
Abstract
Established associative classification algorithms have shown to be very effective in handling categorical data such as text data. The learned model is a set of rules that are easy to understand and can be edited. However, they still suffer from the following limitations: first, they mostly use the support-confidence framework to mine classification association rules which require the setting of some confounding parameters; second, the lack of statistical dependency in the used framework may lead to the omission of many interesting rules and the detection of meaningless rules; third, the rule generation process usually generates a sheer number of rules which puts in question the interpretability and readability of the learned associative classification model.
In this paper, we propose a novel associative classifier, SigDirect, to address the above problems. In particular, we use Fisher’s exact test as a significance measure to directly mine classification association rules by some effective pruning strategies. Without any threshold settings like minimum support and minimum confidence, SigDirect is able to find non-redundant classification association rules which express a statistically significant dependency between a set of antecedent items and a consequent class label. To further reduce the number of noisy rules, we present an instance-centric rule pruning strategy to find a subset of rules of high quality. At last, we propose and investigate various rule classification strategies to achieve a more accurate classification model. Experimental results on real-world datasets show that SigDirect achieves better performance in terms of classification accuracy when measured with state-of-the-art rule based and associative classifiers. Furthermore, the number of rules generated by SigDirect is orders of magnitude smaller than the number of rules found by other associative classifiers, which is very appealing in practice.
Introduction
The concept of association rule mining was first introduced by Agrawal et al. [1] and extensively studied in the past two decades [2, 19, 3]. Association rules describe correlation between items in a transaction database. Assume a transaction database
Classification is another canonical task in the data mining and machine learning community. Given a set of attributes for an object, a classifier tries to assign the object to one or more pre-defined classes. A typical classification method consists of two steps: firstly, it builds a model on the training dataset whose attributes and class labels are known in advance; then the ability of the model to correctly classify objects in the test dataset is evaluated.
Recent studies on associative classification integrates association rule mining and classification together [25, 23, 4, 9]. These associative classifiers have proven to achieve competitive classification accuracies as decision trees [27], rule inductions [26, 13], naïve-bayes [15] as well as some probabilistic methods [24]. Besides, instead of taking a greedy algorithm as most rule-based classifiers, associative classification directly mines the complete set of rules to avoid missing any important ones. Another advantage of associative classification is that each individual rule in the model is human readable. To classify an object, associative classifiers first adopt association rule mining techniques to mine classification association rules (CARs) with given support-confidence thresholds and constrain the consequent of the rule to be a class label. Then a subset of CARs after pruning are selected to form the classifier, the selection is usually made by utilizing the database coverage heuristic [25]. Finally, once the classifier is built, it chooses one or more matching CARs to make predictions on the test dataset.
The existing associative classification methods mine the complete set of CARs mostly in an apriori-like fashion [2] or through a FP-growth way [19]. Although the rule generation process might be slightly different, all of them use the support-confidence framework to find CARs for classification. However, it is difficult to determine the appropriate support and confidence thresholds for each dataset without any prior knowledge. Furthermore, traditional association rule mining methods are based on frequency to prune infrequent patterns. The strength of a rule is decided afterwards with its confidence value. Therefore, CARs cannot capture the actual statistical dependency between attributes and corresponding class. In the worst case, it may only find spurious CARs while leaving statistically significant dependent CARs undiscovered. These two types of scenarios are called type 1 error and type 2 error. Table 1 shows an example of these two types of errors.
An illustrative example of type 1 error and type 2 error
An illustrative example of type 1 error and type 2 error
.
A transaction database is shown in Table 1. Let min_support
To avoid missing any strong CARs, most associative classifiers maintain a small minimum support threshold, but it is still possible to encounter the type 2 error and at the same time it introduces a new problem: association rule mining methods end up generating a huge number of CARs making them impossible to be manually edited and even defeating the readability of the classification model. From another perspective, some post-processing strategies have been proposed to alleviate the type 1 error [23, 7, 11, 32], but the discovered CARs are still not statistically significant and are more or less confronted with type 1 error and type 2 error. In addition, even though that we could find statistically significant CARs, it is still not clear how to reduce noisy CARs and how to make use of multiple informative CARs for a final classification model.
