
Abstract
In order to avoid missing representative features, we should select a lot of features as far as possible when using machine learning algorithms in stock trading. Meanwhile, these high dimensional features can lead to redundancy of information and reduce the efficiency, and accuracy of learning algorithms. It is worth noting that dimensionality reduction operation (DRO) is one of the main means to deal with stock high-dimensional data. However, there are few studies on whether DRO can significantly improve the trading performance of deep neural network (DNN) algorithms. Therefore, this paper selects large-scale stock datasets in the American market and in the Chinese market as the research objects. For each stock, we firstly apply four most widely used DRO, namely principal component analysis (PCA), least absolute shrinkage and selection operator (LASSO), classification and regression trees (CART), and autoencoder (AE) to deal with original features respectively, and then use the new features as inputs of the most six popular DNN algorithms such as Multilayer Perceptron (MLP), Deep Belief Network (DBN), Stacked Auto-Encoders (SAE), Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU) to generate trading signals. Finally, we apply the trading signals to conduct a lot of daily trading back-testing and non-parameter statistical testing. The experiments show that LASSO can significantly improve the performance of RNN, LSTM, and GRU. In addition, any DRO mentioned in this paper do not significantly improve trading performance and the speed of generating trading signals of the other DNN algorithms.
Introduction
Stock investment is one of the most important economic activities. Generally, investors make stock trading decisions based on the prediction of future stock price trends. However, forecasting stock price trends is a great challenge for investors and researchers. In the past many years, researchers have mainly constructed a statistical model to describe the time series of stock price to forecast the trends of future stock prices [1, 2, 3, 4, 5, 6, 7, 8, 9]. It is worth noting that traditional machine learning (ML) methods [10, 11, 12, 13, 14, 15, 16, 17, 18, 19] such as support vector machine [11, 12, 13] and random forest [14, 15], have shown strong ability in the trend prediction of stock prices. These algorithms can effectively capture the dynamic changes in the financial market, discover trading signals of some stocks, and make automatic investment decisions. When using machine learning algorithms to predict the trends of stock price, which features to be used as the inputs of the learning algorithm is one of the most important problems that researchers need to consider. The processes are called feature engineering. Generally, researchers choose as many features as possible to describe the research topics according to their own understanding of the problem and their knowledge backgrounds. In fact, they do not know which features can improve the ability of machine learning algorithms, but to blindly increase the number of features. However, it is generally believed that too many features will lead to redundancy of input information and make the machine learning models too complex, thus reducing the generalization ability of the learning model and the robustness of out-of-sample prediction. Therefore, DRO is a very important part of feature engineering and largely affect the performance of ML algorithms.
In recent years, artificial intelligence computing methods represented by DNN models have made a series of major breakthroughs in the fields of natural language processing, image classification, and voice translation and so on. It is noteworthy that some DNN algorithms have applied in stock price time series prediction and quantitative trading [20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39]. However, most of the previous studies mainly choose a few stocks according to the researcher’s own preference [15, 17, 18, 20, 23, 25, 29, 34], or use the traditional machine learning algorithms combined with some DRO [17, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50] to predict the future stock price trends based on a few stock datasets. Meanwhile, there is a lack of statistical significance test between the trading performance of the prediction algorithm based on different DRO [25, 28, 40, 42, 47]. Therefore, the performance of back-testing may tend to be more optimistic. As far as we know, there is no study on the comparative analysis between the trading performance of DNN models based on different DRO, so whether DRO can significantly improve the trading performance of DNN models is a question worth discussing. The problem constitutes the main motivation of this research. The solution of the problem is of great value for practitioners to recognize the effect of the DRO on DNN models in the stock trading.
In this paper, we select 424 S&P 500 index component stocks (SPICS) and 185 CSI 300 index component stocks (CSICS) as the research objects and the stock symbols are shown in Appendix 1. Then, we construct the 44 technical indicators for each stock in the two markets such as the relative strength index and Bollinger bands as features are shown in Appendix 2. The label on the T-th trading day is the sign of daily return rate of the
The experimental results show that LASSO is an effective DRO and it can significantly improve the trading performance of RNN, GRU, and LSTM both in SPICS and CSICS. In addition, any DRO mentioned in this paper cannot significantly improve the trading performance of the remaining DNN algorithms. In particular, these DRO cannot significantly improve the ATT of any DNN algorithms and even some DRO make the speed of generating trading signals significantly slower. In a word, most of DRO methods used in this paper do not have a significant effect on the promotion of trading performance and the execution speed of the DNN algorithms. Therefore, we need to re-understand the significance and value of DRO, which is of guiding value for implementing DRO in DNN algorithms.
The remainder of this paper is organized as follows: Section 2 reviews statistical models, DRO algorithms, and the stock forecasting models based on DNN models in the existing literature. Section 3 gives the architecture of this paper. Section 4 describes the method of data acquisition, the reason for selecting stock datasets, and data processing tools. Section 5 describes the methods of data preparation, stock dataset generation, and DRO methods. Section 6 gives parameter settings of the DNN models, the algorithm for generating trading signals, and trading strategy. Section 7 gives the trading performance measure indicators for back-testing and uses a non-parameter statistical test to analyze and evaluate the performance of the DNN models based on different DRO in the two markets. Section 8 provides a comprehensive conclusion.
Literature review
Predicting the future price trends of stock is very difficult for investors, but many academic researchers and industry practitioners are trying to apply various theories and methods to complete this task. The methods of predicting the directions of stock movement also change from the early statistical models to DNN models. In this process, a large number of theoretical research results and trading rules that can be used for actual trading have also been produced. Next, we review the latest development of statistical models, DRO algorithms, and DNN models in stock trading.
Statistical models
Statistical models are considered the state of the art for time series modeling and prediction for over a half-century [1]. The traditional statistical models of time series generally assume the linear relationship between independent variables and dependent variables. And the residual between the predicted value of the statistical model and the original value of the interpreted variable is white noise. The existing research literature mainly uses autoregressive model [2], autoregressive moving average model [3, 8], autoregressive integrated moving average model [4, 7, 9], generalized autoregressive conditional heteroscedasticity model [5, 6], and variants based on these models to predict stock price time series. These statistical models assume that the time series of stock price is produced by a linear system. They are not always the most effective in predicting the future price because the stock prices have certain randomness, low signal-noise ratio, and strong volatility. The generation mechanism of price series is very complex, which brings challenges to the price forecasting methods of stock. It is worth noting that the DNN algorithms, which based on data and less restrictive assumptions, have brought new opportunities to learn the internal patterns of stock prices.
