
Abstract
Personal information management enables users to manage and classify information via the social tagging. The personal information management platform has recently successfully adopted social networks, enabling users to conveniently share their preferences of information with each other. The emerging social networks generate new concepts for designing modern recommender systems in personal information management and sharing platforms.
To design a recommender mechanism for the personal information management and sharing platforms, this work incorporates tag-based personalized interest and social network relationships into a modified Bayesian probability model.
The proposed system is demonstrated with experimental datasets obtained from a popular social resource sharing website. The performances of the proposed system are evaluated based on the word2vec word embedding model. Experimental results indicate that incorporating social network information and personalized tag-based preference with the Bayesian model can improve the recommendation quality for social information sharing websites.
Keywords
Introduction
Personal information management (PIM) enables users to collect, highlight, access and share a variety of information on a variety of devices. Many people nowadays manage their personal information on the Internet via Web 2.0 service platforms, including Delicious, Diigo and Pinboard. These systems are also known as the social information/resource sharing or the social annotation systems, which allow users to store, organize, share and discover internet resources with user-defined tags [9]. The use of user-defined tags, also known as “Tagging”, is a characteristic of Web 2.0 technology, allowing users to collectively tag and classify internet resources [13, 25, 33, 34]. Users of these tag-based social information management websites can easily classify, store and retrieve their interested resources (such as websites, documents, photos, and videos), and these activities are essential parts of knowledge management cycle [31].
Social networks are growing rapidly in various applications, including Web 2.0 PIM services. Users not only accumulate internet resources, but also follow or are followed by other users. This social knowledge network is based on personal interests or preferences with a bundle of tags and internet resource bookmarks. A social resource sharing network enlarges the scale of sharing information, extending opportunities to find similar users or interested internet resources, and also enhances the knowledge management cycle: capture, refine, store, manage, disseminate, and create knowledge [8, 31]. More importantly, social networks raise a challenge to designing a modern recommender system that can harness interest-based personalized recommendation systems.
Recommender systems using tag-based personal interest to model user profile and internet resources have been proposed [12, 16]. In contrast with those works, this investigation presents a recommender system that is associated with social networks on social information sharing platforms. Some previous studies focus on the use of social networks to improve recommender systems [20, 22, 6, 36]. Unlike previous researches, the main idea of this study is to employ social network information in both the collaborative stage and the content-based recommendation stage. In the collaborative stage, the nearest neighbors for the target user are discovered from the social networks; in the content-based stage, the recommended items are generated with a modified Bayesian probability scheme that combines the tag-based personal interest, relation strength of social network and the popularity of items from the target user’s social neighbors.
This study aims to investigate the recommendation mechanism that integrates social relationships, tag-based interests and item popularity on social information management systems for knowledge (information) filtering. Therefore, Section 2 of this paper describes related works on personal information management, tagging, social network and recommender systems. Section 3 develops a hybrid collaborative and content-based recommender system by using the social network and Bayesian probability to predict items that interest the target users. Section 4 analyzes the performance of the proposed Bayesian recommender system. Section 5 draws conclusions and suggests future research.
Related works
Tag-based social information sharing system
People like to accumulate, classify, store, search, retrieve and share knowledge or information [11]. In an environment of huge internet resources, a social information sharing system is a helpful tool for people to gather, classify, store, search, retrieve and share information or resources. In these tag-based systems, users tag information or resources for future retrieval and sharing [5, 21]. This tagging plays a significant role as part of useful functions for personal information management. Users, resource items, and tags are three major roles in web 2.0 where users label the resource items using social tags. On the internet, various applications support tagging including photos (Flickr), bibliographic references (CiteULike), bookmarks (Delicious, Diigo, and Pinboard), merchandise (Amazon) and videos (YouTube).
Users gather and classify social resource items using tags, which convey information about the characteristics, content and creation of an internet resource [10]. Therefore, a user’s interest can be partially modeled by analyzing the user’s tag information [12]. Based on the personalized tag information, this investigation constructs a recommender system for the social information sharing websites.
Tag-based recommender systems
Recommender systems are active information filtering systems to suggest resource items (film, television, music, books, news, web pages) that interest the user. Recommender systems are developed to handle information overload, and to provide personalized contents and services to users [2, 3, 28].
Recommender systems make recommendations by three basic steps: acquiring preferences from the user’s input data; computing recommendations using proper techniques, and presenting recommendations to users [30]. Three basic categories of recommendation techniques are content-based filtering (CBF), collaborative filtering (CF) and hybrid-based recommender systems combining CBF and CF [2, 35].
The recommender systems discover the useful information in the social bookmark platform to raise productivity and decrease information overload for users. A tagging system, which is useful for managing and filtering the resource items, can be combined with recommender systems to model users’ interest profiles on the resource sharing platforms. Researchers have used the social tags to classify blogs [5], enhance information retrieval [17, 25], and to improve personalized recommendations [32]. The tags accumulated by the user represent part of this user’s preference or interest in the social bookmarking website. Hence, [16] adopted tag-based user profiles in the collaborative filtering-based recommender systems to alleviate the limitation of the cold-start and sparsity problems, and [34] employed the clustered social ranking to support new users of Web 2.0 websites finding content of interest.
