
Abstract
Measuring semantic textual similarity (STS) lies at the core of many applications in natural language processing (NLP). Recently, most models have considered semantic information or syntactic information, but seldom an unified model to make full use of these two kinds of information. Based on the knowledge from the trained word vectors, this paper proposes a semantic-embedded dependency tree (SEDT) model based on word2vec and glove, which can be treated as a syntactic-semantic representation. In consideration of the words in a sentence for the contribution of the semantic are different, this model extends the semantic-embedded dependency tree model to an enhanced semantic-embedded dependency tree (ESEDT). And a modified partial tree kernel (MPTK) is proposed to automatically extract the syntactic-semantic patterns in this tree. Because the syntactic information, semantic knowledge, and the contribution distribution of the word attention model are all considered in this model, it can measure more comprehensive sentence semantics to improve the accuracy of STS results. Finally, SEDT/E-SEDT is applied to SemEval semantic textual similarity tasks and evaluate its performance through two widely used benchmarks: the Pearson correlation coefficient and the Spearman correlation coefficient. The experimental results show that SEDT/E-SEDT can effectively improve the accuracies of sentence similarity judgments. Compared with the other similar methods to calculate the semantic similarity, such as some neural network models, SEDT/E-SEDT can obtain better performance on most dataset.
Keywords
Introduction
The similarity measurement of textual is one of the basic tasks of natural language processing. In many scenes, textual semantic similarity measurement plays a very important role. In most of the present studies, the main goal of textual semantic similarity is to give the appropriate scoring model associated with human judgment to calculate the similarity of short texts. The semantic textual similarity (STS) can be defined by a set of metrics over a set of documents, and the main idea is to find the semantic similarities,which can be quantized by the semantic relations that exist between them [10, 37]. In initial researches, the STS methods were usually for the short texts [26, 29], and few studies have been concerned with the larger linguistic levels [3].
Measuring the semantic similarity of text pairs was applied in many natural language processing fields. It can evaluate the output quality of machine translation system [24, 47]. In twitter search [38], it can accurately measure semantic relatedness between concepts or entities. In information retrieval [8], it can retrieve a set of documents that the user wants. Semantic textual similarity is also widely used in paraphrases recognition [18], text classification [36, 48], question answering [19, 15], text summarization [43] and textual entailment [4].
STS has already a large number of solutions, which can be categorized into the following ways: topological/knowledge based, statistical/corpus based and string based, etc. The most core idea behind most solutions is to identify and adjust semantically similar or related terms in both sentences, and to bring these similarities together to aggregate an overall similarity. Most STS methods treat input text pairs as feature vectors, where each element is a score that corresponds to a certain type of similarity. The system that follows this idea has achieved the best results in the SemEval 2012 [3] shared tasks. However, using this method does not fully take into account the syntactic information of the sentences. On the other hand, the tree kernel method computes the sentence similarity can effectively learn the syntactic information of the sentences. But most of the structural kernel methods only use the string hard matching to compare the similarities of the tree structures, and these simple judgments will lead to the loss of semantic information. There are also some researches use the soft matching methods to compare the sentence similarity, such as using LSA [13, 7] for semantic annotation, but these methods are judged by stacking some of the semantic features, not only need massive additional resources to generate the features, but also lack of the expression capacity for the short texts. This inspired us to consider these factors. Through an unified model, we can make full use of syntactic information of sentences and semantic information of words in sentences.
In order to obtain a more complete textual representation, syntactic and semantic knowledge of the sentence must be fully considered. To introduce the semantic information, using word vector to make semantic distance comparison is a good choice. The word vector generated by word embeddings can reflect the semantic relation of the words in high dimensional space. This paper proposes a semantic-embedded dependency tree (SEDT) for semantic textual similarity, which treats the input short text pairs as structural objects, and encodes the word vector knowledge into the structural representation, then relies on the power of kernel learning to automatically extract the implicit feature patterns. Moreover, considering the importance of the words in the sentence are different, we extend the original semantic-embedded dependency tree to an enhanced semanticembedded dependency tree (E-SEDT) for distinguishing the contributions of different importance words in calculating the similarity of sentences. In this way, a more comprehensive sentence representation can be gained for calculating the similarity.