DRO Algorithms
Huang and Tsai applied hybrid support vector regression with self-organizing feature map technique and a filter-based feature selection to reduce the cost of training time and to improve the prediction accuracies of stock market price index [40]. Tsai et al. used three well-known feature selection methods (PCA, Genetic Algorithms, CART) to filter out unrepresentative variables based on union, intersection, and multi-intersection strategies. Then they applied back-propagation of neural network to predict the stock trends [41]. Zbikowski used volume weighted SVM and Fisher score to select features for creating a stock trading strategy to improve trading performance [17]. Zhang et al. proposed a causal feature selection algorithm to select more representative features for better stock prediction modeling [42]. Lee proposed a hybrid feature selection method which based on F-score and supported sequential forward search to select the optimal feature subset from an original feature set, and then used SVM and back-propagation neural network to predict the direction of stock market [43]. Su and Cheng proposed a novel adaptive neuro-fuzzy inference system based on integrated nonlinear feature selection method to do stock forecasting [44]. Ng et al. proposed a genetic algorithm which can minimize a new weighted localized generalization error to deal with classifier architecture selection and feature selection for stock and index prediction [45]. Zhou et al. proposed an improved filter feature selection method to select effective features for predicting the listing statuses of the Chinese-listed companies [46]. Zhong and Enke used three DRO techniques (PCA, fuzzy robust PCA, and kernel-based PCA) to simplify and rearrange original data structure and then applied artificial neural networks to predict the daily direction of future market returns [47]. Tayali and Tolun examined a non-negative DRO for the mean-variance portfolio optimization model and the result showed that the non-negative PCA was a promising approach [48]. Chen and Hao proposed an improved method which integrated DRO technique PCA into weight SVM for forecasting trading points of a single stock, where PCA was applied to clean the original data set and re-arrange it to a new data structure [49]. Nobre and Nevers applied PCA to reduce the dimensionality of the financial input dataset and discrete wavelet transform for noise reduction, then used an extreme gradient boosting based on the data to generate trading signals [50].
DNN models
In recent years, applications of DNN models in stock trading have attracted more and more attention from investors and researchers. Bao et al. proposed a deep learning framework, which combined wavelet transform, SAE and, LSTM to do stock price forecasting [20]. Thomas and Chrisstopher deployed LSTM to predict out-of-sample directional movements for the constituent stocks of the S&P 500 index [21]. Makickiene et al. proposed new methods of orthogonal input data to improve the process of RNN learning and financial forecasting [22]. Persio compared performance of multi-layer RNN, LSTM, and GRU on forecasting Google stock price movements [23]. Dunis et al. applied three different types of DNN models including MLP, recurrent, and higher-order neural network model to trade oil futures spreads in the context of a portfolio of contracts [24]. Chong et al. proposed a systematic analysis of the use of DNN models for stock market analysis and prediction, and examined the effect of three unsupervised feature extraction methods on the ability of the DNN models to forecast future market behavior [25]. Krauss et al. implemented and analyzed the effectiveness of DNN, gradient-boosted-trees, random forests, and several ensembles of these methods in the context of statistical arbitrage [26]. Hsieh et al. used wavelet transforms and RNN to forecast stock markets, which was based on an artificial bee colony algorithm [27]. Längkvist et al. gave a review of some development in DNN models and unsupervised learning for time series problems, and then pointed out some challenges in this area [28]. Vella and Ng proposed an improving the time-varying risk-adjusted performance of trading systems controlled artificial neural networks and other models [29]. Liu et al. presented some widely-used DNN architectures and including autoencoder, DBN, and Restricted Boltzmann Machine [30]. Dixon applied RNN to do high-frequency trading and solved a short sequence classification problem of limit order book depths and market orders to predict a next event price-flip [31]. Kim and Won proposed a hybrid LSTM model to predict stock price volatility which combined the LSTM with various GARCH-type models [32]. Shen et al. applied GRU and its improved version for forecasting trading signals for three stock indexes and compared proposed models with some DNN models and the other popular machine learning models [33]. Sezer et al. proposed a DNN model based on stock trading systems with evolutionary optimization technical analysis parameters to improve stock trading performance [34]. Hu et al. presented an improved sine cosine algorithm to optimize the weights of back-propagation of neural networks to predict the directions of the opening stock prices for the S&P 500 index and Dow Jones Industrial Average Indices [35]. Fischer and Krauss used LSTM to predict out-of-sample directional movements for the constituent stocks of the S&P 500 index, and the performance of LSTM was more outstanding than that of random forecast, MLP, and Logistic regression [36]. Hiransha et al. applied four types of DNN architectures to predict the stock price based on historical price available [37]. Lv et al. applied DNN algorithms such as RNN and traditional machine algorithms such as RF as classifiers to generate trading signals and proposed some useful rules to select the optimal trading models for stock investment in different industries [38]. Long et al. presented a multi-filter neural network which integrated convolutional and recurrent neurons for extreme market prediction and implemented trading simulation tasks on the Chinese CSI 300 index [39].
Architecture of the research
The framework of predicting the stock price trends based on DNN algorithms, back-testing, and performance evaluation of trading strategy is shown in Fig. 1. This paper is organized from data acquisition, data preparation, DNN algorithms, trading performance evaluation, and statistical significance test. Firstly, we use R language to obtain SPICS from Yahoo Finance and CSICS from NetEase Finance, respectively. Secondly, the task of data preparation includes ex-dividend /rights for the acquired data, generating a large number of features, normalizing the features, and dimensionality reduction operations, so that the preprocessed data can be used as the input of DNN algorithms. Thirdly, the trading signals of stock are generated by the DNN algorithms. In this part, we train the DNN models by a WFA method to generate trading signal. It is worth noting that we use the data after DRO to train the models at every step of WFA. Fourthly, we give four widely used performance evaluation indicators and implement the back-testing algorithm of trading strategy to calculate the indicators. Finally, we apply non-parameter statistical test methods to evaluate whether there are statistical significant differences among the performance of these DNN algorithms.
