
Abstract
The traditional trajectory privacy protection algorithm approaches the task as a single-layer problem. Taking a perspective in harmony with an approach more characteristic of human thinking, in which complex problems are solved hierarchically, we propose a two-level hierarchical granularity model for this problem. The first level of the proposed model is a coarse-grained layer, in which the original dataset is divided into groups. The second level is a fine-grained layer, where problems are solved in each group instead of on the original dataset, which reduces complexity and computation while improving efficiency. On the basis of this hierarchical model, we propose the interpolation trajectory-anonymous privacy protection algorithm with temporal and spatial granularity constraints. In addition, we propose interpolation-based modified Hausdorff distance on adjacent segment (IMHD_AS), which provides a smaller clustering area and better data utility than the traditional Euclidean distance, as the trajectory similarity criterion for clustering within each group. Further, we theoretically prove that the proposed algorithm outperforms the traditional algorithm in terms of data distortion and anonymity cost and verify its efficacy experimentally. Compared with the classic anonymity algorithm, the maximum information loss and the anonymity cost are reduced by up to 21.04% and 28.32%, respectively.
Keywords
Introduction
The proliferation of GPS applications and mobile devices has led to the accumulation of a large quantity of trajectory data that include valuable information for intelligent transportation, route planning, city computing, and related applications [1]. Trajectory data collected by mobile positioning techniques and location-aware devices include substantial amounts of sensitive spatio-temporal and semantic information that supports many applications through data analysis and mining [2]. Users’ activity trajectories, which may reveal their private information, such as home and workplace details, require proper protection [3]. For instance, a user’s trajectory could expose the user’s interest in places and behaviors in time via inference and link attacks [4]. Therefore, the preservation of individual privacy when data are published is attracting increasing attention [5].
The improvement of data utility is the main objective of spatial and temporal trajectory publication. However, guaranteeing data utility and protecting the privacy of users are conflicting objectives that require optimization of trade-offs. Moreover, some optimization algorithms involve a large number of calculations, leading to extremely low efficiency.
In this paper, we propose a two-level model that solves the above problem from the new perspective of a hierarchical approach with multiple levels of granularity. The first layer of the proposed model is divided into groups to reduce complexity and computation while improving efficiency. The second layer solves the problem via temporal and spatial granularity constraints. In this two-layer model, we first employ the Hausdorff distance with the interpolation points to measure the similarity of trajectories and generate
The main contributions of this paper can be summarized as follows.
To address the high computation cost of the data availability optimization algorithm, we propose a two-layer hierarchical granularity model for solving complex problems at different levels from a novel perspective, which can reduce complexity and computation while improving efficiency. This approach is in alignment with the way human beings characteristically think. First, we generate different equivalence classes, i.e., subsets or groups; this corresponds to the coarse granularity layer. Then, we solve the problems on the subsets instead of on the global dataset, corresponding to the fine granularity layer. To the best of our knowledge, this is the first time that the Hausdorff distance is being employed for trajectory privacy protection to improve data utility. The related proof is presented on the basis of theoretical analysis and experimental results. Using temporal granularity constraints, we propose interpolation-based modified Hausdorff distance on adjacent segment (IMHD_AS) – which provides a smaller clustering area than the traditional Euclidean distance – as the trajectory similarity criterion for clustering. The proof is presented on the basis of theoretical analysis. We use the interpolation points instead of the original sampling points to perturb the trajectory. Because of their uncertainty, the sampling points form an uncertainty region of the trajectory, which can be used for cooperative anonymity. After perturbation, each trajectory in the anonymous set is in the uncertainty region and cannot be distinguished; thus, cooperative anonymity is achieved, and user privacy is protected. Moreover, because the perturbation based on the interpolation point only needs to change a small number of location points, most of the original location points remain unchanged. Furthermore, IMHD_AS yields a shorter distance moved than the traditional Euclidean distance. Therefore, the loss of information can be reduced. It is theoretically proven that the proposed algorithm outperforms the traditional algorithm in terms of data distortion and anonymity cost. The superiority of the algorithm over the classic trajectory k-anonymity algorithm is experimentally verified using two experimental datasets.
The remainder of this paper is organized as follows. Section 2 reviews related work. Section 3 provides background knowledge and an analysis of the problem. Section 4 introduces the concept underlying the proposed algorithm and theoretically proves the effectiveness of the algorithm. Section 5 describes the evaluation criteria adopted in the algorithm. Section 6 outlines the experimental verification of the effectiveness of the algorithm on two datasets in terms of information loss, anonymity cost, and time efficiency. Finally, Section 7 summarizes the study and briefly explores future research directions.
In this section, we review related work on trajectory privacy protection and the Hausdorff distance.
Trajectory privacy protection
To address the problem of the direct hiding of an identifier not achieving privacy protection, Sweeney [6] first proposed the k-anonymity privacy protection model. This model is mainly applicable to relational data tables. The basic assumption is that each tuple in the table corresponds to a unique individual, and these attributes are partitioned into quasi-identifiers and sensitive attributes. The main idea is to generalize
The first type is the dummy trajectory. The purpose of such methods is to interfere with the original data by adding virtual trajectories while ensuring that the statistical properties of the disturbed trajectory set are not significantly changed [8]. You et al. [9] proposed a virtual trajectory generation method that generates a virtual trajectory according to the following principles: (1) the mode of motion of the virtual trajectory is similar to that of the true trajectory; (2) there are as many intersections as possible. Virtual trajectories can be generated using either a random mode or a transformation mode. Lei et al. [10] used a rotation scheme to generate user trajectories that are difficult to distinguish from virtual ones. Gao et al. [11] proposed a way of protecting the privacy of users’ location and trajectory information with high-quality services in participatory sensing applications, and they achieved a trade-off between protection of location and trajectory privacy and quality of service by using a dummy trajectory. Hara et al. [12] took physical constraints into account so that the dummy trajectories generated could be applied to the real environment. They also considered the ability to track user locations to avoid accidental leakage of user privacy. Xiao et al. [13] proposed a centralized privacy-preserving location-sharing system that integrates social network servers and location-based servers into a location-storing social network server (LSSNS), and they mapped dummy and real trajectories using a dedicated mapping protocol between LSSNS and cellular towers (CTs) to protect the trajectory privacy of social networks. Sun et al. [14] proposed a new virtual location privacy protection algorithm that considers the computing costs and the various privacy requirements of different users; compared to the previous algorithm, the computational cost and efficiency are improved while the same privacy level is achieved. In general, the shape and semantic properties of the dummy trajectory should not deviate significantly from those of the original trajectory because severe distortion may allow an attacker to easily deduce the real trajectory of the user [15]. Liao et al. [16] chose
The second type is the mixed-zone method, which ignores points that have sensitive properties or are frequently accessed during a trajectory release; such methods only release non-sensitive sampling points [17]. This can be accomplished by suppressing location updates or using pseudonyms to anonymize trajectories when a user enters a mixed area. Arain et al. [18] proposed an effective privacy protection protocol that provides dynamic pseudonyms to users to improve the security of road networks. Gao et al. [19] proposed a trajectory privacy protection framework to improve the time-dependent theoretical mixed-zone model from the perspective of graph theory and reduce information loss. Typical mixed areas are generally set at road intersections [20]. Liu et al. [21] considered the deployment of multiple mixed areas as a cost-constraint optimization problem. The influence of traffic density was considered to improve the protection efficiency of the system. Terrovitis and Mamoulis [22] hypothesized that different opponents have trajectory information of different moving objects, which indicates that an inhibition method can reduce the probability of disclosure of real trajectories. Their method iteratively inhibits some trajectory segments until the privacy leakage probability is less than a given threshold. Although the published trajectory does not include original sensitive information, such an approach can lead to serious distortion of the trajectory data.
