
Abstract
The classification of customer-voice data is an important matter in real business since it is necessary for customer-voice data to be delivered to relevant departments and responsible individuals. Additionally, customer-voice data typically includes several novel words, such as typo’s, informal terms, or exceedingly general words to discriminate between categories of customer-voice data. Furthermore, noisy data often has a negative effect on the classification task. In this study, advanced novelty detection method is proposed to utilize class vector that possessed high cosine similarity with words to effectively discriminate between classes. The class vector is considered as the centroid or the mean of each word vector distribution as derived from the neural embedding model, and the novelty score of each word is calculated and novel words are effectively detected. Each novelty score is calculated by improvements of GMM and KMC methods utilizing a class vector. The experiments verify the propriety of the proposed method with qualitative observations, and the application of the proposed method with quantitative experiments verifies the representational effectiveness and classification performance of customer-voice data. The experiment results indicate that the performance of a classification of customer-voice data improved with the application of the newly proposed novelty detection method in this study.
Introduction
Customer-voice (Voice of the Customer, VOC) is a term that indicates a customer’s feelings regarding their experience with a business, product, and/or service. A customer-voice analysis provides important outputs and benefits for product developers. It provides a detailed understanding of a customer’s requirements and a common language for a team involved in the product development process. Additionally, it could be a key input to set appropriate design specifications for a new product or service and a highly useful springboard for product innovation [1, 2, 3].
As mentioned above, the customer-voice plays an important role in various fields and is used in various departments. Thus, it is important to categorize customer-voice data and deliver the same to relevant departments and responsible individuals. For instance, categorizing the customer-voice data of mobile device into system, user interface, design and appearance categories enables its delivery to proper departments as well as aids in the overall information of customer-voice data distribution based on function. Hence, it is necessary to classify customer-voice data based on functional categories prior to analyzing the same [4].
Then, the customer-voice data is gleaned across a variety of channels including phone, e-mail, and the web, and it is stored in a text document. The customer-voice data consists of extremely unstructured text since e-mail contents or phone call recordings are stored without any proofreading. Thus, it typically includes mistakes, such as typo’s and other informal terms including interjections and slang as shown in Table 1. With respect to the aspects related to the representation and classification of customer-voices, these words are considered as noisy data since they do not provide significant information on the meaning of a customer-voice. Furthermore, noisy data typically exerts a negative effect on the classification task, and even small amounts of noisy data can severely decrease overall performance [5].
Example of problematic customer-voice data
Example of problematic customer-voice data
Hence, the novelty detection method is considered as an effective solution to remove various noisy words. It is expected that the removal will further improve the representation and classification performance following the detection of words by novelty detection [5]. Furthermore, if it is possible to use novelty detection to detect less important words with extremely low discriminative power for a classification task as well as to detect noisy data, then it is also expected that the removal of these words improves the classification performance. For instance, words that are too general to represent specific classes, such as ‘this’ ‘have’ or ‘and’ could possess extremely low discriminative power with respect to the classification task. Table 2 shows examples of novel words included in real customer-voice data of mobile devices collected from LG Electronics. The examples list novelty words such as typo’s or words with low discriminative power. In this study, improvements of the previously discussed novelty detection method is proposed to effectively remove the fore-mentioned words.
Example of novelty words in customer-voice data
Novelty detection in a textual domain aims to detect novel documents, sentences, words or interesting topics. Several studies and applications apply the novelty detection method in the case of text data as described in Section 2. However, these studies mainly focus on the document or sentence level in which various features could be easily extracted and represented as a vector dimension. Additionally, novelty detection studies of word levels are mostly based on a dictionary or a corpus due to a lack of suitable methods to extract word features.
There are many other methods to detect novelty. However, distance/density based method and probabilistic method are typically used frequently. Distance/density based methods are based on the assumption that normal data are tightly clustered and that novel data occur far away from the other data points. Probabilistic approaches are based on estimating the generative probability density function of the data with the assumption that low density areas in the training set indicate areas with a low probability of containing normal objects [6].
However, the direct application of previous novelty detection methods in the vector space of words causes a misclassification problem. That is, with respect to the previous methods, the words that are unique and less frequent but meaningful for a specific class are classified as novelties since they could be situated at a distance from other words.
