
Abstract
When the sample size is equal or less than the number of covariates, traditional logistic regression is plugged with degenerates and wild behavior. Therefore, classification results are not reliable. We use finite population Bayesian bootstrapping for resampling, such that the new sample size becomes greater than the number of covariates. Combining original samples and the mean of simulated data, and also applying sufficient dimension reduction method, we introduce a new algorithm based on traditional logistic regression for high-dimensional binary classification. Then, we compare the proposed algorithm with the regularized logistic models and other popular classification algorithms using both simulated and real data.
Keywords
Introduction
Classification is one of the most important methods in the multivariate statistical analysis and the supervised learning technique. The aim of classification is to find classes of new data, using a proper classifier, which is learned from the data with known labels. In many scientific areas, such as biology and medical science, we face High-Dimensional Data (HDD), i.e., data with the number of variables often larger than the sample size. In statistical problems, the large number of variables causes some difficulties in fitting the model, estimating parameters, optimizing the objective functions and analyzing numerically. These phenomena are referred to as the curse of dimensionality[3]. In these situations, traditional classifiers such as logistic regression, despite their good accuracy, are not usable. For example, in such a case, logistic regression is plugged with degeneracy and wild behavior. That is, its classification results are not reliable.
Furthermore, other well-known classifiers such as Naive Bayes (NB) and K-Nearest Neighbors (KNN) [8] have restrictive assumptions in the classification of HDD. In NB, we should calculate the posterior distribution of the response variable, given covariates. However, due to the curse of dimensionality and noise accumulation, we need to accept the restricted assumption that is conditional independence of data. Furthermore, KNN is simple to learn, still suffers from overfitting for HDD classification, especially when the sample size is too small.
Using the traditional logistic classifier for HDD classification has received much attention in the recent years. Lim et al. [26], using an ensemble method, proposed a logistic regression for HDD binary classification, which is called Logistic Regression Ensembles (LORENS). Wang et al. [37] used a random subspace sampling method to train the parameter estimation method in a logistic regression for HDD classification. Lee et al. [23] used a multinomial logit model as an ensemble classifier for training data obtained from the random partitioning of the predictors, and developed LORENS for the HDD multiclass classification.
Utilizing traditional logistic regression needs a large amount of training data. However, it is expensive or impossible in practice. An alternative can be generating artificial or synthetic data, but as Nonnemaker and Baird [32] and Zhang et al. [39] express, the idea of combining synthetic and real data is really challenging, due to the following question, “Can we trust artificially generated data?”. Alternatively, “When will be learning the algorithms from synthetic data work as well as-or perhaps better than learning on real data?”.
In fact, the key problem to use synthetic data is to minimize the domain distance between synthetic and actual data distribution. We believe that using a bootstrapping occasion is a way to this goal. Because, we do not have new data and learn the logistic regression classifier with available data. Furthermore, the success of this new model depends on having a valid-labeled HDD.
In this article, a combination of the observed and artificial data is used to solve the non-invertible matrix problem related to estimating parameters of logistc regression when the sample size is smaller than the number of covarites. We use Finite Population Bayesian Bootstrapping (FPBB) [28] for resampling from observed data. Then, using the traditional logistic regression, we introduce Finite Population Bayesian Bootstrapping Logistic Classifier (FPBBLC) for HDD classification.
The rest of the paper is as follows. Some related work about using synthetic data in learning the classifiers are given in Section 2. Bayesian bootstrapping in a finite population is explained in Section 3. In Section 4, sliced inverse regression is discussed. FPBBLC is defined in Section 5. FPBBLC is evaluated via simulation in Section 6, and its application to real microarray data is carried out in Section 7. Finally, concluding remarks are made in Section 8.
Related work
Large and balanced data sets are normally crucial to learn classifiers. However, finding adequate amounts of labeled data is very difficult in the real world. For a comprehensive explanation, we refer the reader to [39] and references therein.
