
Abstract
Data is shared among different organizations for mutual benefit. Data mining techniques are utilized to discover valuable knowledge for decision-making. However, data mining poses a threat to disclose the sensitive information. Thus, the sensitive knowledge should be concealed before releasing data. The pervious works either address the association rule or utility itemsets hiding problem. This paper focuses on preserving the sensitive utility and frequent itemsets, and a sanitization approach named HUFI is presented. The sensitive itemsets are hidden by reducing their support or utility below the minimum thresholds. For a sensitive itemset, the concept of maximum boundary value is introduced to determine the hidden strategy. Then, a transaction supporting minimal number of non-sensitive itemsets is selected to be sanitized. In such a transaction, a weight is assigned to each item contained in the sensitive itemset, and an item with the highest weight is selected to be modified. We compared HUFI with the state of the art algorithms on various databases. The experiment results show that HUFI outperforms the other algorithms in minimizing the side effects on non-sensitive knowledge and maintaining the database quality after the sanitization process. In addition, the impact of database density on sanitization approaches is observed.
Introduction
Data mining is the process of extracting the potentially useful information and knowledge from huge amount of data to aid the users for making effective decisions. Different kinds of techniques are used to find different kinds of knowledge. On the basis of the knowledge we are interested in, the tasks of data mining can be divided into summarization, classification, clustering, association and trend analysis [18]. Association rule mining [23] is the most commonly used technique, which is based on the support and confidence framework to detect the relationship among items in a transaction database. The support measure is used since it is assumed that highly frequent itemsets are likely to be of interest to users. However, the frequency of an itemset may not be a sufficient indicator of interestingness, because it only reflects the number of transactions that support the itemset. It does not reveal the utility of an itemset, which can be measured as profit. Thus, the utility mining is proposed [13]. Previous works focus on the association rule mining or utility mining. In order to find the itemsets with high utility and support, utility and frequent itemset mining is presented.
In the current competitive environment, data is shared among different organizations for mutual benefits during the business collaborations. However, the data sharing brings the risk of disclosing the sensitive knowledge. O’Leary [5] first presented that the knowledge discovery can be a threat to the database security. Clifton and Marks [4] then described a scenario to illustrate the treat of data mining, and the confidential data should be hidden before releasing data. To address this issue, sensitive knowledge can be hidden by transforming the original database to a sanitized one by some specific privacy strategies, and the hidden process is called data sanitization. In recent years, Privacy Preserving Data Mining (PPDM) has become an important research direction. In this paper, we focus on the Privacy Preserving Utility and Frequent itemset Mining (PPUFM). The contributions of our work are summarized as follows. Firstly, the concept of maximum boundary value is proposed to determine whether the support or utility hidden strategy is used to hide a sensitive itemset. Secondly, the transaction with the minimal number of non-sensitive itemsets is selected to be sanitized. Experimental results show that the proposed algorithm outperforms the other algorithms in terms of maintaining the database quality and minimizing the side effects on non-sensitive knowledge.
The remainder of this paper is organized as follows. Section 2 provides a review of related research. Some preliminary definitions are described and the sanitization problem is formulated in Section 3. Section 4 presents a novel hidden approach for concealing the sensitive utility and frequent itemsets. In Section 5, the proposed approach is compared with the state of the art algorithms. Finally, the conclusions are made in Section 6.
The related works
There has been a great number of works on sensitive knowledge hiding. Atallan et al. [16] firstly proved that the optimal sanitization is NP-hard and proposed a heuristic approach to solve the security problem. Following this work, a lot of approaches were presented. Dasseni and Verykios [6, 31]proposed three strategies and five sanitization approaches for hiding the sensitive association rules. Algorithm 1.a hides a sensitive rule by increasing the support of the rules’s antecedent. Algorithm 1.b conceals a sensitive rule by decreasing the frequency of the rule’s consequent. Algorithm 2.a reduces the support of a sensitive rule until its support or confidence is below the given thresholds. Algorithms 2.b and 2.c hide sensitive rules by reducing the support of their generating itemsets. All the five algorithms have the assumption that the generating itemsets of the sensitive rules are disjoint. Thus, they cannot deal with the overlapping rules. Oliveira and Zaïane [27] presented a one-scan sanitization approach named SWA for hiding the sensitive association rules. In addition, a disclosure threshold is assigned to each rule for improving the balance between knowledge discovery and privacy.
Amiri [1] presented three heuristic approaches for hiding the sensitive itemsets. The Aggregate approach directly removes the transaction from the database. The Disaggregate approach deletes some items from the transactions to hide the sensitive itemsets. The Hybrid approach is the combination of the previous two hidden approaches. Wu et al. [35] developed a template-based algorithm to protect sensitive rules. All the class of modifications are recorded in a template, and a hidden method that produces the lowest side effects is selected to hide the rules. Hong et al. [29] borrowed the concept of Term Frequency and Inverse Document Frequency (TF-IDF) in text mining for hiding sensitive itemsets. A greedy algorithm was presented. It calculates the SIF-IDF value of each transaction, and the transaction with the highest value is sanitized. However, the algorithm has poor performance in scalability.
