
Abstract
The k-nearest neighbors (kNN) algorithm is one of the most popular and simplest lazy learners. However, as the training dataset becomes larger, the algorithm suffers from the following drawbacks: large storage requirements, slow classification speed, and high sensitivity to noise. To overcome these drawbacks, we reduce the size of the training data by only selecting the necessary prototypes before the classification. This study proposes an extended prototype selection technique based on the geometric median (GM). We compare the proposed method with seven state-of-the-art prototype selection methods and 1NN as the baseline model. We use 25 datasets from the KEEL and UCI dataset repository website. The proposed method runs at least 3.5 times faster than the baseline model at the cost of slightly reduced accuracy. In addition, the classification accuracy and kappa value of the proposed method are comparable to those of all the state-of-the-art prototype selection methods considered.
Introduction
The k-nearest neighbors classifier (kNN) is a popular instance-based learning classifier. It is easy to understand and implement because classifying unseen data is done by distance calculation and counting. Because kNN is simple and guarantees a low error rate [24], it is widely implemented in data mining and machine learning research. However, kNN has the following disadvantages when used with a huge dataset: 1) it requires large memory space for storing all training instances, 2) it is slow to classify due to its inefficient learning design and 3) it is highly sensitive to noise when the training data contains noises and outliers [17].
The above weaknesses have been studied and handled using many approaches. Data reduction techniques can help a kNN classifier to overcome these drawbacks by reducing the size of the training set. Most algorithms need to search an entire dataset for a set of nearest neighbors for each sample. Even though the nearest neighbors searching process helps such algorithms to create a list of all possible candidates to be selected, it takes a very long time to finish on a large dataset. Therefore, it is still not practical to use these algorithms to classify kNN with a large dataset.
To speed up the selection process, the geometric median prototype selection (GMPS) method is a data reduction method for a kNN classifier that uses the geometric median (GM) as a class prototype [2]. GM minimizes the sum of the distances to other instances. The GMPS method provides better performance than seven other state-of-the-art methods. The GMPS method runs approximately five times faster than the 1NN classifier model with near equal accuracy. Moreover, one important parameter for the algorithm, GMPS partition size, has to be assigned manually. The suitable partition size depends on the features of each dataset, so a human assessor randomly inputs a partition size to test the performance of the GMPS method. This is an expensive task, especially if this process is repeated until an appropriate partition size is found. Thus, this is impractical when this method is applied to unseen datasets. This paper aims to propose another version of the GMPS method that selects a suitable partition size automatically. The proposed method adds Appropriate partition size assignment (APSA) process that calculates the suitable partition size for each dataset. The APSA process helps the proposed method adapted for any unseen datasets.
The paper is organized as follows. The previous prototype selection (PS) methods are reviewed in Section 2. The new APSA method is proposed in Section 3. The details of the experimental setup are explained in Section 4. Finally, the empirical results and future work relating to this research are discussed in Section 5.
Related work
Data reduction techniques decrease the complexity of huge datasets in the execution of data mining algorithms. The reduced datasets still contain the quality of actual knowledge of the original datasets. For a kNN classifier, data reduction techniques can reduce memory consumption and speed-up the classification process. Data reduction techniques can be classified into two major groups: prototype generation and prototype selection, where the prototypes are samples selected from the original dataset by data reduction techniques. A prototype generation (PG) method generates new artificial prototypes by summarizing a number of similar instances and replacing the original training set because PG methods intensively create artificial instances which have different values from the original data [28]. The set of artificial instances can only be used as a training set for classification, not for other purposes. A prototype selection (PS) method selects a subset of the original training instances into prototypes. The PS method has efficient real data handling and low memory usage. The PS method is efficiently applied on many real-world applications. In general, PS methods consume less memory and runs faster than PG methods. PG methods compute several mathematical or statistical functions to summarize the intrinsic knowledge for artificial data generation while PS techniques keep representative data from the original training set by detecting border points or removing noisy instances [18, 21]. There are three types of prototype selection: condensation, edition, and hybrid.
Condensation selection focuses on keeping samples near the decision boundaries. The decision boundary is the region that separates the underlying instances into two sets: one for the concerned class and another for the rest. A sample that is near the decision boundary is called a border point. Condensation selection retains border points by removing internal instances that have little effect on the accuracy of the classifier model. The Condensed Nearest Neighbor (CNN) algorithm is the first well-known condensation method [25]. It focuses on the selection of a consistent subset of the original dataset. The sample that is correctly classified according to its nearest neighbors is removed and the remaining samples become members of the consistent subset. CNN tries to retain class border samples and remove internal samples because the misclassified data normally are located close to the decision boundary. The RNN algorithm [12] extends the concept of CNN by finding a minimally consistent subset. Both of these methods use the same removal criteria but RNN builds the edited set from the opposite direction by starting from a full training set and removing samples that are classified correctly. Furthermore, Fast Nearest Neighbor Condensation (FCNN), a fast condensation method, selects the centroid of each class in the training set and continues to insert a representative of the misclassified samples of each Varonoi cell [10]. The RNN method is the more costly but it provides a slightly smaller subset than CNN method. The FCNN method is at least twice as fast as the CNN and RNN methods with comparable classification accuracies and reduction rates. The condensation methods produce small subsets but they are sensitive to noise.
The edition scheme focuses on removing misclassified samples which is the opposite of the condensation method. Edited Nearest Neighbor (ENN) [4] was the first edition algorithm that followed the Wilson Editing rule, according to which, all instances that are incorrectly classified in the same class as their nearest neighbors are assumed to be noisy samples. ENN initially creates a subset of the same size as the original training set. ENN iteratively removes samples from the subset that are misclassified in the original training set. In other words, it attempts to remove samples that are noisy or disagree with their neighbors. Overall, ENN removes noise very with high level of accuracy but the number of reduced instances is low. However, there are several edition methods based on modifications of the ENN concept such as Repeated ENN (RENN) and All-kNN [14]. The reduction rate of the extended methods is better than that of ENN but their accuracy is similar or worse.