The third type is trajectory k-anonymity. Such methods can ensure that the published data are real, and they achieve a certain degree of balance between privacy protection and data utility. The (k,
Most existing trajectory privacy protection algorithms analyze and solve the problem on a single level and do not consider the possibility of a variety of levels. In the real world, however, complex problems are typically solved using a hierarchy of levels. Therefore, we took a novel perspective and propose a two-layer hierarchical granularity model.
Hausdorff distance
Trajectory similarity is currently used in many applications, such as clustering analysis and pattern mining based on trajectory sequences. The main measure used is the Euclidean distance [23, 28]; other measures include edit distance [24, 30], logarithmic distance [25], and angle distance [27]. The computation of trajectory similarity is also needed in trajectory privacy protection. We have not encountered any studies on the use of the Hausdorff distance for trajectory privacy protection. Table 1 compares various measures.
Distance measures and their characteristics
Distance measures and their characteristics
The Hausdorff distance is used to measure the distance between two given sets of points in Euclidean space. It is employed mainly for point set matching in computer image recognition applications to judge the similarity of image data. However, it has been successfully employed in many fields. For example, in the field of mathematics, Ahn and Hoffmann [31] used the Hausdorff distance to obtain an elliptical approximation of a high-precision polynomial curve, thereby producing a more reasonable offset than other methods. In the field of image recognition, medical imaging in particular, Cui et al. [32] proposed a topological graph model and used the Hausdorff distance to solve the problem of identifying the boundary of an object in anatomical imaging under low contrast or overlapping distributions of adjacent tissues. Qian and Yang [33] used the Hausdorff distance to evaluate a new comprehensive framework for the segmentation of atherosclerotic carotid plaques in ultrasound images. Cheimariotis et al. [34] proposed a segmentation method for the automatic detection of the cavity boundary in the entire cavity of optical coherence tomography images, and the validity of the method was verified using the Hausdorff distance. In the field of industrial manufacturing, Li et al. [35] simplified the measurement model of complex free-form surface components with the directed Hausdorff distance, which can be used for quality detection in the precision manufacturing of parts.
Huttenlocher et al. [36] proved that the Hausdorff distance is more tolerant of location perturbations than other related methods. However, because it is highly sensitive to the presence of outliers, Dubuisson and Jain [37] proposed an arithmetic averaging method based on the Hausdorff distance to increase the robustness of the distance against outliers or noise.
The trajectory information of a moving object consists of a finite series of discrete position-updating points. A trajectory dataset is similar to an image in computer graphics and pattern recognition. The computation of trajectory similarity can be regarded as a multidimensional data matching problem. The distance between trajectories can be regarded as the distance between two location subsets. Inspired by this, we therefore propose trajectory privacy protection based on the Hausdorff distance.
In trajectory point matching, Shao et al. [38] suggested that interpolation points should be used instead of trajectory sampling points to improve the robustness of the Hausdorff distance against the location update strategy. However, the points in a graphic image are not characterized as a time sequence, and as the Hausdorff distance does not involve the attributes of a timestamp, it cannot be used directly in trajectory anonymity. In this paper, we use the trajectory timestamp as a constraint and limit the interpolation points to the corresponding adjacent timestamps, and we propose IMHD_AS as the metric for ascertaining trajectory similarity.
Background knowledge
where
Trajectories can also consist of a continuous series of broken segments
where
The Hausdorff distance between A and B is defined as follows.
where
Because the distance between the point sets is calculated from the maximum and minimum values of the original Hausdorff distance, it will be affected by the presence of outliers. To improve the robustness of the Hausdorff distance against outliers and noise, Dubuisson and Jain [37] used an averaged value to reduce the impact of outliers and proposed a modified Hausdorff distance.
On the assumption of equal time sampling intervals, Shao et al. [38] proposed an improved interpolation distance calculation method based on the modified Hausdorff distance, which overcomes the problem of the inconsistency of the sampling interval in the trajectory space and is robust against changes in the position updating strategy.
Shao et al. [38] proposed the use of interpolation points instead of trajectory sampling points for trajectory point matching to improve the robustness of the interpolation Hausdorff distance against the location update strategy. However, points in a graphic image are not characterized by a time sequence, and the Hausdorff distance does not involve the attributes of a timestamp. Therefore, it cannot be used directly in trajectory anonymity. In this paper, we use the trajectory timestamp as the constraint and limit the interpolation points to the corresponding adjacent timestamps. IMHD_AS is proposed as the criterion for ascertaining trajectory similarity.
On the basis of Definition 4, we propose IMHD_AS under a time constraint as follows.
where
where
Proof. The Euclidean distance between trajectories
Comparison of Euclidean distance and IMHD_AS.
As shown in Fig. 1b, at time t1, when the sampling points cannot form vertical bisection lines for the time-stamped adjacent segments in the trajectory, interpolation points cannot be obtained. In this scenario, the IMHD_AS between the trajectory sampling points is consistent with the Euclidean distance. As shown in Fig. 1b, at time t3, an interpolation point can be obtained when the sampling points can only vertically split the ends of the segments in the trajectory. In this scenario, the IMHD_AS is the Euclidean distance from the sampling point to the interpolation point. Because the three points constitute a right triangle, the length of the oblique is greater than that of either of the other two sides. We can see that the IMHD_AS between the sampling points is less than the Euclidean distance. As shown in Fig. 1b, at time t2, when the sampling points can be used for vertical bisection of the two ends of the adjacent segment to the timestamp in the trajectory, two interpolation points can be obtained. In this scenario, the IMHD_AS takes the shortest distance from the sampling point as the Euclidean distance between the two interpolation points. Again, we see that the IMHD_AS between the sampling points is less than the Euclidean distance.
