
Abstract
Many real-world situations constantly generate concept-drifting data streams at high speed. These situations demand adaptive algorithms able to learn online in accordance with the most recent target function (concept). This paper presents Online Adaptive Classifier Ensemble, a new ensemble algorithm able to learn from concept-drifting data streams. The proposed algorithm uses a change detection mechanism in each base classifier in order to handle possible changes in the underlying target function. Each base classifier in the ensemble can alternate between three different stages during the learning process: stable, warning and drift. In a stable stage, the underlying target function is supposed to remain constant, and the corresponding base classifier is updated with each incoming training instance. In a warning stage, a possible change in the target function can be starting to occur, and an alternative base classifier is created and trained together with the other base classifiers. The alternative classifier is added to the ensemble if the drift stage is reached. The new algorithm is compared with various state-of-the-art ensemble algorithms for online learning. Empirical studies show that this proposal is an effective alternative for learning from non-stationary data streams.
Introduction
Nowadays, very heterogeneous sources generate massive data continuously, without control of the arrival order and at high speed. Internet, cell-phones, cars, and security sensors are examples of such sources [22]. Because of the temporal dimension of the data and the dynamic aspect of many real-world situations, the target function to be learned can change over time. This situation, known as concept drift, complicates the task of estimating the target function, since a previously learned model can become outdated, or even contradictory regarding the most recent data. Learning from data streams is directly related to concept drift, because it is an inherent feature that usually appears when data arrive over time. Examples of real-world situations where these changes can emerge include changes in clothing fashion, news preferences and energy consumption [44, 22]. Spam filtering is another common example: spammers try to elude filters by changing the pattern of spam emails, requiring the continuous update of spam filters [25].
An effective method used to learn from non-stationary data streams is to ensemble classifiers. Ensembles combine learning models with the goal of improving the predictive accuracy obtained by single classifiers. To deal with concept drift, ensemble algorithms have adopted two main strategies in the learning process [21]. In the first strategy, the ensembles adapt their base classifiers at regular time intervals without considering whether a concept drift has occurred or not [40, 41, 12]. These algorithms store training instances in a buffer of a fixed size (time window) at each learning step to train the base classifiers [21]. The principal problem with this approach is the definition of an appropriate buffer size. For abrupt changes, smaller sizes can lead to a faster adaptation process, whilst larger sizes are more suitable for stable concepts. The second strategy, which is usually more effective, constantly monitors the ensemble consistency regarding new data [11, 43, 33, 35]. Significant variations in the predictive performance values can be interpreted as a concept drift. Basically, the ensemble algorithms eliminate, reactivate or add new base classifiers dynamically in response to these variations.
When a concept drift is detected, various state-of-the-art ensemble algorithms simply replace the base classifier with the current worst predictive performance by a new classifier [6, 5, 4]. Therefore, these ensemble algorithms handle concept drift only at the ensemble level, and not at the level of the ensemble’s base classifiers. The current worst classifier in the ensemble may not be the classifier whose predictive performance is affected by a current concept drift. Therefore, the strategy adopted by previous ensemble algorithms can lead to an ineffective adaptation to changes in the data distribution.
Handling concept drifts explicitly in the base classifiers can be more effective when learning from non-stationary data streams. In general, the adaptation mechanism of ensemble algorithms has received little attention in online learning. For example, previous approaches focused on the classifier’s diversity [33], recurrent concepts [35], adding randomization to training the base classifiers [5], or meta-learning [19].
This paper presents Online Adaptive Classifier Ensemble (OACE), a new ensemble-based algorithm that is able to handle concept drifting data in each base classifier. The OACE algorithm handles concept drift in each base classifier by alternating between three drift stages: in-control, warning, and out-of-control. These three stages are compatible with several method for concept drift detection in data streams [16, 3, 21, 2]. A base classifier is in an in-control stage when the current concept is stable, in a warning stage when a concept drift is likely to be starting to occur, and in an out-of-control stage when a concept drift is detected. At the in-control stage, only the corresponding base classifier is trained. At the warning stage, an alternative classifier is induced to replace the corresponding base classifier in response to a possible concept drift. If the warning stage is followed by the out-of-control stage, the alternative classifier replaces the corresponding base classifier and the new base classifier returns to the in-control stage.
The experiment results show that the proposed adaptation mechanism is more effective than the one adopted by previous ensemble algorithms. The experiments included various adaptive ensemble algorithms [6, 5, 4], online change detectors [16, 3, 21, 2], and ensemble algorithms without a change detection mechanism [8, 28, 41].
This paper is structured as follows. The next section defines data stream, concept drift, and presents common types of change in the distribution of the data arriving in the stream. Section 3reviews previous works on adaptive ensemble algorithms and their fundamental drawbacks. The proposed ensemble algorithm, OACE, is described in Section 4. In Section 5, OACE is compared with various state-of-the-art ensemble algorithms for data stream mining. Finally, Section 6 presents the main conclusions derived from this research.
Definitions
In online learning [42], a classification task is generally defined for a sequence (possibly infinite) of instances
It is commonly assumed that the data stream
Real concept drift refers to changes in the distribution of posterior probability of the classes
Virtual concept drift happens when the probability distribution of the instance space changes (
Various previous studies [39, 25, 4] identified two types of changes regarding the transition period between consecutive concepts: abrupt and gradual. An abrupt change occurs when the transition is instantaneous. A gradual change occurs when the transition period contains a certain number of training instances. Dealing with different types of concept drift and the trade-off between noise and sensibility to the change are important factors in the performance of an adaptive learning system.
