
Abstract
Face detection is the first step for automatic face recognition systems. However, detecting faces is not an easy task due to variations in factors such as pose, illumination, scale among others. Efficient face detection algorithms like the one proposed by Viola-Jones allows one to detect faces in real-time with high accuracy rates. However, this algorithm involves several stages that consume huge computation, particularly for the training process. Also, increasing input image’s size for face detection and using large training data sets for face recognition demand additional computing resources to achieve real-time processing. In this paper we present a parallel approach to perform three stages of the Viola-Jones face detection algorithm, particularly for the integral image computation, Haar-like features estimation and the evaluation of these features. Our experimental results show that our proposed approach obtains better performance than the OpenCV library implementations.
Introduction
Parallel computing has become an essential topic in computer science and its application fields, as it is much better suited for modeling, simulating and understanding complex real-world problems when compared to serial computing [23]. For example, parallel computing has been successfully applied in many areas such as genetics, biotechnology, chemistry, physics, mechanical engineering, circuit design, microelectronics, environment, medical imaging and diagnosis, pharmaceutical design, data mining, and big data, among others [23].
Parallel computing, in simple words, is the simultaneous use of multiple computing resources (cores, computers, etc.) to solve a computational problem [12]. Generally, parallel computing is used when facing problems requiring of demanding computing resources, either from large scale problems or applications requiring of real time processing. For instance, parallel computing is essential in computer vision tasks such as visual surveillance, representation learning (e.g., deep learning), image retrieval, human-machine interaction or face recognition. In this last task, guaranteeing real time performance is crucial in most of its applications (e.g., authentication, surveillance and behavior analysis).
However, a first step for those systems and their applications is face detection, a time consuming process that is affected by additional factors as variations in pose, rotation, illumination and scale. Several efficient face detection methods are available nowadays, among the most effective ones is the Viola-Jones algorithm [4]. Although being among the most effective and efficient techniques, it involves several tasks that consume large computing resources, particularly for the training phase.
In recent years, Field-Programmable Gate Arrays (FPGAs) and Graphics Processing Units (GPUs) have become useful tools for putting in practice large scale parallelism in the Viola-Jones algorithm [16]. For example, Junguk et al. introduced a parallel FPGA architecture of multiple classifiers to accelerate the processing for face detection based on the Viola-Jones method [13]. They obtained 3.3 times better performance over the architecture of a single classifier and 84 times over an equivalent software solution. Hiromoto et al. proposed a partially parallel architecture also based on FPGA, achieving higher processing performance and smaller circuit area than the parallel implementation of all classifiers [14]. Their architecture reached 30 fps when processing images of size of 640
In 2011, Oro et al. introduced an optimized Haar-based face detector that works in real-time using high definition videos [18]. They proposed kernel operations by exploiting both, coarse and fine grain parallelism in GPUs, for performing integral image computations and filter evaluations. They achieved competitive results in images sizes of 1080 pixels. Kyrkou and Theocharides presented a systolic array to implement detection in parallel (FPGA) [19]. They detected objects within 1024
In 2013, Chang and Hwang introduced an enhanced training method using the Adaboost algorithm for obtaining the localized sampling optimum (LSO) from a local IP-CAM video [21]. Also, they used an improved motion detection algorithm that cooperates with the former face detector to speed up processing time and achieve better detection rate. Pertsau and Uvarov introduced a parallel algorithm for face detection in images, which is an extension of an OpenCV library [22]. They also developed a scheduling algorithm to balance the workload among GPU’s threads.
In 2014, Bilaniuk et al. presented an embedded FPGA implementation of a face detection method based on boosted LBP features [24]. Their proposed implementation runs at 5 VGA fps, while providing similar accuracy to the PC version of the LBP algorithm included in OpenCV. Wei et al. introduced an FPGA architecture that simulates a small part of the entire Viola-Jones algorithm [6]. This simulation achieved rates up to 15 fps using 120
In 2008, Gao and Lu proposed an FPGA design focused on feature classifier calculation [9]. In their approach, the frame rate was 98 fps on 256
In 2011, Ding et al. [20] introduced techniques for face detection and presented a method to select the stop threshold for the image reduction process, which decreases the total computation by half. Their proposed system achieves real-time face detection at 100 fps for SVGA images. In 2014, Kumar and Agarwal [25] presented an architecture for generating the integral of an image of the current detection window dynamically. They reported that their approach reduces hardware resources usage by around 50% using VGA images.
In this paper, we present a parallel computational model to accelerate three stages of the Viola-Jones face detection algorithm, inherent to the training process using a GPU and the CUDA programming model. The three targeted tasks are: to calculate the integral image, to obtain the haar-like features, and to evaluate the acquired features. Therefore, we present three parallel algorithms in order to improve the performance of the face detection task in computer vision, which demands high computing resources in real time applicacions. Experimental results are compared to the OpenCV implementation, obtaining in almost all cases, a significant acceleration performance in terms of processing times. According to these results we can highlight that the three proposed algorithms improved the implementations of OpenCV, particularly the integral image computation obtained the lowest processing times.
The remainder of the paper is organized as follows. Section 2 presents a brief background of the Viola-Jones face detection algorithm, which comprises three main stages: haar-like feature extraction, integral image, and training. Also, in this section, a brief overview of parallel computing and the CUDA architecture is provided. The proposed parallel approaches are introduced in Section 3. Experimental results are presented in Section 4. Finally, conclusions and directions for future work are presented in Section 5.
Background
In this section the Viola-Jones algorithm with its the three stages considered for acceleration are described. Also, a general overview of GPUs architectural characteristics and the CUDA programming model are presented.
Viola-Jones algorithm
The Viola-Jones algorithm [4] is considered one of the most effective and efficient algorithms for object detection, and particularly for face detection, due to it is fast and accurate performance in real-time applications. This algorithm has three main components: haar-like feature estimation, integral image computation and training a cascade classifier, these components are described in the rest of this section.
