
Abstract
Although recent advances of significant subgraph mining enable us to find subgraphs that are statistically significantly associated with the class variable from graph databases, it is challenging to interpret the resulting subgraphs due to their massive number and their propositional representation. Here we represent graphs by probabilistic logic programming and solve the problem of summarizing significant subgraphs by structure learning of probabilistic logic programs. Learning probabilistic logical models leads to a much more interpretable, expressive and succinct representation of significant subgraphs. We empirically demonstrate that our approach can effectively summarize significant subgraphs with keeping high accuracy.
Keywords
Introduction
Pattern mining [1] is the process of finding multiplicative combinations of features (variables), or patterns, from a dataset, which has been actively studied as one of the central topics of data mining [42]. Various types of patterns have been used in applications. Examples include itemsets [13], which are combinations of binary features originally used in market basket analysis to find frequently co-purchased items, and sequences [24], used in DNA sequence analysis and customer behavior analysis. In this paper we focus on subgraph mining [14, 40], whose task is to find frequently occurring subgraphs from a collection of graphs, which is often called a graph database. Since a graph is a fundamental data structure and a wide range of graph-structured data is available, such as chemical compounds in PubChem [7] and protein structures in PDB [6], subgraph mining has been studied as an important branch of pattern mining to analyze graph-base data.
As an extension of the original subgraph mining problem, significant (discriminative) subgraph mining [19, 33] is recently attracting a considerable attention, which tries to find subgraphs enriched in one class relative to another class. For example, in drug discovery, each chemical compound is modeled as a graph and a collection of graphs is divided into two classes, case and control, and one can find subgraphs that are enriched in the case group while not in the control group. Significant subgraph mining offers to find all subgraphs that are statistically significantly associated with the class variable while correcting for multiple testing to ensure rigorous control of the FWER (family-wise error rate). This means that significant subgraph mining can rigorously control the probability to detect one or more false positive subgraphs, which is indispensable in drug discovery and other scientific fields such as biology and medicine.
However, the challenge of significant pattern mining is that it often produces millions of significant subgraphs in a propositional representation, resulting in hard interpretability of the obtained subgraphs. How to summarize such massive amount of significant subgraphs in a principled way is still an open problem. Although pattern compression has been studied [1, Chapter 8], with the application of the MDL (Minimum Description Length) principle [38] to find representative patterns, or ILP based approaches have been used [11], none of the existing methods has been successfully applied to significant subgraph mining.
Our goal in this paper is to summarize significant subgraphs using Probabilistic Logic Programming to achieve better interpretability of massive subgraphs.
Probabilistic Logic Programming (PLP) is gaining popularity due to its ability to represent relational domains with many entities connected by complex and uncertain relationships. First-order logic is a powerful language to represent complex relational information, thanks to its intrinsic expressivity, while probability is the standard way to represent uncertainty in knowledge. One of the most fertile approaches to PLP is the distribution semantics [30], that is at the basis of several languages such as the Independent Choice Logic [25], PRISM [31], Logic Programs with Annotated Disjunctions (LPADs) [37] and ProbLog [10]. Various algorithms for learning parameters and structure of probabilistic logic programs written in these languages have been proposed, such as PRISM [32], LFI-ProbLog [12] and EMBLEM [4] (for parameter learning), Sem-CP-Logic[20], CLP(BN)[8] and SLIPCOVER [5] (for structure learning).
In this paper, the key to mine a compact general representation of a collection of significant subgraphs is to use the state-of-the-art structure learning algorithm SLIPCOVER for probabilistic logic programs, which enables us to encode a set of significant subgraphs as a probabilistic logical model written in the language of LPADs. The advantages of building such a symbolic model are:
storing a logic program encoding significant subgraphs is significantly cheaper than storing all subgraphs, which are often too large in size and several in number; a single logical rule can describe many significant subgraphs at once; a first-order logic-based representation of a collection of subgraphs is declarative and comprehensible by humans, and much more expressive than a propositional representation; probability allows the management of uncertainty in complex application domains (such as the biological ones).