Some ensemble algorithms divide the input data stream into blocks of training instances. Afterward, the base classifiers are created and trained from these data blocks. These ensemble algorithms update the base classifiers only when a new data block is completed and, consequently, their adaptation mechanism is slow [41, 8, 35]. Two examples of this type of algorithms are Accuracy Weighted Ensemble (AWE) [41] and Accuracy Updated Ensemble (AUE) [8].
Other ensemble algorithms are able to update the base classifiers online, being also able to handle concept drifts more efficiently. Online bagging [7] and boosting [15] are two examples. Online bagging and boosting have also been extended to deal with non-stationary data streams. LeveragingBag [5], OzaBagADWIN and OzaBoostADWIN are some examples [6]. Basically, they use the ADWIN change detector [3] to replace, when a concept drift is detected, the base classifiers with the lowest predictive performance in the ensemble by a new base classifier. LeveragingBag, different from OzaBagADWIN, leverage the performance of bagging with two randomization improvements: increasing resampling and using output detection codes. Another ensemble algorithm based on bagging is DDD (Dealing with Diversity for Drifts) [33]. DDD alternates between two states: (1) before a drift detection and (2) after a drift detection. Depending on the current state, DDD varies the ensemble diversity in order to adapt to changes quickly.
Gama and Kosina [20] presented an online learning algorithm that memorizes decision models whenever a concept drift is detected. The system uses a meta-learning technique to detect reoccurring concepts. The proposed algorithm is able to take proactive action by activating previously induced models. The main benefit of this approach is that the proposed meta-model is capable of selecting similar historical concepts.
Dynamic Weighted Majority (DWM) [28] handles concept drifts by monitoring the predictive performance of the ensemble. For this, DWM periodically performs a test. DWM decreases the weights of base classifiers in accordance with the incorrectly classified instances in this test. During the test, if the ensemble misclassifies a training instance, a new base classifier is created and added to the ensemble with a weight value equal to 1. DWM removes base classifiers from the ensemble when their corresponding weights are less than a fixed threshold
Bifet et al. [2] proposed the induction of an ensemble of decision trees from different attribute subsets. The ensemble combines the output from the base classifiers using a simple perceptron. The combination of decision trees and ensemble techniques has also been adopted in the IADEM-3 algorithm [17]. IADEM-3 uses ensemble techniques to combine class votes from the alternative and main subtrees.
Although these ensemble algorithms are able to handle concept-drifting data, the adaptation mechanism is performed only at the ensemble level. For example, LeveragingBag, OzaBagAdwin, and OzaBoostAdwin monitor the predictive performance of each base classifier by using the ADWIN change detector. However, when a change detector estimates a concept drift, only the worst base classifier is replaced. As mentioned, this can lead to an ineffective adaptation to changes, as the worst classifier may not be the one affected by the current change.
Next section presents a new ensemble algorithm able to handle concept drift in each base classifier. The proposed adaptation mechanism aims to adapt the learning more efficiently than previous approaches when a concept drift is detected.
The new ensemble algorithm
The proposed algorithm, OACE, uses online bagging (Algorithm 4) or online boosting (Algorithm 4) for training the base classifiers of an ensemble. For an ensemble to be effective, its base classifiers must present diversity [29]. For example, if the outputs from the base classifiers are independent and the base classifiers have the same predictive accuracy, the majority vote is guaranteed to improve the predictive performance of the ensemble [30]. This diversity is obtained by bagging and boosting by inducing independent classifiers from variations of the training set. Online versions of bagging and boosting have also been used in online learning [36].