Haar-like features
In 1997, Oren et al. [1] introduced a novel method for people detection using the Haar wavelet concept. Then, in 2000 Papageorgiou and Poggio [2] applied this concept for people and face detection in unconstrained and cluttered scenes. After that, Viola and Jones [4] proposed to use this concept for object detection, calling it as haar-like features. The haar-like features are represented as rectangle regions on the image, which can be defined as:
To compute the value of a feature, the sum of all pixels contained in each of the rectangles making up the feature is calculated,
Because the set of features that can be obtained is almost infinite, some constrains have been proposed to reduce the number of them [5]. Figure 1 shows the haar-like features set proposed by Viola-Jones [4] and the extended set of features proposed by Lienhart and Maydt [5].
Haar-like features proposed by Viola-Jones and the rotated ones proposed by Lienhart and Maydt [5].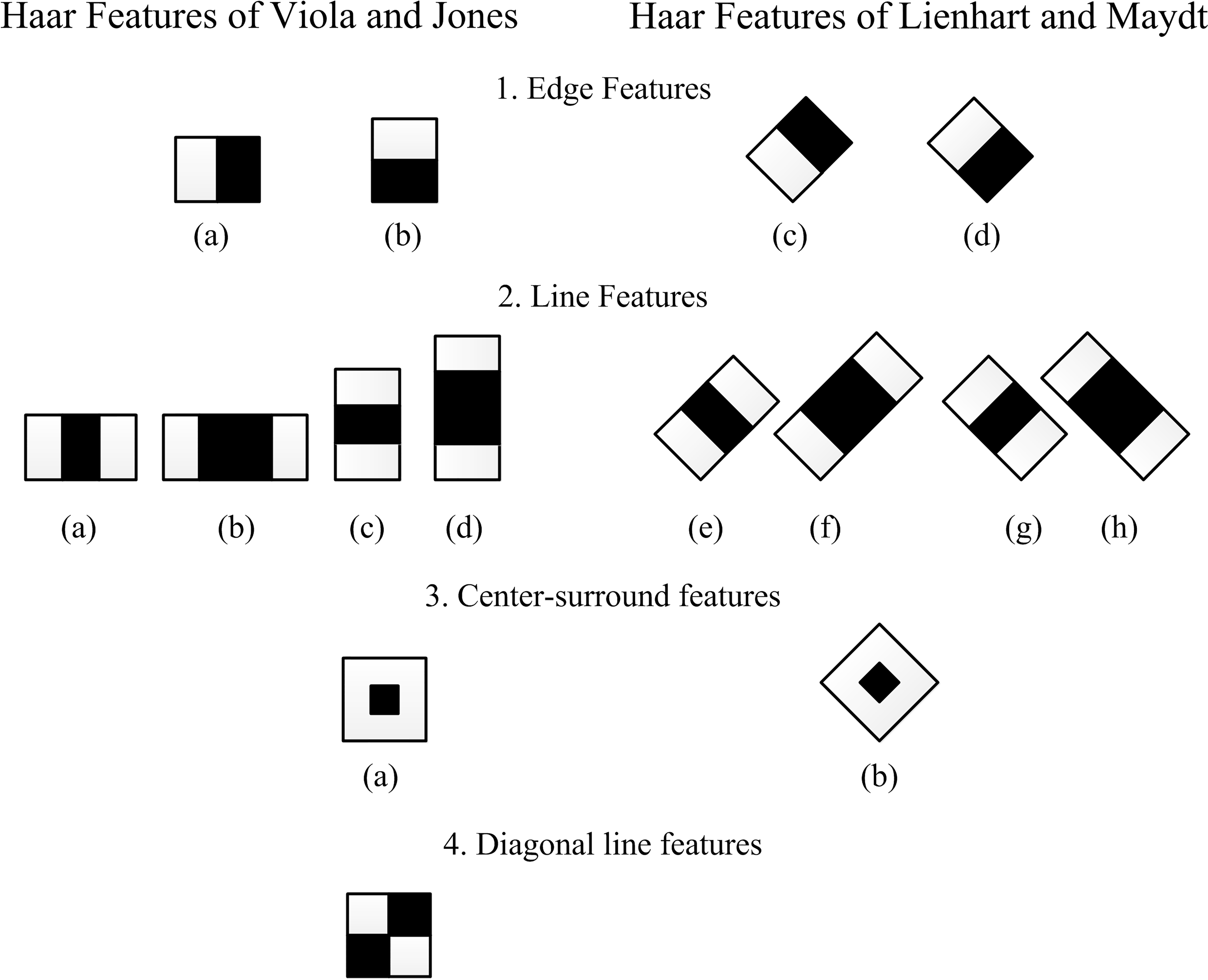
Even taking some restrictions, the number of potential features is large, for example in an image of size of 24
Estimating RecSum in formula (2.1.1), i.e. calculating the sum of pixels within each rectangle of the haar-like features is computationally expensive. Thus, the integral image is used to calculate each haar-like feature in one single pass and in constant time. This concept involves a sum of all the pixels that are above and on the left of a point
where
where
Result of calculating the integral image.
As a result, two array references are obtained with the sum of any rectangular area in the image, that can be calculated efficiently in constant time [4]. Figure 3 shows the sum of the pixels of the ABCD region calculated by the Eq. (4) requires of only four references of the integral image.
Haar-like features are defined as the intensity differences between two or four rectangles, therefore the integral image can be used to calculate one simple rectangular haar-like feature [5]. For example, from the first group in Fig. 1, the feature value of case (a) is the average difference of pixel values between black and white rectangles.
