
Abstract
Research on content-based image retrieval (CBIR) has been under development for decades, and numerous methods have been competing to extract the most discriminative features for improved representation of the image content. Recently, deep learning methods have gained attention in computer vision, including CBIR. In this paper, we present a comparative investigation of different features, including low-level and high-level features, for CBIR. We compare the performance of CBIR systems using different deep features with state-of-the-art low-level features such as SIFT, SURF, HOG, LBP, and LTP, using different dictionaries and coefficient learning techniques. Furthermore, we conduct comparisons with a set of primitive and popular features that have been used in this field, including colour histograms and Gabor features. We also investigate the discriminative power of deep features using certain similarity measures under different validation approaches. Furthermore, we investigate the effects of the dimensionality reduction of deep features on the performance of CBIR systems using principal component analysis, discrete wavelet transform, and discrete cosine transform. Unprecedentedly, the experimental results demonstrate high (95% and 93%) mean average precisions when using the VGG-16 FC7 deep features of Corel-1000 and Coil-20 datasets with 10-D and 20-D K-SVD, respectively.
Keywords
Introduction
Given a set of images S and an input image i, the goal of a content-based image retrieval (CBIR) system is to search S for i and return the most related/similar images to i, based on their contents. This emergent field responds to an urgent need to search for an image based on its content, rather than typing text to describe image content to be searched for. That is, CBIR systems allow users to conduct a query by image (QBI), and the system’s task is to identify the images that are relevant to that image. Prior to CBIR, the traditional means of searching for images was typing a text describing the image content, known as query by text (QBT). However, QBT requires predefined image information, such as metadata, which necessitate human intervention to annotate images in order to describe their contents. This is unfeasible, particularly with the emergence of big data; for example, Flickr creates approximately 3.6 TB of image data, while Google deals with approximately 20,000 TB of data daily[70], which mostly comprise images and videos. Applications of CBIR are massive in terms of numbers and areas, which include, but are not limited to, medical image analysis [67], image mining[30, 55, 50], surveillance[29], biometrics[19], security[68, 22, 27], and remote sensing[54].
The key to the success of a CBIR system lies in extracting features from an image to define its content. These features are stored to describe each image, which is implemented automatically by the system, using specific algorithms developed for the extraction process. Similarly, a query process is conducted by extracting the same features from the query image to determine the most similar images from a feature dataset, using matching techniques or similarity measures (distance metrics). Therefore, feature extraction is critical for developing an efficient CBIR system.
The goal of this study is to compare the performance of the CBIR system using different features, namely deep features, LFDs and low level features (LLFs). Moreover, we use a SR framework with different dictionaries and coefficient learning methods to investigate the effects of deep features compared to state-of-the-art studies. We also study the enhancement of deep features using discrete cosine transform (DCT)-based coefficients. Finally, we study the effect of dimensionality reduction on the CBIR system performance, using principal component analysis (PCA), discrete wavelet transform (DWT) and DCT with different similarity measures under various validation approaches.
The contributions of this study can be summarized as follows:
First of all, different versions of two leading approaches, Deep Learning (DL) and Sparse Representation (SR), are tested to find the best combination. Detailed tests of the combinations are run on two popular data sets. A large number of experiments (842 different tests) are conducted to compare the effectiveness of image features (LFDs and Deep Features). Popular similarity measurements are used to compare the performance of deep features before and after their enhancement using DCT and z-score normalization. Various dimensionality reduction algorithms are employed and tested to investigate the performance of deep features in a small feature space. Our combination of SR with deep features is compared with the state of the art methods and shows superior accuracy.
