
Abstract
Data stream clustering is an unsupervised learning method for sequential data. Data stream clustering has some challenging issues, such as handling limited memory, dealing with evolving clusters, and detecting noise data. We propose a hybrid data stream clustering method that combines model-based clustering and density-based clustering. The proposed method finds evolving clusters quickly and obtains cluster information easily. We use multiple hypothesis testing to handle noise data by controlling a decision error. In this testing method, we employ the positive false discovery rate as the decision error. We use a density-based algorithm to discover cluster evolution from newly arrived data. Then, we estimate a Gaussian mixture model and update the clustering results by combining past cluster information and the cluster information for newly arrived data. We applied the proposed method to several synthetic and real datasets. The experimental results demonstrate that the proposed method works effectively for a data stream that includes noise data. In addition, the proposed method yields robust results relative to input parameters compared to an existing density-based data stream clustering method.
Introduction
As technology advances, a huge amount of data is generated in many fields. Interest in data stream mining, which extracts meaningful information from data streams, also has increased. For example, data stream mining can be applied to monitoring network traffic, where data can change relative to user status, location, or connection purpose. The volume and speed of data streams, i.e., sequences of continuous data generated from networked devices and sensors, are increasing rapidly [19].
Data stream mining differs from conventional data mining, which uses a finite data set and can recall data as required. In contrast, data stream mining uses an infinite sequential data stream that cannot be recalled. Moreover, typically data streams are large and used data should be discarded due to limited storage and memory capacity. Data clustering finds meaningful information by grouping similar multi-dimensional data points. Data stream clustering is an unsupervised learning method for sequential data streams. According to Amini et al. [2], data stream clustering methods can be classified into five categories: partitioning, hierarchical, grid-based, density-based, and model-based methods. Each of them will be described and related algorithms will be surveyed in Section 2.1.
Responding quickly to cluster evolution is a significant issue in data stream clustering. Many density-based clustering algorithms have been developed to address this issue. However, it is typically difficult for density-based clustering to summarize cluster information and find optimal parameters for the best results. Therefore, we develop a hybrid algorithm for data stream clustering that combines model-based and density-based clustering methods to handle cluster evolution quickly and find optimal parameters efficiently. Further, existing data stream clustering algorithms have not dealt with clustering errors particularly when they are associated with noise data. In this paper, noise data indicates an insignificant data point (object) which does not belong to any cluster. The proposed algorithm can control the clustering decision error using multiple tests when handling noise data. A decision error occurs if a true cluster member is declared as noise and vice versa. The positive false discovery rate (pFDR) is adopted to control the error rate. The pFDR is defined as the expected proportion of false positives among all rejected hypotheses given that the number of rejected hypotheses is greater than zero [25].
The remainder of this paper is organized as follows. Section 2 reviews data stream clustering methods and introduces Density-Based Spatial Clustering of Applications with Noise (DBSCAN) [11], a well-known density-based clustering method, and DenStream [5], a popular data stream clustering method based on DBSCAN. Section 3 presents the proposed clustering method. We describe experiments with synthetic and real datasets to evaluate the proposed method in Section 4. Finally, Section 5 concludes the paper by summarizing the results.
Related works
Existing data stream clustering methods
Data stream clustering methods can be classified into five categories: partitioning, hierarchical, grid-based, density-based, and model-based methods [2]. In this section, we briefly explain about each category and introduce some related algorithms.
A partitioning clustering algorithm divides all data points (or objects) into
A hierarchical clustering algorithm is composed of agglomerative (bottom-up) and divisive (top-down) methods. The agglomerative method sets each data as a cluster and merges them sequentially and the divisive method assigns all data into one cluster and divides the cluster into smaller ones. These algorithms repeatedly updates until pre-defined stopping criteria are satisfied. ClusTree [17] generates micro-clusters and merges them based on a hierarchical index.
Grid- and density-based clustering methods assume that the density of a cluster area is high and the density of a noise area is low [26]. A grid-based clustering algorithm divides data space into grid structure. In each grid, the number and information of data points are stored to determine if it is dense area or sparse area, which corresponds to clustered data points and noise data points, respectively. MR-Stream makes use of STING [28], which is grid-based method, and constructs a tree of grid cells. MR-Stream merges child nodes of the same parent node if all of them are dense or sparse to save memory and cluster fast. More recently, Hua et al. [14] developed an algorithm combining the advantages of grid- and density-based methods by using the local density of each object and the distance from the objects.
