
Abstract
There is a need for robust solutions to the challenges of spatio-temporal data quality assessment that include and go beyond assessment of accuracy. Emphasis is often placed on the quality assessment of individual observations from sensors but not on the sensors themselves nor upon site metadata such as location and timestamps. The focus of this paper is on the development and evaluation of such a representative, interpolation-based solution for the assessment of spatio-temporal data quality. We call our method the SMART method, short for Simple Mappings for the Approximation and Regression of Time series. A robust, linear mapping is determined between the observations from pairs of sites over a representative time period and a quadratic estimate of error is derived from these linear mappings. These mappings combine to form a robust interpolator that outperforms other popular interpolators in estimating ground truth in the presence of bad data, and that can be used to estimate ground truth and assess accuracy. The coefficients of the mappings and other derived measures can also help to identify problematic sites, including sites having incorrect location or timestamp metadata. When applied to a real-world, meteorological data set, we identify numerous problematic sites that otherwise have not been flagged as bad. We identify sites for which metadata is incorrect. We believe that there are many problems with real data sets like these and, in the absence of an approach like ours, these problems have largely gone unidentified. Our approach is novel for the simple but effective way that it accounts for spatial and temporal variation, and that it addresses more than just accuracy.
Introduction
The best approach to improving the quality of sensor-data is to start at the source – the sensors – and ensure that they yield observations as close to ground truth as possible. However, it is not feasible to ensure that sensors yield ground truth at all times and under all conditions. Even if sensors are operating correctly, there are numerous potential points of failure: remote processing units (RPUs) that read data from the sensors; intermediate devices that poll the RPUs; middleware that processes sensor data; aggregators and data fusion processes that collect and redistribute the data; networks over which the data is transmitted; software that processes the data, converting it to other units or formats; custom-developed and proprietary software and hardware systems; etc. [1, 2]. And there are many data quality dimensions over which failure can occur including but not limited to accuracy, consistency, timeliness, completeness, reliability, precision [2, 3, 4].
Comparison with neighboring observations is one approach that can be taken to assess accuracy and identify problems in real time or near real time. Assuming correlation of observations having spatial and temporal proximity, we expect similarity in observation. Dissimilarity can indicate errors, i.e., differences between ground truth and observed/sensed conditions. When ground truth is not known, we are left to compare against estimates of ground truth. In making such comparisons, we find ourselves looking at slices in time, and unable to assess overall performance of individual sites. Thus, we find it useful to also compare time series from multiple, neighboring sites to assess the overall quality and fitness of an individual site/sensor.
Comparison of site-based time series becomes complicated when sites report at different times and with varying frequencies. Errors with individual observations further complicate the process when considering their adverse impact on least squares mappings, correlation coefficients, measures of covariance, etc. And if the metadata associated with a site is incorrect, then we may find ourselves comparing observations that are not in spatial or temporal proximity.
Interpolation estimates unknown values on curves or surfaces using known values. Intuitively, interpolation can be applied to assessment of accuracy by estimating ground truth at a location and comparing an observed condition to the estimate. By holding out the observed condition and interpolating at that location using neighboring observations, we can make the desired comparison. However, the errors that we seek to identify in the process of data quality assessment will have an adverse impact on interpolation.
In the absence of ground truth data, we face the challenge of attempting to identify bad data without a solid basis for comparison. As such, we may never truly know if our assessments are correct.
Our contribution: In this paper, we develop a representative, robust, interpolation-based quality assessment algorithm to determine data quality (accuracy) for site-based spatio-temporal data. We develop a representative, artificial data set which we can treat as ground truth and perturb with various types of errors for development and evaluation of our algorithm against ground truth. We then present practical extensions of this method to identify bad sites and bad metadata. We use an interpolated, raster dataset as ground truth for development and evaluation of our methods to identify bad sites and bad metadata. We apply our method to evaluate accuracy and identify bad sites and bad metadata in a prominent, real-world, atmospheric dataset. We demonstrate inconsistencies in provider quality assessment indicators for this dataset.
Scope: In this paper we present an interpolation-based method for quality control assessment of accuracy that is robust and representative, and we demonstrate the challenges of spatio-temporal data quality assessment and how to overcome these challenges. We do not present our method as a general-purpose interpolator. We extend our method to identify problematic sites. We then investigate these sites to verify that they are problematic. We do not attempt to correct erroneous data or improve collection at the source. Others state correctly that correction at the source is the best way to improve data quality [5]. Our objective is to make the most of the data from providers as-is.
Outline: The rest of this paper is organized as follows: Section 1 provides background from a real-life domain and related work, and sets the stage for our approach. SMART Mappings are presented in Section 2 and provide a foundation for the subsequent interpolator and for identifying bad sites. Section 3 presents the SMART Estimator and applies it to quality assessment (accuracy) of an artificial dataset and a real-world dataset. Section 4 applies SMART Mappings to identify bad sites and bad metadata, and presents experimental results. In Section 5, we present conclusions and future work.
Air temperature near donner pass, lake tahoe and reno shown in the one-stop-shop on January 21, 2017.
Since 2003, the Western Transportation Institute (WTI) at Montana State University (MSU), in partnership with the California Department of Transportation (Caltrans), has developed web-based systems for the delivery of information from department of transportation (DOT) field elements and data from other public sources including current weather conditions and forecasts. These systems present traveler information to the traveling public and assist DOT personnel with roadway maintenance and operations. It is critical that we display quality information in these systems, yet assessing the quality of the data remains a challenge.
The WeatherShare System [6] was originally developed by WTI in partnership with Caltrans to provide a single, all-encompassing source for road weather information throughout California. Caltrans operates approximately 170 Road Weather Information Systems (RWIS) along state highways, thus their coverage is limited. It is unrealistic to expect pervasive coverage of the roadway from RWIS alone. Now in Phase 4, we are preparing the WeatherShare system to assume greater responsibility as the repository for Caltrans RWIS data. Other systems such as the One-Stop-Shop for Rural Traveler Information [7] present this information to the traveling public.