The use of the class vector could then decrease the risk that a word that is unique and less frequent but meaningful for a specific class is classified as a novelty. A class vector is trained from a similar neural network of simple neural embedding model. Words as well as the class label of each document are incorporated into the network [7]. Class vectors have high cosine similarity with words to discriminate between classes. Conversely, words with extremely low cosine similarity with each class vector would possess low or no discriminative power for a classification task. Therefore, novel words are effectively detected by assuming each class vector as a centroid or a means of a distribution of words generated from each class. Therefore, the proposed novelty detection method in the present study utilizes a class vector and the performance of representation, and classification is improved after removing words by using the proposed novelty detection method.
Therefore, in this study, two previously discussed novelty detection methods are modified, namely the ad Gaussian mixture model (GMM) that is a probabilistic novelty detection method and the K-means clustering (KMC) that is a distance/density based novelty detection method. Each class vector is assumed as a means of each latent distribution in the Gaussian mixture model and the centroids of each latent cluster in K-means Clustering. The proposed method is used to remove noisy words and this is followed by qualitatively comparing the results of the proposed novelty detection method and the previous method to verify the representational effectiveness and classification performance of customer-voice data with the application of both methods.
Novelty detection can be defined as the task of recognizing that data differ in some respects from the data that are considered as normal. Novelty detection methods are commonly classified into five categories, namely probabilistic approach, distance/density based approach, reconstruction based approach, domain based approach, and information theoretic techniques. The probabilistic approach and distance/density based approach are commonly used among the fore-mentioned approaches [6, 8]. Probabilistic approach uses probabilistic density estimation and assumes that low-density areas correspond to low probabilities of including normal data. The distance/density based approach assumes that normal data is tightly clustered and located close to each other in contrast to novel data. This study includes improvements of these novelty methods that combines a Gaussian mixture model that is a probabilistic approach with the k-means clustering based that is a distance/density based approach.
Novelty detection in the textual domain aims to detect novel documents, sentences, words, or interesting topics. There are many examples of novelty detection methods in the textual domain and these studies apply various methods including the statistical approach, mixture of models approach, neural networks based approach, support vector machine based approach, and clustering based approach in novelty detection [9, 10, 11, 12, 13, 14]. However, these studies focused on novelty detection of a document or sentence level. That is mainly because various features could be easily extracted from a document or sentence such as word frequency, frequent POS list, and average length [15, 16, 17]. Meanwhile, novelty detection studies of word levels are mostly based on a dictionary or a corpus only due to the lack of suitable methods to represent words in a vector space [18, 19].
Recently, the neural embedding model based on neural networks going beyond simple co-occurrence statistics was developed, and it could represent a word in a vector space. The neural embedding approach is based on the assumption that words occurring in a similar context tend to have similar meanings [20, 21]. Based on this assumption, the neural embedding model is trained with an optimization function
The main advantage of the neural embedding model is that words with similar meaning are located close to each other and preserve the semantic distance between words by considering a word’s semantic context. The words are represented in a continuous vector space, and thus various machine learning techniques including novelty detection could be applied with respect to the word level. For instance, Camach-Collados applied the novelty detection method in a vector space of words to present a framework for the intrinsic evaluation of a word vector representation [22]. However, the aim of the present study involves the evaluation of representational performance and not the detection of novelty words in a whole word distribution. Thus, to the best of the author’s knowledge, the present study is the first to propose a novelty detection method in a word vector space by using a class vector.
A class vector is trained from a neural network similar to simple neural embedding model. Sachan and Kumar suggested architecture to embed word vectors in conjunction with a class vector by incorporating both into a neural network [7]. In a manner similar to simple neural embedding model, the neural network model is trained with an optimization function
Example of words with high cosine similarity with each class vector
Example of words with high cosine similarity with each class vector
In this study, an alternative is proposed to previous novelty detection methods, such as Gaussian mixture model [24, 25, 26] and K-means clustering approach [27, 28, 29], to utilize a class vector as described in Section 3. The Gaussian mixture model is a parametric probability density function (PDF) represented as a weighted sum of Gaussian component densities. In a multivariate distribution,
and
The aim of K-means clustering includes partitioning the
where
As described above, customer-voice data involves extremely unstructured data containing mistakes such as typo’s or other informal terms. It also contains less important words to effectively represent each class. The examples shown in the Table 2 clearly specify the noisy words. The removal of these noisy words by novelty detection improves the representation and classification performance.