Architecture of the research.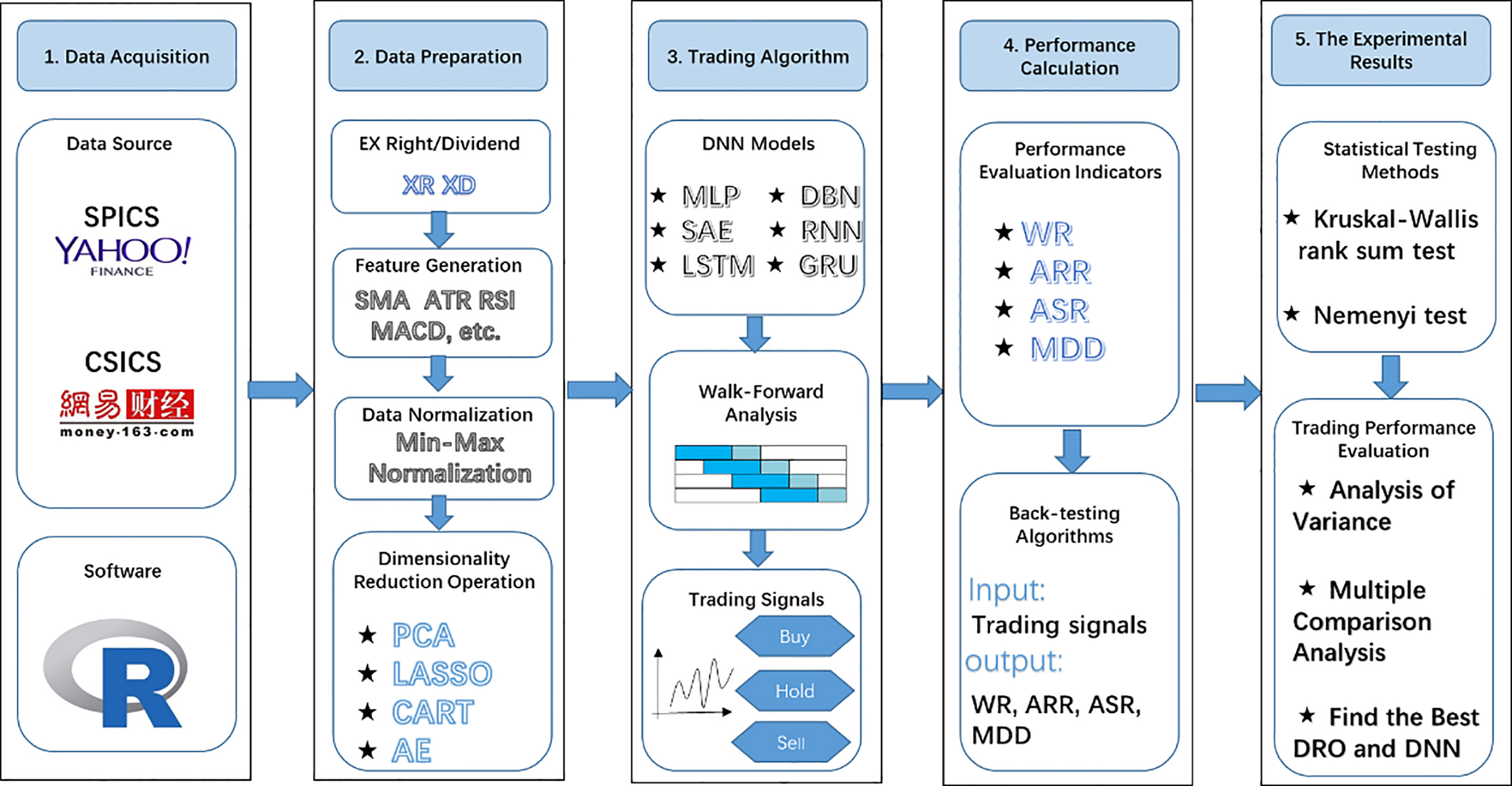
Data source
In order to test the performance difference between any two trading algorithms on the large-scale datasets, we conduct experiments on the US SPICS and the Chinese CSICS, which represent the industry development of the world’s top two economies and are attractive to investors around the world. The reason for our choice of SPICS is that it includes a wide range of industries such as high-tech stocks, public utility stocks, and financial stocks, which account for more than 80% of the total market value of the US stock. These stocks have strong liquidity and can provide good objects for back-testing of trading strategies. Meanwhile, the selection criteria of CSICS are market value and liquidity, which accounts for more than 60% of the total market value of Chinese A-share listed companies. It is worth noting that whether the SPICS or CSICS is dynamically adjusted according to certain rules. Therefore, the stock that does not meet the requirements in a certain period will be removed from the original sample. In the experiments, we select the data from the past 2000 trading days of SPICS and CSICS before December 31, 2017, respectively. In order to get enough data for the experiments, we have removed the stocks that have been suspended, delisted, and less than 2000 trading days. Finally, we select 424 SPICS and 185 CSICS, which account for about 85% and 60% of the total number of stocks, respectively. Stocks are fewer in CSICS because the CSICS is adjusted once a year and their selection rules are more stringent.
We obtain the stock data of SPICS and CSICS from
Software
All processes, from data acquisition, data preprocessing, feature generation, DRO, and DNN algorithms to trading performance measurement, are done used in R language (R version 3.4.3). R language is a statistical computing tool, which is widely used in the fields of statistical analysis, bioinformatics, financial modeling, machine learning and so on. We use quantmod-packet to obtain stock original data from relevant websites and use xts-package and TTR-packet to do data preprocessing and feature generation. we use glmnet-package, psych package, autoencoder-package, and rpart-packet to do DRO. We apply rnn-package and deepnet-package to train DNN models to generate trading signals. We use PerformanceAnalytics-package and pgirmess-package to evaluate the performance of the trading algorithms. All processes are carried out in the Window10 system (8 G memory, CPU frequency 2.81 Hz).
Data preparation
EX-rights/dividend
The data that we downloaded from the Internet include the trading time, the opening price, highest price, the lowest price, the closing price, and the volume. These data reflect the changes of stock price and volume of trading day. The acquired data is not processed by ex-dividend/weight, and we need to process these data accordingly. Because rationed shares, increasing shares by transferring and dividends can cause excessive jump and distortion of and technical indicators, which will affect the performance of trading algorithms.
Feature generation
In this paper, we select 44 relatively well-recognized technical indicators with a high frequency of use as the features, which include trend indicators, volatility indicators, cash flow indicators, investor psychological indicators and so on. The reason for choosing these indicators is that they describe the dynamic changes of stock price and volume in a trading day. It is worth noting that the number of technical indicators of stocks is large and the same indicator can generate many different indicators with the different parameters. In addition to some common indicators such as commodity channel index (CCI), relative strength index (RSI), there are some other indicators such as average true range (ATR), triple exponentially smoothed moving average (TRIX), because these indicators are of great significance for the characterizing the movement pattern of stock.
Data normalization
Data normalization is an important step in data preprocessing. Normalized data are generally used as inputs to machine learning and data mining models. The significance of normalization is to compress every feature in the data sets to the range of [0,1]. In this way, larger value of features can be avoided to have a strong influence on the output of the ML model, so as to improve the robustness of the model. In this article, we adopt max-min normalization. That is, to each feature
DRO algorithms
DRO tries to retain the information contained in the original features while minimizing the number of features. The purpose of DRO is to use a few features to replace the original large number of features for the training of ML models, which can improve the training efficiency of the models, reduce the impact of the redundant features on the model parameter estimation, and improve the robustness and generalization ability of the models. In engineering practice, we often obtain features of the research object as many as possible based on some priori knowledge of practical problems. However, some problems caused by too many features are that some features have nothing to do with the model and there exists multi-collinearity between features. Meanwhile, too many features increase the complexity of the models while reducing the explanatory power of the models. In this part, we mainly use four DRO algorithms (PCA, LASSO, CART, AE) to implement DRO for the original data, where PCA and AE are unsupervised DRO methods while CART and LASSO are supervised DRO methods. Then, we take the features after the DRO as the inputs of the DNN models.
Given a training dataset,
PCA
PCA [51] is to transform
LASSO
In order to prevent overfitting, LASSO regression is introduced to select variables in the least- square regression [51]. The constraint of the coefficient in empirical loss term is
CART
CART [51] is a prediction model of attribute structure and represents a mapping relationship between attributes of an object and value of the object. The CART includes a root node, a series of tree branches, and multiple leaf nodes. In training process of the CART algorithm, which attribute is chosen as its root node and which node to choose as its next node are determined by the importance of the information represented by the attribute for the classification results. The method of measuring the importance of attributes is also a method of DRO. The CART uses Gini coefficient to measure the contribution of an attribute to classification. The degree of importance of a feature or attribute is determined by the degree of reduction in the classification uncertainty. In CART, Gini coefficient is the degree of uncertainty in the classification of datasets under given certain features. Different features often have different Gini coefficients. The smaller the Gini coefficient, the stronger the classification ability. The Gini coefficient is widely used in the classification tree, regression tree, and random forest algorithm.