Hybrid methods are popular because they remove noise better than condensation methods and reduce the dataset more than edition methods. Also, the classifier models are more accurate than hybrid methods having condensation and edition methods on their own. Hybrid methods try to remove the internal and border points using the criteria of the other types. Instance Based Learning (IB3) [7], the first method in this category, starts by incrementally creating a classification record with a summary of a sample抯 classification performance such as the number of correct and incorrect classification attempts. Keeping this classification record facilitates good classification performance with each sample. IB3 removes noise which has a poor classification record and a detrimental effect on significance testing later on. Decremental Reduction Optimization Procedure (DROP3) [5] uses a noise-filtering process based on a rule similar to ENN. Samples in the training set are first classified by the majority vote of their neighbors, after which the misclassified samples are removed. This helps to remove noisy samples and smooth the decision boundary. The points far from the decision boundary are also removed using distance sorting to the nearest enemy. In addition, Iterative Case Filtering (ICF) [13] improves the idea of DROP3 by building two local sets: coverage and reachability. The coverage set is the set of all samples closer to the sample
Moreover, some hybrid methods utilize graph techniques to present the training set as a network of nearest neighbors. The Hit Miss Networks (HMN) method [8] proposes a graph-based representation of a training set that includes a short description of the nearest neighbors connection between pairs of samples. The graph has a directed edge from each sample to the nearest neighbors of each different class, with one edge per class. The structure attributes of the HMN graph correspond to attributes of samples related to the decision boundary of the 1NN rule such as the border point or central point. There are two main functions to evaluate how far a sample is located from the decision boundary: hit-degree and miss-degree. The hit-degree of a node is computed as the number of edges directed to the same class node. The miss-degree is computed in the opposite way to a hit-degree. HMN-EI, the most effective version of HMN, deletes samples or nodes which have no incoming edges in the first place. Then, it iteratively compares and removes samples if the miss-degree value is greater or equal than the hit-degree value. Moreover, Class Conditional Instance Selection (CCIS) [9] extends the concept of HMN network graph. Consequently, CCIS provides two graphs: the between-class and the within-class nearest neighbor graphs. These graphs are used to define a new margin scoring method for sample selection. There are two phases to this method. First, the Class Conditional selection (CC) process removes the outliers, isolated points, and points close to the 1NN decision boundary. Second, the Thin-out selection phase focuses on selecting a small number of instances without any additional 1NN error.
The data reduction techniques have high computational complexity because they generate artificial prototypes or collect sets of instances from a large dataset such as border instances and internal instances [32]. Most PS algorithms in the three selection schemes select each sample by its nearest neighbor’s classification scores or the margin values of its neighbor’s connection graph. The nearest neighbors searching process takes a long time to finish on a large dataset. The proposed method aims to improve the speed of the prototype selection process by selecting only a set of median points in each partition of the dataset.
Adaptive geometric median prototype selection (AGMPS)
This section describes the principle and hypothesis of the Adaptive Geometric Median Prototype Selection (AGMPS) algorithm for kNN classification. Figure 1 shows the process flow of the AGMPS algorithm. AGMPS combines Appropriate Partition Size Assignment (APSA) as a suitable measuring method for the partition size, and geometric median prototype selection (GMPS) as the GM searching method. The first process calculates a suitable partition size for each dataset and passes it on to the next process. The second process uses the number of partitions for splitting the dataset and selecting GM points as class representatives.
The APSA process fits a quartic polynomial function with a list of two dimensional Cartesian coordinates, where the
The process flow of AGMPS algorithm.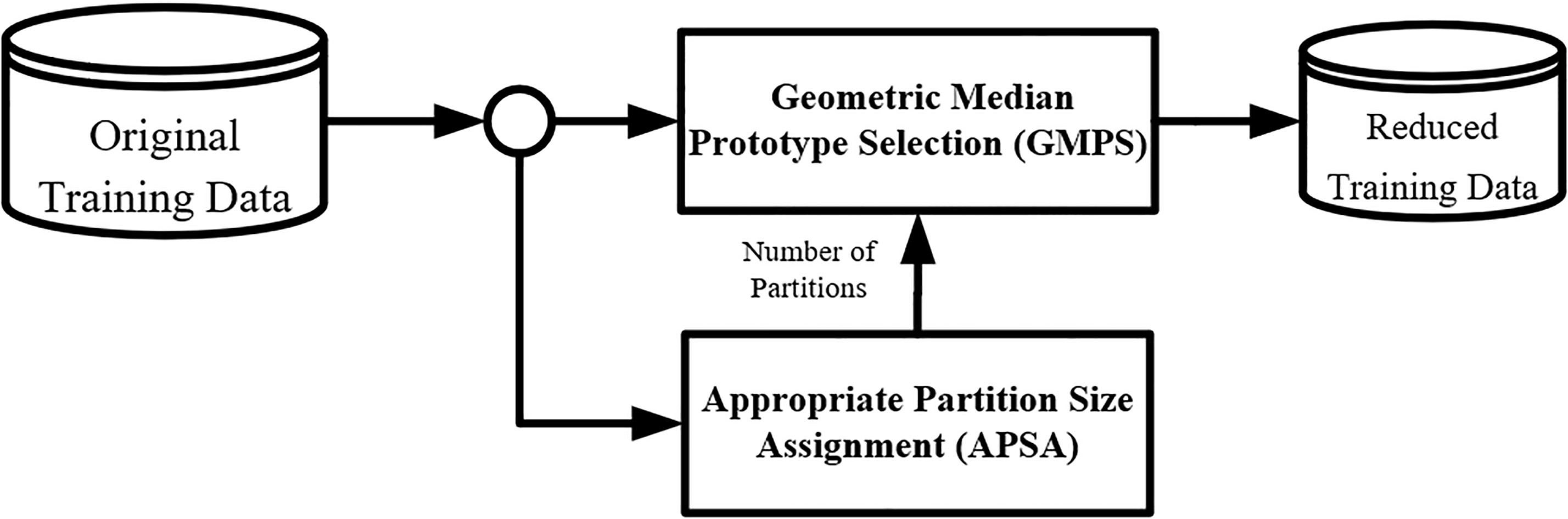
The GM of sample points in a Euclidean space is the sample point that minimizes the sum of distances to all other sample points. The GM is a robust measure of central tendency because it is not excessively affected by outliers. Formally, for a given set of
Here, the arguments of the minimum (abbreviated arg min or argmin) is the value of argument
The idea behind choosing GM is to find a small member of class prototypes for the whole dataset. In statistics, the median is a generally used measure of the properties of a dataset as it provides a better idea of a typical value for the data than arithmetic mean because it is not so sensitive to extremely large or small values. GM is a measure of a typical value that describes the distribution of samples in multidimensional datasets because it is unaffected by the different scales of the different dimensions. Consequently, GM has been applied to various fields such as operation research, machine learning, and information retrieval. In operation research, GM is the optimal solution for a facility location problem as it finds the placement of facilities that minimizes transportation costs [23]. In machine learning, GM is used to cluster data because it can be used as a centroid of a given set of instances in a dataset such as k-median clustering [26]. BIRCH, a hierarchical clustering algorithm for very large datasets, uses GM as a centroid and merges the data points to their closest centroid to obtain a new set of clusters [34]. In information retrieval, GM [27] is also used as a centroid of a data cluster when selecting unlabeled training data for a learning-to-rank algorithm. GM summarizes the properties of data values of all close points. We assume GM is representative of its neighbors.