InputProcedure Bagging
Oror Andand
Initialize base models
Induction of base classifiers based on bagging. The batch bagging algorithm [7] builds a set of
The use of the Poisson distribution
Oza and Russell [36] also proposed the online boosting algorithm. In this algorithm, the base classifiers are induced sequentially, and the induction of each new base classifier depends on the predictive performance of the previously induced classifiers. The key idea is to give more weight to misclassified instances, and to reduce the weight of those correctly classified. For such, the parameter
InputProcedure Boosting
Oror Andand
Initialize base classifiers
Induction of base classifiers based on boosting.Algorithmalgorithmautorefnamelist of algorithms name LeftleftThisthisUpup UnionUnionFindCompressFindCompress InputInput OutputOutput
OACE handles concept drift by a simple and efficient mechanism (see Algorithm 4). Each base classifier
Change detection mechanism used in each base classifier.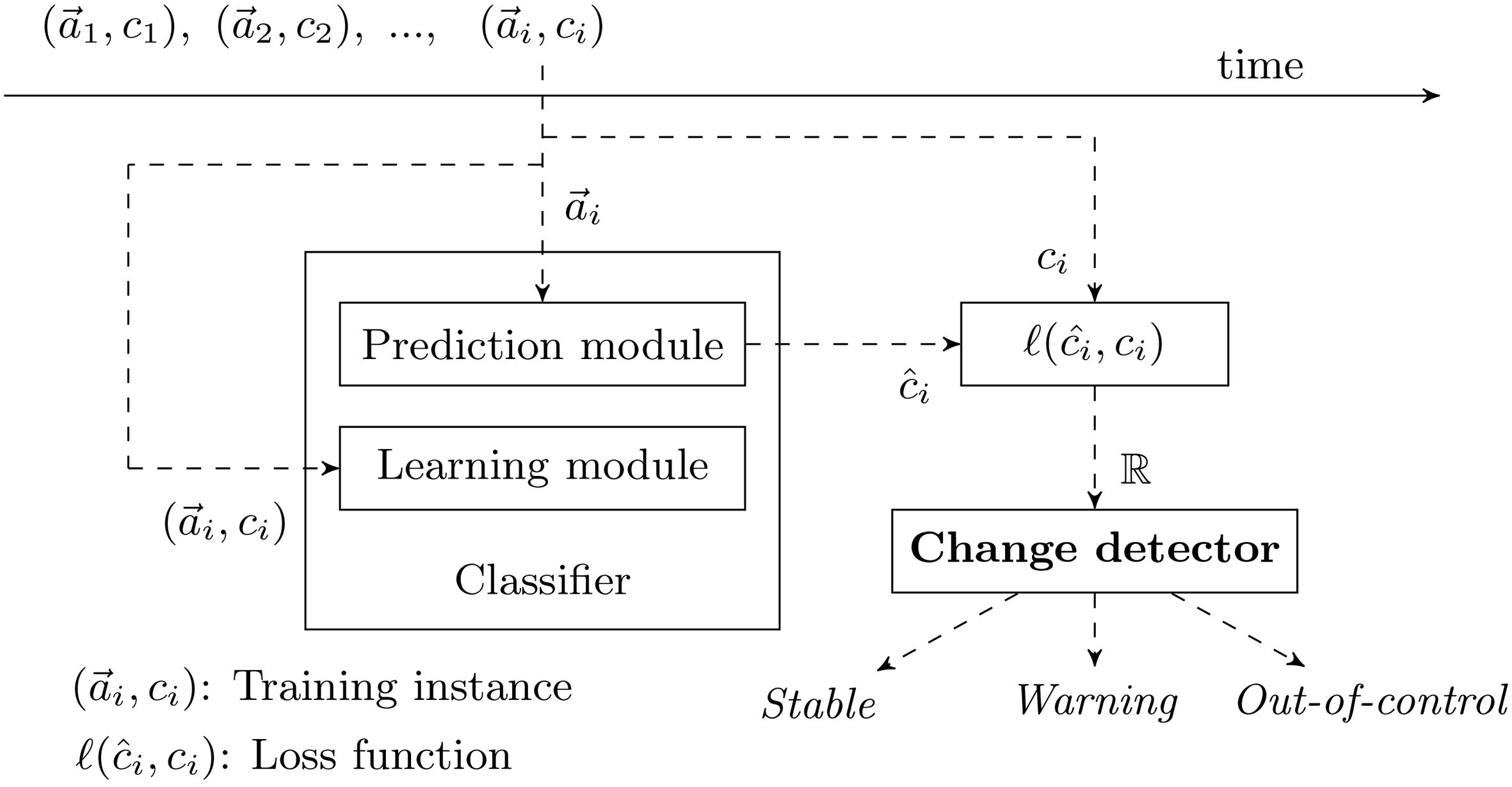
OACE handles concept drift by using two main modules [19]: the change detector module and the learning module (Fig. 1). In the OACE algorithm, each base classifier estimates classification error rates by a predictive sequential approach (test-then-train) [24, 21]. At the arrival of each training instance, the classification model makes a prediction based on the instance attribute values. Next, this instance is made available to the learning module that induces the base classifier. Gama et al. [24] gave mathematical guarantees to the predictive sequential method as a general framework for error estimates in incremental learning domains.
The error rate of the base classifiers is constantly monitored over time as each training instance arrives. Therefore, this monitoring must also be performed with controlled computational resources. Various parametric control charts have been proposed in the statistical community to detect changes online [34]. However, they assume that the input data are regulated by a known probability distribution.
Other change detection methods have been proposed, such as Adaptive Windows (ADWIN) [3], Drift Detection Method (DDM) [21], Early Drift Detection Method (EDDM) [2], and EWMA for Concept Drift Detection (ECDD) [38]. The adaptation mechanism of OACE is compatible with the scheme showed in Fig. 1. Thus, it can be used with all the aforementioned change detectors. Another example is the Hoeffding-based Drift Detection Method (HDDM
This section experimentally compared OACE with various state-of-the-art ensemble algorithms for mining concept-drifting data streams.1
The source code of OACE and additional experiment results are available online at
All the experiments were implemented and performed using the Massive Online Analysis (MOA) software [4]. MOA includes a collection of algorithms for processing data streams, various methods to generate artificial data streams with the possibility of including concept drifts, and several tools to evaluate concept drift detection algorithms.
The algorithms under consideration were evaluated by a test-then-train approach. Test-then-train was used in combination with a sliding window, as a forgetting mechanism [4]. Test-then-train computes the predictive performance of a learning model as each training instance arrives (test step). In the next step, the instance is presented to the learning algorithm for learning (train step) [27]. This methodology is based on the cumulative sum of the values of a given function. Without a forgetting mechanism, the error computed by a test-then-train approach may not reflect the current performance of the learning algorithm, because the current performance measures are averaged in the whole history. In order to overcome this drawback, we calculated metrics by means of a sliding window considering only the last instances [23]. Therefore, at each new instance, the classifier was first tested and then trained. During the learning process, predictive accuracy was calculated with respect to a sliding window of size 100 [4]. Predictive accuracy was calculated every 100 instances processed by means of the fraction between the number of correctly classified instances and the window’s size.