Social networks for knowledge sharing
Disseminating knowledge is an important step in a cycle that a functioning knowledge management system follows. Through the knowledge management cycle, the knowledge learnt is gradually refined over a period of time [31]. Tag-based system provides functions of knowledge store and management, while social networks enable disseminating knowledge. In addition to the three key components of a tag-based system namely users, resources and tags, a social network is another indispensable function for an innovative social information sharing system. People share information with their friends (fans or followers), and learn new information from their friends in the social information systems. Knowledge or information learning and sharing in social information systems often occurs through connections, dialogue and social interaction. Social networks have two basic relationship types: following and follower. Target users follow people in social media because they like to read or collect the information or knowledge from the people that they follow. This is called “following” for this target user. In contrast, a target user may be followed by followers (also known as “fans”), because the followers are interested in this target user’s information. Majority of people use this social media mainly to seek or collect knowledge. A user with a large number of followers is a popular person whose internet resources or knowledge repository are of interest to other users.
The recommender systems need to filter information to avoid providing useless information to users on a social information sharing platform. This triggers our research to incorporate the social network to design a hybrid recommender system that performs collaborative filtering by analyzing the social network, and content-based filtering by deriving the target user’s preferences. Some researchers have worked in this field [6, 20, 22, 36]. However, unlike previous research, this investigation focuses on the combination of personal preference, social network and item popularity in a modified Bayesian probability model.
Tag-based Bayesian probability incorporated with social network information for resource items recommendation
How to discover similar users from the social networks and then suggest items to target users is a critical issue for a recommender system in personal information management platforms. The aim of this investigation is to recommend resource bookmark items that may interest users via social networks.
This study contributes to the modification of the Bayesian recommendation mechanism that tightly integrates social relationships, tag-based interests and item popularity on social information management systems for knowledge (information) filtering. The recommendation procedure includes two main steps: (1) selecting the target user’s collaborative neighbors from the “friend network” comprising followings and followers on the target user’s social network, and (2) suggesting resource items to the target user according to the proposed modified Bayesian probability.
The collaborative stage identifies a target user’s similar neighbors from followings and followers on the social network. The following and follower on the social network provide valuable information for recommending resource items to target users. In the stage of suggesting resource items, the Bayesian probability incorporating the social network information and tag-based personalized preference is computed from the resource items gathered by the target user’s neighbors.
Finding similar users from the social networks may significantly reduce the computation time compared to that of calculating similarity with every user in the platform. The number of candidate items can also be reduced in the item suggestion stage.
Proposed recommendation procedure
The proposed procedure has two main steps, collaborative filtering and content-based filtering. (1) In collaborative filtering, the system searches social networks to find collaborative users with similar interests to the target user. (2) In content-based filtering, the system recommends resource items that are similar to the target user’s interest via the Bayesian probability model. The main steps are as follows:
Prepare data and set predefined parameters.
Prepare item, user, tag information: User-Tag (Eq. (2)), and Item-User (Eq. (7)) and Item-Tag (Eq. (13)) Find the target user’s relation type with other users from friend network. Set weights for the four relation types (Eq. (1)). Set predefined system parameters
For each target user, perform Step 2 and Step 3:
Finding collaborative neighbors via the social network for the target user.
Determine the tag-based similarity between the target user and the users on the target user’s friend network (following, follower) using Eq. (4). The maximum layer of friend network is predefined as two layers. Adjust tag-based similarity with social relation type by Eq. (5). Rank neighbors using the above adjusted-tag-based similarity. Select top- Suggest content-based bookmark items to the target users based on the proposed Bayesian probability.
For each candidate items from the top-
Rank candidate items according to RScore. Suggest top-
The social network in the social bookmarking website reveals a part of a user’s knowledge preferences. This section describes the collaborative filtering procedures, and demonstrates the use of social networks in collaborative filtering.
An essential part of the collaborative filtering stage is finding similar neighbors via the social network for the target users. This process has the following steps: obtain the user’s social relationship on the social network; establish user’s tag-based interest profile, and compute and rank the similarity score of the target user’s neighbors.
The study collects candidate users from the target user’s “friends” (followings and followers) on the social network. A social resource sharing website has two user relations, followers and followings. Users follow people that they like, and are followed by others who are interested in them. Unlike other social network platforms such as Facebook, users on a social resource sharing website usually follow people due to the preference of knowledge content. Therefore, this study exploits the implicit and explicit information provided by the social relationship on the target user’s friend network.
Previous studies (e.g., [12]) focus on collaborative filtering via similarity searches on various users, which exhausts huge search time. This study finds similar users from a user’s social network. The small number of users on a target user’s social network significantly reduces the time taken to search for similar users. Additionally, the recommendation accuracy is maintained, because users in the same social network generally have common preferences on social information sharing systems.
