
Abstract
Over the past decade, there has been a proliferation of online news articles. News articles can contain rich content and contextual information pertaining to groups in societies, such as senior citizens, child rights groups, religious minorities, or environmentalist groups. In addition, news articles contain different object types such as people, organizations, statistical (numerical) information, countries, authors, or events. Thus, it is possible to create a complex heterogeneous graph containing multi-type objects (vertices) and multi-type linkages (edges) among the objects, such as common keywords found between two news articles. We call such a graph a Heterogeneous News Graph (HNG). Currently, it is possible to extract rich information and knowledge from an HNG. It is our belief that one could use an HNG to resolve the bias and visibility issues found in many news sources, as well as capture important news articles. First, due to the amount of news feeds currently available in this digital age, readers want a filtered view of relevant news articles, allowing them to focus on important (breaking) news that contain rich contextual information for their particular societal group. For example, senior citizen groups might want to know new safety measures taken by police for elderly people. Second, visibility is another problem in the world of journalism, where there are multiple objects in the news articles, such as authors and organizations. In this example, readers might need to know who are the relevant authors, or experts, for particular topics, such as Libya, Afghanistan, or climate change. To address the issues of determining importance and visibility of objects, we propose novel graph-based approaches using HNGs that will (1) rank the expertness of an article’s author on a specific topic, and (2) identify articles of particular interest and value. In summary, we propose a novel graph-based approach for determining context and content in news articles so that more personalized recommendations can be realized.
Introduction
The ubiquitous nature of the World Wide Web has resulted in an increase in the volume and variety of available unstructured, heterogeneous data. In particular, online news sources provide a wide range of information on societal issues, events related to crimes, terrorist attacks, and security issues both with respect of the general population and cultures. To date, research has used news articles to solve problems such as predicting future crimes, analyzing patterns, and predicting the locations of offenders. In addition, some sources and systems are connected to each another, such as social networks, GPS maps, and computer networks. Because of the ubiquitous nature of online news networks, they can potentially form a rich and complex, heterogeneous network. A network is potentially heterogeneous based on two criteria. First, it is possible that the information is derived from multiple news sources. For example, if the research or system involves two news sources, such as The New York Times and the Washington Post, then it is called a heterogeneous network. Second, heterogeneous networks can also be viewed as logical networks, consisting of multiple object types and multiple linkages connecting those objects. In this way, each article can be seen in a more abstract form as a collection of different types of object. In this case, each news articles mentions different types of objects, such as organization names, person names, location, dates, numbers, images, keywords (i.e., tags), and image captions. For example, an object type person names mentioned in articles could be the names of statesmen, names of experts who provide opinions on certain societal issues, offenders’ names, or defenders’ names. Similarly, an object type organization names mentioned in articles could be the White House, World Health Organization (WHO), or United Nations (UN).
To ground this in a real-world scenario, let’s take the example of two news articles. The words mentioned in the object type caption of an image found in the first news article can interact with the object type keywords in the second news article. Let’s assume that the first news article has an image with the caption “Nintendo and Universal Studios Japan released concept art for Super Nintendo World. Nintendo is also working with Universal Orlando for a Nintendo component”.1
In this work, we consider news articles as heterogeneous networks possessing multiple object types and linkages, where the graph input files are created chronologically by the published by date in the news article. We propose to mine these types of heterogeneous networks for context in the scope of personalization for different communities, where each community has a particular set of interests.
Personalization in this thesis is based on two notions: (1) physical outlook, and (2) interests. Physical outlook includes but is not limited to gender, race, age, and location. Interests involve a range of topics that a typical citizen and/or interest group would be interested to know, such as climate change, crime, corruption, or human trafficking.
In this work, context refers to important information that could potentially catch the attention of policy makers and/or citizens. There could be specific contextual information related to topics such as corruption, human trafficking, or road accidents. Citizens are looking for specific context related to the issues, such as if any new measures taken by municipal corporations will reduce road accidents, if any new law or regulation passed by Federal government or State government involves human trafficking, or how such laws are going to be implemented.
Why is personalized context mining important?
The users can be of various level of interests based on their job or personal interests. The following are motivational examples from two individual’s perspectives:
Jacob Lawrence works as a policy advisor for a think-tank which serves the United States government. Mr. Lawrence works as a prominent advisor on Middle Eastern policy. In his previous experience, he worked for seven years as a journalist in Iraq. Mr. Lawrence is interested in specific contextual information and knowledge that can be found in the news, such as:
Who are the experts for research and collaboration on a specific Middle Eastern topics such as Syria, Iran, Afghanistan, or terrorism? Articles mentioning security situations of peer journalists in Middle Eastern countries such as Iran, Iraq, or Syria. Articles that mention attacks on Western culture and its citizens (e.g., teachers from Western countries attacked in the Arabian peninsula countries of Saudi Arabia or Qatar).