Furthermore, finding the GM for the facility location problem is an NP-Hard problem which requires a heuristic solution [6, 29, 31]. However, finding the GM of the data cluster is not complicated compared with the facility location problem because we can find the GM in a quadratic time. However, it takes a long time to complete when working with a large scale dataset. We intend to reduce the running time of the proposed method using a metaheuristics searching algorithm. Simulated annealing [30] is chosen as a GM searching algorithm because it has many advantages. First, the cost functions cover quite arbitrary degrees of nonlinearities, discontinuities, and stochasticity. Second, the process runs on the searching space of specified conditions and constraints defined as cost functions. Third, SA is easy to implement with a minimal degree of coding. Finally, SA statistically guarantees that an optimal solution is found [19].
The idea of the APSA process is to find the number of partitions that ensures that all class samples in each partition are close enough to the centroid or GM. A higher number of partitions normally tend to decrease the average distance between the other samples and the GM. Figure 2 shows the relationship between the average distance between other samples and the GM and accuracy of the classifier model that is created and evaluated with a different number of partitions on six training sets. The appropriate partition size is also represented.
The APSA process identifies the appropriate partition size by finding a root of the derivative of the average distance of the GM. We utilize a polynomial function to speedily estimate the appropriate number of partitions and this is then passed on to the next phase. AGMPS generally selects a GM point in each partition, so the number of partitions is nearly equal to the number of selected samples. A suitable partition size helps AGMPS to select GMs close to the other samples within the same partition.
For this reason, we estimate the appropriate partition size by sampling some coordinates (
where
Relationships among accuracy (dashed line), average distance to GM (solid line), and appropriate partition size (vertical dashed line) for several partition sizes.
Pseudocode for the APSA phase[1] AppropriatePartitionSize
Because the appropriate partition point is usually located in a low-slope area of the graph, we differentiate the polynomial function to be a derivative function
The AppropriatePartitionSize function calculates an appropriate partition size of a dataset. The pseudocode of APSA is shown in Algorithm 2. There are two input parameters: TS is the original training set and
The CreateCoordinateXY function creates a list of
The SumofAvgDistanceFromGMs function splits the training data TS into
Pseudocode for creating coordinates (
The CreatePolynomialFunction function creates a set of polynomial coefficients where
The FindMinimumRoot function assigns each root as variable
After the APSA process is complete, the subsequent process, called geometric median prototype selection (GMPS), accepts
One of the main contributions of this study is to show that AGMPS, a new method for prototype selection, scales up for large datasets. The low complexity of the algorithm is the most important characteristic when assessing scalability. There are two processes to AGMPS where we analyze the complexity: APSA and GMPS.
The complexity of APSA is linear
The complexity of the GM prototype selection (GMPS) is also
Noise and missing values
Noise is data providing meaningless information which commonly occurs in the data collection or data preparation processes. Noise affects the features or classes of the training samples making it more difficult to build high-performance classifiers. There are two types of noise that affect the quality of a classification dataset: class noise and attribute noise. Class noise occurs when a sample is incorrectly labeled. Class noise can be caused by human error during the labeling or data entry process. Otherwise, attribute noise relates to worsening in the values of one or more attributes such as erroneous attribute values and missing attribute values. Erroneous attribute values refer to having the wrong value for one or more attributes. The missing values occur when no data value is stored for one or more attributes of training data. Attribute noise is caused by improper data collection or human error in the data entry process. Attribute noise is more damaging than class noise in the classifier performance [3, 35] so we focus on testing the noise tolerance capability of the AGMPS method on datasets with only attribute noise.
Random noise, a random value between the minimum and maximum of the domain of an attribute, is often responsible for a large amount of the attribute noise in data. The edition and hybrid methods aim to keep the generalization of the training set, and consequently remove noise from the training set by removing misclassified samples. The AGMPS method does not have a noise removal process so it selects some noises which are mixed in well with normal data in the same class. However, the AGMPS method can extensively select a class representative in each partition on the training set. Thus, the AGMPS method has better kappa values than the edition or hybrid methods in multi-class classifications. We compare the accuracy and kappa values of the AGMPS method with those of two edition methods (ENN and All-kNN) and the 1NN baseline model on six datasets with attribute noise in Section 5.5.
The missing values are normally replaced by average, median or mode (the most frequency of occurring attribute value) values of that attribute because the replaced value could not lead to more meaningful accuracy in the Euclidean distance. The median selection of the AGMPS method is effective when handling a missing value that was replaced by the average, median or mode value because the Euclidean distance to other points should be insignificantly different from the regular attribute values.
