
Abstract
With the increasing need of personalised decision making, such as personalised medicine and online recommendations, a growing attention has been paid to the discovery of the context and heterogeneity of causal relationships. Most existing methods, however, assume a known cause (e.g. a new drug) and focus on identifying from data the contexts of heterogeneous effects of the cause (e.g. patient groups with different responses to the new drug). There is no approach to efficiently detecting directly from observational data context specific causal relationships, i.e. discovering the causes and their contexts simultaneously. In this paper, by taking the advantages of highly efficient decision tree induction and the well established causal inference framework, we propose the Tree based Context Causal rule discovery (TCC) method, for efficient exploration of context specific causal relationships from data. Experiments with both synthetic and real world data sets show that TCC can effectively discover context specific causal rules from the data.
Introduction
Causal relationships reveal the causes behind the phenomena and provide insights into the mechanisms of complex systems, therefore finding causal relationships is a central task in many areas. Several causal models, such as causal Bayesian network [22], structural equation model [4] and potential outcome model [28], have been proposed to represent and infer causal relationships which are global or context free.
In reality a variable (e.g. a therapeutic procedure) often has a strong causal effect on an outcome only when the other variables (e.g. genomic profiles) having a specific value. The former variable is called a cause or treatment, while the latter is a context to define a subpopulation. Such causal relationships are called context specific causal relationships in this paper.
The discovery of context specific causal relationships has important applications in various areas [11, 35, 10]. For example, for most economical outcomes, it is important to know for different industries (contexts), the most effective polices (causes/treatment) to be implemented. To maximise profit, it is essential to find the customer groups with different shopping profits (contexts) and the profitable products (causes/treatments) for the corresponding groups.
Context specific causal relationships, however, are hidden and difficult to be discovered since the overall causal effect may be averaged out to be marginal in the whole population. For example, for a treatment, some patients respond positively and some respond negatively, and hence the overall effect among all patients is marginal. A straightforward solution is to assess the treatment effect under all different conditions/contexts, but it is infeasible given the large number of all possible conditions.
Recently researchers seek to apply data mining and machine learning techniques to the investigation of treatment effect heterogeneity [34, 2]. These techniques are utilised to efficiently find the contexts (subpopulations) across which heterogeneous effects of a treatment can be observed. The work has made it practical to discover the contexts and heterogeneity of causal effects.
However, from the data mining perspective, these techniques bear a major limitation. They assume a known cause (i.e. treatment) variable and focus on finding the proper contexts where the cause has heterogeneous causal effects on the outcome. Therefore, it is not suitable for the exploration for context specific causal relationships in data, where the causes are unknown. With the assumption of a known cause relaxed, a big challenge arises for finding context specific causal relationships directly from data, that is, how to distinguish potential causal/treatment variables from context variables.
Our goal is to design a data mining method to discover context specific causal relationships without knowing or assuming a cause, that is, to find both contexts and the causal relationships under the contexts simultaneously. Our approach to this challenge, TCC (Tree based Context Causal rule discovery) adapts decision tree induction, like the work in [2], but in a very different way. In [2], a causality based criterion is used to build a causal tree for finding the subpopulations across which a treatment has heterogeneous effects. Instead we directly make use of the highly efficient and mature decision tree algorithm [25] to find candidate causes and context variables with respect to a given target. Then within the much reduced search space, we employ the potential outcome model [28] to assess the candidates to identify causes and their contexts.
We use decision tree as a base for the following two reasons. Firstly, a rational assumption is that contexts and causes are all highly related to the target, so it is reasonable to use decision tree to select the candidates. Meanwhile, each decision rule encodes context specific relationships between predictor variables and the target, which are likely the indicators of context specific causal relationships. Secondly, a decision tree is efficient for both large sized and high dimensional data, and hence basing TCC on decision tree induction will be practical for various applications. In contrast, it is multiple orders of magnitude slower to build a causal tree compared to a normal decision tree, as the causality based criterion is performed in each split of the tree construction to examine each variable for choosing the optimal branching variable [2, 15].
