
Abstract
In practical application, the performances of face recognition are always affected by variations of expression, illumination and so on. To address this problem, an interval type-2 fuzzy linear discriminant analysis (IT2FLDA) method is proposed. In this paper, we first propose the supervised interval type-2 fuzzy C-Means (IT2FCM) algorithm. Moreover, the supervised IT2FCM is incorporated into linear discriminant analysis (LDA). In this method, the membership degree matrix of training samples belonging to each class and means of each class are firstly calculated by the supervised IT2FCM algorithm. They are then applied to the definition of fuzzy within-class scatter matrix and fuzzy between-class scatter matrix, respectively. In doing so, means of each class that are estimated by the supervised IT2FCM can converge to a more desirable location than ones obtained by class sample average and fuzzy k-nearest neighbor (FKNN) method. Furthermore, the IT2FLDA is able to minimize the effects of uncertainties, find the optimal projective directions and make the feature subspace discriminating and robust, which inherits the benefits of the supervised IT2FCM and LDA. The experiment results show that the IT2FLDA improves the recognition rate and reduces sensitivity to variations when compared to results from the previous techniques.
Keywords
Introduction
In face recognition applications, it may be impossible in most cases to obtain perfect knowledge or information for a given face image due to a substantial variation in light direction, different face poses and diversified facial expressions. Uncertain information can create imperfect expressions for face image in various face recognition algorithms. Therefore, various types of uncertainty should be taken into account when performing face recognition methods [3, 9, 15, 22].
The most well-known feature extraction methods used for face recognition are principal component analysis (PCA) [16] and linear discriminant analysis (LDA) [21]. PCA and LDA are the famous algorithms and basic feature extraction techniques. PCA projects the high-dimensional face image space into a low-dimensional feature space by calculating a projection matrix from eigenvectors of the covariance matrix. Since PCA is an unsupervised algorithm, it does not use the class information which affects the performance of classification problems. It is also worth stressing that the PCA can be affected by variations in illumination and different facial expressions. LDA is an improved supervised version of PCA. It seeks the projection matrix by maximizing the ratio of between-scatter matrix to within-scatter matrix. It is worth stressing that LDA produces well-separated classes in a low-dimensional subspace, even under large variation in illumination and facial expressions. However, LDA suffers from some limitations, one of which is the small sample size problem. Researchers have explored a number of effective approaches to solve this problem [8, 10, 25].
From the above algorithm, we note that the relationship of each face to a class is assumed to be crisp. However, as faces are significantly affected by numerous environmental conditions, it is advantageous to investigate these factors and quantify their impact on their “internal” class assignment. That means a substantial variation results in face images belonging to different classes to have similar features. Hence, Kwak and Pedrycz [13] introduced the membership degree of each face pattern to a class in LDA method based upon the fuzzy k-nearest neighbor (KNN) algorithm [11]. Yang et al. [23, 24] extended the idea of incorporating the membership degree of each face pattern into the definition of the between-class and within-class scatter matrices in LDA and 2DLDA. Li [26] applied fuzzy KNN into the computation of the mean matrix for improving the recognition performance of the traditional 2DPCA. Khoukhi and Ahmed [1] further modified by optimizing the parameters of the membership functions of the training images and the number of nearest neighbors used to calculate the membership degrees through genetic algorithm.
In practice, face recognition is a very difficult problem due to the factor of uncertainty being inherently present. To improve the recognition performance of face recognition and address these uncertainties, taking advantage of the type-2 fuzzy theory is a good choice. In fact, the management of uncertainty using type-2 fuzzy theory has been applied to various fields where we cannot obtain satisfactory performance with type-1 fuzzy theory [5, 19, 20, 27, 28, 29]. Inspired by the successful application of them, an interval type-2 fuzzy linear discriminant analysis (IT2FLDA) method is proposed. In this paper, we first propose the supervised IT2FCM, which introduces the classified information to the IT2FCM algorithm. Moreover, the supervised IT2FCM is incorporated into traditional LDA to reduce these outer effects to obtain the correct local distribution information to ensure good performance. The IT2FLDA utilizes the supervised IT2FCM algorithm to weight each face pattern to a class with membership degree and calculate means of each class. They are then applied to the definition of fuzzy within-class scatter matrix and fuzzy between-class scatter matrix, respectively. In doing so, the IT2FLDA is able to find the optimal projective directions by maximizing the ratio of fuzzy between-scatter matrix to fuzzy within-scatter matrix. The resulting embedding subspace has more discriminating and robustness.
This paper is organized as follows. In Section 2, related works are introduced; In Section 3, the proposed IT2FLDA is addressed in detail; Section 4 compares the performance of the proposed method with other previous feature extraction techniques in face recognition. The conclusions are drawn in Section 5.
Related works
In this section, a brief overview of the type-1 FLDA algorithm is introduced first. After that the shortcomings about type-1 FLDA is analyzed.
The type-1 FLDA
The FLDA is first presented by Kwak and Pedrycz in [13]. In traditional LDA approach every vector is assumed to have a crisp membership in the class to which it belongs. But this does not take into account the resemblance of images belonging to different classes, which occurs under varying conditions. In FLDA a vector is assigned the membership grades for every class based upon the class label of its k-nearest neighbors. In this manner, the inter-class image resemblance is accounted.
FLDA suffers the small sample size problem, which can be avoided by using PCA as a preprocessing step. Let a face image
During the training phase the membership degrees are computed though a sequence of steps: first, calculate the Euclidean distances matrix between each pair of feature vectors; second, set diagonal elements of this matrix to infinity and sort the distance matrix (treat each of its column separately) in an ascending order; third, collect the class labels of the
In the above expression,
Taking into account the membership degrees, the mean vector of each class
The between-class fuzzy scatter matrix
where
The optimal fuzzy projection
The feature vectors
where
Face recognition is a complex pattern recognition problem in which face images involve many variations such as facial expression, illumination, pose, and so on. All these non-ideal conditions will produce some outliers in training set. In fact, only a part of the image samples are available for training per class, so it is difficult to give the accurate class mean estimated by the class sample average. As we have found from the above analysis of the FLDA model, the class mean is applied to the definitions of the fuzzy scatter matrices
From the previous section, the membership function of the training vectors used to calculate the class mean, is calculated by Eq. (3), which was proposed by Keller et al. [11]. The membership degree is calculated by weighting the contribution of the k-nearest neighbor vectors, the dominant membership is assigned an offset of 0.51 and only to ensure that the dominant membership remains intact. However, there is no reason reported in [11, 13, 23, 24, 26] for assigning this particular value of offset. Therefore, it appears that the value of the offset in assigning the membership grades will have some influence of artificial factors on the recognition rate. A genetic algorithm is employed to optimize these parameters of the membership functions in [1]. However, it is well-known that the genetic algorithm consumes more time to perform the search and is easy to fall into local optimum. Based on what we have analyzed, we incorporate the proposed supervised IT2FCM into traditional LDA to reduce these outer effects to obtain the correct local distribution information to ensure good performance, and called IT2FLDA method. The proposed IT2FLDA is able to minimize the effects of uncertainties, find the optimal projective directions and make the feature subspace discriminating and robust, which inherits the benefits of type-2 fuzzy theory. The next section will provide details of our proposed IT2FLDA method.