WeatherShare aggregates Caltrans RWIS data along with weather data from other third-party aggregation sources such as NOAA’s Meteorological Assimilation Data Ingest System (MADIS) [8] and the University of Utah’s MesoWest [9] to present a unified view of current weather conditions from approximately 2000 sites within California. A primary benefit of the system is far greater spatial coverage of the state, particularly roadways, relative to the Caltrans RWIS network.
In early phases of WeatherShare we implemented automated quality control procedures for identification of “bad” data with limited success. In Phase 4, we revisit this challenge. The importance of data quality for this application cannot be understated – RWIS data is used by maintenance personnel in determining how and when to treat the road to mitigate ice; it is used by operations personnel to determine when to issue warnings, chain control and when to close lanes or entire roadways; it is used by automated safety-warning systems to issue warnings to drivers; and it is used by traveler information systems that provide road-weather conditions to the traveling public. Bad data leads to bad decisions and bad decisions decrease safety.
For example, consider the temperatures shown in the Lake Tahoe/Donner Pass area including Reno in Fig. 1. Google Traffic shows slowed traffic in proximity to freezing temperatures, emphasizing the importance of correctly sensing road weather conditions. By way of color-coding, the 67
In order to assess the accuracy of data from a given site, we can use data from neighboring sites for validation. Taken in its most rudimentary form, we could simply look for anomalies on the map as we just demonstrated. Or, we could develop spatio-temporal models and compare predicted values to observed values and flag observed values as erroneous when there is a large deviation. Even if such approaches were foolproof, and we show subsequently that they are not, we have encountered little work that addresses the challenge of identifying problem sites – sites which are regularly producing erroneous data. Compounding the problem is the possibility that, like the stopped clock that is correct twice a day, sites may be producing data that is sufficiently close to that of its neighbors so-as to appear to be correct at certain times when in reality it is bad.
Literature review
The most helpful literature comes from the weather and road-weather communities and is devoted to accuracy checks for individual observations. Many of the methods are interpolation-based. The Barnes Spatial Test [10] is a variation of Inverse Distance Weighting (IDW) and has been used by the Oklahoma Mesonet [11] and the Federal Highway Administration’s Clarus project [12]. MesoWest [9] uses multivariate linear regression to assess data quality for air temperature [13, 14].
MADIS [8] implements multi-level, rule-based quality control checks [15, 16]. MADIS implements a level-3 neighbor check using Optimal Interpolation/kriging [17]. All of the approaches mentioned (IDW, Linear Regression, kriging) can be used to check individual observations for deviation from predicted, flag individual observations as erroneous or questionable if the deviation is large, and then use cumulative statistics to flag a site as erroneous. But if the interpolated value is erroneous, then the quality assessment will be bad too. If the metadata such as location or timestamps associated with a site is erroneous, then the quality control assessment may be erroneous because of comparison with the wrong data from the wrong sites. Later in this paper we identify sites for which MADIS has assigned incorrect location metadata and, as a result, the neighborhood observation check for these sites fail frequently since they are being compared to observations from sites that are not neighbors.
MADIS’ level 2 statistical spatial consistency check will flag observations as failed if 75% of the observations for the site/sensor have failed in the prior week. This check will discontinue flagging observations as bad if the failure rate for other checks drops beneath 25% in subsequent weekly statistics. While this does give an overall, general indication of site/sensor health, it is possible that there is a problem with a site while observations from the site still pass quality control.
While it is not our intent to compare interpolation methods for general performance, it is useful to examine work that makes such comparisons and work that enhances traditional interpolation methods. In [18], the authors use a number of artificial surfaces and sampling techniques as well as noise level and strength of correlation to compare Ordinary and Universal Kriging and IDW. The authors found that both kriging methods outperformed IDW across all variations they examined. In [19], the authors found instances in which kriging performed worse than their modified version of IDW, where they vary the exponent depending on the neighborhood. They do indicate that kriging would be favored in situations for which a variogram accurately reflects the spatial structure. The authors of [20] show similar results, saying that IDW is a better choice than ordinary kriging in the absence of semi-variograms to indicate spatial structure. For our problem, additional factors that would impact these methods include age and quality of the neighboring data.
In prior work [21, 22], we proposed a modification of IDW that used a data-based distance rather than geographic distance to assess observation quality. That work focused on the use of robust methods to associate sites for assessment of individual observations. In [23, 24] and in this paper we extend the mappings used in that prior work to better account for spatio-temporal variation to assess observations. In [1, 2] we developed quality measures that extended beyond sites, to help evaluate overall spatial and temporal coverage of a region. In that work, sites were not examined individually.
In [25], the authors investigated Anistropic Inverse Distance Weighting, which allows the weights to vary depending on direction. The cited benefits of this approach including ease of programming, flexibility, and objectivity. In [26], the authors combine linear regression and IDW to produce a method with comparable prediction accuracy to kriging while being less computationally-intensive. In [27], the authors compare multiple linear regression, IDW, Ordinary Kriging, nearest neighbor, and weighting by Gaussian Filter for interpolation of daily minimum and maximum air temperature values using data for British Columbia. They noted that prediction errors varied by elevation and by month, and made use of lapse rates to account for variation due to elevation. They indicated a great deal of variability in lapse rates during the winter. In [28] the authors use Co-Kriging with elevation to model temperature data in Japan and found that it performed better than Simple Kriging, Universal Kriging, Multiple Linear Regression and IDW. They also observed significant seasonal and diurnal variability in prediction error. Distance from water bodies and presence of topographic shadows add to the predictive capability of these methods when used in addition to elevation [29]. However, the authors stress that no one interpolation technique will perform best in all circumstances. While some of these studies used artificial data and introduced noise into their data, none fully accounted for the challenges we face with our data sets, particularly infrequent and varying reporting by sites.