Most of the existing methods address the sanitization problem based on the heuristic strategy. Sun and Yu [33, 34] proposed a border-based [10] approach for hiding sensitive itemsets. The algorithm focuses on preserving the border of non-sensitive itemsets instead of all the non-sensitive frequent itemsets. Moustakides and Verykios [8, 9] proposed two approaches, called MaxMin1 and MaxMin2, for concealing sensitive itemsets, which are based on the border theory and the maxmin criterion in decision theory. Both algorithms perform sanitization by minimizing the side effects on the positive border itemsets. Gkoulalas Divanis and Verykios [3] developed a novel border-based approach to preserve sensitive knowledge. The original database is minimally extended by inserting a set of synthetic transactions, which is based on the CSP. Le et al. [11, 12] proposed two approaches, named HCSRIL and AARHIL, on the basis of the lattice theory to conceal sensitive rules. AARHIL makes an improvement in the selection of victim transactions in comparison with HCSRIL algorithm. Thus, it outperforms HCSRIL in minimizing the side effects and execution time.
Shah and Asghar [24] adopted the GA algorithm for privacy preserving in association rule mining. The selection of the victim transactions depends on the fitness value. Cheng et al. [19, 20, 21, 22] proposed four algorithms for preserving sensitive knowledge. BRDA approach hides the sensitive rules by removing some items on the basis of the positive and negative border rules. EMO-based, EMO-AddItem and EMO algorithm are based on the evolutionary multi-objective optimization (EMO). EMO-based and EMO-AddItem focus on protecting sensitive association rules. EMO-based algorithm utilizes the NSGA-II to find appropriate transactions for sanitization. Some items are removed from the identified transactions to reduce the support and confidence of sensitive rules. EMO-AddItem adopts the HypE algorithm to insert some items into the database. The NSGA-II and HypE algorithms are used to drive the evolution forward in EMO algorithm, and the suitable items are found to remove from the database for concealing the sensitive itemsets. However, the hidden approaches based on the evolutionary algorithm usually generate the spurious rules.
All above algorithms focus on protecting association rules or frequent itemsets. Yeh and Hsu [15] proposed two approaches, named HHUIF and MCISF, for privacy preserving utility mining. HHUIF algorithm removes the items with the maximal utility. MCISF algorithm considers the conflict count during the sanitization process. Yun and Kim [30] presented an algorithm named FPUTT to improve the efficiency of the algorithm HHUIF by adopting a tree structure. However, the side effects of FPUTT are the same as those of HHUIF. Lin et al. [14] designed two algorithms called MSU-MAU and MSU-MIU to protect the high utility itemsets. For a sensitive itemset, both algorithms identify the victim transaction in which the utility of the itemset is maximal.
Rajalaxmi and Natarajan [25] was the first to present two approaches for preserving the sensitive utility and frequent itemsets. Both algorithms hide a sensitive itemset by decreasing its support below the minimum support threshold. Then, the utility of the itemset is checked. If it is still higher than the given utility threshold, the utility of the itemset is reduced until it gets below the threshold. Since both the support and the utility of an itemset should be decreased below the given minimum thresholds, the damage to the non-sensitive knowledge and database quality is large. To tackle this problem, a novel algorithm is proposed in this paper. The concept of maximum boundary value is presented, which is used to determine whether the support or the utility reduction strategy is adopted to hide a sensitive itemset. Therefore, the sanitization is performed with flexibility, and the side effects are minimized.
Preliminary
In this section, we firstly introduce some basic notions about frequent itemsets [23] and utility itemsets mining [17, 26]. Then, the sanitization problem is formulated.
Basic definitions
Let
where
A sample transaction database
For example,
For example,
For example,
An itemset is high utility if its utility is greater than or equal to the user-specified minimum utility threshold, which is denoted by minutil. Otherwise, the itemset is low utility. Utility and frequent itemset mining is to find all the itemsets whose utility and support are beyond the given minimum utility and support thresholds, respectively.
The sanitization problem can be formulated as follows:
Let
Hiding failure (HF): the portion of the sensitive itemsets that are not be hidden after the database sanitization. The hiding failure is computed as follows:
where Missing cost (MC): the portion of the non-sensitive itemsets that are falsely hidden after the hiding process. The missing cost is measured as follows:
where Database utility difference (Diff): the dissimilarity between the utility of original database
Where
The goal of privacy preserving utility and frequent itemset mining is not only to hide all the sensitive itemsets but also to minimize the side effects on non-sensitive knowledge and the integrity of the original database. A sensitive itemset can be hidden by modifying some items until its utility or the support is below the given thresholds. The modified item for hiding a sensitive itemset is called a victim item, which is denoted by
In this section, we propose a sanitization approach named HUFI for hiding sensitive utility and frequent itemsets. To do that, we first present two hiding strategies based on reducing the support or utility of the sensitive itemsets. Then the concept of maximum boundary value is introduced to determine the hiding strategy. After that we describe the proposed algorithm in detail. Finally, a sample is given to illustrate the hiding process.
The hiding strategies
where
Starting from the relationship between the support and the utility of an itemset, we develop two strategies to hide a sensitive itemset
Support reduction strategy: remove a victim item Utility reduction strategy: modify the internal utility of a victim item
where diu refers to the internal utility that should be decreased. It is calculated as
Proof. In order to hide the itemset
Based on the two hiding strategies, the underlying problems should be addressed.
Which transactions are selected for sanitization? Which item is selected to be modified in an identified transaction?