Gray area is computed using four references as 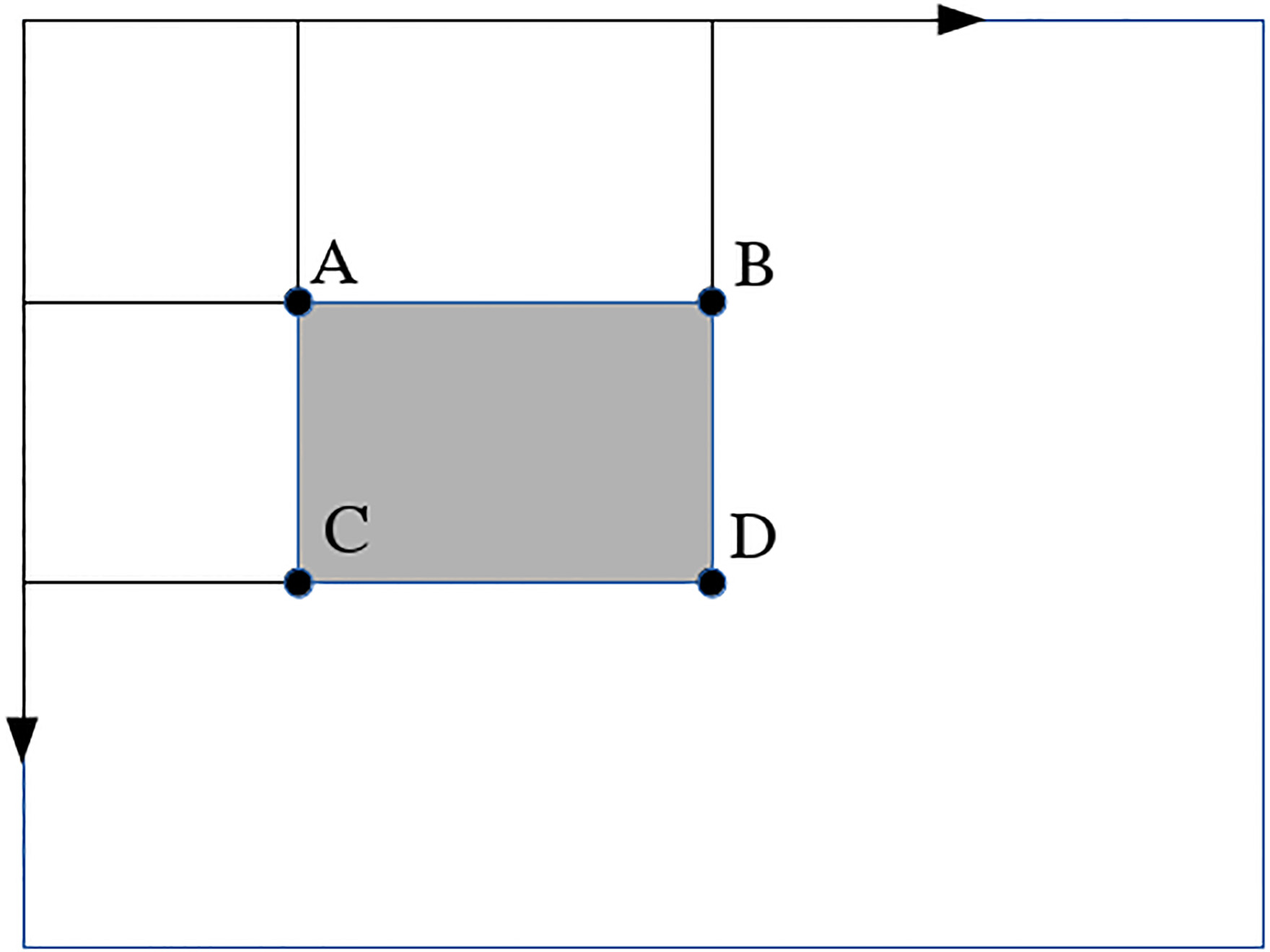
To detect faces of different sizes, either the haar-features can be scaled up or the image can be scaled down. Therefore, the integral image needs to be calculated several times, and this process requires large amount of computation.
Viola-Jones used the AdaBoost algortithm shown in Algorithm 2.1.3 for the training stage. The main goal of Adaboost is to build a strong classifier using a weighted linear combination of weak classifiers (i.e., an ensemble classifier). Briefly, the algorithm performs as follows: Step 2 initializes a weight vector for each positive and negative training sample, this vector is updated in each iteration, allowing the ensemble to become a strong ensemble classifier.
In Step 3 starts the loop from one to the maximum number of training levels
We want to highlight that the algorithm involves a process that requires large amounts of computations because it performs an iterative task of the same instructions with different data. Therefore, parallel computing is an alternative to perform this task in order to reduce the processing time for training.
[h] The AdaBoost algorithm[1] Training set
A classifier
The final strong classifier is:
where
Parallel computing
In several computational problems and applications serial computing is not fast enough to obtain a solution in a reasonable amount of time. Parallel computing is an alternative approach to solve problems requiring of intensive computation and/or handling huge amounts of information [16].
Parallel computing allows the concurrent execution of tasks, in such a way that a single processing load is divided and solved through different processing units. There are several parallel processing schemes, such as having a single instruction or a single program processing multiple data concurrently. At an algorithmic level several considerations must be made, such as data dependency.
It is important to mention that parallel schemes can not be defined for all algorithmic problems. In addition, a parallel processing scheme has some characteristics in order to operate in a correct and efficient way. These characteristics include the following [3]:
Granularity: defines the number of processor elements among which the processing load is divided:
Coarse-grained. A number of tasks are grouped and therefore more intensive computing is required per processing unit. Fine-grained. A minimum number of tasks are grouped implying processing elements are less complex and carry out much less intensive computing. Types of parallel processing:
Explicit. Instructions are included within the program to explicitly specify which tasks are executed in parallel. Implicit. Instructions are inserted by the compiler for parallel program’s execution. Synchronization prevents overlapping of two or more processes. Latency relates to information transition time from request to receipt. Scalability is the parallel’s scheme ability to maintain its performance while increasing the number of processors or the problem size.
In terms of processing architectures, a general taxonomy divides them in multiple cores and many cores processors. Multiple cores processors sequentially execute instructions among processing cores or parallelize their execution to a certain level. On the other hand, many-cores processors are designed to implement different parallel execution schemes such as the Single Instruction Multiple Data (SIMD) and can achieve massively parallel execution [16]. Graphic Processing Units (GPUs) are many-cores architectures that are able to execute Single Program Multiple Data (SPMD) schemes. GPUs are able to launch thousands of threads for execution achieving significantly better processing times on difficult computing tasks in different application arenas.
