
Abstract
Eye detection plays an important role in many fields, because eyes provide prominent facial feature information. However, changes in face pose, illumination variation, with glasses, and eye occlusions can make it difficult to detect eyes well from facial images. This paper proposes a hybrid model for eye detection. The model is an integration of two classifiers: Convolutional Neural Networks (CNN) and Support Vector Machines (SVM). In order to improve the speed of detection in the system, an eye variance filter (EVF) is constructed for eliminating most of noneye images to keep less candidate eye images. The CNN then works as a trainable feature extractor to explicitly extract various latent eye features. Finally, the trained SVM classifier is employed for eye verification instead of using the CNN classification function. Experiments applying the model have been conducted on the BioID, IMM, FERET and ORL face databases. Comparisons with other methods on the same databases indicate that this hybrid model has achieved a higher detection accuracy. Extensive experiments demonstrate the robustness and efficiency of our method by testing it on different facial images with varying eye conditions.
Introduction
Eyes are more prominent features of the human, compared to the nose or mouth. Eye detection is a sub-field of object detection in image processing. Eye detection methods have been widely applied in many fields, such as drowsiness detection for intelligent vehicle systems [1, 2, 3], eye gaze tracking devices [4, 5, 6], human-robot interaction [7, 8, 9], and automatic face detection and recognition systems [10]. However, eye detection is a very difficult task, since structural individualities of eyes vary greatly across the different races of the world. The structural individualities include eye size, iris color, and eyelid boldness and width. Additional factors such as glasses and their glints, changes in illumination, face poses, and occlusions can introduce noise to eye detection methods, which could lead to false detection.
The better eye detection methods need to have the robustness for people with glasses, illumination changes, rotation of the frontal face, and different eye occlusions (e.g., semi-closed eyes, closed eyes, and squinting). In this paper, a coarse-to-fine classifier is designed to locate eye regions. First, an eye variance filter (EVF) is trained as a coarse classifier which can roughly find eye positions, filtering out most noneye regions quickly, and consequently improving the detection speed of the system. Then, we use the CNN architecture as a feature extractor to learn and extract features automatically. Lastly, the final classification for eye images is completed using the SVM classifier.
To verify the feasibility of our methodology, we gave the compared detection results for eye localization with our previous and other researchers’ works on the four face databases, i.e., Biometric Identity (BioID), Informatics and Mathematical Modeling (IMM), Face Recognition Technology (FERET), and AT&T database of faces (ORL). It was observed that the proposed method achieved a better eye detection result on images including eyes with glasses, various illumination scenarios, face pose changes, and eye occlusions.
The remaining parts of this paper are organized as follows. Some related works to eye detection are given in Section 2. The principles of EVF, CNN, and SVM models are described in Section 3. Section 4 presents the process of eye detection. The experimental results and performance analysis are presented in Section 5. The merits of our proposed method are given in Section 6. Finally, Section 7 provides the conclusions.
Related works
By looking at the principles of related methods, eye detection techniques can be divided into four categories: shape-based, feature-based, appearance-based, and hybrid-based methods [11].
The shape-based method depends on the geometric eye model and a similarity measure to decide whether a face image contains eye images. The models consist of simple elliptical shapes and complex shapes. Simple elliptical shape models reply on the viewing angle, then the elliptical iris and pupil regions can be modeled using shape parameters. Complex shape models allow for more detailed modeling of the eye shape. Perez et al. [12] first used the thresholds of image intensities to estimate the pupil ellipse center. Then the limbus and pupil boundaries are extracted using an edge detection technique. Kawaguchi et al. [13] adopted a separability filter to extract the feature, and then the Hough transform was used for model fitting. Increasing the number of parameters used to construct the model will help make the shape based model more precise, but this also increases the computational demand. This limitation makes handling face pose changes and eye occlusions difficult for this method.