For evaluating the practical effects of SEDT/E-SEDT, we compared the six similarity methods and our methods to evaluate the state-of-the-art performance in the STS-12 [3] sharing tasks. In STS-13 [2], STS-14 [1] sharing tasks, SEDT/E-SEDT is also compared against other six the most advanced neural network approachs. The results show that E-SEDT can get the state-of-the-art effect in two of the three STS tasks and achieve the best results on 7 out of 14 datasets. The contribution of this paper is as follows.
Considering the complexity of the sentence semantics, we propose an enhanced semantic-embedded dependency tree that integrates syntactic information, semantic knowledge, and the contributions of different importance words. A modified partial tree kernel (MPTK) is proposed based on the partial tree kernel. MPTK is a tree kernel function that can be calculated using the novel structural tree. We apply SEDT/E-SEDT to semantic textual similarity tasks based on SemEval and evaluate its performance for some of the most common benchmarks. Experiment results show that SEDT/E-SEDT can effectively improve the accuracies of sentence similarity judgments.
The rest of the paper is organized as follows. Section 2 surveys the related works. Section 3 introduces the overall process for STS calculation. Section 4 proposes the semantic-embedded dependency tree and its extended model. The performance evaluation is given in Section 5. Section 6 concludes the paper.
The current methods of STS under study include topological/knowledge based [28], statistical/corpus based and machine learning based etc. Topological/knowledge based methods include node-based [34], edged-base [21] and hybrid which combine node and edge-based. The methods of statistical/corpus are usually based on a statistical model to estimate the semantic similarity. Explicit Semantic Analysis (ESA) [16] is another vectorial representation of texts that uses document corpus as the knowledge base, which can be applied to the individual words or entire documents. In this type of models, a word is represented as a column vector in the TF-IDF matrix of the text corpus. Latent Semantic Analysis (LSA) [13, 7] assumes that words that are close in meaning will occur in similar pieces of text. In these models, the matrixes containing the co-occurrence words per paragraph are constructed from large corpus of text. In this way, the most popular processing means are the machine learning models based on neural network.
Recent works have moved away from handcrafted features and towards modeling with distributed representations and neural network architectures. Kalchbrenner et al. [22] introduced a convolutional neural network for sentence modeling that uses dynamic k-max pooling to better model inputs of varying sizes. Socher et al. [42] used a recursive neural network to model each sentence, recursively computing the representation for the sentence from the representations of its constituents in a binarized constituent parse. Kiros et al. [23] proposed Skip-thought vector, which trains an encoder decoder model that tries to reconstruct the surrounding sentences of an encoded passage. Wang et al. [44] assign different weights to the vectors of the words in order to implement the sentence embedding, which can improve semantic textual similarity performance. A variety of other neural network models have been proposed for similarity tasks [45, 5]. The method of neural network has been greatly improved in the semantic textual similarity task. However, the training processes of these methods are often time-consuming, and the syntactic features of sentences often cannot be fully exploited.
Previous works show the necessity of syntactic information in sentence semantics. Structured trees which include the syntactic information are another way of sentence representation [12]. But it is hard for the sentence structured trees to measure the similarity. Severyn et al. proposed kernel trick to measure the similarity between two elements existing in input space by mapping them into feature space [40]. Collins et al. proposed the concept of tree kernels [9], which can help the structured trees to overcome this shortcomings which are hard to compare efficiently. Haussler et al. proposed convolution kernel [20], which can use the substructure of the discrete structure (e.g. string, tree, and graph) to measure the similarity. Collins and Duffy et al. also proposed convolution tree kernel [9] for natural language processing problems. Duffy proposed the SST kernel [14], which is experimented on the voted perceptron for the parsetree re-ranking tasks. Through the most common tree kernels, such as the partial tree kernel (PTK) [31] and the smoothed partial tree kernel (SPTK) [11], the structured trees can generate various specific structures that in turn represent the syntactic or shallow semantic features.
