
Abstract
Modularity Evaluation (ME) is usually used in community detection for evaluating the disjoint and overlapping communities. In this paper, two obvious defects of ME are revealed and proved, including the non-decreasing contribution of isolated nodes to modularity and lacking of appropriate measures on overlapping community. We also propose a new evaluation criterion, the USI-AUC, which is the Area Under the Curve (AUC), originated from link-prediction of Uniform-Structure-Information (USI) model. We test the new criterion on various datasets, and find that such criterion can avoid the issues exposed in ME.
Introduction
Community structure is an important property in complex networks, with a variety of different types of networks showing strong community effects in society and nature[1, 2], especially in this Big Data era [3]. Taking the social software WeChat as an example, various individuals with common interests form multiple WeChat groups.
In recent years, researches in community detection have been very active, and how to discover valuable community structures in a network remains a hot topic in the field [4]. Researchers have proposed numerous community detection algorithms, which are mainly divided into two categories according to whether they allow overlapping, i.e., disjoint-community detection and overlapping-community detection. For disjoint-community detection, modularity optimization [5, 6], spectral-clustering[7, 8], hierarchical-clustering[9], and label-propagation methods are proposed[10, 11]. The disjoint-community detection algorithm was extended by Palla et al. [12] which allows nodes to belong to different communities. Thereby, it expands the field of overlapping-community researches. Typical methods include the clique-percolation[13], line graph and link partition[14], local expansion and optimization[15], and fuzzy detection methods[16].
With the continuous development of community detection algorithms, evaluation criterion of communities has also become a research hotspot. Because of the unknown community information in the actual network, evaluation strategies from various angles are utilized. However, there is no generally accepted evaluation method for community detection. There exist different evaluation criteria, such as Newman’s typical-modularity criterion[5] and omega index for disjoint communities[17, 18]. For the evaluation of overlapping communities, Pizzuti [19] proposed an overlapping-community evaluation formula based on vertex and edge density; however, the value increases along with the increasing number of communities. Additionally, some studies extended the evaluation metrics from disjoint communities to overlapping communities. Nicosia et al. [20] extended the modularity criterion in directed networks, and Nepusz et al.[16] and Shen et al.[21, 22] extended the modularity in undirected networks with widespread applications. Modularity and extended modularity are of great significance to study community structure. However, for evaluating communities, the ME (containing modularity and extended modularity criteria) also exhibits theoretical defects, including the increasing contribution of isolated nodes to modularity and lacking of appropriate measures on overlapping community. Taking the overlapping community as an example, Fig. 1 shows the original division and overlapping division of the Zachary dataset[23]. Obviously, it is more reasonable to consider nodes 3,9 as common nodes; however, a kind of extended modularity, EQ, is 0.351, which is lower than the modularity of original division (0.371).
Diagram of original and overlapping communities. Nodes 3,9 are active in both the left community and the right community; therefore, it is reasonable to serve nodes 3,9 as common nodes in both communities. However, EQ cannot provide a reasonable evaluation. 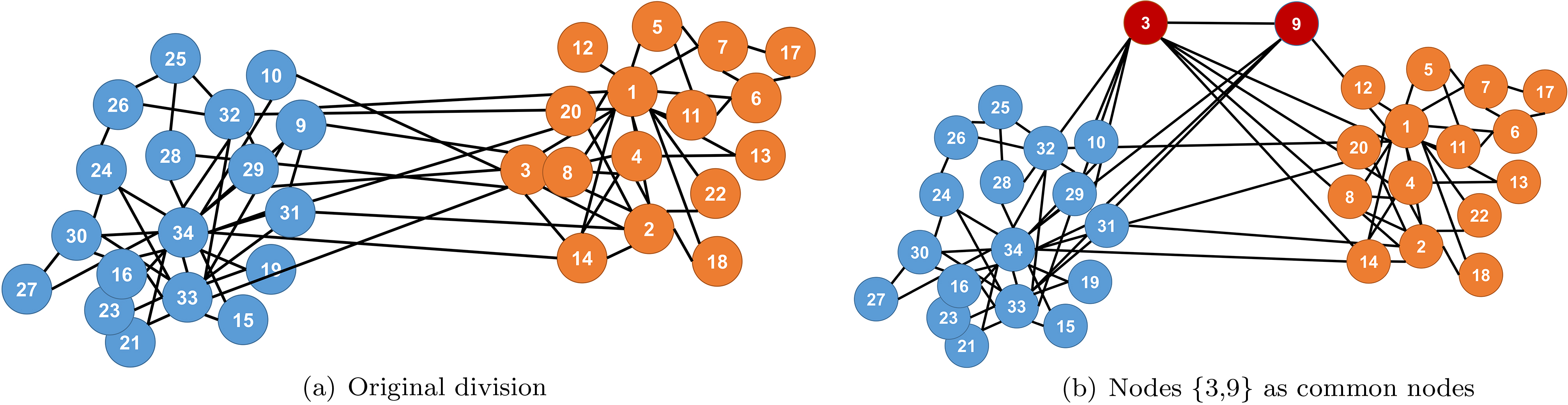
Though this phenomenon was mentioned in Ref. [24], they did not do any theoretical analysis. In this study, the theoretical defects of ME are analyzed in detail through two theorems accompanied by theoretical proofs and data verification. In the analysis of the theoretical defects of ME, the area under the curve (AUC) accuracy of the link-prediction method based on a Uniform-Structure-Information (USI) model is proposed as an evaluation criterion defined as USI-AUC. This criterion allows a unified and effective evaluation of the disjoint and overlapping communities and we find that such criterion can avoid the issues exposed in ME.
