
Abstract
The Skyline concept has been introduced in order to exhibit the best objects according to all the criterion combinations and makes it possible to analyze the relationships between Skyline objects. Like the data cube, the Skycube groups all the multidimensional Skylines and it is so voluminous that reduction approaches are a necessity. In this paper, we define an approach which partially materializes the Skycube. The underlying idea is to discard from the representation the Skycuboids which can be computed again easily. To meet this reduction objective, we characterize a formal framework: the Agree Concept Lattice. It provides a formal framework which makes it possible to improve computation time, reduce representation and easily navigate through the Hasse diagram in order to focus on the most relevant skycuboids. This structure is generic, applies to various database analysis problems and combines both formal concept analysis and database theory. It makes use of the concepts of agree set and database partition. They are associated to define the Agree Concept of a database relation. The set of all the Agree Concepts is organized within the Agree Concept Lattice. From this structure, we derive the Skyline concept lattice which is one of its constrained instances for efficient multidimensional Skyline analysis. The strong points of our approach are: (i) it is attribute oriented; (ii) it provides a boundary for the number of lattice nodes; (iii) it facilitates the navigation within the Skycuboids.
Introduction
The formal concept analysis has been successfully used for solving various database, data mining or data warehouse problems. Let us quote the discovery of frequent itemsets and association rules [31, 38], their concise representation, the extraction of functional dependencies [24] (exact, approximate or conditional), the computation of constrained closed cubes and quotient cubes [11, 26, 10, 23] or the multidimensional database analysis through the concept of skycube [35, 34, 33, 43]. The common points of all these issues are the manipulation and storage of very voluminous data sets and the required complex and costly computations. All these approaches take advantage of the formal concept analysis expressiveness [19] in order to soundly characterize the tackled problems, devise efficient algorithms and propose reduced representations as well as visual navigation tools for navigating through the solution space. Our work shares a similar spirit. In this paper, our aim is to propose a theoretical foundation for the multidimensional skyline analysis and lossless partial materialization of skycube. Moreover the approach is validated through experimental evaluations in order to measure both the size reduction and the regeneration time. Let us remind the context in which the studied issue fits.
In a decisional context, some queries do not yield results because the user is interested in tuples (objects) for which the values of certain criteria are optimal. Such queries are fruitless because of their “multi-criterion” feature. Actually, a tuple can be optimal for a given criterion but not for another one; then it is eliminated from the result whereas it could be relevant for the user. For instance, if we consider a housing database, searching an “ideal” housing can combine conditions on the price, the smallest possible, the surface, the largest possible and the distance from the work place, the most reduced as possible. Of course, this ideal housing does not likely exist and therefore the query does not yield any result. However some housings could be relevant for the user because they are located in a close, but not neighboring, area and satisfy the criteria of maximal surface and minimal price.
In order to answer this kind of queries, the Skyline operator [9] has been introduced in a database context. It proposes a solution for the multi-criterion optimization queries over very large databases. The result of such queries is exactly the Pareto front. It considers the set of the criteria chosen for a search as being preferences and extracts the tuples which are optimal for this set of preferences. Therefore, instead of searching an ideal hypothetic solution, it extracts the candidates which are the closest ones to the user expectations. Its general principle is based on the notion of dominance. An object or a tuple is dominated by another one if, for all the criteria relevant for the decision maker, it is less optimal than this other one. Such a tuple is discarded from the result not because it is not relevant for one of the criteria but because it is not optimal according to the combination of all the criteria. In other words, a better solution exists and will be kept.
Like the data cube [21] which exhibits the relationships existing between the various levels of aggregation, a multidimensional generalization of the Skyline has been proposed: the Skycube [35, 29, 34, 33, 43]. This structure groups all the possible SKYLINES according to the various criterion combinations. Then, it is possible to efficiently retrieve the dominating objects according to criterion combinations. This structure also makes it possible to observe the behavior of the dominating objects through the multidimensional space and hence analyze and understand the different dominance factors.
