
Abstract
Tools that perform pattern recognition analysis of crimes, comprising at the same time forecasting, clustering, and recommendations on real data such as patrolling routes, are not fully integrated; modules are developed separately, and thus, a single workflow providing all the steps necessary to perform this analysis has not been reported. In this paper, we propose forecasting criminal activity in a particular region by using supervised classification; then, to use this information to automatically cluster and find important hot spots; and finally, to optimize patrolling routes for personnel working in public security. The proposed forecasting model (CR-
Keywords
Introduction
Public security and crime fighting are one of the most important social priorities in great cities of the world. Despite the surprisingly big quantity of human and material resources that governments assign for this matter, it is still evident the need for alternative mechanisms that allow to increase the effectiveness and efficiency of police forces [12]. One of the main variables that limit this effectiveness is the response time to crime events. Particularly, immediate-reaction events show that the marginal improvements obtained in this matter are not enough to reduce the general criminal incidence of the zone, as well as to substantially modify the perception of insecurity between citizens [19].
A better perspective of this situation can be achieved if the problem is translated to the sphere of prevention instead of reaction. If public forces were capable to anticipate when and where the criminal activity of a specific kind might be increased, a double benefit could be achieved. On one hand, it would be possible to concentrate resources and logistic activity necessary to fight that specific kind of criminal activity in the anticipated place and time. On the other hand, it could be possible to establish dynamically and with solid foundations several of the common parameters of everyday work in public security, such as the specific design of surveillance rounds, the distribution of forces in time and space, and, of course, the development of security operations, or even information and prevention campaigns through massive communication media [28].
Several systems have been already created in order to help crime analysts in their duties, for example STAC (Spatial and Temporal Analysis of Crime) [w1], and CrimeLink (PCI Precision Computing Intelligence) [w2]. This latter system provides an Event-Time graph, and a Pattern Analysis wheel. Other systems are CrimeView (Omega Group) [w3], and ArcGis (Crime Analysis Extension), providing hotspot analysis on ArcGIS 9, main centroid identification, and probable crime direction identification. More recently, A.T.A.C (Automated Tactical Analysis of Crime) [w4] identifies criminal patterns through data ordering; it provides tools for analysis such as time series based prediction, Google Earth integration, mapping and density analysis. These systems are of great help in crime analysis and prevention; however, being mostly built for commercial purposes, they do not disclose their forecasting algorithms, making difficult to adapt them to the needs of a certain region. Moreover, these systems are not designed to provide recommendations, such as patrolling routes modeling, that are able to guarantee an adequate coverage of the identified hotspots.
In view of this, our work is devoted to a two-folded objective: first, we aim to study the spatial and temporal decisions made by criminals identifying hotspots where criminal activity is concentrated; while the second one is, once these activities are found and properly clustered, to provide a flexible schema – adapted to real needs and availability of resources – for designing adequate patrolling routes that optimally cover these hotspots.
In the following section (Section 2) we will focus on the forecasting of criminal activities; in Section 3 we tackle the problem of clustering and GIS-mapping these activities for the analyst. In Section 4 we cover the problem of patrolling routes design. In Section 5 we present a set of experiments and results of each one of the modules comprising this framework; and finally, in Section 6 we draw our conclusions.
General architecture of the computerized system to support decision-making processes in public security.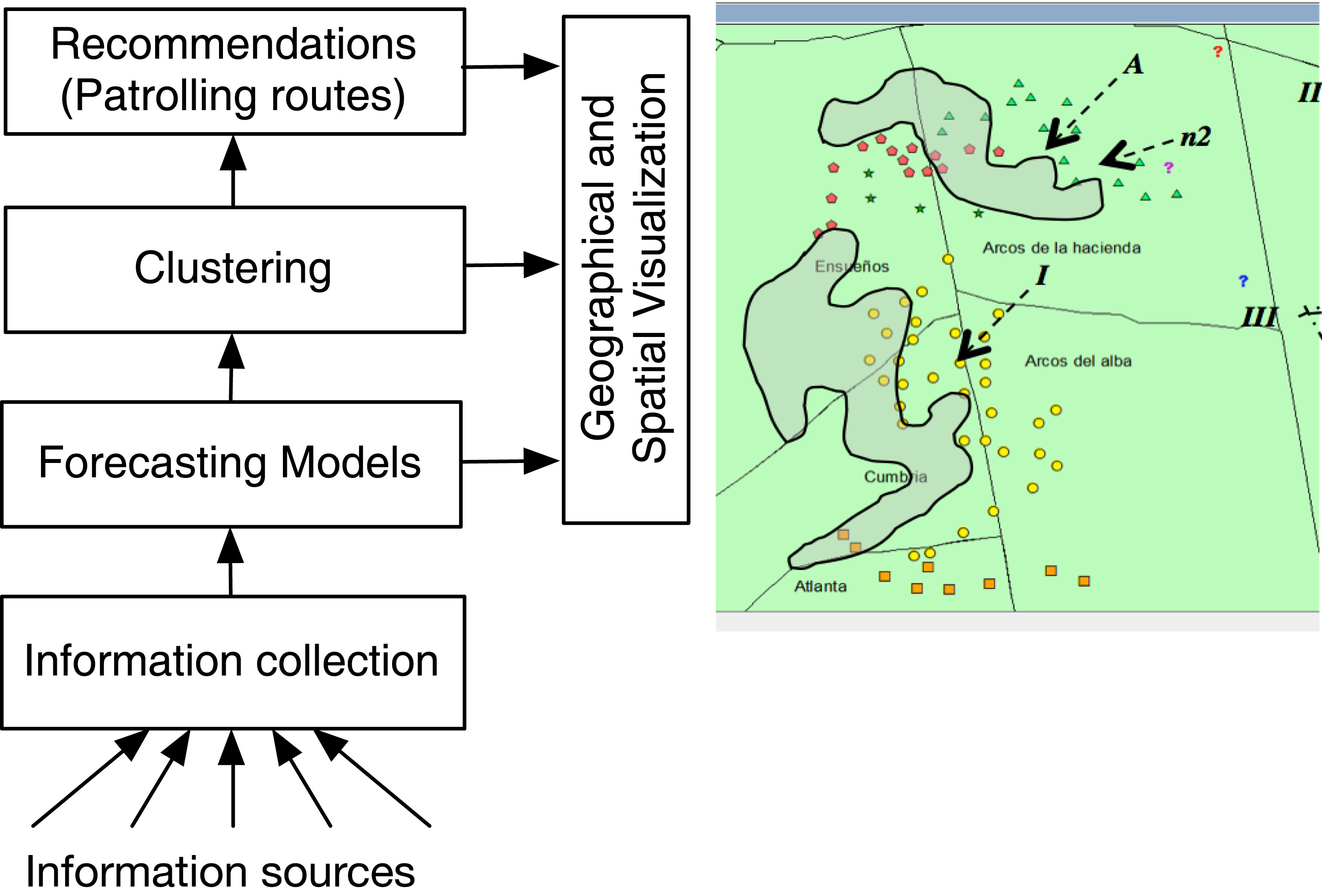
The forecasting, clustering and routing model reported here is a framework designed to prevent and react to crime. This framework is made-up by several layers as shown in Fig. 1.
The function of the first layer is to gather, standardize and analyze data from six established information sources. In terms of pattern recognition, layer one constitutes the supervision sample. The second layer contains several prediction algorithms (see Section 2). The input to the third layer is the set of predictions made by the algorithms of the previous layer and it identifies, clusters and maps important hotspots (see Section 3). The fourth layer generates recommendations for addressing the forecasted scenarios. Particularly in this paper we discuss the patrolling recommendations (see Section 4).