The IT2FLDA method
In this section, the supervised IT2FCM is proposed for calculating the fuzzy membership degree and the mean vector of each class firstly; secondly, the proposed supervised IT2FCM is incorporated into traditional LDA for building IT2FLDA model; then, the design scheme of the IT2FLDA method is described; Finally, the influence of parameters of IT2FLDA method are analyzed.
The fuzzy membership degree and the mean vector of each class
In IT2FLDA method, the fuzzy membership degree and the mean vector of each class can be gained by our proposed supervised IT2FCM. The supervised IT2FCM algorithm is an extension of the IT2FCM algorithm [4, 7, 17], which introduces the classified information to the IT2FCM algorithm. It uses some known information in facial features, which improves the unsupervised IT2FCM. Therefore, the supervised IT2FCM is able to use the classified information and handle the uncertainty found in a given set of feature vectors during the process of feature clustering. It makes feature clustering less susceptible to noise, which achieves the goal that feature vectors can be clustered more appropriately and accurately, especially when pattern distributions contain partitions of different size volumes.
Given a set of feature vectors
where
The supervised IT2FCM algorithm using two fuzzification weighting exponents
Effects on fuzzy clustering by fuzzification weighting exponent. (a) Decision boundary for two clusters of different volumes with a single specific 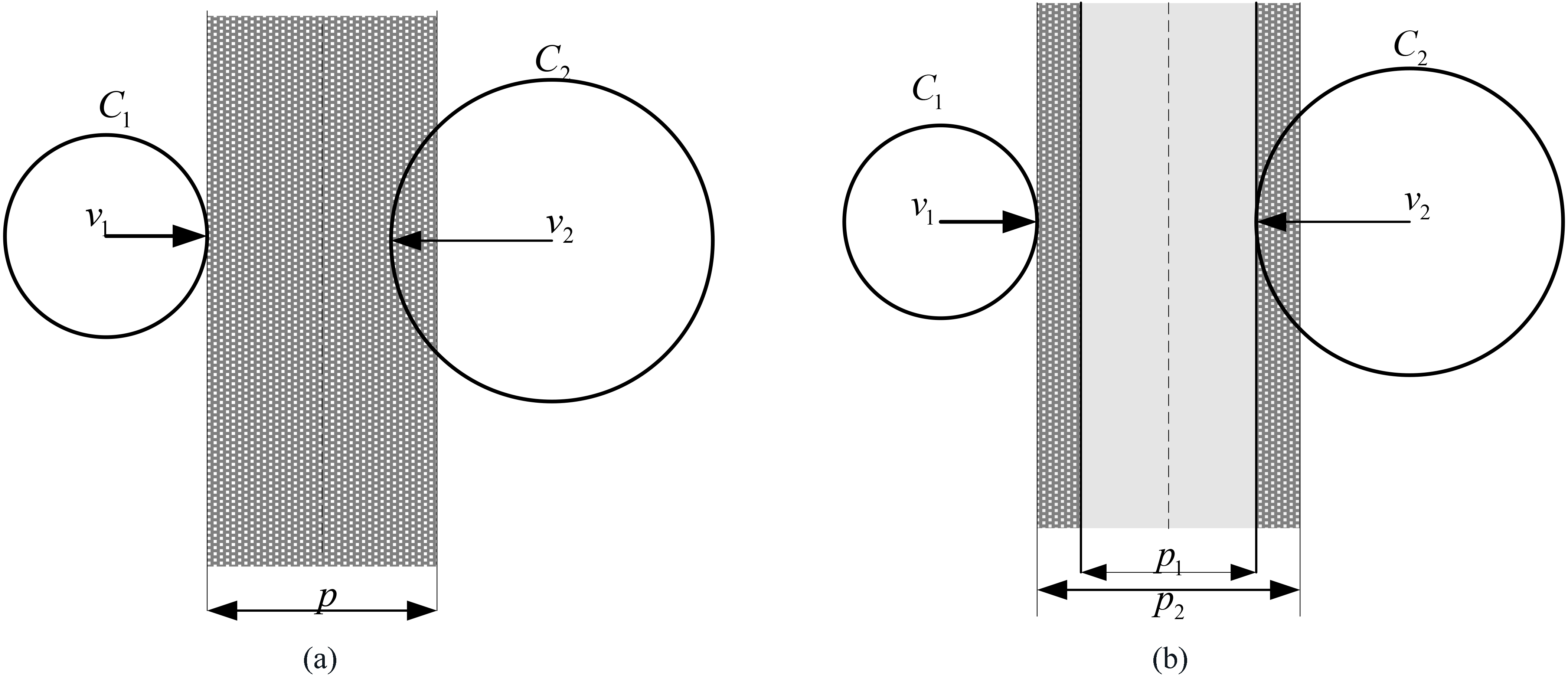
Because
where
Footprint of uncertainty of an interval type-2 fuzzy set for 
In the process of calculating the lower and upper membership degrees
In order to ensure that the sample has the maximum degree of membership in its own class, the lower and upper membership degree
The procedure for updating the type-2 fuzzy cluster center matrix
where
The interval of the coordinates for cluster centers is obtained. They are defuzzified by using the average of
Based on all this, the supervised IT2FCM algorithm consists of the following steps in Fig. 3.
The step of the supervised IT2FCM algorithm.
The procedure of our proposed supervised IT2FCM is illustrated in Fig. 4.