The feature-based method focuses on distinctive features from the eye image, e.g., eyebrow, pupil, and iris, to locate the eye regions. Sirohey and Rosenfeld [14] used the linear and non-linear filters constructed from Gabor wavelets to detect the iris and corner features of the eyes. Then these features were further filtered to remove false features. A voting mechanism was finally applied to make a decision for accurately locating the iris. Feng and Yuen [15] focused on three cues for locating eyes on gray-scale face images. Each cue indicated the candidate eye regions. The precise eye location was determined and validated by a variance projection function. Based on this method, Zhou and Geng [16] proposed a hybrid projection function constructed by the integral projection and variance projection functions. Eye detection performance is decided by the optimal parameters of the hybrid projection function. In Ando [17], a seven-segment rectangular filter is employed to find the between-the-eyes feature of the human face for eye region location. Feature-based methods are generally robust against to illumination and pose changes, so the method requires high-quality images [11].
The appearance-based method relies on models constructed directly by using the photometric appearance of the eyes. The method needs no specific a priori information of eye images, but a sufficient amount of training data to learn the parameters to build an eye model. The feature extraction process is included in the method, which adds the function to eliminate noise and reduce dimensionality. Vijayalaxmi and Rao [18] used a Gabor filter as a feature extractor and SVM as a classifier. The eye images were processed by the Gabor filter, and the output fed into the SVM to train the classifier. Ryu and Oh [19] developed an algorithm that used eigenvectors of the binary edge data set from eye fields, then using neural networks for the eye region detection. Wu and Trivedi [20] used a binary tree to model a human eye statistical structure for locating accurate eye regions. With a clustering method based on the pairwise mutual information between features, the dependent features were separated into different subsets. The process of eye detection would be repeated until the subset features have enough mutual information. The final detection was achieved through the Bayesian criterion. In Fu et al. [21], the orthogonal wavelet analysis method was used as a feature extractor, the output was given to the SVM for locating eye regions. The appearance-based method is based on the machine learning algorithms to learn the model from training data, so the method can apply to all kinds of different eye images.
Compared to the methods mentioned above, the hybrid-based method is more popular for eye region detection. The method combines two methods or more into one system to locate eye regions. Peng et al. [22] and Xia et al. [23] first adopted the feature-based method to locate probable human-eye areas, then accurate eye regions were found with a modified template-matching method. In Hassballah et al. [24], the gray intensity variance was used for locating candidate eye regions. Then with an independent components analysis (ICA) method, the precise eye regions were detected. Kalbkhani et al. [25] used a non-linear RGB to YCBCr color conversion. An eye mapping algorithm was then applied to locate the eye regions on the created face mask. Phromsuthirak and Umchid [26] also adopted the eye mapping algorithm to first locate possible eye regions. The correct eye regions were then determined using the geometrical test method. Our previous research for eye detection also adopted the hybrid-based method [36]. First of all, the eye variance filter was taken as a coarse classifier to filter out most noneye regions. The principal component analysis (PCA) was then used as a feature extractor. Lastly, the accurate eye regions were determined by a trained SVM classifier. The mechanism of the hybrid-based method acts like a cascaded classifier which uses rough initial classification to then achieve accurate eye localization. Consequently, the hybrid-based method aims at combining the advantages of different eye models into a system to overcome their respective shortcomings. Based on the principle, in this paper we proposed a new hybrid eye detection method using the CNN and SVM.