For the first question, we only consider the sensitive transactions for sanitization, because the non-sensitive transactions have no effect on hiding the sensitive itemsets. Moreover, the transaction that affects the minimum number of utility and frequent itemsets is selected to be a victim transaction
where
where
For a sensitive itemset
Proof. In order to hide an itemset
Proof. Since
From the Propertys 2 and 3, we calculate the maximum boundary value and minimum boundary value in advance to select a better hiding strategy for concealing a given sensitive itemset
If
For each sensitive itemset, the hiding strategy is determined beforehand. Given the sensitive itemsets
where
When hiding a sensitive itemset by reducing its support below the threshold minsup, there is no need to future decrease its utility. Also after reducing the utility of an itemset, there is no need to decrease its support since it is no longer significant. Thus, we can hide a sensitive itemset by decreasing its support or utility. Note that when reducing the support of an itemset, its utility will also decrease. Also utilizing the utility reduction strategy to decrease the utility of an itemset, its support will also decrease. But this does not guarantee that both the utility and support will fall below the given thresholds while decreasing the support or utility.
The previous approaches have to perform frequent database scans. Thus, we define the following three structures to speed up the sanitization process.
where Item is
where TID is the unique identifier of
where IID is the unique identifier of
The proposed algorithm uses these structures to conceal the sensitive itemsets. The construction of the T-table and HUFI-table need to scan database twice. The sanitization process is performed on the two table structures. Once a victim item is modified, T-table and HUFI-table are updated respectively. After all the sensitive itemsets are hidden, the result database is obtained from T-table.
Algorithm description
In this subsection, the pseudo-code of the proposed approach is presented in Algorithm HUFI. The designed algorithm hides all the sensitive itemsets in a one by one fashion. Firstly, minimum support count and utility that should be reduced, diffs and diffu, are calculated separately. Then the sensitive transactions
The complexity of the proposed algorithm is
Example
An example is given to illustrate the proposed hiding algorithm. Consider a transaction database displayed in Table 1. The minimum support threshold is set at 0.2, and the minimum utility threshold is set at 50. The utility and frequent itemsets are mined, and the results are listed in Table 2. The sensitive itemsets, {2, 4} and {1, 3, 5}, are identified in boldface in Table 2. The proposed hiding algorithm operates as follows.
Derived utility and support itemsets
Derived utility and support itemsets
For hiding itemset {2, 4}, we first calculate the minimum support and utility that should be reduced, respectively. Then
We continue to hide the next sensitive itemset that is {1, 3, 5}, the diffs and diffu are 1 and 2 respectively. The sensitive transactions