The procedure of the proposed supervised IT2FCM.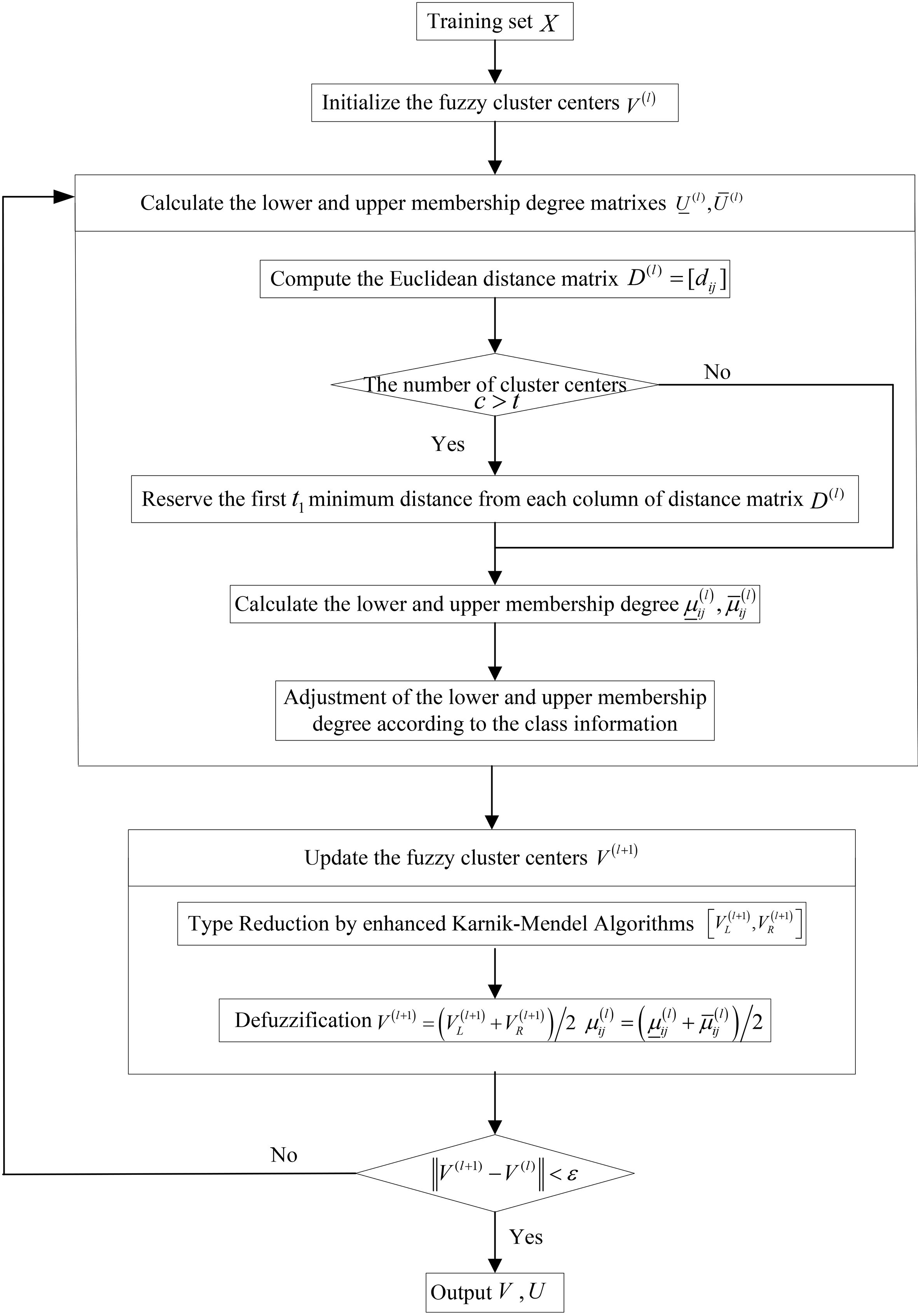
In the step 3, the EKM algorithm [6] is used for updating the type-2 fuzzy cluster center matrix
EKM algorithm for finding minimum of fuzzy cluster center.
EKM algorithm for finding maximum of fuzzy cluster center.
By applying above steps,
The maximum of fuzzy cluster center
By applying above steps,
In the previous subsection, the fuzzy mean vector of each class
The membership degree of each vector (contribution to each class) is considered and the corresponding fuzzy within-class scatter matrix and fuzzy between-class scatter matrix are redefined as follows:
where
The optimal interval type-2 fuzzy projection
where
However, the rank of
Therefore, the optimal projection
where
Note that the optimization
Finally, the feature vectors
where
In this section, the design scheme of the proposed algorithm is presented in detail in Fig. 7. Our overall proposed IT2FLDA method can be summarized in Fig. 8.
The step of the IT2FLDA algorithm.
A diagram of computing for the IT2FLDA method.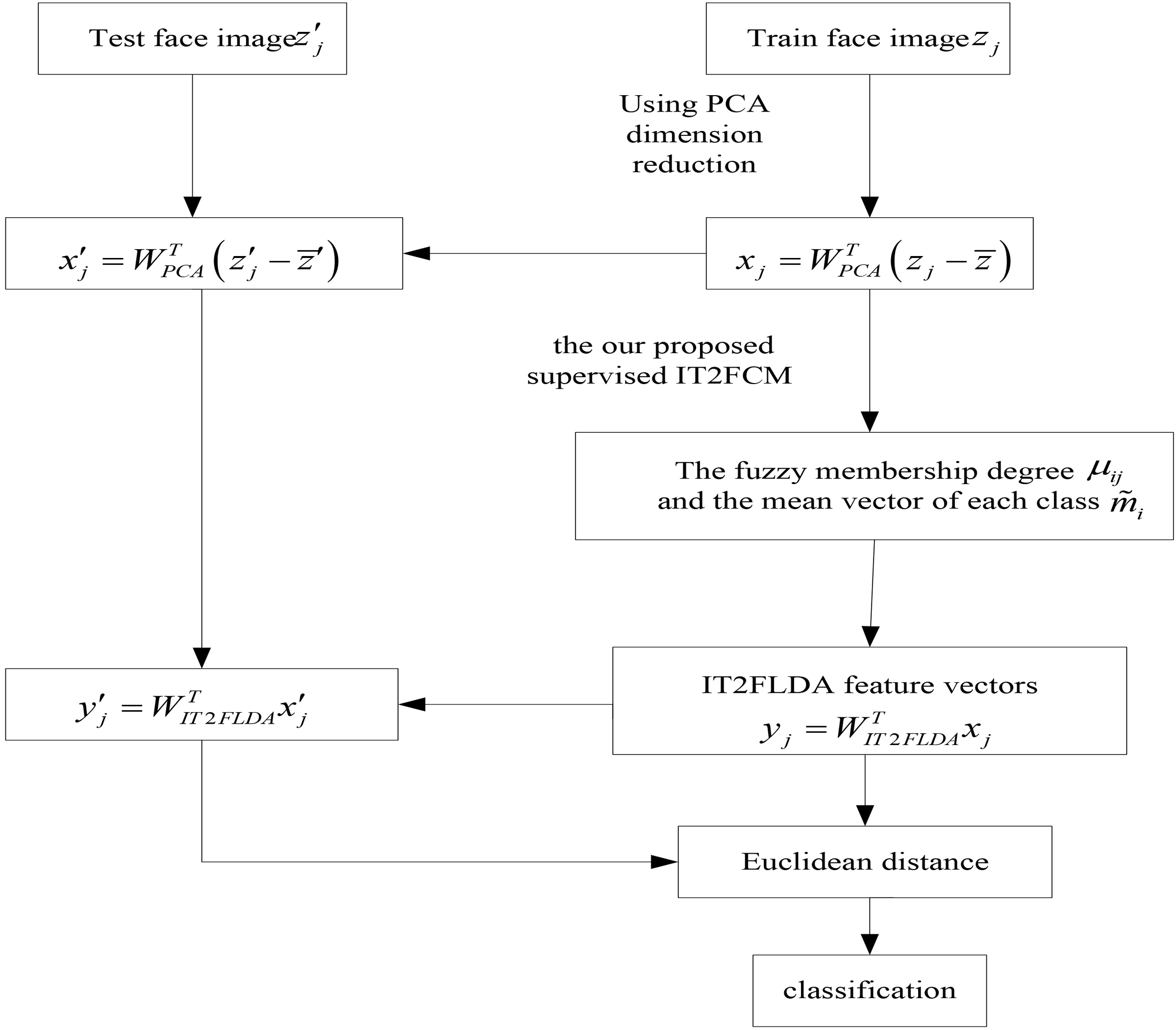
In this section, the influence of parameters of IT2FLDA method on the face recognition rate will be analyzed. Experiments are performed on ORL face database. The ORL database comprises ten different images of each of 40 distinct subjects. For each subject, we randomly selected 5 images for training with the remaining images for testing.