Experimental materials and methods
The details of our experimental evaluation is organized as follows. Section 4.1 shows the list of benchmarking PS methods and the datasets used in the experiment. The definitions of various performance measures used in the evaluation of the AGMPS model with different datasets are explained in Section 4.2. Finally, Section 4.3 details the hardware and software used in this experiment.
State-of-the-art PS methods considered in this study
State-of-the-art PS methods considered in this study
Parameter settings for state-of-the-art PS methods and AGMPS
We evaluate the performance of AGMPS with seven Prototype Selection (PS) algorithms listed in Table 1. All three PS schemes are used in our experiment. The complexities of the PS methods are shown in Table 1 where
In this experimental study, we use 25 datasets that have not any noise and missing values from the UCI data repository [20] and KEEL data repository [15] as shown in Table 3. Each PS method is tested using a 10-fold cross-validation. Each PS algorithm is run using training samples to create a reduced training set.
Description of dataset
Description of dataset
For the noise tolerance test, we use five datasets with uniform attribute noise from the KEEL data repository. Each PS method is tested using a five-fold cross validation. We use the datasets following three different schemes based on where the noise is present: Noisy Train-Noisy Test, Noisy Train-Clean Test, and Clean Train-Noisy Test. In each noise scheme, we test four different noise levels: 5%, 10%, 15%, and 20%. The description of these datasets with attribute noise is shown in Table 4. We compare the accuracy and kappa values of AGMPS with those of two edition methods (ENN and All-kNN) and the 1NN baseline model.
Description of dataset with attribute noise
We use several performance measures to compare the performance of AGMPS with other PS methods. A main goal of PS methods is to reduce storage requirements. Therefore, the reduction rate value is evaluated. The reduction rate shows the percentage of the size of the reduced training set in relation to the original training set size. However, the PS methods usually achieve high reduction rates while they have moderate or low learning performance. This phenomenon is called the trade-off reduction-accuracy rate. We use the accuracy and kappa as learning performance indicators. Furthermore, Barlett’s test and the Wilcoxon Rank Sum test are used to test for significant differences in the accuracy and kappa measurements between AGMPS and other PS methods. In addition, some PS methods which have a high-reduction rate while keeping high accuracy are slow methods because they require an advanced mechanism in the selection process. If the selection process of the PS method takes a very long time, it is impractical for large datasets. The running time and speedup which show how speedily the PS method can finish classification are measured in this experiment. We describe all mentioned evaluation metrics as follows:
Reduction rate: represents the reduction of storage capacity obtained by the PS method:
where size(RS) is the number of instances in the reduced training set and size(TR) is the number of instances in the original training set. This measure is in the range 0 to 1. A larger value indicates that the method can reduce the training set better, requires less memory, and shortens the classification time.
Accuracy: The number of correctly classified instances is related to the total number of classified instances and is the most common performance indicator of classification algorithms. This measure is in the range 0 to 100.
Cohen’s Kappa: Cohen’s Kappa value of classifiers is also measured in this experiment to avoid an accuracy paradox of the states of the classifiers. The accuracy paradox is that classifier models with a given level of accuracy may have a greater classification power than models with higher accuracy. Cohen’s Kappa evaluates the proportion of successful hits that can be attributed to a classifier itself relative to multi-class classifications by compensating for random hits. It is adopted and considered as a standard measure in the same way as the ROC curve indicates the level of accuracy of a classifier when evaluating binary classification [1]. It is easy to compute because it is measured from a confusion matrix that results from a classification This measure is in the range
where
Speeding up the algorithm: The speedup calculation estimates the relation between the running time of PS methods and the 1NN classifier. The running time of the PS method is the total time spent on selecting prototypes, creating a classification model, and classifying the test data. A speedup value greater than 1.0 for a PS method indicates that the PS method completes processing faster than 1NN.
Barlett’s test: the Barlett’s test [22] is a statistical method to test the equality of variances. This test only assumes that there are two samples and that they are quantitative. We perform this test before the Wilcoxon Rank Sum test because the Wilcoxon Rank Sum test assumes that both tested samples are independent and that they have equal variance.
Wilcoxon Rank Sum test: the Wilcoxon Rank Sum test [11] is a non-parametric test for two independent samples often used instead of the
Accuracy distribution of 1NN, AGMPS, and other PS methods.
The experiment was conducted on a personal computer with an Intel core i5-4440 running at 3.10 GHz with 24 GB RAM and a 240 GB SSD operating Ubuntu version 14.04. The KEEL software tool version 2.0 provides seven of the considered PS methods as well as learning performance and running time evaluation. The AGMPS algorithm is implemented in Python version 2.7. The relevant libraries include numpy, scipy, and pandas from the Anaconda package.
Results
Classification performance
Table 5 shows the classification accuracy and standard error of the AGMPS model, the 1NN baseline model, and all the other PS methods. The ENN method has the best accuracy rate on nine out of 25 datasets. However, the size of the reduced training sets of ENN is very large compared with that of the other methods. The HMNEI and AGMPS methods provide the best accuracy rate on seven and five datasets, respectively, and yet HMNEI is ranked the second largest in size of the reduced training set. Even where the average accuracy rate of AGMPS is approximately 1.5% lower than that of the 1NN baseline model, the AGMPS method has a better average accuracy and standard error than all the other PS methods.
Accuracy (%) and standard error of 1NN, AGMPS, and other PS methods
Accuracy (%) and standard error of 1NN, AGMPS, and other PS methods
In Fig. 3, the box plots represent the distribution of the accuracies for all PS methods as well as the 1NN baseline model based on five statistics: minimum, first quartile, median, third quartile, and maximum. Because of the comparatively small size of the box, the AGMPS method is more consistent in accuracy than the other PS methods. Moreover, the mean value (black dot) of the AGMPS method is higher than those of all the other PS methods.
Table 6 shows values for Cohen’s Kappa and the standard error of the AGMPS model, the 1NN baseline model, and all the other PS methods and indicates that HMNEI has the best kappa value on nine out of 25 datasets. The AGMPS method has the best kappa value on seven datasets. The AGMPS method has a better average kappa value than all the other PS methods. However, the average kappa value of the 1NN baseline model is about 0.03 higher than that of the AGMPS method. Moreover, the AGMPS method has a better kappa value than all the other PS methods as shown in Fig. 4, where the smaller size of the box indicates that AGMPS is more consistent than all the other PS methods.