Therefore, in this paper, we propose a novel associative classifier, SigDirect (Statistically SIGnificant Dependent ClassIfication Association RulEs for ClassificaTion). The main contributions of this work are as follows:
We propose a novel associative classifier, SigDirect. It achieves a competitive or even better classification performance as the state-of-the-art rule based and associative classifiers while generates an order of magnitude less of classification association rules. By pushing the rule constraint in the Kingfisher algorithm, we are able to find the complete set of CARs that show statistically significant dependencies efficiently. To reduce noisy CARs, we propose an instance-centric rule pruning strategy to find a globally optimal CAR for each instance in the training dataset without jeopardizing the classification accuracy. In the classification phase, we propose and investigate different rule classification methods to study how to make a label prediction with multiple matching CARs.
The remainder of the paper is organized as follows: Section 2 gives a view of related work on associative classifiers. In Section 3 we introduce the general steps to build the proposed associative classifier SigDirect. Section 4 presents the experimental results. We summarize our work in Section 5.
This section first gives a brief introduction about associative classification and then introduces some popular associative classifiers.
The first reference to using association rules as CARs is credited to [10], while the first classifier using these CARs, CBA, was introduced in [25] and later improved in CMAR [23], ARC-AC and ARC-BC [4]. The idea is very straightforward. Given a training dataset modeled with transactions where each transaction contains all features of an object in addition to the class label of the object, we can constrain the mining process to generate association rules that always have as consequent a class label. In other words, the problem consists of finding the subset of strong association rules of the form
Rule Generation: In this phase, a mining algorithm is used to find classification association rules (CARs) of the form Rule Pruning: The rule generation process usually generates a large number of CARs, especially when the minimum support threshold is very low. Pruning techniques are used to discover the best subset of CARs that can cover the training dataset, meanwhile, they weed out noisy CARs that may mislead or overfit the classification model. Database coverage [25] is the most widely used pruning method which checks the extent of exposure of CARs in the training dataset. Classification: In this phase, the model is able to make a class label prediction for a new unlabeled object. How to utilize the set of left CARs to make a correct prediction is a challenging problem. CBA [25] classifies an object using the matching CAR with the highest confidence. However, making a prediction with a single CAR may lead to poor results. CMAR [23] adopts a chi-square weighting scheme to make a prediction, while ARC [4] predicts new objects using the average confidence of the selected matching CARs within a confidence margin.
There are some other variants for associative classification: Harmony [30] is an example which directly mines CARs, it directly finds the highest confident rule for each training instance and builds the classification model from the union of these rules. It shows to be more effective and scalable than other associative classifiers. 2SARC [6] is a two-stage classification model that is able to automatically learn to select the rules for classification. In the first stage, an associative classifier is learned by standard techniques. Second, multiple predefined features are computed on the associative classifier, they act as input to a neural network model to weigh different features of the associative classifier to achieve a more accurate classification model. CCCS [7] uses a new measure, “Complement Class Support” (CCS) to mine positively correlated CARs to tackle the imbalanced classification problem. It forces the measure of CCS to be monotonic, thus the complete set of CARs are discovered by a row enumeration algorithm. An associative classifier is then built upon these positively correlated CARs. SPAR-CCC [29] is another associative classifier designed for imbalanced data. It integrates another new measure, “Class Correlation Ratio” (CCR) into the statistically significant rules, the classifier works comparably on balanced dataset and outperforms other associative classifiers on imbalanced dataset. ARC-PAN [5] is the first associative classifier that uses both positive and negative CARs. It proposes to add Pearsons correlation coefficient on the basis of the support-confidence framework to mine positively and negatively correlated CARs. The ability of negative CARs have been demonstrated by their usage in the classification phase. Li and Zaiane [21] proposed to leverage both positive and negative CARs that show statistically significant dependencies for classification and the proposed classifier achieves competitive and even better performance compared with other rule based and associative classifiers.