The proposed method
The proposed training and eye detection processes are shown in Fig. 1. In the training stage, three models (EVF, CNN and SVM) are trained. The training samples used for EVF are scaled to the resolution of 48
(a) Training of eye detection framework and (b) Testing of eye detection framework.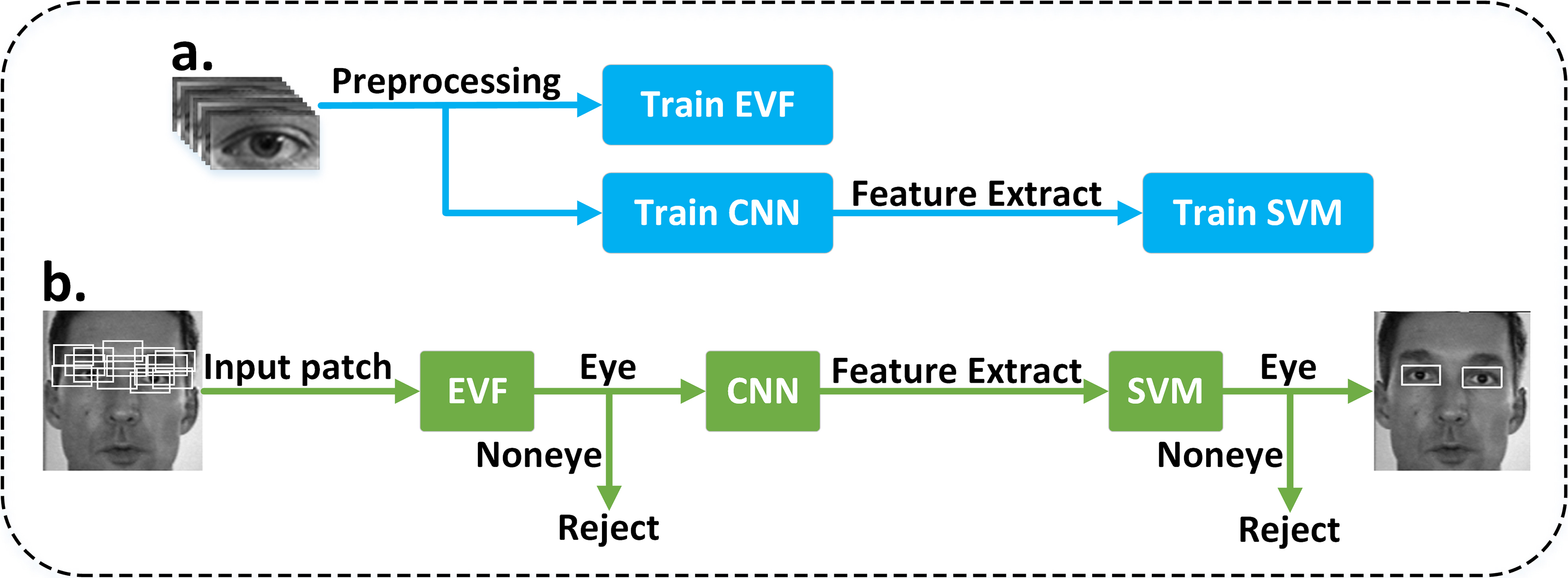
In the testing stage, the boosted cascade face detector [27] is applied for initial face region location. The wrong detecting face regions are then manually corrected. The detected face image is normalized to an image of size 200
Firstly, the eye variance image is introduced into the system. Based on the fact that the change of grey intensity in the eye region is more obvious than in other regions on the face, the second-order moment (or variance on a domain) is used as an indicator of variation in gray intensity. Hence, the variance of the eye image
where
The 48
where
The variance image on each sub-block is calculated by Eq. (3.1). Each sub-block has different features of grey intensity. An example of an eye image from an eye database and its variance image is shown in Fig. 2.
(a) An eye image and (b) its variance image.
Then to construct an EVF, 30 eye images with or without glasses are extracted from our eye database. The EVF on the
where
(a) 30 eye images and (b) corresponding to EVF.
The EVF is used to detect the most probable eye regions. The correlation is calculated between the EVF and eye/noneye variance images on the face. The correlation is defined as:
where
In order to calculate the EVF correlation value, another 60 images with 30 noneye images and 30 eye images are extracted from our eye database. The variance images of the noneye images are constructed in the same manner as the eye variance image. Figure 4 shows that the eye region images have correlation values greater than 0.32, while the noneye region images have correlation values less than 0.32. So 0.32 can be taken as the EVF threshold. Consequently, the role of the EVF in the process of eye detection is used to filter out most of the noneye images and keep the more probable eye regions possibility, i.e. candidate eyes.
