
Abstract
Public bicycle system can improve the public transport travel efficiency and reduce environmental pollution, which has been deployed in many cities all over the world. However, the bicycle usages become quite skewed and imbalanced in different stations. A system which could recommend the nearest available stations for passengers whether they are looking for a dock or a bike, is of great importance. Monitoring the current number of docks or bikes at each station cannot tackle this problem because it’s too late to recommend the station for passengers to rent or return bikes after the imbalance has occurred. To address this issue, we propose a stacking model for variation prediction of public bicycle traffic flow called SMVP based on the real-world datasets. The stacking model integrates multiple base models which we trained by different combinations of features so that it could get better performance. We adopt a machine learning system called XGBoost [25] to train the models and construct the multiple complex factors which impact the public bicycle traffic flow. The traditional factors, such as temporal, spatial, historical and meteorological factors are taken into consideration. A new clustering factor which considers both the geographical positions and transition patterns of stations is also proposed in this framework and then we use the K-Medoids algorithm [12] to cluster stations into groups by constructing a new different station relation matrix which considers these two factors as the distance between different stations. The performance of SMVP is improved on the datasets of Hangzhou and New York City, especially in terms of Coefficient of Determination improved by 25.58% in Hangzhou, compared with the traditional stacking [5] and single model respectively.
Keywords
Introduction
Public bicycle system (also called bicycle-sharing system) is a kind of low-carbon and environment-friendly transportation system, which is vigorously promoted in major cities all over the world, such as Hangzhou, Paris, New York, and other cities. It is designed to solve the “last mile” problem by connecting bus or subway stations to other places. A public bicycle system usually offers bicycles to passengers in a short period of time either for free or costing little charges [20]. The passengers can rent bikes at the stations nearby and return it to the stations near the destination. It is seen as an alternative way of the vehicles for the short-distance trip. It can significantly improve the public transport travel efficiency and reduce environmental pollution. Therefore, public bicycle system is a more and more popular public transportation in cities [10]. As the widely application in recent years, the bicycle usage efficiency has drawn administrators’ attention as the bicycle numbers can be imbalanced at different stations. Some stations have sufficient bikes and no docks while the opposite situation exists as well. The main reason for this problem is the mobility or the one-way use of public bicycles. It means that the passengers rent a bike at one station but return it to another station. Administrators can not schedule the public bicycles in time, which results in the imbalanced bike and dock numbers in each station.
A system which could recommend the nearest available stations for passengers whether they are looking for a dock or a bike, is of great importance nowadays. The ultimate aim of this study is to handle the public bicycle station recommendation problem and get the planning purposes. But the traffic flow prediction is the first step of the recommendation or planning. So, in this paper, we just study the traffic flow prediction of public bicycles traffic flow. The methods of recommendation and the evaluation of planning process will be studied in the future. Indeed, if no prediction method is used in public bicycle system, we also could recommend the stations to passengers based on the real-time monitoring data. But, it may get bad performance because the monitoring the current numbers is too late to recommend the stations for passengers to rent or return bikes after the imbalance has occurred [28]. So, if we can predict the future numbers, passengers could rent or return the bikes to the appropriate stations. The improvement of predicting performance could improve the success rate of renting or returning. So, we try to predict as accurately as possible.
The state of art scalable tree boosting system XGBoost [25] has been widely used by many data scientists to solve the machine learning problems. It has been successfully used in store sale prediction, customer behavior prediction, click through rate prediction, massive online course dropout rate prediction and so on. The success of the system was witnessed in KDD Cup 2015, where XGBoost was used by every winning team in the top-10 [25].
The above observation motivates our work in predicting the public bicycle traffic flow by adopting XGBoost. Other than predicting the bikes, docks, check-in, check-out numbers [28] or passenger flow mentioned in the previous studies. In this paper, we predict the traffic flow variation numbers in a future period. One of the reasons we choose this value as target is that most of the public bicycle systems just store the renting and returning data of the passengers instead of the real-time bike or dock numbers. What’s more, the variation number of bicycles can reflect the number changes at each station immediately. When we recommend the stations to passengers, the dynamically variation values in a future time period can be easily predicted and we can determine whether or not the dynamic changes exceed the threshold we have set before. Combine with the distance between users and stations, we can recommend the best station for the users to help them rent or return bikes successfully. We will verify the proposed model through the datasets of Hangzhou and New York City.
Hangzhou is the first city to set up public bicycle system and it has covered nearly 3 thousand stations, a total of about 60 thousand bicycles. The system produces around 10 millions of record data in a month time. It has already become the largest public bike system in the world. People who are over the age of 16 and under 70 are eligible to rent a bike. We will select the Hangzhou datasets as representative for analysis.
The major contributions of this paper can be concluded as follows:
We design a stacking model for variation prediction of public bicycle traffic flow called SMVP. The stacking model integrates multiple base models which we trained by XGBoost [25] based on different combinations of features. A new clustering factor which considers the geographical positions and transition patterns are analyzed as a feature in proposed model. We construct a new different station relation matrix which considers the two factors as the distance between different stations and use the K-Medoids [12] algorithm to cluster stations into groups. The proposed model is verified through datasets including 40 million real-world records of two cities, in which 90% of the datasets are used for training and the rest 10% are used for validation.
The remaining part of the paper is organized as follow. We firstly discuss the related work in Section 2. In Section 3, the variation of traffic flow prediction problem is formulated. In Section 4, we analyze several factors that impact the bike traffic, especially the new clustering factor we proposed and then we introduce the K-Medoids algorithm and construct a station relation matrix. We construct the features based on the analysis and clustering results, introduce XGBoost to train models and design a stacking model for variation prediction (SMVP) in Section 5. The clustering and prediction results are evaluated in Section 6. Finally, we conclude the paper in Section 7.
In recent years, public bicycle has received increasing attention. Because it is significant for promoting environmental travel and enhance the last mile connection to other transit. DeMaio [19] gave an introduction of bicycle-sharing systems in history, impacts, models and future. Etienne et al. [4] studied the statistical model of public bicycle travel based on Velib public bicycle system in French Paris. Midgley [21] analyzed the state-of-the-art and the experience of the public bicycle system in several European public bicycle stations. These are the early studies of public bicycles and give us the concept and working mechanisms of public bicycle systems. Because the usages of public bikes are quite skewed and imbalanced. Pavone et al. [14] developed methods for maximizing the throughput of a mobility-on-demand urban transportation system and introduced a rebalancing policy that minimizes the number of vehicles performing rebalancing trips and this gives vital inspiration to solve the public bicycle load balance problem.
