
Abstract
In data stream classification, selecting the classifier for the dynamic feature space and considering the concept drift is a challenging task. This paper addresses the major challenges in the data stream classification with recurring concept drift. We developed a novel classification method known as Pearson Guassian Naïve Bayes classification (PGNBC). The proposed PGNBC method is the advancement over the existing Guassian Naïve Bayes classifier (GNBC) by additionally adding the correlation among the attributes. For the data stream classification, the proposed PGNBC is frequently updated based on the concept drift. This newly developed method is experimented by comparing the results with the existing methods such as RGNBC and MReC-DFS. The metrics such as sensitivity, specificity and accuracy are used for measuring the performance. It is found that the improvement in terms of sensitivity, specificity and accuracy values are better for the proposed method, with the values of 4%, 1% and 1% respectively, which is higher for the PGNBC method than the RGNBC method for the skin data. But with the localization data, the improvement in terms of specificity and accuracy values are 6% and 2% respectively which is higher than the RGNBC.
Introduction
Data stream mining includes the patterns from the continuous data streams and uses the Informational structure extraction. A lot of works have been done in the area of data stream mining. In static environments, the data set is subjected to learning algorithm and the data stream mining fully belongs to those types of environments. Also, in this type of environments, the main area of interest is in the data which is devoted to the machine learning algorithms. Additionally, the concept of target must be learned. As a solution to the static classification problem, many types of classifiers are developed. In contrast to this, some learning algorithms are used in the dynamic environment also. Sensor networks, telecommunication, traffic management, web log analysis and monitoring [5] are some of the examples cited for the application of learning algorithms in dynamic environment. In dynamic environment of data stream mining, the classification of data is quite challenging.
Data mining is a very important tool in classification and prediction. For the identification of the set of collected data which explains the model characteristics, helping in the prediction of the unknown variables, classification can be done. Constructing a model is the important part in classification. Naïve Bayes classifier is one of the widely used classifier having a probabilistic approach with independent assumption property, which is not satisfied. To overcome and improve the performance, Bayes classification is developed in [19]. To the Naïve Bayes classifier, additional features are added for better performance and efficiency enhancement. The structure of the Naïve Bayes classifier is extended to show the dependencies among the attributes. Also, different weights are assigned to the attributes for building the Naïve Bayes classifier. The irrelevant attributes are denied using the feature selection approach.
The problem of concept drift [1, 2, 3, 4, 9, 10, 11, 12, 13] is addressed in many works. Other than the drift problem, focus should also be given to the integration of context information, recurring changes in concept and feature space evolution. Feature space evolution involves the feature sets and its importance to target concept may differ [16]. It is better to use learning models to solve the problems but these learning models are time consuming [14, 15, 17]. Relearning must be done, if the concept is new and non-recurring [6]. The novel ideas developed in [18, 19, 20, 21] shows the problem of recurrent concept change resolved without the relearning mechanism. Beyond this achievement, there arises the setting of user defined parameter issues, which tends to make it difficult to take a decision whether the new concept matches with the existing ones [21].
The key challenges in the data stream classification include the concept drift problem, and the classifier selection. The main contribution of this work is the development of novel PGNBC for data stream classification with the recurring drift concept. The contributions of this paper includes: addressing the recurrent concept of drift in data stream classification, proposing a Pearson Gaussian Naïve Bayes Classifier (PGNBC), Using PGNBC for Data Stream Classification with Recurring Concept Drift, Experimentally demonstrating the scenario of the developed model and studying the performance of the proposed method with the existing methods such as RGNBC and MReC-DFS.
This paper is organized as follows. Section 2 reviews about the works related to data stream classification and Section 3 gives the main motivation and the key challenges in the present work. Section 4 explains the construction of the proposed model which includes the modelling and the classification approaches and Section 5 details the updating of the PGNBC model with additional features, Section 6 discusses the results and Section 7 concludes the paper.
Literature review
Research works done in data stream classification are reviewed and presented in Table 1. The drift problem in the data stream classification is one of the commonly noted problems [18, 19, 20] and the researchers used the recurring concept drift for performing data stream classificatio [6, 21]. A lot of solutions are derived for solving this drift problem, but all those methods have their own drawbacks such as weight updating without the use of historical data, outlier data points and sample estimation in the arrival data. These problems are quite challenging in addition to the recurring concept drift. Based on the literature review, the recent research works can be categorized into four major categories. In the first category, Naive bayes classifier is taken for performing the data stream classification. In the second category, weighting mechanism is included to update the classifier model based on the new data. In the third category, dynamic feature space-based data stream classification is performed. In the fourth category, feature selection was used to perform the data stream classification.
Literature review
Literature review
Naive bayes classifier-based data stream classification: Zhou et al. [18] developed the Hierarchy Restricted Naïve Bayes classifier to reduce the unwanted computation of field comparison. The developed method has high performance but it generates extra false non-matching results due to misalignment. For obtaining higher classification accuracy in Naïve Bayes, the differential evolution Naïve Bayes classifier is proposed by Li et al. [19].
Weighting mechanism based data stream classification: The value weighting method is added to the Naïve Bayes method by Lee [20] to minimize the value of error function. This method reduced the error function but it is computationally expensive. To overcome the problem of equal distribution, weighted Naïve Bayes classifier is proposed by Karabatak [21]. But, it has the disadvantage of its initialization weight vector in a case of application dependent way. Brzezinski and Stefanowski [5] proposed accuracy-based weighting mechanisms which considered the periodic weighting with a drawback of difficulty in adapting weight.