Kappa and standard error of 1NN, AGMPS, and other PS methods
Kappa distribution of 1NN, AGMPS, and other PS methods.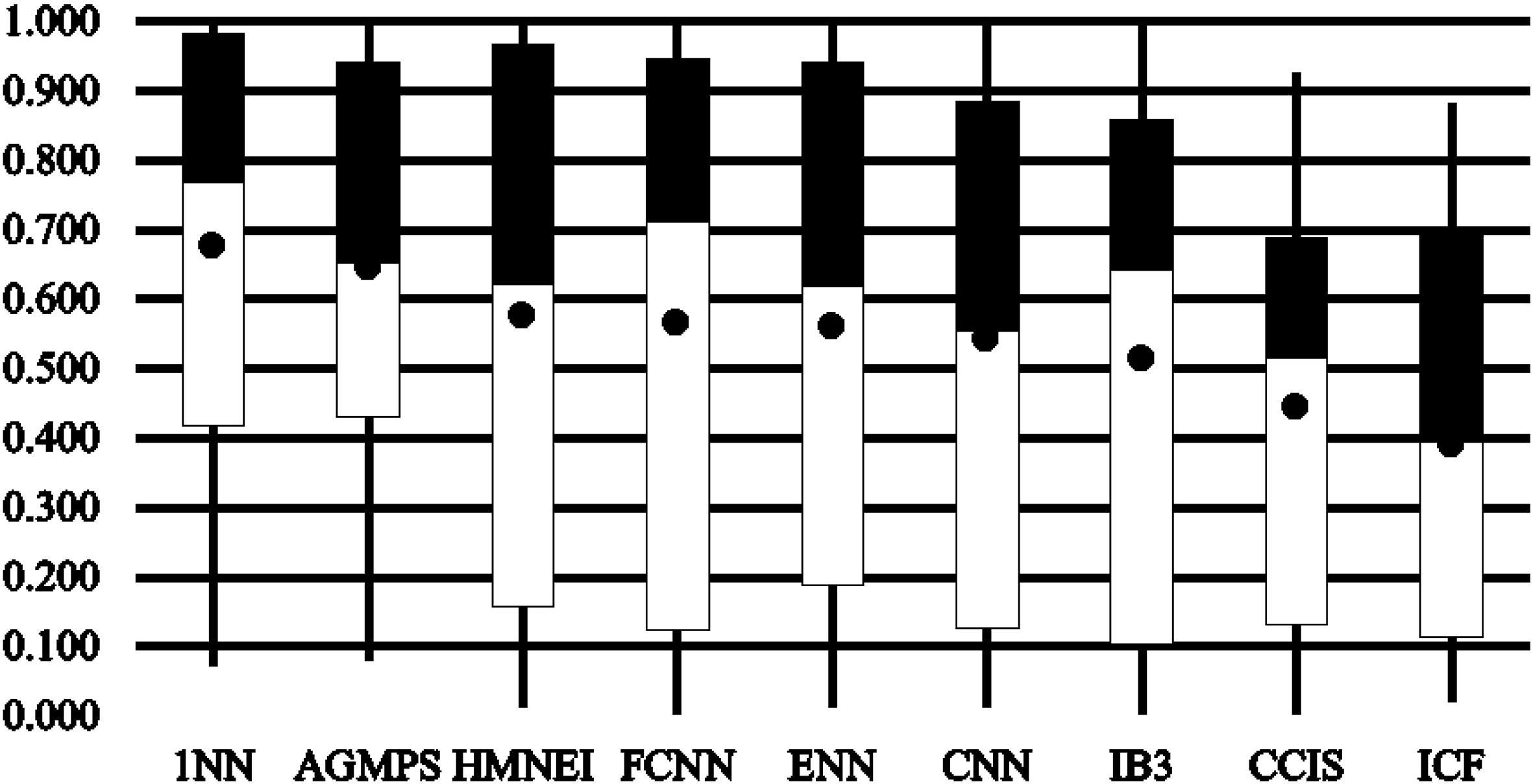
As the AGMPS method achieves the highest accuracy rate and kappa value, we also compare the reduction rate and running time of AGMPS with those of other PS methods. Table 7 shows the reduction rate and the standard error sorted in descending order. The CCIS method has the highest reduction rate (95.39%) because it includes two sample removal processes: one for noise and another for samples ineffective for 1NN performance. The ICF has the second highest value because it removes samples that generalize information from other samples. The FCNN and CNN methods have the third and fourth highest values because they are condensation methods that keep only a small number of samples near the decision boundary. Although the AGMPS method has a relatively low reduction rate (71.21%), it can handle the trade-off between accuracy rate, kappa and reduction rate reasonably well as shown in Figs 5 and 6.
