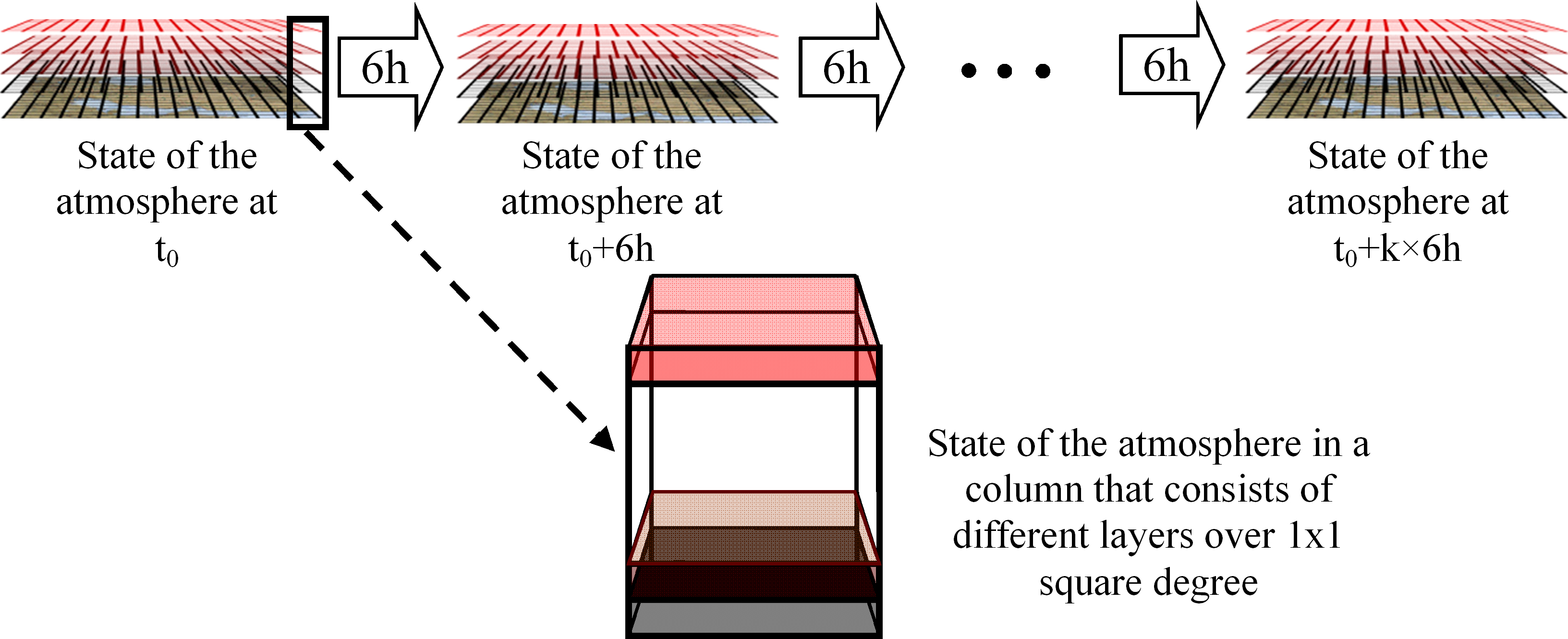
GFS is a Numerical Weather Prediction (NWP) model that consists of several components, i.e. an atmosphere model, an ocean model, a land model and a sea ice model. GFS is an evolving model due to improvements in hardware, data, algorithms and the underlying partial deferential equations solved numerically in the model.
This model runs every 6 hours and produces forecasts for more than 10 days. GFS uses FNL files for initialization and forecasting. In this paper, the term “GFS Data” refers to the output files produced by the GFS system.
The derived data
Forecasting weather means predicting the next state of the atmosphere. Predicting the next state of the atmosphere requires determining the values of each parameter within each cell. In the reported work, to forecast the whole state of atmosphere, a global model is developed that consists of several local models. Each local model can be a black box module predicting a target parameter in the next time-step. This module maps values of all participating parameters in a neighborhood of the target parameter to the value of the target parameter.