AE
AE [52] is a kind of feed-forward neural network, which can be used for data DRO. It is a neural network with a single hidden layer. That is, the network structure consists of an input layer, an output layer, and a hidden layer. The number of neuron in the hidden layer is less than that of the input layer. By minimizing the mean square error between the inputs and outputs, the inputs are reconstructed by the outputs so as to reduce the dimension of the original inputs. AE is an unsupervised DRO method and deal with original features through nonlinear transformation, so it can learn the information of original features. The method is mainly used in the fields of image generation, pattern recognition and so on. In this paper, we choose 10 neurons in the hidden layer. That is, we select the number of variables to be 10 in each DRO process.
Summary of the DRO
Different DRO has its advantages and limitations because of different mathematical principles. Meanwhile, the validity of DRO depends on the characteristics of data. In this paper, we present two unsupervised DRO (PCA and AE). PCA extracts principal components by a linear combination of features and determines the number of features after DRO by cumulative contribution rate. AE specifies the number of features after DRO artificially by a non-linear mapping relationship between features. Both CART and LASSO are supervised DRO. That is, there is a dependency relationship between features and classification labels when DRO is performed. CART chooses features by evaluating the importance of features based on Gini coefficient; LASSO compresses the coefficients of variables that are not important relative to label to be 0, thus realizing DRO. The advantages and limitations of these four methods are shown in Table 1.
A summary of advantages and limitations of the DRO
A summary of advantages and limitations of the DRO
DNN models
The task of us is to construct a DNN model based on a given training dataset after DRO so that the model can predict the directions of stock price movement correctly. In this paper, in order to test whether the DRO can improve the trading performance of the DNN algorithms, we apply the widely used PCA, LASSO, CART, and AE to be the DRO algorithm to deal with the original input features respectively, then use a DNN model such as MLP [53], DBN [54], SAE [55], RNN [56], LSTM [56], and GRU [56] as classifier to predict the rising and falling of the stock prices. The main model parameters and training parameters of these DNN algorithms are shown in Table 2.
In Table 2, features and class labels are set according to the input format of various DNN algorithms in R language. Matrix (
Parameter settings of DNN models
Parameter settings of DNN models
The schematic diagram of WFA.
WFA [57] is a systematic manner of performing what has been referred to as a rolling training and testing (see Fig. 2). One of the primary strengths of the WFA is to determine the robustness of the trading strategy. WFA is to determine the degree of confidence with which the trader may anticipate that the strategy will perform in real-time trading. Another important advantage of WFA is to produce a better trading performance as market changes. Since this periodic re-optimization is done with a strategy-appropriate amount of current price data, which also provides an efficient way to continuously adapt a trading model to ongoing changes in market conditions.
In this paper, we use DNN algorithms and WFA method to predict the stock price trends as trading signals. In each step, we first apply a DRO algorithm to handle raw input data which is from the past 250 days (one year), then apply the new dataset after DRO as the training set to train DNN models. Finally, we use the data of the next 5 days (one week) as the test set to predict the directions of the stock prices. It is worth noting that the features may be different (such as p1, p2,
The algorithm for generating trading signals
In this part, we use DNN algorithms as the classifiers to predict the ups and downs of the stock both in the SPICS and CSICS. Then, we apply the prediction results as trading signals of daily trading. In this process, we use the WFA method to train each DNN algorithm and to test out-of-sample data. We give the generating algorithm of trading signals according to Fig. 2, as is shown in Algorithm 1.
In this section, we give a daily trading strategy. If our DNN model predicts that a stock price of the next day will rise, then we will buy the stock at today’s closing price and sell it at the next day’s closing price. If our DNN model predicts that a stock price of the next day will fall, then we do not implement to buy or sell operation. That is, our strategy does not allow short selling. Therefore, the holding period of stock is one day. In our daily trading strategy, the implicit assumption is that we can complete the stock trading at the closing price. We know that this is very difficult in real trading, but it is entirely possible to do it near the closing price such as the trading price deviates from the closing price of 0.01 or 1 tick. Meanwhile, we do not consider trading cost in our strategy. In fact, it is very simple to consider trading cost in the strategy. Because whether in the U.S. stock market or China’s A-share market, the transparent transaction costs (broker commissions, exchange fees, and taxes) account for only a small part of stock investment returns. Our trading frequency is not particularly high, even may only trade once every few days.
The experimental results
Trading performance measure indicators
Investment performance measurement is an important tool to evaluate the effectiveness of a quantitative trading algorithm or trading strategy. In this paper, we apply the WR [38], ARR [38], ASR [38], MDD, and ATT as the measurement indicators of the trading performance. These indicators reflect the investment ability of investors or the performance of trading algorithms.
Drawdown is a measure of historical loss. It is the largest loss compared to the previous highest value (water level) of the net value curve and helps illustrate potential downside risk. Investment managers usually get performance reward after their investment returns exceed the water level MDD records the lowest peak-to-trough return from the last global maximum to the minimum that occurred prior to the next global maximum that supersedes the last global maximum MDD shows the largest decline in the price or value of the investment period
where
ATT is an average training time for a DNN algorithm to generate the trading signals of individual stock, which is an important performance measure indicator of the trading algorithm. The training speed of the algorithm is very important in daily trading because it must generate the trading signal for the next trading day near the closing price of the trading day so that we can make fast and effective investment decisions. In particular, ATT is a very important consideration when the trading algorithm is used in intraday trading or high-frequency trading because capturing the fleeting trading opportunities is the key to profitability. In this paper, we use second(s) as the unit of time.
Non-parameter statistical test method
In this paper, we study the impact of the DNN algorithms based on different DRO on the trading performance both in SPICS and CSICS. We will implement experiments on 24 trading algorithms, which based on 6 DNN and 4 DRO. The 4 DRO often serve as the important choice for high dimensional data preprocessing in other applications and these DRO usually greatly improve the computational efficiency while losing some information. Next, we mainly test the performance of these algorithms in the two datasets to evaluate whether there are significant differences between a DNN algorithm after the different DRO methods and whether there is a significant difference between the performance of the DNN algorithm after DRO and that of the DNN algorithm itself. Therefore, we use statistical hypothesis testing to compare and analyze the trading performance of different algorithms.