Dynamic feature space model for data stream classification: Dynamic feature space-based model learning method is developed by Gomes et al. [6] for considering all the data sets without involvement of the holdout set. The novel concept-drift and concept-evolution-based ensemble classifier is developed by Masud et al. [7] for solving the problem of infinite length, concept-drift, concept-evolution, and feature-evolution. The developed method cannot differentiate the new set of data. Abdulsalam et al. [8] used the ideas of both streaming decision trees and Random Forests to record the accuracy very fastly, but it cannot work with multiple classes.
Feature selection model-based data stream classification: Wankhade et al. [26] proposed a hybrid feature selection (HFS) method that adopts both filter and wrapper models of feature subset selection. The feature selection algorithm uses Genetic Algorithm to evaluate the contribution of features to the classification task in a feature subset. Lutu [27] have conducted experiments to identify efficient computational methods for selecting relevant features for NB classification based on the sliding window method of stream mining. To overcome these problems, we have proposed a novel method called Pearson Gaussian Naïve Bayes Classifier for Data Stream Classification with Recurring Concept Drift.
Data stream classification had to be done using the recurring concept drift. For this problem, the input data stream is taken as
Where,
If the data is big, the classification of data is hard and so, depending upon the recurring data stream, the classification model can be updated. Still, data stream classification faces some challenges and it is described below:
The data stream changes with respect to time intervals and depending on the change of time, the learning model must be built dynamically with the adapting classifier. During the updating process of the developed model, it is very important to consider the multiple scanning over the original database. The multiple scanning should not be used frequently, since the storage of historic data is very hard. Since the boundary of the feature space varies, it is very necessary to consider the concept drift in the classifier model. In the classification of data stream, selecting the classifier for the dynamic feature space is a challenge which is not addressed effectively. For data stream classification, it is significant to focus on the recurring concept and context changes that occur during the dynamic change of feature space. Preservation and selection of the dynamic features in the recurring concept drift is an added challenge to be considered.
The Naïve Bayes classification algorithm with weighting mechanism is used in [6], for solving the problem of recurring concept drift during data stream classification. The embedded weighting mechanism estimates the error and accuracy values. Because of the dynamicity of data, the considered data and classes are not constant with respect to the time period. Giving importance only to the error and accuracy will produce poor performance. So, it is better to consider specificity and sensitivity that should be added to the weighting mechanism.
The data stream classification with Gaussian Naïve Bayes Classifier [24] includes-Model construction and the classification process. In model construction stage, the method estimates the parameters of a probability distribution, assuming predictors are conditionally independent given the class. During the construction of model, it is necessary to develop the information table, giving consideration to variance and mean of all attributes. More importantly, we additionally add the correlation among the attributes. The data provided is subjected to the next classification process, for calculating the posterior probability and thereby identifying the class labelling. In the classification step, the proposed method computes the posterior probability of that sample belonging to each class. The method then classifies the test data according to the largest posterior probability. Figure 1 shows the algorithmic description of the proposed PGNBC classifier.
Description of the proposed PGNBC algorithm.
Where,
The information table with mean values of the attributes is given by,
where, size of the table is
where,
where,
The information table for the correlation values of the attributes has a table with the size
where,
As we know that,
where,
The relationship between the sets of data can be determined with the correlation. The correlation function for independent data sets for performance improvement is given by,
The ratio between the covariance of the two variables to the product of their standard deviations is known as the Pearson correlation coefficient. The linear correlation among the two data sets can be estimated using
The class-conditional independence assumption greatly simplifies the training step since we can estimate the one-dimensional class-conditional density for each predictor individually. While the class-conditional independence between predictors is not true in general, research shows that this optimistic assumption works well in practice. This assumption of class-conditional independence of the predictors allows the classifier to estimate the parameters required for accurate classification while using less training data than many other classifiers. This makes it particularly effective for data sets containing many predictors.
where,
On the whole, the conditional probability can be calculated using the below equation.
where,
The next process includes the updating of the developed PGNBC model with the input data. The updating process is about to detect the Change of concept Drift (COD) by rough set theory [25], updating of Gaussian Naïve bayes classifier (GNBC) model and updating important features. Figure 2 illustrates the constructed PGNBC model. At different time intervals, the dynamic feature model is build with different features. The information table is created with the input data. The rough set theory is exploited for the concept drift problem. The important features are updated and the classification is performed. Figure 3 shows the algorithmic description of the data stream classification.