Careful structuring of the input data is of utmost importance, so that the forecasting model can be efficient and has an acceptable level of precision [13]. The problem of crime prediction and recommendation generation requires several different information sources, all of them directly related with public security, but not easily accessible. For this project, we have chosen six information sources arranged into four categories as follows: information on (1) crimes committed, (2) citizens’ reports, (3) resources and police activities, and (4) socioeconomic data of the region under study. In each of these categories, information should be precisely located in time and space. For our study, we use data from the municipality of Cuautitlán Izcalli, State of Mexico and data from the Sacramento California (CA) Police Department.
Forecasting criminal activity
There are several works devoted to the study of spatial and temporal decisions made by criminals, i.e., identifying hotspots where criminal activity is concentrated – see [1, 2, 8, 26, 31, 33, 35, 36, 37, 39]. A widely used method is the Spatial and Temporal Analysis of Crime program (STAC) [5], which clusters crime points within ellipses [3]. Jefferis [24] surveys additional hotspot methods, the most sophisticated of which employs a kernel density estimation method [27]. Nevertheless, the main disadvantage of statistical methods is that they do not offer additional semantic information for describing the phenomenon under study. In the specific case of crime prediction, this kind of information is highly desirable, as it is needed to support decision-making processes and, in general, to prepare preventive and corrective policies. Because of this, we have selected inductive classification methods over statistical ones in order to generate an inductive description of each type of criminal activity studied. These descriptions by themselves constitute valuable information that provides a general overview of the criminal activity scenario. Furthermore, by using these inductive definitions, it is possible to identify the expected increase or decrease in specific criminal activities that will most likely occur in specific geographic areas and times.
This section deals with the design of the forecasting model within the proposed framework of criminal activity analysis within a specific time period and location using several different supervised classification techniques. W present details of our forecasting model, from general Forecasting with Inductive Supervised Classification (Section 2.1) to our particular implementations of CR-
Forecasting with inductive supervised classification
One of the most interesting tasks of the Pattern Recognition discipline is the study of forecasting models [10, 30]. The forecasting problem can be treated as a classification problem; this allows taking advantage of the large number of available classification algorithms. The great majority of current forecasting models has a statistical nature and is mainly devoted to time series analysis (for an exhaustive review of these methods, refer to [10, 22]). As stated previously, we are interested in the particular semantics of crime analysis, so we propose an inductive forecasting model.
The forecasting model is expressed as a supervised classification problem in the following terms: Given a database containing a set of patterns corresponding to crimes perpetrated within the region under study that are spatio-temporally labeled, group such patterns into crime families, where a crime family consists of all the crime patterns corresponding to similar crimes that are fought with the same resources. These families form the supervision sample to be used by the classification algorithms. Afterwards, a learning process is carried out to describe each family in both positive and negative ways. In order to predict a specific criminal scenario (i.e., the time, location and type of criminal activity to be predicted), a pattern containing all the relevant data is constructed and submitted for classification in accordance to the previously assembled supervision sample. The classification algorithm gives as a result the degree of membership of such a pattern to each one of the established families. Consequently, each degree of membership is interpreted as the forecasted increase or decrease in the criminal activity for the specified time and location.
To make forecasts, a careful design of the classification problem semantics is required. Specifically, this includes three basic aspects of the problem: (1) the objects under study and the attributes or features that will be used to describe them; (2) the number of classes and how patterns will be classified; and (3) what kind of learning the classification algorithm will use. Each one of these aspects is discussed below.
Objects and descriptive features
The objects under study are either criminal activity scenarios or citizens’ reports recorded in each geographical area at a given time. Temporal information includes the date and time components, whilst the location refers to the area in which the criminal activity was recorded. For each one of the studied scenarios an
We perform two different modes for analyzing the criminal data, considering two different semantics for the crime families to be identified.
The first mode groups the supervision sample patterns into three classes that indicate the kind of environment in which the criminal activity was recorded. These three classes represent criminal activities committed in: (1) public roads and highways; (2) homes; (3) stores and shops.
The second mode groups the patterns into four classes based on the kind of social impact that the criminal activity has. These four classes are: (1) robbery in all its modalities; (2) homicide; (3) injury; (4) property damage.
These groupings were selected considering the main goal of the project, which is to provide recommendations, particularly aimed to patrolling routes, to the public security authorities. Based on the recommendations of our system, authorities will have information to spawn direct actions to prevent the crimes perpetrated in public streets, shops, homes, or industries.
Learning
We use information regarding the crimes committed and reported to the Public Prosecutor’s office. The data corresponding to the crimes committed during a certain time can be used to test the proposed forecasting model. After having initially debugged the information provided by the Public Prosecutor’s office, a supervision sample containing the space-time location of the crimes committed is build. A classifier learning process is trained on data containing a good distribution of crime patterns across the three or four classes mentioned above, depending on the mode under investigation. This learning process consists of constructing inductive definitions that describe in positive and negative ways the patterns contained in each one of the classes in the supervision sample. The inductive definition
where each
We use a combination of the Kora-
A
Where
The CR-
For the previous algorithm,
The CR-
In Fig. 2 we exemplify the effect of this modification. Given a threshold
Once the classifiers are trained, it is necessary to cluster the spatiotemporal features in order to visualize and find important hotspots. This is discussed in next section.
We used an approach based on Nath [32]. He uses a
Example of criminal data [32]
Example of criminal data [32]
By applying a
Nath’s results excerpt [32].
For the clustering layer, we propose the use of a clustering technique based on pattern density, together with a space-time similarity function to identify areas with high concentration of crime (hot-spots). Then we compare the results obtained with our similarity function with those obtained by the proposed similarity function used in the original paper of the ST-DBSCAN algorithm [4]. The comparison criteria used by the space-time similarity function and its specific use to cluster criminal activities are the main contributions of this clustering method.
The purpose of using density-based clustering techniques in the context of crime-analysis is to achieve a non-statistical identification of the observed spatial and temporal trends in the commission of crimes, as well as to isolate exception cases that do not fit into those trends. This information is useful for the crime-analyst in order to develop specific strategies, both to fight and prevent delinquency, in the middle and long terms.
Pattern representation
We consider the crime-pattern output from the previous layer as the abstract representation of a single criminal phenomenon. This crime-pattern consists of three main components: crime specifics, space, and time; all three related to the perpetration of a specific crime. This allows the specialist to identify periods of high criminal activity and their geographic location. Therefore, the components of a criminal pattern are the following:
Data sample (out of 80 patterns) of the burglary dataset
Data sample (out of 80 patterns) of the burglary dataset

Criminal data referred to the geographic area where they were committed. Each red spot represents a crime incident of the “burglary” type.
The trend-identification process starts by analyzing a set of crime-patterns, each one with the same level of detail and within a limited geographic location, occurred within a given time interval. Table 2 contains a sample of burglary patterns obtained from the Cuautitlán Izcalli area, in the State of Mexico.
Figure 4 shows how such patterns are plotted in the map of the corresponding area divided into surveillance sectors.
In Table 3 we show another sample of the same dataset with a different level of detail from the one shown in the former sample. The differences between the two sets can be observed on the temporal and crime specific components of the patterns. This second set contains robbery-patterns and their location is another surveillance center within the same district of Cuautitlán Izcalli, Mexico.
Data sample (out of 126 patterns) from the robbery data set
The complete first dataset (burglary) contains 80 patterns, while the second one (robbery) contains 126 patterns.
Briant and Kut [4] describe an extension of the DBSCAN algorithm for spatio-temporal clustering, called ST-DBSCAN. This extension proposes the separate calculation of space and time similarities between patterns.
The ST-DBSCAN algorithm requires, besides the dataset to be processed, the following two parameters: the minimum number of neighbors around an object to consider a high density situation, which will be called MinPts; and the radius of the neighborhood which will be called Eps.