The influence of parameters
on the recognition rate
The influence of parameters
The influence of parameter 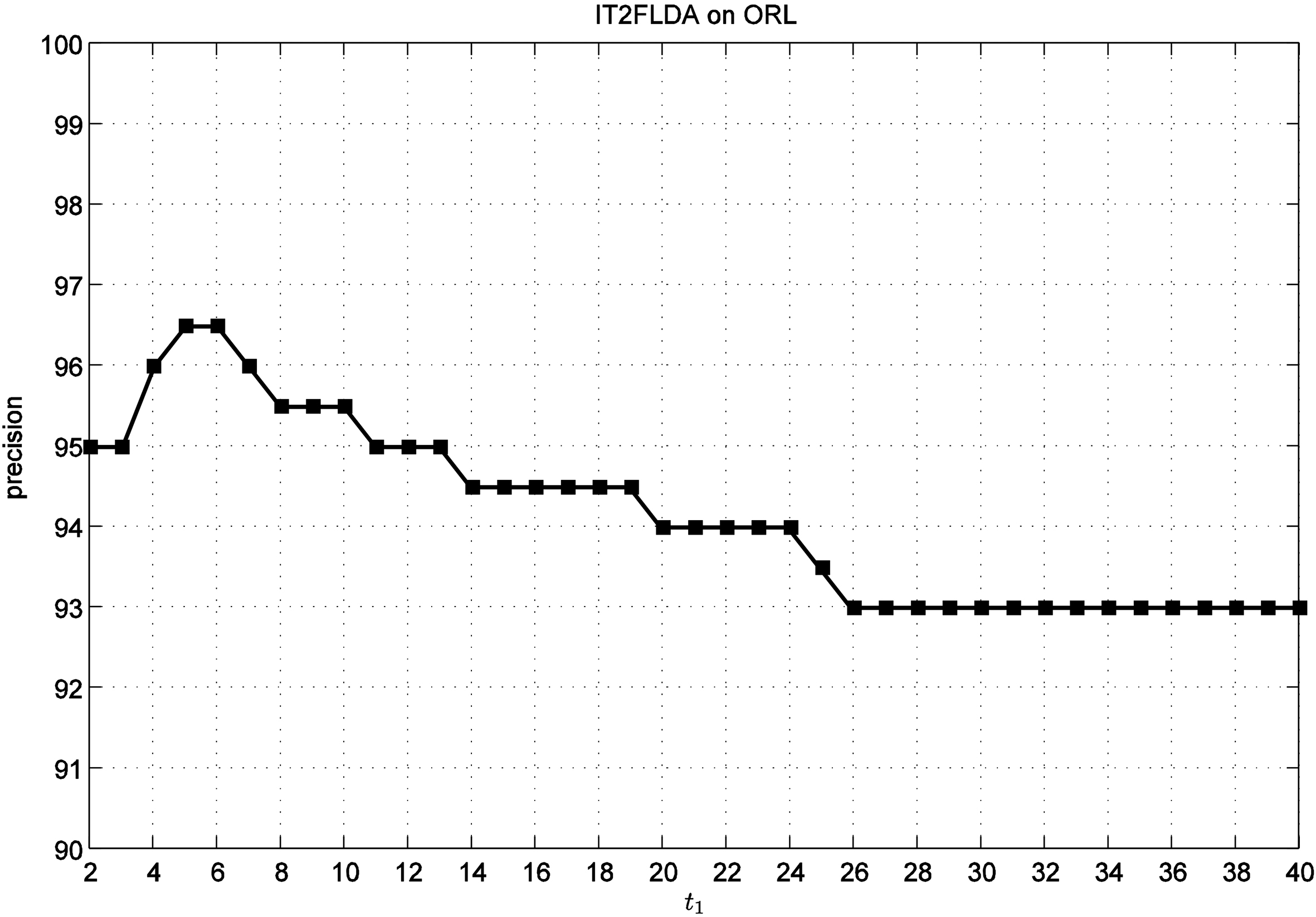
The influence of parameter
Table 1 shows the effect of the values of
The influence of parameters 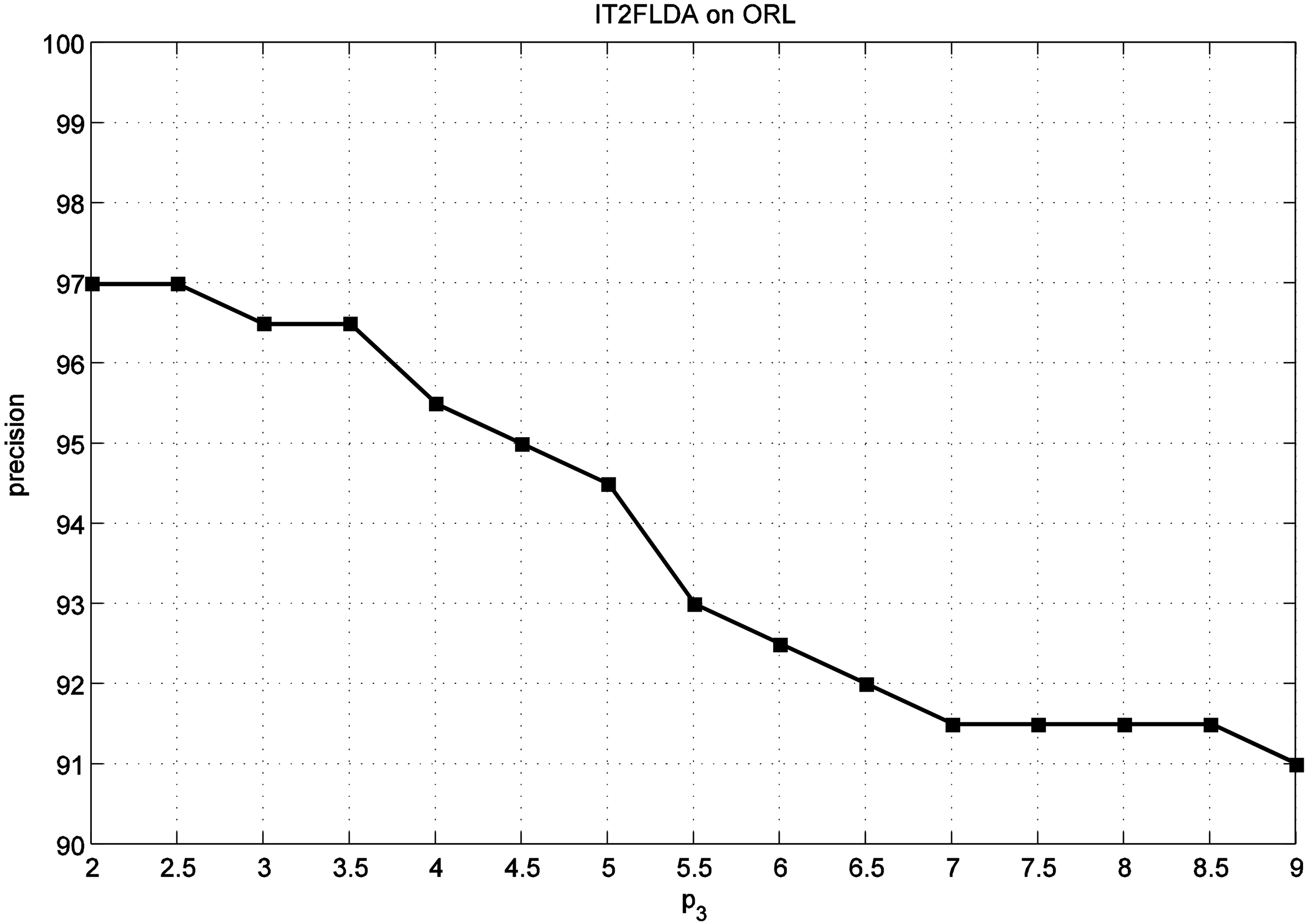
Figure 10 shows the effect of value of
From the above analysis of parameters of IT2FLDA method, it can be concluded that parameters selection has influence on the face recognition rate to some extent. Understanding the role of parameters of IT2FLDA method can help us to choose parameters, which still has some rules to follow.
In this section, we verify the performance of the IT2FLDA algorithm from recognition accuracy and the robustness in face recognition and gender classification. We elaborate on the experimental results for a number of well-known and commonly used face databases. In all scenarios, the results of the IT2FLDA algorithm are compared to the state-of-the-art techniques. Experiments are performed on a personal computer with Intel Core i3 CPU at 3.10 GHz and 2.00 GB RAM. All the algorithms have been implemented using MATLAB programming language.
Face recognition
The proposed algorithm for face recognition is tested on the ORL [18] and Yale [30] face databases. In order to clearly illustrate the advantage of the proposed method, we compare IT2FLDA with LDA [21], FLDA [13] and F2DPCA [26] methods. In all face recognition experiments, we first reduce the dimension of the training set using PCA and determine
ORL face databases
The ORL database comprises ten different images of each of 40 distinct subjects. For some subjects, the images were taken at different times, varying the lighting, facial expressions (open/closed eyes, smiling/not smiling) and facial details (glasses/no glasses). All the images were taken against a dark homogeneous background with the subjects in an upright, frontal position (with tolerance for some side movement). Each image was digitized and stored as a 112