Block diagram of the proposed Pearson Gaussian Naïve Bayes Classifier for data stream classification with recurring concept drift.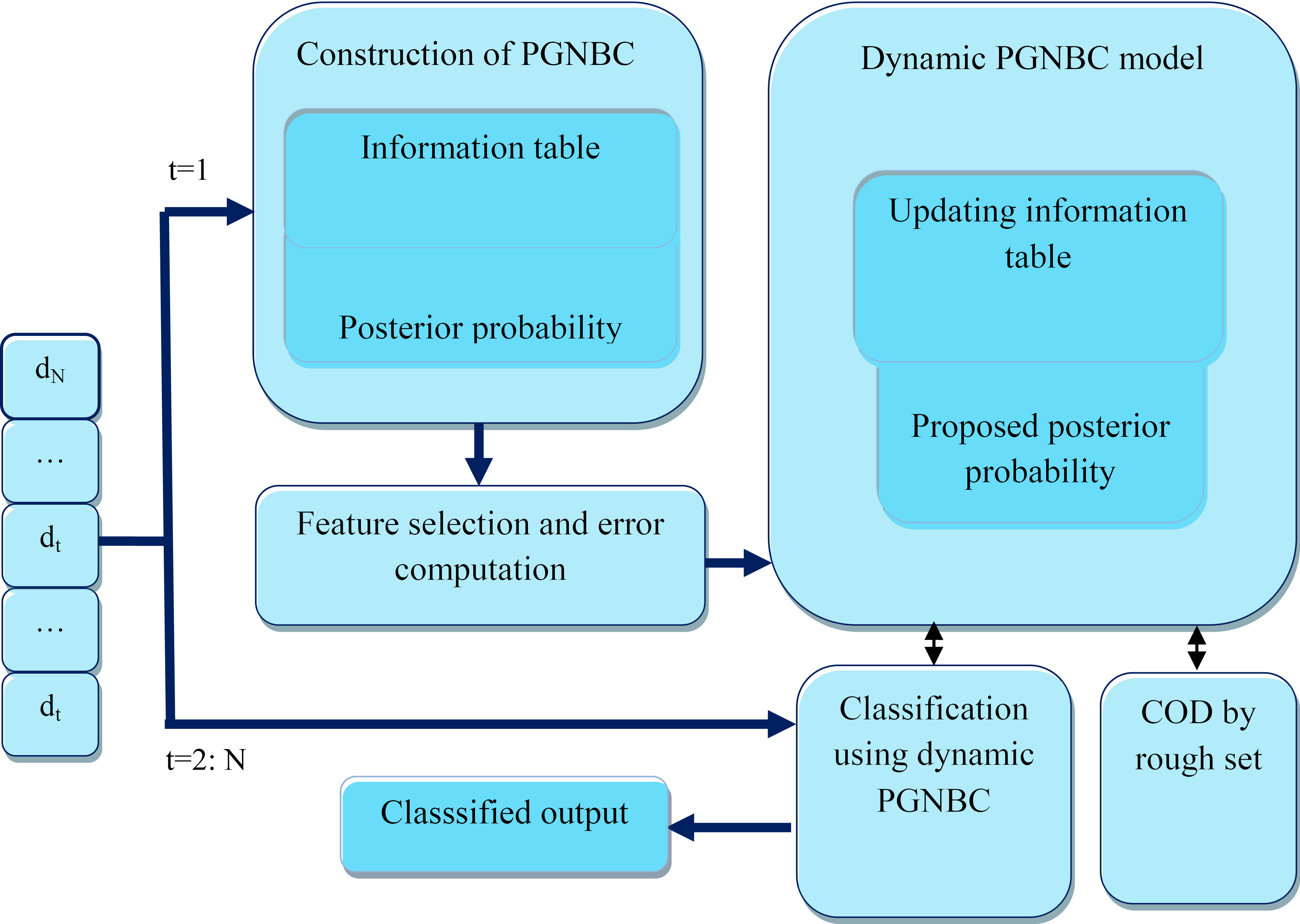
Algorithmic description of the data stream classification.
Once the new data stream is arrived for the classification at time interval
At a particular time interval
The lower approximation that lies within the boundary and upper approximation that lies outside the boundary is represented as
The ratio of lower approximation
The approximation accuracy is calculated and then the value is compared with the predefined threshold (
The updation of PGNBC model is carried out with the new information table with data
where,
where,
where,
where,
The dimension of the data can be minimized with the feature selection process. The objective of feature selection is to reduce the size of the feature vector without sacrificing the performance of the categorization. Feature selection methods are divided into two main approaches: filtering [28], and wrapper [29]. In the wrapper approach, a classifier evaluates many different subsets and selects one with the highest accuracy rate. On the other hand, in filtering approaches, the construction of the final subset is not classifier dependent. Both approaches select a subset of features using an evaluation function. A common measure of relevance in many feature selection algorithms is based on the entropy, considered to be a good indicator of relations between the input feature and the target variable.
The entropy [23] which is a feature evaluation function, helps in determining all the features of the data in all attribute classes, can be used to minimize the dimension of the data. Particularly, the selections of features are based on the degree of significance. If the degree of significance is high, then the final subset of features is selected.The features with low entropy values are considered for the final sequence of processes.
where,
The classification is done with the updated PGNBC model by giving importance to the recurring concept drift. The newly obtained data is represented as
So, the information table obtained is in the minimized form and can be used for the prediction of the class label of the new data with the posterior probability function.
where,
The objective function considers the specificity, sensitivity and accuracy of the values represented with respect to time interval
where,
The experimental results of the proposed PGNBC model are discussed and the comparative analysis with the existing models such as RGNBC and MReC-DFS is calculated using sensitivity, specificity and accuracy as performance measures.
Dataset description
The Skin Segmentation data set and Localization data set collected from UC Irvine Machine Learning [22] is used for the experimental analysis.
Skin Segmentation data set (database 1): The skin dataset is accumulated by using the random sampling of B, G, R values from face images of different age groups, race groups, and genders obtained from FERET database and PAL database. The total number of instances is 245057; among them 50859 are the skin samples and 194198 are non-skin samples.
Localization data for person activity data set (database 2): This database includes the data from the people who were used for recording the data by wearing four tags (ankle left, ankle right, belt and chest). These tags can be detected by anyone attributes. The total number of instances is 164860.
Evaluation metrics
The performance evaluation is done using sensitivity, specificity and accuracy metrics. Sensitivity refers to the proportion of true positives which can be correctly identified by a diagnostic test. Sensitivity is otherwise called as True Detection Percentage (TDP).
Specificity is the proportion of the true negatives correctly identified by a diagnostic test to predict how good the test is for identifying the normal (negative) condition.
Accuracy shows the proportion of true results, which may be either true positive or true negative in a population, thereby measuring the degree of veracity of a diagnostic test on a particular condition.
False detection percentage (FDP) is computed by taking the ratio of false positive with the total number of positive class samples.
Update delay is computed by measuring the delay (in sec) in between the new data arrival and updating of model.