As mentioned before, each FNL file describes the whole state of the atmosphere by a 181
Eight neighbors of a cell. Generic local dataset with more details.
Each dataset consists of records, each mapping a set of parameters in a neighborhood of the target cell onto a parameter within the target cell. Let
Construction of the dataset can be started only when r has been determined.
This paper is aimed at developing a general framework to construct these local models using machine learning and data mining techniques. More precisely, each regressor represents a local model. Training this regressor requires a dataset containing records in ordered pairs such as
Determining what parameters in which neighborhood affect the target parameter is based on dynamical and/or thermodynamics considerations. In order to tune the
Some of the most important parameters of regression tree in the reported experiments
Error map of the GFS system for the surface temperature field. In all pictures, i.e. the planar map and both spheres, pixels with hot colors are related to high error cells and those with cold colors are related to low error cells. Note that the sphere on the left side shows American continent and the one on the right shows asian continent.
In this section, three experiments are reported. The first experiment is a 6-hour forecast using the proposed method and results are compared against the results produced using the GFS. The second experiment is devoted to study the optimum value for the
Experiment 1: Comparing proposed method results against GFS
In this section, results produced by the proposed method are compared against the outputs of the GFS system for 6-hour forecasting. GFS system uses FNL files as input and produces forecasts as output files that have structures similar to FNL files. To compare results produced by the proposed method and the GFS system, first step is to extract their error maps for the surface temperature field. The error map of the GFS system is depicted in Fig. 7. Each point on the map shows the error of a cell within specific latitude and longitude. Hot pixels correspond to those points with high average errors and dark pixels correspond to points with low average error. For the temperature field, the minimum average error of GFS over all points is 0.02 in degrees Celsius and the maximum average error is 1.74 in degrees Celsius. In the reported work, only GFS error map is constructed. This was due to the fact that its forecasts and their corresponding ground truths were available. However, since construction of the complete global model was very time consuming, the proposed model was constructed for only the selected cells.
Comparing the proposed method against the GFS system
Comparing the proposed method against the GFS system
Table 5 compares results produced by the proposed method against the outputs from the GFS system. Training local models is a time consuming task. Therefore, points with diverse GFS errors are selected for the comparison. Columns 2 and 3 of this table show latitude and longitude of the selected points with the error of GFS presented in Column 4. Column 5 shows the number of features selected by GRASP algorithm that is used as the feature selection module in the proposed method. Column 6 shows the error of the proposed method when a single regressor is used. Columns 7 to 9 show the error of the proposed method when ensembles with sizes of 10, 50 and 100 are used. Column 10 shows the distribution of the selected features in the neighborhood of the selected points. The value of
As seen in this table, in most points the error of the GFS is significantly lower than the proposed method (7 cells from all 9 cells). But in one cell with latitude of 28 and longitude of 50 the average error of the proposed method is lower than that of the GFS (see the row with run number 6), and in another one with latitude 26 and longitude 56 errors of the both methods are very close. At the first glance, it seems that the achievements of the proposed method are modestly less accurate compared to the GFS. However, there are several reasons for the usefulness and innovation of the proposed method. First, GFS is a mature system in the class of numerical weather prediction (NWP) systems, whereas the proposed method is an innovative, pioneering work in the category of data-driven methods and there is certainly room for improvement. Second, the quite different nature of the proposed method from NWP models makes it possible to combine it with systems like GFS in order to improve the results of NWP in short range forecasting at least in certain places. Third, the computation power needed in either of the NWP models is significantly larger than the proposed model.
Finding the optimum value for
Comparing the results for different values of
parameter
Comparing the results for different values of
As seen in Table 6, increasing the value of
Scalability is one of the most important features of the proposed method. In this experiment, the scalability of the proposed method is evaluated. Scalable modules of the proposed methods are GRASP and regression ensemble modules. Therefore, the scalable ability of these modules is studied separately in this section.