This paper provides the first application of Probabilistic Logic Programming to the problem of significant subgraph mining from standard biochemical datasets. The effectiveness of the approach, that we call LIPS for “Learning sIgnificant Plp Subgraphs”, is empirically verified by showing that the precision and recall of the LPADs learnt by SLIPCOVER are better than those of a baseline of probabilistic logic programs with fixed probabilities. Since our objective is not classifying graphs for predictive analysis but finding interpretable summarized representations of significant subgraphs for descriptive analysis, existing graph classification approaches (e.g. [15]) cannot be applied to our task.
The paper is organized as follows. Section 2 provides the necessary background about probabilistic logic programming and subgraph mining. Section 3 introduces the proposed approach based on PLP. Section 4 experimentally evaluates the method. Section 5 presents related work and Section 6 concludes the paper.
Probabilistic Logic Programming
We assume that the reader is familiar with basic notions of First-Order Logic (FOL).
In this paper we rely on Probabilistic Logic Programming under the distribution semantics [30] for representing uncertain relational information. We consider Logic Programs with Annotated Disjunctions (LPADs) for their general syntax and we do not allow function symbols; for the treatment of function symbols see [29]. LPADs [37] allow to encode “alternatives” in the head of clauses in the form of a disjunction, in which each atom is annotated with a probability.
These programs consist of a finite set of annotated disjunctive clauses
Here,
An atomic choice is a triple
We consider only sound LPADs, where each possible world has a total well-founded model, so
.
The following LPAD
This LPAD models the fact that if somebody has the flu and the climate is cold the possibility that an epidemic arises has probability 0.6 to be true, that a pandemic arises has probability 0.3 or that no event happens (the implicit atom
Clause
The problem setting of significant subgraph mining.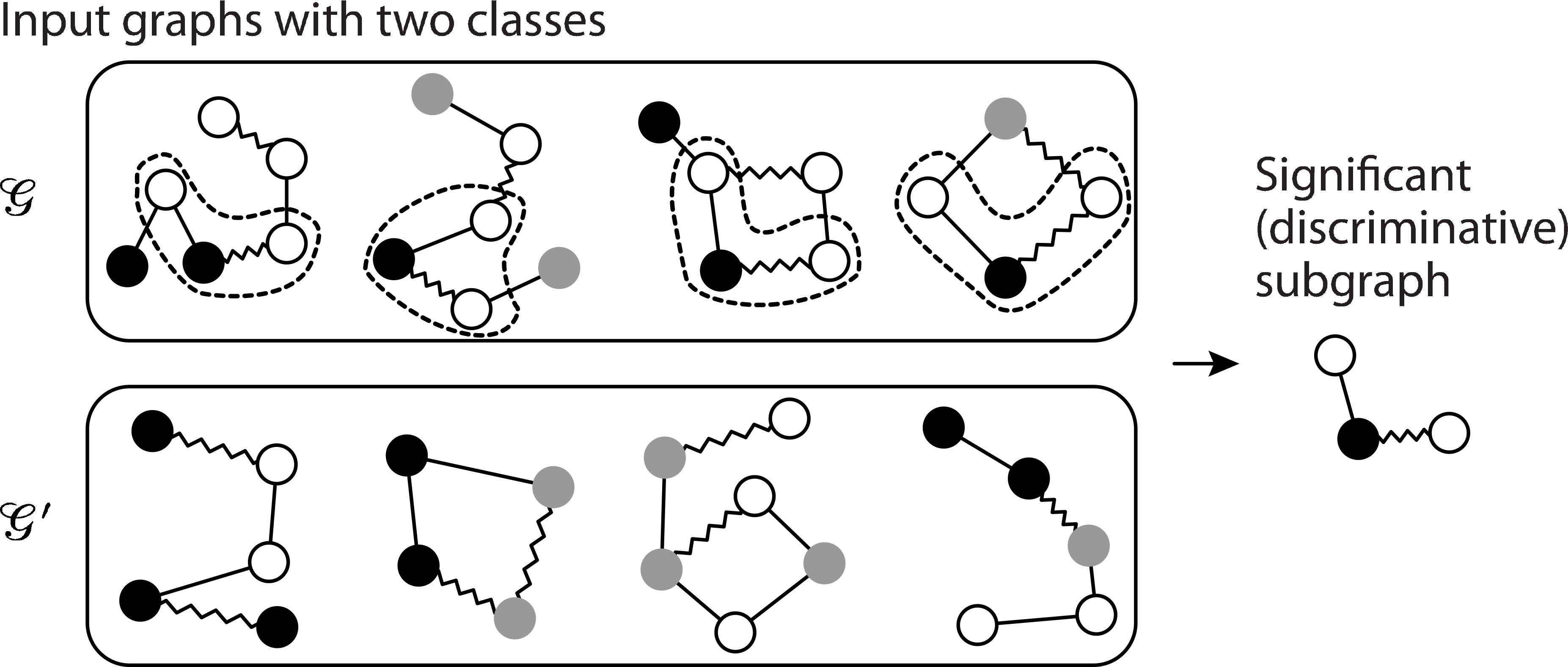