To study the behavior pattern of the public bicycle system can help us to understand the mobility of the public bicycle traffic flow. Froehlich et al. [7] provided a spatiotemporal analysis of 13 weeks of bicycle station usage from Barcelona’s shared bicycling system. Kaltenbrunner et al. [1] provided an analysis of human mobility data in an urban area using the amount of available bikes in the stations of the community bicycle program Bicing in Barcelona. Vogel et al. [23] adopted clustering and validation to analyze the bike usage pattern in Vienna. These studies help us to understand the mobility of public bicycle traffic flow and get the idea of station clustering based on the geographical positions and transition patterns. The reallocation of bikes is very important to compensate the unbalanced bike usage. Contardo et al. [3] and Benchimol et al. [13] presented mathematical formulations to route vehicles to transit the bikes, considering external features, such as the capacity of a vehicle, how unbalanced the distribution of bikes is, etc. Monitoring the current number of docks or bikes at each station is too late to reallocation the bikes after the imbalance has occurred. So the prediction can help to detect the potential imbalance in advance.
There are many studies focus on public bicycle traffic prediction. Borgnat et al. [18] used the dataset of Velov bicycle system to predict the entire traffic in each hour of the day by a combination model. Vogel et al. [23, 22] used the time series analysis to forcast the bike demand in Vienna and Yoon et al. [9] used a modified ARIMA model to predict the available bikes or docks at each station by considering the temporal and spatial factors. We learned the traditional impact influence from this studies. Zheng et al. [28] predicted the traffic flow about chek-in and check-out of the areas on the New York and Washington public bicycle systems from the macro point of view and contribute a clustering algorithm by using K-Means and transition matrix. Zhang et al. [10] used the GBRT and Lasso regression to predict the user behavior and travel time of Chicago public bicycle-sharing system, it was about the microscopic point of view. These studies are focus on predicting the bikes, docks, check-in, check-out numbers or passenger flow. Indeed, there are close internal relationship between these values and the variation traffic flow values which we will predict. Therefore, they provided us the ideas to find the impact factors of public bicycle traffic flow, construct features and train models by machine learning algorithms such as gradient tree boosting.
The researches focus on the gradient boosting methods and ensemble learning methods are also increasing in recent years. The gradient boosting system XGBoost which we adopted in this paper was widely used in many prediction problems recently. Zhang et al. [17] proposed an approach for forecasting passenger boarding choices and public transit passenger flow by using XGBoost. The prediction model was based on mining common user behaviors for semantic trajectories and enriching features using knowledge from geographic and weather data. Wistuba et al. [15] adopted XGBoost to predict the bank card usage for the ECML-PKDD 2016 Discovery Challenge on Bank Card Usage task and achieved better performance on the leaderboard. Horituchi et al. [27] proposed predictive models training by XGBoost and using flight information. The results showed that this regression model predicts the amount of fuel consumption more accurately than flight dispatchers. The stacking methods was first proposed by Wolpert [5] in 1992. Following Wolpert’s stacking methods, Deng et al. [11] constructed many simplified neural network modules further stacked to build a Deep Stacking Network (DSN). Xia et al. [24] obtained the best results in sentiment classification using stacking methods in comparison with other ensemble methods. Li et al. [26] used stacking models with different views of features called Multi-View Stacking Ensemble (MVSE) based on gradient boosting tree to recommend the items for mobile users and they win the first prize of Ali Mobile Recommendation Algorithm Competition in 2015. The implement of stacking models with gradient boosting in other industries had got better performance. Therefore, these studies gave us the idea to adopt XGBoost and train stacking models to get better prediction performance in the field of public bicycle system.
Problem formulation
In this section, we will introduce the formulation of the variation of traffic flow prediction problem of public bicycles. The variation of traffic flow prediction problem aims at inferring the variation number of bikes people rent or return at a certain station in a future period of time and they are continuous values. The positive value means the number of people return bikes is higer than renting bikes while the negative value is the opposite. We regard this problem as a regression problem.
The variation of traffic flow prediction can be expressed as, for the sample
We use the most of the samples in the datasets as training set
Average variation of traffic flow under different weather conditions.
To predict the variation of traffic flow in each public bicycle station, we need to identify the factors that have important impacts on the public bicycle traffic. In this section, we will first analyze the relationship between traditional factors such as meteorological, temporal, historical and spatial factors. Then we will study the geographical positions and transition patterns between different stations and consider a new clustering factor which concludes these two factors. Finally, we propose a new clustering method that can divide the stations into groups in order to represent different stations types. The station clustering considers the geographical positions and transition patterns. It is designed to discover the underlying pattern of the traffic variation in a cluster. The clustering factor is deriving from the existing factors such as the longitude, latitude and the transition patterns of the user’s historical datasets. In Section 5.1, These impact factors will be constructed as features in the following section.
We use over 20 million historical renting and return records of passengers dataset of Hangzhou public bicycle system, which ranges from April 8th to June 22th in 2016. The meteorological dataset of Hangzhou City corresponding to that time periods from China Meteorological Administration website [29] were collected as well. The detail description of the two datasets will be introduced in Section 6.
Traditional factors
Meteorological factors
Meteorological factors are important factors affecting public traffic, public bicycle is no exception [28]. Therefore, analyzing the impact of different meteorological factors on the variation of traffic flow of public bicycle is necessary. Firstly, we sum the variation of traffic flow of all the records on each day and then take the average of the total numbers grouped by different kinds of weather condition, wind direction, Beaufort wind force scale and temperature and draw them on 4 figures. Then we will analyze the relationships between the variation of traffic flow and different kinds of meteorological factors.
Average variation of traffic flow under different wind directions.
Average variation of traffic flow under different wind force scale.