Social relations between target user and the other users.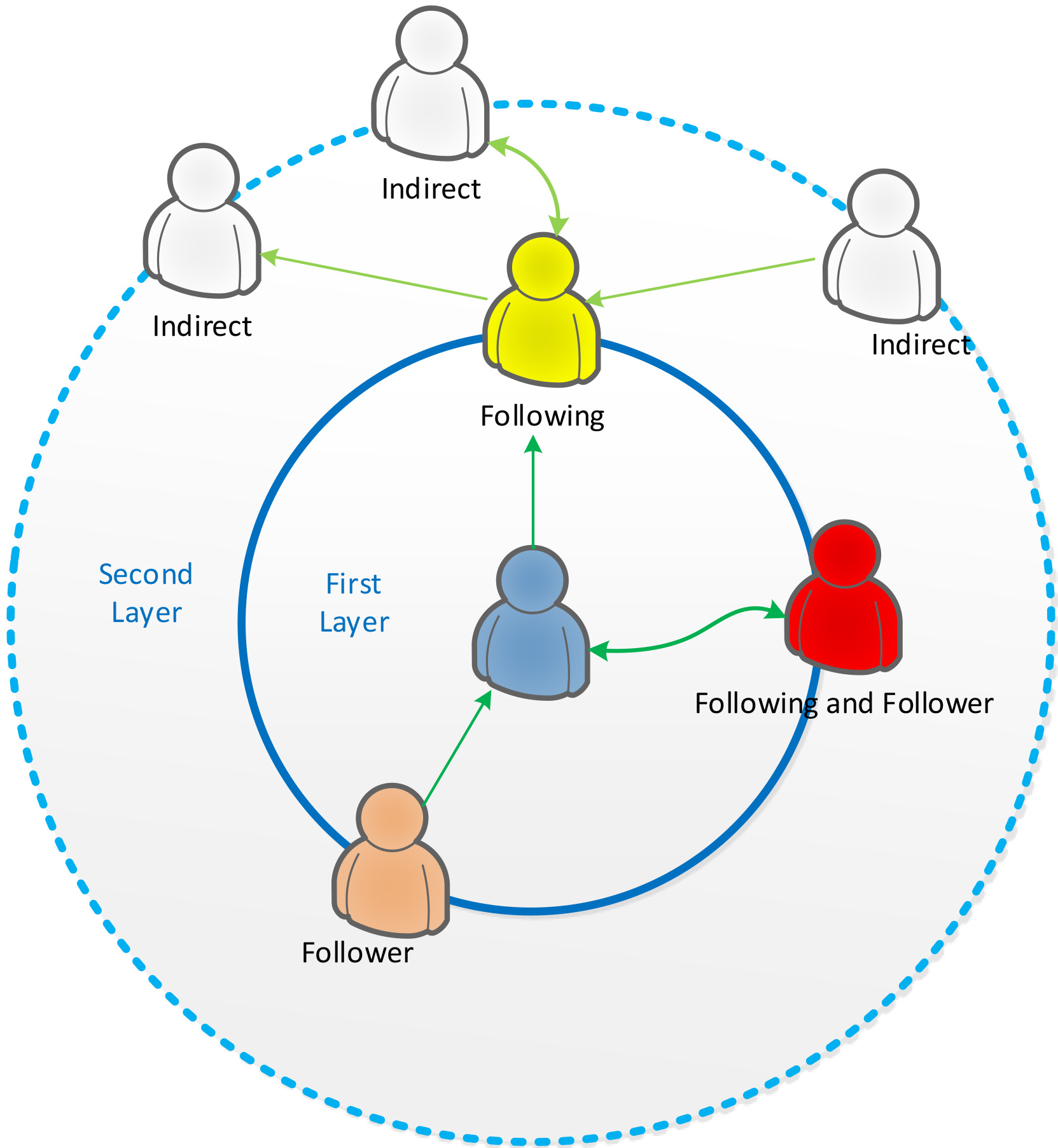
To understand the strength of social relationship for the target user,
where
The user’s tag information includes the tag name and corresponding items collected by this user. A user accumulates a set of tags of interested, implying that the tag-based information can represent the user’s preferences on knowledge collection. A user’s overall preference can be defined as the distribution of tag frequencies. A tag with high frequency means that the user is strongly interested in the category of knowledge represented by this tag. The User-Tag (UT) matrix records the frequencies of tags owned by the user. The frequency of
The user’s tag frequency can be converted into other weighted values, including normalized term frequency and term frequency-inverse user frequency (TF-IUF). This study adopts a logarithmic normalized term frequency, defined as the following formula:
To determine a target user’s collaborative neighbors from the social networks, the tag-based similarity of the target user to other users from the friend network should be calculated first. This work represents the user’s interest similarity using the tag-based cosine similarity. The cosine similarity between
where
To determine the target user’s similar neighbors on the social networks, this study utilizes the adjusted tag-based interest similarity, which combines the user similarity and the strength of social relations introduced in the above section, as follows.
where
Based on the adjusted tag-based user interest similarity, users can be ranked from the predefined number of layers, and the numbers of followings and followers on the social network. The top
The reason for combining the tag-based similarity and the user’s relation strength is as follows. When
The purpose of this section is to recommend items to the target user. Following the previous process of finding similar neighbors via the target user’s social network, this study suggests items from the similar neighbors’ collection based on Bayesian probability.