We further extend decision rules to context specific causal rules for actionable decision making. For example, along a path in a decision tree, a decision rule like
We take this work truly as a journey of causal knowledge discovery from large data sets, therefore our method design has been focused on practical approach and the TCC algorithm has been aimed at quickly finding meaningful causal signals and their contexts in a large data set. The experimental results have shown that TCC performs consistently when it is applied to synthetic or real world data sets, and its high efficiency is also proved by the experiments.
One significance of our work is that we demonstrate that a supervised learning method can be easily adapted for causal discovery with high efficiency and high quality.
In the rest of this paper, Section 2 reviews related work. The problem statement is presented in Section 3, and then a practical definition of context specific causal rules is defined under the potential outcome model. The proposed method is discussed in Section 4. Section 5 demonstrates the performance of the proposed method. Finally, we conclude the paper in Section 6.
Related work
Many attentions have been paid to causal discovery on observational data. Various causal models have been developed for causal relationship discovery [22, 15, 17, 29]. The potential outcome model [28] has been widely used for the estimation of causal relationships. Matching methods [32] are developed to remove confounding when estimating the average causal effect of the treatment on the outcome. Rosenbaum and Rubin [27] proposed the propensity score matching for average causal effect estimation, where a logistic regression is used to estimate the propensity score.
A growing literature focuses on modelling and finding context specific relationships. A stream of research is to derive Context Specific Independence (CSI) based on a known Bayesian network [5, 12]. Researchers intended to speed up the Bayesian network inference algorithms by introducing the concept of CSI. Instead of aiming at fast inference with Bayesian networks, some others focused on extending a Bayesian network by adding special notations, such as labelled graphical models [6], gates [19] and stratified Gaussian graphical models [21], such that the extended Bayesian network can explicitly present the context specific causal relationships. These methods normally assume that global dependency relationships between variables are known in advance.
Another main stream of research that is related to context specific causal discovery is subgroup analysis. Subgroup analysis is commonly used to evaluate the treatment effects in a specific subpopulation defined by some context variables. Su et al. [33] adapted the idea of recursive partitioning to construct an interaction tree for the causal effect estimation. Dud et al. [8] developed an approach to get the optimal policy via the technique of doubly robust estimation. Supervised machine learning approaches have been applied to estimate heterogeneous causal effects [34, 2].
However, these methods are designed to validate hypothesised causal effects of subgroups and the hypotheses have been provided based on the domain knowledge at the commencement of a study. The subjective hypotheses may result in that previously unobserved patterns and relationships would never be tested. What we expect is not only to validate the hypothesised causal relationships, but also to find unobserved causal relationships previously. Thus computational methods are required to discover causal relationships from observational data automatically.
Causal decision tree method [15] was developed to explore both general and context specific causal relationships. Specifically, the causal relationship between the root node and the outcome is context free, while non-root nodes are causes of the outcome under the context of their parent nodes. Although such type of trees have widely practical applications, it has a limitation that the contexts of causes have to be already causes (or context specific causes) of the outcome.
Problem statement and definitions
In this section, we firstly state the research problem of this work, then we define context specific causal rules, and discuss how to identify a context specific causal rule from data.
Research problem
The objective of the work is to find context specific causal relationships in data. Specifically, we aim to find context specific causal rules as stated below.
.
Given a data set
A rule
The first condition specifies a temporal relationship between variables
Similarly, we have the following criteria of identifying a context specific causal rule. A rule
In the next section, we will formally present a practical definition of causal rules and context specific causal rules, and the estimation of causal effects.
Causal rule definition
The potential outcome model [28, 20] is widely used in the estimation of causal effects in social science, health and medical research. In this model, an individual
However, for an individual
The individual level causal effect is expressed as
where
With the definition of ACE, the practical definitions of causal rules and context specific causal rules are formally presented in the following.
(Causal rules).
Given a data set
(Context specific causal rules).
Given a data set
The threshold
Note that in this paper we assume that the differences of individuals could be captured by the covariates, i.e. the set of variables used for stratification. This assumption implies that there are no hidden confounding variables to bias the causal effect estimation.