Most of the studies described above regarded the input text pairs as the feature vectors where each element was a score corresponding to a certain type of similarity, such as lexical, syntactic and semantic similarity metrics. These methods above can be grouped into two categories: (1) those that view a text as a combination of words and calculate the similarity of two texts by aggregating the similarities of word pairs across two texts, and (2) those that model a text as a whole and calculate the similarity of two texts by comparing the two models obtained. To this extent, SEDT/E-SEDT can be classified as the second category.
The following studies are more relevant to our works. Pilehvar and Navigli [33] developed a new algorithm called ADW for measuring semantic similarity, which is an uniform approach that allows for efficient comparison of language items at different language levels. Using personalized PageRank algorithm, they can generate the semantic signatures of language items through external semantic networks such as WordNet, and then compare the language items based on how the language items are characterized. However, it cannot make full of exploit grammatical information due to the simple addition of lexical semantic signatures used to generate the semantic signatures of short texts. We are similar to this method in this point: (1) both for the task of semantic textual similarity; and (2) both represent words or text as vectors through modeling. But its method did not involve the word embeddings knowledge and the dependency structure information, which may cause some degree of semantic loss.
Severyn and Moschitti [39] defined a supervised approach to learning the reordering models by exploiting the structural relationships between the questions and candidate answer sections using sequences and tree kernels. Although they can automatically extract the relational features between relevant questions and answers, using hard-string matching to extract features can only extract the syntactic features. In this case, the semantic information would be lost when calculating the similarity. Therefore, as long as the grammar of the two sentences is completely different and the expression has the same meaning, the calculation score would be very low. SEDT/E-SEDT is similar to this method in this point of making full of using the syntactic tree of sentences. But there are still two drawbacks in this way: (1) the method did not uniformly model the dependency structure information and word embeddings knowledge and (2) the method did not discriminate the importance of the different words to the sentence semantics.
In conclusion, the above models did not give an effective way to fully fuse the factors of the semantic and syntax of the sentences. As a tentative improvement, we propose a semantic-embedded dependency tree that integrates both the syntactic information and the semantic knowledge. We represent a sentence as the dependency tree structure and proposed a modified partial tree kernel function that can calculate the similarity score of the two structural trees with their syntactic information. Moreover, considering the different of influence for each word to the sentence semantics, we also propose an enhanced semantic-embedded dependency tree to quantize the differences in word semantics.
Process overview
The modeling of text similarity becomes complicated due to the ambiguity and variability of language expression. It is difficult to model the syntactic grammatical and semantic information effectively through an unified approach. As a solution, we design a semanticembedded dependency tree (SEDT) by encoding word embeddings knowledge into the dependency relation of the sentence. Considering that most of the existing models often treat each word in a sentence equally, we design an enhanced semantic-embedded dependency tree (E-SEDT) to solve this defect. In the textual similarity task, important words should be given more attentions. As shown in Fig. 1, an attention weight of each word can be obtained by analyzing the data set. We can construct the E-SEDT tree of a sentence based on the information integration of words vector, weights of words and the dependency relations of the sentence. In this way, for a sentence, this type of tree which contains syntactic information, semantic knowledge and weight distribution of word in sentence is a quite effectively syntactico-semantic representation of sentence.
Construction process of the enhanced semantic-embedded dependency tree (E-SEDT).