Figure 1 shows the relationship between weather condition and the variation of traffic flow. We can see that the values are lower in sunny, cloudy and overcast weather conditions, which means that people rent more bikes at most of the stations. However, when the day is raining(include shower, light rain, moderate rain and heavy rain), the variation values are higher while the bike renting amount is less than the other weather condition. In Fig. 2, the variation values are slightly different, but there are no significant relationship between the wind direction and the variation of traffic flow. So the wind direction factor will not be considered being used for the prediction. Compared to the wind direction, as we can see in Fig. 3, the impact of Beaufort wind force scale is greater. In Hangzhou, the Beaufort wind force scale is usually in 3–5 (12–38 km/h). Most of people would like to rent bikes when the Beaufort wind force scale ranges from 3 to 4 (12–28 km/h). When the speed reaches to 5 (29–38 km/h), the bike renting amount decrease significantly. Therefore, Beaufort wind force scale is an important factor. In Fig. 4, with the change of temperature (the unit is Celsius (
Relationship between average temperature and the variation of traffic flow.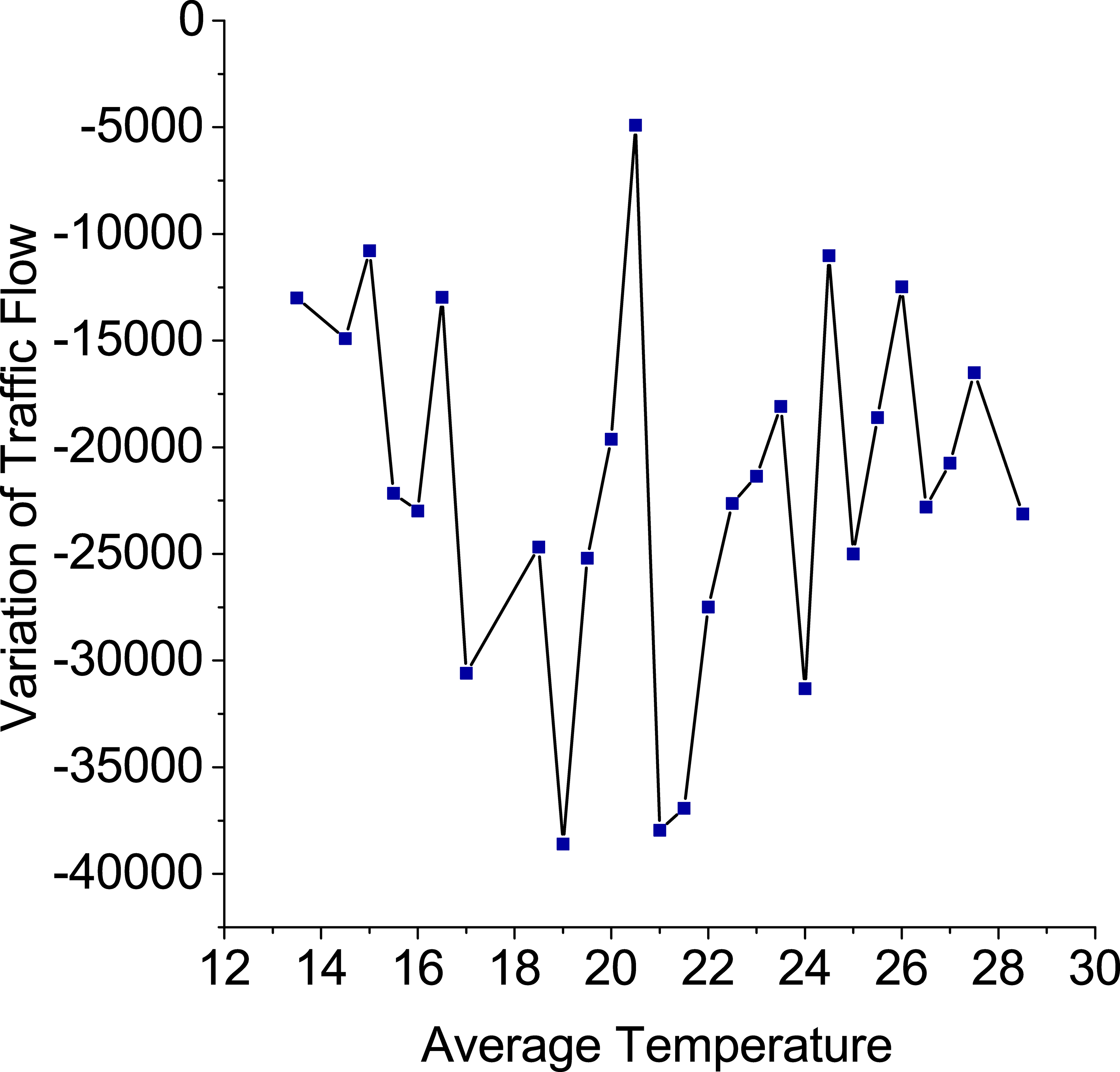
In addition, we can obviously see that the average variation always seems to be negative over the considered period (a day from 6 a.m. to 22 p.m.), which appears to indicate that more bikes are rented than returned every day. This is because that there are many staff of public bicycle company help to maintain some stations which passengers always return the bike to these stations (such as stations near the West Lake). So, these bikes are returned by the staff instead of normal ways and these behaviors are not recorded by the system. There are nearly 300 thousands of passengers using bikes and 30 to 40 thousands of these kinds of abnormal records each day. This also reflects the serious imbalance in different stations.
The temporal factor plays an important role in our problem. In order to view data from the overall focus on the daily usage of the public bicycle, we count the total volume of the number of passengers and the variation of traffic flow of all the public bicycle stations every day. The total volume of the number of passengers means that we calculated the total volume of passengers renting or returning bikes at all the stations each day. First of all, as is shown in Fig. 5a and b, the distribution of passengers and variation of traffic flow in general are relatively stable. There are certain periodic regularity that less people rent public bikes on weekends, holidays and more people rent bikes in working days. Secondly, compared with Fig. 5a and b, we can see that the variation of traffic flow decrease when the number of passengers increase. These two values are in opposite trend. We can also infer that the number of bicycles that rent by passengers are larger than return because most of the values are negative. Because some passengers did not return the bikes on the same day and return later. Finally, it should be noted that there is an abnormal data on May 23, the total number of passengers on that day is just 6 because of the exception taken by the public bicycle system. By the above analysis, we can see that the month and day are important factors which can reflect the variation of traffic flow.
Statistics of the number of passenger and the relative variation of traffic flow of bicycles on each day. (a): The number of passengers; (b): The variation of traffic flow of bicycles.
