
Abstract
Collaborative filtering (CF), one of the most famous methods for building recommendation systems, recommends relevant items to users or predicting ratings of users’ unknown items. Matrix factorization (MF) models are well-known model to deal with predicting the rating problem. However, the recommendation system based on matrix factorization is hard to keep up with the rapidly changing real-world data. When ratings on new users or new items come, the static model can not fit well on new data. As a consequence, if the current thing does not apply, the prediction accuracy will lose. In addition, it is a significant computation cost to rebuild the model on the whole data. To capture these changes, in this paper, we construct an online-and-offline Collaborative Filtering with a multi-method model to improve the traditional CF method, called Online SGD with Offline Knowledge (OSGDO for short). Besides, we propose a real-time incremental recommendation framework on Apache Flink, which is a scalable stream and batch data processing platform. Meanwhile, we implement our proposed method on our proposed framework. Our method proves to be good at online training when new observations arrive. And the results of experiments show that the dynamic training process we proposed is more efficient than rebuild the model on all the data. At the same time, our algorithm performs well in practice and can achieve impressive accuracy quickly when it is tested with the well-known data sets of MoviesLens and Netflix.
Keywords
Introduction
Recommendation systems play an important role in large-scale e-commerce platform like Amazon, Google, and Netflix to solve information overload problem [3, 19, 22]. Traditional CF models for recommendation systems are built on static training data sets and make predictions when new data come, which are unable to adapt to real-time or incremental scenarios. However, users’ behaviours in large-scale e-commerce system usually change fast, so that the user-item rating-matrix changes rapidly in real time [21]. A large number of prior work focuses on improving traditional models by using online learning algorithms. In [1], an online Stochastic gradient descent (SGD) method on MF with (or without) features by minimizing the square loss is proposed to convert a batch-trained algorithm into an online version. Rendle and Schmidt-Thieme [26] propose a regularized kernel MF models which can be updated online. Agarwal et al. [2] present an online learning model which combines feature-based regression and user-item specific learning in a single framework named FOBFM. Yu et al. [36] design one-sided least squares (One-sided LS) to reduce computation and storage cost of incremental learning of MF models. In this line of work, online learning algorithms, updating recommendation model incrementally, achieve good performance and reduce the response time (the time from a user providing input to receiving recommendations from system [34]).
Batch-processing platforms and stream-processing platforms are widely used in large-scale systems. In batch-processing distributed frameworks, Apache Hadoop [8] and Apache Spark [28] are well-known. They all solve the problem of big data offline processing. Hadoop has a rich ecosystem, so it is more adaptable than Spark. However, Spark’s processing speed is faster than Hadoop because it stores intermediate results in memory while Hadoop stores them on disk. In stream-processing distributed frameworks, there are some popular tools for choosing, including: Apache Spark, Apache Storm [13] and Apache Flink [6]. Apache Storm is an open source streaming-processing framework. It empowers developers to build real-time distributed processing systems, which can process the unbounded streams of data very fast. It is also called Hadoop for real-time data. For Apache-Spark, its stream processing component is based on Micro-Batching approach. The incoming data stream is split into receivers and created as Micro-Batches and then processed like other Spark tasks. About Apache Flink, for stream data, processing procedure will execute continuously as long as data are being produced. Besides, Apache Flink supports different notions of time (event-time, ingestion-time, processing-time) in order to give programmers high flexibility in defining how events should be correlated [7].
In some scenarios, some work applies recommendation algorithms to the batch-processing frameworks (e.g. Apache Hadoop, Apache Spark et al.) for solving “big data” problem in recommendation system [37]. Meng et al. [23] propose a keyword-aware service recommendation application which implements on Apache Hadoop. Verma et al. [30] present a recommendation system for a large amount of data available on the web by using Hadoop. Wang et al. [33] use a weighted method which combines CF and the content-based recommendation algorithms to implement a fast recommendation system on Apache Spark. Furthermore, stream-processing frameworks are also frequently utilized by large-scale e-commerce recommendation platform, so that the “real-time” challenges can be solved [11]. Correspondingly, some work applies recommendation algorithms in the stream processing frameworks (e.g. Apache Storm, Apache Flink etc.) to complete the recommendation tasks. Huang et al. [11] build a real-time stream recommender system on Apache Storm by making use of item-based CF, the content based, and the demographic based algorithms. In addition, Ciobanu and Lommatzsch [7] develop a news recommender system on Apache Flink. In this line of work, most of them use traditional recommendation algorithms, because they are classic and practical. However, little work in this branch utilizes the advantages of incremental recommendation algorithms.