Measure the similarity process using the new sentence tree structure.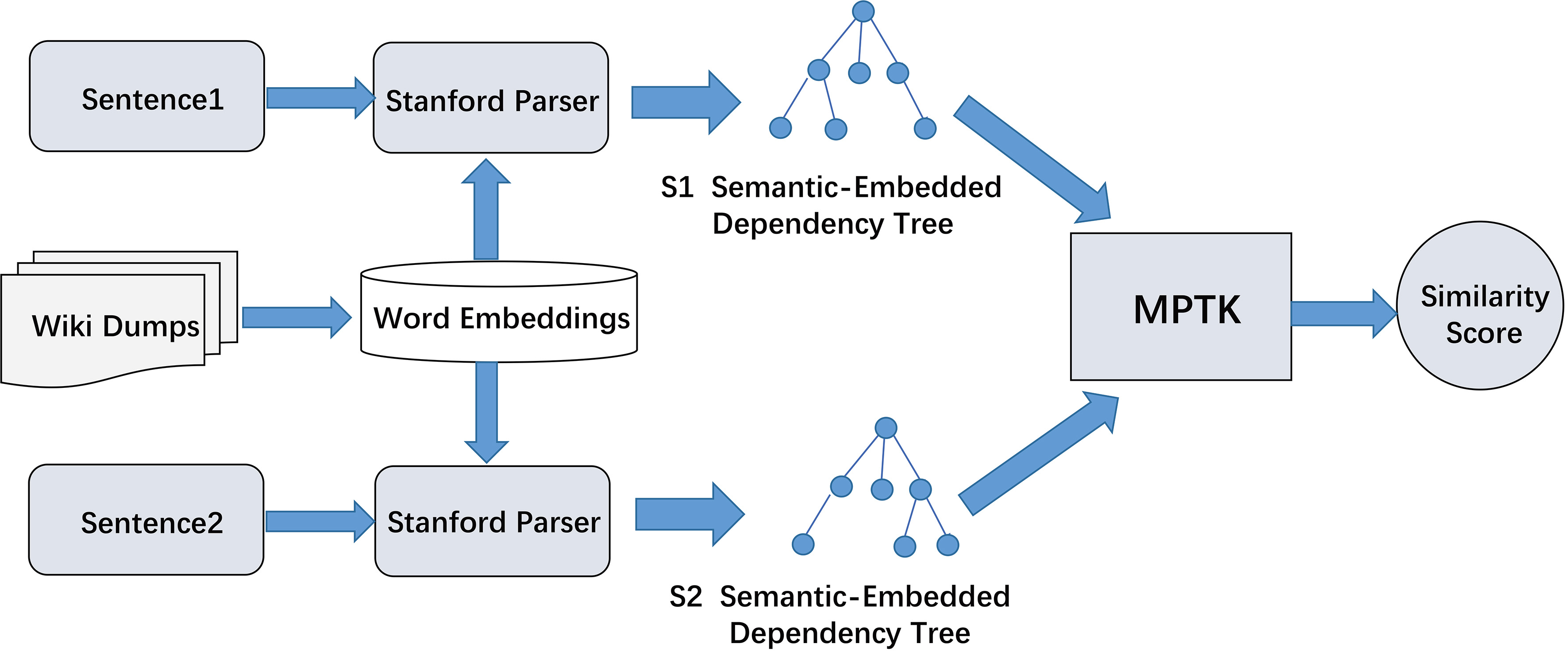
Figure 2 shows the overall process of measuring the similarity of two specific sentences. For the given sentence pairs, they are first converted into the tree structures. In order to build the SEDT and E-SEDT trees, a novel tree kernel function MPTK is proposed on the basis of PTK. Note that MPTK is an universal tree kernel function that can be calculated using both SEDT and E-SEDT without additional modifications.
Tree structure
Previous work has shown the importance of encoding information about lexical semantic between sentences into their structural representations [6, 40]. In this section, we design and compare several syntactic and semantic structural representations of sentence pairs, including dependency tree, semantic-embedded dependency tree, and enhanced semantic-embedded dependency tree. As the core module, an improved tree kernel is given in order to automatically extract the syntactico-semantic patterns of new tree structure.
The dependency-relation and it’s dependency tree (DT).
The dependency tree (DT) with POS tags.