The statistical hypothesis testing uses sample information to reject or accept the distribution hypothesis based on a certain probability. For example, when we test whether there are significant differences between the mean values of two or more populations, we first take a certain number of samples from different populations so that the sample mean is a statistic of the population mean. We assume that the difference between the sample mean and the population mean comes from sampling error. If the value of the sample statistic falls within the region where the probability of occurrence is large in the sampling distribution, we believe that there is no significant difference between the sample mean and the population mean; if this sample statistic falls within the region where the probability of occurrence is very small in the sampling distribution, the researchers have to admit the difference between the sample mean and the population mean based on the principle that small probability event is almost impossible to occur in a random sample. The difference is not caused by sampling errors, but by an essential difference between them. Based on the above theoretical analysis, we propose the following hypotheses of the problems concerned in this paper: Given a DNN algorithm
Hijka: Given a DNN algorithm
Hijkb: Given a DNN algorithm
For example,
Hijka: the WR of MLP, MLP
In statistical hypothesis testing, statistics and their probability in sampling distribution are generally calculated from the null hypothesis. The judgment of rejecting the null hypothesis or accepting the null hypothesis is made according to the comparison between the probability and the significance level. If the probability is less than 0.05, this means that a small probability event has occurred. That is, we have found the reason for rejecting the null hypothesis with a minimum probability of making a mistake. Otherwise, there is not enough reason to reject the null hypothesis.
It is worth noting that any performance measure indicator of all trading algorithms or strategies does not conform to the basic hypothesis of variance analysis in our previous research work. Therefore, it is not appropriate to use t-test in the analysis of variance. And we should take the non-parametric statistical test method. In this paper, we use the Kruskal-Wallis rank sum test [59] to implement the analysis of variance. If the alternative hypothesis is established, we need to apply the Nemenyi test [60] further to do the multiple comparisons between the performance of trading algorithms.
Comparative analysis of the performance between different trading algorithms in SPICS
We give the average value of each performance measure indicator of each DNN after DRO by implementing back-testing. Then we analyze in detail whether the DRO can improve the trading performance of the DNN algorithm and whether there are statistically significant differences between the trading performance of a DNN algorithm based on different DRO.
Performance of MLP based on different DRO methods. Best performance of all trading algorithms is in bold font
Performance of MLP based on different DRO methods. Best performance of all trading algorithms is in bold font
We can see from Table 3 that the performance (WR, ARR, ASR, MDD, and ATT) of MLP is better that of other algorithms. Through the analysis of variance and multiple comparisons, we can find that there is no significant difference between the performance of all trading algorithms. The ATT of MLP is significantly less than those of other algorithms. Therefore, any DRO cannot improve the performance of MLP. Meanwhile, the performance of MLP after different DRO has no significant difference except for ATT.
Performance of DBN based on different DRO methods. Best performance of all trading algorithms is in bold font
We can see from Table 4 that the WR, ARR, and ASR of DBN
Performance of SAE based on different DRO methods. Best performance of all trading algorithms is in bold font
We can see from Table 5 that the performance measure indicator (WR, ARR, and ASR) of SAE is the best in all algorithms; the MDD of SAE
Performance of RNN based on different DRO methods. Best performance of all trading algorithms is in bold font
We can see from Table 6 that the WR, ASR, and MDD of RNN
Performance of GRU based on different DRO methods. Best performance of all trading algorithms is in bold font
We can see from Table 7 that the WR and ASR of GRU
Performance of LSTM based on different DRO methods. Best performance of all trading algorithms is in bold font
We can see from Table 8 that the WR and MDD of LSTM
By means of variance analysis and multiple comparison methods, the experimental results can be found as follows. From the perspective of forecasting accuracy of trading signals, we can see that LASSO can significantly improve the WR of RNN; in addition, any DRO cannot improve the WR of the remaining five DNN models. From the perspective of annual average returns, LASSO can significantly improve the ARR of GRU and LSTM; in addition, any DRO cannot improve the RNN of the remaining four DNN models. From the perspective of risk-adjusted returns, LASSO can significantly improve the ASR of RNN; in addition, any DRO cannot significantly improve the ASR of the remaining five DNN models. From the perspective of trading risk control, LASSO can significantly improve the MDD of RNN; in addition, any DRO cannot significantly improve the MDD of the remaining five DNN models. From the perspective of the speed of the trading signals generated by the algorithms, the ATT of all DNN algorithms are not significantly slower than those of the fastest algorithms based on DRO methods. That is, any DRO cannot significantly improve the execution speed of any DNN models.
Similar to 7.3, we give the average value of each performance measure indicator of each DNN model and the model after DRO. Then we apply variance analysis and multiple comparison methods to analyze whether DRO can improve the performance and execution speed of the DNN models.
Performance of MLP based on different DRO methods. Best performance of all trading algorithms is in bold font
Performance of MLP based on different DRO methods. Best performance of all trading algorithms is in bold font
From Table 9, we can see that the WR of MLP is the greatest; the ARR, ASR, and MDD of MLP
Performance of DBN based on different DRO methods. Best performance of all trading algorithms is in bold font
From Table 10, we can see that the performance (WR, ARR, ASR, and MDD) of DBN
Performance of SAE based on different DRO methods. Best performance of all trading algorithms is in bold font
From Table 11, we can see that the WR of SAE
Performance of RNN based on different DRO methods. Best performance of all trading algorithms is in bold font
From Table 12, we can see that the performance (WR, ASR, and MDD) of RNN
Performance of GRU based on different DRO methods. Best performance of all trading algorithms is in bold font
From Table 13, we can see that the performance (WR, ASR, and MDD) of GRU
Performance of LSTM based on different DRO methods. Best performance of all trading algorithms is in bold font
From Table 14, we can see that the performance (WR, ASR, and MDD) of LSTM
By means of variance analysis and multiple comparison methods, the experimental results on CSICS can be found as follows. From the perspective of forecasting accuracy of trading signals, we can see that LASSO can significantly improve the WR of RNN, LSTM, and GRU; in addition, any DRO cannot significantly improve the WR of the remaining DNN algorithms. From the perspective of annual average returns, any DRO cannot significantly improve the ARR of all DNN algorithms. From the perspective of risk-adjusted returns, LASSO can significantly improve the ASR of GRU; in addition, any DRO cannot significantly improve the ASR of other DNN algorithms. From the perspective of trading risk control, LASSO can significantly improve the MDD of RNN, GRU, and LSTM; in addition, any DRO cannot significantly improve the MDD of other DNN algorithms. From the perspective of the speed of the trading signals generated by the algorithms, the ATT of all DNN algorithms are not significantly slower than that of the algorithms after any DRO.
From Sections 7.3 and 7.4, we can see that the DRO mentioned in this paper cannot significantly improve the trading performance (WR, ARR, ASR, and MDD) and the speed of generating trading signals of the MLP, SAE, and DBN both in SPICS and CSICS. This may be because the three DNN algorithms have the ability to automatically select the original features so that there is no significant difference between the performance of the algorithms and that of the algorithms after any DRO. Meanwhile, the features may be different after the four DRO, but the information which extracted from the features by DNN models is as much as the origin features.
LASSO is a promising DRO method and it can improve some performance measure indicators of RNN, LSTM, and GRU in both SPICS and CSICS. For example, the ASR of RNN is 1.5768 and that of RNN
CART and PCA cannot significantly improve the trading performance of RNN, LSTM, and GRU, even CART and PCA can make the performance of the three DNN algorithms worse. It is noteworthy that CART can accelerate the execution speed of some DNN algorithms and be significantly faster than other DRO. This may be because the features selected by CART cause the three DNN algorithms to be overfitting. PCA only considers the linear relationship between features. Although PCA reduces the multi-collinearity between features, it can cause loss of information. Therefore, PCA can reduce the accuracy of out-of-sample prediction and the trading performance.