A density-based clustering method finds a dense area and increases its size continuously by adding dense neighborhoods. DenStream [5] is a density-based clustering algorithm for data streams. Representative density-based clustering algorithms, DBSCAN and DenStream, will be discussed in more detail in Section 2.2. Recently, Chen and He [6] proposed a new density-based algorithm so as to cluster mixed data stream accurately. Ding et al. [10] presented an adaptive density-based algorithm for mixed type data.
Model-based clustering assumes that data points are generated by an underlying distribution, which is usually estimated by the expectation-maximization (EM) method [9] and clustering is performed based on the estimated distribution. Model-based methods can handle noise data by estimating the responsibility of each data point, where a data point with lower responsibility is declared as noise. In a model-based method, the data stream is typically assumed to follow a Gaussian mixture distribution. Dang et al. [7] proposed a data stream clustering method using a time-based sliding window model with a set of micro-clusters following a multivariate normal distribution. Song and Wang [24] estimated a Gaussian mixture distribution for new data at each time window. Then, they tested for mean and covariance equivalence for new and existing components. Two components are merged if they pass this test; otherwise, a new component will be a separate cluster.
Until recently, many data stream clustering algorithms have been proposed. However, each algorithm has its own advantage and limitation. A recent review article by Nguyen et al. [20] on data stream mining summarizes pros and cons of each data stream clustering category. Partitioning-based clustering is simple and relatively efficient. However, a user needs to pre-define the number of clusters, which has an impact on clustering results. It is limited to only spherical clusters. Hierarchical clustering can find meaningful structure of clusters, but searching the structure is too complex and sensitive to the order of the data. Grid- and density-based clustering can find arbitrary-shape clusters and is robust to noise points. Grid-based clustering is generally fast, but may not be proper in high-dimensional data because the result is dependent on the grid granularity. Density-based clustering requires many parameters such as density or noise thresholds to find arbitrary-shape clusters. In addition, it is difficult to detect clusters with different densities. Finally, model-based clustering is simple and can make use of domain knowledge but it highly depends on model assumptions.
More recent data stream clustering algorithms combine two or more approaches to overcome their limitations. For example, ADStream [10] takes advantages of density-based clustering and affinity propagation clustering to handle irregular data streams such as noise or outliers. The affinity propagation is similar with partitioning methods, which do not require pre-defined number of clusters. DEGDS [14] combines the advantages of grid- and density-based clustering algorithm. DEGDS uses a local density and distance matrix to get clustering centers in the grid and then extends the result or merges grid boundaries by using density concepts. This removes unsuitable selection of initial centroid and saves the memory. Besides, Str-FSFDP [6] develops a density-based clustering algorithm, which uses a novel distance metric in order to handle mixed type data.
DBSCAN and DenStream
In this paper, the performance of the proposed method is compared to that of DenStream [5]. Thus, here, we describe DenStream in detail. First, we explain DBSCAN, a well-known density-based clustering method, because DenStream is based on DBSCAN.
Density-based clustering assumes that a cluster area is dense and other areas are spare. The most popular density-based clustering algorithm is DBSCAN [11]. The input DBSCAN parameters are the minimum number of points (MinPts) and
DenStream assumes a damped window model, in which the weight of each data point decreases exponentially over time with a fading function. The micro-cluster (MC) corresponds to
The DenStream algorithm involves several parameters, including
Proposed hybrid data stream clustering method
We propose a data stream clustering method that combines model-based and density-based clustering. It is assumed that a new dataset arrives at each time window and that a new dataset consists of clustered data plus noise. We assume that the clustered data follow a Gaussian mixture with an unknown number of components and noise data are spread randomly. The characteristics of a new dataset may change over consecutive time windows.
Assume that a d-dimensional data point
where
The proposed algorithm consists of two phases, i.e., initial and incremental phases. The initial phase is used only at the first time window and the incremental phase applies to subsequent time windows. We estimate the Gaussian mixture distribution and perform multiple hypothesis testing in the initial phase. Whenever a new dataset arrives, we check cluster evolution and update the cluster result in the incremental phase. The required steps in our two-phase procedure are as follows.
Initial phase
Eliminate noise points using DBSCAN. This step helps estimate the Gaussian mixture distribution more accurately. Estimate the Gaussian mixture distribution using incremental EM. We must find an optimal number of components in the Gaussian mixture. Apply multiple hypothesis testing and classify data as cluster members or noise points.
Incremental phase
Assign data points from a new dataset to existing clusters based on the previous information. Find new clusters. Make a merge or split decision for the clusters. Find clusters to remove. Update the cluster result.