The major issue for ACE estimation is to unbiasedly estimate the counterfactual outcomes, e.g. what the effect would be if a person had not taken a treatment (actually the person did take the treatment). If we have two groups of individuals, one group taking a treatment and another not, and the two groups of individuals have the same characteristics apart from being treated or not, we can straightforwardly estimate the counterfactual outcomes based on the observed outcomes. In this process, the indistinguishability of two groups apart from treated or not is essential.
Randomised treatment assignment is a way to achieve indistinguishability. However, with observational data, such random assignments of treatments are often not guaranteed. In this case, stratification of the data set is a way of trying to achieve the indistinguishability. In each stratified sub data set, the records of all covariates take the same values in the treatment (
Now we present the details of the procedure of causal effect estimation with observational data.
Variables used for stratification
The first step of causal effect estimation is to determine the set of covariate variables (denoted by
.
The treatment assignment
A causal diagram.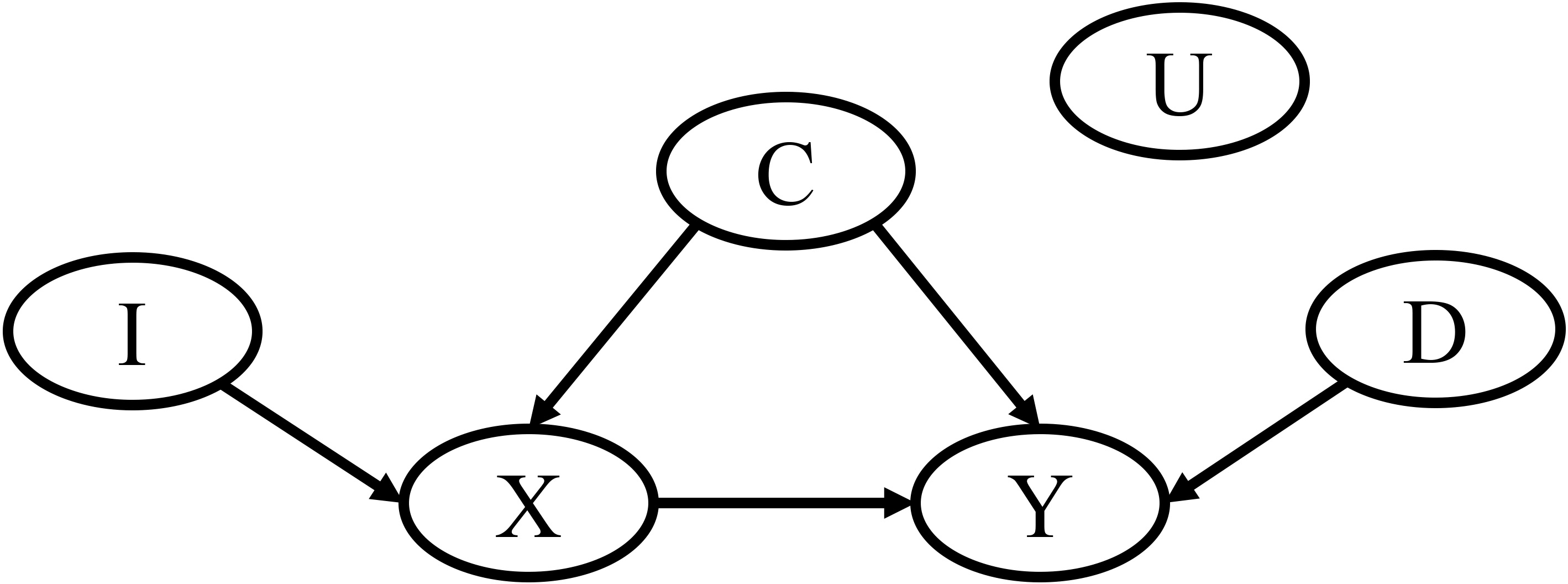
The causal diagram in Fig. 1 is used to help with the following discussions of covariate selection. In this figure, the nodes represent variables and the edges denote the causal links between the nodes.1
Note that a causal diagram is different with an influence diagram, where an arrow denotes an influence and it does not necessarily imply a causal relation.