A large number of contributions have been made to obtaining the optimal features that guarantee superior performance, starting from colour histograms [38, 24, 73], in which the colour frequencies are mainly used to represent the image content. Despite the fact that histograms have been used extensively in CBIR systems, they cannot provide special information regarding the distribution of the colours in the special domain. The co-occurrence matrix has been used to provide such special information in order to gain an improved description of image contents, whereby the appearance of colour intensity with its related neighbours is recorded, followed by the calculation of specific values that are used to describe the contents[60]. Colour co-occurrence matrices are also used to add robustness in describing image contents by extracting different patterns (so-called motifs) [32, 61, 11] from small blocks in the images. Moreover, in addition to colour moments and statistical features, Gabor features [51], wavelet transform[3], cosine transform [65] and Fourier transform [13] have been applied to extract different features from images. Furthermore, shape features have been used in CBIR by extracting the main shapes of objects found in the image, and describing them with different shape descriptors, such as Fourier and invariant moments [41, 66].
Local feature descriptors (LFDs) or feature points have also been used for CBIR. SIFT [44] and SURF[4] are popular methods for extracting feature points to be used in the matching process. The recent and inspiring study [6] presented a comparison between SIFT and SURF points and investigated the efficiency of these methods compared to a set of other methods, such as the histogram of oriented gradient (HOG), local binary patterns (LBP) and local ternary patterns (LTP). The study proposed a CBIR framework with sparse representation (SR) and covered the performance of these methods using dictionary and coefficient learning, which are the main steps of SR. Three types of dictionary learning methods were used, namely random features,
Recently, efforts have been made to use DL to solve computer vision tasks such as recognition, authentication, segmentation and CBIR [62, 56, 64, 34, 46]. In general, there are three different means of using deep learning. Firstly, a convolutional neural network (CNN) is trained on a large-scale dataset to use it for classification. Secondly, it is used as transfer learning, where specific layers are weighted from a pre-trained CNN, which is a CNN trained on a large-scale dataset such as ImageNet. Thirdly, the pre-trained CNN is used as a feature extractor, in which case the images will be used as input and the feed-forward will be calculated to extract the features (deep features) from different layers of the CNN models. For CBIR, the CNN can be used as a feature extractor, and the resultant features applied to present the image contents. Although Deep learning is preferred over SR to improve retrieval accuracy in CBIR problems[7, 40, 33, 14], these algorithms have also been employed together with the same aim [72, 42, 10, 16]. Therefore, this study presents an extensive number of experiments to figure out the best combination between these two leading approaches to maximise the performance of CBIR systems.
Basically, distance metrics and similarity measures play an important role in ensuring the effectiveness of CBIR systems. The significance of this role is evident following extraction of the features from the images, as it is used for finding images whose contents are closer to a query image. In fact, numerous distance metrics have been developed and used for the matching process between a query image and reference images, the most common of which are Euclidian and Manhattan distances, which have been used in various studies[58]. However, in recent years, other measures have been developed mainly to enhance the matching process. For example, a new matching technique to determine the minimum triangular area between a query vector and its relevant images was proposed by[11], and the reported results demonstrated that effective performance can be achieved using this technique. Another dimensionality invariant distance metric known as the Hassanat distance[25] was proposed to deal with high-dimensional feature vectors, without the need to normalise the data. Practically, many distance metrics are available, which vary in their performance and can be used successfully for different matching tasks, including CBIR[49].
Materials and methods
CBIR features can be categorised into two types: low-level and high-level features. Low-level features include Gabor features, colour histogram, SIFT, SURF and others, such as those presented in[9] High-level features include deep features extracted from different layers and pre-trained models, such as AlexNet[35], VGG-16 and VGG-19[57]. In this paper, we compare low-level and high-level features, in addition to comparing the high deep features with one another and investigating the CBIR performance following data pre-processing and dimensionality reduction, as demonstrated in the next sections.