An EM method may be sensitive to noise points or outliers. Thus, we separate these noise points from the data using DBSCAN before estimating a Gaussian mixture using an EM algorithm. Essentially, data points that are not grouped minimally will be declared noise points. Other points will be declared non-noise points. As a result, we obtain a Noise_data set and a Non_noise_data set. These two sets are divided to estimate a more accurate Gaussian mixture distribution. These two sets are updated after clustering.
We use the Non_noise_data set to estimate Gaussian mixture distribution with an unknown number of cluster components. Ueda et al. [27] and Blekas and Lagaris [4] proposed Incremental EM methods to estimate a mixture model with an unknown number of components. We use the method proposed by Blekas and Lagaris [4], which starts with two components and applies the split step and the merge step until the best mixture model is obtained. Here, we use the Bayesian information criterion (BIC) [23] for the model selection, while Blekas and Lagaris [4] originally used the log-likelihood. The BIC is given as follows:
where ln
We divide data into noise points and cluster members using a multiple hypothesis testing. Lee and Jun [18] and Park et al. [21] proposed clustering methods using multiple hypothesis testing. The key idea in those papers is that a clustering problem is viewed as multiple hypothesis testing to control decision error. Here, we apply a similar idea to a data stream. However, we only use
Let
Null hypothesis:
Alternative hypothesis:
If the null hypothesis is true, then the
If
where
Although the result was not reported here, the above approximation provides quite accurate
Using the set of calculated
where
Then, we classify each data point as noise or a cluster member based on the pFDR. Let
Here, let
The incremental phase is applied from the second time window and thereafter. We define the following notations.
Assigning new data points to a cluster using previous cluster information
Initially, we assign new data points at the
We consider that the
We find new clusters, if any exist, as follows.
Apply DBSCAN to temporary noise points to form clusters. Here, let If
Existing clusters with newly added members may be merged or split. We make this decision using the SMILE algorithm [4]. First, we repeat the SMILE algorithm merge operation on the set of existing clusters with newly added members until the BIC does not decrease further. Then, we repeat the SMILE algorithm split operation until the BIC does not decrease.
Finding clusters to remove
We remove clusters whose number of members is less than a specified number. The members in the removed cluster, if any, will be allocated to the closest cluster.
Updating the cluster result
Through the above steps, we identify all clusters for the t-th time window. We update the number of points, as well as the mean and covariance matrix of each cluster as follows.
We then perform multiple hypothesis testing (Section 3.3) to divide noise points (or not) and assign a non-noise point to a cluster index.
We conducted experiments to evaluate the proposed method with synthetic and real datasets.
Validation measures