Generating data is a solution to overcome the lack of training data. This follows from operating in data space or feature space. Geometrical transformation and degradation models are useful data space tools to generate synthetic data [35, 36, 2]. The Synthetic Minority Oversampling Technique (SMOTE) [7] is also a powerful feature space method to generate samples and to achieve better classifier performance for imbalanced datasets. Zhang et al. [39] show that by using a multichannel autoencoder process, it is possible to learn a better feature representation for classification.
The frequentist bootstrap of Efron [14] is one of the most important statistical techniques. It has a variety of applications in statistical theory, especially for computing the mean and variance of a specific statistic with unknown distribution. Despite this, using a bootstrap for generating synthetic data, i.e., obtaining the data from combining the observed data and the bootstrapping data, is not much popular.
Fienberg [15] initially studied the use of bootstrapping to generate synthetic data. Ichim [22] used quantile-based bootstrap for generating continuous synthetic data. However, FPBB for generating data to learn the classifier is a new method that we introduce it in this paper. Furthermore, since the number of covarites is large, we may encounter non-convergence in estimating logistic regression parameters. Sufficient Dimension Reduction (SDR) via Sliced Inverse Regression (SIR) [24] is used for eliminating this divergence and for reducing the application time of the model.
In the proposed algorithm, as it will be completely described in Section 5, the covariate matrix of the training data is replaced with its linear combination so-call Central Subspace (CS) [9] basis. Then, the logistic regression parameters are estimated based on the basis. For predicting the class of new data, we use both basis and estimated parameters and thus expecting that the accuracy of the classification increases. Since this method does not need any new parameter estimation method and uses all variables in the model, it could be a simple and efficient algorithm, especially in the classification HDD with low sample size. In addition, since synthetic data can be used in other fields of statistics (see, e.g., [22]), this method is of our interest.
Bayesian bootstrapping in a finite population
The Finite Population Bootstrapping (FPB) was introduced by Gross [19]. Bickel and Freedman [4] and Chao and Lo [6] developed it and calculated the first-order asymptotic justification for the FPB mean. FPBB is a Bayesian analogue of FPB, based on a generalization of Polya’s urn scheme, and the simulated data is called a Polya sample [28]. Meeden [29] used this method in small area estimation and for estimating population parameters other than means and find sensible estimates of their precision.
The Bayesian approach for finite population is based on finding the posterior distribution of unobserved data given sample data. The conditional probability of unobserved data given sample data is called the Polya posterior. Simulating data from the Polya posterior is easy and is based on the Polya’s urn scheme and simulated data are called a Polya sample [28]. The Polya sample size that is denoted by
Suppose we have the data such that the sample size
Sliced inverse regression
Chang [5] proved that the first components of Principle Components Analysis PCA do not necessarily contain more discriminative information than the others, so PCA may not be useful for clustering and classification. For this reason, we use SDR for dimension reduction. The most well-known algorithm for SDR is SIR. SIR is based on the model
Let
i.e.,
Suppose
In this paper, we assume that
The test statistic
In the logistic regression classifier, we calculate conditional probability
and
where
If we suppose
To compute optimal
where
Here, we introduce a new algorithm for estimating
First, divide the data with respect to the response variable levels into two classes. The first class contains sample values that are related to level one (code 0) of the response variable and second class includes remainder values that are related to level two (code 1) of the response variable. For each covariate in each class and with respect to the proportion of the number of zeros and ones of the response variable, we generate the Polya samples of size Attach labels 0 and 1 to the generated data of classes 1 and 2 as new response values, respectively. Calculate the mean of If the estimation algorithm in step 4 does not converge and to simplify in predictions, use SIR to compute a basis of CS based on the generated synthetic data, and estimate Use the estimated
As an example, suppose we have the training data with 10 covariates and a binary response variable, such that sample size is 7 and response variable has 3 zeros and 4 ones. Furthermore, suppose
The traditional logistic regression is used on this synthetic data to estimate logistic regression coefficients. By applying SIR on the synthetic data, first we compute the basis of CS. Then, synthetic data is multiplied to this basis and the resulting vector is used to estimate logistic regression coefficients. In this case, for predicting purpose, the test data is multiplied to the basis of CS and the class of the resulting vector is predicted.