This section introduces the proposed associative classifier, SigDirect. Similar as most existing associative classifiers, SigDirect consists of three phases: rule generation, rule pruning and rule classification. Before talking about the detailed steps, we introduce some notations and definitions used in this paper.
Basic notations and definitions
.
Dependency of a CARLet
.
Fisher’s exact testThe dependency of the CAR
where
.
ConfidenceThe confidence of the CAR
.
Parent and Child CARLet the CAR
.
Non-redundant CARsThe CAR
.
MinimalityThe CAR
Rule generation
To find the relevant rules for classification, SigDirect first needs to generate the complete set of statistically significant dependent CARs. It means to find rules in the form of
.
[16, 17] In a transaction database
.
[16, 17] In a transaction database
Given these two theorems, we derive three corollaries that enable us to generate statistically significant CARs.
.
There exists a threshold
Proof..
Corollary 1 is a special case of Theorem 1 when
Some impossible items are pruned before further analysis by Corollary 1. It is assumed that
Enumeration of the whole search space.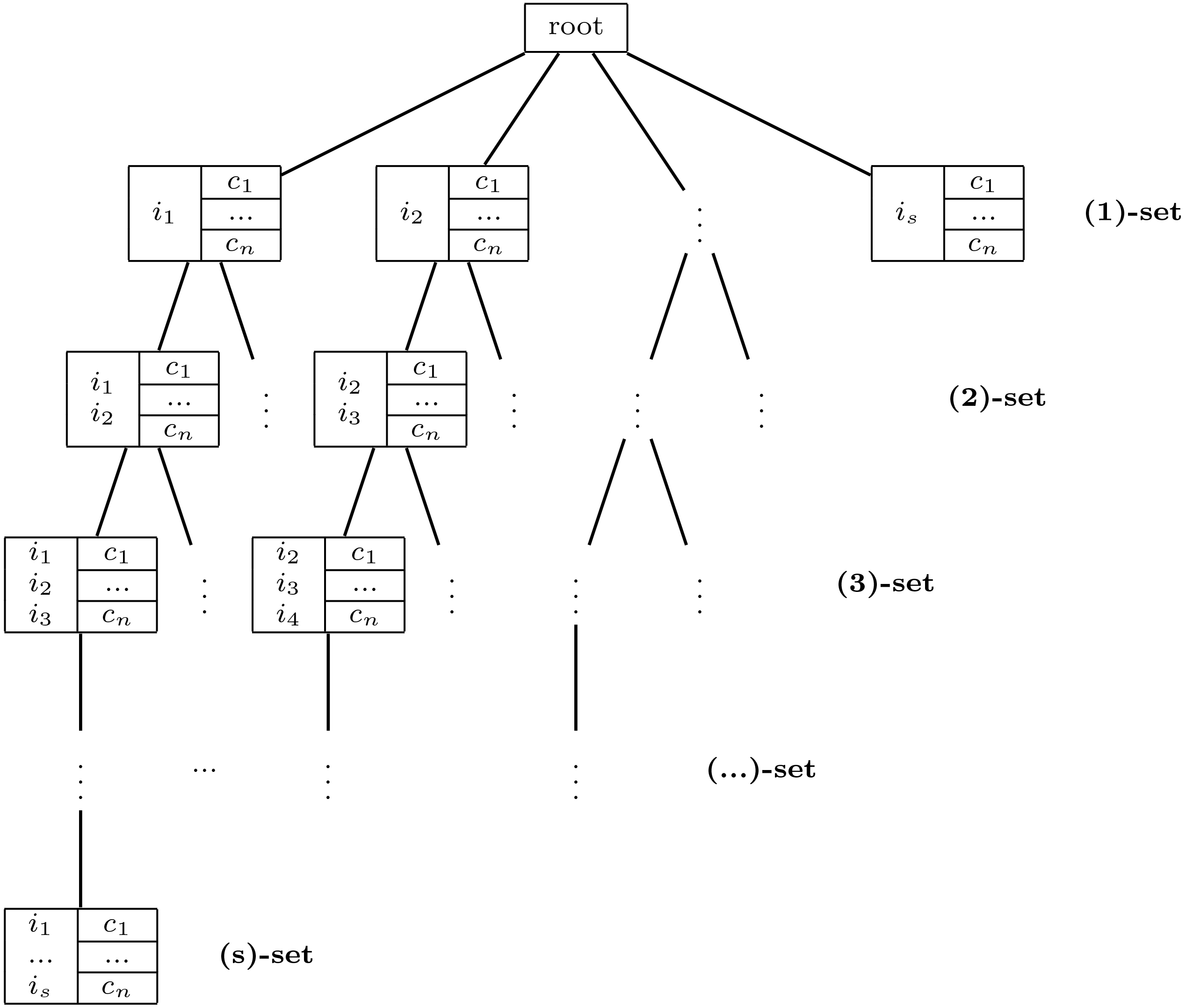
.