CUDA (Compute Unified Device Architecture) was introduced by NVIDIA in 2006, in order to open the usage of GPUs for general purpose computing. CUDA is a software-hardware architecture that enables GPUs to be programmed at a higher level while taking advantage of their implicit massive parallelism [16].
GPU-based architectures have evolved very rapidly through recent years. A GPU architecture consist of a number of streaming multiprocessors (SM) that has access to global and local memory levels. Every SM contains a number of CUDA cores which are smaller processing units that carry out parallel programs execution. The number of SM varies according to the GPU module and it has improved over the years in terms of number of processing elements, memory sizes and access schemes, complexity of arithmetic logic units, power consumption among others.
Starting with the G80 (2006) and evolving into the FERMI architecture (2008), NVIDIA GPUs increased the number of processing cores from 128 to 240, defined larger register file sizes, improved memory access and supported double precision floating point. Latest GPU architectures known as Kepler and Maxwell have improved by doubling the shared memory size, increasing the number of threads per SM, the number of available registers, as well as the grid configuration size. These architectural improvements have allowed a remarkable improvement in terms of performance when targeting complex computational problems such as image processing tasks.
At a programming level, CUDA introduces some concepts that are necessary to launch a parallel process in the GPU. A kernel is a set of algorithmic steps to be executed in the GPU. It is necessary to configure the size of the grid and the thread-block, both are tightly related with the application that is accelerated. Instructions need to be set to indicate which execution lines are for the GPU (device) or for the CPU (host). Input data is normally transferred from CPU to GPU and viceversa, although necessary data transfers between host and device take considerable time and need to be kept to minimum (see Fig. 4).
Structural diagram of CPU and GPU [16].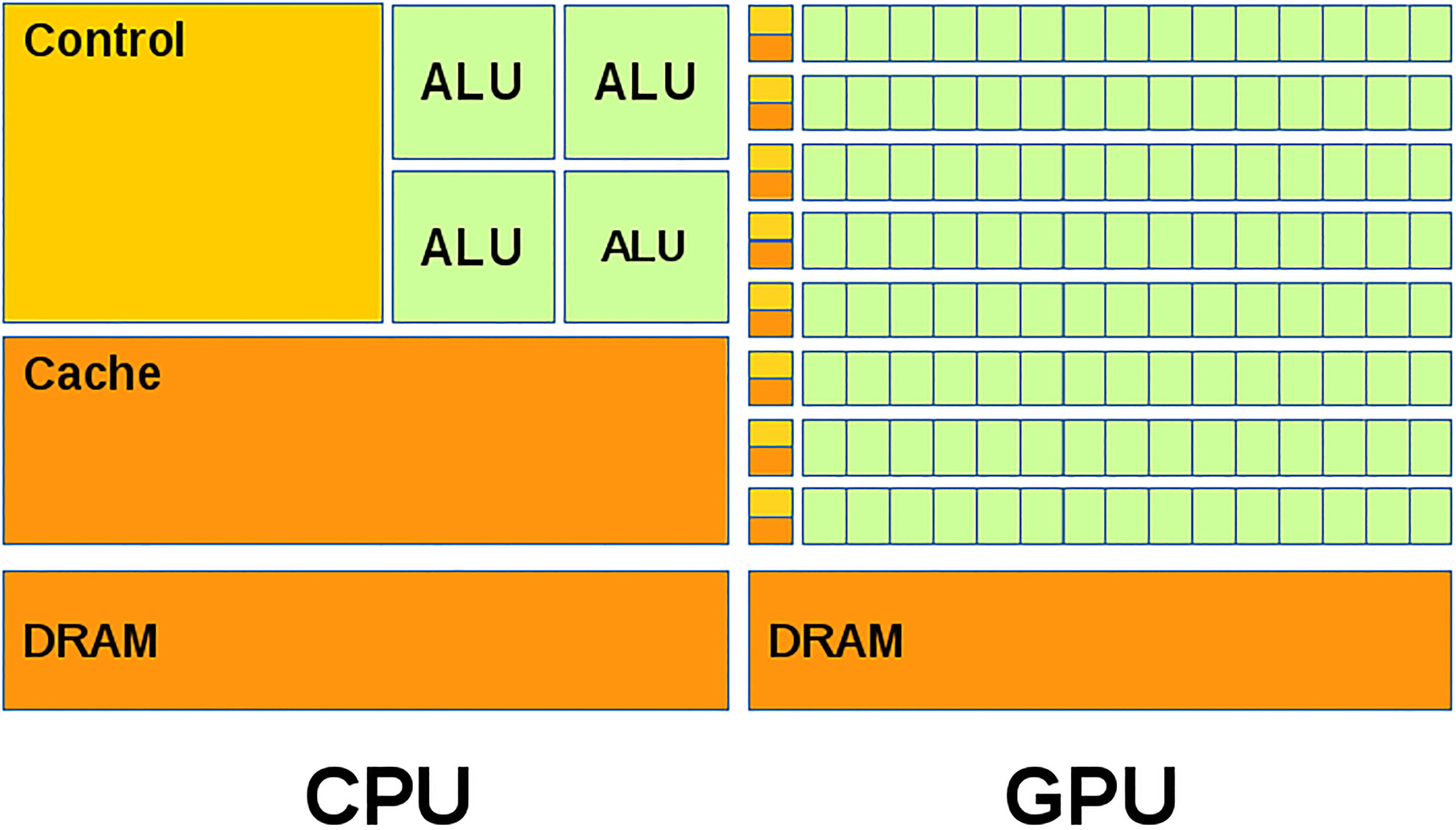
Diagram for parallel computation of the integral image.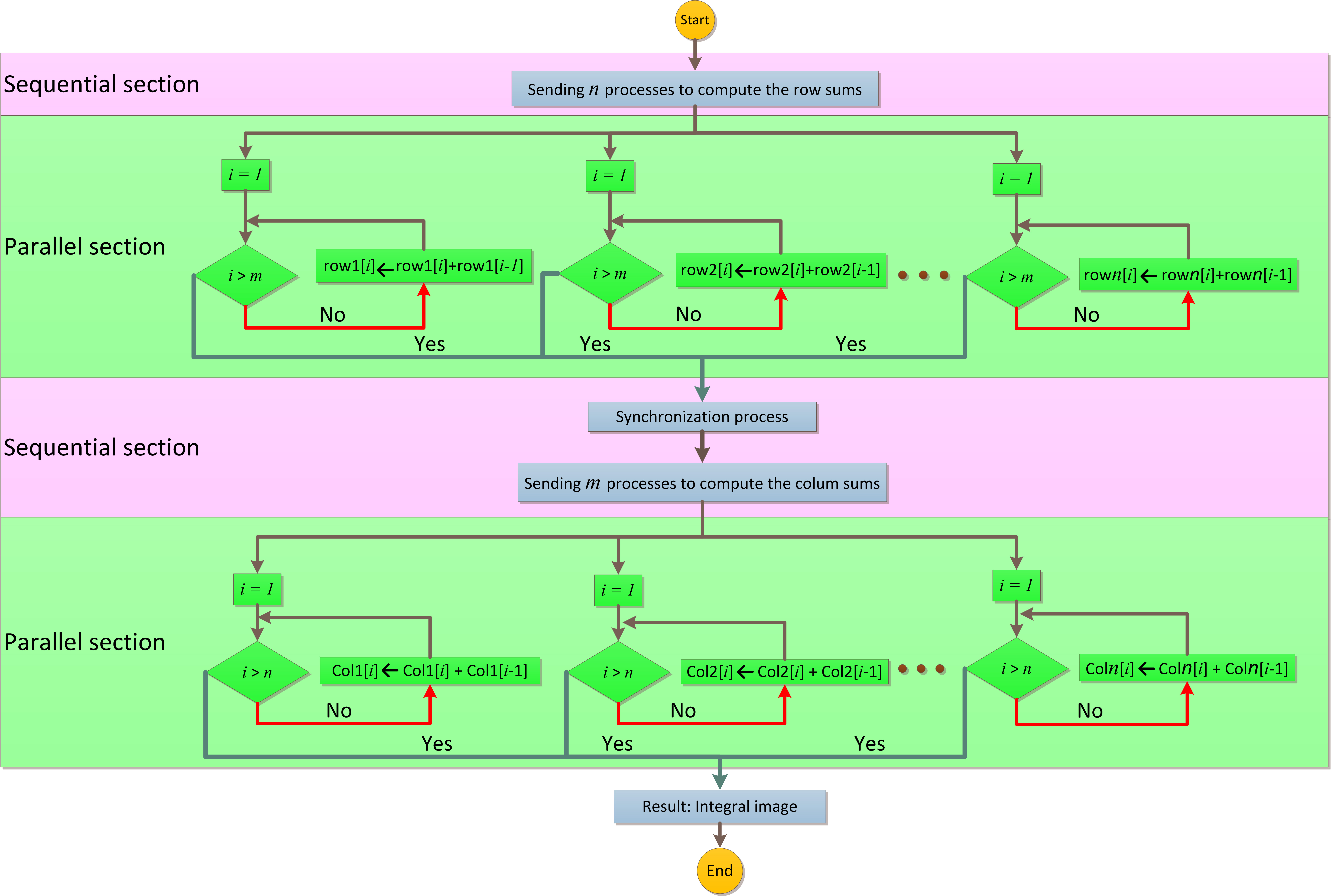
Parallel computation of the integral image. In (a) the sum is calculated for rows, while in (b) for columns.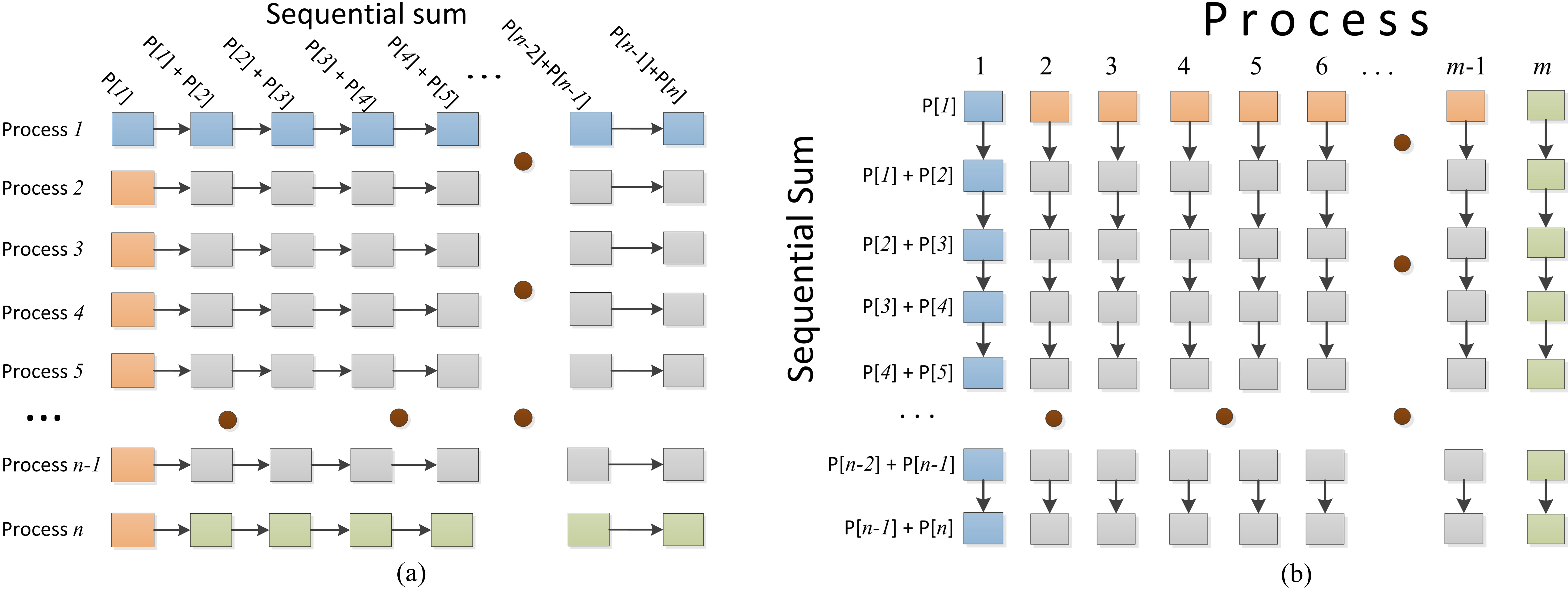
This section presents the proposed parallel computational model targeting the training stage of the Viola-Jones algorithm, comprising the estimation of integral image, generating the haar-like feature and evaluating the obtained features.