Item probability based on the Bayes’ theorem
Bayesian classifiers can predict class membership probabilities, such as the probability that a given tuple belongs to a particular class [2]. This study modified the Bayesian probability based on the Naöve Bayes classifier to suggest items to the target users.
If
This formula incorporates the strength of relationship on the social network, and the tag-based personalized interest, which is unlike previous studies (e.g., [12, 16]).
The Bayesian probability focuses on the fraction part of the above formula, namely the probabilities of
The prior probability of the item’s probability,
Traditionally, the item frequency is the total number of users that own an item as follows:
where
Thus, the relative item probability can be calculated as follows:
Unlike traditional approaches for computing the item probability, the proposed method weights the
where
The new item frequency is obtained from
Thus, the weighted relative item probability can be calculated as follows:
The condition probability,
Each item is labeled with several tags by all users on the social network. The item’s tag information (item profile) is store in the item-tag (IT) matrix, which consists of the tag name and its corresponding frequency tagged by users. The item frequency of
This study adapted the logarithmic normalized term frequency, defined as the following formula:
Traditionally, the relative probability of
Thus, the traditional condition probability
In contrast with the traditional approach for calculating the item-tag frequency, this study incorporates the target user’s personalized interest to adjust the value of the item-tag information. The personalized tag-based preference for the target user is stored in the user-tag (UT) matrix, where the tag distribution indicates the target user’s preferences of interest. The normalized frequency of
Thus, the weighted item-tag information, represented as
where
Thus, the condition probability
This study also adopts the Laplacian correction to avoid calculating probability values of zero as follows:
where
Ranking the posterior probability of
Based on the RScore, this study recommends the top
Evaluation metrics of the recommendation quality
This study suggests the top
The quality of the recommended items can alternatively be evaluated by calculating the similarity of keywords between the recommended items and the target user’s items using a word embedding model. Word2vec is a popular word embedding model in natural language processing, which was created by a team of researchers led by Tomas Mikolov at Google [18, 23, 24]. It is trained by a shallow, two-layer neural networks to reconstruct the linguistic contexts of words by mapping words to vectors of real numbers.
Word2vec can produce a distributed representation of words using either of two model architectures, continuous bag-of-words (CBOW) or continuous skip-gram. In the continuous bag-of-words architecture, the model predicts the current word from a window of surrounding context words. The order of the context words does not influence prediction. This study adapts the CBOW model, because it is faster than continuous skip-gram. Wikipedia is also employed to train corpora of text, because the Wikipedia comprises large number of terms.
In the word2vec model, each unique word in a corpus is assigned a corresponding vector in the word vector space. A word vector is positioned in the vector space such that words that share common contexts in the corpus are located in close proximity to one another in the space.
A word vector is represented as:
where
The cosine similarity between
The above cosine similarity ranges from
Item’s tags and keywords (mainly from title, subtitle, header, meta tag with keywords and description, and other content text defined with paragraph tags) are used to evaluate whether recommended items are appropriate for the target user’s bookmark preferences. The item is described by the content keywords and its tags, labeled by users who collect it. Thus, the tags and keywords of the items are adopted to evaluate recommendation quality. The keywords are extracted from an item, removing the stop words to retain only the noun keywords. Some linkage items without tags or text content are skipped. The frequent tags and keywords of each item are included to calculate similarity between items. The recommendation quality is measured from the similarity between the recommended items (represented as REC) and the target user’s recent collected items (represented as TAR). Thus, the recommendation quality for a target user is measured by calculating the average inter-group item similarity between REC and TAR, as follows:
A higher quality means that the recommendation items are more similar to the target user’s current collected items, that is, the recommendation is better.
This study collected users, social relationships of users, and basic profile information of user-tag, item-user and item-tag from the Diigo social network information sharing website (
The proposed model selected the top 15 neighbors from the target user’s social network. From the similar neighbors, the Bayesian probability of each candidate item was calculated, and then recommended the top 25 items with highest recommendation score to the target user. Other necessary parameters were set as
Experimental results
Comparisons with traditional approaches
To evaluate the relative improvement of the proposed model, this study built the proposed model and other four baseline models, namely popular and random recommenders with and without the target user’s friend network, as described in Table 1. The first two baseline models were based on the same target user’s friend network as follows. (1) The popular recommender suggested the popular items from neighbors (users in the friend network) to the target user, without considering the Bayesian probability. (2) The random recommender recommended random items from neighbors (users in the friend network) to the target user, also without considering the Bayesian probability.