For yielding a Skyline, a naive solution is to compute on line the Skyline query results. Unfortunately, this approach is so time consuming that it cannot apply in practice. On the other side of the coin, another solution is to compute the whole Skycube. Then answering Skyline queries can be easily and efficiently performed because their results have just to be picked out. However, the main drawback of this approach is the tremendous volume of data which must be produced and stored. Between these two extreme cases, a good compromise is to find the best balance between a too costly on line execution time and a too voluminous stored data. The idea under such a compromise is to partially materialize the Skycube. This means that the size of kept data is reduced and for some queries the results are yet available. Nevertheless, when considering the queries for which the result is not yet computed, the issue is to retrieve their result at the lowest cost.
In this paper we characterize the Agree Concept Lattice as a theoretical framework for multidimensional Skyline analysis. From database theory, we make use of the concepts of partition and agree set [5, 36, 24]. The partition of a relation according to a set of attributes
We define an approach based on the Agree Concept Lattice which makes it possible to partially materialize Skycubes and therefore offers a representation with both a reduced size and the guaranty to build up later the whole result. In contrast to [34, 35], our reduction approach is attribute (criterion) oriented and thus is provided with the same navigation qualities as the ones of the full Skycube. Many approaches address the optimisation of Skyline queries and propose efficient algorithms [39, 4, 14]. Nevertheless, when the number of criteria increases, a “curse of dimensionality” can happen [40, 12, 6, 1]. This case is probably more frequent when a Skyline over join is to be processed [39, 37] or if several data sets have to be explored in a distributed context [22]. Our work supplements these approaches by proposing sub-sets of possibly relevant criteria and aids users to choose the best ones.
This paper is an extended and merged version of the work about the agree concept lattice [28] and the Skyline concept lattice [29]. These new structures are studied in more depth and experimental evaluations are performed. The remainder of this article is the following. In Section 2, we recall the context of our work: the concepts of Skyline and Skycube. Then, we propose a theoretical foundation for multidimensional database analysis (Section 3) and applies it to the partial materialization of Skycubes (Sections 4 and 5). It is compared with related work in Section 6. In conclusion, we highlight the advantages of our approach and evoke further research work. In Appendix A, we remind the formal background in which our approach fits.
The Skycube for the multidimensional analysis of Skylines
In this section, we firstly present the Skyline operator as well as the tackled issue. Then, we describe the multidimensional analysis of Skylines through the concept of the Skycube.
The Skyline operator
Before we formally define the Skyline operator, the application context of our issue must be well described. Indeed, the operator does not apply to any relation. In order to perform the required comparisons, the various semantic domains used to define the attributes, choice criteria of the user, must be totally ordered. For the sake of simplicity and from now on, we consider that these attributes are provided with numerical values.
The tuples of relations which can be used by the Skyline operator are as follows:
The relation Housing
The relation Housing
.
The relation depicted in Table 1 lists various housings and is typical for illustrating the use of the Skyline operator. The classical dimensional attributes are here Owner and City and the choice criteria for finding the best housing are: the sale Price in thousands of euros, the Distance from the work place in kilometers, the energy Consumption in kilowatt-hours per year and square meter, the number of Neighbours.
(Dominance relationship).
Let
Without any loss of generality, we only consider from now on the case where all the criteria must be minimized.
When
When a tuple
.
With our relation example (cf. Table 1) and the following criteria
(The Skyline operator).
Let
.
With our relation example (cf. Table 1) and the following criteria
From now on and in order to simplify notations, when there is no ambiguity, we note the sets without braces and commas. For instance,
By using the Skyline Of clause [9], wich is already integrated in PostgreSQL [15], the Sql formulation of the previous example is the following :
SELECT * FROM HOUSING SKYLINE OF DISTANCE MIN, PRICE MIN
This query is equivalent to the following standard Sql query :
SELECT * FROM HOUSING H1 WHERE NOT EXISTS (SELECT * FROM HOUSING H2 WHERE H2.DISTANCE <= H1.DISTANCE AND H2.PRICE <= H2.PRICE AND (H2.DISTANCE < H1.DISTANCE OR H2.PRICE < H2.PRICE));
The Skyline operator is a fundamental tool for database multi-criteria analysis. However, when several Skylines have to be computed from a very same set of data, the operator does not take advantage of the links existing between the different Skylines. This is why a structure called Skycube has been introduced [43, 33]. In fact, the relationship between the Skyline operator and the Skycube is similar to the one between the Group-By operator and the data cube: a multidimensional generalization. When the objective is to efficiently answer all the queries expressed on a set of related Skylines, materializing the associated Skycube is of great interest.