Fatima Bhutto is a citizen of Bangladesh who works as an activist on the issue of human trafficking. Some children from Bangladesh are trafficked to South Asian countries, such as India and Nepal, in order to be eventually sold for bonded labor or prostitution in rich Middle Eastern countries, such as Dubai or the United Arab Emirates. Hence, Ms. Fatima extensively travels to South Asian countries and Middle Eastern countries to bring trafficked children back to their home country. Ms. Fatima is interested in only those news articles that mention specific context and knowledge on human trafficking, such as the following:
Articles having discussions about security issues for foreign travelers and precautions to be taken for one or more countries in either South Asia or the Middle East. Articles containing contextual information on specific social issues such as child labor and human trafficking. Some example are measures/programs introduced by governments, recent statistics, prominent entities involved such as NGOs, and politicians, or interesting patterns and trends pertaining to the trafficking in one or more countries in South Asia or the Middle East. Articles from those who are experts in human trafficking. Such articles might compare different measures taken among different nations in South Asia or Middle East to counter the human trafficking situation.
In summary, exploring interesting contextual information from news streams for different societal issues could better serve different communities such as policy-makers, travelers, or citizens. In other words, we believe that context mining should be based upon the perspectives of relevant persons and societal communities.
In this research, we will convert textual content from news articles into heterogeneous networks containing various object types using Natural Language Processing (NLP) techniques, and explore graph-based mining classification and ranking approaches. This work involves addressing two research problems:
Which are the important news articles to follow on a specific societal issue? Some of the challenges involve the structure of important facts and information, and capturing different entities within the context. Who are the experts in news articles? Currently, there is no visibility on who are the expert journalists on a specific topic. Thus, what needs to be studied is how to rank journalists in terms of their relevance. Some of the challenges involve incomplete information and overlapping topics within news articles.
In addressing these two problem, our hope is that it will provide the right contextual information and knowledge for citizens and policy analysts. First, users will be able to filter the appropriate articles that convey important contextual information. Second, users will know who are the experts on a specific topic.
The change detection approach presented in this work is most closely related to the research that is being done on novelty detection, particularly in a temporal setting. Gaughan and Smeaton [5] study novelty detection using the TREC data set. The NIST TREC2
Schiffman and McKeown [22] leverage contextual information for the novelty detection problem. The authors use the context of the sentence along with novel words and named entities. The algorithm tries to find the optimal value for 11 parameters, weights, and thresholds. The algorithm uses a random hill-climbing algorithm with backtracking for learning weights. The algorithm achieves a recall of 0.86 on the average of all runs, in comparison to cosine similarity with 0.81. Karkali et al. [11] study the problem of online novelty detection on news streams. Their work uses two data sets, one from the Google News RSS feed and another from Twitter. Novelty is defined in terms of a predefined window on the past. The proposed algorithm is based on the TF-IDF, and is evaluated using a linearly combined single detection cost [16].
The work presented in this paper differs from previous efforts, as our proposed method is a graph-based approach. Our graph-based approach has the advantage of leveraging (1) structure, (2) content information, (3) context Information (using an aspect-level and fine-grained approach of individually extracting and using dates, numbers, and organizations), and (4) sentiments in graphs. Also, we currently focus on discovering news articles relevant to policy makers – a problem for those who are tasked with generating relevant societal policies.
In addition to the task of recognizing change in news articles, there is also the issue of ranking the importance of authors. There are two primary general techniques used for ranking authors: topic modeling or PageRank. Tang et al. [27] study the problem of finding a consensus topic in multiple contexts. Using Twitter data, the authors create a multi-view based on the hashtags and dates and times of tweets. Each view creates a set of documents called pseudo documents, for which the authors run a topic model for each individual view finding a consensus topic by majority voting. Balog et al. [2] implement a generative probabilistic language model with two search strategies, leveraging two different types of evidence. Additionally, they extend the model to include co-occurrence information, using the Text REtrieval Conference (TREC) 2005 expert finding data sets.
PageRank [19] performs two basic functions on a network. First, there is a random walk by the surfer. Second, there is a propagation of influence in a network. In terms of using PageRank, little research has been done for the problem of co-ranking. Zhou et al. [31] propose a random walk based algorithm for ranking authors and documents together. The authors propose a novel coupling random walk, which separately ranks authors and documents. The coupling random walk has two networks for random walks: one for a social network of authors, and the other is a citation network of documents. The coupling random walk helps to mutually reinforce the influences between authors and documents, thus leveraging additional information from the network. A similar algorithm is also implemented by Wu et al. [28] for image and tag co-ranking.
CoRanking [30] implements a random walk with restart to simultaneously rank authors, venues, and documents. The authors use the concept of a population propagation factor (PPF) that is added to each link pointing to an object, where different types of objects such as authors, papers, and venues have different propagation factors. In other words, each object type will have a probability parameter for the random surfer. Evaluation is done by using a Discounted Cumulative Gain (DCG) score, where their CoRanking approach is better than PageRank for ranking authors on the topic of Opinion Mining. Additionally, the authors study using user generated content to improve ranking results.
In summary, previous research has focused on ranking authors in networks from the same domain with the same underlying authors. For example, different bibliographic databases are used for ranking the same authors. The primary difference in our co-ranking approach (Section 4) is that we are able to rank two different sets of authors in heterogeneous networks.
Overview
Proliferation of news channels on the Web has introduced a wide range of diverse data. These news articles actively report on stories involving crimes, terrorist attacks, and security issues relevant to the general population. Communities at risk deal with issues, such as children forced into labor, senior citizens traveling in high-risk urban crime zones, and senior citizens not having access to public restrooms. Dark heterogeneous data sources, such as news feeds, html files, pdf files, and tables, provide various statistical information and expert opinion analysis on these issues. For example, an article on child workers reported that “Half of the 5.5 million working children in India are concentrated in five states: Bihar, Uttar Pradesh, Rajasthan, Madhya Pradesh and Maharashtra” (Source: timesofindia.com, 13 Jun 2015). These types of web data provide a rich and complex set of information and knowledge on societal issues, such as policies proposed by the government or the implementation of a new law, that need to be extracted in a meaningful way for knowledge representation.