Correlation between eye/noneye images and EVF.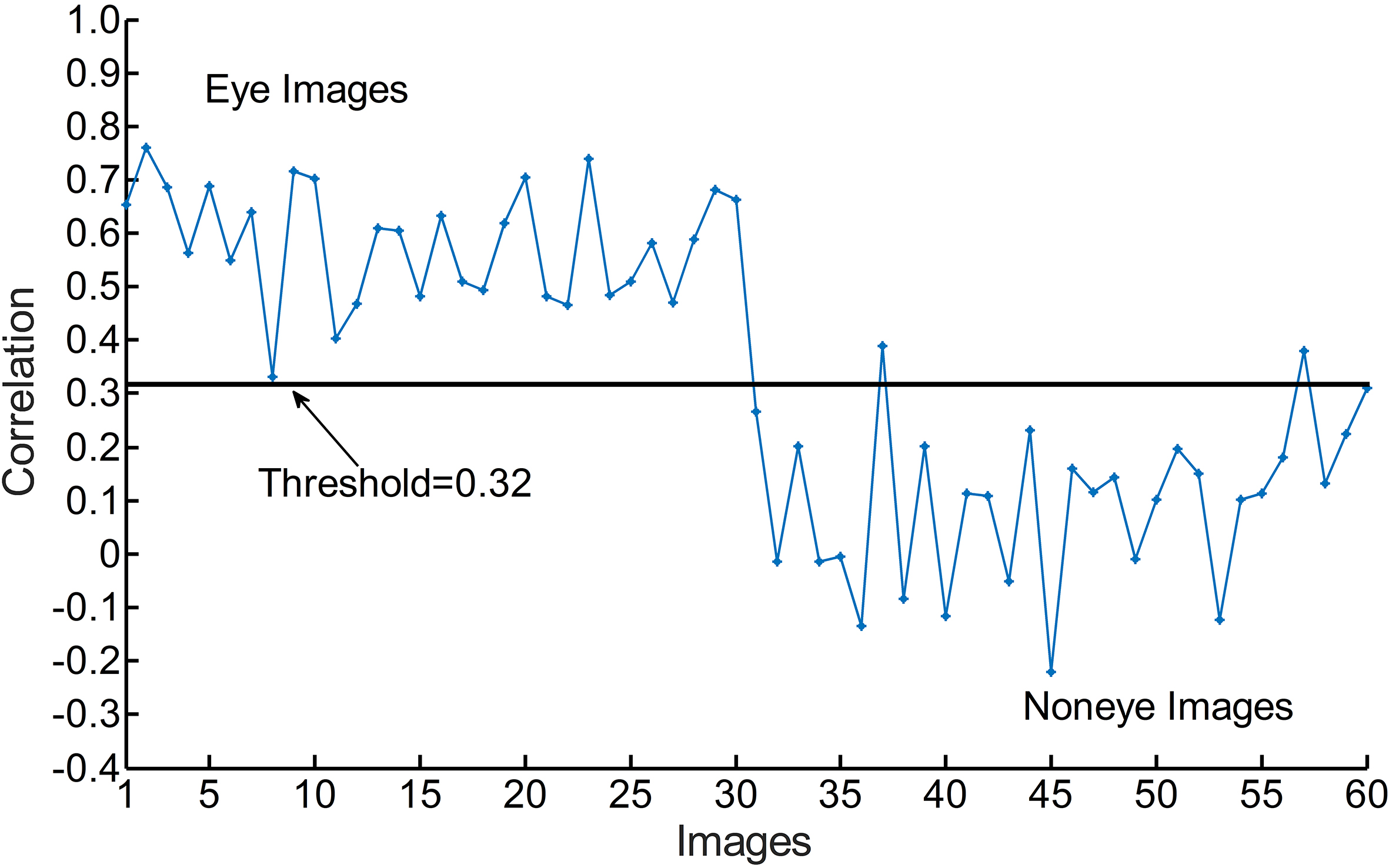
A Convolutional Neural Network is a multi-layered neural network with a deep supervised learning architecture [28]. The CNN architecture consists of two parts: an automatic feature extractor and a trainable classifier. In our research, the trainable classifier is replaced by the SVM classifier and the CNN is used as the feature extractor. Figure 5 shows the architecture of CNN with a SVM classifier.
The architecture of CNN with SVM. Conv: Convolution, Subs: Subsampling.