There are two types of validation measures for a cluster result, i.e., external criteria and internal criteria [13]. Internal criteria are validation measures that evaluate a cluster result using only inherent features in the dataset. The sum of square error and Silhouette [16] are typical internal criteria. External criteria use extrinsic information to evaluate cluster results. Popular external measures are purity, the Rand index [22] and the adjusted Rand index [15]. For a synthetic dataset to be generated from known clusters, external measures may be more objective.
In this study, we use the adjusted Rand index and mean purity for validation measures. We propose a method that can control the decision error by pFDR. If we know the true groups, then the actual pFDR can be obtained by the proportion of false decisions among all rejected hypotheses. Therefore, we report the actual pFDR for synthetic datasets to observe how well the proposed method controls the decision error.
Synthetic datasets
Two-dimensional synthetic data with evolving scenario
This synthetic dataset is generated from bivariate normal distributions over eight time windows with an evolving scenario. Figure 1 shows the dataset over time windows when noise points comprise 5% of the dataset. There are three clusters (blue, green, and cyan points) at the first and second time windows. A new cluster (magenta points) appears at the third time window. Two clusters (blue and magenta points) are merged at the fourth time window. A new cluster (yellow points) again appears at the fifth time window. The cluster with blue points at the fifth cluster is split into two clusters (blue and magenta points) at the sixth time window. The cluster with green points at the sixth time window disappears at the seventh time window. Finally, the cluster with cyan points at the seventh time window is self-evolved to the eighth time window with a different covariance matrix. The cluster distribution parameters are shown in Table 1, where each tuple contains [mean, covariance matrix, number of points]. We prepare three synthetic datasets according to three different proportions of noise points (marked with red dots), i.e., 5%, 10%, and 15%, randomly generated in the area of (
Distributions of true clusters in two-dimensional synthetic data
Distributions of true clusters in two-dimensional synthetic data
A two-dimensional synthetic data set with 5% noise.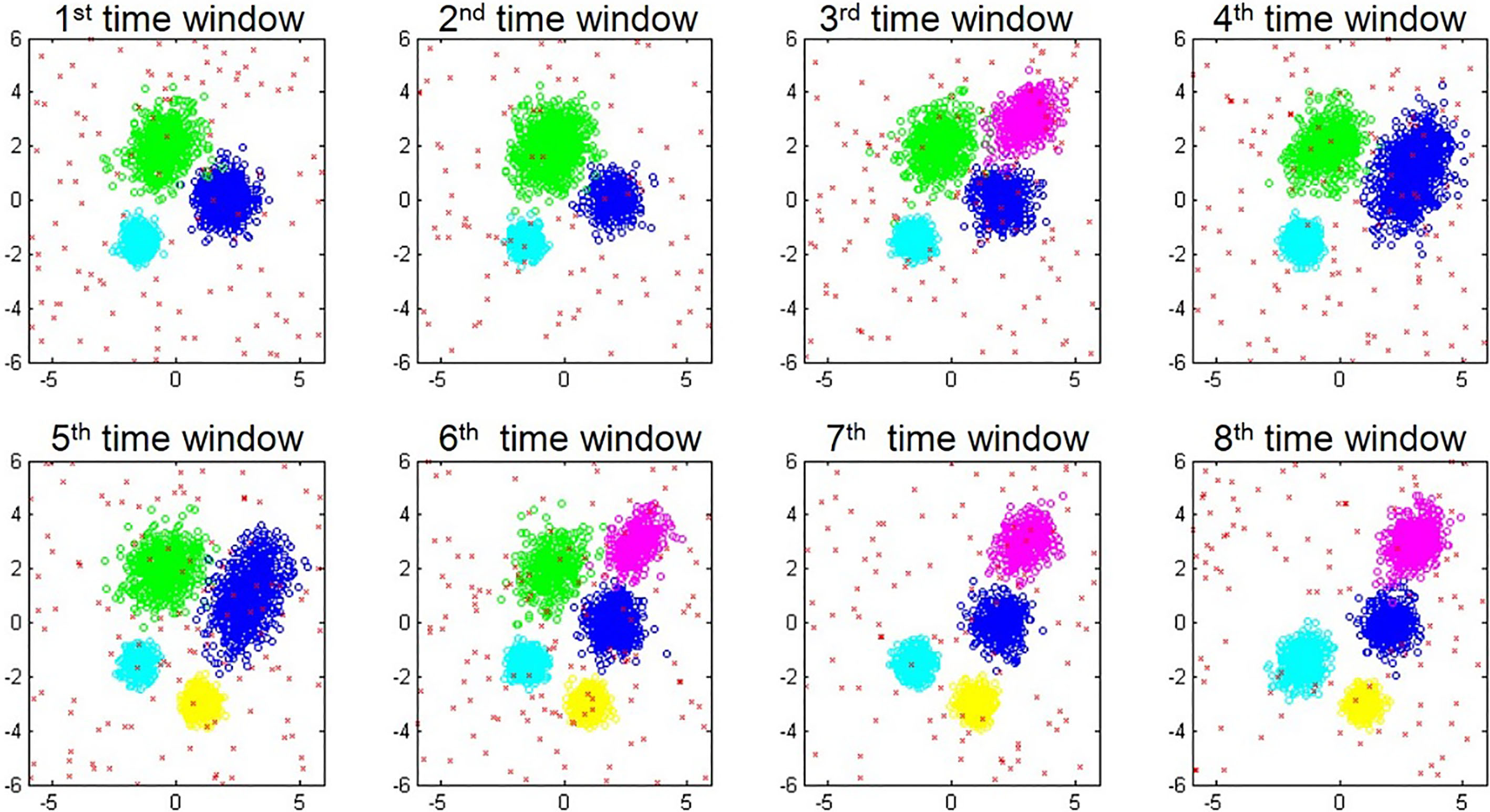
We set the pFDR level to 0.01, 0.05, 0.1, and 0.15 for the proposed method. For comparison, we also apply DenStream, which is a popular density-based data stream clustering method. We repeat the process 10 times to calculate the validation measures.
Although the results are not reported here, the estimated mean vector and covariance matrix for each cluster are very close to the true values even when the proportion of noise is high. Figure 2 shows the results obtained by the proposed method (when pFDR level is 0.1 and the fade rate is 0.9) when applied to a synthetic dataset with 5% noise points, and Fig. 3 shows the cluster results obtained by DenStream with
Clustering result by the proposed method when pFDR level is 0.1 for two-dimensional synthetic data with 5% noise.