Density-based clustering
Density-based clustering algorithms can group patterns with a high spatial concentration within a delimited region isolating in the processes those patterns with a low degree of spatial similarity, which are regarded as non-related appearances of criminal activity. In this project, we used the ST-DBSCAN algorithm, an extension of DBSCAN to work with space-time components [4]. This algorithm was implemented as originally described except for the similarity function. Our proposed spatial comparison criteria and similarity function (Section 3.1.4, Eq. 3) were substituted in place of the original ones based on Euclidean distance and sector division.
Space comparison criterion and the similarity function
The comparison between patterns is achieved by a similarity function formed by the weighted sum of a set of comparison criteria (Cc) normalized according to the number of features that form the pattern. Each of these comparison criteria measures the similarity of each feature that makes-up the pattern. The way in which the similarity of the space component is measured is shown below.
Figure 5 shows an area divided into four surveillance sectors. A surveillance sector is a geographic zone made up by location (residential developments) and it is defined by the police department for the allocation of financial resources. According to the space comparison criterion based on Euclidean distance, patterns belonging to the same sector but separated by a long distance will not be similar (See Fig. 5(a), patterns p4 and p6), while patterns which are geographically close to each other, even if they belong to different sectors, will be considered as similar, see Fig. 5(a), patterns: p1 and p2.
Surveillance sectors. (a) Euclidean comparison; (b) Comparison by sector division.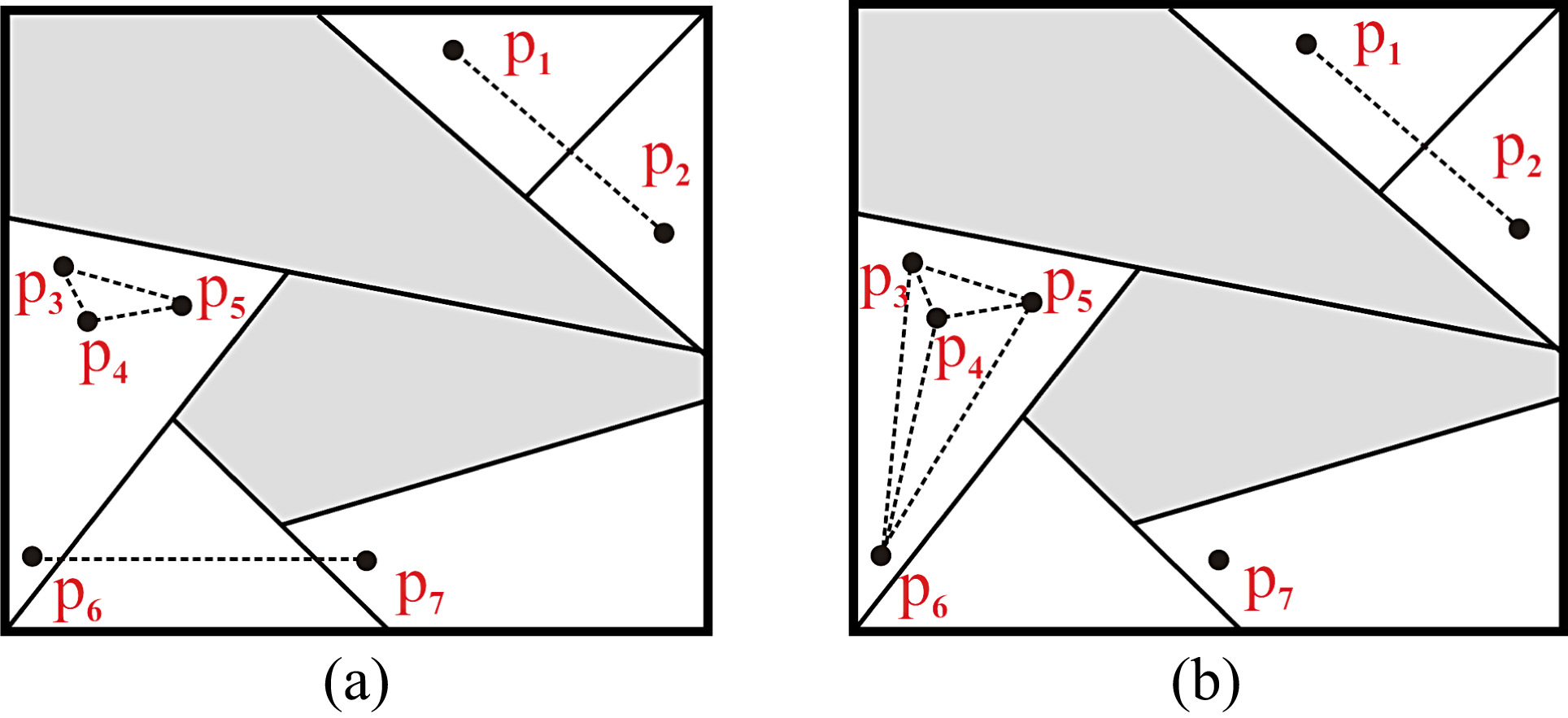
The spatial comparison criterion based on regions divided by surveillance sectors, strongly suggests that the maximum space-similarity should be achieved by patterns belonging to the same sector (See Fig. 5(b), patterns: p3 to p6), followed by patterns belonging to contiguous sectors (See Fig. 5(b), patterns: p1 and p2). This kind of clustering yields much more useful clusters because patrolling routines, as well as investigative teams usually schedule their operations by sector. Of course, different comparison criteria can be considered depending on the needs by each crime-analyst.
Our proposed similarity function is defined by the following equation:
Where:
Experiments in Section 5 will show that this similarity function based on our space comparison criterion produces better results than the space comparison criterion based on Euclidean distance. Once data is properly clustered, important hotspots can be identified. These hotspots are in turn surveillance points that must be considered in a patrolling route. The next section will deal with the construction of such routes.
Several methods have been developed for tackling the problem of route optimization. The field of multi-robot cooperative tasks provides an interesting set of examples; see [1] for a thorough compendium of several models. Within this approach, we found two major drawbacks. The first one is that some of them are designed for small devices [34], and the second one is that they are designed for automatic execution, and usually they do not allow incorporating certain restrictions pertaining to real world human driving and wide area sectorization. Other approaches are based on workload balancing models [40], local search techniques [43], and agents [7]. However, to our knowledge, ant colony systems, while being known to be effective for finding optimal routes [42, 20], have been scantly applied to police patrol route planning considering three real needs:1
Direct communication by the personnel of the Emergency Central C4 of the municipality of Cuautitlán Izcalli.
Ant Colony Optimization algorithms are models inspired in real ant colonies. Studies show how animals that are almost blind, such as ants, can follow the shortest path to their supplies (food) [11]. This is due to the exchanging information ability ants have, since each one of them, while moving, leaves a trace of a substance called pheromone along their path. Thus, while an isolated ant moves essentially in a random way, agents of an ant colony detect the pheromone trace left by other ants, and tend to follow such trace. These ants, in turn, leave their own pheromone along the travelled path, making it more attractive, since the pheromone trace has been reinforced. With time, the pheromone evaporates, causing the trace to weaken. In short, it could be say that the process is characterized by a positive feedback, in which the probability for an ant to choose a path increases with the number of ants that previously have chosen the same path. One of the first known applications of the ant colony system was the travelling salesman problem (TSP) [18], obtaining favorable results. From that algorithm, several heuristics have been developed to improve the original algorithm, and have been applied to other problems such as the vehicle routing problem (VRP) [14] and the Quadratic Assignment Problem (QAP) [29].