Functional Outlier Detection offers overlap with our problem of identifying bad sites and bad metadata. In [30], the authors present several useful types of functional outliers in a taxonomy including isolated outliers, which exhibit outlying behavior over short time periods; persistent outliers which produce outliers over all or nearly all of the time period investigated; shift outliers that have the same shape as other data but are shifted in value; and amplitude outliers, which have the same shape as other data but for which the scale/amplitude differs. Unfortunately, the datasets that we are dealing with may include sites that yield data that is not a function. Disparate reporting frequencies, sporadic and limited reporting, and the potential for bad timestamps introduce further challenges. Minus these challenges, approaches for functional outlier detection such as functional outlier maps [31] and functional adjusted outlyingness [32] may be applicable.
Robust regression methods including Least Trimmed Squares Regression play a role in addressing the problem of identifying bad observations. We use the approach developed in [33] to perform Least Trimmed Squares Regression within methods for the association of like sites and the identification of bad sites to then identify bad observations.
In [34], the authors present a unified approach for detecting spatial outliers and a general definition for spatial outliers, but they do not address the spatio-temporal situation. Mesowest [35] addresses bad timestamps with a “Suspect Time” flag, but their rudimentary check only identifies “future” timestamps, timestamps that occur in the future relative to their collection time.
Unfortunately, none of these approaches directly addresses quality control for spatial-temporal data in a way that meets our needs. And none of them sufficiently identify bad sites and metadata.
Smart mappings
We have developed a representative approach for data quality assessment of site-based, spatio-temporal data using what we call Simple Mappings for Approximation and Regression of Time-series (SMART). Using this approach, we demonstrate the challenges of site-based, spatio-temporal data quality assessment and how to overcome these challenges. We use the SMART approach to identify both bad (inaccurate) observations and “bad” sites/sensors, so that they can be excluded from display and computation. It is not our intent to diagnose problems, although there certainly does appear to be opportunity in this area.
One challenge we face in assessing spatio-temporal data quality is the lack of ground-truth data. Comparison of observations versus ground truth ultimately determines error. In order to develop and evaluate our method to identify bad observations and sites, it was desirable to have a representative data set for which ground-truth is known. We developed such a representative, artificial dataset. In doing so, it was not our intent to model a complex system such as weather but instead to develop a weather-like data set with which we could conduct research and development. We used this dataset to develop an interpolation-based estimator for the quality assessment of individual observations as well as sites/sensors.
Artificial dataset
We developed a weather-like phenomenon representing temperature as approximate fractal surfaces produced using the method of Successive Random Addition [36, 37, 38]: A 513
Errors introduced into sites from artificial dataset
Errors introduced into sites from artificial dataset
We then generated time series of “ground truth” data by combining the surface data with the weather data, a periodic effect and a north-south effect to simulate a weather-like phenomenon similar to the diurnal effect and general north-south variation in the Northern Hemisphere respectively. The weather data is added as-is, with varying offsets in the x-coordinate used to represent a west to east flow in the weather pattern. The surface value is subtracted so that low points are “warmer” than high points. The periodic effect represents warming during the day and cooling at night. The north-south effect yields warmer points to the south and cooler points to the “north”. This yields a time series of length
We then selected 250 “sites” using random uniform
Since sites may have different reporting times and frequencies, the observations from any two sites might not directly match in time. Comparison between sites requires a more robust approach than simply comparing observations with identical timestamps. To address this problem, we will align observations within a preselected time radius for comparison.
As an example, (artificial) Site 11 reports every
Site 11 observations versus neighboring observations in artificial data set.
Let an individual observation be represented as
Selection of the time radius
We now define a site-to-site mapping as a linear function of the x-coordinate (the observed values for site i) of the paired observations
This function will generally be determined to minimize the squared error between the values of the function and the y-coordinates (the observed values from site
We next define a quadratic estimate of the squared error of the linear mapping relative to the time offset between the paired observations:
We expect an increased squared error for increased time differences. This model will help to estimate the squared error and it will account for reporting time offsets between observations. Our method does not require a complex, data-specific covariance model.
These simple mappings are the core elements of our approach, and we must overcome the potential impact of the erroneous data in determining them. Least squares regression suffers from sensitivity to outliers. Thus, we use the method from [33] to perform Least Trimmed Squares Regression. Least Trimmed Squares determines the least squares fit to a subset of the original data by removing data furthest from the fit. Given an initial fit, an iterative process is used to successively improve the fit by removing data furthest from the current fit and re-computing the fit to the remaining data.