Clustering result by DenStream for two-dimensional synthetic data with 5% noise.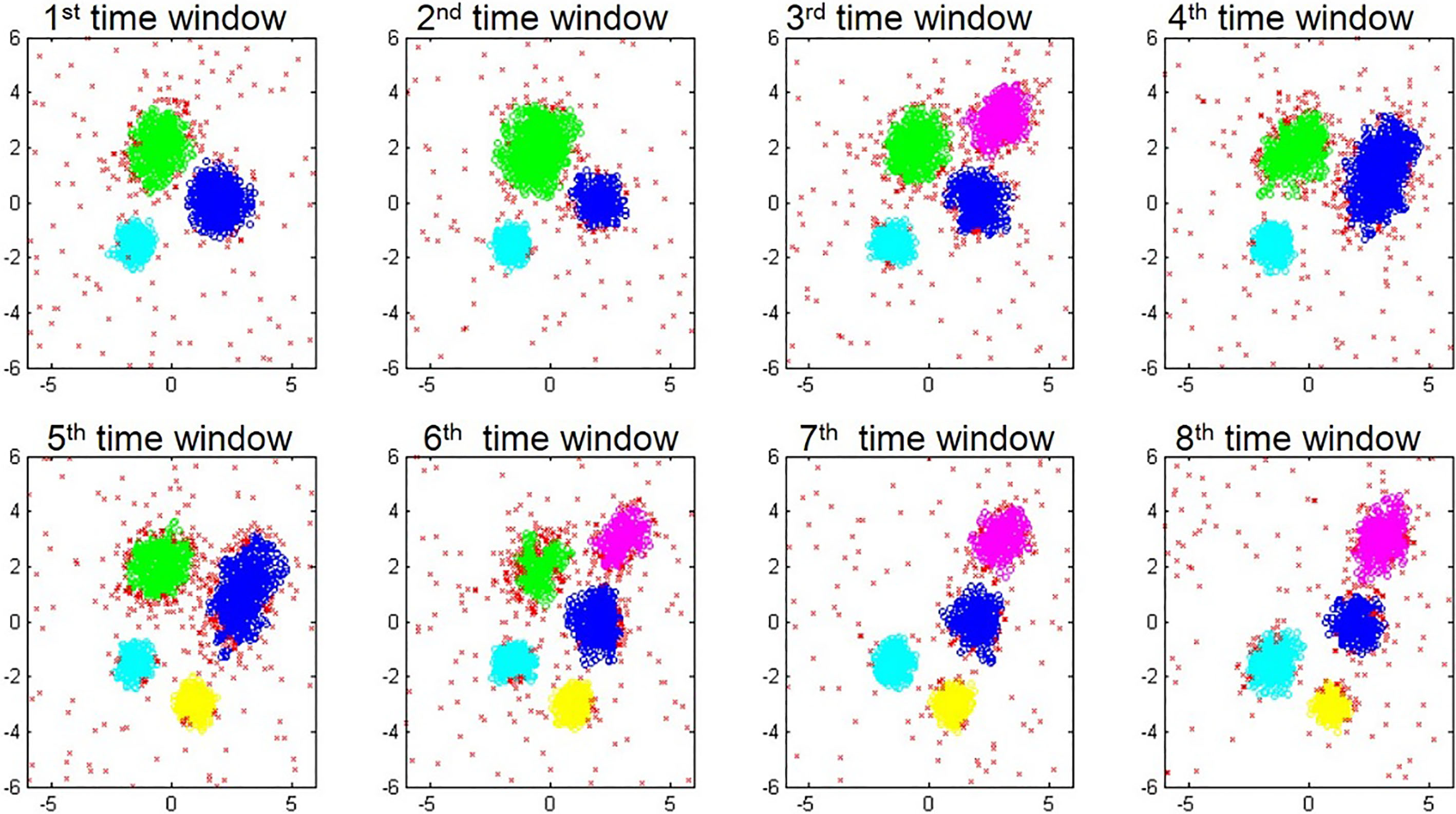
The number of clusters at the third, fifth, and seventh time windows is four; however, each distribution is quite different, as shown in Fig. 1. As can be seen in Fig. 2, the proposed method identifies clusters better than DenStream (Fig. 3) when comparing with the generated data sets.
Tables 2 and 3 show the adjusted Rand index and the mean purity, respectively, of the cluster results obtained by the proposed method and DenStream. Here, the pFDR level and fade rate used for the proposed method are 0.1 and 0.9, respectively.
Adjusted Rand index of cluster result for two-dimensional synthetic data with 15% noise
Mean purity of cluster result for two-dimensional synthetic data with 15% noise
It is clear that the proposed method provides better cluster results than DenStream in terms of adjusted Rand index and mean purity. Although the results are not reported here, these performance measures for the proposed method do not vary significantly as the pFDR level changes. However, for the proposed method, the adjusted Rand index appears to decrease and mean purity increases as the pFDR level increases because the actual cluster members tend to be declared as noise as the pFDR level increases.