First, it is necessary to consider the application of the previously described novelty detection method in a vector space of words calculated by neural embedding model to detect the noisy words. A data set as shown in Fig. 1 is assumed to exist. Each circle refers to word vectors calculated by neural embedding model. Ideally, it is expected that purple circles and green circles are clustered into two main clusters, and a yellow circle is classified as a novelty. However, the application of the GMM novelty detection method on these data leads to the detection of both green and yellow circles as novelties since these words are located at a distance from other words as shown in Fig. 1. Additionally, red ‘+’ and blue ‘+’ indicate the means of each Gaussian distribution. This implies that words that are distant from other words due to their uniqueness and low frequency are classified as novel words based on the previously described novelty detection method although these words constitute meaningful words that explain specific classes or important words with respect to the classification task. Thus, the application of the previously stated novelty detection method without modification is not sufficient for the effective detection of novel words.
Results of previous novelty detection method.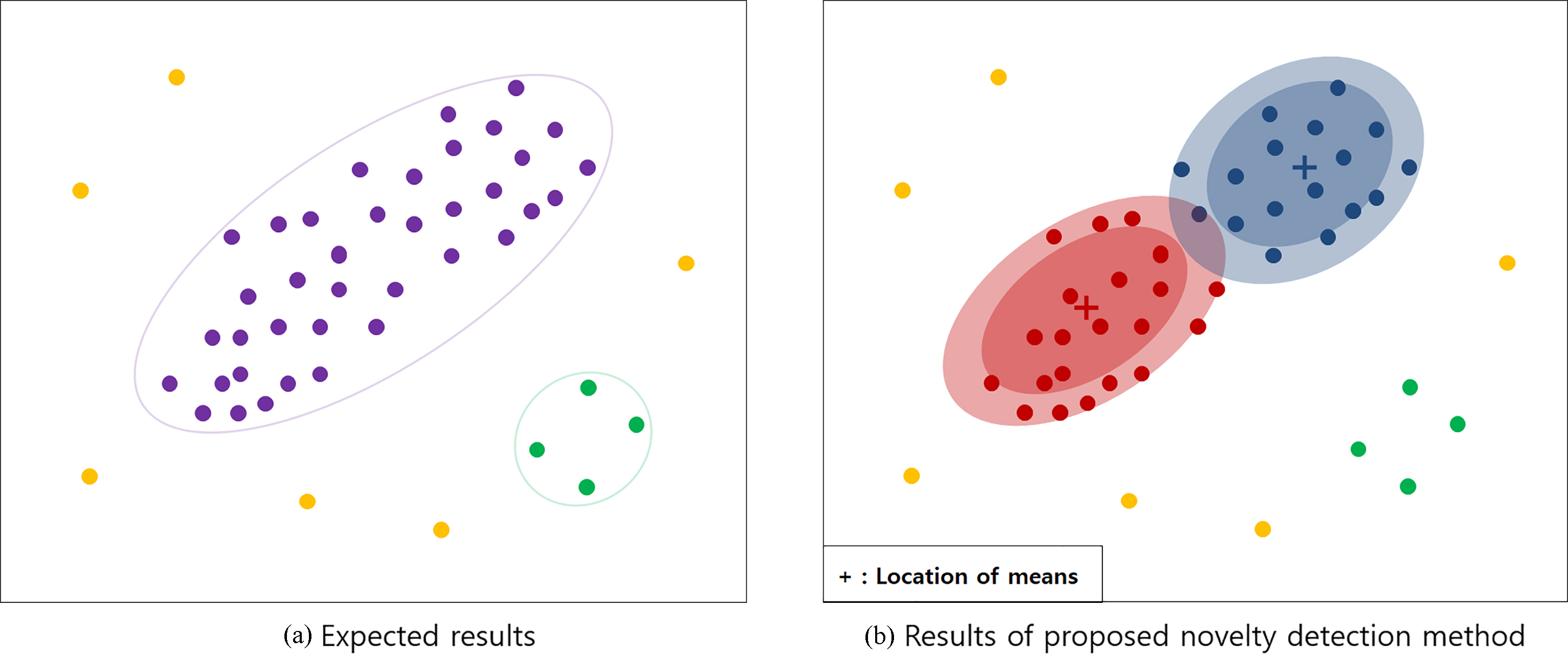
The utilization of the class vector addresses this limitation. As described in Section 2, class vectors have high cosine similarity with words that discriminate between classes. Hence, each class vector is assumed as a mean or centroid of each words distribution to consider words that are close to each class vector or have high PDF value as meaningful words to effectively explain each class. Meanwhile, words that are far from the class vector or possess a low PDF value are considered as noisy words, such as typo’s, or less important words to discriminate between classes. Figure 2 shows the advantage of the proposed novelty detection method that utilizes a class vector. In the proposed method, the class vector is located near the centroid of each word distribution that is composed of words that represent each class. Although a word distribution composed of a small number of green words exists, a class vector that is indicated by a green ‘+’ is located near the centroid of the word distribution. Therefore, the proposed method effectively classifies the meaningful words and novel words by utilizing a class vector. Thus, in this study, an alternative is proposed to previous novelty detection methods, such as Gaussian mixture model and K-means clustering approach which are most frequently used in novelty detection task, to utilize a class vector.