As shown in Fig. 5, the CNN consists of 7 layers, including an input layer, convolution layer, subsampling layer, full connected layer and output layer. Layers C1 through C5 are used for eye image feature extraction. In this processing, a series of successive convolutions and subsampling operations are performed. Each layer is composed of multiple two dimensional planes called feature maps, and each feature map contains multiple independent neurons. Each neuron on a feature map receives inputs from a small neighborhood (identified as the “receptive field” in [29]) in the previous layer. All the neurons in one feature map share the same kernel and connecting weights [29]. The neurons can extract elementary visual features such as oriented edges, end-points, or corners from receptive fields. Extracted features are then combined by the subsequent layers in order to obtaining high-level features.
Convolution and subsampling are very important steps in the CNN feature extractor. In the convolution process, each feature map unit is computed with two steps. The input
In the subsampling (Pooling) process, each feature map unit is also achieved by two steps. Each neuron in the subsampling layer first computes the average over the 2
Figure 5 shows the input layer is an eye image with pixel size 32
In our research, the last output layer of the CNN model is replaced by an SVM classifier. Layers C1 through C5 act as a feature extractor. The output values of the layer C5 can be treated as features for the SVM classifier. The original CNN with the output layer is trained with several epochs until the training process coverages. The SVM classifier then uses the output features from Layer C5 as feature vectors to train the SVM. Once the SVM classifier has been trained, it performs the recognition task and makes decisions on testing eye and noneye images.
The theory of support vector machines (SVM) was proposed by Vapnik in 1995 [33]. The SVM is a learning method based on statistical theory that has been successfully applied to many fields for detection and identification purposes [37, 38]. The main idea of SVM is to seek an optimal hyperplane as the decision surface to separate the classes whilst maximizing the points over the separation margin and minimizes the error. This method is mainly used for solving two-class problems.
In this paper, the classifier is devoted to distinguish between eye images and noneye images. It is a binary classification problem. Suppose that there exists a hyper-plane which could divide sample space into two categories, one positive set (eye images), and a negative set (noneye images).
Suppose a training set
where
The separation margin between the classes is
subject to:
When the training set is linearly inseparable, an optimization algorithm for linearly inseparable problems is introduced. The goal is to motivate SVM to search for the hyperplane that could maximize the margin and minimize number of misclassification errors. The optimization problem of the separating hyperplane becomes:
subject to:
By introducing Lagrange function, the dual problem of quadratic programming is obtained:
subject to:
In general, the training sets are not linearly separable. In the nonlinear case, we need to transform the lower dimensional feature space into a higher dimensional feature space via nonlinear mapping. Suppose there is a nonlinear mapping:
In this case, the optimal function in Eq. (10) becomes:
The general kernel function has three categories: polynomial kernel function, Gaussian kernel function, and RBF kernel function.
Therefore, the final decision function is defined as follows:
The detailed theory of SVM can be found in [33]. The RBF kernel function is used as the SVM kernel function in this paper. The RBF kernel function can be defined as:
Where
This section presents the detailed process of the proposed eye detection method. The method consists of six steps as follows:
The eye detection process.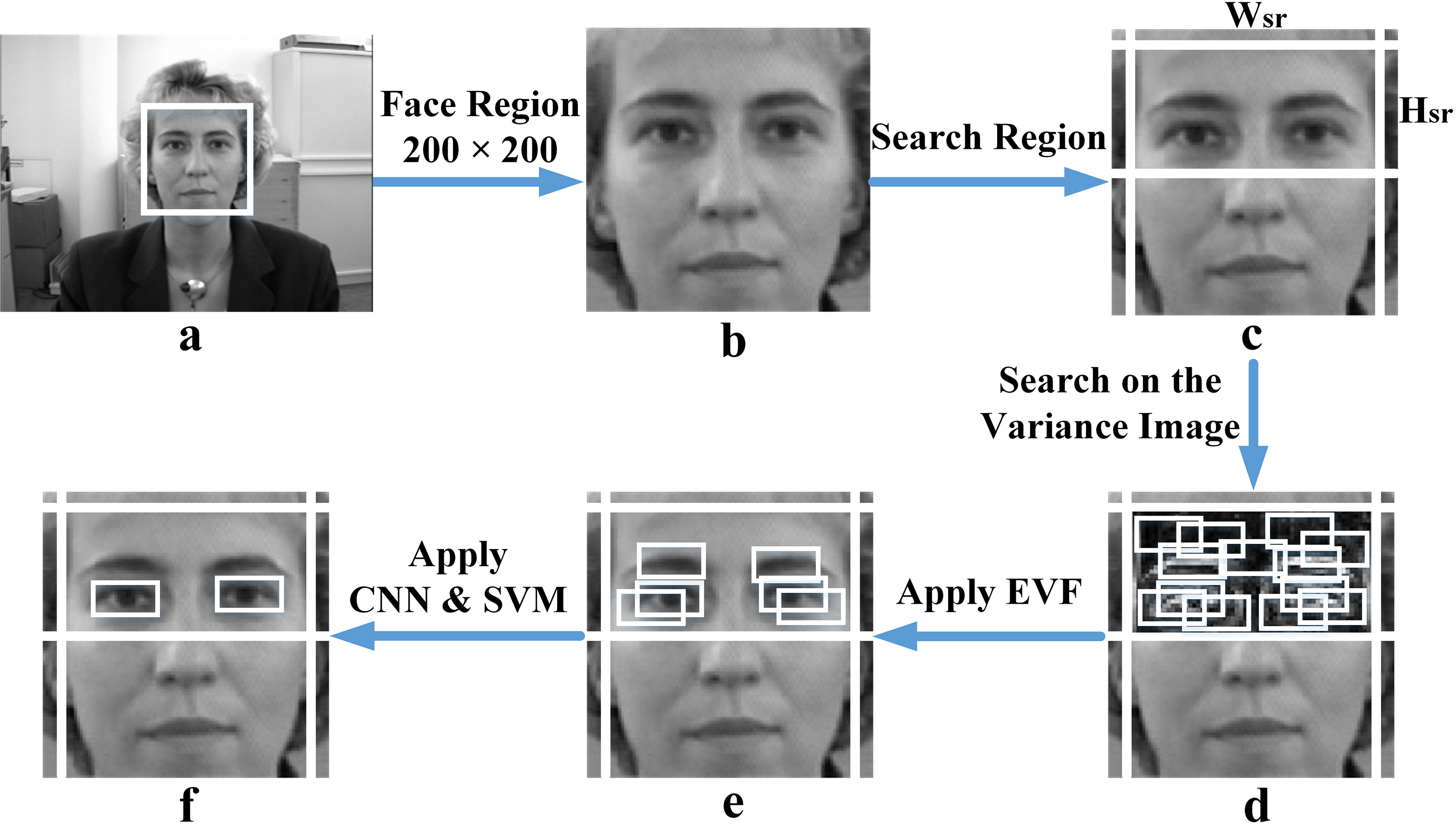
where
The database
The images used for establishment of our database are extracted from the extended M2VTS dabatbase (XM2VTS), Psychological Image Collection at Stirling (PICS) face database, Japanese Female Facial Expression (JAFFE) face database, Milborrow/University of Cape Town (MUCT) face database, California Institute of Technology (Caltech) face database, Self-face database, and face images from Internet websites.
The XM2VTS database contains four recordings of 295 subjects, with each recording consisting of a speaking head shot and a rotating head shot. We select 750 images from XM2VTS used in our database. The PICS face database is a collection of images with many face sets. In this paper, the images are only extracted from 2D face sets including the Aberdeen set with 687 facial images of 90 individuals, the Pain Expressions set with 599 facial images of 23 individuals (13 women and 10 men), and Utrecht ECVP set with 131 facial images of 69 individuals (20 women and 49 men). The JAFFE face database is constructed by Kyushu University in Japan with 213 images of 7 facial expressions posed by 10 Japanese female models. The MUCT face database is provided from University of Cape Town in South Africa with 3755 face images. The Caltech face database is collected by Markus Weber at California Institute of Technology with 450 frontal face images. The self-face database is built by the Measurement & Testing Laboratory of Beijing Institute of Technology (BIT M&T) with 1,000 face images from 10 people. We selected and downloaded 13,000 face images from Google (USA), Bing (USA) and Baidu (China) search engines.