Table 4 shows the actual pFDR from the proposed method according to the pFDR level (fade rate is fixed at 0.9). The results indicate that the actual pFDR values are generally less than the specified pFDR levels; however, it appears that the proposed method controls the pFDR fairly well.
Actual FDR of the proposed method for two-dimensional synthetic data with 15% noise
To observe the performance of the proposed method with higher dimensional data, we generated two more synthetic datasets with five and ten dimensions. Here, each dataset has 20 time windows. Two to five clusters are randomly selected at the first time window. Then, the number of clusters at the following time window decreases by one with a probability of 0.2, remains the same with a probability of 0.4, increases by one with a probability of 0.2, or increases by two with a probability of 0.2. The members of each cluster are generated from a multivariate normal distribution with the identity matrix for the covariance matrix. The mean of each dimensional variable is selected randomly from the set {U (
Table 5 shows the clustering performance of the proposed method for the five-dimensional datasets with three noise cases (N5%, N10%, and N15%) according to various pFDR levels (fade rate is fixed at 0.9), as well as various fade rates (pFDR level is fixed at 0.1). Table 6 shows the results for the ten-dimensional datasets with three noise cases. They clearly show that the proposed method works well for a higher dimensional data sets regardless of the proportion of noise data points.
Clustering performance of the proposed method for five-dimensional data sets
Clustering performance of the proposed method for five-dimensional data sets
Clustering performance of the proposed method for ten-dimensional data sets
To demonstrate the proposed method, we use two real datasets from the UCI repository.
Forest cover type data
This dataset is about forest cover types, including wilderness areas located in the Roosevelt National Forest of northern Colorado, which was analyzed by Blackard and Dean [3]. The total number of data points is 581,012 in seven cover types, where type 1 comprises 36.5% of the dataset, type 2 comprises 48.8%, and other types comprise 14.7%. Each data point has 54 attributes, among which 10 are continuous attributes and 44 are binary attributes. Note that we only use the 10 continuous attributes in this study. We transform this dataset to a data stream with time windows. We divide the dataset into 117 time windows in the order of observations, each of which has 5,000 data points (the last window contains 1,012 data points). Figure 4 shows the proportions of cover types over the time windows. Types 1 and 2 primarily appear at earlier time windows and other types appear after the middle time windows.