The semantics associates one random variable with every grounding of a clause. In some domains, this may result in too many random variables, so we may introduce an approximation at the level of the instantiations, at the expenses of the accuracy in modeling the domain. A typical compromise is to consider the grounding of variables in the head only: in this way, a ground atom entailed by two separate ground instances of a clause is assigned the same probability, all other things being equal, of a ground atom entailed by a single ground clause, while in the standard semantics the first would have a larger probability as more evidence is available for its entailment. In the approximate semantics clause
An efficient technique for computing the probability of a query consists of building a Binary Decision Diagram (BDD), representing the disjunction of its explanations, and performing inference over it. Inference can be performed with a dynamic programming algorithm that is linear in the size of the BDD [10]. Algorithms that adopt such an approach for inference include [26, 27, 28]. BDDs can be built in practice by highly efficient software packages such as CUDD.1
Available at
In significant subgraph mining, each graph is defined as a triple
For each subgraph
Let
Then the occurrence of
For example, for the subgraph shown in Fig. 1,
The technique of significant subgraph mining proposed in [19, 33] finds all subgraphs that are statistically significantly associated with the class variable, that is, the above null hypothesis is rejected, while correcting for multiple testing to ensure rigorous control of the FWER (family-wise error rate). The FWER is the probability that at least one subgraph is a false positive in the set of all subgraphs (hypotheses). Since the FWER approaches one even if the false positive rate is controlled under the significance level
The proposed method: LIPS
We provide here a detailed description of our proposed method, called LIPS (Learning sIgnificant Plp Subgraphs), in three subsequent steps, which summarize a given set of significant subgraphs as a probabilistic logic program.
First-order logic representation of subgraphs
Here we introduce the first step, which provides a FOL representation of a given set of subgraphs.