To evaluate FPBBLC, we compare this method with the penalized logistic regression classifiers, such as Ridge [20], LASSO [34] and Elastic Net (EN) [40] and also with NB and KNN classifiers. We use these methods to classify simulated and real data and compare predicted class with the real class labels. The algorithm with the best average classification accuracy is better. Furthermore, for the real microarray data, we compute sensitivity and specificity [26] for more precision in conclusion.
Penalization techniques are proposed to improve the prediction of the ordinary least squares in the estimating regression parameters. Ridge regression minimizes the residual sum of squares subject to a bound on the
KNN classifies observation based on a similarity measure such as the Euclidean distance. In this method, to determine the class of a particular covarite,
Simulation analysis
In this subsection, we use a high-dimensional and low sample size data, with equal correlation matrix from a standard multivariate normal distribution, to illustrate the performance of FPBBLC in a simulation study. The linearity condition is the most important condition for SIR and this condition is confirmed in the normal family [10].
We assume that correlation among covariates is 0.1, 0.5 and 0.9. The data set is generated from the logistic regression model
where
First of all, we consider the behavior of the Polya sample size on the correct classification rate to choose the correct Polya sample size. For instance, we generate the different Polya sample sizes when training sample size is 50 with correlation 0.1, 0.5 and 0.9. For each iteration, we repeat the algorithm 20 times and choose
Comparison of FPBBLC(sir) with different classifiers based on the average percent of prediction accuracy of simulated test data in 100 runs. The best values are bolded
Determining the population copy size for simulation study of FPBBCL(sir) when 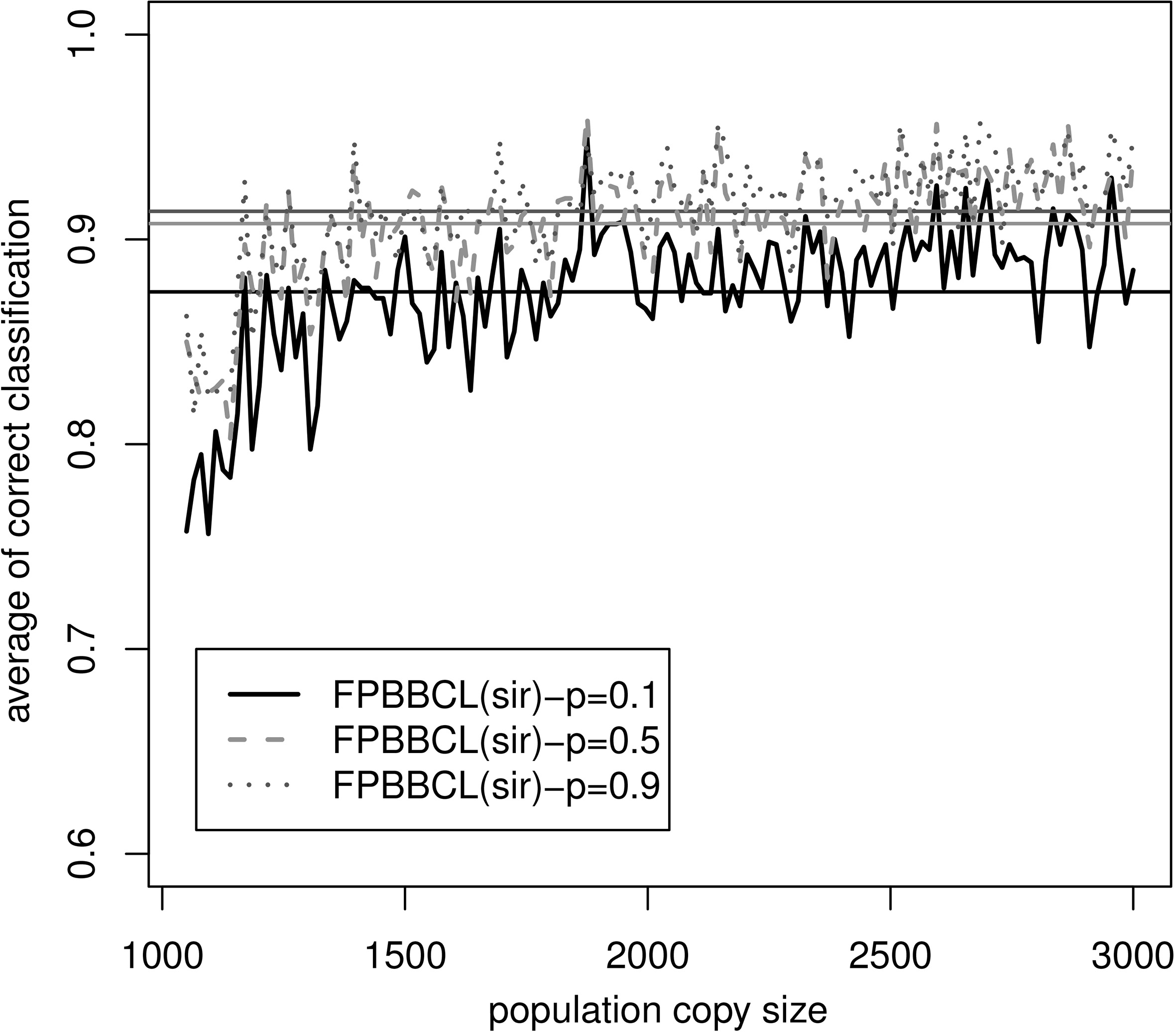
The averages of prediction accuracy of simulated data for the different training sample sizes, different correlations and methods are represented in Table 1. It is generally observed that when the correlation between predictors is low and sample size is small, FPBBLC(sir) has better performance compared to other classifiers. When correlation between covariates increases the average of accuracy improves. For example, when
In general, increasing the sample size