The IMHD_AS takes the mean value of the distance above the locus point, and in each of the three cases, the value is less than or equal to the Euclidean distance. It can be seen that the IMHD_AS from anonymous trajectories to central trajectories is always less than the Euclidean distance. When none of the sampling points is able to make a vertical bisection for the trajectory segments adjacent to the timestamp in the center trajectory, the two calculated values are equal.
The proof is complete.
Because of the imprecise positioning technology in practice, the circular region with the trajectory as the center and having radius
Uncertainty area of the trajectory sampling point 
Abul et al. [23] proposed the (k,
Assume that
Then, every sampling point on
In Fig. 3,
Clustering not satisfying (3, 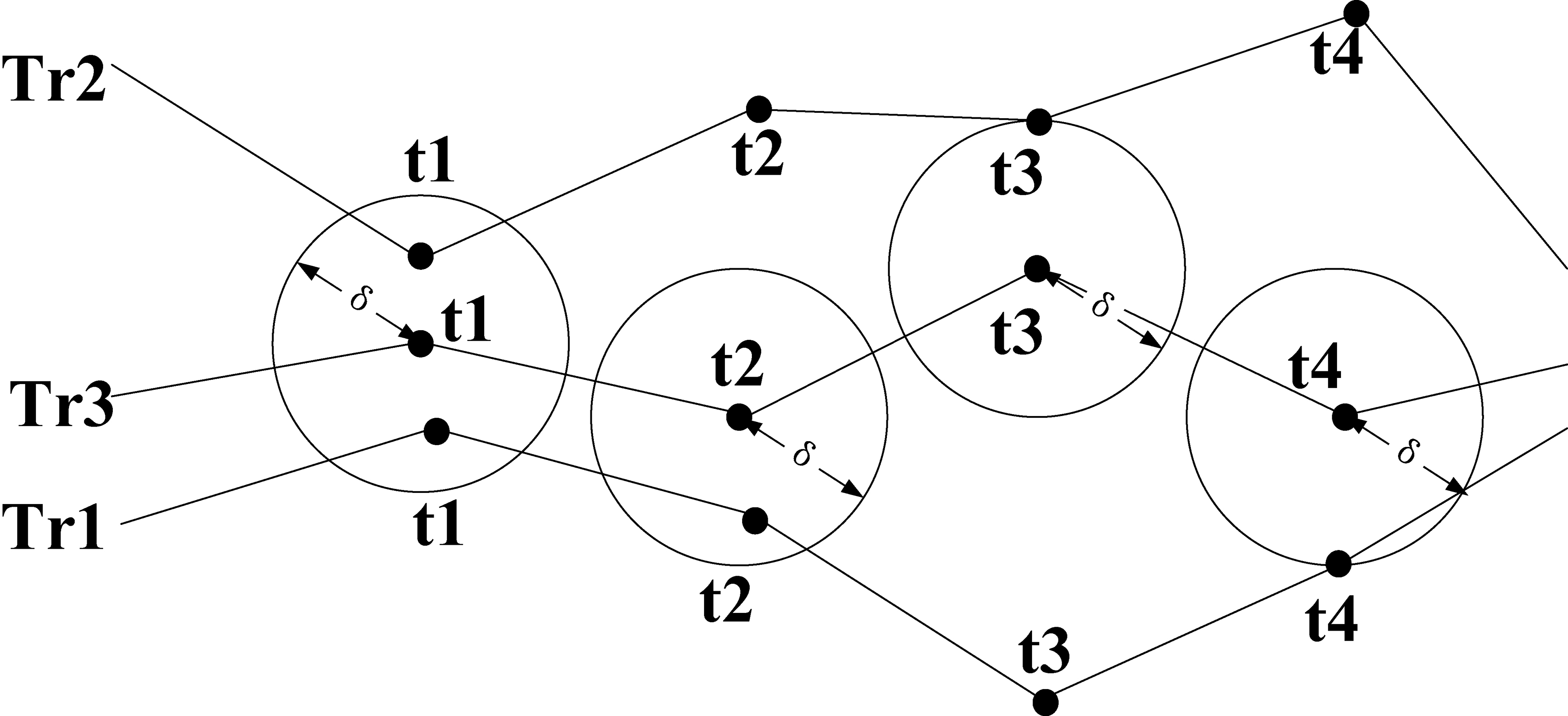
Traditionally, there are two main ways to publish a trajectory-anonymous set. One is to generalize the trajectories in the anonymous group and publish only the feature trajectories, and the other is to generalize the location points for each moment in the anonymous group and publish the anonymous areas after generalization, as shown in Fig. 4a and b, respectively. These two methods have achieved good results, but they need to change all the location points of the original trajectory to achieve privacy protection, which results in significant information loss and adversely affects the availability of data.