Advantage of proposed novelty detection method.
The details of the proposed novelty detection are presented below. Formally, let set of documents
Word vector
Calculate vector dimension of each words Calculate the novelty score with improvements of the Gaussian mixture model and the K-means clustering method utilizing a class vector.
Improvements of Gaussian mixture model: Apply improvements of GMM method considering each class vector as the means of each distribution. Each distribution is assumed as the distribution of words of each class. The improvements of the GMM method is also represented as a weighted sum of
where
Then, mean vector
Improvements of K-means clustering: The improvements of the KMC method considers each class vector as the centroids of each cluster. Each cluster is assumed as the cluster of words of each class. The improvements of the KMC method aims to minimize an objective function
where Finally, PDF value, weighted sum of
In step I, each word vector
This section describes the performance of the proposed novelty detection method with observations and experiments. Figure 3 shows the summary of the experiment flow. First, the results of the novelty detection of both methods are observed. That is, novel words detected by the proposed novelty detection method and the previous method are observed, and those results are compared with respect to the novelty of words. Second, each customer-voice data representation is constructed only with words that are not determined as a novelty by the proposed novelty detection method as well as the previous method. For example, if ‘tpye’ and ‘of’ are determined as novelties by the proposed method, then ‘I hate these tpye of device’ is represented as a document vector such as bag-of-words only with ‘I’, ‘hate’, ‘these’, ‘device’. This is followed by comparing the representational effectiveness and classification performance of customer-voice data representation constructed without novel words as detected by the proposed novelty detection method as well as the previous method.
Data description
In this study, in order to verify the representational effectiveness and classification performance of our proposed method and its applicability on customer-voice data, customer-voice data of mobile devices collected from Mobile Communication (MC) department in LG Electronics is used. The data was collected between April 23, 2014 and March 23, 2017. The customer-voice data were manually labeled by domain experts in LG Electronics into 12 classes. In order to avoid a class imbalance problem, a similar number of customer-voice were collected from each class as shown in the Table 4 below.
Customer-voice data set collected from LG Electronics
Customer-voice data set collected from LG Electronics
Summary of the experiment flow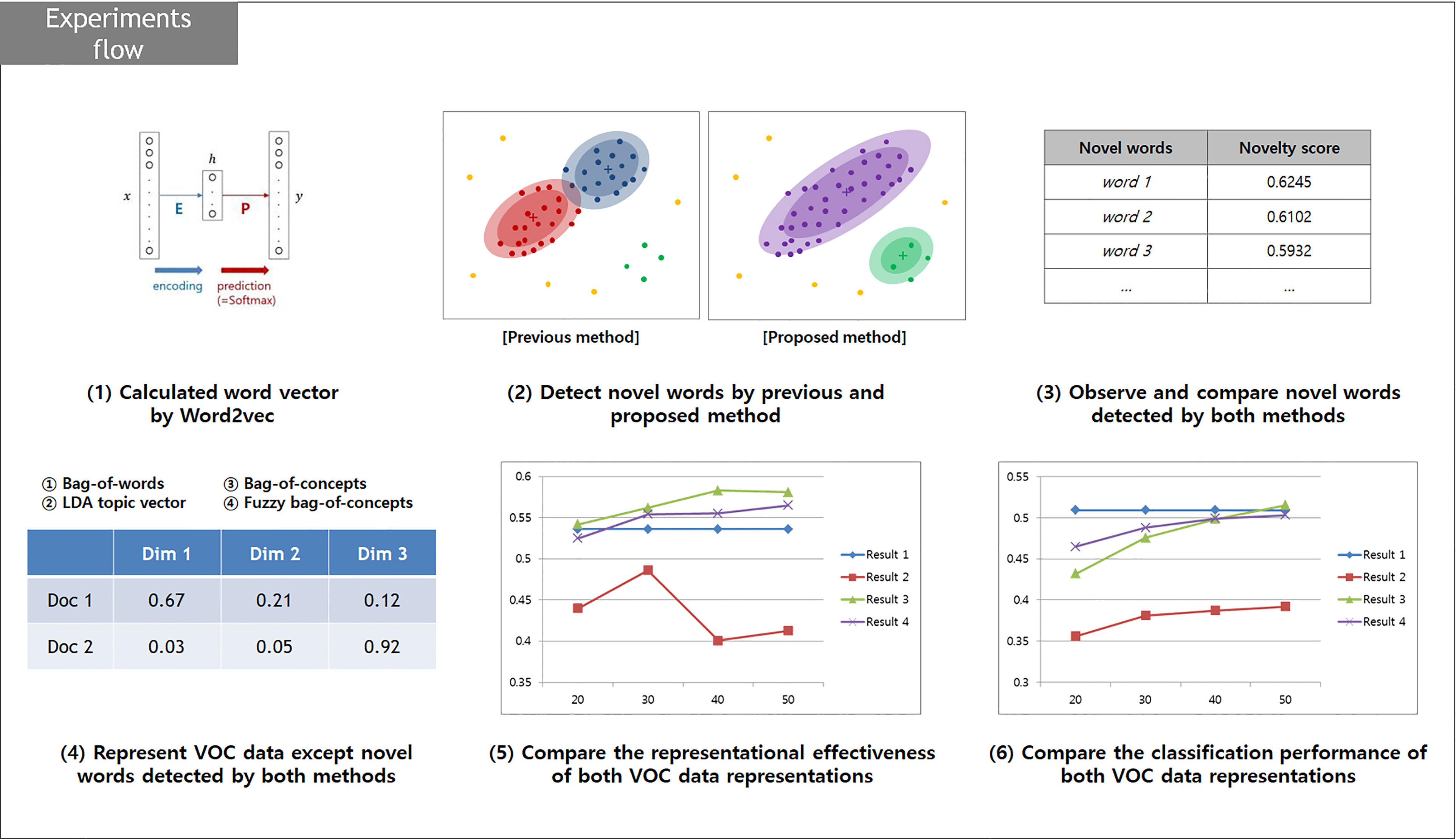
First, in order to calculate the word vector with neural embedding model, neural embedding model is designed with a window size of 8, and the number of hidden layers in training corresponds to 300. These parameter settings are also applied in the construction of various customer-voice data representations, such as neural embedding based word clustering [30] and probabilistic word clustering based approach [31], as described in following paragraph to minimize the impact of hyper-parameters in the overall experiments.