AE cannot significantly improve the trading performance of the three DNN algorithms. In all DRO methods, the trading performance of a DNN algorithm after AE is close to the performance of the algorithm. This may be because AE can maintain most of the information of the original features. AE can realize DRO by reconstructing between input and output. And the features after AE is the non-linear transformation of original feature, which does not lose information.
The ATT of any DNN algorithm is not significantly slower than that of the algorithm after DRO, so it is hard to say that DRO can significantly improve the speed of generating trading signals. In fact, the process of DRO takes a lot of time. In the daily trading, the ATT is the very important consideration, because we have to make a trading decision near the closing prices and the fast implementation of trading signals is a necessary condition for making the profit. Unfortunately, these DNN algorithms after DRO are not significantly faster than those algorithms without DRO.
The experimental results are inconsistent with our intuition that the implementation of feature engineering can improve the running time and the performance of machine learning algorithms. The main reason for this phenomenon may be that the DRO does lose the information of some original features and the DRO can take a lot of time such as the time spent by AE takes up a great part of the DNN algorithms. Meanwhile, the number of selected features is not large enough, or the selected features cannot describe the movement law of stocks well. Therefore, most of the DRO do not achieve the desired result. So, feature engineering is still a huge challenge when modeling stock data.
Conclusion
In this paper, we apply 424 SPICS in the US market and 185 CSICS in the Chinese market as the research objects, select stock data of the 2000 trading days before December 31, 2017, and build 44 technical indicators for each stock as original features. Secondly, we apply four widely used DRO to deal with the original features in each step of WFA and then use the new features as inputs of the DNN algorithms to generate the stock trading signals. Thirdly, we formulate a daily trading strategy based on the trading signals. Finally, we use WR, ARR, ASR, MDD, and ATT as measure indicators and apply the non-parameter statistical test methods to analyze and evaluate the performance of these DNN algorithms based on different DRO.
The experiments show that LASSO can significantly improve some performance measure indicators of RNN, LSTM, and GRU; in addition, the remaining three DRO methods cannot significantly improve the trading performance of the three DNN algorithms. Any DRO mentioned in this paper cannot significantly improve the performance of MLP, DBN, and SAE in both SPICS and CSICS. Especially, any DRO cannot significantly improve the ATT of any DNN algorithm. That is, the DRO cannot improve the execution speed of the DNN algorithms. Therefore, we need to re-examine the impact of feature engineering on the DNN algorithms when they are applied in stock trading.
Footnotes
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China (No. 71571136, 61802258), in part by Technology Commission of Shanghai Municipality (No.16JC1403000), in part by the Shanghai Alliance Program (No. LM201819).
Appendix 1: The stock symbols in the two datasets
Datasets
Stock symbols
SPICS
MAT; MSI; XL; EW; AMZN; NWL; ROP; HCP; BMY; NFLX; EMN; IP; AMGN; HCN; REGN; DHR; SCG; PLD; BXP; CME; AVB; AEP; EL; PPL; VTR; CHRW; EIX; VNO; TWX; CI; NEE; D; EXC; PSA; DUK; SBUX; MMC; GRMN; DGX; GT; SO; BMS; CELG; AEE; PFE; AIV; CNP; AON; FFIV; MDT; PRGO; BIIB; EQR; PGR; NKE; PAYX; JCI; MON; PNC; XEL; MO; SNI; HSY; FOXA; KEY; ABT; ALL; ESS; RSG; MDLZ; AFL; AME; CCI; BSX; SRE; DTE; MET; NRG; PBCT; VFC; PNW; WEC; USB; CMG; GPC; WMT; ED; CINF; ECL; BBT; UNM; JNPR; QCOM; ICE; XRAY; NI; MMM; HRS; CA; DPS; HUM; SNA; SRCL; AIZ; CL; CTL; PDCO; COL; PEG; SYMC; AMT; TIF; HRL; IFF; FIS; NDAQ; PNR; AET; COST; GLW; HIG; LEG; MCHP; TXT; SYY; LMT; INTU; PEP; TRV; MA; TDC; AVGO; AN; GGP; IR; UNH; CB; KMB; PH; MCD; ETR; RF; EXPD; L; LLY; WM; DRI; ZION; KO; RL; ADP; CMS; SYK; TEL; GD; FE; ITW; FITB; VLO; HBAN; YUM; DIS; CCL; ALXN; FSLR; PM; UHS; JNJ; LLL; OMC; TSN; APH; BAC; HAS; PPG; DE; ;FAST; CRM; SEE; AIG; SWK; NOC; TSS; AZO; FISV; BDX; CSCO; CMCSA; PG; ADBE; HON; MTB; EXPE; MNST; VRSN; F; RTN; VAR; DNB; GNW; LH; SPG; WU; MHK; BAX; RHT; DOV; FTI; NTRS; PVH; MAC; TROW; BK; CTAS; TJX; DFS; ESRX; IBM; AMP; ISRG; TMO; CMA; EFX; A; MRK; STZ; XEC; SHW; IPG; TXN; WFC; MYL; CAN; JPM; FLS; HST; BA; WAT; AVY; LOW; FDX; UNP; AMG; CTSH; WYNN; BLL; CAH; NSC; PCLN; CSX; C; APD; GE; CAG; GPS; IVZ; KSU; SLB; VMC; GWW; HOG; PHM; PKI; ADM; VZ; WHR; DVA; KSS; BBY; UPS; XLNX; WIN; CMI; GME; STT; ROK; MSFT; EQT; HRB; LUV; MAS; PCG; PRU; CCE; UTX; TGT; STI; AKAM; FLR; RRC; LUK; WDC; COP; ADI; EMR; IRM; CERN; T; TMK; ADS; JWN; BEN; ETFC; PCAR; EA; M; SCHW; WYN; FLIR; KR; NVDA; KMX; ORCL; JBL; CAT; CVS; FTR; HD; BLK; TAP; VIAB; PX; COF; MCO; MLM; OI; PFG; MOS; WMB; NTAP; ETN; INTC; URBN; EOG; DAL; KIM; NUE; AVP; ABC; OXY; AXP; GIS; OKE; LNC; AGN; AES; ADSK; BWA; XRX; MS; NEM; HPQ; URI; DHI; ROST; R; APC; MKC; CBG; ORLY; FOSL; LB; CHK; V; COG; HP; ATI; VRTX; RHI; FMC; MU; WY; CF; THC; SWN; EBAY; JEC; KLAC; AP; K; GCI; PXD; MCK; HAL; MAR; AAPL; DLTR; GS; LM; LEN;BBBY; NOV; CPB; SJM; CNX; GOOG; AMAT; STX; MRO; TSCO; RDC; PBI; XOM; DVN; GOOGL; NFX; LRCX; NBL; HES; CVX; DISCK; PWR; DISCA; CBS; MUR; NBR; ESV; AA; RIG; NE; CLX; DO; DNR; FCX
CSICS