Two methods for publishing trajectory-anonymous sets.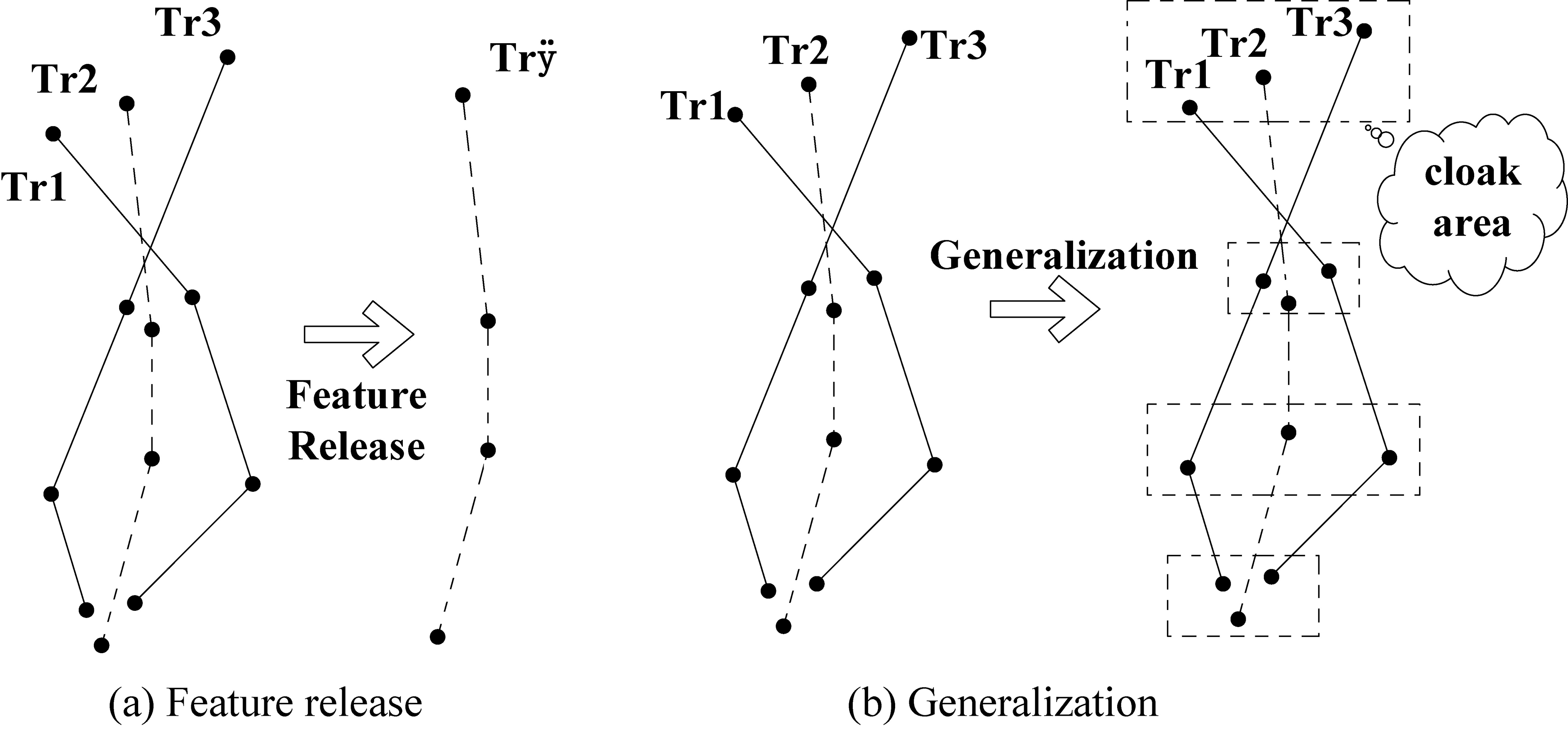
In contrast to the traditional methods of feature release and generalization, the (k,
Process of disturbance from corresponding sampling points.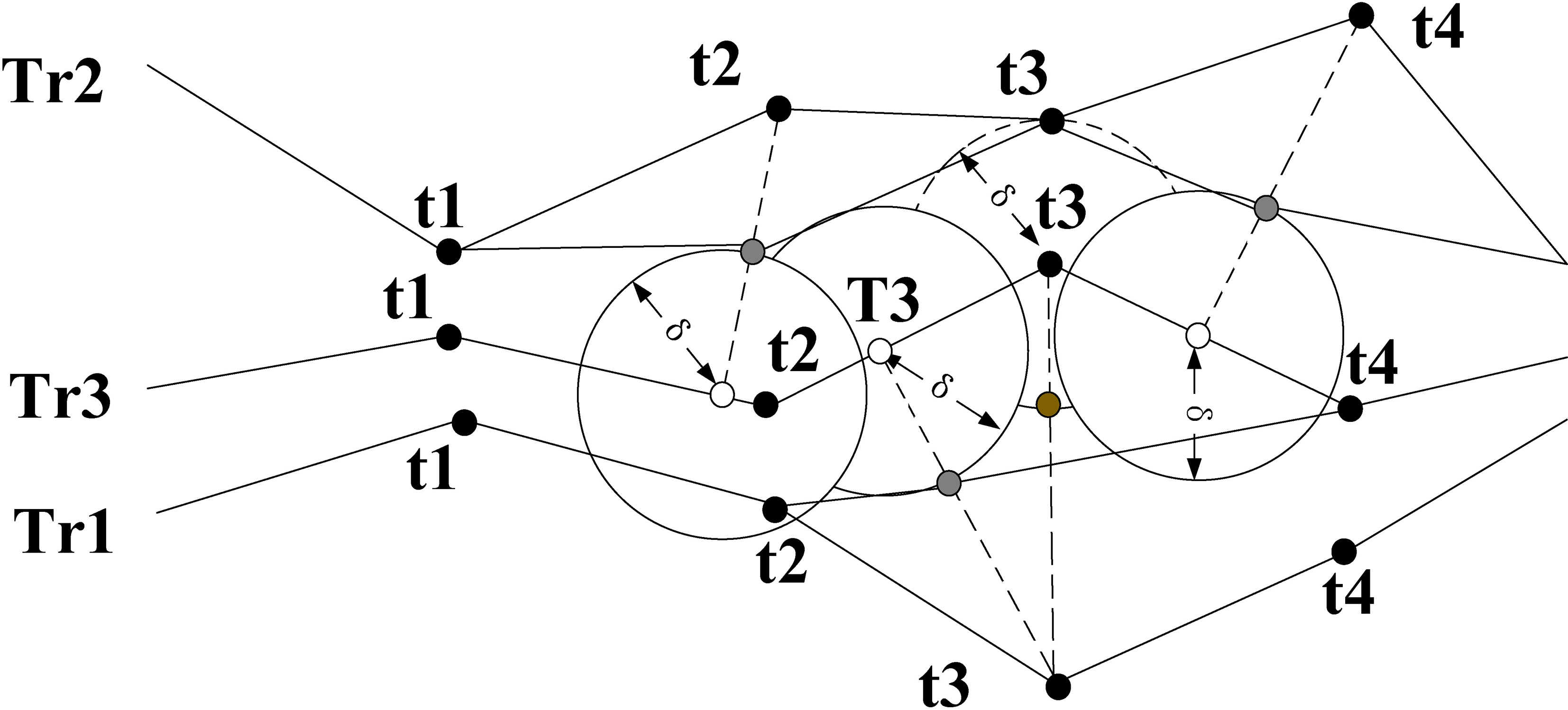
Hausdorff distance calculated using interpolated points in adjacent trajectories.
Hausdorff distance calculated using interpolated points without time constraints.