Low-level features
Gabor features
Gabor features are frequently used for different computer vision tasks, including CBIR. In this study, Gabor features are used as in [9], with different scales and orientations. The 2D Gabor filters in the spatial domain can be defined by
where
HOG features can be used efficiently for object detection [47, 74] and recognition [36], in addition to CBIR [8]. Typically, the calculation and extraction of these features are carried out as follows. The colour and gamma values are normalised as a pre-processing step. Thereafter, the gradient is calculated; generally using horizontal and vertical operators such as
SIFT and SURF
Both SIFT and SURF are reasonably robust LFDs. In SIFT, the features are localised by filtering the image using difference of Gaussians at different scales, following which the local maxima and minima are considered as feature points [44]. Speed is a major problem in SIFT; hence, the SURF method was proposed to improve the SIFT method speed by approximating the Laplacian of Gaussian using box filters, which makes the convolution process easily conducted for different scales simultaneously [4]. In this paper, HOG, SIFT, SURF, LBP and LTP, among other features, are used for comparison with deep features.
High-level features
Deep features are those extracted from a specific layer or layers of a pre-trained deep CNN, such as AlexNet. In this work, we extract these features from various layers of different models, namely AlexNet, VGG-16 and VGG-19. Each of these deep models outputs a 4096-dimensional feature vector for each image, which is very high dimensionality, and negatively affects the speed in the matching process.
Dimensionality reduction
In order to alleviate the problem of dimensionality in the deep features, we compare four popular methods that are normally used to reduce the feature space dimensions, namely DCT, PCA, DWT and probability density functions (PDFs).
DCT
DCT is an invertible linear transform that is widely used in numerous applications and extensively applied to image and audio compression, owing to its ability to extract useful information and exclude redundant data [18]. A 1D DCT can be defined by
where
PCA is a statistical method that makes use of orthogonal transformation to convert a group of variables (in this case, the resultant feature vector) into a group of values known as principal components. Typically, the largest possible data variance is preserved by the first principal component, while the other principal components have different, lower variances. Dimensionality reduction is achieved by maintaining those components with the highest variances, which may explain the main data patterns, and removing those with the lowest variances, which can be considered as redundant data [53].
DWT
DWT has been used extensively in a variety of applications, including dimensionality reduction of the feature vectors of CBIR systems, without a major impact on system performance [52]. Basically, DWT calculates the approximate coefficients that almost represent the same signal (feature vector) shape. Figure 1 illustrates a hypothetical signal, in addition to its first and second wavelet decomposition levels. As can be observed from Fig. 1, we can approximate the signal using 315 or 158 values after the first or second decomposition levels, without excessive loss of its shape and patterns.
Original hypothetical signal (top), signal after first decomposition level (middle) and the signal after second decomposition level (bottom).
We use the Haar DWT to calculate the approximate coefficients, owing to its simplicity and computational efficiency. Algorithm 1 defines the steps for calculating the DWT for the dimensionality reduction of our feature vector.
[H] Steps of proposed method for dimensionality reduction
As indicated by the algorithm, each decomposition level reduces the dimensionality of the input feature vector by half.
PDF is another technique that can be used to reduce the dimensionality of the feature space [23]. Basically, it depends on calculating the histogram of a group of values within a specific range. The histogram can be converted into a probability density function by
where
Here,
As previously mentioned, the similarity measures play a major role in the effectiveness of a CBIR system [24]. In this work, we compare the effects of using different similarity measures in CBIR using deep features.
Euclidian distance
Euclidian distance (ED) is dominant in this field, owing to its simplicity and common use; however, other metrics tend to perform better in case of high dimensional space, as we will discuss in the experimental section. The ED can be defined by
where V1 and V2 are the vectors to be compared and
The Manhattan distance (MD) or city block distance has also been used to compare the feature vectors in CBIR systems. MD is preferable to ED for measuring the distance in high dimensional feature space like deep features [2]. The MD between two vectors is defined by
The Hassanat distance (HD) is a scale and noise invariant distance metric, where the distance (D) between two points can be defined by
and for the total distance along two vectors
The advantage of HD is that it is not significantly affected by different data scales, noises and outliers. A careful look at Eq. (7) reveals that applying this distance to each attribute (dimension) outputs a value within the range of [0, 1], where 0 is similar 1 is dissimilar, and in between the similarity is well defined. The value of the distance for each attribute increases logarithmically to reach 1 if the difference reaches infinity. Therefore, if there is an outlier value from noise or a large value from a different scale, regardless of the difference, the maximum addition to the overall distance is 1. In the case of other distances such as MD, if the difference is 100, this number will be added to the overall distance, which allows one feature to dominate the distance. If this is a noise or unscaled datum, we obtain unpredicted results, as the distance becomes biased by large values.