Inspired by the above observations, in this paper, we absorb the advantages of online learning algorithms to propose an online learning algorithm: OSGDO and construct a Real-time Incremental Recommendation Framework for streaming data system (RIRF for short) based on Apache Flink. Our framework treats new information generated by users as streaming data and uses OSGDO to incrementally update our recommendation model by using the information. Also, we make use of numerous historical data to initialise our model, so that our framework can both consider short-term memory of information which provided by new streaming data. Meanwhile, it also holds a long-term memory of information contained in the historical data. In a nutshell, our framework combines incremental recommender system with streaming data-processing platform.
The main contributions of our work are as follows:
We propose a novel recommendation framework called RIRF for short, which can apply incremental learning in large-scale recommendation system. Especially, our framework is the first time to combine online learning and offline training with Apache Flink. Meanwhile, we introduce the general framework of RIRF in Section 3.2. We propose a novel online learning algorithm named OSGDO, which utilizes historical data and online learning to update recommendation model incrementally. We introduce our algorithm in Section 3.3. We conduct extensive experiments based on widely-used benchmark data sets (MovieLens and Netflix). The results of experiments in Section 4.2 prove that our algorithm and framework have good performance both in accuracy and efficiency.
This section briefly reviews the background of some major groups of related work, including traditional CF and online CF.
CF recommender systems are generally classified into two kinds: memory-based methods and model-based methods. Memory-based recommendation methods are based on the ratings that users rated. User-based CF and item-based CF belong to the memory-based recommendation algorithms. Memory-based methods are easy to implement and understand, they are widely used in real world [27, 5, 17]. However, there are some limitations in some aspects. First, they are more easily effected by the data sparsity problem because the more raw data they have, the higher accuracy of predicting they can achieve. Furthermore, they manipulate the ratings directly in memory, the time complexity of calculation and recommendation is high. Besides, the memory consumption can be potentially very expensive.
In general, model-based approaches train a predefined model in the training step that explains observed ratings, which is used to make recommendations later. Usually, model-based CF methods can achieve better performance [15]. Various approaches of model-based are as follows, including SVD, NMF [16], biased SVD [25], PMF [24], SVD
Online learning algorithms are extensively studied recently to cope with incremental recommendation problem. Part of work converts the offline MF algorithm into online MF algorithm [1, 18], and some work combines multi-task processing with collaborative filtering algorithms [32]. Meanwhile, some work integrates the results of offline training algorithm into online regression algorithms [2]. There is also some work, which combines offline MF and online matrix MF [21, 31, 36].
The following studies are similar to our work. Among them, an early work is [1], a novel online version of MF with (or without) features using SGD is proposed to deal with incremental recommend problem. However, it does not take regularization effects into consideration. In [31], an incremental update of MF model by SGD is studied, named ISGD. However, they initialise the latent factor vectors randomly, which may affect the accuracy.
In [20], the authors propose an incremental Regularized MF model with linear biases which can incrementally update specified latent feature through constructing the expression over new data based on the trained model over historical data. In other words, it can incrementally learn from new data rather than retrain the entire recommendation model. Besides, it incorporates with linear biases, which can increase the recommendation accuracy. However, it needs to store intermediate training results in external files after each epoch, which leads to high storage space. And its linear biases are not trained along with the latent factors but estimated through the unbiased estimator using fixed parameters, which may not able to reflect real information.
Other incremental learning methods also have their own characteristics. Wang et al. [32] focus on online multi-task CF, which trades off between efficacy and efficiency. It not only updates the weight vectors of the user related to the current observed data but also the weight vectors of some other users according to the users interaction matrix. However, it would be slightly less efficient due to the cost of multi-task learning.
Luo et al. [21] design a general incremental-and-static combined scheme for MF-based CF recommenders, whose main idea is dividing rating-matrix
In [2], the authors propose an incremental recommender model named FOBFM which combines feature-based regression and user-item specific learning, yet their model requires extra information about users or items. The information is similar to the age data or gender data, rather than factors trained by MF. And the information is not available under many circumstances like in the Netflix Prize.
Another related work proposes online CF algorithm using ALS in [36], which turns traditional ALS into an online version (One-sided ALS) and uses the result of traditional ALS as initial conditions for One-sided ALS. However, it only updates the one-side latent factor vector at each update procedure when new data coming. For instance, if an old user rates a new item, the One-Sided ALS only updates the latent factor vector of the item instead of updating the latent factor vectors of the user and the item together. In contrast, we think that the vectors of the user and the item will change synchronously after a user rating an item. Therefore, we update the related latent factor vectors of the user and the item at the same time.
Inspired by related work, our work proposes a novel incremental learning algorithm OSGDO, which combines offline knowledge and online MF. We update both the user’s and the item’s latent factor vectors and biases when new data come. Compare with the models we mentioned earlier, our algorithm’s idea is more concise and effective. Moreover, we implement our algorithm in Apache Flink and propose an incremental recommend framework named RIRF. To the best of our knowledge, no existing work has attempted to combine offline training and online learning in Apache Flink.
Real-time incremental recommendation framework
In this section, at first, we briefly review the background of CF and MF algorithms which are widely used in the recommendation system. Then we introduce the general structure of RIRF and the detail of our proposed online learning algorithm for incremental recommendation system: online SGD with offline knowledge.
Recommendation algorithms
CF methods are one of the major approaches to build recommendation systems [18]. MF is one of the most popular methods of CF due to its outstanding performance in rating prediction [15]. It decomposes a large sparse rating matrix into two or more small latent factor matrices, in which each row means user’s or item’s features. In MF algorithms, user-item matrix is denoted by
In order to learn latent factor vectors to make
where
Although MF achieves high accuracy in static data sets, it has a potential problem: when new observations are coming, it should rebuild the model to apply incoming data, which costs too much time and resources [29].
Recently, online learning algorithms achieve attractive performance in incremental recommendation. Instead of rebuilding the whole model, some online learning algorithms only need to update part of the model that related incoming data. Therefore, the online learning algorithms are more adaptable to the scene in which information changes rapidly than the traditional recommendation algorithms. In [1], an online MF algorithm is proposed. In [36], One-sided LS for incremental learning is proposed and a combined method of One-sided LS and offline ALS is proposed in the work as well.
We construct a framework in order to combine incremental recommendation with Apache Flink. Apache Flink is the most popular stream processing framework currently. It utilises in-memory computation to reduce disk IO. In addition, it has its own memory management within JVM. So that, it can spill data or something else to disk when memory is not enough. Moreover, the stream processing of Apache Flink is a real stream processing. It would process data immediately and pass them to next operator without waiting for a whole data batch like Apache Spark Streaming. Our framework is designed for processing incoming stream composed of new observations and updating the recommendation model continuously. Besides, our proposed online updates algorithm uses the Propagation Cut-Off Mechanism to ensure that it only updating the information related to new observations rather than the whole model.
Overview of RIRF.
The framework is mainly composed of six parts: DataReceiver Component, Offline Component, Online Component, Recommender Model, Storage Module and Result Return Module. All of them are interrelated and interdependent. The general framework of RIRF is shown in Fig. 1 and details of these components are as follows:
DataReceiver Component: It delivers data to Recommender Model or Online Component. We divide the data into two types: recommended input data and incremental information data. The format of recommended input data is like
Offline Component: It is mainly used to train historical data and get the latent factor vectors and biases for users and items. Most of traditional MF algorithms can serve as Offline Component, such as SVD, NFM etc. The result of the Offline Component is the initialisation condition of the Online Component.
Online Component: When incremental information data come, the Online Component learns new information incrementally and update the latent factor vectors and biases of users and items online. Note that these latent factor vectors and biases are initialised by using the results of Offline Component.
Recommender Model: The main function of this component is using the latest recommendation model to predict users’ ratings of items.
Storage Module: The main function of the Storage Module is saving the offline training results, which contains the latent factor vectors and biases about users and items. In addition, it also stores the prediction ratings of related users and items.
Result Return Module: The Result Return Module obtains ratings about related users and items from the Storage Module and displays the corresponding information.
In this part, we describe our framework’s workflow. At first, we use historical data to build an offline recommendation model as the Offline Component. Meanwhile, we persist the model into the Storage Module. Then we determine the corresponding operations based on the different types of data received by the DataReceiver Component. There are two types of data: recommended input data and incremental information data. From Fig. 1, we can see that, when incremental information data come, we (1) deliver data to Online Component, and (2) learn new information and update recommendation model by making use of online learning algorithm; when recommended input data come, we (1) deliver data to Recommender Module, (2) predict the ratings by making use of latest latent vector contained in Recommender Module, and (3) store results to Storage Module. Then, we display these results by making use of Result Return Module.
In our proposed RIRF, online learning algorithms, which can update the latent factor vectors and the biases of users and items online, are used in the Online Component. Despite the fact that most of existing online learning algorithms based on MF are able to be applied to our Online Component, they are still not clear and efficient enough. Thus, we propose a new online learning algorithm named OSGDO for adapting Apache Flink. In this section, we first expatiate our propagation cut-off mechanism and then introduce the details of our proposed algorithm: OSGDO.
The difference between traditional way and Cut-Off Mechanism when updating latent factor vectors on 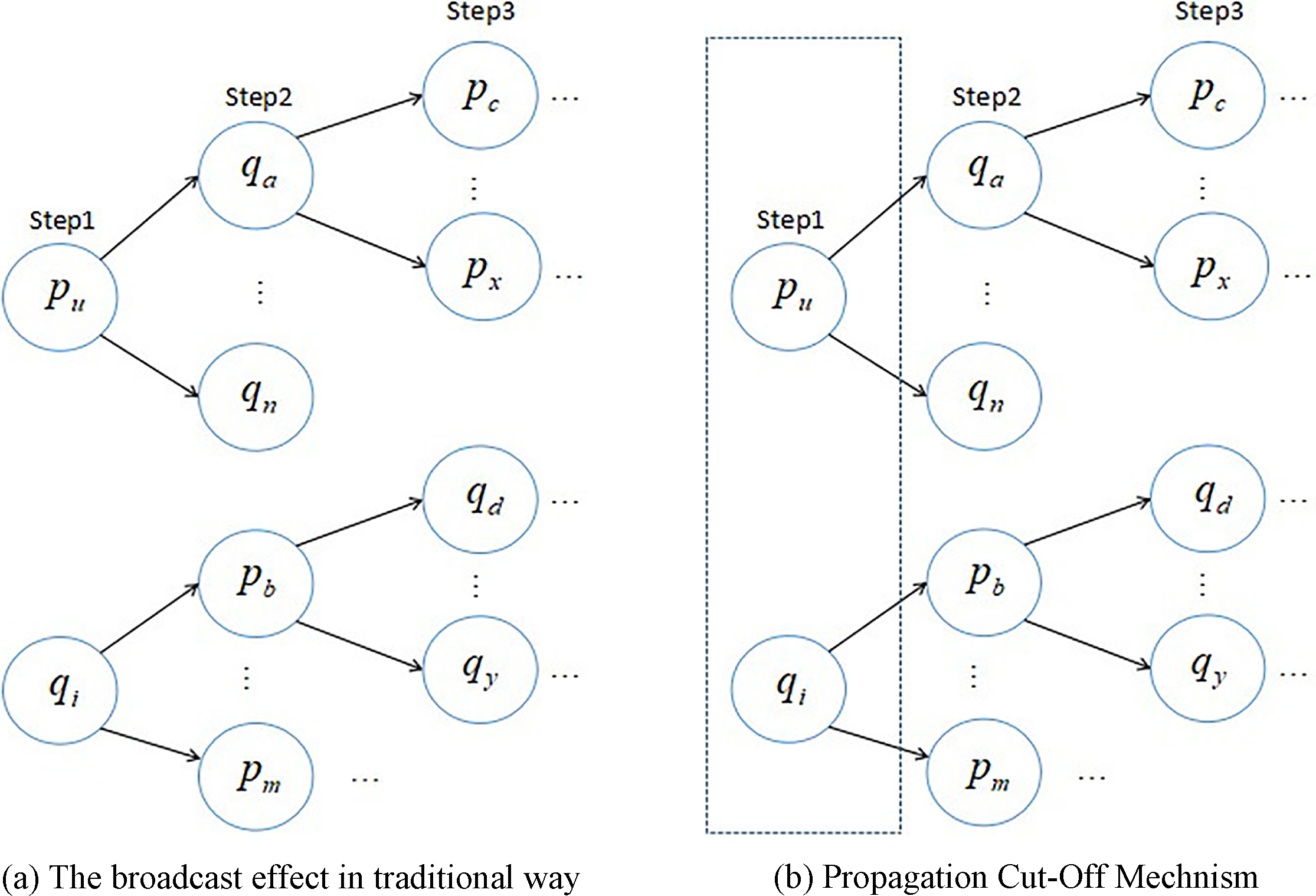
When new data come, the model needs to update the users’ latent factor vectors and items’ latent factor vectors respectively. Since the ratings that the user rates on the previous corresponding items are fixed, when the user’s vector changes, the vectors of these items would change either. In addition, it is same to the case when the item’s latent factor vector changes. For instance, in Fig. 2a,
Online SGD with offline knowledge
As mentioned before, our Online Component is built on the results of Offline Component. So that, we use the Offline Component to build an offline recommendation model to obtain offline knowledge including latent factor matrices and bias sets, as depicted in Fig. 3.
Offline MF’s results: Latent matrices and bias sets.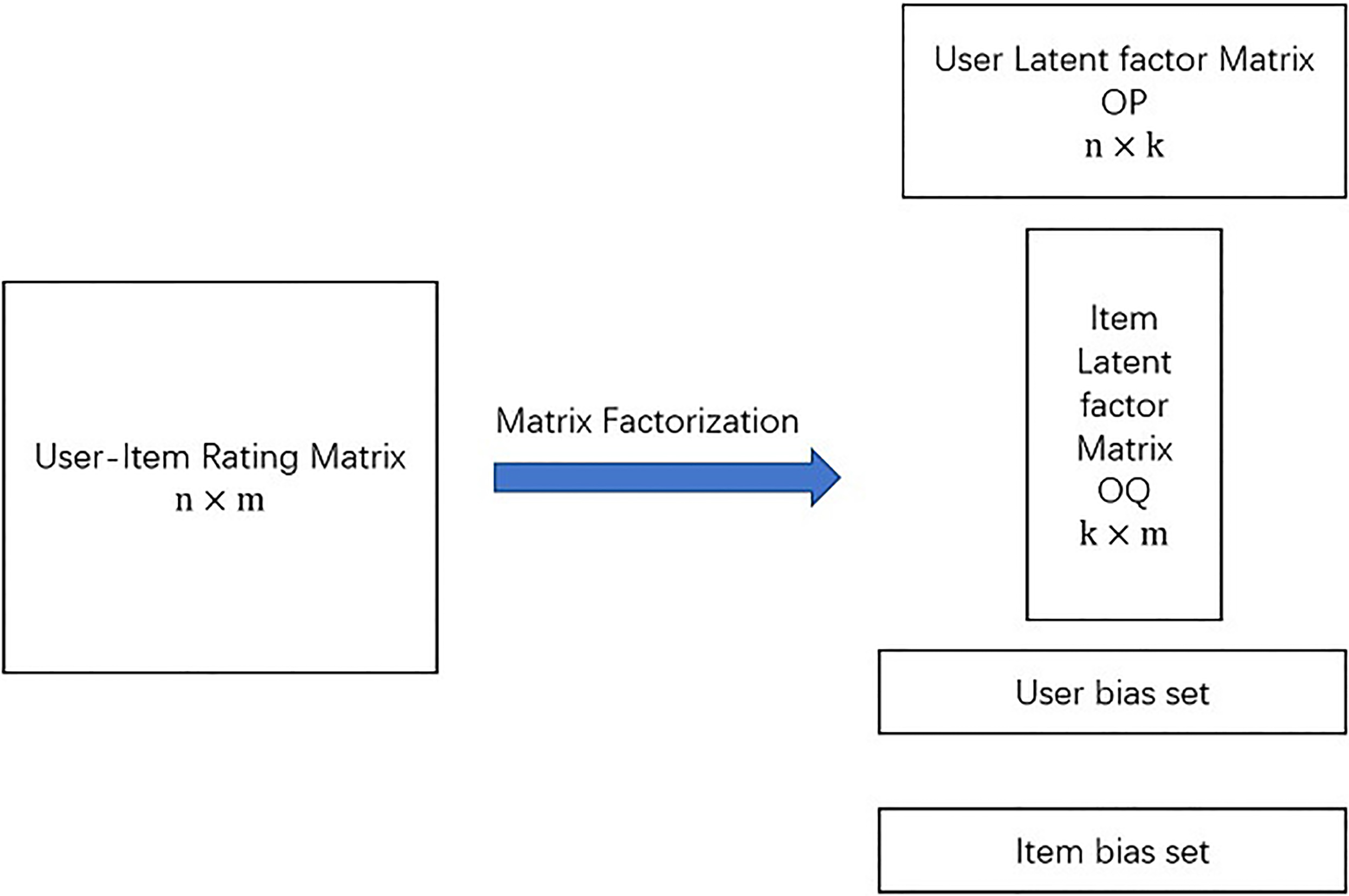
Given an observation like
Finally, we use
The online update formulas for latent factor vectors and biases are as follows:
where
Our algorithm combines SGD with momentum as its optimization method. Compared with traditional SGD, it uses the gradient at a single rating as an estimate of the global gradient. One disadvantage of the SGD method is that its update direction is completely dependent on the current batch, so its update is unstable. A suitable solution is to use the Momentum mechanism, which can speed up the speed of convergence. Therefore, the Eqs (4) and (5) of updating latent factor vectors would be replaced with Eqs (9) and (11).
We define the symbol
In conclusion, we use the latent factor vectors and biases obtained from Offline Component in RIRF as the initialisation parameters of OSGDO and update the recommendation model after multiple rounds of iterative online learning.
In this section, we perform extensive experiments to study the efficiency of our OSGDO method in terms of prediction accuracy and learning time. In our experiments, we do not use any extra characteristics such as gender and age of users or information about movies.
We compare the proposed algorithm with other existing online CF algorithms. Besides, we conduct multiple experiments on each data set to ensure the stability and accuracy of the results of these experiments.
Experimental setting
Date sets
In our experiments, we use five different and classical data sets in our experiments including MovieLens 100K, MovieLens 1M, MovieLens 10M, MovieLens 20M [9] and Netflix [4]. All of the MovieLens data sets are collected by the GroupLens Research Project at the University of Minnesota through the MovieLens website (
MovieLens 100K is composed of 100,000 ratings from 1,683 movies rated by 943 users. In addition, it provides other users’ information such as gender and age. Its rating density is 6.30%.
MovieLens 1M contains 1,000,209 ratings from 6,040 users of 3,883 movies with a rating scale on [0, 5] interval. The density of it’s rating matrix is 4.25%. Meanwhile, there are some user and item features in the data set such as users’ age, occupation and gender, and movies’ genres.
MovieLens 10M contains 10,000,054 ratings and 95,580 tags applied to 10681 movies by 71,567 users of the online movie recommender service MovieLens. In addition, its rating density is 1.31%.
MovieLens 20M contains 20,000,263 ratings and 465,564 tag applications across 27,278 movies. And it is created by 138,493 users. In our experiments, we do not use the tags information.
Netflix data set contains 100,480,507 ratings by 480,189 users on 17,770 items, its rating density is 1.18%. In our experiment, we use its subset containing the ratings on the first 1,000 items (ranked by items ID) of the Netflix data set. Note that we choose this subset because it can represent the whole Netflix data set well. The subset we choose contains 5,010,199 ratings by 404,555 users on the first 1,000 items and its rating density is 1.24%.
Evaluation method
The recommender is evaluated by prediction accuracy and execution time spent on online learning, which is measured in elapsed time. To evaluate the performance of our RIRF framework and incremental learning OSGDO, we use Root Mean Squared Error (RMSE) [10] to evaluate prediction accuracy, which is a widely used metric for evaluating the statistical accuracy of recommendation algorithms. Its formula is as follows:
In the Eq. (12),
Our experiments are running on a server with 8 processors and 8 GB memory. In addition, we use another server with the same configuration as Redis server to store latent factor vectors and biases. We implement our RIRF framework and OSDGO algorithm in Apache Flink to evaluate the execution time in this platform. We use Surprise’s [12] implementation of SVD to generate the offline knowledge of latent matrices and bias sets before online learning of OSGDO. Moreover, there are many other offline training methods to be chosen.
Experimental result
In order to prove that our proposed framework and algorithm can deal with the problem that the traditional recommendation system encounters in online scenes, we split the data set according to the following division plan. At first, we divide each data set into 80% and 20% percent: 80% of the data set is used as offline training data
Accuracy comparison
In this section, we implement OSGDO as the algorithm in Online Component of RIRF and use SVD (based on Surprise) as the offline algorithm in the Offline Component of RIRF. We compare our method OSDGO with other emerging online CF algorithms. Please note that, some users or items do not have a lot of rating data in these data sets, so that we set
“OCF”: An online matrix factorization algorithm, which can learn a low-rank matrix online by online gradient descent method. It is described in [1]; “DA-OCF”: The online MF algorithms with Dual-Averaging method, which is proposed in [18]; “OMTCF-VI”: An online Multi-Task Collaborative Filtering (OMTCF) [32]; “One-sided LS”: An incremental learning approach, which derived from Alternating Least Squares (ALS). It is raised in [36]; “IRMFB”: An incremental Regularized MF with linear biases method, which is proposed in [20]; “SICF”: A scalable item-based collaborative filtering method by using incremental update and local link prediction, which is described in [35]; “FOBFM”: A model learns item-specific factors quickly through online regression and offline training with historical data by expectation maximization (EM) algorithm [2].
First, on the data set of MovieLens 100K, we compare OSGDO with several methods, including OCF, DA-OCF, and OMTCF-VI. Then, on MovieLens 1M, we compare OSGDO with OCF, DA-OCF, OMTCF-VI, IRMFB, SICF, FOBFM. Besides, we also make some comparisons on large-scale data sets. On MovieLens 10 M, we compare OSGDO with OMTCF-VI, One-sided LS, OCF, and DA-OCF. In addition, we also compare our method with One-sided LS on MovieLens 20 M. On Netflix data set, we compare OSGDO with IRMFB.
According to Table 1, several observations can be drawn from the results. Please note that the results of OCF, DA-OCF, OMTCF-VI (one of the most efficient algorithms in OMTCF algorithms), and One-sided ALS are collected from Wang et al. [32] and Yu et al. [36] respectively. In addition, the remaining compared algorithms’ results are collected from corresponding work.