Periodic analysis. (a): variation of traffic flow on each day in a week; (b): variation of traffic flow on each hour in a day.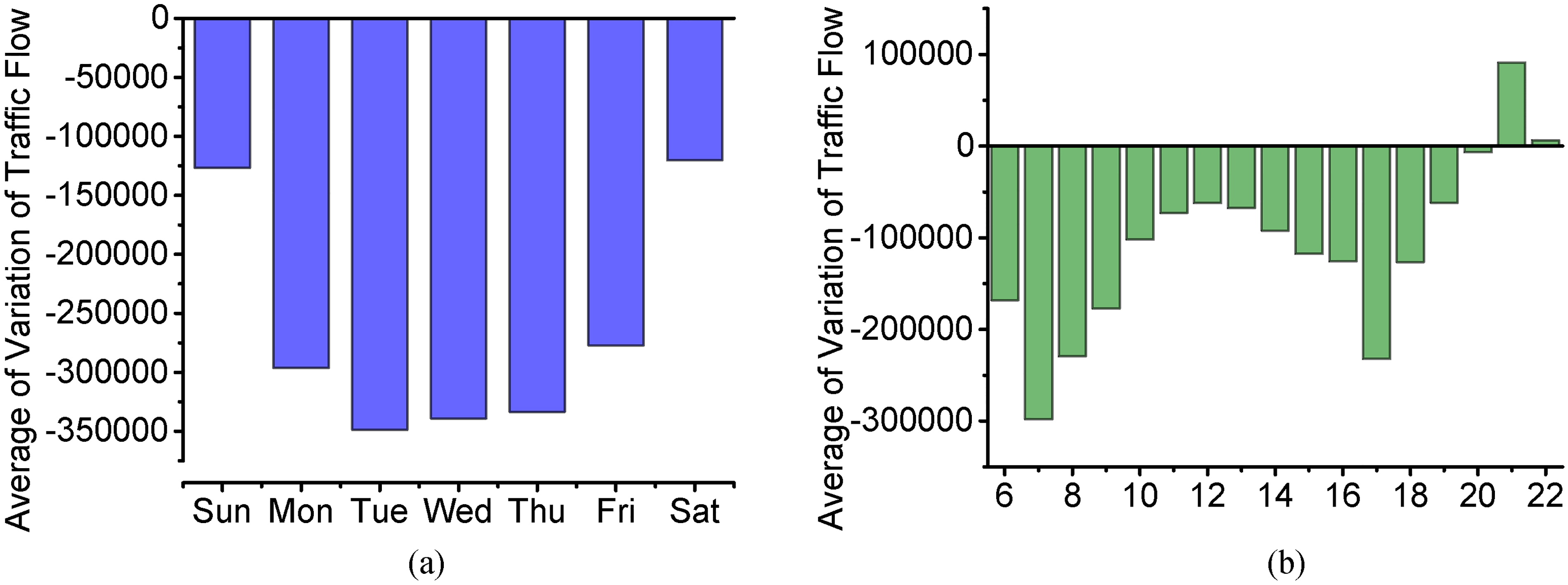
In Fig. 12a, we calculate the sum of variation of traffic flow on each day in a week, which can be analyzed, the renting amount is higher from Monday to Friday and lower on the weekends. In combination with the Fig. 5b, we can see that there is a regular pattern of periodic variation in each week. In Fig. 12b, we calculate the sum of the variation of traffic flow on each hour in a day. It is clear to see that in the early peak (about 7 a.m.) and evening peak (about 17 p.m.), there are more people rent bikes. At noon (about 12 a.m.) and night (about 20 p.m.), less people rent bikes. It is worth noting that lots of people return bike at about 22 p.m. Because people must promptly return the bike on that day, otherwise it will cost more fee. Therefore, it can be found that the week, hour and minute are important factors which can reflect the variation of traffic flow. In Fig. 7, we calculate the average variation of traffic flow grouped by holiday, workday and weekend. It can be seen that compared with the weekend, there are more passenger rent bicycles on holiday. But compared to workday, the number of renting bicycles is smaller. It can be learned that the holiday is also one of the factors affecting public bicycle traffic and the workday also influent the traffic. It is not completely consistent with the workday from Monday to Friday because of the leave reason. Citizens may need to work on the weekend or leave on workday. So if people actually on work is also an important factor.