In this section, we compared the proposed algorithm HUFI with the MCRSU and MSMU algorithms [25] in terms of execution time, hiding failure, missing cost and database utility difference. The experiments were divided into two phases. In the first phase, the EFIM algorithm [28] was used to mine the high utility itemsets. Then, the itemsets that appear frequently were generated from these high utility itemsets. In the second phase, sensitive itemsets were generated randomly, and the sanitization approaches were adopted to hide the sensitive itemsets. All algorithms were implemented in Java and ran on Intel Xeon E5-2360 2.8 GHz CPU and 8 GB RAM. We carried out the experiments on the four real datasets [36], which are listed in Table 3. Density is measured as the average transaction length divided by the number of items. For all datasets, the internal utility of items in transactions were generated using a uniform distribution in the [1, 10] interval, and the external utility of items were generated using a Gaussian normal distribution.
The characteristics of the four datasets
The characteristics of the four datasets
The parameter settings of the four datasets
In order to better demonstrate the performance of the proposed algorithm HUFI, we conducted a series of experiments using various parameter settings, which are displayed in Table 4. Sensitive itemsets size denotes the number of sensitive itemsets,
where minutil is the minimum utility threshold, and
Execution time at various sensitive itemsets sizes.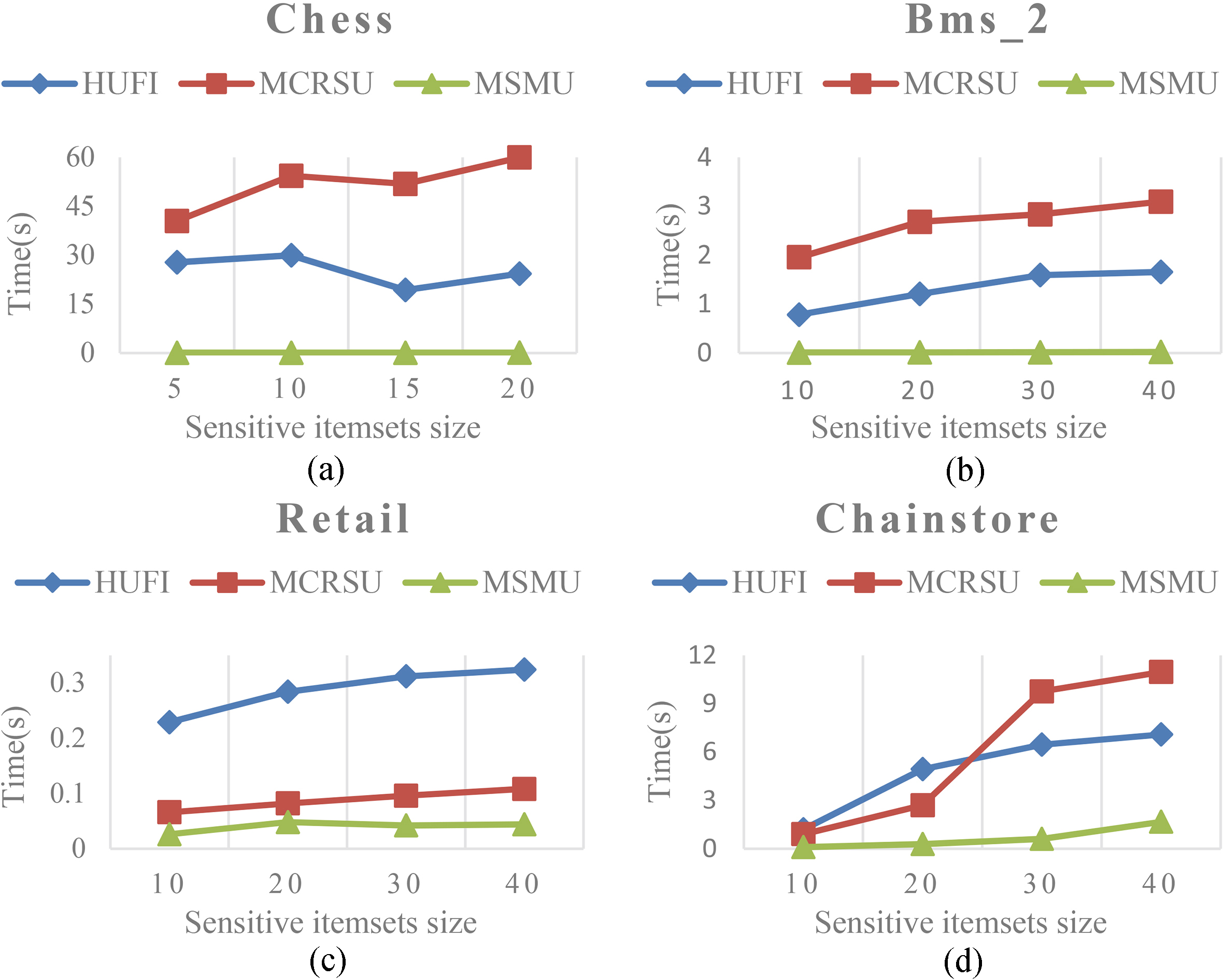
Figure 1 shows the runtime of each algorithm in various datasets as the sensitive itemsets size is increased. It can be observed that the runtime of algorithms are increased with the sensitive itemsets size increases. The reason is that when the number of sensitive itemsets raises, the utilities of sensitive itemsets also increase. Thus, more computations are required to identify the victim items to be modified. Results of the Fig. 1 indicate that MSMU algorithm outperforms the HUFI and MCRSU algorithms. This is because the MSMU and MCRSU algorithms firstly sort the sensitive transactions in ascending order of the number of sensitive itemsets supported by each transaction. Then the victim transaction is selected on the basis of the sorted sensitive transactions. For the MSMU algorithm, when a victim transaction is determined, the item with the minimum support and maximum utility is selected as a victim item. The MCRSU algorithm uses conflict ratio to identify the victim item, and the HUFI algorithm selects the item that affects the minimal number of non-sensitive itemsets and the maximal number of sensitive itemsets to be sanitized. Thus, MSMU algorithm takes less time than other algorithms. In addition, for a sensitive itemset
Execution time at various utility thresholds.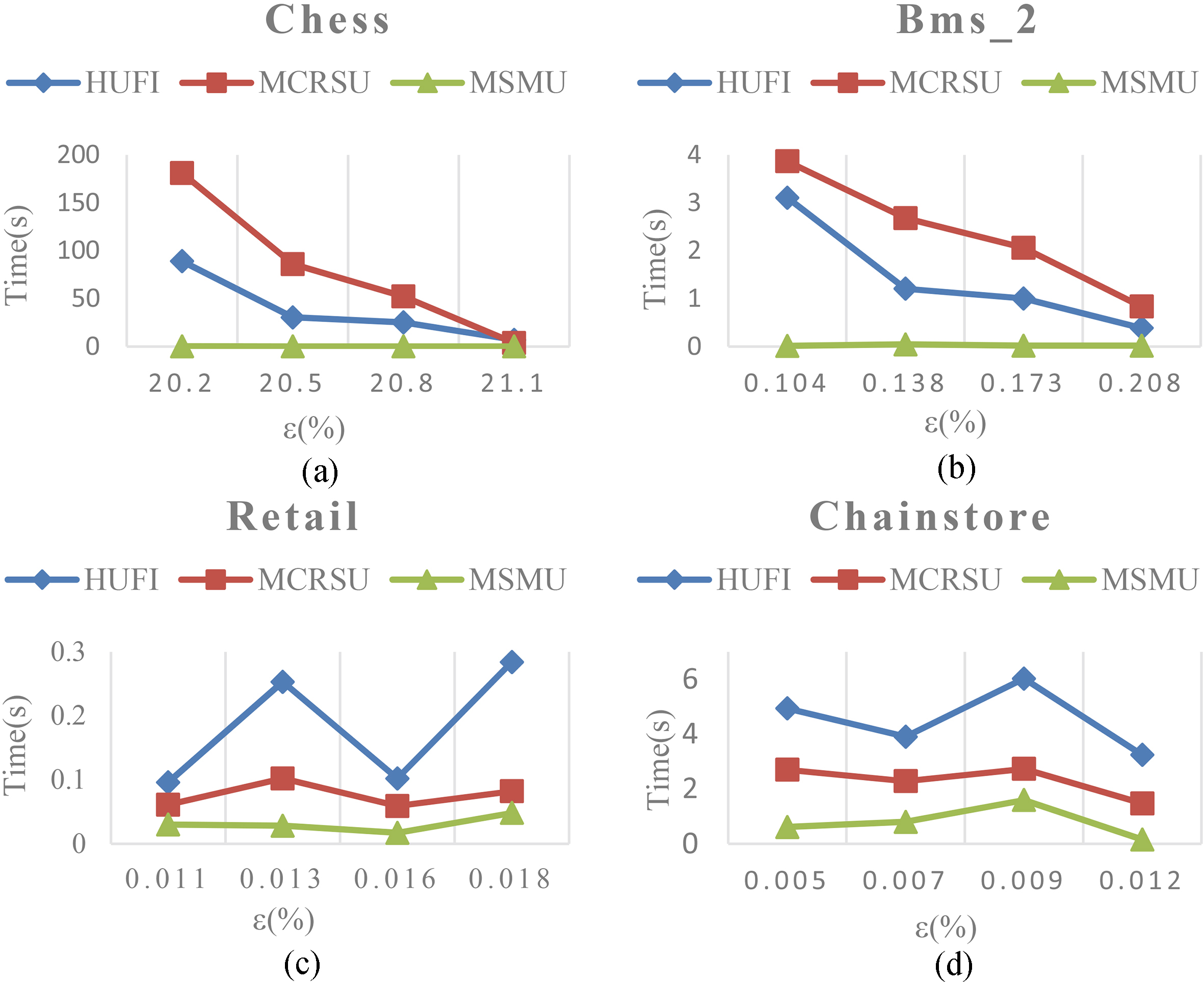
The execution time of the three algorithms under various utility thresholds
Execution time at various minimum support thresholds.