Semantic-embedded dependency tree (SEDT).
Word2vec-embedded dependency tree is encoded word embeddings knowledge which is trained by word2vec tool.1
where
Glove-embedded dependency tree is similar to word2vec-embedded dependency tree, and the only difference is the way to generate the word embeddings knowledge, which is based on glove tool.2
Enhanced semantic-embedded dependency tree (E-SEDT).
Enhanced semantic-embedded dependency tree (E-SEDT) with POS tags.
The weights are defined by the TF-IDF scheme in E-SEDT. And the TF part of the TF-IDF scheme counts the number of times each word occurs in each sentence, which is called its term frequency. Just treat each sentence as a “document”, the value of
where
In the similarity task, an efficient representation for the sentences is essential. A straightforward approach is to prune away all the nodes that are stop words, as they presumably play insignificant role in relating sentence pair, and they do not carry any important contextual information. Removing the stop words in sentence is equivalent to pruning the dependency tree by cutting off the tree nodes of the corresponding lemmas and its corresponding path. For instance, Fig. 8a shows an original sentence of the dependency tree, and Fig. 8b shows the dependency tree of this sentence after structure pruning. It is a concise version of the original sentence while preserving the most essential parts but also reducing the complexity of tree kernel computing.
An example of structure pruning syntactic tree.
In general, the main usage of tree kernels is to compute the number of common substructures between two trees
Otherwise,
where
where
SEDT/E-SEDT are constructed with the word embeddings, dependency relations and attention weight of the words. The following describes how the modified partial tree kernel handles sentence pairs of new tree structure.
The function
If the node
Where If the node
The meaning of the parameters appearing in the Eq. (7) corresponds to the parameters in Eq. (4). If the node
If there is only one leaf in two nodes(
MPTK for STS
The node list of
The similarity score Sum.
initialize an intermediate matrix
//if
//get the weighted cosine similarity;
//if
//if there is one leaf and one syntex node in
The pseudo-codes of the above calculation process are described as Algorithm 1. The function
This section illustrates a group of experiments to verify the effect of SEDT/E-SEDT. All source codes of our experiments are now available in our open-source code repository in GitHub.3
Word analogies datasets
We conduct these experiments on the word analogy tasks.4
We test our methods on the 14 textual similarity datasets including all the datasets from SemEval semantic textual similarity (STS) tasks (2012–2014) [3, 2, 1], except for the STS2013¡¯s SMT dataset, since it was set up with permission, we could not get it. The goal of these tasks is to predict the similarity between the two given sentences. The similarity score is from 0 to 5, where a scale of 0 means unrelated and 5 means complete semantically equivalence. We present the statistics of STS datasets by year. Each year there are actually 4 to 6 STS tasks, as shown in Table 1. Note that tasks with the same name in different years are actually different tasks.
SemEval (Semantic Evaluation) is an ongoing series of evaluations of computational semantic analysis systems, with the aim of comparing systems that can analyse diverse semantic phenomena in text. Each dataset contains many pairs of sentences (e.g. MSRvid dataset in 2012 contains 750 pairs of sentences). These datasets cover a wide range of domains such as news, web forum, images, glosses, twitter, and so on.
Statistics of the provided datasets for the SemEval Semantic Textual Similarity Tasks (2012–2014)
Statistics of the provided datasets for the SemEval Semantic Textual Similarity Tasks (2012–2014)
Word embedding experiment
To generate high quality word vectors, we use Wikipedia Extractor tool5
In word embedding experiments, considering the two key parameters, which are the number of iterations and vector dimension, we set different values to evaluate our trained word embeddings on word analogy task datasets. For the part of the number of iterations, iteration number is set to 5, 10, 15, 30, 50, 100, and the other parameters are the default settings in word2vec software or glove tool. As shown in Fig. 9, the total accuracy gains which include semantic accuracy and syntactic accuracy are not obvious when the iterations exceeds 30. For the part of dimension experiment, vector dimension is set to 50, 100, 200, 300, and the other parameters are the default settings in word2vec software or glove tool. As shown in Fig. 10, the accuracy gain is not obvious when the dimension exceeds 300. Based on the analysis above, we set the number of dimensions in word2vec word embeddings and glove word embeddings as 300:
The number of iteration.