Least trimmed squares linear fit mapping observations from Site 33 to Site 11.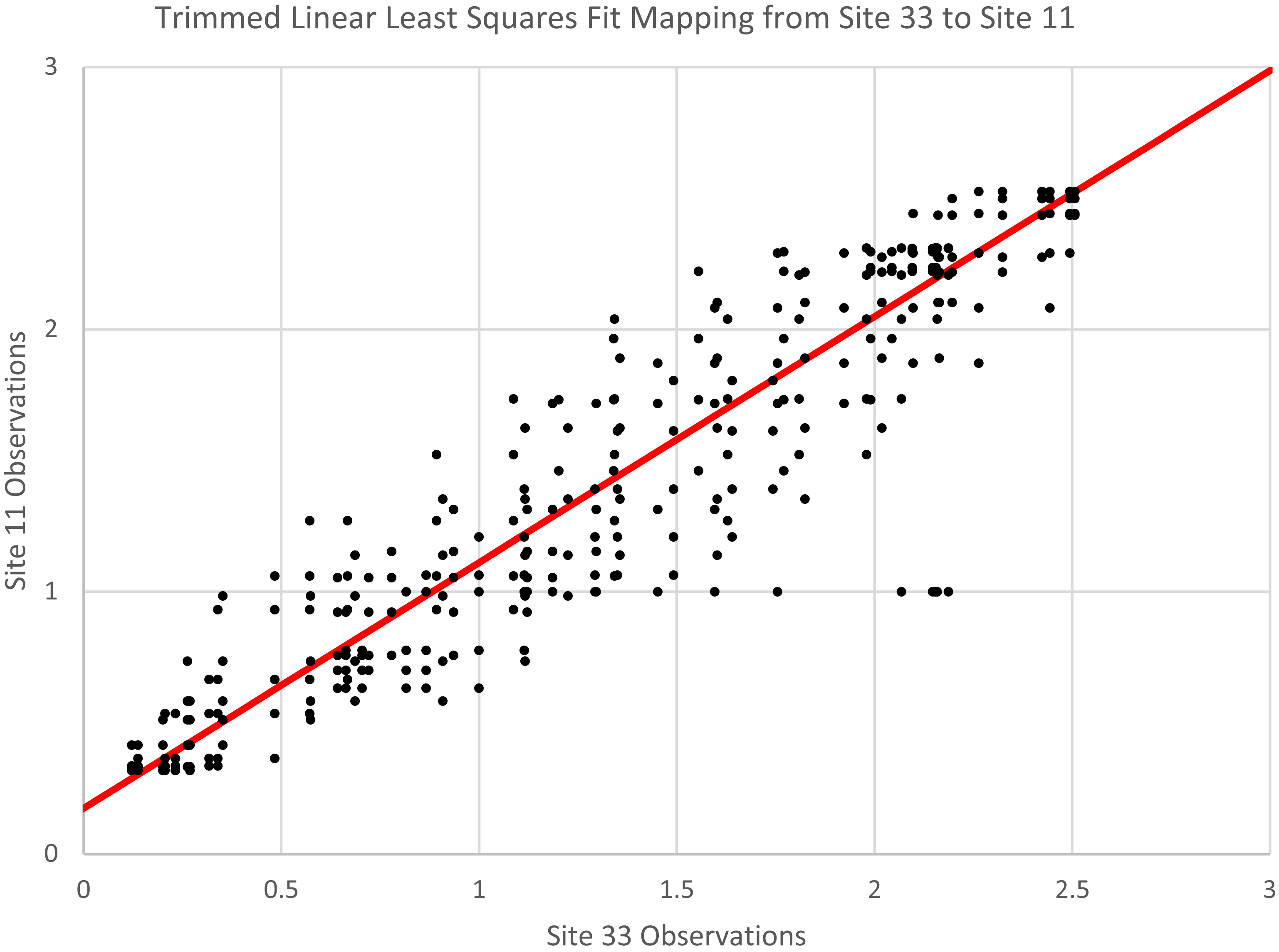
Before applying least trimmed squares to determine the linear fit, we select the percentage of data that will be trimmed before computing the fit. The trim percentage can be interpreted either as our willingness to accept bad data in our models or our estimation of how much data is bad. For our artificial data set we used a trim percentage of 0.1 since we defined several of our erroneous sites to have error rates near this value.
As an example, we show the linear mapping from Site 33 to Site 11 from our artificial data set using the paired observations from these sites within a time radius of 20. The inclusion of data with different time offsets will subsequently provide us with a simple and effective method to account for varying time offsets by way of the quadratic error function. We then apply least trimmed squares linear regression with a trim percentage of 0.1. See Fig. 3. Notice the pairs that include the erroneous observations from Site 11 where the value from that site is 1.0. These are apparent outliers and least trimmed squares helps to eliminate their influence on the result.
Least trimmed squares linear regression yields the following linear fit, mapping observations from Site 33 to Site 11:
We now model the squared error of the linear fit relative to the time offset of the observations from the two sites using a quadratic model. Again, we use least trimmed squares to accomplish this. See Fig. 4. The least trimmed squares quadratic fit that maps time differences of observations from Site 33 and Site 11 to the squared error between the linear mapping from Site 33 and Site 11 and actual observations from Site 11 is:
Least trimmed squares quadratic fit mapping squared errors for linear mapping of observations from Site 33 to Site 11.
Despite our efforts to make the linear site-to-site mappings and quadratic estimates of error robust, there are cases in which the results will be unusable due to bad data or poorly aligned data resulting from large differences in reporting times and infrequent reporting. We can check the coefficients and derived measures for unexpected or unusable results.
In this section, we present our SMART estimator, first developed in [23], after looking at standard, interpolation-based aggregate estimators. Formally: Let
Popular interpolators
Inverse Distance Weighting (IDW) [39] estimates are the weighted average of observation values, using (geographic) distance from the site/location for which an observation is to be estimated as the weight, raised to some exponent
Least Squares Regression (LSR) maps the coordinates of the sites to the observed values. We only use
Universal kriging (kriging with a trend) (UK) [40] uses the covariance between sites along with the coordinates of the sites and the observed values. In our experiments, we used a Gaussian covariance function of distance and estimated the related parameters so-as to minimize error relative to ground-truth for our training data. For kriging, the estimate of covariance could incorporate dimensions such as time and elevation as well, but finding a representative covariance function may be challenging. Alternatively, kriging could be used with covariances computed individually on pairs of sites rather than as a global function. Site-to-site covariance could implicitly account for elevation and other factors. This would be beneficial and would alleviate the challenges of determining an overall covariance function, but a robust approach would have to be used in doing this to mitigate the impact of bad data.
All of these methods can be applied using a restricted radius around the point at which the estimate is to be made or within a restricted bounding box or similar to alleviate computational challenges and to focus on local trends. Other interpolators could be applied in a similar manner. There are obvious risks in using these and other interpolators. Outliers and erroneous values will have an adverse impact on interpolation, causing poor estimates. Lack of data in proximity to a point to be estimated can also result in a poor estimate.
Our SMART interpolator
Our SMART interpolator is similar to IDW and uses our quadratic error estimate as the distance given the time lag between observations and our SMART linear mappings to yield estimated ground truth producing the estimate:
Neither distance nor direction are directly used in the computation. The linear mappings and quadratic error estimates account for similarity between sites. No attempt is made to down-weight clustered sites, although there may be benefit in doing so.