The experiments considered both artificial (LED, SEA, RBF, WAV, AGR, STA, HYP) and real-world datasets (see Table 1). The artificial datasets allowed to evaluate the methods under stable concepts, abrupt and gradual types of change. The experiments also employed datasets with noise, irrelevant attributes, and missing attributes values (see Table 1). The artificial datasets were generated by the MOA software [4].
In the artificial datasets, the target concept changed 10 times. Changes occurred every 25,000 instances. In gradual changes, the transition period between consecutive concepts was set to 5,000 training instances. During the transition period, the probability that a new training instance belongs to the new concept was increased gradually and continuously. In addition, five new datasets were generated from the artificial datasets described in Table 1. The new datasets were obtained using the following definition:
.
Given two data streams
and
In accordance with this definition, the new datasets were
Main characteristics of the datasets used in the experiments
Main characteristics of the datasets used in the experiments
Configuration of the change detector used in the experiments (size of the statistical test)
Predictive performance of the algorithms based on bagging over abrupt and gradual changes
Comparison of OACE variants with the Friedman test and the Bergman Hommel’s procedure for the post hoc analysis. Groups of classifiers that are not significantly different (at 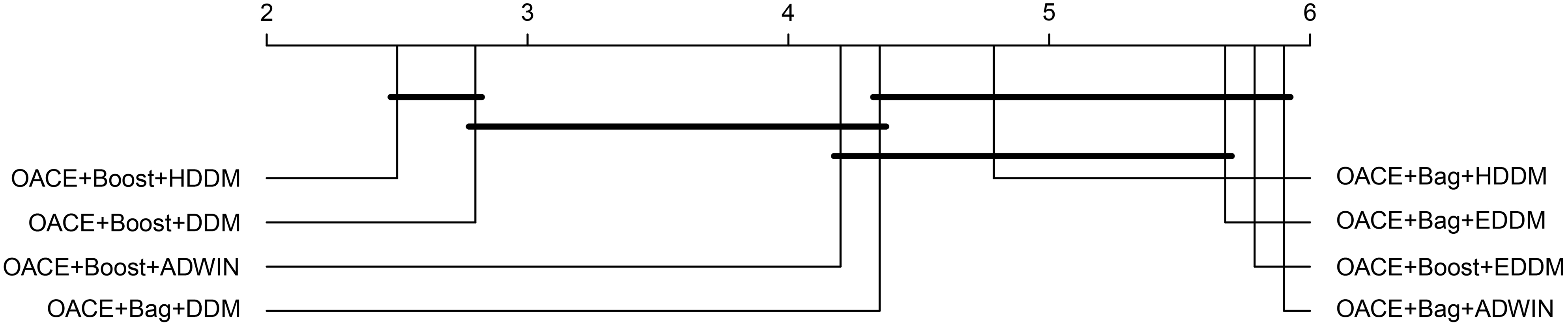
The proposed algorithm used the online bagging (OACE
Predictive performance of the algorithms based on boosting over abrupt and gradual changes
Predictive performance of the algorithms based on boosting over abrupt and gradual changes
Predictive performance of OACE
Figure 2 shows the ranking position of the resulting algorithms with respect to predictive accuracy. The contending algorithms ran over all the datasets and types of change described in Section 5.1. The comparison was performed with the Friedman test and the Bergman Hommel’s procedure for the post hoc analysis. Groups of classifiers that are not significantly different (at
OACE
Ensemble algorithms based on online boosting: OACE+Boost+HDDM, OzaBoostAdwin (OBOA) [6], and OzaBoost (OBO) [36].
Ensemble algorithms that do not deal with concept drift explicitly: Accuracy Weighted Ensemble (AWE) [41], Accuracy Updated Ensemble (AUE) [8] and Dynamic Weighted Majority (DWM) [28].
Finally, in order to assess its adaptation mechanism, OACE was compared with other algorithms compatible with the ADWIN change detector: OBAA, OBOA, and LB.
Predictive performance of the algorithms based on boosting over real-world datasets. OACE
Predictive performance of the algorithms based on boosting over real-world datasets. OACE
All the ensemble algorithms and change detectors were set with the default configuration adopted by MOA [4]. Table 2 shows the parameter values of the statistical tests used by the change detectors. The ensemble size was set to 10 for all the considered ensemble methods. All the ensemble algorithms used Naive Bayes as a base classifier. Naive Bayes was chosen because it is one of the most successful algorithms for learning from data streams [10, 9, 31, 37, 13]: it has a low computational cost, is simple, has a clear semantics, and works well with continuous attributes and missing attribute values. Additional experiments performed in this study revealed that, for the Naive Bayes classifier, an increase in the ensemble size does not increase predictive accuracy significantly.