Overall results in different data sets
For data set MovieLens 100 K, we set the number of iterations and the learning rate to 4 and 0.003 respectively. Meanwhile, we set the dimension of the latent factor vectors to 30. With the above parameters, we compare OSGDO with OCF, DA-OCF, and OMTCF-VI. We observe that our algorithm OSGDO achieves significantly best performance with smaller RMSE values. This shows that our method is more effective than other methods in improving the online prediction performance of incremental recommendation in MovieLens 100 K.
In experiments of MovieLens 1 M, we set the number of iterations to 2, the learning rate to 0.004 and the dimension of the latent factor vectors to 20. And we can see that OSGDO has better accuracy than OCF, DA-OCF, OMTCF-VI, IRMFB, SICF. We believe that our results are better than them owing to the initialisation strategy mechanism. In these methods, the OMTCF-VI, DA-OMF initialises latent factor matrices randomly which will affect the predicting accuracy. IRMF-B initialises latent factor matrices with offline training results. However, it uses unbiased estimator to update biases rather than updating along with the latent factor vectors. From the results, our algorithm is slightly worse than the FOBFM algorithm in terms of RMSE values, but the difference is very small. It is noted that, the FOBFM keep multiple models for each item, then it picks the best model to predict. It will occupy a large amount of memory space. Besides, it needs extra information such as user age or user gender which is usually not available in some scenes. In contrast, we do not require too much memory space to store extra models. Also, our approach does not require an explicit dimensionality reduction step in the offline learning phase.
On MovieLens 10 M, we set the number of iterations to 5. And the dimension of the latent factor vectors and the learning rate are respectively 10 and 0.005. The result shows that our method performs better than One-sided LS, OCF, DA-OCF, and OMTCE-VI. Besides, on MovieLens 20 M, we set the number of iteration and the learning rate are 1 and 0.004 respectively. Meanwhile, the dimension of the latent factor vectors is set to 50. We also achieve higher accuracy than One-sided ALS.
On Netflix data set, we set the number of iterations to 3, the learning rate to 0.005, and the dimension of latent factor vectors is equal to 30. We compare our algorithm with IRMF-B. The result shows that our method performs better than IRMF-B.
We calculate the mean of the RMSE and the standard deviation of the RMSE of our algorithm on all the data sets we used and present them in Table 2. From all the results in Tables 1 and 2, it can be seen that OSGDO has good performance on these data sets. Therefore, the OSGOD is a practical online learning method in incremental recommendation field for the online dynamic environment and our framework RIRF is an effective incremental recommendation framework.
Mean and stand deviation of RMSE of different data sets