600000.SS; 600008.SS; 600009.SS; 600010.SS; 600011.SS; 600015.SS; 600016.SS; 600018.SS; 600019.SS; 600021.SS; 600028.SS; 600029.SS; 600030.SS; 600031.SS; 600036.SS; 600038.SS; 600048.SS; 600050.SS; 600061.SS; 600066.SS; 600068.SS; 600074.SS; 600085.SS; 600089.SS; 600100.SS; 600104.SS; 600109.SS; 600111.SS; 600115.SS; 600118.SS; 600153.SS; 600157.SS; 600170.SS; 600177.SS; 600188.SS; 600196.SS; 600208.SS; 600219.SS; 600221.SS; 600233.SS; 600271.SS; 600276.SS; 600297.SS; 600309.SS; 600332.SS; 600352.SS; 600362.SS; 600369.SS; 600372.SS; 600373.SS; 600376.SS; 600383.SS; 600390.SS; 600406.SS; 600415.SS; 600436.SS; 600482.SS; 600485.SS; 600489.SS; 600498.SS; 600518.SS; 600519.SS; 600522.SS; 600535.SS; 600547.SS; 600549.SS; 600570.SS; 600583.SS; 600585.SS; 600588.SS; 600606.SS; 600637.SS; 600649.SS; 600660.SS; 600663.SS; 600674.SS; 600682.SS; 600685.SS; 600688.SS; 600690.SS; 600703.SS; 600704.SS; 600739.SS; 600741.SS; 600795.SS; 600804.SS; 600816.SS; 600820.SS; 600827.SS; 600837.SS; 600871.SS; 600886.SS; 600887.SS; 600893.SS; 600895.SS; 600900.SS; 601006.SS; 601009.SS; 601088.SS; 601099.SS; 601111.SS; 601166.SS; 601169.SS; 601186.SS; 601318.SS; 601328.SS; 601333.SS; 601390.SS; 601398.SS; 601600.SS; 601601.SS; 601628.SS; 601766.SS; 601857.SS; 601866.SS; 601872.SS; 601898.SS;
Datasets
Stock symbols
601899.SS; 601919.SS; 601939.SS; 601958.SS; 601988.SS; 601991.SS; 601998.SS; 000001.SZ; 000002.SZ; 000008.SZ; 000060.SZ; 000063.SZ; 000069.SZ; 000100.SZ; 000157.SZ; 000338.SZ; 000402.SZ; 000413.SZ; 000415.SZ; 000423.SZ; 000425.SZ; 000503.SZ; 000538.SZ; 000540.SZ; 000559.SZ; 000568.SZ; 000623.SZ; 000625.SZ; 000627.SZ; 000630.SZ; 000671.SZ; 000686.SZ; 000709.SZ; 000723.SZ; 000725.SZ; 000728.SZ; 000738.SZ; 000750.SZ; 000768.SZ; 000783.SZ; 000792.SZ; 000826.SZ; 000839.SZ; 000858.SZ; 000876.SZ; 000895.SZ; 000898.SZ; 000938.SZ; 000959.SZ; 000961.SZ; 000963.SZ; 000983.SZ; 002007.SZ; 002008.SZ; 002024.SZ; 002027.SZ; 002044.SZ;002065.SZ; 002074.SZ; 002081.SZ; 002142.SZ; 002146.SZ; 002153.SZ; 002174.SZ; 002202.SZ; 002230.SZ; 002236.SZ; 002241.SZ
Appendix 2: Features description used in the DRO and DNN algorithms
(1) Basic symbols
Explanation
H[i]
H[i] represents the highest price of a stock on the i day, where H indicates the highest price time series of a stock.
L[i]
L[i] represents the lowest price of a stock on the i day, where H indicates the lowest price time series of a stock.
C[i]
C[i] represents the closing price of a stock on the i day, where H indicates the closing price time series of a stock.
O[i]
O[i] represents the opening price of a stock on the i day, where H indicates the opening price time series of a stock.
V[i]
V[i] represents the volume of a stock on the i day, where H indicates the volume time series of a stock.
SMA(x, n)
The n order simple moving average of the time series x.
EMA(x, n)
The n order exponentially moving average of the time series x.
1:N
1:N represents all positive integers from 1 to N.
runSum(x, n)
runSum(x, n) indicates the rolling sum of the order n of the sequence x, for example, x
1,2,3,4,5,6,7, then runSum (x, 3) is NA, NA, 6, 9, 12, 15, 18.
HH[i]
HH[i] represents the maximum value in the highest price sequence.
LL[i]
LL[i] represents the minimum value in the lowest price sequence.
runMean(x, n)
runMean(x, n) represents the rolling mean of the n order of the sequence x.
runSD(x, n)
runSD(x, n) represents the rolling standard deviation of the n order of the sequence x.
(2) Technical indicators
Calculation method
Explanation
(1) ATR
TR[i]
max(H[i]-C[i], |C[i-1]-H[i]|, |C[i-1]-L[i]|), ATR
SMA(TR, 14)
The ATR is a Welles Wilder style moving average of the True Range. The ATR is a measure of volatility. High ATR values indicate high volatility, and low values indicate low volatility.
(2) ADX
The ADX is a Welles Wilder style moving average of the Directional Movement Index (DX). The values range from 0 to 100, but rarely get above 60. To interpret the ADX, consider a high number to be a strong trend, and a low number, a weak trend.
(3) OBV
If C[i]
C[i-1], OBV[i]
OBV[i]
V[i] If C[i]
C[i-1], OBV[i]
OBV[i]-V[i] If C[i]
C[i-1], OBV[i]
OBV[i]
The On Balance Volume (OBV) is a cumulative total of the up and down volume. A series of rising peaks, or falling troughs, in the OBV indicates a strong trend. If the OBV is flat, then the market is not trending.
(2) Technical indicators
Calculation method
Explanation
(4) WR
%WR[n]
100* (HH[1:n]-C[n]) /(HH[1:n]-LL[1:n])
The values range from zero to 100 and are charted on an inverted scale, that is, with zero at the top and 100 at the bottom. Values below 20 indicate an overbought condition and a sell signal is generated when it crosses the 20 line. Values over 80 indicate an oversold condition and a buy signal is generated when it crosses the 80 line.
(5) RSI
If C[i]
C[i-1], then up[i]
C[i]-C[i-1], dn[i]
0; If C[i]
C[i-1], then dn[i]
C[i-1]-C[i], up[i]
0; Upave[i]
(upave*(i-1)
up)/(i); Dnave[i]
(dnave*(i-1)
dn)/(i); RSI[i]
100*upave[i]/(upave[i]
dnave[i])
The RSI is interpreted as an overbought/oversold indicator when the value is over 70/below 30. You can also look for divergence with price. If the price is making new highs/lows, and the RSI is not, it indicates a reversal.
(6) CMF
VA
(C-(H
L)/2)/(H-L)*V CMF[i]
runSum(VA, i)/runSum(V, i)
When the Chaikin Money Flow(CMF) is above 0.25 it is a bullish signal, when it is below
0.25, it is a bearish signal. If the CMF remains below zero while the price is rising, it indicates a probable reversal.
(7) BandPer
PB
(C-BBDN)/(BBUP-BBDN), where BBDN is the lower track value of the Bollinger bands, and BBUP is the lower track value of the Bollinger bands.