Description and abbreviation of studied models
Description and abbreviation of studied models
Result of paired
This study also constructed two random and popular models without considering the target user’s friend network. These popular and random models suggested items to each target user from 15 randomly selected users, which did not belong to the target user’s two-layered friend network. All models were based on the same size of collaborative users, the same size of suggesting items, and the same system parameters.
Figure 2 compares the word2vec cosine quality among the proposed, popular and random models. The study employed the paired T test with 0.05 significance level to examine the difference of average recommendation quality, as listed in Table 2.
The experimental results indicate that the proposed model performed significantly better than the other baseline models as shown in Table 2. Our proposed Bayesian probability model, incorporating the tag-based personalized interest and weighted social relationship information, can improve recommendation quality. The relative improvement of the proposed model over other models was 82.1%, 96.5%, 224.2% and 234.7%, respectively, as shown in Table 3. Relative improvement of the proposed model against other baseline models
Recommendation quality (word2vec similarity) of the studied models.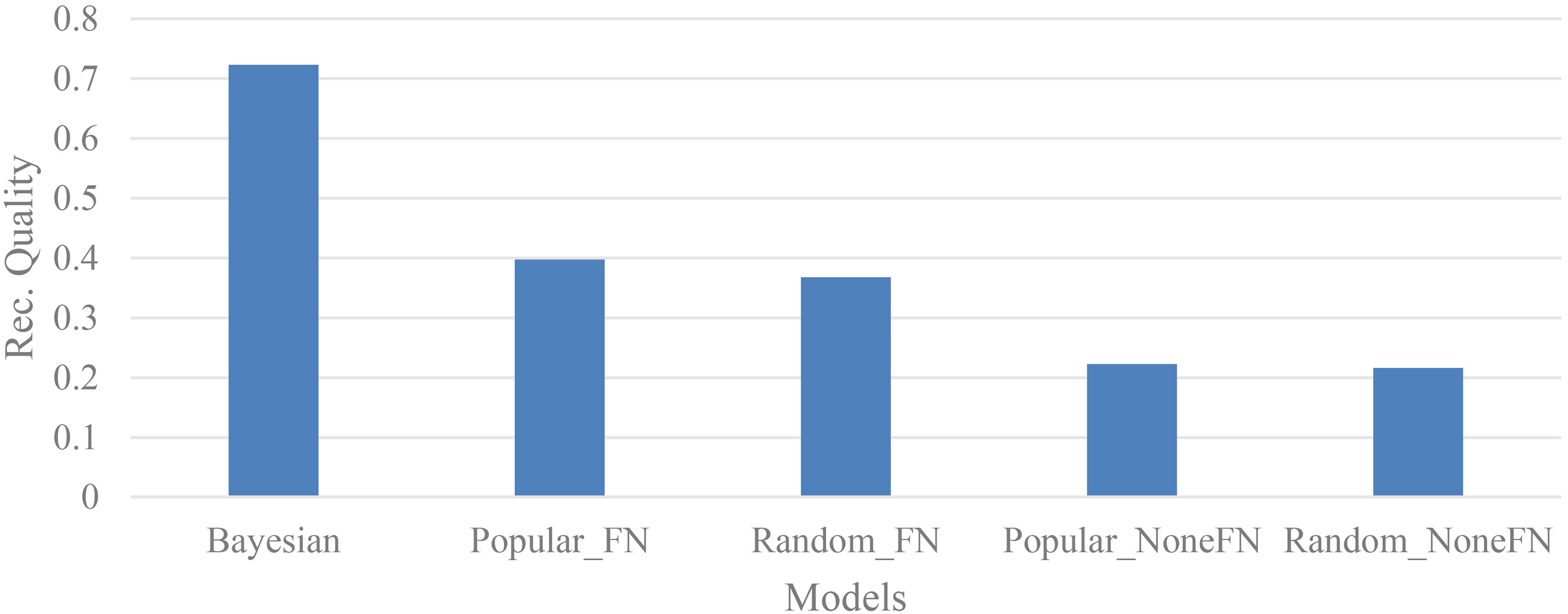
The social network information used in the collaborative stage can improve the recommendation quality. The popular and random models considering friend network had significantly better recommendation quality than the popular and random models without considering the friend network.
The popular model had slightly better recommendation quality than the random model, but the differences between popular and random models were not significant in this study.