Similar to HD, Canberra distance (CD) is very useful in high dimensional spaces as it is less sensitive to noise and outliers than MD. Also, it is useful when one wishes to differentiate things by kind (categories or groups) and not by degree [37, 12] . The CD between two equal-length vectors is defined by
However, the CD is not defined when 0 is compared to 0. As the distance between identical values in this metric is 0, we define
More details about a large number of distance measures can be found in [49].
Representing signals by means of a simple combination of non-zero elements according to a base is an ancient concept known as the principle of sparsity. SR is based on such a principle, and has been used to solve computer vision problems for the past two decades [71]. The SR is obtained by solving the following problem
where
We divide our experiments into two parts. The first part is an investigation into deep features and their performance using different dictionary types of varying sizes, also using CL methods. Moreover, we compare the well-known deep features with state-of-the-art work that has been conducted as a comparative study among SIFT, SURF, HOG, LBP and LTP [6]. In the second part, we compare different types of deep features obtained from various models to determine how their performance varies with/without pre-processing and dimensionality reduction. Moreover, we compare these deep features with another set of features, including Gabor features, colour histograms, invariant histograms and other techniques, using certain similarity measures with the aforementioned dimensionality reduction methods.
Similar to the compared studies, we used the Corel-1000 and Coil-20 datasets. Despite the Corel-1000 dataset being relatively old, it is still used in current research because CBIR on this dataset has not yet been perfected. Figure 2 illustrates samples from both datasets.
Samples from (a) Corel-1000 and (b) Coil-20 datasets.
We used precision-recall curves and MAP for evaluation of the CBIR system. Precision-recall curve is a commonly used curve to evaluate the data retrieval algorithms. Similarly, the MAP is a single number represents the mean of the precision among a number of query examples and it approximately equals to the area under the precision-recall curve.
Algorithm parameters are listed as following:
Feature Extraction and Selection: First, LFDs and Deep features are extracted. Dimensionality reduction techniques are not applied in this part of experiments. Lowe’s toolbox is used to extract SIFT features [43] using the default values of SIFT. SURF and HoG features are extracted using build-in Matlab functions. We set SURFSize SR: First of all, different dictionary sizes (10, 20, 30, 40, 50, 256 and 512) are tested for both Pooling: While mean pooling is applied for SR of LFDs, no pooling algorithms are used for SR of Deep Features. The SRs of LFDs are matrices for an image, on the other hand, SRs of Deep Features are vectors.
MAP of different features using 512-D
Tables 1 and 2 display the direct comparison with [6] when applying the same Dictionary learning and CL methods on the deep features. It can obviously be seen from these tables the results are not satisfying for deep features. HOG and LBP achieved superior results on the Corel-1000 dataset, while LTP recorded the highest MAP rates using all CL methods, except SSF, for both dictionaries on Coil-20. The reason for these results is that, unlike the LFDs, deep features represent an image with one vector, for example. By using a smaller dictionary size, the MAP increased dramatically, as we recorded a 95% MAP on the Corel-1000 dataset using Homotopy, 10-D
MAP of different features using 512-D
A dictionary of size 10 could not be built on the Coil-20 dataset because the number of classes was 20. The superior results achieved on the Coil-20 dataset reached 93% and were achieved by VGG-19 FC7 and SSF using both dictionaries. In general, the features extracted using the VGG-16 model appear to have achieved superior performance. The use of elastic net and SSF achieved the best MAP, using both dictionaries with different sizes. Tables 6 and 7 display the MAP averages for all CL and features used, on both datasets and for all dictionary sizes. This aids in determining which features provide superior performance, and which is the most suitable CL method.