From this causal structure, we can see that confounders
The second step is to choose a distance measure for stratification. Perfect stratification (i.e. all samples in a stratum have exactly same values), is ideal to eliminate the bias, but it does not work when the number of covariates is large since the statistical power is lost quickly with the increase of the number of covariates. To improve the statistical power, approximate stratifications are developed to match individuals with similar covariate distributions (not exact ones).
Various distance measure, e.g. Minkowski distance and Mahalanobis distance, can be used for the stratification, but most of them does not perform well when there are many covariates under study [9]. Propensity score [27, 32] is another commonly used distance measure, which summarises covariates
Subclassification on propensity score [32] is used here to do stratification, i.e. grouping individuals with similar propensity scores to a stratum, such that individuals are indistinguishable (in terms of receiving the treatment or not) within one stratum.
After the data set has been stratified based on propensity scores, we can estimate the causal effect within each stratum and the aggregate the causal effects over the strata to obtain the overall causal effect. In each stratum
An example of notations for a contingency table
An example of notations for a contingency table
Referring to the definition of ACE, the causal effect is the difference of the outcomes in two groups. Thus in the stratum
The ACE in a population is determined by aggregating the ACEs in all strata
where
In this section, we firstly present the proposed algorithm, TCC, for mining context specific causal rules with a single decision tree, then we introduce a variant of TCC to explore context specific causal rules with multiple trees.
TCC with a single decision tree
As shown in Algorithm 4.1, TCC contains two major parts: decision rule selection (lines 1 to 7) and causal rule discovery with a pruning strategy (lines 8 to 25).
TCC firstly picks up a proper search base for finding causal rules by learning a decision tree from the data. C4.5 [25] is employed to build a decision tree from data. We restrict the minimum number of instances per leaf, such that there are enough samples for the ACE estimation. Each path in the decision tree is a decision rule
Tree based Context Causal rule discovery (TCC) algorithm
To guarantee the statistical significance, we also use the Fisher’s exact test to prune branches of a decision tree [16]. With the notation in Table 1,
A low
Given all decision rules of a decision tree, the predictor variables in each decision rule are considered as the search base of both potential causes and contexts, as a decision rule encodes context specific relationships. Then a confidence test (line 5 in Algroithm 4.1) is conducted to remove the decision rules if it has low confidence, since causal signal in a low confidence rule is weak. Here the confidence of
For a high confidence decision rule
Then we move to context specific causal rule discovery. The discovery of context specific causal rules from a decision rule includes two nested loops (lines 10 to 17 in Algorithm 1). In the outer loop, we traverse the predictor variables
A bottle-neck for context specific causal rule discovery is the enumeration of different contexts in the variable set of the antecedent of a decision rule. Thus a pruning strategy is developed to address the efficiency problem. Function RedundantTest() (line 13) is invoked to test if the rule
As we know, if a causal relationship holds in a population, then it should hold in each of the subpopulations. In other words, if
We are not interested in redundant rules as the causal relationships (if any), since the causal relationships are already implied by their more general context specific causal rules. Thus we exclude redundant rules in the algorithm to reduce the search space. Once we find a context-specific causal rule (including a global causal rule where the context variable set
TCC with multiple decision trees
The performance of TCC could be sensitive to the results of decision tree construction. A decision tree normally makes use of a small subset of variables in the decision rules, so a key limitation of using decision tree for our purpose is that it may not cover all possible causal factors and the context variables, and thus we may miss some potential causal relationships. In this section, we present a variant of TCC with an ensemble classifier, Diversified Multiple Trees (DMT) [14], to address the false negative issue.
DMT uses C4.5 [25] to sequentially build
To avoid confusion, we call the TCC algorithm with DMT as “TCC
As DMT is capable of detecting more attributes highly correlated with the target, potentially TCC
Complexity analysis
The time complexity of the proposed method TCC comes from three main parts: tree construction, general causal rule extraction, and context specific causal rule extraction. Here we focus on analysing the performance of context specific causal extraction, since the complexity of two other parts is significantly lower than the complexity of this part. We denote the height of a tree as
The number of paths of the tree is
Experiments
In this section, we firstly introduce the process of synthetic data generation. Then we present the experiments on TCC and TCC
Then we apply TCC and TCC
Synthetic data
In order to evaluate the proposed method, we generate several synthetic data sets containing context specific causal relationships.
