
Abstract
Uncertain data are data accompanied with probability, which makes frequent itemset mining more challenging. This paper focuses on the problem of mining probabilistic maximal frequent itemsets. We redefine the concept of probabilistic maximal frequent itemset to be consistent with the traditional definition and provide a better view on how to devise pruning strategies. A tree-based index called the probabilistic maximal frequent itemset tree is constructed to maintain the probabilistic frequent itemsets. We proposed a depth-first probabilistic maximal frequent itemset mining algorithm to bottom-up generate the exact results, in which support and expected support are used to estimate the range of probabilistic support, enabling the frequency of an itemset to be inferred with less runtime and memory usage. Also, superset pruning is employed to further reduce mining cost. Nevertheless, certain probabilistic supports have to be computed when the minimum support is low, which may result in highly increased mining speed. This problem is addressed in our approximate probabilistic maximal frequent itemset mining method, which uses the expected support to directly compute the probabilistic support. Theoretical analysis and experimental studies demonstrate that our proposed algorithms have high accuracy, expend less computational time and use less memory, and significantly outperform the TODIS-MAX [20] state-of-the-art algorithm.
Keywords
Introduction
Frequent itemset mining, one of the traditional and important fields in data mining, entails discovering itemsets whose occurrences are larger than a specified threshold from massive data. Many efficient algorithms and methods have been developed in recent years [1]. In such methods, a very important assumption is, however, that the mined transactions are exact, regardless of whether they are static or increasingly updated.
The fact is that, uncertainty often exists in the real world. In a traffic system, a wireless sensor network may miss some high-speed vehicles and generate incomplete data. In a Global Position System (GPS), we may locate the positions over only a fuzzy area because of privacy concerns. For two information systems, the same property may have various structures, which will result in errors when we integrate the data. As a result, a probability is given to each value to help users make a better decision. This new feature brings new challenges that cannot be well addressed by employing traditional frequent itemset mining methods.
Motivation
When mining frequent itemsets over exact databases, it has been presented the frequent itemsets have redundant information. Actually, there have been many itemset compression methods proposed, including the maximal itemset [3], the closed itemset [4] and the non-derivable itemset [5]. If the user does not care about the support of an itemset, but only want to know whether it is frequent, the maximal frequent itemset is the best choice because it is the most efficient method to represent the frequent itemsets. Similarly, if we want to discover frequent itemsets over uncertain databases to obtain the maximal frequent itemsets, not only can we make the mining results easier to use, but we can also reduce the computational cost and memory size. Therefore, in this paper, we investigate how to efficiently discover the maximal frequent itemsets over uncertain databases.
Challenges and contributions
To address our proposed problem, an intuitive consideration is to enumerate all the probabilistic frequent itemsets and then to filter the probabilistic maximal frequent itemsets. This method, named pApriori, was proposed in [20], in which some optimized techniques were introduced. First, it used a divide-and-conquer method to compute the probability of an itemset in
However, there are some problems to consider in mining: 1. The top-down method may reach a bottleneck when the number of probabilistic frequent 1-items increases, which will result in an exponentially increasing number of probabilistic infrequent itemsets, and this is difficult to handle even if the time complexity is reduced to
In this paper, we focus on these problems and make the following contributions.
We focus on the problem of maximal frequent itemset mining over uncertain data, and we redefine the probabilistic maximal frequent itemset to be in line with the traditional definition, and supply a better pruning method. We introduce a compact probabilistic maximal frequent itemset tree data structure to maintain the information of probabilistic frequent itemsets, which in a bottom-up manner, can efficiently organize the mining results for the itemset search. We propose a probabilistic maximal frequent itemset mining algorithm to depth-first discover the probabilistic maximal frequent itemsets. We use pruning strategies to reduce the mining cost. We also propose an approximate probabilistic maximal frequent itemset mining algorithm to more efficiently obtain the probabilistic maximal frequent itemsets with a slight loss of accuracy. We compare our algorithms with the TODIS-MAX algorithm [20] on three synthetic datasets and four real-life datasets. Our experimental results demonstrate that our algorithms are more effective and efficient.
The rest of this paper is organized as follows: In Section 2 we summarize the related works. Section 3 presents the preliminaries and then define the problem. Section 4 introduces the data structures, and illustrates our algorithm in detail, Section 5 describes the approximate method. Section 6 evaluates the performance with a theoretical analysis and experimental results. Finally, Section 7 concludes this paper.
The existing uncertain data mining methods can be categorized into two types: those that achieve the expected frequent itemsets [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17], and those that obtain the probabilistic frequent itemsets[18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30].
Expected frequent itemset mining
To address the problem of expected frequent itemset mining, three main methods and their data structures are proposed. The first one is the a priori method: Chui first proposed the uncertain frequent itemset mining method, U-Apriori [6], which used a data trimming framework to raise the mining efficiency; later, he used a decremented pruning method [7] to improve the performance. The second one is the tree-based method: Leung proposed the UF-Growth method with the novel tree structure UF-tree [8], which was further improved [10]; also, he presented a more tight upper bound of expected supports and then introduced a more efficient algorithm called BLIMP-Growth [11]. The third one is the H-struct-based method: Aggarwal employed H-struct, which is efficient in exact data mining, to perform uncertain frequent itemset mining, and proposed UHMine [9].
Besides mining the common results, some algorithms have focused on achieving more valuable and concise results. The constrained frequent itemset mining method U-FPS was also proposed in [12]; it uses user constraints to make the mining more efficient. In addition, Calders used sampling to achieve approximate results [13]. Also, Liu pursued research on how to discovery frequent itemsets from univariate uncertain data [31], and Pei focused on mining fuzzy association rules over probabilistic quantitative databases [32].
In addition, based on database mining methods, stream mining algorithms have also been proposed. In [14], the UF-streaming algorithm used an immediate mode to get approximate results, and the SUF-growth algorithm employed a delayed mode to obtain the exact frequent itemsets; in [15, 16], a time-fading model-based algorithm and a landmark model-based mining algorithm were proposed. Moreover, Leung also studied mining uncertain frequent itemsets with the map-reduce framework [17]. These algorithms can get the expected frequent itemsets in real time, but they also ignored some history results.
For this problem, the expected support will be computed with
Probabilistic frequent itemset mining
Probabilistic frequent itemsets can better discover probabilistic features [25], which entail high computing and memory cost in mining. Generally, the methods can also be split two types: the a priori type and the fp-tree type. Zhang first introduced the concept of probabilistic frequent items [18], and employed dynamic programming (DP) to perform mining. This technique was improved upon by Bernecker, who proposed ProApriori [19] using the a priori rule for further pruning, as well proposed ProFPGrowth [21]with ProFP-tree to maintain the itemsets. Sun regarded the probability computation as the convolution of two vectors; thus, he used the divide-and-conquer(DC) method [20] to conduct mining, during which the Fast Fourier Transform (FFT) was used to reduce the computing complexity from
The probabilistic frequent itemset and the expected frequent itemset were proved to be related in [22, 23] based on a Poisson distribution and in [24] based on a standard normal distribution, and thus two approximate algorithms were proposed.
Recently, Tang began to focus on mining focused on probabilistic frequent closed itemsets and presented the exact algorithm PFCIM [26] and the approximate algorithm A-PFCIM [27]. Tong introduced the new definition of probabilistic frequent closed itemset when the items in one transaction have the same probability, and proposed the MPCFI method. Liu continued to pursue research on mining compressed itemsets, which are called probabilistic representative frequent itemsets; one proposed method, P-RFP [29], employed the distance measure to combine the itemsets, and another method, APM [30], summarized the frequent itemsets by joining the support probabilities approximately, which enables one to estimate the probability that one itemset represents another. In all these algorithms, the goal, like ours, is to get a representation of the mining results. Furthermore, in this paper, we will use a more effective representation, that is, the probabilistic maximal itemset; and we will find more efficient mining algorithms to get the results.
