
Abstract
There is no standard definition of outliers, but most authors agree that outliers are points far from other data points. Several outlier detection techniques have been developed mainly for two different purposes. On one hand, outliers are considered error measurement observations that should be removed from the analysis, e.g. robust statistics. On the other hand, outliers are the interesting observations, like in fraud detection, and should be modelled by some learning method. In this work, we start from the observation that outliers are affected by the so-called simpson paradox: a trend that appears in different groups of data but disappears or reverses when these groups are combined. Given a data set, we learn a regression tree. The tree grows by partitioning the data into groups more and more homogeneous of the target variable. At each partition defined by the tree, we apply a box plot on the target variable to detect outliers. We would expect that the deeper nodes of the tree would contain less and less outliers. We observe that some points previously signalled as outliers are no more signalled as such, but new outliers appear.
Introduction
Data science is a field in constant and rapid evolution. More than ever before we are aware that, acquired knowledge from any data set allow us, not only to understand, but also to predict observations behavior. Normally we aim to identify relevant patterns among populations, but sometimes the most valuable information is not in the general pattern but in the deviant behaviors. Such uncommon observations, denominated as outliers, may be mere errors in measurement or may represent very important observations with very particular features of interest. Sometimes this kind of observations may not be so obvious as they are being intentionally disguised, for example, when trying to cover fraud. Geology studies or public health services are other fields which make the study of methods for outlier detection a matter of interest. There are different kinds of outliers and the technique we choose to use will depend on it. In this paper we propose a method to search for different contexts, in which we can uncover extreme outliers, regarding one specific variable of interest – target variable. Each scenario is chosen based on the other known variables that are used to divide the data in groups as homogeneous as possible. We also propose a score measure to assign to each observation. Using these results, we will point out that outlier detection may be an example of simpsons paradox [1]: a trend that appears in divided sets of data and reverses or disappears when combining them.
The paper is organized as follows: Section 2 introduces important definitions and related work regarding outlier detection; Section 3 presents the problem formulation; Section 4 shows our approach to to the problem; Section 5 presents the experimental results showing an illustrative example to explain the workflow of our method and a comparison of the results of our method and two baselines using a real life data set of a retail company [2], and in two known data sets; finally, in Section 6 we present the conclusions of this work.
Related work
Outlier definition
Outliers are observations that are considered abnormal. Hawkins [4] formally defined: “An outlier is an observation which deviates so much from the other observations as to arouse suspicions that it was generated by a different mechanism”.
Depending on the nature of the outlier, Singh and Upadhyaya [5] classified them as:
When looking for outliers, we must be aware of two possible situations: masking and swamping effect. These situations may disguise some outliers [6]. Both occur when deviant observations skew the mean and the covariance estimated towards it.
Different kinds of outliers require different detection methods. We can find in the literature many outlier detection techniques. Hodge and Austin [7] as well as Chandola et al. [8] or Aggarwal [9] summarize the most important of them. From those, we refer the statistic-based, proximity-based and clustering techniques. We also refer to studies conducted to specifically detect contextual outliers.
Statistical-based Techniques
Statistical-based techniques are divided in
Depending on the number of variables one may divide these techniques in
Two simple methods for univariate outlier detection are described next.
Two of the most known types of outlier detection techniques are distance-based and density-based, which are succinctly described next.
Although the use of clustering algorithms for the detection of outliers being more of a side effect than a goal itself, they may serve this purpose in a satisfactorial way. Assuming that a normal observation is in a cluster, close to the centroid of the cluster, or belongs to a large and dense cluster, we may define as outlier any observation that lies otherwise. A cluster with few observations in it, may be considered a group of outliers. However, it is a hard task to distinguish outliers from noise. Examples of clustering algorithms are K-means, k-medoids or K-NN wich use for instance Euclidean or Mahalanobis distance. Papers [7, 8] summarize the techniques mentioned as well as optimisation specially in what comes to running time and memory issius.
Contextual/conditional outlier detection
There are several outlier detection techniques with the specific goal of finding contextual outliers. We will briefly refer two of those.