For any
Proof..
Corollary 2 can be considered as a special case of Theorem 2 when
According to Corollary 2, the lowest value of
.
The CAR
If a CAR is PSS, we need to calculate the exact
.
If CAR
Proof..
There are two situations making
With these three corollaries, the whole search problem can be summarized as follows. We first use Corollary 1 to prune impossible items, sort and rename the remaining items in an ascending order by their support. Next, all candidate CARs with only one antecedent item are listed. We then use Corollary 2 to check if they are PSS, non-PSS candidate CARs can be pruned directly without further analysis. PSS CARs are further checked to see if they are indeed statistically significant. From PSS 1-itemset CARs, we generate candidate PSS 2-itemset CARs by Corollary 3. The process repeats until no PSS CARs are generated at a certain level. It also needs to be mentioned that in the searching process, the minimality of the CARs is considered, if the CAR is marked as minimal, we stop the expansion from this CAR because all of its children CARs are impossible to get a lower
In the rule generation phase, we have taken the non-redundancy property into consideration. However, the number of statistically significant dependent CARs could still be very large. One possible disadvantage of a large number of CARs is that it could contain some noisy information which may mislead the classification process. Another drawback is that a large number of CARs will make the classification process slower. This could be a problem in applications where fast responses are required. Moreover, in classification applications where evidence checking is required, rule-based models are an advantage but a large number of rules is a significant drawback and defeats the purpose. In order to reduce the number of CARs in the classification phase, many associative classifiers take a sequential database coverage paradigm. However, the final set of CARs may not be the globally best CARs for some instances in the training dataset. In order to reduce the number of CARs and to find the globally best CARs for all training instances, we propose an instance-centric rule pruning approach to select the best CAR for each instance in the training dataset, the best CAR is defined as the matching CAR with the highest confidence value. Each candidate CAR may be selected by multiple training instances, therefore, each candidate CAR is associated with an attribute “count”, it records how many times the CAR is selected in the pruning process. The detailed algorithm is shown in Algorithm 3.3.
[h] Transaction database
[h] Set of statistically significant dependent CARs
Classifying new instances
After the rule pruning phase, the subset of the most statistically significant dependent CARs form the actual classifier. In this phase, we utilize the built classifier to make new predictions. Given a new instance without a class label, the classification process searches the subset of CARs matching the new instance to make a class label prediction. This subsection discusses three approaches that we take to label new instances.
A simple solution is to select the matching CAR in
Then, we propose three different heuristics, denoted as S1, S2 and S3, to consider the sum of
S1: Calculate the sum of S2: Calculate the sum of confidence of matching CARs in each class, the class label of the new instance is determined by the class of the highest value. S3: Calculate the sum of
Algorithm 3.4 describes three heuristic classification methods for an unlabeled new instance.
[h] A new instance
Datasets
We evaluate our SigDirect method on 20 datasets from UCI Machine Learning Repository [8]. In these datasets, the numerical attributes have been discretized by the author of [12], the discretization strategy is different from that used in [25, 23], thus the classification performance may be different from the results reported before. All the following experimental results on each dataset are reported as an average of a 10-fold cross validation.