Preliminaries and problem definition
A brief review of the relevant concepts of uncertain database and frequent itemset mining are presented in this section. We then theoretically define the problem addressed in this paper.
Preliminaries
Uncertain database and possible worlds
Given a set of distinct items
.
(Possible World) A possible world
If we assume that the uncertain transactions are independent, a possible world has an occurrence probability
We denote all the possible worlds generated from
Uncertain transaction database vs. possible worlds.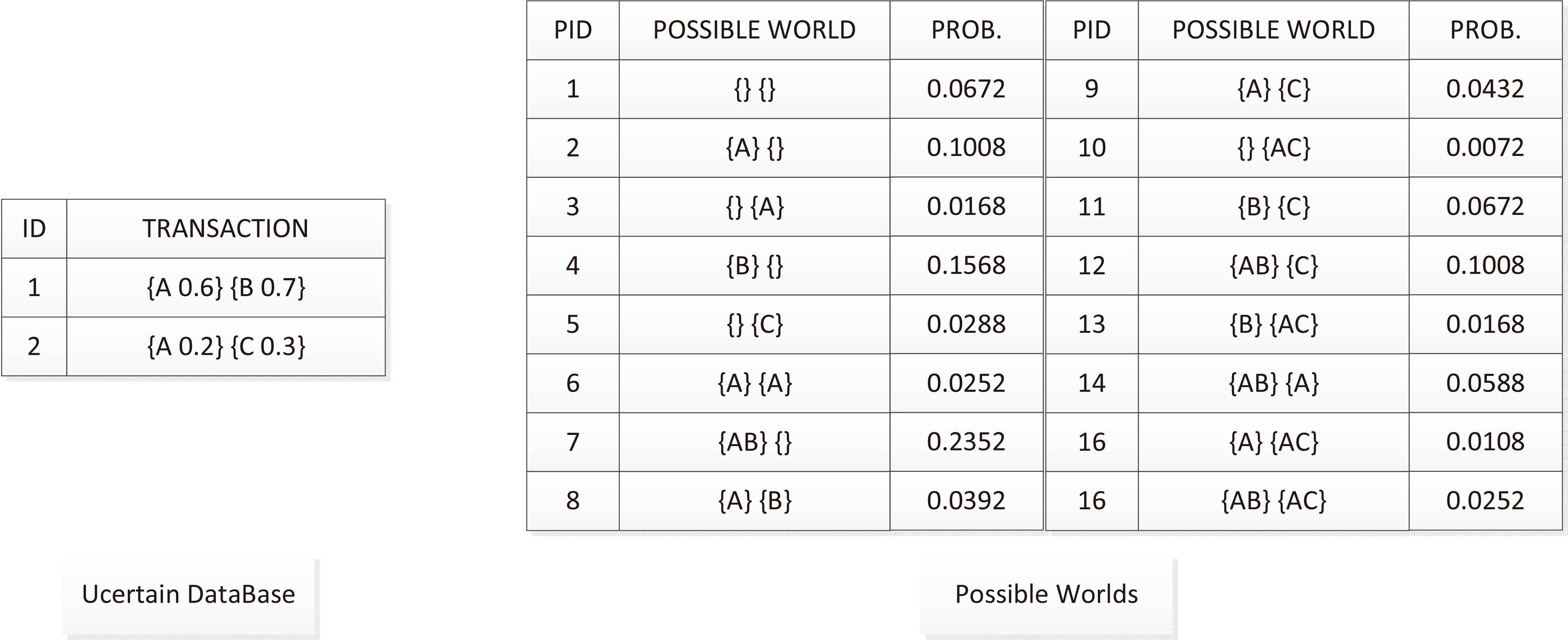
In an exact database
Probabilistic support of itemset 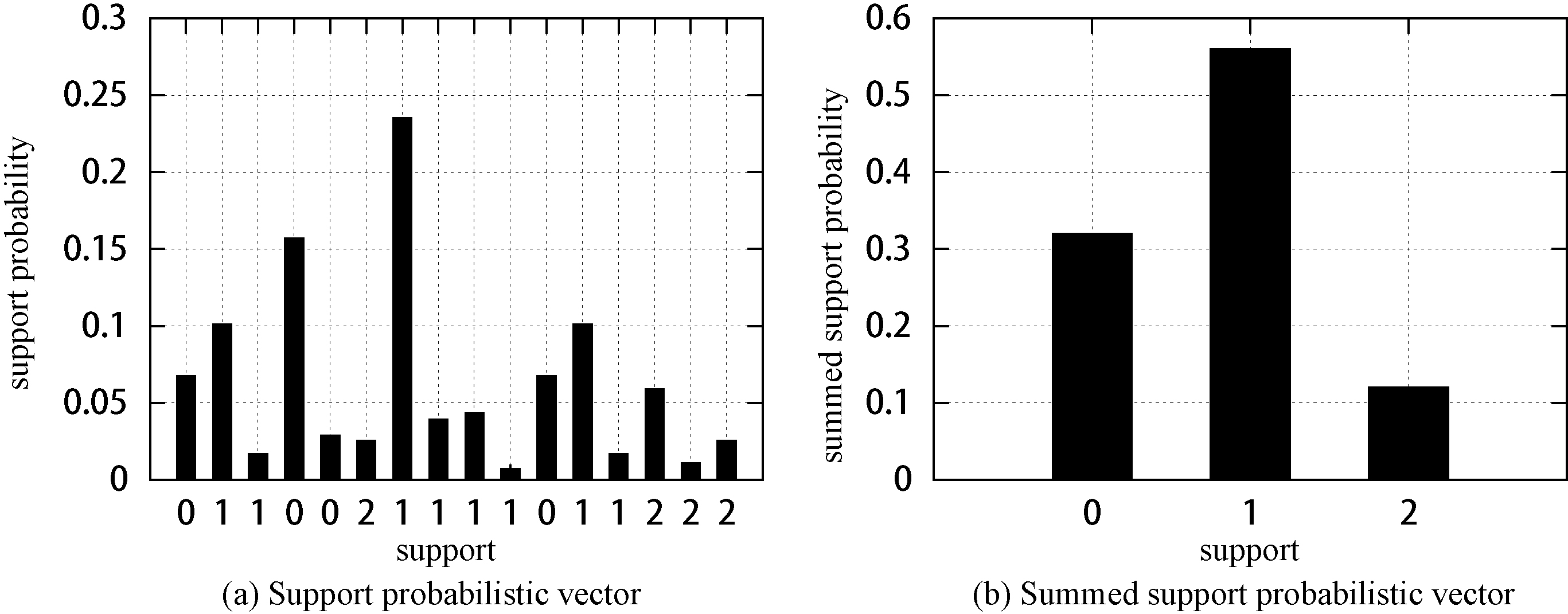
.
(Expected Frequent Itemset [6]) Given an uncertain database
The expected frequent itemset is an intuitive consideration. As an example from Fig. 2a, that the expected support of itemset
Nevertheless, the definition of expected frequent itemset cannot reflect the uncertainty of an itemset [19]. Consequently, the probabilistic frequent itemset was proposed.
.
(Probabilistic Frequent Itemset [19]) Given an uncertain database
The probabilistic frequent itemset focuses on obtaining the possibility of an itemset occurring in at least
Nevertheless, because Definition 3 is not consistent with the traditional concept of frequent itemset, it is not convenient enough to define the related concepts in exact databases, such as closed and maximal itemsets. Therefore, a new equivalent definition of probabilistic frequent itemset with a different description was proposed in [26].
.
(Probabilistic Support [26]) Given the minimum probabilistic confidence
.
(Probabilistic Frequent Itemset [26]) Given the minimum support
.
Given two itemsets
.