True positive (TP) means the correctly identified, False positive (FP) means the incorrectly identified, True negative (TN) means the correctly rejected and False negative (FN) means the incorrectly rejected.
The innovative PGNBC model is implemented with the aid of Java 1.7 with netbeans IDE 7.3. The execution is carried out in a Windows 8.1 system with i5 processor of 2.2 GHz CPU clock speeds having 4 GB RAM and 64 bit operating system. The input data taken for the experimentation is divided into
RGNBC: This scheme utilizes the Gaussian Naive bayes classifier and the updating of model depends on the rough set theory. This scheme is almost similar to the proposed PGNBC method but the classification model utilized for updating is the existing Gaussian Naive bayes classifier.
MReC-DFS: This is a data stream classification system to address the challenges of learning recurring concepts in a dynamic feature space while simultaneously reducing the memory cost associated with storing past models. MReC-DFS is able to detect and adapt to the concept changes using the performance of the learning process and contextual information. To handle recurring concepts, stored models are combined in a dynamically weighted ensemble.
Performance evaluation of the COD threshold
Performance evaluation of skin data at varying COD threshold with metrics: (a) sensitivity, (b) specificity and (c) accuracy.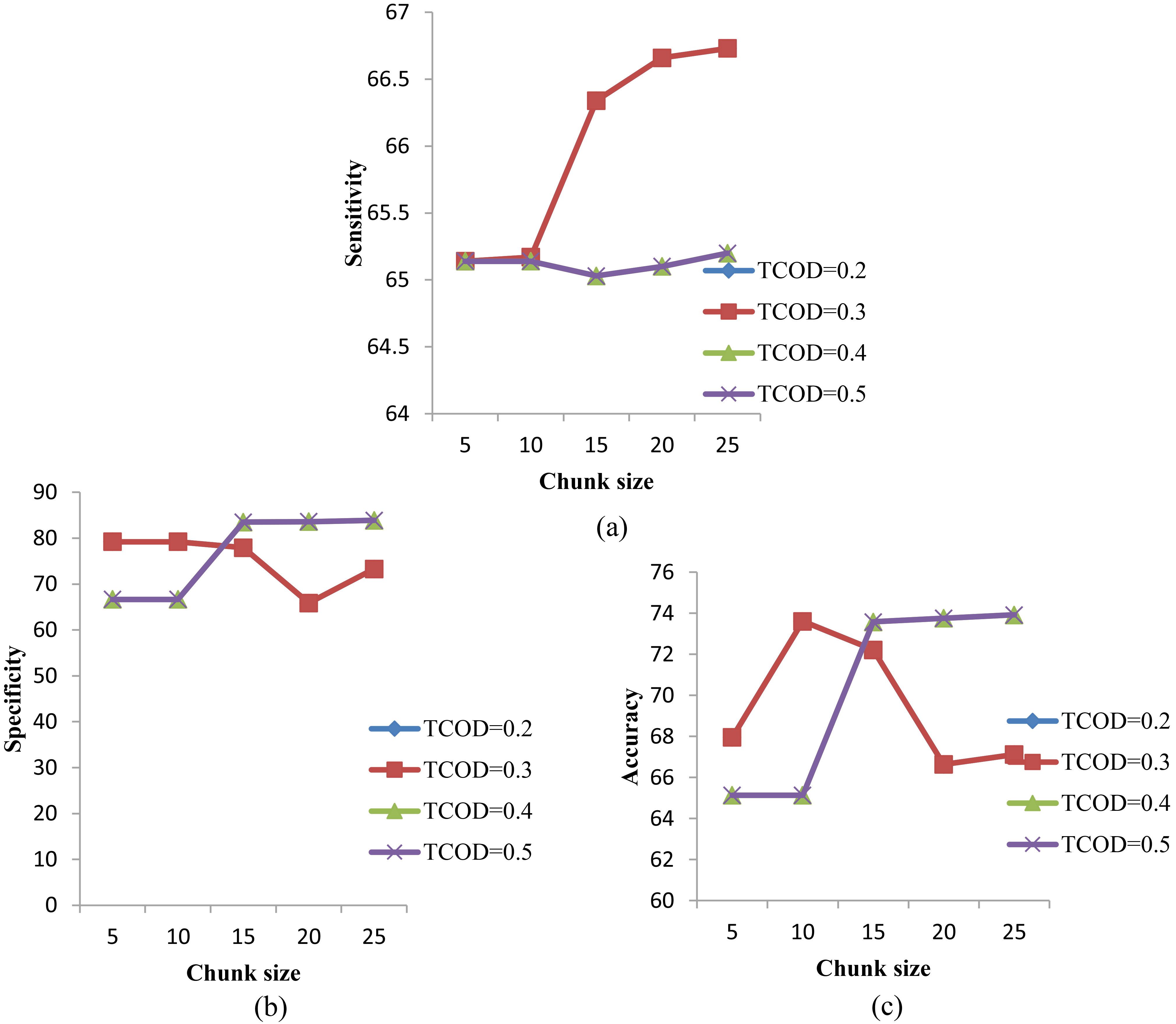
Performance evaluation of localization data at varying COD threshold with metrics: (a) sensitivity, (b) specificity and (c) accuracy.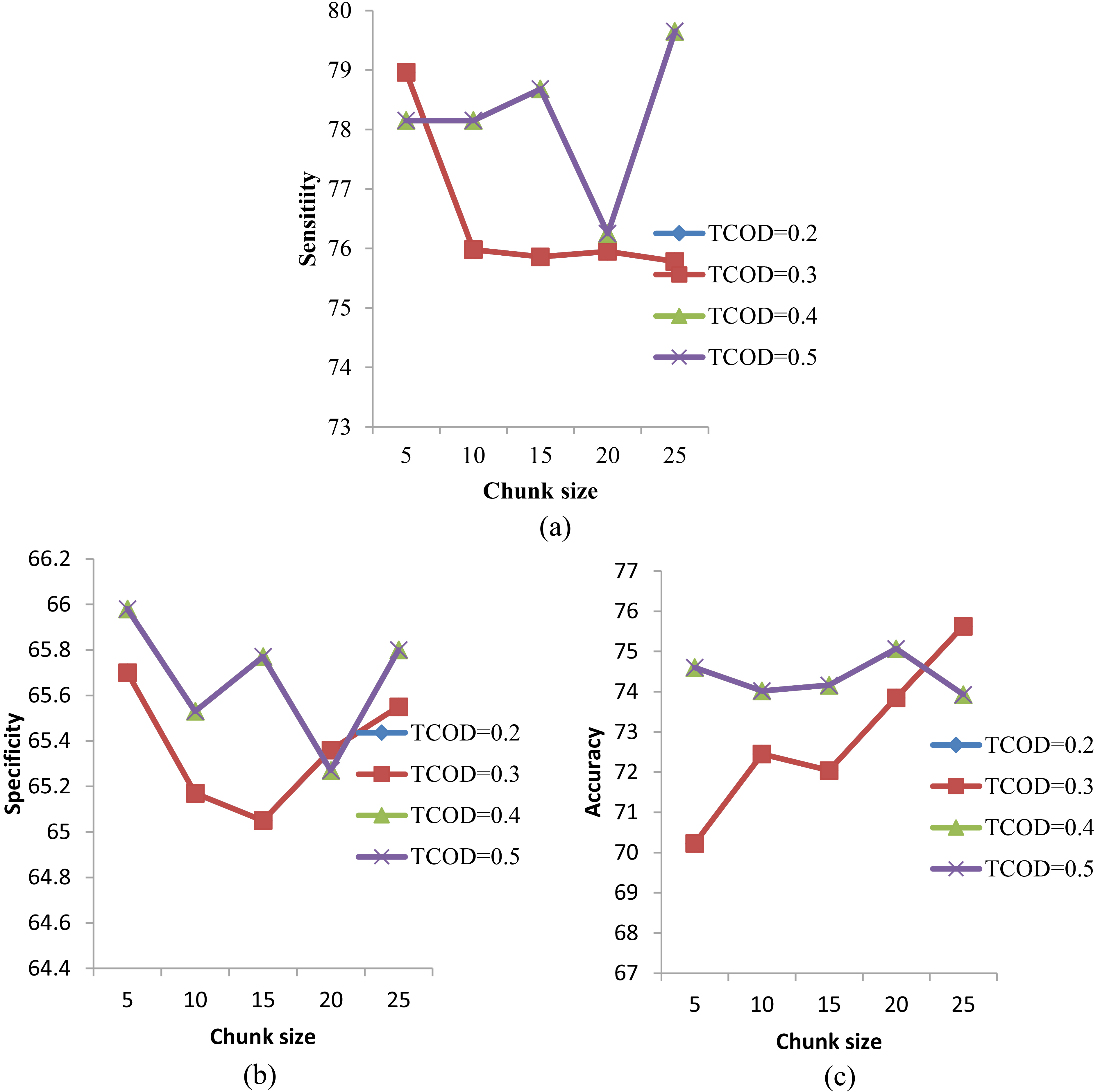
When localization data is used, the sensitivity is found to be very high for both the proposed PGNBC and the existing RGNBC model. It is about 80% for the proposed method. But while comparing the proposed method curve with the MReC-DFS method curve, the deviation difference in sensitivity level is found to be 20%. The existing MReC-DFS curve shows a slight decrease in its sensitivity at increased chunk size. The curve of the existing MReC-DFS method runs parallel to the proposed method curve. In the proposed method, when chunk size is increased, the sensitivity is also increased automatically. When the localization data is used, the sensitivity of the proposed method is high than the sensitivity of the skin data.