In this section, we present results of a heuristic based on an improved version of the ant colony optimization (ACO) algorithm called MMAS (Max Min Ant System) [41].
The ACO algorithms are iterative processes. In each iteration, a colony of
where
When all ants have built a solution, pheromone must be updated on each arc. The formula for this is:
Where
This gives us a global view of the MMAS algorithm. In the next section, we will present its application to the problem of human and material resources for patrolling routes. We aim to a three-folded purpose: (a) To find the optimal route between a patrol’s current location, and a point where a call for help has been raised. (b) To find optimal routes for patrolling a small set of nearby streets in a neighborhood, and finally (c) to find optimal routes for patrolling different points of major criminal incidence in a specified neighborhood.
We will illustrate our methodology with the example case of a neighborhood of the municipality of Cuautitlán Izcalli, Mexico. This neighborhood was selected considering the current geographic level for assignment of patrolling routes. In Fig. 6 the structure at street level can be seen. Patrols must cover the points considered as the most important ones.
Structure showing streets of a neighborhood in Cuautitlán Izcalli, Mexico.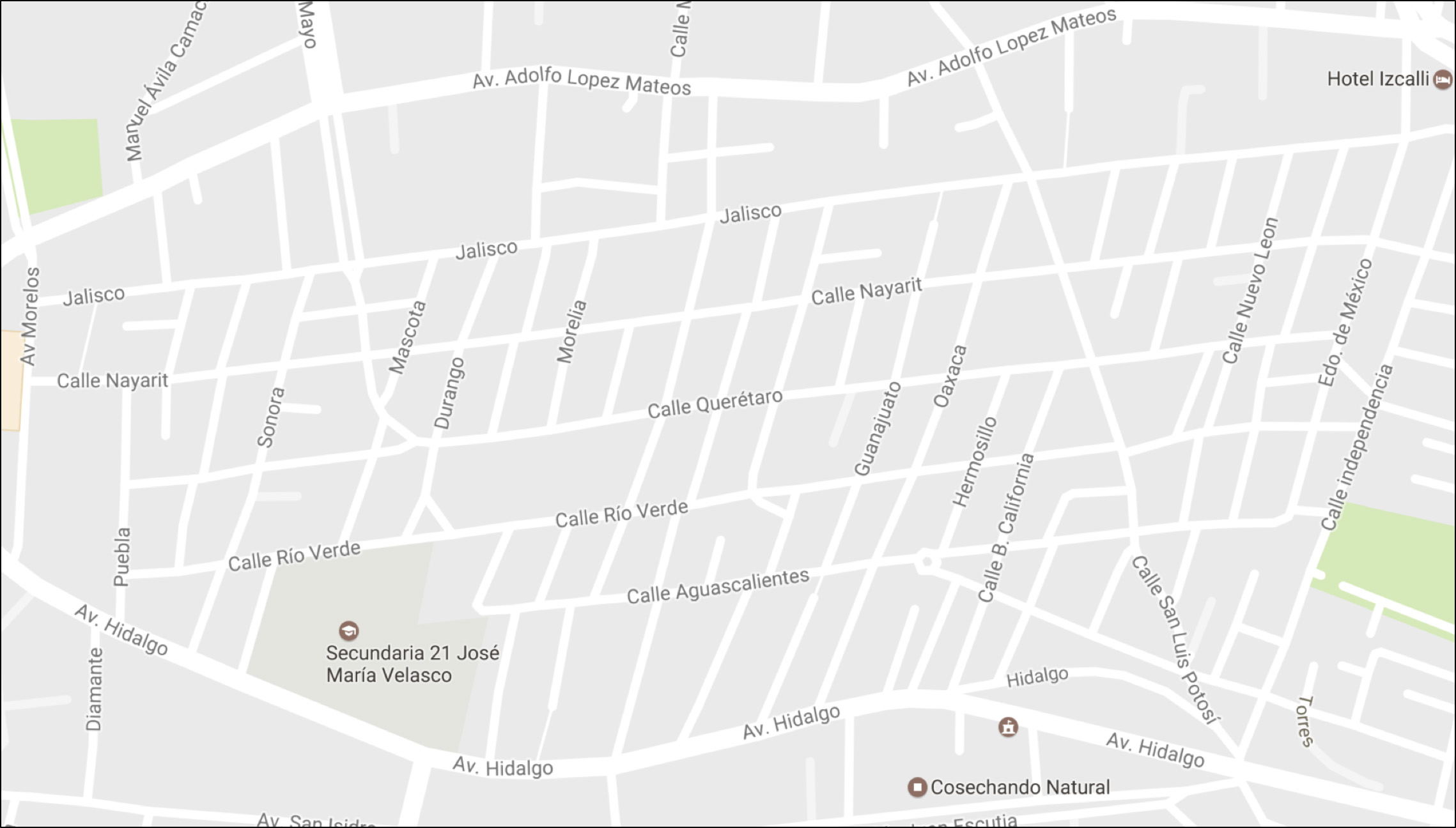
Then, the street structure is transformed to a directed graph
Graph obtained from street structure from a real neighborhood.
Our solution employs the algorithm MAX-MIN Ant [41] with modifications to the original restrictions for the TSP for which it was originally presented. Compared to the original TSP, we are interested on having
Following the architecture of our framework shown in Fig. 1, in this section we will present results of each one of the layers applied to real data of a national municipality in order to validate their effectiveness. For the forecasting model (Section 5.1), we will compare two inductive classification methods (namely the CR-
Forecasting
In the Cuautitlán Izcalli district, located in Mexico, the local Government launched the Centro de Emergencias Cuautitlán (CERCA, Cuautitlán Emergency Center) in 2007. An important part of its function is the gathering of the information corresponding to the three first categories of information sources. Therefore, this district was selected as a case study and test field for the forecasting, clustering, and patrolling recommendation model reported herein.
We perform two analyses: punctual hotspot prediction (Sections 5.1.1 and 5.1.2), and tendency analysis (Section 5.1.3). For the first analysis, we use data from the municipality of Cuautitlán Izcalli, State of Mexico. Within this analysis, we perform experiments for spatial and temporal location of crime (Section 5.1.2.1) and expected family of crime (Section 5.1.2.2). For the tendency analysis (Section 5.1.3) we use data from the Sacramento California (CA), police department.
Pre-processed report used as input to the algorithms – Mode 1
Pre-processed report used as input to the algorithms – Mode 1
Pseudocode for the MMAS algorithm. Asterisks show the steps to be modified for the random walk baseline comparison.
In this Section, we describe the details of our experimentation for applying the different algorithms presented in previous sections to the two modes mentioned in Section 2.1.1. All experiments in this section use data from January 1
Crimes were grouped by kind in different classes, as aforementioned in Section 2.1.1, for two different modes:
(1) public roads and highways; (2) homes; (3) stores and shops. (1) robbery in all its modalities; (2) homicide; (3) injury; (4) property damage.
Data are represented as shown in Table 4, accordingly to Mode 1, and in Table 5, accordingly to Mode 2. For the first mode, we used only 205 from 1551 records because the remaining records did not have enough information to distribute them amongst the classes selected. For the second mode, we were able to use all records. We will use this information as the input of the KORA-
Pre-processed report used as input to the algorithms – Mode 2
In this section, we present the results of our two first experiments, consisting on applying the previously presented algorithms following the two modes mentioned in Section 2.1.1.