Given an itemsets
Property 2 suggests that the larger the minimum probabilistic confidence is, the smaller is the possibility that an itemset becomes frequent. In the uncertain database of Fig. 3, if
Probabilistic maximal frequent itemset tree (PMFIT) for 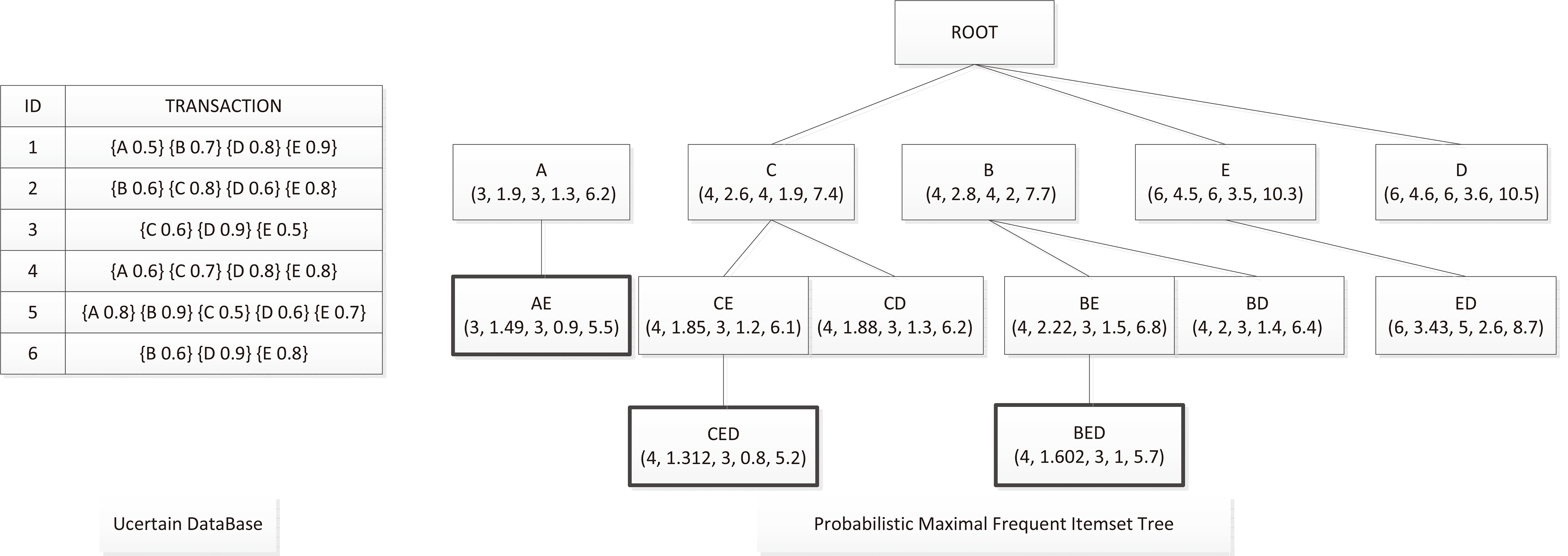
Summary of notations
In this paper we employ Definition 5 to define the maximal frequent itemset of uncertain databases, which is called the probabilistic maximal frequent itemset.
.
(Probabilistic Maximal Frequent Itemset) Given the minimum support
Since Definitions 3 and 5 have been proven to be consistent in [26], Definition 6 is quite reasonable. One can easily see that the support information of a probabilistic frequent itemset
.
For uncertain database
Probabilistic maximal frequent itemset mining method
In this section, we will first introduce our compressed data structures and an enumeration tree with auxiliary data collections. We then further introduce our pruning strategies, and present the details of our mining algorithm.
Data structures
Probabilistic mining frequent itemset tree
To accelerate searching and pruning, we design a simple but effective index tree called the PMFIT (Probabilistic Maximal Frequent Itemset Tree), in which each node
Probability list
We also use an array during implementation to maintain the probability list of an itemset occurring in all transactions. This probabilities list is used to compute the probabilistic support. It is temporary, however, because in our algorithm the probabilistic support need not be computed for each itemset.
Probabilistic maximal frequent itemset collection
Because the final results do not have to maintain the probabilities of each item, we employed a traditional bitmap-based collection to store the probabilistic maximal frequent itemsets, thus reducing memory cost, and increasing the searching speed.
Probabilistic support computing
Because the summed support probabilistic vector of itemset
Items reordering
Bayardo [3] stated that ordering items with increasing support can significantly reduce the search space; together with other pruning strategies, it can further reduce the cost of support computing. In this paper, we employed a similar heuristic rule with a slight differences. That is, the items will be ordered by their expected supports rather their supports. This change can be made because of the instinctive observation that two itemsets occurring in the same transactions may have different probabilities and thus have various expected supports. As a simple example in Fig. 3, itemset
Pruning strategies
We are inspired by the maximal frequent itemset mining methods over regular databases and propose some pruning strategies that can supply tight bounds to infer the probabilistic support or even ignore the computing of probabilistic support and thus improve performance.
Bounds of probabilistic support
For an
.
Given an itemset
.
For an itemset
Theorem 2 shows that the support of an itemset can be regarded as an upper bound of the probabilistic support. That is, for an itemset
.
For an itemset
If we set
If we set
From Eqs (7) and (8), we can conclude that no matter
Theorem 3 provides us with two pruning strategies. For an itemset
.
We used the uncertain database in Fig. 3 as an example. If we set the minimum support
Note that we can use the support
According to our definition, an itemset being probabilistic maximal frequent must satisfy two conditions: 1. The probabilistic support is not less than a threshold; 2. It is not covered by any other probabilistic frequent itemset. Both computation are needed, so the computation with the lower computing cost should be conducted first. As mentioned above, computing the probabilistic support requires
Algorithm description
In this paper, we propose a depth-first probabilistic maximal frequent itemset mining (PMFIM) algorithm to build the bottom-up organized tree; that is, the subsets will be computed first, and then the supersets will be generated if their subsets are all frequent. We discover the itemsets in this manner because the probabilistic frequent itemset also has the apriori property as presented in Property 1. The algorithm can be implemented in five steps. Algorithm 4.5 shows the pseudo code of Steps 3–5.
[b] PMFIM Algorithm[1]
We get all the distinct items and sort them in an incremental order according to their expected supports before we build the PMFIT. In addition, items with support or upper bound lower than the minimum support will be initially pruned. The PMFIT is initialized with only one root node, which represent the null itemset. For a parent node, we begin to generate the child node, and we compute to decide whether it is frequent. First, if the child node is covered by one of the maximal frequent itemsets, it is not a maximal but a frequent itemset. If all the items in it are the last ones in the sorted items list, we can determine that all the right nodes are not the final results, and the loop will be ended immediately. Second, after the support, the expected support and the support bounds are computed, if the upper bound is not larger than the minimum support, then it is an infrequent itemset, and if the lower bound is not less than the minimum support, then it is a frequent itemset. Finally, if we can not determine the frequency by using the previous value, we need to compute the probabilistic support and compare it to the minimum support. If a child node is frequent, we will recall Step 3 for it; otherwise, it will be pruned. If a node has no children and is not in the final results, it is a probabilistic maximal frequent itemset. We can add it to the probabilistic maximal frequent itemset collection. Because of our depth-first mining manner, there is no possibility of removing the subset from the collection.
.