The dimension of word vector.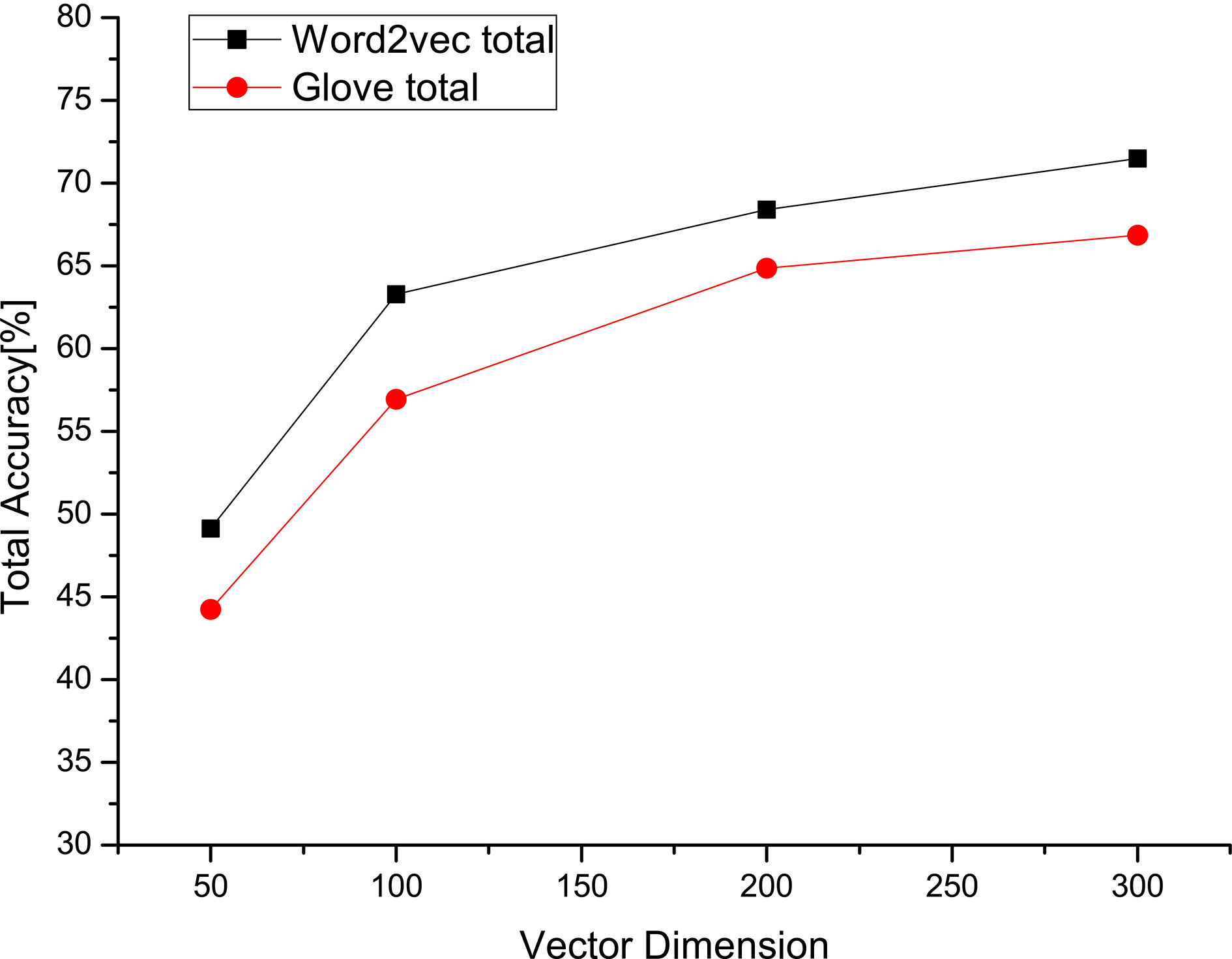
To evaluate the effects of different word embedding techniques on the performance, two word embedding techniques were employed in the experiment: word2vec and glove. The Stanford Parser tool7
To measure the accuracy, this experiment follows the STS tasks and evaluates the performance of the sentence similarity measure according to the pearson coefficient with the gold standard scores. In addition, we also provide the results in terms of the spearman rank correlation on the STS-12 tasks.