(Skyline subspace).
Let
(Skycube).
A Skycube is the set of all the Skylines in all the possible not empty subspaces of
The structure of the Skycube can be represented by a lattice similar to the lattice used for the data cube (cf. Fig. 1). The cuboids of the Skycube are grouped into levels according to their number of criteria. These levels are numbered by begining by the lattice bottom (cuboids encompassing a single criterion) and going up to the lattice vertex (cuboid according to the whole set of criteria). Let us consider two cuboids:
(Skycube).
Figure 1 gives the Skycube associated to the relation Housing (cf. Table 1). The criteria are symbolized by their initial.
Representation as a lattice of the Skycube of the relation Housing
The multidimensional Skyline queries yield the subset of tuples of the original relation making up the Skylines for a given subspace. Once the Skycube is computed, it is possible to efficiently answer these queries for any subspace.
In general, if a tuple
.
With the relation Housing as shown in Fig. 1, by considering the Skylines according to (Price, Distance, Neighbor) and (Distance, Neighbor) we have:
(Price, Distance, Neighbor)
In contrast, if we consider the following Skylines (Price, Distance, Consumption, Neighbor) and (Price, Distance, Consumption), we have:
(Price, Distance, Consumption, Neighbor)
The observation highlighted by the previous example is the following: belonging to a Skyline is not monotone, i.e. a tuple
Like for the data cube, the Skycube can enclose superfluous information [23, 42, 25, 27]. This issue has motivated the proposal of reduced representations of the Skycube presented in [34]. Our contribution is interested in the same issue of reduced representation and also combines the formal concept analysis [19] and the Skyline. In order to avoid the important cost of reconstruction of Skyline cuboids originated by the value oriented grouping of [34], our reduction method chooses a criterion oriented grouping based on the agree sets.
In this section, our objective is to give the definition of a formal framework combining both the concept of agree set and the one of concept lattice. We propose a new structure, the Agree Concept Lattice of a relation [28], which can be used to solve several multidimensional database analysis problems. Then we soundly characterize the Agree Concept Lattice.
The Agree Concepts of a database relation
Our objective is to define a particular concept lattice which is based on the agree sets and the database partitions which is recalled in the appendix. In order to meet this goal, we characterize an instance of the Galois connection between on the one hand the lattice of the power set of the attribute set and on the other hand the lattice of the partitions of the tuple identifier set. This connection makes it possible to define dual closure operators, introduce the Agree Concept and characterize the Agree Concept Lattice.
.
Let
As stated in the prévious section, the Rowid is a virtual attribute which identifies the tuples of a relation. This attribute is generally provided by the database systems.
For an attribute set
.
With the relation Housing, by considering the following attribute sets:
With the partitions
.
The couple of functions
Proof..
Due to the definition of the order relationship between partitions and the definition of
(Closure operators).
The couple
.
With the relation Housing, by considering the attribute sets DC and DCN, according to the previous example, we have:
With the partitions
(Agree concepts).
An Agree Concept of a database relation
Let
(Agree Concept Lattice).
Let AgreeConcepts(
Let
Proof..