News mining has been studied in a variety of contexts. Earlier work involved grouping related news items, the fusion of news articles, and the summarization of information from disparate sources. However, news mining within a specific context could be more useful for a targeted group of users based upon their interests – what is commonly referred to as personalized context mining. Specific targeted groups could be based on age, location, gender, physical attributes, or a variety of aspects based upon one’s own interests. For instance, one could be interested in community challenges, such as corruption, or perhaps safety in public places, such as on a beach or road, or at a railway station. In this work, we particularly examine news articles that catch the attention of policy makers or special interest groups on societal issues such as child labor and human trafficking.
First, we will define the various types of changes that our approach attempts to discover. Section 3.3 presents our definition of what constitutes a news article, or generally, a document. Section 3.4 describes our process of data collection and preparation. Section 3.5 presents our proposed graph topology, and the tool used to extract the information, followed by Section 3.6 that discusses the ground truth and evaluation methods for our experiments. Section 3.7 presents our proposed method. Section 3.8 presents the experimental setup for our proposed method and baseline comparisons, followed by experimental results in Section 3.9. We then conclude with conclusions, and future work.
Change detected
First, we need to define what we mean by a document where there is “change detected”.
Solution-based Change Detected (SBCD): If an article contains a sentence that mentions an intervention or solution, then the article is marked as change detected. Here is an example of precautions against landslips:
“Come rain, Yercaud Ghat Road will be witnessing recurrence of minor landslips. To avoid this and to ensure smooth movement of traffic on Salem-Yercaud Ghat Road, the district administration through the state highways has started carrying out constructing retention walls to prevent mud and rocks slip in rain. Big stone blocks are being used to erect walls.” (Source: thehindu.com)
Context-based Change Detected (CBCD): If an article is rich in context, such as getting attention from public and policy makers, then the article is marked as changed. For example, only a few ebola outbreak warning articles mention expert opinions for possible reasons behind the event, and when they do, information provided is very detailed. In other words, rich context articles provide asymmetric information content on the corresponding topic. For example:
“The death rate in the Ebola outbreak has risen to 70 per cent and there could be up to 10,000 new cases a week in two months, the World Health Organization warned Tuesday.” (Source: ndtv.com)
Resource-damage-based Change Detected (RBCD): If an article contains a number of resource losses, such as through injuries, deaths, or revenue, that are higher than expected, then the article is marked as changed. For example, buildings that collapse due to a conflict or an earthquake, usually result in a significant amount of property and lives lost:
More than 20 persons were killed in road accidents in the district including the two major ones that took place on Dindigul-Palani Road in November. (Source: thehindu.com)
A news article can be represented as a document. Each document (article) is denoted by
Features from a sample document (article)
Features from a sample document (article)
Data statistics from our data set
The goal is that for each document
The following is how we collected and prepared the data.
Data collection
First, we crawled the index page of yearly archive pages from three Indian news papers – The Hindu,3
Second, we analyzed the news articles related to the 12 societal issues for possible changes. Articles that report uncommon incidents within the context of social issues and policy, are marked for change detection. Each article was read by human annotators and searched for one or more of the change detected types defined previously: solution-based, context-based, and/or resource-based. If the article provides a solution or intervention to a social problem, such as the discovery of the ebola virus, it is marked as change detected because of the solution-based impact. If an article mentions experts’ opinions, such as an expert opinion on the ebola outbreak, that is considered a context-based change. If the article mentions huge resource losses, such as mass human casualties due to ebola, it would be considered a resource-based change, and would be marked as change detected.
We also discovered a few out of context (noise) articles. For example, an article mentioning a “cease fire” is inappropriate for a fire accident, and thus is removed from consideration. In addition, a few articles might contain information appropriate for one or more of the different change detected types. For example, the article at [1] is marked for change detection, based on both resource-based and solution-based impact because 30 people died in the stampede, making it eligible for being considered as a resource-based change, and a process was initiated to correct the root cause of the stampede, thereby also providing a solution.