Average reduction rate (%) and standard error of PS methods
Average reduction rate (%) and standard error of PS methods
Graphic comparison of accuracy and reduction rate on the six largest datasets.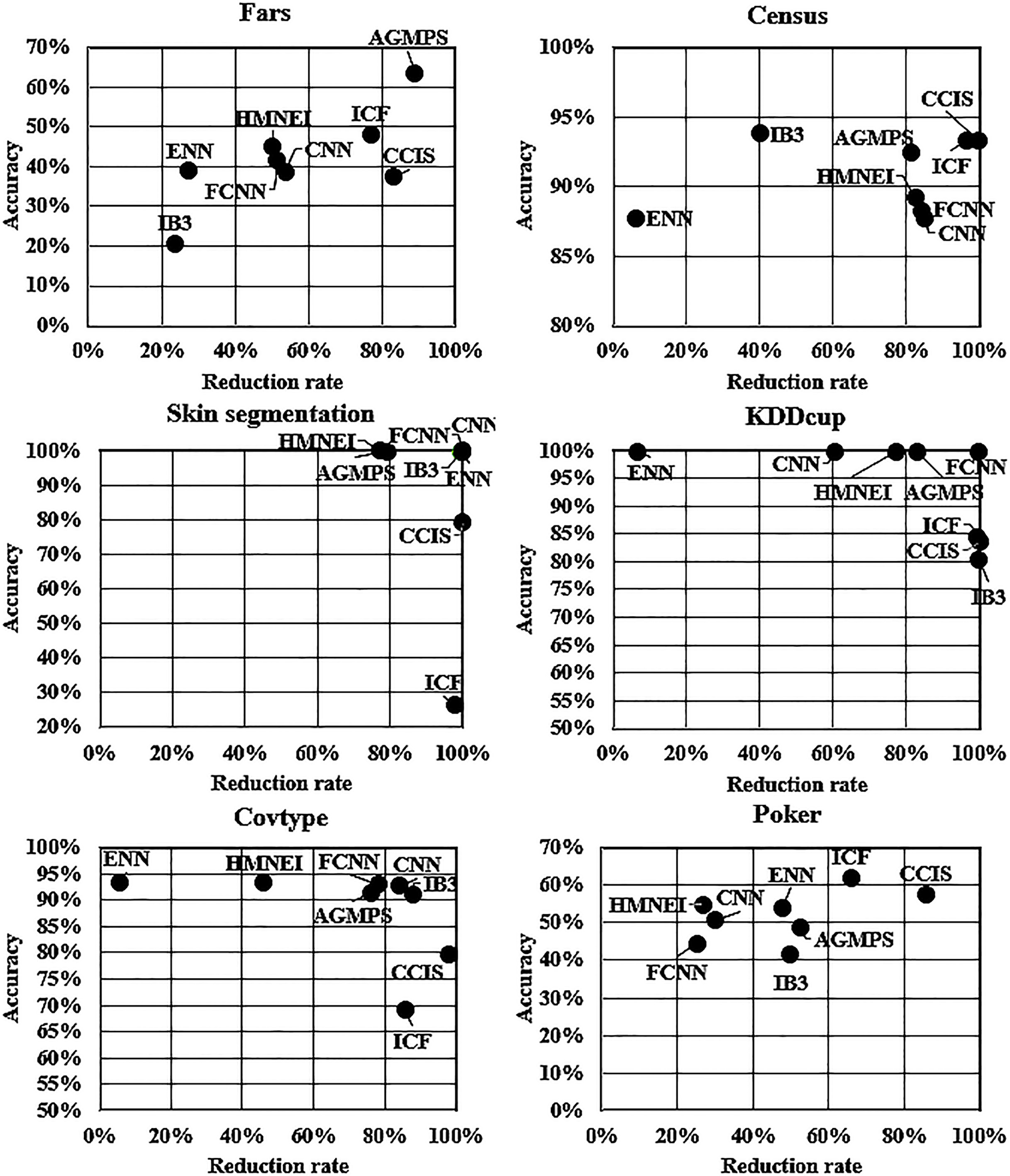
Figure 5 compares graphically the accuracy and reduction rates of AGMPS and all the PS methods considered using six large datasets: Fars, Census, Skin, KDDCup, Covtype, and Poker. The results show how effectively PS methods can handle large amounts of data. The reduction rate of the AGMPS method is slightly lower than those of the top algorithm on these datasets (except for the Poker dataset) with an 80% average reduction rate.
Figure 6 compares graphically the kappa value and reduction rate of AGMPS and all the considered PS methods considered using the six large datasets. The AGMPS method has better performance than all the other PS methods for the Fars and Census datasets. On Skin, KDDcup, and Covtype datasets, AGMPS is only slightly lower than the top right corner of ideal performance.
Graphic comparison of kappa and reduction rate on the six largest datasets.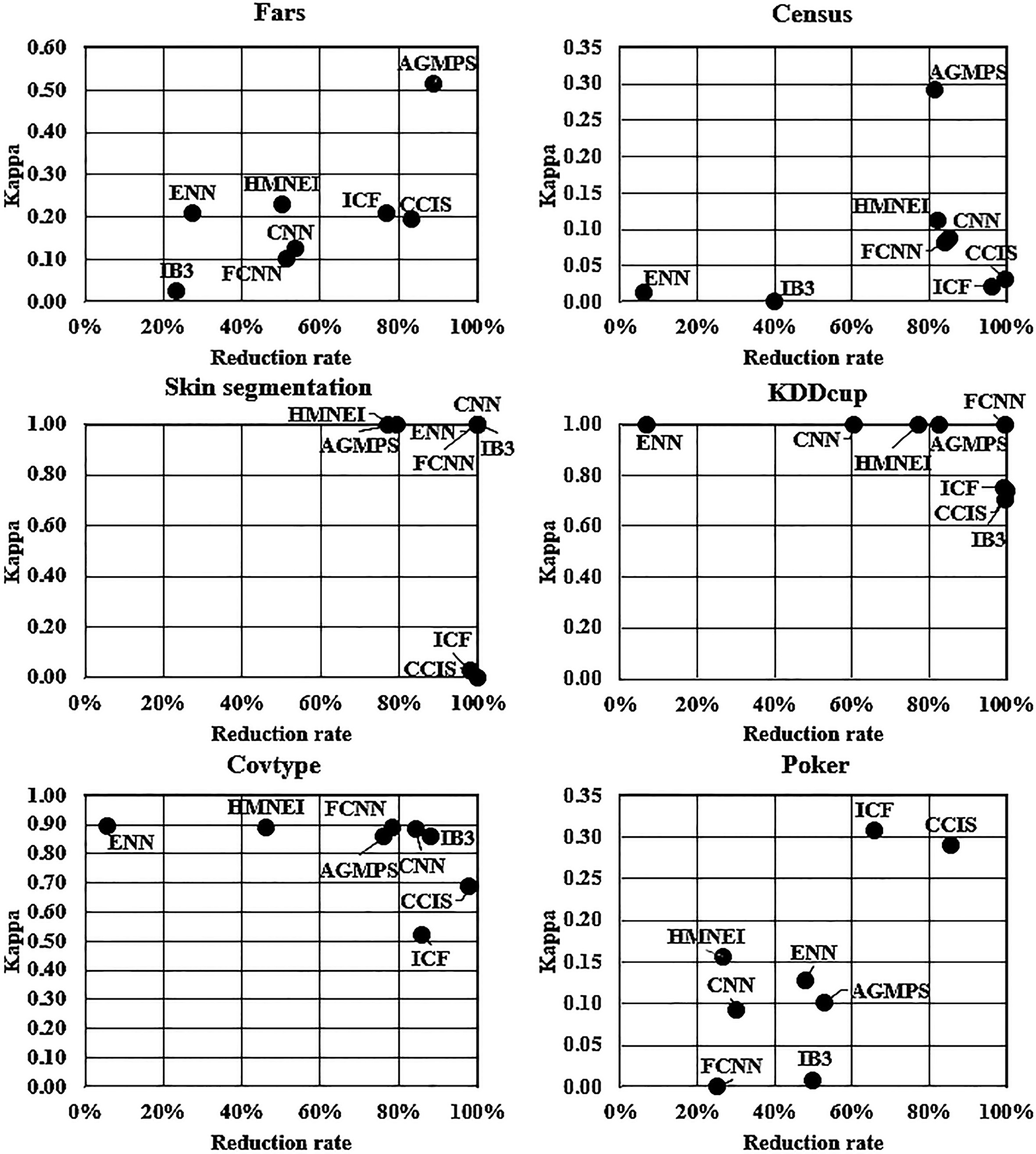
The running time of the AGMPS model, the 1NN baseline model, and all considered PS methods are shown in Table 8 for the the six largest datasets because for the the smaller datasets the running times for all models were similar and the AGMPS method is the fastest.