As both tables indicate, on average, the features extracted from VGG-16 achieved superior performance, while using SSF as the CL provided the highest MAP rate.
| 10-D |
10-D |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CL algorithms | AlexNet FC6 | AlexNet FC7 | VGG-16 FC6 | VGG-16 FC7 | VGG-19 FC6 | VGG-19 FC7 | AlexNet FC6 | AlexNet FC7 | VGG-16 FC6 | VGG-16 FC7 | VGG-19 FC6 | VGG-19 FC7 |
| Homotopy | 0.81 | 0.8 | 0.84 | 0.81 | 0.73 | 0.79 | 0.62 | 0.84 | 0.87 |
|
0.82 | 0.90 |
| Lasso | 0.80 |
|
0.85 | 0.76 | 0.74 | 0.80 | 0.59 | 0.83 | 0.85 | 0.94 | 0.77 | 0.89 |
| Elastic net | 0.76 | 0.85 | 0.80 | 0.78 | 0.73 | 0.81 | 0.60 | 0.82 | 0.82 | 0.93 | 0.76 | 0.88 |
| SSF | 0.81 | 0.80 | 0.85 | 0.83 | 0.75 | 0.80 | 0.63 | 0.83 | 0.88 | 0.94 | 0.82 | 0.88 |
MAP of deep features with different dictionary sizes using
MAP of deep features with different dictionary sizes using
In this part, we ignore the use of SR and focus only on the raw features extracted from deep models. Traditional dimensionality reduction algorithms (DCT, DWT and PCA) as well as pre-processing by normalisation and DCT are applied to explore the effect of these factors on similarity measures between deep features and, therefore, on the performance of retrieval systems. We use the Corel-1000 and Coil-20 datasets with leave-one-out cross-validation to obtain valid comparisons. Leave-one-out cross-validation is an effective means of evaluating the performance of the CBIR system, as it uses all images in the dataset as query images, which mimics a real-world application. However, this approach is not used on large datasets, because it requires a very long time, particularly for a large number of features. Table 8(a) displays the MAP values of all deep features using the aforementioned distance metrics without performing DTC pre-processing or dimensionality reduction. As can be observed from these results, the CD achieved superior performance, followed by HD; this is because neither metrics were affected by noise and outliers, as explained previously. The best MAP reached 84.2%, recorded by using features extracted from VGG-16 FC6 on the Corel dataset and 90.1% using VGG-19 FC6 and CD. The MD and ED exhibited almost the same performance for all features, while HD was slightly superior to both.
Average MAP values of all CL used for all dictionary sizes
Average MAP values of all CL used for all dictionary sizes
Average MAP values of all features used for all dictionary sizes
DCT is normally used for dimensionality reduction, on either one or two dimensions. It has recently been revealed that deep features provide better results after its representation in DCT domain [15]. In this study, the MAP of the CBIR using different similarity measures was significantly enhanced after applying 1D DCT, owing to the strong energy-compaction characteristic of the DCT. However, we used DCT without removing any coefficients, simply for processing the signal in a manner that enhances the features for improved recognition. Unexpectedly, this is proven to be suitable, perhaps owing to the cosine function used in DCT, as it scales or transforms the data so as to enhance matching.
MAP of different deep features using various similarity measures
Precision-recall curves of deep features with DCT processing and normalisation using CD on Corel-1000 database.
A closer inspection of the results in Table 8(b) reveals that the potential exists for deep features to be enhanced by pre-processing techniques such as the DCT for improved retrieval MAP. Such an enhancement was significant when using HD and CD compared to the original deep features, which were extracted directly from the deep models (CNNs). The best MAP values following DCT processing reached 86.3% and 90.6% on the Corel-1000 and Coil-20 datasets, respectively, using the CD and VGG-19 FC7 features. However, in the case of MD, there was no significant improvement, while the MAP remained the same when using ED following pre-processing. It is also interesting to note that HD benefited from the DCT more than CD did, owing to the nature of CD, as most of the distances between different values were equal to 1, while this was not the case in HD.