Comparative analysis of sensitivity measure for the proposed PGNBC, conventional RGNBC and MReC-DFS using (a) skin data and (b) localization data.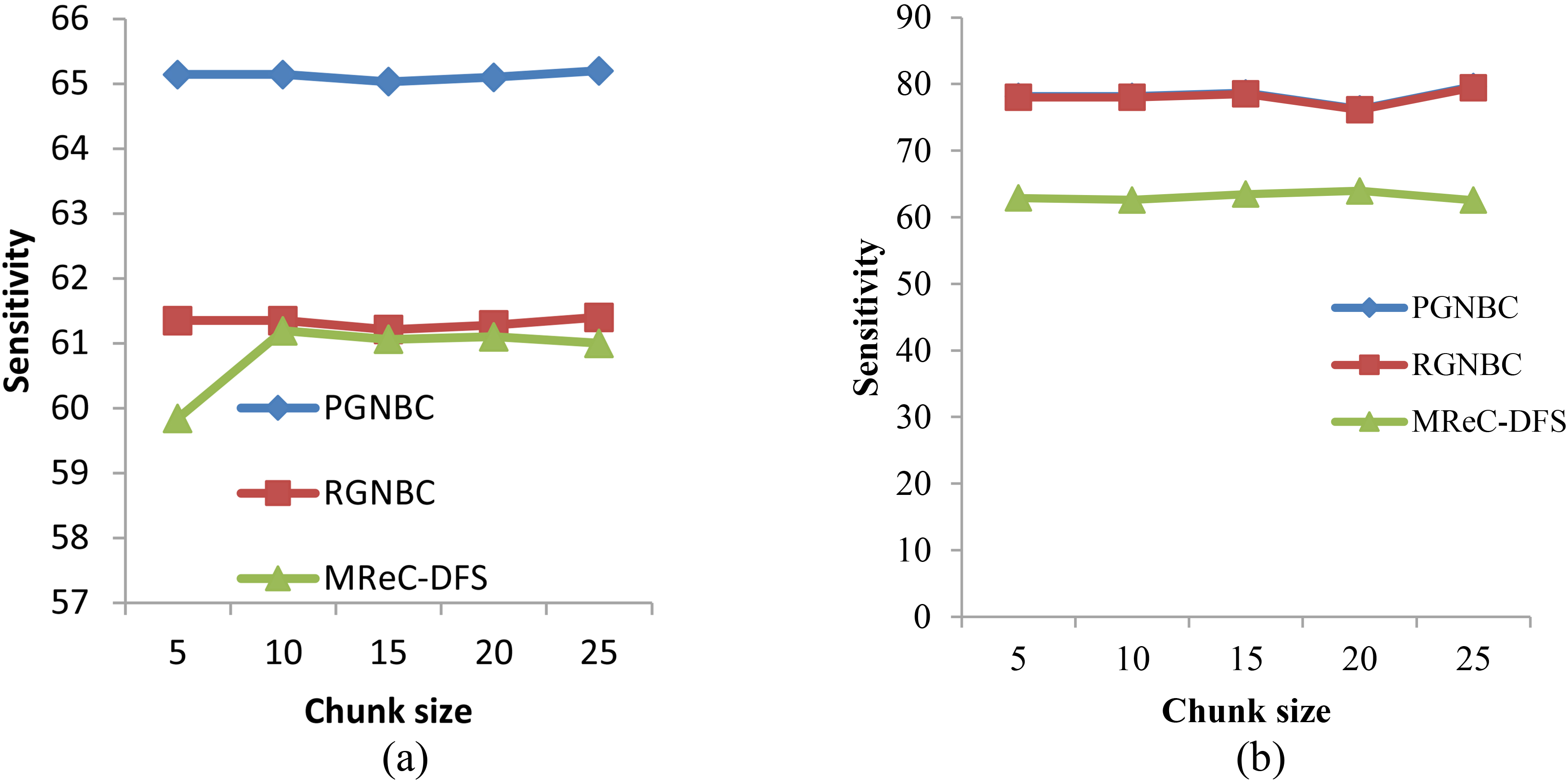
When localization data is utilized, the specificity of the MReC-DFS method is better than the specificity of the skin data. Also, the specificity of the proposed method is about 66%. But for the RGNBC, only 62% is achieved and for existing MReC-DFS method, the specificity is about 60%. The specificity is greatly decreased for the existing MReC-DFS method while increasing the chunk size. For RGNBC also, the specificity decreases when increasing the number of chunks. The deviation is high between the RGNBC and the MReC-DFS. Also, the deviation between the proposed method and the RGNBC method is about 3%. The specificity is high for the proposed method when the skin segmentation data is used.
Comparative analysis of specificity measure for the proposed PGNBC, conventional RGNBC and MReC-DFS using (a) skin data and (b) localization data.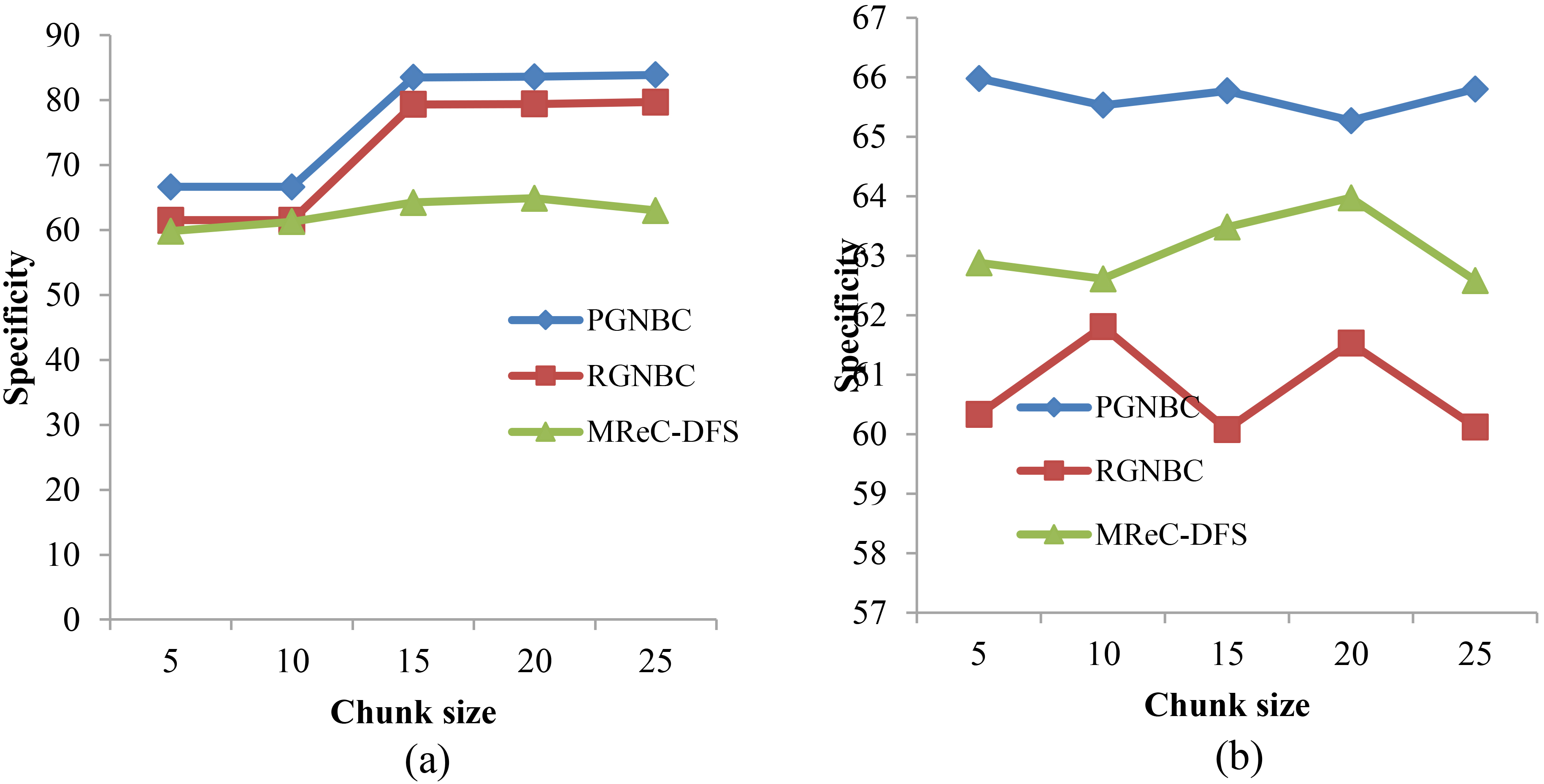
Comparative analysis of accuracy measure for the proposed PGNBC, conventional RGNBC and MReC-DFS using (a) skin data and (b) localization data.