Predictive accuracy of the contending algorithms over various data stream generators.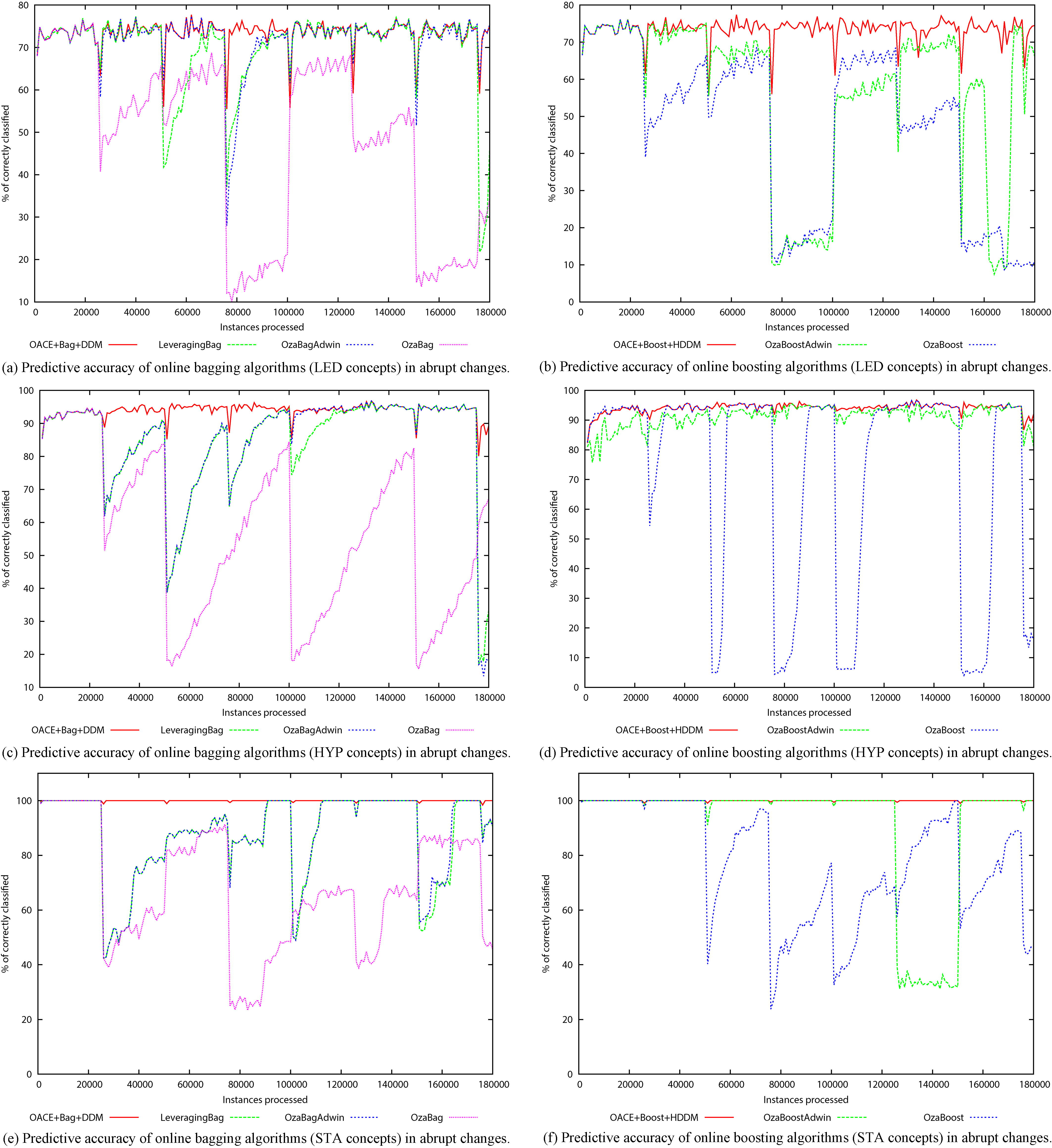
Comparison of all classifiers against each other with the Friedman test and the Bergman Hommel’s procedure for the post hoc analysis. Groups of classifiers that are not significantly different (at 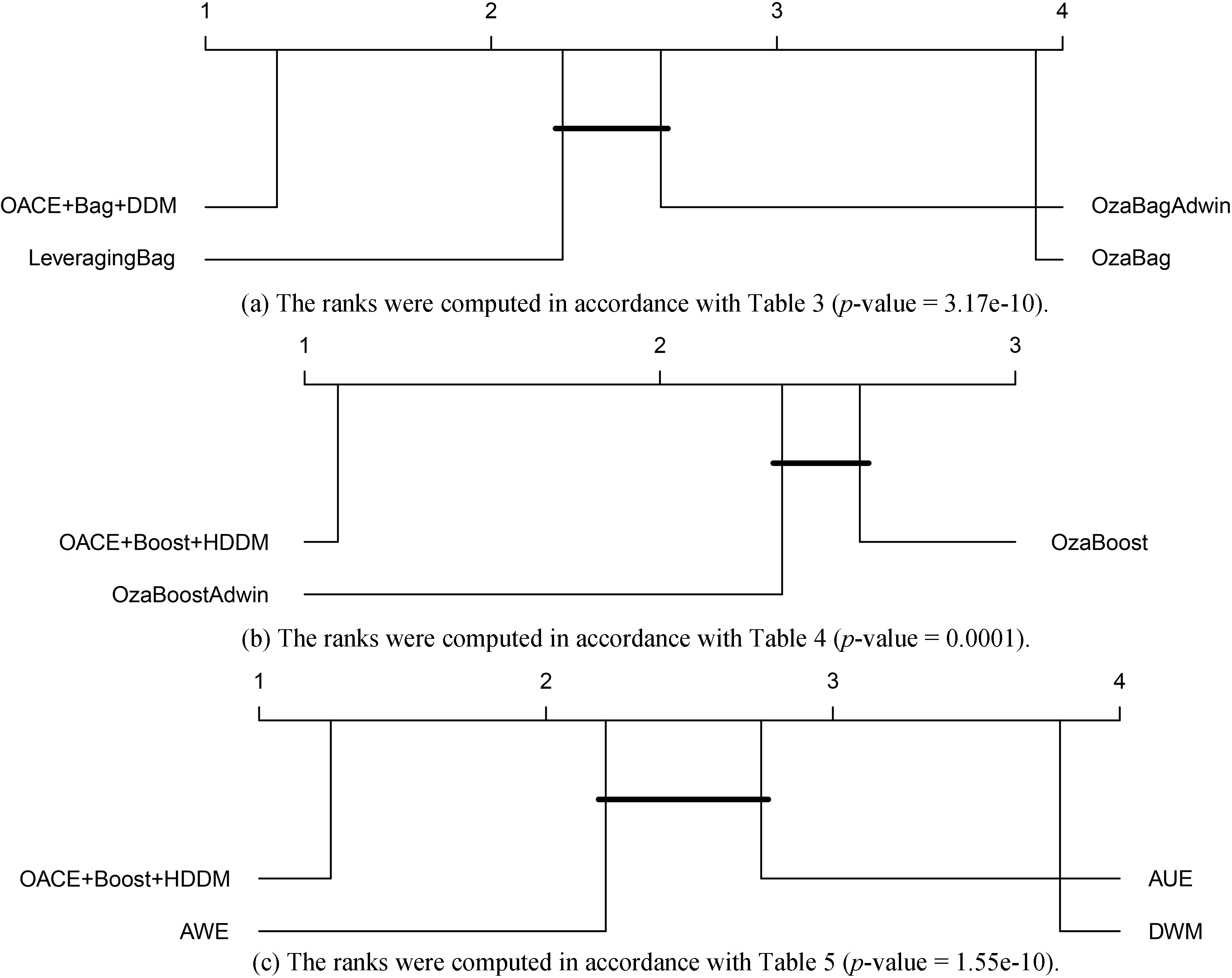
As mentioned, OACE
Tables 3–5 summarize the predictive performance of the algorithms over abrupt and gradual changes in terms of the average (
Table 5 compares the performance of OACE
Figure 3 illustrates the predictive performance of the algorithms for the LED, HYP, and STA datasets. According to Fig. 3, OACE is able to stabilize the learning when concepts are stable. Figure 3 also shows that OACE often adapts the learning more effectively than the contending algorithms.
Figure 4 shows the ranking positions of the algorithms with respect to Tables 3–5. To verify significant differences, we used the Friedman test and the Bergman Hommel’s procedure for the post hoc analysis. Groups of classifiers that are not significantly different (at
Experiments with real-world datasets
Predictive accuracy of the contending algorithms over various real world data.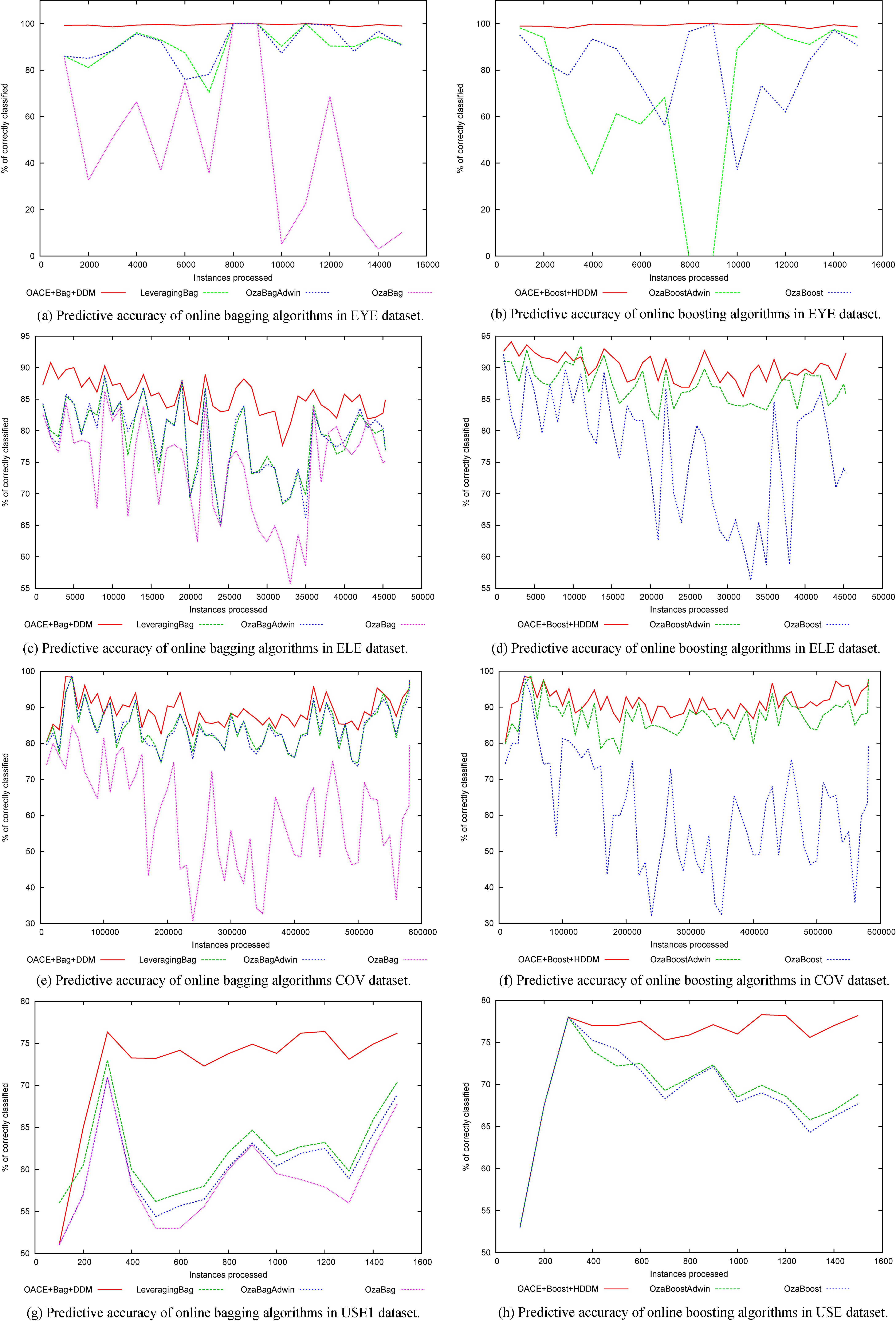
Similar to Section 5.3, this section compares OACE