Graph topology
The input for our approach is a graph. An example of our proposed graph topology of news articles is shown in Fig. 1. In order to create this graph, we used openNLP6
Example graph topology of news articles.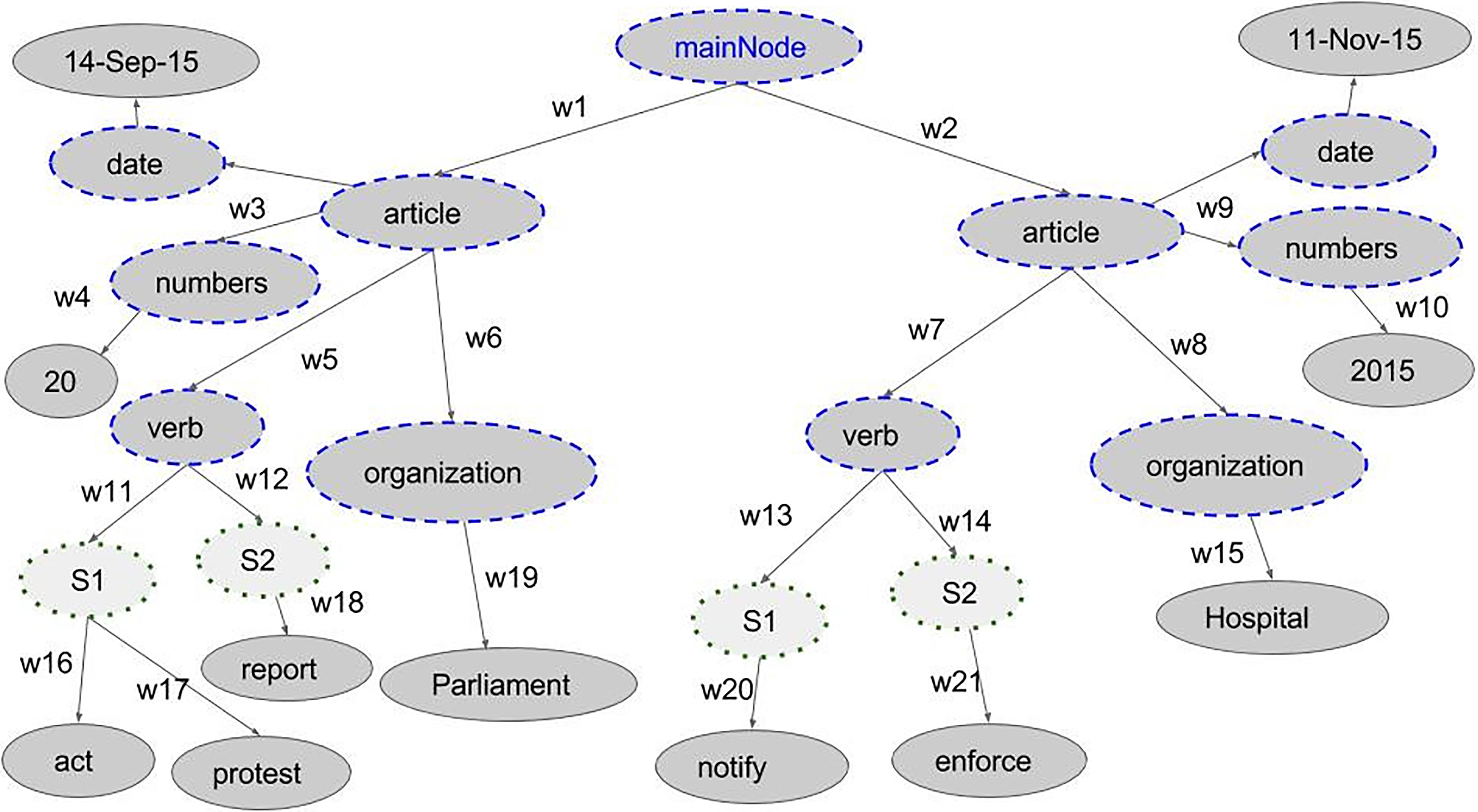
Graph weight. We use the Stanford Sentiment Analysis library8
The result is a weighted graph with vertices consisting of verbs, organization names, dates, and numbers. The resulting graph consists of 117,343 vertices and 231,142 edges.
For the ground truth needed for evaluating our approach, each article is examined in detail by two policy making experts working for think tanks. Annotator 1 is employed by SunWorks Consultant Private Limited, leading a team examining news article publications related to Chinese social policies, government activities, foreign policies, china neighborhood relations, and the economy. Annotator 2 also works in the area of Chinese affairs studies, employed at the Institute of Chinese Studies (ICS). ICS is funded by the Ministry of External Affairs, Government of India. ICS promotes interdisciplinary studies and research on China and the rest of East Asia, with a focus on domestic politics, international relations, economy, history, health, education, border studies, language, and culture. They crawled documents related to the three different change detected documents described previously, using the approaches described in the data preparation section, marking each article as change detected or not. It is important to note that only articles where both annotators would agree were marked as change detected. If there was a disagreement in terms of the context of a specific article, the article was removed from the data set. This resulted in 74 articles (out of the original 8,433) being marked as irrelevant.
In order to evaluate our approach, we use recall, F1-score, and accuracy, compared against existing standard approaches.
Our proposed method
In this section, we propose an algorithm that uses an objective function based upon a graph-cut approach. First, we present the important aspects relevant to change detected documents. Articles that are considered as appropriate for detecting this type of change involve one or more of the following aspects:
In short, in order to classify an article as change detected or not, our method must effectively capture and leverage contextual information that mentions user-based information (e.g., organization), action-based verbs (e.g., protest, strike), and resource-based information (e.g., “32”).
As will be demonstrated shortly, we discover that an N value of 5 gives an increased F1 score as shown in Table 7, and is subsequently used as the minimum neighbor in our experiments.