As mentioned in Section 2, the similarity measurement method is evolved from the corpus based, string based and other methods to the current neural network approach, so the experiments are mainly designed for two parts:
First of all, SEDT/E-SEDT is compared against other five lexical resource-based measures for their accuracies: WUP [46], JCN [21], LIN [27], LCH [25], and RES [35] on STS-12. And we also choose Explicit Semantic Analysis (ESA) [16] as one of comparative methods, which is one of the best similarity measurements in STS-12. ESA represents a term as a high-dimension vector, where the dimension is an article in Wikipedia and the weight is the TF-IDF value of the term in the corresponding articles. In order to compute the similarity of the sentence pairs using these five concept-level similarity measures, this experiment implements the aggregation method proposed by Corley and Mihalcea [10] based on the solution proposed by Mohammad Taher Pilehvar [33].
The aggregation method works out the similarity between sentence
where
Secondly, SEDT/E-SEDT is compared against other six neural network measures: RNN, iRNN, LSTM, ST, GloVe. ST and GloVe are unsupervised methods, where ST denotes the skip-thought vectors [23], and GloVe denotes the unweighted average of the GloVe vectors [32]. RNN, iRNN, LSTM are supervised methods, where RNN denotes the classical recurrent neural network, and iRNN denotes a variant with the activation being the identity and the weight matrices initialized to identity. The LSTM is the version from [17], either with output gates (denoted as LSTM(o.g.)) or without (denoted as LSTM (no)).
Finally, in our paper, we use the Pearson (r) and Spearman (
Table 2 shows the performance of the proposed semantic-embedded dependency tree , enhanced semantic-embedded dependency tree, semantic-embedded dependency tree with POS tag , and enhanced semantic-embedded dependency tree with POS tag, together with the six other similarity measures on the five datasets of STS-12. And the full name of the abbreviated items in Table 2 are illustrated in Table 3. DT is the result of similarity measure through the original dependency tree based on PTK.
Performance of our methods together with other similarity measures on the five datasets of the SemEval-2012 Semantic Similarity task in terms of the Pearson (r) and Spearman (
) correlations. The right-most columns show the average (Avg) performance across the five datasets
Performance of our methods together with other similarity measures on the five datasets of the SemEval-2012 Semantic Similarity task in terms of the Pearson (r) and Spearman (
The rightmost columns in the Table 2 show the average performance on the five datasets (Avg). As can be seen from the table, SEDT/E-SEDT can achieve the satisfactory effect on all the datasets. Particularly it can achieve the best overall performance when construct an enhenced semantic-embedded dependency tree by using word2vec knowledge. (i.e., tfidf-w2v-EDT) according to both Spearman (Avg 0.62) and Pearson (Avg 0.62) correlations. The overall performance of glove-EDT is slightly inferior to the overall performance of w2v-EDT, and their weighted version is as well.
Traditional tree kernels often compare the tree nodes by hard string matching. However, for the similarity on the sentence levels, the direct use of the tree kernel function can only calculate the similarity of the syntax structure, and the word pairs can only be hard string matched. It will lose a lot of semantic knowledge in this way. Because for the sentences with different words, even though they have the same meanings, their similarity score is likely to be zero under those comparison methods. So the method DT which we use the original dependency tree and PTK for similarity measure has the lowest score in the experiment.
