
Abstract
Short-term traffic flow prediction plays a crucial component in transportation management and deployment. In this paper, a novel regression framework for short-term traffic flow prediction with automatic parameter tuning is proposed, with the SVR being the primary regression model for traffic flow prediction and the Bayesian Optimization being the major method for parameters selection. First, the preprocessing of raw traffic flow is carried out by seasonal difference to eliminate the non-stationary of the data. Then, Support Vector Regression model is trained by the pre-processed data. In order to optimize the model parameters, the generalization performance of SVR is modeled as a sample from a Gaussian process (GP). Bayesian optimization determines the parameters configuration of the regression model by optimizing the acquisition function over the GP. Finally, the optimal short-term traffic flow regression model is constructed through repeated GP update and iteratively multiple training of the model. Experiment results show that the accuracy of proposed method is superior to methods of classical SARIMA, MLP-NN, ERT and Adaboost.
Keywords
Introduction
With the economic development and people’s increasing demand for convenient transportation, the vehicles have been experienced fast-growth in recent years, which brings tremendous traffic pressure for limited road resources. Accurate traffic flow prediction could estimate the congestion level of the road, therefore leading the driver to choose the best route to reach the destination and providing more effective guidance to traffic authorities[22]. Among the numerous branches of Intelligent Transportation System (ITS), short-term traffic flow prediction plays a fundamental role and is also a challenging task to be calculated due to a lot of influencing factors. Therefore, short-term traffic flow forecast in recent decades has attracted the attention of many researchers.
Through the mining and learning of the changing trend of traffic flow, and combing the current traffic flow data to predict the future traffic flow, a traffic flow forecast model is constructed. Formally, given a traffic flow time sequence
Since traffic flow prediction is a nonlinear regression problem, the value of the predicted target is not a simple linear relationship with the existing data. To resolve this, in this paper, we choose SVR as basic method for predicting traffic flow. Through the kernel function, the low-dimensional traffic flow data can be transformed into high-dimensional space, and then the regression prediction problem is transformed into a convex quadratic programming problem by constructing a linear decision-making function. SVR could reach the global optimal solution by employing structural risk minimization principle, so that it can avoid falling into the local maximum. As the same with the almost all machine learning algorithms, they are rarely parameter-free. The parameters determine the generalization ability of the underlying SVR model. However, parameter tuning is often a “black art” requiring expert experience, rules of thumb, or sometimes bruteforce search[16]. Nearly all machine learning methods that are used to predict traffic flow have not proposed an effective method to solve the problem of parameters adjustment, which makes the model almost impossible to achieve the optimal effect. Thus, this restricts the development of machine learning algorithms in the field of traffic flow forecasting.
Therefore, in this paper, we propose a new framework, called BO-SVR, for short-term traffic flow forecasting. First, The idea of SARIMA is used to process the traffic flow data to ensure the stationary. Then SVR is selected as basic regression method, data related to traffic flow at preceding periods is considered as input, and traffic volumes at current period are considered as output. The RBF kernel function is used in this SVR model. There are three parameters in SVR: the penalty parameter
The remainder of this paper is organized as follows. Section 2 is related work. Section 3 introduces support vector regression, which is preliminaries for later sections. Section 4 describes the details of the Bayesian optimization based SVR model. Then, experimental process and experimental results which compared with other mainstream methods are presented in Section 5. Finally, some conclusions and directions for the future works are given in Section 6.
Related work
A wide variety of approaches have been proposed for short-term traffic flow forecasting. From the view of spatio-temporal algorithms, the modeling and prediction of traffic flow are based on the probabilistic graph perspective. There are some methods like Markov chains[23], Markov random fields (MRFs) and Kalman filters[13, 21] which have shown the best experimental results. In contrast with the spatio-temporal methods, single-location prediction model is easy to acquire and it is more practical. Therefore, in this paper, we focus on the study on accurately and efficiently predicting traffic flow at single locations. For single-location traffic flow prediction, classical time-series approaches have played an important role. Box and Jenkins[1] are important contributors to this field. They put forward autoregressive moving average (ARMA) algorithm that has achieved reasonable results in traffic flow prediction. Since then, enhanced versions of ARMA, such as ARIMA, seasonal ARIMA, are widely used in traffic flow forecasting. These models can capture the dynamics of linear system well. However, traffic flow forecasting is a non-linear problem, these models are unable to achieve the best predictive results for traffic flow prediction. Research shows that machine learning methods usually have better ability to capture the uncertainty and complex nonlinearity of traffic flow time series. There are three commonly used methods: support vector regression (SVR)[17], artificial neural networks (ANNs)[11] and Bayesian networks[18]. Recently, deep learning has also drawn a lot of academic and industrial interests[10]. For almost all machine learning algorithms, careful tuning of parameters is inevitable. The failure to choose the optimal parameters has become an important factor hindering the performance improvement of the algorithm.
In order to maximize the rate of learning and the capacity of the underlying model, in recent years, some experts have put forward automated method to optimize parameters of machine learning. Specifically, we could regard the process of parameters adjustment as the maximization of a black-box function[16], regard parameters of the model as independent variables of the function, and regard the generalization ability of the model as dependent variables of the function. Through the optimization method to obtain the maximum value of the function, a set of optimal parameters are obtained. For this reason, the traffic flow forecasting model based on the machine learning method can achieve the best learning performance. There are many function optimization methods, such as gradient optimization methods or Monte Carlo sampling methods. However, there is no specific expression for the function that needs to be optimized in this paper. The particle swarm optimization (PSO) algorithm may fall into the local optimal solution[15]. A good choice is Bayesian optimization[12], which has been shown to outperform other state of the art global optimization algorithms on a number of challenging optimization functions[5]. Jasper et al.[16] also proved the application of Bayesian optimization in machine learning achieved good results by theory and experiment.
Support vector regression model
Traffic flow at a fixed point is influenced by many factors and has great variability. The prediction of traffic flow is quite complex, which is a typical nonlinear time series forecasting problem. There are many nonlinear prediction methods which are presented for time series prediction. Support Vector Regression (SVR) based methods are one of the widely applied methods and can achieve satisfactory results in predicting small sample high dimensional data, nonlinear problem and local minima problem, etc.[4]. SVR as a machine learning method was firstly proposed in 1996 by Drucker et al.[3]. It is based on the statistical learning theory and has strict mathematical basis, which enhances the generalization ability by employing structural risk minimization principle and provides better predictions to many practical problems[4].
For a given traffic flow training data
where
where
In Eq. (3), the non-sensitive loss parameter
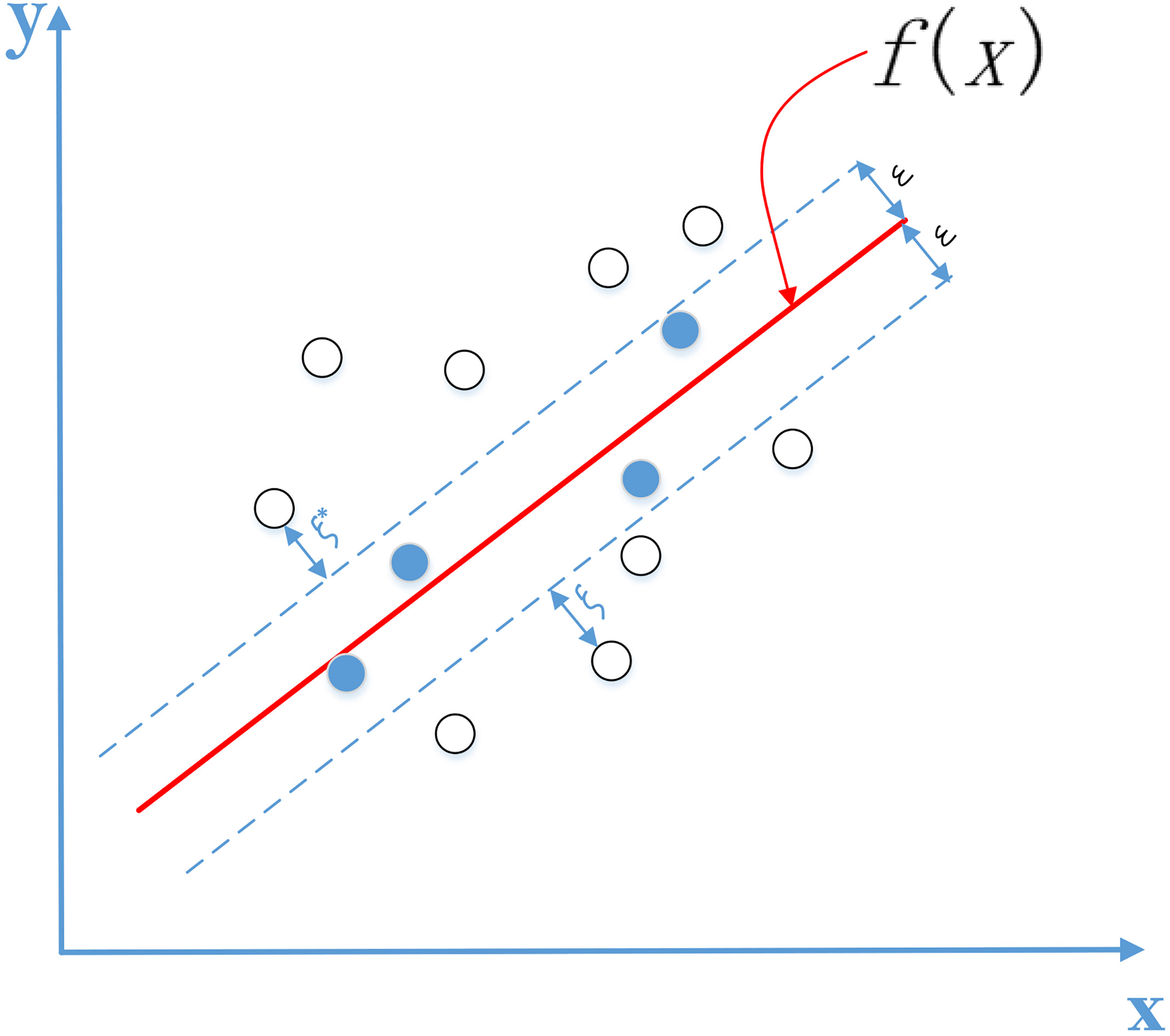
In order to minimize Eq. (2), introducing Lagrange multipliers, and the Lagrange function can be obtained as follows:
then, calculate the partial derivatives of the four independent variables
substituting the above Eqs (5)–(8) into Eq. (3), the problem of Eq. (2) can be transformed into the following dual problem, which is a convex quadratic problem.
The above process is constrained by KKT optimality conditions:
Finally, the regression result can be expressed as:
where
here,
In training the SVR model, the traffic flow data collected in the past is used as input value, and the traffic flow at the current moment is regarded as the output value. For parameter settings, in traditional support vector regression, it is usually manual tuning that can not achieve best results. To improve this, we propose an efficient Bayesian optimization based method that selects parameters automatically.
Bayesian optimization
Bayesian optimization is an effective method for finding the extrema of objective function that does not have a closed-form expression, but can obtain observations by sampling. What makes Bayesian optimization different from other approaches is that it constructs a probabilistic model for objective function
There are two major parts that must be discussed when introducing Bayesian optimization. First, prior distribution expresses assumptions about the function being optimized, so it must be discussed in detail. Because of the flexibility and tractability of the Gaussian process prior, here we choose it as prior over functions. The second point is acquisition function, which is used to construct a utility function to determine the next point to evaluate. Next, we will review the Gaussian process prior and acquisition function. For a detailed overview of the Bayesian optimization formalism, see, e.g., Brochu et al.[2].
Gaussian process
Gaussian process (GP) offers a convenient and powerful prior distribution over the space of smooth functions. A Gaussian process is a set of infinite number of random variables, where any finite number of random variables are subject to a joint Gaussian distribution[14]. The sampling points on an unknown function can be treated as random variables of GP, so it can be assumed that the function conforms to the Gaussian process. The formula is expressed as follows:
The support and properties of Gaussian process are determined by its mean function
is a popular choice for Gaussian process. Matérn kernel is another popular choice of the covariance function[6].
Let’s initialize the sample points from the objective function. We would get
where the diagonal values are 1 and this matrix is the positive definite matrix. Note that we are considering in a noise-free environment. Also, recall that we have chosen the zero-mean function for simplicity.
In each iteration of our optimization task, we use the sampled data to fit the GP and obtain a posterior distribution from an external model. For each iteration we use acquisition function combining the posterior distribution to decide what point
where
where
So far, we have discussed the Gaussian process priors over the objective function, and how to update these prior knowledges according to the new observation.
As mentioned earlier, the acquisition function is used to determine the next point to evaluate, thus it guides the search to the optimum. In Bayesian optimization, the acquisition function could be viewed as a surrogate function, which is easy to evaluate, to optimize the expensive functions. Typically, the high value of the acquisition function corresponds to the potential maximum of the objective function. Because the high acquisition represents the prediction of the objective function is high or the uncertainty is great. Maximizing the acquisition function is used to determine the next point at which to evaluate the objective function. That is, we wish to sample
There are several popular choices of acquisition function, which either using improvement based criteria or using confidence based criteria. The following are introduced separately. In the following,
The strategy of PI is to maximize the probability of improving over the best current value[7]. The attendant drawback is that this formulation is pure exploitation without exploration. As a result, an alternative acquisition function is Expected Improvement(EI), which chooses to maximize the expected improvement over the current best.
Another acquisition function is GP-UCB[19], which uses the upper confidence bound of the GP predictive distribution.
where
In this paper, we will focus on the EI criterion, as it has been shown to be better-behaved than PI, but unlike GP-UCP, it does not require its own tuning parameter. In each iteration, we use the acquisition function to determine whether to exploit or to explore in next sampling. Eventually, the global maximum of the objective function can be obtained instead of the local maximum.
As mentioned above, it is difficult to achieve optimal learning results by manually adjusting the SVR parameters. To improve this, therefore, we propose an effective support vector regression approach based on Bayesian optimization (BO-SVR) for short-term traffic flow prediction.
In the section II, SVR is introduced, which has three tuning parameters
In order to optimize these parameters automatically, we could view such tuning as the optimization of an unknown black-box function
[h] .BO-SVR Algorithm[1] Input: The initial observation
Traffic flow collection sites selected.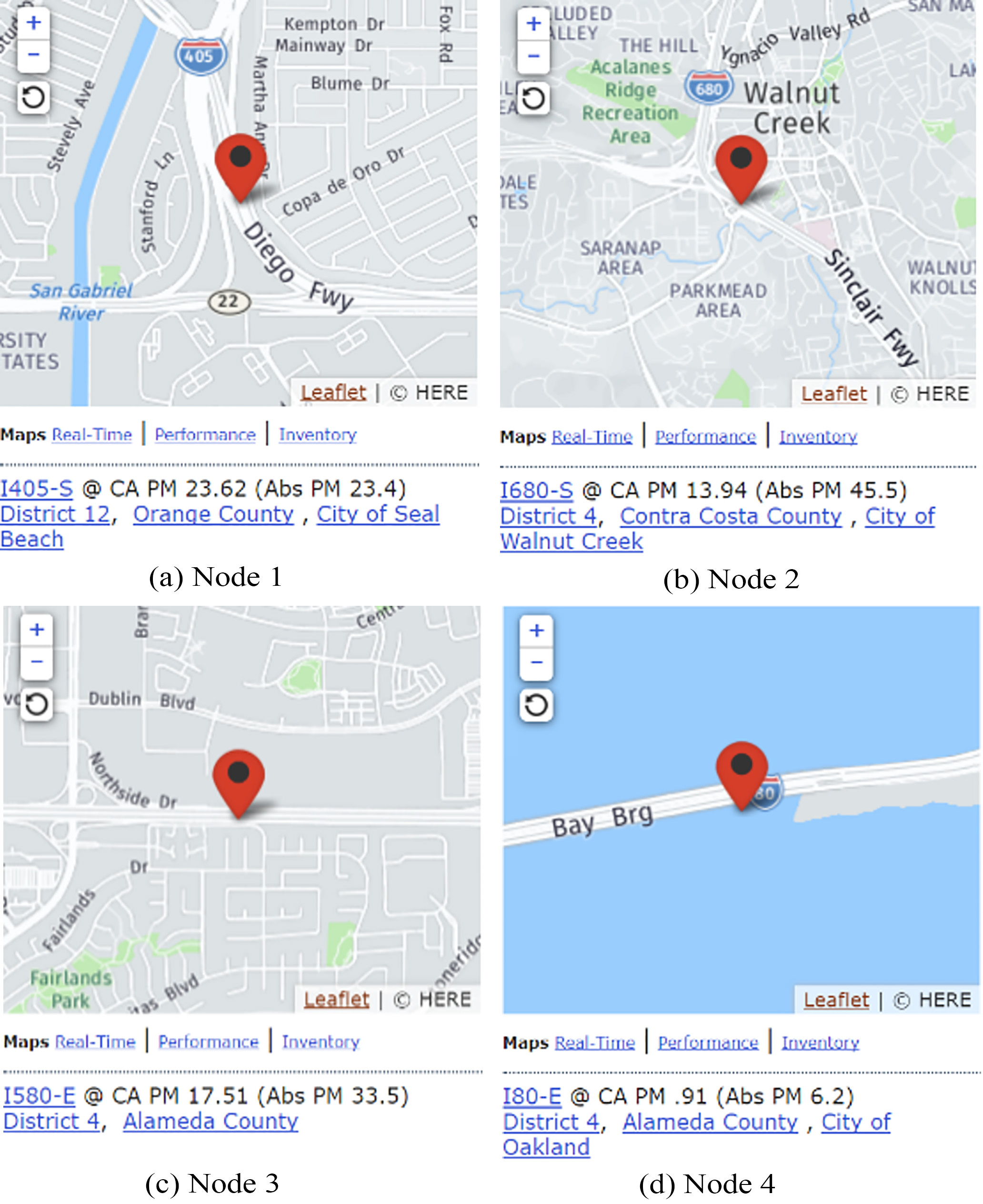
Experimental settings
Data Sets:The data we used for traffic flow prediction is downloaded from Caltrans Performance Measurement System (PeMS) public database, which is the most widely used data set in traffic flow prediction. There are over 15000 individual detectors located all over the state in the freeway system of California. The data is collected every 30 seconds from these detectors. Then, the data is aggregated as counts of cars into 5-min periods and is uploaded to the Internet for researcher to use. In our experiment, we further aggregate the data into 15-min periods. Then, we select 4 typical detectors for study since roads in these cases attract more attention for transportation research. As shown in Fig. 2, Node 1 is a busy road section with larger traffic flow. Node 2 is selected, for its location being near cross roads. Node 3 is the main road, and Node 4 is on the bridge.
The time range selected is from 2017-9-25 to 2017-10-9,from 2017-6-25 to 2016-7-9 and from 2017-9-25 to 2017-10-9. We use the data of the first 2 weeks as the training set and the remaining data as the testing set, mainly used for predicting two peak periods flow including 5:00–10:00 AM and 5:00–10:00 PM, the predicted intervals are 5 minutes and 15 minutes. Inspired by the SARIMA model[20], we perform the following pre-processing in order to ensure the stationary (For detailed explanation, please refer to Appendix) of the data. Denoting
Evaluation metrics: Performance of time series forecasting is typically using error measures. To evaluate the effectiveness of our proposed model, we use three performance indexes, which are mean absolute percentage error (MAPE), root mean square error (RMSE), mean absolute error (MAE). MAPE is a measure of prediction accuracy of a forecasting method. It usually expresses accuracy as a percentage, and we can get the prediction accuracy(m) by
where
Experimental Design: The performance of the proposed traffic flow forecast method (BO-SVR) is examined with two parts. The first set of experiments is designed to verify the effectiveness of Bayesian Optimization for parameter selection of traffic flow method based on support vector regression. The second group will compare to other classical traffic flow prediction methods, with aim of verifing the overall effectiveness of our proposed method.
Performance comparison of using default parameters and using parameters selected by Bayesian optimization.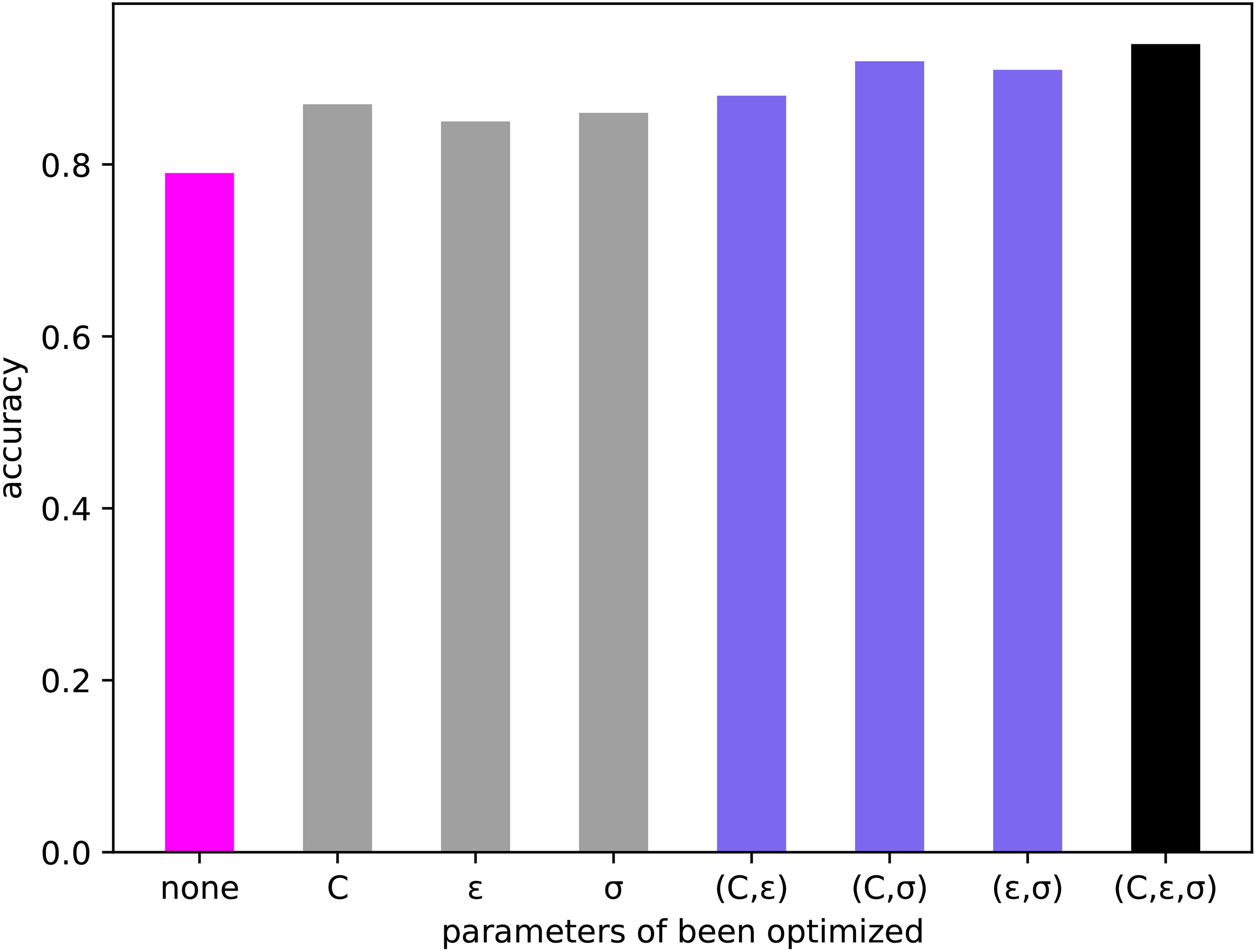
Prediction of the traffic flow and that of the real traffic flow in one day on node 3.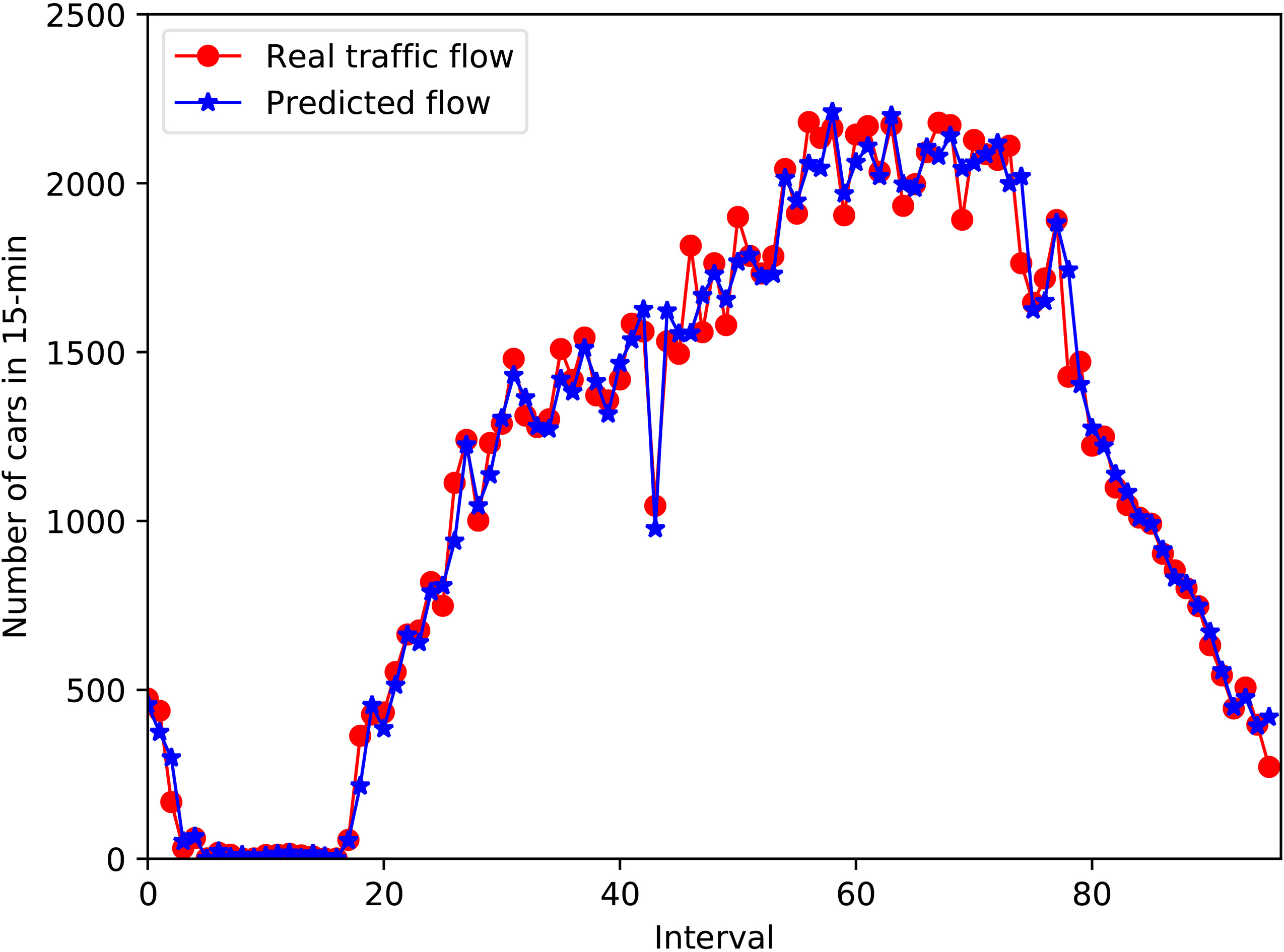
Comparing with SARIMA.
Comparing with MLP-NN.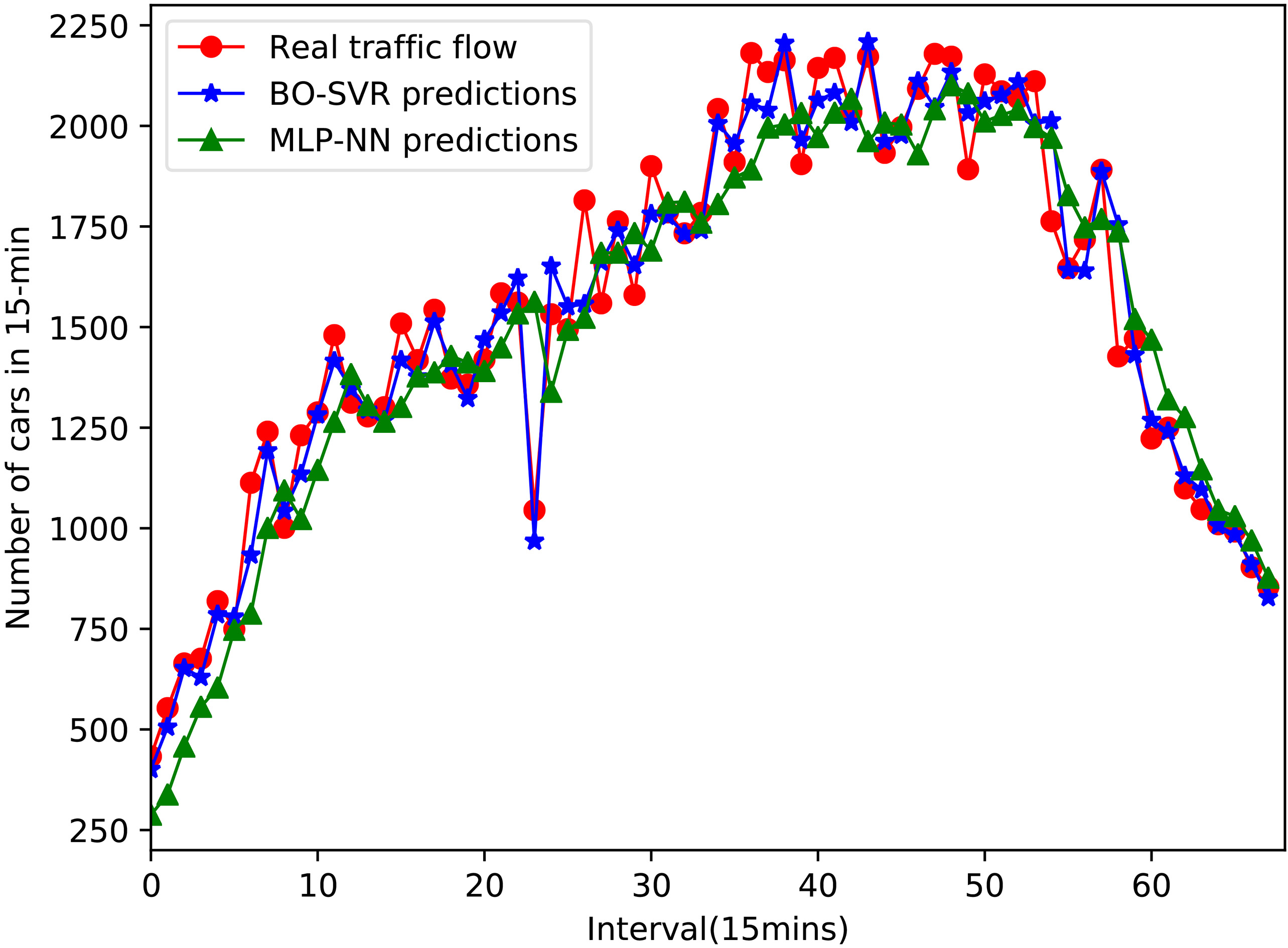
Comparing with ERT.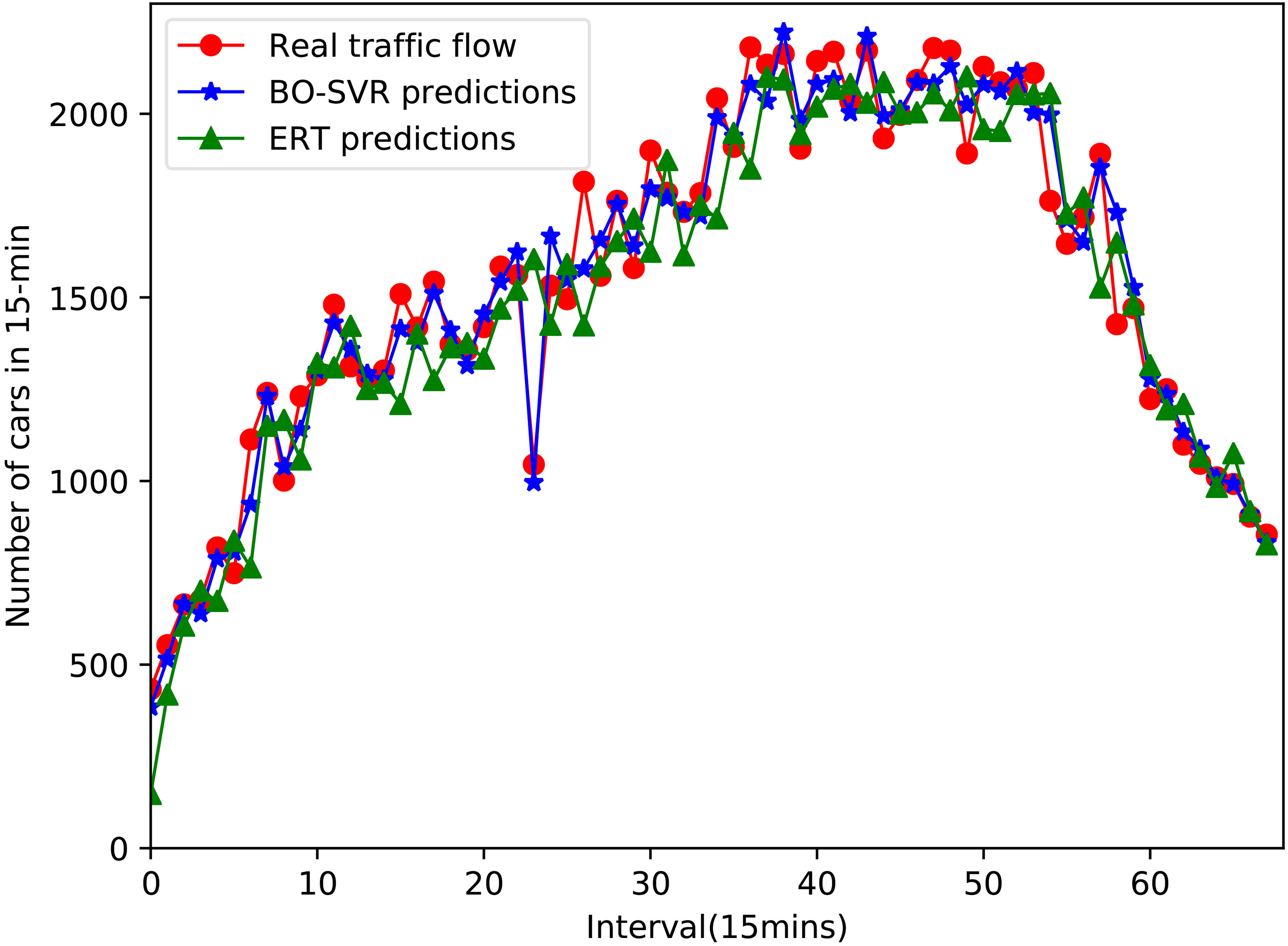
Comparing with Adaboost.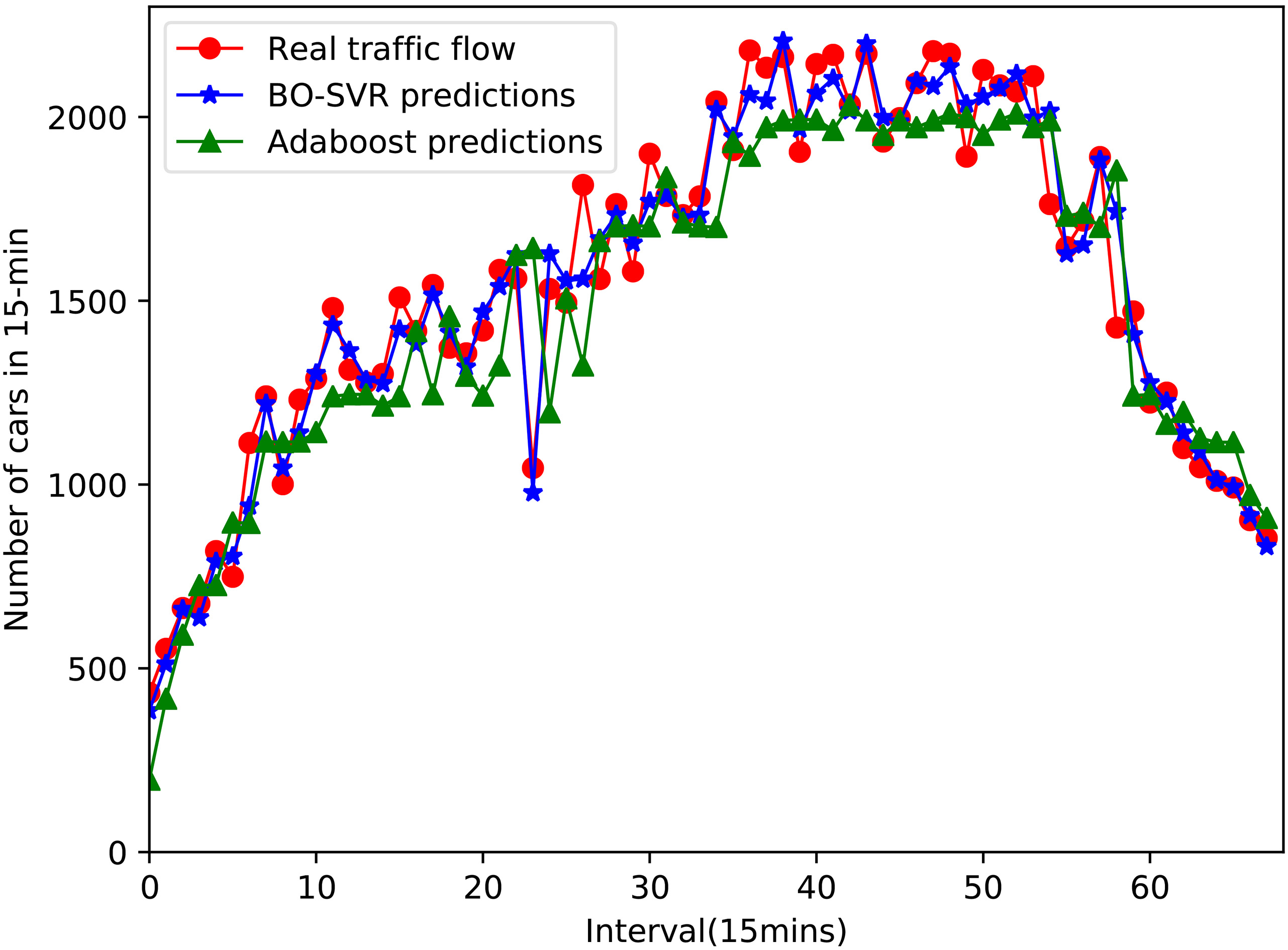
In this section, a contrast experiment is conducted to prove the validity of Bayesian Optimization used in choosing parameters of model. As mentioned above, there are three parameters needed to be optimized in the SVR model we proposed, which are
Performance comparison of the MAPE for SARIMA, MLP-NN, ERT, Adaboost and our BO-SVR
Performance comparison of the RMSE for SARIMA, MLP-NN, ERT, Adaboost and our BO-SVR
The prediction accuracy of these experiments is shown in Fig. 3. In Fig. 3, the abscissa represents the traffic flow forecasting model with different optimization parameters. The ordinate represents the prediction accuracy of each model. We can see the last column, which represents that the model of all parameters are optimized, is over 90% and outperforms all other models obviously. At the same time, we can also see that with the increase of optimization parameters, the accuracy of the model increases significantly. Therefore, it can be concluded that Bayesian optimization is effective for parameter selection of SVR-based short-term traffic flow prediction mode.
Performance comparison of the MAE for SARIMA, MLP-NN, ERT, Adaboost and our BO-SVR
Performance comparison of 15 minutes traffic flow prediction at point 1 using three training sets at different time periods and different forecast methods
In this section, we mainly discuss the overall performance of the proposed BO-SVR method. We use the data collected from the four detectors to experiment separately. The time range is from 2017-9-25 to 2017-10-9. The training set and the data set are set as before. We first give an illustration of the 15 minutes prediction of traffic flow and that of real traffic flow in one day on node 3, it is shown in Fig. 4. We can see that there is peak time in one day’s traffic flow, which is from 5:00 AM to 10:00 PM. As the purpose of traffic flow prediction is to relieve traffic pressure during peak time. Thus, we mainly analyze the effects of the proposed forecast model at peak time.
For the purpose of evaluating the performances of the proposed method, we compare the proposed method with other methods. The comparing methods include the classical time series forecasting method SARIMA, the ensemble learning method ERT and Adaboost, and Multi-Layer Perceptron(MLP-NN). As for MLP-NN, hidden layer is set to five. The network training method is gradient descent with momentum adaptive learning back propagation algorithm, the learning rate is set to 0.3. For all experiments, same training set and test set are used. Figures 5–8 show the 15-minute flow forecast results of proposed algorithm compared with other algorithms at peak hours 5:00 AM to 10:00 PM on node 1.
From the line chart, we could see that the real traffic flow value has a lowest point at time index 24. There may be a traffic jam at this point. It is obviously that only the proposed BO-SVR and SARIMA have predicted this sudden drop. Other methods including MLP-NN, ERT and Adaboost are affected by this incident, so they deviate from the actual flow. SARIMA offsets a lot of real values at adjacent moments. Only the proposed method BO-AVR is capable of eliminating this influence best.
In terms of prediction accuracy, SARIMA forecasts are very unstable during peak periods. This is because that the SARIMA model parameters are fixed. The predicted value of MLP-NN has a significant backward relative to the true value. This may be the reason that inappropriate parameters have been chosen so that the model is not well informed of trends in the traffic flow time series. ERT apparently has a trend below the true value at the peak stage. Adaboost is also the case, and the effect is more unstable. The predictions of BO-SVR are the best, and it can see that the model has learned the inherent tendency of traffic flow time series changes.
The Table 1 to Table 3 show the MAPE, RMSE value and MAE value calculated by different prediction methods at four detectors after running 5 times. The forecast range is the peak time of October 9, 2017. The forecast period is divided into 5 minutes and 15 minutes. From the previous introduction of the evaluation metrics, we know that MAPE is the representative of the relative error of the predicted values, RMSE and MAE represent the absolute error. Since the test data set contained midnight time period, the number of vehicles at this time is almost zero. Therefore, the overall relative error MAPE becomes large, especially at points 1 and 3. Similarly, compared to the 15-minute traffic flow time series, the 5-minute traffic flow is smaller. So, the relative error in 5-minute prediction is greater, while the absolute error is smaller for the RMSE and MAE. Therefore, it can be concluded from the longitudinal comparison of the tables that our experimental results are logical and representative.
By comparing MAPEs horizontally, we find that our BO-SVR predictions are better than the other methods except for individual rows. Especially at point 3, the effect of improvement is obvious. This shows that BO-SVR is more suitable for prediction of non-stationary sequence. In Tables 2 and 3, BO-SVR is also significantly better than other algorithms, and the actual error can be reduced by about 3% to 5% than other optimal algorithms. By analyzing the predicted results from different perspectives, it could be concluded that the proposed BO-SVR method is effective for short-term traffic flow prediction.
In order to better verify the effectiveness of the algorithm and explore the traffic flow characteristics in different years and different seasons. We select three different phases of data sets for repeated experiments from 2016-9-25 to 2016-10-9, from 2017-6-25 to 2016-7-9 and from 2017-9-25 to 2017-10-9 respectively. The Table 4 shows the comparison results of 15 minutes of traffic flow prediction at the point 1 using three training sets at different time periods and different forecast methods. The experimental results show that the proposed BO-SVR method can still achieve good results and has good generalization ability in different data sets. At the same time, we can also draw conclusions from the experimental data. Comparing with the quarter, traffic flow data among different years is more relevant, because of the fluctuations between different seasons. Therefore, when conducting long-term traffic flow forecasting research under big data in the future, we can consider using the previous years’ data to increase the accuracy of the forecast.
Conclusion
In this paper, we propose a regression method based on Support Vector Machine and Bayesian Optimization, called BO-SVR, to predict short-term traffic flow. Using the idea of SARIMA to eliminate the non-stationary of traffic flow data and using Bayesian optimization to select parameters of support vector regression. By compared with classical SARIMA, MLP-NN, ERT and Adaboost methods in typical sections of real road. The results show the superior advantage and generalization of BO-SVR in different conditions. For future work, we may consider to use larger traffic flow data to construct a deep architecture of traffic flow forecasting and to acquire more accurate prediction results. Furthermore, we will focus on some problems in reality, such as missing data and data noise, which have influence on prediction performance, so that we can build a robust prediction system.
Footnotes
Acknowledgments
This work was partially supported by the National Natural Science Foundation of China (grants nos. 61301148, 61272061, 61502162 and 61702175), the Fundamental Research Funds for the Central Universities of China, Fund of State Key Laboratory of Geoinformation Engineering (no. SKLGIE2016-M-4-2), Hunan Natural Science Foundation of China (no. 2018JJ2059), and Open Fund of State Key Laboratory of Integrated Services Networks (no. ISN17-14).
Appendix
Due to the characteristics of the traffic flow data, there is seasonality in weekly data and daily data. Seasonality usually causes the series to be non-stationary, therefore, we perform seasonal differential processing on the data to eliminate seasonality and non-stationarity. Then, By combining the data from the previous moment, the previous day, and the previous week, the following data set are constructed:
Then, due to the different dimensions between the different attributes, this will affect the results of the experiment. In order to eliminate the dimensional impact between the attributes, the previously constructed data set is normalized such that the individual indicators are at the same order of magnitude.