Interestingly, the significant subgraph mining technique [33] always produces the set of testable subgraphs as an intermediate result for the FWER control. Mathematically, a testable subgraph is defined in the following. The tight lower bound
This was firstly considered in [35] and used in [33]. Assume that the set of subgraphs is sorted in increasing order according to the lower bound
Let
The subgraphs
Given two sets of graphs
Our method takes as input a set of testable subgraphs, which includes positive and negative instances, and transforms them into a set of corresponding logical interpretations (sets of ground facts). Let
In the above representation,
For example, if
Finally, an additional predicate
Learning a representation of significant subgraphs by probabilistic logic programming
Given the set of significant subgraphs
Overview of the proposed method LIPS.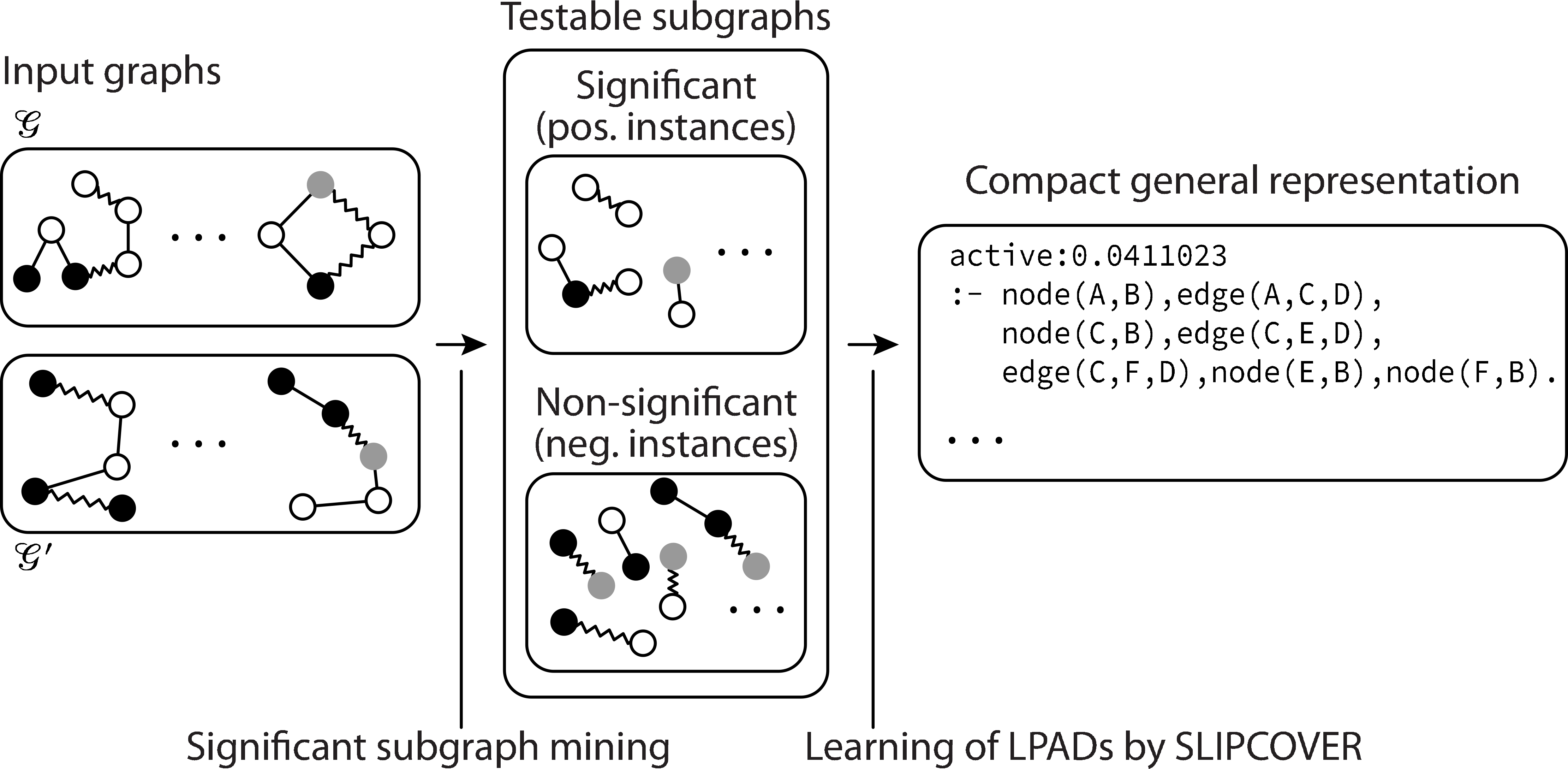
Input consists of a set of logical interpretations
SLIPCOVER is built upon a two-phase search strategy: (1) a beam search in the space of clauses in order to find a set of promising clauses and (2) a greedy search in the space of theories. In the first phase the beam for each target predicate is initialized with a number of bottom clauses built as in Progol [21], which are repeatedly refined according to a “language bias”. The second phase starts from an empty theory which is iteratively extended with one target clause at a time from those generated in the previous phase. If the log-likelihood (LL) of the new theory does not increase, SLIPCOVER discards the clause, otherwise it adds it to the current theory.