Second, de-nosing customer-voice data representation is constructed and is composed of only words that are not determined as a novelty to compare the representational effectiveness and the classification performance of the customer-voice data representations by applying the proposed method and the previous method. Each 1%, 2%, 3%, 4%, 5%, 6%, 8%, 10%, 12%, 15% or 20% of novel words detected by the proposed method and the previous method is removed preliminarily as a means of de-noising prior to constructing the customer-voice data representation. Then, the result of representational effectiveness and classification performance of each customer-voice data representation is compared by applying de-noising.
The customer-voice data representation methods include the Term Frequency-Inverse Document Frequency (TF-IDF), Latent Semantic Analysis (LSA), topic vector, neural embedding based word clustering approach, and probabilistic word clustering based approach. The TF-IDF is most common document representation method in which a document is fundamentally represented by the counts of word occurrences within the document [32, 33]. LSA is the technique applying singular value decomposition (SVD) in term-frequency matrix to reduce the number of rows while preserving the similarity structure among columns [34]. The topic vector is an inferred topic proportion that is typically used as a topic feature to represent the document [35]. Additionally, in the neural embedding based word clustering approach [30, 36] and probabilistic word clustering based approach [31], semantically similar terms are clustered into a common cluster by clustering word generated from neural embedding. Document vectors are subsequently represented by the frequencies of these clusters. The only difference between these methods is that the probabilistic word clustering based approach additionally considers the membership strength of words by utilizing a soft clustering method. In this experiment, the number of clusters is fixed at 150 for the neural embedding based word clustering approach and probabilistic word clustering based approach to minimize the impact of the number of clusters in the experiments.
Finally, the second experiment of representational effectiveness is similar to that performed by Dai et al. [37]. In these studies, triplets of documents were constructed in which two documents were selected from the same class, while the other document was selected from a different class. If the document calculated as most distant is distinctively different from a different class, then the classification result is considered as correct. The dataset of the present study contains 12 different classes, and thus 132 unique combinations of the triplets are constructed. Additionally, 1000 triplets are created for each combination, and thus, the experiment is performed on 132000 triplets. In the third experiment of document classification, the classification result is considered as correct if the document is predicted as its actual class by prediction model. A major voting ensemble model was used in several studies [38, 39] for classification task. The K-Nearest Neighbor classifier [40, 41, 42], Support Vector Machine [43, 44, 45], Logistic Regression [46], Gaussian Naive Bayes classifier [47, 48, 49] and Neural Network [50, 51] models are combined for the ensemble model.