Process of perturbation by interpolation points.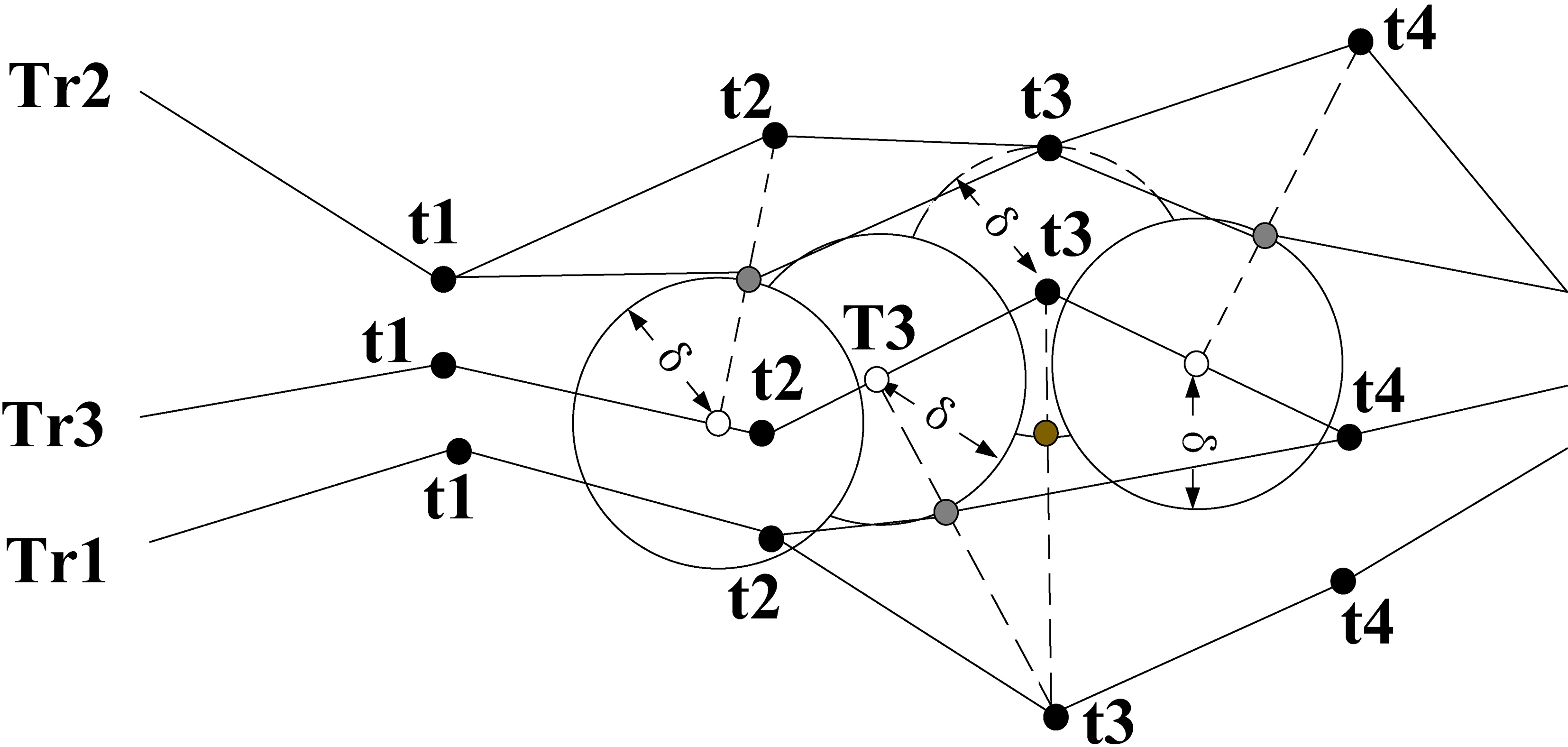
The trajectory distance calculated by the interpolation of points with a time constraint is more consistent with the real trajectory state. Moreover, because time constraints are limited to adjacent trajectory segments, it is not necessary to find interpolation points on all segments of the trajectory, which reduces computation and improves efficiency significantly.
For example, two trajectories
On the basis of the IMHD_AS and (k,
Proof. The anonymity costs of using IMHD_AS and Euclidean distance are as follows:
where
where
According to Inference 1, the IMHD_AS from the anonymous trajectory to the center trajectory is always less than or equal to the Euclidean distance between the same trajectories.
Because the trajectory uncertainty threshold
The proof is complete.
The method proposed in this paper has three main steps. The first step is trajectory preprocessing, by which the trajectory dataset is divided into multiple equivalent classes according to the timestamps. In the second step, each equivalent class is clustered to form a number of anonymous groups. Finally, the trajectories of each anonymous group are perturbed to satisfy the interpolation (k,
Framework of the proposed algorithm
Figure 9 and Algorithm 1 show the framework of the proposed algorithm. The input is the original trajectory dataset
Framework of the proposed algorithm.
In this paper, a preprocessing method for grouping is proposed. Like the NWA method [23], our method carries out modular operations at a given granularity by timestamps, which can regularize inconsistent trajectory sampling times and divide the original dataset into different groups. Compared with the equivalent class of the whole trajectory, a large number of trajectories are retained, which improves the anonymity of the trajectories significantly.
Unlike NWA, however, our method uses multiple granularities to carry out modular operations. The appropriate granularity size is selected according to trajectory and anonymity data quality; we try to maintain the trajectory quality and reduce the quantity of data to be suppressed.
Algorithm 2 shows the preprocessing algorithm. For each equivalent class, we record the start and end stamps. First, the beginning and ending timestamps of the trajectory are recorded as
Clustering algorithm
Algorithm 3 shows the clustering process. Its input is preprocessed trajectory set groups and privacy protection degree
The clustering process needs to divide the trajectories according to their similarity into corresponding clustered sets, and the number in each set must be no less than
IMHD_AS calculation
Algorithm 4 shows the IMHD_AS calculation. Its inputs are trajectories
Shortest-distance calculation
Algorithm 5 shows the calculation of the shortest distance from the sampling point to its adjacent trajectory segment. Its input is the sampling point
Data perturbation algorithm
Algorithm 6 shows the cooperative anonymity algorithm. The input of the algorithm is the clustered trajectory set obtained by the above clustering algorithm and the uncertainty threshold
Evaluation metrics
Information loss
Information loss is defined as follows.
where
where
TranslationNode is the distance the trajectory sampling point moves. Translation is the total distance moved by all the points. The higher the value of translation, the more points to move and the higher the anonymity cost.
Experimental environment
The experimental data were generated by Thomas Brinkhoff [40]. The generator simulates trajectory information for mobile objects on the basis of road network data. The OLDEN dataset is based on the road network in Auden, Germany, and SANFR is based on the road network in San Francisco, USA. Table 2 shows the statistical information for the datasets.