The remainder of the paper is organized as follows. In Section 2, we report the related work on evaluating overlapping communities, especially the evaluation criteria without known real community, i.e., ME. In Section 3, we propose two theorems to verify the defects of ME. In Section 4, we present the USI-AUC-evaluation criterion based on the link-prediction method. In Section 5, we provide experimental verification of the two theorems and comparative analysis of USI-AUC and other criteria.
Unlike disjoint community detection, where a number of measures have been proposed for comparing identified partitions with the known partitions, only a few measures are suitable for a set of overlapping communities[24]. These measures are mainly divided into 2 categories, one is based on the data of labeled network, the other is the evaluation criterion which does not need the labeled data.
Evaluation criterion based on labeled network
In the case of labeled network, accuracy evaluation criterion of precision, recall and F1-score can be used to evaluate the community detection algorithm. Precision is the number of correctly detected overlapping nodes
Lancichinetti et al. [15] has extended the notion of Normalized Mutual Information (NMI)[25] within the framework of information theory to account for the evaluation of overlapping communities. Omega Index[17] is the overlapping version of the Adjusted Rand Index. It is based on pairs of nodes in agreement in two communities. For labeled network datasets, NMI and omega are most wildly used measures.
In community detection studies, most occasions we do not know the true communities, so the evaluation criteria based on modularity are usually adopted. In the unweighted-undirected network, the value of modularity is defined as the proportion of inner edges in communities in the network minus an expected value which is the proportion of inner edges in communities under the same community distribution when the network is set to random network[5]. The underlying assumption of modularity metric is that the higher the densities of edges in communities are, the better the result of community division is. Assuming that
where
Example of modularity calculation. 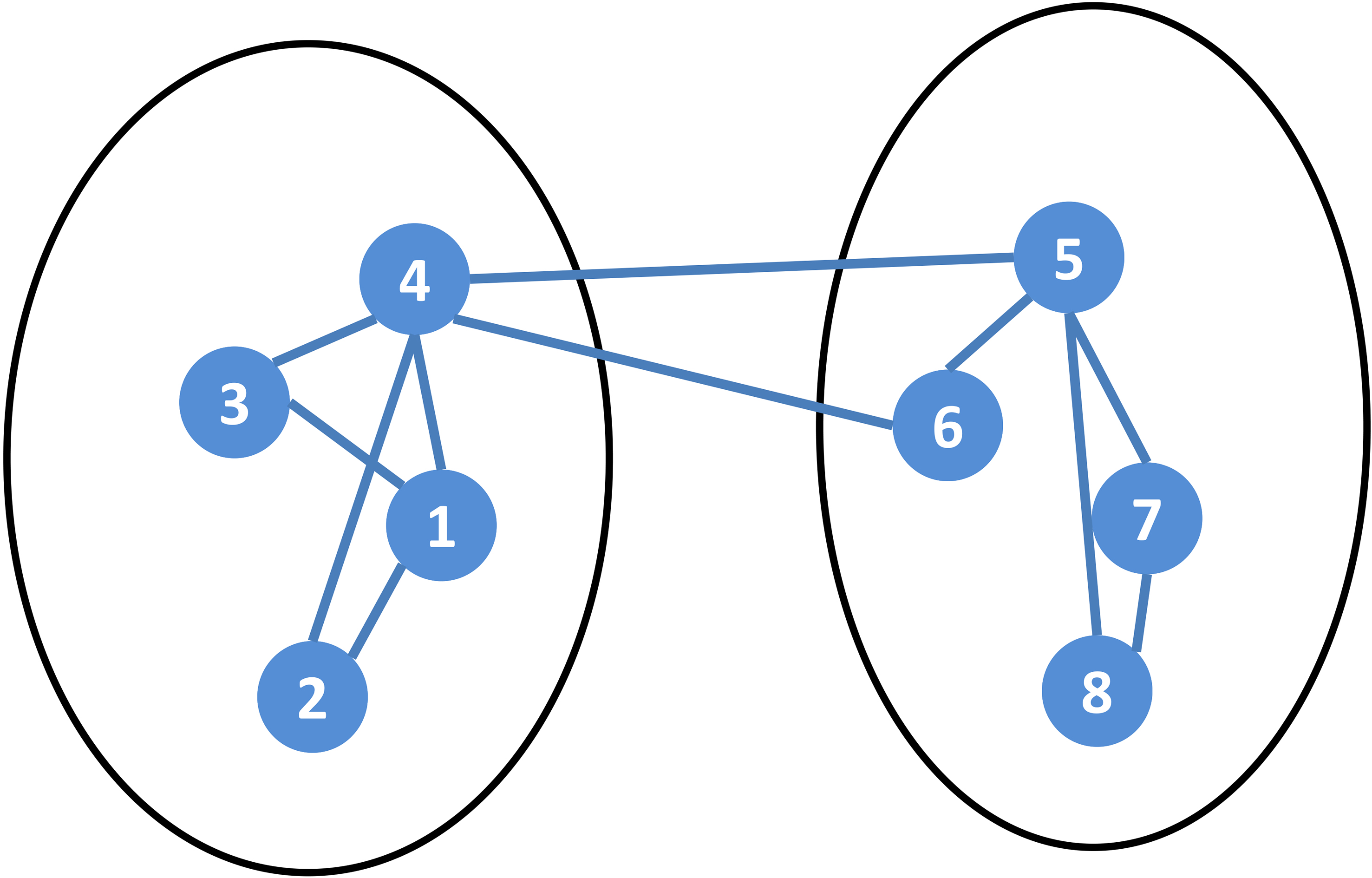
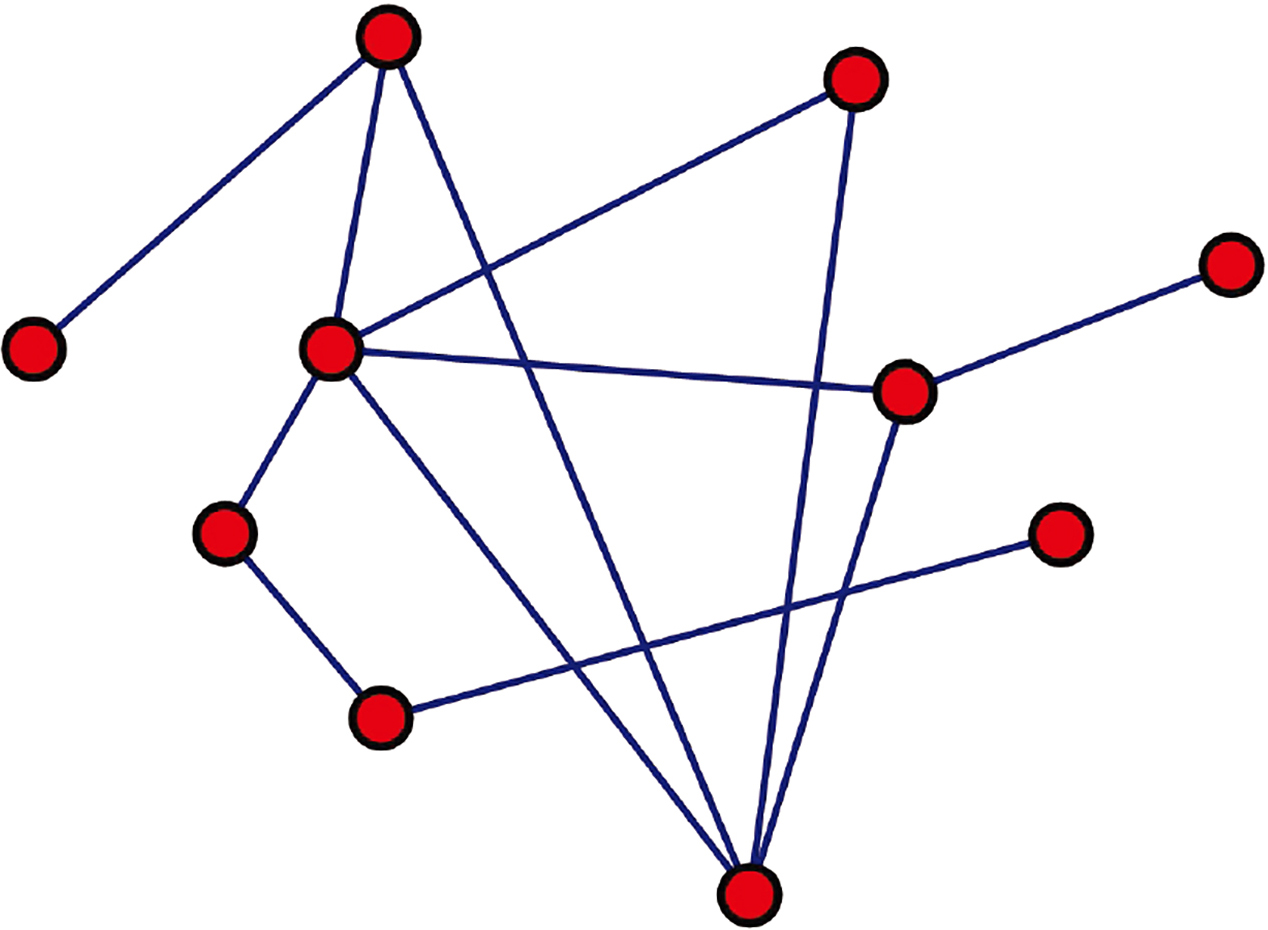
As shown in Fig. 2, the network contains 8 nodes and 11 edges, and its adjacency matrix is
The node degree of
For overlapping-community detection, Nepusz et al.[16] proposed an extension method,
where
The total number of nodes in the network is
To simplify the computing process of weighted coefficient, Shen et al.[21] proposed a specific extension of the modularity,
where
Based on the definition of modularity,
.