Parallel estimation of the integral image
The integral image can be calculated using a sequential double sum. First, row pixels are added, considering all previous elements in all rows. After, corresponding pixels in a column are added, considering also all previous columns. Addition of rows and columns can be calculated independently and therefore a parallel approach can be implemented.
Figure 5 shows the two stages of parallel processing to calculate the integral image: first,
Figure 6 shows the steps of the proposed parallel approach for calculating the integral image graphically. Figure 6a shows the sum considering rows for every pixel with previous ones. After that, there is a delay when all processes are finished using a synchronization process. In (b) is shown the same process but for each column. The sum in one row and one column is performed in sequential way, however it is extended to several rows and columns in parallel.
It is necessary for every block of threads executing in parallel to synchronize. In the proposed model, the integral image is calculated in the following order: rows first, once this stage is completed, columns are calculated. Internally, CUDA executes a synchronization stage in order to avoid running conditions when accessing memory.
CUDA defines a number of built-in identifiers in order to map input data, in this case image data
[h] Pseudocode to compute the integral image using CUDA[1] Vector of the gray scale image GI Vector of the integral image II First, image rows are processed.
Then, the columns are processed.
Steps 2 and 8 are the parallel start of all
Step 4 scans across the image width and to each element that adds the previous one. This process is done in parallel by row, i.e. there is one task for each row. Each sum is performed sequentially, therefore,
Step 10 corresponds to the calculation of the image integral for columns. In this case the index
Finally, the sums of Steps 3 and 4 for the rows, and 9 and 10 for the corresponding columns, provide the integral image as described in the background section.
Parallel generation of haar-like features
According to Viola and Jones viola-2001, 160,000 features can be generated using images of size of 384