Statistical information of the datasets
Statistical information of the datasets
The algorithm was implemented in Java and executed in the Eclipse integrated development environment on a system with an Intel
The first process of the experiment was the data preprocessing, which was designed to divide the original trajectory dataset into a set of trajectory equivalence classes with consistent timestamps. Through preprocessing, we can select the proper granularity value of
In Tables 3 and 4,
Preprocessing results as influenced by
(OLDEN dataset)
Preprocessing results as influenced by
Preprocessing results as influenced by
If
Therefore, according to the experimental results of the preprocessing, we consider the number of discarded and equivalence classes synthetically and select the most suitable value of
We analyze and verify the performance of the algorithm based on data distortion, anonymity cost, and execution time below.
Comparison of information loss (InfoLoss) for the two algorithms as influenced by privacy protection parameter
Comparison of information loss (InfoLoss) for the two algorithms as influenced by privacy protection parameter
Influence of 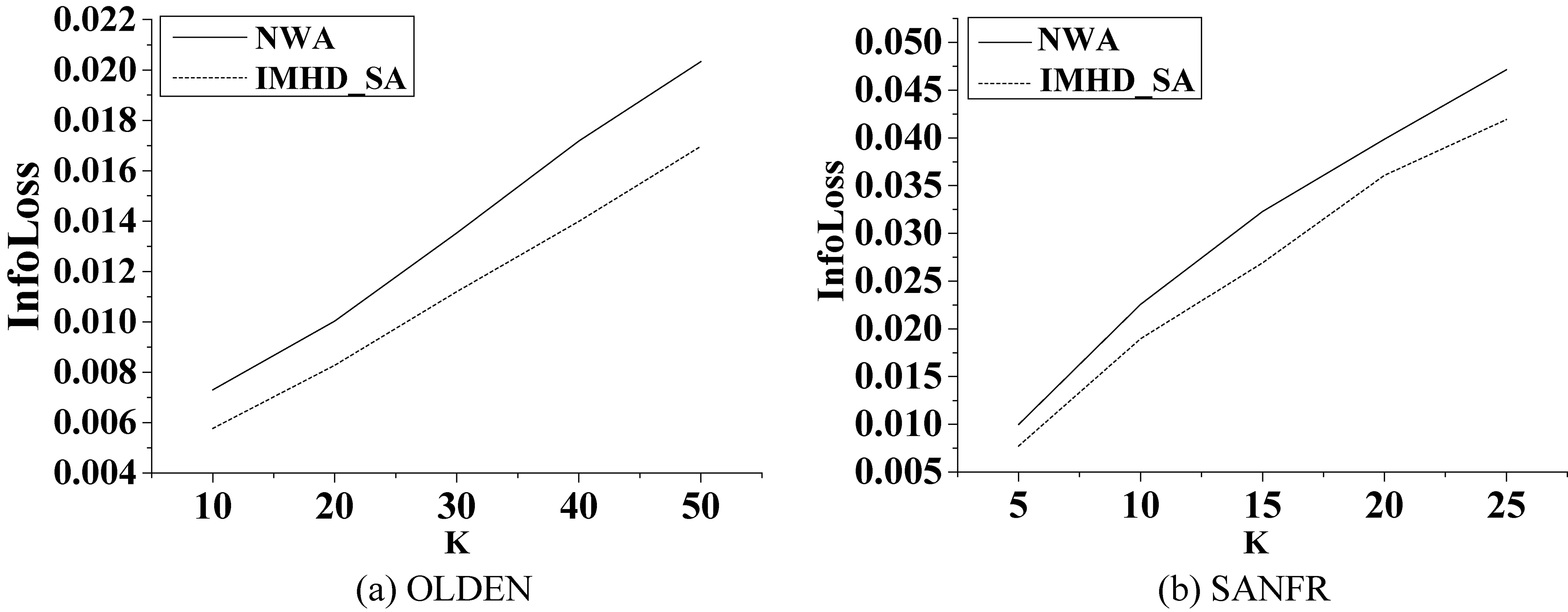
Figure 10 shows that as
As shown in Figs 11 and 12, a change in
Influence of 