Figure 4 shows the time cost of OSGDO and SVD (based on Surprise) when training 1000 incremental data. We consider these data as the incoming stream data of users’ behaviors. The time cost of SVD means it rebuilds recommendation model with whole data including incremental data and the time cost of OSGDO means that the model incrementally learns from coming data and update the model at the same time. We can see that among these data sets, our method is stable and the cost of time obviously is less than retraining all the data with SVD. Therefore, our framework RIRF and online learning algorithms OSGDO are more effective than traditional batch-training methods.
A time cost comparison between OSGDO and SVD.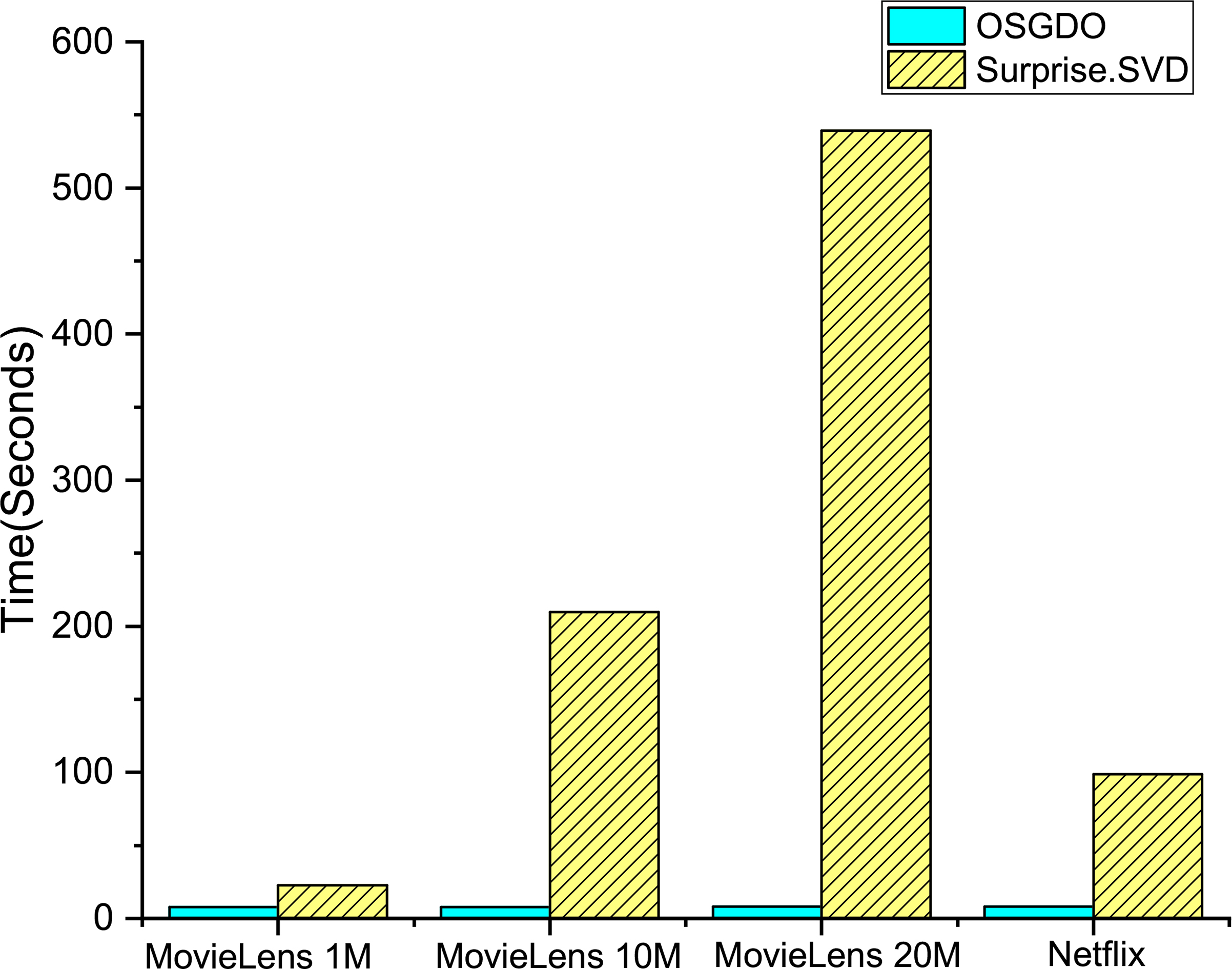
In this section, we study the performance of OSGDO and Surprise’s SVD on MovieLens 1 M data set. Note that, in other data sets, we also tune these parameters in the similar way either. We conduct multiple experiments on this data set and finally determine values of four variables: the learning rate, the dimension of latent factor vextors, the number of incremental training iterations, and the number of
Comparing OSGDO, All training SVD and Normal SVD on MovieLens 1 M. The RMSE is shown on the y-axis.
In these pictures, All training SVD means training with all data including
From the Fig. 5, we can see our method performs similarly to batch-training methods. Even in some cases, it outperforms batch-training algorithms a little bit. This is due to our model uses offline knowledge from the offline training phase. And it is also possible that each element in incremental data set will be trained only several times in OSGDO rather than dozens of times with whole data in SVD. The latter maybe lead users’ latent factor vector or items’ latent factor vectors over-fit and more likely to be trapped in the local optima. In addition, these results can prove that our framework RIRF and online learning algorithm OSGDO are effective.
Online learning in recommendation systems, as one of the most effective ways to solve the incremental recommendation problem, is becoming more and more popular in recommendation systems. Different from existing work which concerns recommendation system with high accuracy on static data, we focus on the recommendation issue on the incremental/streaming data. In this paper, we propose a novel framework named RIRF for stream incremental recommendation and a novel online learning algorithm named OSGDO for incremental recommende. Both theoretical analysis and experimental results show that our method achieves very similar RMSE to traditional MF models with traditional recommendation method: SVD, but at much lower learning time. Moreover, our framework is flexible and can be combined by selecting different offline and online algorithms according to different situations. And it can be parallelised by implementing using Apache Flink.
For future work, we may consider exploring the online recommendation framework with different types of offline batch-training methods and online learning algorithms. Besides, we will make our online learning method OSGOD parallel in Apache Flink in order to achieve better execution efficiency and deal with multiple complex situations. Furthermore, we will focus on some possible solutions to the “cold start” problem in online incremental recommendation system.
Footnotes
Acknowledgments
The work is supported by the National Natural Science Foundation of China (Grant Nos. 61572176, L1624040, 61873090), the National Key Research and Development Program of China (2017YFB02022 01).