The contribution of a single node,
where
It is easy to know from the definition 1,
Example of calculating the contribution of a single node to the extended modularity. 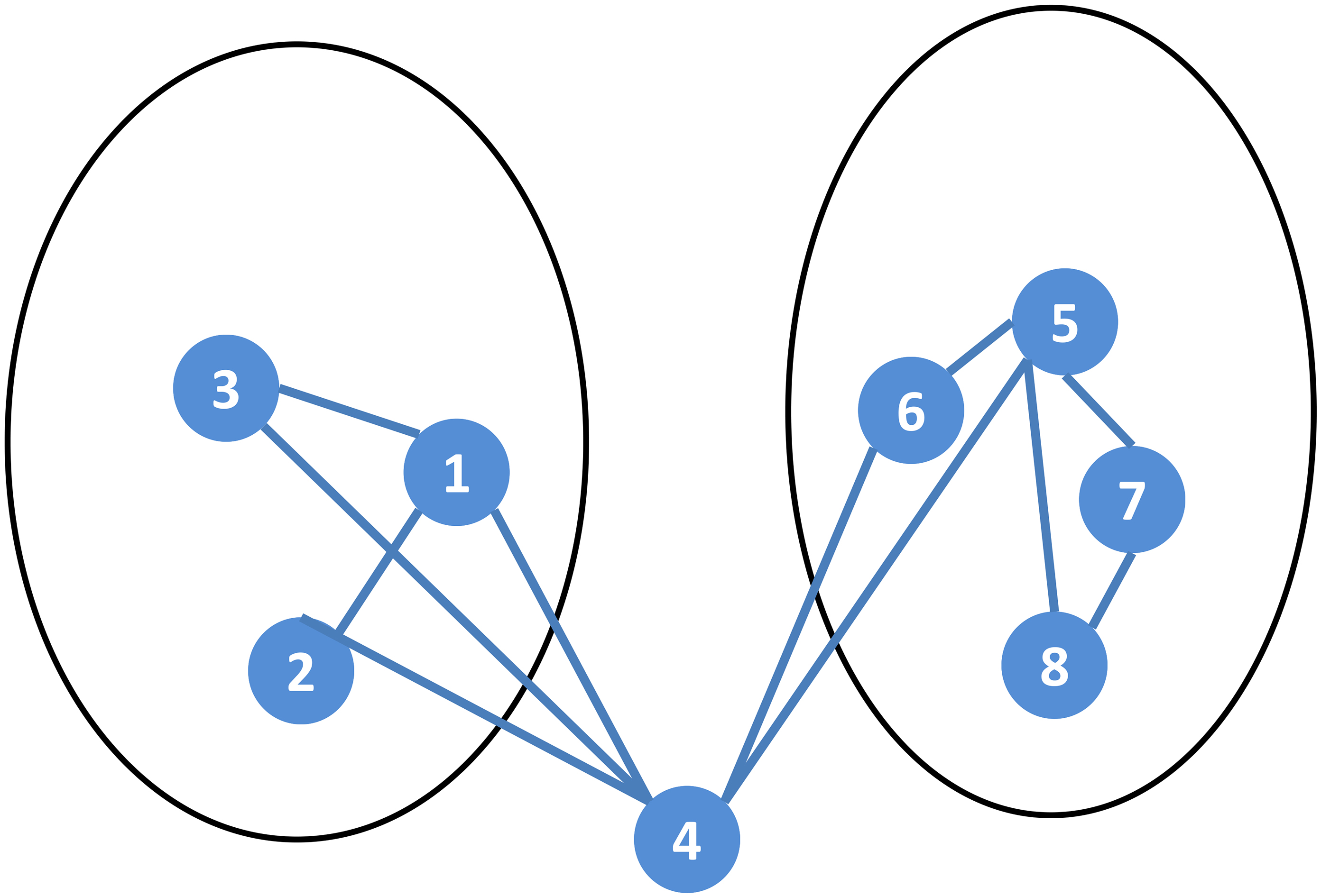
Take Fig. 3 as an example, the modularity of the contribution of node
If the weight coefficients are given in accordance with EQ, i.e.,
On the basis of Definition 1 as well as the modularity definition of Nenwman, and the extension-modularity definition of Nepusz et al.[16] or Shen et al.[21], we obtain the following two theorems.
.
There must be a disjoint community structure, in which an arbitrary single node is a non-negative contributor to the whole modularity, and modularity does not increase when deleting arbitrary nodes in this community structure. Specifically, when the node is isolated, deleting the isolated node does not increase modularity.
Proof..
Assuming that
given that
Therefore, there must be a disjoint community structure, where node
If
This theorem indicates that modularity is sensitive to isolated nodes, although the division of isolated nodes is reasonable, the criterion of modularity also decreases, which cannot reflect the rationality in the division of isolated nodes.
.
If moving a node to a different community does not cause changes in the weighted coefficients of other nodes, the influence of the node on the whole modularity is only related to the change in contribution of this node, and the subsequent change in contribution of the other nodes remains the same as that of this node.
Proof..
Upon changing the community to which arbitrary node
where
Because Eq. (14) holds for arbitrary community
Lemma 1 shows that investigating the impact of moving a node to a different community in the absence of changes in the coefficients of other nodes is only necessary to consider changes in the contribution of the coefficient of the moved node without regard for the subsequent change in contribution of other nodes.
For example, in Fig. 3, moving the common node
.
There must be a disjoint community in which modularity is no less than that of any given overlapping community.
Proof..
For any given overlapping community, assuming that arbitrary nodes
where
Now, inspect the common nodes one by one.
When moving one node (e.g., node When moving one node (e.g., node
∎
Theorem 2 shows that there is no reasonable overlapping community from the perspective of modularity. If we once had a “reasonable†overlapping community, it would be possible to obtain a more reasonable disjoint community in the view of modularity by adjusting common nodes. Therefore, even if the division of the overlapping community is reasonable, it is difficult to give a rational evaluation using
According to this theorem, moving the common node
An example to explain the Theorem 2. 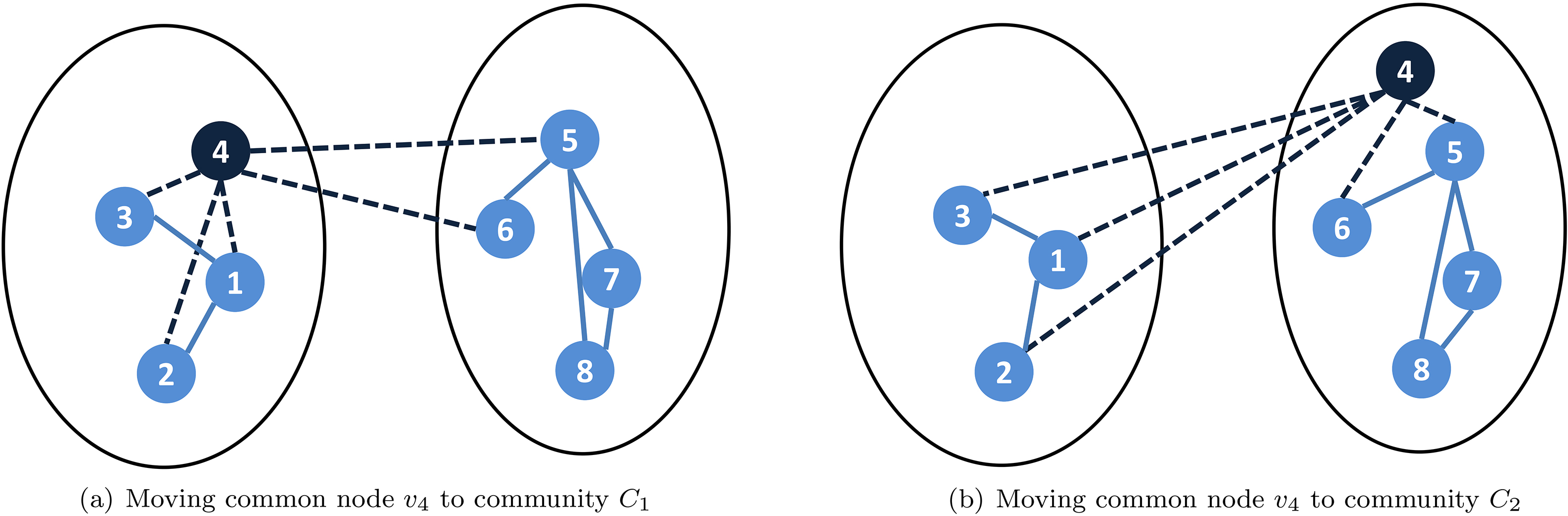
To address the theoretical defects of modularity evaluation, we present an evaluation criterion using the accuracy of a novel link prediction method.