Running time (minutes) and speedup (times) of all methods
Running time (minutes) and speedup (times) of all methods
Furthermore, based on a comparison of the running times of all the PS methods considered with that of the 1NN classifier in terms of speedup, Table 8 also shows that the AGMPS method is approximately 3.59 times faster than the baseline model.
We measure the classification accuracy before conducting significance tests on the result of AGMPS and other PS methods. Due to the assumptions of the Wilcoxon Rank Sum test, we run Barlett’s test that tests the null hypothesis that all input samples are from populations with equal variances. Table 9 shows that the classification accuracy variance of AGMPS is not significantly different from the other PS methods, excluding IB3. Thus we cannot use the Wilcoxon Rank Sum test to compare AGMPS and IB3.
Results of Barlett’s test for accuracy and kappa variance equality
Results of Barlett’s test for accuracy and kappa variance equality
We run the Wilcoxon Rank Sum test for the classification accuracy and kappa measurement, comparing the results of the AGMPS method with those of all considered PS methods at a 0.05 significance level. There are two hypotheses in these tests. The null hypothesis is
Results of the Wilcoxon Rank Sum test for accuracy comparison
However, the difference between AGMPS and the other two methods (ICF and CCIS) is statistically significant. When we test a one-sided Wilcoxon Rank Sum test that has
First, we run Barlett’s test on the equality of variances. Second, we measure the kappa values in order to compare the results of AGMPS with the other PS methods. The results in Table 9 show that the classification kappa variance of AGMPS method is not significantly different from the other PS methods.
Results of the Wilcoxon Rank Sum test for kappa comparisons
Moreover, the result of Wilcoxon Rank Sum test for kappa measurement is shown in Table 11 at the significance level of 0.05. There are two hypotheses in these tests. The null hypothesis is
Otherwise, the difference between AGMPS and the three other methods (IB3, ICF, and CCIS) is significant a 0.05. We also performed one-sided Wilcoxon Rank Sum test for kappa value greatness. This test has two hypotheses:
We use five data sets following three different schemes to compare the classification accuracy and Cohen’s kappa of the AGMPS method with those of two edition (ENN and All-KNN) methods. First, the Noisy Train-Noisy Test scheme is the most common noise scenario because of the low-quality of the data source and the effect of the environment during the data collection process. Therefore, noise occurs in both the training data and test data simultaneously. Second, the Noisy Train-Clean Test scheme commonly can be sourced from errors in the data collection and data preparation processes. This scheme often appears when the new data are handled for the first time. Lastly, the Clean Train-Noisy Test scheme shows that the 1NN classifier model is created from the clean training data before noise occurs in the test data. The two above schemes have higher possibility of occurrence than the Clean Train-Noisy Test scheme.