In this subsection, we compare FPBBLC in three cases to classify the Wisconsin Diagnostic Breast Cancer (WDBC) data set taken from the UCI repository. This data set consists of 569 instances with 30 predictors and diagnosis as a response variable at two levels: malignant and benign. As we emphasized before, SIR needs linearity condition among covariates, thus a Box-Cox Transformation (BCT) is used to fulfill this condition. Therefore, we use BCT on WDBC data and compare our algorithm in two cases with and without dimensionality reduction and in dimensionality reduction with or without BCT. We use suffix BC with FPBBLC(sir) for showing usage of BCT in our algorithm and compare performance of the proposed method with those of some other popular classifiers. Since in WDBC data set, the sample size is equal or bigger than covarites number, we can compare different classifiers with the traditional logistic classifier, which is shown with LR.
Comparing FPBBLC(sir) with different classifiers based on the average percent of prediction accuracy for samples obtained from (WDBC) data set at 1000 runs. The best values are bolded
Comparing FPBBLC(sir) with different classifiers based on the average percent of prediction accuracy for samples obtained from (WDBC) data set at 1000 runs. The best values are bolded
We randomly split WDBC data into two parts train and test data and select four random samples with 30, 90, 180 and 360 instances as training data and reminded data in each case as a test data. We repeat this sampling 1000 times and for every sample, we compare all classifiers and calculate the average of classification accuracy as evaluation criteria. In this case the population copy size is 569, and we iterate each copy 30 times, i.e.,
As we can see in Table 2, both of FPBBLC methods with SIR have better results than FPBBLC without dimensionality reduction because in our algorithm, we use the estimated parameters and estimated base of the CS to predict the class of new data. When the training sample size is small, using BCT causes little improvement in accuracy average. This trend reverses when the training sample size increases. Similar to simulation study, when the training sample size is small, FPBBLC methods based on SIR have a better performance than other classifiers. For example, when the training sample size is 30, the percent of the accuracy average of FPBBLC(sir) is 93%, which is the highest percentage of accuracy in this case excluding FPBBLC(sir)-BC. But, as the training sample size increases, the precision of other classifiers increases more such that EN has the highest accuracy present when the sample size is 360.