Regression ensemble module in the proposed method uses the Bagging algorithm. Size of ensemble is the controlling parameter of this module. By changing this parameter, one can control the trade-off between computation time and precision. Figure 8 shows the effect of mean absolute error of the ensemble against the size of the ensemble for two cells introduced in Section 5.2. As depicted in Fig. 8, for both cells the error of the Bagging decreases smoothly once ensemble size is increased.
There are two main important points in Fig. 8. First, the curves of error against ensemble size for both cells are smooth and predictable. Thus, it is possible to find suitable ensemble size to achieve a specific error. Second, Fig. 8 shows that there is no need to employ a large number of regressors in the ensemble. Error of the ensemble is almost constant for all ensemble sizes larger than 20. The second module, i.e. the feature selection, provides some degree of scalability but its effect is less than the regression ensemble module. Feature selection module works according to the GRASP algorithm which is a multi-solution method. GRASP always produces several feature subsets with different size and precision. Table 7 shows some details on the results of GRASP algorithm for two cells.
| Subset | First cell | Second cell | ||
| number | Number of | Error | Number of | Error |
| selected | selected | |||
| features | features | |||
| 1 | 8 | 0.85 | 23 | 1.03 |
| 2 | 7 | 0.96 | 21 | 1.04 |
| 3 | 1 | 0.97 | 16 | 1.09 |
| 4 | – | – | 13 | 1.25 |
Error of the proposed method versus different ensemble sizes.
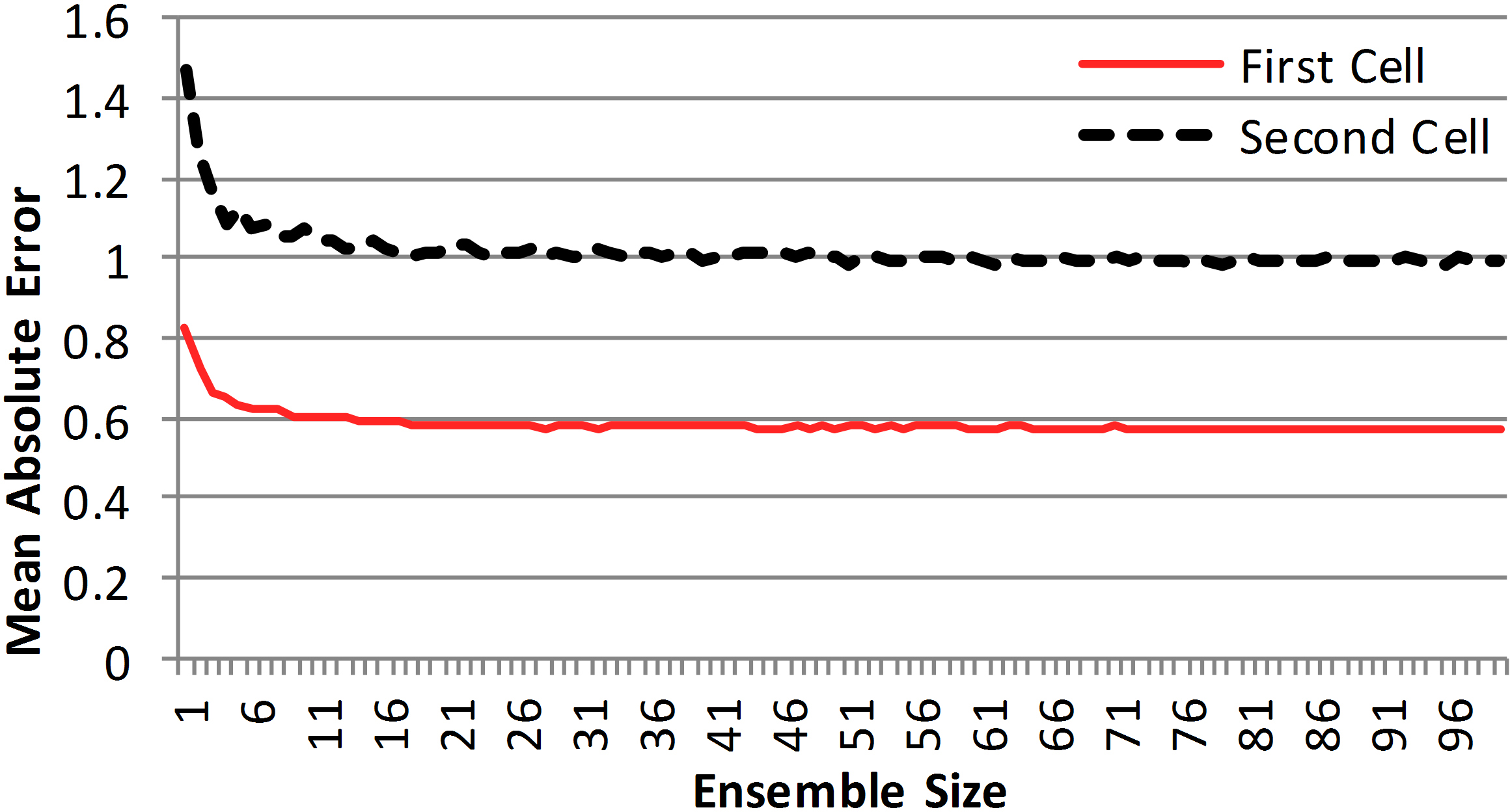
For each cell, the number of the selected features and resulting error using corresponding feature subsets are reported in Table 7. For example, the output of GRASP for the second cell includes 4 feature subsets with sizes 23, 21, 16 and 13 and error values of 1.03, 1.04, 1.09 and 1.25, respectively. GRASP can be regarded as a semi-scalable method, since it is only partially controllable.
The scalability of the proposed method is best illustrated in results depicted in Figs 9 and 10. In Fig. 9, the forecast error of the proposed method is plotted against the ensemble size and the number of features (control parameters of regression ensemble and feature selection modules).
Error of the proposed method plotted against different ensemble sizes and the number of features.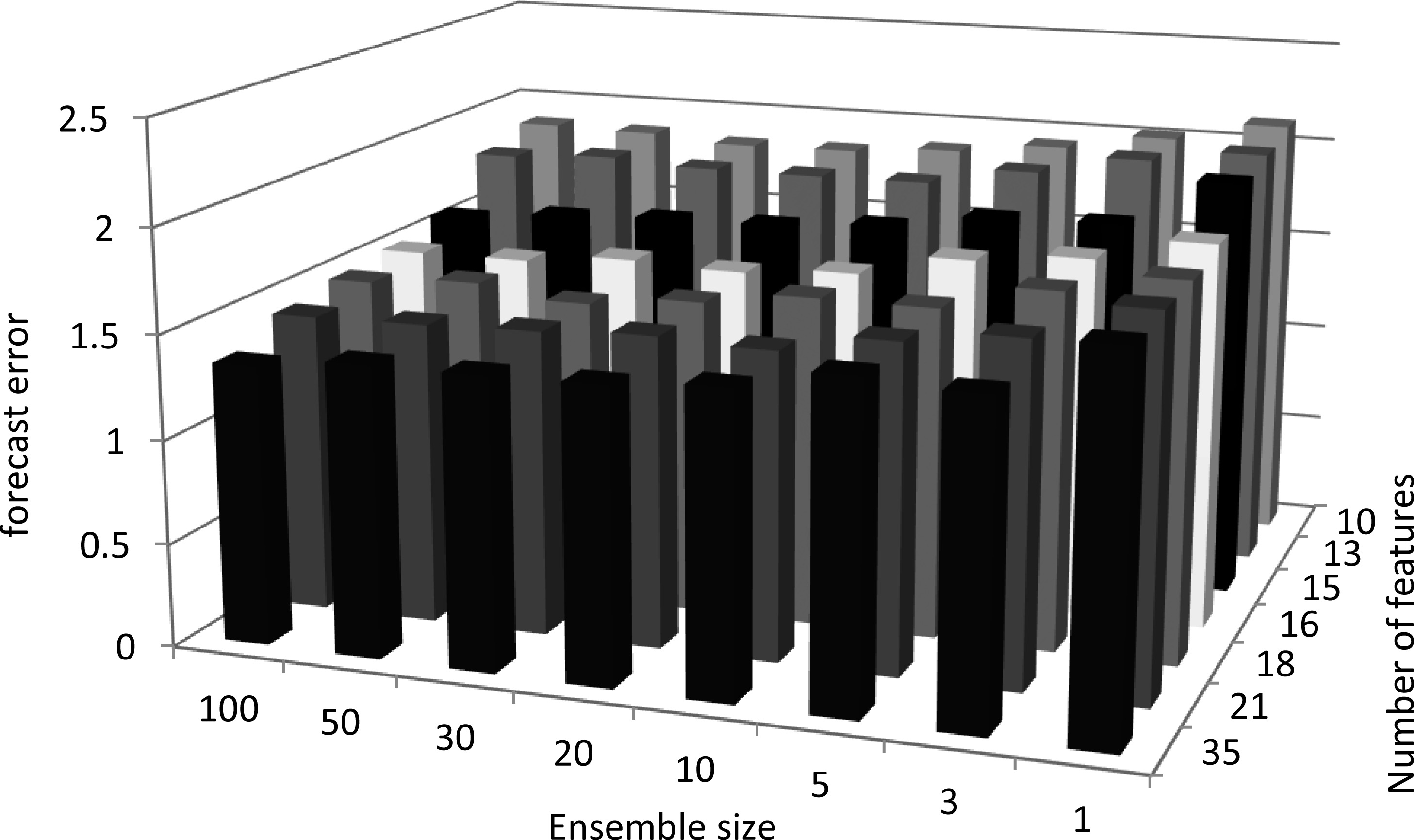
Further, In Fig. 10 the execution time of the proposed method for a period of one year is plotted against the ensemble size and the number of features.
The execution time of the proposed forecast model for a period of one year is plotted against different ensemble sizes and the number of features.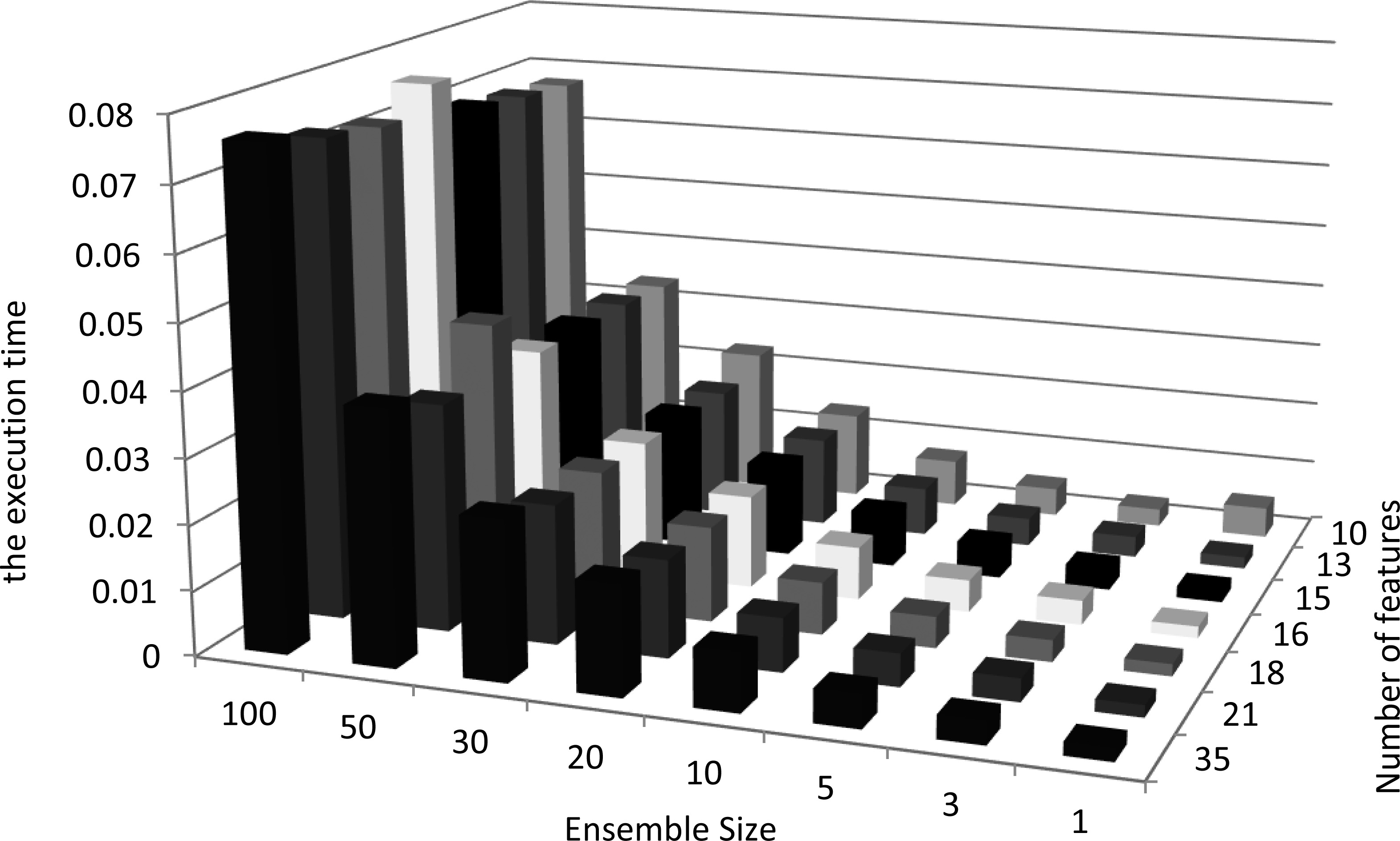
Figure 10 reports the time span for 1460 executions of the proposed model for a period of one year within 6 hours step i.e., 365