We determine the exponent by minimizing error relative to ground truth, if available. For the artificial data set,
Rather than take a simple weighted average, we use a trimmed mean to reduce the influence of outliers on the result. We employ Least Trimmed Squares as a metaheuristic and compute the mean relative to the weights while minimizing the (weighted) mean-squared-error relative to the non-trimmed data.
The algorithm for our SMART estimator is as follows. Note that the constants are specific to our artificial data set.
Using the data from the first time period/weather pattern in our artificial data set, we created mappings between all sites and then made estimates for other time periods. We compared results to those for IDW, LSR and UK. For LSR we investigated three cases with varying radii: a maximum of 50 units, a maximum of 100 units and no maximum/all data. For UK we used a radius of 150 which was chosen as a value for which computation time was still reasonable while not restricting too much data. The mean-squared-error (MSE) over all predictions versus ground truth shows that our SMART method dramatically out-performs the other methods. See Table 2.
MSE from ground truth for interpolators
MSE from ground truth for interpolators
Ground truth, observed and predicted values from the SMART method for Site 11 and errors.
To further demonstrate the performance of our SMART method, we examine Site 11 relative to errors over one of the evaluation weather patterns. See Fig. 5. During the evaluation time period there were three erroneous observations from Site 11. The SMART method predicted values that approximated ground truth reasonably well but with several notable exceptions: the first estimated low occurs subsequent to the actual low, there are jumps in the estimated value, and the second low is underestimated. The jumps are either a result of erroneous values from another site or from inclusion/exclusion of sites depending on reporting frequency and time offset. Still, the result is reasonable and could provide us with insight into how errors could be flagged. The two large errors stand out and would be identified without any false-positives using a cutoff in absolute error of 0.6 or greater. The third, smaller error is problematic. It would not be detected unless the cutoff was dropped below 0.5, which would result in a number of false positives because of the poor estimate of the second low.
As we demonstrate later, the example in Fig. 5 is relatively simple, and there are many types of problems that a site can exhibit. Given this example alone, one might ask why differences or derivatives computed on a series alone could not be used. The answer is that they could, and there certainly is room for derivatives to be incorporated into our method. However, derivatives alone will not identify all types of errors that we are interested in.
We extracted real temperature observations from the MADIS Mesonet subset from December 2015 and bounded between 38.5
MSE by MADIS QCD for interpolators
MSE by MADIS QCD for interpolators
V
Predictions for GISC1 from the interpolators.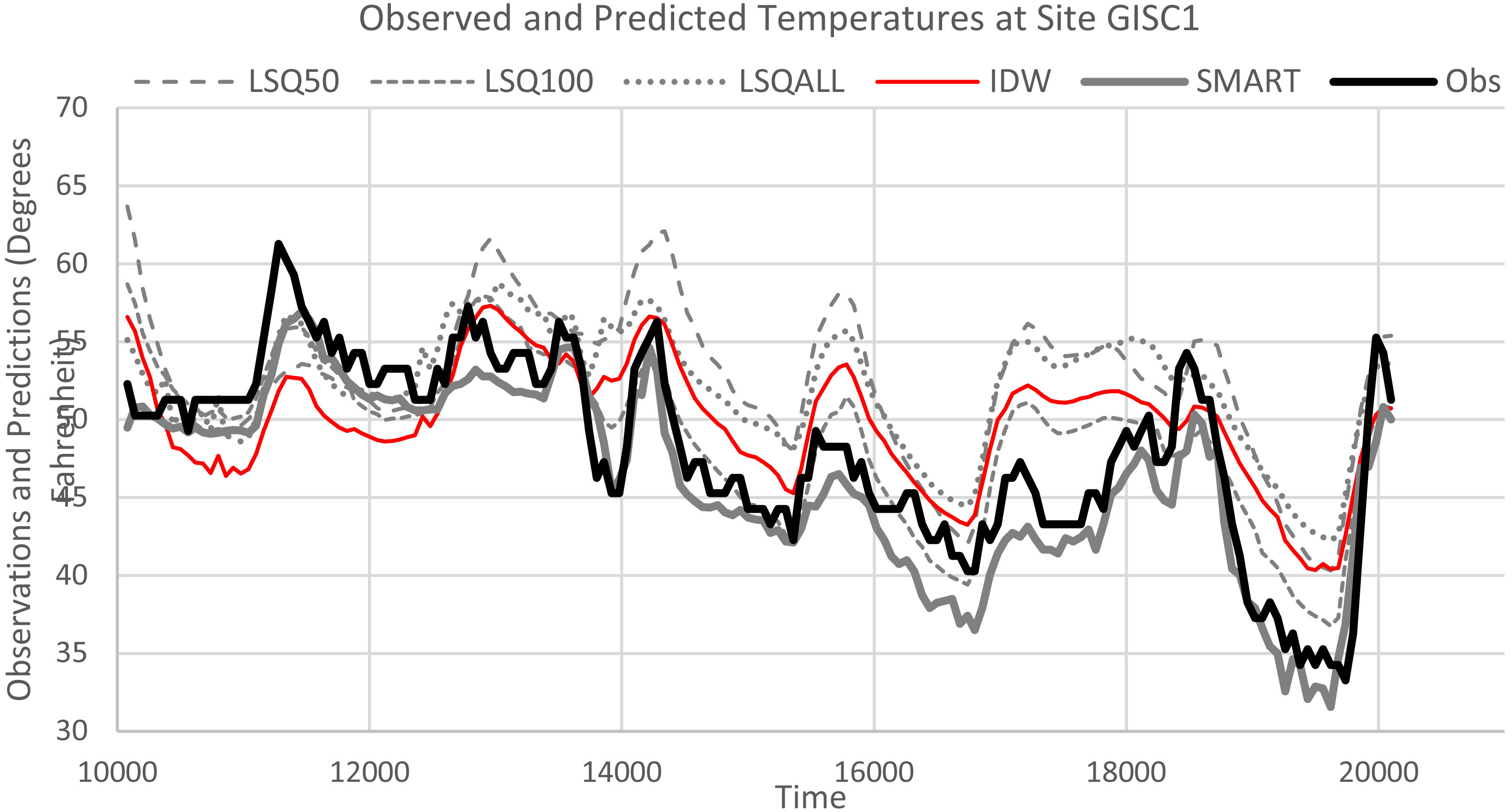
We compared our SMART method to IDW, LSQ50 (50 mile radius), LSQ100 (100 mile radius), and LSQALL (include all data). For all methods, the most recent observations from individual sites were used. We were not able to determine a consistent covariance model and could not get Universal Kriging to work with the MADIS data. Further issues were experienced with non-invertible matrices because of coincident sites, etc. Too much preprocessing would have been necessary, so we did not make predictions using Universal Kriging on the MADIS data set.
Since we do not have ground truth for this data set, we computed mean-squared error relative to observed value and grouped by quality control descriptors (QCD) provided by MADIS. The resulting mean-squared-error by method and QCD is shown in Table 3. The MSE results in Table 3 are very good.
Now we look at the results for site GISC1 (Gibson near Castella), which MADIS located in downtown Sacramento. For this site, our SMART method estimates were reasonably close to the observed values whereas all of the other methods tended to overestimate. See Fig. 6. The MADIS QCD indicators showed a great deal of uncertainty regarding the observations from this site with a mix of Q (questionable), S (subjective) and V (verified) values. However, when we compared the corresponding observations to the absolute error of predictions from our SMART method, there was no apparent pattern. See Fig. 7. There is no apparent pattern in the absolute errors from the other methods either, although the absolute errors are greater relative to our SMART method.
MSE by QCD for GISC1
QCD counts: Q
Observations (by QCD) and predictions for site GISC1 (gibson near castella).
Our SMART method performs better overall but worse than LSQ100 for the V data for Site GISC1. See Table 4. And, it performs better for the Q and S data than for the V data, particularly for the Q data. One way this could happen would be if the data was mislabeled. In fact, we are confident that it is mislabeled because we know that this site was mis-located by MADIS and, as a result, the MADIS level 3 check is invalid. This site is not located in downtown Sacramento but is located 170 miles to the north of Sacramento. The reason it fails MADIS level 3 quality control resulting in Q values for QCD is that quite often it does not agree with sites located in downtown Sacramento. There are times when it comes close, and those times correspond to S and V QCD indicators, but many times the differences are large enough that MADIS flags observations from this site as failing.
Our SMART method helps to identify further site-related problems such as incorrect locations. Next we identify site-related problems including bad metadata.
In this section, we show informally how our SMART mappings can be analyzed to identify bad sites and bad metadata. We compare the coefficients and derived measures from the SMART mappings and look for outliers in those values. We use the general term “bad site” to refer to a site that produces erroneous data. As mentioned earlier, it is not our intent at this point to diagnose specific problems. There are many types of erroneous metadata including incorrect or misspelled site names, mismatched sensor type, wrong units, etc. We focus our attention here on two types of bad metadata: incorrect location and bad timestamps. Both of these error types will adversely affect the interpolation methods that make use of this information, and the effect can be dramatic.
Identification of bad sites
We first looked at the coefficients and MSE values for the site-to-site mappings and determined how these could be used to identify “bad” sites. Initially, for our artificial data set, we labeled sites as “bad” if they included erroneous data. Of course, there are varying degrees of bad. In general, for data sets in which we do not have ground truth, we will not know which sites are bad a priori. In fact, all sites may be bad to one degree or another simply due to lack of precision or accuracy. We found that sites with large numbers of outlying
We again used the temperature observations from the MADIS Mesonet subset, as described earlier.
Sites for which mappings could note be determined
There were 36 MADIS sites for which site-to-site mappings could not be determined during the training period. We examined these sites individually and the results are not surprising, with each site exhibiting one or more of the following issues: there was little or no data during the training period, there were large gaps in reporting, or there was a very narrow range in reported data. These sites could have readily been identified by filtering sites based on measures such as temporal completeness [1, 2]. Still, their handling is non-trivial. Some of these sites began reporting data during the testing period and some of that data could have been useful depending on the application. A potential disadvantage of using our SMART mappings is that we will disregard such sites until a new training period has passed in which there is sufficient data to produce mappings for them. One could argue that it is prudent to hold out data from such a site until the site can be proven to produce quality data.
Sorted 
Sorted 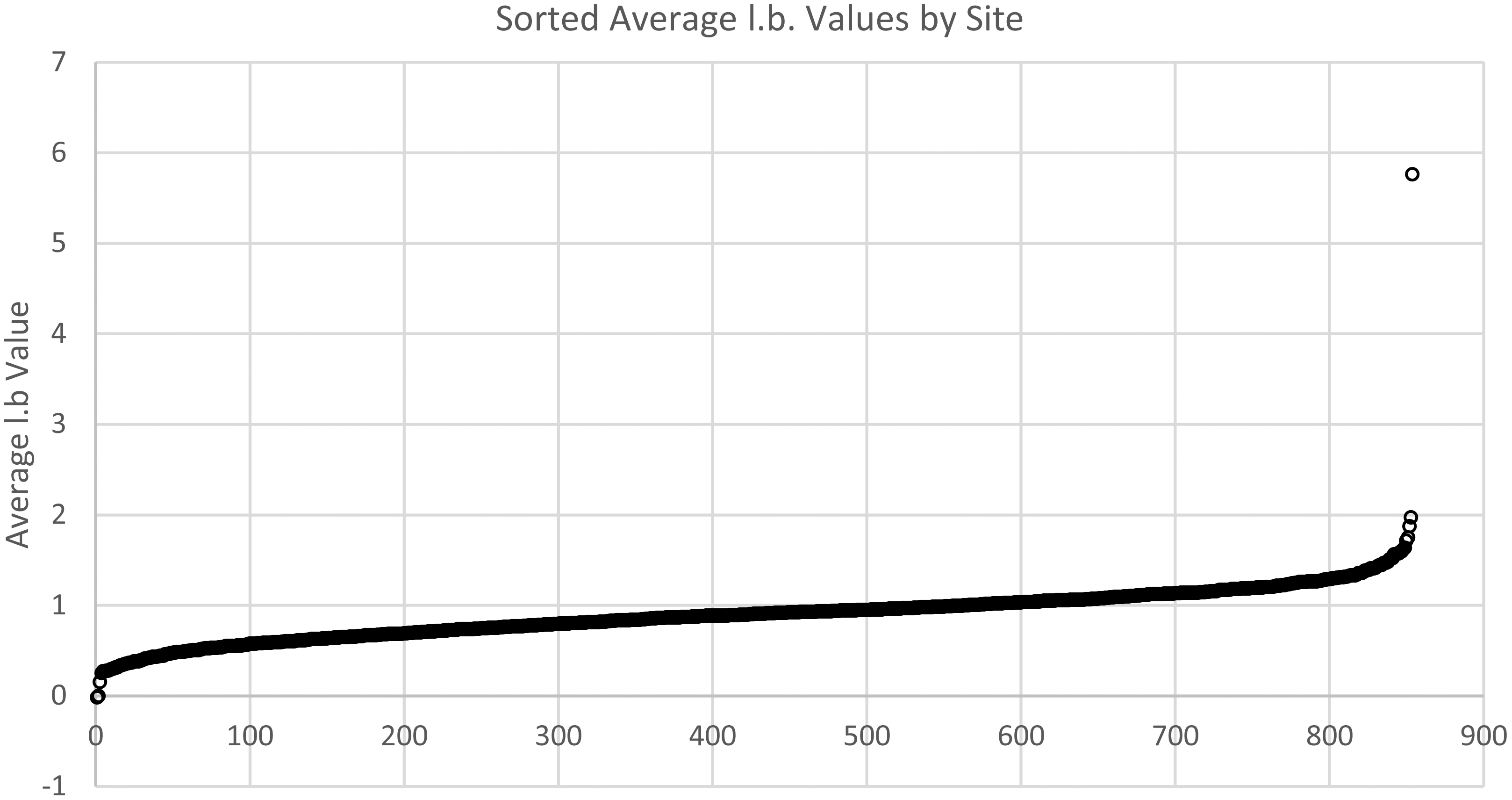
For each site, we averaged the
For the average
Site 293 from MADIS subset showing sporadic reporting and extreme negative temperatures.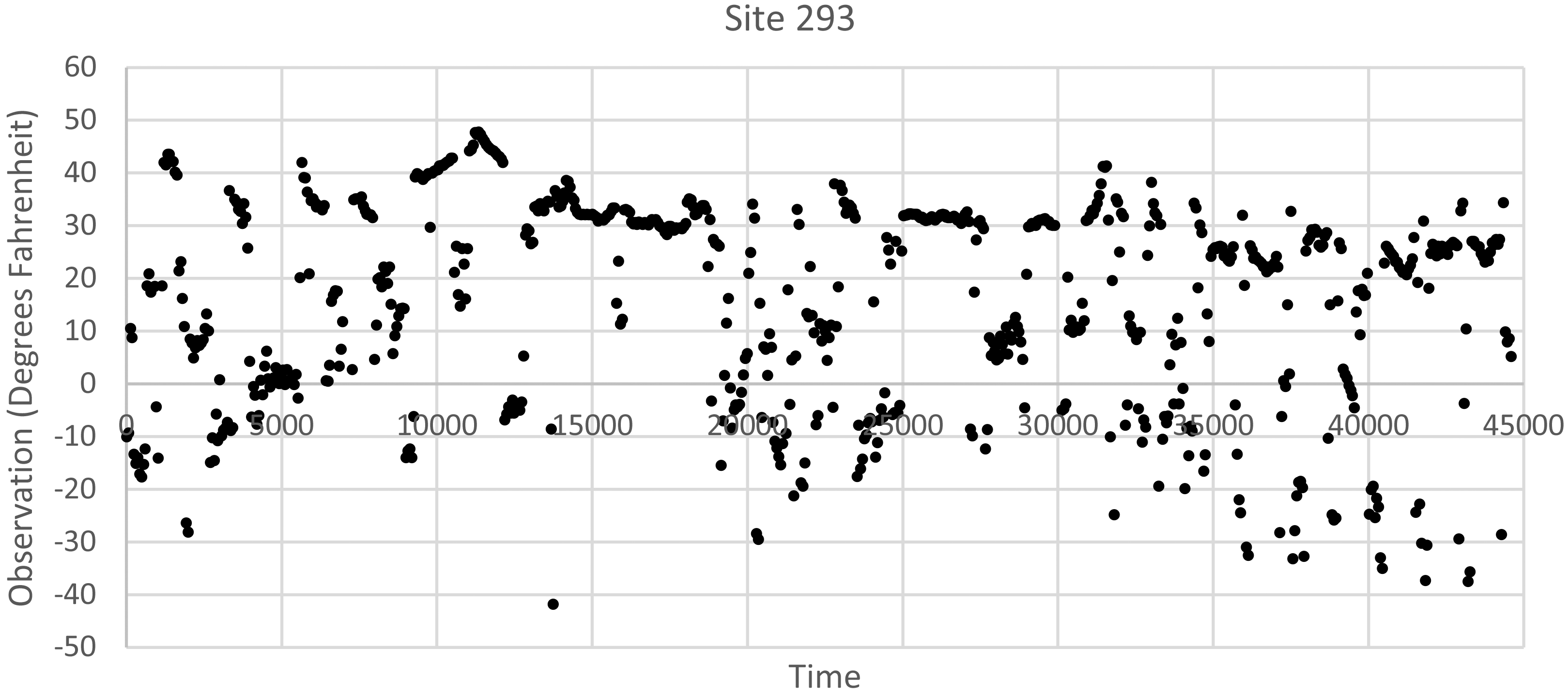
After determining the prospective outlier sites using the site averages of the
In order to develop an approach for identifying bad location metadata, we again needed a representative ground truth dataset. For this purpose, we used the Mesoscale Analysis and Prediction System (MAPS) and the Rapid Update Cycle (RUC) Surface Assimilation Systems (MSAS/RSAS) dataset from NOAA for air temperatures in the Northern California area for the entire month of December 2015 [41, 42]. The MSAS/RSAS data provides estimated surface observations for grid points with 8-mile spatial and one-hour temporal resolution. Since 1-hour temporal resolution was not sufficient for our analysis and was not representative of frequency of reporting of site-based sensor observations, we used bicubic splines to interpolate down to 1-minute temporal resolution. We used existing MSAS/RSAS grid points as site locations, and did not attempt further spatial interpolation to construct site-based observations.