Comparison of classification results: C4.5, FOIL, CBA, CMAR, CPAR and SigDirect
Comparison of classification results: C4.5, FOIL, CBA, CMAR, CPAR and SigDirect
We evaluate our SigDirect with three different classification strategies S1, S2, S3 against two rule-based classifiers C4.5 [27] and FOIL [26], two associative classifiers CBA [25], CMAR [23] and a hybrid between rule-based and associative classifier CPAR [31] on the previous mentioned 20 discretized UCI datasets. The results are reported in the form of average classification accuracy over 10-folds. All classification methods are evaluated on the same generated 10-folds to ensure a fair comparison. The parameters of C4.5 are set as default values [27]. In FOIL, we allow a maximum of 3 attributes in the antecedent of a rule. In CBA and CMAR, the minimum support is set to be 1%, the minimum confidence is 50%, the maximum number of antecedent items and the maximum number of mined CARs are set to be 6 and 80,000, respectively. In CPAR, we also follow the same parameter settings as [31], minimum gain threshold set to 0.7, total weight threshold to 0.05 and decay factor to 2/3.
Table 2 presents the classification accuracy of the following methods: C4.5, FOIL, CBA, CMAR, CPAR and our SigDirect method with three different classification heuristics S1, S2 and S3. Along with the accuracy result, the name of the dataset, the number of antecedent attributes on the discretized transaction dataset, the number of classes and the number of records are also reported.
As can be observed from Table 2, the proposed SigDirect with S2 achieves the best overall classification accuracy, followed by SigDirect with S3 and SigDirect with S1. All of these three classifiers outperform C4.5, FOIL, CBA, CMAR and CPAR on the average over the 20 datasets.
To have a more fair comparison between these classifiers, we show how many times the classifier is the best and how many times it is the runner-up. Table 3 shows the comparison results, SigDirect with S2 (classify by the sum of confidence) is still the best among these classifiers. It wins 7 out of 20 datasets, i.e., 35% of all datasets, and is the runner-up 5 times. CMAR, in the second place, wins in 5 datasets and gets the runner-up three times. Combing the comparison results from Tables 2 and 3 together, SigDirect with S2 is always the best, SigDirect with S1 and SigDirect with S3 can be considered as competitive classifiers. It demonstrates that in the classification accuracy aspect, our SigDirect classification method can be viewed as a better classifier when measured against state-of-the-art rule based and associative classifiers.
Best and runner-up counts comparison
Best and runner-up counts comparison
In associative classification, the number of CARs before and after rule pruning are both very important indicators to measure a classifier. On one hand, if we get a small number of CARs after rule generation, people are able to sift through these rules to determine validity, to choose a subset of them or even to edit them to inject domain knowledge not reflected in the training data. Moreover, rule pruning strategies are possible since these rules are more readable. On the other hand, a small number of rules after rule pruning can make the classification phase faster. In addition, after rule pruning, because of transparency of the rules, manually updating some rules is favourable and practical in many applications if the number of rules is reasonable. Therefore, in this subsection, we evaluate the number of CARs generated by our SigDirect algorithm and the number of CARs after pruning strategy. Table 4 shows the number of rules of two associative classifiers CBA, CMAR and our SigDirect method. The number of rules before and after rule pruning are both presented. We also list the number of rules in C4.5, FOIL and CPAR in Table 4. All the parameter settings of these classifiers are the same as the previous subsection. We also need to notice that CBA and CMAR use Apriori and FP-growth to generate CARs. The number of rules generated by these two methods should be the same. In CBA and CMAR, the rule generation stops if the number of rules is larger than 80,000, but even in this situation, we can find that the number of CARs generated by SigDirect is much smaller than that generated by CBA and CMAR. In most datasets, the number is even an order of magnitude smaller. It can also be observed, after rule pruning, the number of rules by SigDirect is smaller than that by CBA in 13 datasets, when compared with CMAR, the number of rules are smaller in all 20 datasets. Furthermore, in 17 datasets, the number of rules is below 100, which make it more readable and more manually editable.