Since the couple
Hasse diagram of the Agree Concept Lattice of the relation Housing.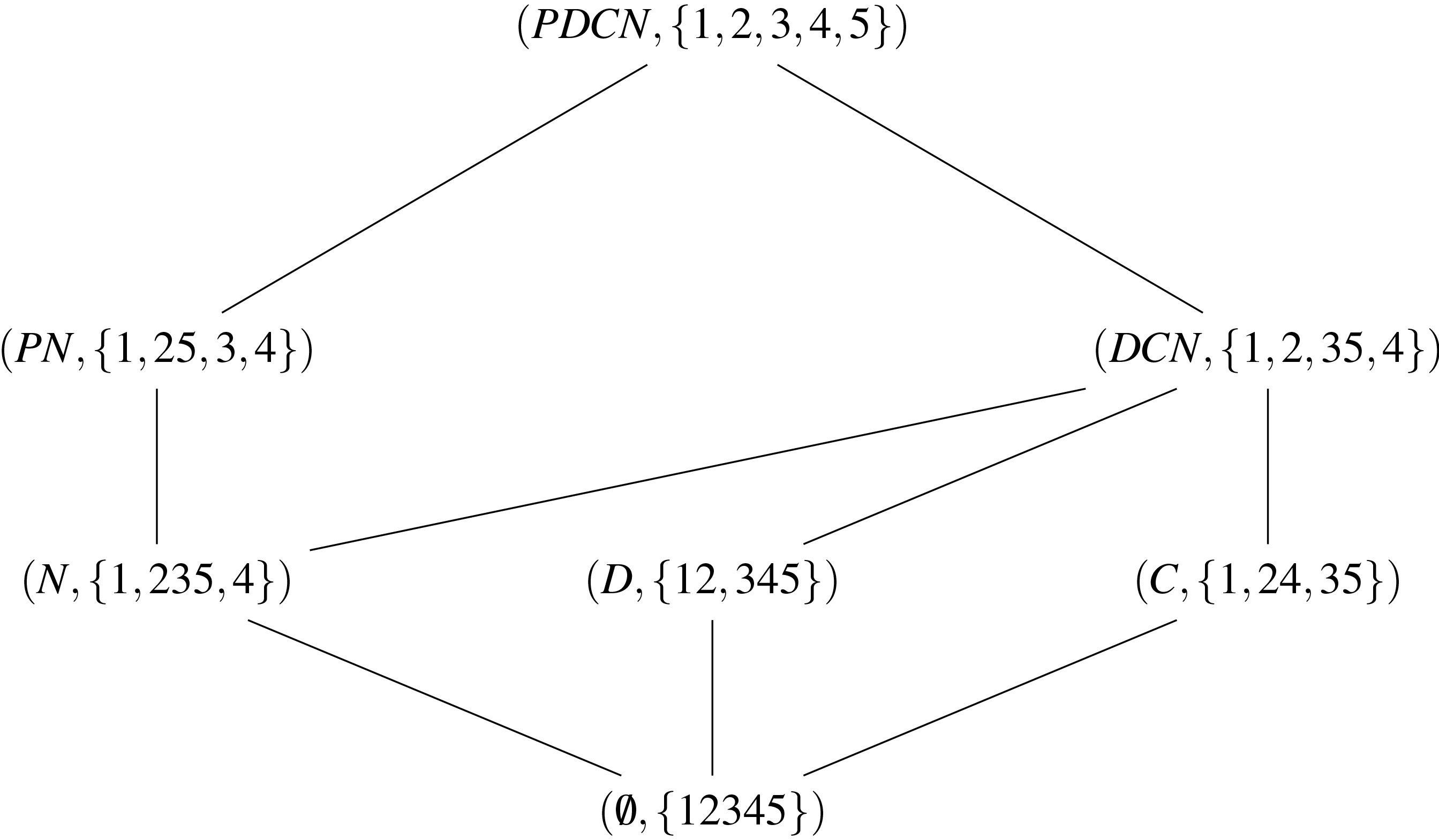
.
Figure 3 gives the Hasse diagram of the Agree Concept lattice of the relation Housing. The couple
.
For any attribute set
Proof..
By definition,
.
With the relation Housing, by considering the set of attributes DC, according to the Examples 6 and 7, we have:
The previous proposition means that the closure of a set of attributes
The lattice of the Skyline concepts is a constrained lattice of Agree concepts. We prove a fundamental property of our lattice which makes it possible to partially materialize the Skycube by discarding certain cuboids. Then, we show how such cuboids can be easily built again. Like in the original definition of Skycube [43, 33], the dimension attributes are ignored. Without any performance drawback, we can projected over this attributes et retrieve them by a simple join thanks to the Rowid virtual attribute.