The ORL face database.
The ORL database is used to evaluate the performance of IT2FLDA method under conditions where the pose and facial details are varied. The recognition rates for various feature extraction methods are shown in Fig. 12. Table 2 contains a comparative analysis of the mean and standard deviation for the obtained recognition rates. It can be seen that the IT2FLDA achieves the average recognition rate of 93.45% and gets the best result. F2DPCA achieves the average recognition rate of 93.4%. FLDA and LDA achieve the average recognition rates of 92.05% and 91.35%, respectively. The average recognition rate of F2DPCA is higher than that of FLDA and LDA in ORL database. The main reason is that the images in ORL database vary slightly and F2DPCA does not need to transform matrix into vector, which can save useful structural information embedding in the original images. Also, it can be seen that the IT2FLDA has minimum standard deviation compare with FLDA, LDA and F2DPCA. Hence, the proposed IT2FLDA algorithm outperforms other methods.
Comparison of the mean and standard deviation for recognition rates on the ORL
The recognition rates of various methods on ORL.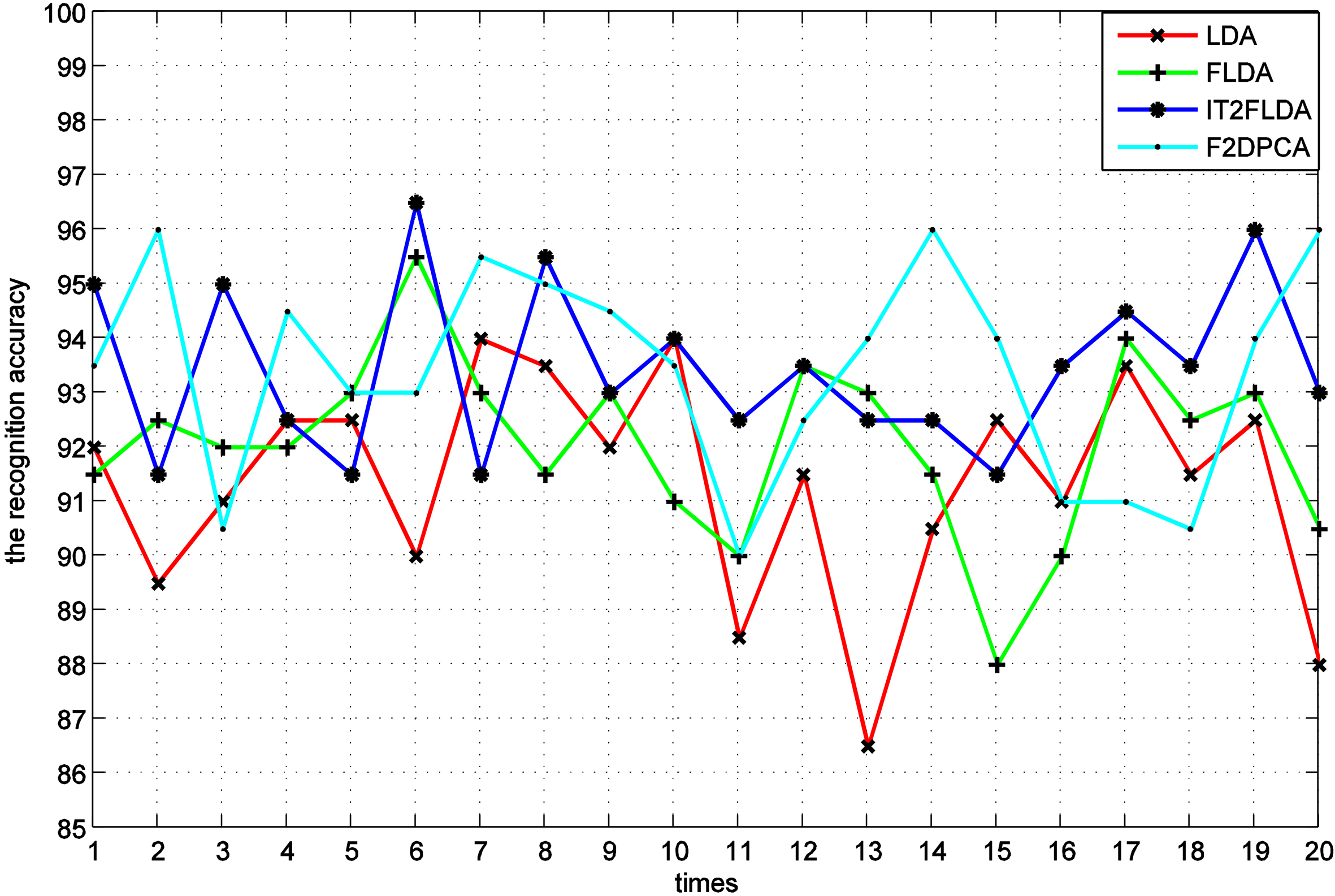
The Yale face database contains 165 face images of 15 individuals. There are 11 images per subject, one for each facial expression or configuration: center-light, glasses/no glasses, happy, normal, left-light, right-light, sad, sleepy, surprised and wink. Each image was digitized and presented by a 231
The Yale face database.