Equation (5) combines the cosine similarity and social relation type to find similar neighbors at the collaborative stage. The predefined parameter
Result of average diversity and quality for tuning parameter 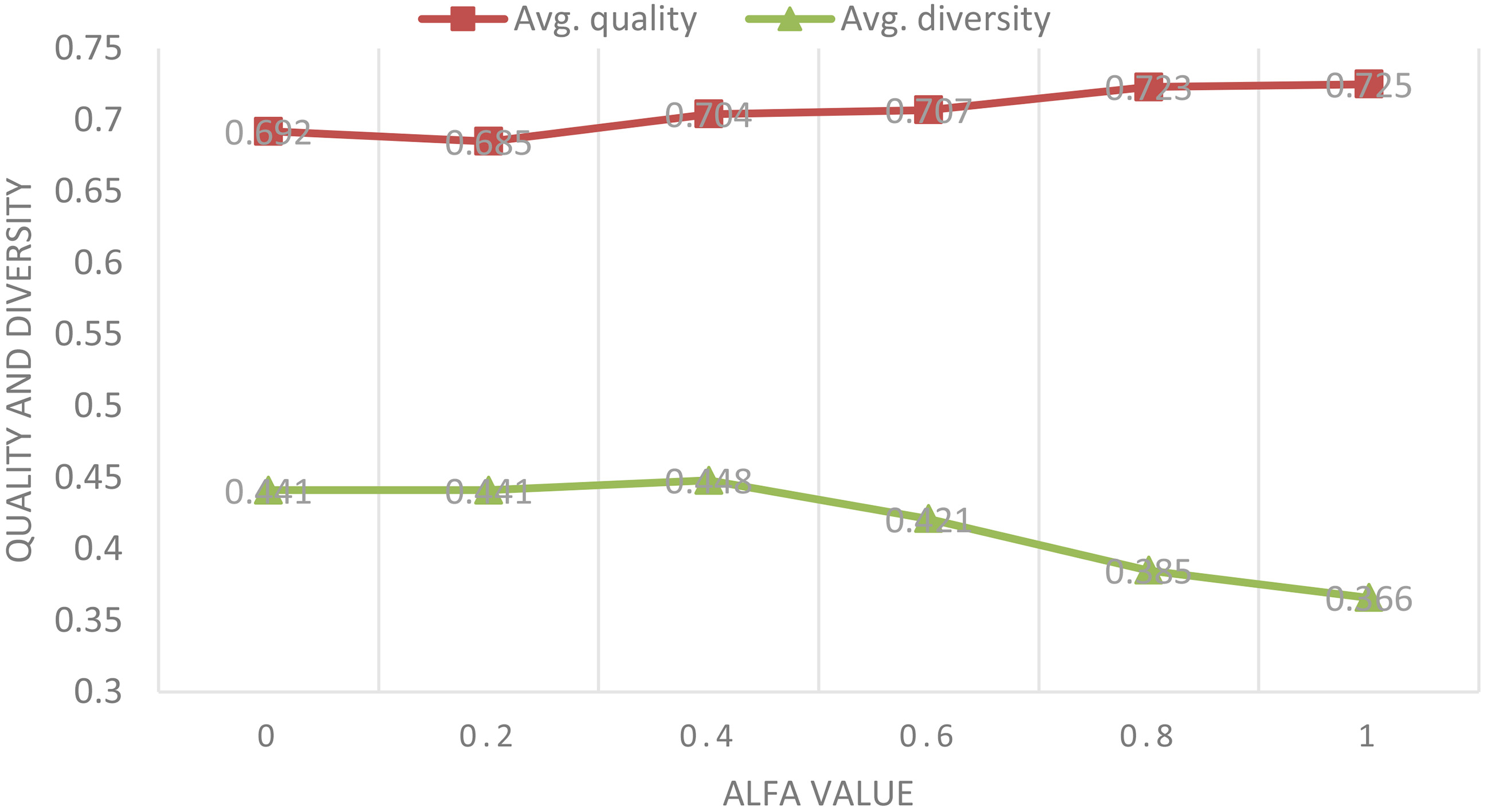
The recommendation quality of
Diversity measures the dissimilarity of recommended items for a user [7, 27]. This similarity is often determined using the item’s content, but can also be determined using how similarly users rate items [1]. Unlike previous research, this study measured the diversity among recommended items using the item vector similarity based on the word2vec vector of the item’s tags and keywords. The diversity of recommended items was measured by calculating the item-similarity within the recommendation lists for the target user, as follows:
Figure 3 shows that the recommendation diversity slightly degraded and the recommendation slightly upgraded generally when
(1) Analysis of model without adjusting item-user information
To compare the recommendation quality without considering the adjusted user similarity, this study calculates item probability from the traditional item-user information,
Recommendation quality of models without adjusting IU and IT information.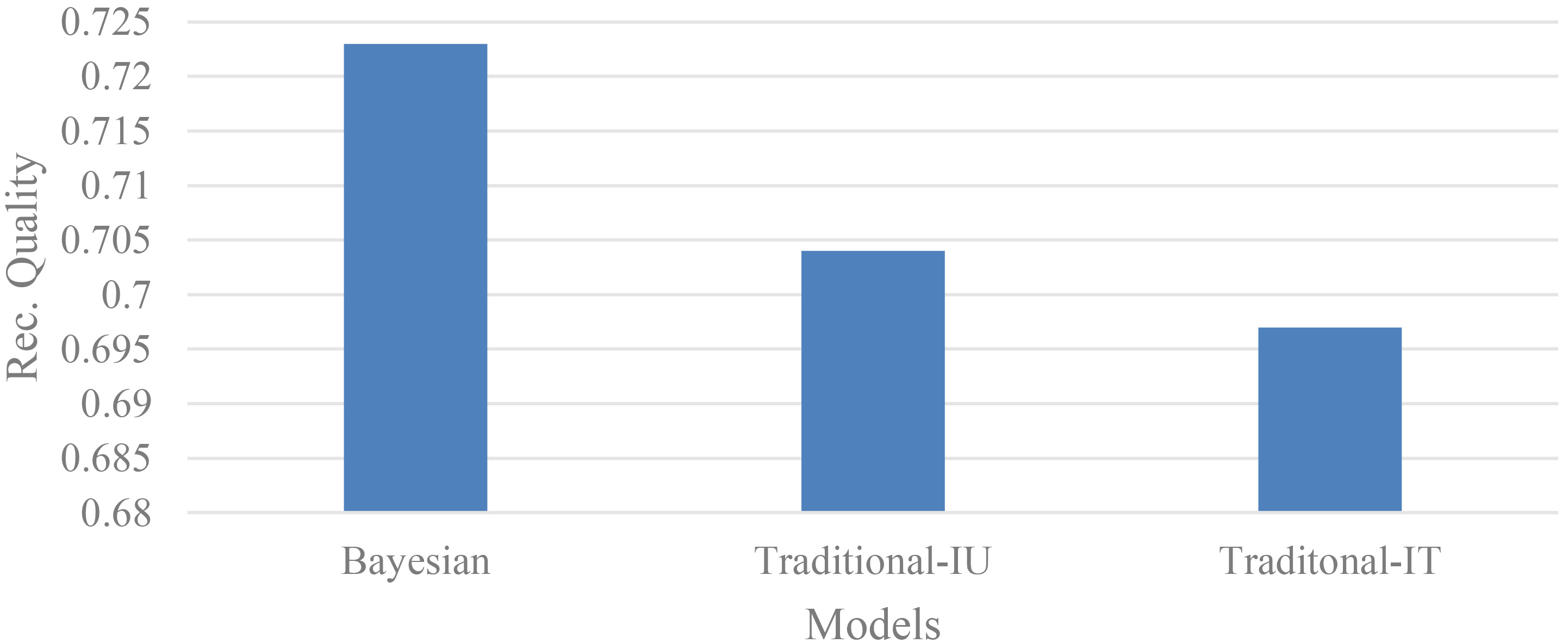
Word vector, keyword co-occurrence and item precision of 15 sampled target users.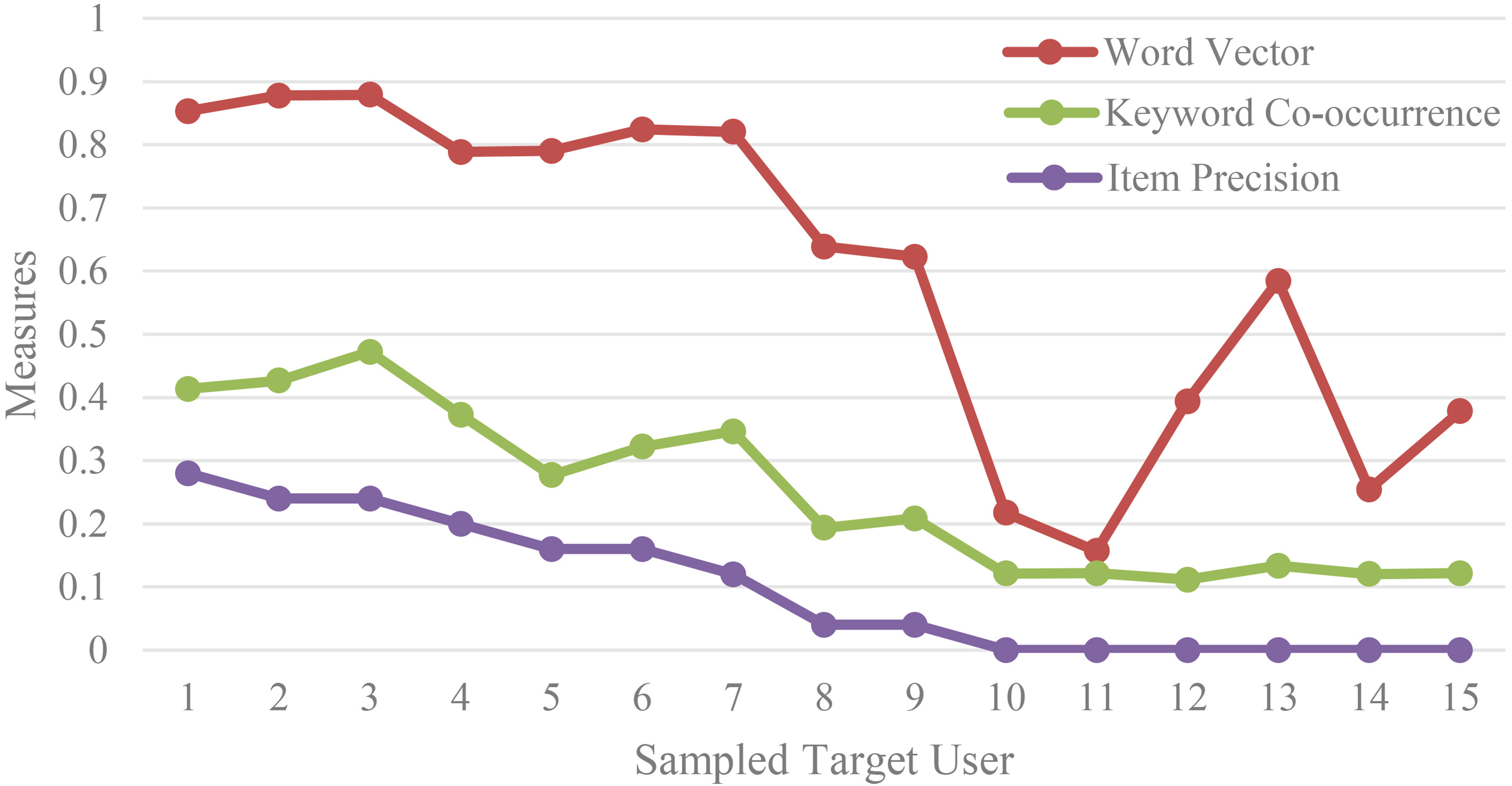
(2) Analysis of model without weighting item-tag frequency
To examine the recommendation quality of model without weighting the item-tag frequency, this study calculated the condition probability from the traditional item-tag frequency (Eq. (16)). Namely, the item-tag values were not adjusted with WUT as defined in Eq. (18). This approach affected the result of Bayesian probability in Eq. (21). As shown in Fig. 4, the Traditional-IT model had significantly inferior recommendation quality compared with the proposed model using