There is a strong positive correlation between the community division predicted by the community detection algorithm and link prediction. If link prediction depends only on community structure information, the more reasonable the community structure, the more accurate link prediction will be. Conversely, the more precise the link prediction, the more rational the community structure will be. Based on this analysis, link prediction can be performed using only community information, taking the AUC determined by link prediction as the evaluation criterion for community detection.
The existing methods for link prediction using community information are divided into the following two types: calculating the similarity index from the whole network to the specific community interior[26, 27] and regarding the community information as a kind of property information and weighting it to the similarity index[28]. Both of these methods regard community information as supplementary information in order to improve the accuracy of link prediction. However, the link-prediction method for evaluating the performance of community detection should take only the community information into consideration without other information. Therefore, the above two methods are not applicable to the evaluation of community detection. This paper presents an evaluation criterion based on link-prediction using the USI model that adopts only community information and uses AUC accuracy to evaluate community detection (USI-AUC). This method can be applied to assess disjoint, overlapping, and hierarchical communities among others.
First, we provide the definition of the USI model, then present to the link prediction algorithm based on the USI model, followed by evaluation of the USI-AUC metric. This process is illustrated in Fig. 5.
Diagram of the USI-AUC-evaluation criterion for community detection. 
.
USI model.
For arbitrary
where
Specifically, when
Define a discrete metric space based on the elements of family set
The USI model establishes a concise description for hierarchical and overlapping relationships of nodes in the network and can explain various relationships between the connection and organization of nodes in the network. Definition 2 (i) describes that nodes or sets can consist of a new set in which elements have specific relationships or properties. In Definition 2 (ii), the metric
From the definition of the USI model, the elements of a set could consist of sets or non-sets. When the elements are non-sets, the metric
.
The order of elements.
In the USI model, elements of
.
The order of sets.
In the USI model, the order of elements contained within a set is referred to as set order.
For example, considering a network with 3 nodes,
The USI model is a generalization of the hierarchical-structure model[29] and the stochastic block model[30, 31]. From the USI model, if and only if each set contains two elements and each element belongs only to the corresponding order set, the USI model degenerates to a hierarchical-structure model that could contain high-order elements. When the highest order of a set is one and the intersection of all elements is the empty set, the USI model degenerates to a stochastic block model.
When the specific relationship describes that the division results of the community detection algorithm describe elements consisting of a set, the AUC of link prediction for the USI model is used as the evaluation criterion for the community detection algorithm. Because the USI model does not require that 0-order elements belong to the set, this criterion can evaluate both the disjoint and overlapping communities.
.
A
Clearly,
.
A
Proof..
According to Pproposition 1, a k-order set can be reduced in order to a
For example, we assume a 3-order set,
Evidently,
the 2-order set is reduced to 1-order set,
and the 1-order set is reduced to 0-order set,
.
A
Proof..