Variation of traffic flow in different kind of days.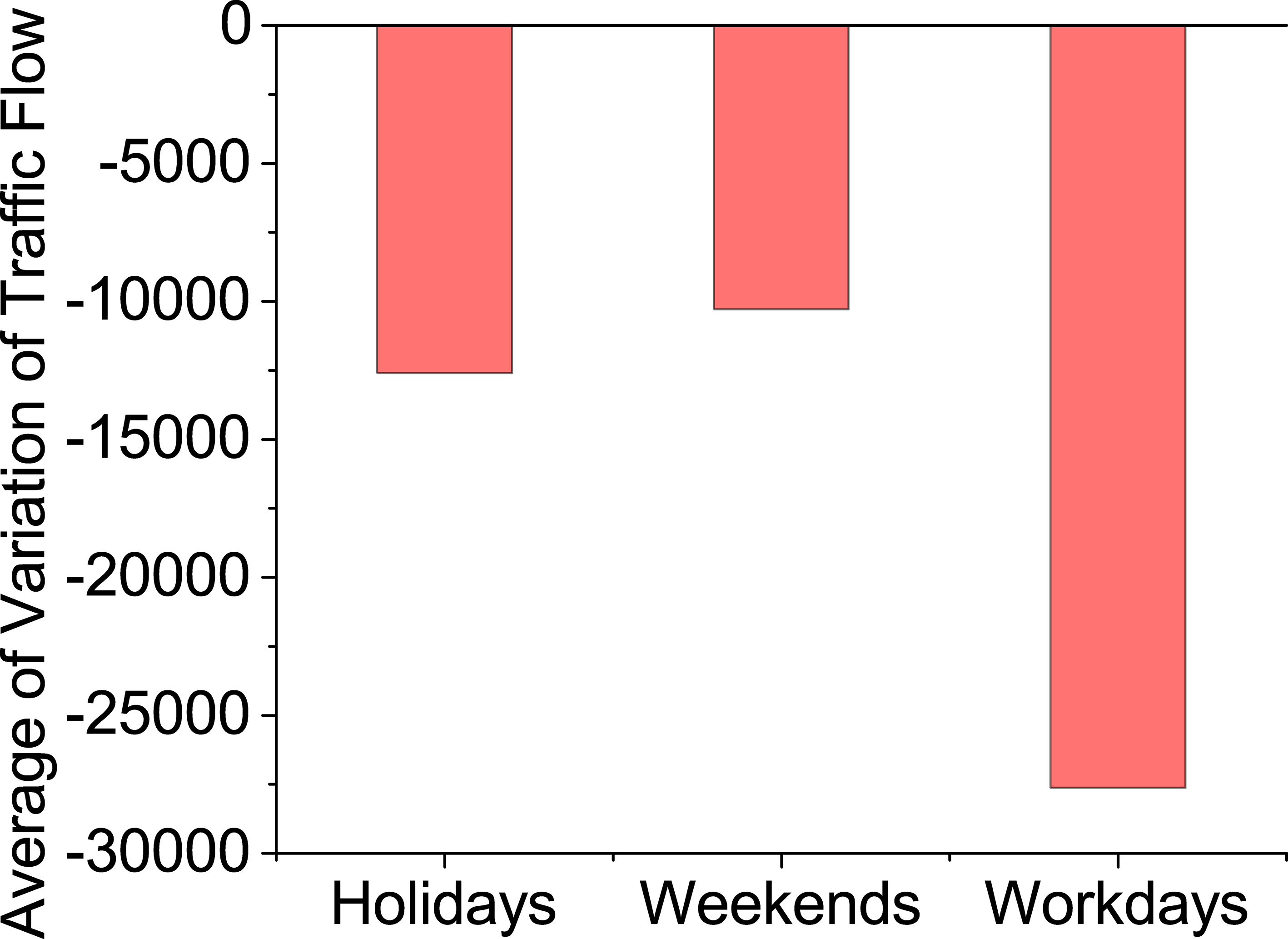
Variation of traffic flow in different historical days.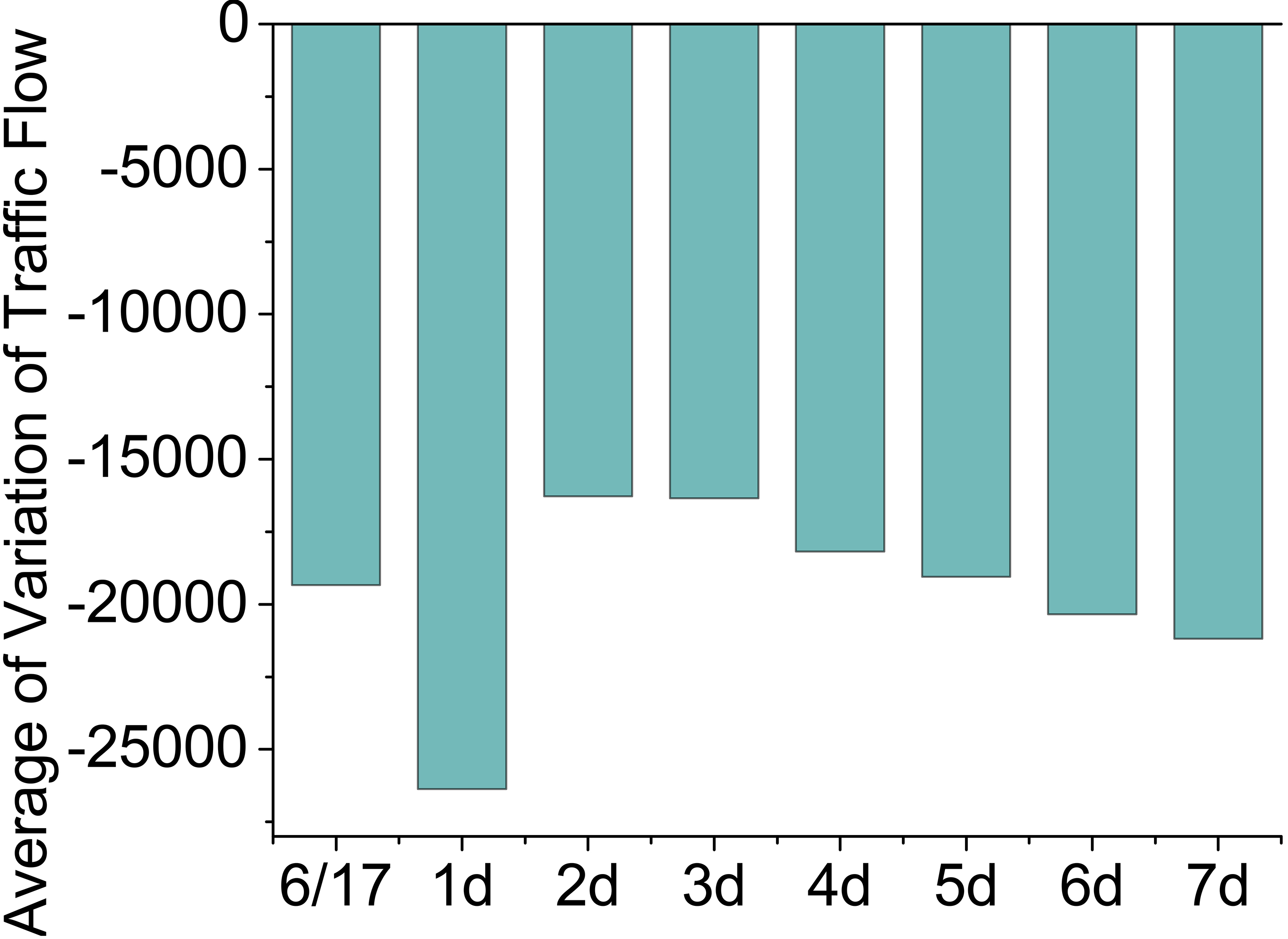
The historical data is also helpful to the public bicycle traffic prediction [28]. In Fig. 8, we chose June 17 as an example and calculate the average variation of traffic flow from several days ago before that day. It can be seen that compared with the June 17, when the day is earlier than this day, the average values are nearly approached to the value of this day. Because we take the mean values of several days, it will be more stable and regular. It’s the same to the several weeks or several months ago. To a certain extent, the historical values reflect the average numbers of several days ago at each station. It can help to estimate the future prediction values. So the historical values are verified through our dataset as an important factors.
Spatial factors
In order to see the spatial distribution of Hangzhou public bicycle on the whole, we plotted each station on the map by the location in Fig. 9, we can clearly see that most of the stations are in urban traffic intensive areas, there are some stations located in the scenic areas such as West Lake, Lingyin Temple and the nearby and some stations distributed near the suburban location. So we choose the station ID as a factor that can distinguish different stations. The latitude and longitude values also reflect the spatial characteristics of the stations, and they will also be used in the following new clustering factor we proposed in this paper.