MC at various sensitive itemsets sizes.
MC at various utility thresholds.
The missing cost (MC) of the three algorithms under various sensitive itemsets sizes for the four datasets are displayed in Fig. 4. As shown in Fig. 4, the missing cost generally increases as the sensitive itemsets size increases. This is reasonable since when sensitive itemsets size is increased, the utilities that need to be reduced of the sensitive itemsets are also increased, and correspondingly the side effects on the non-sensitive itemsets are more serious. From Fig. 4, it also can be seen that the HUFI algorithm produces the lowest missing itemsets in each dataset. By applying the maximum boundary value to select the hidden strategy, HUFI algorithm effectively reduces the side effects on non-sensitive itemsets. However, the MCRSU and MSMU algorithms directly hide the sensitive itemsets by using the support reduction strategy without considering the impact on the non-sensitive knowledge. Besides, a sensitive itemset is hidden until the utility and support are below the thresholds respectively. Thus, the proposed HUFI algorithm has the best performance in minimizing the missing cost.
The missing cost of the three algorithms under various utility thresholds and support thresholds are respectively displayed in Figs 5 and 6. In Fig. 5, it can be seen that the HUFI algorithm achieves the best performance in minimizing the missing cost compared with the MCRSU and MSMU algorithms for all datasets. Especially in Fig. 5a, when utility threshold is 21.1%, the MC of HUFI is 20.7% while the MC of MCRSU and MSMU achieve 92.8% and 98.3% respectively. It is caused by the hidden method of HUFI algorithm. In addition, an interesting observation is that the MC of Chess dataset is greatly higher than that of Retail dataset. This is reasonable since Chess dataset is much denser than Retail and the average support of itemsets contained in Chess dataset is higher. As a result, the damage to the non-sensitive knowledge in Chess is larger. From the results displayed in Fig. 6, we find that the proposed HUFI algorithm achieves better performance compared to the other algorithms under various minsup. The reason is that the HUFI algorithm applies the concept of maximum boundary value to select a better hidden strategy for concealing sensitive itemsets. Thus, the HUFI algorithm is more flexible compared to the MCRSU and MSMU algorithms.
MC at various minimum support thresholds.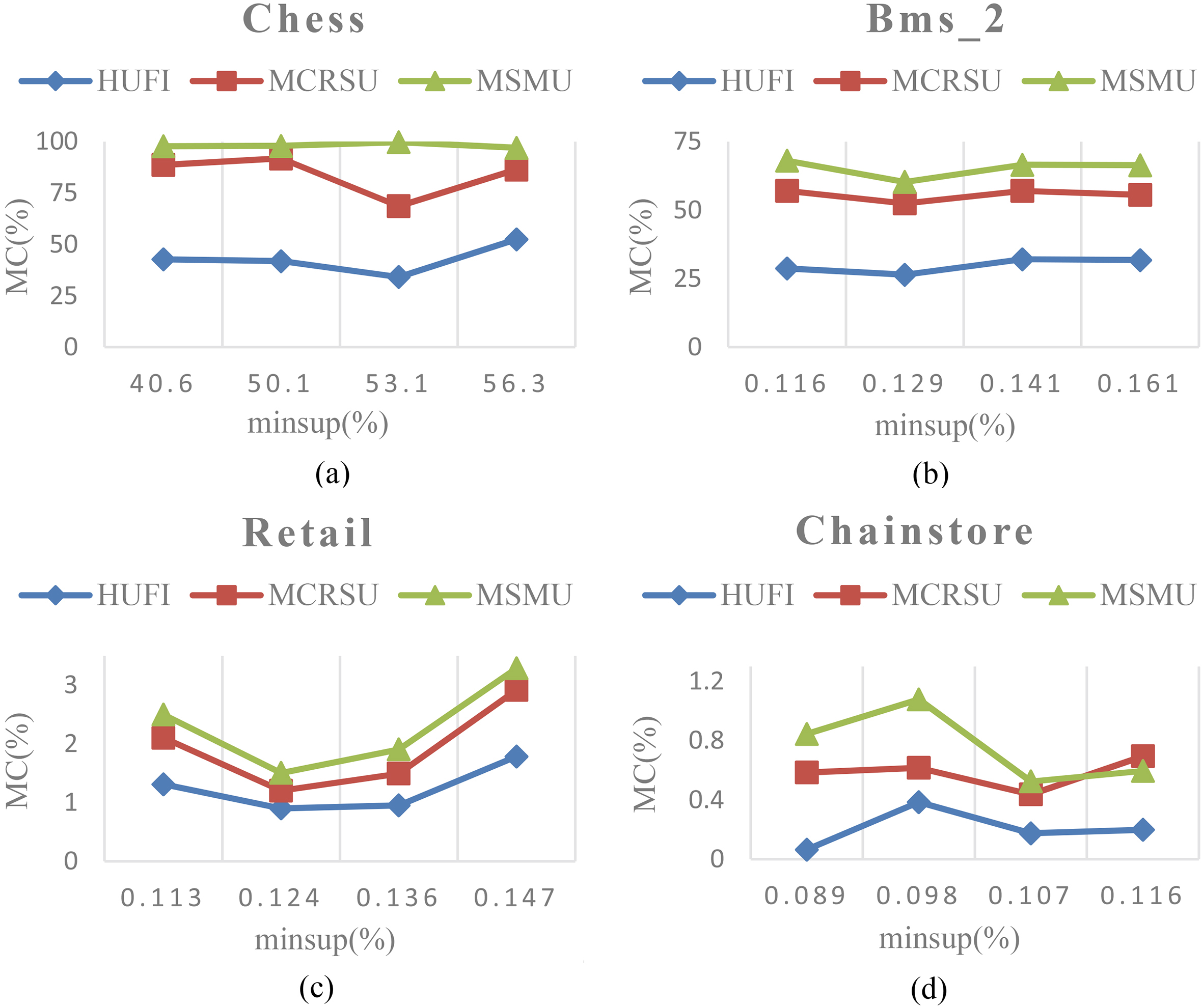
Diff at various sensitive itemsets sizes.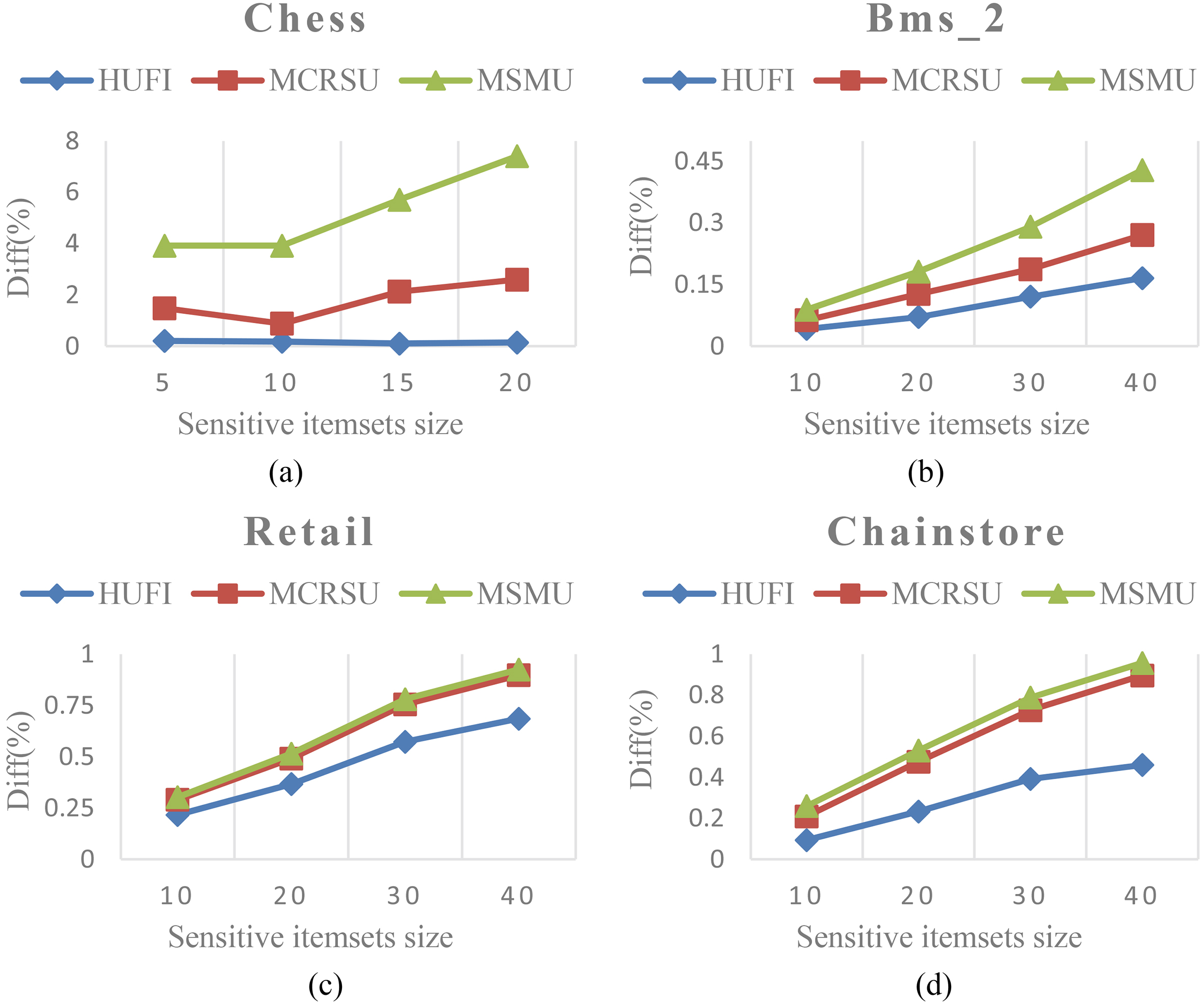
Diff at various utility thresholds.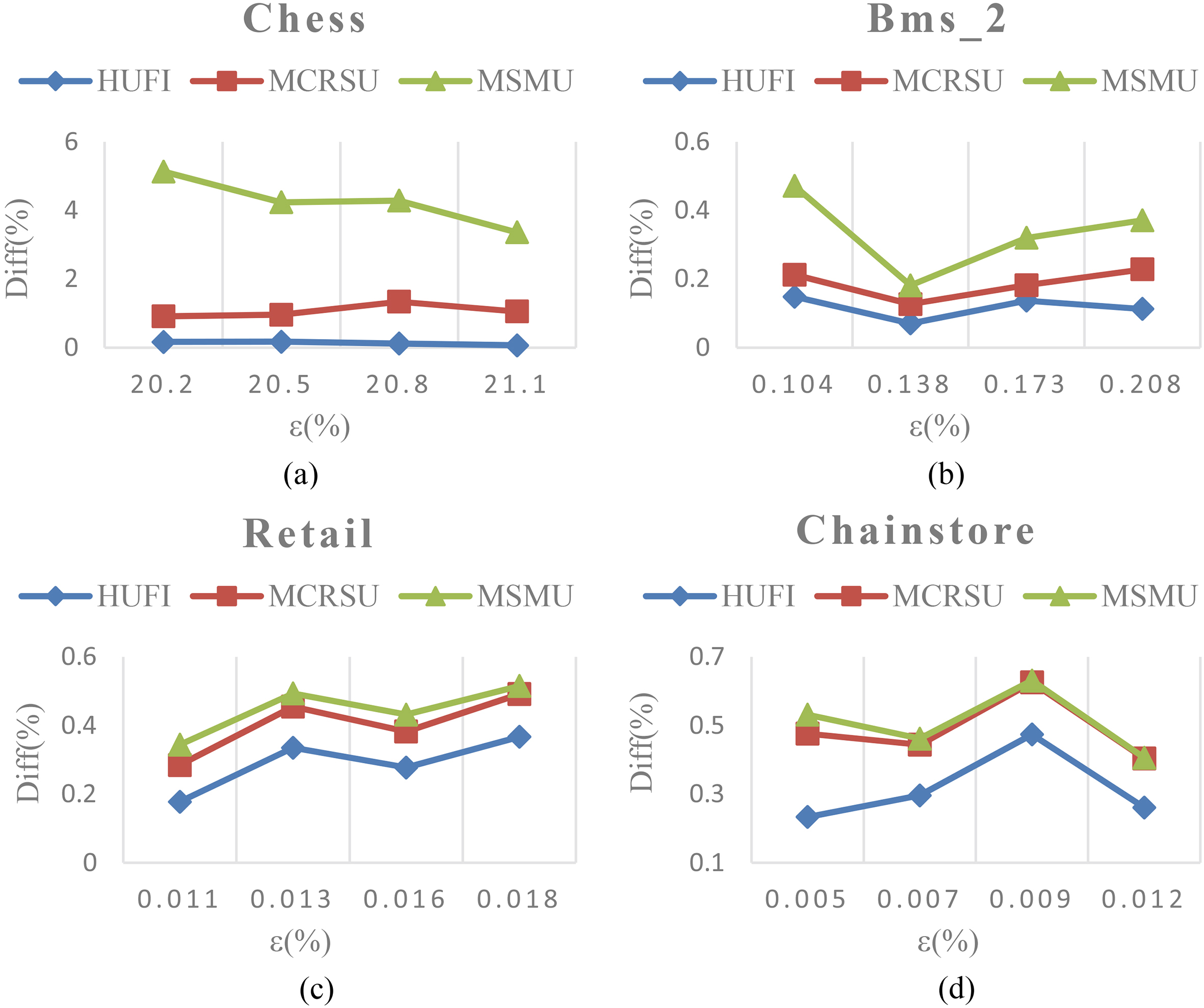
Diff at various minimum support thresholds.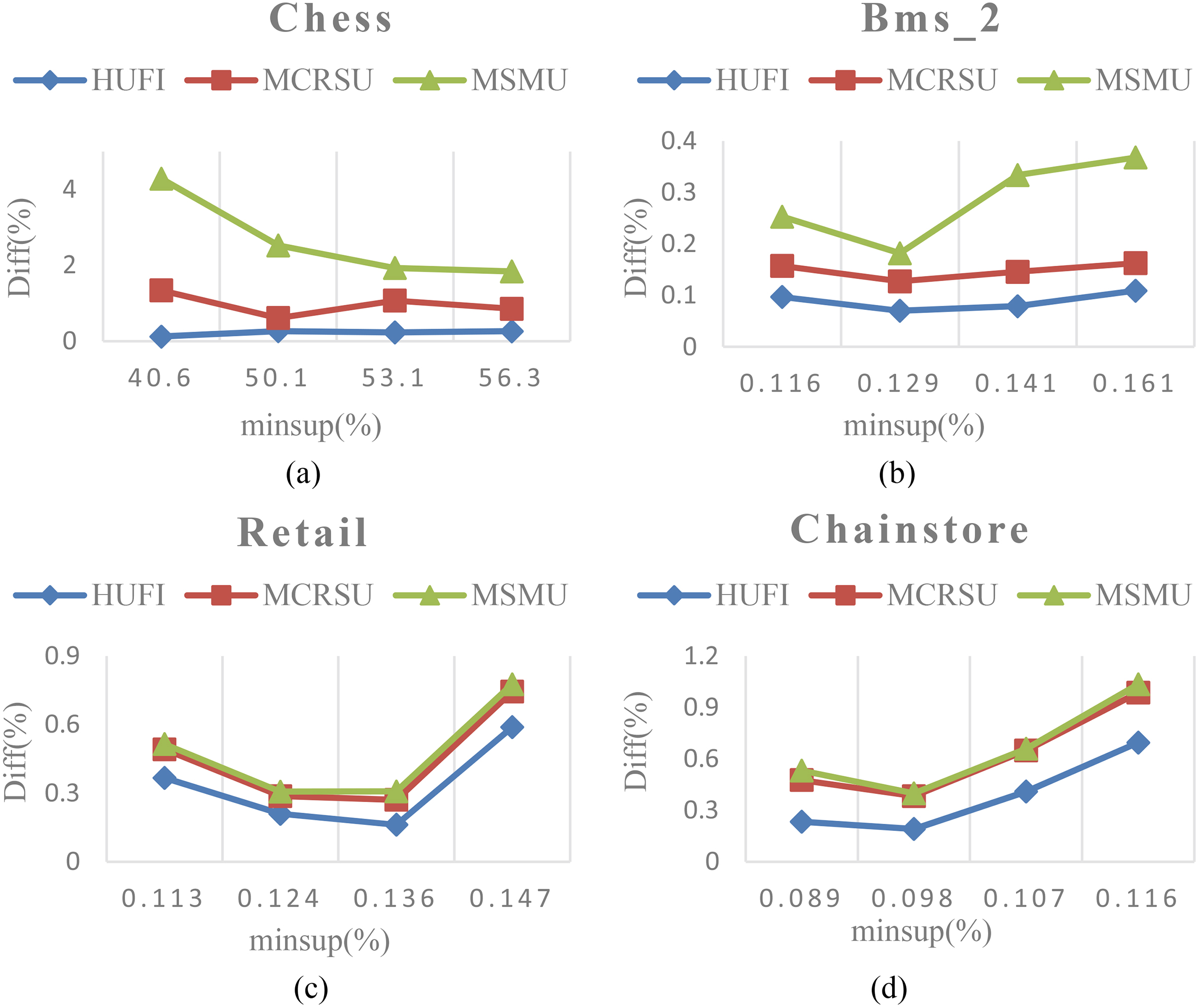