Influence of 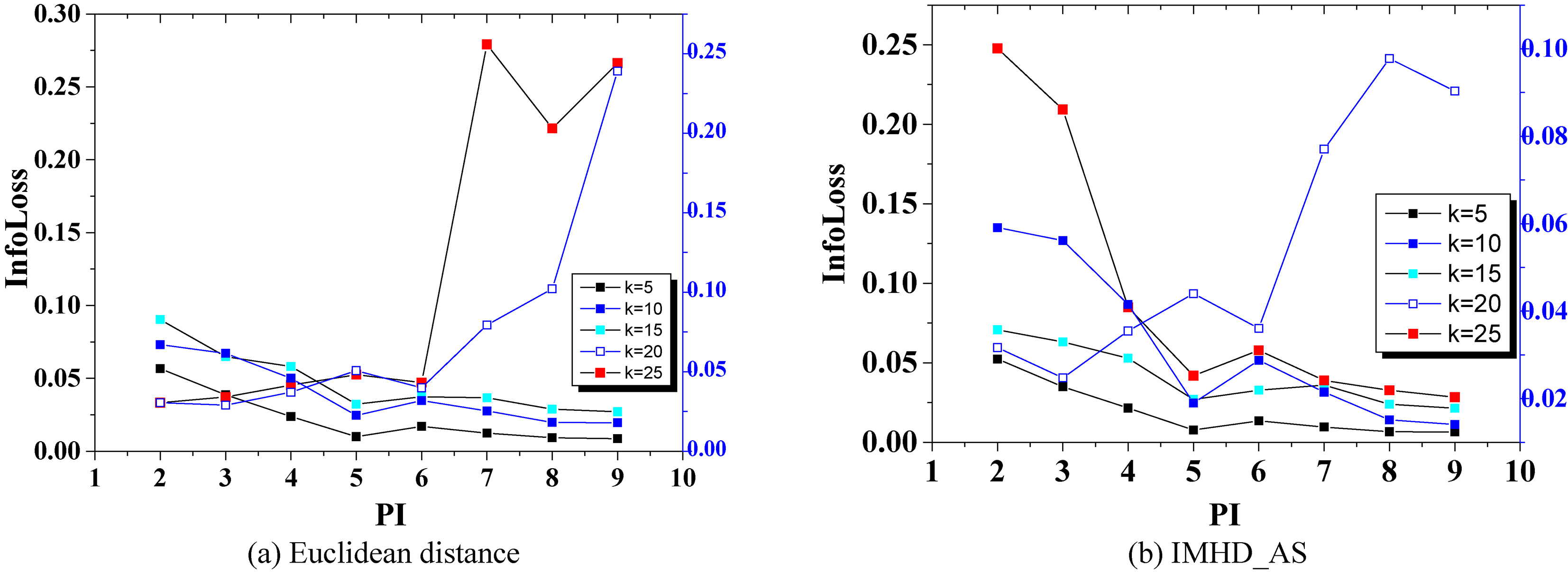
From Figs 13 and 14, we can see that on both the SANFR dataset and the OLDEN dataset, translation decreases as
Influence of trajectory uncertainty threshold 
Influence of trajectory uncertainty threshold 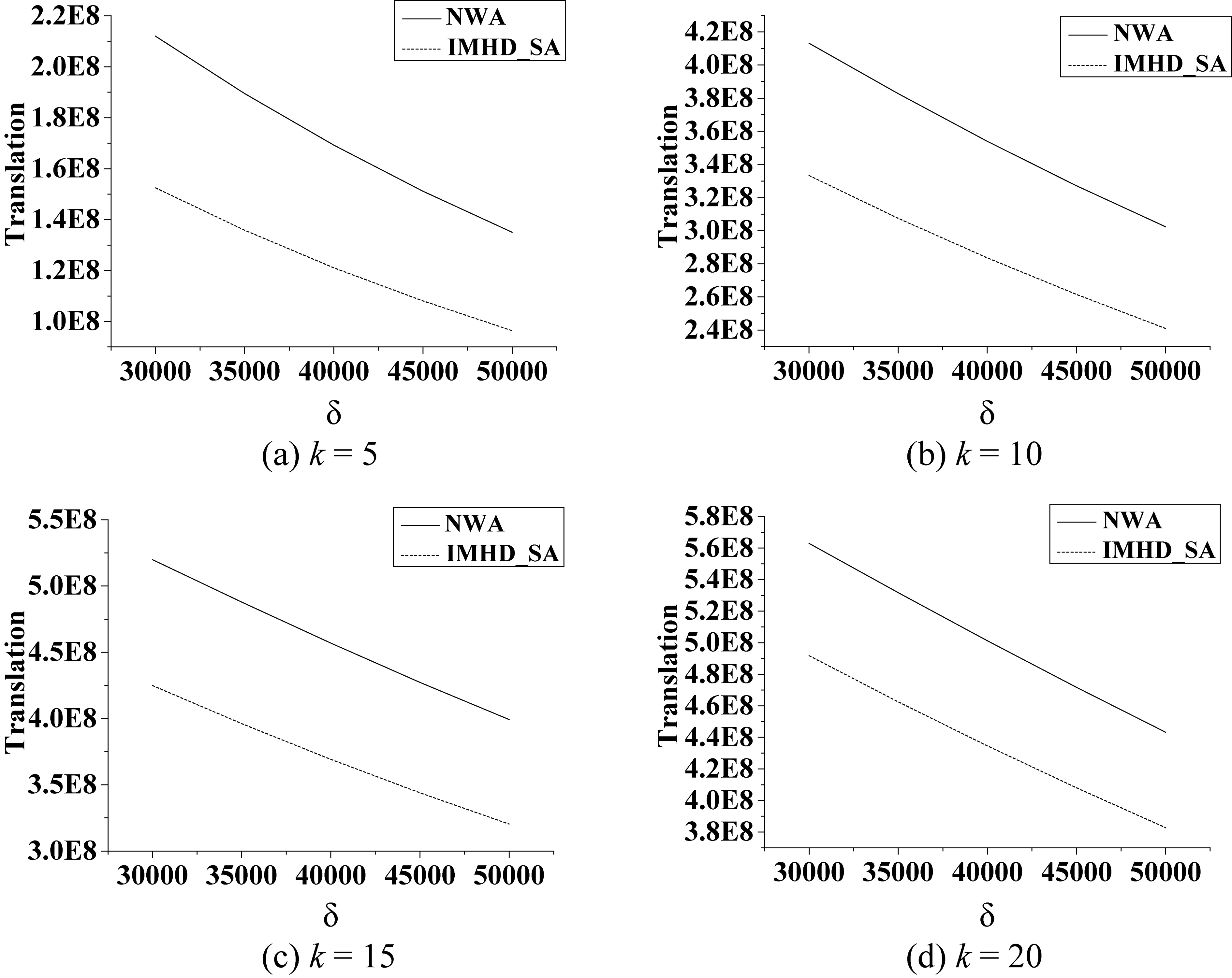
As shown in Fig. 15, translation increases with
Comparison of translation for the two algorithms as influenced by trajectory uncertainty threshold
Comparison of translation for the two algorithms as influenced by trajectory uncertainty threshold
Influence of 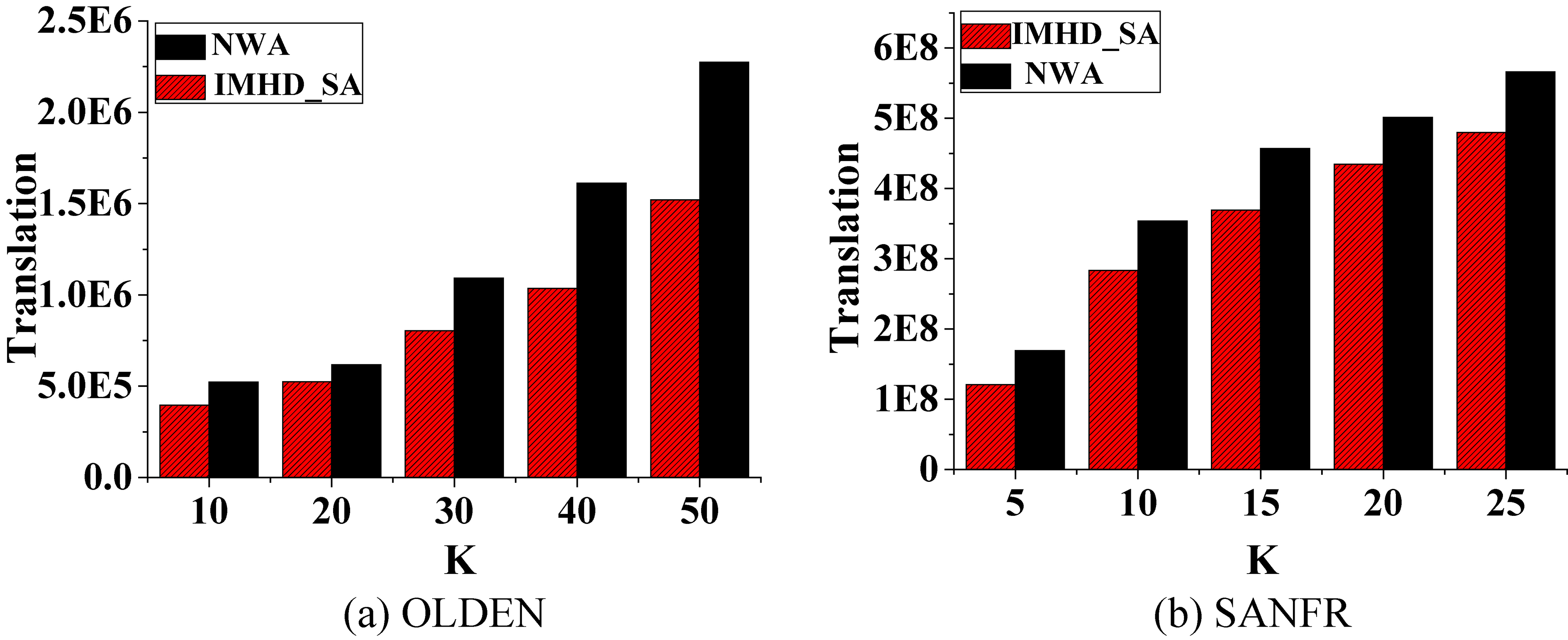
Influence of 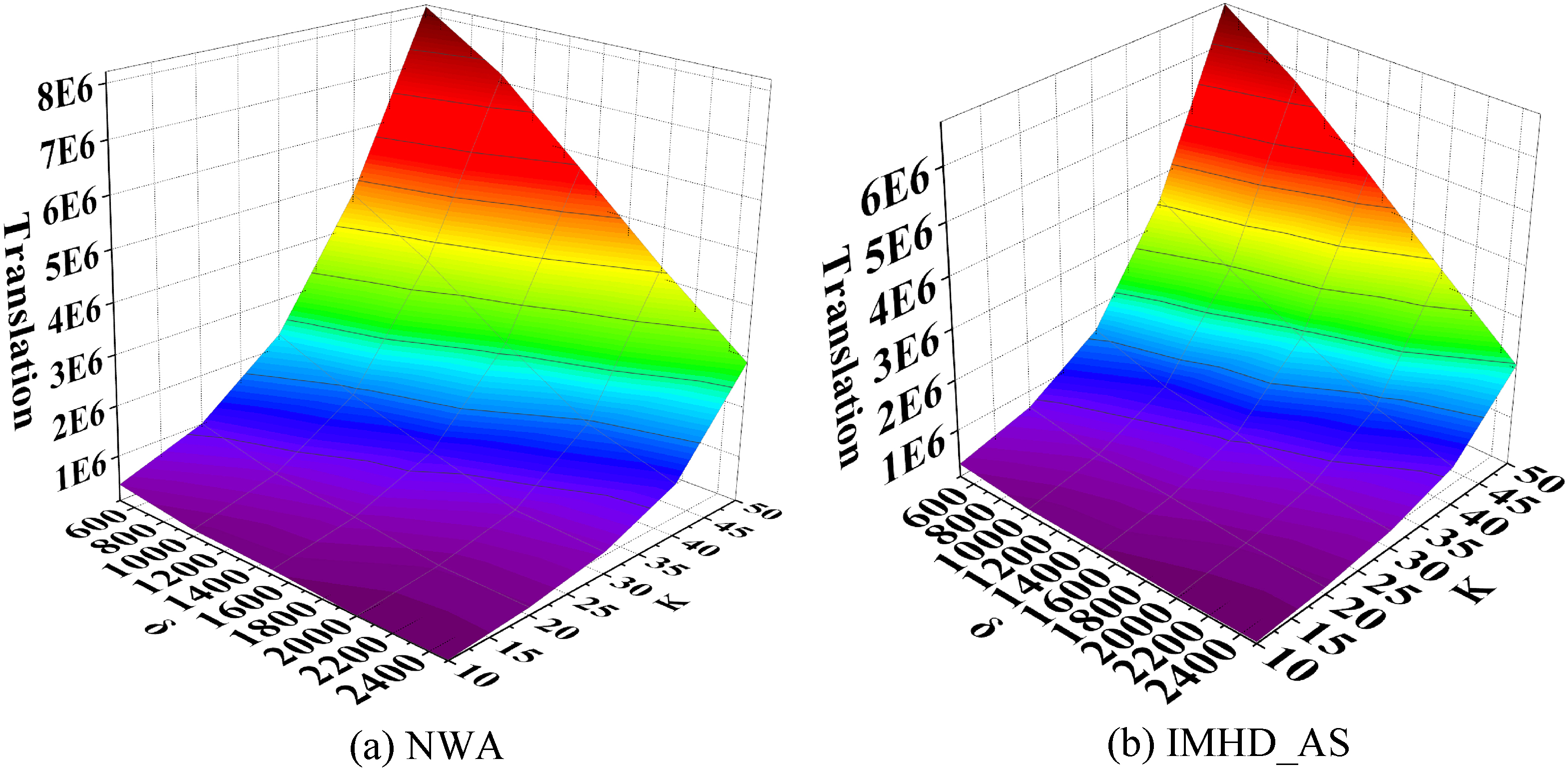
Influence of 
Influence of 
As shown in Figs 16 and 17, translation decreases with
As shown in Fig. 18, the execution time for IMHD_AS is longer than that for NWA on both the OLDEN and SANFR datasets. This is because the calculation of IMHD_AS needs to determine the interpolation points, whereas the Euclidean distance is calculated directly. This results in a large amount of computation and requires a longer time. However, in the preprocessing, we generate equivalence classes and multiple groups by partitioning. Solving problems within each group can simplify problems, reduce computation, and improve efficiency significantly. When data availability is optimized, time efficiency will not be significantly reduced. Therefore, it is feasible, at the expense of some execution time, to improve the data utility of the proposed algorithm. In general, both algorithms have good time efficiency.
Conclusions and future work
In this paper, we proposed a novel algorithm for trajectory privacy protection that considers the problem from the perspective of hierarchical granularity and interpolation points. By using interpolation points, we improve the data utility while maintaining privacy protection. Use of the hierarchical granularity model can reduce the high computation cost of data utility optimization and thus improve efficiency. We also proposed the temporal granularity constraint of IMHD_AS to guarantee high data quality and the spatial granularity constraint of the uncertainty threshold
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers for their invaluable comments and suggestions. This work was supported by the National Natural Science Foundation of China (Grant Nos. 61672039, 61972439, 61602009 and 61702010), the Natural Science Foundation of Colleges and Universities in Anhui Province (Grant No. KJ2019A0481), and the Natural Science Foundation of Anhui Province (Grant Nos. 1808085MF172 and 1708085MF156).