As the Table 2 shows, our approach cannot perform well on some tasks, we try to find out the reasons. As for STS12’ SMTeuroparl and STS12’ SMTnews tasks, it could be due to that some particular properties such as a large number of numerical items or special characters in these tasks weaken the performance of our approach. For example, in the STS12’ SMTeuroparl task, the items like “5.30 pm” and “(A5-0323/2000)” account for around 10% of the total test sample; in the STS12’ SMTnews task, the items like “5.2%” and “24 May” account for around 8% of the total test sample. We must know that, our approach currently lacks for the strong ability to handle the numerical items and special characters.
When we add the POS tags to the original dependency tree, the experimental results do not preferment better than the E-SEDT. We speculate the reason may be that: we adopt the dependency-relations of words to form the dependency tree, the preterminal nodes in the tree represent the grammatical structure between two words, and the addition of the part-of-speech tags to the leaf nodes may affect the calculation of the tree core. The dependency tree is formed by the sentence which removed from the stop words, that makes the part-of-speech tag less important in the sentence.
The description of methods
In Table 2, it is easy to see that w2v-EDT and tfidf-w2v-EDT based on word2vec are superior to glove-EDT and glove-tfidf-EDT based on glove. Hence, we can select the two best methods (i.e., w2v-EDT and tfidf-w2v-EDT) to perform experiments on multiple STS tasks, and compare them with the neural network approaches.
Table 4 provides the results for each task. Our methods get better or comparable performance compared to others. tfidf-w2v-EDT gets the best results in two of the three STS tasks and achieves the best results on 8 out of 14 datasets. In general, tfidf-w2v-EDT performs better compared to w2v-EDT, though it would decrease the performance on rare cases such as SMTeuroparl. Compared with these methods, even if tfidf-w2v-EDT does not get the best performance on all datasets, it does not differ by much compared to the best, such as OnWn and SMTnews datasets in 2012, image datasets and tweets news datasets in 2014. It is just as that the result of tfidf-w2v-EDT based on the tweets news datasets is 0.75, and the best method is 0.77.
As can be seen from Table 4, our approach differs far from the best method on the FNWN datasets and deft forum datasets (over 0.05). The FNWN dataset contains gloss pairs FrameNet-WordNet (FNWN), and the differences in length of its sentence pairs are too much. Facts proved that tfidf-w2v-EDT is suitable for comparing two linguistic level of comparable length. Deft-forum contains many forum post sentences, and in general, the authors do not consider syntactic rigor when writing in forums. Hence, the accuracy of the grammar of these sentences cannot be guaranteed, and it is also doped with a large number of colloquial terms and network abbreviations.
Experimental results (Pearson’s r) on semantic textual similarity tasks (2012–2014). The highest score in each row is in boldface. See the main text for the description of the methods
Experimental results (Pearson’s r) on semantic textual similarity tasks (2012–2014). The highest score in each row is in boldface. See the main text for the description of the methods
As a typical semantic-embedded dependency tree structure, SEDT/E-SEDT provide a novel combined model for measuring semantic similarity of sentences based on the semantic enhanced tree kernel. The approach proposed that the word embedding technique was encoded into the dependency tree structure to get the structured representation which contains the semantic knowledge. In this model, a much richer representation is proposed for the learning algorithm to extract useful syntactic and semantic patterns. Experiments on multiple STS tasks prove that this structure can effectively reflect the semantics of sentences. Moreover, we extend the enhanced semantic-embedded dependency tree with leaf weights, and make it can distinguish the contribution of different words in sentences. Experiments show that SEDT/E-SEDT can outperform the most advanced methods in most datasets. And this also proves that the proposed method considering syntactic information and semantic knowledge can understand the practical semantics of sentences more fully.
Footnotes
Acknowledgments
The work is supported by the National Natural Science Foundation of China (Grant Nos. 61572176, L1624040), the National Key Research and Development Program of China (2017YFB0202201).