Each of the synthetic data sets is generated with four main steps: (
We use the above procedure to generate five synthetic data sets with 10, 20, 30, 40 and 50 variables (Syn-10, Syn-20, Syn-30, Syn-40, and Syn-50) respectively. Each data set also has 10K samples. Then we use precision (
The accuracy of TCC, TCC
, TCC
and CT on synthetic data sets
The accuracy of TCC, TCC
The results discovered by TCC, TCC
Performance of TCC and TCC
To further examine the performance of TCC and TCC
To evaluate the efficiency of TCC and TCC
Scalability evaluation with TCC and TCC
We run TCC, TCC
We also apply the proposed method to real world data, the METABRIC data set [31]. The data set contains clinical traits and outcomes for 1981 primary breast cancer patients collected from participants of the Molecular Taxonomy of Breast Cancer International Consortium (METABRIC) trial. We run the proposed method on the data set with two different outcomes, 10 years Overall Survival (OS) and 10 years Disease Free Survival (DFS), respectively. The 10 years OS status indicates whether a patient died from breast cancer within 10 years or is alive 10 years after initial consultation. The 10 years DFS status indicates whether a patient survives more than 10 years or not without any signs or symptoms of breast cancer after the cancer ends due to the primary treatment. The METABRIC data set contains 570 and 762 patients who have positive and negative 10 years OS status, respectively, and 820 and 516 patients with positive and negative 10 years DFS status, respectively. Note that to avoid unexpected noise or/and incorrectness involved, instead of imputing missing data [3], we directly removed the records with missing values from the METABRIC data set.
Firstly, the decision tree method is employed to detect association based relationships with respect to breast cancer. Then each decision rule is considered as the search base of both potential causes and contexts. In the set of experiments with this real world data set, available domain knowledge can be utilised to further reduce the search space, to improve the computational efficiency, that is, a potential cause could only be one of three different treatment therapies: chemotherapy, hormone therapy and radiotherapy. Note that these three therapies could also be the contexts to define specific subpopulations, who received multiple treatments.
Top context specific causal rules discovered by TCC from METABRIC with 10 years OS as the outcome
Top context specific causal rules discovered by TCC from METABRIC with 10 years OS as the outcome
We firstly run TCC on the METABRIC data set with 10 years OS as the outcome, and extract top context specific causal rules based on causal effects, shown in Table 4. The causal rules discovered by TCC are supported (or partially supported) by domain knowledge and literature. The first rule in the table indicates that chemotherapy is very effective within the subpopulation, where patients received a lumpectomy to remove a part of the breast tissue, instead of the entire breast [30]. Some interesting context specific causes are also detected. The other two significant causal rules are showing that chemotherapy is not an effective treatment for the subpopulation that has low tumor cellularity mass and the subpopulation with high tumor cellularity mass and low nottingham prognostic index.
Top context specific causal rules discovered by TCC from METABRIC with 10 years DFS as the outcome
We then set 10 years DFS as the outcome, and run the proposed method on the data set. Some interesting and reasonable results are found (Table 5). For example, the third rule in the table shows that chemotherapy has a negative impact on older people (Age
Top context specific causal rules discovered by TCC
We also apply TCC with three trees (TCC
In this paper, a novel method, Tree based Context Causal rule discovery (TCC) has been proposed to explore context specific causal relationships from observational data. Finding causes and contexts simultaneously is important but challenging. Decision tree is utilised to make the complex problem manageable. We have designed TCC based on a well-known causal framework, the potential outcome model, to assess context specific causal relationships. A variant, TCC
The experiments results show that TCC can achieve high performance with the synthetic data sets and find insights from real world data sets. TCC also outperforms an existing causal tree method, in terms of the exploration of short and meaningful context specific causal relationships and easy operation without specifying a candidate cause. TCC provides a scalable and automated way to address the increasing need of uncovering context specific causal relationships for personalised decision making.
Footnotes
Acknowledgments
This work has been supported by Australian Research Council (ARC) Discovery Project Grant DP170101306 and the National and Medical Research Council (NHMRC) Grant 1123042.