We again use the uncertain database in Fig. 3 as an example. Let the minimum support be
Building the PMFIT for 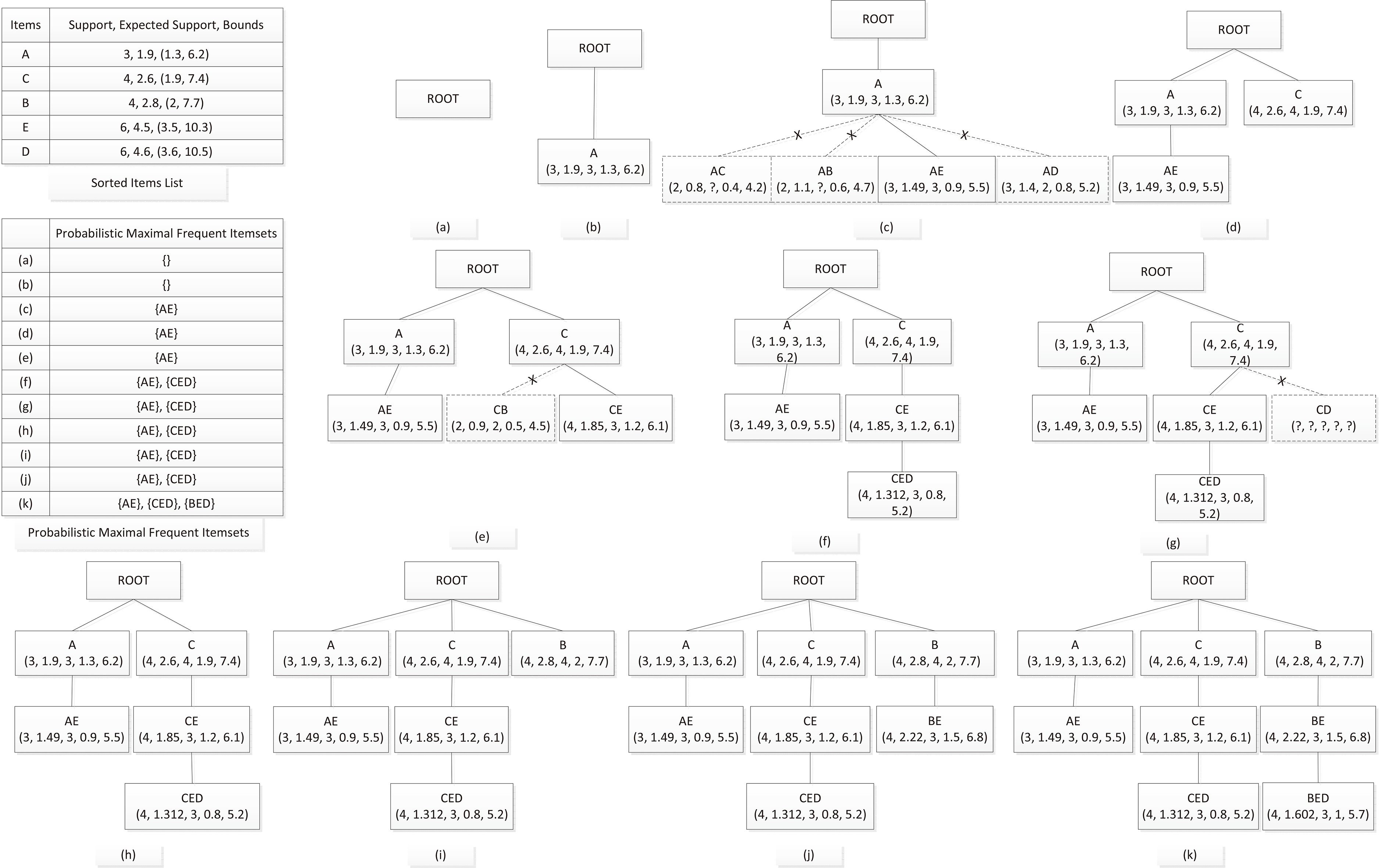
The sorted items list has five items ordered by the expected support incrementally. All of them have “ Itemset Itemset Itemset Itemset
Note that in this example we never use the pruning of support bounds, which does not mean that it is not useful, only just that the data size is too small. In our experiments, we find that, when the data size is large, our pruning from support bounds is efficient.
Even though we employ pruning strategies to reduce the runtime cost, there is still the possibility that we have to compute the probabilistic supports in the PMFIM algorithm. In this section, we propose an efficient way to approximately estimate the probabilistic support from the expected support and the variance [24].
For an itemset
.
Given an itemset
Based on our computing method of the probabilistic support, if the approximate probabilistic support is not less than the minimum support, then the itemset is a probabilistic frequent itemset, with which we can reduce the time complexity from
Consequently, we employ the same framework in Algorithm 4.5 with a slight difference to implement the approximate probabilistic maximal frequent itemset mining (APMFIM) method. On the one hand, we sort the 1-items by their approximate probabilistic support rather than the expected support, which can further reduce the search space. On the other hand, we will prune the itemsets directly according to the approximate probabilistic support.
We conducted experiments to evaluate the performance of the PMFIM and APMFIM methods. The state-of-the-art top-down algorithm TODIS-MAX [20], which has been presented in [20] as much more efficient than pApriori, was used as the evaluation method. The dataset size, the minimum support and the minimum probabilistic confidence are the main elements that may affect uncertain data mining. Therefore, these properties were used to compare the algorithms in runtime and memory cost.
Running environment and datasets
All the algorithms were implemented with C
Because there are no public real-world uncertain datasets, we used the datasets from [25], in which a probability of Gaussian distribution is assigned to each item. This technique is widely accepted in uncertain data mining research. We used three synthetic datasets and four real-life datasets to generate the uncertain datasets. Datasets T25I15D320K, T25I15D320K, and T40I10D100K are generated with the IBM synthetic data generator, in which T25I15D320K is to used to evaluate the scalability of the algorithms. The KOSARAK dataset contains the click-stream data of a Hungarian online news portal. The ACCIDENTS dataset is a report of multiple accidents. The GAZELLE dataset contains the clickstream data from e-commerce, and the CONNECT4 dataset contains all legal eight-ply positions in the game of Connect Four in which neither player has won yet, and in which the next move is not forced. The detailed data characteristics are given in Table 2.
In a dataset, given the distinct item number
We also presented the mean and variance of each dataset. As can be seen, T25I15D320K, T25I15D320K, and GAZELLE datasets have high means and low variances, T40I10D100K and CONNECT4 datasets have high means and high variances, the ACCIDENTS dataset has a low mean and a high variance, and the KOSARAK dataset has a low mean and a low variance.
Uncertain DataSet characteristics
Uncertain DataSet characteristics
We first evaluated the scalability of these three algorithms; that is, we performed the algorithms with respect to different database sizes, which are shown in Fig. 5. The T25I15D320K dataset was used as the evaluation dataset; it was separately divided into the first 20,000, 40,000, 80,000, 160,000 and 320,000 transactions to run the algorithms. The relative minimum support and the minimum probabilistic confidence were set to fixed values of 0.1 and 0.9, respectively. Note that, even though the relative minimum support is fixed, the minimum support will change because the data sizes are different. As shown in Fig. 5a, when the dataset became larger, the runtime cost of the three algorithms also increased, but the PMFIM and APMFIM algorithms were much more stable when the dataset became larger. Also, in Fig. 5b, we can see that, with the increase in the number of transactions, the memory cost of the algorithms increased linearly. This is reasonable because for more transactions, the expected support and the probabilistic support require more computation and memory usage; also, more probabilistic frequent itemsets will be maintained.