Proportions of cover types over time windows in forest cover type data.
Mean purity of cluster results for forest cover type data.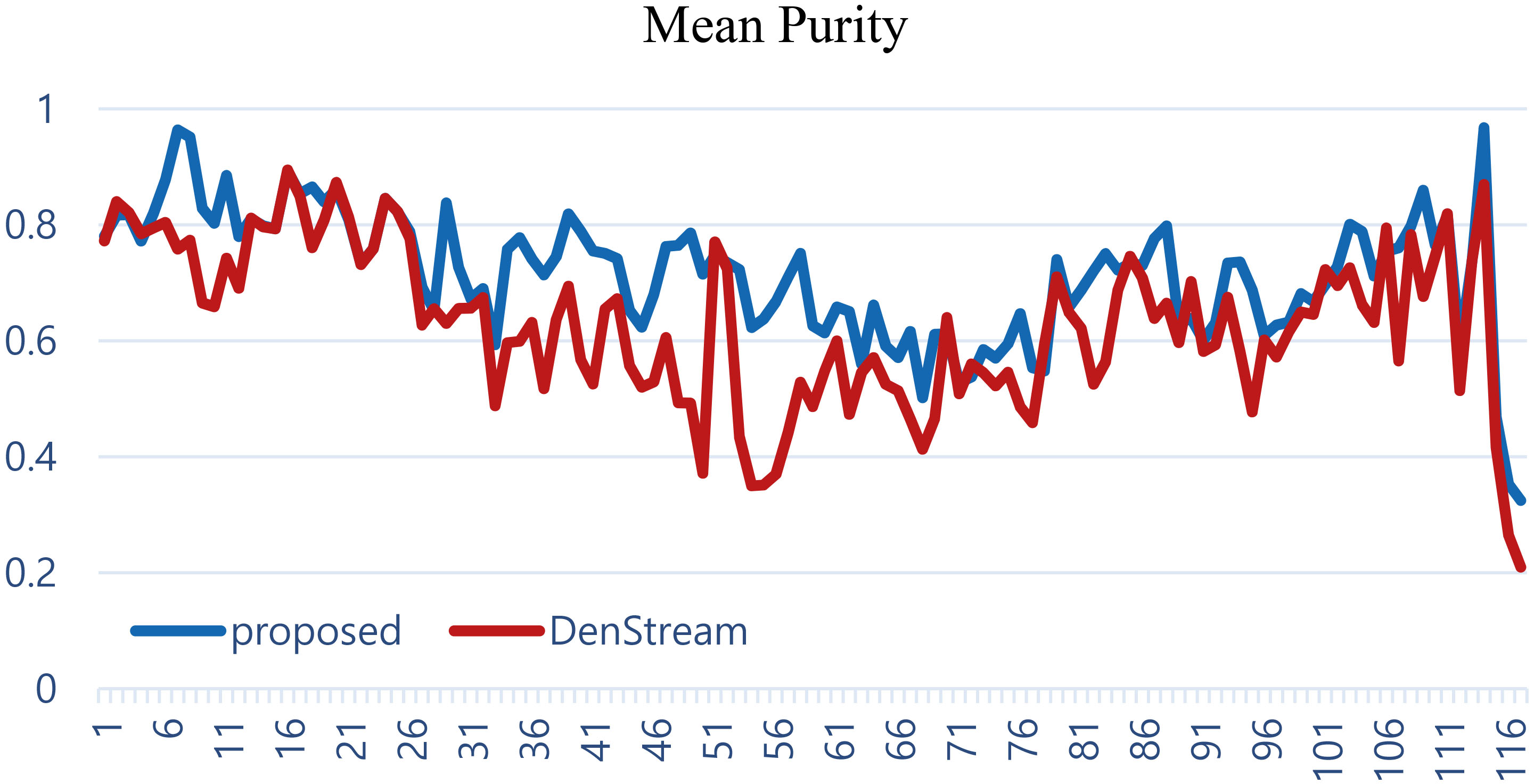
Adjusted rand index of cluster results for forest cover type data.
When applying the proposed method, we set the pFDR level to 0.01 and fade rate to 0.9. For DenStream, we use
This dataset is time series data from 16 chemical sensors exposed to gas mixtures under various mixing ratios, which was analyzed by Fonollosa et al. [12]. There are two gas mixtures, i.e., ethylene and methane in air, and ethylene and CO in air. Note that we selected a set of ethylene and CO in air. The total number of data points is 4,208,261. There are 73 different types of mixing ratios. Among them, we use 1,000,000 data points in 41 different mixing ratios. The number of type 1 data points is 24%, and the ratios of other types are less than 7%. There are 16 attributes from the sensors for each data point. We transform the dataset to a data stream with 5,000 data points at each time window such that there are 200 time windows. Table 7 shows the number of types and the major types at selected time windows. As can be seen, most time windows contain only one type; however, the major type changes over the time windows.
The numbers of types and the major types at selected time windows in gas sensor array data
The numbers of types and the major types at selected time windows in gas sensor array data
For this dataset, we set the pFDR level to 0.01 and fade rate to 0.9 for the proposed method. Figure 7 shows the mean purity of the cluster results at 43 selected time windows. We selected time windows that contains at least two types of gas mixtures and whose major type is at most 80%. The maximum proportion represents the estimated proportion of the major type. Note that the clustering results have the same or higher purity than the maximum proportion. Figure 8 shows the adjusted Rand index of the cluster results for the selected time windows. The bar chart indicates the number of clusters found at each time window. The Rand index tends to be lower if the number of clusters is larger due to the imbalanced distribution of mixture types. Generally, the proposed method shows good performance in terms of these measures.
Mean purities over selected time windows by the proposed method for gas sensor array data.