Regarding the elements of k-order sets as the
According to Corollary 2,
and the 2-order elements
So, we get the 1-order set,
Here, the process of link prediction was performed on a training set. First, the network set
In this section, we regarded the community division of community detection algorithm as the partition of sets in the USI model and estimated the metric
The partition of sets
For the 0-order sets,
For 1-order sets, if the community divided using the algorithm do not contain hierarchical-structure information, considering interactions between two 0-order sets, the specific relationship,
Assume
When
we obtain
For 1-order and higher-order sets, if the community divided using the algorithm contains hierarchical-structure information, regard the hierarchical information as specific relationships,
According to the difference in set order, the estimation method for metric
The estimation of metric Assume
where In a set consisting of only 0-order elements, the distinction between the elements is whether they are connecting or non-connecting. Metric The likelihood function is
where Let
We can obtain
Example of estimating the matric As shown in Fig. 6, the 0-order set has 10 nodes and 12 edges, and the estimation of metric The estimation of metric
There may be intersections between 1-order elements divided using the overlapping-community detection algorithm:
The maximum number of possible links between 1-order elements is
Therefore, metric As Fig. 7a shows, there is no intersection of 1-order sets, we only need to consider the actual number of edges (6) and probably the largest number of edges (
Example of estimating the matric The estimation of metric According to Corollary 2, reduce the order of set
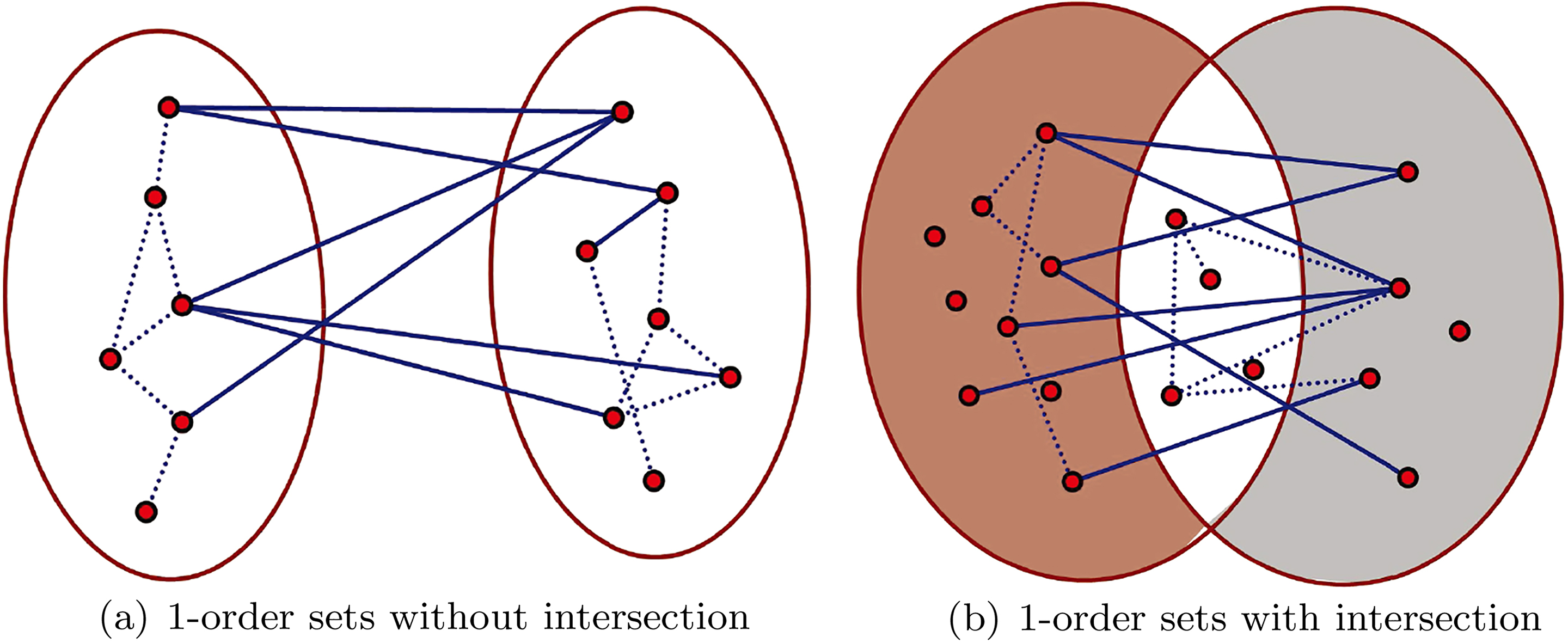
For the overlapping-community detection algorithm, a node can be subordinate to multiple communities; therefore, there exist multiple channels for two nodes to generate a link, which is very similar to human communications. Each increase in one contacting channel indicates an increase in the probability of two nodes consisting of a link. For the USI model, one node can belong to different sets; therefore, calculate the parallel probability of contacts between node pairs through each channel as a link-prediction score.
where
According to the final score of node pair
This AUC is defined as the evaluation criterion based on the USI model (USI-AUC). The steps of this algorithm are listed in Table 1.
Algorithm steps.
In order to reduce computational complexity and simplify the problem, here, we only considered partitions of 0-order sets. First, the experiment focused on EQ to verify the validity of the theorems. We then comparatively analyzed the evaluation effects of the USI-AUC criterion and the modularity criterion to disjoint and overlapping communities using several datasets, At last we tested the statistical significance for the comparison of the USI-AUC criterion and other criteria.
Verification of the validity of the two theorems
Experimental verification of Theorem 1
Using the classical Newman-modularity algorithm[5] on the Dolphin dataset[33] for partitioning communities resulted in five divided communities (see Table 2), with modularity criterion for this division at
Partitions of the Dolphin dataset using the Newman-modularity algorithm. Each column indicates a community, and the contents are node numbers
Partitions of the Dolphin dataset using the Newman-modularity algorithm. Each column indicates a community, and the contents are node numbers
We observed reductions in modularity after deleting arbitrary nodes in these communities (see Table 3), and verified Theorem 3.
Modularity values after deleting individual nodes in Dolphin dataset, with values representing the modularity after deleting a corresponding node. Each cell corresponds to the node number 1–62 in turn
We chose one node as a common node in two communities and tested EQ. We obtained 248 EQ values, with 244 values lower than the original modularity
We then chose two nodes as common nodes in two communities and tested the EQ. Using the above adjusting results, we obtained 7560 EQ values, with 7558 values lower than the original modularity
Adjusted communities, with each column indicating a community and its node numbers
Adjusted communities, with each column indicating a community and its node numbers
It is possible to generalize the case involving two common nodes to cases involving multiple common nodes; therefore, it is unnecessary to enumerate these results here.
This section comparatively analyzed the evaluation effect of the USI-AUC criterion and modularity criterion for 11 kinds of disjoint-community detection algorithms used on six datasets. The 11 disjoint-community detection algorithms and corresponding parameters are listed as Table 5.