The Yale database is used to examine the performance of IT2FLDA method when both facial expressions and illumination are varied. The recognition rates for various feature extraction methods are shown in Fig. 14. Table 3 contains a comparative analysis of the mean and standard deviation for the obtained recognition rates. We can see that the IT2FLDA achieves the average recognition rate of 97.33% and gets the best result. FLDA and LDA achieve the average recognition rates of 96.88% and 95.33%, respectively. F2DPCA achieve the average recognition rates of 84.05%, and gets the worst result. The reason is that F2DPCA is sensitive to substantial variations in light direction and facial expression. Although the IT2FLDA is not significant increase on the average recognition rate, it substantially reduces the standard deviation. That is because type-2 fuzzy sets revealed more robust characteristics, especially the uncertainty occurring, such this case that the illumination and facial expressions variations result in face images belonging to different classes to have similar features. Hence, IT2FLDA has better performance as compared to other methods.
Comparison of the mean and standard deviation for recognition rates on the Yale
The recognition rates of various methods on Yale.
We apply the proposed algorithm to gender classification on the LFW [14] and AR [2] face databases. In all gender classification experiments, we first reduce the dimension of the training set using PCA and determine 100 eigenvectors representing the best performance; then, we extract discriminant vectors using IT2FLDA. Since it is a 2-class classification problem, one basis discriminant vector is sufficient for efficient classification. The parameters of the supervised IT2FCM are chosen with
LFW face database
LFW face database contains images of 5749 different individuals. Of these, 1680 people have two or more images in the database. The remaining 4069 people have just a single image in the database. These images are collected from the web, which has the characteristics of pose complexities, rich facial expressions, illumination variation and so on. In this experiment, 5749 images are chosen from 5749 individuals (with only one image per person), 4257 of which belong to class male and 1492 to class female. We randomly select 50% images (2129 males and 746 females) as the training data, and the remaining part (2128 males and 746 females) are used for the test. Original images were normalized (in scale and orientation) such that the two eyes were aligned at the same position. The size of each cropped image is 50
Comparison of the mean and standard deviation for gender recognition rates on LFW
Comparison of the mean and standard deviation for gender recognition rates on LFW
The LWF face database.
The gender recognition rates of various methods on LFW.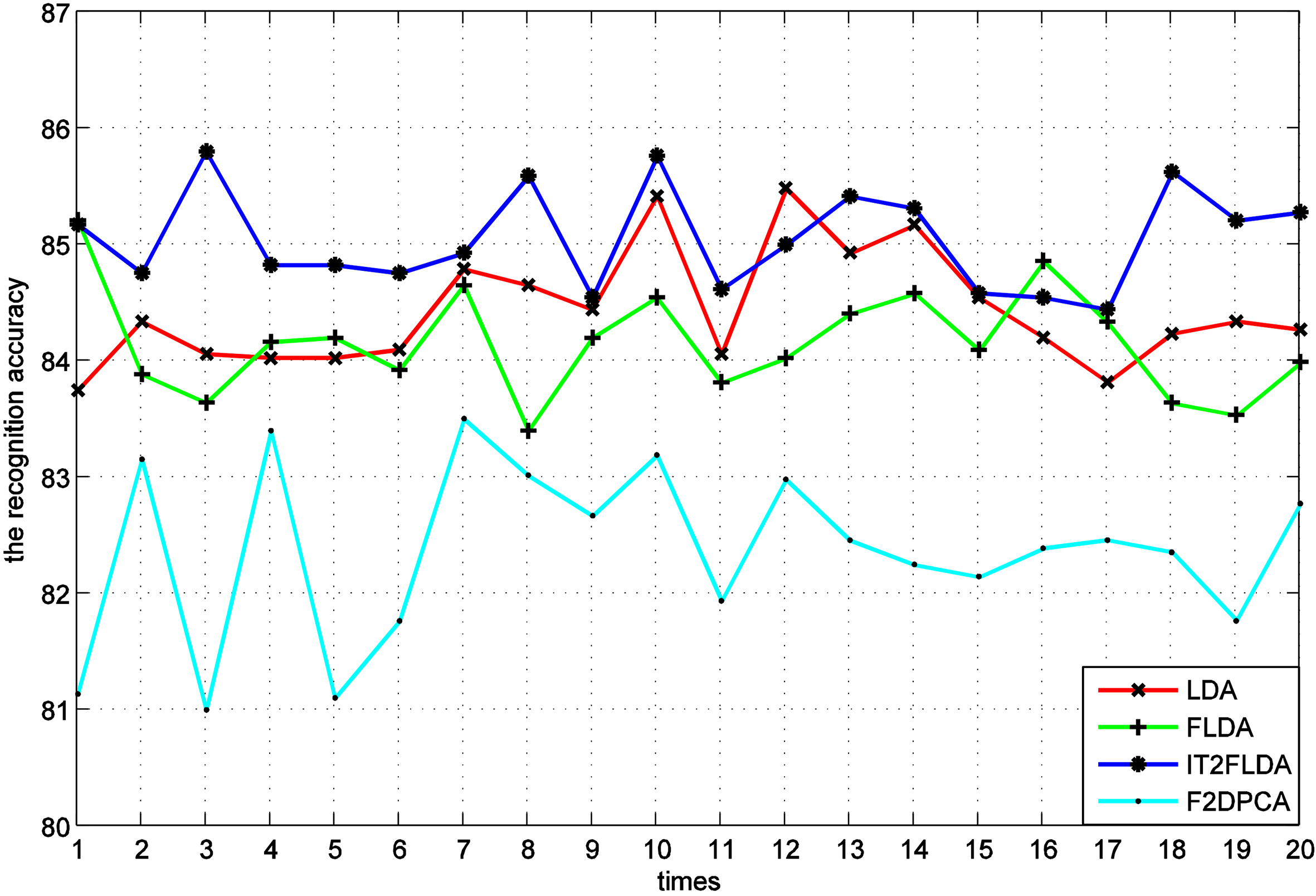
Comparison of the mean and standard deviation for gender recognition rates on AR
The non-occluded subset of AR database.