Effect of data size for 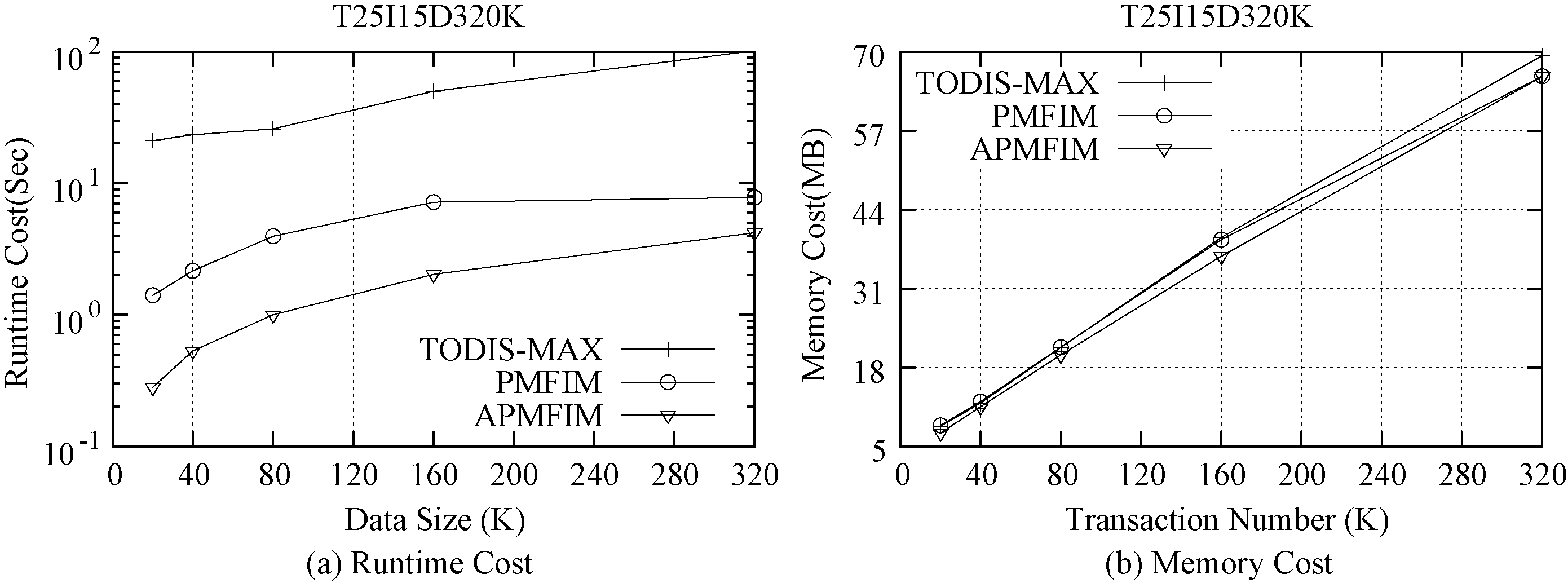
It has been proved in Property 2 that a larger minimum probabilistic confidence may result in a lower possibility that an itemset becomes frequent, which will reduce the computational cost and the memory usage. We evaluated the runtime and memory cost of our algorithms for different minimum probabilistic confidence (from
In Figs 6 and 7, we separately present the runtime cost and the memory usage over six datasets. We find that, when the minimum probabilistic confidence increases, both the runtime and the memory cost of the three algorithms remain almost unchanged. This demonstrates that the minimum probabilistic confidence has little effect on the performance of these three algorithms. This is because the summed support probabilistic vector is highly sparse when the dataset size is large, such that most of the minimum probabilistic confidence can slightly change the value of the support, and thus it can almost not turn the itemset from frequent to infrequent, or from infrequent to frequent.
Runtime cost vs. minimum probabilistic confidence for 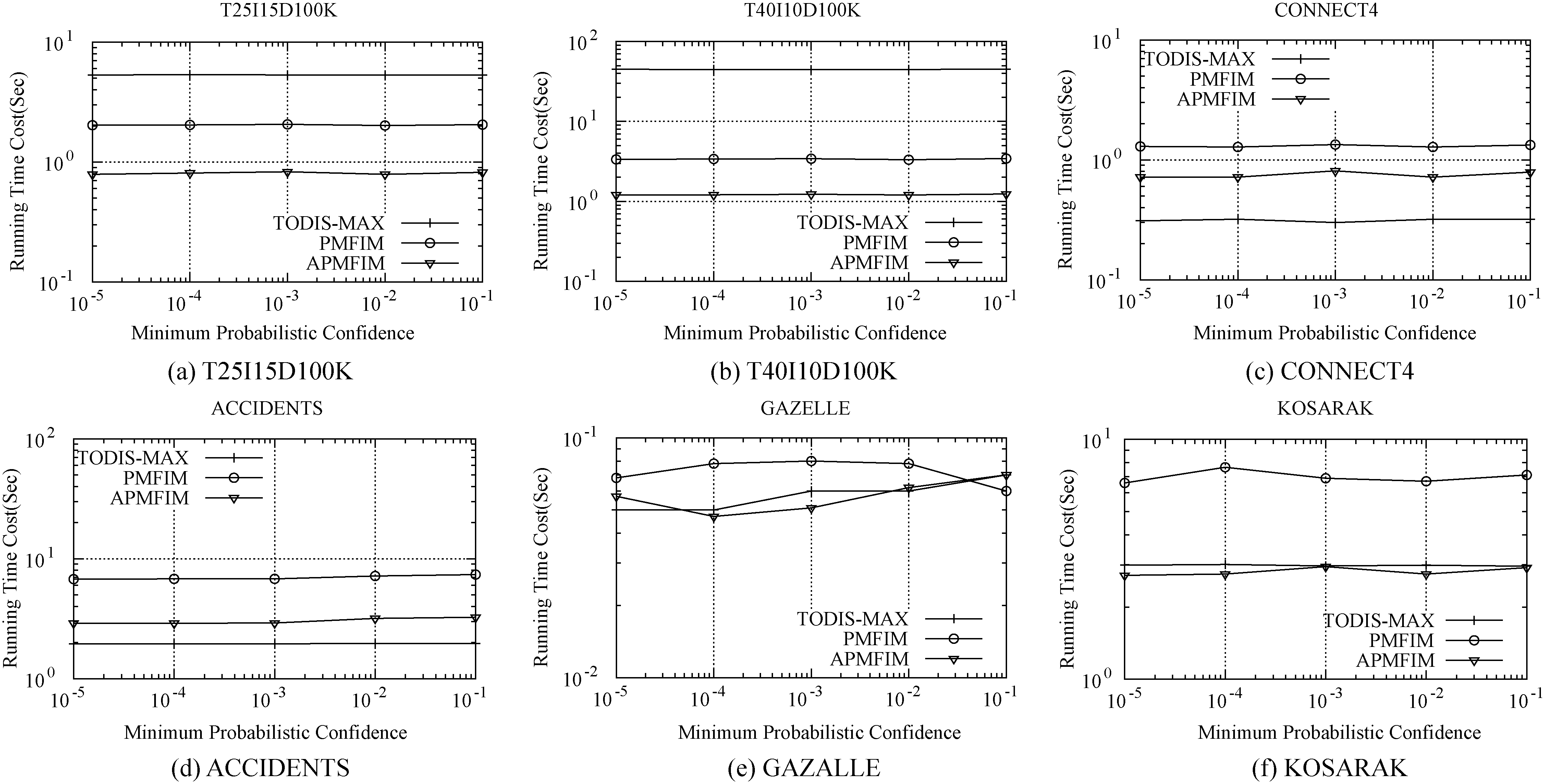
Memory cost vs. minimum probabilistic confidence for 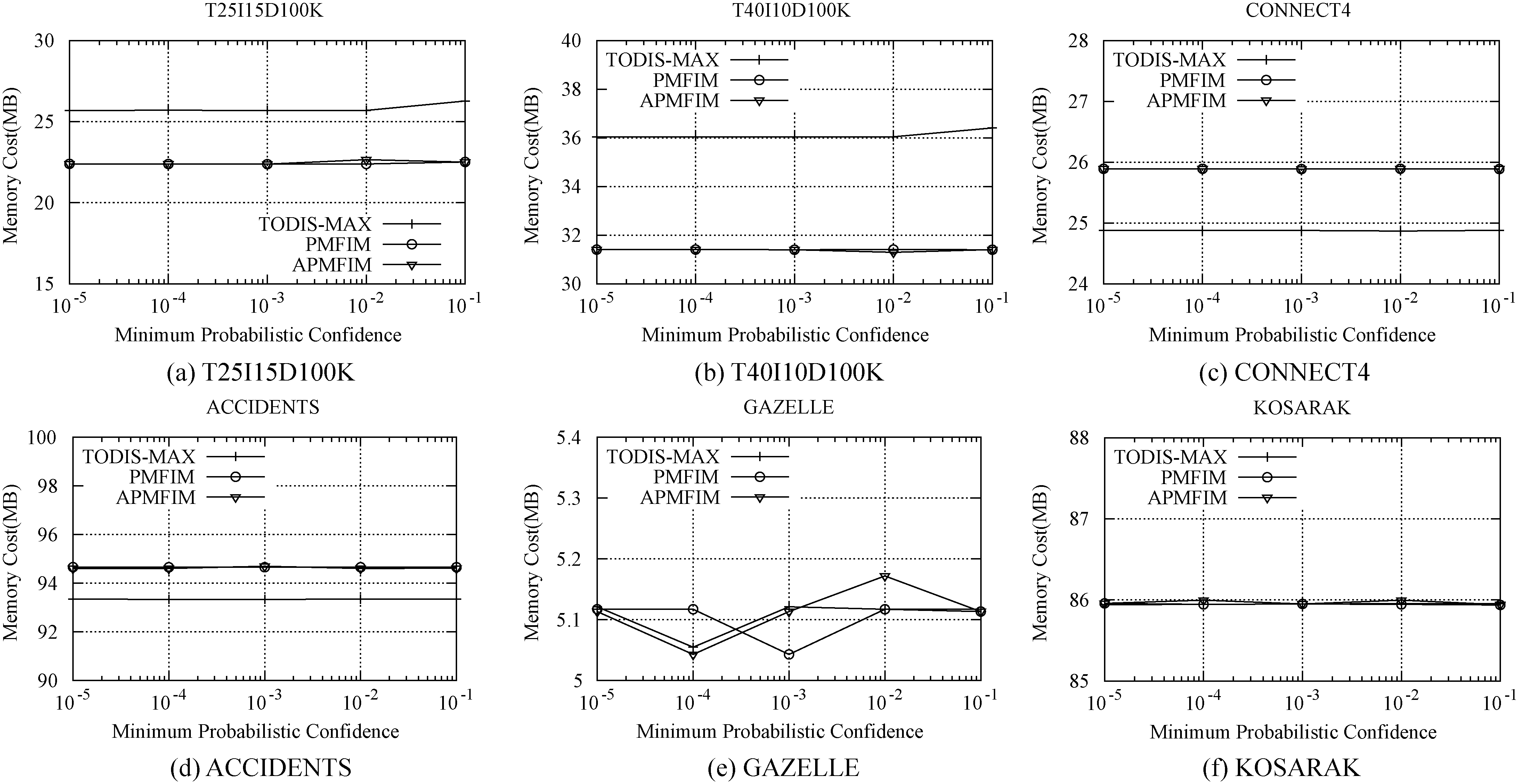
Theoretically, the minimum support is a very important parameter that will impact performance. When the minimum support becomes larger, certain probabilistic frequent itemsets will become infrequent, thereby reducing the runtime and memory cost. We set a fixed minimum probabilistic confidence, that is,
Runtime cost evaluation
We compared the runtime cost in Fig. 8 of the three algorithms being conducted over 6 datasets. Because of time constraints, we only conducted and presented the running results within one hour.
Running time cost vs. minimum support for 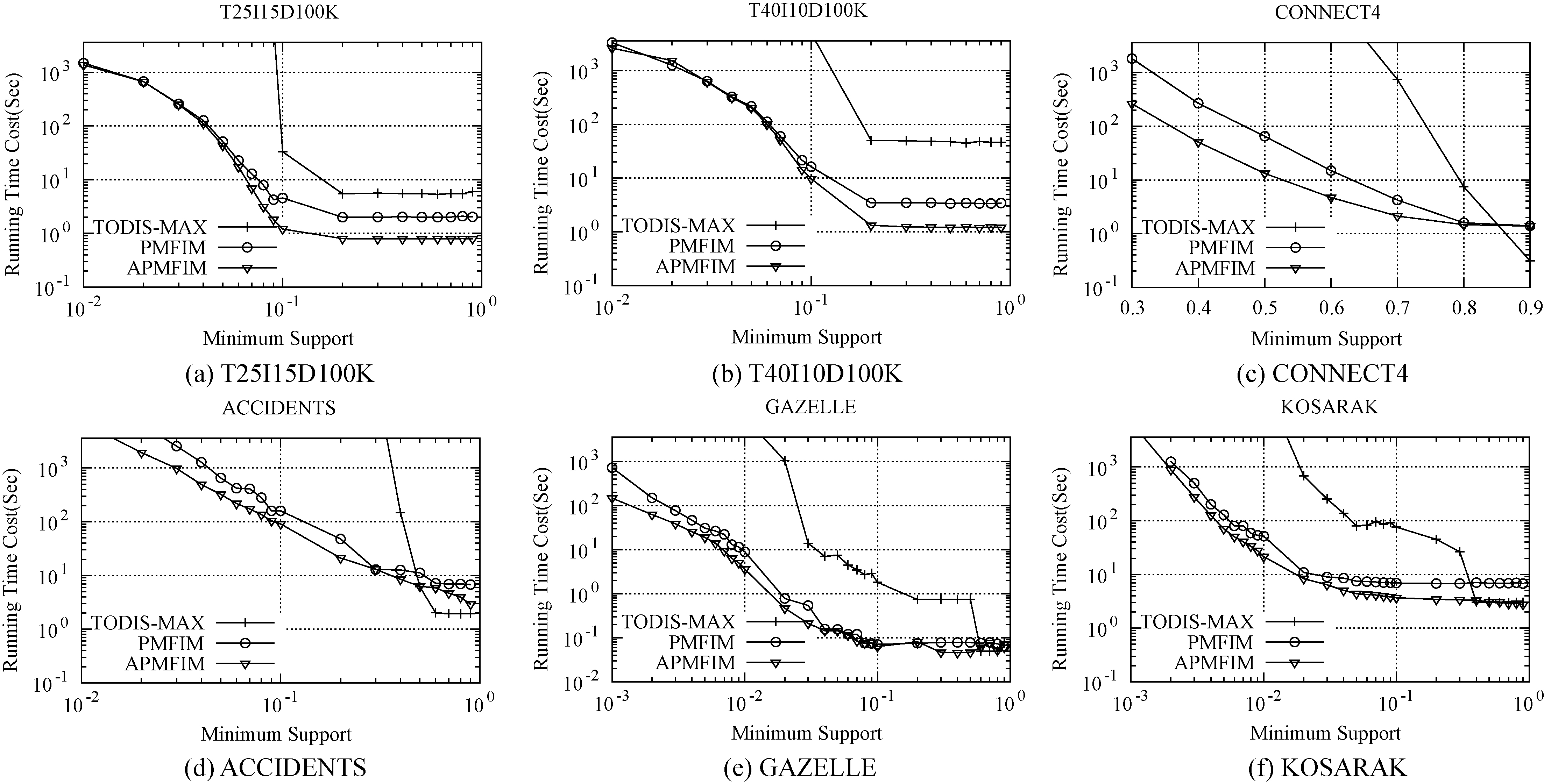