The brief description of 11 disjoint-community detection algorithms and corresponding parameters
The brief description of 11 disjoint-community detection algorithms and corresponding parameters
The six datasets are Lesmis[43], Zachary[23], Football[1], CKM-3[44], PPI-Cell[45], and Metabolic[46]. The basic topological features of 6 real networks are listed in Table 6.
The basic topological features of six example networks
For the six datasets, we obtained 57 divisions using different parameters. Each division was evaluated by USI-AUC criterion and modularity criterion, with evaluation results shown in Fig. 8 (sorting from small to large according to modularity).
Comparison of USI-AUC and modularity criteria. The “*” represents the score associated with the USI-AUC criterion, and the “+” represents the score associated with the modularity criterion. Each scatter diagram showing modularity is sorted from small to large and shows the corresponding points for the USI-AUC score. 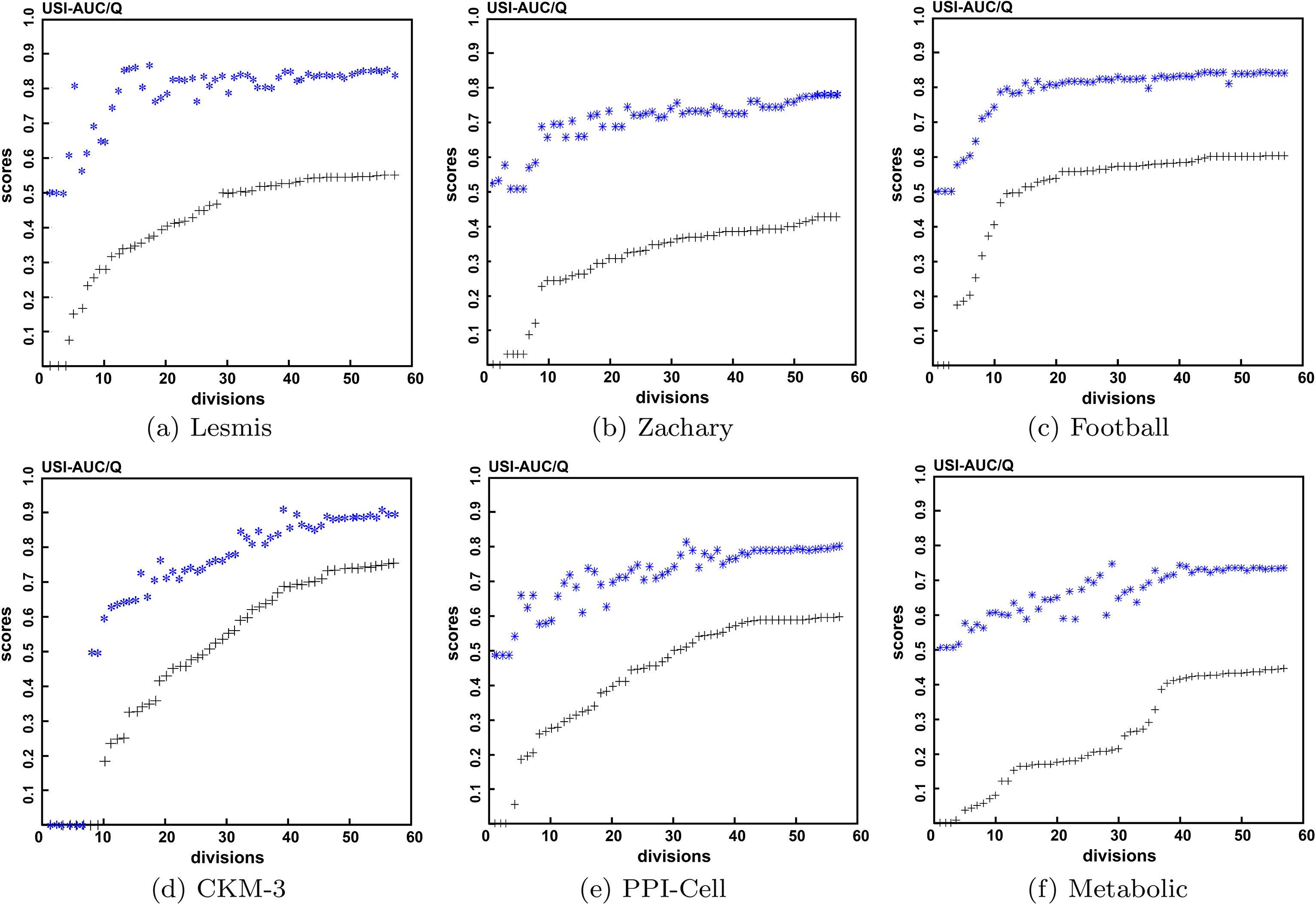
Representative experimental results are listed in Table 8. For each community detection algorithm, we selected an optimal parameter according to the USI-AUC criterion and listed the scores from the two criteria and their corresponding rankings.
The scores and rankings of disjoint-community detection algorithms using USI-AUC and modularity criteria. We selected the optimal parameter allowing the USI-AUC criterion to reach the maximum value in each algorithm
Comparing the evaluation of USI-AUC and modularity criteria using the labeled dataset Zachary
For the disjoint-community detection algorithms, the USI-AUC and modularity criteria exhibited positively correlated trends, indicating their joint capabilities. With increases in modularity, the USI-AUC also increased; however, according to data shown in Fig. 8 and Table 7, there were also fluctuations between the two indices mainly caused by isolated nodes. For example, the reason for the strong fluctuation in the fifth division of the lesmis dataset from Fig. 8a concerned the use of {11, 14, 15, 16, 31, 33, 34, 41, 43, and 68} nodes as isolated nodes, with the degrees of the nodes {11, 14, 15, 16, 33, 41, and 68} all equal to 1 and linked with nodes of larger degree. The degrees of nodes {31, 34, and 43} were two or three and were linked with nodes of larger degree. Therefore, when node information was limited, regarding these nodes as isolated was reasonable. We were unsure whether these nodes were attached to the community containing large-degree nodes. These results were consistent with Theorem 1, indicating that USI-AUC criterion provided a reasonable evaluation of communities containing isolated nodes.