Experimental results
Observation of novelty detection results
Words with lowest novelty score
Words with lowest novelty score
Table 5 shows words with the lowest novelty score as determined by the proposed method and the previous method. Novelty score of GMM method is calculated by minus of logarithm of the PDF value and that of KMC is calculated by distance from the closest centroid. In the proposed method, words with lowest novelty score constitute considerably discriminative words to represent each class such as ‘LCD’, ‘voice’, ‘security’ and ‘WiFi’. In the previous method, words with the lowest novelty score are general words to discriminate between classes such as ‘phone’, ‘again’ and ‘after’. Especially, in the previous KMC method, extremely general words, such as ‘my’, ‘of’ and ‘it’ are extracted. This implies that the novelty score of the proposed method is a proper measure when compared to the previous method to determine whether each word effectively represents each class.
Words with highest novelty score
Table 6 shows words with the highest novelty score determined by each method. Typo’s including ‘de’, ‘sus’ and ‘uu’ and meaningless words including ‘blah’, ‘last’ and ‘may’ are effectively detected in the proposed method and not detected in the previous method. From a qualitative viewpoint, these results indicated that the proposed method performed better in the detection of novel words. Additionally, it is intuitively expected that the representational effectiveness and classification performance will improve when those words are detected and removed by the proposed method.
Accuracy of representational effectiveness
Accuracy of representational effectiveness
Accuracy of representational effectiveness.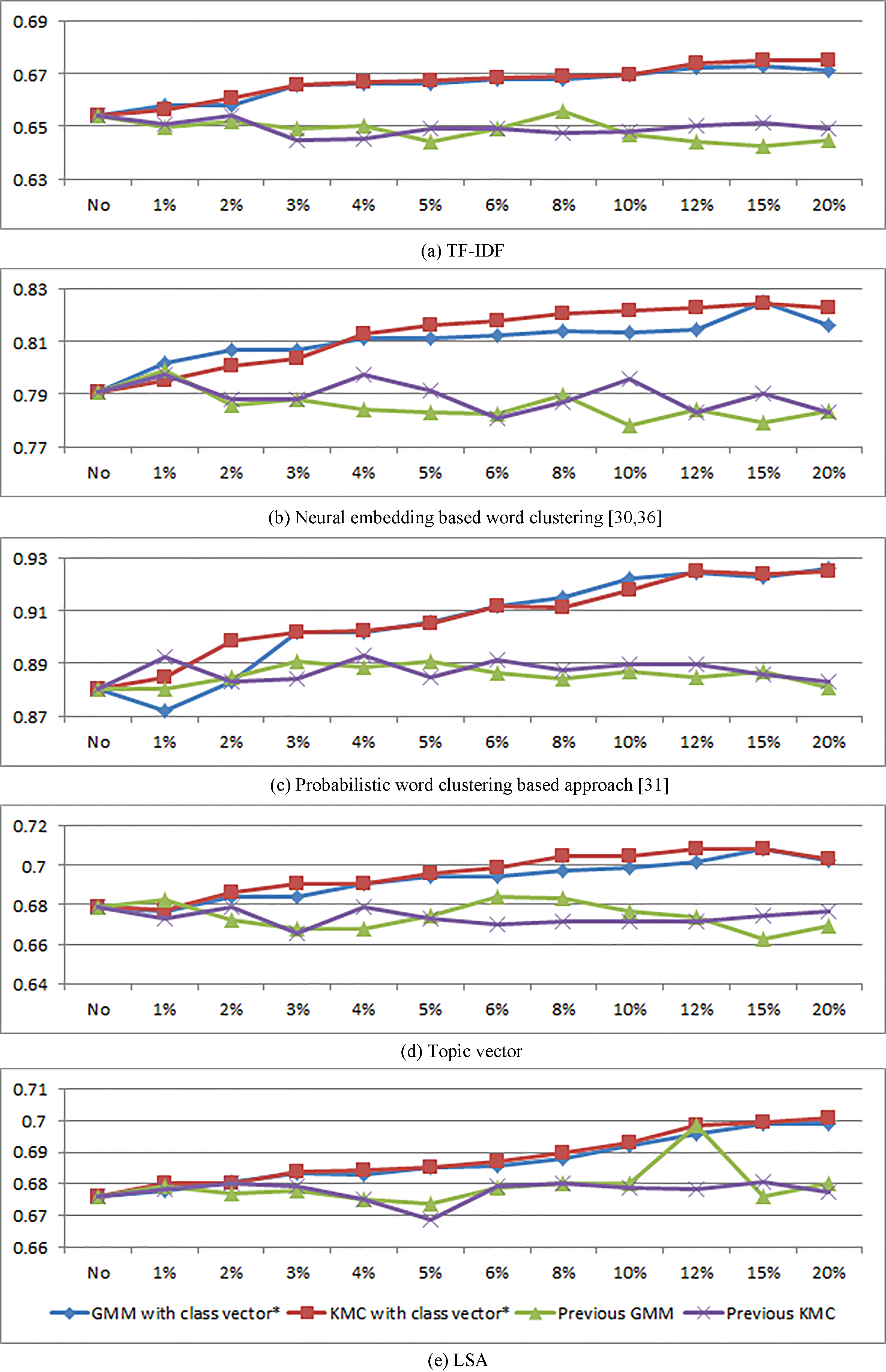
Accuracy of classification performance.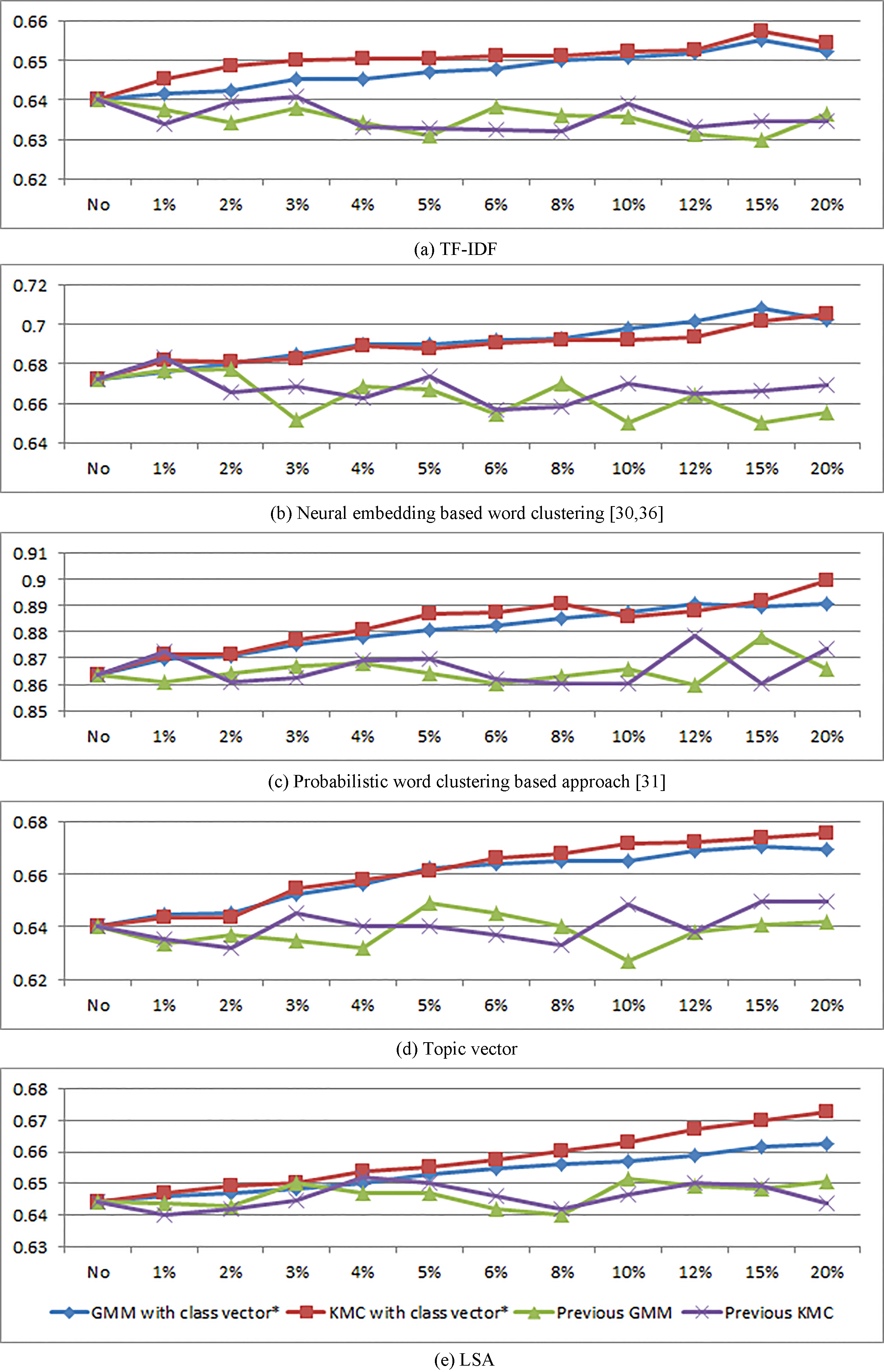
Table 7 and Fig. 4 show the results of the representational effectiveness of the customer-voice data by applying the proposed method and the previous method. As shown in Fig. 4, the results of representational effectiveness of the proposed method increase steadily when the removal ratio of novel words increases from zero to twenty irrespective of the document representation method. Furthermore, the results of representational effectiveness of the previous method increase and decrease irregularly with changes in the removal ratio and even decreases in specific document representation methods such as the neural embedding based word clustering approach. The results of the representational effectiveness of the proposed method outperform that of the previous method with respect to most of the removal ratios.