As can be seen, the runtime cost of all three algorithms decreased linearly with a decreasing of the minimum support, which is consistent with our theoretical analysis. We also compared our algorithms to TODIS-MAX. When the minimum support was low, the runtime cost of the TODIS-MAX method was a little higher than those of the PMFIM and APMFIM methods over most of the datasets except for CONNECT4 and ACCIDENTS, the two densest datasets. This is due to the advantage of the top-down mining manner in TODIS-MAX; that is, faster pruning will be employed if the supersets are not frequent, which is more useful in terms of performance with dense datasets. However, when the minimum support becomes much higher, the performance of TODIS-MAX significantly deteriorates, which can also be clearly noticed over denser datasets. As shown in the figure, over CONNECT4, the densest dataset, PMFIM and APMFIM algorithms performed faster than TODIS-MAX by a factor of nearly 1000 when the relative minimum support was 0.7; over KOSARAK, the sparsest dataset, a factor of 100 increase in performance can also be achieved when the relative minimum support was 0.05. Also, this out-performance increased when the minimum support became lower. This is also because of the different mining fashions: TODIS-MAX employed the top-down method, which, when the minimum support is low, will use more frequent items to generate infrequent itemsets, whose number will exponentially increase along with the number of frequent items. Even though TODIS-MAX employed the expected support to prune most of the probability mass function computations, the remaining computations were still too numerous to calculate. In comparison, our two algorithms were bottom-up methods, with which only frequent itemsets were generated, so, with the help of superset pruning, the number of computations will not increase sharply when the minimum support became lower.