Skyline concept lattice for efficient multidimensional Skylines analysis
Let
.
Let
(Concepts Skylines).
Let
There are exactly as many Skyline concepts as there are Agree concepts. The set of Skyline concepts associated to the Agree concepts of
The Skyline concepts are Agree concepts for which the partitions have been constrained. Thus, this type of concept is not necessarily ordered by the order relation
(Lattice of Skyline concepts).
The ordered set
.
Figure 3 gives the Hasse diagram of the Skyline concept lattice of the relation Housing. According to the Example 8, the couple
Hasse diagram of the Skyline concept lattice of the relation Housing.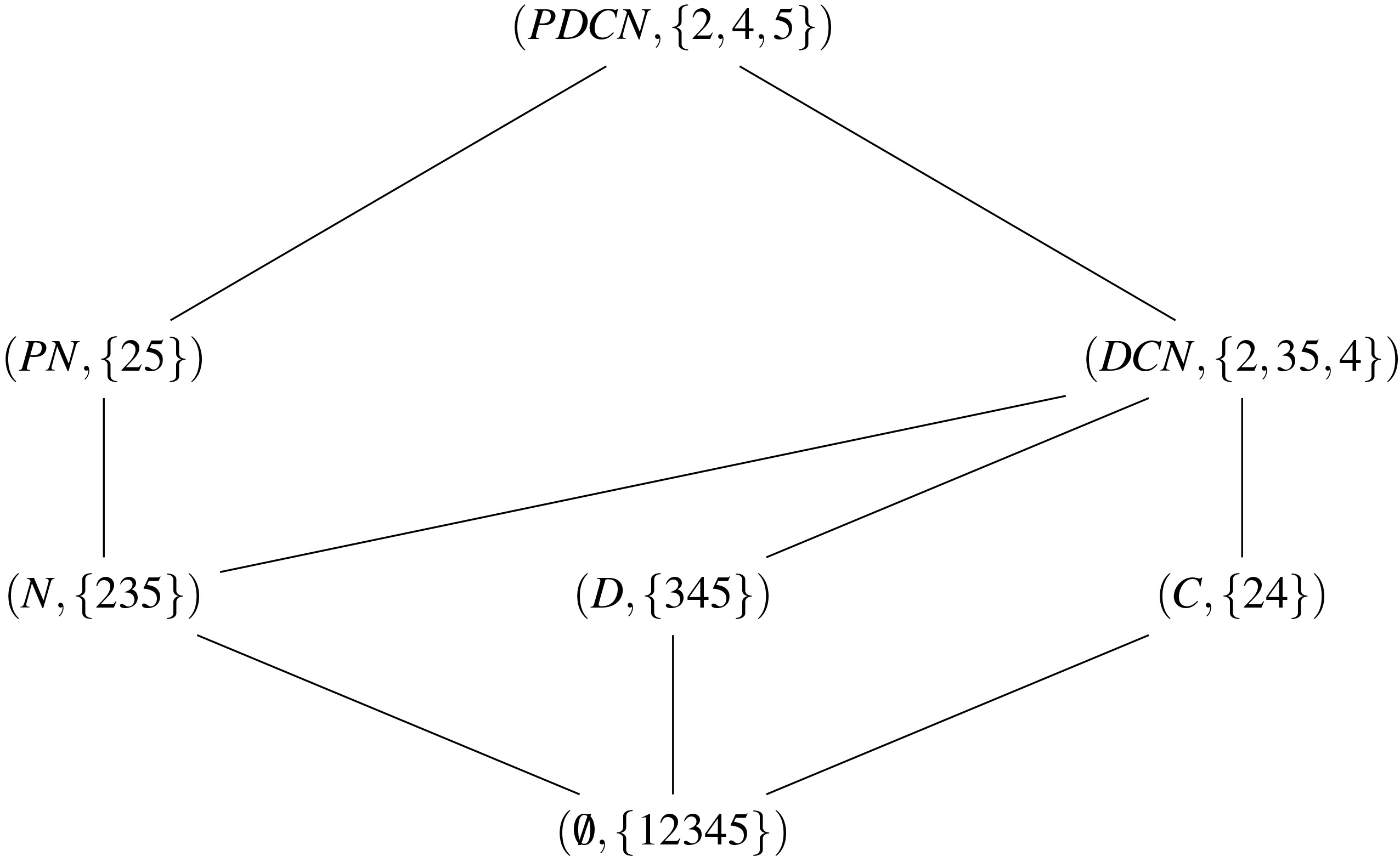
In this section, we propose the Skyline concept lattice as a partial materialization approach for the Skycubes. The underlying idea for obtaining a reduced representation is to eliminate the cuboids which can be the most efficiently rebuilt.