Again, we discover that the precision and recall of the graph-cut with
Our proposed probabilistic graphical model CBLDA.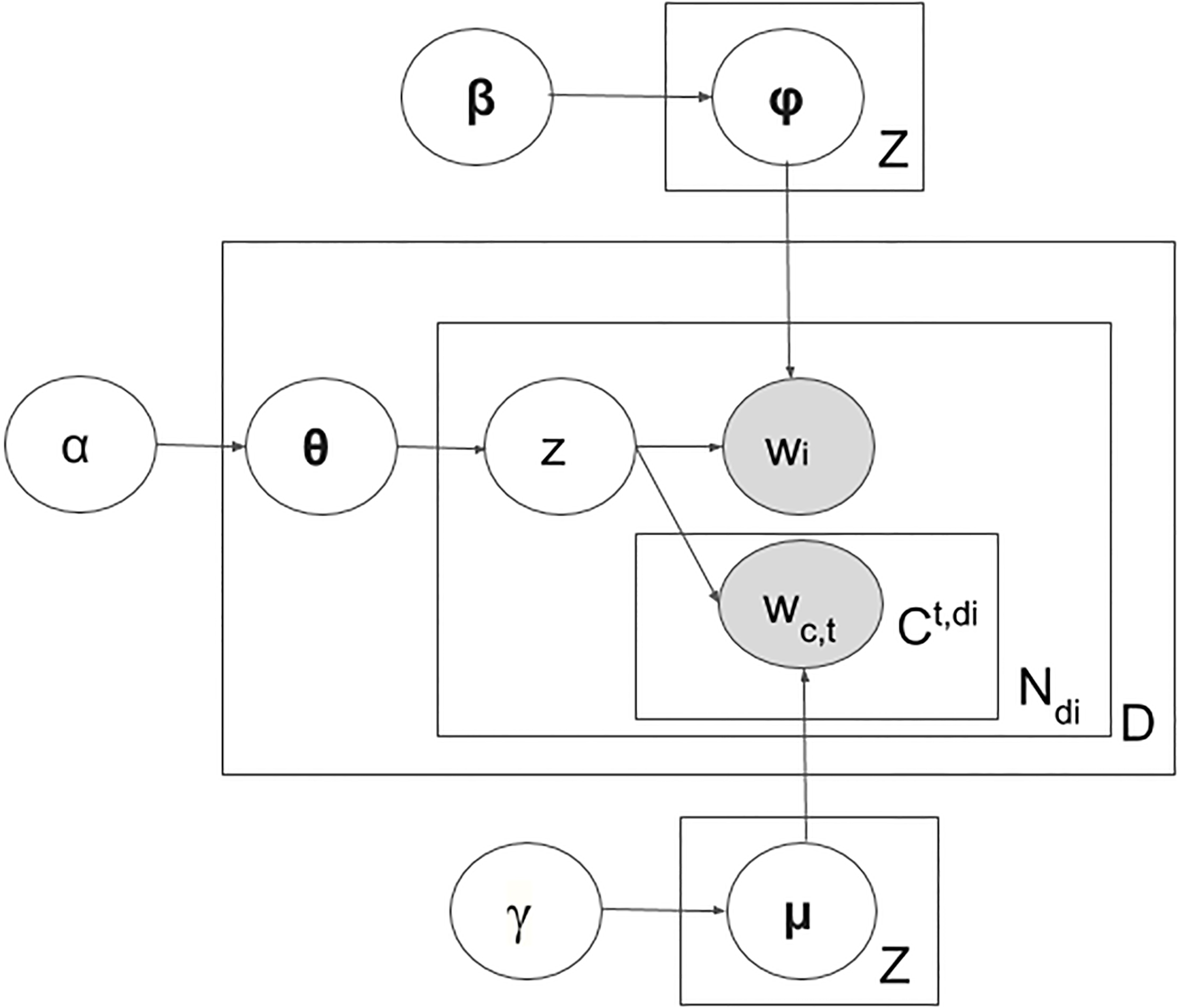
Effect of penalty parameter alpha.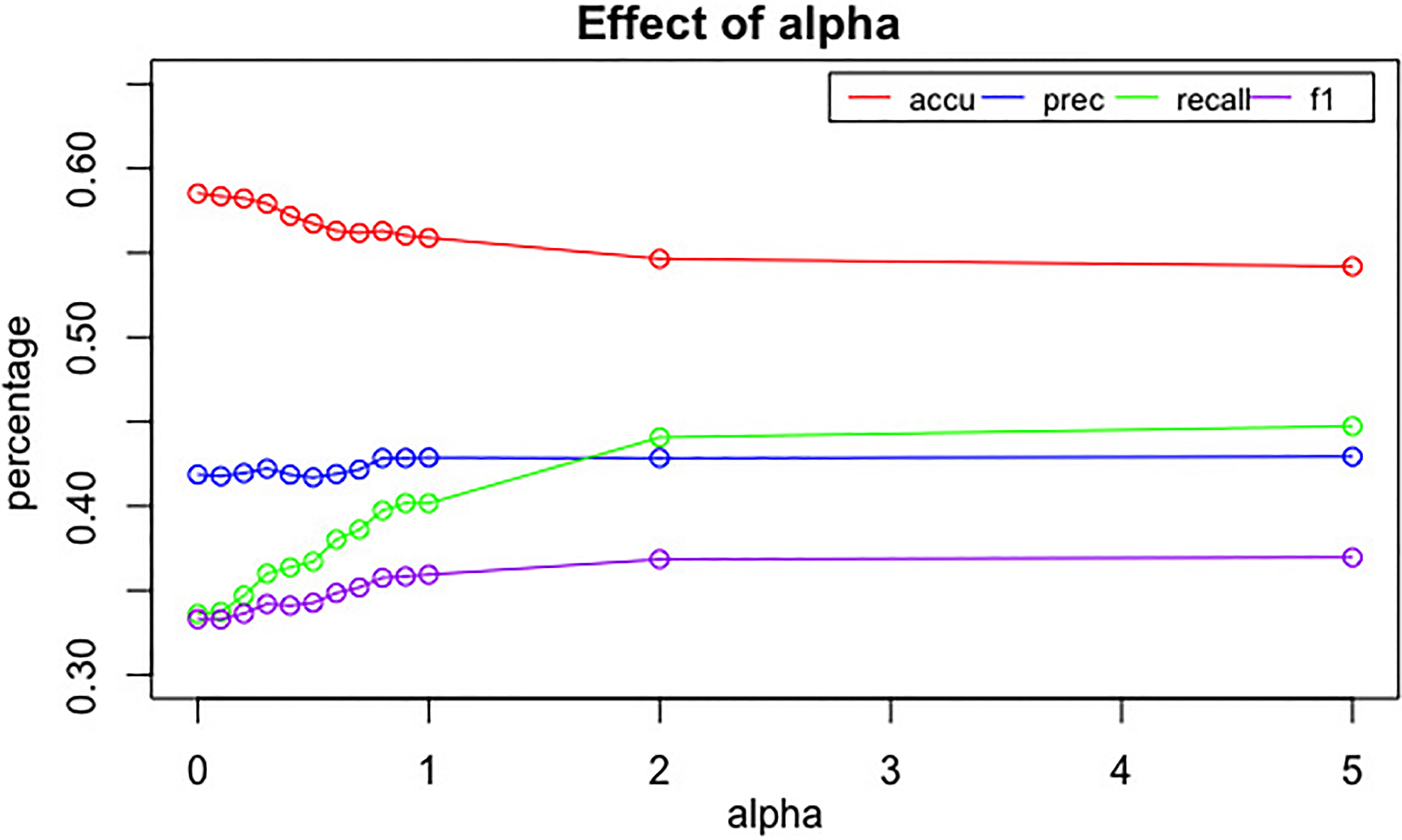
Parameter
Graph-Cut Algorithm[1] Input:
Table showing set of articles for three different case studies for polarity of cut-cost in Eq. (2). Each case study has three news articles, where one article is a change detected article, and other two are neighbors of the change detected article. For example, article id 3 is change detected article, whereas news article ids 1 and 2 are neighbors of article id 3
Table showing values of
First, it is worth noting that smoothened verb
There are two types of news articles that mention years and numbers: (1) not change detected news articles that have some statistical information mentioned (not from experts) in the news articles. We call these “recent history type” news articles that give detailed explanations of a topic such as kidnapping. For example, article id 7 discusses the rise in kidnapping events with the years and numbers mentioned.; and (2) change detected news articles, particularly context-based/resource-based news articles, have the opinions of experts with numbers and years mentioned. These articles are more likely to have lesser numbers and years compared to its neighbors, which might include recent history. In this case, the polarity of Relatively higher new words compared to the average of their neighbors, which is generally expected for change detected news articles. This will make Part C more likely positive.
The four comparison methods we use are cosine similarity, new word count, new word count with threshold, and Jaccard coefficient. In our comparison methods, as mentioned earlier, for all
Our proposed method
We implement our proposed method as an iterative algorithm, as shown in Algorithm 3. The algorithm iterates over one document
Comparison methods
Cosine similarity [3] and the Jaccard coefficient [7] are the two most popularly used methods. These methods have also been applied to problems such as novelty detection [11] and the discovery of similar documents [24]. We use them to calculate the TF-IDF similarity between 2 articles. Another approach involves calculating the new words count when comparing a document to past documents, which can be used to discover an uncommon document. We also chose this technique as one of our baselines as it has been used repeatedly in other related research [13, 14, 15].