The word vector is adequate for evaluating the recommendation quality of item content. This section compares the word vector similarity with the traditional keyword co-occurrence and item precision measures. The co-occurrence measure is defined as follows:
High co-occurrence means a large number of common keywords for the TAR and REC. In other words, the corpus contains many same-word vectors exists, thus has a large word vector similarity.
Another traditional measure is item precision, which is the ratio that the recommended items successfully hit (predict) the target user’s item URLs, defined as follows.
Figure 5 illustrates the word vector, keyword co-occurrence, and item precision from fifteen sampled target users. For the first nine samples with non-zero item precision, the three measures generally correlate in each other. The correlation coefficient between word vector and keyword co-occurrence was 0.92, and the correlation coefficient between word vector and item precision was 0.89. For the last six samples with zero item precision, the correlation coefficient between word vector and keyword co-occurrence was 0.70, and there was no correlation between word vector and item precision. As mentioned in the previous section, because a user’s collection may have a wide variety of items, the recommended item rarely hits the target user’s item, but may be similar to this in content. In this case, using the item precision fails to measure the recommendation quality, but the word vector measure as an alternative and complement can still evaluate the recommendation quality in terms of content similarity.
Conclusions
Social information sharing platforms implement main functions in a cycle of knowledge management, and enable users to store, create, and disseminate any information on the internet, including articles, reports, documents, photos and videos. Modern social information sharing platforms allow people to follow other users, or be followed by fans, based on common interest via the social networks. This study designs recommendation systems for social networks incorporating personalized tag-based interest, based on Bayesian probability.