In addition, we compared our two algorithms and noticed that when the minimum support was high, both algorithms had similar runtime cost, but the APMFIM algorithm was more efficient than the PMFIM algorithm when the minimum support turned lower; as shown in Fig. 8c, APMFIM performed nearly ten times faster than PMFIM when the relative minimum support changed to 0.3. This is because, in most cases, the PMFIM algorithm used the computed upper and lower bounds to infer whether an itemset was frequent, which had the same time complexity as that of the APMFIM algorithm. Unless the minimum support was much lower, this computation can replace almost all the probabilistic support computation. Two exceptions were the performance over T25I15D100K and T40I10D100K datasets. We find this to be reasonable because the APMFIM and PMFIM algorithms arrange items in different order; that is, in the APMFIM algorithm, the items were sorted by their approximate probabilistic support but, in the PMFIM algorithm, the items were sorted by their expected support. This difference may result in slightly varied performances even though the time complexities are similar.
Additionally, to compare the runtime under the same minimum support, we can easily find that when the transaction correlation is lower, which means that the dataset is denser, more runtime cost is needed. This conclusion is reasonable because a dense dataset will generate more frequent itemsets, which may consume more computing resources. As a result, we conclude that the transaction correlation is also an important factor that can affect the performance of the algorithms.
Memory cost vs. minimum support for 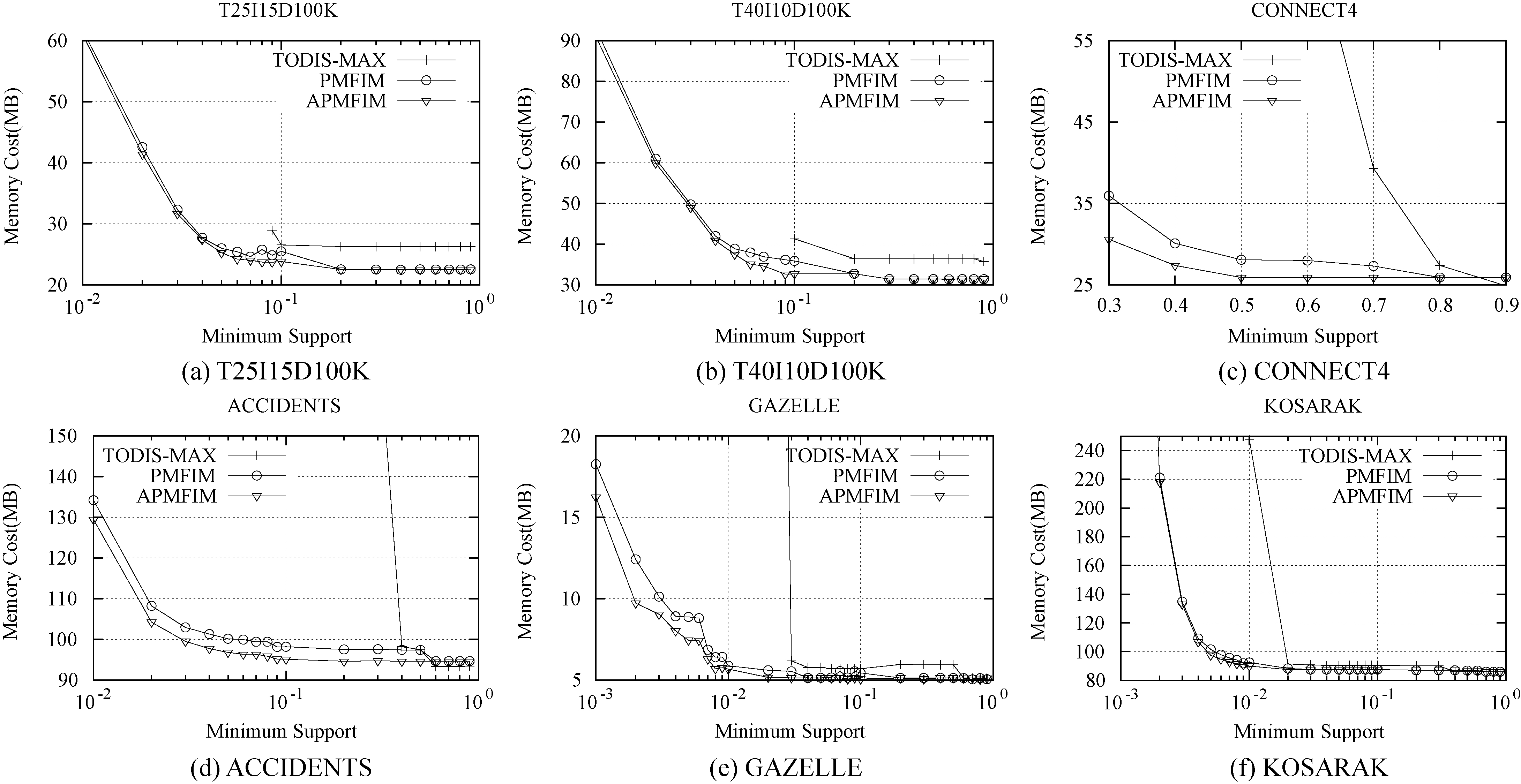
We also compared the running memory cost of the three algorithms. As shown in Fig. 9, similar to the runtime cost, the memory usages will decrease as the minimum support decreases. In addition, we can see that in most cases TODIS-MAX used more memory than our two algorithms. Because our algorithm employed the divide-and-conquer method proposed in TODIS-MAX, which had a space complexity of
Itemsets size analysis
To further shown the effectiveness of probabilistic maximal frequent itemsets, we presented the ratio between the probabilistic maximal frequent itemsets size and the probabilistic frequent itemsets size in Fig. 10. Over the densest dataset Connect4, the probabilistic maximal frequent itemsets were much decreased when the minimum support was low; also, an average of 25% reduction was maintained over the sparsest dataset KOSARAK. This can reduce both the runtime cost and memory usage, and enabling users to make easier decisions.