For our experiments, the articles from all three newspapers listed in Table 2 are merged and sorted chronologically. Since several articles from thehindu newspaper have missing dates, we only use the month and year for the chronological ordering of news articles. Our basic intuition is that rich (uncommon) contextual documents will have less similarity with their recent past and future documents. For each of the baseline methods,
In all the above methods, we iterate through each document from a chronologically sorted set. We usually take
Table 7 shows our experimental results, comparing baseline methods to our proposed Graph-Cut approach. We first compare and discuss results when dealing with the Top 20% and
Results showing Precision (Prec), Recall, F1-Score, and Accuracy (Acc) for baseline methods and our Graph-Cut approach. For baseline methods, the Top 20% of articles are marked as change detected. Different values for
representing number of preceding document (neighbors) experiments and results are shown
Results showing Precision (Prec), Recall, F1-Score, and Accuracy (Acc) for baseline methods and our Graph-Cut approach. For baseline methods, the Top 20% of articles are marked as change detected. Different values for
In addition, we evaluated the baseline methods with different values for the Top n% other than the Top 20% marked for change detection. It is worth noting that the percentage of change detected articles in our data set is approximately 14%, so we experimented with values of the Top 10% and Top 15% being marked as change detected. We include Table 8 to further show that results are only impacted by different values of
Results showing effect of different Top n % values marked as change detected on performance of baselines
It should also be noted that the running time of the baseline algorithms ranges anywhere from 5–10 seconds. In comparison, our Graph-Cut method takes approximately 1 second to complete. Our Graph-Cut method has a linear running time of
Overview
The rapid growth of news channel entities over the past decade has revolutionized the way people consume news. Digitization and Internet penetration have encouraged people to read news articles online. Until recently, research has primarily studied areas like news recommendation, summarizations, and actors’ interplay in news articles. However, the Web is highly complex with a rich set of diverse news channels or networks, and the heterogeneous nature of these networks results in an even more complex interaction of people, places, and things.