The signal following DCT pre-processing contains different scaled features, and as we conducted similarity matching based on distance metrics, there might be a risk of false decisions by allowing large-scale features to dominate the final distance. Therefore, we opted for data normalisation. Table 8(c) displays the MAP values following Z-score normalisation of the DCT coefficients.
As can be seen from Table 8(c), the Z-score normalisation of the DCT coefficients enhanced certain results, as the best MAP increased to 87.3% and 90.9% on Corel-1000 and Coil-20, respectively. Figures 3 and 4 depict the precision-recall curves for different pre-processing and normalisation of the deep features using CD on both datasets. As one can see from Fig. 3, very deep features like the VGG ones outperform the less deep AlexNet features on Corel-1000 dataset. On the other hand, Fig. 4 shows that the performance of all the tested features are convergent. Perhaps, the reason behind this phenomenon is that the images of Coil-20 have less complexity in their content than Corel-1000 dataset images, so their content can be represented sufficiently by all the proposed models.
Precision-recall curves of deep features with DCT processing and normalisation using CD on Coil-20 database.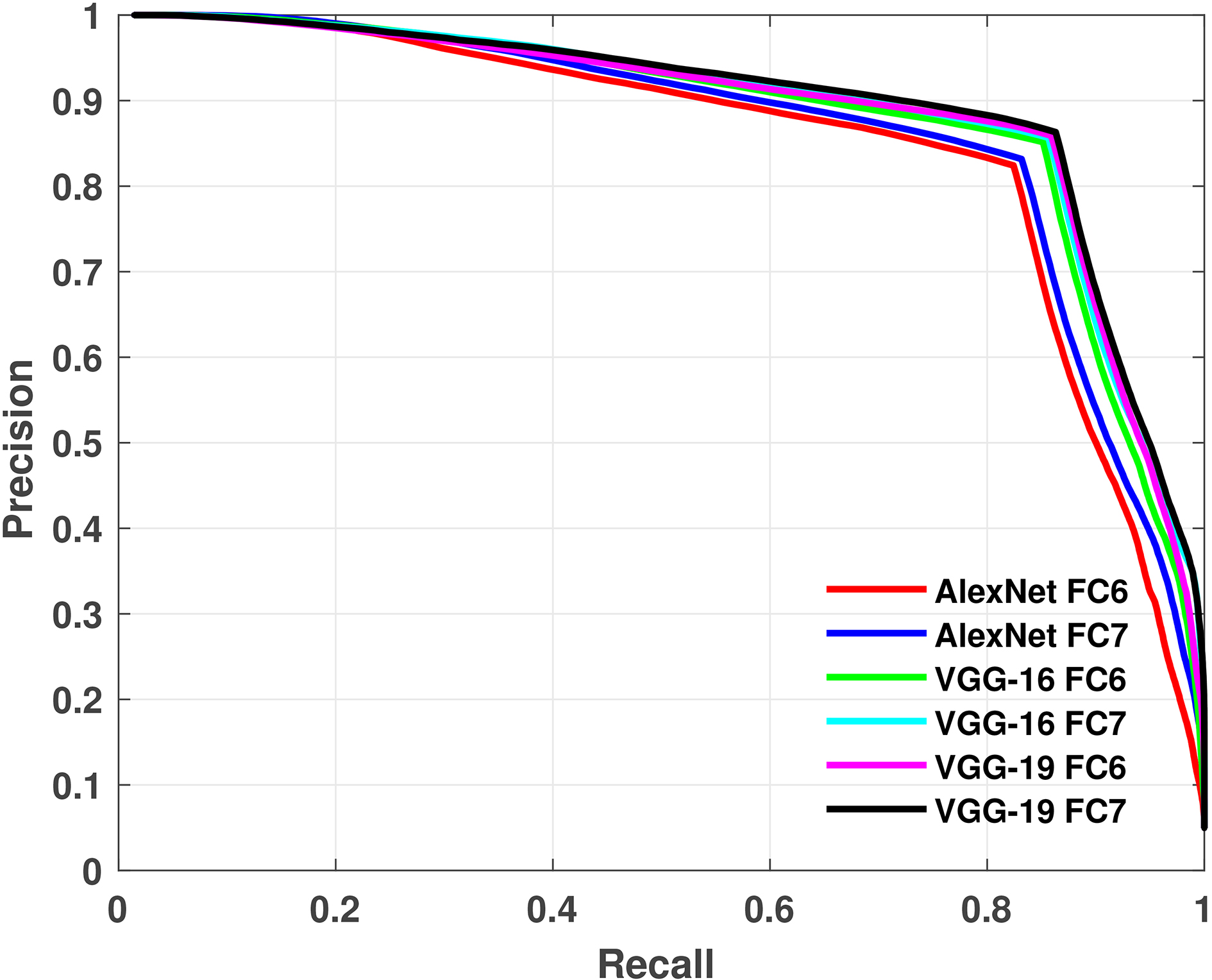
MAP values using different number of DCT coefficients on both datasets.
MAP as a function of different PCA components.
Normally, the number of deep features is relatively high, and when using similarity measures, the matching process becomes very slow; therefore, reducing the number of features will enhance the searching speed for query images. It is important in this case to reduce the number of features without affecting the CBIR system accuracy. Reduction techniques such as DCT, PCA or DWT significantly reduce the dimensionality of the feature vectors, while maintaining effective system performance.
Based on Table 8(c), we selected the first N coefficients to approximate the original signal to a smaller number of coefficients. Figure 5 illustrates the effect of the number of DCT coefficients used on the CBIR system MAP.