Figure 5 reflects that in the real-world datasets, changes probably occur gradually and continuously over time. This figure shows that OACE also outperformed the competing algorithms regarding predictive accuracy in these situations.
We also verified significant differences between the contending algorithms by the Friedman test and the Bergman Hommel’s procedure for the post hoc analysis. Groups of classifiers that are not significantly different (at
Comparison of all classifiers against each other with the Friedman test and the Bergman Hommel’s procedure for the post hoc analysis. Groups of classifiers that are not significantly different (at 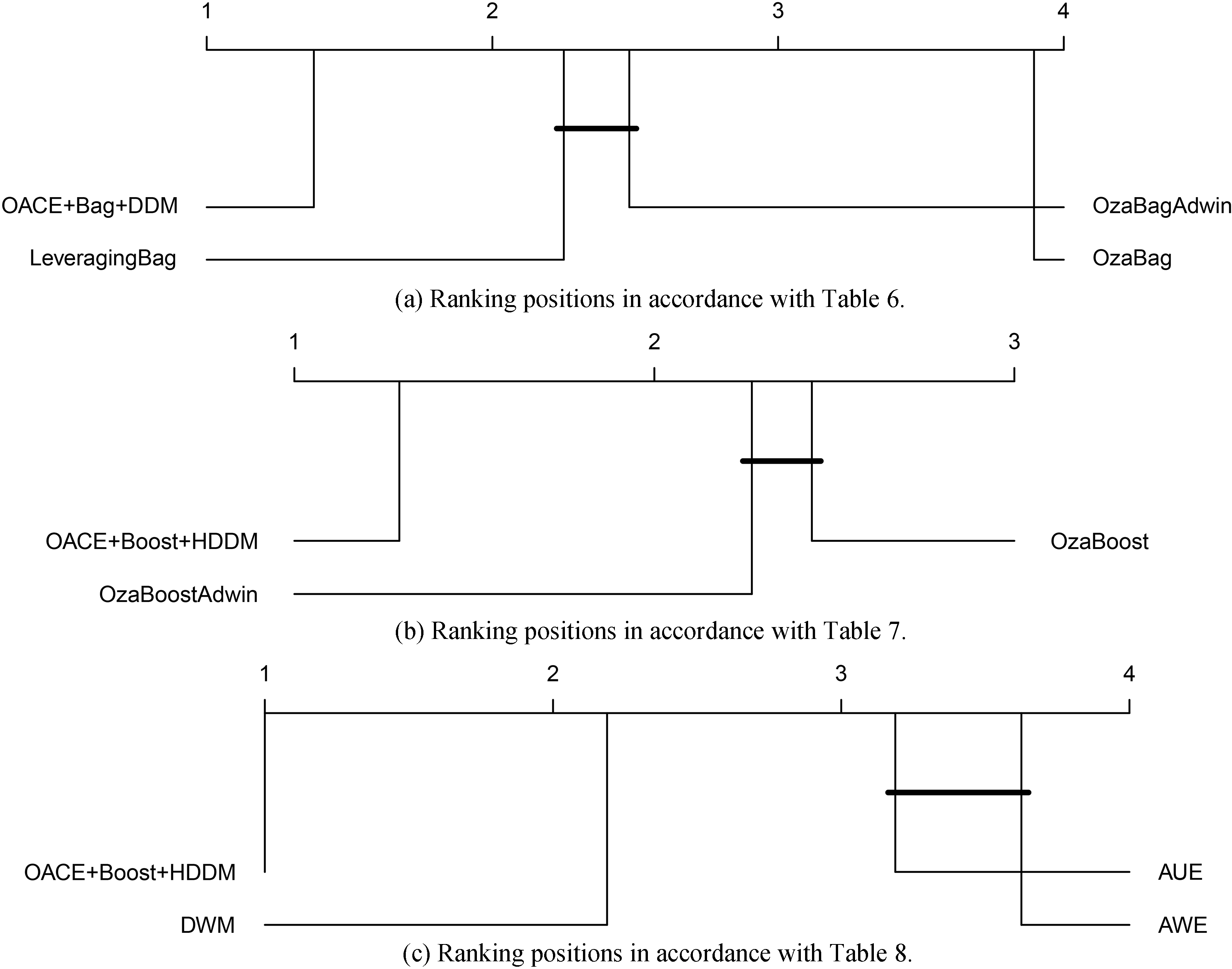
Algorithms’ predictive performance in combination with ADWIN over abrupt and gradual changes
Algorithms’ predictive performance in combination with ADWIN over real-world datasets
In this section, we compared OACE in combination with the ADWIN change detector against three state-of-the-art ensemble algorithms: OzaBagAdwin (OBAA) [6], OzaBoostAdwin (OBOA) [6]and LeveragingBag (LB) [5]. All the contending algorithms used ADWIN as change detector to assess OACE’s adaptation mechanism. Tables 9 and 10 summarize the predictive performance of the algorithms over the datasets described in Table 1. Tables 9 and 10 show that OACE