(Disagree condition).
Let
When
This disagree condition is a weakened version of the condition of distinct values [43] because it applies on the projections instead of the individual values of each criterion.
(Dominance under Cna).
Let
.
Let
Proof..
Under the hypothesis
The following counter-example shows that the reverse property does not hold.
.
Let
.
Let
This property holds for any super-set of
(Fundamental theorem).
Let
Proof..
By definition,
.
In the relation Housing, we have:
Moreover the following properties are verified :
Thus we have
The theorem given above shows an inclusion between some Skylines cuboids. More exactly, for any set of criteria, there is a chain of inclusions from its minimal generators to its closure. This means that a cuboid can be computed from another one which contains it. Then, instead of using the original relation, we only consider a limited subset of it. The Skyline concepts are the largest cuboids (according to the inclusion relationship) which make it possible to compute other cuboids. With the above theorem, we are provided with a local monotony w.r.t the inclusion. By only preserving the Skyline concepts (i.e. non-materialization of the non-closed cuboids), missing cuboids can be quickly built up merely by finding the closed cuboid from which they can be computed. Furthermore, thanks to the equivalence classes of Skyline concepts, we avoid a great number of useless comparisons. Tuples which cannot be distinguished are considered by groups and the computation complexity no longer depends on the number of tuples but depends on the number of groups (equivalence classes).
The lattice of Skyline concepts constitutes a partial materialization of the Skycube, from which the information which is not materialized can be efficiently computed.
In this section, our aim is to validate our theoretical materialization approach through various experiments. The latter are conducted according to a twofold objective: on the one hand, measuring the size reduction and, on the other hand, evaluating the response time for answering Skyline queries.
For our experiments, we generate synthetic databases7
The synthetic data generator is given at
Query response time.
Size reduction.
In this experiment, we want to measure both the size of the Skycube and the size of our Skyline Concept Cattice in order to compare them. The Fig. 5 shows the obtained results when the cardinality of the criteria varies from one hundred to ten thousands. The more the cardinality increases, the more our representation is interesting regarding the storage space it needs to be materialized, whereas the Skycube keeps becoming more and more voluminous.
.
With our relation example, the Skycube of Housing according to Price and Distance, Consumption and Neigbourg encompasses 29 tuples.The size of the associated Skyline Concept Lattice is of 22 tuples.
Query response time
In this experiment, we want to compare the response time of a Skyline query using the SFS [13] algorithm (a short description is given in Appendix A.3) when there is no materialization and when our Skyline Concept Lattice is available. When provided with our partial materialization, two cases have to be considered. In the simplest one, the result of the query is enclosed in our materialization and therefore the cost of the query is also minimal. In the second one, the result of the query must be computed from the associated closed skycuboid by using Theorem 2. In order to improve the quality of our evaluation and to obtain meaningful results from this experiment, each point on the curve in Fig. 4 stands for the average execution time of hundreds of queries while the cardinality of the criteria varies from one hundred to ten thousands. Also, to simulate the user queries, we determine the number of criteria for each of them thanks to binomial distribution centered on the number of possible criteria divided by two and then we pick the combination of criteria randomly. This way, the processed queries often consider several (but not too many) criteria so they have more meaning than if they were picked randomly. The results show that our Skyline Concept Lattice is effective because it can quickly answer to any Skyline query and that its gain factor is constant.