The database consists of a positive image set and a negative image set. The positive image set contains 18,000 eye images, which are captured manually from face images from the above face databases, with different sizes, different gaze directions, with/without glasses, rotation, under various lighting conditions, etc. The negative image set contains 20,000 noneye images including eyebrow, incomplete eye image, skin, nose, etc. The size of all images in eye database is normalized to 48
Evaluation of eye detection
The proposed method was tested separately on the BioID, IMM, FERET, and ORL face databases. The BioID face database contains 1521 grayscale, frontal facial images of pixel size 384
The proposed algorithm in this paper is run on the corrected face regions captured by the boosted cascade face detector. However, the face detector could not achieve 100% detection accuracy on the face databases. Hence, in order to achieve the eye detection accuracy on each image on the four databases, we manually extracted the face regions on the in-corrected face images.
At present, there is still no criterion to evaluate the accuracy of eye region detection. In this paper, we considered the correct test results that the upper and lower eyelid and two corners of the eye fallen into the eye regions. Comparison of results with existing methods are proposed in Table 1. Because the picked methods proposed by researchers are tested on different face databases and different number of face images, we only provide the detection rates on the corresponding face database in Table 1. In order to show the advantages of the proposed detection method, Table 1 also gives the compared result with the CNN, which is not only used as the features extractor, but as the output predictor. Additionally, eye detection rates are given separately on the BioID and ORL face images with glasses and without glasses.
Detection accuracy (NR: not reported, NG: no glasses, WG: with glasses, LE: left eye, RE: right eye)
Detection accuracy (NR: not reported, NG: no glasses, WG: with glasses, LE: left eye, RE: right eye)
The bold numbers represent the best accuracy in each face database.
Examples of eye images from our database, including (a) variance from structural individuality, (b) variance from iris motion and eye condition, and (c) variance from noise (Such as glare, eye glasses, etc).
The average eye detection rate obtained on the whole BioID face database is 98.16%, which is higher than Hassaballah et al. [24] and Zhou and Geng [16]’s methods. The images from IMM face database have high quality with respect to other databases. Our proposed method obtained 99.17% detection rate on the IMM. Its result is better performance than the Kalbkhani et al. [25]’s method. For the ORL face database, we obtain the eye detection rates of 97.15% and 94.12% on images with and without glasses, respectively. The accuracy on face images without glasses is higher than Peng et al. [22]’s method. The average eye detection rate on the ORL database is 96.25% compared with the 94.7% in Xia et al. [23]. Dasgupta et al. [2] uses a baseline EVF for eye detection and achieved a detection rate of 92.5% on the MIT AI laboratory face database, whereas the proposed method obtains an average detection rate of 97.92% on the four databases.
Results of eye detection on the four face databases, including (a) BioID without glasses, (b) BioID with glasses, (c) IMM, (d) FERET, (e) ORL without glasses, and (f) ORL with glasses.
According to the merits in Section 4, if this system uses the CNN only as the feature extractor and the classifier, the result shows the eye detection accuracy is lower than the model integrating CNN and SVM. Additionally, compared results with our previous research [36] indicates that the proposed method by this paper achieves higher accuracies on the BioID, IMM and FERET databases, respectively. It also has an evidence that the performance of CNN used as the feature extractor is better than the PCA. The reason is great likely the CNN could extract more features with more representations than the PCA feature extractor. Furthermore, for the images with glasses on BioID face database, the detection accuracy obtained by the CNN and SVM is much higher than the PCA and SVM.
In this paper, the robustness evaluation of the proposed eye detection method under illumination changes is provided. Here, the Yale Face Database B was used in the test. The Database contains 5700 grayscale images of 10 subjects under 576 viewing conditions with 9 poses and 64 illumination conditions. The size of each image is 640
Examples of face images with big shadows from Yale Face Database B.
The qualitative samples of eye detection results obtained from four subjects in the subsets of the Yale Face Database B. The results show the better detection performance under the light source directions varying from different angles (
Results of the robustness to illumination changes on Yale Face Database B.
Through experiments, we obtain the 97.64% correct rate of eye detection on the 3175 face images. The conclusion could be given that the proposed eye detector has a better robustness to illumination and pose changes. In order to further test the robustness of the method to pose changes, the next subsection provides more detection results.