Comparative study with the localization data shows the increased accuracy of the proposed model. When the chunk size increases up to 20, the accuracy increases and then shows a significant decrease at chunk size 25. However, the proposed method is better than the other two existing methods used for the comparative study. In the case of MReC-DFS, the curve decreases for increase in chunk size. The accuracy is about 74% for the PGNBC and 71% for the RGNBC method. Between the RGNBC and the MReC-DBS curve, high deviation is found which automatically shows the less accuracy of the existing MReC-DFS method. The accuracy level is very poor for the existing MReC-DFS method which shows the effectiveness of the proposed method which shows high accuracy levels. The difference in accuracy values between the existing MReC-DFS and the proposed method curve is about 6% at lower chunk size and about 1% between the RGNBC and the proposed PGNBC method. On the whole, the accuracy is better for the proposed method when the localization data is used.
Comparative analysis of FDP measure for the proposed PGNBC, conventional RGNBC and MReC-DFS using (a) skin data and (b) localization data.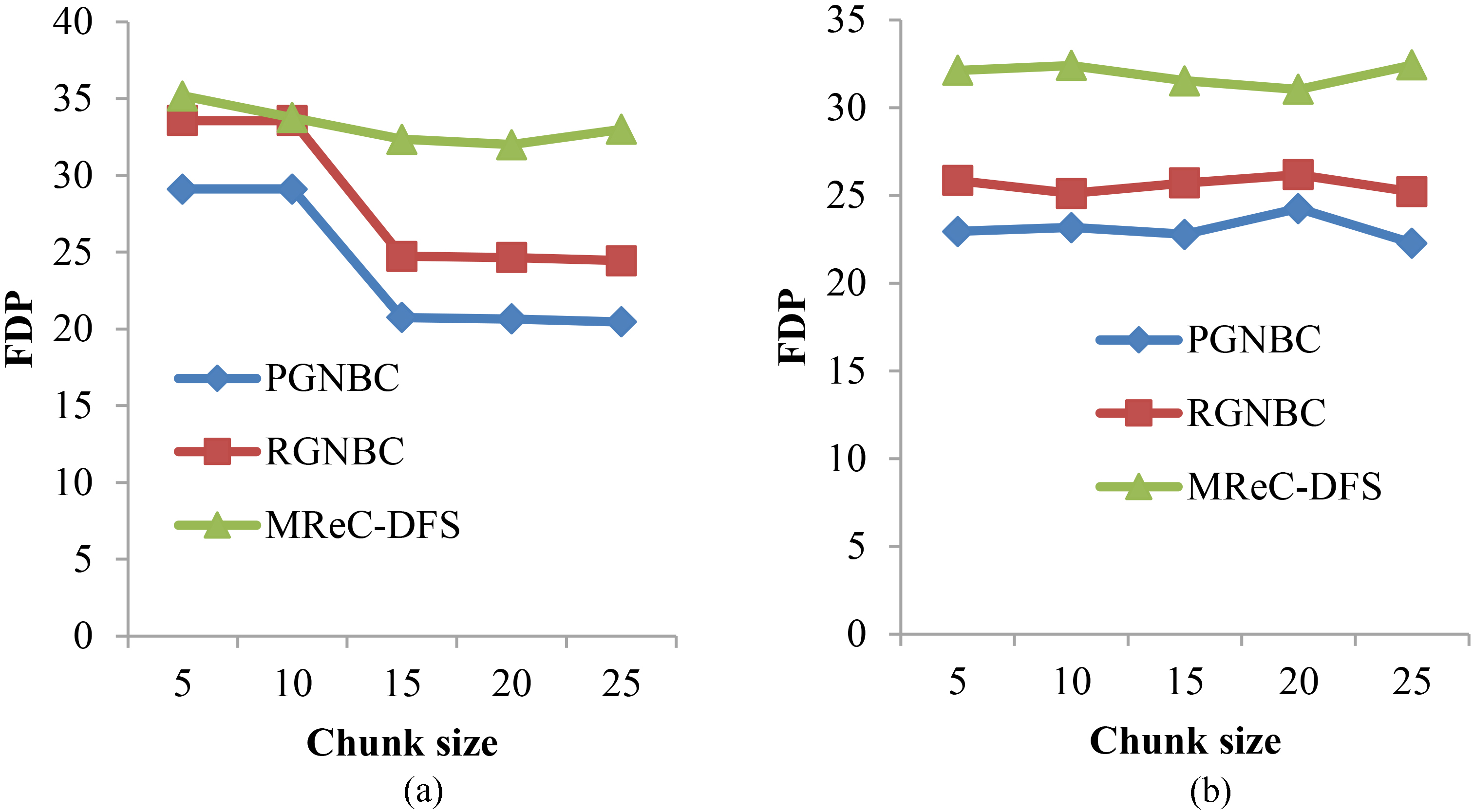