For instance, if we are interested in the less expensive housings, we have to compute
Related work and comparison
The Skyline operator [9] is intended for retrieving the most relevant objects according to some criteria in a database context. It originates from the maximal vector problem [3, 7]. However, due to the context features, specific algorithms have been developped. The most famous ones are Bnl[9], Sfs[13], Less[20] and Salsa [4]. Other more efficient algorithms like Bbs[30] have been proposed but make use of index structures which are costly to maintain.
When computing Skyline queries, if numerous criteria are considered, the risk is to obtain a huge amount of Skyline objects not necessarily informative. Several approaches attempt to solve this problem [40] proposes a ranking approach of Skyline objects for a Skycube in order to focus on the most informative objects. A Skyline graph is built up and captures the dominance relationships between Skyline objects belonging to different subspaces.
The ”curse of dimensionality” is likely to be more frequent when several relations are scanned (Skyline over join) or several databases in a distributed context [22]. Some approaches address Skyline query optimization and propose efficient algorithms to compute the Skyline of several relations without performing join operator [39] proposes a novel algorithm to reach such an objective. For effectiveness sake, the algorithm does not access all the tuples of relations and the join result is not entirely generated. Moreover it is robust and early ends. Semi-Skylinediscards [16, 17], from relations, the tuples which never belong to the result. Obviously this operation reduces the relation size and the cost for computing latter joins. A semi-Pareto preference is defined for preference queries combined with selections. As mentioned above a critical problem is to deal with numerous criteria. Thus a main question is to supply the user with the most relevant criteria.
The Skyline operator is a decision making tool and the user will likely compute several Skylines before he finds the ones which are really interesting. In order to address such an issue, the Skycube concept [43, 33] has been proposed. The underlying general idea is to compute all the possible Skylines in advance, therefore it is necessary to reduce as much as possible the storage cost of the result.
Reduction approaches have been proposed by [34, 35]. Their objectives are to solve the problem related to objects belonging to several Skycuboids. Their solutions are a representation of the Skycube, based on formal concept analysis, where each node corresponds to a couple made of an equivalence class (set of objects) and the sub-spaces in which they belong to the Skyline. The main drawback of this value oriented approach is that the number of nodes is bounded by the cardinality of the lattice of the tuple powerset (
Another interesting approach is proposed in [41] and is cuboid oriented (attribute oriented). Its objective is to obtain a very important reduction of the Skycube by discarding the elements considered as redundant in the different cuboids. Its drawback is that the reconstruction of a Skycuboid is difficult and relatively costly because the underlying data structure must be scanned to retrieve redundant elements. Moreover, in contrast with the approach described in [34, 32] and ours, the representation is not based on a theoretical support as sound as the formal concept analysis. However, in addition to the great reduction of the storage cost, one of the main interests of the approach is the efficiency of data actualization.
In addition to the Skyline materialization, our approach can take advantage of efficient existing algorithms in order to propose criterion sets likely interesting and achieve the associated Skylines. An objective of our approach is the Skycuboid reconstruction at the least cost, and it ideally behaves when such a task must be performed. Despite its targeted orientation, it is a good compromise for both data actualization and storage space reduction.
Conclusion
In this paper, we have defined a new theoretical foundation for multidimensional Skyline analysis which is at the cross road between formal concept analysis and database theory.
We have presented the Agree Concept Lattice [28] by combining on the one hand the concepts of database partition [36] and agree set [5] and on the other hand the formal concept lattice [19]. This structure can be redefined with pattern structures [18].
Then we have introduced the lattice of Skyline concepts which is a constrained instance of the Agree Concept Lattice. This new structure offers the partial and lossless materialization of Skycubes as well as the efficient reconstruction of missing cuboids. An additional advantage of our lattice is that the number of its nodes depends on the number of dimensions, generally small and constant, and not on the number of the dimension values.
One of the main features of our Agree Concept Lattice structure is its generic feature and that it can be applied to several application fields, in particular for mining both exact and approximate functional dependencies or computing data cubes. Our idea when proposing this structure is to make use of database concepts to solve database and Olap problems. This makes it possible to take advantage of existing and efficient database tools. Various approaches address the Skyline query optimisation and our work can be seen as a complementary step which aims to aid the decision maker to choose the most relevant criteria.
We can easily extend our materialization approach to the cases of