Adjusted Rand indices over selected time windows by the proposed method for gas sensor array data.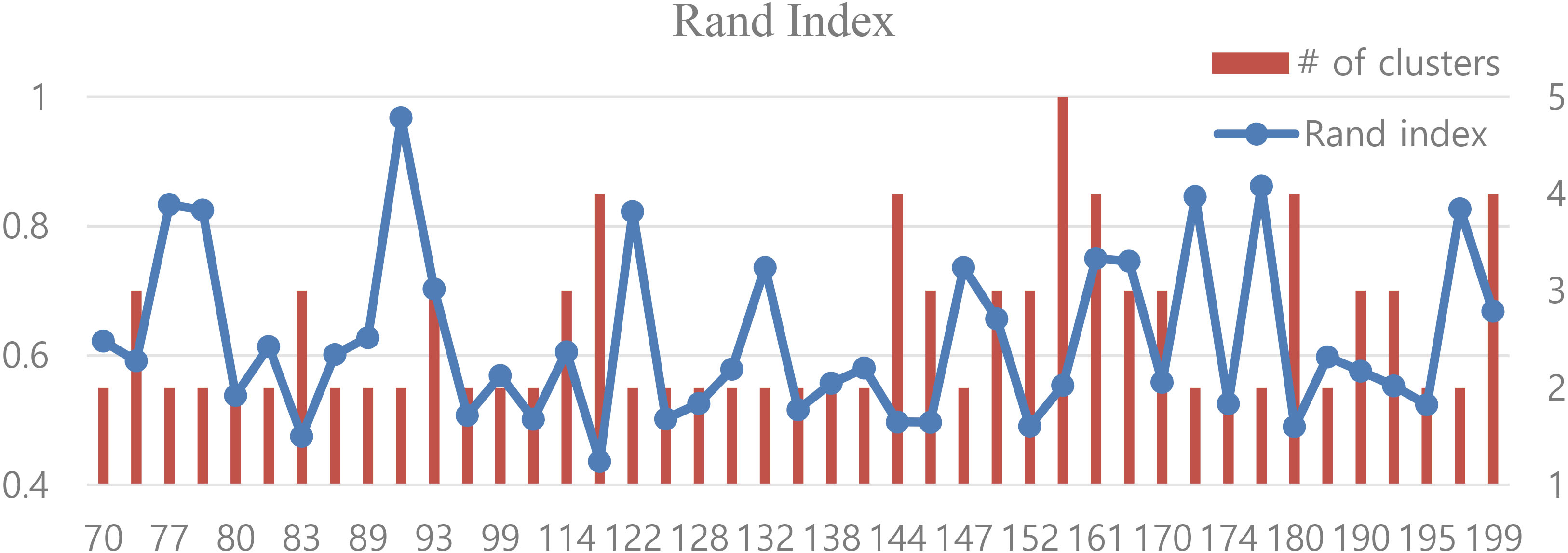
We also attempted to apply DenStream to this dataset; however, it turned out that all data points were determined as a single cluster or noise at each time window.
In this study, a hybrid data steam clustering method that combines model-based and density-based clustering is proposed. The performance of the proposed method is evaluated in terms of mean purity and the adjusted rand index. Experiments with synthetic datasets and two real datasets show that the proposed method responds quickly to cluster evolution and detects noise quite well by controlling the decision error of the pFDR near a predefined level. Compared to DenStream, the proposed method shows better and more robust performance.
As observed from the experimental results obtained with higher dimensional datasets, the performance of the proposed method may degrade as dimension increases. Therefore, suitable dimension reduction is recommended for this clustering procedure. Note that the two real datasets are not originally data streams; however, these datasets were transformed to data streams. This shows the possibility of handling and analyzing big data by transforming it into a data stream with time windows.
The analysis of big data with the aid of data stream clustering may be an interesting problem, which should be further studied in a future research. Also, missing values in some variables are present frequently in a real data set, so the handling missing values in a data stream algorithm can be included in a future study.
Footnotes
Acknowledgments
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea Government MEST (No 2017R1A2B4005450).
Appendix Pseudo code of the proposed algorithm
Proposed algorithm
Input: Dataset
, radius
, Minimum number of points MinPts-1, 2, min_cluster_num, desired number of clusters
,
p-threshold
, cluster-threshold
Initial Phase
1. Separate Non_noise_data and Noise_data by using DBSCAN (X,
, MinPts-1)
2. Update cluster information
by using incremental EM based on BIC
3. Compute
-value
of each data points in Eq. (3)
4. If
, then
is a noise data
5. Else,
is a cluster member of
where
Incremental Phase
6. For new data points at
-th time window, (use notations in Section 3.4)
7. Compute
-values for each component of the GMM
8. Calculate proportion of cluster members
for
9. For each cluster, assign top-
data points in terms of
-values
10. Data points assigned to two or more clusters, randomly select one cluster and unassigned data points are classified as
temporarily noise points
11.
for
is new clustering result from DBSCAN on temporarily noise data
12. If
min_cluster_num, then
13. Find the closest existing cluster
to
14. Estimate BIC-1 of the Gaussian mixture model with 1 component on
15. Estimate BIC-2 of the Gaussian mixture model with 2 component on
16. If BIC-2
BIC-1, then
is declared as a new cluster, else is assigned into existing clusters
17. update cluster information
,
,
by using incremental EM based on BIC
18. If number of members
MinPts-2 for some clusters, then remove the cluster and re-allocate members in it
19. Update the cluster result using Eqs (8)–(10)
20. Separate noise data by multiple hypothesis testing (3.
5.)