Intuitively, using more DCT coefficients results in a higher MAP being obtained; however, a closer look at Fig. 5 reveals that the MAP becomes extremely close to that of the original signal when using only 300 coefficients on both datasets, which allows for faster CBIR without affecting the retrieving results. PCA reduces the dimensionality more effectively than DCT, by obtaining almost the same results with a significantly lower number of features. For example, Table 8(d) illustrates the MAP using only 10 principal components (those with the highest data variance) with different distance metrics, while Table 8(e) illustrates the CBIR MAP using the same number of components after normalising the data.
MAP and number of features for each DWT level
ER of all deep features following each retrieved image.
As can be seen from Table 8(d) and 8(e), the MAP is still high after transforming the features from 4096 to 10-dimensions. In this case, ED and MD perform better, owing to the small number of features, which reduces the probability of features that dominate the distance.
We opted to use the 10 components of PCA for the experiments displayed in Table 8(e), because using these achieves the highest system MAP, as indicated in Fig. 6. Despite the fact that there are several methods to determine the number of components to be used for PCA [31, 5], in this study, we wish to show that choosing the right number of components is critical for CBIR systems as it can be seen in Fig. 6.
MAP and ER of different deep features compared to the low-level features presented in [9] on the Corel-1000 dataset
In order to investigate the effect of the dimensionality reduction of the deep features on the CBIR system MAP further, we used the DWT for dimensionality reduction, as in [1, 63]. We applied three decomposition levels, and at each DWT level, the number of features was reduced by half. Table 9 illustrates the system performance after three decomposition levels using the VGG-16 FC6 and VGG-19 FC6 with CD (with the best features and distance metric indicated in Table 8(a)) on both datasets.
As can be observed from Table 9, the signal or feature vector began to change as the number of levels used increased, as the MAP deceased by approximately 7% after each level on the Corel-1000 dataset, which is a significant system performance degradation. In the case of the Coil-20 dataset, the loss was not significant; however, the CBIR system performance with dimensionality reduction using DWT was not satisfactory if compared to DCT and PCA, in terms of the number of features and system MAP. Converting the features into PDF reduces the dimensionality by grouping the features in the same range in order to produce less length feature vectors [23]. Table 8(f) presents the MAP of the 10 bins PDF using the studied distances.