Comparative analysis using labeled datasets
We selected community labeled datasets Zachary and Football to analyze the two metrics. In the Zachary dataset, the original division consisted of two communities. Using the 11 algorithms, we obtained three types of divisions consisting of two communities from five algorithms. The experimental results are listed as Table 8.
From rankings of USI-AUC and modularity results, the two metrics are almost the same based on evaluating the division of the Zachary dataset, with the original division of each scoring highest in the two indices and showing that both methods were reasonable.
The same experiment using the Football dataset (see Table 9) showed that both USI-AUC and modularity criteria were better for the divisions of the algorithms as compared with the original communities, indicating that the two indexes either exhibited evaluation errors or some communities were unlabeled. For example, although nodes representing teams in the dataset were attributed to their own leagues, there may still be teams capable of establishing relationships with teams from other leagues, resulting in potentially unmarked community structures.
Comparison of evaluations using USI-AUC and modularity criteria on the labeled dataset Football
Comparison of evaluations using USI-AUC and modularity criteria on the labeled dataset Football
Rankings of disjoint- and overlapping-community detection algorithms according to the use of USI-AUC and extended modularity (EQ) criteria on the Dolphin and football datasets based on selecting the parameter optimizing USI-AUC-criterion results for both algorithms
Parameter description of LFR benchmark
If communities overlap, USI-AUC criterion can also be used for their evaluation. For example, Fig. 1 shows that using nodes 3 and 9 as common nodes in the Zachary dataset results in a value according to USI-AUC criterion of 0.742, which is greater than the USI-AUC value associated with the original division. However, the value of EQ was 0.351, which was lower than the EQ value associated with the original division according to Theorem 2. As illustrated in Fig. 1, nodes 3 and 9 are active in both communities; therefore, use of the USI-AUC criterion was more reasonable.
Parameter setting of LFR benchmark network generation
Parameter setting of LFR benchmark network generation
The basic topological features of 4 generated networks
Statistical significance test for the comparison of the USI-AUC measure with other evaluation measures
For evaluation of the overlapping-community detection algorithm, we used the Dolphin and Football datasets and partitioned the networks using the fast overlapping community detection algorithm (FOCS) [47] and the other 11 disjoint algorithms. Evaluation results according to USI-AUC and EQ are shown in Table 10.
Use of USI-AUC criterion was able to evaluate both the disjoint and overlapping communities. Based on the evaluation results, values associated with the USI-AUC criterion were highest when using the FOCS algorithm with parameters (2 and 0.5), indicating that this type of division was more reasonable. However, the value associated with use of USI-AUC criterion for the FOCS algorithm was lower than that observed using the other algorithms on the Football dataset, indicating that this type of overlapping division was of little significance. As for the EQ criterion, because of the overlapping communities, the EQ value was low, which was consistent with the analysis using Theorem 2. Therefore, EQ did not provide a reasonable evaluation of the overlapping-community detection algorithm.
In the experiment, we use some artificial network data sets generated by LFR benchmark[48] with community labels to do comparative analyses with other evaluation measures such as precision, recall, F1-score, NMI, omega and modularity. The parameters description of LFR benchmark is listed in Table 11; parameters setting of LFR benchmark to generate 4 networks with labeled overlapping communities is shown in Table 12; the basic topological features of 4 generated networks are listed in Table 13.
FLR1, FLR2, LFR3, LFR4 are networks generated by LFR benchmark within overlapping communities. FLR1-1, FLR2-1, FLR3-1, FLR4-1 are the disjoint community networks by adjusting common nodes to a community randomly from FLR1, FLR2, LFR3, LFR4, respectively. FLR1-2, FLR2-2, FLR3-2, FLR4-2 are adjusted networks within overlapping communities simulated as algorithm found. We can see from Table 14, USI-AUC criterion has a better consistency with criteria based on labeled network. However, there exists phenomenon the modularity of disjoint community is higher than the extended modularity of standard overlapping community, which is assistant with Ttheorem 2.
Conclusions
In this paper, we have proved that ME actually has theoretical defects in the presence of evaluation disjoint and overlapping communities. On that basis, we have proposed a method using AUC accuracy for the link-prediction method based on the USI model as an evaluation criterion (USI-AUC). Avoiding defects associated with contributions from isolated nodes to modularity and the inability to determine a best overlapping community according to ME, this criterion effectively evaluated the disjoint and overlapping communities, and has a better consistency with criteria based on labeled network. However, this criterion exhibited fluctuations, indicating that USI-AUC will not be consistent based on differences in the training or test sets, indicating that this criterion requires datasets with multiple partitions.
In this paper, we use an USI-AUC-evaluation index for the 0-order set, which can be extended to a 1-order set or a higher-order set. Our results also indicated that the USI model was suitable for weighted networks; therefore, the USI-AUC index is applicable for the evaluation of community detection in weighted networks. However, for directed networks, the USI model was not directly applied. Future work lies in generalizing the use of the USI model and USI-AUC criterion in directed networks. Moreover, we will also try to apply current HPC techniques (e.g., cloud computing [49]) to meet the challenges of massive networks.
Footnotes
Acknowledgments
We acknowledge Xi Tan and Wei Liu for their inspirations. This work was partially supported by the Foundation for Innovative Research Groups of the National Natural Science Foundation of China (No. 61521003), and National Natural Science Foundation of China (No. 61601513).