BDDs are employed to efficiently perform the parameter learning phase of the LPAD, i.e. to compute the optimum probabilities for the clauses’ heads. This is done by the algorithm EMBLEM [4], based on an Expectation Maximization (EM) cycle. Both parameter and structure learning use the log-likelihood of the data as the guiding heuristic to find the best parameters and the best theory. This guarantees that the final LPAD returned by SLIPCOVER locally maximizes the (log-)likelihood with respect to the set of positive and negative examples (subgraphs) for the target predicate(s). LIPS is shown in Algorithm 2, while a simplified version of SLIPCOVER (relevant for the understanding of the method) in Algorithm 2.
[1]#1: [ht]
Function LIPS[1] LIPS
return
[1]#1:
[ht]
Function SLIPCOVER
[1] SLIPCOVER
The analyzed domains are graphs of chemical compounds, with nodes labeled according to the atom type (predicate
output indicates the target predicate, while input the other predicates of the domain, together with their arity. The modeh predicate indicates that at most 1 occurrence of
The output of SLIPCOVER consists of LPAD theories whose clauses predict the target predicate with a given probability
The clause states that a subgraph where some nodes A, C, E, F are of type B, and there is a direct edge between nodes A and C, C and E, C and F of type D is testable significant (active), which is illustrated in Fig. 3. The figure shows how several subgraphs can be compactly represented by a single clause. The value
Experimental validation
In this section we empirically evaluate the performance of LIPS on standard graph datasets. These datasets include: MUTAG, NCI1 and NCI109.2
These datasets are available at
Implementation is available at
Characteristics of graph datasets. #Pos ex denotes the number of positive examples (significant subgraphs), while #Neg ex denotes the number of negative examples (testable but non-significant subgraphs). The number of ground facts (column 5) does not include facts for the target predicate. #Graphs is the total number of subgraphs in each dataset
The left graph corresponds to 
For training and test we employed a
In order to verify the effectiveness of the approach, we tested the same LPADs learnt by SLIPCOVER where parameters were replaced with fixed and randomly chosen values, i.e. we tested the same clauses with non-optimized parameters on the datasets. All experiments were performed on GNU/Linux machines with an Intel Xeon Haswell E5-2630 v3 (2.40 GHz) CPU with 128 GB RAM.
In order to reach a compromise between accuracy (performance) and learning time, we tuned the following SLIPCOVER settings: the type of semantics (standard or simplified), the limit on the number of different solutions retrieved when computing the probability of a query, the maximum number of theory search iterations, the maximum number of clause search iterations, the size of the beam, the maximum number of variables in a rule.
For MUTAG_10 and NCI1_10, we employed a 10-fold cross-validation due to the large number of positive and negative examples. For NCI1_3 and NCI109_3 we employed a 5-fold cross-validation. For MUTAG_5 we employed a 4-fold cross-validation due to the presence of only 8 positive examples. This information is reported in Table 2.
As an example, we report in the following the output of the learning algorithm on one fold of the MUTAG_10 dataset, a LPAD composed of 3 probabilistic logical clauses:
Test
We computed the Area Under the Precision-Recall Curve (AUC-PR) for the probabilistic logic programs learned by SLIPCOVER and for the programs with the same structure but fixed parameters (“baseline”).
The Precision-Recall Curves have been obtained by collecting the testing examples, together with the probabilities assigned to them in testing by the LPADs, in a single set and then building the curves with the method reported in [9].