Accuracy of classification performance
Accuracy of classification performance
Table 8 and Fig. 5 show the results of the classification performance of customer-voice data by applying the proposed method and the previous method. In a manner similar to the results of representational effectiveness, the results of the classification performance of the proposed method improve steadily with increases in the removal ratio of novel words and outperform that of the previous method with respect to all representation methods. The reason for the better performance of the proposed method is attributed to the fact that it can detect novel words more effectively than previous method by utilizing a class vector.
In this study, advanced novelty detection method utilizing class vector is proposed to effectively detect and remove novel words such as typo’s or meaningless words. Noisy data has a negative effect on the classification task and even small numbers of noisy data can severely decrease the overall performance. Previously, a pre-processing method that removes parts of speech, such as prepositions or article, was applied for this purpose. However, this method is not sufficient for the removal of all the different types of noisy words such as typo’s and other informal words.
Recently, the development of the neural embedding model to represent words in vector space has opened up the possibility to apply various novelty detection methods in a word vector space. Therefore, previous novelty detection methods, such as a density based method or a probabilistic method, could constitute an another option to deal with these problems. Nevertheless, with respect to the previous method, the words that are unique and less frequent albeit meaningful for a specific class are classified as a novelty since it could be situated at a distance from other words.
Thus, an advanced method that utilizes a class vector is proposed in the present study. The class vector is trained from similar neural network of simple neural embedding model by embedding word vectors in conjunction with a class vector by incorporating both into the neural network. According to the previous study, class vectors possess high cosine similarity with words that discriminate between classes. Thus, the utilization of the class vector decreases the risk that unique and less frequent but meaningful words for a specific class are classified as a novelty.
The class vector is utilized in the proposed method that modifies the previous novelty detection methods, such as GMM and KMC based methods, to observe that the proposed method detects novel words more effectively than the previous method. In the actual experiments, representation effectiveness and classification performance of customer-voice representation by applying the proposed method outperformed those of the previous method. Additionally, results of the proposed method improved steadily with increases in the removal ratio of novel words irrespective of the document representation method. Therefore, it is concluded that the novelty score of the proposed method is a more proper measurement when compared with the previous method to determine whether a word effectively represents a class. Furthermore, it is concluded that the reason for the better performance of the proposed method is attributed to the fact that it can detect novel words more effectively when compared to the previous method by utilizing a class vector.
In this study, novel words are detected and preliminarily removed prior to document representation. Thus, the proposed method can be effectively applied in unordered document representation methods such as TF-IDF, neural embedding based word clustering based approach, LSA and probabilistic word clustering based approaches. However, it is difficult to apply the proposed method in ordered document representation methods such as convolutional neural networks based model [52, 53] or Recurrent neural networks based model [54] since intermittently missed words in sentences impairs the sequentiality of a sentence. Thus, future studies will involve the development of more comprehensive methods that can be effectively applied in ordered document representation methods. It is expected that future studies will aid in the wide application of the proposed novelty detection method utilizing a class vector in various text mining tasks arising in the context of a real business environment.
Footnotes
Acknowledgments
I would like to express my appreciation to LG Electronics who provided me the dataset of customer-voice used in experiments section in our study.