The spatial distribution of Hangzhou public bicycle stations.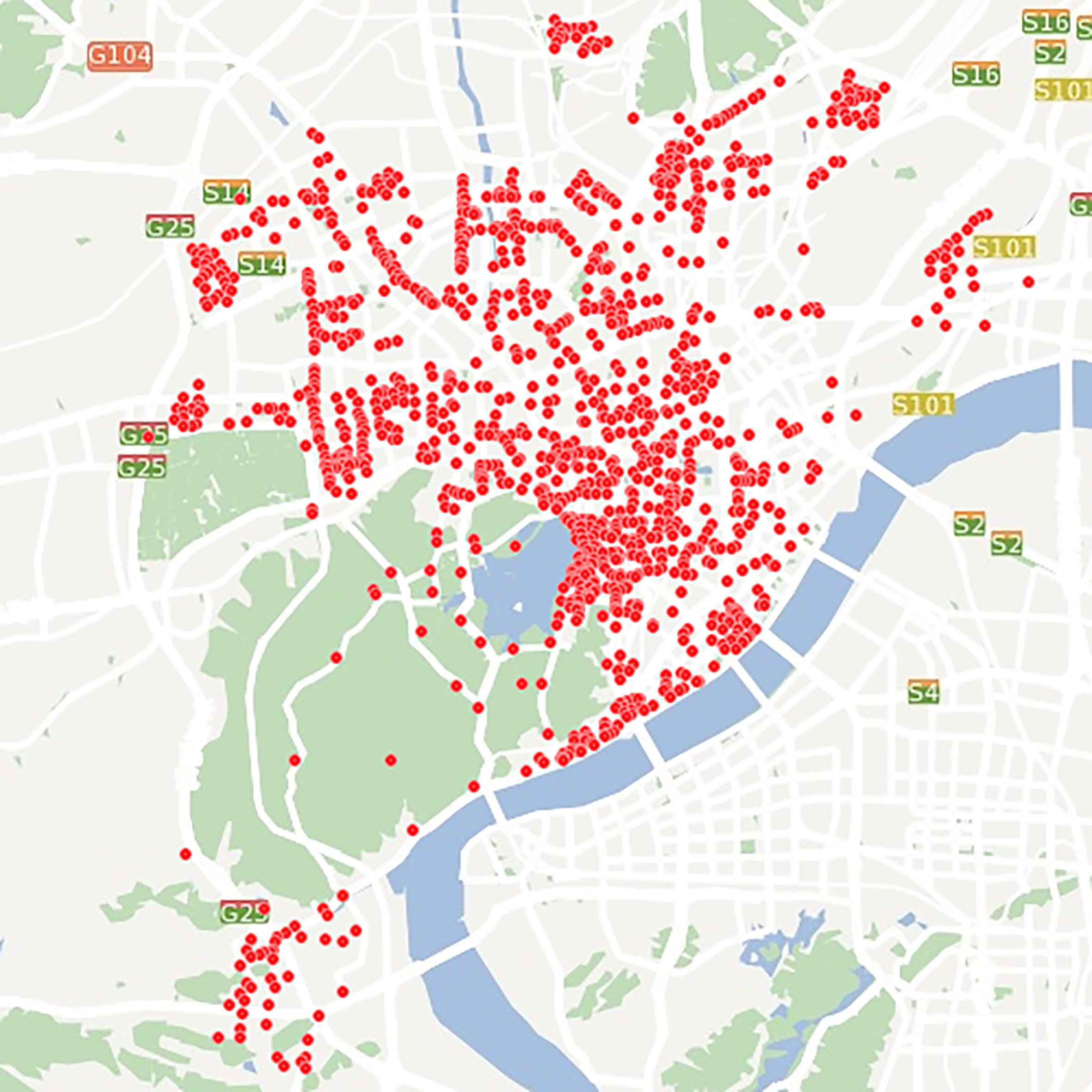
The traditional spatial factors just consider the geographical positions of the stations, in this section, we will introduce a new clustering factor that considers both the geographical positions and the transition patterns between the stations. We will analyze the relationship between different stations and use the K-Medoids algorithm to cluster stations into groups by constructing a station relation matrix which considers these two factors as the distance between different stations.
Relationship between stations
There are different regularities in different stations, but stations at the same area may have similar regularities, such as the stations at shopping district, community, attractions area, etc. So we consider clustering the stations into different groups. We need to discuss the relationship between stations firstly. There are two kinds of relation between the stations. One is the geographical position and another is the transition pattern between the stations. If users rent a bike at station A and then return the bike at station B, there will be a transition pattern between stations A and B. In order to find the spatial distribution of relationship between the nearby stations, we draw the station number 1001 and the other stations that are close to it by transition patterns on the map. Station 1001 is the famous spots in West Lake scenic. As we can see in Fig. 10, the stations that have geographical relationship with the station 1001 means that they are close to it on distance and they are marked by blue points. The transition pattern means that the stations that are related with station 1001 by the renting and return behaviors of passengers and they are marked by purple points. The brown points marked in the Fig. 10 are the stations that both have geographical relationship and transition pattern with station 1001. From the points of the map, we can see that the stations close to station 1001 are all belong to the West Lake area. So we consider clustering these stations together by the two aspects and discovering the underlying pattern of the traffic variation in a cluster by the machine learning model. This factor will be transformed as a feature and validated in the experiment section.
The nearest stations linear station 1001.
In the above section, we have studied the traditional spatial distribution and the relationship between different public bike stations. The station clustering considers the geographical positions and transition patterns. It is designed to discover the underlying pattern of the traffic variation in a cluster. The K-Medoids algorithm is a clustering algorithm related to the Kmeans algorithm [6] and the medoid shift algorithm [2]. K-Means and K-Medoids both set points into several classes, trying to reduce the distance between classes. However, compared with the K-Means, K-Medoids choose the data point as the clustering center instead of the mean point. In each iteration, the algorithm calculates the distance between the different points to the cluster data point.
The most common way of K-Medoids is Partitioning Around Medoids (PAM) Algorithm [16]. It uses a greedy search method to find the optimal result, but it’s much faster than exhaustive search method. The execution procedure of PAM Algorithm used to cluster the station is as follows. The cost means the sum of distances of stations to their medoid.
Station Clustering by PAM Algorithm
Station relation matrix
When calculate the medoid stations
Where
In order to calculate the transition patterns between two stations, we need to calculate
Each element
Where
The aim of this paper is to predict the variation traffic flow of the public bicycle. So, we can see the clustering as a feature extraction method to improve the prediction accuracy. Maybe the other techniques could also be used to extract the features. More methods to extract the features can be studied in the future works.
We design the prediction model to predict the variation of traffic flow based on the previous analysis. First, we construct the feature vector by the important factors which we analyzed in Section 4. Then we adopt a new and scalable machine learning system called XGBoost to train the base and stacking models. Finally, we design a stacking model for variation prediction called SMVP based on feature combination by using several base models to improve the prediction accuracy.
Features construction
Based on the impact factors we have analyzed in Section 4, we transform them into features. These features are divided into five groups, meteorological features, temporal features, historical features, spatial features and clustering feature. We will introduce the construction details below.