In order to address the issue of personalized news recommendation for different target groups, we have hypothesized a dual-layered approach. So far, we have presented our novel graph-cut approach that addresses the issue of filtering out unimportant news articles. However, in order to address the issue of finding news articles from authoritative news sources, we need to be able to rank the authors on interested topics such as Syria and human trafficking. In order to do that, we will introduce our novel context-based graphical model, which deals with the issue of handling two different (heterogeneous) news sources. One is a traditional news network, or TNS (e.g., Los Angeles Times, New York Times, etc.), which presents various local and international topics, such as corruption, new law proposals, crimes, and elections. The other is an institutional news network from policymaker institutes, or PNS (e.g., World Health Organization (WHO), Brookings Institute, etc.), that also publish on similar events and topics. There are two main points about the nature of TNS and PNS. First, TNS focuses on influencing citizens, and increasing more users globally. PNS focuses on influencing policymakers, academics, and politicians. Second, TNS journalists are more likely to cover topics in breadth rather than depth. In contrast, PNS journalists are more likely to cover topics in depth rather than breadth. Users are often overwhelmed by too many news articles, as well as the questionable reputation of what they are reading. Users want to know who are the experts to follow on specific topics? The problem of identifying experts in a bibliographic network has been previously studied [2, 26, 29]. However, such a ranking problem study has not been done for authors of news articles. We will study the problem of finding experts on specific topics from our proposed heterogeneous network of news sources. Our goal is to discover who are the expert journalists and policy analysts on specific topics. In order to achieve our goal, we will address two challenges. First, the two networks are heterogeneous in their object types, such as the mentions of people, locations, etc. Second, many news articles have incomplete information.
The following section addresses the issue of determining which news authors are relevant by: (1) combining two networks where the news stories are written by different authors with different objectives – one is playing the role of a journalist serving the public, and the other is playing the role of policy adviser, like for a thinktank. In other words, TNS and PNS are heterogeneous networks; and (2) showing that our method improves the performance for co-ranking authors compared to other methods. In this section, we first discuss the problem in detail. Section 4.3 presents the data that will be used in our evaluation, the data source and how the data is prepared. In Section 4.4, we present our proposed approach and Section 4.5 discusses various comparison methods. Section 4.6 explains our experimental setup, followed by how our approach is evaluated in Section 4.7. We then conclude with results in Section 4.8, followed by concluding remarks in Section 5.
Problem statement
In this section, we present some definitions and define the problem statement. Table 9 presents the important symbols, and their description, that are discussed in this section.
Notation
Notation
For the purpose of presenting and evaluating our proposed approach, we will define our news feed collection as one that takes a set of documents (articles)
The contexts are extracted from the body of each article using a natural language processing technique. We employ the Stanford NLP library9
We formally define our problem statement as follows: given a query topic
Data statistics and data preparation
Data statistics
In this section, we discuss the data, data statistics, and ground truth that will be used in this paper. We collect the news articles using an RSS feed collection. We then match and choose articles that contain at least one of the six queries of interest: Syria, climate change, election, India, crime, and boko haram. The TNS network is captured from a total of 118 RSS news feeds, while the PNS network is captured from a total of 54 RSS news feeds. The unique number of authors from TNS and PNS is 1,826 and 997, respectively. The number of documents mentioning the six queries from TNS and PNS is 6,198 and 2,918, respectively. Hence, the total number of documents is 9,116. Table 10 shows a sample of the various TNS and PNS data sources used in this work.
Sample of news feed sources TNS and PNS networks
Sample of news feed sources TNS and PNS networks
Ground Truth. In order to evaluate the effectiveness of our proposed approach, the same two human annotators mentioned in Section 3.6 compiled the ground truth for our six topics, and ranked all the authors. For each article, the Stanford NLP Library is used to extract people, locations, and organization. Statistics, such as the number of articles by an author, the average number of locations per document, the average number of persons mentioned per document, the average number of numbers per document, and the average number of organizations per document, are then calculated and given to the annotators. The annotators then read all the supplied articles to familiarize themselves with the content and context.
Our idea for labeling ground truth is based upon the work of Zhang et al. [4, 29]. Similar to the work of [29], we use a method called pooled relevance judgments used with human judgments. In the work of [29], a two-step method is used to rank (ground truth) the authors in a bibliographic network. First, the top N ranked authors from three existing systems (Rexa, Libra, and ArnerMiner) are combined into a single list. Second, two human judges make an assessment on the ranking of each author based on criteria such as the number of publications, the number of top conference papers, and what distinguished awards were received by each author, etc. However, in our work, labeling is a three-step process. Because this is the first known work (at the time of this writing) in the domain of ranking journalists, we do not have others systems from which we can collect pooling like was done by Zhang et al. [29]. Therefore, we must create a pooled relevance judgment with initial scores. So, for each author, the annotators calculate an initial score by combining the number of articles per topic and the average number of persons per document, resulting in an initial ranking list of all authors. The initial score is then normalized by dividing by the total of all initial scores. Second, the annotators compare each author in the initial list with their nearest positioned authors for an initial score threshold of less than 5, which was intuitively chosen based upon their experiences. The result was 26 unique authors (13 author pairs). Third, the annotators then use objective measures, such as the average number of locations mentioned per document, the average number of numbers per document, and the average number of organization per document, for a potential re-ranking. Out of the 26 authors, 8 authors do not require any change in their ranking position. Of the remaining 18 authors (9 author pairs, or approximately 0.63% of the 2823 unique total authors), they are re-ranked by swapping their ranking positions.