All in all, SigDirect dramatically reduce the number of CARs compared with CBA and CMAR in the rule generation phase without jeopardizing accuracy and even improving it. After rule pruning, the number of rules for classification is still smaller than that by CBA and CMAR. The overall smaller number of rules makes SigDirect superior to other associative classifiers when there is slight difference between classification accuracies. The number of rules remains comparable and even smaller than the case of C4.5, FOIL and CPAR.
Comparison of the number of rules generated by different classifiers
Comparison of the number of rules generated by different classifiers
In SigDirect, we propose an instance-centric method to do rule pruning to reduce the number of CARs. Here, we first compare the effect of this pruning strategy with the database coverage paradigm. In Table 5, the classification results with these two different rule pruning strategies are presented and compared. As can be observed, the classification accuracy indeed improves when we take the instance-centric pruning strategy, no matter what kind of classification heuristics are used. The average classification accuracy is higher around 1% to 2%.
Comparison of instance-centric and database coverage pruning methods
Comparison of instance-centric and database coverage pruning methods
Comparison of classification heuristics S1 with (B1, A1), S2 with (B2, A2) and S3 with (B3, A3)
In order to investigate the efficacy of some measurement
B1: Select the matching rule with the lowest A1: Calculate the average value of B2: Select the matching rule with the highest confidence value, the class label of the new instance is determined by the selected rule; A2: Calculate the average of confidence value for matching rules in each class, the class label of the new instance is determined by the class of the highest value; B3: Select the matching rule with the lowest A3: Calculate the average of
As shown in Table 6, S1, S2 and S3 have a better classification performance than their counterpart (B1, A1), (B2, A2), (B3, A3), respectively. Table 7 shows the count of wins, losses and ties for S1, S2 and S3 when compared with their alternatives.
Classification heuristics S1, S2, S3 compared with their alternatives
From these two tables, it can be concluded that the classification heuristics in the “A” category are always the worst, “B” category heuristics are better than “A” category, but are still not as good as “S” category heuristics. Therefore, the classification heuristic that classifying a new instance by the sum of measurement
From Table 2, we can conclude that our SigDirect algorithm gets better classification performance compared to other methods and the confidence is a better measure when measured against
To better validate the conclusions we get, we use Demsar’s [14] method, conducting a set of non-parametric statistical tests to compare different classifiers over multiple datasets.
In the first step, Friedman test is applied to measure if there is a significant difference between different classification models on Table 2. We first rank different classifiers on each dataset separately,
when
The Friedman statistic of 8 classification methods from Table 2 exceeds the critical value, so we continue to use Wilcoxon signed-ranks test to compare the differences between different methods pairwisely. In Wilcoxon signed-ranks test,
Let
If
A series of Wilcoxon signed-ranks tests from Tables 2, 4–6 are listed in Table 8. It shows the count of wins, losses, ties and corresponding
In this paper, we study the problem using statistically significant dependent CARs for classification and propose a novel associative classifier SigDirect. The proposed associative classifier consists of three steps: rule generation, rule pruning and rule classification. In the first phase, we adapt upon the Kingfisher algorithm by pushing the rule constraint in the rule generation phase to enable the discovery of statistically significant CARs. After the rule generation step, there are still many noisy CARs which may jeopardize the classification phase or overfit the model, therefore we propose an instance-centric rule pruning strategy to select a subset of CARs of high quality. At the last step, we present and compare different rule classification methods to ensure the correct prediction of unlabeled data.
The experimental results are very encouraging. The proposed SigDirect classifier achieves better classification results on many real-world datasets when measured against state-of-the-art rule based and associative classifiers. Apart from the promising classification performance, the number of CARs before and after rule pruning phase are both very small, making SigDirect more appealing than other methods when there is little difference in classification performance. The number of CARs before rule pruning phase is even an order of magnitude smaller than that by CBA and CMAR. After rule pruning phase, the number of rules is still very small. The small set of CARs in both phases makes it possible and practical for users to sift through them to edit and update according to their own needs, which can be very important in many applications.