Table 2 shows the comparison between LIPS (in terms of area under the PR curve, SLIPCOVER learning time, number of LPAD clauses and number of body literals per clause, all averaged over the folds) and the baseline (in terms of area under the PR curve averaged over the folds). The comparison with a baseline of LPADs with fixed parameters demonstrates that LIPS successfully learned a more accurate summarization for significant subgraphs in a short time in all cases except for the NCI1_10 dataset. Even in the case of NCI1_10, composed of thousands of examples, the obtained AUCPR is larger than the baseline.
As for the number of clauses and body literals of the learned LPADs, Table 2 shows that we can get a very concise description of significant subgraphs, with less than 8 clauses in the analyzed domains, and with short clauses in most cases.
The possibility of tackling the problem of summarizing significant subgraphs by means of the SLIPCOVER system comes from the relational nature of the tested domains and from the discriminative learning setting of the algorithm; this property has been exploited to distinguish significant from non-significant subgraphs by means of a target predicate (active) in the first-order logic representation.
Results of the experiments comparing LIPS with a baseline of LPADs with fixed parameters for each dataset, in terms of average Area Under the PR Curve (AUC-PR), SLIPCOVER average execution time (in seconds), average number of LPAD clauses and average number of body literals per clause. Column “Folds” specifies the number of folds used for cross-validation
Results of the experiments comparing LIPS with a baseline of LPADs with fixed parameters for each dataset, in terms of average Area Under the PR Curve (AUC-PR), SLIPCOVER average execution time (in seconds), average number of LPAD clauses and average number of body literals per clause. Column “Folds” specifies the number of folds used for cross-validation
Significant pattern mining have been firstly achieved in [35] in the context of itemset mining [2, 3] using the Tarone’s testability trick [34] and further developed in [19, 36] by considering Westfall-Young permutation test [39]. Such methods can find all statistically significant patterns from databases while rigorously controlling the FWER. Recently, significant pattern mining has been applied to various data including interval data [17] and datasets with categorical covariates [23]. The software library of significant pattern mining is available [18] and an efficient parallelized implementation is also available [41].
Sugiyama et al. [33] applied significant pattern mining to graph structured data using subgraph mining algorithms [22, 40] and established significant subgraph mining. The technique can find all statistically significant subgraphs while controlling the FWER. However, since significant subgraph mining tends to generate a huge number of significant subgraphs, how to summarize such subgraphs is a challenging task for further analysis in applications. This paper has addressed the problem using probabilistic logic programming for the first time. The ProbLog language was employed in the context of local query mining from probabilistic biological databases [16], but with a different goal than significant subgraph mining.
Conclusions
We proposed the first method to find a compact general representation of a collection of significant subgraphs in the form of (probabilistic) logic programs. This was achieved through the application of a structure learning algorithm for probabilistic logic programs, SLIPCOVER, to standard graph-based datasets. The key idea is to formulate the problem of summarization of significant subgraphs as classification of testable and significant subgraphs to allow the application of learning algorithms of probabilistic logic programs. Experiments show that we can massively compress the set of significant subgraphs with reasonably high precision and recall. Since significant pattern summarization is the problem of not only subgraph mining but the general setting of pattern mining including itemset mining and sequence mining, our approach combining significant pattern mining and probabilistic logic programming has an impact to a wider range of applications of significant pattern mining. For instance, the approach might be applied to many interesting applications in chemoinformatics, structural biology, and precision medicine. In the future, we plan to apply other structure learning algorithms of logic programs targeted to big knowledge bases in order to reduce the computational time.
Footnotes
Acknowledgments
This work has been done in the context of a research agreement between the University of Ferrara (Italy) and the National Institute of Informatics (Tokyo, Japan). Mahito Sugiyama has been supported by JSPS KAKENHI Grant Numbers JP16K16115, JP16H02870, and JST, PRESTO Grant Number JPMJPR1855, Japan. Elena Bellodi has been partially supported by the Italian National Group of Computing Science (GNCS-INDAM).