The gender recognition rates of various methods on AR.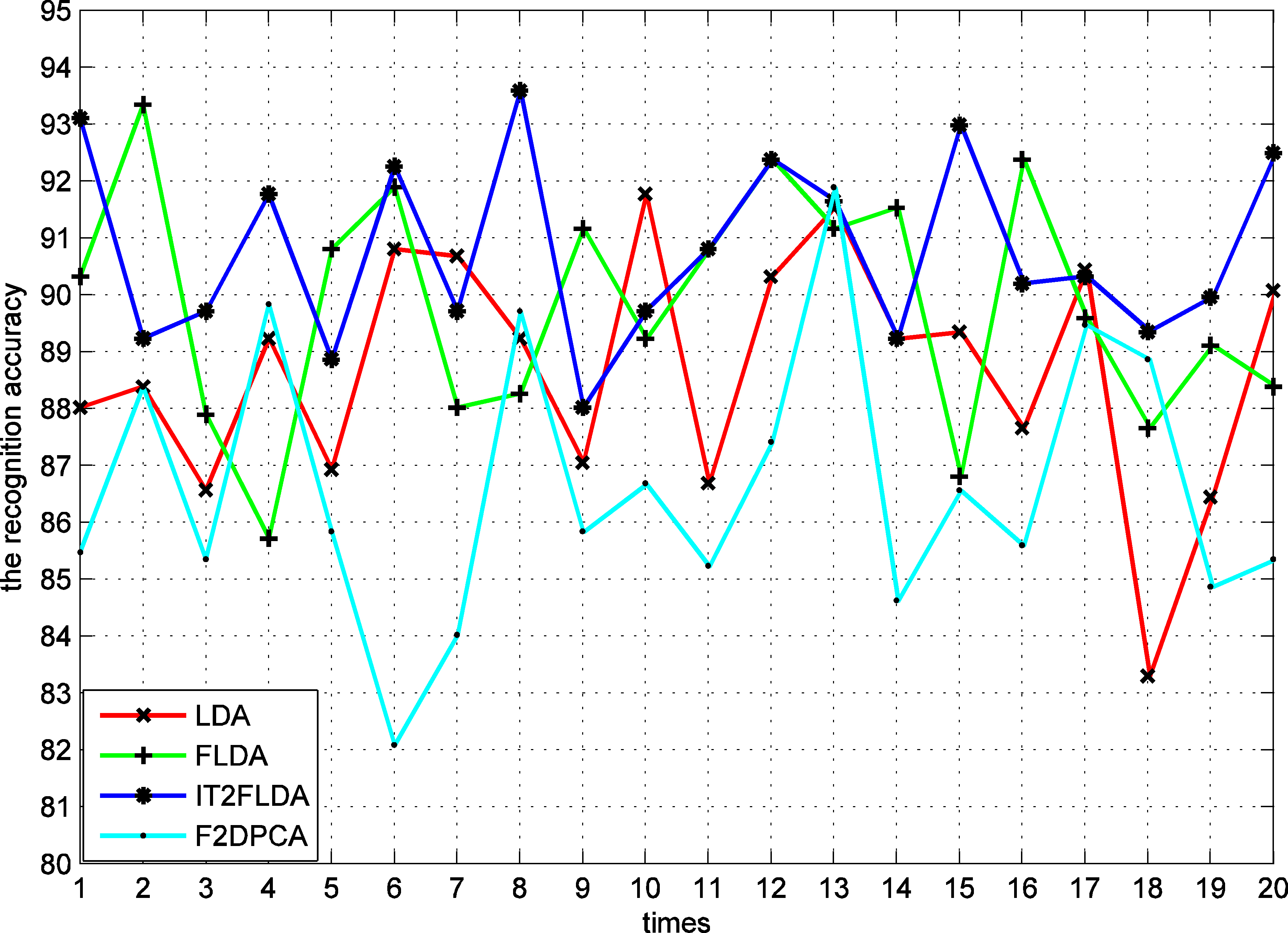
The gender recognition rates for various feature extraction methods are shown in Fig. 16. Table 4 contains a comparative analysis of the mean and standard deviation for the obtained gender recognition rates. The proposed IT2FLDA method outperforms other methods. IT2FLDA achieves the average gender recognition rates of 85.05% and gets the best result. FLDA, LDA and F2DPCA achieve the average gender recognition rates of 84.15%, 84.43% and 82.37%, respectively. From the Table 4, it can be seen that there is a big gap, at least 9 percent, between male recognition rate and female recognition rate in F2DPCA method. Since F2DPCA is an unsupervised algorithm, it does not use the class information that leads to extract vectors with weaker ability of classification. Moreover, the average gender recognition rate of LDA is slightly better than that of FLDA. The reason is that FLDA use the k-nearest neighbor, which is influenced by the uneven distribution of samples. In this experiment, the number of male samples is much greater than female one. FLDA and F2DPCA methods get the membership degree of each face pattern to a class based upon the k-nearest neighbor, which is easily disturbed by male samples and makes the values of membership degree inaccurate.
The AR database consists of over 4000 frontal images from 126 individuals. For each individual, 26 pictures were taken in two separated sessions. We chose a non-occluded subset (14 images per subject) of AR consisting of 65 males and 55 females to conduct experiments of gender classification. We randomly select 33 males and 28 females were used for training, and the remaining 32 males and 27 females for testing. The size of each image is 50
The AR database was employed to test the performance of the IT2FLDA under conditions where there is a variation over time, in facial expressions, and in lighting conditions. The gender recognition rates for various feature extraction methods are shown in Fig. 18. Table 5 contains a comparative analysis of the mean and standard deviation for the obtained gender recognition rates. IT2FLDA achieves the average gender recognition rate of 90.76% and gets the best result. FLDA, LDA and F2DPCA achieve the average gender recognition rates of 89.81%, 88.68% and 86.65%, respectively. In F2DPCA method, there is a big gap, at least 12 percent, between male recognition rate and female recognition rate. Since F2DPCA does not obtain good discriminating feature vectors. IT2FLDA has less standard deviation than other methods. IT2FLDA is able to make the feature subspace discriminating and robust. Hence, the proposed IT2FLDA method outperforms other methods.