5.1.2.1 First experiment: Location of crime
Mode 1 has three classes: (1) public roads and highways; (2) homes; (3) stores and shops. Using the KORA-
We used the CR-
Comparison of recall measures
Comparison of recall measures
5.1.2.2 Second experiment: Crime families
One of the main disadvantages depicted in the first analysis is the low number of records that can be used for prediction, although this allowed predicting the place where crimes are more likely to be perpetrated. For this experiment, we grouped the sample data in the following classes: (1) robbery in all its modalities, (2) homicide, (3) injury, and (4) property damage. This analysis allows using 1231 records out of 1551. For the sake of considering the heterogeneous distribution of the data between different dates, we tested the algorithms against:
150 new events corresponding to the month of April of 2007. 123 new events corresponding to the month of July of 2007. 321 new events corresponding to the month of April of 2008.
In contrast with the previous experiment, where the 1551 records from January 1
5.1.2.3 Results
Table 6 shows the results in terms of recall of applying the algorithms CR-
The CR-
In our second analysis, we used the whole data set from January 1
We have shown how both algorithms, the CR-
In order to compare with other related systems, we performed tests with a different dataset and compared against predictions using a Naïve Bayes classifier. We compare results using the Spatio-Temporal Root Mean Square of Errors (STRMSE) measure proposed by Ivaha et al. [23] with the Naïve Forecasting Method (NFM) described as well in [23]. The STRMSE measure consists of daily measurements of forecast errors, and it is based on the root mean squared error, divided by the number of days of the sample. Two or more models may be compared using STRMSE as a measure of how well they explain a given set of observations: the unbiased model with the smallest STRMSE is generally interpreted as best explaining the variability in the observations. STRMSE is calculated as shown in Eq. 6.
To test the proposed forecasting algorithm, we used the Sacramento dataset. This dataset contains 152,812 registered crimes and was made available by the Sacramento CA, police department.2
By analyzing only records from the last five years (2004 to 2008), a forecast was calculated for time-unit January 2009, all registered crime-families and within all 19 surveillance sectors. The foretold number of crimes was then compared with the real-life police-registers from that same space-time unit (2,219 crimes during January 2009).
5.1.3.1 Results
Using the aforementioned method, all positive and negative characteristic space-time properties for each crime-family were found. For the training set from 1/1/2004 to 31/12/2008, and test set from January 2009, the STMRSE of the Bayes (NFM) forecast was 7.05, while ours was 0.90. A similar behavior was observed for the test set of February 2009 (using the same training set): Bayes STMRSE yielded 8.45, while we obtained 0.97. We can (indirectly) compare with the system presented by Ivaha et al. [23]. His results are shown in Table 7, along with ours. NFM is the Naïve Forecasting Method, OLS-NI is the Ordinary Least Square method on Number of Incidences, and OLS-PC is the Ordinary Least Square method on Percentages of Crime (OLS-PC). For details on how NFM, OLSI-NI and OLS-PC results are obtained, please refer to [23].
Comparison with the systems presented by Ivaha et al.
These results show that the proposed method has very high effectiveness, with an STRMSE below 1.0 forecasting all space-units, during January 2009 (with a total of 2,219 crimes). This means that, in average, the proposed method only fails in less than five occurrences of each crime-family. Such precision is fairly acceptable for automated crime-analysis systems and might constitute a useful tool for planning preventive police operations.
The values of Eps and MinPts in our implementation of ST-DBSCAN were calculated with Eqs 7 and 8:
where
where:
The first experiment was conducted over the burglary dataset. For this experiment the feature called weapon is the most relevant attribute, so the best result is deemed to be the one that groups criminal incidents committed with the same weapon.
A very important aspect to be considered is the clarification of the difference between the patterns identified as noise and the outliers in the dataset. Noise refers to those patterns that may be spatially similar to other patterns or groups, but do not share other similar characteristics, while an outlier is a pattern geometrically separated from other patterns or groups. This clarification is necessary because the ST-DBSCAN identifies noise.
The results generated by the Euclidean space similarity function vs. our proposed space competition criteria are shown in Fig. 9. Type of crime is described by different geometric shapes, described in Table 8. In both parts (Figs 9(a) and (b)) the patterns labeled by question signs represent noise patterns (elements that do not have characteristics similar to others).
ST-DBSCAN results: (a) with Euclidean space similarity function (left), (b) with space similarity function based on sector division (right).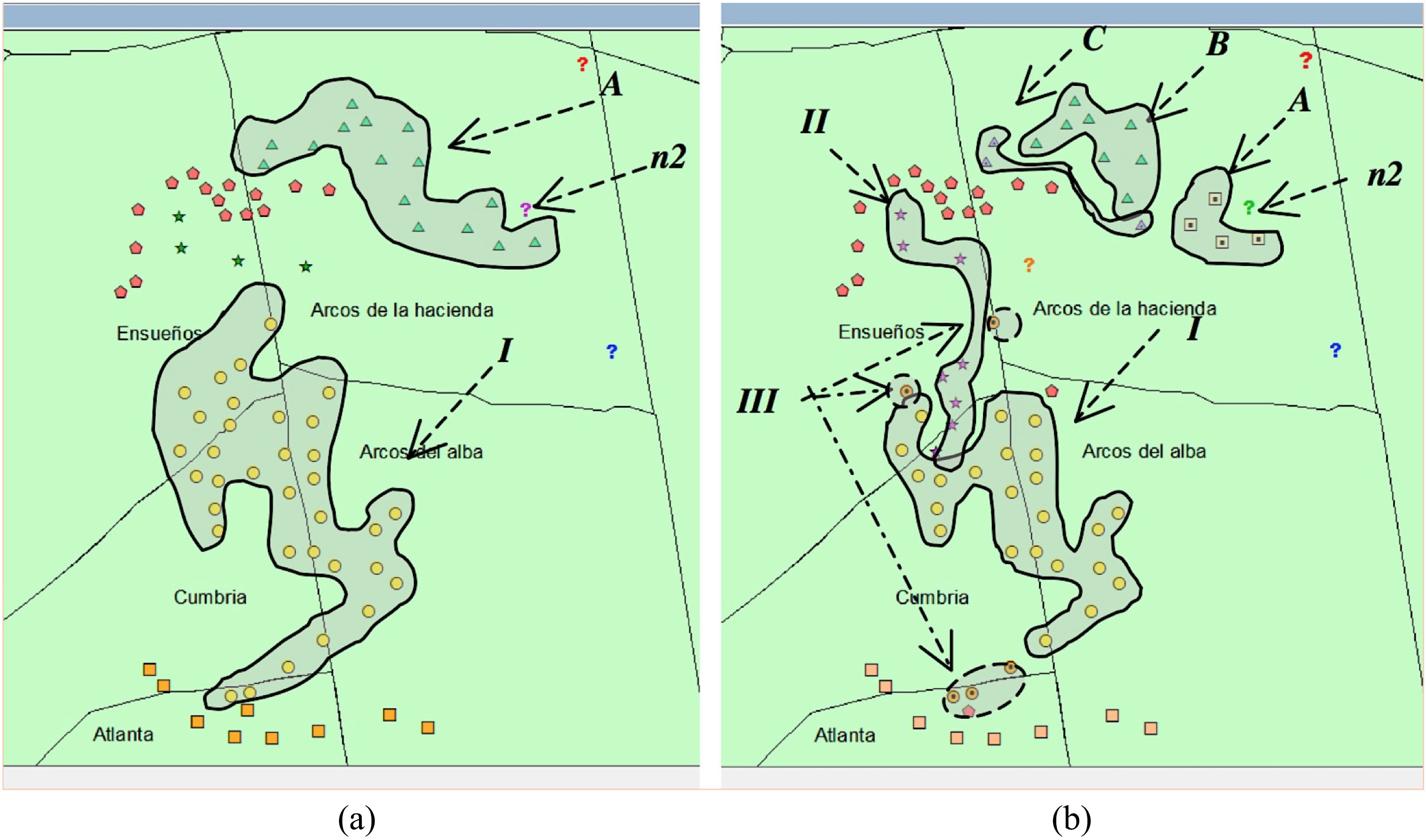
Cluster A (see Fig. 9(a)) represents burglary acts perpetrated with a firearm, while the n2 noise pattern is another burglary crime perpetrated with a “non-specified” weapon. Despite this, not all the patterns in cluster A were perpetrated with a “firearm”. The four triangular patterns surrounding the n2 pattern were committed “without weapons” (see Fig. 9(a)). There is where the Euclidean space similarity function fails, because it groups them in the same cluster given their geographic similarity, although they are not closely related.
Figure 9(b) shows this difference, the noise pattern identified by n2 is the same as the noise pattern identified in Fig. 9(a). Cluster A (Fig. 9(b)) contains the four criminal patterns perpetrated using a firearm, while the patterns that make-up Cluster B were committed without weapons. This result turns out to be very important because, following this path, crimes that were probably perpetrated by the same aggressors can be semantically identified.
In the second experiment we worked with patterns that have a higher level of detail, which means more descriptive features. Also, each component (set of related features) in the crime-patterns, were weighted as follows: 60% space-time, 30% crime-specifics and 10% crime features, due to the fact that some features are more important than others.
This experiment is more related with the work performed by the preventive police, since the family of crimes related to robbery is the one under study. This crime-family is made up by: robbery to passerby, break-in, and auto-parts theft.
The weighting may be obtained through a criminology expert. The objective is to identify trends by taking advantage of the expert’s knowledge in criminology. Figure 6 shows the results achieved.
Results of clustering of the “robbery” type of crime data
Table 8 shows the results of our last experiment. Of the two residential areas studied in the North areas, the one containing a higher amount of crimes from the robbery family is the Santa Barbara residential area, which belongs to the sector with the same name. Besides, we found that those months of the year with the highest incidence of crime are July and September, so it is necessary to undertake programs and campaigns in such sector, and in that season of the year have prevention programs and campaigns to fight this type of crime.
In this section, we present results of three selected cases with MMAS for solving patrolling routes optimization problems as described in previous paragraphs. After several tests, we found the optimal parameters shown in Table 9. We compared our results against a random walk baseline, which consists basically on using the algorithm shown in Fig. 9 (see Section 4.2) without using Eqs 1 and 2, i.e., using a plain random roulette with equal probabilities, and not using pheromones at all.
| Alert | Start | End | Ant colony MMAS | Random walk baseline | ||||
| # | point | point | Cost | Time | Optimal? | Cost | Time | Optimal? |
| 1 | 1 | 31 | 716 | 23 | Yes | 819 | 32 | No |
| 2 | 1 | 109 | 674 | 35 | Yes | 674 | 35 | Yes |
| 2 | 1 | 105 | 780 | 35 | Yes | 1432 | 43 | No |
| 4 | 1 | 89 | 1197 | 37 | Yes | 1781 | 57 | No |
| 5 | 1 | 64 | 1964 | 96 | Yes | – | – | N/A |
Results obtained from experiment A
The goal of this experiment is to optimize routes that were created as a preventive perimeter given an alert call in a point or specific street. For this purpose, 5 points in the map’s neighborhood were randomly selected, as well as a common starting point. See Fig. 12 and Table 10.
Clusters identified with ST-DBSCAN with a space similarity function based on sector division (Northern area).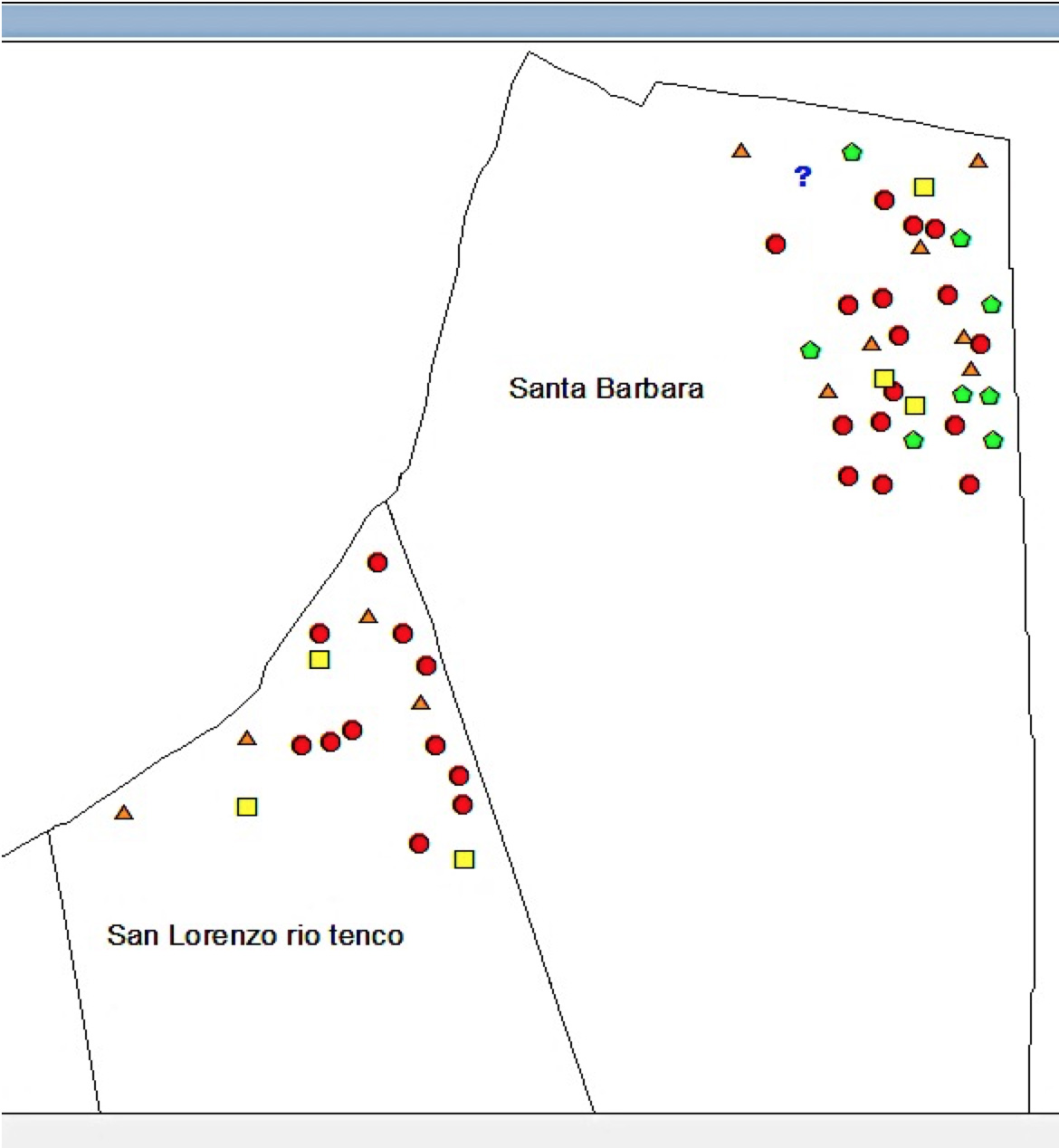
We can see in all cases that the optimal route was automatically found by the ant colony algorithm, while the random walk algorithm did not converge to the optimal solution after the same number of iterations (50), except for Alert 2. For Alerts 1 to 4 the random walk algorithm obtained a route, but for Alert 5 the maximum number of iterations was reached without finding a route to the target node.
The goal of this experiment is to find optimal routes for patrolling a small set of nearby streets in a neighborhood. This kind of routes is generally assigned to individual patrols.
For this experiment, three different surveillance areas were selected, each one with 6 nearby points, located randomly in the studied neighborhood, as well as a common point, see Fig. 12. It is important to note that the selected areas were managed independently, and that this experiment aims to illustrate the optimal route from a specific point to a particular area, and so, it does not model interaction with other areas. Optimal routes are shown in Table 11. Our Ant Colony algorithm was able to find all optimal routes for this experiment, whereas the random walk baseline found routes for Alerts 2 and 3, but they were not optimal. See Found routes are ready to be implemented in a real patrolling scenario. Routes like these were calculated for all neighborhoods of Cuautitlán Izcalli, always finding optimal routes.
Optimal routes for experiment B
Optimal routes for experiment B
Selected alerts in experiment A.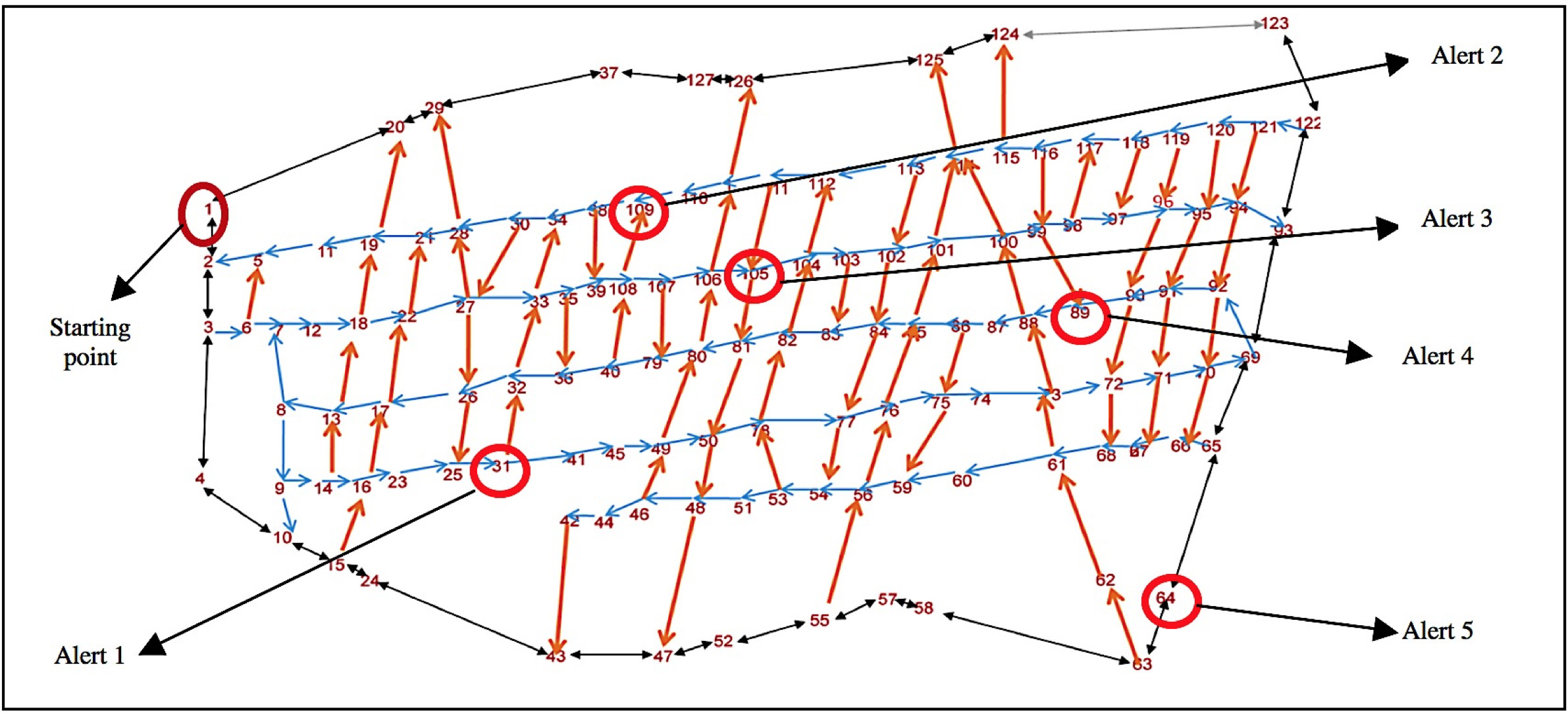
Selected areas in experiment B from the sample neighborhood.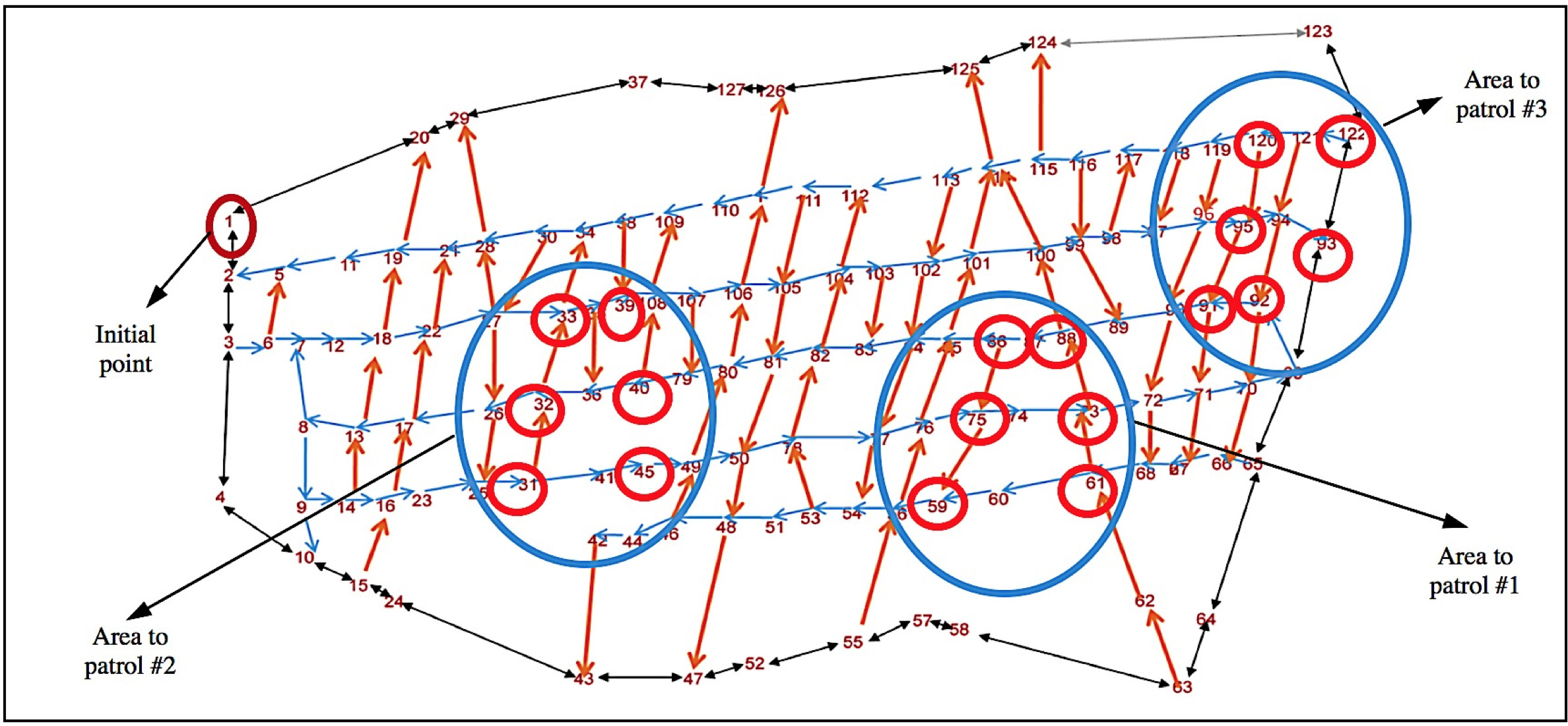
MMAS vs. Random walk routes for experiment B
Optimal routes for experiment C
Areas to be covered by the routes sought in experiment C.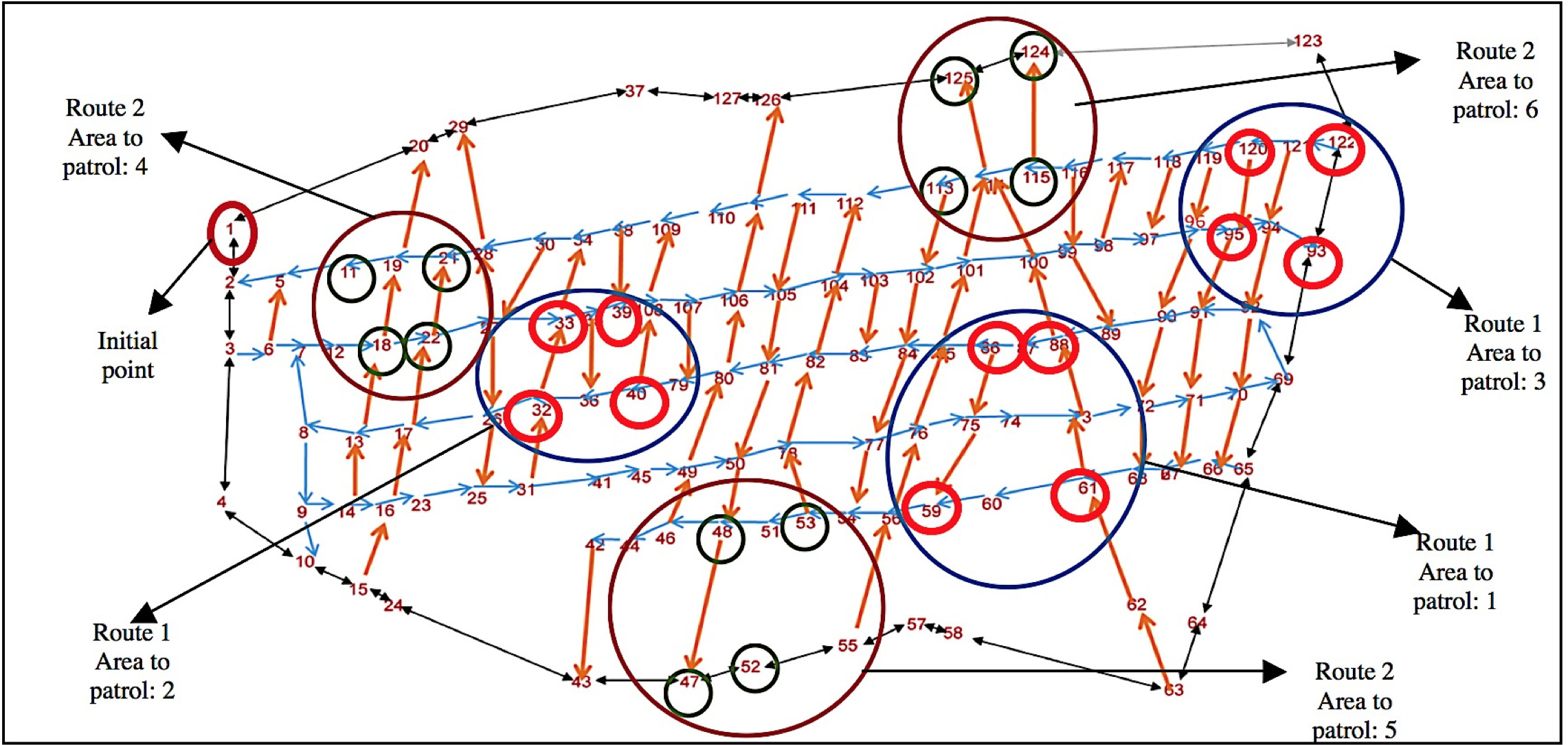
The goal of this experiment is to find optimal routes for patrolling diverse areas that are distributed throughout the whole neighborhood. For this experiment, the algorithm was executed to find two optimal routes. Each one of them must pass through three different surveillance areas. Each area is integrated with 4 nearby points, randomly selected from the studied neighborhood. All routes depart from a common initial point. See Fig. 13.
All optimal routes shown in Table 13 were found by our Ant Colony Algorithm, while the Random walk algorithm was not able to find a route covering the requested route points within the specified number of iterations. In general, several routes were calculated for all neighborhoods in the municipality of Cuautitlán Izcalli, always finding optimal routes, implying the proposed algorithm is a reliable way of calculating patrolling routes given important points to be covered. These points can be obtained from daily operation of patrolling routes planning sessions.
Conclusions and future work
We have presented a framework for forecasting, clustering and patrol routes recommending in order to prevent crime incidents. To our knowledge, this is the first work comprehending a single workflow from raw data of crime events, to patrolling routes recommendation. Each stage of this framework has been validated against methods commonly used by commercial state of the art crime analysis systems, such as Bayesian tendency analysis, Euclidian distance-based clustering, and random walk route generation. In all cases, we were able to provide a performance improvement, as well as other advantages such as obtaining valuable information for describing the criminal scenarios under study by using inductive definitions. We added other flexibilities such as the use of thresholds, which allow us to determine the level of precision we want in the inductive description of each class, and managing several restrictions for covering real patrolling needs.
We performed two analyses: punctual prediction and tendency analysis, which show that it is possible to predict punctually one of four crimes to be perpetrated (crime family, in a specific space and time), and 66% of prediction of the place of crime, despite of the noise of the dataset. The tendency analysis yielded an STRMSE (Spatio-Temporal RMSE), of less than 1.0.
For clustering relevant hotspots, we implemented the ST-DBSCAN algorithm, proposing a space similarity function based on sector division. This generates better results than the standard one based on Euclidean distance, taking the following aspects into account: (1) The semantics adapt better to reality under the context of the type of analysis made and (2) Higher percentage of noise identification contributes to the reduction of elements for the analysis.
Our recommendations on route patrolling were based on ant colony systems, finding that they are efficient and effective for optimizing several kinds of routes. In all cases, we were able to find an optimal route within a limited number of iterations, while the random walk algorithm found an optimal route in only a few cases. For Patrolling Area Optimization, the random walk algorithm was not able to find a patrolling route within the specified number of iterations. These experiments show that computing the probability of transition for an ant based on a pheromone component improves the ability of an exploration algorithm to find a feasible solution in short time.
The problems tackled in our experiments are extendable to cover many problems arising currently in great urban zones of the world. Around 50 iterations were needed to find an optimal route with our method. The compared method was not able to find an optimal route within this number of iterations.
As a future work, there are several paths to explore in this project. First, it is necessary to incorporate other information sources available. Second, it is of the utmost importance to calculate the optimal thresholds for the learning process. A statistical analysis of the data included in the supervision sample would make this task easier, as well as exploring evolutionary techniques [38].
Further experimentation with the baseline algorithm for finding the needed number of iterations to obtain an optimal route (if possible) has been left as future work.
Also, as future work, we plan considering traffic factors affecting patrolling maneuvers, as well as considering other factors impeding free vehicular transit and thus, affect the response time of a patrol.
Footnotes
Acknowledgments
We thank the support of Mexican Government (SNI, SIP-IPN, COFAA-IPN, and BEIFI-IPN), and CONACYT, Red TTL.