The proposed method for creating the haar-like features is composed of two stages: the first one runs in sequential order while the second one in parallel. The creation process starts considering one type, among the four types of haar-like features. Then, a validation process is performed with the goal of finding features within the search window. When a feature is found, this one is stored into a queue data structure; otherwise the feature will be scaled to height and the process will be repeated. Once the feature has reached the maximum height size of the search window, the feature will be scaled to width, and the process will be repeated. When the process has finished another feature will be selected, and the process will be started until all types of features have been considered. Figure 7 shows the parallel process to create all possible haar-like features within the window.
[h] Pseudocode for creation of haar-like features using CUDA (sequential section)[1] Integral image vector II
Parallel process to create haar-like features.
Algorithm 3.2 shows the pseudocode of the sequential section for feature creation. Steps 1 and 2 run two loops, where the scaling, width
[h] Pseudocode for one type of haar-like feature creation using CUDA (parallel section)[1]
Feature selection process.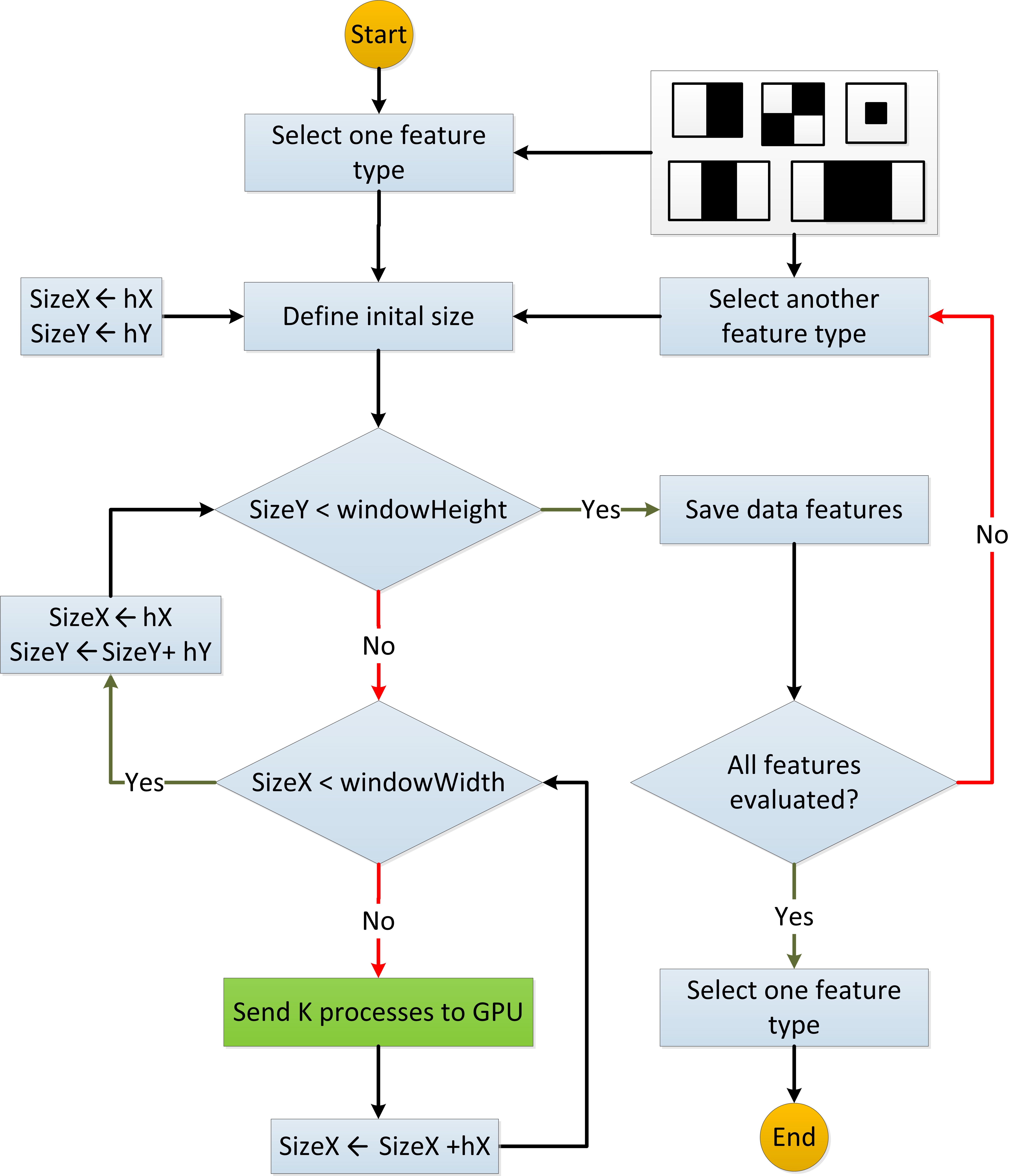
Diagram for parallel feature evaluation.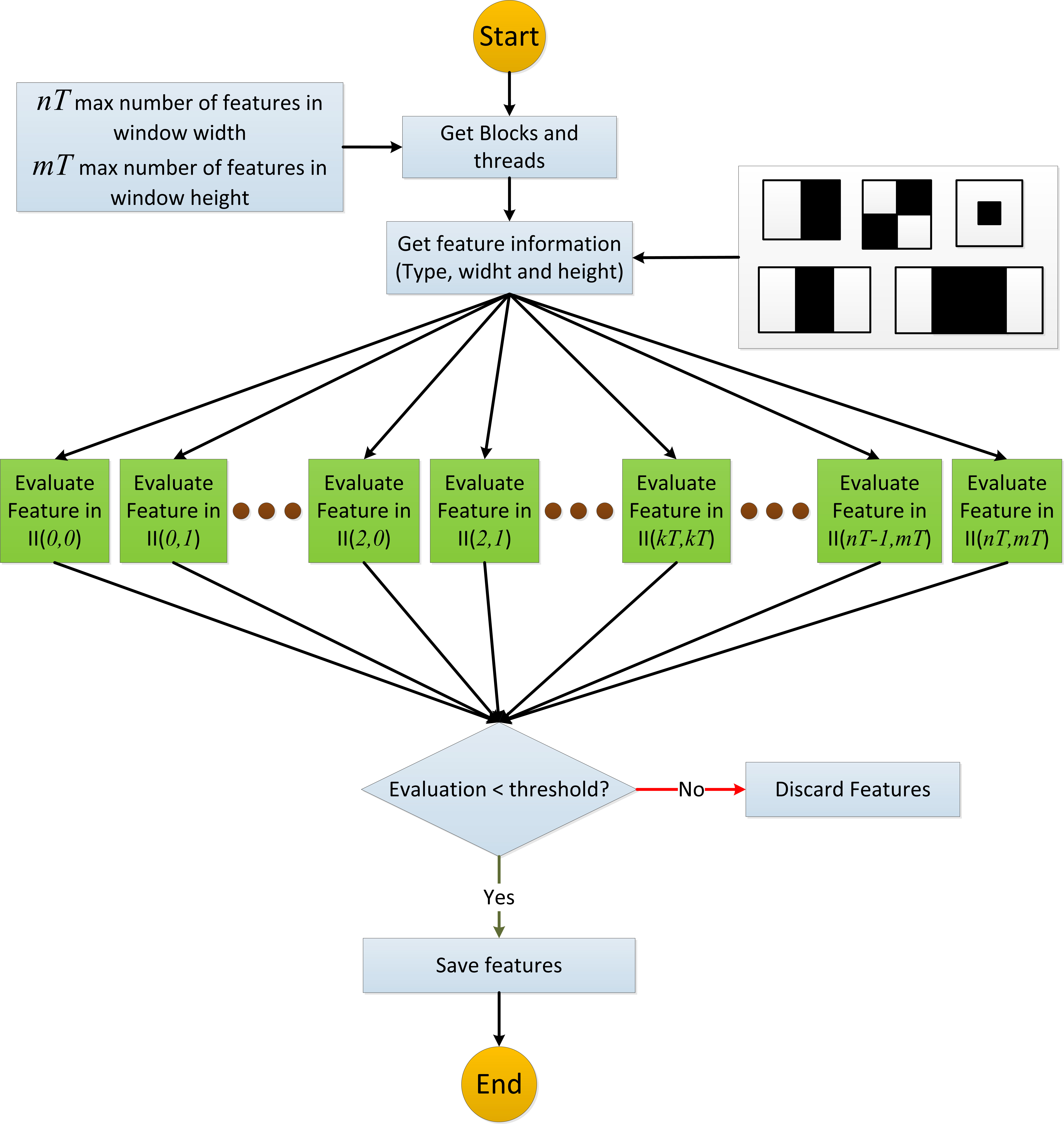
Algorithm 7 describes the feature creation process according to a specific type, width and height, using a window size of 24
Once all features are created, the next step is to evaluate them within the integral image. This process is performed during the training stage to determine if the selected features correctly classify the objects.
First, in Fig. 8, is shown the process to select features. Then, once the features are obtained,
Algorithm 3.3 shows the pseudocode to accept a valid feature. In Step 1 a identifier of the task is defined while in Step 2 all tasks start in parallel. Step 3 evaluates a specific feature of the array, this corresponds to the function in Step 10. Then, in Step 11 the variable ret sets as the sum of intensities of the first 2 rectangles. Steps 12 and 13 are the sum of the third rectangle, and the result is returned in Step 15. In the main function, if the evaluation is less than a threshold, the information of the feature is stored in another array, otherwise zeros values are assigned to all positions of the same array. The last action was done, because all threads blocks in CUDA execute the instructions concurrently even for those where no features were found. Thus, if there is a valid feature, data is stored, otherwise zeros are assigned.