Graphic comparison of average accuracy and kappa on six datasets with attribute noise.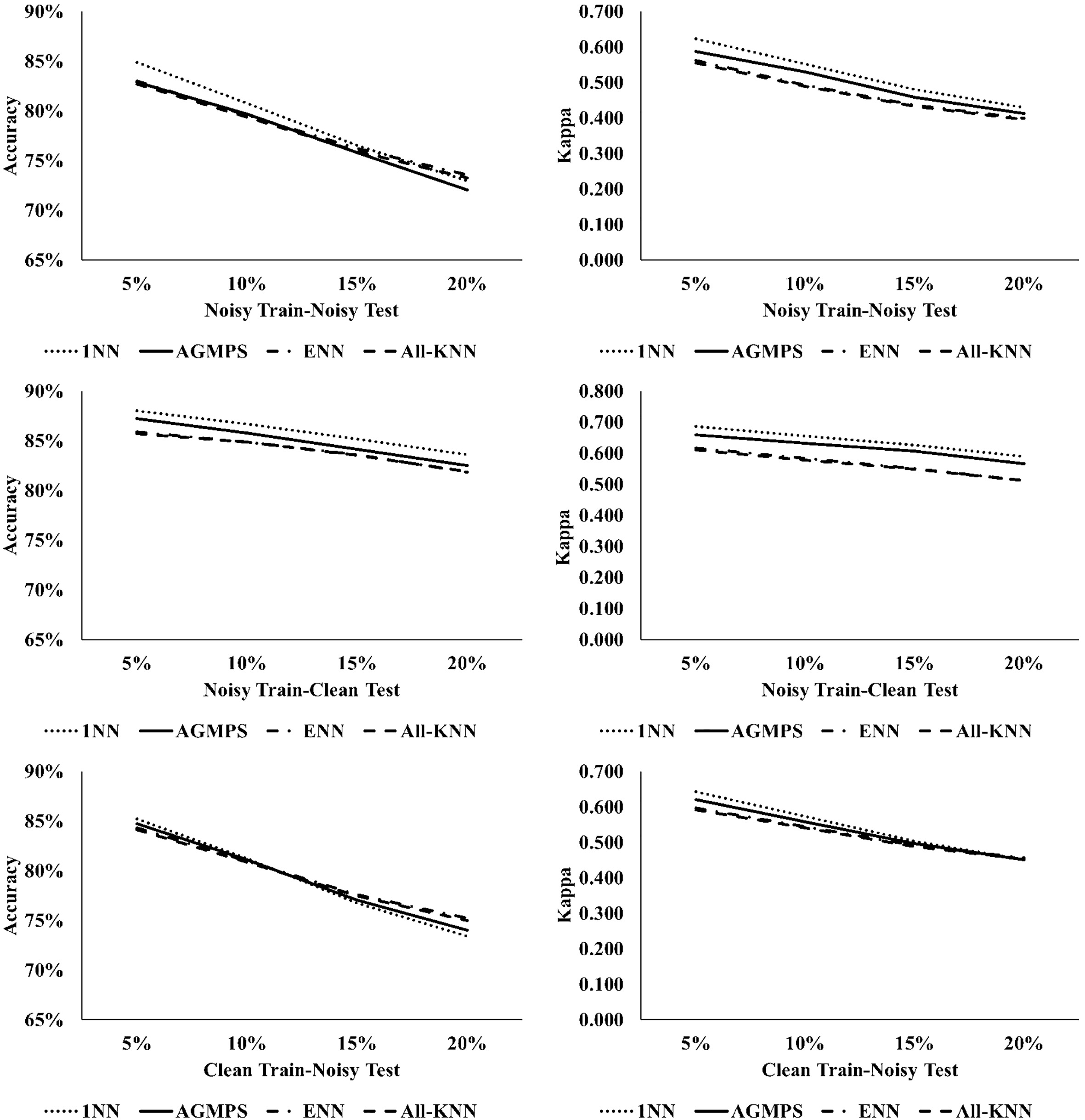
In Fig. 7, the line plots represent the trend of the accuracies and kappa values of all PS methods as well as the 1NN baseline model in the three different noise schemes. The accuracy values of the AGMPS method and the other compared methods are similar in two noise schemes (Noisy Train-Noisy Test and Noisy Train-Clean Test). The AGMPS method has a better kappa value than the ENN and All-KNN methods, where the higher line indicates that AGMPS has a higher degree of agreement between the predicted label and the actual label than the ENN and All-KNN methods in multi-class classifications.
Results of Barlett’s test for accuracy and kappa variance equality in attribute noise test.
Results of the Wilcoxon Rank Sum test for accuracy comparison in attribute noise test
We run Barlett’s test for the null hypothesis that all input samples are from populations with equal variances. Table 12 shows that the classification accuracy and kappa variance of AGMPS is not significantly different from the ENN and All-KNN methods. The results in Table 13 indicate that the classification accuracy differences between AGMPS and the All-KNN method are not significant. However, the results of the one-sided Wilcoxon Rank Sum test indicate that the accuracy rate of AGMPS method is significantly less than that of the ENN method. Moreover, Table 14 shows the kappa difference between AGMPS and the two other methods (ENN and All-KNN) is significant at the 0.05 level. In addition, the kappa values of AGMPS are significantly greater than those of the ENN and All-KNN methods.
Results of the Wilcoxon Rank Sum test for kappa comparison in attribute noise test
This paper proposes an extended prototype selection approach based on the Geometric Median (GM). This approach focuses on speeding up the overall processing time while still providing a comparable reduction rate and classification accuracy. The process of building the classifier model is the most time-consuming part when large amounts of training data are processed. To speed up this process, we partition the data into independent subsets and process the data in each partition separately. The AGMPS method is designed to select a class representative in each disjoint partition. There are two main processes to the AGMPS method. First, the Appropriate Partition Size Assignment (APSA) process calculates the optimal number of partitions by finding a root of the derivative based on the average distance of the GM. Second, the geometric median prototype selection (GMPS) process selects a subset of class representatives from the dataset. Both processes calculate and select a prototype from a subset of samples in each partition. Therefore, this does not require the entire dataset to be loaded into memory. Furthermore, the time complexity of each process is linear. This speed of data partitioning process means that the method scales well when applied to processing large quantities of data.
The results of this experiment show that speed is the main strength of our method. The running time of our AGMPS method is much shorter than that of all other PS methods studied because the AGMPS method does not require complex computations such as finding nearest neighbors in the whole dataset or finding samples close to decision boundaries. The AGMPS method provides classification accuracy and kappa values that are comparable to those of four state-of-the-art PS methods (CNN, FCNN, ENN, and HMNEI). When compared with IB3, AGMPS is significantly more accurate based on Cohen’s kappa. In addition, the classification accuracy and kappa of AGMPS are significantly better than those of the ICF and CCIS methods which have the top two highest reduction rates in this experiment.
Finally, the results of our tests on a variety of datasets confirm the initial premise of the effectiveness of the proposed method for improving the running time of kNN algorithms with comparable reduction rate and classification accuracy.
In future work, the AGMPS method will be applied in a parallel and distributed processing system. This work should improve the processing speed of the AGMPS method. Furthermore, we aim to continue to reduce the issues associated with processing handling real-world big datasets with AGMPS. This research will show the scalability of AGMPS on the Big Data problem.
Footnotes
Acknowledgments
This work was financially supported by the Department of Computer Science and was partially supported by a grant from the Faculty of Science, Kasetsart University, Bangkok, Thailand. The authors thank Dr. Miro Lehtonen for providing many useful comments.