It can be noted from Table 8(f) that the results are not satisfactory. Perhaps grouping the same range deep features together in a bin reduces the significance of the features by being in their original place. Moreover, binning does not transform the features in a specific manner within a space, but simply performs blind grouping without prior information regarding the features, while it may be effective for special features as in [23], it appears not to with complex structure features such as deep features. The term error rate (ER) is used as an evaluation measure in this comparison, and is given by
Figure 7 presents the ER following each retrieved image up to 99, which is the number of relevant images of each image in the Corel-1000 dataset.
As can be seen from Fig. 7, very deep features such as VGG-19 FC7 yield a lower ER than less deep features such AlexNet FC6. In VGG models, the relevant images are retrieved earlier than in the AlexNet feature.
In this paper, different types of low-level and deep features for CBIR have been tested and compared. The comparison was conducted using different SR and CL methods, and various similarity measures with different validation approaches. Furthermore, we examined the features with/without data normalization and experimentally demonstrated the effect of different dimensionality reduction techniques on the system performance, using two popular data sets in this field.
Eight hundred forty-two different tests are done on both Corel and Coil datasets using different SR methods, dictionary learning algorithms, similarity measures, dimensional reduction techniques and many deep features from different layers deep models.
Results show that combination of DL and SR lead to accurate retrieval models. Especially, when the results of these combinations are compared with LFD based SR, the usage of DL as deep features increase the retrieval accuracy.
The experimental results indicate high MAPs on both datasets using
We determined that the system performance varies based on the used distance and pre-processing methods. In general, the VGG models performed better in extracting more efficient features.
Selecting the optimal distance relies on the data itself, and in this study, CD and HD achieved superior performance to MD and ED in most cases. However, in the case of PCA reduction, ED provided superior results to the other metrics. Furthermore, the results indicate that the deep features can be enhanced by using DCT as a pre-processing stage. Such a step increases the system performance and achieves higher accuracy than using the pure deep features; however, selecting the appropriate distance metric is critical to the system performance following pre-processing.
Moreover, PCA was found to be the most suitable option among the investigated dimensionality reduction algorithms, as it reduced the dimensionality of the deep features dramatically, to 10 features, while maintaining effective performance. Similarly, the DCT provides a high approximation of the performance with the original features, by using only 300 features.
In future studies, we will investigate the performance of SSF with deep features in many other computer vision problems, including face recognition, fingerprint identification and authentication, facial and medical image retrieval, etc. Studying the response time of the discussed SR methods with the deep features is also planned. Moreover, we are going to conduct some experiments for comparison among state-of-the-art approaches to study how they work with the high-level and low-level features over different approaches and show the effectiveness. For instance, [28] proposed various masking schemes to select a representative subset of local convolutional features and employed recent embedding and aggregating methods to further enhance feature discriminability. In addition to the high-level and low-level features, there are more features to be extracted, such as those extracted from halftoning-based block truncation coding. For instance, [17] proposed color co-occurrence feature (CCF) and bit pattern features (BPF) extracted from block truncation coding to exploit the advantage of efficient ordered-dither block truncation coding for image content descriptor generation. Such features will be investigated in our future work, along with conducting more feature selection experiments to observe what features are indeed crucial. We also plan to increase the speed of the retrieval process using efficient indexing techniques, such as, [45, 26, 20, 21].
Footnotes
Acknowledgments
The first author would like to thank Tempus Public Foundation for sponsoring his PhD study, also, this paper is under the project EFOP-3.6.3-VEKOP-16-2017-00001 (Talent Management in Autonomous Vehicle Control Technologies), and supported by the Hungarian Government and co-financed by the European Social Fund.