Pseudocode for haar-like features evaluation using CUDA[1]
At the end of the evaluation process the error is validated for each classifier and will be chosen the one with the least error using the Eq. (5). This equation comes from the Adaboost Algorithm 2.1.3, where it is used for calculating single errors from classifiers (Line 6).
where
The experiments were carried out using a personal computer with AMD
Different sizes of images were tested for the integral image computation. Thus, the experiments were performed using five datasets with ten images each with sizes: 256
Table 1 shows the processing times of the first parallel task, the integral image computation, while in Fig. 10 is shown a comparative graph. We can observe from these results, that our approach obtained lower times than OpenCV in almost all cases. Only in one result, our approach was not able to obtain the best result, that is for images of size of 256
Results for the integral image computation using OpenCV and our approach
Results for the integral image computation using OpenCV and our approach
Results for creating haar-like features using OpenCV and our approach
Comparative time-graph of CPU vs GPU for the integral image computation.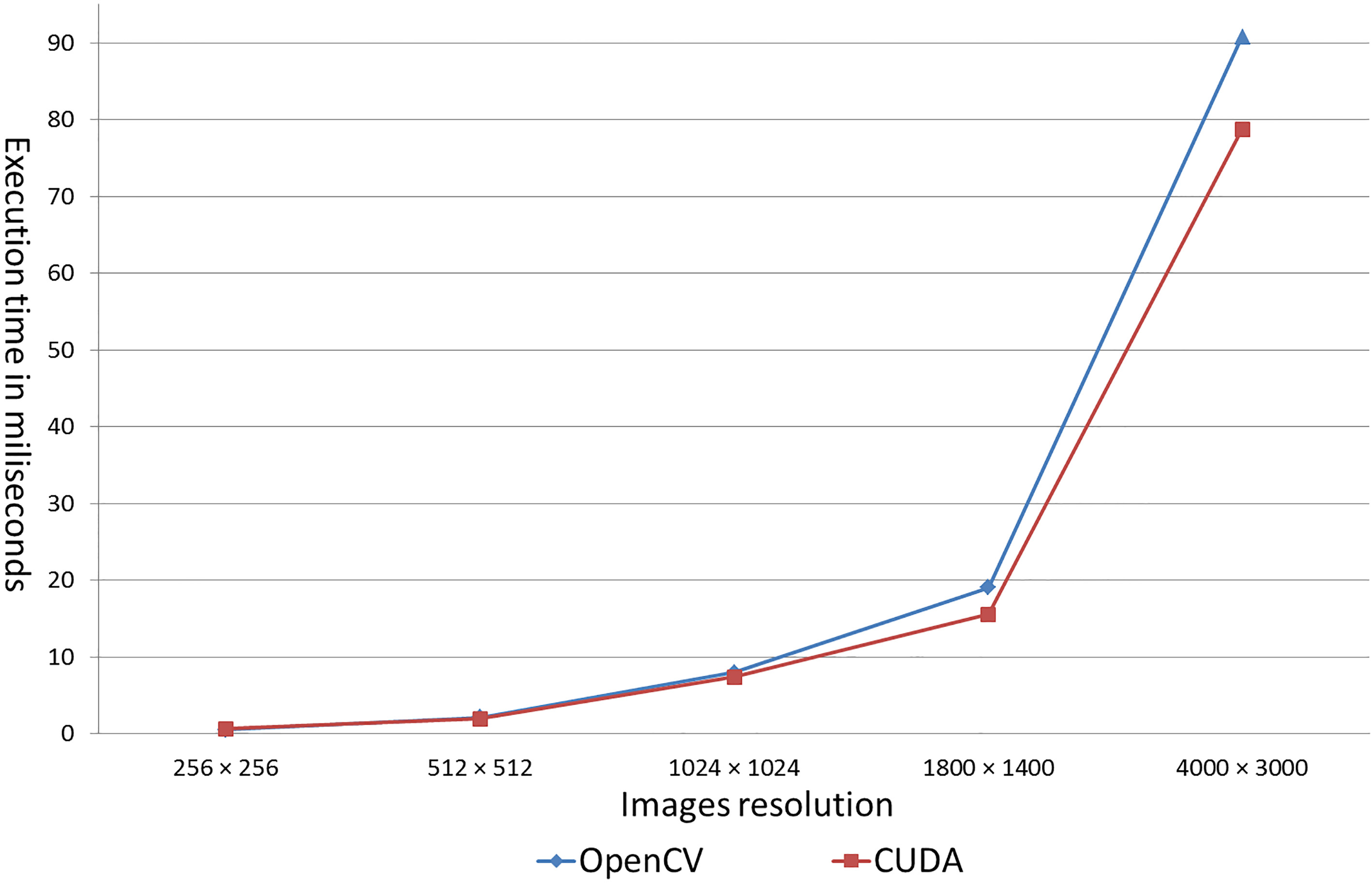
Results of times in miliseconds for haar-like features evaluation using CUDA
Comparative graph of execution times of our approach vs CPU for haar-like features creation.
Table 2 shows the results for haar-like feature creation using OpenCV and our proposed approach. In all results, the proposed solution using CUDA obtained lower processing times than the OpenCV ones; in fact, we can observe that our results almost reduce by half the others. The experiments for creating all possible features were calculated using a window of 24
Figure 11 shows the execution times for creation of features. We can observe that some executions obtained results lower than 10 milliseconds in most of the cases. This may be due to the run-time system of CUDA, because the processes are sent to the core by this system trying to take advantage of the maximum number of cores.
The last proposed parallel task was for evaluating the haar-like features. This evaluation was performed using images of size of 50
In this work we have presented a parallel approach for three tasks of the Viola-Jones face detection algorithm, particularly for the training stage. The three tasks are the following: the integral image computation, haar-like features creation, and evaluation of these features. Thus, we have proposed three parallel algorithms applied to the face detection problem in computer vision that demand high computing resources in real time processing. The CUDA programming model was used to accelerate the calculation of these tasks. Our experimental results have shown that the proposed methods improve OpenCV implementations. In fact, for the integral image computation our approach obtained lower processing times in almost all cases, for different image sizes. Also, for feature creation the proposed method obtained lower times in all experiments. In the future, we plan to implement the proposed methods on new GPU architectures such as the NVDIA’s next generation Kepler. In addition, to develop parallel methods for other object detection algorithms which involves large computational loads.