In each sample size, LR has the worst performance because the correlation between covariates of WDBC is high and collinearity is possible. Furthermore, when
Here, we compare our proposed methods with other classifiers on three famous gene expression datasets: Colon, Leukemia and Prostate. The Colon data set [1] contains 2000 genes and 62 samples, and tissue type is response variable, which consists of 22 normal tissues and 40 cancer tissues. Leukemia microarray data set [18] includes 7,129 genes and 72 sicks that categorized 47 patients with Acute Lymphoblastic Leukemia (ALL) and 25 patients with Acute Myeloid Leukemia (AML). Liang et al. [25] based on the protocol defined by Dudoit et al. [13] and after doing the filtering, standardizing and using a logarithmic transformation, provided data set comprising 3,571 genes that we used this data for our evaluations. Furthermore, the original prostate data set contains 12,600 genes for 102 tissues, i.e., 50 normal tissues and 52 prostate tumor tissues. Our experiment is based on optimized prostate data [38] that contains 6033 genes and 102 samples.
To evaluate performance of the proposed algorithm, we randomly split datasets into two parts, approximately, 70% for training and 30% for testing. Each procedure is repeated 100 times and the averaged accuracy of prediction, sensitivity, specificity and Standard Deviation (SD) of each index, are reported in Tables 3 to 5. Similar to Liang et al. [25], we select the train/test sample size of Leukemia, Prostate and Colon data 50/22, 71/31 and 42/20 respectively.
Percent of accuracy (SD in parentheses) of classification algorithms for Colon gene expression datasets
Percent of accuracy (SD in parentheses) of classification algorithms for Colon gene expression datasets
Percent of accuracy (SD in parentheses) of classification algorithms for Leukemia gene expression datasets
Percent of accuracy (SD in parentheses) of classification algorithms for Prostate gene expression datasets
As shown in Table 3, for Colon data set, FPBBLC(sir) and FPBBLC(sir)-BC give the average predictive accuracy 81.1% and 81.5%, respectively. Comparing these values with the values of the other classifiers shows that these methods, especially FPBBLC(sir)-BC, are suitable for classification of Colon data set rather than other classifiers. Considering the sensitivity and specificity indices confirms this again. Furthermore, the low amount of SD shows that the suggested method is robust too. Note that since the response variable has two levels, we have one base for each data set, at the result; our methods only use one variable to getting such accuracy. This means that, after calculating the basis of CS with SIR and training the algorithm, using this algorithm to predict the classes of new data, needs less time than other classifiers. With respect to Table 4, for Leukemia data set FPBBLC(sir) and FPBBLC(sir)-BC give the average predictive accuracy 96.4% and 95.2%, respectively. In this case, FPBBLC(sir) has the maximum of accuracy and sensitivity among all classifiers. Furthermore, considering Table 5, gives the similar results. This means that both FPBBLC(sir) and FPBBLC(sir)-BC methods have the credible performance to HDD classification.
Our results show that the linearity condition imposed with SIR, in general, does not have a significant effect on the accuracy of FPBBLC(sir). That is because as Li [24] states often low projections of HDD have approximately the normal distribution, so the linearity condition is not a restrictive condition for our algorithm. Also, the sensitivity and specificity are extremely balanced in our algorithm in comparison with other algorithms. Furthermore, in all cases, the average accuracy of classifying the training data is almost 1 which is significantly better than those of other classifiers.
We introduced a new algorithm for the classification of HDD. Our method is based on utilizing traditional logistic regression classifier on a combination of real data and the mean of different resampling data simulated from FPBB. We generate data until the Polya sample size is greater than the number of covariates. Simulation studies and analysis of real microarray data show that our algorithm is more accurate, particularly when the sample size is too small. The proposed algorithm is simple, does not need variable selection that is computer-intensive for HDD, applicable for extremely correlated data and also unbalanced data. The interpretation of why the combined data improve performance, whereas traditional logistic classifier, is not fairly straightforward. However, in the logistic regression classifier, determining class of new data is based on the positive or negative value of
Footnotes
Acknowledgments
The authors would like to thank anonymous referees for their helpful comments and for careful reading that greatly improved the article.