The experimental results indicate the proposed Bayesian recommender system is promising for social information sharing platforms. Social relations on a target user’s social network help find interest similar users in collaborative filtering. The Bayesian model can incorporate a target user’s similarity strength with friends on social networks, and tag-based personalized preference.
This study redesigns the Bayesian recommendation mechanism to tightly integrate social relationships, tag-based interests and item popularity into social information management systems. The proposed method can be applied in applications that provide tagging systems and social networks, such as blogs, books, articles, documents, pictures, audios and videos.
Future research
Future work will include investigating extensions to the proposed model, including enlarging the layers of social networks, analyzing the relationships in social networks, and combining users’ other explicit and implicit interests (e.g., clicking, sharing, forwarding, commends, responses). In addition, future research aims to alleviate the problem of ambiguity and tag synonyms in tagging systems, and cold start problems in recommender systems [14, 19, 26, 29]. Employing state-of-the-art word embedding technology e.g., word2vec [23, 24] and fasttext [4, 15] to integrate the users’ tag-based interest model in both collaborative and content-based filtering systems is a promising way to further enhance the proposed recommender system.
Footnotes
Acknowledgments
The authors would also like to thank Mr. W.-C. Chen, Mr. C.-H. Liao, and Mr. H.-J. Chiang, members of the Business Intelligence and Big Data Laboratory in NKUST, for collecting experimental data and training word2vec model.