Song et al. [13] propose an approach to detect anomalies that starts with the division of the variables of the data set in environmental and indicators attributes. The environmental attributes define different contexts and each observation is evaluated depending on the context. A statistical model is created to represent the data. It consists of a Gaussian Mixture Model to model the set of environmental attributes, an additional set of Gaussians to model the indicator attributes and a probabilistic mapping function between this two sets of Gaussians. The three algorithms presented to learn the model are based on the Expectation Maximization Algorithm for parameters estimation.
Also dividing the variables in contextual and indicative, Liang and Parthasarathy [14] present an approach (ROCOD) that uses weight combination of two measures: Local Expected Behavior and Global Expected Behavior. The first one refers to the average values of behavioral attributes of observations similar to each other in what comes to contextual variables. The second is computed using all the observations, learning regression models that use contextual attributes as input and each of the behavioral attributes. This approach aims to overcome the limitations of applicability presented by other approaches, in what comes to sparsity of the contexts. In both approaches there is the necessity of the user to choose the attributes that define the context.
Problem formulation
Let us assume a variable of interest
Still, rather than detecting outliers in a set of user pre-defined set of contextual variables, we aim to detect outliers in a target numeric variable using for that purpose other variables as context information to group the individuals of the population.
Thus, we can collect other variables that provide contextual information about the
Assuming two contextual variables
For this specific problem, the data set division must consider all the variables in the data set but there has to be an optimization criteria concerning the target variable while using the other variables to define possible contexts to test the mentioned optimization function.
Methods mentioned in Section 2.2 are designed to detect global outliers that use variables equally or divide the variables in indicators and contextual. The indicator variables do not have an influence on the groups created by contextual variables.
Our approach
Our goal is to find outliers regarding one variable when dividing the data set according to the other variables. These subsets should be well defined for results interpretation purpose. Next, we explain how the data partitioning is done. Based on the obtained partitions, we then explain how we assign a “outlierness” score to each observation of the target variable. This work is a large extension of our previous work [3].
Partition the data into different contexts
As mentioned before, data partition may lead to exponential combinations of subsets. To avoid so, and as we are targeting specifically one variable to detect outliers, we learn a regression tree for this variable using as explanatory variables the contextual ones. A regression tree grows by selecting the explanatory variables that present the higher reduction of the variance in the target variable. This way, we obtain subsets of growing homogeneity in terms of variance of
To learn the regression tree we will use the CART (classification and regression trees) algorithm, Breiman [15], from 1984. The basic idea is, at each node, to choose the best (binary) split based on the decreasing of the variance of the target variable. Depending on the target variable type, categorical or continuous, we have classification trees or regression trees, respectively. The splits are defined by the predictor variables. They also can be categorical or continuous. In the categorical case, the number of possible splits depends on the number of categories, if there are
The tree growth consists in the recursive partitioning of the tree from the root until a stopping criterion is reached. This happens repeating the following steps:
at each node compute the possible splits and choose the better one for each predictor variable; from the results of 1) choose the better split for the node; if a stopping criterion is not satisfied, divide the node using the result in 2).
The best split is the one that maximizes the splitting criterion. In the case that the target variable is continuous the goal is to decrease the variance of the target variable. It starts by computing the sum of squares for each node
There are different stopping criteria that may or may not be user defined. If the observations in a node present identical values for the target variable (pure node) or for the predictor variables the node will not be split. As for user defined parameters we have the depth of the tree, the minimum node size for a splitting takes place, a minimum size for each child node and a minimum to the improvement of the best split. The use of the regression tree provides automatically different scenarios that change as the tree grows. This way we will know which observations are abnormal at each context.
In this paper, we propose a method to detect outliers and assign score values to them. The goal is to measure the “outlierness” of an observation
[h]
BoxplotTree Algorithm
Given a regression data set
The “outlierness” score assigned to each observation
Experimental study
In this section, we present the results of the method previously described applied to a data set of a retail company regarding transaction of returned items. We also propose an experimental setup to validate our method and discuss the obtained results.
An illustrative example – fraud detection
This data set was the case study of [2]. The data refers to a large real-world retail company. The goal is to identify unusual cases that may suggest the occurrence of fraud in the returning of items process. For that purpose, and in order to make the inspection process effective, the identified outliers should be ranked by a score. We believe that this case study is one intuitive example in what comes to understand the importance of the context in an outlier detection problem.
The provided data set contains information on transactions of returned items collected in a three month period in fourteen different stores. At all we have 43206 transactions correspondent to the period from December of 2014 to February of 2015. Notice that in the respective period there are two days (December, 25th and January, 1st) on which the stores were closed to the public.
Table 1 summarizes the available variables for our analysis. To each observation is associated the total number of returned items as well as its average value when they happen in the exact same conditions. Meaning that each line represents a unique combination of Supervisor, Store, Region, Weekday, Period and Product Type. To each one of the combinations are associated the values of the target variables.
Fraud detection data set variables description
Fraud detection data set variables description
To understand how fraud may occur, we must know how the return items process takes place. Any customer is entitled to return an item if it is not satisfied with it as long as the item is in perfect condition, the establish period of devolution is not over and the proof of purchase is presented. At the store, a supervisor makes the return registration and reimburses the customer. In this process, fraud may occur in two different setups: one happens if the return process is fictitious, meaning there is no customer returning anything and the supervisor makes a refund to his advantage; another one is when the process occurs normally, the customer is reimbursed but the supervisor illicitly keeps the returned item for himself. In both cases there is no physical return of the item to the store although it will be an input to the theoretical stock.
Let us start with the univariate analysis of the variables
Basic statistics measures of TotalNr and AvgVal
Basic statistics measures of TotalNr and AvgVal
Boxplot analysis for the univariate detection of outliers in the target variables.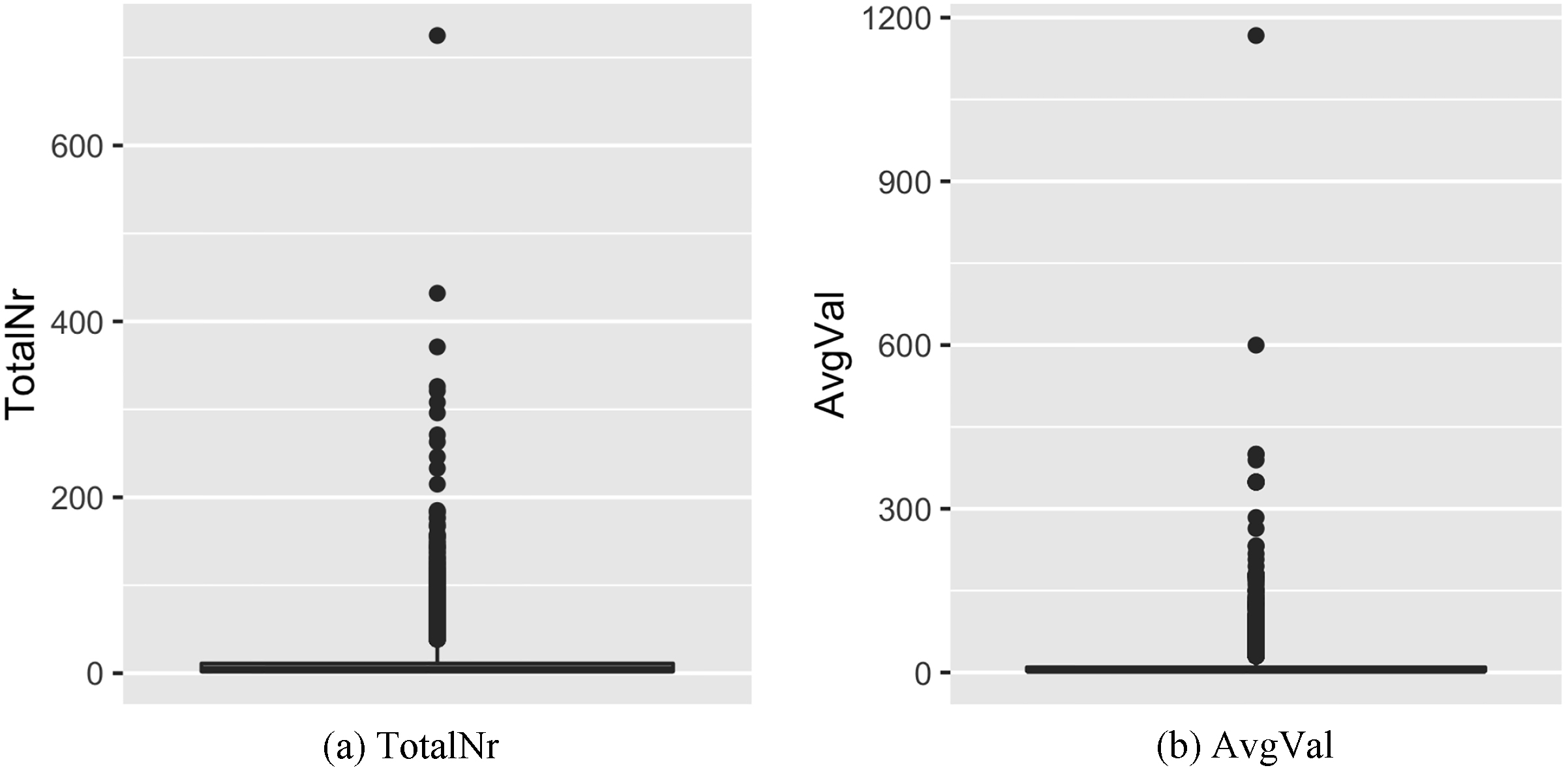
As mentioned before, the possible number of combinations when using the contextual variables to divide the data set and provide different contexts to each subset of variables may be exponential. To overcome this, as described in the previous section, we learned a regression tree for each one of the target variables using the categorical variables. We choose the CART algorithm [15], which is one of the best known algorithms and it is implemented on rpart package [16] using R language [17]. To illustrate the result, Fig. 2 shows the learned tree until depth four of the target variable TotalNr. At each node we can see information about the number of observations, the number of extreme outliers, and, how many of them were considered as such at the father node. As the tree grows, outliers “appear” and “disappear”. Each node represents a different context so the same observation may be considered as an extreme outlier in one node but not in the others. This figure exemplifies how easy it is to the final user the interpretation of the contexts generated by the regression tree.
To better illustrate the example, Table 3 presents information for five different observations about
for target variable TotalNr and considering a tree depth of 4
BoxplotTree analysis on TotalNr.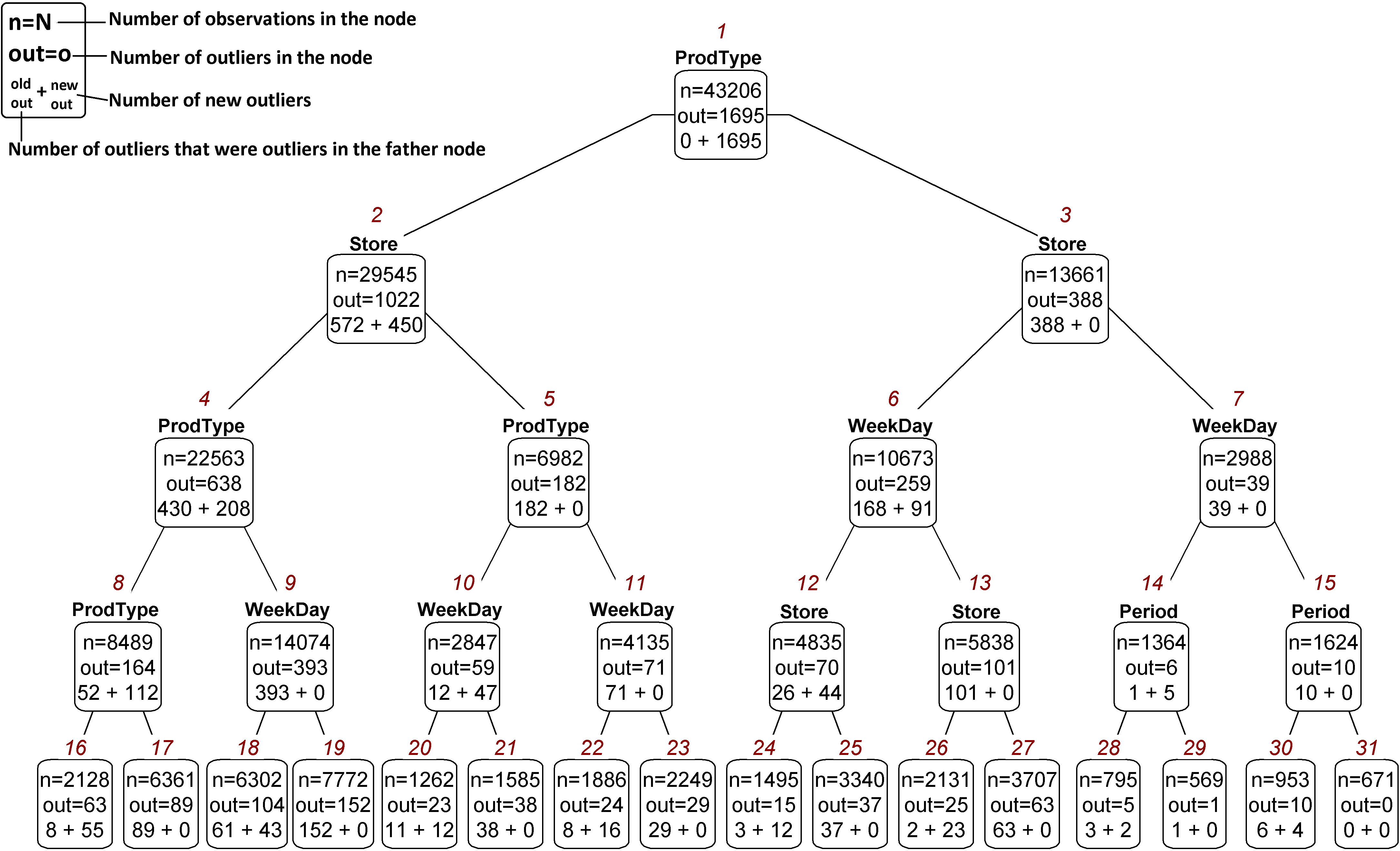
A negative value means that the observation was not considered extreme outlier at the level correspondent to the column. Observations 220 and 252 stopped being considered as extreme outliers after levels two and one respectively. Observations 269, 1022 and 1460 “appear” and “disappear” as outliers along the tree. Notice that observation 1460 was detected as extreme outlier for the first time at level one.
In what comes to assign a score value, we follow the BoxplotTree method described in Algorithm 1. For the regression tree we set cp
In order to have a comparison baseline, we compute the difference to the median normalized by the standard deviation of the extreme outliers detected with a simple Boxplot analysis.
Let us illustrate the process of wDist score calculation using the example of transaction 22152 that presents a TotalNr of 725. Table 4 shows the values we use for this purpose. This observation was considered as an extreme outlier at all the nodes. Each column refers to one level of the tree. The second line shows the node
wDist calculation for transaction
Table 5 shows the first twenty observations ranked by BoxplotTree as well as the variable value and the score value assigned to the the observations using the same method but considering only extreme outliers detected by a simple Boxplot. The rank is presented between parenthesis.
We can observe that the observations are ranked differently by the two methods. BoxplotTree increases the importance of the observations that were considered extreme outliers in other tree levels besides the root. Notice observation 28442 who occupied the 3
Scores and rank values by Boxplot and BoxplotTree for the target variable TotalNr
In order to get a real conclusion as if fraud is occurring or not, a deeper inspection is needed. The presented method is only a tool that suggests suspicious observations not only by the abnormal value they may present but also by their capacity to integrate a group with similar characteristics and not be considered as an extreme outlier.
Due to the sensitive of the matter, the access to the ground truth of the fraudulent transactions in this real life case was denied to authors of this paper. However, the fact that instances that were detected as extreme outliers in higher levels of the tree were observations of interest was confirmed.
As it is very difficult to obtain data sets with ground truth results regarding outlier detection, we propose the following experimental setup to validate the effectiveness of our method. We use a 10-fold cross validation method to compare the mean absolute error of predictions made by rpart [16] when no observation is removed from the training set and when outliers detected by some baseline methods and by BoxplotTree are withdrawn from the training set. Our assumption is that removing outliers from a training set should, in principle, improve the predictions and thus reduce the error of the model.
As baseline methods, we use the Boxplot analysis and LOF. At each iteration, we compare the Mean Absolute Error (MAE) of the predictions obtained when using as training set:
all observations; all observations except the ones considered severe outliers by the Boxplot; all observations except the outliers detected by BoxplotTree; all observations except the outliers detected by LOF.
Number of outliers in common detected by Boxplot (BP), BoxplotTree (BPTree) and LOF
Besides the Fraud data set described in Section 5.1, we also performed experiments on UCI data sets Housing and Energy Efficiency described below.
Housing data set: data set used in the CART book [15]. The regression problem consists of predicting the house value in the suburbs of Boston. We use the version of the data set available at the UCI repository [18]. It consists of 506 instances evaluated in 14 variables, 12 of them continuous, 1 binary and the target variable, “MEDV” which is the house value. Energy efficiency: data set created by Angeliki Xifara and processed at University of Oxford, UK [19]. It consists of 768 instances (buildings) characterized by eight real and integer variables. There are two target variables – “Heating Load” and “Cooling Load”. Due to redundant results in what comes to outlier detection we chose to show the “Cooling Load” results.
Regarding the outliers detected by the Boxplot Analysis, we consider only the extreme ones as explained in Section 2.2.1. As for LOF, due to the fact that it takes a long time to process the score values with a large number of neighbors, we decide to use only 3 neighbors. For each data set the score value was chosen based on a percentage of outliers of approximately 4% of the data set instances. We chose the MAE to compare the predictions of the four cases mentioned above since it is more robust to the presence of outliers.
Figure 3 shows the distribution of OutScore values assigned by the BoxplotTree at one of the iterations for the four regression problems. The results of the ten iterations were all very similar. As expected, most scores present a negative value, meaning that they were not considered as outliers at any level of the regression tree, or they were considered as outliers in some context but the value was not very significant. The tendency is to a very small quantity of observations present score values above zero. The Energy Efficiency data set does not present any score above zero for any of the ten training sets. So, from this point forward, we are not going to consider this data set for the experiments.
P-value for the Wilcoxon Signed Rank Test performed on the results obtained by considering the all the observations (O) and removing the oultliers detected by Boxplot (BP), BoxplotTree (BPTree) or LOF
OutScore distribution regarding the target variable of each data set obtained by BoxplotTree.
Lets start the analysis of the results by comparing the outliers detected by each method. If we observe Table 6, we see that BoxplotTree detects the outliers detected by Boxplot and more. However, LOF detects only 38 and 39 outliers in common with Boxplot and BoxplotTree, respectively.
The results for the same data set but the target variable “AvgVal” are similar, as shown in Table 8 in the Appendix section. Also in the Appendix section, we present Table 9 that shows that, for the Housing data set, Boxplot and BoxplotTree detect exactly the same outliers but none of them are in common with the ones detect by LOF.
Figure 4 presents the boxplot of MAE regarding Fraud and Housing data sets. In the Fraud case, considering both target variables, it is suggested that the MAE values decrease considerably when withdrawing the outliers detected by Boxplot and BoxplotTree. At the Housing example, this decay is not as notorious and when removing outliers detected by LOF the median is higher. The outliers detected by the BoxplotTree and the Boxplot analysis are the same.
We used a one-tailed Wilcoxon signed rank test with the hypotheses
Mean absolute errors (MAE) Boxplots.
Target variable vs prediction absolute error for the Fraud Nr. data set when considering all the observations in the original data set, removing the outliers detected by Boxplot (BP), BoxplotTree (BPTree) and LOF.
For a 0.05 significance level, we conclude that, in fact, the MAE for the Fraud case are significantly lower when withdrawing the outliers detected by the BoxplotTree than the considering all observations or the ones when withdrawing the Boxplot or LOF outliers from the training set. In the Housing data set none of the differences are significant.
Another interesting result is presented in Fig. 5. The four plots show the target variable value and the absolute error of the prediction. Regarding the Fraud data set on both target variables (Fig. 7 at the Appendix), when outliers are removed we notice that the linear tendency observed between the target variable and the absolute error of the predictions is much clear. The predictions made using the original data set do not present such a clear tendency in what comes to absolute error then the predictions made when withdrawing outliers, specially the ones detected by the Boxplot analysis and BoxplotTree. The higher the target value, the higher the error. For the Housing data set example this tendency does not show (see Fig. 7 in the Appendix).
In order to understand if an observation could be considered an outlier or not according to one target variable, we should contextualize it considering the other available variables.
Learning a regression tree automatically provides different contexts at each node, and combining it with the boxplot analysis we were able to uncover conditional outliers in different data sets as well as score and rank them.
As expected, some extreme outliers “disappear” but some “appear”. These last cases are of special importance, as we would expect that observations with similar characteristics would show similar values in the target variable.
We may say that BoxplotTree measures how an observation may or may not fit in a subgroup of observations that is becoming more restrict and homogeneous in what comes not only to the target variable, but also to the contextualizing variables.
The appearance and disappearance of outliers seems to be an instance of the simpson’ paradox. Different outliers are detected depending if we take partitions of a data set or if we use the data set as a whole. Outliers change when context changes.
The score value assigned to an observation is based on the distance to the median of the target variable normalized by its standard deviation along the nodes of the tree. The higher scores may not be assigned to the most persistent outliers in terms of times they are considered as such. The number of observations at the respective nodes influences the score values, the higher this number, the higher the importance. Our method suggests possible contextual outliers, but only deeper investigations can show the meaning or reason for such deviant observations.
Experimental results show a decrease of the MAE, mean absolute error, of predictions made when outliers detected by the BoxplotTree are removed from the training set. As future work, we plan to extend our experiments by including other regression methods such as support vector machines, neural networks, random forests. We also intent to inspect the impact that different parameterizations of CART has on our proposed method.
Overall, we think that this context outlier detection and scoring method may be a robust tool in many applications such as fraud detection, medical diagnosis or earth science.
Footnotes
Acknowledgments
This research was carried out in the context of the project FailStopper (DSAIPA /DS /0086/2018). We also acknowledge the support of the project TEC4Growth RL SMILES Smart, mobile, Intelligent and Large Scale Sensing and analytics NORTE-01-0145-FEDER-000020 which is financed by the North Portugal regional operational program (NORTE 2020), under the Portugal 2020 partnership agreement, and through the European regional development fund. João Gama acknowledges the project ML-ABA – Machine Learn based Adaptive Business Assurance, Individual Demonstration Projects, NUP: FCOMP-01-0202-FEDER-038204, a project co-funded by the Incentive System for Research and Technological Development, from the Thematic Operational Program Competitiveness of the national framework program – Portugal2020.
Appendix
Outliers quantities – Fraud AV
BP
%
BPTree
%
LOF
%
BP & BPTree
BP & LOF
BPTree & LOF
1
1334
3,43
1408
3,62
597
1,54
1334
22
26
2
1335
3,43
1348
3,47
609
1,57
1335
21
21
3
1326
3,41
1386
3,56
590
1,52
1326
22
27
4
1347
3,46
1406
3,62
607
1,56
1347
16
19
5
1332
3,43
1388
3,57
637
1,64
1332
25
27
6
1339
3,44
1401
3,60
629
1,62
1339
18
24
7
1315
3,38
1374
3,53
611
1,57
1315
20
23
8
1330
3,42
1388
3,57
604
1,55
1330
21
26
9
1316
3,38
1373
3,53
601
1,55
1316
14
18
10
1334
3,43
1388
3,57
609
1,57
1334
18
22
Outliers quantities – Housing
BP
%
BPTree
%
LOF
%
BP & BPTree
BP & LOF
BPTree & LOF
1
15
3,29
15
3,29
12
2,63
15
0
0
2
15
3,29
15
3,29
14
3,07
15
0
0
3
15
3,29
15
3,29
12
2,63
15
0
0
4
15
3,29
15
3,29
12
2,63
15
0
0
5
16
3,51
16
3,51
13
2,85
16
0
0
6
12
2,63
12
2,63
13
2,85
12
0
0
7
16
3,51
16
3,51
8
1,75
16
0
0
8
14
3,07
14
3,07
12
2,63
14
0
0
9
14
3,07
14
3,07
7
1,54
14
0
0
10
15
3,29
15
3,29
15
3,29
15
0
0
Target variable VS Prediction absolute error. Target Variable VS Prediction Absolute Error.