Comparative analysis of update delay measure for the proposed PGNBC, conventional RGNBC and MReC-DFS using (a) skin data and (b) localization data.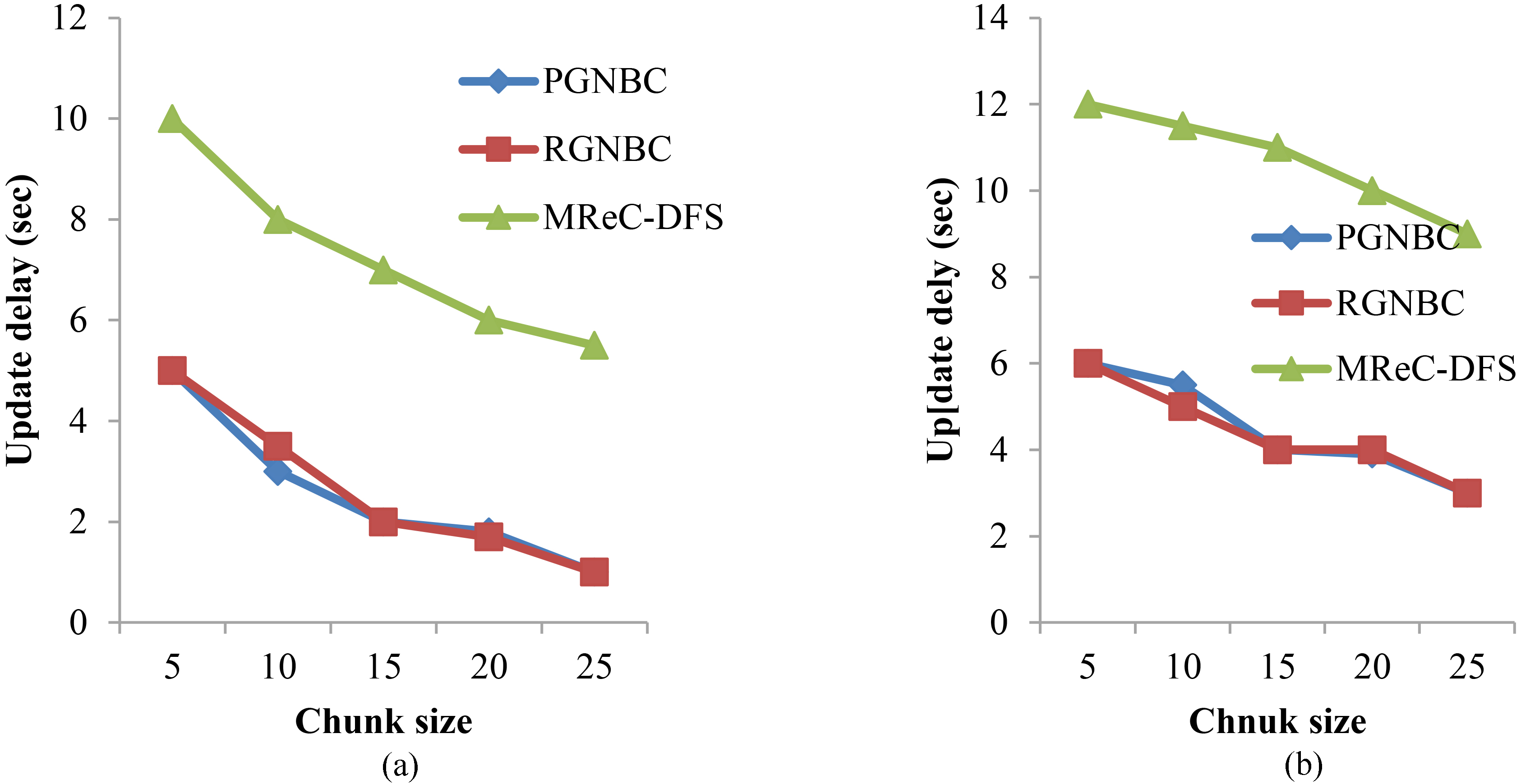
Considering the concept drift with a suitable classifier has been a great task in data stream classification. The proposed work had been focused on the recurrent concept drift with updating a new model. The Pearson Guassian Naïve Bayes classification model has been proposed with new dynamic features. Here, correlation and objective measure were additionally included in PGNBC method and the updating of classification model ws performed based on the rough set theory. The data sets such as skin database and localization database are used for the experimentation and the performance is evaluated with metric measures such as sensitivity, specificity and accuracy. It was found that, at higher threshold value, the accuracy, sensitivity and specificity is better for the localization data than the skin data. When skin data is used, the improvement in terms of sensitivity, specificity and accuracy has been found to be 4%, 1% and 1% respectively, which is high for PGNBC method than RGNBC method. With the localization data, the improvement in terms of specificity and accuracy has been found to be 6% and 2% for the proposed method which is more than the RGNBC method.