BandPer index can tell us where the current price is in the Bollinger line, which can be used for morphological identification and quantitative trading.
(8) BandWid
BW
(BBUP-BBDN)/BBMA, where BBMA is the value of the middle track of the Bollinger bands.
BandWid is a measure of volatility. The BandWid value is higher when volatility is high, and lower when volatility is low.
(9) Chaikin A/D Oscillator
AD[i]
AD[i-1]
(C[i]-L[i])
(((C[i]-L[i])-(H[i]-C[i]))/(H[i]-L[i]
0.01))*V[i] CO
EMA (AD, 3) – EMA (AD, 10)
Chaikin A/D Oscillator is a stock index related to trading volume, which can be used to observe the flow of funds in the market.
(10) DIS
DIS
C/SMA(C, 20))*100
Disparity Index can measure the relative position of the most recent closing price to a selected moving average and reports the value as a percentage.
(11) EOM
EOM[1]
(H[1]
L[1])/2 EOM[i]
((H[i]
L[i])/2-(H[i-1]
L[i-1])/2)*(H[i]-L[i])/V[i]
Ease of Movement Value Index is used to relate an asset’s price change to its volume. Ease of Movement highlights the relationship between volume and price changes and is particularly useful for assessing the strength of a trend.
(12) FI
FI[i]
(C[i]-C[i-1])*V[i] FI
SMA(FI, 2)
The force index (FI) is used to illustrate how strong the actual buying or selling pressure is. High positive values mean there is a strong rising trend, and low values signify a strong downward trend.
(13) MAO
MAO
SMA(C, 12)-SMA(C, 26)
MA oscillator index is the difference of the moving average of two different time periods, reflecting the degree of swinging of stock prices.
(14) MFI
The Money Flow Index calculates the ratio of money flowing into and out of a security.
(2) Technical indicators
Calculation method
Explanation
(15) MI
r
H-L ema1
EMA(r, 9) ema2
(EMA(r, 9))^2 x
ema1/ema2 MI
runSum(x, 9)
Mass Index Momentum is used to predict trend reversals. It is based on the notion that there is a tendency for reversal when the price range widens, and therefore compares previous trading ranges (highs minus lows).
(16) MOM
MOM[i]
(C[i]/C[i-9])*100
Momentum Index is the (rate of) change of a series over n periods.
(17) NCO
NCO[i]
C[i]-C[12]
Net Change Oscillator Index is the change of series over n periods.
(18) PO
PO
(SMA(C, 5)-SMA(C, 10))/(SMA(C, 10))
Price Oscillator Index removes the trend in prices by subtracting a moving average of the price from the price. The PO shows cycles and overbought/oversold conditions.
(19) PSY
ROC[i]
(C[i]-C[i-10])/C[i-10] PSY[i]
sum(ROC((i-10):i)
0)/10
PSY index reflects the psychological fluctuations of investors in the stock market.
(20) RMI
mo[i]
C[i]-C[i-1] RMI[i]
sum(mo[mo[(i-13):i]
0])/(sum(mo[mo[(i-13):i]
0])
sum(mo[mo[(i- 13):i]
0])
0.01), where mo[mo
0] represents a sequence consisting of values greater than 0 in sequence mo. sum (x) represents the sum of all the values in the sequence x.
Relative Momentum Index is a swinging indicator, which shows the same strength and weakness as other overbought/oversold indicators.
(21) ROC
ROC[i]
log(C[i]/C[i-1])
The ROC indicator provides the percentage difference of a series over two observations.
(22) SROC
SROC
(EMA(C, 20)/EMA(C,10))*100
Smoothed Rate of Change Index, like ROC, is used to reflect the rate of change in stock prices.
(23) SONAR
SONAR
MOM(EMA(C, 25), 25)
Sonar index is the (rate of) change of exponential moving mean of the closing price over n periods.
(24) SONSIG
SONSIG
EMA(SONAR, 9)
SONSIG index is exponential moving mean of SONAR series over n periods.
(25) TRIX
M
EMA(EMA(EMA(C,20),20),20) TRIX[i]
100*(M[i]-M[i-1])/M[i]
The TRIX indicator calculates the rate of change of a triple exponential moving average.
(26) VMA
VMA
SMA(VO, n )
Moving Average of the Volume.
(27) VOS
Vm
EMA (V, 12) Vn
EMA (V, 26) VOS
((Vm-Vn)/Vn)*100
Volume Oscillator index can analyze the trend of turnover and judge the direction of trend change in time.
(28) VROC
VROC[i]
log(V[i]/V[i-13])
VROC index applies movement of the volume of to measure the trend of volume turnover in order to detect the strength of supply and demand in advance.
(29) Return
Ret
log(C[i]/C[i-1]) Return
runMean(Ret, 14)
Return represents means of logarithmic return rate over a n-period moving window.
(30) Sigma
Ret
log(C[i]/C[i-1]) Return
runSD(Ret, 14)
Sigma represents standard deviations of logarithmic return rate over a n-period moving window.
(2) Technical indicators
Calculation method
Explanation
(31) CCI
TP[i]
(HH[1:i]
LL[i]
C[i])/3 ATP
SMA(TP, 20) MDTP
runMean(
TP-ATP
,20) CCI
(TP-ATP)/(0.015*MDTP)
The Commodity Channel Index (CCI) attempts to identify starting and ending trends.
(32) RSV
RSV[i]
100* (C[i]-LL[(i-8):i])/(HH[(i-8):i]-LL[(i-8):i])
The RSV index is mainly used to analyze whether the market is in an overbought or oversold state. The market is overbought when RSV is higher than 80%; The market was oversold when RSV was below 20%.
(33) Kvalue
Kvalue
EMA(RSV, 2)
The K, D, and J index can be used to judge the market more quickly and intuitively and is widely used in the analysis of the short and medium term trend of the stock market.
(34) Dvalue
Dvalue
EMA(Kvalue, 2)
(35) Jvalue
Jvalue
(36) MACD
Fast
The MACD signals trend changes and indicates the start of new trend direction.
(37) CAD
CAD[i]
The Chaikin Accumulation/Distribu-tion (CAD) line is a measure of the money flowing into or out of a security. It is similar to OBV.
(38) VOLA
EMAHL
Chaikin Volatility measures the rate of change of the security’s trading range.
(39) NBIAS
NBIAS
The NBIAS index reflects the deviation between price and moving average in a certain period and contribute to obtaining the possibility of return or rebound caused by the deviation from the moving average trend in the violent fluctuation.
(40) Ret
Ret[i]
Ret represents logarithmic return rate on i day.
(41) SMA_5
SMA_5
SMA_5 represents the arithmetic mean of the closing price over the past 5 days.
(42) SMA_10
SMA_10
SMA_10 represents the arithmetic moving mean of the closing price over the past 10 days.
(43) EMA_5
EMA_5
EMA_5 represents the exponential moving mean of the closing price over the past 5 days.
(44) EMA_10
EMA_10
EMA_10 represents The exponential moving mean of the closing price over the past 10 days.
(45) Label
If log(C[i
The classified label is an important sign to supervise learning algorithm.