The mean and standard deviation for recognition rates on Yale with “salt and pepper” noise
The mean and standard deviation for recognition rates on Yale with “salt and pepper” noise
The recognition rates of various methods on Yale with “salt and pepper” noise.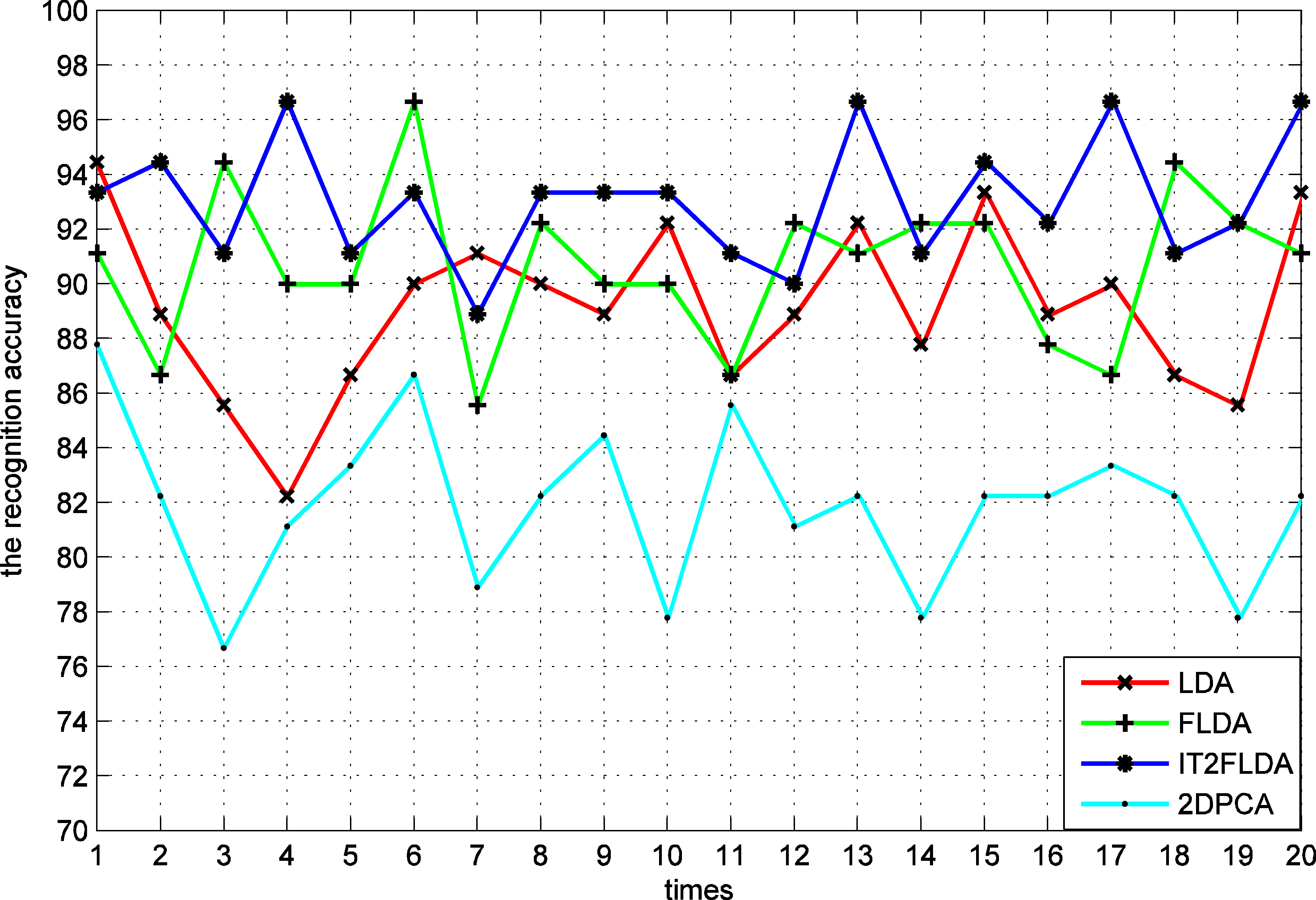
In order to verify the robustness of the proposed method, experiments are conducted under “salt and pepper” noise environments on Yale database. All images incorporate “salt and pepper” noise, whose density is 0.1. This procedure was repeated 20 times by randomly choosing different plus noise training sets and testing sets.
The recognition rates for various feature extraction method are shown in Fig. 19. Table 6 contains a comparative analysis of the mean and standard deviation for the recognition rates. From Table 6, we can see that the recognition rates go down and have lager standard deviation under noise. From the perspective of descent rate and standard deviation, the three fuzzy methods perform better than LDA. In LDA method, the sample must be fully belongs to one class. It means that the sample fully contribute to the class mean calculation, even through the sample stay away from other samples of this class. That caused the class mean is not exact. In the fuzzy methods, the sample belongs to one class according to its fuzzy membership degree. Hence, if the sample is isolated, it has less contribution to computing the class mean. It can reduce the influence and make the class mean to be more reasonable.
Conclusions
In this paper, the IT2FLDA method for face recognition is proposed. We first propose the supervised IT2FCM, which introduces the classified information to the IT2FCM algorithm. Then the supervised IT2FCM is incorporated into traditional LDA to reduce these outer effects to obtain the correct local distribution information to ensure good performance. Experimental results show that IT2FLDA has high recognition rates compared with LDA, FLDA and F2DPCA when applied to a number of well-known face databases. It is worth stressing that IT2FLDA developed in the setting of type-2 fuzzy sets revealed more robust characteristics. The advantage is more obvious when the uncertainty occurs, such as the large variation of illumination, facial expression and noise environment. Moreover, IT2FLDA yields a better performance can be attributed to the fact that the supervised IT2FCM can make feature clustering less susceptible to noise. The supervised IT2FCM achieves the goal that feature vectors can be clustered more appropriately and accurately, especially when pattern distributions contain partitions of different size volumes. The cluster centers have a great impact on the projection directions of IT2FLDA, and ultimately affect the robustness of IT2FLDA. Therefore, IT2FLDA is able to find the optimal projective directions by maximizing the ratio of fuzzy between-scatter matrix to fuzzy within-scatter matrix. The resulting embedding subspace has more discriminating and robustness.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 61374194&No. 61403081), the National Key Science and Technology Pillar Program of China (No. 2014BAG01B03), the Natural Science Foundation of Jiangsu Province (No. BK20140638) and a Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions.