
Abstract
Reddit is a popular social media website where users can submit content such as direct links and text posts into a forum called subreddit. The average number of new subreddits created reaches 500 per day. Because of the vast and growing number of subreddits, users need to discover and familiarize themselves with all existing communities before submission. In this paper, we propose new feature sets for an online community which are text posts ratio, the average length of text in the post and the domain-specific features. The community recommendation framework is designed and experimented based on Reddit dataset. The framework successfully identifies and collects textual communities by finding their representatives using clustering algorithm namely DBSCAN, then a logistic regression algorithm is applied to recommend a list of communities with high content similarity to a given post. Comprehensive experimental evaluations on Reddit dataset reveal that the proposed framework achieves high precision at 90%.
Introduction
Reddit is a social website that encourages users to share a variety of contents including text, news article, picture, video clip. Content sharing is organized into subreddits or communities that are freely created by members. Each subreddit is monitored by the moderators or creator that has the right to configure, customize and set up additional rules for the communities. The content of each subreddit can be different regarding both breadth and depth of the topic they interested. Registered users can subscribe to subreddits that align with their interests to join and share their contents. As of 2017, Reddit has 542 million monthly visitors (234 million unique users), ranking as the #5 most visited website in U.S. and #8 in the world [5].
Reddit supports two types of submission, link post, and text post. A link post requires a title and URL that links to an external website in which users are allowed to view the content. The text post contains discussion, comment or question answering that the community shares their ideas responding to the post. Therefore the motivation of these two types of post is different. Users who submit text posts usually expect the feedback that fulfill their needs, this means that the right subreddit should meet their expectations. Unfortunately, there is no automatic tool that can recommend the appropriate subreddits to the user.
Moreover, the number of existing subreddits is continually growing, it is impossible for users to explore and get familiar with those contents. Therefore, we propose a community recommendation framework focusing on text post using data on Reddit as a case study. Our framework recommends a set of ranked communities for users and allow them to choose base on their preferences. By offering options to users, they can review and choose the one they prefer to share from a list of subreddits. The probabilistic classifier, namely logistic regression is employed to obtain a set of probabilities of all textual communities for a given post based on content similarity. Then a selection of subreddits with high probability values is proposed to users as a recommendation list. The remainder of this paper is organized as follows:
Textual community identification procedures, including feature extraction, representative finding and collection processes in Section 3.2. Community recommendation framework for text post on Reddit based on content similarity determined by logistic regression in Section 4. Experimental result of domain-specific features associated with Reddit post in term of classification performance is shown in Section 4.
Reddit has become a growing source of information for social media data mining tasks in recent years. One of the reasons might be the massive, diverse and acceptable quality of content on the website. Weninger et al. [23] did an in-depth study on topical cohesiveness and other aspects of discussion on the website. One of their findings is that the discussed content represents the topical hierarchy, not chaotic. They encouraged that the data can be used for mining-related tasks. Choi et al. [8] also analyzed different trends and characteristics of both content and users in an extensive data set of discussion posts from the website. They found clear evidence of social structure and topic coherence-driven conversation. They also hoped that their work would assist others that wish to better understand discussions on social media websites. These phenomena led to the surge of studies that taking advantage of the massive and diverse information gold mine, e.g., [14, 21, 22, 9].
A few research related to recommendation using Reddit data set has been found in the literature. Nguyen et al. [17] proposed a framework that aims to recommend Reddit posts that fit user’s interest. The framework employed user’s Twitter data to create a user profile based on pre-defined topics. Ensemble classification method based on Naïve Bayes was applied and reached 58% precision. They continued their experiments dealing with user profiles creation using WordNet database in [18]. They applied natural language processing tools and machine learning algorithms to develop a recommendation system for subreddit articles based on interest profiles derived from users’ tweets. They introduced a simple WordNet-based genre classifier based on a similarity measure derived from the WordNet ontology. They found that the WordNet approach has poor precision when the number of tweets is small.
Association rule mining algorithm was applied by [13] to find relations among subreddits. They proposed a web-based application named Recommenddit that allowed users to query subreddits that are associated with a given subreddit. However, their work focused only on large subreddits only.
There were some research works related to community recommendation in other online domains such as IBM Connections dataset. Pal et al. [19] proposed a framework for selecting a set of communities that most likely to provide the best answer for a given question. Their framework measures various similarities between the question (e.g. tf-idf and parts of speech), obtained from users and the existing communities. Then the k-nearest neighbor algorithms were applied to rank the communities. The evaluated performance is based on IBM Connections datasets. The performance evaluated by precision@5 reached 65%.
The collection of tweets related to “presidential campaigns” between Barack Obama and Mitt Romney, obtained from March 1
A subreddit page, namely “PoliticalDiscussion” community, displaying a portion of posts within the community.
A text post in the “PoliticalDiscussion” community. The community name, title, body and voting score are annotated.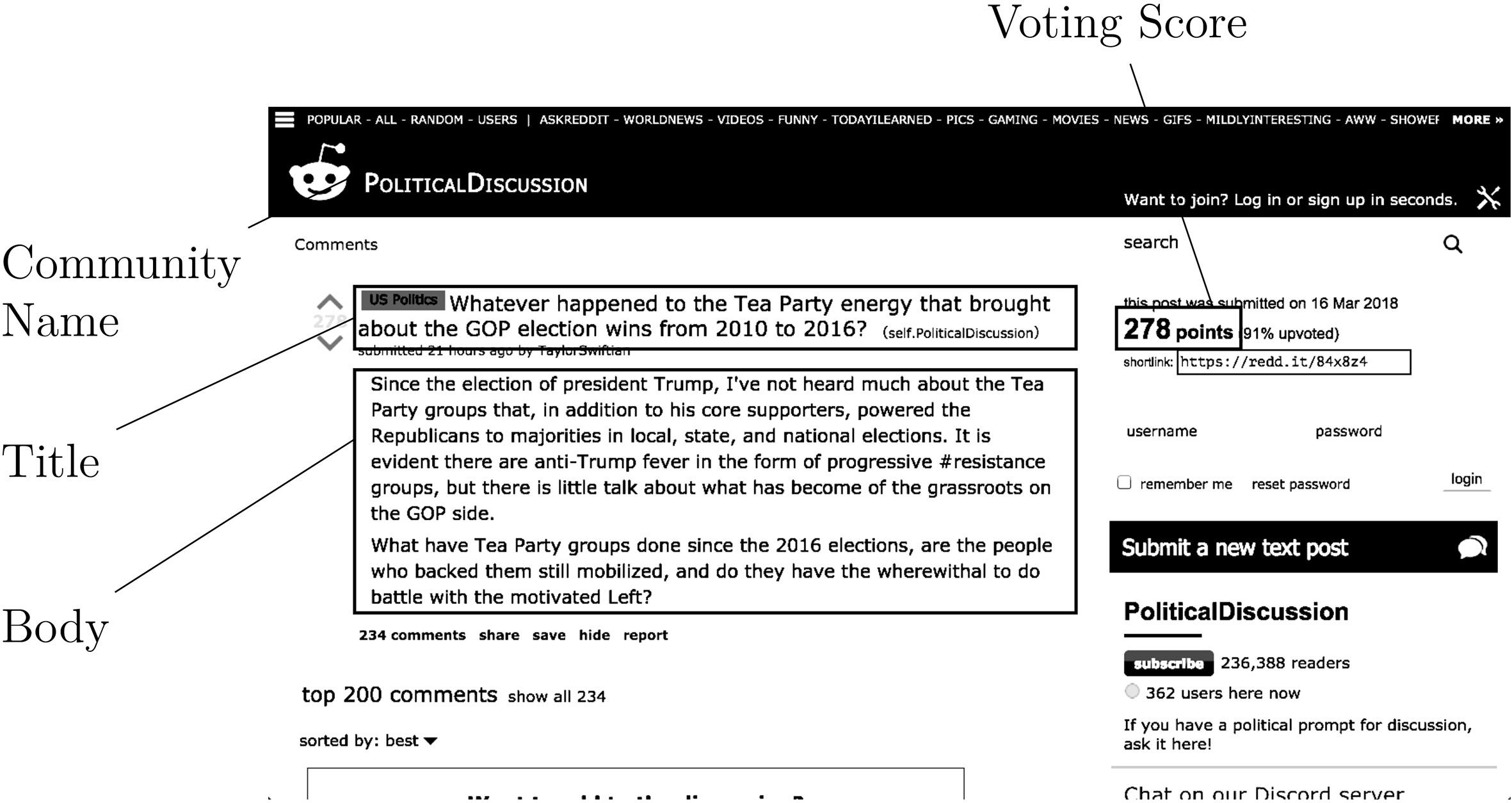
Our proposed framework explores the top 4,271 communities ranked by the number of members as reported by redditlist.com on October 16
The structure of a post consists of community name, title, body, voting score, author name and time of creation (see Fig. 2). The title may contain post’s tags specified by community’s moderators. The body contains the text of a text post and is blank in case of a link post. The voting score is calculated from the total vote count. A post normally contains hidden fields, including a unique identifier and a type indicator (see Table 1).
A sample of the collected posts with some essential fields. The range of score is varied depend on the number of users in the community
A sample of the collected posts with some essential fields. The range of score is varied depend on the number of users in the community
Textual community identification processes.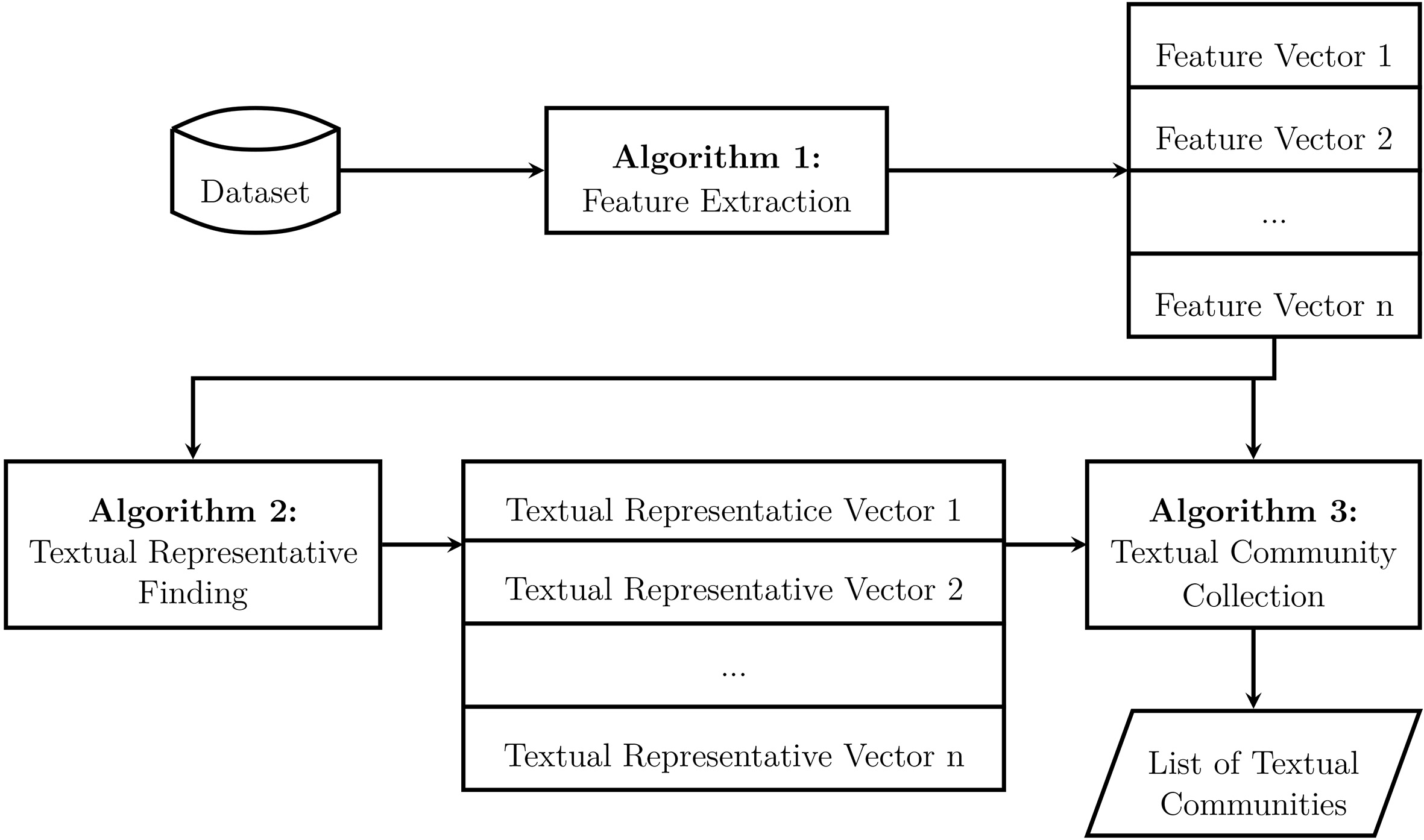
Given a text post (see Fig. 2), the title and the body are concatenated and converted to the lower cases. The preprocessing includes Markdown tags and URLs removal. Then, a bag of words representation is created for the next processes.
Textual community identification
Since our research focuses on textual community recommendation, therefore a set of textual community needs to be identified. We propose an approach that can automatically analyze the data set without the needs of domain experts. There are three main steps which are feature extraction, textual representative finding, and textual community collection steps (see Fig. 3).
Community feature extraction
Since Reddit allows users to freely post text or link in the communities, therefore we need to specify the community that mainly concentrates on the text post (see Algorithm 3.2.1).
[h] Community feature extraction algorithm.[1] ExtractCommunityFeaturesDataset
We propose two community features which are the ratio of the text posts and the average length of text in the post. The ratio of text posts is calculated from the number of text posts divided by the number of all posts in that subreddit where n is the number of posts in the community (see Eq. (1)).
Normalized community features obtained from community feature extraction algorithm.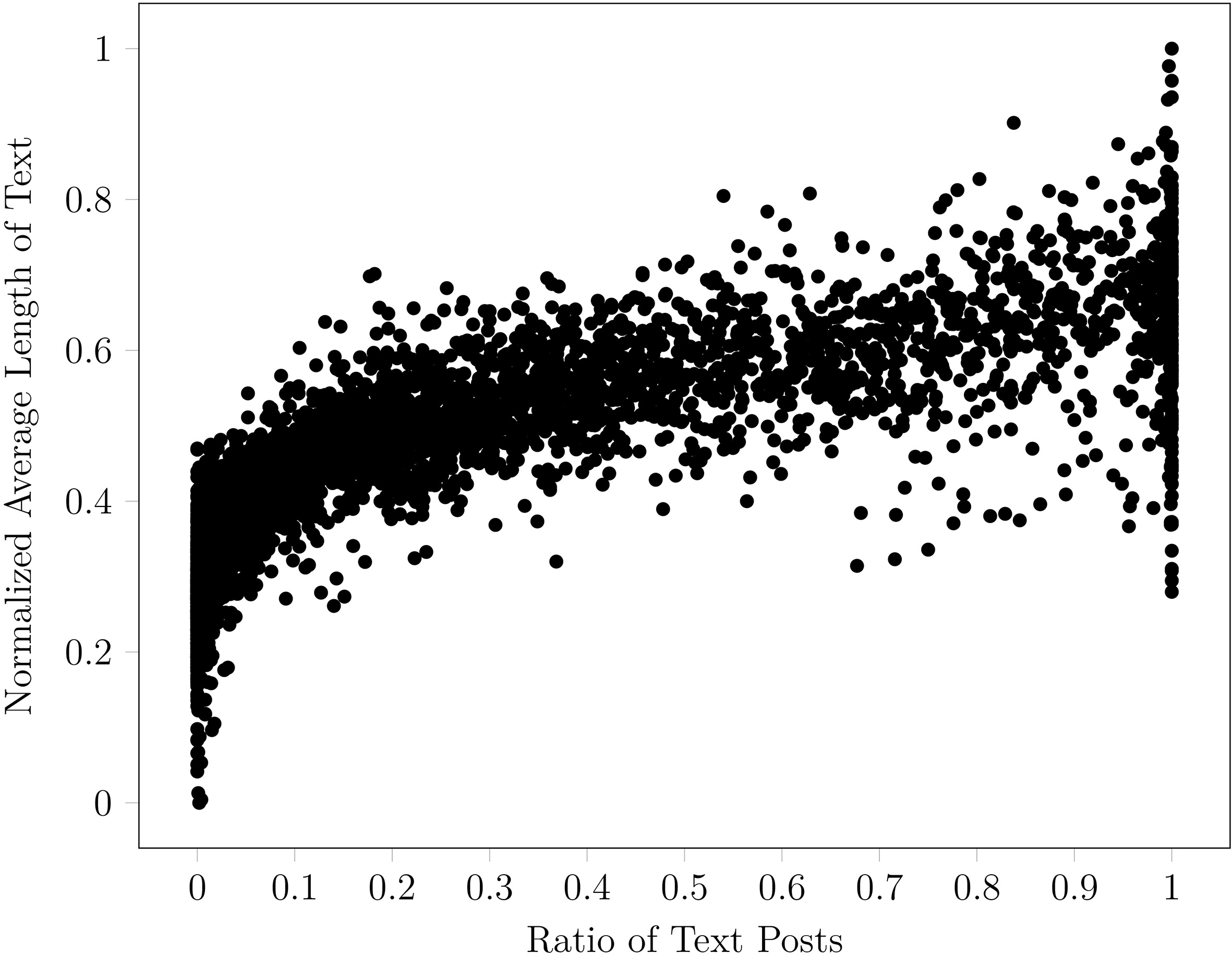
Clustered community features separated by colors. The two largest clusters are circled and annotated, the large one with lower values of normalized average length of text and ratio of text posts, and the smaller one with higher of both values.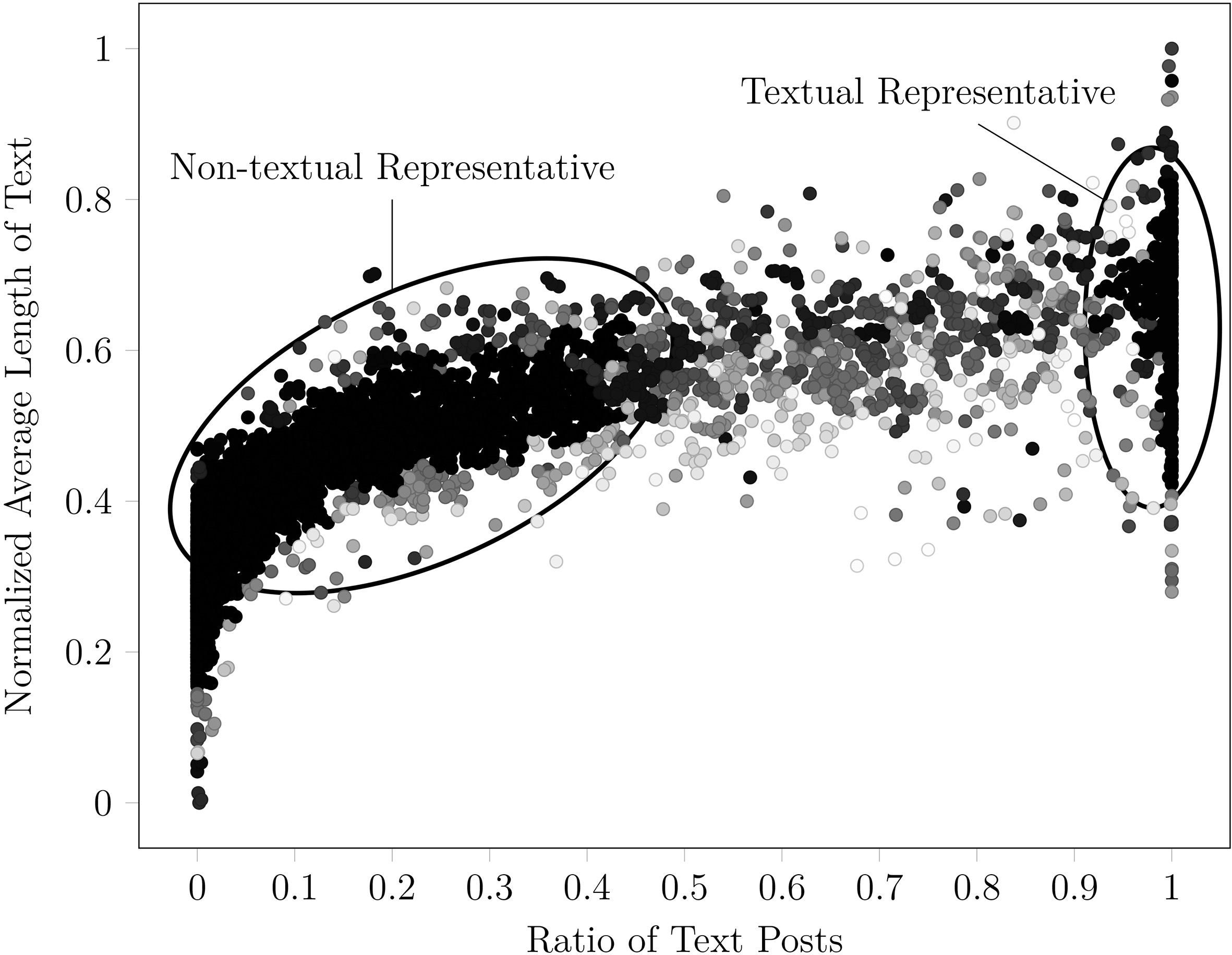
Two largest clusters, the black cluster with lower feature values represents non-textual communities and the white cluster represents the textual communities.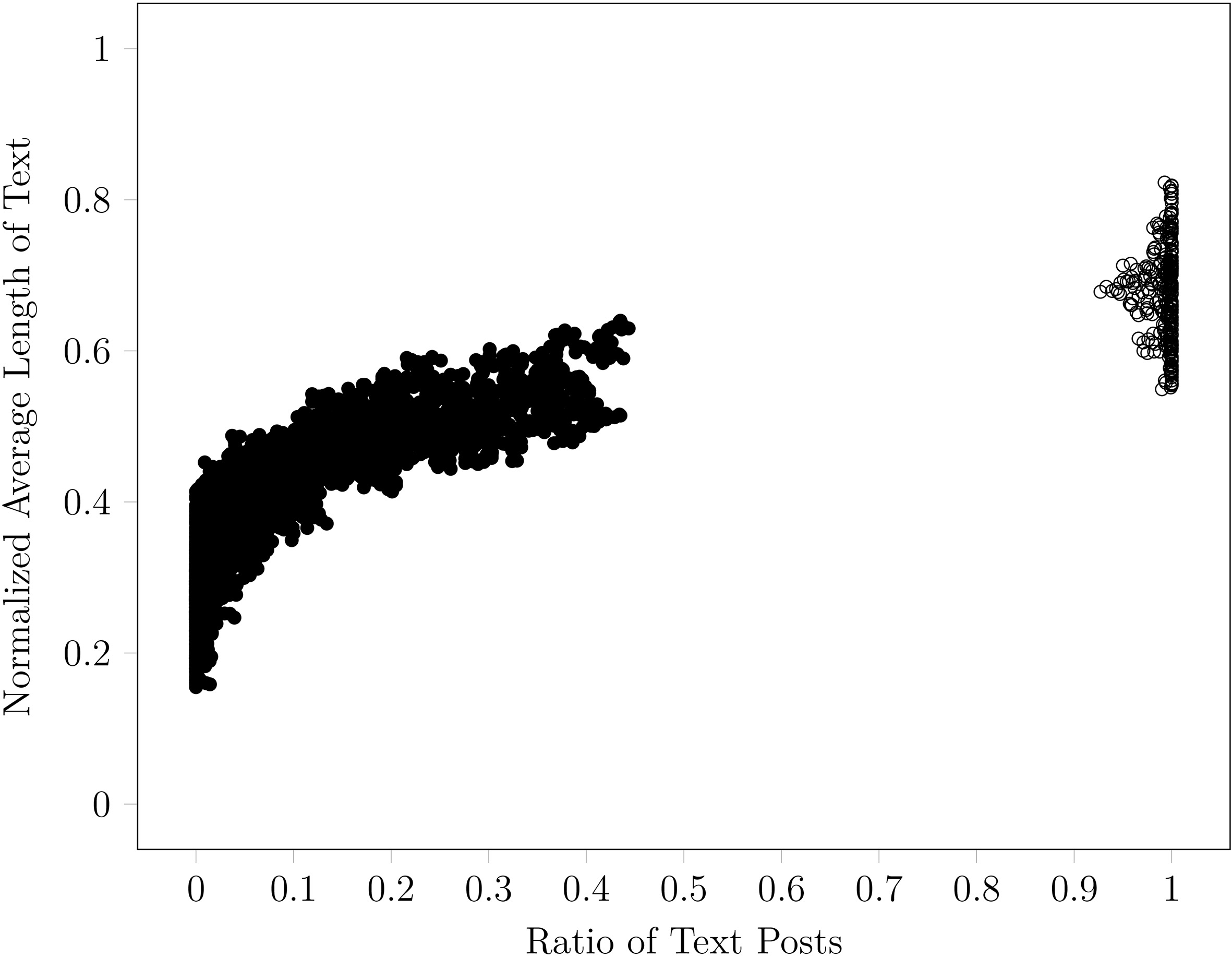
The average length of the text is obtained by averaging the number of characters in the title and the body of the post found in that community where
The result obtained from the feature extraction algorithm is visualized as shown in Fig. 4. We found that there are different degrees of post types mixing in the communities. The right-most and the left-most plotting area are the two high-density regions that represent low and high values of text length and text posts proportion.
[b] Textual community finding algorithm.[1] FindTextualRepresentativeCommunity feature vectors
To obtain the textual community representatives, we apply a clustering algorithm to select the communities based on their feature similarities. Base on the data visualization in Fig. 4, we apply density-based spatial clustering of applications with noise (DBSCAN) [10] which is a method of choice since it uses density as a mechanism to group the instances by excluding outliers. After the clustering process is finished (see Fig. 5), the set of clusters is sorted according to the number of instances in descending order. The first two clusters that have the highest numbers of instances are selected as representatives for both types of extreme community (see Fig. 6). Then the textual cluster (or representative) is determined by its higher average values of both features. The representative contains 280 communities with the ratio of text posts between 0.927 to 1.0 and the average normalized length of text between 0.549 to 0.822 (or 384 to 3,726 characters). Algorithm 6 describes the community clustering and the textual representative finding process in detail.
Textual community collection
To obtain the final collection of textual communities ready for recommendation process, we use the average feature values of the textual representative as a minimum threshold to create the collection. The average length of text is 0.676 (1,263 characters) and the average ratio of text posts is 0.991. We finally get 98 communities (see Table 2) with the data of 92,382 posts for the final dataset. Algorithm 3.2.3 describes textual community collection process.
[h] Textual community collection algorithm.[1] CollectTextualCommunitiesTextual community representative
The list of communities selected using the average values of both features calculated from the textual representative
The list of communities selected using the average values of both features calculated from the textual representative
We found that Algorithm 3.2.3 plays an important role in the recommendation steps. The experimental results using different collections (280 communities obtained from DBSCAN and 98 communities from Algorithm 3.2.3) shows significant improvement (see Section 5 for details).
Our goal is to provide a list of recommended communities for users to choose based on their preferences. Doing so can give the user more freedom to pick a subreddit from the list. Given a title and body of the post, the algorithm recommends communities based on the content similarity between the post and communities. The framework consists of two steps (see Fig. 7). First, it utilizes probabilistic classification to obtain probability as the similarity between each subreddit and a given post. A probabilistic classifier predicts the probability of each target class instead of one certain result. We study the classification performance of naïve Bayes (NB) [4] and logistic regression (LR) with stochastic gradient descent (SGD) [24] and coordinate descent (CD) [11] optimization. Second, the framework picks a list of communities that are highly associated with the post based on the predicted probabilities. The list is presented as options for users to further review and choose for their posts, all of which are considered to be most relevant. The advantage of our framework is the ability to recommend communities with high content relevance even they might be small or less known communities.
Community recommendation framework.
The framework uses probability obtained from a probabilistic classifier to determine the content similarity. Naïve Bayes and logistic regression are studied to see their performance. Since Logistic regression is typically a binary classifier, therefore, we apply one-vs-rest technique to fit with our multiclass problem domain [7]. Normally the classification determines the highest probability class as the predicted result. But our framework saves all predicted probability values to be used in the next process. Algorithm 4.1 describes the training process of multiclass logistic regression using one-vs-rest technique. Algorithm 4.1 describes the probability prediction process using classifiers trained with one-vs-rest method.
[h] Logistic regression training algorithm using one-vs-rest.[1] TrainClassifiersDataset
[h] Probability prediction algorithm using trained classifiers.[1] PredictProbabilitiesClassifiers
We study two optimization methods for logistic regression which are stochastic gradient descent and coordinate descent. The term frequency-inverse document frequency (tf-idf) from the post is extracted as a feature vector and we use the corresponding subreddit as the label.
Domain-specific features
To investigate the classification performance, we study new features associated with the Reddit’s post. These features include the length of title and body, voting score and user behavior. Equation (5) shows text lengths scaled between zero and one. The minimum and maximum lengths are calculated from the data set.
The score feature is obtained from the voting score from users and use as the instance weights for the post to emphasize on user engagement in the community Eq. (6).
Feature set combination. Set A consist of solely tf-idf vectors. Set B to G consist of tf-idf vectors with additional features. Set X to Z consist of high potential features indicated by performance exploration of set B to G
Classification performance of studied algorithms, measured using standard metrics with different feature sets for comparison
We explore the performance of each algorithm using different feature sets (see Tables 3 and 4). Each feature set is created based on tf-idf with an additional extra feature. Feature set X, Y, and Z are created using the most effective features for each algorithm. We found that the most significant features in most cases are the length of title and score weighting. After testing, we decide to apply logistic regression optimization using coordinate descent with feature set Z in our framework since it exhibits higher performance than others.
After obtaining the predicted probabilities for a given post from the classification process, the framework will pick communities with the highest probability values and provide to the user. The number of recommended communities is varied in the experiment to see their performance. In our experiment, we set the number of proposed communities starting from 1 to 5 for performance comparison. Algorithm 4.2 describes the community selection process using predicted probabilities and the number of final results. Algorithm 4.2 describes the overall community recommendation using previous algorithms.
[h] Top-K community selection using predicted similarity.[1] TopKCommunitiesProbabilities
The average precision of the framework with the number of recommended communities (K) set to be from 1 to 5 compared with different algorithms and feature sets
The average precision of the framework with the number of recommended communities (K) set to be from 1 to 5 compared with different algorithms and feature sets
Classification performance of studied algorithms, measured using standard metrics with different feature sets for comparison, using the 280 communities in textual representative as dataset
The average precision of the framework with the number of recommended communities (K) set to be from 1 to 5 compared with different algorithms and feature sets, using the 280 communities in textual representative as dataset
We evaluate the performance of the framework using 10-fold cross-validation and use the community names as the label data. To determine the performance of the ranked classification result, we measure the precision with different numbers of results known as precision@k. Note that precision@k is a performance metric used in information retrieval related tasks to determine the relevance of the results without considering their positions. In our case, this means that a recommendation is treated as correct if the originally specified community is in the recommended list. We measure the average precision of all folds with different feature sets, numbers of recommended communities and compare with baseline methods, which are k-nearest neighbors (KNN) [6], random forest (RF) [12] of 10 trees and NB with the basic feature set A (see Table 5). The result indicates that the framework archives 90% precision by recommending a list of 3 to 5 communities (K
The contribution of textual community collection is investigated as shown in Tables 6 and 7. We found that using only the textual community representative (
The effect of noise on the performance of probability prediction measured in precision at K 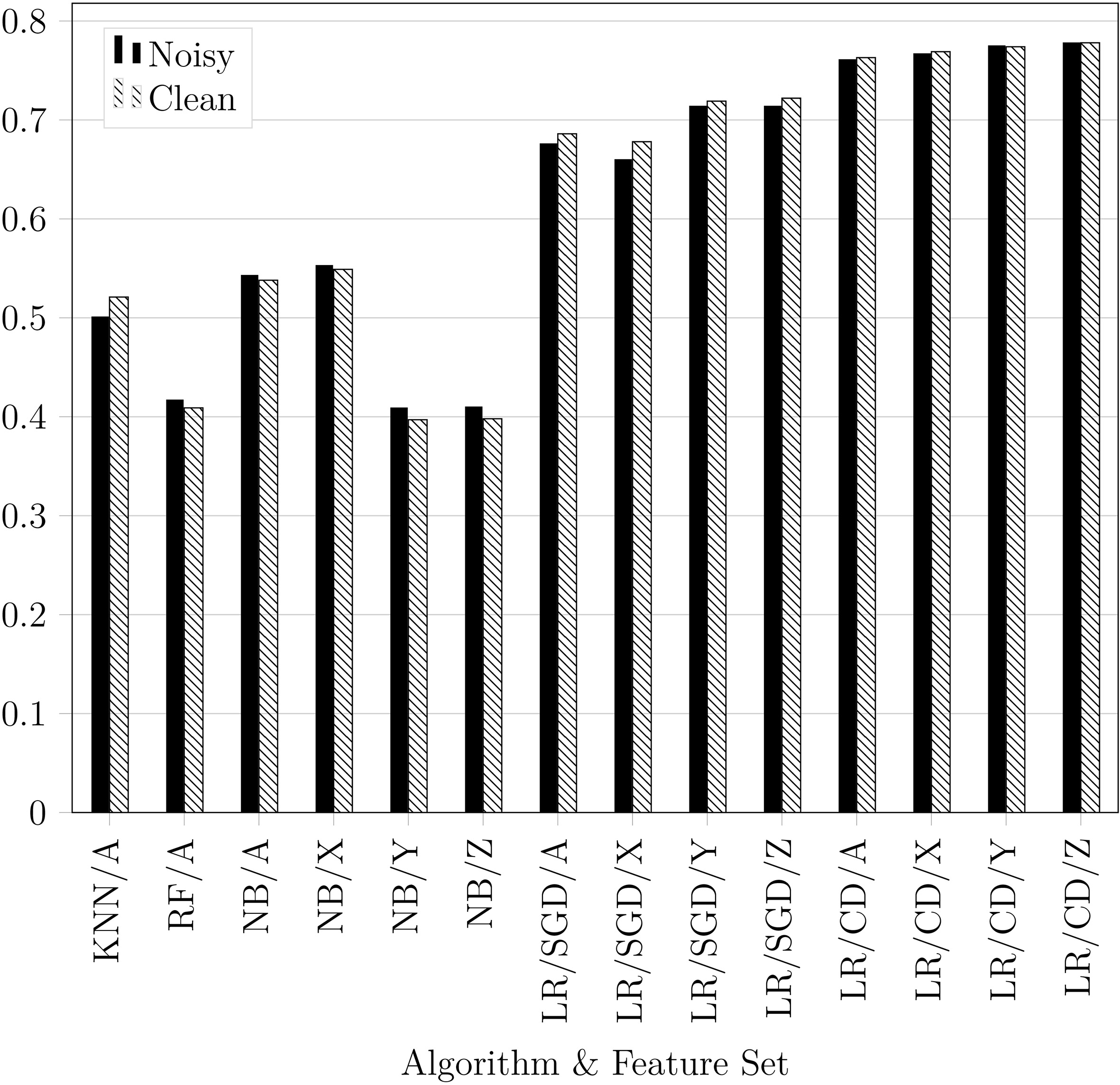
The effect of noise is studied to see the robustness of our framework. For text-mining domain, stop words are considered as noise [20]. We performed two more experiments, one without preprocessing (noisy data) and the other with noise removal (cleaned data), then we measure their precisions at K
The result shows that KNN performed slightly worse on the noisy dataset because stop words increase the chance of algorithm taking incorrect instances with those features in as neighbors. RF performed slightly better on the noisy dataset than the clean one. Since RF randomly select a subset of feature to be the candidates during the tree construction. We found that NB and LR are robust to noise because they are based on probability calculation. The precisions of LR (CD) using the feature set Z applied on both noisy and cleaned dataset are almost identical which are 0.779 and 0.778. This indicates the robustness of the framework on noisy data. However, removing more features can worsen the performance in some cases due to the nature of the dataset, some words may have good classification power in social media datasets than others. For example, some communities like to ask questions more than others. We found that our method exhibits the highest performance and robust to noise compare to the baseline methods.
The time complexity of each algorithm.
is the number of posts in the dataset.
is the number of available communities.
is the number of features in a vector.
is the number of recommended communities
The time complexity of each algorithm.
The time complexity of each algorithm is shown in Table 8. The community feature extraction algorithm need to iterate all
Conclusion
We propose a community recommendation framework designed for text post and experiment with the data on Reddit. Our framework starts with textual community identification using DBSCAN to get the textual community representatives on the website then used it as a threshold to select them from the dataset. The strength of our framework is the automatically learning without the needs of domain experts. The logistic regression is applied to predict the content similarity of each community for a post. Finally, the framework selects a set of communities with high probability values and provides it to the user as a recommendation. We also propose domain-specific features of post on Reddit in term of classification performance improvement. The performance shows that by recommending a list of 3 to 5 communities, the framework achieves 90% precision. We also examine the effect of noise in the dataset and the time complexity of proposed algorithms. We plan to investigate our framework on more extensive datasets to see the impact of the top-k recommendation process in the near future.
Footnotes
Acknowledgments
We would like to gratefully acknowledge and thank for the financial support from Kasetsart University Research and Development Institute and SCIKU 50