Database utility difference (Diff) is used to measure the utility difference between the original and the sanitized database. The measure can reveal the amount of utility that is lost after the sanitization process. A lower Diff indicates that less information is lost. Figure 7 shows the results of the HUFI, MCRSU and MSMU algorithms at various sensitive itemsets sizes for the four datasets. It is obvious to see that Diff is increased as the number of sensitive itemsets increases. This is reasonable since more sensitive itemsets are hidden and more information is lost. In Fig. 7, we also find that the proposed HUFI algorithm achieves better performance compared to the state-of-the-art algorithms MCRSU and MSMU. This is because the maximum boundary value is used as a criterion to select an appropriate hidden strategy in the HUFI algorithm. MSMU algorithm has the worst performance in term of Diff, because only the minimum support value and maximum utility value are utilized to choose the victim items. Besides, the impact on the non-sensitive itemsets is not taken into consideration. In addition, we note that the Diff of Chess dataset is much higher than that of the other datasets. Since Chess is a very dense dataset, the average support of itemsets contained in a dense dataset is higher. Thus, the modification of transactions in Chess dataset would cause more information lost after the sanitization process.
The database utility difference of the three algorithms for various
Conclusions
In this paper, a hidden algorithm named HUFI is proposed to conceal the sensitive utility and frequent itemsets. The designed algorithm utilizes the concept of maximum boundary value to determine whether the support or utility reduction strategy is adopted to hide a sensitive itemset. HUFI algorithm identifies a transaction that supports the minimum number of non-sensitive itemsets to be sanitized. In such a transaction, an item with the highest weight is selected as a victim item, which indicates that the item affects the maximal number of sensitive itemsets and minimal number of non-sensitive itemsets. The performance of the proposed algorithm is compared with the state of the art algorithms MCRSU and MSMU on real databases. The experimental results demonstrate that the HUFI algorithm has the better performance compared to the other algorithms in maintaining database quality and minimizing the side effects on non-sensitive knowledge. Another advantage of HUFI is that it provides more flexibility to hide sensitive itemsets. In addition, it is observed that the density of a database has a great impact on the performance of the sensitive knowledge hiding.
In the future, we will focus on utility and frequent itemset mining. The existing algorithms spend a lot of time mining the utility and frequent itemsets. How to design the pruning strategies to effectively reduce the search space is the main challenge.
Footnotes
Acknowledgments
This work is partially supported by NSF-China and Guangdong Province Joint Project (Grant No. U1301252); National Natural Science Foundation of China (Grant No. 61272543).