Meteorological features
Based on the analysis of the influence of meteorological factors, there are more effects on weather, temperature and Beaufort wind force scale. The wind direction has little impact so we do not use this factor. We construct
According to the temporal factors, we construct features
Historical features
From the regularity between the day and its historical days, there are similar rules. So we construct the same period of time in past several days as features, such as
The spatial features
According to the analysis in Section 4, the rules between different stations is different. So we can construct the station ID as
The clustering features
After the analysis and clustering in Section 4, we cluster the stations into different groups by geographical relationship and the transition pattern. The stations in the same clusters have similar regularities. So we use the clustering result and one-hot encode the cluster each station belongs to as features
For the station
Gradient boosting model
Based on the features constructed above, the proposed model
Gradient Boosted Tree is a kind of ensemble learning method using multiple CART (Classification And Regression Tree). It can get more accurate results than the single regression tree [8]. XGBoost is a scalable gradient boosted tree machine learning system and the source code is provided on the Github. The performance of traditional GBM (Gradient Boosted Machine) is pretty good, but the speed is slower than XGBoost. It also supports sparse data and has the approximate algorithm to find the optimal partition using Weighted Quantile Sketch and parallel distributed training, greatly enhance the performance of the learning model and save more time [25].
Given the
Where
The variation prediction is a regression problem. So, we define the objective function as a square loss function like Eq. (8) shows.
After the training process, the XGBoost could get several best tree structures and the prediction results are ensembled by these trees on the training set. Then these tree structures ensemble as the prediction model
The stacking model (also called stacked generalization) is a kind of ensemble learning method [5], which is used to train the model and predict the result by using the prediction results of bases model as features. First, we can use several machine learning algorithms to train the original data, get multiple prediction models and then construct the results of multiple models as features to train an ensemble model. The prediction result of ensemble model is the final result. Usually, the performance of the stacking model is better than that of the single model. The previous studies such as Deng et al. [11] build a Deep Stacking Network (DSN) and get better performance. Li et al. [26] used stacking models with different views of features called Multi-View Stacking Ensemble (MVSE) based on gradient boosting tree to recommend the items for mobile users. Therefore, these studies gave us the idea to adopt XGBoost and train stacking models to get better prediction performance in the field of public bicycle system.
In the previous part, we constructed several different groups of features from different aspects. Each group of features reflects the traffic regularities of public bicycles from a certain point of view. But using one group of these features to train is one-sided and it’s easy to get weak base models so that the performance of stacking model may not be significantly improved. Therefore, in this paper, we design a stacking model for variation prediction based on feature combination called SMVP. We make the diversity between base models as large as possible. This can avoid training weak base models and get better prediction result after using stacking method. The method in detail is as follows.
First of all, we obtained the feature vector of each station
After that, we set the combination of the above features. Because the spatial and temporal features reflect the station property and time period. They’re too important for prediction so that these two feature subsets are essential in the training model. Then we combine the two feature subsets with the other feature subsets. After this, we put them into XGBoost to train a new stacking model and then use this ensemble model to predict the final results of the test set. The whole processes are as follows.
Among them,
The SMVP can not only avoid training weak base models and increase the diversity between different base models and improve the performance of ensemble learning, but also dig out the combination regularities from different combinations of features. This method can improve the generalization ability of the prediction model and enhance the accuracy. The structure of the whole process is as shown in Fig. 7.
Settings
Datasets
We conduct experiments on four datasets (bike renting data and meteorology data) from Hanzhou in China and New York City in U.S. The details of initial datasets are presented in Table 1.
The details of the initial datasets
The details of the initial datasets
Hangzhou (HZ) Data: We use near 20 million historical records and 1300 stations (part) in Hangzhou Public Bicycle System which range from 8th April to 22nd June, 2016. The dataset of user’s historical records includes the record ID, bike ID, card ID, check-in station, check-out station, check-in timestamp, check-out timestamp, check-in dock, check-out dock and etc. We also collect the meteorology data of Hangzhou City corresponding to that time span from China Meteorological Administration website, include weather condition, temperature, wind direction, Beaufort wind force scale and other information.
New York City (NYC) Data: We use the data of Citi Bike System [30] in New York City from 1st Janurary to 31st March, 2017. There are over 2 million historical records, near 10 times less than Hangzhou. The data contains: trip duration, start time, stop time, station ID, station name, station latitude, station longitude, bike ID, user type, birth year, gender and so on. And we use the meteorology data corresponding to that time.
The data preprocessing is carried out in the following way. Firstly, we find out the abnormal data in the historical dataset. For example, (1) there are some records that the return time is earlier than renting time; (2) some passengers rent a bike at a station and then return it into the same station in a short time; (3) there are lots of artificial reallocated data in some stations; (4) there contains missing values at some time period, such as 23th May in Hangzhou, due to the exception of the public bicycle system.
To solve these problems, we need to do some work on data cleaning. We cleaned the records which the return time is earlier than the renting time, passengers rent bikes and return bikes at the same station just in 3 minutes. We also delete the artificial reallocated data in some stations because we only study the variation of traffic flow generated by the passenger of the public bicycle. And we do not need to process the missing values because the XGBoost can treat the missing values when training models.
After data cleaning and features construction, we split each city datasets into two parts, the training set and test set. The Hangzhou datasets range from 8th April to 15th June (10 weeks) are used as training set and the test set ranges from 16th June to 22nd June (a week). The New York City datasets ranges from 9th January to 19th March (10 weeks) are used as training set and the test set rages from 20th March to 26th March (also a week).
In order to see the effect of the features we constructed, we train 4 models by XGBoost and choose
ST (Spatial & Temporal Features): We use only the spatial and the temporal features to train the models by XGBoost. It’s used to validate the impact of spatial and temporal features.
STH (Spatial & Temporal & Historical Features): We use the spatial, temporal features and the historical features to train the models by XGBoost. It’s used to validate the impact of historical features.
STHM (Spatial & Temporal & Historical & Meteorological Features): We use the spatial, temporal features, historical features and meteorological features to train the models by XGBoost. It’s used to validate the impact of meteorological features.
STHMC (All Features): We use all the features include the clustering feature to train the models by XGBoost. It’s used to validate the impact of clustering feature. This is the new feature we proposed in this paper.
Comparison baseline for models
The previous studies of public bicycle traffic flow prediction are focus on the number of bikes, docks, check-in, check-out or passenger flow. There are no efficient baseline for the variation prediction of public bicycle traffic flow. Therefore, we build several baselines to compare the performance of different methods on test set to validate the effort of SMVP:
HA (Historical Average): We use the historical average variation values which are one week before the target time period as the prediction results. We use the average variation values from May 19th to June 15th as the prediction results of the test set.