We also verified significant differences between the contending algorithms by the Friedman test and the Bergman Hommel’s procedure for the post hoc analysis. Figure 7 shows the ranking position of various ensemble algorithms when using ADWIN as a change detector. In this case, the algorithms ran over all the datasets according with Tables 9 and 10. This figure also shows that OACE is a good alternative for learning from concept-drifting data streams.
Ranking positions of the resulting algorithms with respect to predictive accuracy in combination with ADWIN change detector over all datasets. Groups of classifiers that are not significantly different (at 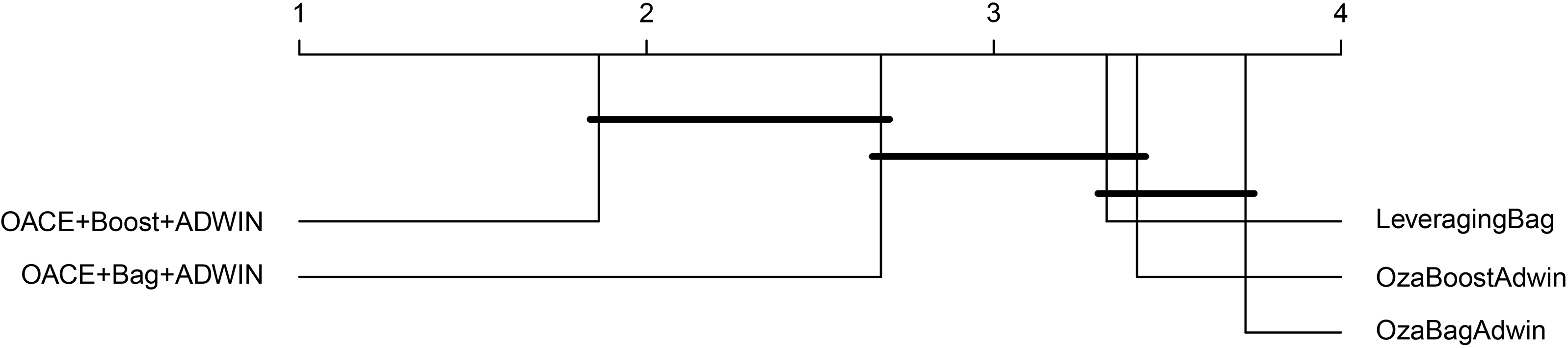
This paper presented a new learning algorithm able to learn from non-stationary data streams. The proposed algorithm, named Online Adaptive Classifier Ensemble (OACE), processes the input data with constant time and space computational complexity, and learns with a simple scan over the training data. To deal with concept drift, OACE uses a change detector to monitor the performance of each base classifier. OACE’s base classifiers alternate between three different drift stages in the adaptation process: in-control, warning, and out-of-control.
A base classifier is in-control when the corresponding change detector estimates that the current concept is stable. The warning stage is reached when a concept drift is likely to be approaching. At the warning stage, an alternative classifier is trained together with the corresponding base classifier. When a concept drift is detected the corresponding base classifier reaches the out-of-control stage, and the base classifier is replaced by the alternative one.
OACE was empirically compared with various state-of-the-art ensemble algorithms for mining data streams. For this, Naive Bayes was used as a base classifier. The experiments included both artificial and real-world benchmark datasets. The contending algorithms were tested under common types of change (abrupt and gradual), different levels of noise, irrelevant attributes, and missing attribute values. The experiment results showed that OACE is a good option for learning from concept-drifting data streams.
We plan to continue with this research by using other learning algorithms as base classifiers in OACE, such as Hoeffding trees and Perceptron. We also plan to study situations in with previous concepts can reappear over time.
Footnotes
Acknowledgments
The authors wish to thank the editor and the anonymous reviewers for their useful comments and suggestions. This work was partially supported by FAPESP, grant number 2015/03355-0; and by CeMEAI-FAPESP, grant number 13/07375-0.