Scalability and flexibility are two main privileges of the proposed method. The trade-off between speed and precision is selective and more controllable in the proposed method. The computational power needed in GFS and other NWP systems cannot be easily manipulated. The required execution power can be reduced only by reduction in spatial scale (grid resolution) and step size (time resolution). In the proposed method since each cell has its own model, it is possible to forecast different cells using different precisions. The proposed method can be applied to a wide range of application areas. It can model different spatio-temporal systems that have long and regular history. It should be noted that NWP method can model a system only if the analytical model of system is available in form of differential equations (white box approach).
In this paper, a new data-driven method for short-range forecasting of spatio-temporal systems is proposed. It constructs forecasting model based on huge set of records from the target system. The paper is focused on weather forecasting and its spatio-temporal target system is the atmosphere. In all the reported experiments two types of data files from National Centers for Environmental Prediction (NCEP) are used i.e. FNL and GFS files. These datasets are used as raw data to construct datasets for local models. Each local model is a component of the global model that is used to forecast the next state of the atmosphere. Process of constructing local models is designed in such a way that the complexity of each local model is controllable. Using two scalable modules make it possible to control the trade-off between speed and precision. The relative stability of the error resulting from application of different feature and ensemble sizes that are directly linked to the execution time of the method, are presented to prove the scalability of the proposed method. Regression ensemble module is the first module that is fully scalable. The second is feature selection module which is semi-scalable. In addition to scalability of the proposed method, in some points it can even result in more accurate forecasts than the GFS system.
From theoretical point of view, as well as in its demonstrated application in weather forecasting, the proposed method can be used for forecasting purposes in other spatio-temporal systems. A large numbers of spatio-temporal systems exist all around the world whose state can be describe using large collection of data encompassing a long period of time.
Scalable modules in the proposed method have certainly potential for improvement. Making feature selection method fully scalable is an option for improvement. Also, feature selection and regression ensemble modules are independent. Proposing a way to interact these modules may improve the proposed method. The feature selection module may produce diverse feature subsets and these feature subsets can be used for constructing ensemble members.