SM (Single Models): We use all the features include the new station clustering feature to train a single model by XGBoost. It’s used to be compared with the historical average values in order to validate the effort of the new single model trained by XGBoost which we adopted in this paper.
Process of Stacking Model for Variation Prediction (SMVP).
TSM (Traditional Stacking Model): We combine the prediction results of XGBoost single model (using all features) and original features as a new feature vector and then train a traditional stacking model. It will be compared with the single model and the SMVP we designed in this paper.
SVMP (Stacking Model for Variation Prediction): We train the SMVP designed in Section 5.3 by using several base models which trained by different kinds of features. It will be used to compare with the other methods to validate the performance.
We use the MAE (Mean Absolute Error), MSE (Mean Square Error), RMSE (Root Mean Square Error) and
Where,
Results of station clustering
In the clustering experiment, we use empirical parameters
The results (average) of different features on
-fold cross validation
The results (average) of different features on
Station clustering results. (a): Hangzhou; (b): New York City.
The effect of different features on 
The results of models based on different features are shown in Table 2 and Fig. 13. We also concentrate on the result of Hangzhou data and the New York City data are similar. We can clearly see the effects of different features. The traditional method which only used the spatial and the temporal features effects the maximum error. The MAE is 1.025, MSE is 2.614, RMSE is 1.699 and
The results of different models on the test set
The results of different models on the test set
The effect of different models on the test set. (a): MAE; (b): MSE; (c): RMSE; (d): 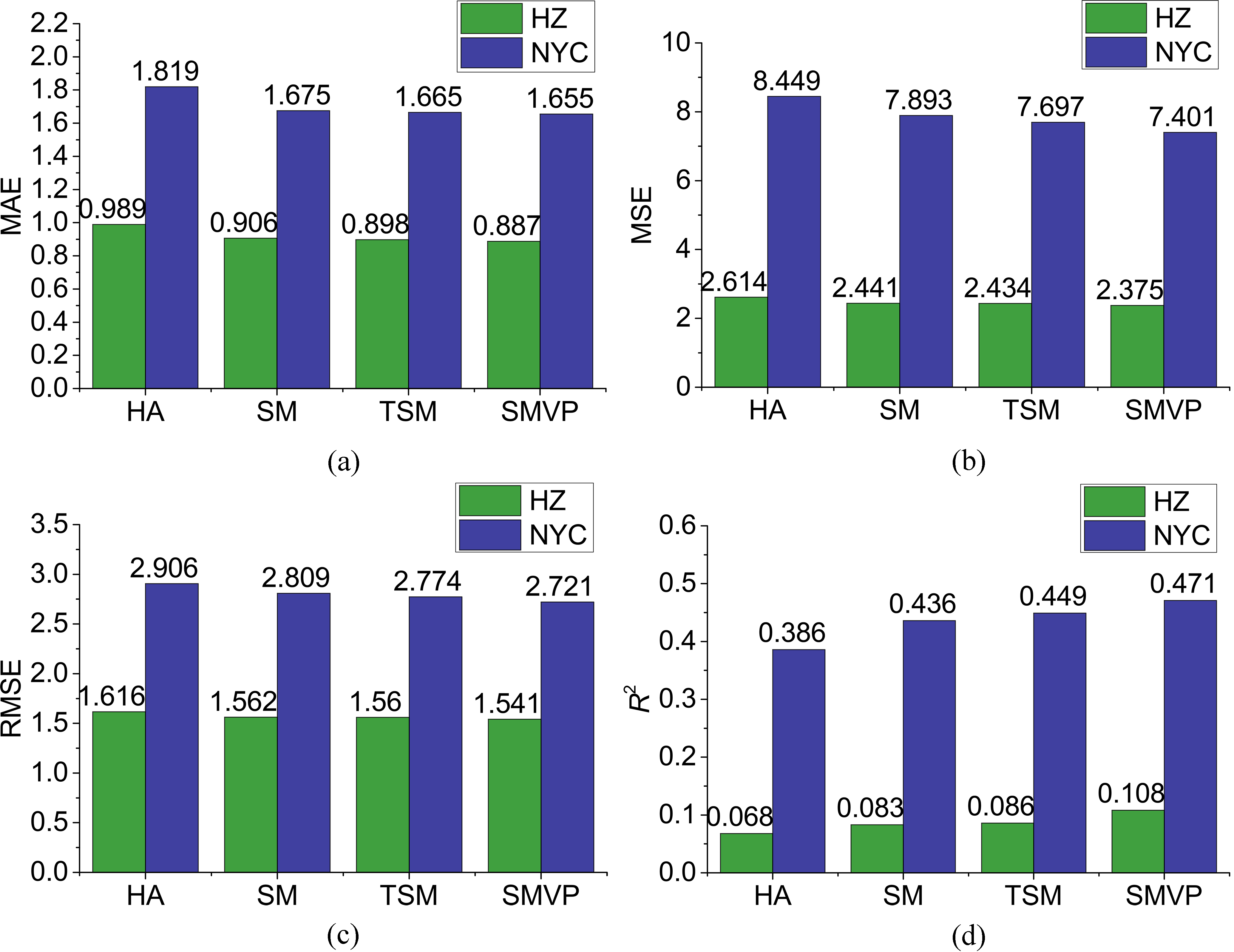
We compare the results of different methods and concentrate on the result of Hangzhou data as those of New York City data are similar. From the Table 3 and Fig. 14, we can see that the method of historical average effects the maximum error. The MAE of Hangzhou data is about 0.989, the MSE is about 2.614, the RMSE is about 1.616 and the
Conclusion
In this paper, we proposed a stacking model for variation prediction of public bicycle traffic flow at each station called SMVP based on the real-world datasets. We adopted XGBoost [25] to train the models and constructed the multiple complex factors which impact the public bicycle variation of traffic flow. Beside the traditional factors, such as temporal, spatial, historical and meteorological factors were taken into consideration, a new clustering factor which considered the geographical positions and transition patterns of stations was also proposed in this framework. Then we used the K-Medoids algorithm to cluster stations into groups by constructing a new different station relation matrix which considers these two factors as the distance between different stations. We evaluated our models on the datasets of Hangzhou and New York City public bicycle system, the performance of SMVP was improved, especially improved by 25.58% in Hangzhou, compared with the traditional stacking [5] and single model respectively in terms of
Footnotes
Acknowledgments
This work is partially supported by the grant from the National Natural Science Foundation of China (No. 61602141 and 61401135), Zhejiang Provincial Public Welfare Technology Application Research Project of China (No. 2015C33067) and the Xinmiao Talent Program of Zhejiang Province (No. 2016R407068).