The effects of pose changes on the proposed eye detection method are evaluated using the FEI Face Database. The database contains images of 200 subjects captured under an upright frontal position with profile rotation of up to 180 degrees for a total of 2800 images (14 images of each subject). The scale of rotation angle might vary by about 10% and the size of each image is 640
Detection results on different facial rotation angles
Detection results on different facial rotation angles
Examples of face images with large rotations from FEI Face Database.
The experiment gives the results from images with horizontal rotations of 0
Results of the robustness to pose changes on FEI Face Database.
Based on the fact that the proposed hybrid model could incorporate the merits of the CNN and SVM classifiers, the aim is to avoid the limitations of the two classifiers.
Feature extraction
The extracted features for a classifier usually have a great impact on the final classification results. More features result in more representations, the classification accuracy will be improved better. Numerous studies and applications have demonstrated that a SVM classifier could obtain better classification performance. However, the SVM alone does not have a strong ability to extract the features, so it must depend on other methods. The CNN model can combine low-level representation into high-level representation, which is abstract, complex, and non-linear, its main advantage is that it automatically extracts the salient features of the input image. Because the CNN model uses the weights sharing technique, the extracted features are invariant at a certain degree to the scale and shift and shape the distortion invariance of input characters. The eye image characters generally contain different conditions regarding face rotation and head movement. Hence, the CNN model presents a better ability for feature extraction while the eye may be rotating. Furthermore, the elementary features, such as eye corner, eyelid edge, etc., play an important role in eye classification. According to the CNN theory in Section 3.2, it is known that CNN uses the receptive field concept successfully to obtain the locally features such as oriented edges, end-points, or corners from receptive fields. The trainable features of CNN can therefore be used as the feature extractor to collect more representative and relevant information for eye classification compared with other feature extractors such as PCA. As a result, the SVM generalization ability is maximized to enhance the classification accuracy of the hybrid model after replacing the C5 output unit in the CNN.
Hyperplane
If the CNN classifier is used in one system only, it would face two limitations based on previous research [35]. The aim of the learning method for one classifier is to find a hyperplane for two classes and attempt to minimize the errors in the training set. In the CNN training process, once the first separating hyperplane with the back-propagation algorithm is obtained, the algorithm does not continue to improve the separating hyperplane solution. For the SVM classifier, the separating hyperplane can be optimized through the quadratic programming problem solution. The margin area between two classes of training samples then reaches its maximum. At the output layer, the CNN aims to achieve a high value (nearly
Comparison of detection times
Comparison of detection times
In the testing process, the eye region detections are performed on the face image, so the system needs to extract a large number of features. In this case, if the eye detection system uses the CNN and SVM, it can increase computational complexity. Because the trainable EVF could remove more noneye images from the candidate images, it is an ideal solution. Table 3 provides a comparison of detection time with and without EVF in the system. It is evident that the processing time is faster when CNN and SVM are used for eye classification while adopting the EVF.
In this paper, a new hybrid model based on Convolutional Neural Networks and Support Vectors Machines has been proposed to solve the eye detection problem. In general, the multilayer architecture of the CNN is very complex with a computational cost. In order to improve the detection speed of the system, an eye variance filter is trained to quickly filter out most noneye regions and demonstrate that the eye detection is faster than a system without EVF. Feature representation for eye images is a very important factor in eye detection. The CNN has the advantage of extracting various latent eye features, and acts as this system’s automatic feature extractor. The SVM is used as an output predictor to further classify noneye and eye regions. The experimental results and performance comparisons are reported in detail, providing evidence that the proposed hybrid model is effective at solving the eye detection problem.
From the reported accuracy of the system, we believe that this eye detection method can provide enabling technology to applications in the future. The proposed eye method was completed in Python and run on a laptop with 2.4 GHz i7-4700MQ CPU and 8GB DDR3 RAM.
Footnotes
Acknowledgments
This work has been financially supported by National Natural Science Foundation of China through grand No. 81271568 and 81471743, and U.S. National Science Foundation (NSF) through the grant No. 0954579 and 1333524, and Zhejiang University State Key Laboratory Open Funding GZKF-201512. We thank all the participants who have participated in this work.