As mentioned earlier, sparsity in the applied tags of news articles is a challenge. The following discusses how we attempt to overcome this issue.
Context-based latent dirichlet allocation (CBLDA)
In this section, we present our proposed CBLDA probabilistic graphical approach, as shown in Fig. 2.
First, we will present the probabilistic generating algorithm for CBLDA. Then, we will discuss the objective function for generating the probability. And finally, we will discuss the implemented inference algorithm.
Let
CBLDA[1] Input:
Second, we estimate the posterior probabilities of
Third, we employ the Gibbs sampling approach [6] for inference, as shown in the Algorithm 4.4. The algorithm converges in about 320 iterations.
After the Gibbs sampling, the probability of a topic given a document is defined by Eq. (7) using a chain rule similar to LDA [8]. The probability of a word given a topic is defined by Eq. (8). The probability of a word in a specific context type
In this section, we discuss various existing approaches with which we will compare our approach.
Experimental setting
In this section, we discuss the settings in our experiments for our proposed approach, and the other four methods used in the evaluation. The following settings are based upon the typical settings used in other reported research work.
Results showing Precision@N (P@N), MAP@N, and DCG@N with N ranging [10–50] for network
and
Results showing Precision@N (P@N), MAP@N, and DCG@N with N ranging [10–50] for network
Results showing Average Difference in Precision, MAP, and DCG for each of the baselines with our approach CBLDA for both Traditional Network (TNS) and Policy Network (PNS)
In this section, we discuss the ground truth, the different datasets used, and the evaluation metrics used in our experiments.
We want to calculate DCG for the top
In order to get a value between 0 and 1 for easy comparison, we need to normalize
The results of precision@N, MAP@N, DCG@N results are shown in Table 11.
Table 11 shows that our CBLDA approach achieves a second best precision at 0.25 after PAM on the traditional network, and best precision at 0.5666 on the policy network, when P@10. On average for all values of P@N, the traditional network precision of CBLDA is on average better than PLSI (
Table 11 also shows the mean average precision (MAP) results. On average for all values of P@N, the traditional network MAP of CBLDA is better than LDA (
Similarly, the table shows that the DCG of CBLDA is comparable with that of PLSI for the traditional network. However, for the policy network, the DCG of CBLDA is
In summary, PageRank gives the worst performance in terms of precision, MAP, and DCG. Our approach significantly outperforms (anywhere from 1% to 42%) the baseline methods for Precision@N, outperforms the baseline methods for MAP@N (1%–41%), and outperforms the baseline methods for DCG@N (2%–31%). PLSI and LDA give better precision or MAP in either traditional or policy networks, while CBLDA performs better in both networks using these metrics. PAM appears equivalent in precision to CBLDA, however the MAP and DCG of CBLDA is much better than that of PAM. In other words, CBLDA is still better, since it will show highly ranked authors at the top of recommendation.
Conclusion
In summary, we showed that through contextual graphs, enriched with heterogeneous objects extracted from news articles using NLP techniques, we can improve the two mining tasks of classification and ranking. The result is that we are able to personalize news recommendation to the needs of the different readership communities.
In our study and proposed approach for classifying news articles (Section 3), we presented a novel graph-cut algorithm that outperforms baseline methods in terms of precision, recall, and F1, while still being comparable in accuracy. We collected data from three different news sources, extracted common verbs, organization, and numbers, and built a weighted graph using sentiments of each sentence in news articles. We also studied the penalty parameter
In our study and approach for ranking authorship (Section 4), we presented novel co-ranking algorithms applied to two different networks, i.e., traditional and policy networks. Our work is different from other ranking algorithms in that we rank authors from two different types of networks, extracting 6 different contexts from news articles. We proposed our method CBLDA, which is an extension of the Latent Dirichlet Allocation model. We demonstrated that our proposed approach performs better overall in terms of precision, mean average precision and discounted cumulative gain. In the future, we will investigate the extraction of additional context from the documents, such as the designation of individuals (e.g., Prime Minister, President, etc.). Another idea is to implement a multiple Gibbs sampling approach [26]. In our case, we would like to implement separate Gibbs sampling for each network sharing a common Multinomial-Dirichlet parameter, so as to better incorporate local and global network information.
In this work, we consider that our proposed graph-cut and CBLDA approaches could be integrated together – the goal of our next step. First, we will extract features such as verbs and organization from the news articles, and use our proposed Graph-Cut approach for change detection to capture contextually important news articles in the stream. Second, we will classify the news articles as either important or not, using the features extracted from these news articles as context for our CBLDA algorithm. In addition, we will apply both algorithms to a sequence of articles from real-time news streams.
Footnotes
Acknowledgments
We sincerely thank Jayshree Borah with the China Studies Centre, and the Indian Institute of Technology Madras in helping with the labeling of the articles as well as providing useful feedback. This material is based upon work supported by the National Science Foundation under Grant No. 1318957.