Prob. maximal frequent itemsets size/prob. frequent itemsets size for 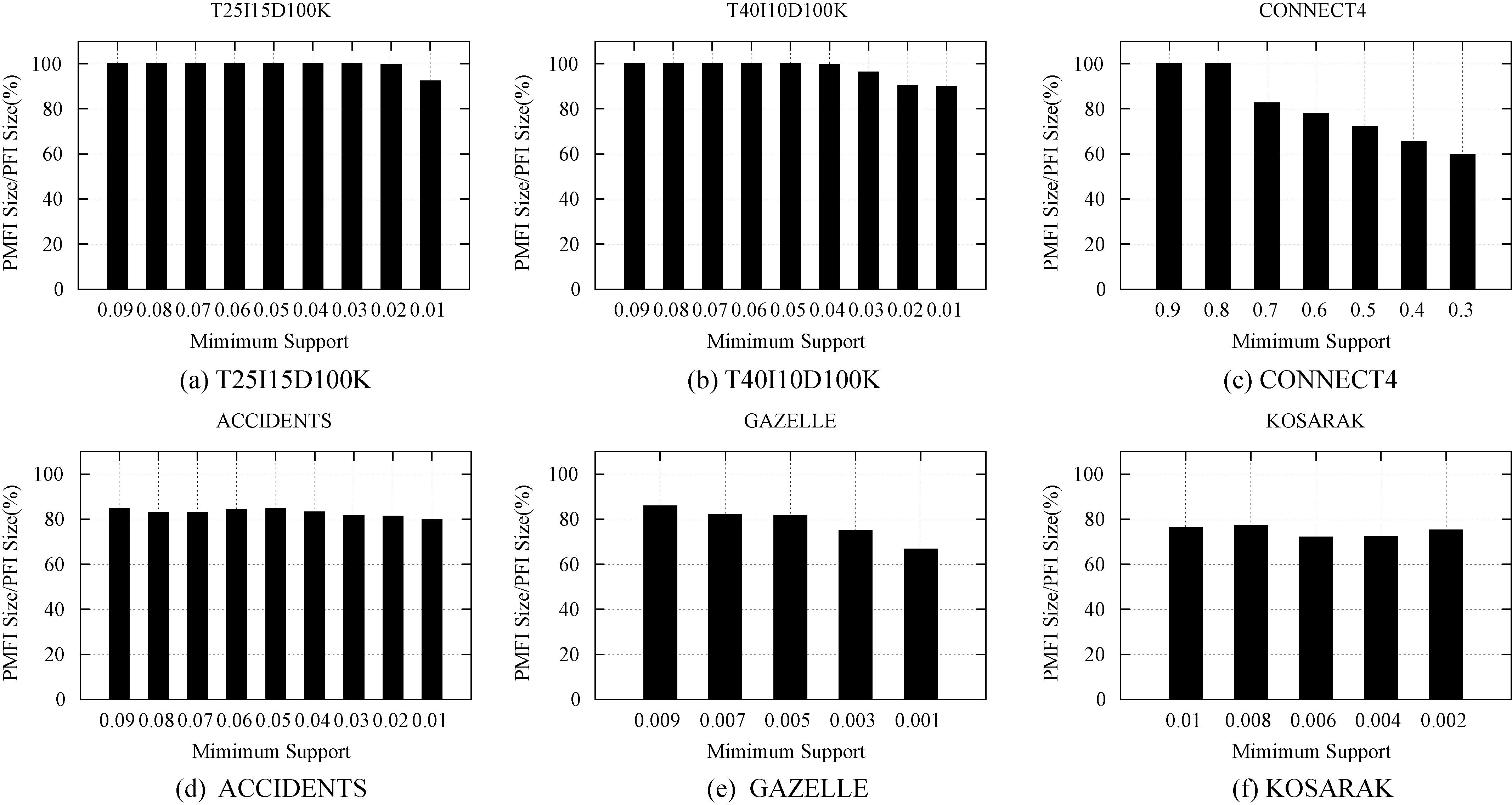
Our algorithm APMFIM is an approximate algorithm that may result in both false positives and false negatives; that is, it may select the wrong itemsets or will miss certain real results because the value of probabilistic support is not accurate. We used precision and recall to represent the approximation of the mining results of our algorithm, which is defined as follows: For an actual collection
Precision and recall of APMFIM for 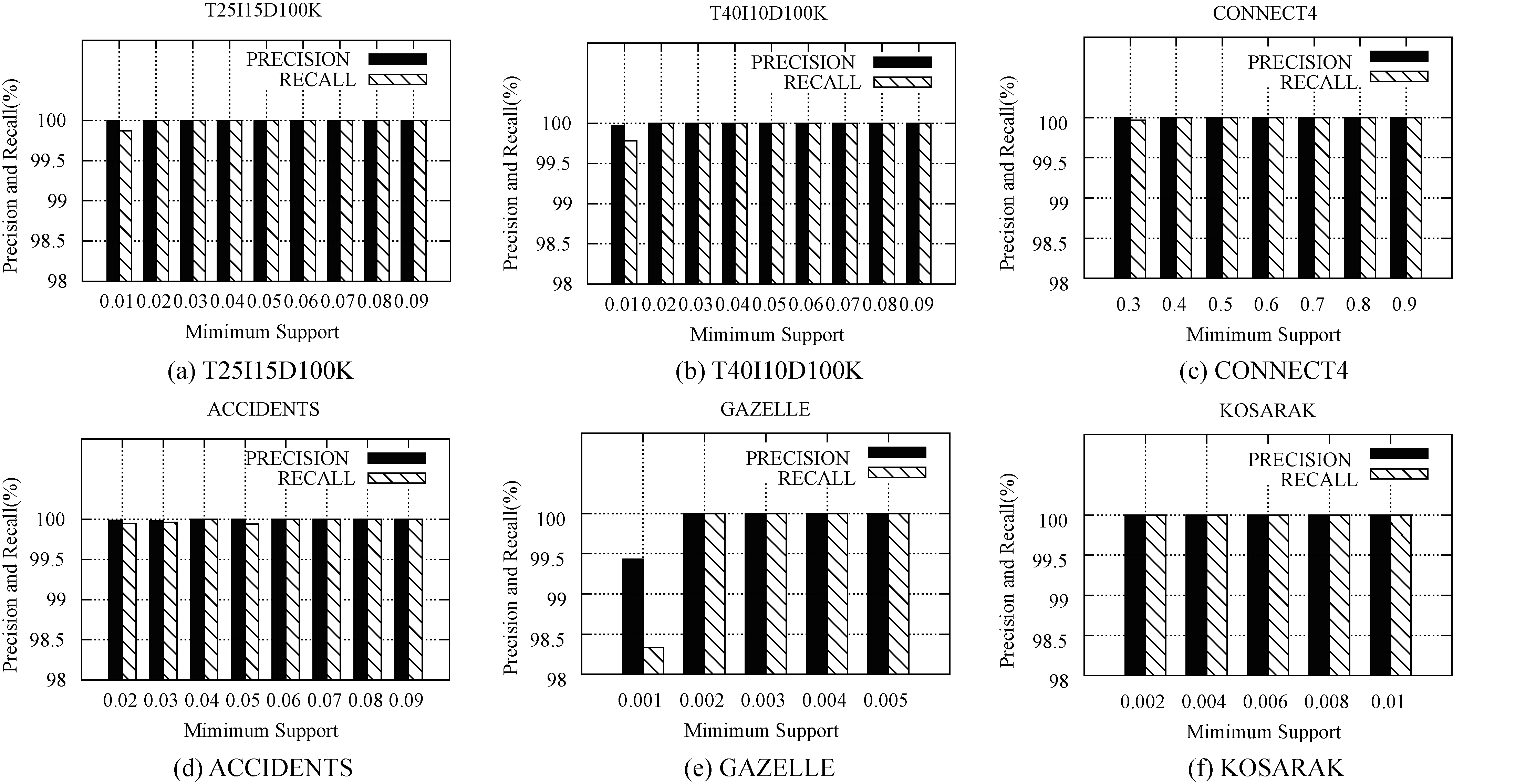
Figure 11 showed the precision and recall of the APMFIM algorithm over six datasets under different minimum supports. As can be seen, unless the minimum support is much lower, our algorithm can achieve 100% precision and 100% recall. Moreover, even though under low minimum support, our algorithm can also achieve
From our experimental results, we can conclude the following: First, because computing the probabilistic support requires
Conclusions
In this paper we studied the behavior of maximal frequent itemset mining over uncertain databases. We redefined the probabilistic maximal frequent itemset to make it more reasonable and more conducive to pruning. Based on this, the extended enumeration tree PMFIT was introduced as an efficient index to maintain the probabilistic frequent itemsets. A bottom-up algorithm PMFIM, mining in a depth-first manner, was proposed, in which we used the support and the expected support to estimate whether an itemset was probabilistic frequent, which greatly reduced the probabilistic support computing. In addition, a superset pruning method was employed to further improve mining performance. Furthermore, we used the expected support to directly derive the value of probabilistic support, and then we developed an approximate method APMFIM, which yielded mining efficiency and lower memory usage. Our extensive experimental studies showed that our PMFIM algorithm significantly outperformed the TODIS-MAX method. Additionally, the APMFIM algorithm was more efficient in terms of computation and memory usage than the PMFIM algorithm and yielded higher accuracy.
Footnotes
Acknowledgments
This research is supported by the National Natural Science Foundation of China (61100112, 61309030), Beijing Higher Education Young Elite Teacher Project (YETP0987), National Key R&D Program of China under Grant (2017YFB1400701), Discipline Construction Foundation of Central University of Finance and Economics, CUFE Young Teacher Foundation (QJJ1706).