In general, the series from near sites should be similar and the series from far sites should be less similar. The
We now turn our attention to sites in the MADIS set. For this experiment, we used data for the entire month of December 2015. We found a number of mis-located sites using the relationship between distance and
For instance, MADIS mis-located Site WVVCA at (40.680,
Distance versus 
MADIS mis-located Site KLHM (Lincoln Regional Airport) at (38.91,
As mentioned earlier, Site GISC1 (Gibson near Castella) was mis-located by MADIS at (38.56556,
Our approach for identifying mis-located sites does work, as confirmed by examination of sites known to have been mis-located by MADIS. While the approach we have outlined identifies large errors, it should be possible to identify lesser errors. Our method also shows promise in identifying the approximate correct location for a mis-located site by way of the location of the sites corresponding to the least
The last type of error we investigate is bad timestamps. It is our belief that many if not most of the MADIS sites have data for which the timestamps are not synchronized with the correct time. In order to investigate this possibility, we started again with the RSAS data. Here we made an assumption that clocks were synchronized and timestamps were correct for sites represented by grid points in the RSAS data. We then plotted
We next investigated the MADIS data to see if we could find similar patterns to identify sites with bad timestamps. Unlike the mis-located sites for which we could be certain of the original errors and subsequent corrections for several sites, we do not have concrete examples for which we know that the timestamps are incorrect. However, we are fairly certain that the extreme errors we identify correspond to real errors in the timestamps.
We believe that the timestamps for the Caltrans Dunsmuir (CTDUN) site are correct or nearly correct. The plot of

Site BUGC1, is located in a remote part of the Klamath National Forest near near Bestville, approximately 47.5 miles west of Dunsmuir. When we plot
We found numerous other examples of sites for which we are confident that the timestamps are incorrect, and we have found a great deal of variability in this data. Ultimately, we believe that there are both large and small errors in the timestamps.
The SMART method presented in this paper shows promise as an interpolator for spatio-temporal data in the presence of errors. It accounts for errors in multiple facets of the interpolation process. In terms of neighborhood formation, it maps like sites to like sites rather than assignment based on geographic proximity, and it assigns weights according to quadratic error in simple, linear mappings. Through the use of least trimmed squares, errors are mitigated up to a predetermined tolerance level. In turn, a trimmed, weighted mean is used to compute final, interpolated values, reducing the potential for single or even multiple erroneous values to bias the result. In tests with a representative, artificial data set, we demonstrate that this approach far out-performs popular interpolation methods in estimating ground truth in the presence of multiple types of errors. It also outperforms these methods in ability to distinguish bad data from good data. With a real data set we find similar results in terms of estimation, although we are challenged by not having ground truth, and use provider quality control flags to perform evaluation. When investigating ability to distinguish bad data from good data we find that the provider quality control flags are questionable. We further demonstrate that bad metadata such as incorrect location data can adversely affect results.
We presented a representative method for accuracy assessment and compared and contrasted it with other interpolation methods to demonstrate the importance of mitigating erroneous data throughout the process. All interpolation methods presented are susceptible to erroneous data, particularly if used as-is. Their use must account for and mitigate erroneous data. For instance, it is not sufficient to use robust estimates of covariance to get good results with kriging methods. Kriging methods will still fail in the presence of erroneous data.
The SMART method presented in this paper also shows promise for identifying sites that have bad data. The simple (linear) site-to-site mappings and (quadratic) error estimates for the mappings can be used to identify erroneous sites. The coefficients of the mappings and associated performance measures can be compared across all sites, and outlier values of these parameters correspond to bad sites.
The SMART method further helps to identify bad location metadata and bad timestamp (unsynchronized) metadata. Using a raster dataset derived from meteorological sensor data as ground-truth, we developed and demonstrated methods to identify both of these types of bad metadata. In turn, we demonstrated that these methods identify known or highly likely instances of bad metadata in our original, site-based sensor data set.
Our SMART approach provides a representative method for assessing and handling site-based spatio-temporal data quality. In addition to providing assessment of accuracy at the observation level, our method helps to identify problematic sites including sites with bad metadata.
In future work, we intend to characterize the impact of the various components of spatio-temporal data quality including accuracy, precision, timeliness, reliability, completeness and coverage on interpolation-based methods for data quality assessment including our SMART method. We also intend to continue formalizing our method and test it against other datasets.
Footnotes
Acknowledgments
We acknowledge the California Department of Transportation (Caltrans) for its sponsorship of the WeatherShare project and other related projects. In particular, we acknowledge ian Turnbull and Sean Campbell from Caltrans. We further acknowledge Daniell Richter and other staff at the Western Transportation Institute for their work on WeatherShare, the Western States One Stop Shop and other related projects. The work presented in this paper has been conducted subsequent to and separate from this prior work.